Embed Size (px)
Citation preview

12.12.2005 1
Soft Computing
Lecture 22Using of NN in NLP and speech recognition

12.12.2005 2
Agenda
• Introduction to NLP
• Using of recurrent NN for recognition of correct sentences
• Example of learning software for searching of documents by query in natural language

12.12.2005 3
Programs based on NLP• Question-Answering Systems
• Control by command in Natural Language
• Readers from text to speech
• Translators
• Search of information by query in Natural Language
• OCR – Optical Characters Recognition
• Virtual Persons

12.12.2005 4
Main areas of NLP
• Understanding of NL
• Generation of NL
• Analyzing and synthesis of speech

12.12.2005 5
Levels of language• Words, parts of words (lexical level, morphology)
– Structure of words
• Phrases, sentences (Syntax, syntactic level)
– Structure of phrases and sentences
• Sense, meaning of phrases (Semantics, semantic level)
– The meaning here is that associated with the sentential structure, the juxtaposition of the meanings of the individual words
• Sense, meaning of sentences (Semantics, discourse level)
– - Its domain is intersentenial, concerning the way sentences fit into the context of a dialog text
• Sense as goals, wishes, motivations and so on (Pragmatics)
– Deals with not just a particular linguist context but the whole realm of human experience

12.12.2005 6
Example• Following sentences are unacceptable on the basis of syntax,
semantics, and pragmatics, respectively: – John water drink.– John drinks dirt.– John drinks gasoline.
• Note that the combination of "drink" and "gasoline" is not unacceptable, as in "People do not drink gasoline" or the metaphorical "Cars drink gasoline.“
• It is traditional for linguists to study these levels separately and for computational linguists to implement them in natural language systems as separate components. Sequential processing is easier and more efficient but far less effective than an iterated approach.

12.12.2005 7
Syntactic analyzing• A natural language grammar specifies allowable sentence structures in
terms of basic syntactic categories such as nouns and verbs, and allows us to determine the structure of the sentence. It is defined in a similar way to a grammar for a programming language, though tends to be more complex, and the notations used are somewhat different. Because of the complexity of natural language a given grammar is unlikely to cover all possible syntactically acceptable sentences.
• To parse correct sentences:
– John ate the biscuit.
– The lion ate the schizophrenic.
– The lion kissed John.
• To exclude incorrect sentences:
– Ate John biscuit the.
– Schizophrenic the lion the ate.
– Biscuit lion kissed.

