Embed Size (px)
Citation preview

Universidade de São Paulo
2014
Relative validity criteria for community mining
algorithms RABBANY, Reihaneh et al. Relative validity criteria for community mining algorithms. In: ALHAJJ,
Reda; ROKNE, Jon, eds. Encyclopedia of social network analysis and mining. New York : Springer,
2014. p. 1562-1576http://www.producao.usp.br/handle/BDPI/48887
Downloaded from: Biblioteca Digital da Produção Intelectual - BDPI, Universidade de São Paulo
Biblioteca Digital da Produção Intelectual - BDPI
Departamento de Ciências de Computação - ICMC/SCC Livros e Capítulos de Livros - ICMC/SCC

R
R&D (Research and Development)Collaborations
� Innovator Networks
R&DNetworks
Jan KratzerTechnical University Berlin, Berlin, Germany
Glossary
Design Structure Matrix (DSM) Symmetricmatrix that indicates the links/interfacesbetween decomposed product components
Hierarchical Decomposition Methods todecompose products in to components andsubcomponents following product hierarchies
Systematic Variation Method that refers to thesearch for and combination of solutions todesign subproblems
Satisficing Method that refers to the evaluationand selection of alternative solutions and theunderstanding that searches should not befocused on finding the optimal solution
Discursiveness Method that refers to a step-by-step, yet iterative, approach to the productdevelopment process
Lead User Person who are ahead of trends anddevelop and/or modify for their own benefitnew products and processes
Definition
Perhaps the first attempts to characterize indus-trial organizations as networks were containedin the records of the Hawthorne Experiments.Shortly later, the analytic tools to scientificallyengage in networks were presented: the sciogramintroduced in 1934 and the sociomatrix intro-duced in 1946. The decades after, with increasingcompetitions, globalization, and customer indi-vidualization, the pressure on organizational re-search and development efforts has dramaticallyincreased. This process brought research and de-velopment networks (R&D networks) into thepicture of academic research.
These early studies also exemplify themultilevel character of such R&D networks.The smallest elements in R&D are humans,so interaction networks among them mold thelowest level. Humans are grouped into teamsin aggregation departments and functionaldivisions, so there are a number of levelswithin organizations. Further, organizationsare embedded in environments with partners,competitors, and customers within an economic,political, and societal system. Hence, onedimension in defining R&D networks is theinherent existence of different levels (Gabbay andLeenders 1999). Another dimension is the natureof nodes and arcs. Nodes may be humans, butalso teams and departments. However, nodes mayalso be product components (Sosa et al. 2004) inR&D networks. In this case, the linking element,the arcs, would be interfaces between product
R. Alhajj, J. Rokne (eds.), Encyclopedia of Social Network Analysis and Mining,DOI 10.1007/978-1-4614-6170-8,© Springer ScienceCBusiness Media New York 2014

R 1486 R&D Networks
components, whereas interaction between hu-mans, teams, and departments most often refersto some kind of communication. In addition,like all networks, R&D networks can be openor closed, are denoted by strong or weak ties,and have structural features such as centrality.Generally speaking, R&D networks are like othernetworks and can be defined as other networks,as a number of ties or arcs between a number ofnodes, whereby arcs and nodes are embedded in amultilevel hierarchy and can be of different kind,strength, and structural consequence. Researchon different levels of analysis has shown that so-cial network ties have an impact on performance:On an individual level, Burt (1992) shows thatmanagers with a high quantity of disconnected,nonredundant social network ties achieve fasterpromotions to managerial positions. On an orga-nizational level, Tsai and Ghosal (1998) foundthat social interaction, as a manifestation of thestructural dimension, is significantly related tothe extent of interunit resource exchange. On aninterorganizational level, Gabbay and Leenders(1999) illustrate how a key position in a cohesiveclique of an interorganizational network providesa corporate actor with a rent-seeking capacityenabling a business organization to extend itsprofitability or to accrue valuable resourcesnecessary for corporate success. R&D networksare distinct in being embedded in research and de-velopment efforts, and with this the focus is partlyon specific nodes such as product components,arcs such as problem-solving communication,and levels of analyses such as R&D teams.
ExamplesFollowing there are two examples of typical R&Dnetwork research. The first example is adaptedfrom Journal of Product Innovation Management(Leenders et al. 2007), and the second fromResearch Policy (Kratzer et al. 2008). Thestructure of formal and informal networks ofteams in R&D projects define the opportunitiespotentially available to create new knowledge.As many scholars have argued, networks oforganizational linkages are critical to a host oforganizational processes and outcomes (e.g.,Reagans and Zuckerman 2003).
Can organizations exert control and providestructure for R&D activities while at thesame time encouraging and managing creativeperformance? This question was addressed inthe publication “Systematic Design Methodsand the Creative Performance of New ProductTeams: Do They Contradict or ComplementEach Other?” (Leenders et al. 2007). Most R&Dprojects are executed with the R&D team as theorganizational nucleus. As a result, managingcreativity in R&D thus implies managing thecreativity of R&D teams. Besides having tomanage creative performance, companies aregenerally also concerned with improving theefficiency and effectiveness of the R&D process.Modern R&D projects therefore have the needfor an approach that can be planned, optimized,and verified. As a consequence, systematicdesign methods have become widely usedin R&D. In this article a conceptual modelis developed of the effect of modern designmethodology on the creative performance ofR&D teams. It is then proposed that fourprinciples underlie modern design methodology:hierarchical decomposition, systematic variation,satisficing, and discursiveness. These principlesaffect R&D communication by, respectively,influencing the establishment of subgroups,the frequency of communication, the level ofagreement or disagreement in the team, andthe level of centralization of communication.These patterns of communication are thenrelated to team-level creative performance.The main conclusion of the entry, is that thedesign principles work together and need to beconsidered as an integrated whole: the creativeperformance of R&D teams can only effectivelybe managed by using and aligning all four ofthem.
In another publication “Revealing dynamicsand consequences of fit and misfit betweenformal and informal networks in multi-institutional product development collabora-tions” (Kratzer et al. 2008), the interplay betweencommunication networks and product componentor design networks is highlighted. The sizeand complexity of most multi-team R&Dproject structures characterize the importance

R&D Networks 1487 R
R
of addressing and defining the interfaces betweenproduct sub-components; it is also importantto determine if the teams actually interactaccording to their formally ascribed interfaces,an inevitable requirement for the project tofunction. Unfortunately, informal communicationnetworks often compete with such aspects oforganizations as formal structure (Cross et al.2002). One of the most consistent findings inthe social science literature is that who youknow often has a great deal to do with what youcome to know (e.g., Szulanski 1996). In multi-team R&D projects, therefore, it would be naiveto expect a perfect alignment between designinterfaces – the “Design Structure Matrix” – andthe informal communication network as Sosaet al. (2004) have shown. The study revealedthree important findings: (1) formally ascribeddesign interfaces and informal communicationnetworks correlate only marginally. The mainreason is that informal communication is muchmore dense than ascribed; (2) although theformally ascribed design interfaces change, thestructure of informal communication remainslargely stable throughout time; and (3) the mostintriguing finding is that this communicationalmisfit is associated with higher effectiveness,but it negatively impacts the institutional unit’sefficiency.
Other Directions and Future DirectionsThese two examples show that R&D networks donot solely focus on human interaction, but alsotake the structure of products and processes assystematic methods into account. There are otherexamples of research on R&D networks reachingbeyond the organizational boundaries. Anotherstream of research is focused on the diffusion ofinnovation (Rogers 1974), on the identificationof certain roles as lead users important to propelR&D efforts (Kratzer and Lettl 2009) and R&Dalliances (Hagedoorn 2002) among others. Theinvestigations of R&D networks in the future maystudy networks increasingly by addressing morethoroughly the multilevel character, may focusmore on longitudinal research designs, may applymore sophisticated statistical analytics to cap-
ture the dynamics of networks, and finally mayclose the gap between qualitative and quantitativeresearch designs.
Cross-References
� Innovator Networks� Inter-organizational Networks� Intra-organizational Networks�Networks of Practice�Top Management Team Networks
References
Burt R (1992) Structural holes. Harvard University Press,Cambridge
Cross R, Borgatti SP, Parker A (2002) Making invisiblework visible: using social network analysis to sup-port strategic collaboration. California ManagementReview 44:25–46
Gabbay SM, Leenders RT (1999) The structure of advan-tage and disadvantage. In: Leenders RT, Gabbay SM(eds) Corporate social capital and liability. Kluwer,Boston, pp 1–14
Hagedoorn J (2002) Inter-firm R&D partnerships: anoverview of major trends and patterns since 1960. ResPolicy 3:477–492
Kratzer J, Lettl C (2009) Distinctive roles of lead users andopinion leaders in the social networks of schoolchil-dren. J Consum Res 36:646–659
Kratzer J, Gemuenden HG, Lettl C (2008) Reveal-ing dynamics and consequences of fit and misfitbetween formal and informal networks in multi-institutional product development collaborations. ResPolicy 37:1356–1370
Leenders RTAJ, Van Egelen JML, Kratzer J (2007) Sys-tematic design methods and the creative performanceof new product teams: do they contradict or comple-ment each other? J Prod Innov Manag 24:166–179
Reagans R, Zuckerman E (2003) Networks, diversity, andproductivity: the social capital of corporate R&D units.Organ Sci 12:502–517
Rogers DL (1974) Sociometric analysis of interorgani-zational relations: application of theory and measure-ment. Rural Sociol 39:487–503
Sosa ME, Eppinger SD, Rowles CM (2004) The mis-alignment of product architecture and organizationalstructure in complex product development. Manag Sci50:1674–1689
Szulanski G (1996) Exploring internal stickiness: im-pediments to the transfer of best practices within the?rm. Strategic Management Journal, 17:27–43
Tsai W, Ghosal S (1998) Social capital and value cre-ation: The role of intrafirm networks. The Academyof Management Journal 41:464–476

R 1488 Random Networks
Random Networks
� Sources of Network Data
Random Processes
� Probabilistic Analysis
Random Structures
� Probabilistic Analysis
RandomWalks
�Legislative Prediction with Political and SocialNetwork Analysis
Ranking
�Misinformation in Social Networks, AnalyzingTwitter During Crisis Events
RankingMethods for Networks
Yizhou Sun1 and Jiawei Han2
1College of Computer and Information Science,Northeastern University, Boston, MA, USA2Department of Computer Science, University ofIllinois at Urbana-Champaign, Urbana, IL, USA
Synonyms
Identify influential nodes; Importance ranking;Link-based ranking; Relevance ranking
Glossary
Ranking Sort objects according to some orderGlobal Ranking Objects are assigned ranks
globallyQuery-Dependent Ranking Objects are
assigned with different ranks according todifferent queries
Proximity Ranking Objects are ranked accord-ing to proximity or similarity to other objects
Homogeneous Information Network Networksthat contain one type of objects and one typeof relationships
Heterogeneous Information Network networksthat contain more than one type of objectsand/or one type of relationships
Learning to Rank ranking is learned accordingto examples via supervised or semi-supervisedmethods
Definition
Ranking objects in a network may refer to sortingthe objects according to importance, popular-ity, influence, authority, relevance, similarity, andproximity, by utilizing link information in thenetwork.
Introduction
In this entry, we introduce the ranking methodsdeveloped for networks. Different from otherranking methods defined in text or database sys-tems, links or the structure information of thenetwork are significantly explored. For most ofthe ranking methods in networks, ranking scoresare defined in a way that can be propagated in thenetwork. Therefore, the rank score of an object isdetermined by other objects in the network, usu-ally with stronger influence from closer objectsand weaker influence from more remote ones.
Methods for ranking in networks can becategorized according to several aspects, suchas global ranking vs. query-dependent ranking,based on whether the ranking result is dependenton a query; ranking in homogeneous information

Ranking Methods for Networks 1489 R
R
networks vs. ranking in heterogeneous in-formation networks, based on the type ofthe underlying networks; importance-basedranking vs. proximity-based ranking, based onwhether the semantic meaning of the rankingis importance related or similarity/proximityrelated; and unsupervised vs. supervised or semi-supervised, based on whether training is needed.
Historical Background
The earliest ranking problem for objects in anetwork was proposed by sociologists, who in-troduced various kinds of centrality to definethe importance of a node (or actor) in a socialnetwork. With the advent of the World WideWeb and the rising necessity of web search,ranking methods for web page networks are flour-ishing, including the well-known ranking meth-ods PageRank (Brin and Page 1998) and HITS(Kleinberg 1999). Later, in order to better supportentity search instead of web page ranking, objectranking algorithms is proposed, which usuallyconsider more complex structural information ofthe network, such as heterogeneous informationnetworks. Moreover, in order to better person-alize search quality, ranking methods that canintegrate user guidance are proposed. Learningto rank techniques are used in such tasks, andnot only the link information but the attributesassociated with nodes and edges are commonlyused.
Methods and Algorithms
In this section, we introduce the most representa-tive ranking methods for networks.
Centrality and PrestigeIn network science, various definitions andmeasures are proposed to evaluate the promi-nence or importance of a node in the network.According to Wasserman and Faust (1994),centrality and prestige are two concepts toquantify prominence of a node within a network,where centrality focuses on evaluating the
involvement of a node no matter whether theprominence is due to the receiving or thetransmission of the ties, whereas prestige focuseson evaluating a node according to the ties that thenode is receiving.
Given a network G D .V; E/, where V andE denote the vertex set and the edge set, severalfrequently used centrality measures are listed inthe following:• Degree centrality. Degree centrality (Niemi-
nen 1974) of a node u is defined as the degreeof nodes in the network: CD.u/ D P
v Au;v ,where A is the adjacency matrix of G. Nor-malized degree C 0D.u/ D CD.u/=.N � 1/
can also be used to measure the relative impor-tance of a node, where N is the total numberof nodes in the network and N � 1 is themaximum degree that a node can have.
• Closeness centrality. Closeness centrality(Sabidussi 1966) assigns a high score to anode if it is close to many other nodes in thenetwork and is calculated by the inverse of thesum of geodesic distance (shortest distance)between the node and other nodes:
CC .u/ D 1P
v d.u; v/
where d.u; v/ is the geodesic distance be-tween u and v. A normalized closeness cen-trality score (Beauchamp 1965) is defined as
C 0C .u/ D N � 1P
v d.u; v/
where N � 1 is the possible minimum sum ofdistances between a node and the remainingN � 1 nodes.
• Betweenness centrality. Betweennesscentrality evaluates how many times the nodefalls on the shortest or geodesic paths betweena pair of nodes:
CB.u/ DX
v<w
gvw .u/
gvw
where gvw is the number of shortest pathsbetween v and w and gvw .u/ is the number

R 1490 Ranking Methods for Networks
of shortest paths between v and w containingu. A normalized betweenness centrality scoreis given in Freeman (1977):
C 0B.u/ D 2CB.u/
N 2 � 3N C 2
where .N 2�3NC2/=2 can be proved to be themaximum value of CB.u/, when u is a centerpoint in a star network.The readers may refer to Freeman (1978) and
Wasserman and Faust (1994) for detailed intro-duction of these centrality measures.
In Wasserman and Faust (1994), severalprestige measures are proposed for directednetworks.• Degree prestige. Degree prestige is defined
as the in-degree of each node, as a node isprestigious if it receives many nominations:
PD.u/ D din.u/ DX
v
Av;u
The normalized version of degree prestige is
P 0D.u/ D PD.u/
N � 1
where N is the total number of nodes in thenetwork and thus N � 1 is the maximum in-degree that a node can have .
• Eigenvector-based prestige. In order to cap-ture the intuition that a node is prestigiousif it is linked by a lot of prestigious nodes,eigenvector-based prestige is proposed in aniterative form:
P.u/ D 1
�
X
v
Av;uP.v/
It turns out that p D .P.1/; : : : ; P.N //0 is theprimary eigenvector of the transpose of adja-cency matrix AT . p is also called eigenvectorcentrality.
• Katz prestige. In Katz (1953), attenuationfactor ˛ is considered for influence withlonger length transmissions, and the Katzscore is calculated as a weighted combinationof influence with different lengths:
PKat´.u/ DX
kD1
˛kX
v
.Ak/vu
which can be written into the matrix from:
PKatz D ..I � ˛A/�1 � I /01
where PKatz D .PKat´.1/; : : : ; PKat´.N //0,I is the identity matrix, and 1 is an all-onevector with length N . Katz score is also calledKatz centrality.
Global RankingAlong with the flourish of web applications,many link-based ranking algorithms are pro-posed. We first introduce the ranking algorithmsthat assign global ranking scores to objects in thenetwork.PageRank In information network analysis, themost well-known ranking algorithm is PageR-ank (Brin and Page 1998), which has beensuccessfully applied to the web search problem.PageRank is a link analysis algorithm that assignsa numerical weight to each object in the informa-tion network, with the purpose of “measuring” itsrelative importance within the object set.
More specifically, for a directed web page net-work G with adjacency matrix A, the PageRankrank score of a web page u is iteratively deter-mined by the scores of its incoming neighbors:
PR.u/ D 1 � ˛
NC ˛
X
v
AvuPR.v/=dout .v/
where ˛ 2 .0; 1/ is a damping factor and is set as0.85 in the original PageRank paper, N is the totalnumber of nodes in the network, and dout .v/ DP
w Avw is the degree of outgoing links of v.The iterative formula can also be written in thefollowing matrix form:
PR D 1 � ˛
N1C ˛M T PR
where M is the row normalized matrix of A,i.e., Muv D Auv=
Pv0 Auv0 , and 1 is an all-one
vector with length N .The iterative formula can be proved to con-
verge to the following stable point:

Ranking Methods for Networks 1491 R
R
PR D .I � ˛M T /�1 1 � ˛
N1
where I is the identity matrix.PageRank score can be viewed as a stationary
distribution of a random walk on the network,where a random surfer either randomly selectsan out-linked web page v of the current page u
with probability ˛=dout .u/ or randomly selectsa web page from the whole web page set withprobability .1 � ˛/=N .
Query-Dependent RankingDifferent from global ranking, query-dependentranking produces different ranking results fordifferent queries.
HITS Hyperlink-Induced Topic Search(HITS) (Kleinberg 1999) ranks objects basedon two scores: authority and hub. Authorityestimates the value of the content of the object,whereas hub measures the value of its links toother objects.
HITS is designed to be applied on a query-dependent subnetwork, where the most relevant(e.g., by keyword matching) web pages to thequery are first extracted. Then, the authority andhub scores are calculated according to the follow-ing two rules:1. An object has a high authority score if it is
pointed by many nodes with high hub scores.2. An object has a high hub score if it has pointed
to many nodes with high authority scores.Mathematically, the two rules can be repre-
sented as two formulas:
Auth.u/ DPv AvuHub.v/
Hub.u/ DPv AuvAuth.v/
where A is the adjacency matrix of the subnet-work. The two formulas are calculated iteratively,where normalization is needed after each itera-tion such that the score summation for each typeequals to 1.
By reforming the two formulas into matrixform, we can find the authority score vector is theprimary eigenvector of AT A matrix, and the hubscore vector is the primary eigenvector of AAT
matrix.
Note that the authority and hub scores can onlybe calculated at query time, as the subnetworkneeds first to be extracted according to the query.Therefore, efficiency is a major issue of the HITSalgorithm.Topic-Sensitive PageRank In order to obtainboth the offline computation benefit as PageRankand the query-dependent ranking benefit as HITS,topic-sensitive PageRank is proposed in Haveli-wala (2002).
The topic-sensitive PageRank is comprised oftwo steps. In step 1, a biased PageRank scorevector is computed for each predefined topicoffline, and in step 2, the probabilities that a querybelongs to each topic are determined online, andthe final query-dependent ranking is a weightedcombination of the rankings for each topic.
More specifically, in step 1, let Tj be the webpage set for topic cj , and let pj be the initialranking score vector for topic cj , where pj .u/ D1=jTj j if web page u 2 Tj and Pj .u/ D 0;otherwise, the biased PageRank score for topic cj
is calculated as
PRj D .1 � ˛/M T � PRj C ˛pj
where M is the row normalized matrix of adja-cency matrix A, as defined in PageRank section,and ˛ is the parameter indicating the weight forthe initial ranking vector. Note that, in PageRank,the initial ranking score is 1=N for all the webpages in the network.
In step 2, for a given query q, the probabilitythat it belongs to each topic cj is calculatedaccording to the term distribution in each topic:
P.cj jq/ / P.cj /P.qjcj /
where P.cj / is the prior distribution of topiccj and P.qjcj / is the probability that query q
can be generated in topic cj according to termdistribution in cj . Then, the query q-dependentimportance score for web page u can be calcu-lated as:
squ DX
j
P.cj jq/PRj .u/

R 1492 Ranking Methods for Networks
where PRj .u/ is the biased PageRankscore for web page u for topic cj .Personalized PageRank In Jeh and Widom(2003), personalized PageRank is proposed andhow to scale the computation is introduced.Personalized PageRank aims at calculatingbiased PageRank score to a personalized queryvector q, which is called preference vector:
PPRq D .1 � ˛/M T � PPRq C ˛q
where M is the row-normalized matrix for thenetwork and ˛ 2 .0; 1/ is the parameter indicat-ing the probability a random walk will teleport tothe query vector. PPRq is called the personalizedPageRank vector (PPV) for preference vector q.
Different from topic-sensitive PageRank,where the query vectors are fixed for predefinedtopics, query vectors in personalized PageRankare arbitrary. Therefore, how to computepersonalized PageRank efficiently onlinebecomes critical, and the readers may refer toJeh and Widom (2003) for more discussions.
A similar idea, TrustRank, that is used forranking web pages according to their trustabilityis proposed in Gyongyi et al. (2004), where thequery vector is determined by a set of carefullyselected trustable websites.
Ranking in Heterogeneous InformationNetworksTraditional ranking problem is considered in ho-mogeneous information networks, where the net-works contain only one type of objects and theobjects are connected via one type of relation-ships. Recently, ranking algorithms for heteroge-neous information networks are proposed, wherethe networks contain multiple types of objectsand/or multiple types of relationships.ObjectRank ObjectRank is proposed in Balminet al. (2004), which aims at ranking the ob-jects according to a keyword-based query in adatabase. A database is represented using a la-beled data graph, D.VD ; ED/, where nodes rep-resented objects from different types and linksrepresented relationships from different types. Aschema graph, G.VG; EG/, is used to describethe structure of the data graph. Each node also
contains several attribute-value pairs, which de-termine a set of keywords each node is associatedwith.
An authority transfer schema graph,GA.VG ; EA
G/, is then defined according to theschema graph, where authority transfer rates aregiven to the edges in the schema graph, that is,a certain link type in the data graph. The rate isspecified by domain experts or obtained by trialand error. Afterwards, an authority transfer datagraph, DA.VD; EA
D/, can be derived, where theauthority transfer rate between two objects u andv is defined by
M.u; v/ D(
w.T /dout .u;T /
if dout .u; T / > 00 if dout .u; T / D 0
where T is the type of edge e D .u; v/, w.T / isthe authority transfer rate on the type of edgesT , and dout .u; T / is the total number of outedges from u and of type T . After defining theauthority transfer data graph and obtaining thenew transition matrix M defined on objects, theonline query processing is similar to personalizedPageRank. For a keyword query k, the systemwill prepare the query vector q according tothe set of objects containing the keyword. If anobject u contains the keyword, then q.u/ D1=Nk, where Nk is the total number of objectscontaining the keyword k; otherwise, q.u/ D 0.Then, the ObjectRank vector for objects given thekeyword k is defined as
ORq D .1 � ˛/M T �ORq C ˛q
where ˛ is the parameter indicating the proba-bility a random walk will teleport to the queryvector.PopRank In Nie et al. (2005), PopRank is pro-posed to rank web objects by using both weblinks and object relationship links. The PopRankscore vector RX for objects from type X isdefined as a combination of their web popularityREX and impacts from objects from other types:
RX D �REX C .1� �/X
Y
�YXM TYX RY

Ranking Methods for Networks 1493 R
R
where � is the weighting parameter of the twocomponents, �YX is the popularity propagationfactor (PPF) of the relationship link from anobject of type Y to an object of type X , andP
Y �YX D 1, MYX is the row-normalized ad-jacency matrix between type Y and type X , andRY is the PopRank score vector for type Y .
In the paper, a simulated annealing-based al-gorithm for learning popularity propagation fac-tor �YX is also proposed, according to somepartial ranking lists given by users. Note thatPopRank assigns a global score for every object.Authority Ranking for Heterogeneous Bibli-ographic Network In reality, ranking functionis not only related to the link property of aninformation network but also dependent on thehidden ranking rules used by people in somespecific domain. Ranking functions should becombined with link information and user rules inthat domain. Authority ranking for heterogeneousbibliographic network is proposed in Sun et al.(2009a, b), which gives an object higher rankscore if it has more authority.
Without using citation information, as citationinformation could be unavailable or incomplete(such as in the DBLP data, where there is no ci-tation information imported from Citeseer, ACMDigital Library, or Google Scholars), two simpleempirical rules similar to HITS are proposed torank authors and venues:• Rule 1: Highly ranked authors publish many
papers in highly ranked venues.• Rule 2: Highly ranked venues attract many
papers from highly ranked authors.Let X and Y denote the venue type and author
type, respectively, and WY Y and WYX denote theadjacency matrices for co-author relationshipsand author-venue relationships in a bibliographicnetwork, according to Rule 1, each author’s scoreis determined by the number of papers and theirpublication forums:
rY .j / DmX
iD1
WYX .j; i/rX .i/ (1)
At the end of each step, rY .j / is normalized byrY .j / rY .j /Pn
j 0D1 rY .j 0/
:
According to Rule 2, the score of each venue isdetermined by the quantity and quality of papersin the venue, which is measured by their authors’rank scores:
rX .i/ DnX
jD1
WXY .i; j /rY .j / (2)
The score vector is then normalized by rX .i/ rX .i/Pm
i 0D1 rX .i 0/
.
The two formulas will converge to the primaryeigenvector of WXY WYX and WYX WXY , respec-tively.
When considering the co-author information,the scoring function can be further refined by athird rule:• Rule 3: The rank of an author is enhanced if
he or she co-authors with many highly rankedauthors.Adding this new rule, we can calculate rank
scores for authors by revising Eq. (1) as
rY .i/ D ˛
mX
jD1
WYX .i; j /rX .j /
C.1 � ˛/
nX
jD1
WY Y .i; j /rY .j / (3)
where parameter ˛ 2 Œ0; 1� determines howmuch weight to put on each factor, which can beassigned based on one’s belief or learned by sometraining dataset.
Similarly, we can prove that rY shouldbe the primary eigenvector of ˛WYX WXYC.1 � ˛/WY Y and rX should be the primaryeigenvector of ˛WXY .I � .1 � ˛/WY Y /�1WYX .Since the iterative process is a power method tocalculate primary eigenvectors, the rank scorewill finally converge.
The idea is extended to ranking medical treat-ments based on medical literature, and an algo-rithm called MedRank is proposed in Chen et al.(2013).
Proximity RankingDifferent from previous ranking methods thateither rank objects according to their global

R 1494 Ranking Methods for Networks
importance or find the important objects thatare relevant to a query, ranking objects accordingto their similarity or proximity to a given objectis also important. Note that proximity rankingdoes not necessarily return highly visible objectsin the network.SimRank SimRank is proposed in Jeh andWidom (2002) to calculate pairwise similaritybetween objects in a network based on the linkinformation. The intuition of the similarity modelis based on the idea that “two objects are similarif they are related to similar objects.” In otherwords, the similarity between objects can bepropagated from pair to pair via links.
For a directed graph G D .V; E/, the sim-ilarity between two nodes a and b is definedto be 1, if a D b, that is, s.a; b/ D 1 whena D b. Otherwise, it is calculated iteratively viathe following formula:
s.a; b/ D C
jI.a/jjI.b/jjI.a/jX
iD1
jI.b/jX
jD1
s.Ii .a/; Ij .b//
where C is the damping factor and is set as 0:8in the paper, I.a/ represents the in-neighbors ofnode a, jI.a/j is the total number of in-neighborsof a, and Ii .a/ represents the i th in-neighborof a.
SimRank can also be applied to bipartite net-works, where similarity between one type en-hances the quality of the other type alternatively.
It can be shown that SimRank computation ona network G is equivalent to the pairwise randomsurfer model on a network of G2. The rank scoreof a node in G2 represents the similarity score ofa pair of nodes in the original network G. Theconvergence of the SimRank computation can beguaranteed.
The time complexity of computing SimRankis high, as the similarity score between a pair ofobjects is dependent on the similarityZ between
every other pair of objects. Different algorithmsare proposed to fast computing SimRank, such asLi et al. (2010a, b).PathSim PathSim (Sun et al. 2011) is designedto evaluate peer similarity between objects ina heterogeneous information network. Differentfrom previous query-based ranking and similaritymeasure, PathSim is proposed for (1) evaluatingsimilarity between objects in a heterogeneousinformation network and (2) evaluating similarityin terms of peers between objects.
In heterogeneous information networks, ob-jects can be connected via different types ofconnections, and similarity with different seman-tics can be defined using different types of con-nections. Meta-path, the meta-level connectionbetween objects, is then proposed to systemat-ically capture how objects are connected in aheterogeneous network.
In many scenarios, finding similar objects innetworks is to find similar peers, such as find-ing similar authors based on their fields andreputation, finding similar actors based on theirmovie styles and productivity, and finding sim-ilar products based on their functions and pop-ularity. A meta-path-based similarity measure,called PathSim that captures the subtlety of peersimilarity, is proposed. The intuition behind itis that two similar peer objects should not onlybe strongly connected but also share comparablevisibility. Given a symmetric meta-path P , Path-Sim between two objects x and y of the sametype is
where px y is a path instance between x andy, px x is that between x and x, and py y isthat between y and y.
Meta-path-based similarity is a general frame-work, on which other measures can be definedto evaluate similarity or proximity between ob-jects. For example, Shi et al. (2012) proposea proximity measure between different types ofobjects.
s.x; y/ D 2 � jfpx y W px y 2 Pgjjfpx x W px x 2 Pgj C jfpy y W py y 2 Pgj

Ranking Methods for Networks 1495 R
R
Learning to RankMost of the previously discussed ranking meth-ods are unsupervised. However, in may cases,ranking should be different for different datasetsand/or for different purposes. Thus, learning isimportant to select the best parameters for aparameterized ranking method. For example, thepreviously mentioned PopRank (Nie et al. 2005)can automatically learn the best popularity prop-agation probabilities between object types. Be-sides PopRank, there are several other recentlyproposed supervised or semi-supervised rankingmethods, as introduced below.Adaptive PageRank In Tsoi et al. (2003), theauthors propose to help administrators alterPageRank scores according to their preference bymodifying PageRank equations and introducingconstraints.
The administrator of a system may want tointervene the PageRank score, such as modifythe page scores to some target scores or estab-lish a predefined ordering on the pages. Theseconstraints can be represented as some linearconstraints. At the same time, the administratorwants to find a scoring function that is mostsimilar to the original PageRank scoring func-tion. The problem can then be transformed toa quadratic programming problem with an in-equality constraint set. And the parameters can beautomatically learned to derive an administratorpreferred ranking function.Learn to Rank Networked Entities (NetRank)In Agarwal et al. (2006), the authors propose toparameterize the conductance values betweenobjects and rank networked entities basedon Markov walks with these parameterizedconductance value. The goal is to learn thoseparameters according to a given preference orderamong objects.
The conductance value between two objects u
and v is defined as the network flow between u
and v:
puv D P r.u! v/ D pup.vju/
where pu is the probability that a random surferstays at node u and p.vju/ is the transitionprobability from u to v.
The conductance value is considered tobe parameterized in two ways. First, it canbe parameterized according to the hiddencommunities that the two nodes belong to.Intuitively, edges within the same communityhave a higher conductance and edges thatbridge different communities have a lowerconductance. Second, the conductance value canbe parameterized according to the edge type that.u; v/ belongs to. Intuitively, different types ofedges may have different conductance.Semi-Supervised PageRank A semi-supervisedlearning framework, called semi-supervisedPageRank, is proposed in Gao et al. (2011),which aims at ranking nodes on a very largegraph. In the algorithm, the objective functionis defined based upon Markov random walk onthe graph. The transition probability and the resetprobability of the Markov model are defined asparametric models based on the features on bothnodes and edges.
For the objective function, the goal is to find aranking that is as close to the parametric Markovprocess stationary probability as possible. At thesame time, the constraints indicate the guidancefrom the users and require that the ranking is asconsistent with the user supervision as possible.
It turns out that adaptive PageRank and Ne-tRank are both special cases of the proposedapproach.Similarity Search by Meta-Path SelectionA query-dependent semi-supervised rankingmethod in heterogeneous information networkis proposed in Yu et al. (2012), which aims tofind entities with high similarity to a given queryentity.
Due to the diverse semantic meanings in aheterogeneous information network that containsmulti-typed entities and relationships, similaritymeasurement can be ambiguous without con-text. A meta-path-based ranking model ensem-ble is proposed to represent semantic meaningsfor similarity queries. Users can provide severalsample similar objects while issuing the query,and the algorithm will automatically select thebest ranking model according to such hints anddispatch the query to the selected ranking modelonline.

R 1496 Ranking Methods for Networks
Key Applications
Ranking methods are important for many ap-plications. For example, ranking is critical forsearch engine systems, either web search or entitysearch. It can also be used in entity ranking forapplications in a particular domain, such as in abibliographic database or a medical informationsystem. Proximity ranking turns out to be veryuseful in recommender systems. Identifying themost influential actors in social networks can helpviral marketing. Ranking can also be used forspam detection and trustworthy analysis.
Cross-References
�Centrality Measures�Data Mining�Eigenvalues, Singular ValueDecomposition� Social Influence Analysis� Social Web Search
References
Agarwal A, Chakrabarti S, Aggarwal S (2006) Learningto rank networked entities. In: Proceedings of the 12thACM SIGKDD international conference on knowl-edge discovery and data mining, KDD ’06, pp 14–23.doi:10.1145/1150402.1150409, http://doi.acm.org/10.1145/1150402.1150409
Balmin A, Hristidis V, Papakonstantinou Y (2004) Objec-trank: authority-based keyword search in databases. In:Proceedings of the thirtieth international conferenceon very large data bases – volume 30, VLDB Endow-ment, VLDB ’04, pp 564–575
Beauchamp MA (1965) An improved index of centrality.Behav Sci 10:161–163
Brin S, Page L (1998) The anatomy of a large-scale hypertextual web search engine. Comput Netw30(1–7):107–117
Chen L, Li X, Han J (2013) Medrank: discovering in-fluential medical treatments from literature by infor-mation network analysis. In: Proceeding of the 2013Australasian database conference, ADC ’13, Adelaide
Freeman LC (1977) A set of measures of centrality basedon betweenness. Sociometry 40:35–41
Freeman LC (1978) Centrality in social networksconceptual clarification. Soc Netw 1(3):215–239.doi:10.1016/0378-8733(78)90021-7
Gao B, Liu TY, Wei W, Wang T, Li H (2011)Semi-supervised ranking on very large graphs withrich metadata. In: Proceedings of the 17th ACMSIGKDD international conference on knowledge dis-covery and data mining, KDD ’11, pp 96–104.doi:10.1145/2020408.2020430, http://doi.acm.org/10.1145/2020408.2020430
Gyongyi Z, Garcia-Molina H, Pedersen J (2004) Com-bating web spam with trustrank. In: Proceedings ofthe thirtieth international conference on very largedata bases – volume 30, VLDB endowment, VLDB’04, pp 576–587. http://dl.acm.org/citation.cfm?id=1316689.1316740
Haveliwala TH (2002) Topic-sensitive pagerank. In: Pro-ceedings of the 11th international conference on worldwide web, WWW ’02, pp 517–526
Jeh G, Widom J (2002) Simrank: a measure of structural-context similarity. In: Proceedings of the eighthACM SIGKDD international conference on knowl-edge discovery and data mining, KDD ’02, pp 538–543. doi:10.1145/775047.775126, http://doi.acm.org/10.1145/775047.775126
Jeh G, Widom J (2003) Scaling personalized web search.In: Proceedings of the 12th international conference onworld wide web, WWW ’03, New York, pp 271–279.doi:10.1145/775152.775191
Katz L (1953) A new status index derived from sociomet-ric analysis. Psychometrika 18(1):39–43
Kleinberg JM (1999) Authoritative sources in a hyper-linked environment. J ACM 46(5):604–632
Li C, Han J, He G, Jin X, Sun Y, Yu Y, WuT (2010a) Fast computation of simrank for staticand dynamic information networks. In: Proceed-ings of the 13th international conference on extend-ing database technology, EDBT ’10, pp 465–476.doi:10.1145/1739041.1739098, http://doi.acm.org/10.1145/1739041.1739098
Li P, Liu H, Xu J, Jun Y, Du HX (2010b) Fast single-pairsimrank computation. In: In Proceedings of the SIAMinternational conference on data mining, SDM ’10
Nie Z, Zhang Y, Wen JR, Ma WY (2005) Object-level ranking: bringing order to web objects. In:Proceedings of the 14th international conferenceon world wide web, WWW ’05, pp 567–574.doi:10.1145/1060745.1060828
Nieminen J (1974) On the centrality in a graph. Scand JPsychol 15(1):332–336
Sabidussi G (1966) The centrality index of a graph.Psychometrika 31:581–603
Shi C, Kong X, Yu PS, Xie S, Wu B (2012) Rele-vance search in heterogeneous networks. In: Proceed-ings of the 15th international conference on extend-ing database technology, EDBT ’12, pp 180–191.doi:10.1145/2247596.2247618, http://doi.acm.org/10.1145/2247596.2247618
Sun Y, Han J, Zhao P, Yin Z, Cheng H, Wu T (2009a)Rankclus: integrating clustering with ranking for het-erogeneous information network analysis. In: Proceed-ings of the 12th international conference on extendingdatabase technology (EDBT ’09), pp 565–576

RDF 1497 R
R
Sun Y, Yu Y, Han J (2009b) Ranking-based clustering ofheterogeneous information networks with star networkschema. In: Proceedings of the 15th ACM SIGKDDinternational conference on knowledge discovery anddata mining, KDD ’09, pp 797–806
Sun Y, Han J, Yan X, Yu PS, Wu T (2011) Pathsim:meta path-based top-k similarity search in heteroge-neous information networks. In: Proceeding of 2011international conference on very large data bases,VLDB ’11
Tsoi AC, Morini G, Scarselli F, Hagenbuchner M,Maggini M (2003) Adaptive ranking of web pages.In: Proceedings of the 12th international confer-ence on world wide web, WWW ’03, pp 356–365. doi:10.1145/775152.775203, http://doi.acm.org/10.1145/775152.775203
Wasserman S, Faust K (1994) Social network analy-sis: methods and applications. Cambridge UniversityPress, Cambridge
Yu X, Sun Y, Norick B, Mao T, Han J (2012) Userguided entity similarity search using meta-path se-lection in heterogeneous information networks. In:Proceedings of the 21st ACM international conferenceon information and knowledge management, CIKM’12, pp 2025–2029. doi:10.1145/2396761.2398565
RDF
Thomas Gottron and Steffen StaabInstitute for Web Science and Technologies,Universitat Koblenz-Landau, Koblenz, Germany
Glossary
RDF Resource Description FrameworkRDFS RDF SchemaURI Uniform Resource Identifier
Definition
The Resource Description Framework (RDF)provides a model for representing data. Its back-ground is set historically in a web environmentwhere it is used for representing information in adevice- and platform-independent way. The datamodel of RDF corresponds to a directed, labelledgraph. Technically RDF consists of several W3Crecommendations which define its concepts andabstract syntax (Klyne and Carroll). Work on
the RDF 1.1 specifications has commenced andreached a draft status at W3C (Cyganiak andWood).
The core idea of RDF is to represent “things”by URIs. Information is provided by statementsabout the things and statements are expressedas triples. These triples consist of a subject, apredicate, and an object and express that thesubject is in a certain relation (identified by thepredicate) with the object. The relations betweenthings can be interpreted and represented in agraph format, where subjects and objects aregraph nodes and the predicate is a labelled edgebetween the nodes.
The choice of using URIs to represent thingsis intentionally broad in its definition. In RDFa URI can stand for a web resource (e.g., anHTML web document), for a real-world entity(e.g., a person), for abstract constructs (e.g., auser account in an online community), a classconcept (e.g., a class type for documents), or todenote the properties connecting entities (e.g., therelation “creator” linking an author to a documenthe or she wrote). The advantage of using URIsin the triple statements for subject, predicate, andobject is that URIs are typically assigned to anauthority. For instance, http://west.uni-koblenz.de/staff/Staab# is under the authority of the Insti-tute WeST at Universitat Koblenz-Landau; hence,this identifier is not easily to be confused with anidentifier of another Steffen Staab, which mightbe given by https://www.facebook.com/steffen.staab.9#. In this way the URIs provide globallyunique identifiers. The object of a triple can alsobe a literal value (e.g., to denote the name of aperson by a String value). Subject and object canfurthermore be implemented by so-called blanknodes, which represent nodes in the graph whichare neither identifiable by a URI nor are they aliteral.
RDF Schema (RDFS) (Brickley and Guha2004) is an extension to RDF for defining spe-cific vocabularies for RDF applications, i.e., fordefining the predicates and class types to beused in a specific application context. To thisend, RDFS implements and provides some of theconcepts used in RDF itself. For instance, RDFSprovides a concrete property for assigning a type

R 1498 RDF
RDF, Fig. 1 An exampleRDF data graph
class to a URI and defines how to specify a URIto be a property which can be used as predicate intriples. With RDFS it is also possible to providesome information about the vocabulary termswhich allow for simple forms of inferencing. Forinstance, it is possible to define the domain andrange of properties or to define a subsumptionrelation between class concepts.
Example
Assume a scenario where we want to provideinformation about the university of Koblenz-Landau. We can use the URI http://www.uni-koblenz-landau.de/uni# to represent theuniversity as an institution. We also want tostate that the thing identified by this URIis an entity of type College or Universityas defined by the schema.org vocabulary.Furthermore, we want to state that it canbe presented to human users by the String“University of Koblenz-Landau.” While thehuman readable label is given as a literal value,the type is represented as a URI as well. Thegraph representation of these two statementsis shown in Fig. 1. Using the subsumptionrelations in the schema.org vocabulary, we caninfer, for instance, that the described entityis also an educational organization, as http://schema.org/CollegeOrUniversity is modelledto be a subclass of the type http://schema.org/EducationalOrganization.
RDF itself is defined only via an abstractsyntax. There are several ways to serial-ize an RDF data graph into a machine-readable format. The most common serial-izations are RDF/XML (Beckett 2004), N3
(Berners-Lee and Connolly 2011), N-Triples(Beckett 2013), and Turtle (Beckett 2013). Whileall serializations are intended for the exchange ofRDF-encoded data between applications, someserializations are deemed more human readable(e.g., N3) while other are easier to integrate dueto well-established tool chains (e.g., RDF/XML).
Cross-References
�Linked Open Data�SPARQL
References
Beckett D (2004) RDF/XML syntax specification(Revised). http://www.w3.org/TR/2004/REC-rdf-syntax-grammar-20040210/. Accessed 19 Aug 2013
Beckett D (2013) N-Triples. http://www.w3.org/TR/2013/NOTE-n-triples-20130409/. Accessed 19 Aug 2013
Beckett D, Berners-Lee T (2013) Eric Prud’hommeauxand Gavin Carothers. Turtle. http://www.w3.org/TR/2013/CR-turtle-20130219/. Accessed 19Aug 2013
Berners-Lee T, Connolly D (2011) Notation3 (N3):a readable RDF syntax. http://www.w3.org/TeamSubmission/2011/SUBM-n3-20110328/. Accessed 19Aug 2013
Brickley D, Guha RV (2004) RDF vocabulary descriptionlanguage 1.0: RDF Schema. http://www.w3.org/TR/2004/REC-rdf-schema-20040210/. Accessed 19 Aug2013
Cyganiak R, Wood D, RDF 1.1 concepts and abstract syn-tax (W3C last call working draft 23 July 2013). http://www.w3.org/TR/2013/WD-rdf11-concepts-201307-23/. Accessed 19 Aug 2013
Klyne G, Carroll JJ, Resource descriptionframework (RDF): concepts and abstract syntax.http://www.w3.org/ TR/2004/ REC-rdf-concepts-20040210/. Accessed 19 Aug 2013

Reasoning 1499 R
R
RealityMining
�Extracting Individual and Group Behavior fromMobility Data
Real-Time Social Media Analysis
�Twitris: A System for Collective SocialIntelligence
Reasoning
Cong Wang and Pascal HitzlerDepartment of Computer Science andEngineering, Wright State University, Dayton,OH, USA
Glossary
First-order Logic A formal logic system inmathematics distinguished from propositionallogic by its use of quantified variables
Deductive Reasoning The process of reasoningfrom one or more general statements(premises) to reach a logic conclusion
Tableaux A proof procedure for formulas of first-order logic based on tree expansion
Resolution A proof procedure for formulas offirst-order logic based on a set of inferencerules for clauses
Definition
When considering logical reasoning, it is oftendivided into three basic paradigms: deductive,inductive, and abductive reasoning. Deductivereasoning concerns what follows necessarilyfrom the given premises (if ˛, then ˇ) in a top-down approach, while inductive reasoning, theopposite of deductive reasoning, tries to derive a
reliable generalization from observations in abottom-up approach. Abductive reasoning isseeking the explanation for given rules andconclusions (if ˛ ! ˇ and ˇ, then perhaps ˛.)For each of them, there are many varied usecasesin computer science area. For example, inmodel checking area, we encode programs withtemporal states and do reasoning on them to showthe correctness, or in knowledge representationarea, we encode knowledge as logical formulasand try to infer hidden knowledge from them. Inthis section, we will give a high-level introductionof deductive reasoning. Without specification, weonly consider first-order logic (FOL) on a purelysyntactic basis. Since many other forms of logicsare actually variations or fragments of FOL,some of following reasoning approaches can alsobe applied. One can either reduce the logics intoFOL and then apply these reasoning approachesor modify these algorithms for particular uses.
When talking about FOL deductive reasoning,we usually call it “deductive system,” whichis used to demonstrate that one formula is alogical consequence of another formula. Thereare many such systems for FOL, including nat-ural deduction, sequent calculus, tableaux, andresolution. All of these reasoning methods aresound (all provable statements are true) and com-plete (all true statements are provable).
From many of these approaches, tableaux andresolution methods are the most popular. Given aset of formulas, the Tableaux method (Robinsonand Voronkov 2001) derives a tree. To show thata formula A is provable, the tableaux methodattempts to demonstrate that :A is unsatisfiable.The tree of the derivation has :A at its root; thetree branches in a way that reflects the structure ofthe formula. If there is no A and :A occurring inone branch, then this branch has no clash. If thereis no clash in all branches, then the formulas haveno conflict. (see demonstration at http://www.umsu.de/logik/trees/) Resolution (Robinson andVoronkov 2001) method works with formulasin disjunctive forms. The Resolution rule statesthat from the hypotheses A1 _ : : : _ Am _ C
and B1 _ : : : _ Bn _ :C the conclusion A1 _: : : _ Am _ B1 _ : : : _ Bn can be obtained.After applying resolution inference on arbitrarily

R 1500 Reasoning
two of the formulas, one can know there is nological conflict if it does not infer ?, i.e., emptyclause. The famous Modus ponens can be seen asa special case of resolution of a one-literal clauseand a two-literal clause.
Reasoning for FOL is semidecidable, i.e.,there is no procedure that, given formulasA and B , always correctly decides whetherA logically implies B , but much progresshas been made such that they can be usedin practical usecases. For example, Prolog,which is a logic programming implementation,applies SLD-resolution (Robinson and Voronkov2001) and the tabling technique to achieveefficiency. (However, the efficiency is sensitiveto the order of input rules in the program.)Datalog, a query and rule language for deductivedatabases, uses the Magic Sets algorithm andtabled logic programming to perform queriesquickly; that is why many systems reduceproblems to datalog queries. In addition, thereare even some mixed reasoning algorithms.For example, hypertableaux (Baumgartner et al.1996; Robinson and Voronkov 2001) combinestableaux and resolution in order to absorb bothadvantages. And more recently, people usedistributive systems to speed up the reasoningprocess. On the other hand, one can even applysome restrictions to attain decidability, suchas the two-variables fragment and the guardedfragment. The core idea is a trade-off betweenexpressivity and complexity. Among many of itsdecidable fragments, description logic (Baaderet al. 2007) attracts many researchers for study.It is more expressive than propositional logic andstill decidable, and it is of particular importancein providing a logical formalism for ontologiesand the Semantic Web. When reasoning for thesedecidable fragments, simply applying the de-ductive algorithm cannot guarantee termination,and thus, one must refine the algorithms. Forexample, the tableaux algorithm for descriptionlogic requires a so-called blocking technique(Baader et al. 2007) to stop unnecessaryexpansion, and similarly the resolution procedureneeds to restrict an order on terms such that thelength of clauses can be limited according to theknowledge base (Motik 2006).
However, regardless of the semi-decidabilityissue, it is still less powerful to deal with in somecases, because all its assumptions have to beguaranteed correct and provide enough premisesin order to infer correct and complete knowledge.We humans do not require much knowledge butcan still infer correct answers. We usually expectan answer, jump to conclusions, generalizeadditional rules on the fly, and are dependenton environment. We draw no clear distinctionbetween deduction, induction, abduction, andpossibly more mechanisms. Therefore, manyresearchers attempt to find a subtle combinationof these reasoning paradigms. NARS (see detailsat https://sites.google.com/site/narswang/home)implements a multilayer logic frameworkaiming at a general intelligent system. Thelayers progressively provide more expressivity,including the three reasoning paradigms andeven some quantitative properties. There are alsosome works combining abduction and inductionwith statistical learning (Ray et al. 1996). Butone recent research shows that reasoning is asimulation of the world fleshed out with ourknowledge, not a formal rearrangement of thelogical skeletons of sentences (Johnson-Laird2011). So, all of these approaches might not trulymimic human reasoning.
Conclusion
In this section, we give a general description ofthe deductive reasoning paradigm. We talk abouttwo deductive systems, tableaux and resolution,and some of their modern variants. And finally,we argue that deductive reasoning alone may notperform well for “real” intelligent systems andthat one needs other mechanisms to achieve it.
Acknowledgments
This work was supported by the National ScienceFoundation under award 1017225 “III: Small:TROn—Tractable Reasoning with Ontologies.”

