Embed Size (px)
Citation preview

Conference Guide
MLSP 2012
September 23-26, 2012
Santander, SPAIN
2012 IEEE International Workshop on Machine Learning for Signal Processing

Copyright and Reprint Permission: Abstracting is permitted with credit to the source. Libraries are permitted to photocopy beyond the limit of U.S. copyright law for private use of patrons those articles in this volume that carry a code at the bottom of the first page, provided the per-copy fee indicated in the code is paid through Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923. For other copying, reprint or republication permission, write to IEEE Copyrights Manager, IEEE Operations Center, 445 Hoes Lane, Piscataway, NJ 08854. All rights reserved. Copyright ©2012 by IEEE. IEEE Catalog Number CFP12NNS-USB ISBN 978-1-4673-1025-3

i
Contents MLSP 2012 Program at a glance .......................................................................................... 1 MLSP 2012 Sponsors ........................................................................................................... 3 MLSP 2012 Supporters ........................................................................................................ 3 General Chairs Welcome ..................................................................................................... 4 Organizing Committee ......................................................................................................... 5 Technical Program Committee ............................................................................................ 6 General Information ............................................................................................................ 8
Welcome to Santander .............................................................................................. 8 Beaches of Santander ......................................................................................... 8
Shopping ............................................................................................................. 8
Restaurants and dining ....................................................................................... 8
What to eat ......................................................................................................... 9
Local Transportation in Santander ............................................................................ 9 Additional Information .............................................................................................. 9
Insurance .......................................................................................................... 10
Currency and banks .......................................................................................... 10
Conference Information .................................................................................................... 11 Venue....................................................................................................................... 11 Internet Access ........................................................................................................ 12 MLSP Bus ................................................................................................................. 12 Registration ............................................................................................................. 12 Social Program ......................................................................................................... 12
Welcome Reception ......................................................................................... 12
Luncheons ......................................................................................................... 13
Banquet ............................................................................................................ 13
Boat trip and lunch in Pedreña ......................................................................... 13
MLSP TC Meeting ..................................................................................................... 14 Technical Program ............................................................................................................. 15
Tutorials ................................................................................................................... 15 Privacy-Preserving Speech and Audio Processing ............................................ 15
Manifold Learning: Modeling and Algorithms .................................................. 16
Plenary Lectures ...................................................................................................... 17 Learning and Message-passing in Graphical Models ........................................ 17

Large-scale Convex Optimization for Machine Learning .................................. 18
Adaptation and Learning over Complex Networks ........................................... 18
Oral Session 1: Pattern Recognition and Classification ........................................... 20 Poster Session 1.A: Biomedical Applications ........................................................... 21 Poster Session 1.B: Image and Video Processing Applications ................................ 25 Poster Session 2.A: Speech, Audio and Music Applications .................................... 28 Poster Session 2.B: Other Applications of Machine Learning .................................. 32 Oral Session 2: Bayesian Learning ........................................................................... 35 Oral Session 3: Special Session on Social Network Analysis & Data Competition ... 36 Poster Session 3.A: Learning Theory and Algorithms I ............................................ 38 Poster Session 3.B: Learning Theory and Algorithms II ........................................... 41 Oral Session 4: Learning Theory and Algorithms ..................................................... 44
Author Index ...................................................................................................................... 47 Notes ................................................................................................................................. 51

1
MLSP 2012 Program at a glance
Sunday Sept. 23
Monday Sept. 24
Tuesday Sept. 25
Wednesday Sept. 26
9:15-9:30 Opening
9:30-10:30 Plenary Lecture 1
Plenary Lecture 2
Plenary Lecture 3
10:30-11:00 Coffee Break Coffee Break Coffee Break
11:00-13:00 Oral Session 1
Oral Session 2
Oral Session 4
13:00-14:00 Lunch Lunch
(& TC meeting) Boat trip, Lunch
(in Pedreña) and good bye
14:00-15:00 Registration starts at 14:00
15:00-17:00 Tutorial 1 Poster Session 1
Oral Session 3
17:00-17:30 Coffee Break Coffee Break Coffee Break
17:30-19:30 Tutorial 2 Poster Session 2
Poster Session 3
20:30 Welcome Reception
(Palacio Magdalena)
Banquet
(Gran Casino Sardinero)

2
Sunday September 23, 2012 14:00-19:30 Recepción Registration 15:00-17:00 Riancho Tutorial 1: Privacy Preserving Speech and Audio Processing
Dr. Bhiksha Raj 17:00-17:30 Comedor I Coffee Break 17:30-19:30 Riancho Tutorial 2: Manifold Learning: Modeling and Algorithms
Dr. Raviv Raich 20:30-21:30 Hall Real Welcome Reception
Monday September 24, 2012 8:30-19:30 Recepción Registration 9:15-9:30 Salón de Baile Opening 9:30-10:30 Salón de Baile Plenary Lecture 1: Learning and Message-Passing in Graphical
Models Prof. Martin J. Wainwright
10:30-11:00 Comedor I Coffee Break 11:00-13:00 Salón de Baile Oral Session 1: Pattern Recognition and Classification 13:00-15:00 Real Sociedad
de Tenis de La Magdalena
Lunch
15:00-17:00 Comedor I Poster Session 1.A. Biomedical Applications 15:00-17:00 Comedor II Poster Session 1.B. Image and Video Processing Applications 17:00-17:30 Comedor I Coffee Break 17:30-19:30 Comedor I Poster Session 2.A. Speech, Audio and Music Applications 17:30-19:30 Comedor II Poster Session 2.B. Other Applications of Machine Learning
Tuesday September 25, 2012 9:00-19:30 Recepción Registration 9:30-10:30 Salón de Baile Plenary Lecture 2: Large-Scale Convex Optimization for Machine
Learning Dr. Francis Bach
10:30-11:00 Comedor I Coffee Break 11:00-13:00 Salón de Baile Oral Session 2: Bayesian Learning 13:00-15:00 Real Sociedad
de Tenis de La Magdalena
Lunch
13:00-15:00 Comedor de Gala
MLSP TC Meeting
15:00-17:00 Salón de Baile Oral Session 3: Special Session on Social Network Analysis & Data Competition
17:00-17:30 Comedor I Coffee Break 17:30-19:30 Comedor I Poster Session 3.A. Learning Theory and Algorithms I 17:30-19:30 Comedor II Poster Session 3.B. Learning Theory and Algorithms II 21:00-23:00 Gran Casino
El Sardinero Banquet
Wednesday September 26, 2012 9:00-13:00 Recepción Registration 9:30-10:30 Salón de Baile Plenary Lecture 3: Adaptation and Learning over Complex
Networks Prof. Ali H. Sayed
10:30-11:00 Comedor I Coffee Break 11:00-13:00 Salón de Baile Oral Session 4: Learning Theory and Algorithms 13:00-17:00 Pedreña Boat trip, lunch in Pedreña and good bye

3
MLSP 2012 Sponsors
MLSP 2012 Supporters

4
General Chairs Welcome Dear colleagues, The organizing committee of MLSP 2012 is delighted to welcome you to the 22nd International Workshop on Machine Learning for Signal Processing 2012. This series of workshops is the major event organized annually by the Machine Learning for Signal Processing Technical Committee, and is sponsored by the IEEE Signal Processing Society. This year’s workshop will take place in the unique framework of Palacio de la Magdalena, located on the Magdalena Peninsula of the city of Santander, being the first time the workshop comes to Spain. This year we received a record number of 202 submissions, of which 104 were accepted after the review process, a 51% acceptance rate. We would like to thank all authors for their high-quality contributions. Accepted papers have been arranged in four oral and three poster sessions, including a special session on Social Network Analysis. In addition to these, there is also a report on the 2012 Data Competition and the two top performers will present their works during the conference. This workshop will cover several hot topics in the field, including Bayesian learning, Gaussian Processes, Kernel Methods, Distributed Learning, and Social Networks. Several papers will also deal with applications of MLSP techniques. The workshop will also include three keynotes by recognized experts. We would like to thank Prof. Martin Wainwright, Dr. Francis Bach and Prof. Ali H. Sayed for their willingness to present at the workshop some of the most recent advances in salient topics. For the traditional first-day tutorials, we are pleased to count on Drs. Bhiksha Raj and Raviv Raich. An event such as the MLSP workshop would not be possible without the work of many individuals, to who we are in debt. Thanks to the Technical Chairs for an excellent work and for putting together such an interesting program, and to the 113 reviewers whose expert opinion made the whole process possible. We would also like to recognize the excellent and professional work of the Organizing Committee, including the Special Session Chairs Emilio Parrado-Hernández and Jocelyn Chanussot, Publicity Chairs Marc Van Hulle and Luis Gómez Chova, Web and Publication Chair Jan Larsen, Data Competition Chairs Kenneth E. Hild II, Vince Calhoun, Weifeng Liu, Ken Montanez, and Catherine Huang and the Local Organizing Chairs Jesús Ibáñez, Javier Vía and Steven Van Vaerenbergh. Finally, we would like to acknowledge the support of the following companies and institutions: Amazon, PASCAL 2 Network of Excellence, Ministerio de Ciencia e Innovación, Universidad de Cantabria, Universidad Carlos III de Madrid, Gobierno de Cantabria, Ayuntamiento de Santander, and Asociación Española de Ingenieros de Telecomunicación. We hope you enjoy the workshop! General Chairs: Technical Chairs:
Ignacio Santamaría Deniz Erdogmus Jerónimo Arenas-García Fernando Pérez-Cruz Gustavo Camps-Valls

5
Organizing Committee
General chairs Ignacio Santamaría (Universidad de Cantabria) Jerónimo Arenas-García (Universidad Carlos III de Madrid) Gustavo Camps-Valls (Universitat de València)
Technical chairs Deniz Erdogmus (Northeastern University) Fernando Pérez-Cruz (Universidad Carlos III de Madrid)
Special session chairs Emilio Parrado-Hernández (Universidad Carlos III de Madrid) Jocelyn Chanussot (Grenoble Institute of Technology)
Publicity chairs Marc Van Hulle (K. U. Leuven) Luis Gómez Chova (Universitat de València)
Web and publication chair Jan Larsen (Technical University of Denmark)
Data competition chairs Kenneth E. Hild II (Oregon Health & Science University) Vince Calhoun (University of New Mexico) Weifeng Liu (Amazon, USA) Ken Montanez (Amazon, USA) Catherine Huang (Intel Labs, USA)
Local Organizing chairs Jesús Ibáñez (Universidad de Cantabria) Javier Vía (Universidad de Cantabria) Steven Van Vaerenbergh (Universidad de Cantabria)

6
Technical Program Committee Tülay Adali, University of Maryland Baltimore County, USA Jerónimo Arenas-Garcia, Universidad Carlos III de Madrid, Spain Antonio Artés, Universidad Carlos III de Madrid, Spain Esra Ataer-Cansizoglu, Northeastern University, USA Erhan Bas, Howard Hughes Medical Institute, USA Jose Bioucas-Dias, Instituto Superior Técnico, Portugal Giorgos Borboudakis, ICS FORTH, Greece Vince D. Calhoun, The Mind Research Network, USA Gustavo Camps-Valls, Universitat de València, Spain Taylan Cemgil, Bogaziçi University, Turkey Andrzej Cichocki, Brain Science Institute, RIKEN, Japan Jesús Cid-Sueiro, Universidad Carlos III de Madrid, Spain Tom Claassen, Radboud University Nijmegen, The Netherlands Justin Dauwels, Nanyang Technological University, Singapore Konstantinos I. Diamantaras, TEI of Thessaloniki, Greece Gerard Dreyfus, ESCI-ParisTech, France Frederik Eberhardt, Carnegie Mellon University, USA Doris Entner, Helsinki, Finaland Mário A. T. Figueiredo, Instituto Superior Técnico, Portugal Cédric Févotte, CNRS-Telecom Paris Tech, France Paul Gader, University of Florida, USA Darío García, National University, Australia Nastaran Ghadarghadar, Northeastern University, USA Luis Gómez-Chova, Universitat de València, Spain Juan Manuel Górriz, Universidad de Granada, Spain Moritz Grosse-Wentrup, Max Planck Institute for Intelligent Systems, Germany Vanessa Gómez-Verdejo, Universidad Carlos III de Madrid, Spain Lars Kai Hansen, Technical University of Denmark, Denmark Alain Hauser, ETHZ, Switzerland Patrik Hoyer, University of Helsinki, Finland Catherine Huang, Intel, USA Marc M. Van Hulle, K.U. Leuven, Belgium Kenneth E. Hild II, University of California, San Francisco, USA Nuri Firat Ince, University of Minnesota, USA Robert Jenssen, University of Tromso, Norway Christian Jutten, LIS-Grenoble, INPG-LIS, France Ken Kreutz-Delgado, University of California at San Diego, USA Olexiy Kyrgyzov, CEA, France Vincenzo Lagani, ICS FORTH, Greece Jan Larsen, Technical University of Denmark, Denmark Sune Lehmann, Technical University of Denmark, Denmark Jan Lemeire, Vrije Universiteit Brussel, Belgium Weifeng Liu, Amazon, USA Cassio G. Lopes, University of Sao Paulo, Brazil José Luis Rojo Álvarez, University Rey Juan Carlos, Spain Jiebo Luo, University of Rochester, USA Miguel Lázaro-Gredilla, Universidad Carlos III de Madrid, Spain Jesús Malo, Universitat de València, Spain Elias Manolakos, University of Athens, Greece Daniele Marinazzo, University of Gent, Belgium Manel Martínez-Ramón, Universidad Carlos III de Madrid, Spain Mamadou Mboup, Université de Reims, France

7
Joris Mooij, Radboud University Nijmegen, The Netherlands Eric Moreau, University of Toulon, France Juan José Murillo, Universidad de Sevilla, Spain Jordi Muñoz, Universitat de València, Spain Morten Mørup, Technical University of Denmark, Denmark Klaus-Robert Müller, TU Berlin, Germany Atsushi Nakamura, NTT Communication Science Laboratories, Japan Asoke K. Nandi, The University of Liverpool, UK Ángel Navia-Vázquez, Universidad Carlos III de Madrid, Spain Niamh O'Mahony, Universidad Carlos III de Madrid, Spain Pablo M. Olmos, Universidad de Sevilla, Spain Umut Orham, Northeastern University, USA Umut Ozertem, Microsoft, USA Francesco Palmieri, Seconda Università di Napoli, Italy Emilio Parrado, Universidad Carlos III de Madrid, Spain Jaakko Peltonen, Aalto University, Finland Jonas Peters, ETHZ, Switzerland José C. Príncipe, University of Florida, USA Shalini Purwar, Northeastern University, USA Raviv Raich, Oregon State University, USA Alain Rakotomamonjy, INSA-Rouen, France Peter Ramadge, University of Princeton, USA David Ramírez, Paderborn University, Germany Jesse Read, Universidad Carlos III de Madrid, Spain Sancho Salcedo Sanz, Universidad de Alcalá, Spain Ignacio Santamaría, Universidad de Cantabria, Spain Ali H. Sayed, University of California at Los Angeles, USA Peter Schreier, Paderborn University, Germany, Magno T. Silva, University of Sao Paulo, Brazil Konstantinos Slavakis, University of Peloponnese, Greece Paris Smaragdis, University of Illinois at Urbana Champaign, USA Jamshid Sourati, Northeastern University, USA Alberto Suárez, Universidad Autónoma de Madrid, Spain Michael Tangermann, TU Berlin, Germany Jianhua Tao, Chinese Academy of Sciences, China Sergios Theodoridis, University of Athens, Greece Jin Tian, Iowa State University, USA Tanaka Toshihisa, Tokyo University of Agriculture and Technology, Japan Sofia Triantafillou, ICS FORTH, Greece Devis Tuia, EPFL, Switzerland Steven Van Vaerenbergh, Universidad de Cantabria, Spain Javier Via, Universidad de Cantabria, Spain Enrique Vidal, Technical University of Valencia, Spain Jane Wang, The University of Bristish Columbia, Canada Yue Wang, Virginia Tech, USA Joost Van De Weijer, Computer Vision Center, Spain Luis Weruaga, Khalifa University of Science, Technology & Research (KUSTAR), UAE Yanxin Zhang, Palo Alto Networks, USA Kun Zhang, Max Plank Institute Tübingen, Germany