12.12.2005 8
Simple context free grammar for previous examples
• sentence --> noun_phrase, verb_phrase.
• noun_phrase --> proper_name.
• noun_phrase --> determiner, noun.
• verb_phrase --> verb, noun_phrase.
• proper_name --> [Mary].
• proper_name --> [John].
• noun --> [schizophrenic].
• noun --> [biscuit].
• verb --> [ate].
• verb --> [kissed].
• determiner --> [the].
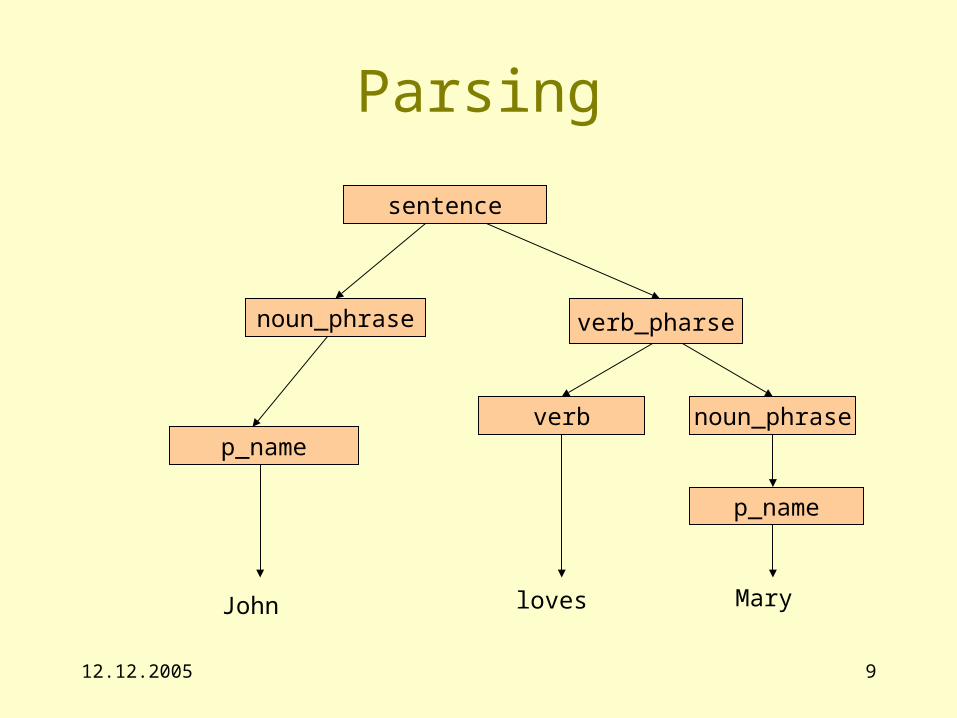
12.12.2005 9
Parsing
sentence
noun_phrase verb_pharse
verb noun_phrasep_name
p_name
John loves Mary
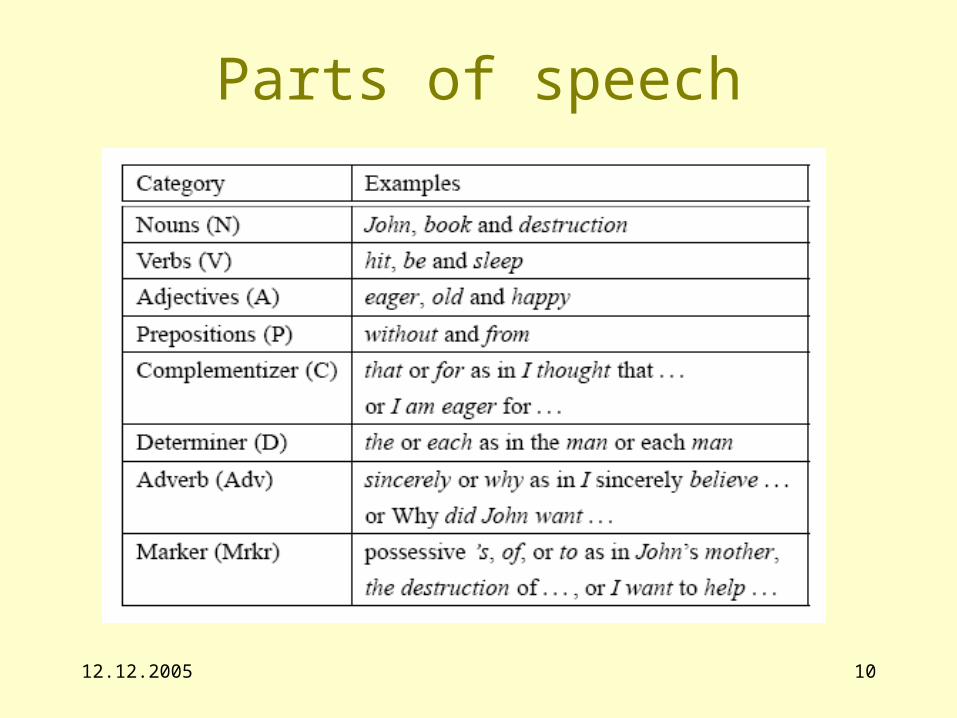
12.12.2005 10
Parts of speech
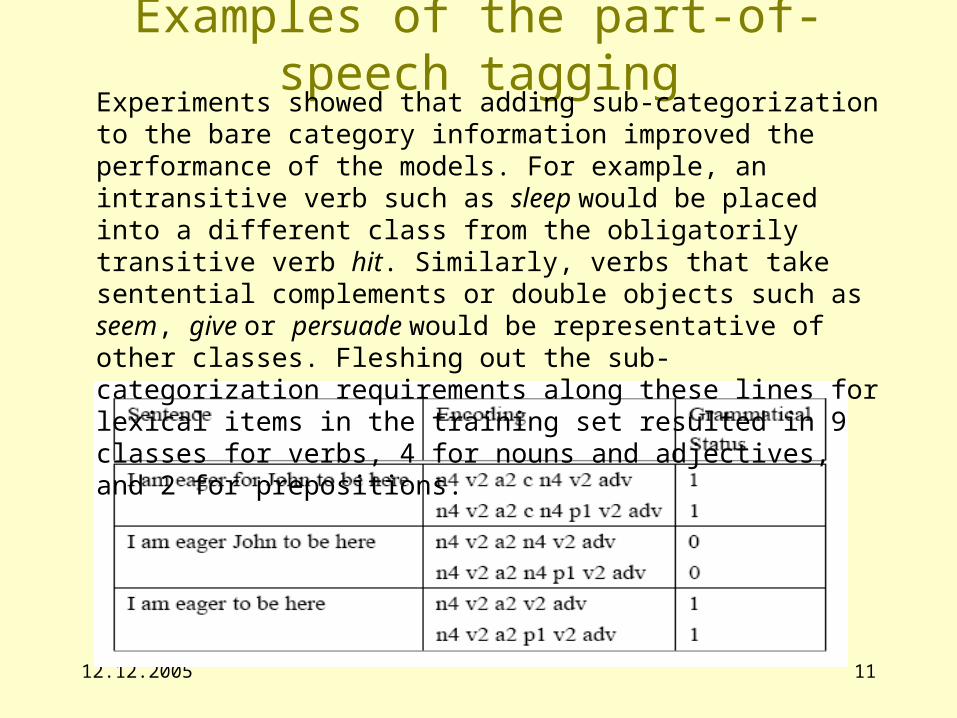
12.12.2005 11