Recommender Systems, Semantic-Based 1501 R
R
Cross-References
�Description Logics�Web Ontology Language (OWL)
References
Baader F, Calvanese D, McGuinness D, Nardi D, Patel-Schneider P (2007) The description logic handbook.Cambridge University Press, Cambridge
Baumgartner P, Furbach U, Niemel I (1996) Hypertableaux. JELIA 1126:1–17
Johnson-Laird P (2011) Mental models and human rea-soning. PNAS 108(50):19862–19864
Motik B (2006) Reasoning in description logics usingresolution and deductive databases. Karlsruhe Instituteof Technology, pp 1–249
Ray O, Broda K, Russo A (2003) Hybrid abductiveinductive learning: a generalisation of progol. ILP2835:311–328
Robinson J, Voronkov A (2001) Handbook of automatedreasoning (in 2 volumes). MIT, Boston
Recommended Reading
Gabbay D, Hogger C, Robinson, J (1994) Handbook oflogic in artificial intelligence and logic programming.Oxford University Press, Oxford
Recommendation Systems
�Recommender Systems: Models andTechniques�Recommender Systems Using Social NetworkAnalysis: Challenges and Future Trends
Recommender Systems
� Social Web Search
Recommender Systems,Semantic-Based
Fatih Gedikli and Dietmar JannachDepartment of Computer Science,TU Dortmund, Dortmund, Germany
Synonyms
Social Recommender System; Tag-based recom-mendation; Web 2.0 recommender systems
Glossary
Collaborative Filtering A recommendationmethod which is based on rating informationof the user community
Content-Based Filtering A recommendationmethod which is based on characteristics ofthe recommended items as well as individualuser feedback
Hybrid Recommender System A recom-mender system that combines differentrecommendation approaches or data sources
Rating Matrix A grid containing the users’ im-plicit or explicit item ratings
Cold-Start Problem The ramp-up phase ofa recommender where preference data ismissing
Definition
Recommender systems (RS) are software toolsthat are predominantly used on e-commerce sitesand for other online services as a means to helpthe online customer find the most relevant shop-ping items or pieces of information quickly. To-day, such systems can be found for a variety ofdifferent domains such as books, movies, music,hotels, restaurants, or news.
The particularity of RS is that they are ableto provide personalized recommendations, whichare based on the past and current behavior orthe explicit preferences of individual users,

R 1502 Recommender Systems, Semantic-Based
the preferences of a user community as awhole, or on various other forms of availableinformation.
The main task of an RS usually is to predict asprecisely as possible which of the recommend-able items will be of interest for and accepted bythe user. Since the mid-1990s, when RS startedto emerge as a research field of their own, alarge variety of methods have been proposedto increase the quality of the recommendations,measured, e.g., in terms of their accuracy.
In their early years, RS were mainly con-sidered as a tool for e-commerce sites or forpersonalized information filtering. However, theemergence of the Social Web – or, more gen-erally, the Web 2.0 – soon had a strong impacton the field of RS. One aspect is related tothe amount of information we know about theusers, which is crucial for the recommendationquality. The Web 2.0 is participatory: Peopleconnect on social networks and share informa-tion about their personal profile and their inter-ests, they actively contribute content on blogsand micro-blogs, and they share, rate, and re-view all types of resources online. Overall, muchmore information about the user is theoreticallyavailable than in the past, when explicit andimplicit rating data and the past transaction his-tory were often the only available knowledgesources.
Besides an increased engagement of users, theWeb 2.0 also brought new application fields forRS technology. Today, we can find systems onSocial Web platforms that recommend people toconnect with or people to follow systems thatgenerate personalized information feeds based onthe user’s interests and systems that recommendpotentially interesting Web resources such as im-ages, web pages, or blog posts. Even the choiceof an appropriate set of tags and annotationsfor user-contributed content can be driven byan RS.
In this entry, we will focus on RS that exploit(semantic) knowledge sources that have becomeavailable in the Social Web. In particular, we willfocus on the role of user-provided tagging data inthe recommendation process.
Introduction
With the continuously growing amount of infor-mation on the Web, the availability of appropriatetools that help the online user retrieve or dis-cover interesting items becomes more and moreimportant. Recommender systems are one typeof such tools which are capable of generatingpersonalized lists of shopping items, reading lists,or, more generally, action alternatives (Jannachet al. 2010).
The recommendations of an RS can be basedon different types of information. In most casesthe quality of the recommendations and the corre-sponding effect on the users are directly related tothe amount and quality of the available informa-tion on which the recommendations are based on.Today, the most popular class of recommendationmethods is called collaborative filtering (CF). CFmethods rely on the existence of item ratingswhich are provided by an implicit online com-munity. Amazon.com is an example of an onlineretailer who relies among others on such methodsin their recommendation engines (Linden et al.2003).
The other major type of systems is based onwhat is called “content-based filtering.” While CFrecommender systems recommend items similarusers liked in the past, the task of a content-basedrecommender system is to recommend items thatare similar to those the target user liked in thepast.
We illustrate the basic rationale of a content-based recommendation method with an examplefrom the movie domain. Table 1 represents anexcerpt from an example movie database whichalso provides plot keywords for each movie, i.e.,an item’s content description is represented by aset of plot keywords. Table 2, on the other hand,shows an excerpt from the user database.
A simple content-based recommender com-putes recommendations for Alice by selectingmovies Alice is not aware of and which aresimilar to those movies she watched before. Inthis example similarity between movies couldbe defined by the number of overlapping key-words. The unseen movie Amelie, for example,

Recommender Systems, Semantic-Based 1503 R
R
Recommender Systems, Semantic-Based, Table 1 Movie data set with content description
Movie Plot keywords
Heat Detective Criminal Thief Gangster
Scarface Gangster Criminal Drugs Cocaine
Amelie Love Waitress France Happiness
Eat, Pray, Love Divorce India Love Inner peace
Recommender Systems, Semantic-Based, Table 2User database
User Preference profile
Alice Eat, Pray, Love, What Women Want
Bob Scarface, Carlito’s Way, Terminator II
has one keyword in common with Eat, Pray,Love (“Love”). Therefore, we can assume somedegree of similarity between both movies. SinceAlice liked Eat, Pray, Love in the past, the movieAmelie could be recommended to her.
Note that for a content-based recommender,no user community is required for generatingrecommendations. However, the target user has toprovide an initial list of “like” and “dislike” state-ments or ratings on a given scale. Alternatively,customer actions such as viewing or purchasingan item can be interpreted as positive signals.New items, on the other hand, can be incor-porated in the recommendation process becausesimilarity to existing items can be computedwithout the need for any rating data.
In the example discussed above, theimportance of each keyword was not takeninto account, that is, each keyword gets thesame importance. However, it appears intuitivethat keywords which appear more often indescriptions are less representative. Therefore,the TF-IDF encoding format was proposed andgained popularity in particular in the field ofinformation retrieval and is also the basis forvarious approaches that exploit Social Web data.TF-IDF stands for term frequency – inversedocument frequency and is used to determine therelevance of terms in documents of a documentcollection. For convenience, we will assume inthe following that the underlying item set consistsof text documents; e.g., the plot keywords for
each movie in Table 1 can be seen as onedocument. As the name suggests the TF-IDFmeasure is composed of two frequency measures.The idea of the term frequency measure TF .i; j /
is to estimate the importance of a term i in agiven document j by counting the number oftimes a given term i appears in document j .Additionally, a normalization is possible, e.g., bydividing the absolute number of occurrences ofterm i in document j by the absolute numberof occurrences of the most frequent word indocument j . Several other schemes are howeverpossible.
On the other hand, the idea of the inversedocument frequency measure IDF .i/ is to cap-ture the importance of a term i in the wholeset of available documents. Therefore, IDF .i/
can be seen as a global measure which reducesthe weight of words that appear in many doc-uments (e.g., stop words such as “a,” “by,” or“about”), since they are usually not representativeand helpful to differentiate between documents.Formally, inverse document frequency is usuallycomputed as IDF.i/ D log N
n.i/where N is the
size of the document set and n.i/ is the numberof documents in which the given term i appears.We assume that each term appears in at least onedocument, i.e., n.i/ � 1. If n.i/ D N thelogarithm function returns indicating that term i
is of no importance for discriminating documentsas it appears in all documents.
Finally, the TF-IDF measure which representsthe weight for a term i in document j is de-fined as the combination of these two measures:TF-IDF.i; j / D TF.i; j / � IDF.i/.
With the help of the TF-IDF measure, textdocuments, or generally speaking the textual de-scription of items, can be encoded as TF-IDFweight vectors.

R 1504 Recommender Systems, Semantic-Based
One way of computing n recommendationsis to find the n most similar items to the user’saverage TF-IDF weight vector of the user’s likeddocuments. The cosine similarity metric is oftenused for computing the proximity between items.
Next, we will view user-provided tags as con-tent descriptors and describe the role of taggingdata in the recommendation process.
Recommendations Based on SocialWeb Tagging Data
The advent of the Social Web opened new waysof promoting and sharing user-generated content.Web site visitors turned from passive recipientsof information into active and engaged contribu-tors. The Social Web allows users to create andshare a large amount of different types of con-tent such as pictures, videos, bookmarks, blogs,comments, or tagging data. It allows users tocollaborate with other users on new types of Webapplications called Social Web platforms such asDelicious (http://www.delicious.com) and Flickr(http://www.flickr.com). Leveraging useful datafrom the large amount of user-contributed dataavailable in the Social Web represents a chal-lenging topic which however also opens newopportunities for recommender system research.
For example, user-contributed tags are today apopular means for users to organize and retrieveitems of interest in the Social Web. As the ap-plication areas of tags are manifold, they playan increasingly important role in the Social Web.They can be used to categorize items, expresspreferences about items, retrieve items of interest,and so on.
Collaborative tagging or social tagging de-scribes the practice of collaboratively annotatingitems with freely chosen tags (Golder andHuberman 2006) which plays an important role insharing content in the Social Web (Ji et al. 2007).In a social tagging system such as Deliciousand Flickr, users typically create new content(items), assign tags to these items, and sharethem with other users (Cantador et al. 2010). Theresult of social tagging is a complex network ofinterrelated users, items, and tags often referred
to as a community-created folksonomy. Theterm folksonomy is a neologism introduced bythe information architect Thomas Vander Wal(http://vanderwal.net/folksonomy.html) and iscomposed of the terms folk as in people andtaxonomy which stands for the practice andscience of classification. A folksonomy is definedas a tuple F WD .U; T; R; Y / where U , T and R
are finite sets, whose elements are called users,tags, and resources, and Y is a ternary relationbetween them, i.e., Y � U � T � R called tagassignments.
In contrast to typical taxonomies includingformal Semantic Web ontologies, social taggingrepresents a more lightweight approach, whichdoes not rely on a predefined set of concepts andterms that can be used for annotation.
Tagging data also gained importance in thefield of RS. User-generated tags not only conveyadditional information about the items; they alsotell something about the user. For example, if twousers use the same set of tags to describe an item,we can assume a certain degree of similarity be-tween those. Therefore, tagging data can be usedto augment the basic user–item rating matrix.
In the following, a possible categorization ofbuilding tag-based RS is given.Using Tags as Content Maybe the easiest wayto use tagging data for RS is to consider taggingdata as an additional source of content. Severalworks exist that view tags as content descriptorsfor content-based systems; see, for example, inFiran et al. (2007), Li et al. (2008) or Vatturi et al.(2008).
Similarly, in de Gemmis et al. (2008),tagging data is used for an existing content-based recommender system in order to increasethe overall predictive accuracy of the system.Machine learning techniques are applied bothon the textual descriptions of items (static data)and on the tagging data (dynamic data) to builduser profiles and learn user interests. The userprofile consists of three parts: the static content,the user’s personal tags, and the social tags whichbuild the collaborative part of the user profile.Thus, in this work, tags are seen as an additionalsource of information used for learning the profileof a particular user. The authors compare their

Recommender Systems, Semantic-Based 1505 R
R
tag-based approach with a pure content-basedrecommender in a user study. The results showthat the recommendations made by the tag-augmented recommender are slightly moreaccurate than the recommendations of the purecontent-based one.
In Firan et al. (2007) tags are also seen ascontent descriptors for different content-basedsystems. Tags are used for building user profilesfor the popular music community site Last.fm.To address the so-called cold-start problem (whennew users or items enter in the system), the userprofiles are inferred automatically, e.g., from themusic tracks available on the computer of eachuser, thus reducing the manual effort from theuser’s side to express his or her preferences. Theauthors show that tag-based profiles can lead tobetter music recommendations than conventionaluser profiles based on song and track usage.
In Cantador et al. (2010) tags are considered ascontent features that describe both user and itemprofiles. The authors propose weighting functionswhich assess the importance of a particular tagfor a given user or item and similarity functionswhich compute the similarity between a userprofile and an item profile. These weighting andsimilarity functions are then combined in differ-ent content-based recommendation models.
In that work, user interests and itemcharacteristics are modeled as vectors um D.um;1; : : : ; um;L/ and in D .un;1; : : : ; un;L/ oflength L, respectively, where L is the numberof tags in the folksonomy, um;l is the numberof times user um has annotated items with tagtl , and in;l is the number of times item in hasbeen annotated with tag tl . After modeling usersand items as vectors accordingly, the authors canadopt the TF-IDF vector space model.
The evaluation results on the Delicious andLast.fm data sets show that the recommendationmodels focusing on user profiles outperform themodels focusing on item profiles.
Tagging data can also be incorporated insearch engines to personalize the search results.According to Pitkow et al. (2002), two basicapproaches to Web search personalization canbe differentiated. In the first approach, a user’soriginal query is modified and adapted to the
profile of the user. For example, the query“eclipse” might be extended to “eclipse softwaredevelopment environment” if we know that theuser has an interest in software development. Inthe second approach, the query is not modified,but the returned list of search results is re-rankedaccording to the user profile.
An example for the latter approach is given inNoll and Meinel (2007). The authors propose apure tag-based personalization method to re-rankthe Web search results which is independent fromthe underlying search engine. The basic idea isto use bookmarks and tagging data to re-rank thedocuments in the search result list. The authorspropose a concept called tagmarking which trans-lates the keywords in the search query to tags andassign them to the bookmarked Web page that isassociated with the query. Bookmarks and tagsare aggregated in a binary tag–document matrixwhere each column (vector) represents a book-mark of a document with its components set to1 when the corresponding tag is associated withthe document and otherwise. The user profile ismodeled as a vector which contains the weightsassigned to each tag. The tag–user matrix and thedocument profile are built analogously. Finally,in the personalization step the documents are re-ranked according to a similarity matrix whichcombines both the user profile and the documentprofile. Table 3 shows in an example of howpersonalization affects Google’s result list forthe search query “security”; see also Noll andMeinel (2007). The ranking of the Web site ofthe US Social Security Administration (ssa.gov),for instance, has increased because – accordingto the authors – the user who submitted the queryalso showed interest in insurance matters.Clustering Approaches Many tag-based cluster-ing approaches have been proposed in the liter-ature which cluster users and items according totopics of interest by exploiting additional taggingdata; see, for example, Li et al. (2008), Xu et al.(2011b) or Zanardi and Capra (2011).
In Li et al. (2008) the authors propose a systemcalled Internet Social Interest Discovery (ISID)and show its application for the social bookmark-ing system Delicious. The ISID system, as thename suggests, is a system specifically designed

R 1506 Recommender Systems, Semantic-Based
Recommender Systems, Semantic-Based, Table 3Re-ranking Google’s result list (Noll and Meinel 2007)
Rank � Rank URL
1 � securityfocus.com
2 " C7 cert.org
3 � microsoft.com/technet/security/def. . .
4 " C4 w3.org/Security
5 " C2 ssa.gov
6 " C4 nsa.gov
7 # �5 microsoft.com/security
8 # �2 windowsitpro.com/WindowsSecurity
9 # �4 whitehouse.gov/homeland
10 # �6 dhs.gov
to reveal common user interests based on user-provided tags. The basic assumption, which isthen justified in the work, is that user-providedtags are more effective at reflecting the users’understanding of the content than the most in-formative keywords extracted from the corpus ofa Web page. Therefore, tags are seen as goodcandidates for capturing user interests.
Similarly, in Xu et al. (2011b), co-occurringtags are used to build topics of interests. In theresource–tag matrix, each tag is described by a setof resources to which this tag has been assigned.Afterwards, the authors obtain the tag similaritymatrix by computing the cosine similarity be-tween the tag vectors in the resource–tag matrix.Based on this similarity matrix, a graph is con-structed where the tags represent the nodes andthe edges represent the similarity relationshipsbetween the tags. Afterwards, a clustering algo-rithm is used to cluster the tags and to extract thetopics of interests. Finally, the authors present thetopic-oriented tag-based recommendation systemTOAST. TOAST applies preference propagationon an undirected graph called the “topic-orientedgraph” which consists of three kinds of nodes:users, resources, and topics. In their recommen-dation strategy the authors propagate a user’spreference through transitional nodes such asusers, resources, and topics, to reach an unknownresource node along the shortest connecting path.
In Shepitsen et al. (2008), the authors focus ona recommendation scenario where a user selectsa tag and expects a recommendation of related
resources. They thus present a recommendationapproach which recommends items for a givenuser–tag pair .u; t/. Tag clusters are presumedto act as a bridge between users and items. Theidea behind tag clusters is to account for the ef-fects of unsupervised tagging such as redundancyand ambiguity. The authors first determine theitems which have some similarity to the querytag t . These items are then re-ranked accordingto the user profile. The ranking algorithm firstcalculates the user’s interest with respect to eachtag cluster as well as the nearest clusters ofeach item. The nearest clusters are determinedby counting the number of times the item wasannotated with a tag from the cluster divided bythe total number of times the item was annotated.Both measures are then combined in the finalpersonalized rank score used to re-rank the itemsets. The results show that data sparsity has a biginfluence on the quality of the clusters which, onthe other hand, corresponds with the accuracy ofthe recommendations.Hybrid Approaches Hybrid approaches in gen-eral combine different sources of information ordifferent algorithms to make recommendations.In the context of semantic-based recommenders,social data such as tagging data can be combinedwith other types of information such as contentdata (Seth and Zhang 2008) or data from theSemantic Web (Durao and Dolog 2010).
In Seth and Zhang (2008), a Bayesian model-based recommender that leverages contentand social data is presented. In Durao andDolog (2010), on the other hand, a tag-basedrecommender which recommends Web pages isextended such that also semantic similaritiesbetween tags are discovered which are usuallynot taken into account in syntax-based similarityapproaches. Consider the example in Table 4.
If we assume a syntax-based similarity mea-sure, the Web pages P1 and P3 will be consideredmore similar than P1 and P2 as P1 and P3have two tags in common (“Programming” and“Framework”), whereas P1 and P2 only shareone tag (“Web 2.0”). However, if we analyzethe tags in more detail, we see that P1 is closerto P2 than to P3 because P1 and P2 are aboutWeb technologies, whereas P3 focuses on C++

Recommender Systems, Semantic-Based 1507 R
R
Recommender Systems, Semantic-Based, Table 4Exploiting semantic relations between tags
Web page Tags
P1 Programming, Web 2.0, Framework
P2 PHP, Scripting, Web 2.0
P3 C++, Programming, Framework
which is a programming language that is usu-ally not associated with Web technologies. In asemantic-based similarity approach which takeslexical and social factors of tags into account,these semantic relations can be made explicit.For example, “Web 2.0” would be consideredtogether with “Scripting,” and “Programming”together with “PHP.” The authors try to overcomethis problem of ignoring the semantic term re-lations by hybridizing syntax-based approachessuch as tag popularity with a new semantic-basedapproach. In particular, they also make use ofexternal semantic sources such as the WordNetdictionary and different ontologies from OpenLinked Data available on the Web to identifysemantic relations between tag. These semanticrelations are then considered in the similaritycalculations. Their experimental results show in-creases of precision when semantic relations areexploited as additional knowledge sources.Tag-Enhanced Collaborative Filtering Asubstantial number of papers have been publishedin recent years on tag-enhanced CF recommenderalgorithms in which tagging data is usedfor improving the performance of traditionalcollaborative filtering recommender systems. Ingeneral, tagging data can be incorporated intoexisting collaborative filtering algorithms indifferent ways in order to enhance the qualityof recommendations Durao and Dolog (2010),Tso-Sutter et al. (2008) or Zhen et al. (2009).
In Tso-Sutter et al. (2008), for example,the authors incorporate tags into standardcollaborative filtering algorithms. The ideais to reduce the three-dimensional relationhuser; item; tagi to three two-dimensionalrelations, namely, huser; tagi hitem; tagi,and huser; itemi. The projection is based onviewing the tags as items (“user tags”), andusers (“item tags”), respectively. For example,in the huser; tagi relation tags, are viewed as
items in the user–item rating matrix. Theseso-called user tags represent tags that are usedby the users to tag items. On the other hand,item tags in the hitem; tagi relation correspondto tags that describe the items. Consideringthe ternary relation as three two-dimensionalrelations enables the authors to apply standardcollaborative filtering techniques. The authorsalso propose a fusion method which recombinesthe individual relations. The results of theirempirical analysis show that the predictiveperformance of their proposed fusion methodwhich incorporates tags outperforms the standardtag-unaware collaborative filtering algorithms.
Exploiting tagging data without reducing thethree-dimensional huser; item; tagi relation wasthe next logical step. In recent years, recommen-dation methods were proposed which can directlyexploit the ternary relationship in tagging data(Symeonidis et al. 2008; Rendle et al. 2009;Rendle and Schmidt-Thieme 2010).
In Hotho et al. (2006), the authors present agraph-based tag recommender algorithm calledFolkRank. As the name suggests, the FolkRankalgorithm is based on Google’s PageRank algo-rithm. The main idea of PageRank is that pagesare important when linked by other importantpages. Therefore, PageRank views the Web as agraph and uses a weight-spreading algorithm tocalculate the importance of the pages. FolkRankadopts this idea and assumes that a resource isimportant if it is tagged with important tags fromimportant users.
A major problem of FolkRank is that itdoes not scale to larger problem sizes, whichis crucial for real-world scenarios. Therefore,in Kubatz et al. (2011), LocalRank – a graph-and-neighborhood-based tag recommendationapproach – is presented. Rank computationand weight propagation in LocalRank are donein a similar way to FolkRank but withoutiterations. As the name suggests, LocalRankcomputes the rank weights based only onthe local “neighborhood” of a given user andresource. Unlike the FolkRank algorithm whichconsiders all elements in the folksonomy,LocalRank focuses on the relevant ones only.Thus, LocalRank can significantly reduce the

R 1508 Recommender Systems, Semantic-Based
time needed for computing the recommendationswhile maintaining or slightly improvingrecommendation quality.
Tensor factorization (TF) represents anothermethod to directly exploit the ternary relationshipin tagging data. In Rendle et al. (2009), theauthors see the ternary relationship as a three-dimensional tensor (cube) and apply the idea ofcomputing low-rank approximations for tensorson a tag recommender algorithm. The evaluationresults show that their TF-based method achieveseven better accuracy results than the tag recom-mender algorithm FolkRank (Hotho et al. 2006).However, the TF-based model comes with theproblem of a cubic runtime in the factorizationdimension for prediction and learning. This prob-lem is addressed in the work of Rendle andSchmidt-Thieme (2010). The authors present apairwise interaction tensor factorization (PITF)model with a linear runtime in the factorizationdimension. The PITF model explicitly models thepairwise interactions between users, items, andtags.
In Sen et al. (2009), the authors propose tag-based recommender algorithms which they call“tagommenders.” The idea is to utilize tag prefer-ence data in the recommendation process in orderto generate better recommendation rankings thanstate-of-the-art baseline algorithms. The authorsdefine a user’s preference for a tag as the user’slevel of interest in items, e.g., movies, exhibitingthe concept represented by the tag. Thus, a usercan, for example, indicate that he or she likes an-imated movies, but dislikes movies about serialkillers. However, since no tag preference data isavailable, the tag preferences of the target userhave to be estimated before the algorithm canpredict a user’s preference for the target item.To that purpose, the authors evaluate a varietyof tag preference inference algorithms. Such al-gorithms estimate the user’s attitude toward atag, that is, if and to which extent a user likesitems that are annotated with a particular tag.Their results show that a linear combination ofall preference inference algorithms performedbest, that is, algorithms that exploit a variety ofsignals such as implicit and explicit user datawork best.
The proposed tagommender algorithms relyon “global” tag preferences: A tag is either likedor disliked by a user, independent of a spe-cific item. In contrast, in Gedikli and Jannach(2013) and Vig et al. (2010), the concept of item-specific tag preference data was introduced. Theintuition behind this idea is that the same tagmay have a positive connotation for the userin one context and a negative in another. Forexample, a user might like action movies fea-turing the actor Bruce Willis, but at the sametime the user might dislike the performance ofBruce Willis in romantic movies. Based on suchan approach, users are able to evaluate an itemin various dimensions and are thus not limitedto the one single overall vote anymore. Accord-ing to the study presented in Vig et al. (2010),users particularly appreciated this new feature,a fact that was measured in increased user sat-isfaction. In Gedikli and Jannach (2013), theauthors present first recommendation schemesthat take item-specific tag preferences into ac-count when generating rating predictions. Theresults show that the accuracy can be further im-proved by exploiting item-specific tag preferencedata.Tag-Based Explanations Tagging data is notonly a means to enhance existing recommenderalgorithms, but it can also serve as a means tostrengthen and improve explanations for recom-mendations. Explanations are one of the currentresearch topics in recommender system research.They play an increasingly important role as theycan significantly influence the way a user per-ceives the system.
In Vig et al. (2009), tag-based explanationinterfaces which the authors call “tagsplanations”are described and evaluated. The authors proposeexplanation interfaces which use tag relevanceand tag preference as two key components.Tag relevance measures the strength of therelationship of the tag to the item, whiletag preference indicates the strength of therelationship between a user and the tag. Consider,for example, the tag “love” for a given user–item (movie) pair. Tag preference measureshow well the tag “love” describes the particularmovie, while tag preference indicates the user’s

Recommender Systems, Semantic-Based 1509 R
R
Recommender Systems, Semantic-Based, Fig. 1Personalized tag cloud explanation
interest in movies about love, that is, howmuch the user likes/dislikes movies aboutlove in general, independent from a particularmovie.
In Gedikli et al. (2011), the authors introduceexplanation interfaces based on personalized andnonpersonalized tag clouds. They compare tagcloud-based explanations with keyword-style ex-planations proposed in previous work. In orderto personalize the explanations, the personalizedtag cloud interface makes use of tag preferencedata proposed in Gedikli and Jannach (2013).These item-specific tag preference values are thenmapped to colors which indicate whether the userwill like, dislike, or feel neutral about the itemfeatures represented by the tags in the cloud. Inthe example tag cloud in Fig. 1, blue is used asa color for users, for which the system knowsor assumes that the user has positive feelingsabout, e.g., the tag “family.” Red tags such as“divorce,” on the other hand, represent aspectsthe user will probably not like. Tags which aremarked as neutral are printed in black. The resultsof their user study showed that users can makebetter decisions faster when using the tag cloudinterfaces rather than the keyword-style expla-nations. In addition, users generally favored thetag cloud interfaces over keyword-style explana-tions.
Perspectives
In recent years, exploiting tagging data forrecommendations has become an active researchtopic in the field of RS. Tag-based computingcan further improve the quality of RS and leads
to new possibilities but also to a number ofnew research questions. For example, opinionmining based on folksonomies represents onechallenging topic which is currently beingaddressed in literature. The task of opinionmining is to extract the users’ sentimentalorientations or attitudes to items based ondifferent information sources such as reviews,blogs, and comments. Recently, user-providedtags are recognized as one such informationpool as the tagging of items also tells somethingabout the user. The hybridization of theseinformation sources also plays an increasinglyimportant role. In Liang et al. (2012), e.g., theauthors combine a user-provided folksonomyand an expert-driven taxonomy to assess auser’s opinion about an item and to makepersonalized recommendations. They showthat by taking the expert’s viewpoint intoaccount, the accuracy of item recommendationscan be further improved. Future work mightaim to integrate tagging data with furtherinformation sources such as reviews orblogs.
Furthermore, we believe that future work willconcentrate on topics of bringing semantics totagging data (see, for example, Xu et al. 2011b;Cattuto et al. 2008). Semantically enhanced tagswill further improve various aspects of recom-mender systems such as accuracy, diversity, orexplanation facility.
In general, we see tagging data as a promisingsource of information to further improve differenttechnologies and approaches related to the Se-mantic Web and the Social Web (Passant 2007)and in particular to develop more powerful appli-cations for search and recommendation (Noll andMeinel 2007).
Cross-References
�Analysis and Mining of Tags, (Micro)Blogs,and Virtual Communities�Folksonomies�Human Behavior and Social Networks�Tag Clouds

R 1510 Recommender Systems, Semantic-Based
References
Cantador I, Bellogin A, Vallet D (2010) Content-basedrecommendation in social tagging systems. In: Rec-Sys’10, Barcelona, pp 237–240
Cattuto C, Benz D, Hotho A, Stumme G (2008) Semanticgrounding of tag relatedness in social bookmarkingsystems. In: ISWC’08, Karlsruhe, pp 615–631
de Gemmis M, Lops P, Semeraro G, Basile P (2008) Inte-grating tags in a semantic content-based recommender.In: RecSys’08, Lausanne, pp 163–170
Durao F, Dolog P (2010) Extending a hybrid tag-based recommender system with personalization. In:SAC’10, Sierre, pp 1723–1727
Firan CS, Nejdl W, Paiu R (2007) The benefit of usingtag-based profiles. In: LA-WEB’07, Santiago de Chile,pp 32–41
Gedikli F, Jannach D (2013) Improving recommendationaccuracy based on item-specific tag preferences. ACMTrans Intell Syst Technol 4(1):1–19
Gedikli F, Ge M, Jannach D (2011) Understanding rec-ommendations by reading the clouds. In: EC-Web’11,Toulouse, pp 196–208
Golder SA, Huberman BA (2006) Usage patterns of col-laborative tagging systems. J Inf Sci 32(2):198–208
Hotho A, Jaschke R, Schmitz C, Stumme G (2006) Infor-mation retrieval in folksonomies: search and ranking.In: ESWC’06, Budva, pp 411–426
http://vanderwal.net/folksonomy.htmlhttp://www.delicious.comhttp://www.flickr.comJannach D, Zanker M, Felfernig A, Friedrich G (2010)
Recommender systems – an introduction. CambridgeUniversity Press, Leiden
Ji A-T, Yeon C, Kim H-N, Jo G-S (2007) Collabora-tive tagging in recommender systems. In: AUS-AI’07,Gold Coast, pp 377–386
Kubatz M, Gedikli F, Jannach D (2011) LocalRank –neighborhood-based, fast computation of tag recom-mendations. In: EC-Web’11, Toulouse, pp 258–269
Li X, Guo L, Zhao YE (2008) Tag-based social interestdiscovery. In: WWW’08, Beijing, pp 675–684
Liang H, Xu Y, Li Y (2012) Mining users’ opinions basedon item folksonomy and taxonomy for personalizedrecommender systems. In: ICDM’10, Sydney
Linden G, Smith B, York J (2003) Amazon.com recom-mendations: item-to-item collaborative filtering. IEEEInternet Comput 7(1):76–80
Noll MG, Meinel C (2007) Web search personal-ization via social bookmarking and tagging. In:ISWC’07/ASWC’07, Busan, pp 367–380
Passant A (2007) Using ontologies to strengthen folk-sonomies and enrich information retrieval in weblogs.In: ICWSM’07, Boulder
Pitkow J, Schutze H, Cass T, Cooley R, Turnbull D,Edmonds A, Adar E, Breuel T (2002) Personalizedsearch. Commun ACM 45(9):50–55
Rendle S, Schmidt-Thieme L (2010) Pairwise interactiontensor factorization for personalized tag recommenda-tion. In: WSDM’10, New York, pp 81–90
Rendle S, Balby Marinho L, Nanopoulos A, Lars S-T(2009) Learning optimal ranking with tensor factoriza-tion for tag recommendation. In: SIGKDD’09, Paris,pp 727–736
Sen S, Vig J, Riedl JT (2009) Tagommenders: connectingusers to items through tags. In: WWW’09, Madrid,pp 671–680
Seth A, Zhang J (2008) A social network based approachto personalized recommendation of participatory me-dia content. In: ICWSM’08, Seattle
Shepitsen A, Gemmell J, Mobasher B, Burke R (2008)Personalized recommendation in social tagging sys-tems using hierarchical clustering. In: RecSys’08,Lausanne, pp 259–266
Symeonidis P, Nanopoulos A, Manolopoulos Y (2008)Tag recommendations based on tensor dimensionalityreduction. In: RecSys’08, Lausanne, pp 43–50
Tso-Sutter KHL, Marinho LB, Schmidt-Thieme L (2008)Tag-aware recommender systems by fusion of col-laborative filtering algorithms. In: SAC’08, Fortaleza,pp 1995–1999
Vatturi PK, Geyer W, Dugan C, Muller M, BrownholtzB (2008) Tag-based filtering for personalized book-mark recommendations. In: CIKM’08, Napa Valley,pp 1395–1396
Vig J, Sen S, Riedl JT (2009) Tagsplanations: explain-ing recommendations using tags. In: IUI’09, SanibelIsland, pp 47–56
Vig J, Soukup M, Sen S, Riedl JT (2010) Tag expression:tagging with feeling. In: UIST’10, New York, pp 323–332
Xu G, Gu Y, Dolog P, Zhang Y, Kitsuregawa M (2011a)Semrec: A semantic enhancement framework for tagbased recommendation. In: AAAI’11, San Francisco,pp 1267–1272
Xu G, Gu Y, Zhang Y, Yang Z, Kitsuregawa M (2011b)Toast: a topic-oriented tag-based recommender sys-tem. In: WISE’11, Sydney, pp 158–171
Zanardi V, Capra L (2011) A scalable tag-based recom-mender system for new users of the Social Web. In:DEXA’11, Toulouse, pp 542–557
Zhen Y, Li W-J, Yeung D-Y (2009) Tagicofi: tag in-formed collaborative filtering. In: RecSys’09, NewYork, pp 69–76
Recommended Reading
Jannach D, Zanker M, Felfernig A, Friedrich G (2010)Recommender systems – an introduction. CambridgeUniversity Press, Leiden
Ricci F, Rokach L, Shapira B, Kantor PB (eds) (2011)Recommender systems handbook. Springer, New York

Recommender Systems: Models and Techniques 1511 R
R
Recommender Systems:Modelsand Techniques
Francesco RicciFaculty of Computer Science, Free Universityof Bozen-Bolzano, Bozen-Bolzano, Italy
Synonyms
Advisory systems; Recommendation systems
Glossary
Context Situational factors influencing theevaluation of a user for an item
Experience The interaction of a user with anitem that is resulting in an evaluation
Evaluation Prediction The system’s predictionof the user’s evaluation for an item
Information Filtering Technique for providingonly relevant information to a user
Item Information content that can be recom-mended by a RS
Personalization Providing a user with contentadapted or suited to their needs and wants
Preferences A structured representation of theuser preferences for items
Recommendations System’s selected items thatare suggested to a user
RSs Recommender systemsSituation Conditions under which an item is
evaluated by a userTag Metadata in the form of freely chosen
keyword
Definition
RSs are information search and filtering toolsthat provide suggestions for items to be of useto a user. They have become common in a largenumber of Internet applications, helping users tomake better choices while searching for news,music, vacations, or financial investments. RSsexploit data mining and information retrieval
techniques to predict to what extent an itemsuits the user needs and wants and recommendthose items with the largest predicted fitscore.
Introduction
The explosive growth and variety of informa-tion available on the Web and the rapid intro-duction of new e-business and social services(buying products, product comparison, auction,forums, social networking, multimedia fruition)have created such a richness of choices that,instead of producing a benefit, this overabun-dance risks to backfire. While choice is good,more choice is not always better. Indeed, choice,with its implications of freedom, autonomy, andself-determination, can become excessive, cre-ating a sense that freedom may come to beregarded as a kind of misery-inducing tyranny(Schwartz 2004). Moreover, if dozens of differenttypes of jams are likely to confuse and paralyzea buyer, as it is illustrated in Schwartz (2004),thousands or even millions of songs are simplyimpossible to scan if the ultimate goal is just toplay some of them.
Such a scenario motivated the introduction ofrecommender systems (RSs) (Ricci et al. 2011;Konstan and Riedl 2012). RSs are informationsearch and filtering tools that provide suggestionsfor items to be of use to a user. They havebecome common in a large number of Internetapplications, helping users to make better choiceswhile searching for news, music, vacations, orfinancial investments. “Item” is the general termused to denote what the system recommends toits users, and a specific RS normally focuseson one type of items (e.g., movies or news).Accordingly, its core algorithmic component andits graphical user interface are customized to pro-vide useful and effective suggestions for that spe-cific type of items. Recommender systems playan important role in highly rated Internet sites,such as Amazon.com, YouTube, Netflix, Yahoo,Tripadvisor, Last.fm, and IMDb. More recently,social networks, such as Linkedin and Facebook,

R 1512 Recommender Systems: Models and Techniques
have introduced recommender systems to suggestgroups to join or people to relate with.
In their simplest form, personalized recom-mendations are offered as customized lists ofitems. In performing this selection the systemtries to predict what the most suitable productsor services (items) are, based on the user’s char-acteristics and preferences. In order to completesuch a computational task, a RS must elicit fromusers such characteristics and preferences, eitheralong the full history of previous interactionswith the users or exploiting information enteredby the users at the time the recommendationis requested. Moreover, such information eithercan be explicitly expressed, e.g., as ratings forproducts, or can be inferred by interpreting useractions. For instance, the navigation to a par-ticular page can be interpreted as an implicitsign of preference for the items shown on thatpage.
The study of recommender systems is rela-tively new compared to research in other classicalinformation system tools and techniques (e.g.,databases or search engines). Recommender sys-tems emerged as an independent research areain the mid-1990s (Goldberg et al. 1992; Resnicket al. 1994), and it is still fast growing. Researchworks on RSs are published in major conferenceson machine learning (ICML, KDD, NIPS), infor-mation retrieval (SIGIR, WISDM, CIKM), intel-ligent user interfaces (IUI), and personalization(UMAP). A specific ACM conference on recom-mender systems has been launched on 2007, andevery year it attracts more and more submissionsand attendees. In total, thousands of papers arepublished every year on this subject.
In this paper we provide a description of thegeneral computational model of a recommendersystem. We aim at modeling in a compact butrigorous presentation the core functionality ofa recommender system. We will decompose itinto three fundamental tasks: user’s preferenceselicitation, prediction of user’s evaluations foritems, and recommendations generation and pre-sentation. In the last section we will conclude thisshort article with a discussion of some challengesfor RSs.
Recommendation Modeland Techniques
A general computational model for recommendersystems was previously described in Adomavi-cius and Tuzhilin (2005). In this model, a RSis defined as a machinery implementing a real-valued function defined on the product spaceof the users and items r� W U � I ! Rthat predicts how a pair consisting of a useru 2 U and an item i 2 I is mapped to theevaluation r�.u; i/ of the user u for the itemi . They call this number r�.u; i/ the predicted“utility” of the item for the user. We preferhere not to use the term “utility,” as in the RSliterature no special assumption is made on thecharacteristics of the evaluation function, while autility function does satisfy specific constraints.For that reason we call it “predicted evalua-tion.” Then, having predicted evaluations of usersfor items, a RS recommends to a user u theitems i with the largest predicted evaluationsr�.u; i/. Evaluations are called ratings of usersfor items in Collaborative Filtering RSs (see nextsection on Evaluation Prediction Techniques).A RS computes the prediction r�.u; i/ on thebase of a collection of observations: these areinteractions between users and items, and theyprovide the system with information about theusers’ preferences. In many cases these inter-actions produce explicit evaluations performedby some users on some items. In some othercases, more complex types of relationships areobserved, for instance, the relative preference ofa user for an item when it is compared to anotheritem.
In this survey we introduce a generalizationof this two-dimensional model (Users � Items)that is inspired by the multidimensional modelintroduced in Adomavicius et al. (2005), andit is motivated by recent researches on socialnetworks and tagging recommender systems(Marinho et al. 2011). Moreover, we delineate amodel for RSs that decomposes its behavior intothree fundamental tasks: preference elicitation,item evaluation prediction, and recommendationgeneration.