8
General Information
Welcome to Santander The beautiful seaside city of Santander has a lot to offer to visitors such us excellent beaches, a lively city center, interesting museums, beautiful gardens and astounding landscapes. Follow our tips and suggestions and make the most of your time in Santander.
Beaches of Santander There are several beaches in the city, most of them centrally located and well communicated by public transport such the beach of “Los Peligros”, close to the “Reina Victoria” avenue and the beach of “Los Bikinis” and “La Madgalena”, both located inside the Peninsula of “La Magdalena”. Also, the visitor can enjoy the beaches of “El Sardinero”, actually composed of four beaches, and a bit further away from the city centre, the beaches of “Molinucos” and “Mataleñas” close to the lighthouse, an area with beautiful cliffs and sights.
Shopping A number of stylish shopping districts are spread around Santander allowing tourists to easily find whatever is needed. Santander is different from most of the Spanish cities as its shopping area is not only concentrated within the city centre, but within the suburbs and near the airport. Particularly popular and on the city's outskirts is the “El Corte Inglés”, a shopping mall located on the “Polígono de Nueva Montaña”, in which you can find almost anything. Among other things, it holds a supermarket, cinemas, a huge selection of themed seaside souvenirs and much more. In the centre of Santander, the “Alameda de Oviedo” boulevard stretches from the “Cuatro Caminos” roundabout to the lively pedestrianized “Calle Burgos”, being lined with shops. If you are shopping in this area, you will likely encounter a number of street vendors, who will try and sell you anything from flowers and jewellery, to handbags, shoes and other fashion accessories. Also, passing the city hall, you will find a wide range of shops in the avenue of “Calvo Sotelo”, the streets of “San Francisco”, “Lealtad” and “Isabel II”.
Restaurants and dining Cantabrian cuisine is likely to be a highlight of any holiday in Santander, and many restaurants and eateries can be found within the city's old wine cellars, which are known to the locals as the “bodegas”. Dining out in Santander is always an enjoyable activity and the waterfront promenades are brimming with cafes and bars. Many of the bars in Santander serve tasty snacks and tapas, while others referred to as “bares de copas” just serve drinks, being in good numbers around the “Plaza de Cañadío”. A large number of restaurants and bars with separate dining rooms are to be found just a short stroll from the “Plaza de Cañadío”, on streets such as the “Calle de Daoiz y Velarde”, “Calle de Hernán Cortés”, “Peña Herbosa”, and “Río de la Pila”. Price

9
range varies from less than 10€ if it comes to tapas to 50€ if your choice is a high quality restaurant.
What to eat Santander is located between the sea and the mountains and has a mixture of both in its gastronomy. Typical dishes from the sea are "rabas" (fried squid), "bocartes rebozados" (whitebait), fresh fish and seafood. There are also excellent meat dishes such as “cocido montañés” (a stew made of beans, meat and cabbage) and traditional desserts like "quesada" (cheesecake), "sobaos pasiegos" (sponge cakes) and "corbatas" (puff pastry cakes).
Local Transportation in Santander Buses to Santander airport run from Santander bus station to the airport every 30 minutes (at quarter to and quarter past) from 6:30 am to 10:45 pm. It is also easily accessible by taxi, the ride costs around 15€. Buses to the Bilbao airport with the “Alsa Company” depart every half an hour from Santander bus station which is located in the heart of the city in “Plaza de Las Estaciones”. The same is applied for the arrivals, the buses leave Bilbao airport at quarter past and quarter to and drops you off there. To move from the city center to the Sardinero area where the Palacio Real de La Magdalena is and the majority of hotels are located, there are several public buses available (lines number 1, 2, 3, 4, 7C2, 13, 15) in different stops in the city. There is an exception for the Hotel Real because the only bus that stops there is line number 5. Municipal buses run throughout the city every 5 minutes. Buses number 1, 2, 3, 5, 6 7, 9, 13 and 20 run from the city center (City Hall “Ayuntamiento” for instance) to “El Sardinero” (“Plaza de Italia” for instance). The buses operate all day and just a few at night every half an hour until 5:00 am. Taxis offer a 24 hour service. There will be taxis stops waiting outside the train and bus stations, on “Vargas” street, “Paseo Pereda” and near the city hall. You can always order a taxi by phone at (+34) 942 333333. Since Santander is a small city, it is not expensive to move around by taxi. The ride from “El Sardinero” to the city center costs around 6€ in the day and 15€ in the night as the night carries a supplement. The taxi cabs are white with a blue line. Bus station Plaza de las Estaciones 39002 Santander Telephone: +34 942 211 995. Cantabria (Spain) www. transportedecantabria.es
Additional Information
• International Calling Code for Spain: 0034 • Language: Spanish

10
• Weather: Santander is under the influence of the oceanic or Atlantic climate, characterized by mild temperatures all year around, with a limited thermal variation. The average temperature in September is approximately 18°C.
• Time Zone: Europe • Electricity: Voltage in Spain is 220V and network frequency is 50Hz • Tipping: Tipping is not common in Spain, however, it is often expected in
restaurants and taxis. There is not a fixed percentage of service charges so you can tip as much as you wish to.
Insurance AFID Congresos, S.L. cannot accept responsibility for personal accidents or damage to the delegates’ private property. All delegates are therefore advised to ensure that they have their own insurance cover.
Currency and banks The official currency is Euro. The banks in Spain open from Monday to Friday from 8:30 to 14:00.

11
Conference Information
Venue The conference will be held at the Palacio Real de La Magdalena, whose peninsula boasts the landmark of the city. The Palace is surrounded by nature, beaches and offers spectacular views of the Bay of Santander. The Palacio Real de La Magdalena is the most emblematic building of Santander, does not have a definite style though he is catalogued like "eclectic picturesque", a mixture of English and French styles with incorporation of typical elements of the highland architecture. One finds placed in the peninsula of the same name, which has an extension of 28 hectares. The Tutorials on Sunday 23rd will take place at the “Riancho” Room and the Plenary Lectures and Oral Sessions will take place at the “Salón de Baile” on the main floor of the Royal Palace. Posters Sessions and coffee breaks will take place at Comedor I and Comedor II on the ground floor of the Palace. You can find below a map of the main and ground floors with the location of the different rooms. Palacio Real de La Magdalena Avda. de la Magdalena s/n 39005 Santander, Cantabria Telephone: +34 942 20 30 84
Palacio Real de La Magdalena main floor

12
Palacio Real de La Magdalena ground floor
Internet Access Wireless is provided throughout The Palacio Real de La Magdalena for your convenience. A username and a password will be provided upon registration along with the rest of documentation.
MLSP Bus A dedicated MLSP Bus is available in order to transfer MLSP attendees from Plaza de Italia (near of the MLSP Hotels and just in front of the Gran Casino de El Sardinero entrance) to the Palacio de La Magdalena venue. Bus departures will be on Monday at 8:30 and on Tuesday and Wednesday at 9:00.
Registration The registration will be located at the reception of the Palacio Real de La Magdalena on Sunday from 14:00 to 19:30, Monday from 8:30 to 19:30, Tuesday from 9:00 to 19:30 and Wednesday from 9:00 to 13:00.
Social Program Tickets are required for entry to the social events (except for the Welcome Reception). They will be given to the attendees along with the conference material upon registration. Please keep them with you and show them at the entrance of the venue
Welcome Reception Date: Sunday, September 23 Time: 20:30 – 21:30 Place: Palacio de la Magdalena, Hall Real

13
Luncheons Date: Monday 24 and Tuesday 25 Time: 13:00 – 15:00 Place: Real Sociedad de Tenis de la Magdalena The Real Sociedad de Tenis de la Magdalena is located short walking distance from The Royal Palace of The Magdalena (see map bellow).
Banquet Date: Tuesday, September 25 Time: 20:30 – 22:30 Place: Restaurante Gran Casino de El Sardinero A restaurant facing the El Sardinero magnificent beach. It is located in the emblematic building of the Grand Casino of El Sardinero, in one of the towers that flank the facade, it’s a must in Santander.
Boat trip and lunch in Pedreña Date: Wednesday, September 26 Time: 13:00 – 17:00 Place: Restaurante Marina de Pedreña, Pedreña The Local Organizing Committee has organized a boat trip and lunch in Pedreña as part of the Conference's social agenda. The Marina de Pedreña restaurant is located in Pedreña (the village of birth of the legendary golfer Severiano Ballesteros), in the middle of the bay so the way to get there is by small ferries called “Los Reginas”. There will be a shuttle bus waiting for all the participants at the Royal Palace of La Magdalena at 13:00 h. to take you to the “Embarcadero” for the boat trip to Pedreña
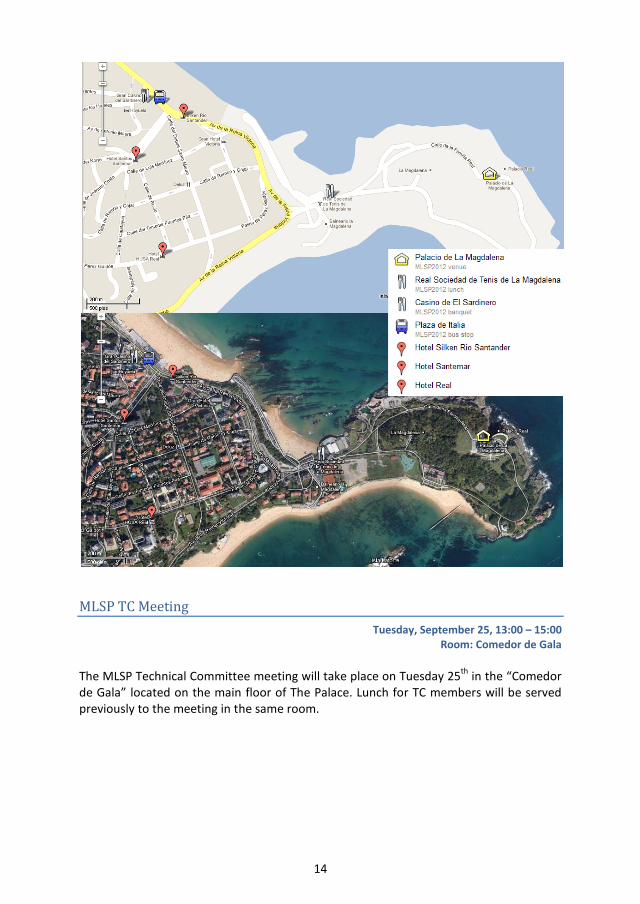
14
MLSP TC Meeting Tuesday, September 25, 13:00 – 15:00
Room: Comedor de Gala The MLSP Technical Committee meeting will take place on Tuesday 25th in the “Comedor de Gala” located on the main floor of The Palace. Lunch for TC members will be served previously to the meeting in the same room.

15
Technical Program
Tutorials
Privacy-Preserving Speech and Audio Processing Sunday, September 23, 15:00 – 17:00
Room: Riancho Bhiksha Raj Associate Professor, Carnegie Mellon University, USA
Bhiksha Raj is an Associate Professor in the Language Technologies Institute of the School of Computer Science at Carnegie Mellon University, with additional affiliations to the Electrical and Computer Engineering and Machine Learning departments. Dr. Raj obtained his PhD from CMU in 2000 and was at Mistubishi Electric Research Laboratories from 2001-2008. Dr. Raj's chief research interests lie in automatic speech recognition, computer audition, machine learning and data privacy. Dr. Raj's latest research interests lie in the newly emerging field of privacy-preserving speech processing, in which his research group has made several contributions.
Abstract The privacy of personal data has generally been considered inviolable. On the other hand, in nearly any interaction, whether it is with other people or with computerized systems, we reveal information about ourselves. Sometimes this is intended, for instance when we use a biometric system to authenticate ourselves, or when we explicitly provide personal information in some manner. Often, however, it is unintended; for instance a simple search performed on a server reveals information about our preferences. An interaction with a voice recognition system reveals information to the system about our gender, nationality (accent), and possibly emotional state and age. Regardless of whether the exposure of information is intentional or not, it could be misused, potentially setting us at financial, social and even physical risk. Those concerns about exposure of information have spawned a large and growing body of research, addressing various issues about how information may be leaked, and how to protect it. One area of concern is sound data, particularly voice. For instance, voice-authentication systems and voice-recognition systems are becoming increasingly popular and commonplace. However, in the process of using these services, a user exposes himself to potential abuse: as mentioned above the server, or an eavesdropper, may obtain unintended demographic information about the user by analyzing the voice and sell this information. It may edit recordings to create fake recordings the user never spoke. Other such issues can be listed. Merely encrypting the data for transmission does not protect the user, since the recipient (the server) must finally have access to the data in the clear (i.e. decrypted form) in order to perform its processing. In this tutorial, we will discuss solutions for privacy-preserving sound processing, which enable a user to employ sound- or voice-processing services without explosing

16
themselves to risks such as the above. We will describe the basics of privacy-preserving techniques for data processing, including homomorphic encryption, oblivious transfer, secret sharing, and secure-multiparty computation. We will describe how these can be employed to build secure "primitives" for computation, that enable users to perform basic steps of computation without revealing information. We will describe the privacy issues with respect to these operations. We will then briefly present schemes that employ these techniques for privacy-preserving signal processing and biometrics. We will then delve into uses for sound, and particularly voice processing, including authentication, classification and recognition, and discuss computational and accuracy issues. Finally we will present a newer class of methods based on exact matches built upon locality sensitive hashing and universal quantization, which enables several of the above privacy-preserving operations at a different operating point of privacy-accuracy tradeoff.
Manifold Learning: Modeling and Algorithms Sunday, September 23, 17:00 – 19:00
Room: Riancho Raviv Raich Assistant Professor, Oregon State University, USA
Raviv Raich is an assistant Professor of Electrical Engineering in the school of Electrical Engineering and Computer Science at Oregon State University. Raviv Raich received the B.Sc. and M.Sc. degrees from Tel Aviv University, Tel-Aviv, Israel, in 1994 and 1998, respectively, and the Ph.D. degree from Georgia Institute of Technology, Atlanta, in 2004, all in electrical engineering. From 2004 to 2007, he was a Postdoctoral Fellow with the University of Michigan, Ann Arbor. Since fall 2007, he has been an Assistant Professor in the School of Electrical Engineering and Computer
Science, Oregon State University, Corvallis. His main research interest is in statistical signal processing and machine learning.
Abstract Recent advances in data acquisition and high rate information sources give rise to high volume and high dimensional data. For such data, dimension reduction provides means of visualization, compression, and feature extraction for clustering or classification. In the last decade, a variety of methods for nonlinear dimensionality reduction have been a topic of ongoing research. In effort to alleviate the curse of dimensionality, it is often assumed that data possess a geometric structure which can be captured with a low dimensional representation. Dimension reduction focuses on the identification of a mapping from the high-dimensional data to a low-dimensional representation. When a collection of data points is assumed to reside on a hyper-plane, a linear transformation is sought after giving rise to well-known algorithms such as principal component analysis. Manifolds offer a generalization to linear spaces and present a natural alternative when the data points no longer reside on linear subspace. Manifold learning and data dimension reduction have many applications, e.g., visualization, classification, and information processing. Data

17
visualization in 2D or 3D provides further insight into the data structure, which can be used for either interpretation or data model selection. In this tutorial, we will present methods of dimensionality reduction used for analysis of high dimensional data. We will begin with an introduction of principled criteria for data dimension reduction. Specifically, we will introduce criteria for both supervised and unsupervised dimension reduction and their corresponding computational solutions. We will then continue with an introduction of a variety of approaches for geometric representation of data linking the high dimensional to its low dimensional representation for both linear and nonlinear models (e.g., via local neighborhood graphs or kernel methods). We will introduce optimization approaches for the different methods. Finally, we will review probabilistic approaches for nonlinear dimension reduction.
Plenary Lectures
Learning and Message-passing in Graphical Models Monday, September 24, 9:30 – 10:30
Room: Salón de Baile Martin Wainwright University of California at Berkeley, USA
Martin Wainwright joined the faculty at University of California at Berkeley in fall 2004, with a joint appointment between the Department of Statistics and the Department of Electrical Engineering and Computer Sciences. He received his Bachelor's degree in Mathematics from University of Waterloo, and his Ph.D. degree in Electrical Engineering and Computer Science (EECS) from Massachusetts Institute of Technology (MIT), for which he was awarded the George M. Sprowls Prize from the MIT EECS department in 2002. He is interested in large-scale statistical
models, and their applications to communication and coding, machine learning, and statistical signal and image processing. He has received an NSF-CAREER Award (2006), an Alfred P. Sloan Foundation Research Fellowship (2005), an Okawa Research Grant in Information and Telecommunications (2005), the 1967 Fellowship from the Natural Sciences and Engineering Research Council of Canada (1996--2000), and several outstanding conference paper awards. Abstract Graphical models provide a powerful framework for modeling complex dependencies in structured signals, including image and video data, language and text corpora, social networks, and biological data. They also come with distributed message-passing algorithms, which generalize the familiar Kalman and Viterbi algorithms, for statistical computation. In this talk, we discuss some recent advances in the use of graphical models, including low-complexity stochastic forms of sum-product message-passing, and computationally efficient algorithms for learning graphical structure from high-dimensional data. Based on joint work with Nima Noorshams and Po-Ling Loh, UC Berkeley.