Examples of the part-of-speech taggingExperiments showed that adding sub-categorization to the bare category information improved the performance of the models. For example, an intransitive verb such as sleep would be placed into a different class from the obligatorily transitive verb hit. Similarly, verbs that take sentential complements or double objects such as seem, give or persuade would be representative of other classes. Fleshing out the sub-categorization requirements along these lines for lexical items in the training set resulted in 9 classes for verbs, 4 for nouns and adjectives, and 2 for prepositions.
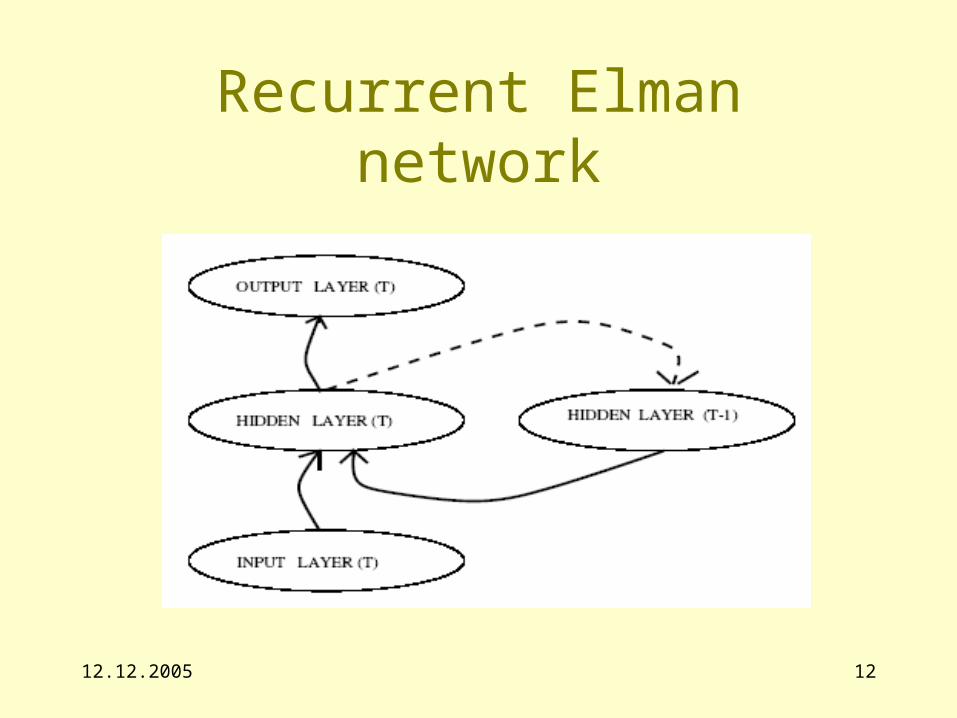
12.12.2005 12
Recurrent Elman network