Recommender Systems: Models and Techniques 1513 R
R
Preference ElicitationThe first task that a recommender system mustimplement is the elicitation of user preferences;this means, in RS terminology, that the systemmust be able to collect from users a set of eval-uations for items.
More formally, let us assume that there existthree sets U; I , and M . U is the set of users,I is the set of items, and M is the set of possiblesituations under which the items can be experi-enced. For instance, M can be the user’s locationwhen the item, e.g., a restaurant, was searchedand selected or the location of the user whena recommendation for a restaurant is required(more on this is discussed later on).
Then the experience of a user for an itemis a quadruple .u; i; m; r.u; i; m// 2 U � I �M � R where u is the user who interactedwith item i in the situation m and evaluated theitem r.u; i; m/ 2 R. We use here the functionnotation r.u; i; m/ to stress that the evaluation isa function of the user, the item, and the situation.R is an evaluation scale containing the possible(ordered) evaluation values. Evaluations are com-monly called ratings, and a popular evaluationscale is the finite set f1; 2; : : : ; 5g. This scaleis used, for instance, by Amazon.com. But, dif-ferent evaluation scales are possible and havebeen used both in the scientific literature andin some deployed RSs; for instance, the simplerevaluation schema provided by positive (“like,”C1) vs. negative (“not like,” �1) evaluation isused in YouTube.com. It is interesting to note thatrating scales are not neutral and they influence theuser evaluation process (Kuflik et al. 2012) andconsequently the RS behavior.
A recommender system, in order to gener-ate recommendations, must first collect a set ofexperiences from the users in U , for items in I , insome situations M , i.e., to acquire a set E.D/ Df.u; i; m; r.u; i; m// W .u; i; m/ 2 D � U � I �M g. The evaluation r.u; i; m/ can be collectedeither explicitly or implicitly. By “explicitly” wemean that the user is explicitly entering in someform her evaluation r.u; i; m/ on the presenteditem. In “implicit” models the user is not en-tering evaluations but is acting on the presented
items, e.g., is watching a recommended video,or is browsing the presented information aboutan item. The system is then inferring the userevaluation (a value in R) from the user action.We first discuss the “explicit” approach and thenthe “implicit” one.
Many recommender systems allow usersto “explicitly” evaluate (rate) items as theyencounter them while interacting with the system.In addition, many RSs explicitly request the userto evaluate a certain number of items (e.g., 20books) before providing recommendations (fornew books). This may happen in the sign upstage, i.e., when the user registers to the systemand obtains the credential to access it. Anotherpopular approach for collecting evaluations is tolet the user to “correct” the system predictionsby entering evaluations for items that have beenrecommended, hence possibly fixing erroneouspredictions. In this case the system may learn thatsome of the recommended items are not goodoptions, i.e., the user may enter low evaluationsfor them.
In more sophisticated approaches the systemmay implement a precise preference elicitationstrategy by applying active learning techniques(Rubens et al. 2011). So, for instance, the sys-tem may identify the most popular items andrequest the user to rate them, with the objectiveof maximizing the probability that the user knowsthese items and can really evaluate them. Or,in a completely different approach, the systemmay ask the user to evaluate the items that havereceived so far the most diverse evaluations, sincethe opinion of the user on these items can betterreveal the specific users’ preferences.
In “implicit” feedback approaches the useris not directly entering evaluations for items bychoosing values from the evaluation scale Rconsidered by the system. So, for instance, theuser is not entering a star-based score for thebooks she has read. The underlying assumption isthat the user may not want to spend time for thistask; hence, the system must infer the evaluationsin the target R scale from another measure in an-other scale R0. For instance, in the music recom-mender system presented in Moling et al. (2012)

R 1514 Recommender Systems: Models and Techniques
the system is measuring the percentage of a sug-gested track that is actually listened to by the userto decide what type of track to recommend next.Another popular implicit evaluation scale is thenumber of times a user visited the item (playeda track or browsed a page). Yet another exampleof the “implicit” approach is offered by systemsthat do not ask the user to evaluate individualitems, but allow them to compare two items or tocriticize them (McGinty and Reilly 2011). In thiscase the system first presents some recommendeditems. These are primarily generated for lettingthe user to specify the characteristics of the pre-ferred items. In response, the user can inform thesystem that the presented items do not completelyconform to her preferences and select one itemthat is almost good but is still lacking a preferredfeature (e.g., it should be cheaper). In these casesthe system uses the user input, which is composedby the selected item and the “critique,” to updatethe evaluation prediction function for that userr�.u; �; �/.
Item Evaluation PredictionThe second task, item evaluation prediction, usesa data set of user-provided evaluations to predictnew evaluations. In fact, this is the most impor-tant task of a recommender system: exploiting adata set of experiences, its background knowl-edge, E.D/ D f.u; i; m; r.u; i; m// W .u; i; m/ 2D � U � I �M g to generate predictions of theuser evaluations for other experiences E�.D�/ Df.u; i; m; r�.u; i; m// W .u; i; m/ 2 D� � U �I � M g, where r�.�; �; �/ is the evaluation pre-diction function that is estimated with a specificrecommendation technology. In the next section,we will present some techniques, e.g., collabora-tive filtering or content-based, which have beenintroduced to compute the evaluation predictionfunction r�.�; �; �/. D� is the set containing theuser, item, and situation combinations for whichthe recommender system can generate evaluationpredictions. D� is disjoint from D and may beequal to .U � I � M / n D or smaller. It issmaller when the RS is not able to generate eval-uation predictions for all the items and situationscombinations that the user has not evaluated yet.In fact, recommender systems find it difficult,
for instance, to make recommendations for newusers and new items. These are users who neverentered any evaluation in the system or items thatwere never evaluated by any user (users and itemsnot present in D) (Ricci et al. 2011; Konstan andRiedl 2012).
We note that I; U , and M are sets of objectsand may, or may not, have an internal structure,i.e., they may have features. For instance, inplain collaborative filtering systems, which willbe described later on, items’ and users’ fea-tures, even if available, are not exploited, andthe situation space is ignored. For that reasonthe evaluation function is modeled as a matrixR D Œru;i �m�n, where u and i are simple indexesranging from 1 to m and n, respectively, andru;i 2 R. Whereas, in content-based systems,items have an internal structure and are describedwith features. Items’ features are used to generateuser-specific classifiers that can predict the userevaluation for (unseen) items (Lops et al. 2011).
It is worth noting that some recommendersystems do not collect user evaluations for itemsin order to make predictions, i.e., they can makerecommendations even though E.D/ is empty.For instance, case-based recommender systemslet the user to enter a partial description of thepreferred item q, as query, and then, using thisinput, they generate predictions r�.u; i; q/ of theuser evaluation for item i . They accomplish thistask by exploiting the similarity of q and i , basedon some description of i . Hence, in CBR RSs, thesituations set M is the space of all possible userqueries (Bridge et al. 2006).
Evaluation Prediction TechniquesIn order to implement the item evaluation pre-diction function, RSs can exploit a range oftechniques. This has been the major topic ofresearch in RSs. We will here briefly indicate themost important types of techniques, referring theinterested reader to Ricci et al. (2011) for moreexamples, references, and details.
Recommendation techniques vary in terms ofthe addressed domain, the knowledge used, andthe recommendation algorithm, i.e., essentiallyhow the item evaluation prediction is actuallycomputed. We provide here an overview of the

Recommender Systems: Models and Techniques 1515 R
R
different types of RS techniques by quoting ataxonomy introduced by Burke (2007) that hasbecome classical for distinguishing between rec-ommender systems and referring to them. Burke(2007) lists six different types of recommenda-tion approaches:
Content-BasedThe system implements for each user a “classi-fier” that learns to evaluate (classify) higher theitems that are similar to the ones that the userevaluated higher in the past. The similarity ofitems, or more in general the item classificationrule, is calculated based on the features associatedwith the compared items. For example, if a userhas systematically positively rated movies thatbelong to the action genre, then the system canlearn that other movies from this genre shouldhave a high value for that user (Lops et al. 2011).
Collaborative FilteringThe simplest and original implementation of thisapproach predicts that the active user, i.e., theuser asking for recommendations, will evaluatehigher the items that other users with similartastes liked in the past (Desrosiers and Karypis2011). The similarity in taste of two users iscalculated based on the similarity of the evalua-tions’ history of the users. Collaborative filteringis probably the most popular and widely imple-mented technique in RSs. The latest approachesto CF use latent factor models, such as matrixfactorization (e.g., using Singular Value Decom-position, SVD). These methods map both itemsand users to the same latent factor space. Thenthe predicted evaluation of a user for an item isbasically computed by the dot multiplication oftheir representative vectors, which gives a kindof similarity between the user and the item in thiscommon representation space (Koren and Bell2011).
DemographicThese techniques predict item evaluations basedon the demographic profile of the user. Theassumption is that different recommendationsshould be generated for different demographicniches. Many Web sites adopt simple and
effective personalization solutions based ondemographics. For example, users are dispatchedto particular Web sites based on their languageor country. Or suggestions may be customizedaccording to the age of the user.
Knowledge-BasedKnowledge-based systems predict item evalua-tions based on specific domain knowledge abouthow certain item features meet user’s needsand preferences and ultimately how the itemis useful for the user. Notable knowledge-basedrecommender systems are case-based (Bridgeet al. 2006). In these systems a similarity functionestimates how much the user needs (problemdescription) match the recommendations(solutions of the problem). Here the similarityscore can be directly interpreted as the predicteditem evaluation of the user. Another group ofknowledge-based systems uses constraints, torepresent user preferences and to find relevantitems (Jannach et al. 2010).
Community-BasedIn this type of systems, item evaluationpredictions are based on the preferences of theuser’s friends. Evidence suggests that peopletend to rely more on recommendations from theirfriends than on recommendations from similarbut anonymous individuals. This observation,combined with the growing popularity ofopen social networks, is generating a risinginterest in community-based systems or socialrecommender systems (Golbeck 2006). Thistype of RS techniques acquires and exploitsinformation about the social relations of the usersand the preferences of the user’s friends. Theitem evaluation predictions are based on ratingsthat were provided by the user’s friends.
Hybrid Recommender SystemsThese RSs are based on the combination of theabovementioned techniques. A hybrid systemcombining techniques A and B tries to use theadvantages of A to fix the disadvantages of B.For instance, CF methods suffer from new-itemproblems, i.e., they cannot generate evaluationpredictions for items that have no ratings.

R 1516 Recommender Systems: Models and Techniques
This does not limit content-based approachessince the prediction for new items is based ontheir description (features) that are typicallyeasily available. Given two (or more) basic RStechniques, several ways have been proposed forcombining them to create a new hybrid system(see Burke 2007 for the precise descriptions).
Recommendation GenerationRSs, after having generated evaluation predic-tions for items, can generate recommendations,i.e., absolve their primary role. The classicaland common approach for recommendationgeneration is to recommend to user u insituation m the N items i that have the largestpredicted evaluation in that situation, i.e., the setTopN.u; m/ � I , where jTopN.u; m/j D N ,and if i 2 TopN.u; m/, then r�.u; i; m/ �r�.u; j; m/, for all j 62 TopN.u; m/ (Adomavi-cius and Tuzhilin 2005). N is normally a smallvalue, such as 5 or 10. Reducing the number ofrecommendations is essential to address the maingoal of a recommender system, as we mentionedin the Introduction, namely, to filter irrelevantitems and simplify the user’s decision-makingprocess.
Similarly, the system can rank all the items forwhich the recommender can generate an evalua-tion prediction and present to the user the rankedlist of these items, ordered by decreasing value ofthe predicted evaluation r�.u; i; m/. It is worthnoting that this ranked list is not generally equalto the full set of items I , since, as we mentionedabove, the RS may not be able to generate an eval-uation prediction for all the items (in all the situa-tions). Hence, in practice this ranked list containsthe TopN.u; m/ items for a large value of N .
In fact, there is a growing understanding thatthis apparently obvious design choice may not bethe most appropriate in many cases. For instance,the top N items may be all very similar; hence,it would be more useful to introduce in the rec-ommendation list those items, which may have alower predicted evaluation but are, all together,providing a more useful information to the user.The essential point that we raise here is that,while the item evaluation prediction function es-timates to what extent the user likes an item, the
user decides what item to select by browsing therecommendation list. Hence, items presented inthe recommendation list must fulfil two, possiblyconflicting, criteria: be interesting to the user andhelp the user to make a decision. As the diversityissue points out, items that can better help the userto make a decision may not be just the best topfive items that he may select.
Another related issue is pertaining to theinformation that is provided together withthe recommendations. In practice this hasbeen dealt by including explanations for therecommendations (Tintarev and Masthoff 2012).Explanations may be directed to enhance thetransparency or the scrutability of the system, i.e.,giving to the users hints about the system internalbehavior. Or they may increase the trust, thepersuasiveness, and the subjective satisfaction ofthe user. Or ultimately explanations can improvethe efficiency and effectiveness of the decision-making process supported by the recommender.
Key ApplicationsAs we mentioned above, the illustrated recom-mender system model focuses on three types ofentities: users U , items I , and situations M . Inthe following sections we will illustrate three keyapplications of this model, where the situationspace is representing, the context, or the group ofusers, or a tag. We must stress that the simplerand more popular model, which is describedin Adomavicius and Tuzhilin (2005), does notconsider any situation space M . In that case therecommendations are generated for a user, inde-pendently from any other additional informationthat may specify the recommendation situation.
Context-Aware Recommender SystemsThe first application of the model described inthe previous section refers to context-aware rec-ommender systems (Adomavicius et al. 2011).In this case M contains the possible alternativecontextual situations that may be concurrent withthe experience that a user makes of an itemand can have an impact on the item evaluation.The goal is to make predictions of user evalu-ations for items in a particular target contextualcondition m.

Recommender Systems: Models and Techniques 1517 R
R
For instance, Baltrunas et al. (2012) describe aplace of interests (POIs) recommender system forthe tourism domain, where 14 contextual factorsare considered. To mention some examples, thereare factors that describe the time of the travel, theweather condition, the mood of the user, or thetype of group that is accompanying the traveler.We refer the reader to Baltrunas et al. (2012) fora detailed description of these contextual factors.For each factor a finite set of possible valuesis defined. For instance, the weather factor cantake the values: snowing, clear sky, sunny, andrainy. Hence, in this recommender system M
is the space of all the possible combinationsof the values for these 14 contextual factors:M D F1 � � � �F14, where, for instance, F9 Dfsnowing; clear sky; sunny; rainyg is the weatherfactor that we mentioned above. This system usesa collection of users’ evaluations for a collectionof places of interests in Bolzano (items), in dif-ferent contextual situations, to predict the users’evaluations for POIs not yet experienced in somepossibly new contextual situations.
Context-aware RSs are now an active researcharea and we refer the reader to Adomaviciuset al. (2011) for more examples and techniques.The major technical difficulties are related tothe following: understanding the impact of thecontextual factors on the personalization pro-cess; selecting (dynamically) the right factors,i.e., relevant in a particular personalization task;obtaining sufficient and reliable data describingthe user preferences in context; and embeddingthe contextual information in a more classicalrecommendation computation technique.
Group Recommender SystemsThe second application refers to group recom-mender systems (Jameson and Smyth 2007). Inthis case M represents the possible groups ofusers that u may belong to, and the ultimatesystem goal is to offer the same set of recom-mendations for items to the users belonging toa group. The underlying assumption is that theitems will be experienced together, e.g., in atravel recommender system, the users will traveltogether to the recommended place. The dataset of the users’ experiences E.D/ in this case
contains quadruples of the type .u; i; g; r.u; i; g//,where g is a subset of users in U that containsu, and r.u; i; g/ is the evaluation provided by theuser u, for item i , when the item was experiencedtogether with the other users in g. The idea is thatthe user evaluation is influenced by the presenceof other users (Masthoff 2011), i.e., r.u; i; g/ isin principle different from r.u; i; h/ if h ¤ g.
A group recommender system with such back-ground knowledge must predict the evaluationof u for other items, let us say i 0, when she istogether with the users in g0. It is worth notingthat no group recommender system is actuallymaking predictions for the user evaluations as afunction of the group g the user belongs to. Con-versely, the current leading approach is to firstpredict the individual evaluations independentlyfrom the group, using a standard two-dimensionalmodel, i.e., neglecting the situation in M , whichmeans that r�.u; i; h/ D r�.u; i; g/ D r�.u; i/,for all groups h; g 2 M . Then, in a secondstep, group RSs compute the “group evaluationprediction” for an item by aggregating the variousevaluation predictions for that item for the groupsmembers. So, for instance, if the average aggre-gation method is used, the predicted evaluation ofthe group g for the item i is AVGu2gfr�.u; i/g,and the items with the largest group aggregatedevaluations are recommended.
Other approaches, instead of aggregating eval-uation predictions, aggregate the input evalua-tions of the users u belonging to a group g,hence generating (fictitious) group evaluationsr.g; i; g/. These group evaluations, which consti-tute the group model, are again computed by, forinstance, averaging the evaluations of the users inthe group for a given item. Then, the group evalu-ation predictions are computed for these fictitioususers considering them as normal users. One candescribe this approach in the model proposed inthis article, by introducing new fictitious usersthat represent groups g, and then the evaluationprediction function for a group g is r�.g; �; g/.
The group recommendation application isstressing once more the fundamental, but sofar neglected, difference between the evaluationprediction and the recommendation generationtasks of a recommender system. As we mentioned

R 1518 Recommender Systems: Models and Techniques
above, the best recommendations may not be forthe items having the largest predicted evaluation.For group recommendations, a better approachis instead to really try to predict r.u; i; g/, i.e.,the evaluation of u for item i when experiencedtogether with the other users in g. Then thesystem must compute recommendations for u
when she is together with the users in g notsimply by taking the highest predicted items, buttrying to generate a recommendation list that isreally useful for the group, e.g., by combiningitems that would help the group to make a jointand agreed decision.
Tag-Based Recommender SystemsThe last application refers to social taggingrecommender systems (Marinho et al. 2011).In social tagging systems, such as Delicious,BibSonomy, and Last.fm, users can searchand browse the items managed by the system,which in these three examples are bookmarks,bibliographic references, and music, respectively.But, in addition to this basic functionality, userscan tag the items with tags, i.e., metadata in theform of freely chosen keywords. On top of thesesystems, various kinds of recommendations arepossible. One can recommend items to user, butalso tags to be assigned by a user to an item, oreven users to users. In tag-based recommendersystems, M , the space of situations, is a tagvocabulary V . An evaluation r.u; i; t/ in thesesystems is taking values just in the set f1g, wherer.u; i; t/ D 1 means that the user u has tagged theitem i with the tag t . Hence, in this scenario, a setof collected experiences E.D/ D f.u; i; t; 1/ W.u; i; t/ 2 D � U � I � V g represents tagassignments performed by users to items. Thisset of experiences, actually considering only thetriples .u; i; t/, i.e., discarding the redundant 1,is called in social tag systems a Folksonomy. So,given a Folksonomy, the evaluation predictiontask of a tag-based recommender system can bespecialized by saying that it predicts whether auser u will assign the tag t to the item i , or inother words, if the triple .u; i; t/ not yet includedin the Folksonomy should be added to it.
As we mentioned above, while the basic eval-uation prediction task in this case is predictingif r.u; i; t/ is 1, i.e., if a user will assign atag to an item, various specific recommendationgeneration tasks have been considered. The twomore popular are to recommend a set of itemsto a user and to recommend a set of tags toa user for tagging an item. The first one isthe classical (two-dimensional) recommendationtask of a RS, i.e., where the recommendationsare not supposed to be dependent on the tagthat the user is giving to the target item (thesituation). In fact, tag assignments are used togenerate item recommendations, e.g., by usingtag assignments to identify similar items (taggedin a similar way) or similar users (tagging com-mon items) in collaborative filtering techniques.But in this case, the recommendations offeredto a user are not depending on the tags that theuser may have selected for the recommendeditem. In this case, the original three-dimensionalmatrix of observed tag assignments (experiences)r.u; i; t/ D 1 can be projected into the twoclassical two-dimension space of users and itemsevaluations r.u; i/. This is performed by simplyassigning to r.u; i/ the value 1 if there existsa tag t such that r.u; i; t/ D 1. Then, on thistwo-dimensional space of U � I , standard rec-ommendation techniques, such as collaborativefiltering, can be applied to compute evaluationpredictions (i.e., if a user likes or not the items)and generate the final recommendation sets.
Conversely, if the goal is to recommend tags toa user for tagging an item, one must consider theoriginal three-dimensional model. After havingidentified the triples .u; i; t/ that are predicted,i.e., such that r�.u; i; t/ D 1, the system simplyrecommends the tag t for tagging the item i
to the user u. In practice, prediction functionsare scoring the triples not yet observed, e.g., byassigning a predicted evaluation in Œ0; 1�, andthen the N tags, for a given pair .u; i/, that arepredicted to score higher are recommended to theuser u for tagging the item i . A large number oftechniques have been proposed to compute thisscore, and we refer to Marinho et al. (2011) for asurvey in this fast-growing research area.

Recommender Systems: Models and Techniques 1519 R
R
Future Directions
The research on RSs is still very active, andnumerous issues and challenges are still open. Wewant to list here some of them, with the obviouscaveat that this list cannot be complete and isinfluenced by our personal vision. The reader isalso referred to Konstan and Riedl (2012) foranother discussion on the future of recommendersystems.
Group RecommendersGroup recommenders deal with situations whenit would be good if the system could recommendinformation or items that are relevant to a groupof users rather than to an individual (Jamesonand Smyth 2007). For instance, a RS mayselect television programs for a group to viewor a sequence of songs to listen to, basedon preference models of all group members(Masthoff 2011). Recommending to groups isclearly more complicated than recommendingto individuals. Assuming that we knowprecisely what is good for individual users,the issue is how to combine individual userpreferences or aggregate recommendationsfor the group members into group-specificrecommendations (Jameson and Smyth 2007).Even if several techniques have been proposedso far (Masthoff 2011), very few experimentshave been conducted in live-user studies (Senotet al. 2010), and it is challenging to definemeasures for assessing the quality of grouprecommendations.
Proactive Recommender SystemsProactive recommenders can decide to push rec-ommendations even if not explicitly requested.The largest majority of the recommender sys-tems developed so far follow the “pull” model,where the user originates the request for a rec-ommendation. In the scenarios emerging today,where computers are ubiquitous and users arealways connected, it seems natural to imaginethat a RS can detect needs even if they are notexplicitly stated by the user with a request. Inthis scenario, the system therefore must predict
what to recommend but also when and how to“push” its recommendations. By accurately esti-mating when the RS can become proactive with-out being perceived as disturbing, the perceivedutility of the recommendations may greatly in-crease.
Active LearningRSs need to actively look for new data duringthe operational life (Rubens et al. 2011) (ActiveLearning). This issue is normally neglected onthe assumption that there is not much spacefor controlling what data (e.g., ratings) thesystem can collect, because these decisions areautonomously taken by the users when visitingthe system. Actually, a RS provokes the userswith its recommendations. In fact, many systems(e.g., MovieLens.org) explicitly ask for userratings during the recommendation process.Hence, by tuning the process, users can be pushedto enter into the system a range of differentinformation. Specifically, they can be requestedto rate particular items, because the knowledge ofthe user’s opinions about these items is estimatedas beneficial for improving a particular aspect ofthe system performance, e.g., in order to generatemore diverse recommendations or just to improvethe prediction accuracy. Some recent works haveaddressed these issues (Harpale and Yang 2008;Rashid et al. 2008), but more research activityis required to assess the proposed techniques inlive-user studies and to design more adaptivesolutions to the dynamics of the data managedby the system (Elahi et al. 2011; Golbandi et al.2011).
Privacy PreservingRSs exploit user data to generate personalizedrecommendations. In the attempt to buildincreasingly better recommendations, theycollect as much user data as possible. This canclearly have a negative impact on the privacy ofthe users, and the users may start feeling thatthe system knows too much about their truepreferences (Kobsa 2008). Therefore, there is aneed to design solutions that will parsimoniously,sensibly, and cooperatively collect user data.

R 1520 Recommender Systems: Models and Techniques
At the same time these solutions will ensure thatthe acquired knowledge about the users cannotbe freely accessed by malicious users.
DiversityAssuring the diversity of the items recommendedto a target user is an important feature of arecommender system (Smyth and McClave2001). For instance, it is more likely that the userwill find a suitable item in a recommendation list,if there is a certain degree of diversity amongthe recommendations. There is a limited value inhaving perfect recommendations for a restrictedtype of products, unless the user has expresseda narrow set of preferences. There are manysituations, especially in the early stage of arecommendation process, in which the userswant to explore new and diverse directions. Insuch cases, the user is using the recommender asa knowledge discovery tool. The research on thistopic is still in an early stage and is now tryingto characterize the nature of this “diversity”(Vargas and Castells 2011), i.e., whether thesystem must produce diversity among differentrecommendation sessions, or within a session(Adomavicius and Kwon 2012), and how toachieve simultaneously diversity and accuracyof the recommendations (Vargas and Castells2011).
Generic User ModelsGeneric user models (Kobsa 2007) and cross-domain recommender systems are able to medi-ate user data (item evaluations) through differentsystems and application domains (Berkovskyet al. 2008). Using generic user model techniques,a single RS can produce recommendations abouta variety of items. This is normally not possiblefor a traditional RS which can combine moretechniques in a hybrid approach, but cannot easilybenefit from the user preferences collected in onedomain to generate recommendations in a differ-ent one. Solutions to this problem may furtherpush the adoption of personalized mobile rec-ommender systems, running on the user personalcommunication device and offering ubiquitoussupport in many user’s activities (Ricci 2011).
Sequential RecommendationsRecommender Systems may optimize asequence of recommendations (Shani et al. 2005;Baccigalupo and Plaza 2006), for instance, asequence of songs broadcast by a personalizedradio channel. Sequential recommendations maybe generated by systems that manage a structureddialogue between the user and the recommender.These systems are called conversational andhave emerged in the attempt to improve thequality of the recommendations that are normallyoffered by simpler systems based on a one-time request/response. Conversational RSs canbe further improved by implementing learningcapabilities that can optimize not only the itemsthat are recommended at each conversational stepbut also how the dialogue between the user andthe system must unfold in all possible situations(Mahmood et al. 2009).
Robust Recommender SystemsFinally, the topic of robust recommender sys-tems has become a major issue in the past fewyears. New research activities have focused onalgorithms designed to generate more robust rec-ommendations, i.e., recommendations that areharder for malicious users to influence. In fact,collaborative recommender systems are depen-dent on the goodwill of their users, i.e., thereis an implicit assumption that users will interactwith the system with the aim of getting goodrecommendations for themselves while providinguseful data for their neighbors. However, usersmight have a range of purposes in interactingwith RSs, and in some cases, these purposesmay be opposed to those of the system owneror those of the majority of its user population.Namely, these users may want to damage the Website that is hosting the recommender or to biasthe recommendations, e.g., to score some itemsbetter or worse, rather than to arrive at a fairevaluation (Burke et al. 2011).
Cross-References
�Collective Intelligence, Overview�Computational Trust Models

Recommender Systems: Models and Techniques 1521 R
R
�Data Mining�Distance and Similarity Measures�E-Commerce and InternetBusiness� Folksonomies�Group Representation and Profiling�Matrix Algebra, Basics of�Matrix Decomposition� Privacy and Disclosure in a Social NetworkingCommunity�Recommender Systems using Social NetworkAnalysis: Challenges and Future Trends� Social Media� Social Recommendation in DynamicNetworks�Trust in Social Networks
References
Adomavicius G, Kwon Y (2012) Improving aggre-gate recommendation diversity using ranking-basedtechniques. IEEE Trans Knowl Data Eng 24(5):896–911
Adomavicius G, Tuzhilin A (2005) Toward the next gen-eration of recommender systems: a survey of the state-of-the-art and possible extensions. IEEE Trans KnowlData Eng 17(6):734–749
Adomavicius G, Sankaranarayanan R, Sen S, Tuzhilin A(2005) Incorporating contextual information in recom-mender systems using a multidimensional approach.ACM Trans Inf Syst 23(1):103–145
Adomavicius G, Mobasher B, Ricci F, Tuzhilin A(2011) Context-aware recommender systems. AI Mag32(3):67–80
Baccigalupo C, Plaza E (2006) Case-based sequentialordering of songs for playlist recommendation. In:Advances in Case-Based Reasoning, Proceedings ofthe 8th European Conference on Case-Based Reason-ing, ECCBR 2006, Fethiye, Turkey, Roth-BerghoferT, Goker MH, Guvenir HA (eds) ECCBR, Fethiye.Lecture notes in computer science, vol 4106. Springer,pp 286–300
Baltrunas L, Ludwig B, Peer S, Ricci F (2012) Con-text relevance assessment and exploitation in mobilerecommender systems. Personal Ubiquitous Comput16(5):507–526
Berkovsky S, Kuflik T, Ricci F (2008) Mediation of usermodels for enhanced personalization in recommendersystems. User Model User Adapt Interact 18(3):245–286
Bridge D, Goker M, McGinty L, Smyth B (2006)Case-based recommender systems. Knowl Eng Rev20(3):315–320
Burke R (2007) Hybrid web recommender systems.In: The adaptive web. Springer, Berlin/Heidelberg,pp 377–408
Burke RD, O’Mahony MP, Hurley NJ (2011) Robustcollaborative recommendation. In: Ricci F, RokachL, Shapira B (eds) Recommender systems handbook.Springer, New York, pp 805–835
Desrosiers C, Karypis G (2011) A comprehensive surveyof neighborhood-based recommendation methods. In:Ricci F, Rokach L, Shapira B, Kantor PB (eds) Rec-ommender systems handbook. Springer, New York,pp 107–144
Elahi M, Repsys V, Ricci F (2011) Rating elicitationstrategies for collaborative filtering. In: Proceedingsof the E-commerce and web technologies – 12thinternational conference, EC-Web, Toulouse, 30 Aug–1 Sept 2011. Lecture notes in business informationprocessing, vol 85. Springer, pp 160–171
Golbandi N, Koren Y, Lempel R (2011) Adaptive boot-strapping of recommender systems using decisiontrees. In: Proceedings of the forth international con-ference on web search and web data mining, WSDM,Hong Kong, 9–12 Feb 2011, pp 595–604
Golbeck J (2006) Generating predictive movie recommen-dations from trust in social networks. In: Proceedingsof the trust management, 4th international conference,iTrust, Pisa, 16–19 May 2006, pp 93–104
Goldberg D, Nichols D, Oki BM, Terry D (1992)Using collaborative filtering to weave an informationtapestry. Commun ACM 35(12):61–70
Harpale A, Yang Y (2008) Personalized active learn-ing for collaborative filtering. In: Proceedings of the31st annual international ACM SIGIR conference onresearch and development in information retrieval,SIGIR, Singapore, 20–24 July 2008. ACM, pp 91–98
Jameson A, Smyth B (2007) Recommendation to groups.In: The adaptive web. Springer, Berlin, pp 596–627
Jannach D, Zanker M, Felfernig A, Friedrich G (2010)Recommender systems: an introduction. CambridgeUniversity Press, New York
Kobsa A (2007) Generic user modeling systems. In:Brusilovsky P, Kobsa A, Nejdl W (eds) The adaptiveweb. Lecture notes in computer science, vol 4321.Springer, Berlin, pp 136–154
Kobsa A (2008) Privacy-enhanced personalization. In:Proceedings of the twenty-first international Floridaartificial intelligence research society conference,Coconut Grove, 15–17 May 2008. AAAI, p 10
Konstan JA, Riedl J (2012) Recommender systems: fromalgorithms to user experience. User Model User AdaptInteract 22(1-2):101–123
Koren Y, Bell R (2011) Advances in collaborative fil-tering. In: Ricci F, Rokach L, Shapira B (eds) Rec-ommender systems handbook. Springer, New York,pp 145–186
Kuflik T, Wecker AJ, Cena F, Gena C (2012) Evaluat-ing rating scales personality. In: Proceedings of theuser modeling, adaptation, and personalization – 20thinternational conference, UMAP, Montreal, 16–20July 2012, pp 310–315

R 1522 Recommender Systems Using Social Network Analysis: Challenges and Future Trends
Lops P, de Gemmis M, Semeraro G (2011) Content-basedrecommender systems: state of the art and trends. In:Ricci F, Rokach L, Shapira B, Kantor PB (eds) Rec-ommender systems handbook. Springer, New York,pp 73–105
Mahmood T, Ricci F, Venturini A (2009) Improving rec-ommendation effectiveness by adapting the dialoguestrategy in online travel planning. Int J Inf TechnolTour 11(4):285–302
Marinho LB, Nanopoulos A, Schmidt-Thieme L, JaschkeR, Hotho A, Stumme G, Symeonidis P (2011) Socialtagging recommender systems. In: Ricci F, Rokach L,Shapira B, Kantor PB (eds) Recommender systemshandbook. Springer, New York, pp 215–644
Masthoff J (2011) Group recommender systems: combin-ing individual models. In: Ricci F, Rokach L, ShapiraB (eds) Recommender systems handbook. Springer,New York, pp 677–702
McGinty L, Reilly J (2011) On the evolution of cri-tiquing recommenders. In: Ricci F, Rokach L, ShapiraB (eds) Recommender systems handbook. Springer,New York, pp 419–453
Moling O, Baltrunas L, Ricci F (2012) Optimal radiochannel recommendations with explicit and implicitfeedback. In: RecSys’12: Proceedings of the 2012ACM conference on recommender systems, Dublin,pp 75–82
Rashid AM, Karypis G, Riedl J (2008) Learning pref-erences of new users in recommender systems:an information theoretic approach. SIGKDD ExplorNewsl 10:90–100
Resnick P, Iacovou N, Suchak M, Bergstrom P, RiedlJ (1994) Grouplens: an open architecture for collab-orative filtering of netnews. In: Proceedings ACMconference on computer-supported cooperative work,Chapel Hill, pp 175–186
Ricci F (2011) Mobile recommender systems. Int J InfTechnol Tour 12(3):205–231
Ricci F, Rokach L, Shapira B, Kantor PB (2011) Recom-mender systems handbook. Springer, New York
Rubens N, Kaplan D, Sugiyama M (2011) Active learn-ing in recommender systems. In: Ricci F, Rokach L,Shapira B, Kantor PB (eds) Recommender systemshandbook. Springer, New York, pp 735–767
Schwartz B (2004) The paradox of choice. ECCO,New York
Senot C, Kostadinov D, Bouzid M, Picault J, AghasaryanA, Bernier C (2010) Analysis of strategies for buildinggroup profiles. In: Proceedings of the user model-ing, adaptation, and personalization, 18th internationalconference, UMAP, Big Island, 20–24 June 2010.Springer, pp 40–51
Shani G, Heckerman D, Brafman RI (2005) An mdp-based recommender system. J Mach Learn Res6:1265–1295
Smyth B, McClave P (2001) Similarity vs diversity. In:Case-Based Reasoning Research and Development,Proceedings of the 4th International Conference onCase-Based Reasoning, ICCBR 2001, Vancouver, BC,Canada. Springer
Tintarev N, Masthoff J (2012) Evaluating the effectivenessof explanations for recommender systems – method-ological issues and empirical studies on the impactof personalization. User Model User Adapt Interact22(4–5):399–439
Vargas S, Castells P (2011) Rank and relevance in noveltyand diversity metrics for recommender systems. In:Proceedings of the 2011 ACM conference on rec-ommender systems, RecSys’11, Chicago, 23–27 Oct2011. ACM, pp 109–116
Recommender SystemsUsing SocialNetwork Analysis: Challenges andFuture Trends
Johann Stan1, Fabrice Muhlenbach2, andChristine Largeron2
1ISCOD - Institut Henri Fayol, Ecole NationaleSuperieure des Mines, Saint-Etienne, France2Laboratoire Hubert Curien, CNRS UMR 5516,Universite de Lyon, Universite Jean Monnet,Saint-Etienne, France
Synonyms
Collaborative filtering; Content-based filter-ing; Information filtering; Recommendationsystems
Glossary
Recommender System (RS) Special type of in-formation filtering system that provides a pre-diction that assists the user in evaluating itemsfrom a large collection that the user is likely tofind interesting or useful
Status Update (Micropost) Short message,shared in an online social platform, expressingan activity, state of mind, or opinion
Folksonomy Whole set of tags that constitutesan unstructured collaborative knowledgeclassification scheme in a social taggingsystem

Recommender Systems Using Social Network Analysis: Challenges and Future Trends 1523 R
R
Definition
Recommender systems (RSs) are software toolsand techniques dedicated to generate meaningfulsuggestions about new items (products and ser-vices) for particular customers (the users of theRS). These recommendations will help the usersto make decisions in multiple contexts, such aswhat items to buy, what music to listen to, whatonline news to read (Ricci et al. 2011), or, in thesocial network domain, which user to connect toor which user to consider as a trustful adviser.
Overview
Main Components of a Web 2.0 SocialNetworkA social network can be defined as a set of entitiesinterconnected, and it is usually represented as agraph where the entities are described by nodesand their relationships by links. It should benoticed that this concept is not limited to thecase of online social networks such as Facebook,LinkedIn, MySpace, or Twitter, the main focusof our work. A common characteristic of thesenetworks, and more specifically modern onlinesocial networks, is that they are composed of(i) users (with a user profile, activities, and con-nections) and (ii) social objects representing theintermediations, e.g., topics of user interactions,shared videos, and photos.
The user profile generally includes staticpersonal information, such as the name, e-mail,and address, as well as more dynamic informationabout the interests and information needs of theuser. The role of the user profile is essentialin online communities. Generally user profilesare different from one application to another, asusers present themselves differently, based onthe targeted population of the given application(which are sometimes very specific). Anotherdimension of users is represented by the activitiesthey perform in the social platform. This includescontent sharing, media uploading, and contentdescription (such as photo tagging). Finally, thethird dimension of users is represented by thesocial connections they establish with others in
the network. Users in these online networks aregenerally connected to different communities,belonging to different social spheres (e.g.,friends, family, coworkers).
Another important user characteristic is re-lated to trust. Indeed, the different applicationson social content sites allow users to be closerto their communities and to be aware of peeractivities and opinions. This brings new dimen-sions to trust and allows users to have higherconfidence in the recommendations, suggestions,and sentiments of friends.
Shared social objects influence interactionsbetween users. An object in this context hasa concrete and perceptible, physical and/ornumeric, manifestation. Some objects arethe source of conversational interactions andkeepers of collective attention. They constitutea conversation support. In our actual digitalcontext, objects are mainly multimedia ones asarticles (WordPress, Wikipedia), videos (Youtube,Dailymotion), pictures (Flickr, Picasa), orspecific status updates shared by users.
In such systems, users can employ differenttypes of annotations to describe social objects:structured annotations (in this case, the termsemployed in the annotation are regulated by acommon domain vocabulary that must be used bythe members of the system) and semi-structuredannotations (these annotation are generally freelyselected keywords without a vocabulary in thebackground, and a collection of these annotationsis called a folksonomy). The last category of suchannotations is unstructured, which is the mostfrequently used in social platforms, and therefore,we describe it in more detail.
This can be found in the majority of social net-works and microblogging systems and primarilyconsists of free texts in the form of short mes-sages describing a resource, a finding, an impres-sion, a feeling, a recent activity, a mood, or a fu-ture plan. A common practice is either to expressan opinion about the resource (e.g., web page) orto provide its short summary for the community.
The limitations of this kind of content sharingfrom the viewpoint of information retrieval andknowledge management are similar to that ofsocial tagging, as users have complete freedom

R 1524 Recommender Systems Using Social Network Analysis: Challenges and Future Trends
in the formulation of these messages. More con-cretely, it is difficult to extract interesting topicsor named entities from such messages, giventhe fact that there is an ambiguous, frequentlychanging underlying vocabulary.
Recommender Systems and SocialPlatforms: The Mutual BenefitsNowadays, the wide use of Internet around theworld allows a lot of people to connect. Thisexplosion of the Web 2.0 (blogs, wikis, con-tent sharing sites, social networks, etc.) givesrise to a growing need for RSs based on socialand information network mining methods. Forsuch systems, the underlying social structure,also called social network or virtual community,can be leveraged.
The substantial growth of the social webposes both challenges and new opportunities forresearch in RSs. The main reason for this is thefact that the social web transforms informationconsumers into active contributors, allowingthem to share their status, comment, or rate webcontent. Finding relevant and interesting contentat the right time and in the right context is chal-lenging for existing recommender approaches.
At the same time, the major added value of so-cial platforms is to encourage interaction betweenusers. Each interaction can be extracted and usedas an input for the RS, as it helps to betterunderstand the user interests and informationneeds. Also, the structure of the underlying socialnetwork in a social platform can contribute togenerate recommendations that are more trustedby users (e.g., by considering the social distancein the recommendation process, as generally wetrust more recommendations from closer connec-tions). Therefore, we can conclude that the socialweb provides a huge opportunity for improvingRSs (Fig. 1).
On the other hand, RSs can clearly help toimprove user participation in social systems, asthey can recommend new friends or interestingcontent. Thus, the user will be more motivated tokeep ongoing participation in the social platform,because the more content he/she shares, the morerelevant connections the system can recommend,having a precise profile about him/her.
Using this connection between social plat-forms and RSs, new scenarios can be definedfor advanced applications, such as people recom-mendation or various content recommendations(e.g., tags for photo annotation).
Introduction and State of the Art
Social Network AnalysisSocial network analysis and social mining canbe very useful in this context where RSs cantake benefit from social networks and conversely,where the formation and evolution of the networkcan be affected by the recommendations. In orderto illustrate this point, we can mention three well-known tasks in social network analysis and socialnetwork mining:• The first one is the identification of key
actors which play a particular role or whichhave a particular position in the network.Different indicators, such as the centrality orthe prestige, were initially introduced mainlyin order to highlight the “most important”actors in the network (Wasserman and Faust1994). With the appearance of online socialnetworking, these measures were recentlyrevisited to detect actors called, dependingon the authors, mediators, ambassadors,or experts. Among the actors who havereceived a lot of attention appears notablythe influencer who can be defined as an actorwho has the ability to influence the behavioror opinions of the other members in the socialnetwork (Anagnostopoulos et al. 2008). Theidentification of the influencers can be seenas an optimization problem better knownas “influence maximization” (or “spreadmaximization”) that is NP complete, butapproximated solutions can be determined,thanks to greedy algorithms like “Cost-Effective Lazy Forward” (CELF) algorithmor its extensions Newgreedy, Mixedgreedy, orCelf++ (Kempe et al. 2003; Domingos 2005).
• Another well-known problem in the contextof social networks is that of communitydetection. This problem has mainly beenstudied in the literature in the case where

Recommender Systems Using Social Network Analysis: Challenges and Future Trends 1525 R
R
Recommender Systems Using Social Network Analysis: Challenges and Future Trends, Fig. 1 Reciprocalcontributions made by recommender systems to social networks
the community structure is described by apartition of the network actors where eachactor belongs to one community (Schaeffer2007; Lancichinetti and Fortunato 2009), andamong the core methods, we can mentionthose that optimize a quality function toevaluate the goodness of a given partition, likethe modularity, the ratio cut, the min-max cut,or the normalized cut, and the hierarchicaltechniques like divisive algorithms basedon the minimum cut, spectral methods, orMarkov clustering algorithm and its exten-sions. However, in real networks, an actor canoften belong to several groups, and theseoverlapping communities can be detectedusing, for example, the clique percolationalgorithm implemented in CFinder or OSLOM(Order Statistics Local Optimization Method).Other recent works have attempted to detectcommunities, taking into account the profileof the users and their relationships (Combeet al. 2012). These methods can be appliedto determine groups of users with similarcharacteristics or the same interests, andconsequently, they can be integrated inneighborhood-based collaborative systems.
• The evolution of the network is anotherchallenge. Indeed, in many networks, thestructure of the network, in other wordsthe actors as well as their relationships,changes quickly over time. The identificationof evolving communities or their detectionover time is also a subject of recent researchwhich can be integrated in systems to improverecommendations, but the dynamic analysisof the network is also related to the linkprediction problem which aims to determinethe appearance of new links or the deletion oflinks in the network (Namata and Getoor2010; Liben-Nowell and Kleinberg 2007;Getoor 2010; Hasan and Zaki 2011). It isobvious that link prediction can be usefulfor people recommendation, and, conversely,recommendation approaches can allow topredict the evolution of the network. Thistemporal dimension is notably important inthe context of mobile applications in whichmoving actors are interacting with each other.
Recommender SystemsThe field of social network analysis is a complexand rapidly changing area. To understand the

R 1526 Recommender Systems Using Social Network Analysis: Challenges and Future Trends
mutual contributions of social networks in recom-mender systems (and vice versa), it is necessaryto clarify the basic principles of these systems.
RSs are dedicated to the help of the userswhen they must make a decision, taking as basisthe fact that in ordinary life, people often makedecisions based on the recommendation of others.At work, employers count on recommendationletters when they want to recruit new employees;with friends, we talk about books that we lovedto read, music or movies that we liked, purchasesthat have given us satisfaction, or products thatdisappointed us; and more generally, we trustreviews of specialists before seeing a TV show, anart exhibit, or purchasing an item. This behavioris based both on the belief that our friends havesimilar tastes to ours and on the trust that we canprovide to the expert opinion. The recommenda-tions provided by automated systems are tryingto mimic those two principles, depending on theavailable information, and they are supplied to theusers in the form of a prediction or a list of items.
The information used for the recommendationprocess can be extracted from the content avail-able from the users and the items, or it can beinferred from the explicit ratings when the usersare asked to rate the items. Depending on theway of how the information is used, the RS isconsidered to be a content based, a collaborativefiltering, or a hybrid (where both information,collaborative and content based, are used) RS(Adomavicius and Tuzhilin 2005).
Whatever approach is used, the key elementsof an RS are (i) the users, (ii) the items, and (iii)the transactions. The users of an RS, which mayhave very diverse goals and characteristics, areboth those who benefit from the system andthose who supply it with information. Itemsare the objects (products or services) that arerecommended, and they may be characterizedby their complexity and their value or utilityfor a given user. Transactions are the recordedinteractions between a user and the RS, especiallythe relation between a user and a given item,which can be an explicit feedback, e.g., the ratingof a user for a selected item.
In the content-based approach, which has itsroots in information retrieval and information
filtering research, an item is recommended to auser based upon a description of the item and aprofile of the user interests (Ricci et al. 2011).This family of RSs has some advantages (userindependence, transparency, easy recommenda-tion of new items) but also some drawbacks:content analysis is limited and the system suffersfrom overspecialization that leads to homophily(a person is only recommended by people whothink like he or she).
In the collaborative filtering approach, an itemis recommended to a given user by followinganother way: the collaborative filtering methodsproduce user-specific recommendations of itemsbased on patterns of ratings without the needfor exogenous information about either items orusers (Ricci et al. 2011). The preferences of theusers are explicit: the users are asked to rate theitems (e.g., in terms of l–5 star scale or “I like”/“I don’t like”). This approach needs only a setof ratings of users on sets of items: a list of n
users, a list of m items, and a rating rx;t thatindicates the rating of user x on the item t . Ina typical collaborative filtering scenario, it is veryrare (if not impractical) for a user x to rate all them items, so the R matrix of all ratings users �items is sparse. To result in recommendation, thecollaborative filtering can be either neighborhoodbased (memory based) or model based (Melvilleand Sindhwani 2010; Ricci et al. 2011). Themodel-based approaches try to propose a modelable to predict the unknown rating of a userx for an item t by discovering the underlyingpreference class of users and the category classof the items. In neighborhood-based collaborativefiltering, the rating matrix R is directly used topredict ratings for new items, either when theneighborhood derives from a similarity betweenthe users (for user-based systems) or when theneighborhood derives from a similarity betweenthe items (for item-based systems); e.g., twoitems are considered as neighbors if several usershave rated these items in a similar way. In mostcases, the similarity estimated between users oritems in these approaches is Pearson correlationor vector cosine-based similarity.
The efficiency of an RS is measured in termsof relevance of the recommendations and forecast

Recommender Systems Using Social Network Analysis: Challenges and Future Trends 1527 R
R
accuracy, in particular seeking to narrow thedifference between the predicted ratings made bythe system and the real ratings made by the users.Moreover, the system has to be a good filteringsystem and not present to users uninterestingitems while not missing interesting items (e.g.,in the case of commercial RS, for increasing thenumber of items sold). It is important to proposeto the users items that might be hard to find with-out a precise recommendation. Many systemssuffer from novelty discovery, i.e., they fail tofind serendipitous items. All these properties willincrease the user satisfaction and the fidelity tothe use of the system.
The latest trends in RS domain seek to takeinto account how human beings function withtheir peers, especially in their interpersonalbehaviors, which brings it closer to the fieldof social network analysis. Some users try tofind credible recommenders so they can followthem; it is thus interesting to investigate themost influential members. It is also important todevelop a method to better understand each userof the system and improve the understandingof their profiles, to identify what they like anddislike or are expecting from the system. TheRS must seek to enable individual mechanismsthat users can work together, because some userslike to contribute to the system with their ratingsand express their opinions and beliefs or can behappy to help the others by contributing withinformation. However, it should be cautious asthere are malicious users who seek to influenceothers in the system just to promote or penalizecertain items. A detailed overview of theseproperties is presented in the different chapters ofthe collective book edited by Ricci et al. (2011).
Social Search SystemsFrameworks that specifically target recommen-dation services based on user profiles are mostlyin the category of people recommendationand question answering systems. Such systemsexplore either the topology of the network or thecontent of the exchanges between communitiesand peers. The main difference to content-basedsocial search is the fact that the result of arecommendation is not a document, but another
user or group of users. In this way, the personcan interact directly with the recommendeduser, which provides a more secure and trustedenvironment for the communication process.Also, such people-to-people interactions aremore interesting for the service provider, asthey can contribute to the growth of the socialplatform, which is generally measured by thenumber of users and connections between them.
Guy et al. (2009) present a people recom-mendation strategy specially adapted for theenterprise ecosystem. The recommendationengine uses information from an organizationIntranet for computing similarity scores betweenemployees. Such information include (i) paper orpatent coauthorship, (ii) commenting of each oth-ers’ blogs or profiles, and (iii) mutual connectionin other social networks, internal to the organiza-tion. Based on an aggregated score computed foreach relationship, people are recommended to beadded in an employee internal messenger system.For each recommendation, an explanation isgenerated, considered an important component ofsuch systems (Herlocker et al. 2000). A limitationof this approach can be considered the factthat the recommendation only uses statisticalinformation to infer the social proximity betweenusers. More concretely, the content of interactionsand exchanges is not taken into account tomeasure the similarity of interests or informationneeds. We also mention here the fact that mostpeople recommendation strategies in popularsocial networks, such as Facebook or Orkut, arealso based on this statistical similarity schema.
Lin et al. (2009) also target the issue of exper-tise location in the enterprise environment. Theproposed system, SmallBlue (Lin et al. 2009),similarly to Guy et al. (2009), employs datamining and statistical data analysis techniques toextract profile information for employees. Morespecifically, the system uses company e-mail asa source of information. Keywords are extractedfrom each e-mail, and a bag-of-words-based pro-file is constructed for employees. An innovativefeature of the system is the social explanationof people recommendations, by displaying thesocial path that connects the user to the recom-mended person on a specific topic.