18
Large-scale Convex Optimization for Machine Learning Tuesday, September 25, 9:30 – 10:30
Room: Salón de Baile Francis Bach PASCAL invited speaker INRIA, France
Francis Bach is a researcher in the Sierra INRIA project-team, in the Computer Science Department of the Ecole Normale Superieure, Paris, France. He graduated from the Ecole Polytechnique, Palaiseau, France, in 1997, and earned his PhD in 2005 from the Computer Science division at the University of California, Berkeley. His research interests include machine learning, statistics, optimization, graphical models, kernel methods, sparse methods and statistical signal processing. He has
been awarded a starting investigator grant from the European Research Council in 2009. Abstract Many machine learning and signal processing problems are traditionally cast as convex optimization problems. A common difficulty in solving these problems is the size of the data, where there are many observations ("large n") and each of these is large ("large p"). In this setting, online algorithms which pass over the data only once are usually preferred over batch algorithms, which require multiple passes over the data. In this talk, I will present several recent results, showing that in the ideal infinite-data setting, online learning algorithms based on stochastic approximation should be preferred, but that in the practical finite-data setting, an appropriate combination of batch and online algorithms leads to unexpected behaviors, such as a linear convergence rate with an iteration cost similar to stochastic gradient descent. Joint work with Nicolas Le Roux, Eric Moulines and Mark Schmidt.
Adaptation and Learning over Complex Networks Wednesday, September 26, 9:30 – 10:30
Room: Salón de Baile Ali H. Sayed University of California at Los Angeles, USA
Ali H. Sayed is Professor of Electrical Engineering at the University of California, Los Angeles (UCLA), where he directs the UCLA Adaptive Systems Laboratory. He is the author or coauthor of over 370 articles and 5 books. He is the author of the textbooks Adaptive Filters (New York: Wiley, 2008), and Fundamentals of Adaptive Filtering (New York: Wiley, 2003), and co-author of Linear Estimation (Prentice-Hall, 2000). Dr. Sayed's research interests span several areas including adaptation and learning, adaptive and cognitive networks, bio-
inspired networks, flocking and swarming behavior, cooperative behavior, distributed

19
processing, self-healing circuitry, and statistical signal processing. His research has been awarded several recognitions including the 1996 IEEE Donald G. Fink Prize, a 2002 Best Paper Award from the IEEE Signal Processing Society, the 2003 Kuwait Prize in Basic Sciences, the 2005 Frederick E. Terman Award, and a 2005 Young Author Best Paper Award from the IEEE Signal Processing Society. He served as Editor-in-Chief of the IEEE Transactions on Signal Processing (2003-2005) and the EURASIP Journal on Advances in Signal Processing (2006-2007). He also served as a 2005 Distinguished Lecturer of the IEEE Signal Processing Society, and as General Chairman of the 2008 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). He served as Vice-President-Publications of the IEEE Signal Processing Society (2009-2011), and as member of the Board of Governors (2007-2011) of the same society. Abstract Complex patterns of behavior are common in many biological networks, where no single agent is in command and yet forms of decentralized intelligence are evident. Examples include fish joining together in schools, birds flying in formation, bees swarming towards a new hive, and bacteria diffusing towards a nutrient source. While each individual agent in these biological networks is not capable of complex behavior, it is the combined coordination among multiple agents that leads to the manifestation of sophisticated order and learning abilities at the network level. The study of these phenomena opens up opportunities for collaborative research across several domains including economics, life sciences, biology, machine learning, and information processing, in order to address and clarify several relevant questions such as: (a) how and why organized and complex behavior arises at the group level from interactions among agents without central control? (b) What communication topologies enable the emergence of order at the higher level from interactions at the lower level? (c) How is information quantized during the diffusion of knowledge through the network? And (d) how does mobility influence the learning and tracking abilities of the agents and the network. Several disciplines are concerned in elucidating different aspects of these questions including evolutionary biology, animal behavior programs, physical biology, and also computer graphics. In the realm of machine learning and signal processing, these questions motivate the need to study and develop decentralized strategies for information processing that are able to endow cognitive networks with real-time adaptation and learning abilities. Cognitive networks consist of spatially distributed agents that are linked together through a connection topology. The topology may vary with time and the agents may also move. The agents cooperate with each other through local interactions and by means of in-network processing. Such networks are well-suited to perform decentralized information processing, decentralized optimization, and decentralized learning and inference tasks. They are also well-suited to model and understand self-organized and complex behavior encountered in nature and in social and economic networks. This presentation examines several patterns of decentralized intelligence in biological networks, and describes powerful diffusion adaptation and online learning strategies that our research group has been developing in recent years to model and reproduce these kinds of learning behavior over cognitive networks.

20
Oral Session 1: Pattern Recognition and Classification Monday, September 24, 11:00 – 13:00
Room: Salón de Baile Chair: Jan Larsen, DTU Informatics, Denmark
11:00-11:20 Facial Expression Recognition With Robust Covariance Estimation And Support Vector Machines
Vretos Nicholas, Tefas Anastasios, Pitas Ioannis
In this paper, a new framework for facial expression recognition is presented. A Support Vector Machine (SVM) variant is proposed, which makes use of robust statistics. We investigate the use of statistically robust location and dispersion estimators, in order to enhance the performance of a facial expression recognition algorithm by using the support vector machines. The efficiency of the proposed method is tested for two-class and multi-class classification problems. In addition to the experiments conducted in facial expression database we also conducted experiments on classification databases to provide evidence that our method outperforms state of the art methods.
11:20-11:40 Local Distance Metric Learning For Efficient Conformal Predictors
Michael Pekala, Ashley Llorens, I- Jeng Wang
Conformal prediction is a relatively recent approach to classification that offers a theoretical framework for generating predictions with precise levels of confidence. For each new object encountered, a conformal predictor outputs a set of class labels that contains the true label with probability at least 1-ε, where ε is a user-specified error rate. The ability to predict with confidence can be extremely useful, but in many real-world applications unambiguous predictions consisting of a single class label are preferred. Hence it is desirable to design conformal predictors to maximize the rate of singleton predictions, termed the efficiency of the predictor. In this paper we derive a novel criterion for maximizing efficiency for a certain class of conformal predictors, show how concepts from local distance metric learning can provide a useful bound for maximizing this criterion, and demonstrate efficiency gains on real-world datasets.
11:40-12:00 Simultaneous And Proportional Control Of 2D Wrist Movements With Myoelectric Signals
Janne Mathias Hahne, Hubertus Rehbaum, Felix Biessmann, Frank C. Meinecke, Klaus-Robert Müller, Ning Jiang, Dario Farina, Lucas C. Parra
Previous approaches for extracting real-time proportional control information simultaneously for multiple degrees of Freedom (DoF) from the electromyogram (EMG) often used non-linear methods such as the multilayer perceptron (MLP). In this pilot study we show that robust control is also possible with conventional linear regression if EMG power measures are available for a large number of electrodes. In particular, we show that it is possible to linearize the problem with simple nonlinear transformations of band-pass power. Because of its simplicity the method scales well to high dimensions, is easily regularized when insufficient training data is available, and is particularly well suited for real-time control as well as on-line optimization.
12:00-12:20 Landmine Detection With Multiple Instance Hidden Markov Models
Seniha Esen Yuksel, Jeremy Bolton, Paul Gader
A novel Multiple Instance Hidden Markov Model (MI-HMM) is introduced for classification of ambiguous time-series data, and its training is accomplished via Metropolis-Hastings sampling. Without introducing any additional parameters, the MI-HMM provides an elegant and simple way to learn the parameters of an HMM in a Multiple Instance Learning (MIL) framework. The efficacy of the model is shown on a real landmine dataset. Experiments on the landmine dataset show that MI-HMM learning is very effective, and outperforms the state-of-the-art models that are currently being used in the field for landmine detection.

21
12:20-12:40 Handling Missing Features In Maximum Margin Bayesian Network Classifiers
Sebastian Tschiatschek, Nikolaus Mutsam, Franz Pernkopf
The Comprehensive Nuclear-Test-Ban Treaty Organization (CTBTO) records hydroacoustic data to detect nuclear explosions. This enables verification of the Comprehensive Nuclear-Test-Ban Treaty once it has entered into force. The detection can be considered as a classification problem discriminating noise-like, earthquake-caused and explosion-like data. Classification of the recorded data is challenging because it suffers from large amounts of missing features. While the classification performance of support vector machines has been evaluated, no such results for Bayesian network classifiers are available. We provide these results using classifiers with generatively and discriminatively optimized parameters and employing different imputation methods. In case of discriminatively optimized parameters, Bayesian network classifiers slightly outperform support vector machines. For optimizing the parameters discriminatively, we extend the formulation of maximum margin Bayesian network classifiers to missing features and latent variables. The advantage of these classifiers over classifiers with generatively optimized parameters is demonstrated in experiments.
12:40-13:00 Classifier-Based Affinities For Clustering Sets Of Vectors
Darío García-García, Raúl Santos-Rodríguez, Emilio Parrado-Hernández
We focus on the task of clustering sets of vectors. This can be seen as a special case of sequence clustering when the dynamics are not taken into account. We propose to use the error probability of binary classifiers to obtain a measure of the affinity between two sets so that a standard similarity-based clustering algorithm can be applied.
Poster Session 1.A: Biomedical Applications Monday, September 24, 15:00 – 17:00
Room: Comedor I Chair: Emilio Parrado-Hernández, Universidad Carlos III de Madrid, Spain
1. ECG-Based Biometrics: A Real Time Classification Approach
Andre Lourenco, Hugo Silva, Ana Fred
Behavioral biometrics is one of the areas with growing interest within the biosignal research community. A recent trend in the field is ECG-based biometrics, where electrocardiographic (ECG) signals are used as input to the biometric system. Previous work has shown this to be a promising trait, with the potential to serve as a good complement to other existing, and already more established modalities, due to its intrinsic characteristics. In this paper, we propose a system for ECG biometrics centered on signals acquired at the subject’s hand. Our work is based on a previously developed custom, non-intrusive sensing apparatus for data acquisition at the hands, and involved the pre-processing of the ECG signals, and evaluation of two classification approaches targeted at real-time or near real-time applications. Preliminary results show that this system leads to competitive results both for authentication and identification, and further validate the potential of ECG signals as a complementary modality in the toolbox of the biometric system designer.
2. Prediction Of Respiratory Motion Using Wavelet Based Support Vector Regression
Robert Dürichen, Tobias Wissel, Achim Schweikard
In order to successfully ablate moving tumors in robotic radiosurgery, it is necessary to compensate the motion of inner organs caused by respiration. This can be achieved by track-ing the body surface and correlating the external movement with the tumor position as it is implemented in CyberKnife Synchrony. Due to time delays, errors occur which can be reduced by time series prediction. A new prediction algorithm is presented, which combines a trous wavelet decomposition and support vector regression (wSVR). The algorithm was tested and optimized by grid search on simulated as well as on real patient data set. For these real data, wSVR outperformed a wavelet based least mean square (wLMS) algorithm by > 13% and standard Support Vector

22
Regression (SVR) by > 7.5%. Using approximate estimates for the optimal parameters wSVR was evaluated on a data set of 20 patients. The overall results suggest that the new approach combines beneficial characteristics in a promising way for accurate motion prediction.
3. Kernel-Based Parametric Validity Index For Assessing Clusters From Microarray Gene Expression Data
Rui Fa, Asoke K. Nandi
In this paper, we develop a kernel-based parametric validity index (KPVI), which not only inherits robust feature from the newly proposed PVI, but possesses extra superiority inherited from the kernel method. The KPVI employs the kernel method to calculate both the inter-cluster and the intra cluster dissimilarities. Furthermore, we develop several rules to guide the selection of parameter values by examining the dissimilarity densities of different datasets such that the maximal appropriate values of the parameters for individual dataset can be obtained. We evaluate the new KPVI for assessing five clustering algorithms in both synthetic and real gene expression datasets. The experimental results support that the KPVI has the most superior performance among the existing validation algorithms, even better than the PVI.
4. Long Term Human Activity Recognition With Automatic Orientation Estimation
Blanca Florentino-Liaño, Niamh O’mahony, Antonio Artés-Rodríguez
This work deals with the elimination of sensitivity to sensor orientation in the task of human daily activity recognition us- ing a single miniature inertial sensor. The proposed method detects time intervals of walking, automatically estimating the orientation in these intervals and transforming the observed signals to a "virtual" sensor orientation. Classification results show that excellent performance, in terms of both precision and recall (up to 100%), is achieved, for long-term recordings in real-life settings.
5. ESWT-Tracking Organs During Focused Ultrasound Surgery
C. Grozea, D. Luebke, F. Dingeldey, M. Schiewe, J. Gerhardt, C. Schumann, J. Hirsch
We report here our results in a multi-sensor setup reproducing the conditions of an automated focused ultrasound surgery environment. The aim is to continuously predict the position of an internal organ (here the liver) under guided and non-guided free breathing, with the accuracy required by surgery. We have performed experiments with 16 healthy human subjects, two of those taking part in full-scale experiments involving a 3 Tesla MRI machine recording a volume containing the liver. For the other 14 subjects we have used the optical tracker as a surrogate target. All subjects where volunteers who agreed to participate in the experiments after being thoroughly informed about it For the MRI sessions we have analyzed semi-automatically offline the images in order to obtain the ground truth, the true position of the selected feature of the liver. The results we have obtained with continuously updated random forest models are very promising, we have obtained good prediction-target correlation coefficients for the surrogate targets (0.71+/-0.1) and excellent for the real targets in the MRI experiments (over 0.91), despite being limited to a lower model update frequency, once every 6.16 seconds.
6. Breast Ultrasound Images Gland Segmentation
Rui Braz, António M. G. Pinheiro, J. Moutinho, Mário Freire, Manuela Pereira
This paper introduces a study for the segmentation of the breast ultrasound images. The objective is to separate the breast gland, which is the region of interest for the breast cancer diagnosis, from other tissues. Images are pre-processed with four different algorithms that consider the image surrounding: speckle reducing anisotropic diffusion, homomorphic filter, Perona and Malik non -linear diffusion and Moran index. For each image pixel a four bins descriptor is created composed by the corresponding pixels of each of these pre-processed images. The segmentation is based on the classification of the image pixel descriptors, using two methods: the unsupervised K-means and the supervised Support Vector Machines. Using the separation between regions that result from the pixel classification, a set of heuristic rules is established in order to provide a separation line between the two regions. For training and testing, a breast ultrasound database collected at "Hospital da Cova da Beira" is used.

23
7. Blind Separation Of Ballistocardiogram From EEG Via Short And Long-Term Linear Prediction Filtering
Saideh Ferdowsi, Vahid Abolghasemi, Saeid Sanei
In this paper the problem of removing ballistocardiogram (BCG) artifact from EEG signals is addressed. This kind of artifact appears in simultaneous EEG-fMRI recordings. We propose a new Blind source extraction method based on linear prediction technique. The proposed method is a joint short-and-long-term prediction (SLTP) strategy to extract the BCG sources. The main reason of using this technique is to jointly model the temporal structure (short-term prediction) of sources and exploiting the prior information of BCG sources (long-term prediction). The results of extensive experiments on both synthetic and real data confirm the strength of the proposed technique to effectively remove the BCG artifact.
8. Ultra Low Power Automaton For Heartbeat Classification Based On Integrate And Fire Sampler.
Gabriel Nallathambi, José C. Príncipe, Choudur Lakshminarayan
In this paper, we propose a novel methodology for the classification of heart arrhythmias which is a major cause of fatalities in patients with cardiovascular diseases. We focus especially on a type of arrhythmia known as the premature ventricular contraction. The classification scheme is based on deterministic finite state automata and can be implemented in ultra low power electronics. The signal encoding is based on the integrate and fire (IF) sampler and the diagnostics are performed directly on the pulses obtained from the IF with a set of grammatical rules. The time encoded morphological features are derived from the pulses and classification depends exclusively on relational and logical operators resulting in ultra fast recognition. The algorithm was evaluated using the MIT-BIH arrhythmia database and results show that our algorithm is comparable to the state of the art algorithms proposed in the literature
9. Comprehensive Analysis Of Multiple Microarray Datasets By Binarization Of Consensus Partition Matrix
Basel Abu-Jamous, Rui Fa, David J. Roberts, Asoke K. Nandi
Clustering methods have been increasingly applied over gene expression datasets. Different results are obtained when different clustering methods are applied over the same dataset as well as when the same set of genes is clustered in different microarray datasets. Most approaches cluster genes" profiles from only one dataset, either by a single method or an ensemble of methods; we propose using the binarization of consensus partition matrix (Bi-CoPaM) method to analyze comprehensively the results of clustering the same set of genes by different clustering methods and from different datasets. A tunable consensus result is generated and can be tightened or widened to control the assignment of the doubtful genes that have been assigned to different clusters in different individual results. We apply this over a subset of 384 yeast genes by using four clustering methods and five microarray datasets. The results demonstrate the power of Bi-CoPaM in fusing many different individual results in a tunable consensus result and that such comprehensive analysis can overcome many of the defects in any of the individual datasets or clustering methods.
10. Observer And Feature Analysis On Diagnosis Of Retinopathy Of Prematurity
Esra Ataer-Cansizoglu, Sheng You, Jayashree Kalpathy-Cramer, Katie Keck, Michael F. Chiang, Deniz Erdogmus
Retinopathy of prematurity (ROP) is a disease affecting low-birth weight infants and is a major cause of childhood blindness. However, human diagnoses is often subjective and qualitative. We propose a method to analyze the variability of expert decisions and the relationship between the expert diagnoses and features. The analysis is based on Mutual Information and Kernel Density Estimation on features. The experiments are carried out on a dataset of 34 retinal images diagnosed by 22 experts. The results show that a group of observers decide consistently with each other and there are popular features that have a high correlation with labels.