12.12.2005 13
Extraction of grammar (DFA) from learned recurrent Elman network
• The algorithm we use for automata extraction works as follows: after the network is trained (or even during training), we apply a procedure for extracting what the network has learned—i.e., the network’s current conception of what DFA it has learned.
• The DFA extraction process includes the following steps:1. clustering of the recurrent network activation space, S, to
form DFA states,2. constructing a transition diagram by connecting these
states together with the alphabet labelled arcs,3. putting these transitions together to make the full digraph
– forming loops,4. reducing the digraph to a minimal representation.

12.12.2005 14
s p ee ch l a b
Graphs from Simon Arnfield’s web tutorial on speech, Sheffield:http://lethe.leeds.ac.uk/research/cogn/speech/tutorial/
“l” to “a”transition:
Acoustic Waves• Human speech generates a wave
– like a loudspeaker moving
• A wave for the words “speech lab” looks like:

12.12.2005 15
25 ms
10ms
. . .
a1 a2 a3
Result:Acoustic Feature Vectors
Acoustic Sampling• 10 ms frame (ms = millisecond = 1/1000 second)
• ~25 ms window around frame to smooth signal processing

12.12.2005 16
Acoustic Features: Mel Scale Filterbank
• Derive Mel Scale Filterbank coefficients
• Mel scale:
– models non-linearity of human audio perception
– mel(f) = 2595 log10(1 + f / 700)
– roughly linear to 1000Hz and then logarithmic
• Filterbank
– collapses large number of FFT parameters by filtering with ~20 triangular filters spaced on mel scale
... m1 m2 m3 m4 m5 m6
frequency… coefficients

12.12.2005 17
Phoneme recognition system based onthe Elman predictive neural networks.
• The phrases are available in segmented form with speech labeled into a total of 25 phonemes.
• Speech data was parametrisized into 12 liftered mel-frequency cepstral coeficients (MFCCs) without delta coeficients. The analysis window is 25ms and the window shift 10ms.
• Each phoneme is modeled by one neural network. The architecture of the neural networks which is seen during recognition with the Viterbi algorithm (when the neural network models provide the prediction error as distortion measure) corresponds to a HMM with 3 states (supposing that the second state is modeling the speech signal, and the first and last state act as input and output states, respectively).
• Results of experiments – Elman network provides best results of recognition on training set in comparison with HMM
12.12.2005 18
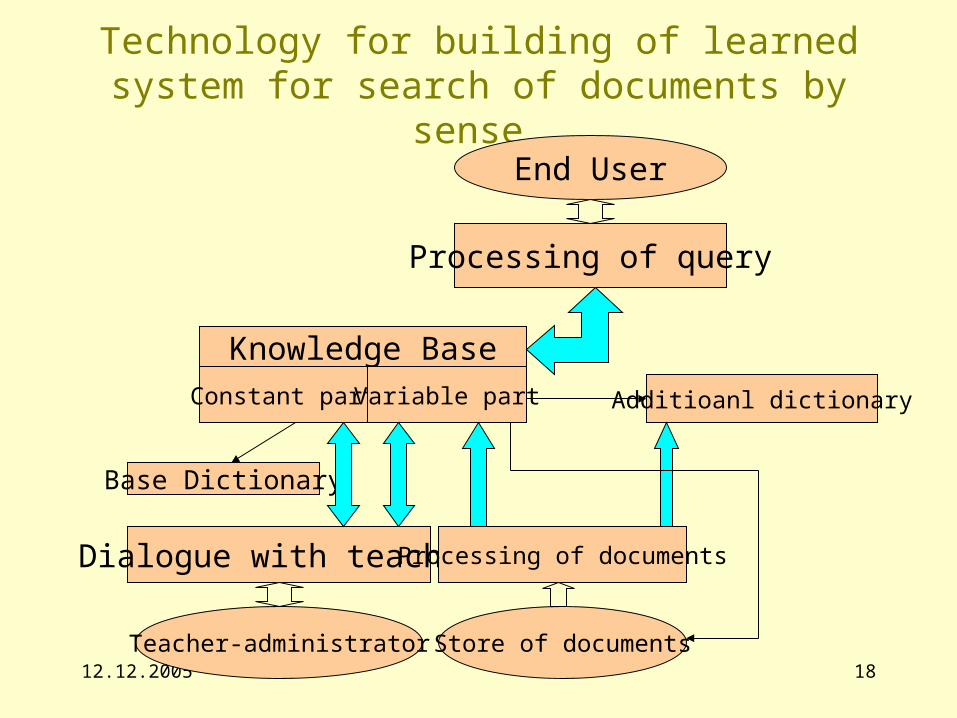
Technology for building of learned system for search of documents by sense
End User
Processing of query
Knowledge Base
Constant part Variable part
Base Dictionary
Dialogue with teacher Processing of documents
Additioanl dictionary
Teacher-administrator Store of documents

12.12.2005 19
Main principles in proposed technology
• Orientation to recognition of semantics with minimum usage of knowledge about syntax of the language,
• Creation of hierarchies from concepts with horizontal (associative) links between nodes of these hierarchies as result of processing of documents,
• Recognition of words and word collocations on maximum resembling with usage of neural algorithms.