R 1528 Recommender Systems Using Social Network Analysis: Challenges and Future Trends
Hannon et al. (2010) go beyond the previ-ous approach and build a recommendation strat-egy using the content of interactions (e.g., statusupdates) as input. Designed for recommendingpeople to follow in Twitter, the Twittomendersystem allows users to expand their network byconnecting to people that they do not know di-rectly, but with whom they share similar interests.Each user in the system is represented by a vector,comprised of terms extracted from their sharedmessages. A kind of social expansion of thisbasic profile is performed, by taking into accountmessages shared by people connected to the user.This is based on the observation that connectedpeople share close interest. The computation ofprofile similarities is achieved by the traditionaltf-idf weighting schema in information retrievaland cosine similarity. The Twittomender systemis original and different from existing collabora-tive filtering approaches, as it takes into accountthe structure of the underlying social network tobetter approximate the interests of the user. It ishowever a considerable limitation in the systemthat no disambiguation or semantic expansionof profile terms is considered. More concretely,the user profile is composed of keywords thatmight have multiple meanings, and this couldbe a considerable drawback for the relevance ofrecommendations.
A new generation of social search engines isrepresented by the so-called question answeringsystems. The main difference to the previousapproaches is the fact that in this case, the systembuilds a user profile from some kind of useractivity (content production or consumption) anduses it to match them with a question formulatedby another user.
Aardvark (Horowitz and Kamvar 2010) iscertainly the most promising social searchengine. Aardvark introduced several innovationsin the field of social search. First of all, it is thefirst system that models the users based on theirgenerated content. For this reason, users providetopics of interest to the system when theysubscribe. Then, a crawler extracts further topicsfrom the user’s profiles and status updates insocial platforms to expand the initially enteredprofile items. The extraction of topics from social
updates is achieved by linear classifiers, suchas support vector machines and probabilisticclassifiers. Aardvark is not built on top of existingsocial platforms and lacks a global approach forconceptualizing user profiles.
In another recent social search engine, CQA(Li and King 2010), the objective is similar to thatof Aardvark: route a question to the right personin a community of answerers. In their paper, Liand King (2010) introduce two important dimen-sions for such systems: (i) the consideration ofthe answerer availability and (ii) the question ofthe quality of answers. The quality of answersis estimated by taking into account statisticalinformation about the length of the answer, thetime the user took to send it, and the feedbackof other users. In the case of availability, thesystem monitors the user log-ins and performs aprediction of whether the user will be available ata specific time and date in the future.
We can finally conclude that in current socialsearch systems that offer a people recommen-dation service, the issue of recommendationexplanation is still not well tackled (which isalso strongly related to privacy management).Also, few frameworks benefit from semantic webtechnologies on a data storage or data enrichmentlevel.
Another possibility to build an RS is to lever-age the content shared by users in the socialnetwork. More specifically, we consider the con-tent productions of users in order to better un-derstand their interests and information needsand more concretely build expertise profiles. Insuch way, the recommender engine is able torecommend people that have similar or comple-mentary interests. From a conceptual viewpoint,such a recommender engine is composed of twoparts: (i) the identification of semantic data (e.g.,entities extracted from status updates) that willcompose the profile and (ii) the scoring of the saidsemantic data (measuring the user expertise).
We consider X the domain of all n usersinvolved in the social platform. Tx represents theset of items correlated with user x, i.e., Tx Dt jWeight.t; x/ > 0. Therefore, user x and item t
are correlated when Weight.t; x/ > 0, Weightbeing the weight of the item in the profile.

Recommender Systems Using Social Network Analysis: Challenges and Future Trends 1529 R
R
An item in the user profile can be repre-sented by a keyword or a concept. The maindifference is that concepts have URIs that pro-vide them the exact semantic meaning. Generally,such URIs can be retrieved from the so-called se-mantic knowledge graphs, such as DBpedia. Eachprofile item is an entity (keyword, named entity)extracted from at least one content production ofthe user and connected to at least one semanticconcept present in at least one semantic knowl-edge base. The main arguments for this choice isthat this kind of representation is richer and lessambiguous than a keyword-based or item-basedmodel. It provides an adequate grounding forthe representation of coarse- to fine-grained userinterests. A semantic knowledge base providesfurther formal, computer-processable meaning onthe concepts (who is coaching a team, an actorfilmography, financial data on a stock) and makesit available for the system to take advantageof knowledge base-originated semantic conceptsthat are more precise and reduce the effect of theambiguity caused by simple keyword terms.
Normally in a conversation, we depend essen-tially on the context of the conversation to disam-biguate a word. Similarly, in order to associatekeywords or entities in a social update to theright concept in linked data, contextual cues arenecessary to allow restricting the semantic fieldof the social update. In traditional documents,generally there are sufficient contextual cues toovercome such ambiguous situations, where themeaning of a term is not straightforward.
In the case of social platforms, the short natureof posts requires to find these cues elsewhere, sowe may consider two main additional sources ofcontextual cues:• The first contextual cue is user related, which
consists in building incrementally a vocabu-lary from all social updates of the user. Theassumption behind this first additional contextis that there is a probability that the userpreviously shared some content in a relatedsemantic field (e.g., a user who posted about“Apple” might have shared before about otherApple products, such as the “iPhone”).
• The second additional contextual cue iscommunity related. On social platforms,
users are members of different communities,which influence each other in terms ofinterests. Users participate in a group ora community because they are interestedin what community members say, and asa consequence of this participation, usershave the intention of using commonly knownkeywords to make his/her contents easilyunderstandable by the community. Thissecond contextual cue is used only if theuser-related one is not yet available or notsufficiently rich (e.g., user has shared fewmessages but has lots of friend connections).More specifically, it is a solution for theso-called cold-start situation and consistsof aggregating the most recent messages offriends connected to the user and constructinga vocabulary from the content of thesemessages.
After the construction of the vector containingalso such items that represent the context of thekeyword, several similarity measures can be usedto compare it with the description of candidateconcepts in the knowledge base and the bestmatching concept selected. A further, optionalstep is to leverage the semantic neighborhood ofthe concept to better describe the user expertise(e.g., include more general concept into the pro-file). This could be interesting in case of profileextracted from status updates, as such messagesare short, and therefore, we have little availableinformation about the user information needs orinterests.
Future Directions/Open Questions
As seen in the previous section, over the lasttwo decades, some major advances have beenachieved in the area of RSs using techniques ofsocial network analysis and mining.
In this section, we present some current chal-lenges and open questions, that we think, will bea major preoccupation for scientific communitiesbut also the industry in the upcoming years. Wewill consider two practical future directions andlist the corresponding open challenges that needto be considered.

R 1530 Recommender Systems Using Social Network Analysis: Challenges and Future Trends
Recommender Systems in the EnterpriseNowadays, more and more companies showincreasing interest towards the integrationof RSs in the Intranet in order to furtherimprove communications and internal knowledgemanagement. Several reasons push companies toinvest in such infrastructures:• It can improve social interactions between
employees (e.g., a people recommender in theenterprise may help in finding the best expertfor a specific problem (Joly et al. 2010), whichmay reduce costs and increase efficiency).
• It can provide new means for the dynamiccomposition of teams for a specific project,as the expertise of employees can be easilyretrieved. Also, internal documents and videoscan be recommended for a project or learning.
• Such a system may provide specific toolsfor employees in order to keep motivationand a good atmosphere in the company, e.g.,associating specific tags to colleagues, suchas expertise tags and specific badges, whenbeing an active contributor in providing helpto colleagues or other scenarios.
• With such a system, an implicit internal socialnetwork can be built that links employees withsimilar interests and activities. This can helpthe company in improving its organization andalso optimize human resources management(changing dynamically teams, finding the bestinternal resources for a new project, etc.).The deployment of an RS in a company faces
several challenges, and its design depends onseveral criteria, such as the type of activity thecompany performs or the degree of sensibility ofthe information they share. A first challenge, butalso the most important, is what kind of internalcontent to use as input for the RS. Companye-mails are a rich source for learning more abouteach employee’s expertise and interests, but theymay have privacy and security concerns. Another,more acceptable source for such an RS maybe represented by content shared by employeeson internal or web-based social networks, suchas Twitter (Stan et al. 2011) or Yammer. Suchcontent is shorter and generally does not con-tain confidential information. Furthermore, the
content of web pages employees read may alsorepresent and additional source for such systemsfor the construction of the expertise profiles (Jolyet al. 2010).
Among the challenges for building such asystem, the most important are technical andrelated to human-computer interaction (HCI).More concretely, technical challenges include theimplementation of content extraction tools frominternal mail servers, microblogging platforms,and web browsers. All the extracted content mustbe aggregated and stored in a secure database.Challenges related to HCI include the design ofuser interfaces that allow users to control whatcontent to share with the system (e.g., there maybe e-mails for private usage).
An important issue when designing RSs is togenerate an explanation for each recommenda-tion. Such explanations could be useful as theyincrease trust. They can be of several types: (i)the explanation of the social path between the twousers, i.e., by showing part of the social graphand the paths in the employee social network thatconnect them or (ii) a semantic explanation thatincludes areas of expertise of the recommendedemployee. According to the social distance, suchareas of expertise may be shown with differentlevels of granularity, by using hierarchical pathsof concepts in semantic knowledge bases, such asDBpedia (e.g., expert in Twitter is more specificthan expert in microblogging platforms).
In a nutshell, the following questions shouldbe considered for building a successful RS specif-ically targeted to an enterprise:• How to extract the named entities from short,
unstructured messages and status updates andin other words, how to transform each socialinteraction that occurs in the company or thatemployees share into useful knowledge for theRS.
• How to combine structural and semantic anal-ysis for recommendation ranking.
• What are the next generation privacy protec-tion mechanisms that would allow an easyadoption of such a system in a company?
• How to generate useful and meaningful expla-nations for a recommendation.

Recommender Systems Using Social Network Analysis: Challenges and Future Trends 1531 R
R
• How to make good recommendations withoutviolating privacy concerns.The use of such RSs in an enterprise may be
useful also for generating a profile for the entirecompany, e.g., by aggregating all individual userprofiles. Such a profile may be useful for thenext generation enterprise social networks, whereeach node in the network is a company. Sucha network could facilitate collaboration betweencompanies, e.g., by finding the best company fora collaborative European project.
Recommendation inMobile SocialNetworks: A Multi-agent ApproachA second scenario for RSs concerns mobilityand ubiquity, as more and more users havesmartphones, capable of sensing context. Themost widely used context in such a scenariois the user location, which may significantlyimprove recommendation (other context datamay include available networks (Wifi, Bluetooth)or other physical data). By integrating locationin an RS, a preliminary filtering of items can beperformed, by selecting only a subset that is in awell-defined perimeter. Such items may includeother users with similar interests (e.g., lookingfor people who like similar artists in a givenlocation), as well as restaurants, cinema, or otherservices the city provides. The deployment ofsuch an RS faces several challenges, dependingon its design. A first important design principlewhich needs to be fixed early is whetherthe system is centralized or decentralized.Clearly, a centralized system would faceimportant performance and scalability issues.A decentralized system is more interesting,as a local server can be associated to eachlocation in the city, which could support thisrecommendation service.
A further step towards decentralizationcan be considered, by integrating multi-agentprinciples to the RS, i.e., to design andimplement a customizable approach wheredifferent autonomous decision-making entities(agents) have to communicate, exchangeknowledge, and cooperate in order to achieveindividual and/or collective objectives. It allows
the creation of different communities, withdifferent possible functions and modes ofexchanges. Such an approach aims to meetseveral challenges, such as decentralization of thecommunity management, personalized automaticmanagement and discovery of communities,and flexibility so that any agent can create itsown community. In addition, it should coverall levels of abstractions (agent, environment,and organization) that are required for thedevelopment of sophisticated multi-agentsystem. In this design, each smartphone isequipped with an agent, capable of exchangingknowledge with other agents, using the localserver associated to a given location in thecity.
Using a multi-agent approach for an RS inmobility, agents can act as a personal assistanton the behalf of each user, present in a givenlocation. The agent perceives knowledge from thecommunities of individual interests and acts uponthe communities to meet their goals. Thus, agentscan bring the appropriate people having commongoals or interests together share their knowledgewith each other at ease.
Other scientific challenges for such advancedRSs include the traditional cold-start problem,i.e., how to provide recommendations to userswith little information about their profile orhow to recommend items with few ratings. Also,an important general challenge is how to makerecommendation users trust, i.e., how to provideusers an easy way for giving feedback onrecommendations. With regard to trust, recentworks try to integrate the notion of distrust, i.e.,how to deal with users or items that cannot betrusted.
Cross-References
�Centrality Measures�Combining Link and Content for CommunityDetection�Recommender Systems�Research Designs for Social Network Analysis�Social Recommendation in Dynamic Networks

R 1532 Reconnaissance
References
Adomavicius G, Tuzhilin A (2005) Toward the next gen-eration of recommender systems: a survey of the state-of-the-art and possible extensions. IEEE Trans KnowlData Eng 17(6):734–749
Anagnostopoulos A, Kumar R, Mahdian M (2008) In-fluence and correlation in social networks. In: Li Y,Liu B, Sarawagi S (eds) Proceedings of the 14th ACMSIGKDD international conference on knowledge dis-covery and data mining, Las Vegas, 24–27 Aug 2008.ACM, pp 7–15
Combe D, Largeron C, Egyed-Zsigmond E, Gery M,Getting Clusters from Structure Data and AttributeData, 2012 IEEE/ACM International Conference onAdvances in Social Networks Analysis and Mining,pp. 710–712, 2012 International Conference onAdvances in Social Networks Analysis and Mining(ASONAM 2012), 2012
Domingos P (2005) Mining social networks for viralmarketing. IEEE Intell Syst 20(1):80–82
Getoor L (2010) Link mining and link discovery. In:Sammut C, Webb GI (eds) Encyclopedia of machinelearning. Springer, New York/London, pp 606–609
Guy I, Ronen I, Wilcox E (2009) Do you know?: rec-ommending people to invite into your social network.In: Conati C, Bauer M, Oliver N, Weld DS (eds)Proceedings of the 2009 international conference onintelligent user interfaces (IUI), Sanibel Island, 8–11Feb 2009. ACM, pp 77–86
Hannon J, Bennett M, Smyth B (2010) Recommend-ing twitter users to follow using content and col-laborative filtering approaches. In: Amatriain X, Tor-rens M, Resnick P, Zanker M (eds) Proceedings ofthe 2010 ACM conference on recommender systems,RecSys 2010, Barcelona, 26–30 Sept 2010. ACM,pp 199–206
Hasan MA, Zaki MJ (2011) A survey of link prediction insocial networks. In: Aggarwal CC (ed) Social networkdata analytics. Springer, New York, pp 243–275
Herlocker JL, Konstan JA, Riedl J (2000) Explaining col-laborative filtering recommendations. In: Proceedingsof the 2000 ACM conference on computer supportedcooperative work, CSCW’00, Philadelphia. ACM,New York, pp 241–250
Horowitz D, Kamvar SD (2010) The anatomy of alarge-scale social search engine. In: Rappa M, JonesP, Freire J, Chakrabarti S (eds) Proceedings ofthe 19th international conference on World WideWeb, WWW 2010, Raleigh, 26–30 Apr 2010. ACM,pp 431–440
Joly A, Maret P, Daigremont J (2010) Contextual rec-ommendation of social updates, a tag-based frame-work. In: An A, Lingras P, Petty S, Huang R (eds)Proceedings of the 6th international conferenceon active media technology, AMT 2010, Toronto,28–30 Aug 2010. Lecture notes in computer science,vol 6335. Springer, pp 436–447
Kempe D, Kleinberg JM, Tardos E (2003) Maximizingthe spread of influence through a social network.In: Getoor L, Senator TE, Domingos P, Faloutsos C(eds) Proceedings of the 9th ACM SIGKDD interna-tional conference on knowledge discovery and datamining, Washington, DC, 24–27 Aug 2003. ACM,pp 137–146
Lancichinetti A, Fortunato S (2009) Community detec-tion algorithms: a comparative analysis. Phys Rev E80(5):056117
Li B, King I (2010) Routing questions to appropriateanswerers in community question answering services.In: Huang J, Koudas N, Jones GJF, Wu X, Collins-Thompson K, An A (eds) Proceedings of the 19thACM conference on information and knowledge man-agement, CIKM 2010, Toronto, 26–30 Oct 2010.ACM, pp 1585–1588
Liben-Nowell D, Kleinberg J (2007) The link-predictionproblem for social networks. J Am Soc Inf Sci Technol58(7):1019–1031
Lin CY, Cao N, Liu S, Papadimitriou S, Sun J, Yan X(2009) Smallblue: social network analysis for exper-tise search and collective intelligence. In: IoannidisYE, Lee DL, Ng RT (eds) Proceedings of the 25thinternational conference on data engineering, ICDE2009, Shanghai, 29 Mar 2009–2 Apr 2009. IEEE,pp 1483–1486
Melville P, Sindhwani V (2010) Recommender systems.In: Sammut C, Webb GI (eds) Encyclopedia of ma-chine learning. Springer, New York/London, pp 829–838
Namata G, Getoor L (2010) Link prediction. In: Sam-mut C, Webb GI (eds) Encyclopedia of machine learn-ing. Springer, New York/London, pp 609–612
Ricci F, Rokach L, Shapira B, Kantor PB (eds) (2011)Recommender systems handbook. Springer, NewYork/London
Schaeffer SE (2007) Graph clustering. Comput Sci Rev1(1):27–64
Stan J, Do VH, Maret P (2011) Semantic user interac-tion profiles for better people recommendation. In:International conference on advances in social net-works analysis and mining, ASONAM 2011, Kaoh-siung, 25–27 July 2011. IEEE Computer Society,pp 434–437
Wasserman S, Faust K (1994) Social network analysis:methods and applications. In: Structural analysis inthe social sciences, vol 8, 4th edn. Cambridge Univer-sity Press, New York, http://www.cambridge.org/gb/knowledge/isbn/item1138907/?site locale=en GB
Reconnaissance
�Reconnaissance and Social Engineering Risksas Effects of Social Networking

Reconnaissance and Social Engineering Risks as Effects of Social Networking 1533 R
R
Reconnaissance and SocialEngineering Risks as Effects of SocialNetworking
Katina MichaelSchool of Information Systems and Technology,University of Wollongong, Wollongong, NSW,Australia
Synonyms
Footprinting; Hacker; Penetration testing;Reconnaissance; Risk; Security; Self-disclosure;Social engineering; Social media; Socialreconnaissance; Vulnerabilities
Glossary
Social Reconnaissance A preliminary paper-based or electronic web-based survey togain personal information about a memberor group in your community of interest. Themember may be an individual friend or foe, acorporation, or the government
Social Engineering With respect to security, isthe art of the manipulation of people whilepurporting to be someone other than your trueself, thus duping them into performing actionsor providing secret information
Data Leakage The deliberate or accidental out-flow of private data from the corporation to theoutside world, in a physical or virtual form
Online Social Networking An online social net-work is a site that allows for the buildingof social networks among people who sharecommon interests
Malware The generic term for software that hasa malicious purpose. Can take the form of avirus, worm, Trojan horse, and spyware
Lead
. . . not what goes into the mouth defiles a man, butwhat comes out of the mouth, this defiles a man.”
Matthew 15:11 (RSV)
Introduction
For decades we have been concerned with howto stop viruses and worms from penetrating orga-nizations and how to keep hackers out of organi-zations by luring them toward unsuspecting hon-eypots. In the mid-1990s Kevin Mitnick’s “dark-side” hacking demonstrated, and possibly evenglamorized (Mitnick and Simon 2002), the needfor organizations to invest in security equipmentlike intrusion detection systems and firewalls, atevery level from perimeter to internal demilita-rized zones (Mitnick and Simon 2005).
In the late 1990s, there was a wave of securityattacks which stifled worker productivity. Duringthese unexpected outages, employees would takelong breaks queuing at the coffee machine, spendtime cleaning their desk, and try to look busyshuffling paper in their in- and out-trays. It wasclear by the downtime caused by malware hittingservers worldwide that corporations had begunto rely on intranets for content and workflowmanagement so much and that employees wouldbe left with very little to do when they werenot connected. Nowadays, everything is onlinewith respect to the service industry, and there isa known vulnerability in the requirement to bealways connected. For example, you can cripplean organization if you take away their abilityto accept electronic payments online, or rendertheir content management system inaccessibledue to denial of service attacks, or hack into acompany’s webpage.
When the “Melissa” virus caught employeesunaware in 1999, and was then followed by the“Explorer.zip” worm in the same year, publicfolders had Microsoft Office files either deletedor corrupted. At the time, anecdotal stories in-dicated that some people (even whole groups)lost several weeks of work, after falling victimto the worm that had attacked their hard drive.This led many to seek backup copies of their files,only to find that the backups themselves were notactivated (Michael 2003).
The moral of the story is that for decadeswe have been preoccupied with stopping data(executables, spam, false log-in attempts, and thelike) from entering the organization when the real

R 1534 Reconnaissance and Social Engineering Risks as Effects of Social Networking
problem since the rise of broadband networks,3G wireless, and more recently social media hasbeen how to stop data from going out of theorganization. While this sounds paradoxical, themajor concern is not what data traffic comesinto an organization, but what goes out of anorganization that matters. We have become ourown worst enemy when it comes to security inthis online-everything world we live in.
In short, data leakage is responsible for mostcorporate damage, such as the loss of competitiveinformation. You can secure a bucket and makeit water tight, put a lid on it, even put a lockon the lid, but if that bucket has even a singletiny hole, its contents will leak out and causespillage. Such is the dilemma of informationsecurity today – while we have become moreaware of how to block out unwanted data, thegreatest risk to our organization is that whichleaves the organization – through the network,through storage devices, and via an employees’online personal blog, even the spoken word. Itis indeed what most security experts call the“human” factor (Michael 2008).
Reconnaissance of Social Networksfor Social Engineering
Social NetworkingThe Millennials, also known as Gen Ys, havebeen the subject of great discussion by commen-tators. If we are to believe what researchers sayabout Gen Ys, then it is this generation that hasvoluntarily gone public with private data. Thisgeneration, propelled by advancements in broad-band wireless, 3G mobiles, and cloud computing,is always connected and always sharing theirsentiments and cannot get enough of the newapps. They are allegedly “transparent” with mostof their data exchanges. Generally, Gen Ys do notthink deeply about where the information theypublish is stored, and they are focused on conve-nience solutions that benefit them with the leastamount of rework required. They tend not to liketo use products like Microsoft Office and wouldrather work on Google Drive using Google Docs
collaboratively with their peers. They are lessconcerned with who owns information and moreconcerned with accessibility and collaboration.
Gen Ys are characterized with creating cir-cles of friends online, doing everything digitallythey possibly can, and blogging to their heart’scontent. In fact, Google has recently released astudy that has found that 80 % of Gen Ys makeup a new generation dubbed “Gen C.” Gen Csare known as the YouTube generation and arefocused on “creation, curation, connection, andcommunity” (Google 2012). It is generally em-braced in the literature that this is the generationthat would rather use their personally purchasedtools, devices, and equipment for work purposesbecause of the ease of carrying their “life” and“work” with them everywhere they go and theease of melding their personal hobbies, interests,and professional skillsets with their workplaceseamlessly (PWC 2012). Bring your own de-vice (BYOD) is a movement that has emergedfrom this type of mind-set. It all has to do withcustomization and personalization, with workingwith settings that have been defined by the userand with lifelogging in a very audiovisual way.Above all the mantra of this generation is Open-Everything. The claim made by Gen Cs is thattransparency is a great force to be reckoned withwhen it comes to accessibility. Gen Cs allegedlydefine their social network and are what theyshare, like, blog, and retweet. This is not withoutrisk, despite that some criminologists have playeddown the fear as related to privacy and securityconcerns (David 2008).
Despite that online commentators regularlylike to place us all into categories based onour age, most people we’ve spoken to throughour research do not feel like any particular“generation.” Individuals like to think they aresmart enough to exploit the technologies forwhat they need to achieve. People may generallychoose not to embrace social networking forblogging purposes, for instance, but might seehow the application can be put to good usewithin an institutional setting and educationalframework. For this reason they might beheavy users of social networking applications

Reconnaissance and Social Engineering Risks as Effects of Social Networking 1535 R
R
like LinkedIn, Twitter, Facebook, and GoogleLatitude but also understand its shortcomingsand the potential implications of providing a realname, gender, and date of birth, as well as otherpersonal particulars like geotagged photos or livestreaming.
This ability to gather and interpret cyber-physical data about individuals and theirbehaviors has a double-edged spur when relatedback to a place of work. On the one hand, wehave data about someone’s personal encountersthat can be placed in a context back to a placeof employment (Dijst 2009). For instance, asocial networking update might read: “In themorning, I met with Katina Michael, we spokeabout putting a collaborative grant together onlocation-based tracking, and then I went andmet Microsoft Research Labs to see if theywere interested in working with us, and hadlunch with [email protected] (Cperson)(#microsoft) who is a senior software engineer.”This information is pretty innocent on its ownbut there are a lot of details in there that mightbe used for gathering information: (1) a realname, (2) a real e-mail address, (3) an identifiableposition in an organization, (4) potentially linksto an extended social network, and (5) possiblyeven a real physical location of where the meetingtook place if the individual had a location-tracking feature switched on their mobile socialnetwork app. The underlying point here is thatyou might have nothing to fear by bloggingor participating on social networks under yourcompany identity, but your organization mighthave much to lose.
Social ReconnaissanceDespite that many of us don’t wish to admitit, we have from time to time conducted socialreconnaissance online for any number of reasons.In the most basic of cases, you might be visitinga location you have not previously been to andyou use Google Street View to take a quick lookat what the dwelling looks like for identificationpurposes. You might also browse the web withyour own name, dubbed “ego surfing,” to seehow you have been cited, quoted, and tagged in
images or generally what other people are sayingabout you. But businesses also are increasinglykeeping their eye out on what is being said abouttheir brand using automatic web alerts based onhashtags, to the extent that new schemes offeringinsurance for business reputation have begun toemerge. Now, my point here is not whether or notyou conduct social reconnaissance on yourself, oryour family, or your best friend, or even strangersthat look enticing, but on what hackers out theremight learn about you and your life and yourorganization by conducting both social and tech-nical reconnaissance. Yes, indeed, if you didn’tknow it already, there are people out there thatwill (1) spend all their work time looking up whatyou do (depending on who you are), (2) thinkabout how that information they have gatheredcan be related back to your place of work, and (3)exploit that knowledge to conduct clever socialengineering attacks (Hadnagy 2011).
Chris Hadnagy, founder of social-engineer.com, was recently quoted as saying: “[i]nfor-mation gathering is the most important part ofany engagement. I suggest spending over 50percent of the time on information gathering: : :
Quality information and valid names, e-mails,phone number makes the engagement have ahigher chance of success. Sometimes duringinformation gathering you can uncover serioussecurity flaws without even having to test, testingthen confirms them” (Goodchild 2012).
It is for this reason that social engineers willfocus on the company website, for instance, andbuild their attack plan off that. Dave Kennedy,CSO of Diebold, complements this idea byfirsthand experience: “[a] lot of times, browsingthrough the company website, looking throughLinkedIn are valuable ways to understand thecompany and its structure. We’ll also pull downPDF’s, Word documents, Excel spread sheets andothers from the website and extract the metadatawhich usually tells us which version of Adobe orWord they were using and operating system thatwas used” (Goodchild 2012).
Most of us know of people who do not wishto be photographed and who have painstakinglyattempted to un-tag themselves from a variety

R 1536 Reconnaissance and Social Engineering Risks as Effects of Social Networking
of images on social networks, who have triedto delete their online presence and be judgedbefore an interview panel for the person they aretoday, not the person they were when MySpaceor Facebook first came out. But what about theseparate group of people who do not acknowl-edge that there is a fence between their work lifeand home life, accept personal e-mails on a workaccount, and then are vocal about everything thathappens to them on a moment-by-moment basiswith a disclaimer that reads: “anything you readon this page is my own personal opinion and notthat of the organization I work for.” Some wouldsay these individuals are terribly naıve and areprobably not acting in accord with organizationalpolicies. The disclaimer won’t help the companynor will it help them. Ethical hackers, who havebuilt large empires around their tricks of the tradesince the onset of social networking, have spentthe last few years trying to educate us all – “dataleakage is your biggest problem folks” not thefact that you have weak perimeters! You are, inother words, your own worst enemy because youdivulge more than you can afford to, to the onlineworld.
No one is discounting that there are clearbenefits in making tacit knowledge explicit byrecording it in one form or another, or openlysharing our research data in a way that is con-ducive to ethical practices, and making thingsmore interoperable than what they are today – butthe world keeps moving so fast that for the greaterpart people are becoming complacent with howthey store their datasets and the repercussions oftheir actions. But the repercussions do exist, andthey are real.
Social EngineeringExpert social engineers have never relied on verysophisticated ways of penetrating security sys-tems. It is worth paying a visit to the social engi-neering toolkit (SET) at www.social-engineer.orgwhere you might learn a great deal about ethicalhacking (Palmer 2001) and pentesting (Social-Engineer.Org 2012). Here social engineeringtools are categorized as physical (e.g., cameras,GPS trackers, pen recorders, and radio-frequency
bug kits), computer based (e.g., common userpassword profilers), and phone based (e.g., callerID spoofing). In phase 1 of their premeditatedattacks, social engineers are merely engaged inthe practice of observation of the informationwe each put up for grabs willingly. And beyond“the information” itself, subjects and objects arealso under surveillance by the social engineersas these might give further clues to the potentialhack. It is when there is enough informationthat a social engineer will think about the nextphase 2 which could mean dumpster diving andcollecting as much hard copy and online evidenceas possible (e.g., company website info). Socialnetworks have given social engineers a wholenew avenue of investigation. In fact, socialnetworking will keep social engineers in full-time work forever and ever unless we all get a lotsmarter with how to use these applications.
In phase 3, the evidence gathered by thehacker is used to good practice as they clawtheir way deeper and deeper into organizationalsystems. It might mean having a few fullnames and position profiles of employees ina company and then using their “hacting”(hacking and acting) skills to get more and moredata. Think about social engineers, buildingon steps and penetrating deeper and deeperinto the administration of an organization.While we might think executives are theleast targeted individuals, social engineersare brazen to ‘attack’ personal assistants ofexecutives as well as operational staff. One ofthe problems associated with social networkingis that executives casually give over their log-in and passwords to personal assistants to takecare of their online reputations, thus becomingincreasingly easier to manipulate and hijack thesespaces and use them to as proof for a givenaction. When social engineers get that level ofauthority they require to circumvent systems orthey are able to use a technical reconnaissanceto exploit data found via social reconnaissance(or vice versa), then they can gain access to anorganization’s network resources remotely, freeto unleash cross-site scripting, man-in-the-middleattacks, SQL code injection, and the like.

Reconnaissance and Social Engineering Risks as Effects of Social Networking 1537 R
R
Organizational Risks
We have thus come full circle on what socialreconnaissance has to do with social networks.Social networking sites (SNS) provide socialengineers with every bit of space they need toconduct their unethical hacking and their ownpenetration tests. You would not be the firstperson to admit that you have accepted a “friend”on a LinkedIn invitation without knowing whothey are, or even caring who they are. Just anothere-mail in the inbox to clear out, so pressing acceptis usually a lot easier than pressing ignore andthen delete or even blocking them for life.
Consider the problem of police in metropoli-tan forces creating LinkedIn profiles and ac-cepting friends of friends on their public socialnetwork profile. What are the implications of thisfrom a criminal perspective? Carrying the anal-ogy of police further, what of the personal gad-gets they carry? How many police are currentlycarrying e-mails on personal mobile phones thatthey should not be for security concerns? Or evenworse, police who have their Twitter, Facebook,or LinkedIn profile always connected via theirmobile phone? The police can be said to berapidly introducing new policies to address theseproblems, but the problems regardless still ex-ist for mainstream employees of large, medium,and even small organizations. The theft does nothave to be complex like the stealing of softwarecode or other intellectual property in designs andblueprints but as simple as the theft of compet-itive information like customer lead lists in aMicrosoft Access database, or payroll data storedin MYOB, or even the physical device itself.
Penetration testing done periodically can beused as feedback into the development of a morerobust information security life cycle that canaid those in charge of information governance toreact proactively to help employees understandthe implications of their practices (Bishop 2007).Trustwave (2012) advocates for four types of as-sessment and testing. The first is straightforwardand traditional physical assessment. The secondis client-side penetration testing which validateswhether every staff member is adhering to
policies. The third is business intelligence testingwhich is investigating how employees are usingsocial networking, location-enabled devices, andmobile blogging to ensure that a company’sreputation is not at risk and to find out whatdata exists publically about an organization.And finally, red team testing is when a group ofdiverse subject matter experts try to penetrate asystem reviewing security profiles independently.
No one would ever want to be the cause be-hind the ransacking of their organization’s onlineinformation above and beyond the web scrapingtechnologies becoming widely available (Poggiet al. 2007). It would help if policies were en-forceable within various settings but these too aredifficult to monitor. How does one get the mes-sage across that while blocking unwanted trafficat the door is very important for an organization,what is even more important is noting what goeswalkabout from inside the organization out? Itwill take some years for governance structures toadapt to this kind of thinking because the securityindustry and the media have previously beenrightly focused on Denial of Service (DoS) at-tacks and botnets and the like (Papadimitriou andGarcia-Molina 2011). But it really is a chickenand egg problem – the more information wegive out using social networking sites, the morewe are giving impetus to DoS, DDoS, and theproliferation of botnets (Kartaltepe et al. 2010;Huber et al. 2009).
Conclusion
Possibly this entry may not have convinced em-ployees that greater care should be taken aboutwhat they publish online, on personal blogs, orthe pictures or footage post on lifelogs or onYouTube, but it may have convinced employ-ees that the biggest problems today in securitysystems arise from the information that userspost publicly in environments that rely on so-cial networks. This information is just waitingto be harvested by people unsuspecting to usersthat they will probably never meet physically.Employers need to get their staff educated on

R 1538 Reconstruction
company policies periodically and even reviewthe policies they create no less than every 2 years.As an employer you should also be consideringwhen the last time was that your organization per-formed a penetration test that considered new so-cial networking applications. Individuals shouldextend this kind of pentesting to their own onlineprofiles and review their own personal situation.Sure you might not have nothing to hide, but youmight have a lot to lose.
Cross-References
�Corporate Online Social Networks andCompany Identity�Ethical Issues Surrounding Data Collection inOnline Social Networks�Location-Based Status Updates and CameraPhone Apps in Social Networks� Privacy Issues for SNS and Mobile SNS� Social Engineering/Phishing� Social Media Policy in the Workplace: UserAwareness
References
Bishop M (2007) About penetration testing. IEEE SecurPrivacy 5(6):84–87
David SW (2008) Cybercrime and the culture of fear. InfCommun Soc 11(6):861–884
Dijst M (2009) ICT and social networks: towards a situa-tional perspective on the interaction between corporealand connected presence. In: Kitamura R, Yoshii T,Yamamoto T (eds) The expanding sphere of travelbehaviour research. Emerald, Bingley
Goodchild J (2012) 3 tips for using the social engineeringtoolkit, CSOOnline- data protection. http://www.csoonline.com/article/705106/3-tips-for-using-the-social-engineering-toolkit. Accessed 3 Dec 2012
Google (2012) Introducing Gen C: the YouTubegeneration. http://ssl.gstatic.com/think/docs/introducing-gen-c-the-youtube-generation research-studies.pdf.Accessed 1 Apr 2013
Hadnagy C (2011) Social engineering: the art of humanhacking. Wiley, Indianapolis
Huber M, Kowalski S, Nohlberg M, Tjoa S (2009)Towards automating social engineering using socialnetworking sites. In: IEEE international conferenceon computational science and engineering, CSE’09,Vancouver, vol 3. IEEE, Los Alamitos, pp 117–124
Kartaltepe EJ, Morales JA, Xu S, Sandhu R (2010)Social network-based botnet command-and-control:emerging threats and countermeasures. In: Ap-plied cryptography and network security. Springer,Berlin/Heidelberg, pp 511–528
Michael K (2003) The battle against security attacks. In:Lawrence E, Lawrence J, Newton S, Dann S, Cor-bitt B, Thanasankit T (eds) Internet commerce: digi-tal models for business. Wiley, Milton, pp 156–159.http://works.bepress.com/kmichael/263/. Accessed 1Feb 2013
Michael K (2008) Social and organizational aspects of in-formation security management. In: IADIS e-Society,Algarve, 9–12 Apr 2008. http://works.bepress.com/kmichael/46/. Accessed 1 Feb 2013
Mitnick K, Simon WL (2002) The art of deception:controlling the Human element of security. Wiley,Indianapolis
Mitnick K, Simon WL (2005) The art of intrusion. Wiley,Indianapolis
Palmer CC (2001) Ethical hacking. IBM Syst J 40(3):769–780
Papadimitriou P, Garcia-Molina H (2011) Data leakagedetection. IEEE Trans Knowl Data Eng 23(1):51–63
Poggi N, Berral JL, Moreno T, Gavalda R, Torres J (2007)Automatic detection and banning of content stealingbots for e-commerce. In: NIPS 2007 workshop onmachine learning in adversarial environments forcomputer security. http://people.ac.upc.edu/npoggi/publications / N.%20Poggi%20-%20Automatic%20Detection%20and%20Banning%20 of % 20Content%20Stealing%20Bots%20for%20E-commerce.pdf.Accessed 1 May 2013
PWC (2012) BYOD (Bring your own device): agilitythrough consistent delivery. http://www.pwc.com/us/en/increasing-it-effectiveness/publications/byod-agility-through-consistent-delivery.jhtml. Accessed 3Dec 2012
Social-Engineer.Org: Security Through Education (2012)http://www.social-engineer.org/. Accessed 3 Dec 2012
Trustwave (2012) Physical security and social engineeringtesting. https://www.trustwave.com/socialphysical.php. Accessed 3 Dec 2012
Reconstruction
� Imputation of Missing Network Data: SomeSimple Procedures
Regional Networks
� Inter-organizational Networks

Regression Analysis 1539 R
R
Regression Analysis
Andreas ArtemiouDepartment of Mathematical Sciences, MichiganTechnological University, Houghton, MI, USASchool of Mathematics, Cardiff University,Cardiff, Wales, UK
Synonyms
Regression line; Regression model
Glossary
Akaike Information Criterion (AIC) It is acriterion used to check the goodness of fitof a model and thus is used for comparisonbetween models. A model with smaller AICis usually preferred. It describes the amount ofinformation one loses from the fitted model
Bayesian Information Criterion (BIC) It is acriterion used to check the goodness of fitof a model and thus is used for comparisonbetween models. A model with smaller BIC isusually preferred. It is based on the likelihoodfunction information
Binary Logistic Regression (also as binomiallogistic regression). It is the set of tools usedfor regression when the response variable isbinary
Binomial Logistic Regression See binarylogistic regression
Coefficient See slope and/or interceptDependent Variable See responseError See residualEstimated Response It is the value that the
regression equation assigns to an observation,based on the value(s) of the predictor(s)
Independent Variable See predictorInteraction Term It is the term in a regression
function which is a result of a multiplicationbetween two or more predictors
Intercept It is the value of the response variablewhen all predictors are equal to 0
Logistic Regression It is the set of tools usedfor regression when the response variable iscategorical
Multiple Linear Regression It is the set oftools used to find the relationship betweenmultiple (more than 2) variables when one isthe response/dependent and all the rest are thepredictors/independent
Multivariate Linear Regression It is the setof tools used to find the linear relationshipbetween a number of variables where theresponse is a vector
Nonlinear Regression It is the set of tools usedwhen the regression model includes nonlinearterms of predictors. One example is polyno-mial regression
Observed Response It is the value of theresponse variable we observe for eachobservation
Ordinary Least Squares It is the optimizationmethod most frequently used in regressionwhen we are interested in estimating the con-ditional mean E.Y jX/, with the main objec-tive being minimizing the sum of the squareof residuals
Polynomial Regression It is when the regres-sion function has predictors with higher-orderterms
Predictor (also known as the independent vari-able). It is the variable which can be manip-ulated in order to see a possible effect on theresponse variable
Quantile Regression It is the set of tools used tofind the relationship between variables, whenour interest is to estimate a conditional per-centile rather than conditional mean
Regression Through the Origin It is when amodel is forced to have intercept equal to 0
Residual It is the distance between the observedand the estimated response. It is calculated asobserved – estimated. It shows the distance anobservation will have from the regression line
Response (also known as the dependent vari-able). It is the variable which is considered anobserved result of a possible effect from thepredictors variable(s)
Simple Linear Regression It is the set oftools used to find the relationship between

R 1540 Regression Analysis
two variables; one is the predictor/independentand the other is the response/dependent
Slope It is related to one of the predictors inthe model, and it shows the rate with whichthe response variable is changed when thatpredictor is increased by one unit and all otherpredictors are held constant
Definition
Regression analysis is the set of techniques andtools used in statistics to explore the relationshipbetween variables. In the simplest form (simplelinear regression), there is one variable that istreated as the response and one variable that istreated as the predictor and ordinary least squares(OLS) is used to estimate the linear regressionline, which is, the line that best fits the data.
Regression analysis can be used in severalways. The most common one is to estimatethe effect each unit increase on the predictor(or independent) variable(s) has on the response.It can also be used for prediction, especiallyif it is used with statistical/machine learningmethodology.
Introduction
In many science fields, there is a need to assess ifthere is a relationship between different variables,evaluate that relationship between variables, anduse the conclusion for future predictions. Regres-sion analysis was one of the first tools developedin the statistics literature to achieve this goal.In regression analysis, one needs to collect datafor a number of variables (for simplicity, weassume two variables) and then determine if thereis an actual relationship between those two vari-ables. One of the variables is called the predic-tor/independent variable, and the other variableis called the response/dependent variable. If arelationship is established, then that equation canbe used to predict what will be the value of theresponse variable if the predictor takes a specificvalue. For example, if one is interested to exam-ine if the number of hours a student studies per
week affects the GPA, the predictor variable is the“hours of study” and the response is the “GPA.”Finding an equation between the two variableswill help predict in the future the expected GPAof a student (who has the characteristics of theoriginal population) who studies x number ofhours per week.
Key Points
Regression analysis is a huge subject and dependson the type of the objects that are used as well aswhat is of interest. In this article, we are going todiscuss the classic form of regression where con-tinuous variables are used, and we are interestedin finding a linear relationship for the conditionalmean of the predictor given the response. Othertypes of regression include logistic regression,quantile regression, and multivariate regression,among others (see glossary terms for a briefexplanation of other types of regression). Thereare many good books in the literature; Kutneret al. (2004) is one of them.
Historical Background
Francois Galton was the first to use the termregression in the nineteenth century for biologicalphenomenon, but Karl Pearson was the one todevelop the idea in a statistical context in theearly twentieth century. It is worth noting thatthe idea of least squares was first developedseparately by Legendre and Gauss in the earlynineteenth century. Since then regression becameone of the most common topics in statistics andis taught in all introductory statistics courses(Staunton 2001).
Simple Linear RegressionModelIn simple linear regression, the objective is tofind the relationship between two variables, one isthe independent variable (or predictor), denotedwith X , and the other is the dependent variable,denoted with Y . We further assume that therelationship is linear, and the objective is to findthe regression equation of the line (known as

Regression Analysis 1541 R
R
regression line), which best fits the data, giventhe fact that the data will most probably not lieon a straight line but around it. If we assume wehave n pairs of observed data points .Yi ; X i /, thesimple linear regression model takes the form
Yi D ˇ0 C ˇ1X i C "i ; i D 1; : : : ; n
where "i denotes the distance of each observedpoint from the regression line, known as theerror or the residual. Estimating the regressionequation is equivalent to estimating the regres-sion coefficients ˇ0; ˇ1. The first is known asthe intercept and it is the point where the linemeets the y-axis, and the second is known as theslope and it shows the type of the relationshipand the how quickly it changes. If the slope ispositive(negative), then the relationship is calledpositive(negative), and the absolute value, jˇ1j,means that for each unit increase in the predictor,there is a jˇ1j increase(decrease) in the expectedvalue of the response variable.
In the sample version, if we observe n pairs.yi ; xi /, we have the equation
Oyi D b0 C b1xi
where b0 denotes the estimate for the interceptˇ0 and b1 denotes the estimate for the slopeˇ1. The most used method to estimate the co-efficients in the equation is known as ordinaryleast squares (OLS), and the idea is to minimizethe sum of squared error (SSE). Thus, weminimize:
nX
iD1
"2i D
nX
iD1
.yi� Oyi /2D
nX
iD1
�yi � .b0 C b1xi /
�2
This will give the following equations, alsoknown as normal equations, to estimate thecoefficients.
b0 D Ny � b1 Nx
b1 DPn
iD1.xi � Nx/.yi � Ny/Pn
iD1.xi � Nx/2
Multiple Linear RegressionThere are cases where we are interested in theeffect on the response variable from more thanone variable. If we assume that there are p pre-dictors, the model takes the form
Yi D ˇ0Cˇ1X 1iC: : :CˇpXpiC"i ; i D 1; : : : ; n
and the sample version of the equation is
Oyi D b0 C b1xi C : : :C bpxi
This can be expressed using matrix notations asfollows:
OY D X OBwhere X is a n � .p C 1/ matrix
2
64
1 X11 : : : Xp1:::
:::: : :
:::
1 Xn1 : : : Xnp
3
75
and OB D .b0; b1; : : : ; bp/T 2 RpC1. The OLS
estimator in matrix form is
OB D .XT X/�1XT Y
Assumptions
Other than assuming there is a linear relationshipbetween the predictors and the response variable,there are some other important assumptions in thelinear regression case. These are as follows:(a) The errors are normally distributed.(b) Homoscedasticity (or constant variance)
which implies that the variance of the errorterm is constant and does not depend on thevalue of the predictors. If this assumption isviolated, one can use a different estimationtechnique to estimate regression coefficients,with weighted least squares being a verycommon choice.
(c) Independence of errors, which implies thatthe errors are uncorrelated between them. Ifthis assumption is violated, there are different

R 1542 Regression Analysis
estimation techniques with the generalizedleast squares being a common choice.
To test the above assumptions, usually oneneeds to run the ordinary least squares and createplots of the residuals versus the predictors andthe response variable. If the plots indicate thatthe assumptions are violated, then one needs torepeat the procedure using a different estimationtechnique.
Other Types of Regression
(a) Nonlinear regression: There are cases ofinterest where the response variable is relatedto the predictors in a nonlinear trend, forexample, a polynomial link function or anexponential link function.
(b) Logistic regression: In the case where theresponse variable is categorical, we can applylogistic regression, which models the proba-bilities of getting a single outcome. A specialcase of logistic regression is the case wherethe response is binary, in which case we havethe binary logistic regression. In the casewhere we have multiple categories, it is alsoknown as multinomial logistic regression. Tomodel the probabilities, one uses the logisticfunction which is written as
�.x/ D eˇ0CPp
iD1 ˇi XiC�
eˇ0CPp
iD1 ˇiXiC� C 1
In order to turn it into a linear regressionfunction, one can use the logit function whichis the natural logarithm:
ln�.x/
1 � �.x/D ˇ0 C
pX
iD1
ˇi Xi C �
(c) Functional regression: There are cases wherethe predictors are not random variableor random vectors, but they are randomfunctions. In those cases, we have functionalregression.
(d) Quantile regression: When we are not inter-ested for the conditional mean E.Y jX/ but
instead we are interested for a conditionalpercentile, then the type of regression we useis quantile regression (Koenker 2005; Haoand Naiman 2007).
Regression Diagnostics
(a) Coefficient of determination: (most com-monly known as R-square and written as R2/.It is a metric that shows the linear strength ofthe regression model. It takes values between0 and 1. The closer it is to 1, the strongerthe relationship is (and the closer the pointsare to the regression line). The closer it is to0, the weaker the relationship is. It can alsobe interpreted as the percentage of variabilityof the data points that can be explained bythe linear regression model of Y on X . Tocalculate it, we use the formula
R2 D SSR
SSTD 1 � SSE
SST
where SSE is the sum of squared error, SSRis the sum of squared regression, and SSTis the total sum of squares and these arecalculated by
SSR DnX
iD1
. Oyi � Ny/2; SST DnX
iD1
.yi � Ny/2
where Ny is the mean of the observedresponses:
Ny DPn
iD1 yi
n
(Also note that SST = SSR + SSE) In multi-ple linear regression (the case with multiplepredictors), the more predictors you add in amodel, the higher the R2 is, and as a result,a model with all the predictors, even the onesthat are almost irrelevant, is the one with thehighest R2. Thus, adjusted R2 (adjR2/ hasbeen introduced which takes into account thenumber of predictors in the model:

Regression Analysis 1543 R
R
adjR2 D 1 � SSE=dfe
SST=dft
where dfe denotes the error degrees offreedom, which are equal to n � p � 1where p denotes the number of predictors inthe model and dft denotes the total degreesof freedom which are equal to n � 1.
(b) Existence of relationship: To check if thereis a statistically significant relationship, werun hypothesis tests. This can be done intwo ways. One is by testing if the correlationbetween the two variables is different than 0,and the other is by testing if the slope is equalto 0. Since the regression equation gives usdirectly the slope, we are going to show howto do the second one here. The test statistictakes the form of
estimate � null value
s:e: of the estimatorDO1 � 0
s O1
where s.e. stands for “standard error.” Theestimate of the slope is given by the equation,and the estimate of its standard error is givenby most software outputs, but the easier wayto do it in simple linear regression is tofind the sum of squares of residuals SSE DPn
iD1 "2i and then divide by n � p � 1 and
divide the result byPn
iD1 .xi � Nx/2, that is,
s O1 DSSE
n�p�1Pn
iD1.xi � Nx/2
The above test statistic follows a t distribu-tion with n�p�1 degrees of freedom, wherep is the number of predictors in the model.
Variable Selection
While adjusted R2 can be used to see how wella model linearly fits the data, other metrics arealso used in order to perform variable selection.Variable selection is a set of techniques thatare used to reduce the number of predictors inthe model, mainly for the purpose of reducing
the dimensionality of the model and improvingthe model interpretation. Many type of algo-rithms are used, the most common ones are asfollows:(a) Forward selection: One starts with an
empty model with no predictors. At eachiteration, the algorithm selects the best (in thesense that including it will have the biggestimprovement in the performance of a metric)variable to include in the model among thevariables that are not already in the model.When including more variables will notimprove the existing model, the algorithmstops, and the model is the best one.
(b) Backward elimination: One starts with thefull model, which is the model that includesall the predictors. At each iteration, thealgorithm selects the worst (in the sensethat excluding it will have the biggestimprovement on the performance of a metric)variable which is excluded from the model.When excluding more variables will notimprove existing model, the algorithm stopsand the model is the best one.
(c) Forward/backward selection: It is whenany model is used as the starting point, andat each iteration either a variable is includedor a variable is excluded, based on whichaction will improve the model based on theperformance of the model.
More complicated algorithms like geneticalgorithms and simulated annealing can beused when the number of predictors is huge andan exhaustive estimation of all possible modelscan be time consuming. During variable selectionmethods, a variable is included in the model orexcluded from the model based on a criterion. Anumber of criteria are available in the literaturewith the most famous ones being the Akaikeinformation criterion (AIC) and the Bayesianinformation criterion (BIC).
Feature Extraction
Like variable selection, feature extraction is usedmainly to reduce the dimensionality of a model.In variable selection, one selects a subset among

R 1544 Regression Analysis
the original variables to be included in the model,while in feature extraction functions of the origi-nal variables are considered to be the new predic-tors and will be used in the reduced model.
One example of linear feature selection isprincipal component analysis (PCA) whichselects the linear functions of the predictorswhich show the most variability in the data.Kernel principal component analysis (KPCA)selects the number of functions (not necessarilylinear) of the predictors that have the mostvariability in the data. KPCA is used for nonlinearfeature extraction. Although PCA and KPCAare very common tools and can recover usefullinear and nonlinear functions of the predictorsin most cases, there are cases where the extractedfeatures are not the ones that are more correlatedwith the response. This is a common problem ofunsupervised dimension reduction methods,that is, when no information from the response isused for feature extraction.
Supervised dimension reduction methodssuch as projection pursuit and sufficient dimen-sion reduction methods have been developed totake advantage of the information of the responsein feature extraction. These methods have theadvantage of extracting features more correlatedwith the response, but they are relatively newand they have not yet been extensively used inapplications.
Illustrative Example(s)
We will show several instances of what wetalked in the main part of this entry throughan example where we are interested to predictbody fat through some anatomical variables.The following variables are included in thedataset from 252 people: Density of the bodyfrom underwater weighing; percentage of bodyfat, as was calculated by Siri (1956) usingequation 495/Density – 450; indicator of agegroup (0 up to 45, 1 for greater than 45);weight (lbs); height (inches); neck circumference(cm); chest circumference (cm); abdomen cir-cumference (cm); hip circumference (cm); thighcircumference (cm); knee circumference (cm);
ankle circumference (cm); biceps circumference(cm); forearm circumference (cm); and wristcircumference (cm).
Although measuring body fat is done accu-rately by Siri’s equation, it is very expensive andinconvenient to measure density underwater. Allother variables are easier to measure, and weare interested to see if one or more of them canpredict the percentage of body fat.
To run the code, we used R packages (Fox andWeisberg 2010).
Examples on Simple Linear RegressionExample 1 We use the same procedure to see ifheight affects the percentage of body fat. In thiscase, the equation is
perbodyfatD 35:51� 0:23 � height
with an R2 D 0:01025 which indicates a veryweak (almost inexistent) linear relationshipbetween the two variables.
Looking at the scatterplot of the data (Fig. 1),it is clear that one needs to do a prescreening ofthe values that are in the dataset. There is one datapoint which is an unusual observation as this per-son is very short, around 30 in., while the rest ofthe data is for people between 60 and 70 inches.
It makes sense to remove that observation asotherwise it will be an observation with very highinfluential value (high Cook’s distance value)on the equation (Fig. 2).
Removing that point shows more clearly thatthere is no relationship between the two variables.The equation of the regression line is
perbodyfatD 24:34� 0:0746� height
with an R2 D 0:0005468 which indicates anextremely weak (essentially inexistent) linearrelationship between the two variables.
Example 2 We fit a simple linear regression, tosee if abdomen circumference is a predictor of thepercentage of body fat. The regression equation isthe following:
perbodyfatD �39:28C 0:63 � abdomen

Regression Analysis 1545 R
R
30 40 50 60 70
0
10
20
30
40
Height
% b
ody
fat
Regression Analysis,Fig. 1 A scatterplotbetween height andpercentage of body fatindicates that there is aproblematic point
64 66 68 70 72 74 76 78
0
10
20
30
40
Height
% b
ody
fat
Regression Analysis,Fig. 2 The scatterplot withthe regression line forpercentage of body fat onheight when one point isremoved from the dataset
which from the slope we learn that for every cmincrease in the abdomen circumference, there is0.63 % increase in the body fat. Also, from theintercept, we can see that someone with 0 cmabdomen circumference has �39.19 % body fatwhich of course doesn’t make any sense. This is
called extrapolation, a well-known problem inregression, where we try to make inference forvalues of the predictors that are beyond the rangeof the values the predictors have in the avail-able data. The range of values of the abdomencircumference is between 69.4 and 148.1, which

R 1546 Regression Analysis
indicates that the line should not be interpretedoutside that range (because nothing can ensureus the relationship will be the same if data on adifferent range is collected).
The coefficient of determination, R2, is 0.6617which indicates a relatively strong linear rela-tionship between abdomen circumference andpercentage of body fat. Another way to interpretthis number is by saying that 66.17% of thevariability in body fat percentage is explained byits relationship with the abdomen circumference.
The first thing we want to look in this equationis if some assumptions are satisfied and if there issomething else (Fig. 3).
The normal probability plot (Fig. 4) is theone that will indicate if the assumption of nor-mality is satisfied. We can see that excludingtwo points on the left tail the others are veryclose to, a straight line which indicates that thenormality assumption can be assumed. This isthe easiest and most frequent way of testingnormality although sometimes it can be objec-tive especially if there is curvature but not aclear one.
The second assumption is the independenceand homoscedasticity of the residuals. This canbe seen in a plot of the residuals with the fittedvalues. This plot doesn’t show any trend; all ofthem form a pretty nice cloud, which indicatesindependence. Also, the range of the residuals isconstant throughout the range of the predictor (itis obvious with this picture as well that we needto further investigate the point that has residualvalue of �20 (Fig. 5)).
A way to find unusual observations is by cre-ating the influence plot. Unusual points are pointswith standardized residuals with high absolutevalue or large leverage. Residuals tell us howfar away from the line in the y direction are thepoints, and leverage tells us how far away fromthe data center in the x direction are the points.A common way to check both is by calculatingthe Cook’s distance which combines the twomeasures to create a unique measurement thatindicates high influential points, that is, pointsthat affect a lot the equation of the line. As arule of thumb of Cook’s distance is larger than
4n
, it is considered an influential point, althoughpeople use number 1 as a definite cutoff point.As the picture shows, there is a clear indica-tion of point 39 being an influential point andalso maybe points 41 and 216. It is importantto note that influential points don’t necessarilyneed to be removed from the analysis, becausewhen the analysis is run without current influ-ential points, new highly influential points willappear. So, it is better if the researcher lookscarefully at the points that are influential be-fore removing them. We decide to remove point39, because we suspect there is a typo there(Fig. 6).
Then the equation becomes:
perbodyfatD �42:96C 0:67 � abdomen
with an R2 D 0:6801, which is a small differencefrom the original equation where all the pointswere included. The overall pictures for the newmodel though, like normal probability plot andresidual plot, make us feel more comfortableabout satisfying the assumptions.
Finally, one can perform tests, to check ifthere is a statistically significant relationship.We use the test statistic for the slope. In ourcase, the estimate is 0.67, the s.e. of the es-timator is 0.02921, and the value of the teststatistic is 23.01. The test statistic follows at distribution with n � 2 degrees of freedom,and the resulting p-value is essentially 0 whichindicates that indeed there is a statistically sig-nificant evidence that there is relationship be-tween the abdomen circumference and the bodyfat.
Example on Nonlinear RegressionExample 3 One might claim that the ratio be-tween weight and height is an indication of bodyfat. This means that we need to fit the modelperbodyfat weight
height . This uses the ratio of twovariables, and it is the simple case of nonlinearregression. Like in many cases where nonlin-ear regression needs to be used, one can createa new variable called ratio and fit the modelperbodyfat ratio. This reduces the problem to

Regression Analysis 1547 R
R
80 100 120 140
0
10
20
30
40
Abdomen circumference
% b
ody
fat
Regression Analysis,Fig. 3 The scatterplot andthe regression line ofpercentage of body fat onabdomen circumference
2
Sta
ndar
dize
d re
sidu
als
−2
−4
−3 −2 −1
0
0
Theoretical Quantiles
204
207
39
1 2 3
Regression Analysis,Fig. 4 Normal probabilityplot for the regression ofthe percentage of body faton the abdomencircumference. The pointsare close to a straight line
the simple linear regression, where we have seentwo examples above.
Example on Multiple Linear RegressionExample 4 A full model with all anatomic vari-ables is applied to check which of those are
statistically significant in predicting the percent-age of body fat. We excluded age which is abinary variable. We run ordinary least squares,and we list below the value of the coefficientwith the p-value given by the test for statisticallysignificant coefficient different from 0.

R 1548 Regression Analysis
10 20 30 40 50
−20
−15
−10
−5
0
5
10
Fitted values
Res
idua
ls
Regression Analysis,Fig. 5 The scatterplot ofthe residuals shows notrend and a constant rangethroughout the fittedvalues, which impliesindependent residuals withconstant variance
2 216
0.5
41
39
0
Sta
ndar
ized
res
idua
ls
−2
−4
0.00 0.02 0.04 0.06
Leverage
Cook’s distance
0.08 0.10
0.5
1Regression Analysis,Fig. 6 Influence plot,where it is clear that point39 is very influential andpoints 41 and 216 can beconsidered influential aswell
Table 1 indicates that a lot of these variableshave no real relationship with the percentageof body fat. As a result, it makes sense forsomeone to eliminate useless variables. Thiscan be done with variable selection. Running aforward selection procedure, it is indicatedthat the model that has the smallest AICis the one that includes weight and neck,
abdomen, biceps, forearm, and wrist circum-ferences. The equation is:
perbodyfatD� 32:23� 0:138 � weight� 0:410
� neckC 1:013 � abdomen
C 0:257 � bicepsC 0:426
� forearm� 1:236 �wrist

Regression Model 1549 R
R
Regression Analysis, Table 1 The coefficients and cor-responding p-values when fitting the full model for thebody fat data
Variable Coefficient p-value
Weight �0.110 0.038
Height �0:094 0.326
Neck circumference �0.430 0.066
Chest circumference �0:017 0.863
Abdomen circumference 1.030 0.000
Hip circumference �0:230 0.117
Thigh circumference 0.135 0.320
Knee circumference 0.132 0.576
Ankle circumference 0.130 0.559
Biceps circumference 0.205 0.233
Forearm circumference 0.390 0.050
Wrist circumference �1.272 0.013
All the variables with the coefficient value andthe p-value for the test of significance of thecoefficient are shown on Table 1. Bold variablesare the ones which suggest statistically significantcoefficient and with italic are the variables withcoefficients that are barely outside the statisticallysignificant region.
Cross-References
�Data Mining�Eigenvalues, Singular ValueDecomposition� Independent Component Analysis�Least Squares� Principal Component Analysis�Theory of Statistics, Basics, andFundamentals
References
Fox J, Weisberg HS (2010) An R companion to appliedregression, 2nd edn. Sage, Los Angeles
Hao L, Naiman DQ (2007) Quantile regression. Sage,Thousand Oaks
Koenker R (2005) Quantile regression. CambridgeUniversity Press, New York
Kutner M, Nachtsheim C, Neter J (2004) Applied lin-ear regression models, 4th edn. McGraw-Hill/Irwin,Boston
Siri WE (1956) Gross composition of the body. In:Lawrence JH, Tobias CA (eds) Advances in bi-ological and medical physics, vol IV. Academic,New York
Staunton JM (2001) Galton, pearson and the peas: a briefhistory of linear regression for statistics instructors.J Stat Educ 3. http://www.amstat.org/publications/jse/v9n3/stanton.html
Recommended Reading
Allison PD (1998) Multiple regression: a primer. PineForge, Thousand Oaks
Chatterjee S, Hadi AS (2006) Regression analysis byexample. Wiley Interscience, New York
Cook RD (1998) Regression graphics: ideas for study-ing regressions through graphics. Wiley Interscience,New York
Cook RD, Weisberg HS (1999) Applied regression includ-ing computing and graphics. Wiley, New York
Gelman A, Hill J (2006) Data analysis using regres-sion and multilevel/hierarchical models. CambridgeUniversity Press, New York
Kutner M, Nachtsheim C, Neter J, Li W (2004) Appliedstatistical models, 5th edn. McGraw-Hill/Irwin,New York
Mendenhall W, Sincich T (2011) A second course instatistics: regression analysis, 7th edn. Prentice Hall,Upper Saddle River
Schroeder DL, Sjoquist DL, Stephan PE (1986) Under-standing regression analysis: an introductory guide(quantitative applications in the social sciences). Sage,Newbury Park
Seber GA, Lee AJ (2003) Linear regression analysis, 2ndedn. Wiley, Hoboken
Seber GA, Wild CJ (2003) Nonlinear regression. Wiley-Interscience, Hoboken
Weisberg HS (2005) Applied linear regression, 3rd edn.Wiley, Hoboken
Regression Line
�Regression Analysis
Regression Model
�Regression Analysis

R 1550 Regulatory Concerns
Regulatory Concerns
�Legal Implications of Social Networks
Relational Analysis
�Origins of Social Network Analysis
Relational DataMining
�Relational Models
Relational Feature
�Collective Classification, Structural Features
Relational Learning
�Collective Classification�Relational Models
Relational Models
Volker Tresp1; 2 and Maximilian Nickel21Siemens AG, Munchen, Germany2Department of Computer Science, LudwigMaximilian University of Munich, Munchen,Germany
Synonyms
Relational data mining; Relational learning;Statistical relational learning; Statistical rela-tional models
Glossary
Entities are (abstract) objects. An actor in asocial network can be modelled as an entity.There can be multiple types of entities, entityattributes and relationships between entities.Entities, relationships, and attributes are de-fined in the entity-relationship model, which isused in the design of a formal relational model
Relation A relation or relation instance I.R/ isa finite set of tuples. A tuple is an orderedlist of elements. R is the name or type of therelation. A database instance (or world) is a setof relation instances
Predicate A predicate R is a mapping of tuplesto true or false. R.tuple/ is a ground predicateand is true when tuple 2 R, otherwise, it isfalse. Note that we do not distinguish betweenthe relation name R and the predicate name R
Possible Worlds A (possible) world corre-sponds to a database instance. In a proba-bilistic database, a probability distributionis defined over all possible worlds underconsideration
RDF The Resource Description Framework(RDF) is a data model with binary relationsand is the basic data model of the SemanticWeb’s Linked Data. A labelled directed linkbetween two nodes represents a binary tuple.In social network analysis, nodes wouldbe individuals or actors and links wouldcorrespond to ties
Linked Data Linked (Open) Data describes amethod of publishing structured data so thatit can be interlinked and can be exploited bymachines. Much of Linked Data is based onthe RDF data model
Collective Learning Refers to the effect thatan entity’s relationships, attributes, or classmembership can be predicted not onlyfrom the entity’s attributes but also frominformation distributed in the networkenvironment of the entity
Collective Classification A special case ofcollective learning: The class membershipof an entity can be predicted from the classmemberships of entities in the networkenvironment of the entity. For example, a

Relational Models 1551 R
R
person’s wealth can be predicted from thewealth of this person’s friends
Relationship Prediction The prediction of theexistence of a relationship between entities,for example, friendship between persons
Entity Resolution The task of predicting if twoconstants refer to the identical entity
Homophily The tendency of a person toassociate with similar other persons
Graphical Models A graphical description ofa probabilistic domain where nodes representrandom variables and edges represent directprobabilistic dependencies
Latent Variables Latent variables are quantitieswhich are not measured directly and whosestates are inferred from data
Definition
Relational models are machine-learning modelsthat are able to truthfully model some or alldistinguishing features of a relational domainsuch as long-range dependencies over multiplerelationships. Typical examples for relational do-mains include social networks and knowledgebases.
Introduction
Social networks can be modelled as graphs,where actors correspond to nodes and whererelationships between actors such as friendship,kinship, organizational position, or sexualrelationships are represented by directed labelledlinks (or ties) between the respective nodes.Typical machine-learning tasks would concernthe prediction of unknown relationships betweenactors, as well as the prediction of attributes andclass labels of actors. To obtain best results,machine learning should take the networkenvironment of an actor into account. Relationallearning is a branch of machine learning that isconcerned with this task, i.e., to learn efficientlyfrom data where information is represented inform of relationships between entities.
Relational models are machine-learning mod-els that truthfully model some or all distinguish-ing features of relational data such as long-rangedependencies propagated via relational chainsand homophily, i.e., the fact that entities withsimilar attributes are neighbors in the relationshipstructure. In addition to social network analysis,relational models are used to model preferencenetworks, citation networks, and biomedical net-works such as gene-disease networks or protein-protein interaction networks. Relational modelscan be used to solve typical machine-learningtasks in relational domains such as classification,attribute prediction, clustering, and reinforcementlearning. Moreover, relational models can be usedto solve learning tasks characteristic to relationaldomains such as relationship prediction and en-tity resolution. Instances of relational models arebased on different machine-learning paradigmssuch as directed and undirected graphical modelsor latent variable models. Some relational mod-els define a probability distribution over a rela-tional domain. Furthermore, there is a close linkbetween relational models and first-order logicsince both depend on relational data structures.
Key Points
Statistical relational learning is a subfield of ma-chine learning. Relational models learn a proba-bilistic model of a complete networked domainby taking into account global dependencies inthe data. Relational models can lead to more ac-curate predictions if compared to non-relationalmachine-learning approaches. Relational mod-els typically are based on probabilistic graphicalmodels, e.g., Bayesian networks, Markov net-works, or latent variable models.
Historical Background
Inductive logic programming (ILP) wasmaybe the first effort to seriously focus on arelational representation in machine learning. Itgained attention around 1990 and focusses onlearning deterministic or close-to-deterministic

R 1552 Relational Models
dependencies, with a close tie to first-order logic.As a field, ILP was introduced in a seminalpaper by Muggleton (1991). A very early andstill very influential algorithm is Quinlan’sFOIL (Quinlan 1990). In contrast, statisticalrelational learning focusses on domains withstatistical dependencies. Statistical relationallearning started around 2000 with the work byKoller and Pfeffer (1998) and Friedman et al.(1999). Since then many combinations of ILPand relational learning have been explored.The Semantic Web and Linked Open Dataare producing vast quantities of relational dataand (Tresp et al. 2009; Nickel et al. 2012)describe the application of statistical relationallearning to these emerging fields.
Learning in Relational Domains
Machine learning can be applied to relationaldomains in different ways. In this section, wediscuss what distinguishes relational models fromrelational learning and from machine learning inrelational domains.
Relational DomainsA relational domain is a domain which can truth-fully be represented by a set of relations, where arelation itself is a set of tuples. For each relationR we define a predicate R, which is a functionthat maps a tuple to true if the tuple belongsto the relation R and to false otherwise. Thecontext should make clear if we refer to a relationor a predicate. In relational learning the term“relational” is used rather liberally and encom-passes any domain where relationships betweenentities play a major role. Social networks aretypical relational domains, where information isrepresented via multiple types of relationshipsbetween entities (here: actors), as well as throughthe attributes of entities.
Machine Learning in Relational DomainsA standard statistical learning approach appliedto a relational domain would, for instance, ran-domly sample entities from the domain and studytheir properties. Data created in such a setting
is independently and identically generated froma fixed (but maybe unknown) distribution (so-called i.i.d.) and can be analyzed by standardstatistical tools. A statistical analysis might notuse simple random sampling; for example, in adomain with different social clusters, one mightwant to get the same number of samples fromeach group (stratified sampling). A standard sta-tistical analysis of data sampled from a relationaldomain is absolutely valid but one can oftenobtain more precise predictions by employingrelational learning and relational models in par-ticular.
Learningwith Relationship InformationRelational features provide additional informa-tion to support learning and prediction tasks.For instance, the average income of a person’sfriends might be a good covariate to predict aperson’s income in a social network. The un-derlying mechanism that forms these patternsmight be homophily, the tendency of individualsto associate with similar others. Another taskmight be to predict relationships themselves: incollective learning, a preference relationship foran entity can be predicted from the preferencesfor other entities. In a social network one canpredict friendships for a person based on infor-mation about existing friendships of that person.Relational features are often high dimensionaland sparse (there are many people, but only asmall number of them are a person’s friends; thereare many items, but a person has only boughta small number of them). As an example ofa typical learning task, to predict a friendshiprelationship between two persons, one might ob-tain attribute features of both involved persons(such as income, gender, age), information onexisting friendships to other persons, informationon preferences on some items (e.g., on moviesand books), and information on other sharedrelationships (if they attended the same school,and if the know each other).
Good relational features for a particularprediction task in a relational domain are notalways obvious and some approaches apply asystematic search for good features. Some re-searchers consider this as an essential distinction

Relational Models 1553 R
R
between relational learning and non-relationallearning: in non-relational learning, features areessentially defined prior to the training phase,whereas relational learning includes a systematicand automatic search for features in the relationalcontext of the involved entities. Inductive logicprogramming (ILP) is a form of relationallearning with the goal of finding deterministic orclose-to-deterministic dependencies, which aredescribed in logical form such as Horn clauses.Traditionally, ILP involves a systematic searchfor sensible relational features Dzeroski (2007).
In some domains it can be easier to defineuseful kernels than to define useful features. Re-lational kernels often reflect the similarity ofentities with regard to the network topology. Forexample, a kernel can be defined based on count-ing the substructures of interest in the intersectionof two graphs defined by neighborhoods of thetwo entities (Losch et al. 2012) (see also thediscussion on RDF graphs further down).
Relational ModelsIn the discussion so far, information on a rela-tional domain was gained by analyzing its pat-terns. For a deeper analysis, one can attemptto obtain a complete (probabilistic) relationalmodel of a relational domain in the sense that themodel can derive predictions (typically in formof predicted probabilities) for a large number oreven all ground predicates in a relational domain.
Typically, relational models can exploit long-range or even global dependencies and haveprincipled ways of dealing with missing data.Relational models are often displayed asprobabilistic graphical models and can bethought of as relational versions of regulargraphical models, e.g., Bayesian networks,Markov networks, and latent variable models.The approaches often have a “Bayesian flavor,”but not always a fully Bayesian statisticaltreatment is performed.
PossibleWorlds for Relational ModelsA set of possible worlds or an incompletedatabase is a set of database instances (orworlds), and a probabilistic database defines aprobability distribution over the possible worlds
under consideration. The goal of relationallearning is to derive a model of this probabilitydistribution. The precise definition of the set ofpossible worlds under consideration is domainand problem specific. In a typical setting, thepredicate types are fixed and all entities (moregenerally all constants) are known (domainclosure constraints). Furthermore, one assumesthat different constants refer to different entities(unique names constraint). A possible worldunder consideration is then any database instancewhich follows these constraints. All theseconstraints and assumptions can be relaxed.Considering the domain closure assumption, inparticular: All presented relational models havemeans to make predictions for entities not knownduring model training; for details please consultthe corresponding publications.
In a next step one maps ground predicates tostates of random variables. A canonical proba-bilistic model assigns a binary random variableXR.tuple/ to each ground predicate. XR.tuple/ isin state one in case R.tuple/ is true and is zerootherwise. The goal now is to obtain a modelfor the probability distribution of all randomvariables in a domain, i.e., to estimate P.fXg/.It is desirable that relational models efficientlyrepresent and answer queries on P.fXg/.
Depending on a specific application, onemight want to modify this canonical represen-tation. For example, discrete random variableswith N states are often used to implement theconstraint that exactly one out of N groundpredicates is true, e.g., that a person belongsexactly to one out of N income classes.
In probabilistic databases (Suciu et al. 2011)the canonical representation is used in tuple-independent databases, while multistate randomvariables are used in block-independent disjoint(BID) databases.
RDF Graphs and ProbabilisticGraphical Networks
If a relational domain is restricted to binary orunary relations, a graphical representation of adatabase can be obtained: An entity is represented

R 1554 Relational Models
as a node, and a binary relationship is repre-sented as a directed labelled link from the firstentity to the second entity in the relationship.The label on the link indicates the relation type.This is essentially the representation used both inthe Semantic Web’s RDF (Resource DescriptionFramework) standard which is able to representweb-scale knowledge bases and in sociogramsthat allow multiple types of directed links. Re-lations of higher order can be reduced to bi-nary relations by introducing auxiliary entities(“blank nodes”). Figure 1 shows an example ofan RDF graph. A mapping to a probabilistic de-scription can be achieved by introducing randomvariables that represent the ground predicates ofinterest (see the last section). In Fig. 1 theserandom variables are represented as elliptical rednodes. For example, we introduce the binarynode Xlikes.John;HarryP ot ter/, which assumesthe state Xlikes.John;HarryP ot ter/ D 1 if theground predicate likes(John, HarryPotter) is truein the domain and zero otherwise. Similarly,XhasAge.Jack;AgeC lass/ might be a random vari-able with as many states as there are age classesfor Jack.
Relational Models
Relational models describe probability distribu-tions P.fXg/ over the random variables in arelational domain. Often, the joint distributionis described using probabilistic graphical mod-els to efficiently model high-dimensional proba-bility distributions by exploiting independenciesbetween random variables. We describe threeimportant classes of relational graphical models.In the first class, the probabilistic dependencystructure is a directed graph, i.e., a Bayesiannetwork. The second class encompasses modelswhere the probabilistic dependency structure isan undirected graph, i.e., a Markov network.Third, we consider latent variable models.
Directed Relational ModelsThe probability distribution of a directed rela-tional model, i.e., a relational Bayesian model,can be written as
P .fXg/ DY
X2fXgP.X jpar.X//: (1)
Here fXg refers to the set of random variablesin the directed relational model, while X denotesa particular random variable. In a graphical rep-resentation, directed arcs are pointing from allparent nodes par.X/ to the node X (Fig. 1). AsEq. 1 indicates, the model requires the specifica-tion of the parents of a node and the specificationof the probabilistic dependency of a node from itsparent nodes. In specifying the former, one oftenfollows a causal ordering of the nodes, i.e., oneassumes that the parent nodes causally influencethe child node. An important constraint is that theresulting directed graph is not permitted to havedirected loops, i.e., that it is a directed acyclicgraph.
Probabilistic Relational ModelsProbabilistic relational models (PRMs) wereone of the first published directed relationalmodels and found great interest in the statisticalmachine-learning community (Koller and Pfeffer1998; Getoor et al. 2007). An example ofa PRM is shown in Fig. 2. PRMs combinea frame-based (i.e., object-oriented) logicalrepresentation with probabilistic semanticsbased on directed graphical models. The PRMprovides a template for specifying the graphicalprobabilistic structure and the quantification ofthe probabilistic dependencies for any groundPRM. In the basic PRM models, only theentities’ attributes are uncertain, whereas therelationships between entities are assumed tobe known. Naturally, this assumption greatlysimplifies the model. Subsequently, PRMs havebeen extended to also consider the case thatrelationships between entities are unknown,which is called structural uncertainty in the PRMframework (Getoor et al. 2007).
In PRMs one can distinguish parameter learn-ing and structural learning. In the simplest case,the dependency structure is known and the truthvalues of all ground predicates are known aswell in the training data. In this case, parameterlearning consists of estimating parameters in the

Relational Models 1555 R
R
Jack JohnfriendsWith
likes
HarryPotter
likes
hasAgehasAge
Young
typebook
Xlikes(John,HarryPotter)Xlikes(Jack,HarryPotter)
XhasAge(Jack,AgeClass)
XfriendsWith(Jack,John)
MiddleOld
MiddleOld
Young
Relational Models, Fig. 1 The figure clarifies the re-lationship between the RDF graph and the probabilisticgraphical network. The round nodes stand for entities inthe domain, square nodes stand for attributes, and thelabelled links stand for tuples. Thus, we assume that it isknown that Jack is friends with John and that John likesthe book HarryPotter. The oval nodes stand for randomvariables, and their states represent the existence (value 1)or nonexistence (value 0) of a given labelled link; seefor example the node Xlikes.John;HarryPotter/ whichrepresents the ground predicate likes(John, HarryPotter).Striped oval nodes stand for random variables with manystates, useful for attribute nodes (exactly one out of many
ground predicates is true). Relational models assume aprobabilistic dependency between the probabilistic nodes.So the relational model might learn that Jack also likesHarryPotter since his friend Jack likes it (homophily).Also Xlikes.John;HarryPotter/ might correlate withthe age of John. The direct dependencies are indicatedby the red edges between the elliptical nodes. In PRMsthe edges are directed (as shown), and in Markov logicnetworks they are undirected. The elliptical random nodesand their quantified edges form a probabilistic graphicalmodel. Note that the probabilistic network is dual to theRDF graph in the sense that links in the RDF graphbecome nodes in the probabilistic network
conditional probabilities. If the dependency struc-ture is unknown, structural learning is applied,which optimizes an appropriate cost functionand typically uses a greedy search strategy tofind the optimal dependency structure. In struc-tural learning, one needs to guarantee that theground Bayesian network does not contain di-rected loops.
In general the data will contain missing in-formation, i.e., not all truth values of all groundpredicates are known in the available data. Forsome PRMs, regularities in the PRM structurecan be exploited (encapsulation) and even exactinference to estimate the missing information ispossible. Large PRMs require approximate in-ference; commonly, loopy belief propagation isbeing used.
More Directed Relational Graphical ModelsA Bayesian logic program is defined as a set ofBayesian clauses (Kersting and Raedt 2001).A Bayesian clause specifies the conditionalprobability distribution of a random variablegiven its parents. A special feature is that, for a
given random variable, several such conditionalprobability distributions might be given andcombined based on various combination rules(e.g., noisy-or). In a Bayesian logic program, foreach clause, there is one conditional probabilitydistribution, and for each random variable,there is one combination rule. RelationalBayesian networks (Jaeger 1997) are related toBayesian logic programs and use probabilityformulae for specifying conditional probabilities.The probabilistic entity-relationship (PER)models (Heckerman et al. 2007) are relatedto the PRM framework and use the entity-relationship model as a basis, which is often usedin the design of a relational database. Relationaldependency networks (Neville and Jensen 2004)also belong to the family of directed relationalmodels and learn the dependency of a nodegiven its Markov blanket (the smallest node setthat make the node of interest independent ofthe remaining network). Relational dependencynetworks are generalizations of dependencynetworks as introduced by Heckerman et al.(2000) and Hofmann and Tresp (1997).

R 1556 Relational Models
ProfID
CourseID
RegID
StuID
teachingA
popularity
hasProf
hasCourse
hasStudent
rating
difficulty
satisfaction
grade
intelligence
H
ranking
Professor
D,I A B C
H,H 0.5 0.4 0.1
H,L 0.1 0.5 0.4
L,H 0.8 0.1 0.1
L,L 0.3 0.6 0.1
Course Student
Registration
TeachingAbility
Popularity
Rating
Difficulty
Intelligence
Ranking
Satisfaction
Grade
ABC
L
HL
HL
HL
HL
HL
HIL
hasProf
hasCourse
hasS
tude
nt
Relational Models, Fig. 2 Left: a PRM with do-main predicates Professor(ProfID, TeachingAbility, Pop-ularity), Course(CourseID, ProfID, Rating, Difficulty),Student(StuID, Intelligence, Ranking), and Registra-tion(RegID, CourseID, StuID, Satisfaction, Grade). Dot-ted lines indicate foreign keys, i.e., entities defined inanother relational instance. The directed edges indicatedirect probabilistic dependencies on the template level.Also shown is a probabilistic table of the random variableGrade (with states A, B, C) given its parents Difficulty andIntelligence. Note that some probabilistic dependencieswork on multisets and require some form of aggrega-tion: for example, different students might have differentnumbers of registrations, and the ranking of a student
might depend on the (aggregated) average grade fromdifferent registrations. Note the complexity in the depen-dency structure which can involve several entities: forexample, the Satisfaction of a Registration depends on thethe TeachingAbility of the Professor teaching the Courseassociated with the Registration. Consider the additionalcomplexity when structural uncertainty is present, e.g., ifthe Professor teaching the Course is unknown. Redrawnfrom Getoor et al. (2007). Right: shows an example of acorresponding RDF graph as a simple ground PRM. Thered directed edges indicate the probabilistic dependency.With no structural uncertainty, the relationships betweenentities are assumed known and determine the dependencystructure of the attributes
A relational dependency network typicallycontains directed loops and, thus, is not a properBayesian network.
Undirected Relational Graphical ModelsThe probability distribution of an undirectedgraphical model, i.e., a Markov network, iswritten as a log-linear model in the form
P .fXg D fxg/ D 1
Zexp
X
i
wi fi .xi /;
where the feature functions fi can be any real-valued function on the set xi � x and wherewi 2 R. In a probabilistic graphical represen-tation, one forms undirected edges between allnodes that jointly appear in a feature function.Consequently, all nodes that appear jointly in afunction will form a clique in the graphical repre-sentation. Z is the partition function normalizingthe distribution.
Markov Logic Network (MLN)A Markov logic network (MLN) is a proba-bilistic logic which combines Markov networks

Relational Models 1557 R
R
A Bfriends
friends
smokes smokes
Yes
cancer cancer
friends friends
friends(A, A)
friends(A, B)
friends(B, B)
friends(B, A)cancer(A) cancer(B)
smokes(A) smokes(B)
NoYesNo
YesNo No
YesNo
Relational Models, Fig. 3 Left: an example of a MLN.The domain has two entities (constants) A and B andthe unary relations smokes and cancer and the bi-nary relation friends. The eight elliptical nodes are theground predicates. Then there are two logical expres-sions 8x smokes.x/ ! cancer.x/ (someone whosmokes has cancer) and 8x8y f riends.x; y/ !.smokes.x/ $ smokes.y// (friends either bothsmoke or both do not smoke). Obviously and fortunatelyboth expressions are not always true, and learned weights
on both formulae will assume finite values. There are twogroundings of the first formula (explaining the edges be-tween the smokes and cancer nodes) and four groundingsof the second formula, explaining the remaining edges.The corresponding features are equal to one if the logicalexpressions are true and are zero else. The weights on thefeatures are adapted according to the actual statistics inthe data. Redrawn from Domingos and Richardson (2007).Right: the corresponding RDF graph
with first-order logic. In MLNs the random vari-ables, representing ground predicates, are part ofa Markov network, whose dependency structureis derived from a set of first-order logic formulae(Fig. 3).
Formally, a MLN L is defined as follows: LetFi be a first-order formula (i.e., a logical expres-sion containing constants, variables, functions,and predicates), and let wi 2 R be a weightattached to each formula. Then L is defined as aset of pairs .Fi ; wi / (Richardson and Domingos2006; Domingos and Richardson 2007).
From L the ground Markov network ML;C isgenerated as follows. First, one generates nodes(random variables) by introducing a binary nodefor each possible grounding of each predicate ap-pearing in L given a set of constants c1; : : : ; cjC j(see the discussion on the canonical probabilisticrepresentation). The state of a node is equal to oneif the ground predicate is true and zero otherwise.The feature functions fi , which define the proba-bilistic dependencies in the Markov network, arederived from the formulae by grounding themin a domain. For formulae that are universallyquantified, grounding is an assignment of con-stants to the variables in the formula. If a formulacontains N variables, then there are jC jN such
assignments. The feature function fi is equal toone if the ground formula is true and zero oth-erwise. The probability distribution of the ML;C
can then be written as
P .fXg D fxg/ D 1
Zexp
X
i
wini .fxg/!
;
where ni .fxg/ is the number of formula ground-ings that are true for Fi and where the weight wi
is associated with formula Fi in L.The joint distribution P .fXg D fxg/ will be
maximized when large weights are assigned toformulae that are frequently true. In fact, thelarger the weight, the higher is the confidencethat a formula is true for many groundings.Learning in MLNs consists of estimating theweights wi from data. In learning, MLN makes aclosed-world assumption and employs a pseudo-likelihood cost function, which is the product ofthe probabilities of each node given its Markovblanket. Optimization is performed using alimited memory BFGS algorithm.
The simplest form of inference in a MLN con-cerns the prediction of the truth value of a groundpredicate given the truth values of other ground

R 1558 Relational Models
predicates. For this task, an efficient algorithmcan be derived: In the first phase of the algo-rithm, the minimal subset of the ground Markovnetwork is computed that is required to calculatethe conditional probability of the queried groundpredicate. It is essential that this subset is smallsince in the worst case, inference could involveall nodes. In the second phase, the conditionalprobability is then computed by applying Gibbssampling to the reduced network.
Finally, there is the issue of structural learning,which, in this context, means the learning offirst-order formulae. Formulae can be learnedby directly optimizing the pseudo-likelihood costfunction or by using ILP algorithms. For thelatter, the authors use CLAUDIAN (Raedt andDehaspe 1997), which can learn arbitrary first-order clauses (not just Horn clauses, as in manyother ILP approaches).
An advantage of MLNs is that the features andthus the dependency structure is defined usinga well-established logical representation. On theother hand, many people are unfamiliar withlogical formulae and might consider the PRMframework to be more intuitive.
Relational Markov Networks (RMNs)RMNs generalize many concepts of PRMs toundirected relational models (Taskar et al. 2002).RMNs use conjunctive database queries as cliquetemplates, where a clique in an undirected graphis a subset of its nodes such that every two nodesin the subset are connected by an edge. RMNsare mostly trained discriminately. In contrast toMLNs and similarly to PRMs, RMNs do notmake a closed-world assumption during learn-ing (Fig. 3).
Relational Latent VariableModelsIn the approaches described so far, the structuresin the graphical models were either defined usingexpert knowledge or were learned directly fromdata using some form of structural learning. Bothcan be problematic since appropriate expert do-main knowledge might not be available, whilestructural learning can be very time-consumingand possibly results in local optima which are
difficult to interpret. In this context, the advantageof relational latent variable models is that thestructure in the associated graphical models ispurely defined by the entities and relations in thedomain. Figure 4 shows an example: the greenrectangles represent the entities’ latent variables;latent variables are variables that have not beenobserved in the data but are assumed to be hiddencauses that explain the observed variables. Anobjective of a latent variable model is then to inferthe states of these hidden causes. The probabilityof a labelled link between two entities are derivedfrom a simple operation on their latent repre-sentations. The additional complexity of workingwith a latent representation is counterbalancedby the great simplification in avoiding structurallearning.
The IHRM: A Latent Class ModelThe infinite hidden relational model (IHRM)(Kemp et al. 2006; Xu et al. 2006) is a directedrelational model (i.e., a relational Bayesianmodel) in which each entity is assigned toexactly one out of N possible latent classesC D fC1; C2; : : : ; CN g. The latent class ofan entity and the number of possible classesare assumed to be unknown and thus have tobe inferred from data. Considering the groundpredicate R.Ei ; Ej / with entities Ei and Ej , wewould obtain
P.R.Ei ; Ej / D 1jL.Ei /; L.Ej //
D �R;L.Ei /;L.Ej /;
with 0 �R;L.Ei/;L.Ej / 1. The equation statesthat the probability of a ground predicate beingtrue depends on the predicate and the two latentclasses L.Ei / 2 C; L.Ej / 2 C of the involvedentities. In the example in Fig. 4 this would meanthat
P .friendsWith(John, Jack) D 1jL(John);
L(Jack)/ D �friendsWith, L(John), L(Jack):
In the IHRM the number of states (latentclasses) in each latent variable is allowed to be

Relational Models 1559 R
R
Jack JohnfriendsWith
likes
HarryPotter
likes
hasAgehasAge Young
typebook
MiddleOld
MiddleOld
Young
Relational Models, Fig. 4 In relational latent variablemodels, entities are represented by latent variables, whicheither represent latent classes (shown as green rectangles)or sets of latent factors (in which case the green rect-angles become sets of continuous latent nodes). Theselatent variables are the parents of the random vari-ables standing for the truth values of the associated
links. In the figure, XfriendsW ith.Jack;John/ dependson the latent states of the entities Jack and John.Similarly, XhasAge.John;Young/ depends on the la-tent representation of John and of Young. Althoughthe model appears local, global propagation of infor-mation is achieved since the latent representations areunknown
infinite, and fully Bayesian learning is performedbased on a Dirichlet process mixture model. Forinference, Gibbs sampling is employed whereonly a small number of the infinite states areoccupied in sampling, leading to a clusteringsolution where the number of states in the latentvariables is automatically determined.
Since the dependency structure in the groundBayesian network is local, one might get theimpression that only local information influencesprediction. This is not true, since in the groundBayesian network, common children with evi-dence lead to interactions between the parentlatent variables. Thus, information can propagatein the network of latent variables.
The IHRM has a number of key advantages.First, no structural learning is required, since thedirected arcs in the ground Bayesian network aredirectly given by the structure of the RDF graph.Second, the IHRM model can be thought of asan infinite relational mixture model, realizing hi-erarchical Bayesian modeling. Third, the mixturemodel can be used for a cluster analysis providinginsight into the relational domain.
The IHRM has been applied to socialnetworks, to recommender systems, for gene
function prediction, and to develop medicalrecommender systems. The IHRM was thefirst relational model applied to trust learning(Rettinger et al. 2008).
In Airoldi et al. (2008) the IHRM isgeneralized to a mixed-membership stochasticblock model, where entities can belong to severalclasses.
RESCAL: A Latent Factor ModelThe RESCAL model was introduced in Nickelet al. (2011) and follows a similar dependencystructure as the IHRM. The main difference isthat the latent variables do not describe entityclasses but are latent entity factors. The proba-bility of a binary link is calculated as
P�R.Ei ; Ej / D 1jA; GR
�/
rX
kD1
rX
lD1
GRk;lai;kaj;l ;
where r is the number of latent factors, A
is the latent factor matrix, and GR 2 Rr�r
is a full, asymmetric, relation-specific matrix..A/i;k D ai;k 2 R is the k-th factor of entity

R 1560 Relational Models
j-th entity
relation R
GRA
AT
i-th entity
Relational Models, Fig. 5 The figure illustrates the fac-torization of the multi-relational adjacency tensor usedin the RESCAL model. In the multi-relational adjacencytensor on the left, two modes represent the entities in thedomain and the third mode represents the relation type.
The i -th row of the matrix A contains the factors of thei -th entity. GR is a slice in the G-tensor and encodes therelation-type specific factor interactions. The factorizationcan be interpreted as a constrained Tucker decomposition
Ei and .A/j;l D aj;l 2 R is the l-th factor ofentity Ej .
As in the IHRM, common children with ob-served values lead to interactions between theparent latent variables in the ground Bayesiannetwork. This leads to the propagation of infor-mation in the network of latent variables andenables the learning of long-range dependencies.The relation-specific matrix GR encodes the fac-tor interactions for a specific relation, and itsasymmetry permits the representation of directedrelationships.
The calculation of the latent factors is basedon the factorization of a multi-relational adja-cency tensor where two modes represent theentities in the domain and the third mode rep-resents the relation type (Fig. 5). The relationallearning capabilities of the RESCAL model havebeen demonstrated on classification tasks andentity resolution tasks, i.e., the mapping of enti-ties between knowledge bases. One of the greatadvantages of the RESCAL model is its scala-bility: RESCAL has been applied to the YAGOontology (Suchanek et al. 2007) with severalmillion entities and 40 relation types (Nickelet al. 2012)! The YAGO ontology, closely relatedto DBpedia (Auer et al. 2007) and the Knowl-edge Graph (Singhal 2012), contains formalizedknowledge from Wikipedia and other sources.
RESCAL is part of a tradition on relationprediction using factorization of matrices and
tensors. Yu et al. (2006) describes a Gaussianprocess-based approach for predicting a singlerelation type, which has been generalized toa multi-relational setting in Xu et al. (2009).Whereas RESCAL is calculated based ona constrained Tucker decomposition of themulti-relational adjacency tensor, the SUNSapproach (Tresp et al. 2009) is based on aTucker1 decomposition.
Key Applications
Typical applications of relational models arein social networks analysis, bioinformatics,recommendation systems, language processing,medical decision support, knowledge bases, andLinked Open Data.
Future Directions
A wider application of relational models so farwas hindered by their complexity and scalabil-ity issues. With a certain personal bias, we be-lieve that the relational latent variable models(RESCAL, SUNS) point in a promising direction.Maybe an application with billions of internetusers is still somewhat far in the future; an appli-cation with millions of patients is within reach.