24
11. Level Sets For Retinal Vasculature Segmentation Using Seeds From Ridges And Edges From Phase MAPs
Bekir Dizdaroğlu, Esra Ataer-Cansizoglu, Jayashree Kalpathy-Cramer, Katie Keck, Michael F. Chiang, Deniz Erdogmus
In this paper, we present a novel modification to level set based automatic retinal vasculature segmentation approaches. The method introduces ridge sample extraction for sampling the vasculature centerline and phase map based edge detection for accurate region boundary detection. Segmenting the vasculature in fundus images has been generally challenging for level set methods employing classical edge-detection methodologies. Furthermore, initialization with seed points determined by sampling vessel centerlines using ridge identification makes the method completely automated. The resulting algorithm is able to segment vasculature in fundus imagery accurately and automatically. Quantitative results supplemented with visual ones support this observation. The methodology could be applied to the broader class of vessel segmentation problems encountered in medical image analytics.
12. Neural Spike Detection And Localisation Via Volterra Filtering
Mamadou Mboup
The spike detection problem is cast into a delay estimation. Using elementary operational calculus, we obtain an explicit characterization of the spike locations, in terms of short time window iterated integrals of the noisy signal. From this characterization, we derive a joint spike detection and localization system where the decision function is implemented as the output of a digital Volterra filter. Simulation results using experimental data shows that the method compares favorably with one of the most successful one in the literature.
13. Complex-Valued Analysis And Visualization Of FMRI Data For Event-Related And Block-Design Paradigms
Pedro A. Rodriguez, Vince D. Calhoun, Tulay Adali
Independent Component Analysis (ICA) has been noted to be promising for the study of functional magnetic resonance imaging (fMRI) data also in its native complex-valued form. In this paper, we demonstrate the first successful application of group ICA to complex-valued fMRI data of an event- related paradigm. We show that networks associated with event-related responses as well as intrinsic fluctuations of hemodymamic activity can be extracted for data collected during an auditory oddball paradigm. The intrinsic networks are of particular interest due to their potential to study cognitive function and mental illness, including schizophrenia. More importantly, we show that analysis of fMRI data in its complex form can increase the sensitivity and specificity in the detection of activated brain regions both for event-related and block design paradigms when compared to magnitude-only applications. In addition, we introduce a novel fMRI phase-based visualization (FPV) technique to identify activated voxels such that the complex nature of the data is fully taken into account.
14. Sequential Nonnegative Tucker Decomposion On Multi-Way Array Of Time-Frequency Transformed Event-Related Potentials
Fengyu Cong, Guoxu Zhou, Qibin Zhao, Qiang Wu, Asoke K. Nandi, Tapani Ristaniemi, Andrzej Cichocki
Tensor factorization has exciting advantages to analyze EEG for simultaneously exploiting its information in the time, frequency and spatial domains as well as for sufficiently visualizing data in different domains concurrently. Event-related potentials (ERPs) are usually investigated by the group-level analysis, for which tensor factorization can be used. However, sizes of a tensor including time-frequency representation of ERPs of multiple channels of multiple participants can be immense. It is time-consuming to decompose such a tensor. The low-rank approximation based sequential nonnegative Tucker decomposition (LraSNTD) has been recently developed and shown to be computationally efficient with respect to some benchmark datasets. Here, LraSNTD is applied to decompose a fourth-order tensor representation of ERPs. We find that the decomposed results from LraSNTD and a benchmark nonnegative Tucker decomposition algorithm are very similar. So, LraSNTD is promising for ERP studies.

25
15. Sparse Spectral Analysis Of Atrial Fibrillation Electrograms
Sandra Monzón, Tom Trigano, David Luengo, Antonio Artés-Rodríguez
Atrial fibrillation (AF) is a common heart disorder. One of the most prominent hypotheses about its initiation and maintenance considers multiple uncoordinated activation foci inside the atrium. However, the implicit assumption behind all the signal processing techniques used for AF, such as dominant frequency and organization analysis, is the existence of a single regular component in the observed signals. In this paper we take into account the existence of multiple foci, performing a spectral analysis to detect their number and frequencies. In order to obtain a cleaner signal on which the spectral analysis can be performed, we introduce sparsity-aware learning techniques to infer the spike trains corresponding to the activations. The good performance of the proposed algorithm is demonstrated both on synthetic and real data.
Poster Session 1.B: Image and Video Processing Applications Monday, September 24, 15:00 – 17:00
Room: Comedor II Chair: Jesús Ibáñez, Universidad de Cantabria, Spain
1. Exemplar-Based Image Inpainting: Fast Priority And Coherent Nearest Neighbor Search
Raul Martinez-Noriega, Aline Roumy, Gilles Blanchard
Greedy exemplar-based algorithms for inpainting face two main problems, decision of filling-in order and selection of good exemplars from which the missing region is synthesized. We propose an algorithm that tackles these problems with improvements in the preservation of linear edges, and reduction of error propagation compared to well-known algorithms from the literature. Our improvement in the filling-in order is based on a combination of priority terms, previously defined by Criminisi, that better encourages the early synthesis of linear structures. The second contribution helps reducing the error propagation thanks to a better detection of outliers from the candidate patches carried. This is obtained with a new metric that incorporates the whole information of the candidate patches. Moreover, our proposal has significant lower computational load than most of the algorithms used for comparison in this paper.
2. Differential Edit Distance As A Countermeasure To Video Scene Ambiguity
Panagiotis Sidiropoulos, Vasileios Mezaris, Ioannis Kompatsiaris
In this work the problem of how to evaluate video scene segmentation results is examined. The evaluation, which is typically conducted by comparison of the experimental output of scene segmentation algorithms with a ground-truth temporal decomposition, often suffers from ambiguity in the definition of the ground truth. To alleviate this drawback the use of a string comparison measure, called differential edit distance (DED), is proposed. After defining video scene segmentation evaluation as a string comparison problem, the proposed measure is applied to limit the effect of scene segmentation ambiguity in the performance estimation uncertainty. The experimental results, which include comparisons with state of the art evaluation measures, demonstrate the ambiguity extent and verify the validity of the conducted analysis.
3. Towards Dictionary Learning From Images With Non Gaussian Noise
P. Chainais
We address the problem of image dictionary learning from noisy images with non Gaussian noise. This problem is difficult. As a first step, we consider the extreme sparse code given by vector quantization, i.e. each pixel is finally associated to 1 single atom. For Gaussian noise, the natural solution is K-means clustering using the sum of the squares of differences between gray levels as the dissimilarity measure between patches. For non Gaussian noises (Poisson, Gamma,...), a new measure of dissimilarity between noisy patches is necessary. We study the use of the generalized likelihood ratios (GLR) recently introduced by Deledalle et al. in [1] to compare non Gaussian noisy patches. We propose a K-medoids algorithm generalizing the usual Linde-Buzo-Gray K-means using the GLR based dissimilarity measure. We obtain a vector quantization which provides a dictionary that can be very large and redundant. We illustrate our approach by dictionaries learnt from images featuring non Gaussian noise, and present preliminary denoising results.

26
4. Fusion Of Local Degradation Features For No-Reference Video Quality Assessment
Martin Dimitrievski, Zoran Ivanovski
We propose a blind/No-Reference Video Quality Assessment (NR-VQA) algorithm using models for visibility of local spatio-temporal degradations. The paper focuses on the specific degradations present in H.264 coded videos and their impact on perceived visual quality. Joint and marginal distributions of local wavelet coefficients are used to train Epsilon Support Vector Regression (ε-SVR) models for specific degradation levels in order to predict the overall subjective scores. Separate models for low/medium/high activity regions within the video frames are considered, inspired from the nature of H.264 coder behavior. Experimental results show that blind assessment of video quality is possible as the proposed algorithm output correlates highly with human perception of quality.
5. Context Dependent Spectral Unmixing
Hamdi Jenzri, Hichem Frigui, Paul Gader
A hyperspectral unmixing algorithm that finds multiple sets of endmembers is introduced. The algorithm, called Context Dependent Spectral Unmixing (CDSU), is a local approach that adapts the unmixing to different regions of the spectral space. It is based on a novel objective function that combines context identification and unmixing into a joint function. This objective function models contexts as compact clusters and uses the linear mixing model as the basis for unmixing. The unmixing provides optimal endmembers and abundances for each context. An alternating optimization algorithm is derived. The performance of the CDSU algorithm is evaluated using synthetic and real data. We show that the proposed method can identify meaningful and coherent contexts, and appropriate endmembers within each context.
6. A Kullback-Leibler Divergence Approach For Wavelet-Based Blind Image Deconvolution
Abd-Krim Seghouane, Muhammad Hanif
A new algorithm for wavelet-based blind image restoration is presented in this paper. It is obtained by defining an intermediate variable to characterize the original image. Both the original image and the additive noise are modeled by multivariate Gaussian process. The blurring process is specified by its point spread function, which is unknown. The original image and the blur are estimated by alternating minimization of the KullbackLeibler divergence between a model family of probability distributions defined using a linear image model and a desired family of probability distributions constrained to be concentrated on the observed data. The intermediate variable is used to introduce regularization in the algorithm. The algorithm presents the advantage to provide closed form expressions for the parameters to be updated and to converge only after few iterations. A simulation example that illustrates the effectiveness of the proposed algorithm is presented.
7. Microvascular Blood Flow Estimation In Sublingual Microcirculation Videos Based On A Principal Curve Tracing Algorithm
Sheng You, Esra Ataer-Cansizoglu, Deniz Erdogmus, Michael Massey, Nathan Shapiro
Microcirculatory perfusion is an important metric for diagnosing pathological conditions in patients. Capillary density and red blood cell (RBC) velocity provide a measure of tissue perfusion. Estimating RBC velocity is a challenging problem due to noisy video sequences, low contrast between the vessels and the background, and thousands of RBCs moving rapidly through video sequences. Typically, physicians manually trace small blood vessels and visually estimate RBC velocities. The task is labor intensive, tedious, and time-consuming. In this paper, we present a novel application of a principal curve tracing algorithm to automatically track RBCs across video frames and estimate their velocity based on the displacements of RBCs between two consecutive frames. The proposed method is implemented in one sublingual microcirculation video of a healthy subject.
8. Constrained Spectral Clustering For Image Segmentation
Jamshid Sourati, Dana H. Brooks, Jennifer G. Dy, Deniz Erdogmus
Constrained spectral clustering with affinity propagation in its original form is not practical for large scale problems like image segmentation. In this paper we employ novelty selection sub-sampling strategy, besides

27
using efficient numerical eigen-decomposition methods to make this algorithm work efficiently for images. In addition, entropy-based active learning is also employed to select the queries posed to the user more wisely in an interactive image segmentation framework. We evaluate the algorithm on general and medical images to show that the segmentation results will improve using constrained clustering even if one works with a subset of pixels. Furthermore, this happens more efficiently when pixels to be labeled are selected actively.
9. Hidden Markov Models For Detecting Anomalous Fish Trajectories In Underwater Footage
C. Spampinato, S. Palazzo
In this paper we propose an automatic system for the identification of anomalous fish trajectories extracted by processing underwater footage. Our approach exploits Hidden Markov Models (HMMs) to represent and compare trajectories. Multi-Dimensional Scaling (MDS) is applied to project the trajectories onto a low-dimensional vector space, while preserving the similarity between the original data. Usual or normal events are then defined as set of trajectories clustered together, on which HMMs are trained and used to check whether a new trajectory matches one of the usual events, or can be labeled as anomalous. This approach was tested on 3700 trajectories, obtained by processing a set of underwater videos with state-of-art object detection and tracking algorithms, by assessing its capability to distinguish between correct trajectories and erroneous ones due, for in- stance, to object occlusions, tracker misassociations and background movements.
10. Online Learning For Quality-Driven Unequal Protection Of Scalable Video
Amin Abdel Khalek, Constantine Caramanis, Robert W. Heath Jr.
Video packet losses affect perceived video quality non-uniformly due to several factors related to video encoding such as inter-frame coding and motion compensation as well as due to psycho-visual perception of natural scenes with unequal motion. This motivates protecting video packets unequally based on their loss visibility. This paper proposes an adaptive online algorithm for unequal error protection driven by two key motivations: On one hand, for real-time video, where a video sequence is not pre-encoded, an offline approach is infeasible and determining the unequal protection levels to maintain a target video quality level must be performed online. On the other hand, an online approach enables adapting to scene changes as well as changes in video temporal and spatial characteristics. The proposed online algorithm uses local linear regression to learn the mapping between packet losses from each scalable video layer and quality degradation without assuming an underlying statistical model. The notion of locality captures the similarity in video scene characteristics as well as proximity in time. The algorithm provably guarantees an average target video quality level and converges rapidly to a stable solution. Furthermore, it provides a bias/variance tradeoff between factual estimation of loss visibility and fine adaptation to the changing video temporal characteristics.
11. Fast Design Of Efficient Dictionaries For Sparse Representations
Cristian Rusu
One of the central issues in the field of sparse representations is the design of overcomplete dictionaries with a fixed sparsity level from a given dataset. This article describes a fast and efficient procedure for the design of such dictionaries. The method implements the following ideas: a reduction technique is applied to the initial dataset to speed up the upcoming procedure; the actual training procedure runs a more sophisticated iterative expanding procedure based on K-SVD steps. Numerical experiments on image data show the effectiveness of the proposed design strategy.
12. Efficient High Dynamic Range Imaging Via Matrix Completion
Grigorios Tsagkatakis, Panagiotis Tsakalides
Typical digital cameras exhibit a limitation regarding the dynamic range of the scene radiance they can capture. High Dynamic Range (HDR) imaging refers to methods and systems that aim to generate images that exhibit higher dynamic range between the lightest and the darkest parts of the an image. A typical approach for generating HDR images is exposure bracketing where multiple frames, each one with a different exposure setting, are captured and combined to a HDR image of the scene. The large number of images that exposure bracketing requires often leads to motion artefacts that limit the visual quality of the resulting HDR image. In this work, we propose a novel approach in HDR imaging that significantly reduces the necessary number of images. In our proposed system, we employ the notion of random exposure where each pixel of a single frame collects light for a random amount of time. By collecting a small number of such images, the full sequence of

28
low dynamic range images can be reconstructed and subsequently used for HDR generation. The problem is solved by casting the reconstruction of the sequence as a nuclear norm minimization problem following the premises of the recently proposed theory of Matrix Completion. Experimental results suggest that the proposed method is able to reconstruct the sequence from as low as 20% of the images that traditional techniques require with minimal reduction in image quality.
Poster Session 2.A: Speech, Audio and Music Applications Monday, September 24, 17:30 – 19:30
Room: Comedor I Chair: Weifeng Liu, Amazon, USA
1. Nonnegative Matrix Factorization Based Self-Taught Learning With Application To Music Genre Classification
Konstantin Markov, Tomoko Matsui
Availability of large amounts of raw unlabeled data has sparked the recent surge in semi-supervised learning research. In most works, however, it is assumed that labeled and unlabeled data come from the same distribution. This restriction is removed in the self-taught learning approach where unlabeled data can be different, but nevertheless have similar structure. First, a representation is learned from the unlabeled data via non-negative matrix factorization (NMF) and then it is applied to the labeled data used for classification. In this work, we implemented this method for the music genre classification task using two different databases: one as unlabeled data pool and the other for supervised classifier training. Music pieces come from 10 and 6 genres for each database respectively, while only one genre is common for both of them. Results from wide variety of experimental settings show that the self-taught learning method improves the classification rate when the amount of labeled data is small and, more interestingly, that consistent improvement can be achieved for a wide range of unlabeled data sizes.
2. Joint Feature And Model Training For Minimum Detection Errors Applied To Speech Subword Detection
Magne H. Johnsen, Alfonso Canterla
This paper presents methods and results for joint optimization of the feature extraction and the model parameters of a detector. We further define a discriminative training criterion called Minimum Detection Error (MDE). The criterion can optimize the F-score or any other detection performance metric. The methods are used to design detectors of subwords in continuous speech, i.e. to spot phones and articulatory features. For each subword detector the MFCC filterbank matrix and the Gaussian means in the HMM models are jointly optimized. For experiments on TIMIT, the optimized detectors clearly outperform the baseline detectors and also our previous MCE based detectors. The results indicate that the same performance metric should be used for training and test and that accuracy outperforms F-score with respect to relative improvement. Further, the optimized filterbanks usually reflect typical acoustic properties of the corresponding detection classes.
3. Improving Sparse Echo Cancellation Via Convex Combination Of Two NLMS Filters With Different Lengths
Álvaro Gonzalo-Ayuso, Magno T. M. Silva, Vítor H. Nascimento, Jerónimo Arenas-García
In this paper, we propose a scheme for sparse echo cancellation which uses a convex combination of two normalized least-mean-squares (NLMS) filters with different lengths. As is normally the case in acoustic echo cancellation, the first filter includes a large number of taps to guarantee that the active (i.e., non-null) coefficients of the true echo path are correctly identified. The second filter is a shorter and faster one, intended to span just the region of active coefficients. To identify this active region, we present a method based on clustering of the combined filter coefficients. We also propose two different combination strategies that simultaneously improve steady-state and convergence performance. When the echo path is very sparse, the computational cost incurred by our schemes is just slightly higher than that of a single NLMS filter. Simulation results show the superior performance of the proposed schemes when compared to other methods in the literature.