12.12.2005 20
Kinds of frames
1. frame coupled immediately to the word or the document (the frame-word or the frame-document)
2. frame, with which associates a word collocation (composite frame)
3. frame-concept including the links on several other frames, playing the defined role in this concept
4. frame-heading circumscribing concept, which is "exposition" of all concepts and documents coupled to this heading

12.12.2005 21
Slots of frame• Parent - link on the frame - parent or class (vertical links)
• Owner - list of links to frames - concepts or the composite frame, in which structure enters the given frame
• Obj - object participating in concept,
• Subject - subject (or main object), participating in concept
• Act - operation (action) participating in concept
• Prop - property participating in concept
• Equal - list of concepts - synonyms circumscribed in the given frame (horizontal links)
• UnEqual - list of concepts - antonyms circumscribed in the given frame
• Include - list of links to the frames switched on in the given concept constituent (vertical links)

12.12.2005 22
Other main parameters of frame
• Level - level of the frame in hierarchy
• DocName - index of filename (path) of document coupled to the frame
• IndWord - index of a word in the dictionary coupled to the frame
• H - threshold of operation of the frame, as neuron
• Role - role of the frame in concept, which it enters or can enter (A-operation, O-object, S-subject, P-property, U-undefined or D - the operation at the analysis (by special procedure)
• NO - indication of inversion of the frame

12.12.2005 23
Dictionaries
• Basic, in which the words with their roles (essence, operation or property, in other words - noun, verb or adjective are stored
• The supplemented (dynamic) dictionary including a words, not recognized in the base dictionary
• Dictionary of special words, associated with separators and analyzed as separators.

12.12.2005 24
Steps of analyzing of sentence in context of learning
1) selection of words (using signs of punctuation and spaces)
2) the recognition of words on maximum resembling with words in the dictionary, thus if the approaching word is not in the fundamental dictionary, then searching of this word in the supplemented dictionary, and in fail case this word adds in this dictionary
3) the creation of the frames of a level 0, the result of this stage is object-sentence representing list of the frames
4) replacement in this object of special words by signs-separators,
5) processing of the object-sentence by a procedure of recognition-creation of the frames of levels 1 and 2

12.12.2005 25
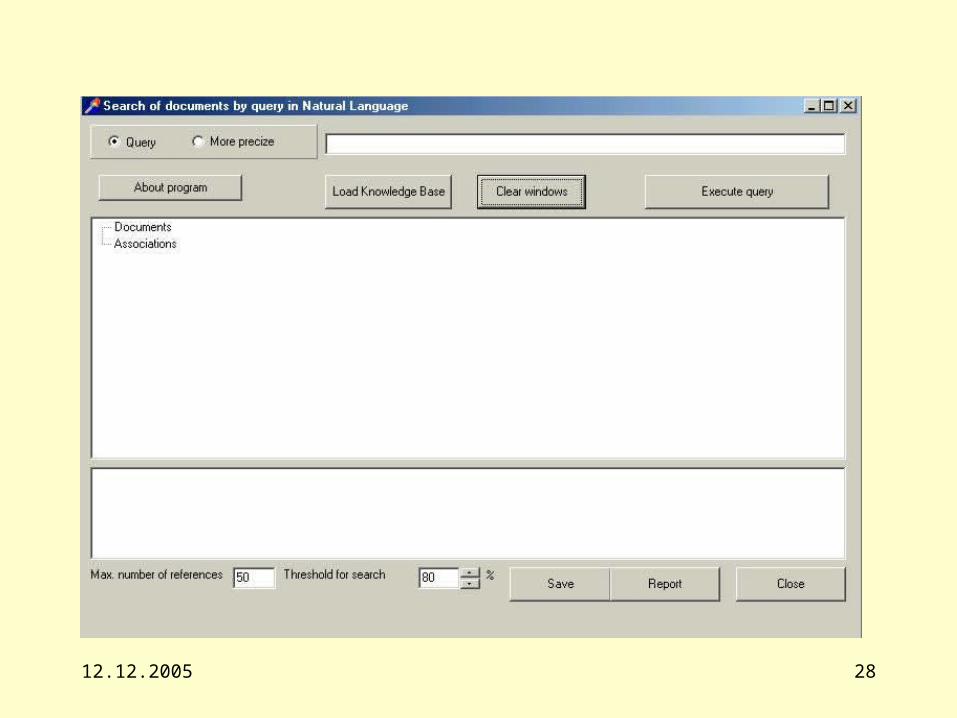
Steps of analyzing of sentence in context of processing of query1) selection of words (using signs of punctuation and spaces),
2) the recognition of words on maximum resembling with words in the dictionaries. In case of unknown word system ask question "what is < new word >?". The answer of the user is processed in context of learning.
3) the creation of the frames of a level 0, the result of this stage is object-sentence representing list of the frames,
4) the recognition of the frames of a level 1 or 2 - word collocations in the knowledge base maximum similar to recognized phrase (here is used neural algorithm, i.e. weighed addition of signals from words, entering into the frame, or frames and matching with a threshold),
5) the searching associatively coupled by the links Equal with the recognized phrases of the frames (level 0), coupled with documents,
6) the searching of frames-documents from the retrieved frames on connections such as include, act, obj, subject, prop from above downwards
7) the output of the retrieved names of documents or words which are included in structure of the retrieved frames.