Relational Models 1561 R
R
Cross-References
�Collective Classification�Data Mining�Eigenvalues, Singular ValueDecomposition�Gibbs Sampling�Linked Open Data�Matrix Decomposition� Principal Component Analysis� Probabilistic Graphical Models� Probabilistic Logic and RelationalModels�RDF�Recommender Systems: Models and Tech-niques� Statistical Research in Networks – LookingForward
References
Airoldi EM, Blei DM, Fienberg SE, Xing EP (2008)Mixed membership stochastic blockmodels. J MachLearn Res 9:1981–2014
Auer S, Bizer C, Kobilarov G, Lehmann J, Cyganiak R,Ives ZG (2007) Dbpedia: a nucleus for a web of opendata. In: ISWC/ASWC, Busan, pp 722–735
Domingos P, Richardson M (2007) Markov logic: a uni-fying framework for statistical relational learning. In:Getoor L, Taskar B (eds) Introduction to statisticalrelational learning. MIT, Cambridge, pp 339–369
Dzeroski S (2007) Inductive logic programming in anutshell. In: Getoor L, Taskar B (eds) Introductionto statistical relational learning. MIT, Cambridge,pp 57–92
Friedman N, Getoor L, Koller D, Pfeffer A (1999) Learn-ing probabilistic relational models. In: IJCAI, Stock-holm, pp 1300–1309
Getoor L, Friedman N, Koller D, Pferrer A, Taskar B(2007) Probabilistic relational models. In: Getoor L,Taskar B (eds) Introduction to statistical relationallearning. MIT, Cambridge, pp 129–174
Heckerman D, Chickering DM, Meek C, Rounthwaite R,Kadie CM (2000) Dependency networks for inference,collaborative filtering, and data visualization. J MachLearn Res 1:49–75
Heckerman D, Meek C, Koller D (2007) Probabilisticentity-relationship models, PRMs, and plate models.In: Getoor L, Taskar B (eds) Introduction to statisticalrelational learning. MIT, Cambridge, pp 201–238
Hofmann R, Tresp V (1997) Nonlinear markov networksfor continuous variables. In: NIPS, Denver
Jaeger M (1997) Relational Bayesian networks. In: UAI,Providence, pp 266–273
Kemp C, Tenenbaum JB, Griffiths TL, Yamada T, Ueda N(2006) Learning systems of concepts with an infiniterelational model. In: AAAI, Boston, pp 381–388
Kersting K, Raedt LD (2001) Bayesian logic programs.ILP work-in-progress reports 2000
Koller D, Pfeffer A (1998) Probabilistic frame-based sys-tems. In: AAAI/IAAI, Madison, pp 580–587
Losch U, Bloehdorn S, Rettinger A (2012) Graph kernelsfor rdf data. In: ESWC, Heraklion, pp 134–148
Muggleton S (1991) Inductive logic programming. NewGener Comput 8(4):295–318
Neville J, Jensen D (2004) Dependency networks forrelational data. In: ICDM, Brighton, pp 170–177
Nickel M, Tresp V, Kriegel HP (2011) A three-way modelfor collective learning on multi-relational data. In:ICML, Bellevue, pp 809–816
Nickel M, Tresp V, Kriegel HP (2012) Factorizing yago:scalable machine learning for linked data. In: WWW,Lyon, pp 271–280
Quinlan JR (1990) Learning logical definitions from rela-tions. Mach Learn 5:239–266
Raedt LD, Dehaspe L (1997) Clausal discovery. MachLearn 26(2–3):99–146
Rettinger A, Nickles M, Tresp V (2008) A statistical re-lational model for trust learning. In: AAMAS, Estoril,vol 2, pp 763–770
Richardson M, Domingos P (2006) Markov logic net-works. Mach Learn 62(1–2):107–136
Singhal A (2012) Introducing the knowledge graph:things, not strings. Technical report, Official GoogleBlog, May 2012. http: / /googleblog.blogspot.com/2012/05/introducing-knowledge-graph-things-not.html
Suchanek FM, Kasneci G, Weikum G (2007) Yago: a coreof semantic knowledge. In: WWW, Banff, pp 697–706
Suciu D, Olteanu D, Re C, Koch C (2011) Probabilisticdatabases. Synthesis lectures on data management.Morgan & Claypool Publishers, San Rafael
Taskar B, Abbeel P, Koller D (2002) Discriminative proba-bilistic models for relational data. In: UAI, Edmonton,pp 485–492
Tresp V, Huang Y, Bundschus M, Rettinger A (2009)Materializing and querying learned knowledge. In:First ESWC workshop on inductive reasoning and ma-chine learning on the semantic web (IRMLeS 2009),Heraklion
Xu Z, Tresp V, Yu K, Kriegel HP (2006) Infinite hiddenrelational models. In: UAI, Cambridge
Xu Z, Kersting K, Tresp V (2009) Multi-relational learn-ing with Gaussian processes. In: IJCAI, Pasadena,pp 1309–1314
Yu K, Chu W, Yu S, Tresp V, Xu Z (2006) Stochasticrelational models for discriminative link prediction. In:NIPS, Vancouver, pp 1553–1560

R 1562 Relational View
Relational View
�Top Management Team Networks
Relationship Extraction
�Link Prediction: A Primer
Relationship Formation
� Privacy and Disclosure in a Social NetworkingCommunity
Relationship Mining
� Inferring Social Ties
Relationships
� Social Network Analysis in a Digital Age
Relative Validity Criteria forCommunity Mining Algorithms
Reihaneh Rabbany1, Mansoreh Takaffoli1,Justin Fagnan1, Osmar R. Zaıane1, andRicardo Campello1; 2
1Computing Science Department, University ofAlberta, Edmonton, AB, Canada2Department of Computer Science, University ofSao Paulo, Sao Carlos, SP, Brazil
Synonyms
Clustering evaluation; Clustering objective func-tion; Community mining; Evaluation approach-es; Graph clustering; Graph partitioning; Qualitymeasures
Glossary
Social Network A graph of interconnectednodes
Ground Truth The right answerA Adjacency matrixC ClusteringED Edge PathSPD Shortest Path DistanceARD Adjacency Relation DistanceNOD Neighbor Overlap DistancePCD Pearson Correlation DistanceICD ICloseness Distance
Definition
Grouping data points is one of the fundamentaltasks in data mining, which is commonly knownas clustering if data points are described by at-tributes. When dealing with interrelated data,data represented in the form of nodes and theirrelationships and the connectivity is consideredfor grouping but not the node attributes, this taskis also referred to as community mining. Therehas been a considerable number of approachesproposed in recent years for mining communi-ties in a given network. However, little workhas been done on how to evaluate communitymining results. The common practice is to use anagreement measure to compare the mining resultagainst a ground truth; however, the ground truthis not known in most of the real-world applica-tions. In this article, we investigate relative clus-tering quality measures defined for evaluation ofclustering data points with attributes and proposeproper adaptations to make them applicable in thecontext of social networks. Not only these relativecriteria could be used as metrics for evaluatingquality of the groupings, but also they could beused as objectives for designing new communitymining algorithms.
Introduction
The recent growing trend in the Data Miningfield is the analysis of structured/interrelated data,

Relative Validity Criteria for Community Mining Algorithms 1563 R
R
motivated by the natural presence of relationshipsbetween data points in a variety of the present-day applications. The structures in these interre-lated data are usually represented using networks,known as complex networks or information net-works; examples are the hyperlink networks ofweb pages, citation or collaboration networks ofscholars, biological networks of genes or pro-teins, trust and social networks of humans, andmuch more.
All these networks exhibit common statisticalproperties, such as power law degree distribution,small-world phenomenon, relatively hightransitivity, shrinking diameter, and densificationpower laws (Newman 2010; Leskovec et al.2005). Network clustering, a.k.a. communitymining, is one of the principal tasks in the analy-sis of complex networks. Many community min-ing algorithms have been proposed in recent years(for a recent survey, refer to Fortunato (2010)).These algorithms evolved very quickly fromsimple heuristic approaches to more sophisticatedoptimization-based methods that are explicitly orimplicitly trying to maximize the goodness ofthe discovered communities. The broadly usedexplicit maximization objective is the modularity,first introduced by Newman and Girvan (2004).
Although there have been many methodspresented for detecting communities, verylittle work has been done on how to evaluatethe results and validate these methods. Thedifficulties of evaluation are due to the factthat the interesting communities that have tobe discovered are hidden in the structure ofthe network; thus, the true results are notknown for comparison. Furthermore, thereare no other means to measure the goodnessof the discovered communities in a realnetwork. We also do not have any largeenough dataset with known communities, oftencalled ground truth, to use as a benchmarkto generally test and validate the algorithms.The common practice is to use syntheticbenchmark networks and compare the discoveredcommunities with the built-in ground truth.However, it is shown that the networks generatedwith the current benchmarks disagree withsome of the characteristics of real networks.
These facts motivate investigating a properobjective for evaluation of community miningresults.
Key Points
Defining an objective function to evaluate com-munity mining is nontrivial. Aside from the sub-jective nature of the community mining task,there is no formal definition on the term commu-nity. Consequently, there is no consensus on howto measure “goodness” of the discovered com-munities by a mining algorithm. However, thewell-studied clustering methods in the MachineLearning field are subject to similar issues, andyet there exists an extensive set of validity cri-teria defined for clustering evaluation, such asthe Davies-Bouldin index (Davies and Bouldin1979), Dunn index (Dunn 1974), and Silhouette(Rousseeuw 1987) (for a recent survey, referto Vendramin et al. 2010). In this article, wedescribe how these criteria could be adapted tothe context of community mining in order tocompare results of different community miningalgorithms. Also, these criteria can be used asalternatives to modularity to design novel com-munity mining algorithms.
In the following, we first briefly introducewell-known community mining algorithms andcommon evaluation approaches including avail-able benchmarks. Next, different ways to adaptclustering validity criteria to handle comparisonof community mining results are proposed. Then,we extensively compare and discuss the adaptedcriteria on real and synthetic networks. Finally,we conclude with a brief analysis of these results.
Historical Background
A community is roughly defined as “densely con-nected” individuals that are “loosely connected”to others outside their group. A large numberof community mining algorithms have beendeveloped in the last few years having differentinterpretations of this definition. Basic heuristicapproaches mine communities by assuming that

R 1564 Relative Validity Criteria for Community Mining Algorithms
the network of interest divides naturally intosome subgroups, determined by the networkitself. For instance, the clique percolation method(Palla et al. 2005) finds groups of nodes that canbe reached via chains of k-cliques. The commonoptimization approaches mine communitiesby maximizing the overall “goodness” ofthe result. The most credible “goodness”objective is known as modularity Q, proposed inNewman and Girvan (2004), which considers thedifference between the fraction of edges that arewithin the communities and the expected suchfraction if the edges are randomly distributed.Several community mining algorithms foroptimizing the modularity Q have been proposed,such as fast modularity (Newman 2006). Al-though many mining algorithms are based on theconcept of modularity, Fortunato and Barthelemy(2007) have shown that the modularity cannotaccurately evaluate small communities due to itsresolution limit. Hence, any algorithm based onmodularity is biased against small communities.As an alternative to optimizing modularityQ, we previously proposed the TopLeaderscommunity mining approach (Rabbany et al.2010), which implicitly maximizes the overallcloseness of followers and leaders, assuming thata community is a set of followers congregatingaround a potential leader. There are manyother alternative methods. One notable familyof approaches mines communities by utilizinginformation theory concepts such as compression(e.g., Infomap Rosvall and Bergstrom 2008) andentropy (e.g., entropy base Kenley and Cho2011). For a survey on different communitymining techniques refer to Fortunato (2010).
The standard procedure for evaluating resultsof a community mining algorithm is the externalevaluation of results, particularly when compar-ing accuracy of different algorithms; which isassessing the agreement between the results andthe ground truth that is known for benchmarkdatasets. These benchmarks are typically smallreal-world datasets or synthetic networks. Onthe other hand, there is no well-defined criterionfor evaluating the resulting communities for net-works without any ground truth, which is the casein most of real-world applications. The common
practice is to validate the results partly by ahuman expert. However, the community miningproblem is NP-complete; the human expert val-idation is limited and rather based on narrowintuition than on an exhaustive examination ofthe relations in the given network. Alternatively,modularity Q is sometimes reported to showthe quality of discovered communities. In thisarticle, we investigate other potential measuresfor comparing different (nonoverlapping) com-munity mining results and examine the perfor-mance of these measures parallel to the modular-ity Q. All these new measures are adapted fromwell-grounded traditional clustering criteria forevaluating data points with attributes. Recently,Vendramin et al. comprehensively compared theirperformances in Vendramin et al. (2010), basedon the idea that the better a criterion, the morecorrelated is its ranking of different partitions tothe ranking of an external index.
The external evaluation requires knowing thetrue communities. For this purpose, several gen-erators have been proposed for synthesizing net-works with built-in ground truth. GN benchmark(Girvan and Newman 2002) is the first syntheticnetwork generator. This benchmark is a graphwith 128 nodes, with expected degree of 16,and is divided into four groups of equal sizes;where the probabilities of the existence of a linkbetween a pair of nodes of the same group andof different groups are ´in and 1 � ´in, respec-tively. However, the same expected degree forall the nodes and equal-size communities are notaccordant to real social network properties. LFRbenchmark (Lancichinetti et al. 2008) amendsGN benchmark by considering power law distri-butions for degrees and community sizes. Similarto GN benchmark, each node shares a fraction1 � � of its links with the other nodes of itscommunity and a fraction � with the other nodesof the network. In this article, we generate oursynthetic networks using LFR benchmark, due toits more realistic structure.
There are recent studies on the comparisonof different community mining algorithmsin terms of evaluating their performance onsynthetic and real networks. For example,refer to studies by Danon et al. (2005) and

Relative Validity Criteria for Community Mining Algorithms 1565 R
R
Lancichinetti and Fortunato (2009). All thesestudies are based on the agreements of thegenerated communities with the true one inthe ground truth and are using GN and/orLFR benchmarks. Orman et al. (2011) furtherperformed a qualitative analysis of the identifiedcommunities by comparing the distribution ofresulting communities with the community sizedistribution of the ground truth. None of thesestudies, however, considers any different validitycriteria other than modularity to evaluate thegoodness of the detected communities. In thisarticle, we plan to examine potential validitycriteria specifically defined for evaluation ofcommunity mining results. In the future, thesecriteria can be used not only as a means to measurethe goodness of discovered communities but alsoas an objective function to detect communities.
Community Quality Criteria
In this section, we overview several validity cri-teria that could be used as relative indexes forcomparing and evaluating different partitioningsof a given network. All of these criteria aregeneralized from well-known clustering criteria.The clustering quality criteria are defined withthe implicit assumption that data points consistof vectors of attributes. Consequently their def-inition is mostly integrated or mixed with thedefinition of the distance measure between datapoints. The commonly used distance measure isthe Euclidean distance, which cannot be definedfor graphs. Therefore, we first review differentpossible distance measures that could be usedin graphs. Then, we present generalizations ofcriteria that could use any notion of distance.
Distance Between NodesLet A denote the adjacency matrix of the graph,and let Aij be the weight of the edge betweennodes ni and nj . The distance d.i; j / denotesthe dissimilarity between ni and nj , which canbe computed by one of the following measures.
Edge Path (ED)The distance between two nodes is the inverse oftheir incident edge weight:
dED.i; j / D 1
Aij
For avoiding division by 0, when Aij is 0, 1=�
is returned where � is a very small number; thesame is true for all other formula whenever adivision by zero may occur.
Shortest Path Distance (SPD)The distance between two nodes is the lengthof the shortest path between them, which couldbe computed using the well-known Dijkstra’sShortest Path algorithm.
Adjacency Relation Distance (ARD)The distance between two nodes is the structuraldissimilarity between them, that is computed bythe difference between their immediate neighbor-hood.
dARD.I; j / DsX
k¤j;i
.Aik �Ajk/2
Neighbor Overlap Distance (NOD)The distance between two nodes is the ratio of theunshared neighbors between them:
dNOD.i; j / D 1 � j@i \ @j jj@i [ @j j
where @i is the set of nodes directly connectedto ni . Note that there is a close relation betweenthis measure and the previous one, since similarlydNOD could be rewritten as
dNOD.i; j / D 1 �P
k¤j;i
jAikCAjk j�P
k¤j;i
jAik�Ajk jP
k¤j;i
jAikCAjk jC P
k¤j;i
jAik�Ajk j
The latter formulation of dNOD in terms of theadjacency matrix can be straightforwardly gener-alized for weighted graphs.
Pearson Correlation Distance (PCD)The Pearson correlation coefficient betweentwo nodes is the correlation between theircorresponding rows of the adjacency matrix:

R 1566 Relative Validity Criteria for Community Mining Algorithms
C.i; j / DP
k .Aik � �i /.Ajk � �j /
Ni j
where N is the number of nodes, the average�i D .
Pk Aik/=N and the variance i DpP
k .Aik � �i /2=N . Then, the distancebetween two nodes is computed as dPCD.i; j / D1 � C.i; j /, which lies between 0 (when the twonodes are most similar) and 2 (when the twonodes are most dissimilar).
ICloseness Distance (ICD)The distance between two nodes is computedas the inverse of the connectivity between theircommon neighborhood:
dICD.i; j / D 1P
k2@i\@jns.k; i/ns.k; j /
where ns.k; i/ denotes the neighboring score be-tween nodes k and i that is computed iteratively(for complete formulation, refer to Rabbany andZaıane (2011)).
Community CentroidIn addition to the notion of distance measure,most of the cluster validity criteria use averagingbetween the numerical data points to determinethe centroid of a cluster. The averaging is notdefined for nodes in a graph; therefore, we mod-ify the criteria definitions to use a generalizedcentroid notion, in a way that, if the centroid isset as averaging, we would obtain the originalcriteria definitions, but we could also use otheralternative notions for centroid of a group of datapoints.
Averaging data points results in a point withthe least average distance to the other points.When averaging is not possible, using medoid isthe natural option, which is perfectly compatiblewith graphs. More formally, the centroid of acommunity can be obtained as:
C D arg minm2C
X
i2C
d.i; m/
Relative Validity CriteriaHere we present our generalizations of well-known clustering validity criteria defined as qual-ity measures for internal evaluation of clusteringresults. All these criteria are originally definedbased on distances between data points, whichis in all cases the Euclidean or other inner prod-uct norms of difference between their vectorsof attributes; refer to Vendramin et al. (2010)for comparative analysis of these criteria in theclustering context. We alter the formulae to usea generalized distance, so that we can plug inour graph distance measures. The other alterationis generalizing the mean over data points to ageneral centroid notion, which can be set asaveraging in the presence of attributes and themedoid in our case of dealing with graphs and inthe absence of attributes.
In a nutshell, in every criterion, the average ofpoints in a cluster is replaced with a generalizednotion of centroid, and distances between datapoints are generalized from Euclidean/norm toa generic distance. Consider a clustering C DfC1 [ C2 [ : : : [ Ckg of N data points, whereC denotes the centroid of data points belongingto C . The quality of C can be measured usingone of the following criteria.
Variance Ratio Criterion (VRC)This criterion measures the ratio of thebetween-cluster/community distances to within-cluster/community distances which could begeneralized as follows:
VRC D
kP
lD1jCl jd.C l ; C /
kP
lD1
Pi2Cl
d.i; C l/
� N � k
k � 1
where C l is the centroid of the cluster/communityCl , and C is the centroid of the entiredata/network. The original clustering formulaproposed in Calinski and Harabasz (1974) forattribute vectors is obtained if the centroid isfixed to averaging of vectors of attributes anddistance to (square of) Euclidean distance.

Relative Validity Criteria for Community Mining Algorithms 1567 R
R
Davies-Bouldin Index (DB)This minimization criterion calculates the worstcase within-cluster/community to between-cluster/community distances ratio averaged overall clusters/communities (Davies and Bouldin1979):
DB D 1
k
kX
lD1
maxm¤l
..d l C d m/=d.C l ; C m//
d l D 1
jCl jX
i2Cl
d.i; C l /
Dunn IndexThis criterion considers both the minimum dis-tance between any two clusters/communities andthe length of the largest cluster/community diam-eter (i.e., the maximum or the average distancebetween all the pairs in the cluster/community)(Dunn 1974):
Dunn D minl¤mf ı.Cl ; Cm/
maxp .Cp/g
where ı denotes distance between two commu-nities and is the diameter of a community.Different variations of calculating ı and areavailable; ı could be single, complete, or averagelinkage or only the difference between the twocentroids. Moreover, could be maximum oraverage distance between all pairs of nodes or theaverage distance of all nodes to the centroid. Forexample, the single linkage for ı and maximumdistance for are ı.Cl ; Cm/ D min
i2Cl ;j2Cm
d.i; j /
and .Cp/ D maxi;j2Cp
d.i; j /. Therefore, we have
different variations of Dunn index in our ex-periments, each indicated by two indexes fordifferent methods to calculate ı (i.e., single(0),complete(1), average(2), and centroid(3)) and dif-ferent methods to calculate (i.e., maximum(0),average(1), average to centroid(3)).
Silhouette Width Criterion (SWC)This criterion measures the average of silhouettescore for each data point. The silhouette score ofa point shows the goodness of the community it
belongs to by calculating the normalizeddifference between the distance to its nearestneighboring community and its own community(Rousseeuw 1987). Taking the average one has:
SWCD 1
N
kX
lD1
X
i2Cl
minm¤l
d.i; Cm/� d.i; Cl/
max fminm¤l
d.i; Cm/; d.i; Cl/g
where d.i; Cl/ is the distance of point i tocommunity Cl , which is originally set tobe the average distance (called SWC2) (i.e.,1=jCl j
Pj2Cl
d.i; j /) or could be the distance
to its centroid (called SWC4) (i.e., d.i; Cl/). Analternative formula for Silhouette is proposed inVendramin et al. (2010):
ASWC D 1
N
kX
lD1
X
i2Cl
minm¤l
d.i; Cm/
d.i; Cl/
PBMThis criterion is based on the within-communitydistances and the maximum distance betweencentroids of communities (Pakhira and Dutta2011):
PBM D 1
k� maxl;m d.C l ; C m/
kP
lD1
Pi2Cl
d.i; C l/
C-IndexThis criterion compares the sum of the within-community distances to the worst and best casescenarios (Dalrymple-Alford 1970). The bestcase scenario is where the within-communitydistances are the shortest distances in the graph,and the worst case scenario is where the within-community distances are the longest distances inthe graph.
� D 1
2
kX
lD1
X
i;j2Cl
d.i; j /
CIndex D � �min �
max � �min �

R 1568 Relative Validity Criteria for Community Mining Algorithms
The min �=max � is computed by summingthe m1 smallest/largest distances between every
two points, where m1 DkP
lD1
jCl j.jCl j�1/2 .
Z-StatisticsThis criterion is similar to C-Index, however, witha different formulation (Hubert and Levin 1976):
ZIndexD � � E.�/p
var.�/
E.�/ D 1
N
NX
iD1
NX
jD1
d.i; j /
Var.�/ D
NP
iD1
NP
jD1d.i; j /
!2
� 2NP
iD1
NP
jD1d.i; j /
!2
N.N � 1/
�
NP
iD1
NP
jD1d.i; j /
!2
N 2C
NP
iD1
NP
jD1d.i; j /2
N
Point Biserial (PB)This criterion computes the correlation of thedistances between nodes and their cluster co-membership which is dichotomous variable(Milligan and Cooper 1985). Intuitively, nodesthat are in the same community should beseparated by shorter distances than those whichare not:
PB D M1 �M0
S
rm1m0
m2
where m is the total number of distances,i.e., N.N � 1/=2 and S is the standarddeviation of all pairwise distances, i.e.,q
1m
Pi;j .d.i; j /� 1
m
Pi;j d.i; j //2, while M1,
M0 are, respectively, the average of within andbetween-community distances, and m1 and m0
represent the number of within and betweencommunity distances. More formally:
m1 DkX
lD1
Nl.Nl � 1/
2m0 D
kX
lD1
Nl.N �Nl/
2
M1 D 1=2kX
lD1
X
i;j2Cl
d.i; j /
M0 D 1=2kX
lD1
X
i2Cl
j…Cl
d.i; j /
ModularityModularity is the well-known criterion proposedby Newman and Girvan (2004) specifically forthe context of community mining. This criterionconsiders the difference between the fraction ofedges that are within the community and theexpected such fraction if the edges were ran-domly distributed. Let E denote the number ofedges in the network, i.e., E D 1
2
Pij Aij , then
Q-modularity is defined as
Q D 1
2E
kX
lD1
X
i;j2Cl
ŒAij �P
k Aik
Pk Akj
2E�
The computational complexity of different va-lidity criteria is provided in the previous work byVendramin et al. (2010).
ComparisonMethodology andResults
In this section, we compare the proposed rela-tive community criteria. First, we describe theapproach we have used for the comparison. Then,we report the criteria performances in differentsettings. The following procedure summarizesour comparison approach.
The performance of a criterion could beexamined by how well it could rank differentpartitionings of a given dataset. More formally,consider we have a dataset d and a setof m different possible partitionings, i.e.,P.d/ D fpd1; pd2; : : : ; pdmg. Then, theperformance of criterion c on dataset d could

Relative Validity Criteria for Community Mining Algorithms 1569 R
R
D fd1; d2 : : :dngfor all dataset d 2D dofgenerate m possible partitioningsgP.d/ fpd1 ; pd2 : : :pdm
gfcompute external scoresgE.d/ fa.pd1 ; p�
d/; a.pd2 ; p�
d/ : : :
a.pdm; p�
d/g
for all c 2 Criteria dofcompute internal scoresgIc.d/ fc.pd1 /; c.pd2/ : : : c.pdm
/gfcompute the correlationgscorec.d/ correlation.E; I /
end forend forfrank criteria based on their average scoresgscorec 1
n
PndD1 scorec.d/
be determined by how much its values, Ic.d/ Dfc.pd1/; c.pd2/; : : : ; c.pdm/g, correlate with the“goodness” of these partitionings. Assumingthat the true partitioning (i.e., ground truth)p�
dis known for dataset d , the “goodness”
of partitioning pdi could be determinedusing partitioning agreement measure a,a.k.a. external evaluation. Hence, for datasetd with set of possible partitionings P.d/,the external evaluation provides E.d/ Dfa.pd1; p�
d/; a.pd2; p�
d/; : : : ; a.pdm; p�
d/g, where
.pd1; p�d
/ denotes the “goodness” of partitioningpd1 comparing to the ground truth. Then, theperformance score of criterion c on dataset d
could be examined by the correlation of itsvalues Ic.d/ and the values obtained from theexternal evaluation E.d/ on different possiblepartitionings. Finally, the criteria are rankedbased on their average performance score over aset of datasets.
External evaluation is done with an agreementmeasure, which computes the agreement betweentwo given partitionings or between a partitioningand the ground truth. There are several choicesfor the partitioning agreement measure. The com-monly used ones are pair counting based, suchas adjusted rank index (ARI) (Hubert and Arabie1985) and Jaccard coefficient (Jaccard 1901), andthe information theoretic-based, such as normal-ized mutual information (NMI) (Kvalseth 1987;Danon et al. 2005) and the adjusted mutual in-formation (AMI) (Vinh et al. 2010). There are
also different ways to compute the correlationbetween two vectors. The classic options are thePearson product-moment coefficient or the Spear-man rank correlation coefficient. The reportedresults in our experiments are based on the Spear-man correlation, since we are interested in thecorrelation of rankings that a criterion providesfor different partitionings and not the actual val-ues of that criterion. However, the reported resultsmostly agree with the results obtained by usingthe Pearson correlation, which are reported in thesupplementary materials available from http://cs.ualberta.ca/�rabbanyk/criteriaComparison.
Sampling the Partitioning SpaceIn our comparison, we generate different parti-tionings for each dataset d to sample the space ofall possible partitionings. For doing so, given theperfect partitioning, p�
d, we randomized different
versions of p�d
by randomly merging and splittingcommunities and swapping nodes between them.The sampling procedure is described in moredetails in the supplementary materials.
Results on Real-World DatasetsWe first compare performance of different criteriaon five well-known real-world benchmarks:Karate Club (weighted) by Zachary (1977),Sawmill Strike dataset (Nooy et al. 2004), NCAAFootball Bowl Subdivision (Girvan and Newman2002), and Politician Books from Amazon (Krebs2004). Table 1 shows general statistics about thedatasets and their generated samples. We can seethat the randomized samples cover the space ofpartitionings according to their external indexrange.
Figure 1 exemplifies how different criteriaexhibit different correlations with the externalindex. It visualizes the correlation between fewselected relative indexes and an external index forone of our datasets listed in Table 1.
Similar analysis is done for all 4 datasets � 19criteria � 7 distances � 4 external indexes, whichproduced over 2,000 such correlations. The top-ranked criteria based on their average perfor-mance over these datasets are summarized inTable 2. Based on these results, CIndex whenused with PCD distance has a higher correlation

R 1570 Relative Validity Criteria for Community Mining Algorithms
Relative Validity Criteria for Community Mining Algorithms, Table 1 Statistics for sample partitionings of eachreal-world dataset. For example, for the Karate Club dataset which has 2 communities in its ground truth, we havegenerated 60 different partitionings with average 3:57˙ 1:23 clusters ranging from 2 to 6 and the “goodness” of thesamples is on average 0:46˙ 0:27 in terms of their AMI agreement
Dataset K� # K AMI
Strike 3 60 3.17˙12[2,5] 0.59˙0.272[�0.04,1]
Polboks 3 60 3.17˙1.132[2,6] 0.44˙0.252[0.04,1]
Karate 2 60 3.57˙1.232[2,6] 0.46˙0.272[�0.02,1]
Football 11 60 10.17˙4.552[4,19] 0.68˙0.162[0.4,1]
K� denotes the perfect/true number of clusters
Q
0
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
5 10 15 20 25 30 35
Partitionings
Val
ue
Clndex PCD AMI AMI
40 45 50 55 60 0
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
5 10 15 20 25 30 35
Partitionings
Val
ue
40 45 50 55 60
0
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
5 10 15 20 25 30 35
Partitionings
SWC2 NOD Dunn01 ICD AMIAMI
Val
ue
40 45 50 55 60 0
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
5 10 15 20 25 30 35
Partitionings
a b
c d
Val
ue
40 45 50 55 60
Relative Validity Criteria for Community Mining Al-gorithms, Fig. 1 Visualization of correlation betweenan external agreement measure and some relative qualitycriteria for Karate dataset. The x axis indicates differentrandom partitionings, and the y axis indicates the valueof the index. While, the blue/darker line represents thevalue of the external index for the given partitioning and
the red/lighter line represents the value that the criteriongives for the partitioning. Please note that the value ofcriteria are not generally normalized and in the same rangeas the external indexes, in this figure AMI. For the sake ofillustration, therefore, each criterion’s value is scaled to bein the same range as of the external index. (a) CINDEXPCD. (b) Q. (c) SWC2 NOD. (d) Dunn01 ICD
with the external index comparing to the modu-larity Q. And this is true regardless of the choiceof AMI as the external index, since it is rankedabove Q also by ARI and NMI.
The correlation between a criterion and anexternal index depends on how close the random-ized partitionings are from the true partitioningof the ground truth. This can be seen in Fig. 1.For example, Dunn01 (single linkage network
diameter and average linkage within communityscores) with the ICD distance agrees stronglywith the external index in samples with higherexternal index value, i.e., closer to the groundtruth, but not on further samples. On the otherhand, Q is very well matched for the samples toofar or too close to the ground truth, but is notdoing as well as others in the middle. With thisin mind, we have divided the generated clustering

Relative Validity Criteria for Community Mining Algorithms 1571 R
R
Relative Validity Criteria for CommunityMining Algorithms, Table 2 Overall ranking of criteria on the real-worlddatasets, based on the average Spearman correlation of criteria with the AMI external index, AMIcorr. Ranking basedon correlation with other external indexes is also reported
Rank Criterion AMIcorr ARI Jaccard NMI
1 CIndex PCD 0:907˙ 0:058 1 1 1
2 SWC2 NOD 0:857˙ 0:031 4 4 2
3 Q 0:85˙ 0:083 2 2 3
4 CIndex ARD 0:826˙ 0:162 6 15 5
5 CIndex SPD 0:811˙ 0:126 3 10 4
6 ASWC2 NOD 0:809˙ 0:043 5 11 6
7 CIndex NOD 0:794˙ 0:096 12 3 9
8 SWC2 PCD 0:789˙ 0:103 7 7 8
9 SWC4 NOD 0:778˙ 0:075 9 5 7
10 ASWC2 PCD 0:772˙ 0:088 10 9 10
11 SWC2 SPD 0:751˙ 0:121 8 6 11
12 Dunn01 ICD 0:742˙ 0:111 18 24 12
13 ASWC2 SPD 0:733˙ 0:116 11 8 13
14 Dunn00 PCD 0:721˙ 0:1 21 30 14
15 DB ICD 0:712˙ 0:063 24 22 16
16 Dunn00 ICD 0:707˙ 0:133 28 28 15
17 Dunn03 ICD 0:703˙ 0:055 25 23 17
18 SWC4 PCD 0:7˙ 0:072 14 12 21
samples into three sets of easy, medium, and hardsamples and re-ranked the criteria in each of thesesettings. Since the external index determines howfar a sample is from the optimal result, the sam-ples are divided into three equal length intervalsaccording to the range of the external index.Table 3 reports the rankings of the top criteria ineach of these three settings. We can see that theseaverage results support our earlier hypothesis,i.e., when considering partitionings medium farfrom the true partitioning, CIndex PCD performssignificantly better than modularity Q, while theirperformances are not very different in the near-optimal samples or the samples very far from theground truth. One may conclude based on thisexperiment that CIndex PCD is a more accurateevaluation criterion comparing to Q, especiallywhen the results might not be very accurate orvery poor.
Synthetic Benchmarks DatasetsLastly, we compare the criteria on a larger setof synthetic benchmarks. We have generated ourdataset using the LFR benchmarks (Lancichinetti
et al. 2008) which are the generators widely inuse for community mining evaluation. Similar tothe last experiment, Table 4 reports the rankingof the top criteria according to their averageperformance on synthesized datasets of Table 5.Based on which, modularity Q overall outper-forms other criteria especially in ranking poorpartitionings; while CIndex PCD performs betterin ranking finer results.
The LFR generator can generate networkswith different levels of difficulty for the parti-tioning task, by changing how well separated thecommunities are in the ground truth. To examinethe effect of this difficulty parameter, we haveranked the criteria for different values of thisparameter. We observed that modularity Q is thesuperior criterion for these synthetic benchmarksup to some level of how mixed are the commu-nities, but this changes in more difficult settings.Results for other settings are available in thesupplementary materials.
Table 6 reports the overall ranking of thecriteria for a difficult set of datasets that havehigh mixing parameter. We can see that in this

R 1572 Relative Validity Criteria for Community Mining Algorithms
Relative Validity Criteria for Community Mining Algorithms, Table 3 Difficulty analysis of the results: consid-ering ranking for partitionings near-optimal ground truth, medium far, and very far. The reported results are based onAMI and the Spearman correlation
Near-optimal samples
Rank Criterion AMIcorr ARI Jaccard NMI
1 Q 0:736˙ 0:266 5 5 2
2 CIndex PCD 0:72˙ 0:326 1 1 3
3 SWC2 SPD 0:718˙ 0:389 3 3 4
4 CIndex SPD 0:716˙ 0:14 4 4 1
5 SWC2 ICD 0:713˙ 0:396 2 2 5
6 ASWC2 ICD 0:687˙ 0:334 11 10 7
Medium-far samples
1 CIndex PCD 0:608˙ 0:202 8 18 1
2 CIndex NOD 0:58˙ 0:053 39 13 2
3 CIndex ARD 0:513˙ 0:313 26 62 5
4 Dunn01 ICD 0:457˙ 0:173 58 83 8
5 SWC2 NOD 0:447˙ 0:19 5 9 3
6 ASWC2 PCD 0:446˙ 0:191 7 3 9
7 SWC2 PCD 0:446˙ 0:19 6 2 10
8 Dunn03 ICD 0:439˙ 0:109 43 37 11
9 Dunn31 SPD 0:437˙ 0:177 56 47 15
10 Dunn01 SPD 0:434˙ 0:205 29 67 7
11 Q 0:409˙ 0:353 4 7 16
12 DB ICD 0:405˙ 0:072 40 38 18
Far-far samples
1 SWC2 NOD 0:634˙ 0:217 3 13 1
2 ASWC2 NOD 0:583˙ 0:191 5 21 2
3 Q 0:498˙ 0:179 4 38 5
4 CIndex PCD 0:493˙ 0:282 2 4 13
5 CIndex SPD 0:437˙ 0:291 1 11 4
6 SWC3 NOD 0:436˙ 0:344 8 2 25
setting, PB index used with PCD, NOD, SPD orARD distances is significantly more reliable thanmodularity Q, particularly considering the muchhigher variance of the latter.
In short, the relative performances of differentcriteria depends on the difficulty of the networkitself, as well as how far we are sampling fromthe ground truth. Altogether, choosing the rightcriterion for evaluating different communitymining results depends both on the application,i.e., how well-separated communities mightbe in the given network and also on thealgorithm that produces these results, i.e., howfine the results might be. For example, if the
problem is hard and communities are heavilymixed, modularity Q might not distinguish thegood and bad partitionings very well. Whileif we are choosing between fine and well-separated clusterings, it indeed is the superiorcriterion.
Conclusion
In this article, we generalized well-knownclustering validity criteria originally used asquantitative measures for evaluating quality ofclusters of data points represented by attributes.

Relative Validity Criteria for Community Mining Algorithms 1573 R
R
Relative Validity Criteria for Community Mining Algorithms, Table 4 Overall ranking and difficulty analysis ofthe synthetic results. Here communities are well separated with mixing parameter of 0:1. Similar to the last experiment,the reported results are based on AMI and the Spearman correlation
Overall results
Rank Criterion AMIcorr ARI Jaccard NMI
1 Q 0:894˙ 0:018 1 2 1
2 ASWC2 NOD 0:854˙ 0:056 3 4 2
3 SWC2 NOD 0:854˙ 0:051 4 3 3
4 CIndex PCD 0:826˙ 0:07 2 1 4
5 CIndex SPD 0:746˙ 0:137 8 24 5
6 SWC2 PCD 0:743˙ 0:047 5 5 6
7 ASWC2 PCD 0:739˙ 0:048 6 6 7
8 Dunn00 PCD 0:707˙ 0:11 11 26 8
9 SWC4 NOD 0:699˙ 0:131 7 7 9
10 SWC4 ARD 0:689˙ 0:124 9 8 10
11 ASWC2 ARD 0:683˙ 0:108 15 21 11
12 ASWC2 ED 0:665˙ 0:139 10 11 12
13 SWC2 SPD 0:657˙ 0:124 14 16 13
14 ASWC2 SPD 0:651˙ 0:196 16 17 15
15 Dunn03 NOD 0:645˙ 0:156 23 33 14
Near optimal results
1 CIndex PCD 0:729˙ 0:17 1 1 1
2 Q 0:722˙ 0:111 6 5 5
3 SWC2 SPD 0:717˙ 0:185 18 18 2
4 SWC4 NOD 0:709˙ 0:201 5 6 4
5 SWC2 ICD 0:704˙ 0:216 15 15 3
6 SWC4 ARD 0:674˙ 0:183 7 7 6
7 ASWC2 NOD 0:66˙ 0:261 20 19 7
8 SWC2 NOD 0:649˙ 0:264 14 14 9
Medium far results
1 SWC2 NOD 0:455˙ 0:191 5 11 3
2 CIndex PCD 0:453˙ 0:245 1 2 5
3 Q 0:45˙ 0:236 2 9 2
4 ASWC2 NOD 0:435˙ 0:187 4 14 1
5 Dunn00 ARD 0:386˙ 0:243 119 111 7
6 Dunn00 PCD 0:38˙ 0:195 58 91 6
7 CIndex NOD 0:373˙ 0:213 7 1 14
8 Dunn01 NOD 0:358˙ 0:146 108 95 15
Far far results
1 Q 0:63˙ 0:139 1 4 2
2 ASWC2 NOD 0:596˙ 0:164 2 2 3
3 SWC2 NOD 0:57˙ 0:159 3 3 5
4 CIndex SPD 0:565˙ 0:132 4 25 1
5 CIndex PCD 0:446˙ 0:142 5 1 21
6 CIndex ARD 0:433˙ 0:25 10 106 4
7 ASWC4 NOD 0:397˙ 0:119 15 63 11
8 SWC2 PCD 0:356˙ 0:143 6 6 25

R 1574 Relative Validity Criteria for Community Mining Algorithms
Relative Validity Criteria for Community Mining Algorithms, Table 5 Statistics for sample partitionings of eachsynthetic dataset. The benchmark generation parameters: 100 nodes with average degree 5 and maximum degree 50,where size of each community is between 5 and 50 and mixing parameter is 0.1
Dataset K� # K AMI
Network1 4 60 3:4˙ 1:172[2,6] 0:46˙ 0:232[0,1]
Network2 3 60 3:1˙ 1:272[2,7] 0:49˙ 0:222[0.13,1]
Network3 2 60 3:3˙ 1:132[2,6] 0:47˙ 0:232[0.11,1]
Network4 7 60 5:17˙ 2:492[2,12] 0:57˙ 0:22[0.18,1]
Network5 2 60 3:5˙ 1:362[2,8] 0:44˙ 0:222[0.11,1]
Network6 5 60 5:8˙ 2:552[2,12] 0:68˙ 0:22[0.27,1]
Network7 4 60 5:2˙ 2:652[2,12] 0:47˙ 0:192[0.13,1]
Network8 5 60 5:37˙ 2:042[2,10] 0:67˙ 0:212[0.32,1]
Network9 5 60 5:5˙ 2:052[2,10] 0:69˙ 0:192[0.37,1]
Network10 6 60 5:33˙ 2:512[2,11] 0:63˙ 0:192[0.24,1]
K� denotes the perfect/true number of clusters
Relative Validity Criteria for Community Mining Algorithms, Table 6 Overall ranking of criteria based on AMIand the Spearman correlation on the synthetic benchmarks with the same parameters as in Table 5 but much highermixing parameter, 0.7. We can see that in these settings, PB indexes outperform modularity Q
Rank Criterion AMIcorr ARI Jaccard NMI
1 PB PCD 0:454˙ 0:15 1 1 1
2 PB NOD 0:448˙ 0:146 2 2 2
3 PB SPD 0:445˙ 0:144 3 3 4
4 PB ARD 0:44˙ 0:149 4 4 5
5 VRC ICD 0:424˙ 0:117 5 5 3
6 Q 0:391˙ 0:381 17 6 12
7 CIndex ARD 0:365˙ 0:173 6 7 6
8 ASWC4 SPD 0:358˙ 0:101 12 12 7
9 DB PCD 0:358˙ 0:108 15 9 10
10 ASWC4 NOD 0:357˙ 0:114 10 10 8
The first reason of this generalization is toadapt these criteria in the context of communitymining of interrelated data. The only commonlyused criterion to evaluate the goodness ofdetected communities in a network is themodularity Q. Providing more validity criteriacan help researchers to better evaluate andcompare community mining results in differentsettings. Also, these adapted validity criteriacan be further used as objectives to design newcommunity mining algorithms. Our generalizedformulation is independent of any particulardistance measure unlike most of the originalclustering validity criteria that are defined basedon the Euclidean distance. The adopted versionstherefore could be used as community criteriawhen plugged in with different graph distances.
In our experiments, several of these adoptedcriteria exhibit high performances on rankingdifferent partitionings of a given dataset, whichmakes them possible alternatives for the Qmodularity. However, a more careful examinationis needed as the rankings depend significantly onthe experimental settings and the criteria shouldbe chosen based on the application.
Acknowledgment
The authors are grateful for the support from Al-berta Innovates Centre for Machine Learning andNSERC. Ricardo Campello also acknowledgesthe financial support of Fapesp and CNPq.

Relative Validity Criteria for Community Mining Algorithms 1575 R
R
Cross-References
�Combining Link and Content for CommunityDetection�Community Detection, Current and FutureResearch Trends�Competition Within and Between Communi-ties Within and Across Social Networks�Extracting and Inferring Communities via LinkAnalysis�Game-Theoretic Framework for CommunityDetection
References
Calinski T, Harabasz J (1974) A dendrite method forcluster analysis. Commun Stat Theory Methods 3:1–27
Dalrymple-Alford EC (1970) Measurement of clusteringin free recall. Psychol Bull 74:32–34
Danon L, Guilera AD, Duch J, Arenas A (2005) Com-paring community structure identification. J Stat MechTheory Exp 2005(09):09008
Davies DL, Bouldin DW (1979) A cluster separationmeasure. IEEE Trans Pattern Anal Mach Intell 1(2):224–227
Dunn JC (1974) Well-separated clusters and optimal fuzzypartitions. J Cybern 4(1):95–104
Fortunato S (2010) Community detection in graphs. PhysRep 486(3–5):75–174
Fortunato S, Barthelemy M (2007) Resolution limit incommunity detection. Proc Natl Acad Sci 104(1):36–41
Girvan M, Newman MEJ (2002) Community structure insocial and biological networks. Proc Natl Acad Sci99(12):7821–7826
Hubert L, Arabie P (1985) Comparing partitions. J Classif2:193–218
Hubert LJ, Levin JR (1976) A general statistical frame-work for assessing categorical clustering in free recall.Psychol Bull 83:1072–1080
Jaccard P (1901) Etude comparative de la distributionflorale dans une portion des alpes et des jura. Bulletindel la Societe Vaudoise des Sciences Naturelles 37:547–579
Kenley EC, Cho YR (2011) Entropy-based graph clus-tering: application to biological and social networks.In: IEEE international conference on data mining,Vancouver
Krebs V (2004) Books about us politics. http://www.orgnet.com/
Kvalseth TO (1987) Entropy and correlation: some com-ments. IEEE Trans Syst Man Cybern 17(3):517–519.doi:10.1109/TSMC.1987.4309069
Lancichinetti A, Fortunato S (2009) Community detec-tion algorithms: a comparative analysis. Phys Rev E80(5):056117
Lancichinetti A, Fortunato S, Radicchi F (2008) Bench-mark graphs for testing community detection algo-rithms. Phys Rev E 78(4):046110
Leskovec J, Kleinberg J, Faloutsos C (2005) Graphs overtime: densification laws, shrinking diameters and pos-sible explanations. In: ACM SIGKDD internationalconference on knowledge discovery in data mining,Chicago, pp 177–187
Milligan G, Cooper M (1985) An examination of proce-dures for determining the number of clusters in a dataset. Psychometrika 50(2):159–179
Newman MEJ (2006) Modularity and community struc-ture in networks. Proc Natl Acad Sci 103(23):8577–8582
Newman M (2010) Networks: an Introduction. OxfordUniversity Press, New York
Newman MEJ, Girvan M (2004) Finding and evaluat-ing community structure in networks. Phys Rev E69(2):026113
Nooy Wd, Mrvar A, Batagelj V (2004) Exploratory socialnetwork analysis with Pajek. Cambridge UniversityPress, Cambridge
Orman GK, Labatut V, Cherifi H (2011) Qualitativecomparison of community detection algorithms. In:International conference on digital information andcommunication technology and its applications, Dijon,vol 167, pp 265–279
Pakhira M, Dutta A (2011) Computing approximate valueof the PBM index for counting number of clustersusing genetic algorithm. In: International conferenceon recent trends in information systems, Kolkata,pp 241–245
Palla G, Derenyi I, Farkas I, Vicsek T (2005) Uncover-ing the overlapping community structure of complexnetworks in nature and society. Nature 435(7043):814–818
Rabbany R, Zaıane OR (2011) A diffusion of innovation-based closeness measure for network associations. In:IEEE international conference on data mining work-shops, Vancouver, pp 381–388
Rabbany R, Chen J, Zaıane OR (2010) Top leaders com-munity detection approach in information networks.In: SNA-KDD workshop on social network miningand analysis, Washington, DC
Rosvall M, Bergstrom CT (2008) Maps of random walkson complex networks reveal community structure.Proc Natl Acad Sci 105(4):1118–1123
Rousseeuw P (1987) Silhouettes: a graphical aid tothe interpretation and validation of cluster analysis.J Comput Appl Math 20(1):53–65
Vendramin L, Campello RJGB, Hruschka ER (2010)Relative clustering validity criteria: a comparativeoverview. Stat Anal Data Min 3(4):209–235
Vinh NX, Epps J, Bailey J (2010) Information theoreticmeasures for clusterings comparison: variants, proper-ties, normalization and correction for chance. J MachLearn Res 11:2837–2854

R 1576 Relevance Ranking
Zachary WW (1977) An information flow model forconflict and fission in small groups. J Anthropol Res33:452–473
Relevance Ranking
�Ranking Methods for Networks
Reliability
�Quality of Social Network Data
Reliance
�Trust in Social Networks
Report Confirmation
� Spatiotemporal Proximity and Social Distance
Reputation Systems
� Fraud Detection Using Social Network Analy-sis, a Case Study
Research Challenges
� Statistical Research in Networks – LookingForward
Research Design
� Process of Social Network Analysis
Research Designs for SocialNetwork Analysis
Katarzyna MusialDepartment of Informatics, King’s CollegeLondon, London, UK
Synonyms
Graph analysis; Knowledge discovery innetworks; Social network mining
Glossary
SNA Social network analysisSN Social network
Definition
Social network analysis – a set of tools and meth-ods that enable to analyze structures calledsocial networks.
Social network – set of nodes and connectionsbetween nodes. Nodes may represent peo-ple, organizations, departments within organi-zations, or other social entities. Connectionsreflect interactions or common activities be-tween nodes.
Introduction
Research design for social network analysis(SNA), as for any other type of research, isa process during which the research questionand set of methods that enables to answer thestated question are described. Social networkanalysis is a multidisciplinary research area, andin consequence a wide range of approaches toanalyze network data exists. Nevertheless, eachstudy in the field of social networks contains thefollowing stages: (i) selecting sample, (ii) datacollection, (iii) data preparation, (iv) choosing

Research Designs for Social Network Analysis 1577 R
R
and applying the method of social networkanalysis, and (v) drawing conclusions. Each ofthe elements is equally important and mistakesmade during designing one of them can causethat conclusions drawn from the study may beinvalid.
The main goal of this work is to describe eachof the enumerated above phases. This will helpresearchers from different backgrounds to un-derstand main concepts connected with researchdesign for social network analysis and make themaware that none of steps can be neglected and thateach of the stages should be carefully planned andexecuted.
Historical Background
The concept of social network, first coined byJ. A. Barnes in 1954, has been in a field of studyof modern sociology, anthropology, geography,social psychology, and organizational studies forlast the few decades.
The person who built the modern social net-work theory, and designed and conducted thefirst well-known research experiments using earlyconcepts of social network analysis was Stan-ley Milgram. He studied the small-world phe-nomenon, which states that if persons x and y
do not know each other, then in order to reachfrom x to y one needs to travel through a chainconsisting of at most 5 people (Pool and Kochen1978; Travers and Milgram 1969). The theoreti-cal model of this small-world phenomenon wascreated by Pool and Kochen (1978) and served asthe basis for Milgram’s research that was purelypictorial. Stanley Milgram conducted two experi-ments – Kansas Study and Nebraska Study – inwhich he asked many people from one city toforward a letter to a chosen person in anothercity. The only stipulation was that a sender couldonly forward this letter to a person whom heor she knew on a first-name basis. AfterwardMilgram analyzed the results of the experimentand concluded that people in the USA createthe social network and they are connected withinthis network with “six degrees of separation.”
It means that a message in such a network wouldbe delivered on average through the usage of fiveintermediaries (Pool and Kochen 1978). Kochenconfirmed that this value is relatively stable evenif the starter selection criteria is changed (De-genne and Forse 1999). Howard claims that sixdegrees of separation may by true off-line whileless than three degrees is more likely in an onlinecase (Howard 2008).
Since 1967 social networks have becomeone of the research areas where scientists fromdifferent fields are looking for inspiration andnew methods of network analysis have been de-veloped. The concept of social network has beenstudied in many different contexts, e.g., corporatepartnership networks (law partnership) (Lazega2001), scientist collaboration networks (Newman2001; DiMicco et al. 2008), movie–actornetworks, friendship network of students (Amaralet al. 2000), a set of business leaders whocooperate with one another (Liben-Nowelland Kleinberg 2003; Robins and Alexander2004), sexual contact networks (Morris 1997),customer networks (Yang et al. 2006; Kazienkoand Musial 2006; Golbeck and Hendler 2006),labors market (Montgomery 1991), public health(Cattell 2001), psychology (Pagel et al. 1987).Recently, with the expansion of the Internetand the increasing popularity of social andcollaborative computing, social networks haveemerged as a significant and promising fieldof study within computer science (Musial andKazienko 2012). Social computing involves suchactivities as collecting, extracting, accessing,processing, computing, and visualizing of allkind of social information.
The fact that social networks have been in-vestigated in many areas, different approachesto network analysis have been developed de-pending on the focus and research interests ofa specific group of scientists. Nevertheless, eachof these approaches has one important elementin common – they cope with network data, i.e.,the emphasis is put on the connections betweenpeople rather than on individuals themselves, andthis is a very important characteristic of socialnetwork analysis.