29
4. Redundant Time-Frequency Marginals For Chirplet Decomposition
Luis Weruaga
This paper presents the foundations of a novel method for chirplet signal decomposition. In contrast to basis pursuit techniques on over-complete dictionaries, the proposed method uses a reduced set of adaptive parametric chirplets. The estimation criterion corresponds to the maximization of the likelihood of the chirplet parameters from redundant time–frequency marginals. The optimization algorithm that results from this scenario combines Gaussian mixture models and Huber’s robust regression in an iterative fashion. Simulation results support the proposed avenue.
5. Single-Sided Objective Speech Intelligibility Assessment Based On Sparse Signal Representation
Giovanni Costantini, Massimiliano Todisco, Renzo Perfetti, Andrea Paoloni, Giovanni Saggio
Transcription of speech signals, originating from a lawful interception, is particularly important in the forensic phonetics framework. These signals are often degraded and the transcript may not replicate what was actually pronounced. In the absence of the clean signal, the only way to estimate the level of accuracy that can be obtained in the transcription is to develop an objective methodology for intelligibility measurements. In this paper a method based on the Normalized Spectrum Envelope (NSE) and Sparse Non-negative Matrix Factorization (SNMF) is proposed to evaluate the signal intelligibility. The approaches are tested with three different noise types and the results are compared with the speech intelligibility scores measured by subjective tests. The results of the experiments show a high correlation between objective measurements and subjective evaluations. Therefore, the proposed methodology can be successfully used in order to establish whether a given intercepted signal can be transcribed with sufficient reliability.
6. Language Informed Bandwidth Expansion
Jinyu Han, Gautham J. Mysore, Bryan Pardo
High-level knowledge of language helps the human auditory system understand speech with missing information such as missing frequency bands. The automatic speech recognition community has shown that the use of this knowledge in the form of language models is crucial to obtaining high quality recognition results. In this paper, we apply this idea to the bandwidth expansion problem to automatically estimate missing frequency bands of speech. Specifically, we use language models to constrain the recently proposed non-negative hidden Markov model for this application. We compare the proposed method to a bandwidth expansion algorithm based on non-negative spectrogram factorization and show improved results on two standard signal quality metrics.
7. 2D Sound-Source Localization On The Binaural Manifold
Antoine Deleforge, Radu Horaud
The problem of 2D sound-source localization based on a robotic binaural setup and audio-motor learning is addressed. We first introduce a methodology to experimentally verify the existence of a locally-linear bijective mapping between sound-source positions and high-dimensional interaural data, using manifold learning. Based on this local linearity assumption, we propose an novel method, namely probabilistic piecewise affine regression, that learns the localization-to-interaural mapping and its inverse. We show that our method outperforms two state-of-the art mapping methods, and allows to achieve accurate 2D localization of natural sounds from real world binaural recordings.
8. Optimal Cost Function And Magnitude Power For NMF-Based Speech Separation And Music Interpolation
Brian King, Cédric Févotte, Paris Smaragdis
There has been a significant amount of research in new algorithms and applications for nonnegative matrix factorization, but relatively little has been published on practical considerations for real-world applications, such as choosing optimal parameters for a particular application. In this paper, we will look at two applications, single-channel source separation of speech and interpolating missing music data. We will present the optimal parameters found for the experiments as well as discuss how parameters affect performance.

30
9. Noise-Robust Digit Recognition With Exemplar-Based Sparse Representations Of Variable Length
Emre Yilmaz, Jort F. Gemmeke, Dirk Van Compernolle, Hugo Van Hamme
This paper introduces an exemplar-based noise-robust digit recognition system in which noisy speech is modeled as a sparse linear combination of clean speech and noise exemplars. Exemplars are rigid long speech units of different lengths, i.e. no warping mechanism is used for exemplar matching to avoid poor time alignments that would otherwise be provoked by the noise and the natural duration distribution of each unit in the training data is preserved. Speech and noise separation is performed by applying non-negative sparse coding using a separate exemplar dictionary for each labeled unit (in this case half-digits) rather than a single dictionary of all units. This approach does not only provide better classification of speech units but also models the temporal structure of speech and noise more accurately. The system performance is evaluated on the AURORA-2 database. The results show that the proposed system performs significantly better than a comparable system using a single dictionary at positive SNR levels.
10. Pattern Search In Dysfluent Speech
Juraj Palfy, Jiri Pospichal
Pattern recognition in time series is often used in data mining and in bioinformatics. Speech can be considered only as a different type of signal and processed as a time series. Stuttered speech is rich in events also known as dysfluencies, typically repetitions. This paper describes a new method for enumerating complex repetitions. Classical approaches to stuttered speech analyzed dysfluencies in very short intervals, which were sufficient for recognizing simple repetitions of phonemes. However, the problem of repetitions of syllables or words was typically ignored due to high computational demands of classical methods for analysis of longer intervals. Our approach uses a method adopted from data mining and bioinformatics, together with efficient representation of speech signal, which simplifies processing of speech enough to enable analysis of longer intervals. Results show applicability of the proposed method.
11. Distributed Microphone Array Processing For Speech Source Separation With Classifier Fusion
Mehrez Souden, Keisuke Kinoshita, Marc Delcroix, Tomohiro Nakatani
We propose a new approach for clustering and separating competing speech signals using a distributed microphone array (DMA). This approach can be viewed as an extension of expectation-maximization EM-based source separation to DMAs. To achieve distributed processing, we assume the conditional independence (with respect to sources activities) of the normalized recordings of different nodes. By doing so, only the posterior probabilities of sources activities need to be shared between nodes. Consequently, the EM algorithm is formulated such that at the expectation step, local posterior probabilities are estimated locally and shared between nodes. In the maximization step, every node fuses the received probabilities via either product or sum rules and estimates its local parameters. We show that, even if we make binary decisions (presence/absence of speech) during EM iterations instead of transmitting continuous posterior probability values, we can achieve separation without causing significant speech distortion. Our preliminary investigations demonstrate that the proposed processing technique approaches the centralized solution and can outperform Oracle best node-wise clustering in terms of objective source separation metrics.
12. Stereophonic Spectrogram Segmentation Using Markov Random Fields
Minje Kim, Paris Smaragdis, Glenn G. Ko, Rob A. Rutenbar
There is a good amount of similarity between source separation approaches that use spectrograms captured from multiple microphones and computer vision algorithms that use multiple images for segmentation problems. Just as one would use Markov random fields (MRF) to solve image segmentation problems, we propose a method of modeling source separation using MRFs, and then solving such problems via common MRF inference methods. To this end, as a preprocessing, we convert stereophonic spectrograms into a integrated form based on their inter-channel level differences (ILD), which is a procedure analogous to getting a disparity map from stereo images for matching problems. Given the ILD matrix as an observed image, we estimate latent labels which stand for the responsibility of each spectrogram’s time/frequency bin to a specific sound source. It is shown that the proposed method shows reasonable separation performance in a variety of mixing environments including online separation and moving sources. We expect this new way of formulating

31
source separation problems to help exploit advantages of probabilistic graphical models and the recent advances in low-power, high-performance hardware suited for such tasks.
13. Voice Analysis Of Patients With Neurological Disorders Using Acoustical And Nonlinear Tools
María Eugenia Dajer, Paulo Rogério Scalassara, Jamille L. Marrara, José Carlos Pereira
In this paper, we analyze voice signals recorded from patients with neurological disorders of different etiologies. The study was based on three samples of each patient: one before any ingestion, one after the swallowing of a liquid solution, and one after the swallowing of a pasty solution. We used three approaches: first, acoustical analysis, specifically fundamental frequency, jitter and shimmer; second, a proposed analysis method of vocal dynamic visual patterns, which are based on phase space reconstruction of the signals; and third, relative entropy analysis between the groups of signals. We show that the acoustical measures were not able to differentiate the study cases, relative entropy was only partially able to perform this task, but the visual patterns analysis was successful.
14. Designing Spatial Filters Based On Neuroscience Theories To Improve Error-Related Potential Classification
Sandra Rousseau, Christian Jutten, Marco Congedo
In this paper we present an experiment enabling the occurrence of the error-related potential in high cognitive load conditions. We study the single-trial classification of the error-related potential and show that classification results can be improved using specific spatial filters designed with the aid of neurophysiological theories on the error-related potential.
15. Extraction Of Sparse Spatial Filters Using Oscillating Search
Ibrahim Onaran, N. Firat Ince, Aviva Abosch, A. Enis Cetin
Common Spatial Pattern algorithm (CSP) is widely used in Brain Machine Interface (BMI) technology to extract features from dense electrode recordings by using their weighted linear combination. However, the CSP algorithm is sensitive to variations in channel placement and can easily overfit to the data when the number of training trials is insufficient. Construction of sparse spatial projections where a small subset of channels is used in feature extraction can increase the stability and generalization capability of the CSP method. The existing ℓ0norm based sub-optimal greedy channel reduction methods are either too complex such as Backward Elimination (BE) which provided best classification accuracies or have lower accuracy rates such as Recursive Weight Elimination (RWE) and Forward Selection (FS) with reduced complexity. In this paper, we apply the Oscillating Search (OS) method which fuses all these greedy search techniques to sparsify the CSP filters. We applied this new technique on EEG dataset IVa of BCI competition III. Our results indicate that the OS method provides the lowest classification error rates with low cardinality levels where the complexity of the OS is around 20 times lower than the BE.
16. Hierarchical Sparse Brain Network Estimation
Abd-Krim Seghouane, Muhammad Usman Khalid
Brain networks explore the dependence relationships between brain regions under consideration through the estimation of the precision matrix. An approach based on linear regression is adopted here for estimating the partial correlation matrix from functional brain imaging data. Knowing that brain networks are sparse and hierarchical, the l1-norm penalized regression has been used to estimate sparse brain networks. Although capable of including the sparsity information, the l1-norm penalty alone doesn’t incorporate the hierarchical structure prior information when estimating brain networks. In this paper, a new l1 regularization method that applies the sparsity constraint at hierarchical levels is proposed and its implementation described. This hierarchical sparsity approach has the advantage of generating brain networks that are sparse at all levels of the hierarchy. The performance of the proposed approach in comparison to other existing methods is illustrated on real fMRI data.

32
Poster Session 2.B: Other Applications of Machine Learning Monday, September 24, 17:30 – 19:30
Room: Comedor II Chair: Robert Jenssen, University of Tromso, Norway
1. Tree-Structured Expectation Propagation For LDPC Decoding Over The AWGN Channel
Luis Salamanca, Juan José Murillo-Fuentes, Pablo M. Olmos, Fernando Pérez-Cruz
In this paper, we propose the tree-structured expectation propagation (TEP) algorithm for low-density parity-check (LDPC) decoding over the additive white Gaussian noise (AWGN) channel. By imposing a tree-like approximation over the graphical model of the code, this algorithm introduces pairwise marginal constraints over pairs of variables, which provide joint information of the variables related. Thanks to this, the proposed TEP decoder improves the performance of the standard belief propagation (BP) solution. An efficient way of constructing the tree-like structure is also described. The simulation results illustrate the TEP decoder gain in the finite-length regime, compared to the standard BP solution. For code lengths shorter than n=512, the gain in the waterfall region achieves up to 0.25 dB. We also notice a remarkable reduction of the error floor.
2. Neural Correlates Of Visual Perception In Rapid Serial Visual Presentation Paradigms
Yonghong Huang, Kenneth E. Hild II, Misha Pavel, Santosh Mathan, Deniz Erdogmus
Human brain signals associated with visual perceptual processes have been used for image recognition. This paper presents several insights on the neural correlates of human visual perception by analyzing the neural correlates that result when humans view realistic images using a rapid serial visual presentation (RSVP) image display paradigm. We propose an image information extraction model and examine the relationship between the brain evoked response – using event related potential (ERP) characteristics – and the level of difficulty for humans to detect targets as a function of both visual stimulus complexity and task difficulty. We develop a computational model to quantify subject performance and the difficulty of realistic stimuli. Our results show that: (1) more difficult trials produce less prominent ERP patterns, thus reducing the performance of machine-based ERP detection; (2) on average for the same behavioral performance level, a pair of ERP"s extracted from two easy trials are more similar than a pair of ERP"s from two hard trials; and (3) both stimulus and task difficulty are correlated with neural activity. Our findings indicate that, for dynamic tasks involved in visual information processing, the brain may allocate additional cognitive resources, such as attention, to a given visual stimulus, as the task and/or stimulus difficulty increases.
3. Helicopter Vibration Sensor Selection Using Data Visualisation
Waljinder S. Gill, Ian T. Nabney, Daniel Wells
The main objective of the project is to enhance the already effective health-monitoring system (HUMS) for helicopters by analysing structural vibrations to recognise different flight conditions directly from sensor information. The goal of this paper is to develop a new method to select those sensors and frequency bands that are best for detecting changes in flight conditions. We projected frequency information to a 2-dimensional space in order to visualise flight-condition transitions using the Generative Topographic Mapping (GTM) and a variant which supports simultaneous feature selection. We created an objective measure of the separation between different flight conditions in the visualisation space by calculating the Kullback-Leibler (KL) divergence between Gaussian mixture models (GMMs) fitted to each class: the higher the KL-divergence, the better the inter-class separation. To find the optimal combination of sensors, they were considered in pairs, triples and groups of four sensors. The sensor triples provided the best result in terms of KL-divergence. We also found that the use of a variational training algorithm for the GMMs gave more reliable results.
4. A Sift-Point Distribution-Based Method For Head Pose Estimation
Nastaran Ghadarghadar, Esra Ataer-Cansizoglu, Peng Zhang, Deniz Erdogmus
Estimating the head pose of a person in a video or image sequence is a challenging problem in computer vision. In this paper, we present a new technique on how to estimate the human face pose from a video sequence, by creating a probabilistic model based on the scale invariant features of the face. This method consists of four

33
major steps: (1) the face is detected using the basic CAMSHIFT algorithm, (2) a training dataset is created for each face pose, (3) the distinctive invariant features of the training and test face image sets are extracted using the scale-invariant feature transform (SIFT) algorithm, (4) a kernel density estimate (KDE) of SIFT points on each image is generated. Pose classification is achieved by nearest-neighbor search using a KDE overlap measure. Results indicate that the proposed method is robust, accurate, not computationally expensive, and can successfully be used for pose estimation.
5. Efficient Optimization For Data Visualization As An Information Retrieval Task
Jaakko Peltonen, Konstantinos Georgatzis
Visualization of multivariate data sets is often done by mapping data onto a low-dimensional display with nonlinear dimensionality reduction (NLDR) methods. Many NLDR methods are designed for tasks like manifold learning rather than low-dimensional visualization, and can perform poorly in visualization. We have introduced a formalism where NLDR for visualization is treated as an information retrieval task, and a novel NLDR method called the Neighbor Retrieval Visualizer (NeRV) which outperforms previous methods. The remaining concern is that NeRV has quadratic computational complexity with respect to the number of data. We introduce an efficient learning algorithm for NeRV where relationships between data are approximated through mixture modeling, yielding efficient computation with near-linear computational complexity with respect to the number of data. The method inherits the information retrieval interpretation from the original NeRV, it is much faster to optimize as the number of data grows, and it maintains good visualization performance.
6. Modelling Dense Relational Data
Tue Herlau, Morten Mørup, Mikkel N. Schmidt, Lars Kai Hansen
Relational modelling classically considers sparse and discrete data. Measures of influence computed pairwise between temporal sources naturally give rise to dense continuous-valued matrices, for instance p-values from Granger causality. Due to asymmetry or lack of positive definiteness they are not naturally suited for kernel K-means. We propose a generative Bayesian model for dense matrices which generalize kernel K-means to consider off-diagonal interactions in matrices of interactions, and demonstrate its ability to detect structure on both artificial data and two real data sets.
7. Optimal Portfolios Under Transaction Costs In Discrete Time Markets
Mehmet A. Donmez, Sait Tunc, Suleyman S. Kozat
We study portfolio investment problem from a probabilistic modeling perspective and study how an investor should distribute wealth over two assets in order to maximize the cumulative wealth. We construct portfolios that provide the optimal growth in i.i.d. discrete time two-asset markets under proportional transaction costs. As the market model, we consider arbitrary discrete distributions on the price relative vectors. To achieve optimal growth, we use threshold portfolios. We demonstrate that under the threshold rebalancing framework, the achievable set of portfolios elegantly form an irreducible Markov chain under mild technical conditions. We evaluate the corresponding stationary distribution of this Markov chain, which provides a natural and efficient method to calculate the cumulative expected wealth. Subsequently, the corresponding parameters are optimized using a brute force approach yielding the growth optimal portfolio under proportional transaction costs in i.i.d. discrete-time two-asset markets.
8. Markov Chain Monte Carlo Inference For Probabilistic Latent Tensor Factorization
Umut Simsekli, Ali Taylan Cemgil
Probabilistic Latent Tensor Factorization (PLTF) is a recently proposed probabilistic framework for modeling multiway data. Not only the popular tensor factorization models but also any arbitrary tensor factorization structure can be realized by the PLTF framework. This paper presents Markov Chain Monte Carlo procedures (namely the Gibbs sampler) for making inference on the PLTF framework. We provide the abstract algorithms that are derived for the general case and the overall procedure is illustrated on both synthetic and real data.