12.12.2005 26
Steps of learning of System• Initial tutoring to recognition of structure of sentence by input
of sentences as "word - @symbol”. This step provides creation of dictionary of special words
• Initial tutoring. During this step the knowledge base is filling by fundamental concepts from everyday practice or data domain as sentences such as "money - means of payment", "morals - rule of behavior", ”kinds of business: trade, production, service" etc.
• Base tutoring. In this step the explanatory dictionary of data domain is processed, where the concepts of any area are explained with use "-" or corresponding words.
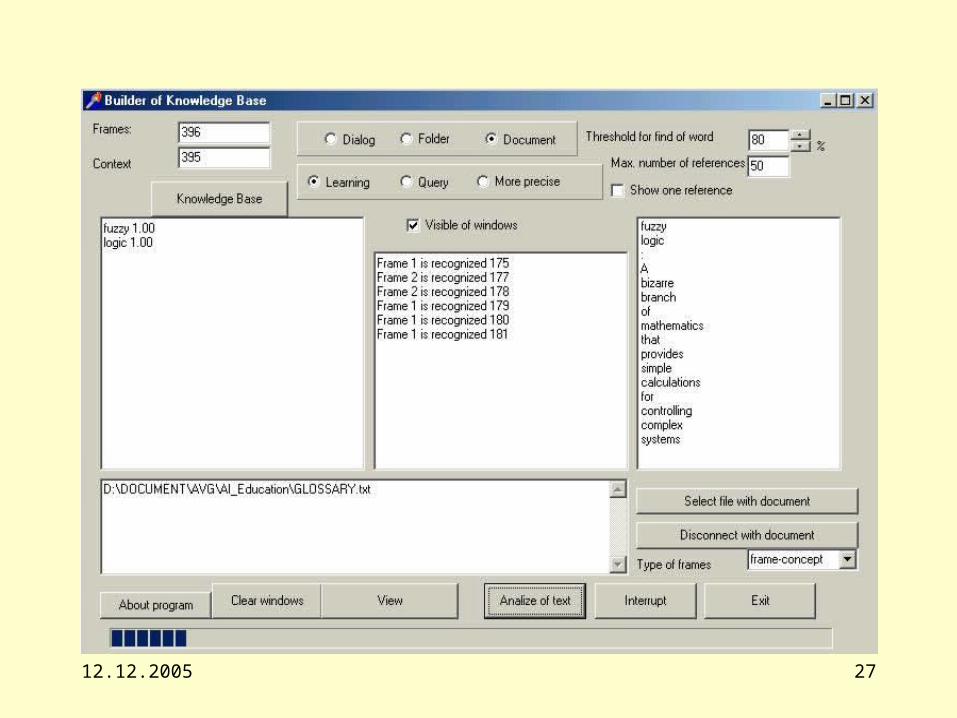
• Information filling. In this step the real documents are processed.
12.12.2005 27
12.12.2005 28





