R 1578 Research Designs for Social Network Analysis
Research Designs for Social NetworkAnalysis
This section is devoted to the research designs forsocial network analysis. First the concept of SNAis introduced and after that the goals and methodsused in the network analysis are presented anddescribed in details.
Social Network AnalysisIn social networks some typical phenomena suchas small-world effect (Pool and Kochen 1978),clustering (Davis 1967), both strong and weakties (Granovetter 1983), and many others maybe observed. Various human features, extractedfrom user profiles, which can have more or lesssignificant influence on the process of formationof a relationship, can be also discovered. In orderto identify these phenomena the appropriate SNAmethod ought to be applied.
Social network analysis stems from traditionalsocial analysis used by sociologists and anthro-pologists in the first half of the twentieth century.After introducing mathematical interpretation ofsocial networks, scientists started developing so-cial network analysis.
SNA can be defined as “the disciplined inquiryinto the patterning of relations among socialactors, as well as the patterning of relationshipsamong actors at different levels of analysis (suchas persons and groups)” (Breiger 2004). Anotherdefinition of SNA was proposed by Valdis Krebs:“Social network analysis (SNA) is the mappingand measuring of relationships and flows be-tween people, groups, organizations, computers,web sites, and other information/knowledge pro-cessing entities. The nodes in the network are thepeople and groups while the links show relation-ships or flows between the nodes. SNA providesboth a visual and a mathematical analysis ofhuman relationships” (Krebs 2000).
Social Network DataEach research design for social network analysisstarts with defining what kind of data and forwhat purpose will be gathered. It should be em-phasized that the regular social data (Table 1) isquite different than social network data (Table 2).
Research Designs for Social Network Analy-sis, Table 1 Example of simple social data
Name Surname Gender Age Marital status
Kate Davis Female 29 Single
Frank Martin Male 37 Divorced
Jason Smith Male 56 Married
Ann Jones Female 25 Married
Carol Damon Female 43 Single
Research Designs for Social Network Analy-sis, Table 2 Example of social network data. 0 meansthat person A does not know person B , and 1 means thatperson A knows person B
Name A/B Kate Frank Jason Ann Carol
Kate – 1 0 1 1
Frank 1 – 0 0 1
Jason 0 0 – 0 1
Ann 1 0 0 – 1
Carol 1 1 1 1 –
Traditional social data describes actors, whereassocial network data mainly describes connec-tions between actors rather than actors them-selves (Hanneman and Riddle 2005). In otherwords, network data analysis puts emphasis noton the individuals themselves, but on the rela-tionships among people (Hanneman and Riddle2005). Because of the fact that the social networkanalysis focuses on investigation of connections,it does not mean that SNA is not interested inactors. After drawing conclusions network anal-ysis may focus on actors to retrieve additionalinformation and to better understand the network;however, it is not its primary goal.
Social network data can include informationabout relations type and character, direction, andweight. Also more than one type of relation be-tween two actors can be distinguished. All of thiscan serve as an input for social network analysis.
Steps in Social Network AnalysisIn social network analysis, five main steps can bedistinguished:– Selecting a sample from population– Collecting data– Data preparation– Choosing and applying the method of SNA– Drawing conclusions

Research Designs for Social Network Analysis 1579 R
R
It should be noted that a specific research designcan include all these steps or just a subset of them.
Selecting a Sample from PopulationIn order to identify and investigate the patternsthat occur within the network, first the selectionof a group of people (or other social entities) thatare to be investigated should be done. Sometimes,due to the research question, some network datacan be neglected. For example, if one would liketo investigate relationships between teenagers,data about adults are not important and will notbe included in the study. Also the possibility ofanalyzing every node of the network (especiallythese huge and heterogeneous) is usually limitedby the available resources and because of that therepresentative group of actors ought to be cho-sen for data collection and further analysis. Thisgroup of actors is called population (Hannemanand Riddle 2005) or sample (Garton et al. 1997).
Selecting a proper sample is especially im-portant when the data is collected using surveys,questionnaires, or observations (please see thenext section). In such situation researchers havelimited capacity when it comes to collecting dataas they can conduct only certain number of inter-views, observations, etc.
Another issue occurs when it comes tonetwork data generated in different device-supported social services. These datasets, storedin the databases, are huge and it causes a problemwith their efficient analysis. Although sometimesit is possible to analyze the whole availabledataset, in vast majority of cases the tools andcomputational power that is at the researcherdisposal are not sufficient. Thus, sampling largeonline datasets, which include information aboutpeople, is also a challenging task. One of theapproaches to sampling is a random approachwhich randomly selects a group of users.
In both cases the sampling procedure shouldbe defined before the data collection will be per-formed. Before the next step, data collection, willtake place, it has to be determined how and whatdata will be obtained. This process is commonfor all social sciences and it abstracts from therelational nature of the analysis as at this stagethe information about social connections is not
available. In other words the sample is selectedfrom a given population and not from a socialnetwork graph.
Collecting DataThe next step is data collection. As it was brieflymentioned before, many methods of obtainingnetwork data such as questionnaires, interviews,observations, and artifacts exist (Garton et al.1997). Preparation that needs to be done priorto employing one of these methods is very timeconsuming. Moreover, it enables to gather dataabout small subset of nodes – up to few hundreds.One of the characteristics, which is perceived tobe a shortcoming of these approaches, is thatpeople are aware that they take part in the studyso they can be biased and give answers or behavein a way that they think is required. These ap-proaches were commonly used in social sciencesthroughout XX century and are still very popularespecially in cases when data cannot be gatheredin more automatic way.
For the last few years, due to the rapid de-velopment and explosion of Internet and WorldWide Web services that enable people to com-municate, collaborate, and share interests in thevirtual world, the approach to data collection hasstarted changing. For the first time in history,we have at our disposal vast amount of dataabout people, their activities and interactions thatare available online. In this case the process ofcollecting data is very simple, one just needs toquery database to get required data. However,data preparation and cleansing is far more com-plex than in the case of traditional approaches andcan be seen as data mining task. As people are notaware of the fact that data about their behaviorsis used, they act in more natural way and thisprovides information about their “real” actionsand reactions. The drawback of this approachis that, in contrary to questionnaires and othertraditional methods where the amount of gathereddata is small, the volume of available data islarge which results in information overload. Withthe development of information technologies, theslow shift in approach to social network analysiscan be observed. The focus is changing frominvestigation of small (up to few hundreds of

R 1580 Research Designs for Social Network Analysis
nodes) samples to data that includes informationabout millions of users. Nowadays, the analysisof social networks copes with two types of data:the one that represents regular, small communi-ties and the one that represents online world andonline society that has been formed. One canargue that the former one still dominates in socialsciences, while the latter one took its origins incomputer science and with time made its way tosocial sciences.
Data PreparationAs it was mentioned before, network data differsfrom conventional sociological data (Hannemanand Riddle 2005). Network data in contrast to tra-ditional data, which consists of rectangular arrayof measurements, consists of a square array ofmeasurements. The SNA research has identifiedthree types of data also called units of analysis,which should be and are investigated: relations,ties (Garton et al. 1997), and actors. Actors arenodes of the network that have such characteris-tics as degree, centrality, prestige, clustering co-efficient, and others. Relations describe connec-tions between actors and tie is a set of differentrelations that can link two actors.
Collected data has to be represented in away that facilitates the application of SNAmethods. A very common representation isgraph or matrix. The adjacency matrix describesrelationships that exist between actors withinthe network. For example, matrix in Table 2represents a social network that is undirected andnot weighted. This is not the only type of networkrepresentation that can be analyzed. In generalfour types of networks can be distinguished:(i) undirected–unweighted, (ii) undirected–weighted, (iii) directed–unweighted, and (iv)directed–weighted. Analyst is responsible forchoosing network type that will represent theavailable data. The decision made depends on thetype of data or on the type of analysis that one isinterested in.
The goal of data preparation is to representthe collected data in a form of network, e.g.,matrix or graph. This can be done manually byextracting information from surveys, interviews,and observations or in automatic manner using
data mining techniques for data cleansing. Theresulting matrix serves as an input to the nextphase of research where the appropriate methodof SNA is chosen.
Choosing and Applying the Method of SNAOnce the sample has been selected, appropriatedata gathered, and social network extracted, thenext step is to perform network analysis on theobtained network. However, before any analysisis done, researcher must decide which part of theextracted network will be used. While “selectinga sample” is concerned with choosing peoplefrom the whole population and is common forall social sciences, choosing one of the methodsof SNA is concerned with selecting users andtheir connections from the previously extractedsocial network and is typical for research whererelations are of key importance for the analysis
The most popular methods, which arecurrently used to sample social network data,are (Fig. 1):– Full network method– Snowball method– Egocentric method “with alter connections”– Egocentric method “ego-only” (Hanneman
and Riddle 2005; Garton et al. 1997)The full network method is the most complex
one, because all members of the created networkand all their possible connections are taken intoconsideration (Hanneman and Riddle 2005). Toanalyze the whole network not only the completelist of connections between people is created, butalso the links to external environment (Gartonet al. 1997). The biggest advantage of this ap-proach is that it provides one full and integratedview on all ties within the network. On the otherhand, it is really hard to create such description,because it demands resources, and is time con-suming and sometimes the required informationis not available. Additionally there is alwaysthe possibility that some of the connections willbe missed, especially in a case of an extensivenetwork with many ties.
An alternative strategy, which is less complex,is the snowball method (Hanneman and Riddle2005). Firstly, we define a group of actors (nodes)who describe their connections to other people.

Research Designs for Social Network Analysis 1581 R
R
Research Designs for Social Network Analysis, Fig. 1Methods of social network analysis. (a) Example of socialnetwork. (b) Full network method. (c) Snow ball method.(d) Egocentric method
Next the same task, i.e., an identification of alloutgoing connections, is done for the actors thathave been identified in the first step. This recur-rence is executed until all ties have been definedor we have decided to stop creating new ties dueto time limits. The biggest shortcoming of thismethod is the strong possibility that not all con-nections and not all actors, particularly isolatedones, will be identified. Also, if social networkis not connected (i.e., in the undirected represen-tation of network, it is not possible to reach allnodes from every single node), then only someparts of the structure will be analyzed, whereasother can be neglected. One of the approachesis to use random walks to obtain representativegroup of users.
If there is no need to identify all connectionsin the network, the egocentric method can beused (Hanneman and Riddle 2005). It focuseson a single individual rather than on groups orpairs. In the first step, one “ego” is chosen.The information about this ego connections isretrieved, together with their target actors andrelationships among them. As a result, a sub-network is created that helps to understand the
possibilities and constraints of a given individual.In this approach, we consider the “ego” and theiralter direct connections (Hanneman and Riddle2005). However, the “ego-only” approach can bealso exploited. In this case, we are not interestedin the connections between the various alters butwe only concentrate on a single ego and their firstlevel connections (Hanneman and Riddle 2005).
The decision which method to choose shouldbe made based on the type of analysis to beperformed. If the research interest is to investigatethe global characteristics of network, then fullmethod is the most appropriate, but if the goalis to analyze local structure, e.g., local clusteringcoefficient, then the egocentric approach will bebetter. The characteristics that can be investigatedon the selected network are centrality, prestige,clustering coefficient, communities detection,density, modularity, motifs, and others (Wasser-man and Faust 1994). Specific measures and theiranalysis are described in other sections, so pleaserefer to Cross-References section for more detail.
Drawing ConclusionsThe last step that enables to identify the exist-ing within the particular social network patternsis to draw the conclusion from the conductedinvestigation and answer the research question.Depending on the goal of the analysis, the resultscan be interpreted only in the context of existingdataset or generalized. In both cases the statisticalsignificance of the obtained results should beinvestigated. The research outcomes can be com-pared with the characteristics of existing networkmodels (e.g., random, small-world, or scale-freenetworks) in order to better understand the phe-nomena present in a given network.
The issue that has to be emphasized is thatcollecting network data and picking the rightmethod of analysis is an extremely challengingtask, and it should be done very carefully.
Cross-References
�Centrality Measures�Clustering Algorithms

R 1582 Research in Network Visualization
�Combining Link and Content for CommunityDetection�Community Detection�Data Mining�Link Prediction�Motif Analysis� Probabilistic Analysis� Process of Social NetworkAnalysis�Role Discovery� Sentiment Analysis
References
Amaral LAN, Scala A, Barthelemy M, Stanley HE (2000)Classes of small-world networks. Proc Natl Acad SciUSA 97(21):11149–11152
Barnes JA (1954) Class and committees in a NorwegianIsland parish. Hum Relat 7:39–58
Breiger RL (2004) The analysis of social networks. In:Hardy M, Bryman A (eds) Handbook of data analysis.SAGE, London, pp 505–526
Cattell V (2001) Poor people, poor places, and poorhealth: the mediating role of social networks and socialcapital. Soc Sci Med 52(10):1501–1516
Davis JA (1967) Clustering and structural balance ingraphs. Hum Relat 20:181–187
Degenne A, Forse M (1999) Introducing social networks.SAGE, London
DiMicco J, Millen DR, Geyer W, Dugan C, BrownholtzB, Muller M (2008) Motivations for social networkingat work. In: Proceedings of the computer supportedcooperative work 2008 conference, San Diego. ACM,pp 711–720
Garton L, Haythorntwaite C, Wellman B (1997) Studyingonline social networks. J Comput-Mediat Commun3(1). http://jcmc.indiana.edu/vol3/issue1/garton.html
Golbeck J, Hendler J (2006) FilmTrust: movie recom-mendations using trust in web-based social networks.In: Proceedings of consumer communications and net-working conference, IEEE conference proceedings 1,Las Vegas, pp 282–286
Granovetter MS (1983) The strength of weak ties: anetwork theory revisited. Sociol Theory 1:201–233
Hanneman R, Riddle M (2005) Introduction to so-cial network methods. Online textbook. Avail-able from Internet: http://faculty.ucr.edu/�hanneman/nettext/, (01.04.2006)
Howard B (2008) Analyzing online social networks. Com-mun ACM 51(11):14–16
Kazienko P, Musial K (2006) Recommendation frame-work for online social networks. In: Proceedings ofthe 4th Atlantic web intelligence conference. Stud-ies in computational intelligence. Beer-Sheva, Israel,pp 111–120
Krebs V (2000) The social life of routers. Internet Protoc J3:14–25
Lazega E (2001) The collegial phenomenon. The so-cial mechanism of co-operation among peers in acorporate law partnership. Oxford University Press,Oxford
Liben-Nowell D, Kleinberg J (2003) The link predic-tion problem for social networks. In: Proceedingsof the 12th international conference on informationand knowledge management, New Orleans. ACM,pp 556–559
Montgomery J (1991) Social networks and labor-marketoutcomes: toward an economic analysis. Am Econ Rev81(5):1407–1418
Morris M (1997) Sexual network and HIV. AIDS11:206–219
Musial K, Kazienko P (2012) Social networks on theinternet. World Wide Web J. doi:10.1007/s11280-011-0155-z
Newman MEJ (2001) The structure of scientific col-laboration networks. Natl Acad Sci USA 98:404–409
Pagel M, Erdly W, Becker J (1987) Social networks: weget by with (and in spite of) a little help from ourfriends. J Pers Soc Psychol 53(4):793–804
Pool I, Kochen M (1978) Contacts and influence, SocialNetworks 1(1):5–51
Robins GL, Alexander M (2004) Small worlds amonginterlocking directors: network structure and distancein bipartite graphs. Comput Math Organ Theory10:69–94
Travers J, Milgram S (1969) An experimental study of thesmall world problem. Sociometry 32(4):425–443
Wasserman S, Faust K (1994) Social network analy-sis: methods and applications. Cambridge UniversityPress, New York
Yang WS, Dia JB, Cheng HC, Lin HT (2006) Min-ing social networks for targeted advertising. In: Pro-ceedings of the 39th Hawaii international conferenceon systems science. IEEE Computer Society, Kauai,pp 425–443
Research in Network Visualization
�Arts and Humanities, Complex Network Anal-ysis of
ResearchMethodology
�Process of Social Network Analysis

Retrieval Models 1583 R
R
Resource Exchange Networks
�Web Communities Versus Physical Communi-ties
Restructuring Social Networks
�Transforming and Integrating Social Networksand Social Media Data
Retrieval Models
Benno Stein, Tim Gollub, and Maik AnderkaBauhaus-Universitat Weimar, Weimar, Germany
Synonyms
Document indexing; Document model; Documentrepresentation
Glossary
Feature A characteristic property of a docu-ment. Usually, a document’s terms are usedas features, but virtually every measurabledocument property can be chosen, suchas word classes, average sentence lengths,principal components of term document-occurrence matrices, or term synonyms
Information Need Specifically here, a lack ofinformation or knowledge that can be satisfiedby a text document
Query Specifically here, a small set of wordsthat expresses a user’s information need
Relevance The extent to which a document iscapable to satisfy an information need. Withinprobabilistic retrieval models, relevance ismodeled as a binary random variable
Definition
Retrieval models provide the formal means toaddress (information) retrieval tasks with the aidof a computer. A retrieval task is given if an in-formation need is to be satisfied against an infor-mation source. More specifically, the informationneed is represented as a term query provided bya user, the information source is given in formof a text document collection, and the solution ofthe retrieval task is a subset of such documentsof the collection, which the user considers asrelevant with respect to the query. Though abroad range of retrieval tasks can be imagined,including all kinds of multimedia queries andmultimedia collections (consider, e.g., “query byhumming” or medical image retrieval), the term“retrieval model” is predominantly used in theaforementioned narrow sense. Retrieval modelsin this sense are based on a linguistic theory andcan be considered as heuristics that operational-ize the probability ranking principle (Robertson1997): “Given a query q, the ranking of docu-ments according to their probabilities of beingrelevant to q leads to the optimum retrieval per-formance.” The principle cannot be applied to allkinds of retrieval tasks. In comment ranking, forexample, the differential information gain mustbe considered.
Retrieval models can be classified according tothe linguistic theory they are based upon. In theliterature a distinction between empirical models,probabilistic models, and language models isoften made, which is rooted in the query-orientedunderstanding of retrieval tasks but which alsohas historical reasons.1. Empirical models, sometimes referred to as
vector space models, focus on the documentrepresentation (Salton and McGill 1983). Bothdocuments and queries are considered as high-dimensional vectors in the Euclidean space,whereas a compatible representation is pre-sumed: a particular document term or queryterm is always associated with the same di-mension; the term importance is specified bya weight. Usually, the cosine of the anglebetween two such vectors is used to quantifytheir similarity. In particular, the concept of

R 1584 Retrieval Models
similarity is put on a level with the conceptof relevance. Empirical models can be distin-guished with regard to the dimensions that areconsidered (the features that are chosen) andhow these dimensions (features) are weighted.
2. Probabilistic models strive for an explicitmodeling of the concept of relevance.Statistics comes into play in order to estimatethe probability of the event that a documentis relevant for a given information need.Most probabilistic models employ conditionalprobabilities to quantify document relevanceunder term occurrence.
3. Language models are based on the ideaof language generation as it is used inspeech recognition systems. A language-basedretrieval model is computed individually foreach document in a collection and is usuallyterm-based. Given a query q, documentranking happens according to the generationprobability of q under the language model ofthe respective document.
Historical Background
Figure 1 illustrates the historical developmentof well-known retrieval models. From each ofthe three modeling paradigms (empirical models,probabilistic models, language models), selectedrepresentatives are characterized in the followingalong with the respective publications.
The Boolean retrieval model uses binary termweights, whereas a query is a Boolean expres-sion with terms as operands. Drawbacks of theBoolean model include its simplistic weightingscheme, its restriction to exact matches, and thefact that no document ranking is possible. TheVector Space Model (VSM) and its variants con-sider documents and queries embedded in theEuclidean space (see above). The main problemof these kinds of models is the term weight-ing. Salton et al. (1975) proposed the tf � idf -scheme, which combines the term frequency tf(the number of term occurrences in a document)with the inverse document frequency idf (theinverse of the number of documents that contain
this term). The Latent Semantic Indexing (LSI)model was developed to improve query interpre-tation and semantic-based matching (Deerwesteret al. 1990). For example, a document d shouldmatch a query even if the user specified validsynonyms that do not occur literally in d . The LSImodel attempts to achieve such a smart match-ing effects by projecting documents and queriesinto a “semantic space,” which is constructedby a singular value decomposition of the term-document matrix. The Explicit Semantic Anal-ysis (ESA) model was introduced to computethe semantic relatedness of natural language texts(Gabrilovich and Markovitch 2007). The modelrepresents a document d as a high-dimensionalvector whose dimensions quantify the pairwisesimilarities between d and the documents ofsome reference collection such as Wikipedia.Potthast et al. (2008) demonstrated how the ESAprinciples are applied to develop a very effectivecross-language retrieval approach, the so-calledCL-ESA model.
Under the Binary Independence Model (BIM),the documents are ranked by decreasing proba-bility of relevance (Robertson and Sparck-Jones1976). The model is based on two assumptionsthat allow for a practical estimation of the re-quired probabilities: documents and queries arerepresented under a Boolean model, and, theterms are modeled as occurring independently ofeach other. The Best Match (BM) model com-putes the relevance of a document to a querybased on the frequencies of the query termsappearing in the document and their inverse doc-ument frequencies (Robertson and Walker 1994).Three parameters tune the importance of thethree characteristics document length, documentterm frequency, and query term frequency. TheBest Match model belongs to the most effectiveretrieval models in the Text Retrieval Conference(TREC) series.
The Language Modeling approach toinformation retrieval was proposed by Ponteand Croft (1998); the idea is to rank documentsby the generation probabilities for a given query(see above). The algorithmic core of the modelis a maximum likelihood estimation of the

Retrieval Models 1585 R
R
pLSI
MixtureUnigram
LDALanguageModel
Language Models
BIIBIM
2-PoissonProbabilityIndex Inquery
BestMatch
BeliefNet
Probabilistic Models
Empirical Models
DivRand CL-ESA
ESA
SuffixTree
VSM
Boolean
GVSM
LSI
Genre
FuzzySet WebGenre
1960 1970 1980 1990 2000 201074 75 83 85 91 94 96 98 99 0302 04 07 0876 86
Retrieval Models, Fig. 1 Historical development of retrieval models, organized according to three paradigms:empirical models, probabilistic models, and language models
probability of a query term under a document’sterm distribution. The Latent Dirichlet Allocation(LDA) model is a sophisticated generativemodel in the context of probabilistic topicmodeling. Under this model it is assumedthat documents are composed as a mixtureof latent topics, where each topic is specifiedas a probability distribution over words. Themixture is generated by sampling from a Dirichletdistribution.
Cross-References
�Analysis and Mining of Tags, (Micro)Blogs,and Virtual Communities�Data Mining�Distance and Similarity Measures�Eigenvalues, Singular ValueDecomposition�Microtext Processing�Mining Trends in the Blogosphere� Social Web Search�Theory of Probability, Basics and Fundamen-tals�Theory of Statistics, Basics, and Fundamentals
References
Deerwester S, Dumais S, Landauer T, Furnas G, Harsh-man R (1990) Indexing by latent semantic analysis.J Am Soc Inf Sci 41(6):391–407
Gabrilovich E, Markovitch S (2007) Computing semanticrelatedness using Wikipedia-based explicit semanticanalysis. In: Veloso MM (ed) IJCAI 2007: proceedingsof the 20th international joint conference on artificialintelligence, Hyderabad, 6–12 Jan 2007, pp 1606–1611
Ponte J, Croft W (1998) A language modeling approachto information retrieval. In: SIGIR’98: proceedings ofthe 21st annual international ACM SIGIR conferenceon research and development in information retrieval,Melbourne. ACM, New York, pp 275–281
Potthast M, Stein B, Anderka M (2008) A Wikipedia-based multilingual retrieval model. In: Macdonald C,Ounis I, Plachouras V, Ruthven I, White R (eds)Advances in information retrieval, 30th European con-ference on IR research (ECIR 08), Glasgow. Lec-ture notes in computer science, vol 4956. Springer,Berlin/Heidelberg/New York, pp 522–530
Robertson S (1997) The probability ranking principle inIR. Morgan Kaufmann Publishers Inc., San Francisco
Robertson S, Sparck-Jones K (1976) Relevance weightingof search terms. Am Soc Inf Sci 27(3):129–146
Robertson S, Walker S (1994) Some simple effectiveapproximations to the 2-poisson model for probabilis-tic weighted retrieval. In: SIGIR’94: proceedings ofthe 17th annual international ACM SIGIR conferenceon research and development in information retrieval,Dublin. Springer, New York, pp 232–241

R 1586 Rewarding
Salton G, McGill M (1983) Introduction to modern infor-mation retrieval. McGraw-Hill, New York
Salton G, Wong A, Yang C (1975) A vector spacemodel for automatic indexing. Commun ACM 18(11):613–620
Rewarding
� Social Interaction Analysis for TeamCollaboration
Rich Communication Suite
� Social Networking in the Telecom Industry
RIF: The Rule Interchange Format
Michael KiferDepartment of Computer Science, Stony BrookUniversity, Stony Brook, NY, USA
Synonyms
Datalog; Logic programming; Production rules;Rule-based systems
Glossary
Rule A statement that has a premise and a con-clusion. It states that if the premise is true thenso must be the conclusion
Rule Head An alternative name for the conclu-sion of a rule
Rule Body An alternative name for the premiseof a rule
Fact An type of a rule that has no premiseProduction Rule A type of a rule whose head is
an action, which inserts or deletes information
Horn Rule A type of a rule whose conclusion isa predicate statement. The body of a Horn rulehas no negated premises
Definition
Rule languages and rule-based systems havebeen playing an important role in the informationtechnology. The applications of rule systemsinclude expert systems, decision-support,deductive databases, and business rules. Mostpeople do not realize that even the ubiquitousdatabase query language SQL is also rule-based.Although the basic idea of a rule is simple: it isjust a statement with a premise and a consequent,there is a remarkable variety of dissimilar,incompatible rule-based systems and languages.
With the advent of the Web and the pushtowards the semantic Web, new opportunities forrule-based applications have emerged. However,to realize these opportunities and make effectiveuse of the Web as a global information system,standards are needed so that the different applica-tions and systems could interoperate.
To help this process along, the World WideWeb Consortium (W3C) created a workinggroup chartered with the task of designing astandardized language for exchanging rulesamong different and dissimilar rule engines –The Rule Interchange Format or RIF. After RDF(Klyne and Carroll 2004) and OWL (Dean andSchreiber 2004), RIF is the latest installment ina series of semantic Web standards (to whichSPARQL was also recently added). It is asuite of documents designed to facilitate ruleexchange among systems, especially amongWeb-enabled rule engines – engines thatare aware of such semantic Web standardsas IRIs (Duerst and Suignard 2005), RDF(Klyne and Carroll 2004), and can import andprocess distributed knowledge published as Webdocuments. Several key components of RIF havebecome W3C recommendations in June 2010.These documents as well as a number of relatedspecifications are available on the RIF workinggroup Web site http://www.w3.org/2005/rules/wiki/RIF Working Group.

RIF: The Rule Interchange Format 1587 R
R
Overview of RIF
RIF is called an “interchange format” to empha-size its purpose—facilitation of inter-operationbetween the different rule engines, primarily onthe Web. Given the diversity of the different usesof the rules in the applications, RIF is not tryingto solve the universal interoperation problem,which is believed to be impossible. Instead, itprovides a family of languages, called dialects,with rigorously specified syntax and semantics.
The main idea behind rule exchange throughRIF is that the different systems will providesyntactic mappings from their native languagesto appropriate RIF dialects and back. These map-pings are required to be semantics-preserving andthus rule sets and data could be communicated byone system to another provided that the systemscan talk through a suitable dialect, which theyboth support.
The family of RIF dialects was intended to beextensible and uniform. Extensibility here meansthat it should be possible to add new dialectsthat various user groups might want to develop.RIF uniformity means that dialects are expectedto share much of the syntactic and semanticapparatus.
The current crop of RIF standards is focusingon two kinds of dialects: logic-based dialects anddialects for rules with actions. Generally, logic-based dialects include languages that employsome kind of a logic, such as the first-orderlogic or non-first-order logics underlying thevarious logic programming languages (e.g., logicprogramming under the well-founded or stablesemantics (Van Gelder et al. 1991; Gelfond andLifschitz 1988)). Rules-with-actions dialectsinclude production rule systems, which aretypically based on the Rete algorithm (Forgy1982). Currently, only two logical dialects havereached the status of W3C recommendations: theCore dialect (RIF-Core) and its extension, theBasic Logic Dialect (RIF-BLD) (Boley and Kifer2010a). The Production Rule Dialect (RIF-PRD)(de Sainte Marie et al. 2010) is currently the onlyrepresentative of the rules-with-actions group ofdialects. Other dialects are expected to be definedby the various user communities.
RIF-BLD is essentially a rule language that isbased on Horn rules with a number of syntacticadditions such as frames, which are modeledafter F-logic (Kifer et al. 1995). RIF-CORE isa minimal logical dialect that is in the inter-section of RIF-BLD and the production rulesdialect RIF-PRD. This pair of dialects is gener-ally viewed as insufficient for many applicationsand various extensions based on more advancedsemantic theories, such as the well-founded andstable semantics (Van Gelder et al. 1991; Gelfondand Lifschitz 1988)), are expected.
In addition, RIF includes a framework forlogic dialects, RIF-FLD (Boley and Kifer 2010b;Kifer 2010, 2008), which provides extensivesupport and guidelines for the development offuture logic RIF dialects. The anticipated exten-sions of RIF-BLD are expected to be defined inthis framework.
Every RIF dialect has a well-defined syntaxand semantics. For human consumption and rule-authoring, the presentation syntax is used. Forrule exchange among different engines, XML-based syntax is used. The following is an exampleof an RIF document that contains a rule anda fact.
Document(Base(<http://example.com/people#>)Prefix(cpt <http://example.com/concepts#>)Prefix(prj <http://example.com/projects#>)Group (
Forall?Pers1?Pers2?Proj(cpt:coworker(?Pers1?Pers2):-cpt:works(?Pers1?Pers2?Proj)
)cpt:works(<John> <Mary> prj:RIF)
))
This document contains a rule that says thatpeople working together on a project are co-workers. The statement below the rule is a factthat says that Mary and John work togetheron a project called RIF. The example relieson a macrofacility called curi or compact URI(Birbeck and McCarron 2008). A curi suchas prj:RIF stands for http://example.com/projects#RIF. That is, prj is expanded intoa URL specified in the appropriate Prefix

R 1588 Risk
statements in the preamble to the document. TheBase statement applies to constants that have noprefix, such as <John>, which are thought ofas having the “empty” prefix whose expansionis given in the Base statement. Thus, <John>expands into http://example.com/people#John.
Applications
Applications of RIF are expected to range fromquestion–answering and intelligent planning sys-tems to decision support and business rules. Atypical scenarios are consumption and exchangeof rules published on the Web in the RIF format.Such rules could be either imported into one’srule language in order to make desired infer-ences or they can be sent to remote engines forevaluation.
Cross-References
�Description Logics�RDF�Reasoning� SPARQL�Web Ontology Language (OWL)
References
Birbeck M, McCarron S (2008) CURIE Syntax 1.0: asyntax for expressing compact URIs, W3C workingdraft. Available at http://www.w3.org/TR/curie/
Boley H, Kifer M (2010a) RIF basic logic dialect. W3Crecommendation 3 July, W3C. http://www.w3.org/TR/rif-bld/
Boley H, Kifer M (2010b) RIF framework for logicdialects. W3c recommendation, W3C. http://www.w3.org/TR/rif-fld/
de Sainte Marie C, Paschke A, Hallmark G (2010) RIFProduction Rule Dialect. W3c recommendation, W3C.http://www.w3.org/TR/rif-prd/
Dean M, Schreiber G (2004) OWL Web ontology lan-guage reference. Recommendation 10 Feb 2004, W3C.http://www.w3.org/TR/owl-ref/
Duerst M, Suignard M (2005) Internationalized resourceidentifiers (IRIs). http://www.ietf.org/rfc/rfc3987.txt
Forgy C (1982) Rete: a fast algorithm for the many pat-tern/many object pattern match problem. Artif Intell19:17–32
Gelfond M, Lifschitz V (1988) The stable model seman-tics for logic programming. In: Logic programming:proceedings of the fifth conference and symposium,pp 1070–1080
Kifer M (2008) Rule interchange format: the framework.In: Calvanese D, Lausen G (eds) Proceedings of thesecond international conference (RR 2008) on Webreasoning and rule systems, Karlsruhe, 31 Oct–1 Nov2008. Lecture Notes in Computer Science, vol 5341.Springer, pp 1–11
Kifer M (2010) Knowledge representation and reasoningwith the rule interchange format. In: Domingue J,Fensel D (eds) Handbook of semantic web technolo-gies. Springer, Heidelberg/New York
Kifer M, Lausen G, Wu J (1995) Logical foundationsof object-oriented and frame-based languages. J ACM42:741–843
Klyne G, Carroll JJ (2004) Resource description frame-work (RDF): concepts and abstract syntax. Recom-mendation 10 February 2004, W3C. http://www.w3.org/TR/rdf-concepts/
Van Gelder A, Ross K, Schlipf J (1991) The well-founded semantics for general logic programs.J ACM 38(3):620–650. httpciteseer.ist.psu.edu/gelder91wellfounded.html
Risk
�Reconnaissance and Social Engineering Risksas Effects of Social Networking
Risks
�Social Media Policy in the Workplace: UserAwareness
Risks Involved in SensitiveIdentifiable Personal InformationDisclosure in Online Social Networks
�Consequences of Publishing Real PersonalInformation in Online Social Networks

Role Discovery 1589 R
R
Role Discovery
Chi Wang and Jiawei HanDepartment of Computer Science, University ofIllinois at Urbana-Champaign, Urbana, IL, USA
Synonyms
Actors, Nodes; Latent relationship, Hidden role;Role discovery, Relationship mining; Socialstatus, Social location, Position; Structuralmeasure, Link mining metric
Glossary
Position The location of an actor or class ofactors in a system of social relationships
Expectation An evaluative standard applied toan incumbent of a position, such as rights,duties, norms, and behavior, that a person hasto face and to fulfill
Role A set of expectations that are coupled to thepositions
Positional Sector An element of the relationalspecification of a position; specified by therelationship of a focal position to a singlecounter position
Role Theory A perspective in sociology orsocial psychology that considers most ofeveryday activities to be the acting out ofsocially defined categories (e.g., mother,manager, teacher)
Role Discovery Extracting implicit knowledgeabout roles from behavior data in a socialnetwork
Network A graph that assigns some semanticsto the nodes and some kind of interaction tothe links
Ego Network The subgraph that represents allof the direct relationships between a selectedentity (the ego) and others (the alters)
Definition
One of the useful applications in social networksis to discover the role of an individual or a setof entities. It is a data mining problem of un-covering the hidden social roles from a networkthat link people with semantic interactions. Com-puter scientists have studied the empirical rolediscovery problems in scattered context, withoutany significant attempt on defining or delimitingthe concept theoretically or hypothetically. Werefer to the literature of sociology (Gross et al.1966; Lorrain and White 1971; Everett 1985;Coulson 2010).
A simple definition of social role is a set ofrights, duties, expectations, norms, and behaviora person has to face and to fulfill. Substantialdebate exists in the field over the meaning of the“role” in role theory. A role can be defined as asocial position, behavior associated with a socialposition, or a typical behavior. Some theoristshave put forward the idea that roles are essentiallyexpectations about how an individual ought tobehave in a given situation, while others considerit as means on how individuals actually behavein a given social position. Others have suggestedthat a role is a characteristic behavior or expectedbehavior, a part to be played, or a script forsocial conduct. Most authors consider the ideasof social location, expectations, and behavior. Forinstance, Gross et al. (1966) defined a role to be aset of expectations or, in terms of their definitionof expectations, a set of evaluative standardsapplied to an incumbent of a particular position.This definition is dependent on the definition ofposition as a location of an actor or class of actorsin a system of social relationships. Position hastwo aspects in specification, namely, relationaland situational. In a position-centric model, thefocal position is specified by its relationship toone or multiple counter positions. For example,a school superintendent has relationships withmany other positions such as school board mem-ber, principal, and teacher. Situational specifica-tion describes the scope of the social system inwhich the position to be studied. For example,the superintendent position can be studied in a

R 1590 Role Discovery
specific community, in the state of Illinois or inthe United States. It is necessary to specify atwhich level one intends to work.
With these backgrounds, we characterize therole discovery problem in social networks, in adata mining point of view, as to answer the fol-lowing two typical questions from investigators:1. What is the role of X?2. Who has the role R?
The first type of question asks the role ofone or multiple actors; X can be an individualor a set of actors. An investigator can specifyseveral predefined roles and ask for the rolelabels of X, such as to label one’s Facebookfriends as relatives, schoolmates, colleagues, orother friends. One can also ask for finding un-known roles based on positions with relationaland situational specifications, such as finding thedifferent organizational roles of every worker ina company, with the knowledge of the existenceof a social hierarchy specified by the manager-subordinate relationship. Note that when the roleis not predefined, the expected behavior of eachrole needs to be discovered as well as the actorswho have these roles.
The second type of question asks which actorshave a certain role. The answers are often givenin a comparative sense – some actors are morelikely to have a role than others – except when theevaluative standards are readily defined and com-putationally easy to measure. Examples of thiskind of question include role discovery at differ-ent levels, such as finding advisors of researchers,parents of people, finding leaders of a commu-nity, finding initiators of discussion topics, andfinding influencers of information diffusion in thewhole network.
Introduction
The concept of role is pivotal in the analysisof the structures and functions of social systemsand explanation of individual behavior. Unfortu-nately, the knowledge of people’s roles is oftenhidden in the network data. The main goal of rolediscovery is to recover such hidden knowledge tofacilitate social network analysis.
Researchers use different specification of rolesin the existent work on role discovery and donot have a unified theoretical framework for it.However, we find that most of the work can fitin our definition. It is beneficial to categorize thework first according to the nature of the task theycan perform.
Type 1: What is the Role of X. We considermultiple possible roles, either predefined orautomatically discovered. The goal is todetermine the role label of a target object X,which can be one actor or a set of actors.The label of X can be one or multiple roles.Representative studies are mining the roles ofemail communicators (Freeman 1997; Leuski2004; McCallum et al. 2005; Rowe et al. 2007),inferring social hierarchy in an organization(Memon et al. 2008; Maiya and Berger-Wolf2009), discovering overlapping roles in syntheticdata (Wolfe and Jensen 2004), and miningdifferent types of relationships in online socialnetwork (Leskovec et al. 2010; Tang et al. 2011;Wang et al. 2012).
Type 2: Who has the Role R. It focuses onfinding actors with a certain role. The expecta-tion of the role is however undefined or hard toevaluate. Representative work includes rankinghubs and authorities (Page et al. 1999; Kleinberg1999), mining influential people in viral mar-keting (Kempe et al. 2003; Chen et al. 2010a);exploring community-based roles and its appli-cation in influence maximization (Scripps et al.2007; Hopcroft et al. 2011), inferring friendship(Eagle et al. 2009; Crandall et al. 2010), miningadvising roles in author network (Wang et al.2010), and detecting topic initiators on the Web(Jin et al. 2010).
Not all of these studies state their problem as“role discovery.” In fact, most of them do not. Butwe include them because they can be regardedas solving role discovery problems in specificcontexts and different emphases. Some of themexplicitly use the concept role, such as Leuski(2004), Wolfe and Jensen (2004), and McCallumet al. (2005). Some do not use the term role butexplicitly specify the role name to detect such

Role Discovery 1591 R
R
as “influencers” (Kempe et al. 2003), “initiators”(Jin et al. 2010), and “key players” (Shaparenkoet al. 2005). Some focus on the social positions(Freeman 1997; Rowe et al. 2007; Memon et al.2008; Maiya and Berger-Wolf 2009; Wang et al.2010), which is a fundamental concept of socialroles. Some have an emphasis on the relationship,which is a necessary concept of defining socialpositions. Diehl et al. (2007), Eagle et al. (2009),Crandall et al. (2010), Leskovec et al. (2010), andTang et al. (2011) belong to this category.
Most of the studies use heuristically definedrole concept, either explicitly or implicitly. Jinet al. (2011) theoretically studies the axiomaticrole similarity measure based on theory fromsociology (Everett 1985).
Key Points
The role discovery problem asks two types ofquestions which have slightly different emphasis:what is the role of X and who has the role R.The first emphasizes on differentiating the rolesof different nodes, and the second aims to find thesimilar nodes that share certain roles. Both paymajor attention to the accuracy and quality of theresults, whereas the challenge for answering thesecond question is sometimes the efficiency.
Historical Background
The concept of role has assumed a key positionin the fields of sociology, social psychology, andcultural anthropology. Yet, despite its frequentuse and presumed heuristic utility since 1920sand 1930s, the conceptualization of role is lackof progress until 1950s. The debate has been onwhether role is a redundant concept in sociologysince then. In Coulson (2010), the criticisms aresummarized. Even without a consensus of theexact definition of social roles, the operationalproblem of role analysis has attracted a lot ofresearch interests. Recently, with the emergenceof large-scale social network data and analysis,computer scientists can contribute to the empiri-cal role discovery problem with new computing
techniques. We have seen such kind of practicein the past decade. However, when differentcomputer scientists tackled with the seeminglydistinct tasks in their own context, the same termrole is used in an even more arbitrary way thansociologists. No one has explicitly defined theubiquitous role discovery problem in a genericsocial network, nor connected to the role theoryin sociology research community except the veryrecent work by Jin et al. (2011) and Hendersonet al. (2012). We attempt to delimit the concept ofrole with resort to sociology study and define therole discovery problem toward the interest andview of computer scientists. Our definition ofrole discovery problem has a clear task-drivenflavor and captures the scattered practice bycomputer scientists. More importantly, we cancategorize the existent work within our definitionand identify a broad range of tasks awaiting study.
The role discovery problem we defined hereshould be distinguished from the role miningproblem in the database and security communityand the semantic role labeling problem in thenatural language processing community.
Solutions andMethodology
While role discovery can be related to varioustraditional data mining tasks and techniques suchas clustering, classification, and ranking, there isno generic solution to the role discovery problemwe defined in this essay. We describe the diverseattempt to solving part of this problem, accordingto the nature of the methodology: (1) link or con-tent analysis via probabilistic modeling, (2) socialnetwork analysis with structural measurement,(3) combinatorial optimization, and (4) machinelearning to classify or rank.
Link or Content Analysis via ProbabilisticModelingProbabilistic modeling covers a vast body ofapproaches to role discovery. Various modelsbased on different stochastic assumptions areproposed for link or content analysis in socialnetworks. We describe one of them in detail andreview others briefly.