34
9. Recursive Outlier-Robust Filtering And Smoothing For Nonlinear Systems Using The Multivariate Student-T Distribution
Robert Piche, Simo Särkkä, Jouni Hartikainen
Nonlinear Kalman filter and Rauch-Tung-Striebel smoother type recursive estimators for nonlinear discrete-time state space models with multivariate Studen’s t-distributed measurement noise are presented. The methods approximate the posterior state at each time step using the variational Bayes method. The nonlinearities in the dynamic and measurement models are handled using the nonlinear Gaussian filtering and smoothing approach, which encompasses many known nonlinear Kalman-type filters. The method is compared to alternative methods in a computer simulation.
10. Accelerometer Based Gesture Recognition System Using Distance Metric Learning For Nearest Neighbour Classification
Tea Marasovic, Vladan Papic
The need to improve communication between humans and computers has been motivation for defining new communication models, and accordingly, new ways of interacting with machines. In many applications today, user interaction is moving away from traditional keyboards and mouses and is becoming much more physical, pervasive and intuitive. This paper examines hand gestures as an alternative or supplementary input modality for mobile devices. A new gesture recognition system based on the use of acceleration sensor, that is nowadays being featured in a growing number of consumer electronic devices, is presented. Accelerometer sensor readings can be used for detection of hand movements and their classification into previously trained gestures. The proposed system utilizes Mahalanobis distance metric learning to improve the accuracy of nearest neighbour classification. In the approach we adopted, the objective function for metric learning is convex and, therefore, the required optimization can be cast as an instance of semidefinite programming. The experiments, carried out to evaluate system performance, demonstrate its efficacy.
11. Kernelizing Geweke's Measures Of Granger Causality
Pierre-Olivier Amblard, Rémy Vincent, Olivier Michel, Cédric Richard
In this paper we extend Geweke"s approach of Granger causality by deriving a nonlinear framework based on functional regression in reproducing kernel Hilbert spaces (RKHS). After giving the definitions of dynamical and instantaneous causality in the Granger sense, we review Geweke"s measures. These measures quantify improvement in predicting a time series when the past of another one is taken into account. Geweke"s measures are based on linear prediction, and we present an alternative using nonlinear prediction implemented using regularized regression in RKHS. We develop the approach and describe the cross-validation step implemented to optimize the hyperparameters (kernel and regularization parameters). We illustrate the approach on two examples. The first one shows the importance of taking into account side information and possible nonlinear effects. The second one is an illustration of the complete inference problem: surrogate data are generated to create the null hypothesis and the nonlinear measures of causal influence are presented in a test framework.
12. Stochastic Triplet Embedding
Laurens Van Der Maaten, Kilian Weinberger
This paper considers the problem of learning an embedding of data based on similarity triplets of the form "A is more similar to B than to C". This learning setting is of relevance to scenarios in which we wish to model human judgments on the similarity of objects. We argue that in order to obtain a truthful embedding of the underlying data, it is insufficient for the embedding to satisfy the constraints encoded by the similarity triplets. In particular, we introduce a new technique called t-Distributed Stochastic Triplet Embedding (t-STE) that collapses similar points and repels dissimilar points in the embedding -- even when all triplet constraints are satisfied. Our experimental evaluation on three data sets shows that as a result, t-STE is much better than existing techniques at revealing the underlying data structure.

35
Oral Session 2: Bayesian Learning Tuesday, September 25, 11:00 – 13:00
Room: Salón de Baile Chair: Fernando Pérez-Cruz, Universidad Carlos III de Madrid, Spain
11:00-11:20 Distributed Variational Sparse Bayesian Learning For Sensor Networks
Thomas Buchgraber, Dmitriy Shutin
In this work we present a distributed sparse Bayesian learning (dSBL) regression algorithm. It can be used for collaborative sparse estimation of spatial functions in wireless sensor networks (WSNs). The sensor measurements are modeled as a weighted superposition of basis functions. When kernels are used, the algorithm forms a distributed version of the relevance vector machine. The proposed method is based on a combination of variational inference and loopy belief propagation, where data is only communicated between neighboring nodes without the need for a fusion center. We show that for tree structured networks, under certain parameterization, dSBL coincides with centralized sparse Bayesian learning (cSBL). For general loopy networks, dSBL and cSBL are different, yet simulations show much faster convergence over the variational inference iterations at similar sparsity and mean squared error performance. Furthermore, compared to other sparse distributed regression methods, our method does not require any cross-tuning of sparsity parameters.
11:20-11:40 Trading Approximation Quality Versus Sparsity Within Incremental Automatic Relevance Determination Frameworks
Dmitriy Shutin, Thomas Buchgraber
In this paper a trade-off between sparsity and approximation quality of models learned with incremental automatic relevance determination (IARD) is addressed. An IARD algorithm is a class of sparse Bayesian learning (SBL) schemes. It permits an intuitive and simple adjustment of estimation expressions, with the adjustment having a simple interpretation in terms of signal-to-noise ratio (SNR). This adjustment allows for implementing a trade-off between sparsity of the estimated model versus its accuracy in terms of residual mean-square error (MSE). It is found that this adjustment has a different impact on the IARD performance, depending on whether the measurement model coincides with the used estimation model or not. Specifically, in the former case the value of the adjustment parameter set to the true SNR leads to an optimum performance of the IARD with the smallest MSE and estimated signal sparsity; moreover, the estimated sparsity then coincides with the true signal sparsity. In contrast, when there is a model mismatch, the lower MSE can be achieved only at the expense of less sparser models. In this case the adjustment parameter simply trades the estimated signal sparsity versus the accuracy of the model.
11:40-12:00 Estimation Of The Forgetting Factor In Kernel Recursive Least Squares
Steven Van Vaerenbergh, Ignacio Santamaría, Miguel Lazaro-Gredilla
In a recent work we proposed a kernel recursive least-squares tracker (KRLS-T) algorithm that is capable of tracking in non-stationary environments, thanks to a forgetting mechanism built on a Bayesian framework. In order to guarantee optimal performance its parameters need to be determined, specifically its kernel parameters, regularization and, most importantly in non-stationary environments, its forgetting factor. This is a common difficulty in adaptive filtering techniques and in signal processing algorithms in general. In this paper we demonstrate the equivalence between KRLS-T"s recursive tracking solution and Gaussian process (GP) regression with a specific class of spatio-temporal covariance. This result allows to use standard hyperparameter estimation techniques from the Gaussian process framework to determine the parameters of the KRLS-T algorithm. Most notably, it allows to estimate the optimal forgetting factor in a principled manner. We include results on different benchmark data sets that offer interesting new insights.
12:00-12:20 Latent Dirichlet Learning For Hierarchical Segmentation
Jen-Tzung Chien, Chuang-Hua Chueh

36
Topic model can be established by using Dirichlet distributions as the prior model to characterize latent topics in natural language. However, topics in real-world stream data are non-stationary. Training a reliable topic model is a challenging study. Further, the usage of words in different paragraphs within a document is varied due to different composition styles. This study presents a hierarchical segmentation model by compensating the heterogeneous topics in stream level and the heterogeneous words in document level. The topic similarity between sentences is calculated to form a beta prior for stream-level segmentation. This segmentation prior is adopted to group topic-coherent sentences into a document. For each pseudo-document, we incorporate a Markov chain to detect stylistic segments within a document. The words in a segment are generated by identical composition style. This new model is inferred by a variational Bayesian EM procedure. Experimental results show benefits by using the proposed model in terms of perplexity and F measure.
12:20-12:40 Identifying Modular Relations In Complex Brain Networks
Kasper Winther Andersen, Morten Mørup, Hartwig Siebner, Kristoffer H. Madsen, Lars Kai Hansen
We evaluate the infinite relational model (IRM) against two simpler alternative nonparametric Bayesian models for identifying structures in multi subject brain networks. The models are evaluated for their ability to predict new data and infer reproducible structures. Prediction and reproducibility are measured within the data driven NPAIRS split-half framework. Using synthetic data drawn from each of the generative models we show that the IRM model outperforms the two competing models when data contain relational structure. For data drawn from the other two simpler models the IRM does not overfit and obtains comparable reproducibility and predictability. For resting state functional magnetic resonance imaging data from 30 healthy controls the IRM model is also superior to the two simpler alternatives, suggesting that brain networks indeed exhibit universal complex relational structure in the population.
12:40-13:00 Probabilistic Interpolative Decomposition
Ismail Ari, Ali Taylan Cemgil, Lale Akarun
Interpolative decomposition (ID) is a low-rank matrix decomposition where the data matrix is expressed via a subset of its own columns. In this work, we propose a novel probabilistic method for ID where it is expressed as a statistical model within a Bayesian framework. The proposed method considerably differs from other ID methods in the literature: It handles the model selection automatically and enables the construction of problem-specific interpolative decompositions. We derive the analytical solution for the normal distribution and we provide a numerical solution for the generic case. Simulation results on synthetic data are provided to illustrate that the method converges to the true decomposition, independent of the initialization; and it can successfully handle noise. In addition, we apply probabilistic ID to the problem of automatic polyphonic music transcription to extract important information from a huge dictionary of spectrum instances. We supply comparative results with the other proposed techniques in the literature and show that it performs better. Probabilistic interpolative decomposition serves as a promising feature selection and de-noising tool to be exploited in big data problems.
Oral Session 3: Special Session on Social Network Analysis & Data Competition
Tuesday, September 25, 15:00 – 17:00 Room: Salón de Baile
Chair: Morten Mørup, DTU Informatics, Denmark
15:00-15:20 Quantifying Spatiotemporal Dynamics Of Twitter Replies To News Feeds
Felix Bießmann, Jens-Michalis Papaioannou, Andreas Harth, Matthias L. Jugel, Klaus-Robert Müller, Mikio Braun
Social network analysis can be used to assess the impact of information published on the web. The spatiotemporal impact of a certain web source on a social network can be of particular interest. We contribute a novel statistical learning algorithm for spatiotemporal impact analysis. To demonstrate our approach we

37
analyze Twitter replies to individual news article along with their geospatial and temporal information. We then compute the multivariate spatiotemporal response pattern of all Twitter replies to information published on a given web source. This quantitative result can be interpreted with respect to a) how much impact a certain web source has on the Twitter-sphere b) where and c) when it reaches it maximal impact. We also show that the proposed approach predicts the dynamics of the social network activity better than classical trend detection methods.
15:20-15:40 Link Prediction In Weighted Networks
David Kofoed Wind, Morten Mørup
Many complex networks feature relations with weight information. Some models utilize this information while other ignore the weight information when inferring the structure. In this paper we investigate if edge-weights when modeling real networks carry important information about the network structure. We compare five prominent models by their ability to predict links both in the presence and absence of weight information. In addition we quantify the models ability to account for the edge-weight information. We find that the complex models generally outperform simpler models when the task is to infer presence of edges, but that simpler models are better at inferring the actual weights.
15:40-16:00 A Random Walk Based Model Incorporating Social Information For Recommendations
Shang Shang, Sanjeev R. Kulkarni, Paul W. Cuff, Pan Hui
Collaborative filtering (CF) is one of the most popular approaches to build a recommendation system. In this paper, we propose a hybrid collaborative filtering model based on a Makovian random walk to address the data sparsity and cold start problems in recommendation systems. More precisely, we construct a directed graph whose nodes consist of items and users, together with item content, user profile and social network information. We incorporate use’s ratings into edge settings in the graph model. The model provides personalized recommendations and predictions to individuals and groups. The proposed algorithms are evaluated on MovieLens and Epinions datasets. Experimental results show that the proposed methods perform well compared with other graph-based methods, especially in the cold start case.
16:00-16:20 Iterative Collaborative Filtering For Recommender Systems With Sparse Data
Zhuo Zhang, Paul W. Cuff, Sanjeev R. Kulkarni
Collaborative filtering (CF) is one of the most successful techniques in recommender systems. By utilizing corated items of pairwise users for similarity measurements, traditional CF uses a weighted summation to predict unknown ratings based on the available ones. However, in practice, the rating matrix is too sparse to find sufficiently many co-rated items, thus leading to inaccurate predictions. To address the case of sparse data, we propose an iterative CF that updates the similarity and rating matrix. The improved CF incrementally selects reliable subsets of missing ratings based on an adaptive parameter and therefore produces a more credible prediction based on similarity. Experimental results on the MovieLens dataset show that our algorithm significantly outperforms traditional CF, Default Voting, and SVD when the data is 1% sparse. The results also show that in the dense data case our algorithm performs as well as state of art methods.
16:20-16:40 Opportunistic Sensing: Unattended Acoustic Sensor Selection Using Crowdsourcing Models
Po-Sen Huang, Mark Hasegawa-Johnson, Wotao Yin, Thomas S. Huang
Unattended wireless sensor networks have been widely used in many applications. This paper proposes automatic sensor selection methods based on crowdsourcing models in the Opportunistic Sensing framework, with applications to unattended acoustic sensor selection. Precisely, we propose two sensor selection criteria and solve them via greedy algorithm and quadratic assignment. Our proposed method achieves, on average, 5.64% higher accuracy than the traditional approach under sparse reliability conditions.

38
16:40-17:00 The Eight Annual MLSP Competition: Overview
Ken Montanez, Weifeng Liu, Vince D. Calhoun, Catherine Huang, Kenneth E. Hild II
This marks the eighth year the Machine Learning for Signal Processing (MLSP) Technical Committee has hosted a data analysis competition, which is held in conjunction with the annual MLSP workshop. For this year’s competition, which was sponsored by Amazon Corporation, entrants were asked to write an algorithm that attempts to automatically provision an employe’s access to company resources in an optimal manner. In this paper, we (the organizers of the competition) briefly describe the application, the data, the rules, and the outcomes of the competition. A total of 4 teams entered the contest. We provided real (declassified) training data to the entrants and tested the algorithms using disjoint test data. The two teams with the best performing entries describe the approach they used in two separate companion papers, both of which appear in this year’s conference proceedings.
Poster Session 3.A: Learning Theory and Algorithms I Tuesday, September 25, 17:30 – 19:30
Room: Comedor I Chair: Javier Vía, Universidad de Cantabria, Spain
1. The Eighth Annual MLSP Competition: First Place Team
Ankit Gupta, Shashwat Mishra, Amitabha Mukerjee
Our basic strategy is to examine the spatial neighborhood of the point, P, for its classification. Each point Q in P’s neighborhood contributes a binary vote. The sum of these votes, VP , is compared against a threshold τ and access is granted if the value VP is greater than the threshold.
2. The Eight Annual MLSP Competition: Second Pace Team
Heikki Huttunen, Timo Erkkila, Pekka Ruusuvuori, Tapio Manninen
This paper describes our submission to the eighth annual MLSP competition organized by Amazon during the 2012 IEEE MLSP workshop. Our approach is based on a nearest-neighbor-like classifier with a distance metric learned from samples. The method was second in the final standings with prediction accuracy of 81 %, while the winning submission was 87 % accurate.
3. On Comparing Hard And Soft Fusion Of Dependent Detectors
Antonio Soriano, Luis Vergara, Gonzalo Safont, Adisson Salazar
A detection problem, where we have a set of two types of different measurements or modalities of one event, is considered. The optimal fusion rule to combine both modalities in one detector needs the knowledge of the joint statistics of modalities. In many cases we do not know these joint statistics and it is usual to consider independence between modalities for implementing a suboptimal fusion rule. Another suboptimum alternative not much used is to make hard fusion, that is, to thresholding every modality to obtain a set of binary decisions to be fused in only on final decision. In some situations, we can obtain better results using hard fusion instead of soft fusion under the independence assumption. The goal of this paper is to show that the later sentence is generally true.
4. Sequential Anomaly Detection In A Batch With Growing Number Of Tests: Application To Network Intrusion Detection
David J. Miller, Fatih Kocak, George Kesidis
For high (N)-dimensional feature spaces, we consider detection of an unknown, anomalous class of samples amongst a batch of collected samples (of size T), under the null hypothesis that all samples follow the same probability law. Since the features which will best identify the anomalies are a priori unknown, several common detection strategies are: 1) evaluating atypicality of a sample (its p-value) basedon the null distribution defined on the full N-dimensional feature space; 2) considering a (combinatoric) set of low order distributions, e.g. all singletons and all feature pairs, with detections made based on the smallest p-value yielded over all such low