R 1592 Role Discovery
A stochastic blockmodel is a model for ana-lyzing link data characterized by block structure.It can be used to answer the type-1 question bypartitioning nodes of the network into subgroupscalled blocks (roles). The basic assumption isthat the distribution of the ties between nodesis dependent on the blocks to which the nodesbelong (Holland et al. 1983).
Formally, let hB1; : : : ; Bt i be a partition ofthe nodes into mutually exclusive and exhaustivesubsets called node blocks. Nodes in the samenodeblock are stochastically equivalent in thefollowing sense. Consider a block Br and anynode j in the network. The likelihood of anygiven pattern of ties with node j is the same forall nodes in the block Br . In other words, if i
and i 0 are two nodes (excluding j ) belonging tonode block Br , any probability statement aboutthe links in the network can be modified byexchanging the links between i and j and thelinks between i 0 and j , without changing its prob-ability. Stochastic equivalence is a generalizationof the algebraic notion of structural equivalence(Lorrain and White 1971).
As an example, we show how to model anetwork with n nodes and a single relation R
between them. For any two nodes i and j in thenetwork,
xij D�
1 if iRj;
0 otherwise:
We assume the matrix X D .xij /n�n is generatedby the following steps:
Step 1. Decide the number of blocks, t . In thesimplest case we can assume the number ofblocks is known. In the actual analysis, thevalue of t can be varied to see how it changesthe results and selected with certain modelselection criteria (e.g., BIC).
Step 2. Sample the block-size distribution vec-tor
� D .�1; : : : ; �t /
where �i > 0;P
i �i D 1. The a prioriprobability that a node is in block j is �i . �
can be sampled from a Dirichlet distributionor determined according to expected behavior
of the model. For example, for a 4-blockmodel where we wish to have approximatelythe same number of nodes in each block, welet t D 4 and �i D 1=4; i D 1; 2; 3; 4. Suchassumptions do not force the node blocks tobe equally large but do keep their size similar.
Step 3. Sample the block-membership indicator-
matrix CD.cij /n�t , i.e., cijD�
1 if i 2 Bj
0 otherwisewith P.cij D 1j�; t/ D �j . Here we assumethe a priori membership of every node isindependent and identically distributed given� and t .
Step 4. Sample the density parameters � D.�rs/t�t for every pair of blocks Br and Bs .Based on the stochastic equivalence assump-tion, we have Prrs.xij D 1/ D �rs for anytwo nodes i 2 Br and j 2 Bs . �rs can begenerated from a beta prior B.˛; ˇ/:
P.�rs/ D K�˛�1rs .1 � �rs/ˇ�1;
where K is a normalizing constant. When ˇ islarge and ˛ is small, the prior is concentratedon low values of � . This can be used to modelthe sparse interaction of a pair of blocks.When both ˛ and ˇ are small, the prioris “flat” (i.e., more approaching to uniformdistribution) to model the unspecified pattern.
Step 5. Sample X with a priori blocks and pair-wise block patterns,
P.xij D 1jC ; �/ DY
1�r;s�t
�circjsrs
Given a matrix X generated from thisBayesian model, we can use the Bayes’ theoremto compute the posterior probability distributionof the block membership of each node:
P.cij D 1jX/; i D 1; : : : ; n; j D 1; : : : ; t:
This n�t array of values gives the probability thateach node belongs to each block. If the data fit theblockmodel, these probabilities should be near 0or 1. If the posterior probabilities are not near 0or 1, the blockmodel is not informative, and onecannot tell which nodes go into which blocks.

Role Discovery 1593 R
R
If the blockmodel cannot explain the data, theposterior probabilities will be near their a priorivalues (i.e., �1 through �t ).
The parameters of the model can be estimatedwith the maximum-likelihood estimation (MLE)principle or maximum a posteriori (MAP) princi-ple. The difference of them is MLE only fits thedata, while MAP fits both data and prior on theparameters. When the amount of data is small,MAP avoids overfitting. For example, if we wantto estimate the pairwise density parameter �, theMAP estimation has the form
P.�jX/ D P.�/P.X j�/
P.X/
/ P.�/X
C
P.X jC ; �/P.C j�; t/
Since there are hidden variables C , the log like-lihood is not easy to maximize. The MAP can besolved by Expectation-Maximization (EM) algo-rithm approximately.
This simple stochastic blockmodel can be gen-eralized in many ways. First, it can be usedto analyze multiple relations instead of a singlerelation, and the paired measurements of eachrelation can be nonbinary and multivariate. Toachieve this we need to sample more than onerelation matrix X , from different distributionsrather than Bernoulli. Second, reciprocity can bemodeled for asymmetric relations by samplingxij and xji together rather than separately andencode the reciprocity in the joint probability ofthem. Third, each node can have multiple roles,and each observed relation can be associatedwith multiple blocks rather than a single block.This can be modeled by assigning each node asubset of a set of role labels (Wolfe and Jensen2004), or a mixed membership of these blocks(Airoldi et al. 2008). Fourth, the number of rolescan be learned automatically instead of beingpredefined or selected by model selection criteria.For example, we can assume t is infinite, and therole membership vectors are generated from a hi-erarchical Dirichlet process in the nonparametricsetting.
We have discussed the stochastic blockmodelin detail. Now we briefly review other
probabilistic models. All of them answer thetype-1 question “what is the role of X” except thelast one.– Scalable “Social” Bayesian Network: Gold-
enberg (2007). This model considered person-event relation instead of direct interactionbetween people. A person’s participation inany event is indicated by a binary variable. Forexample, if two people coauthored a paper, theparticipation indicator variables for both ofthem in this “co-authoring paper” event take 1.It is assumed the roles of people decide thedependency structure of these variables. Sucha representation of data casts the problemof learning interaction networks in terms ofstructural learning of probabilistic graphicalmodels for binary variables. The goal is tolearn the underlying dependencies that triggerevents. In other words, based on knowninformation about simultaneous participationof people in observed events, we can constructa probabilistic generative model that woulddescribe those events. The advantage of thisrepresentation is that the sparseness of socialnetwork interaction is helpful to efficientlylearn the model. The problem is that the rolesare indirectly modeled and it requires furtherinterpretation of the structure of the learnedBayesian network.
– Proximity-Based Interaction Model: Maiyaand Berger-Wolf (2009) proposed a proba-bilistic generative model for weighted socialnetworks governed by a latent social hierarchyamong individuals. The goal is to discover thehierarchy from observed interaction data. Thehierarchy can be regarded as a special socialorganization in which each node can find itsposition. The fundamental hypothesis of theinteraction generation from the hierarchy isthat for each pair of nodes, there is a probabil-ity of interaction, and the highest rates of inter-action are assigned between parents and theirchildren or between siblings. The interactionprobabilities for all other pairs of nodes eitherdecay with tree distance or remain constant.Based on this hypothesis the authors definedfour specific instantiations of the model. Theweight of interaction, which can be explained

R 1594 Role Discovery
as the frequency of social interactions, is as-sumed to be generated from a Bernoulli dis-tribution according to some model of them.Given a weighted social network, they inferredboth the hierarchy and the model from whichit is generated with the maximum-likelihoodprinciple.
– Author-Recipient-Topic (ART) Model:McCallum et al. (2005) argued that networkproperties are not enough to discover all theroles in a social network. As they argued,the email messages in a corporate networkcan have no obvious traffic patterns, and therole of manager becomes obvious only whenone accounts for the language content of theemail messages. They proposed a directedgraphical model of words in a messagegenerated given their author and a set ofrecipients. Compared to related topic modellatent Dirichlet allocation (LDA) and author-topic (AT) model, ART considers both theauthor and recipients of a message. Eachauthor-recipient pair has a multinomial topicdistribution. For each word in a message,a recipient is chosen uniformly from theobserved set of recipients, a topic is chosenfrom the topic distribution of this author-recipient pair, and then the word is generatedfrom that topic, which is a multinomialdistribution over the vocabulary. From theobserved email messages, we can infer thetopic distribution of each author-recipientpair, as well as the marginal distributionconditioned on an author, or a recipient. Thetopic distribution can then be used to find outthe relations between senders and receivers,as well as the roles of each person.
– Time-Dependent Probabilistic FactorGraph (TPFG): Wang et al. (2010) studiedthe case when the role of a person canchange with time. Specifically, it designedan undirected probabilistic graphical modelto predict the role of a researcher based oninferred advisor-advisee relationship from thepublication network composed of authorsand papers. The number of coauthoredpublications, as well as the publicationsof one’s own in each year, is used to
compute a rough estimate of the likelihoodof the advising relationship between twoauthors and the advising duration. The roleof a researcher has an important temporalconstraint: one cannot become an advisorbefore he graduated. This constraint isutilized in TPFG via a factor function whichconnects the hidden variables representingeach author’s advisor, and they are jointlypredicted throughout the network. Themarginal probability of each variable isused to rank the potential advisors for eachresearcher.
Social Network Analysis with StructuralMeasurementIn social network analysis, people have studiednumerous structural metrics. With these metrics,social positions and roles can be inferred from thelink behavior without referring to content infor-mation. In this subsection, we introduce severalpieces of work that are most relevant to our rolediscovery problem.– Hierarchy-Based Role: (Rowe et al. 2007)
proposed a social network analysis algorithmto extract social hierarchy from email flowswithin an organization. They used Enronemail dataset which showcased the internalworking of a real corporation over a periodbetween 1998 and 2002. Without takinginto account the actual contents of the emailmessages, they automatically rank the majorofficers, group similarly ranked and connectedusers in order to accurately reproduce theorganizational structure, and understandrelationship strengths between specific sets ofusers. This can be regarded as a role discoveryproblem where the role is determined by thesocial position in a hierarchy.The algorithm works in two stages. In the
first stage, each email user is profiled by twosets of statistics pertaining to the flow ofinformation, both volumetric and temporal.With these individual features, users can bemeasured against one another for the purposeof ranking and grouping. In the second stage,users are ranked by analyzing cliques and othergraph theoretical qualities of the email network.

Role Discovery 1595 R
R
All the statistics are normalized and combined tocalculate an overall social score with which theusers are ultimately ranked.
Freeman (1997) also studied the hierarchy inan organization with a procedure called canonicalanalysis of asymmetry. We omit the details here.
Different with above work, Memon et al.(2008) studied the hidden hierarchy detectionin terrorist networks which are undirected. Thelinks are not observed communication records butcollected from co-mentioning in news articles.They defined the problem as a process ofcomparing different centrality values of differentnodes to identify which node is more powerful,influential, or worthy to neutralize than others.Their analysis was based on centrality measure.Different centrality measures can be used forfinding the hierarchical view of a network, eachassociated with a particular meaning. A review ofkey centrality concepts can be found in Freemanet al. (1988).– Community-Based Role: Roles can be
studied with the knowledge of communityand community attachment. Community-based roles provide useful information toanalysts in areas such as anti-terrorism andlaw enforcement. In searching for potentialterrorist threats, for example, analysts mayfind it useful to identify suspects with certainroles (mastermind, financier, facilitators,military commander, etc.). They have differentinteraction characteristics with communities.Scripps et al. (2007) defined the community-
based role of a node according to the num-ber of communities (community score) and linksincident to it (degree). Ambassadors provide con-nections to many different communities. Big fish,named after the clich “big fish in a small pond,”are very important only within a community.They have a high degree but a relatively smallcommunity score. Contrasting with them are peo-ple with a low degree but a high communityscore. These are called bridges because theyserve as bridges between a number of commu-nities. Finally, loners have a low relative degreeand low community score. When the commu-nity membership is not available, it needs tobe inferred from the network in order to define
the community-based role. Moreover, overlappedmembership must be considered as a naturalrequirement to measure the number of communi-ties linked to each node. When the notion of com-munity is well aligned with the network topology,the authors show that the approximations becomequite reliable.
Combinatorial OptimizationIn the previous sections, we have considered therole for an individual node. Now, we considermining the roles of a group of nodes. Combina-torial optimization techniques are used to find agroup of nodes that can holistically play someimportant role in the whole network.– Influence Maximization: Influence maxi-
mization, defined by Kempe et al. (2003), isthe problem of finding a small set of seednodes in a social network that maximizes thespread of influence under certain influencecascade models. It is the abstraction of wordof mouth or viral marketing: a small companyhas a limited budget but wants to select asmall number of initial users in the network tomarket and wishes they would influence theirfriends’ friends and so on and thus affect alarge population in the social network to adoptthe application. The problem is whom to selectas the initial users so that they eventuallyinfluence the largest number of people in thenetwork. These users play the role of seeds ofinformation propagation.Influence maximization is formulated as a dis-
crete optimization problem. Influence is assumedto be propagated according to a stochastic cas-cade model, and the goal is to find k nodes suchthat under the influence cascade model, the ex-pected number of nodes activated by the k seeds(referred to as influence spread) is the largestpossible. Kempe et al. proved that the optimiza-tion problem is NP-hard, and Chen et al. (2010a)proved that computing the influence spread givena seed set is #P-hard. Kempe et al. (2003) pro-posed a greedy approximation algorithm guaran-teeing the influence spread is within 1 � 1=e � �
of the optimal influence spread, where e is thebase of natural logarithm and � depends on theaccuracy of their Monte-Carlo estimate of the

R 1596 Role Discovery
influence spread given a seed set. This algorithmis not scalable to large networks, and several stud-ies have been devoted to address it. ? presented astate-of-the-art scalable algorithm under the inde-pendent cascade model, and Chen et al. (2010b)under the linear threshold model. However, noalgorithm has been able to beat Kempe et al.’sgreedy algorithm in terms of the optimality of thesolution.– Community Kernel: Hopcroft et al. (2011)
defined and explored community kerneldetection problem. It is similar to Scrippset al. (2007) in the sense of studying thedependence of community membership androle. The difference is that Hopcroft et al.(2011) distinguished two roles of users in eachcommunity. One role is named communitykernels, such as influential users on Twitter.The other role is auxiliary communities,such as the followers of the communitykernels on Twitter. The authors gave theformal definition of the two types of rolesand cast the problem of finding communitykernels as combinatorial optimization. Theypresented two algorithms. First algorithmGREEDY is based on maximum cardinalitysearch, which is efficient but does not havea bounded error. The second one is based onrelaxation of the combinatorial optimizationto continuous optimization. And then anear-optimal iterative algorithm weight-balanced algorithm (WeBA) was proposed.WeBA also has a nice property: easy forparallelization.
Supervised Learning of RolesIn the previous sections, most of the approachesare unsupervised. Now we consider supervisedmethods with machine learning techniques.Learning to classify and learning to rank aredeployed, respectively, to answer type-1 andtype-2 questions.– Learning to Classify: Leuski (2004) studied
the roles from email content collected ina research group. He tagged the messageswith eight speech acts including plan, requestadvice, request meeting, and so on. With thestandard tf-idf feature, a single support vector
machine (SVM) classifier for each speechact is trained. Each message is predictedto have one or more speech acts. Then, theroles of professor, graduate student, secretary,researcher, and programmer are distinguishedthrough the speech act patterns in theirincoming and outcoming emails.Wang et al. (2012) presented a model to learn
the roles when nodes can be positioned in ahidden hierarchy. As an example of application,they recovered family trees of Kennedy’s andRoosevelt’s. The model was similar to the un-supervised model in Wang et al. (2010), butallowed to learn feature weights from observedlabels. With that model, local features of objectattributes, interaction patterns, and rules and con-straints for knowledge propagation can be used toinfer the hierarchical relationships. They summa-rized the heterogeneous features in eight differentcategories.– Learning to Rank: Diehl et al. (2007)
proposed a different model for relationshipidentification. The focus is to find manager-subordinate relationship using the Enronemail corpus. Therefore, it falls into thecategory of type-2 role discovery. It performsthe ranking for all the candidate relationshipsin each ego network. The goal of thelearning is to find a scoring function for therelationships that minimizes the number ofrank violations committed by the scoringfunction. For every possible pairing ofrelevant and irrelevant relationships in anego network, we desire a scoring functionthat scores the relevant relationships higherthan the irrelevant relationships. A large-margin approach is used to learn the scoringfunction. Two kinds of features are used inthis work to obtain two different rankers. Oneis traffic statistics and the other is messagecontent. It is found that content-based rankingoutperforms traffic-based ranking overall;but for some ego networks, content-basedranking performs worse. It is suggested thatthis problem is caused by more complexrelationships (e.g., one performed similartasks for different individuals as performedfor the direct manager).

Role Discovery 1597 R
R
Key Applications
The rich knowledge of roles can provide in-teresting semantics of a social network and isused to improve organizational role and structureor utilized for economy, security, or educationpurposes.
For one example, discovery of roles incustomer social network helps with viralmarketing. Word of mouth or viral marketingdifferentiates itself from other marketingstrategies because it is based on trust amongone’s close social circle of families, friends, andco-workers. People trust the information obtainedfrom their close social circle far more than theinformation obtained from general advertisementchannels such as TV, newspaper, and onlineadvertisements. Role discovery helps to answerthe question whom to select as the initial users sothat they eventually influence the largest numberof people in the network.
For another example, discovery in roles inadversary social network helps with counterterrorism. It is critical for successful identifi-cation who are the commanders, communicators,etc. in the terrorist network where the roles aremostly hidden.
For the third example, finding roles amongresearchers helps the community detection inacademia. Within each community, there areresearchers of different roles such as cliquey,bridge, and periphery. Also, communities can bediscovered more accurately when the existence ofadvisor, advisee, coworker, external collaborator,etc. is taken into consideration.
Future Directions
First, there is no generic solution to the role dis-covery problem defined in this essay. There is agreat opportunity for one to develop a systematicsolution with some of the described methodologyas basis. Second, theoretical study of notionsin role theory is another promising direction.For example, role similarity is studied recentlyby Jin et al. (2011) with axiomatic principles.Third, role discovery in heterogeneous network
has been largely unexplored. There is consider-able room for advancing the technology to tacklethat challenge.
Cross-References
�Centrality Measures�Community Detection, Current and FutureResearch Trends�Counter-Terrorism, Social Network Analysis in�Human Behavior and SocialNetworks�Patterns in Productive Online Networks: Roles,Interactions, and Communication�Probabilistic Graphical Models�Role Identification of SocialNetworkers
References
Airoldi E et al (2008) Mixed membership stochasticblockmodels. J Mach Learn Res 9:1981–2014
Chen W, Wang C, Wang Y (2010a) Scalable influencemaximization for prevalent viral marketing in large-scale social networks. In: SIGKDD, Washington
Chen W, Yuan Y, Zhang L (2010b) Scalable influencemaximization in social networks under the linearthreshold model. In: ICDM, Berlin
Coulson M (2010) Role: a redundant concept in soci-ology? Some educational considerations. In: JacksonJA (ed) Role: sociological studies, vol 4. CambridgeUniversity Press, Cambridge
Crandall D et al (2010) Inferring social ties from geo-graphic coincidences. PNAS 107:22436–22441
Diehl C, Namata G, Getoor L (2007) Relationship iden-tification for social network discovery. In: AAAI,Vancouver
Eagle N, Pentland A, Lazer D (2009) Inferring friendshipnetwork structure by using mobile phone data. PNAS106(36):15274–15278
Everett M (1985) Role similarity and complexity in socialnetworks. Soc Netw 7:353–359
Freeman L (1997) Uncovering organizational hierarchies.Comput Math Org Theory 3(1):5–18
Freeman L, Freeman S, Michaelson A (1988) On humansocial intelligence. J Soc Biol Struct 11:415–425
Goldenberg A (2007) Scalable graphical models for socialnetworks. Phd thesis, Carnegie Mellon University
Gross N, Mason W, Mceachern A (1966) Explorationsin role analysis: studies of the school superintendencyrole. Wiley, New York

R 1598 Role Discovery, Relationship Mining
Henderson K et al (2012) RolX: structural role ex-traction and mining in large graphs. In: SIGKDD,Beijing
Holland P, Laskey K, Leinhardt S (1983) Stochastic block-models: first steps. Soc Netw 5:109–137
Hopcroft J et al (2011) Detecting community kernels inlarge social networks. In: ICDM, Vancouver
Jin X et al (2010) Topic initiator detection on the WorldWide Web. In: WWW, Raleigh
Jin R, Lee V, Hong H (2011) Axiomatic ranking ofnetwork role similarity. In: SIGKDD, San Diego
Kempe D, Kleinberg J, Tardos E (2003) Maximizingthe spread of influence through a social network. In:SIGKDD, Washington
Kleinberg J (1999) Sources in a hyperlinked environment.J ACM 46:668–677
Leskovec J, Huttenlocher D, Kleinberg J (2010)Predicting positive and negative links in onlinesocial networks. In: WWW, Raleigh
Leuski A (2004) Email is a stage: discovering people rolesfrom email archives. SIGIR, Sheffield
Lorrain F, White H (1971) Structural equivalence ofindividuals in social networks. J Math Sociol 1:49–80
Maiya A, Berger-Wolf T (2009) Inferring the maximumlikelihood hierarchy in social networks. In: IEEE in-ternational conference on computational science andengineering (CSE), Vancouver
McCallum A, Corrada-Emmanuel A, Wang X (2005)Topic and role discovery in social networks. In: IJCAI,Edinburgh
Memon N et al (2008) Detecting hidden hierarchy interrorist networks: some case studies. In: IEEE in-ternational conference on intelligence and securityinformatics (ISI), Taipei, pp 477–489
Page L et al. (1999) The PageRank citation ranking:brining order to the web. Technical report, StanfordInfoLab
Rowe R et al (2007) Automated social hierarchy detectionthrough email network analysis. In: Joint 9thWEBKDD and 1st SNA-KDD workshop,San Jose
Scripps J, Tan P, Esfahanian A (2007) Exploration of linkstructure and community-based node roles in networkanalysis. In: ICDM, Leipzig
Shaparenko B et al (2005) Identifying temporal patternsand key players in document collections. In: SIGKDD,Chicago
Tang W, Zhuang H, Tang J (2011) Learning to infer socialties in large networks. In: ECMLPKDD, Athens
Wang C et al (2010) Mining advisor-advisee relationshipsfrom research publication networks. In: SIGKDD,Washington
Wang C et al (2012) Learning hierarchical relationshipsamong partially ordered objects with heterogeneousattributes and links. In: SDM, Anaheim
Wolfe A, Jensen D (2004) Playing multiple roles: discov-ering overlapping roles in social networks. In: ICML,Banff
Role Discovery, Relationship Mining
�Role Discovery
Role Identification of SocialNetworkers
Anna ZygmuntDepartment of Computer Science, AGHUniversity of Science and Technology, Krakow,Poland
Synonyms
Finding social positions; Key users
Glossary
Key Members (Users) Those who contribute tothe success and health of the community
Social Media Set of web-based technologies tar-geted at forming and enabling a potentiallymassive community of participants to produc-tively collaborate
Categories of Social Media Blogs (e.g.,Wordpress, Blogcatalog), Friendship Net-works (e.g., Facebook, MySpace, LinkedIn),Microblogging (e.g., Twitter), Media Sharing(e.g., Flickr, YouTube), Social Bookmarking(e.g., Del.icio.us), Social News (e.g., Digg),Social Colaboration (e.g., Wikipedia,Scholarpedia)
Social Networker Person building her/his posi-tion by creating its own social networks ina variety of social media (categories) (http://www.wikihow.com/Be-a-Social-Networker)
Definition
The concept of “social role” has been thesubject of analysis for more than 100 years,which underlines the importance of the problem.

Role Identification of Social Networkers 1599 R
R
The meaning of this term is broad and definitionslargely dependent on the application. Therefore,it is difficult to give one definition which wouldwidely be recognized.
Most of the definitions of roles in networkanalysis have their origin mainly in sociologicaland psychological research, where social rolesare treated as “cultural objects that are recog-nized, accepted and used to accomplish prag-matic interaction goals in a community” (Gleaveet al. 2009). Sociological research emphasizes theimportance of relations to others and expectationsfor systematic behavior. So roles describe theintersection of behavioral, meaningful and struc-tural attributes that emerge regularly in particularsettings and institutions (Wesler et al. 2011).
In role theory, roles are defined as “thosebehaviors characteristic of one or more personsin a context” (Biddle 1986). In turn, in networkanalysis: a role is identified as a position that hasa distinct pattern of relations to other positions(Wasserman and Faust 1994). In social media, adefinition of a role that seems to be most appro-priate treats it as a set of characteristics (relevantmetrics) that describe behavior of individuals andtheir interactions between them within a socialcontext (Junquero-Trabado and Domingues-Sal2012).
Introduction
A social network consists of a set of actors and aset of relationships between them which describecertain patterns of communication. Most currentnetworks are huge and difficult to analyze andvisualize. One of the methods frequently usedto analyze social networks is to extract the mostimportant features, namely to create a certainabstraction, that is the transformation of a largenetwork to a much smaller one, so the latter is auseful summary of the original one, still keepingthe most important characteristics. In the caseof a social network it can be achieved in twoways. One is to find groups of actors and presentonly them and relationships between them.The other is to find actors who play similar rolesand to construct a smaller network in which the
connection between the actors would be replacedwith connections between the roles.
Work on assigning actors to roles greatly in-tensified with the advent of the possibility ofcollecting vast amounts of data capable of beingthen analyzed using methods of social networkanalysis. Social media, whose rapid growth canbe observed for several years provide us with newopportunities to define and use roles.
Classifying actors by the roles they are playingin the network can help to understand “whois who.” This classification can be very useful,because it gives us a comprehensive view ofthe network and helps to understand how theit is organized, and to predict how it could be-have in the case of certain events (internal orexternal).
In the beginning, the analysis of social media(mainly Usenet – the oldest social media devel-oped in 1979) indicated a very unbalanced partic-ipation of users, i.e., most messages were writtenby a small percentage of users. It was thoughtthat the identification of such popular users wouldhelp to understand processes taking place in thecommunity. Many approaches, therefore, focusedon finding only leaders in the community.
Another group of similar topics is findinginfluential users. Referring to the fundamentalarticle (Keller and Barry 2003) attempts weremade to translate influential users characteristics(e.g., recognition, generation activity, novelty,eloquence) described therein into SNA measures.
However, to become important or influential,the group must have users performing differentroles (more or less important) that will supportsuch key users and influential users, as well ascause the group formed around these users to bemore or less stable.
A lot of studies relate to certain social mediaand attempt to define their specific roles, sothat a different set of roles is characteristic ofdiscussion forums, blogosphere, etc. It is based ofthe assumption that different communities havedifferent needs and the roles that support theseneeds vary greatly (Nolker and Zhou 2005). Inaddition, even for the same social media, differentauthors define different roles, different namingand characteristics.

R 1600 Role Identification of Social Networkers
Roles are also considered as a tool for simpli-fying patterns of action, distinguishing betweendifferent types of users and understanding humanbehavior.
Since it was noticed that human activity isdetermined and restricted by social structures(such as social context, history of actions, struc-ture of interactions, attributes people bring to theinteraction) (Gleave et al. 2009), the concept of“social roles” is being broadened by a combina-tion of social psychology, social structures andbehaviors.
Thus, a huge network can be defined as the in-teraction of relatively small sets of roles that existin different proportion, making up a diversity ofrole ecologies.
Characteristics of Social Media
People use various social media services for dif-ferent reasons, in different ways, and generallybehave accordingly in each of them. For example,they use Flickr to display photos with friends;Twitter to show their status; Facebook to be intouch with friends, blogs to express their opin-ions, interests and beliefs; Delicious to bookmarkWeb pages, etc. (Agarwal et al. 2012).
Members demonstrate different activity levels,but generally only a small percentage of them areactive, participating regularly in discussions andwith a very large number of followers, as wellas the number of friends and social connections.The rest are not very active, which confirmsthe power law phenomena (Mathioudakis andKoudas 2009).
Some people are active only in few socialmedia sites, while others use most of the sites.Each social media has a different structure and adifferent way to use it. However, it must be noted,that the vast majority have the structure contain-ing the link information and content information(Agarwal et al. 2012) and are built around themessage thread data structure (some messagesare sent as a reply to a particular previous mes-sage).
By combining information about the roles per-formed by users on various social networking
sites more extensive (comprehensive) user profilecan be obtained. If the user has a similar behavioron various social media, their behavior on othermedia can predicted, without the need to analyzethem. It can be indicated what types of media willinspire greater commitment of users and why.Identification of the same users on different socialnetworking sites is not easy, and often an as-sumption that users behave similarly performingsimilar roles is used (e.g., in Agarwal et al. (2012)they discovered that the user who is influential onone site, has also a tendency to be influential onthe other, using similar style of speaking).
Examples of Roles Performed bySocial Networkers
A lot of the early studies on finding roles dealtwith Usenet discussion groups. After some time,it turned out that some similar roles can be iden-tified in other threaded discussion spaces (e.g., inthe majority) where some messages are sent as areply to a particular previous message, and in thisway a chain of messages is created (Wesler et al.2007; Fisher et al. 2006).
Based on a combination of visualization ofauthors posting behavior, posting behaviors ofeach author’s neighbors and egocentric networkgraph, three important roles were identified insuch spaces: “answer person,” “discussion per-son” and “reply magnet.”
The primary mode of interaction for the “an-swer person” is to provide useful answers to otherquestions asked by members of the group. “Dis-cussion people” reply to one another about thetopics introduced by the topic started by “replymagnet.” “Discussion people” are characterizedby frequent reciprocal exchanges with a relativelyhigh number of other participants. This socialrole is the source of most of the discussion con-tent contributed to long threaded conversations.“Reply magnet” is responsible for the majorityof messages that initiate long threads. The keybehavior of these individuals is creating newthreads, usually by posting quoted material fromexternal news sources.

Role Identification of Social Networkers 1601 R
R
It was noted that the two roles: “answerperson” and “discussion person” are criticalfor many threaded discussion media; theirpresence contributes to the fact that given socialmedia are living: questions are asked, answersgiven, there are new topics for discussion.Thus, these roles have a positive impact on thecommunity. Unfortunately, negative roles, suchas “spammers” or “flammers” may appear incommunity.
Analyzing Usenet from the perspective offinding important roles for the durability ofcommunity, two types of roles were identified:“leaders” (spread knowledge and maintain thecohesiveness of the group) and “motivators”(keep conversation going) (Nolker and Zhou2005). Both roles were defined on the basisof their behavior, conversations and memberrelationships. The third role, “chatters,” wasintroduced, which refers to those who areengaged in a single discussion but rarely getinvolved in other discussions.
Defining a role only on the basis of anindividual’s behavioral patterns, other roles withdifferent characteristics were found (Viegas andSmith 2004): “answer persons (pollinators),”“debaters,” “spammers” and “conversationalists.”For example, “pollinators” are characterized by ahigh number of days active, mostly responding tothreads started by other authors with one or justa small number of messages sent to each thread.In turn, “debaters” with a high number of daysactive, mostly respond to threads started by otherauthors with large numbers of messages sent toeach thread.
Recently,many studiesconcernTwitter (mainlydue to the easy availability of data and thepossibility of analysis of the network dynamic).In the literature, many different sets of roleshave been proposed, for example: “mainstreamnews source” (spreads information through thenetwork); “celebrities” (public figures followed bymany persons); “opinion leaders” (spread widelytheir opinions and exercise a big influence amongtheir persons in the network). A negative roleis performed by “social spammers” who usesocial network to disseminate malware, or spreadcommercial spam messages (Cha et al. 2010;
Junquero-Trabado and Domingues-Sal 2012).An-othersetofrolesispresentedin(Fazeenetal.2011):“leaders” (who start tweeting, but do not followothers,buttheycanhavemanyfollowers);“lurkers”(generally inactive, but occasionally follow sometweets); “spammers” (the unwanted tweeters,also called twammers), and “close associates”(including friends, family members, relatives,colleagues, etc.).
In Wesler et al. (2011) and Gleave et al.(2009), roles in Wikipedia were identified (notingthat Wikipedia differs from discussion spaces inthat the primary activity of the community is theconstruction of an artifact): “technical editors”(correct small errors related to style or formattingof articles); “vandal fighters” (revert vandalismand sanction norm violators); “substantive ex-perts” (improve the quality of the content of thearticles); “social networkers” (support commu-nity aspects of Wikipedia and contribute littleto the content and form of articles directly).As can be seen, there is quite a large flexibilityin defining sets of roles.
TheMethodology of Finding Roles
The most general approach to finding rolesconsists of two main stages (Wesler et al. 2007;Junquero-Trabado and Domingues-Sal 2012):an in-depth understanding of the community inorder to identify roles which may be detected,and then creation of a role with observedcharacteristics and rules that will allow theclassification of individuals into the pre-definedroles.
Social roles can be conceptualized at severaldifferent levels of abstraction (Gleave et al. 2009;Wesler et al. 2011). A good starting point isto first identify roles at the level of meaningfulsocial action, and descend to a lower level ofabstraction to identify the key behavioral regular-ities and distinctive positions in social networks.Then make generalizations to abstract theoreticalcategories that will make it possible to tie theseparticular roles to general research objectives.
Finding roles should rely on both structuraldata and detailed qualitative description of the

R 1602 Role Identification of Social Networkers
context and meaning of interaction (Gleave et al.2009). In the past, this approach was very difficult(only one of these aspects could be taken intoconsideration). Now, we have great opportunitiesto find significant structural roles and understandtheir meaning within the social context.
Social roles are often inherently defined inrelational terms: a role only exists in relationto others, who are likewise enacting social roles(Wesler et al. 2007). Therefore, it is necessaryto adopt a macro perspective that combines bothindividual behavior and ecology of the entire so-cial roles (balance and interaction of roles withina given population Gleave et al. 2009) within agiven social space.
Methods of Finding Social Roles
There are four main approaches to identifyingsocial roles.
Approach Based on Equivalence ClassesIt is the oldest approach to identifying roles(Wasserman and Faust 1994). It is assumed thata given person is a representative of a groupof people who are somehow “equivalent”; thatare similar to and different from those of theother categories. Categories are defined in thecontext of the similarity between patterns of re-lationships among actors. Formally, these cate-gories are presented using a family of algebraicequivalence classes on nodes: structural, auto-morphic and regular and their variants, and withthe use of blockmodels which are produced byapplying these reduction to social networks. Theleast restrictive reduction is regular equivalenceand is best suited for the sociological conceptof the role: two nodes are said to be regularlyequivalent if they have the same profile of tieswith members of other sets of actors that arealso regularly equivalent (Hannemann and Riddle2005; Lerner 2005). Regular equivalence can betreated as clustering actors, according to theirsocial positions (Brynielsson et al. 2012).
There are many algorithms for findingregular equivalence. All are based on searchingthe neighbourhood of actors to find actors
of other types. As long as they have similar“types” of actors at similar distances in theirk-neighbourhoods, they are regularly equivalent.
Approach Based on the Identification ofthe Core/Periphery StructureThis approach is based on extracting certain areasof varying activities and assigning roles to usersbased on membership of a particular area.
The concept of the core and the periphery wasfirst introduced in Borgatti and Everett (1999).In the directed graph two classes of nodes canbe distinguished: belonging to a coherent sub-graph (the core), in which nodes are connectedto each other in some maximal way, and looselyconnected nodes (the periphery). The core shouldhave a lot of links with the periphery, and shouldbe connected with the core members much morethan with the periphery. In turn, the peripheryshould indicate mainly nodes in the core, andthose in the periphery, but only to a small extent.
A core/periphery model was used in theanalysis of dynamics of community (Yahoo!)(Backstrom et al. 2008). The concept of the corewas redefined by introducing a definition of thek-core. Members belonging to the k-core musthave an appropriate activity (e.g., replied to andbeen replied by minimum number of distinctusers) during a specified time period. People whodo not belong to the k-core are “light” users. Dueto the time they are part of, the users can furtherbe classified as “long-core” and “short-core.” Itwas noticed, for example, that it is more likelythat the users will be long-core, if they belongto a smaller number of groups (probably becausethey can then focus on those groups, at the levelnecessary to become long-term users). Moreover,it was noticed that the core is approximately thesame size regardless of the size of the group. Therelatively simple model was proposed, which didnot take into account the quality of written postsby Yahoo! users (they might as well be spam).
In the case of blogosphere, work on theextracting structure similar to the core/peripheryhas gone in the direction of discovery A-Listblogs, defined as “those that are most widelyread, cited in the mass media, and receivethe most inbound links from other blogs”

Role Identification of Social Networkers 1603 R
R
(Obradovic and Baumann 2009). Blogs fromA-List are strongly connected with one another,but poorly with the rest of blogosphere, which isa decisive majority (long tail). Blogs from A-listare often linked to from the long tail, often link toeach other and rarely link to the long tail. To findblogs from the A-list, the modified definition ofthe k-core as connected components that containonly nodes of a minimum degree of k was used.
Analyzing the dynamics of social media(Flickr, Yahoo!) it was noted (Kumar et al.2006) that the structure of the periphery is nothomogenous and can be distinguished in the“singletons” (nodes not linked to any othernetwork nodes) and “middle region” (isolatedgroups who interact with one another, but notwith the network as such). These isolated groupsare in fact influential individualities that act as“stars” combined with a varying number ofother users who, in turn, have very few otherconnections. An analysis of network dynamicsshows that such “stars” may be included in thecore, or disappear as soon as they lose interest inthe group.
Approach Based on the Analysis of BasicSNAMeasuresThis approach takes into consideration the funda-mental features of users’ structural position suchas their number of neighbors and relies on vari-ous centrality measures, i.e., local (within socialcommunities) or global (for the entire network)structural features (Newman and Girvan 2004;Zygmunt et al. 2012).
There are three traditional roles based on nodenetwork structure: “hubs,” “brokers” (“gatekeep-ers”) and “bridges” (“pustakers”) (Nolker andZhou 2005; Denning 2004). “Hub” is a personwho links to many others; “broker” is the onlyconnection between communities; “bridge” linksseveral communities. Such roles can be foundby analyzing the basic SNA centrality measures,such as degree centrality (the number of con-versations that a user is engaged in or the num-ber of users that a user has conversed with);betweenness centrality (the number of pairs ofother members who can converse with each otherdirectly through a user with shortest distance);
closeness centrality (average conversation dis-tance between a user and all the others in thecommunity). In Goldenberg et al. (2009) “hub”was defined as “people with both in- and out-degrees that are larger than three standard devi-ations above the mean.” The presence of suchroles in the community promotes the spread ofinnovations such as: innovations are most likelyto spread if “hubs” adopt and recommend them;“brokers” and “bridges” play important roles inspreading the idea to new groups.
An analysis of the basic measures of SNAhas been used in several studies to define socialroles of “starters” and “followers” on discussionforums and in blogosphere (Hansen et al. 2010;Mathioudakis and Koudas 2009; Sun and Ng2012). “Starters” receive messages mostly frompeople who are well-connected to each other,and therefore can be identified by low in-degree,high out-degree and high clustering coefficientin the graph. The distinction between the rolesis obtained by combining the difference betweenthe number of in-links and out-links of theirblogs.
In a similar way an “answer person” was iden-tified on discussion forums (Fisher et al. 2006),noting that it is a person who responds to manyother people, but rarely to those who provideanswers to the questions raised by the com-munity. So it should have high out-degree andlow in-degree. For each author one-degree andtwo-degree egocentric social networks were con-structed through patterns of reply. These net-works were then grouped (e.g., on the basis ofcollective in-degree and out-degree, degree dis-tribution coefficient across groups), and for eachdistribution of the out-degree of each actor’s out-neighbors were calculated.
Wesler et al. (2007) observed that social rolescan be described using patterned characteristicsof communication between network members,which is called “structural signatures.” It washypothesized that it is possible to recognize theroles that people play by measuring behavioraland structural signature of their participation.The goal is to identify general structural featuresthat are associated with a particular role. Ego-centric network and visualization was used to

R 1604 Role Identification of Social Networkers
identify structural attributes associated with therole. Thus, for example, “answer persons” aremainly connected with users with low degree,their local networks tend to have small propor-tions of three cycles (i.e., their neighbors are notneighbors of each other, they seldom send multi-ple messages to the same recipient (few intenseties), they tend to reply to discussion threadsinitiated by others, and generally contribute oneor two messages per thread. Ego network for an“answer person” is similar to a star and differsfrom ego network persons performing other tworoles (Gleave et al. 2009).
In Nolker and Zhou (2005), to define rolesa combination of SNA measures with behavior-based measures from the information retrieval(term frequency and inverse document frequency:TF * IDF) was used. TF*IDF indicates the weightof conversation relationships between members.It was observed that betweenness plays an impor-tant role in predicting the relationship potentialthat a member has with other members. In turn,high in-closeness indicates a member who pro-vides consistency and high out-closeness – amember who spreads knowledge.
Approach Based on Clustering FeatureVectorsIn this approach, each person in the network isrepresented by a vector of some of the featuresthat represents its behavior and relationships withthe other members of the community. These fea-tures can be for example: the number of peoplesthe user knows, the number of people that knowthe user, the number of reciprocal relationshipsof the user, the number of messages that theuser receives, and the number of documents thatdepict the user etc.
Such vectors can then be clustered so thatpeople with similar characteristics are placed inone group (Maia et al. 2008; Junquero-Trabadoand Domingues-Sal 2012; Pal and Counts 2011).Mostly well known in statistics and data min-ing, k-means algorithm was used. The cluster isdescribed with the use of relevant metrics thatare important for a given role. Thus, each rolecan have a different number of relevant metrics.On Twitter, for example, the role of “celebrities”
means the most followed and mentioned persons,most connected but generally not the most in-fluential, so the relevant metrics for this role areshown in the number of followers and the numberof documents depicting a given person. In turn,the role of “information propagators” is mainlya source of information, so the relevant metricsare expressed in the number of followers, aver-age and maximum information propagation, thenumber of publications, the number of words intweets that exist in dictionary. It is the user, whoon the basis of the results of the clustering cancreate a set of roles, therefore, such an approachcan be regarded as most universal and one ofthe few independent of the particular application(Junquero-Trabado and Domingues-Sal 2012).
Key Applications
• Marketing, opinion diffusion, advertising:finding people that will ensure that informa-tion about new product will come down to thelargest number of other people and will cause,for example, an increase in sales.
• Recommendation systems: individuals, whoshare the same social role might be expectedto share the same taste.
• Political campaign: which roles are necessaryto ensure the success of campaign.
• Detecting important members of criminal orterrorist groups.
Future Directions
• Searching for new roles, creating a uniformformal model describing the community, tak-ing into account the roles and interactionsbetween them.
• Searching roles in several heterogeneous net-works, trying to find roles for a user in multi-ple, heterogeneous networks.
• Developing recommendations for the struc-ture of the system of roles (roles ecologies)(qualitative and quantitative) for the effectivefunctioning of communities.

Role Identification of Social Networkers 1605 R
R
Cross-References
�Centrality Measures� Patterns in Productive Online Networks: Roles,Interactions, and Communication�Role Discovery
References
Agarwal N, Kumar S, Gao H, Zafarani R, Liu H (2012)Analyzing behavior of the influentials across socialmedia. In: Cao L, Yu PS (eds) Behavior computing:modeling, analysis, mining, and decision. Springer,London, pp 3–19
Backstrom L, Kumar R, Marlow C, Noval J, Tomkins A(2008) Preferential behavior in online groups. In: 1stACM WSDM international conference on web searchand data mining, Palo Alto, pp 117–128
Biddle BJ (1986) Recent developments in role theory.Annu Rev Sociol 12:67–92
Borgatti SP, Everett MG (1999) Models of core/peripherystructures. Soc Netw 21:375–395
Brynielsson J, Kaati J, Svenson P (2012) Social posi-tion and simulation relations. Soc Netw Anal Min2(1):39–52
Cha M, Haddadi H, Benevenuto F, Gummadi P (2010)Measuring user influence in Twitter: the million fol-lower fallacy. In: 4th international AAAI conferenceon weblogs and social media (ICWSM), Washington,DC
Denning PJ (2004) Network laws. Commun ACM Publ47:15–20
Fazeen M, Dantu R, Guturu P (2011) Identification ofleaders, lurkers, associates and spammers in a socialnetwork: context-dependent and context-independentapproaches. Soc Netw Anal Min 1(3):241–254
Fisher D, Smith M, Welser HT (2006) You are whoyou talk to: detecting roles in usenet newsgroups. In:Proceedings of the 39th annual Hawaii internationalconference on systems sciences, HICSS’06, Kauai.IEEE Computer Society
Gleave E, Welser HT, Lento TM, Smith MA (2009) Aconceptual and operational definition of ‘social role’in online community. In: Proceedings of the 42ndHawaii international conference on systems sciences,HICSS’09, Waikoloa, Big Island. IEEE ComputerSociety, pp 1–11
Goldenberg J, Han S, Lehmann DR, Hong JW (2009) Therole of hubs in the adoption process. J Mark 73(2):1–13
Hannemann RA, Riddle M (2005) Introduction tosocial network methods. University of California,Riverside
Hansen DL, Shneiderman B, Smith MA (2010) Visual-izing threaded conversation networks: mining mes-sage boards and email lists for actionable insights.
In: Proceedings of the 6th international confer-ence of active media technology (AMT’10), Toronto.Springer, Berlin/Heidelberg, pp 47–62
Junquero-Trabado V, Domingues-Sal D (2012) Building arole search engine for social media. In: Proceedingsof the 21st international conference companion onworld wide web (WWW’12), Lyon. ACM, New York,pp 1051–1060
Keller E, Barry J (2003) The influentials: one american inten tells the other nine how to vote, where to eat, andwhat to buy. Free Press, New York
Kumar R, Noval J, Tomkins A (2006) Structure andevolution of online social networks. In: Proceedingsof the 12th ACM SIGKDD international conferenceon knowledge discovery and data mining (KDD’06),Philadelphia. ACM, New York, pp 611–617
Lerner J (2005) Role assignments. Network analysis.In: Brandes U, Erlebach T (eds) Methodologicalfoundations. LNCS 3418. Springer, Berlin/Heidelberg,pp 216–252
Maia M, Almeida J, Almeida V (2008) Identifying userbehavior in online social networks. In: SocialNets,proceedings of the 1st workshop on social networksystems (SocialNets’08), Glasgow, Scotland. ACM,New York, pp 1–6
Mathioudakis M, Koudas N (2009) Efficient identificationof starters and followers in social media. In: Proceed-ings of the 12th international conference on extendingdatabase technology: advances in database technol-ogy (EDBT’09), Saint-Petersburg. ACM, New York,pp 708–719
Newman MEJ, Girvan M (2004) Finding and evaluat-ing community structure in networks. Phys Rev E69(2):026113
Nolker RD, Zhou L (2005) Social computing andweighting to identify member roles in online com-munities. In: Web intelligence, proceedings of theIEEE/WIC/ACM international conference on web in-telligence, Compiegne, pp 87–93
Obradovic D, Baumann S (2009) A journey to the coreof the blogosphere. In: Social network analysis andmining, ASONAM’09, international conference on ad-vances in social networks analysis and mining, Athens.IEEE Computer Society, pp 1–6
Pal A, Counts S (2011) Identifying topical authori-ties in microblogs. In: Proceedings of the 4th in-ternational conference on web search and data min-ing (WSDM’11), Hong Kong. ACM, Hong Kong,pp 45–54
Sun B, Ng VTY (2012) Identifying influential users bytheir postings in social networks. In: Proceedings ofthe 3rd international workshop on modeling socialmedia (MSM’12), Milwaukee, pp 1–8
Viegas FB, Smith MA (2004) Newsgroup crowds andauthor lines: visualizing the activity of individuals inconversational cyberspace. In: Proceedings of the 37thHawai’i international conference on systems sciences,Kauai. IEEE, Los Alamitos

R 1606 Role-Playing
Wasserman S, Faust K (1994) Social network analy-sis: methods and applications. Cambridge UniversityPress, Cambridge, New York
Wesler HT, Gleave E, Fisher D, Smith M (2007) Visualiz-ing the signature of social roles in online discussiongroups. J Soc Struct 8(2). http://www.cmu.edu/joss/content/articles/volume8/Welser/
Wesler HT, Cosley D, Kossinets G, Lin A, DokshinF, Gay G, Smith M (2011) Finding social roles inwikipedia. In: Proceedings of the 2011 iConference,Seattle. ACM, Seattle, pp 122–129
Zygmunt A, Brodka P, Kazienko P, Koylak J (2012)Key person analysis in social communities within theblogosphere. J UCS 18(4):577–597
Recommended Reading
Bettencourt BA, Sheldon K (2001) Social roles as mecha-nisms for psychological need satisfaction within socialgroups. J Personal Soc Psychol 81(6):1131–1143
Golder SA, Donath J (2004) Social roles in electroniccommunities. AoIR, Brighton, England
Obradovic D, Rueger C, Dengel A (2011) Core/peripherystructure versus clustering in international weblogs. In:Proceedings of the international conference on com-putational aspects of social networks (CASoN 2011).IEEE, Salamanca
Role-Playing
�Gaming and Virtual Worlds
Roll Call Prediction
�Legislative Prediction with Political and SocialNetwork Analysis
Routine Discovery
�Extracting Individual and Group Behavior fromMobility Data
Ruby on Rails
�Server-Side Scripting Languages
Rule-Based Systems
�RIF: The Rule Interchange Format




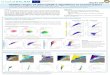











![Relative clustering validity criteria: A comparative overviewhcao/paper/icredits/2010...Clustering techniques can be broadly divided into three main types [7]: overlapping, partitional,](https://img.pdfslide.net/doc/110x75/5f100dbc7e708231d4473706/relative-clustering-validity-criteria-a-comparative-overview-hcaopapericredits2010.jpg)