39
order tests. The first approach relies on accurate estimation of the joint distribution, while the second may suffer from increased false alarm rates as N and T grow. Alternatively, inspired by greedy feature selection commonly used in supervised learning, we propose a novel sequential anomaly detection procedure with a growing number of tests. Here, new tests are (greedily) included only when they are needed, i.e., when their use (on currently undetected samples) will yield greater aggregate statistical significance of (multiple testing corrected) detections than obtainable using the existing test cadre. Our approach thus aims to maximize aggregate statistical significance of all detections made up until a finite horizon. Our method is evaluated, along with supervised methods, for a network intrusion domain, detecting Zeus bot (intrusion) packet flows embedded amongst (normal)Web flows. It is shown that judicious feature representation is essential for discriminating Zeus from Web.
5. On The Performance Of Histogram-Based Entropy Estimators
Ciprian Doru Giurcaneanu, Panu Luosto, Petri Kontkanen
Histograms are widely used for estimating the density of a continuous signal from existing data. In some practical applications, they are also employed for entropy estimation. However, a histogram involves implicitly a discretization procedure because the unknown density is approximated by a piecewise constant density model. In the previous literature, the impact of the discretization procedure on the accuracy of the entropy estimate was either ignored or evaluated in the particular case of a regular histogram, in which all bins are equally wide. In this work, we provide bounds on the performance of the histogram-based entropy estimators without relying on the restrictive assumptions which have been used by other authors. The proof of our theoretical results is mainly based on concentration inequalities which have been already employed to analyze the performance of histograms as density estimators. After establishing the theoretical results, we illustrate them by numerical examples.
6. An Online Learning Algorithm For Mixture Models Of Deformable Templates
Florian Maire, Sidonie Lefebvre, Randal Douc, Eric Moulines
The issue addressed in this paper is the unsupervised learning of observed shapes. More precisely, we are aiming at learning the main features of an object seen in different scenarios. We adapt the statistical framework from [1] to propose a model in which an object is described by independent classes representing its variability. Our work consists in proposing an algorithm which learns each class characteristics in a sequential way: each new observation will improve our object knowledge. This algorithm is particularly well suited to real time applications such as shape recognition or classification, but turns out to be a challenging problem. Indeed, the so-called classic machine learning algorithms in missing data problems such as the Expectation Maximization algorithm (EM) are not designed to learn from sequentially acquired observations. Moreover, the so-called hidden data simulation in a mixture model cannot be achieved in a proper way using the classic Markov Chain Monte Carlo (MCMC) algorithms, such as the Gibbs sampler. Our proposal, among other, takes advantage from the contribution of Capp´e and Moulines [2] for a sequential adaptation of the EM algorithm and from the work of Carlin and Chib [3] for the hidden data posterior distribution simulation.
7. Online Learning With Kernels: Overcoming The Growing Sum Problem
Abhishek Singh, Narendra Ahuja, Pierre Moulin
Online kernel algorithms have an important computational drawback. The computational complexity of these algorithms grows linearly over time. This makes these algorithms difficult to use for real time signal processing applications that need to continuously process data over prolonged periods of time. In this paper, we present a way of overcoming this problem. We do so by approximating kernel evaluations using finite dimensional inner products in a randomized feature space. We apply this idea to the Kernel Least Mean Square (KLMS) algorithm, that has recently been proposed as a non-linear extension to the famed LMS algorithm. Our simulations show that using the proposed method, constant computational complexity can be achieved, with no observable loss in performance.
8. Nearest Neighbor-Based Importance Weighting
Marco Loog
Importance weighting is widely applicable in machine learning in general and in techniques dealing with data covariate shift problems in particular. A novel, direct approach to determine such importance weighting is

40
presented. It relies on a nearest neighbor classification scheme and is relatively straightforward to implement. Comparative experiments on various classification tasks demonstrate the effectiveness of our so-called nearest neighbor weighting (NNeW) scheme. Considering its performance, our procedure can act as a simple and effective baseline method for importance weighting.
9. Transient Analysis Of Convexly Constrained Mixture Methods
Mehmet A. Donmez, Huseyin Ozkan, Suleyman S. Kozat
We study the transient performances of three convexly constrained adaptive combination methods that combine outputs of two adaptive filters running in parallel to model a desired unknown system. We propose a theoretical model for the mean and mean-square convergence behaviors of each algorithm. Specifically, we provide expressions for the time evolution of the mean and the variance of the combination parameters, as well as for the mean square errors. The accuracy of the theoretical models is illustrated through simulations in the case of a mixture of two LMS filters with different step sizes.
10. The Discounted Cumulative Margin Penalty: Rank-Learning With A List-Wise Loss And Pair-Wise Margins
Carlos Renjifo, Craig Carmen
In recent years, the fields of rank-learning and information retrieval have received substantial attention. Algorithms developed within these domains have shown promising results in a variety of problem spaces, especially in document retrieval and web search. In this paper, a new rank-learning algorithm is proposed that combines list-wise loss measurements with pair-wise margins. The list-wise loss term is inspired by the Normalized Discounted Cumulative Gain (NDCG) metric, and the resulting objective function is solvable with gradient-free optimization techniques. Experiments using the LETOR 3.0 and 4.0 collections demonstrate that the ranking performance achieved by an algorithm using this loss measure is competitive with reported baselines.
11. Mahalanobis Distance On Grassmann Manifold And Its Application To Brain Signal Processing
Yoshikazu Washizawa, Seiji Hotta
Multi-dimensional data such as image patterns, image sequences, and brain signals, are often given in the form of the variance-covariance matrices or their eigenspaces to represent their own variations. For example, in face or object recognition problems, variations due to illuminations, camera angles can be represented by eigenspaces. A set of the eigenspaces is called the Grassmann manifold, and simple distance measurements in the Grassmann manifold, such as the projection metric have been used in conventional researches. However, in linear spaces, if the distribution of patterns is not isotropic, statistical distances such as the Mahalanobis distance are reasonable, and their performances are higher than simple distances in many problems. In this paper, we introduce the Mahalanobis distance in the Grassmann manifolds. Two experimental results, an object recognition problem and a brain signal processing, demonstrate the advantages of the proposed distance measurement.
12. Haussdorff And Hellinger For Colorimetric Sensor Array Classification
Tommy S. Alstrøm, Bjørn Sand Jensen, Mikkel N. Schmidt, Natalie V. Kostesha, Jan Larsen
Development of sensors and systems for detection of chemical compounds is an important challenge with applications in areas such as anti-terrorism, demining, and environmental monitoring. A newly developed colorimetric sensor array is able to detect explosives and volatile organic compounds; however, each sensor reading consists of hundreds of pixel values, and methods for combining these readings from multiple sensors must be developed to make a classification system. In this work we examine two distance based classification methods, K-Nearest Neighbor (KNN) and Gaussian process (GP) classification, which both rely on a suitable distance metric. We evaluate a range of different distance measures and propose a method for sensor fusion in the GP classifier. Our results indicate that the best choice of distance measure depends on the sensor and the chemical of interest.

41
13. A Subspace Learning Algorithm For Microwave Scattering Signal Classification With Application To Wood Quality Assessment
Yinan Yu, Tomas Mckelvey
A classification algorithm based on a linear subspace model has been developed and is presented in this paper. To further improve the classification results, the full linear subspace of each class is split into subspaces with lower dimensions and characterized by local coordinates constructed from automatically selected training data. The training data selection is implemented by optimizations with least squares constraints or L1 regularization. The working application is to determine the quality in wooden logs using microwave signals [1]. The experimental results are shown and compared with classical methods.
14. Exploiting Graph Embedding In Support Vector Machines
Georgios Arvanitidis, Anastasios Tefas
In this paper we introduce a novel classification framework that is based on the combination of the support vector machine classifier and the graph embedding framework. In particular we propose the substitution of the support vector machine kernel with sub-space or sub-manifold kernels, that are constructed based on the graph embedding framework. Our technique combines the very good generalization ability of the support vector machine classifier with the flexibility of the graph embedding framework resulting in improved classification performance. The attained experimental results on several benchmark and real-life data sets, further support our claim of improved classification performance.
15. Kernels For Time Series Of Exponential Decay/Growth Processes
Zineb Noumir, Paul Honeine, Cédric Richard
Many processes exhibit exponential behavior. When kernel-based machines are applied on this type of data, conventional kernels such as the Gaussian kernel are not appropriate. In this paper, we derive kernels adapted to time series of exponential decay or growth processes. We provide a theoretical study of these kernels, including the issue of universality. Experimental results are given on a case study: chlorine decay in water distribution systems.
16. Temporal Context In Object Recognition
Rakesh Chalasani, José C. Príncipe
Sparse coding has become a popular way to learn feature representation from the data itself. However, temporal context, when present, can provide useful information and alleviate instability in sparse representation. Here we show that when sparse coding is used in conjunction with a dynamical system, the extracted features can provide better descriptors for time varying observations. We show a marked improvement in classification performance on COIL-100 and animal datasets using our model. We also propose a simple extension to our model to learn invariant representations.
Poster Session 3.B: Learning Theory and Algorithms II Tuesday, September 25, 17:30 – 19:30
Room: Comedor II Chair: Cédric Févotte, CNRS - Télécom ParisTech, France
1. Nonlinear Data Description With Principal Polynomial Analysis
V. Laparra, D. Tuia, S. Jiménez, Gustavo Camps-Valls, J. Malo
Principal Component Analysis (PCA) has been widely used for manifold description and dimensionality reduction. Performance of PCA is however hampered when data exhibits nonlinear feature relations. In this work, we propose a new framework for manifold learning based on the use of a sequence of Principal Polynomials that capture the eventually nonlinear nature of the data. The proposed Principal Polynomial Analysis (PPA) is shown to generalize PCA. Unlike recently proposed nonlinear methods (e.g. spectral/kernel methods and projection pursuit techniques, neural networks), PPA features are easily interpretable and the method leads to a fully invertible transform, which is a desirable property to evaluate performance in

42
dimensionality reduction. Successful performance of the proposed PPA is illustrated in dimensionality reduction, in compact representation of non-Gaussian image textures, and multispectral image classification.
2. Perturbation Regulated Kernel Regressors For Supervised Machine Learning
S.Y. Kung, Pei-Yuan Wu
This paper develops a kernel perturbation-regulated (KPR) regressor based on the errors-in-variables models. KPR offers a strong smoothing capability critical to the robustness of regression or classification results. For Gaussian cases, the notion of orthogonal polynomials is instrumental to optimal estimation and its error analysis. More exactly, the regressor may be expressed as a linear combination of many simple Hermite Regressors, each focusing on one (and only one) orthogonal polynomial. For Gaussian or non-Gaussian cases, this paper formally establishes a “Two-Projection Theorem” allowing the estimation task to be divided into two projection stages: the first projection reveals the effect of model-induced error (caused by under-represented regressor models) while the second projection reveals the extra estimation error due to the (inevitable) input measuring error. The two-projection analysis leads to a closed-form error formula critical for order/error tradeoff. The simulation results not only confirm the theoretical prediction but also demonstrate superiority of KPR over the conventional ridge regression method in MSE reduction.
3. GLRT For Testing Separability Of A Complex-Valued Mixture Based On The Strong Uncorrelating Transform
David Ramírez, Peter J. Schreier, Javier Vía, Ignacio Santamaría
The Strong Uncorrelating Transform (SUT) allows blind separation of a mixture of complex independent sources if and only if all sources have distinct circularity coefficients. In practice, the circularity coefficients need to be estimated from observed data. We propose a generalized likelihood ratio test (GLRT) for separability of a complex mixture using the SUT, based on estimated circularity coefficients. For distinct circularity coefficients (separable case), the maximum likelihood (ML) estimates, required for the GLRT, are straightforward. However, for circularity coefficients with multiplicity larger than one (non-separable case), the ML estimates are much more difficult to find. Numerical simulations show the good performance of the proposed detector.
4. A Modified Version Of The Mexico Algorithm For Performing ICA Over Galois Fields
Daniel G. Silva, Everton Z. Nadalin, Jugurta Montalvão, Romis Attux
The theory of ICA over finite fields, established in the last five years, gave rise to a corpus of different separation strategies, which includes an algorithm based on the pairwise comparison of mixtures, called MEXICO. In this work, we propose an alternative version of the MEXICO algorithm, with modifications that - as shown by the results obtained for a number of representative scenarios - lead to performance improvements in terms of the computational effort required to reach a certain performance level, especially for an elevated number of sources. This parsimony can be relevant to enhance the applicability of the new ICA theory to data mining in the context of large discrete-valued databases.
5. A Novel Adaptive Nyström Approximation
Lingyan Sheng, Antonio Ortega
We propose a novel perspective on the Nyström approximation method. Sampling the columns of the kernel matrix can be interpreted as projecting the data onto the subspace spanned by the corresponding columns. Thus, the quality of Nyström approximation can be quantified by the distance between the subspace spanned by the sampled columns and the subspace spanned by the data mapped to the eigenvectors corresponding to the top eigenvalues of the kernel matrix. Based on this interpretation, we design a novel adaptive Nyström approximation algorithm, BoostNyström. BoostNyström is efficient in terms of both time and space complexity. Experiments on benchmark data sets show that BoostNyström is more effective than the state-of-art algorithms.
6. Learning With The Kernel Signal To Noise Ratio
Luis Gómez-Chova, Gustavo Camps-Valls

43
This paper presents the application of the kernel signal to noise ratio (KSNR) in the context of feature extraction to general machine learning and signal processing domains. The proposed approach maximizes the signal variance while minimizes the estimated noise variance in a reproducing kernel Hilbert space (RKHS). The KSNR can be used in any kernel method to deal with correlated (possibly non-Gaussian) noise. We illustrate the method in nonlinear regression examples, dependence estimation and causal inference, nonlinear channel equalization, and nonlinear feature extraction from high-dimensional satellite images. Results show that the proposed KSNR yields more fitted solutions and extracts more noise-free features when confronted with standard approaches.
7. Semisupervised Kernel Orthonormalized Partial Least Squares
Emma Izquierdo-Verdiguier, Jerónimo Arenas-García, Sergio Muñoz-Romero, Luis Gómez-Chova, Gustavo Camps-Valls
This paper presents a semisupervised kernel orthonormalized partial least squares (SS-KOPLS) algorithm for non-linear feature extraction. The proposed method finds projections that minimize the least squares regression error in Hilbert spaces and incorporates the wealth of unlabeled information to deal with small size labeled datasets. The method relies on combining a standard RBF kernel using labeled information, and a generative kernel learned by clustering all available data. The positive definiteness of the kernels is proven, and the structure and information content of the derived kernels is studied. The effectiveness of the proposed method is successfully illustrated in standard UCI database classification, Olivetti face database manifold learning, and in high-dimensional hyperspectral satellite image segmentation. High accuracy gains are obtained over KPLS in terms of expressive power of the extracted non-linear features. Matlab code is available at http://isp.uv.es for the interested readers.
8. Local Linear Approximation Of Principal Curve Projections
Peng Zhang, Esra Ataer-Cansizoglu, Deniz Erdogmus
In previous work we introduced principal surfaces as hyper-ridges of probability distributions in a differential geometrical sense. Specifically, given an n-dimensional probability distribution over real-valued random vectors, a point on the d-dimensional principal surface is a local maximizer of the distribution in the subspace orthogonal to the principal surface at that point. For twice continuously differentiable distributions, the surface is characterized by the gradient and the Hessian of the distribution. Furthermore, the nonlinear projections of data points to the principal surface for dimension reduction is ideally given by the solution trajectories of differential equations that are initialized at the data point and whose tangent vectors are determined by the Hessian eigenvectors. In practice, data dimension reduction using numerical integration based differential equation solvers are found to be computationally expensive for most machine learning applications. Consequently, in this paper, we propose a local linear approximation to achieve this dimension reduction without significant loss of accuracy while reducing computational complexity. The proposed method is demonstrated on synthetic datasets.
9. Online Regularized Discriminant Analysis
Umut Orhan, Ang Li, Deniz Erdogmus
Learning the signal statistics and calibration are essential procedures for supervised machine learning algorithms. For some applications, e.g ERP based brain computer interfaces, it might be important to reduce the duration of the calibration, especially for the ones requiring frequent training of the classifiers. However simply decreasing the number of calibration samples would decrease the performance of the algorithm if the algorithm suffers from curse of dimensionality or low signal to noise ratio. As a remedy, we propose estimating the performance of the algorithm during the calibration in an online manner, which would allow us to terminate the calibration session if required. Consequently, early termination means a reduction in time spent. In this paper, we present an updating algorithm for regularized discriminant analysis (RDA) to modify the classifier using the new supervised data collected. The proposed procedure considerably reduces the time required for updating the RDA classifiers compared to recalibrating them, that would make the performance estimation applicable in real time.
10. Pseudo Inputs For Pairwise Learning With Gaussian Processes
Jens Brehm Nielsen, Bjørn Sand Jensen, Jan Larsen

44
We consider learning and predictions of pairwise comparisons between instances. The problem is motivated from a perceptual view point, where pairwise comparisons serve as an effective and massively used paradigm. A state-of-the-art method for modeling pairwise data in high dimensional domains is based on a classical pairwise probit likelihood imposed with a Gaussian process prior. While extremely flexible, this non-parametric method struggles with an inconvenient 𝒪(𝑛3) scaling in terms of the n inputs which limits the method only to smaller problems. To overcome this, we derive a specific sparse extension of the classical pairwise likelihood using the pseudo-input formulation. The behavior of the proposed extension is demonstrated on a toy example and several real-world data sets which outlines the potential gain and pitfalls of the approach by examining the evidence, error rates and predictive likelihood. Finally, we discuss the relation to other similar approximations that have been applied in standard Gaussian process regression and classification problems such as FI(T)C and PI(T)C.
11. Graphical Methods For Inequality Constraints In Marginalized Dags
Robin J. Evans
We present a graphical approach to deriving inequality constraints for directed acyclic graph (DAG) models, where some variables are unobserved. In particular we show that the observed distribution of a discrete model is always restricted if any two observed variables are neither adjacent in the graph, nor share a latent parent; this generalizes the well known instrumental inequality. The method also provides inequalities on interventional distributions, which can be used to bound causal effects. All these constraints are characterized in terms of a new graphical separation criterion, providing an easy and intuitive method for their derivation.
12. Learning Smooth Models Of Nonsmooth Functions Via Convex Optimization
Fabien Lauer, Van Luong Le, Gérard Bloch
This paper proposes a learning framework and a set of algorithms for nonsmooth regression, i.e., for learning piecewise smooth target functions with discontinuities in the function itself or the derivatives at unknown locations. In the proposed approach, the model belongs to a class of smooth functions. Though constrained to be globally smooth, the trained model can have very large derivatives at particular locations to approximate the nonsmoothness of the target function. This is obtained through the definition of new regularization terms which penalize the derivatives in a location-dependent manner and training algorithms in the form of convex optimization problems. Examples of application to hybrid dynamical system identification and image reconstruction are provided.
Oral Session 4: Learning Theory and Algorithms Wednesday, September 26, 11:00 – 13:00
Room: Salón de Baile Chair: David J. Miller, The Pennsylvania State University, USA
11:00-11:20 Mixture Weight Influence On Kernel Entropy Component Analysis And Semi-Supervised Learning Using The Lasso
Jonas N. Myhre, Robert Jenssen
The aim of this paper is two-fold. First, we show that the newly developed spectral method known as kernel entropy component analysis (kernel ECA) captures cluster structure, which is very important in semi-supervised learning, and we provide an analysis showing how mixture weights influence kernel ECA in a mixture of cluster components setting. Second, we develop a semi-supervised kernel ECA classifier based on the Lasso framework, and report promising results compared to the state-of-the art.
11:20-11:40 On Surrogate Supervision Multiview Learning
Gaole Jin, Raviv Raich
In semi-supervised multi-view learning, the input vector is partitioned into two views and a classifier based on each view is sought after. In such settings, often examples which include the two views and a label are

45
available. In this paper, we are interested in the setting where a classifier for examples from one view is sought after although no labeled examples are provided for that view. Specifically, we consider the setting where labeled examples are provided only for the other view along with additional unlabeled examples of the two views jointly. To solve this problem, we present the Classification -Constrained Canonical Correlation Analysis (C4A) algorithm. We apply our algorithm to an audiovisual classification task. In comparison to two alternatives, the proposed method demonstrates superior performance.
11:40-12:00 On The Generalization Ability Of Distributed Online Learners
Zaid J. Towfic, Jianshu Chen, Ali H. Sayed
We propose a fully-distributed stochastic-gradient strategy based on diffusion adaptation techniques. We show that, for strongly convex risk functions, the excess-risk at every node decays at the rate of O(1/Ni), where N is the number of learners and i is the iteration index. In this way, the distributed diffusion strategy, which relies only on local interactions, is able to achieve the same convergence rate as centralized strategies that have access to all data from the nodes at every iteration. We also show that every learner is able to improve its excess-risk in comparison to the non-cooperative mode of operation where each learner would operate independently of the other learners.
12:00-12:20 A Novel Scheme For Diffusion Networks With Least-Squares Adaptive Combiners
Jesús Fernández-Bes, Luiz A. Azpicueta-Ruiz, Magno T. M. Silva, Jerónimo Arenas-García
In this paper, we propose a novel diffusion scheme for adaptive networks, where each node preserves a pure local estimate of the unknown parameter vector and combines this estimate with other estimates received from neighboring nodes. The combination weights are adapted to minimize a local least-squares cost function. Simulations carried out in stationary and nonstationary scenarios show that the proposed scheme can outperform other existing schemes for diffusion networks with adaptive combiners in terms of tracking capability and convergence rate when the network nodes use different step sizes.
12:20-12:40 Unsupervised Feature Selection Based On Non-Parametric Mutual Information
Lev Faivishevsky, Jacob Goldberger
We present a novel filter approach to unsupervised feature selection based on the mutual information estimation between features. Our feature selection approach does not impose a parametric model on the data and no clustering structure is estimated. Instead, to measure the statistical dependence between features, we employ a mutual information criterion, which is computed by using a nonparametric method, and remove uncorrelated features. Numerical experiments on synthetic and real world tasks show that the performance of our algorithm is comparable to previously suggested state-of-the-art methods.
12:40-13:00 Stochastic Unfolding
Ke Sun, Eric Bruno, Stéphane Marchand-Maillet
This paper proposes a nonlinear dimensionality reduction technique called Stochastic Unfolding (SU). Similar to Stochastic Neighbour Embedding (SNE), N input signals are first encoded into a N×N matrix of probability distribution(s) for subsequent learning. Unlike SNE, these probabilities are not to be preserved in the embedding, but to be deformed in the way that the embedded signals have less curvature than the original signals. The cost function is based on another type of statistical estimation instead of the commonly-used maximum likelihood estimator. Its gradient presents a Mexican-hat shape with local attraction and remote repulsion, which was used as a heuristic and is theoretically justified in this work. Experimental results compared with the state of art show that SU is good at preserving topology and performs best on datasets with local manifold structures.

46

47
Author Index
Abdel Khalek, Amin, 27 Abolghasemi, Vahid, 23 Abosch, Aviva, 31 Abu-Jamous, Basel, 23 Adali, Tulay, 24 Ahuja, Narendra, 39 Akarun, Lale, 36 Alstrøm, Tommy S., 40 Amblard, Pierre-Olivier, 34 Andersen, Kasper Winther, 36 Arenas-García, Jerónimo, 28, 43, 45 Ari, Ismail, 36 Artés-Rodríguez, Antonio, 22, 25 Arvanitidis, Georgios, 41 Ataer-Cansizoglu, Esra, 23, 24, 26, 32, 43 Attux, Romis, 42 Azpicueta-Ruiz, Luiz A., 45 Bach, Francis, 18 Biessmann, Felix, 20 Bießmann, Felix, 36 Blanchard, Gilles, 25 Bloch, Gérard, 44 Bolton, Jeremy, 20 Braun, Mikio, 36 Braz, Rui, 22 Brooks, Dana H., 26 Bruno, Eric, 45 Buchgraber, Thomas, 35 Calhoun, Vince D., 24, 38 Camps-Valls, Gustavo, 41, 42, 43 Canterla, Alfonso, 28 Caramanis, Constantine, 27 Carmen, Craig, 40 Cemgil, Ali Taylan, 33, 36 Cetin, A. Enis, 31 Chainais, P., 25 Chalasani, Rakesh, 41 Chen, Jianshu, 45 Chiang, Michael F., 23, 24 Chien, Jen-Tzung, 35 Chueh, Chuang-Hua, 35 Cichocki, Andrzej, 24 Cong, Fengyu, 24 Congedo, Marco, 31 Costantini, Giovanni, 29 Cuff, Paul W., 37 Dajer, María Eugenia, 31 Delcroix, Marc, 30 Deleforge, Antoine, 29 Dimitrievski, Martin, 26 Dingeldey, F., 22 Dizdaroğlu, Bekir, 24 Donmez, Mehmet A., 33, 40 Douc, Randal, 39 Dürichen, Robert, 21 Dy, Jennifer G., 26 Erdogmus, Deniz, 23, 24, 26, 32, 43 Erkkila, Timo, 38
Evans, Robin J., 44 Fa, Rui, 22, 23 Faivishevsky, Lev, 45 Farina, Dario, 20 Ferdowsi, Saideh, 23 Fernández-Bes, Jesús, 45 Févotte, Cédric, 29 Florentino-Liaño, Blanca, 22 Fred, Ana, 21 Freire, Mário, 22 Frigui, Hichem, 26 Gader, Paul, 20, 26 García-García, Darío, 21 Gemmeke, Jort F., 30 Georgatzis, Konstantinos, 33 Gerhardt, J., 22 Ghadarghadar, Nastaran, 32 Gill, Waljinder S., 32 Giurcaneanu, Ciprian Doru, 39 Goldberger, Jacob, 45 Gómez-Chova, Luis, 42, 43 Gonzalo-Ayuso, Álvaro, 28 Grozea, C., 22 Gupta, Ankit, 38 Hahne, Janne Mathias, 20 Han, Jinyu, 29 Hanif, Muhammad, 26 Hansen, Lars Kai, 33, 36 Harth, Andreas, 36 Hartikainen, Jouni, 34 Hasegawa-Johnson, Mark, 37 Heath Jr., Robert W., 27 Herlau, Tue, 33 Hild II, Kenneth E., 32, 38 Hirsch, J., 22 Honeine, Paul, 41 Horaud, Radu, 29 Hotta, Seiji, 40 Huang, Catherine, 38 Huang, Po-Sen, 37 Huang, Thomas S., 37 Huang, Yonghong, 32 Hui, Pan, 37 Huttunen, Heikki, 38 Ince, N. Firat, 31 Ivanovski, Zoran, 26 Izquierdo-Verdiguier, Emma, 43 Jensen, Bjørn Sand, 40, 43 Jenssen, Robert, 44 Jenzri, Hamdi, 26 Jiang, Ning, 20 Jiménez, S., 41 Jin, Gaole, 44 Johnsen, Magne H., 28 Jugel, Matthias L., 36 Jutten, Christian, 31 Kalpathy-Cramer, Jayashree, 23, 24 Keck, Katie, 23, 24

48
Kesidis, George, 38 Khalid, Muhammad Usman, 31 Kim, Minje, 30 King, Brian, 29 Kinoshita, Keisuke, 30 Ko, Glenn G., 30 Kocak, Fatih, 38 Kompatsiaris, Ioannis, 25 Kontkanen, Petri, 39 Kostesha, Natalie V., 40 Kozat, Suleyman S., 33, 40 Kulkarni, Sanjeev R., 37 Kung, S.Y., 42 Lakshminarayan, Choudur, 23 Laparra, V., 41 Larsen, Jan, 40, 43 Lauer, Fabien, 44 Lazaro-Gredilla, Miguel, 35 Le, Van Luong, 44 Lefebvre, Sidonie, 39 Li, Ang, 43 Liu, Weifeng, 38 Llorens, Ashley, 20 Loog, Marco, 39 Lourenco, Andre, 21 Luebke, D., 22 Luengo, David, 25 Luosto, Panu, 39 Madsen, Kristoffer H., 36 Maire, Florian, 39 Malo, J., 41 Manninen, Tapio, 38 Marasovic, Tea, 34 Marchand-Maillet, Stéphane, 45 Markov, Konstantin, 28 Marrara, Jamille L., 31 Martinez-Noriega, Raul, 25 Massey, Michael, 26 Mathan, Santosh, 32 Matsui, Tomoko, 28 Mboup, Mamadou, 24 Mckelvey, Tomas, 41 Meinecke, Frank C., 20 Mezaris, Vasileios, 25 Michel, Olivier, 34 Miller, David J., 38 Mishra, Shashwat, 38 Montalvão, Jugurta, 42 Montanez, Ken, 38 Monzón, Sandra, 25 Mørup, Morten, 33, 36, 37 Moulin, Pierre, 39 Moulines, Eric, 18, 39 Moutinho, J., 22 Mukerjee, Amitabha, 38 Müller, Klaus-Robert, 20, 36 Muñoz-Romero, Sergio, 43 Murillo-Fuentes, Juan José, 32 Mutsam, Nikolaus, 21 Myhre, Jonas N., 44 Mysore, Gautham J., 29
Nabney, Ian T., 32 Nadalin, Everton Z., 42 Nakatani, Tomohiro, 30 Nallathambi, Gabriel, 23 Nandi, Asoke K., 22, 23, 24 Nascimento, Vítor H., 28 Nielsen, Jens Brehm, 43 Noumir, Zineb, 41 O’mahony, Niamh, 22 Olmos, Pablo M., 32 Onaran, Ibrahim, 31 Orhan, Umut, 43 Ortega, Antonio, 42 Ozkan, Huseyin, 40 Palazzo, S., 27 Palfy, Juraj, 30 Paoloni, Andrea, 29 Papaioannou, Jens-Michalis, 36 Papic, Vladan, 34 Pardo, Bryan, 29 Parra, Lucas C., 20 Parrado-Hernández, Emilio, 21 Pavel, Misha, 32 Pekala, Michael, 20 Peltonen, Jaakko, 33 Pereira, José Carlos, 31 Pereira, Manuela, 22 Pérez-Cruz, Fernando, 32 Perfetti, Renzo, 29 Pernkopf, Franz, 21 Piche, Robert, 34 Pinheiro, António M. G., 22 Pitas, Ioannis, 20 Pospichal, Jiri, 30 Príncipe, José C., 23, 41 Raich, Raviv, 16, 44 Raj, Bhiksha, 15 Ramírez, David, 42 Rehbaum, Hubertus, 20 Renjifo, Carlos, 40 Richard, Cédric, 34, 41 Ristaniemi, Tapani, 24 Roberts, David J., 23 Rodriguez, Pedro A., 24 Roumy, Aline, 25 Rousseau, Sandra, 31 Rusu, Cristian, 27 Rutenbar, Rob A., 30 Ruusuvuori, Pekka, 38 Safont, Gonzalo, 38 Saggio, Giovanni, 29 Salamanca, Luis, 32 Salazar, Adisson, 38 Sanei, Saeid, 23 Santamaría, Ignacio, 35, 42 Santos-Rodríguez, Raúl, 21 Särkkä, Simo, 34 Sayed, Ali H., 18, 45 Scalassara, Paulo Rogério, 31 Schiewe, M., 22 Schmidt, Mikkel N., 33, 40

49
Schreier, Peter J., 42 Schumann, C., 22 Schweikard, Achim, 21 Seghouane, Abd-Krim, 26, 31 Shang, Shang, 37 Shapiro, Nathan, 26 Sheng, Lingyan, 42 Shutin, Dmitriy, 35 Sidiropoulos, Panagiotis, 25 Siebner, Hartwig, 36 Silva, Daniel G., 42 Silva, Hugo, 21 Silva, Magno T. M., 28, 45 Simsekli, Umut, 33 Singh, Abhishek, 39 Smaragdis, Paris, 29, 30 Soriano, Antonio, 38 Souden, Mehrez, 30 Sourati, Jamshid, 26 Spampinato, C., 27 Sun, Ke, 45 Tefas, Anastasios, 20, 41 Todisco, Massimiliano, 29 Towfic, Zaid J., 45 Trigano, Tom, 25 Tsagkatakis, Grigorios, 27 Tsakalides, Panagiotis, 27 Tschiatschek, Sebastian, 21 Tuia, D., 41
Tunc, Sait, 33 Van Compernolle, Dirk, 30 Van Der Maaten, Laurens, 34 Van Hamme, Hugo, 30 Van Vaerenbergh, Steven, 35 Vergara, Luis, 38 Vía, Javier, 42 Vincent, Rémy, 34 Vretos, Nicholas, 20 Wainwright, Martin, 17 Wang, I- Jeng, 20 Washizawa, Yoshikazu, 40 Weinberger, Kilian, 34 Wells, Daniel, 32 Weruaga, Luis, 29 Wind, David Kofoed, 37 Wissel, Tobias, 21 Wu, Pei-Yuan, 42 Wu, Qiang, 24 Yilmaz, Emre, 30 Yin, Wotao, 37 You, Sheng, 23, 26 Yu, Yinan, 41 Yuksel, Seniha Esen, 20 Zhang, Peng, 32, 43 Zhang, Zhuo, 37 Zhao, Qibin, 24 Zhou, Guoxu, 24

50

51
Notes

52
Notes

53
Notes

54
Notes

MLSP 2012 Conference Guide Copyright ©2012 by IEEE. IEEE Catalog Number CFP12NNS-USB ISBN 978-1-4673-1025-3




























