Embed Size (px)
Citation preview

SVEUČILIŠTE J.J. STROSSMAYERA U OSIJEKU, EKONOMSKI FAKULTET U OSIJEKU
3. Neuronske mreže
MARIJANA ZEKIĆ-SUŠAC
1

Što ćete naučiti u ovom poglavlju?▪ Objasniti što su umjetne neuronske mreže kao metoda strojnog učenja i čemu služe.
▪ Objasniti arhitekturu neuronskih mreža i obradu u svakom sloju.
▪ Nabrojati i objasniti faze rada neuronske mreže i postupak učenja.
▪ Objasniti postupak pronalaženja najboljeg modela i ocjene njegove uspješnosti.
▪ Kreirati model neuronske mreže za klasifikaciju i predviđanje.
2
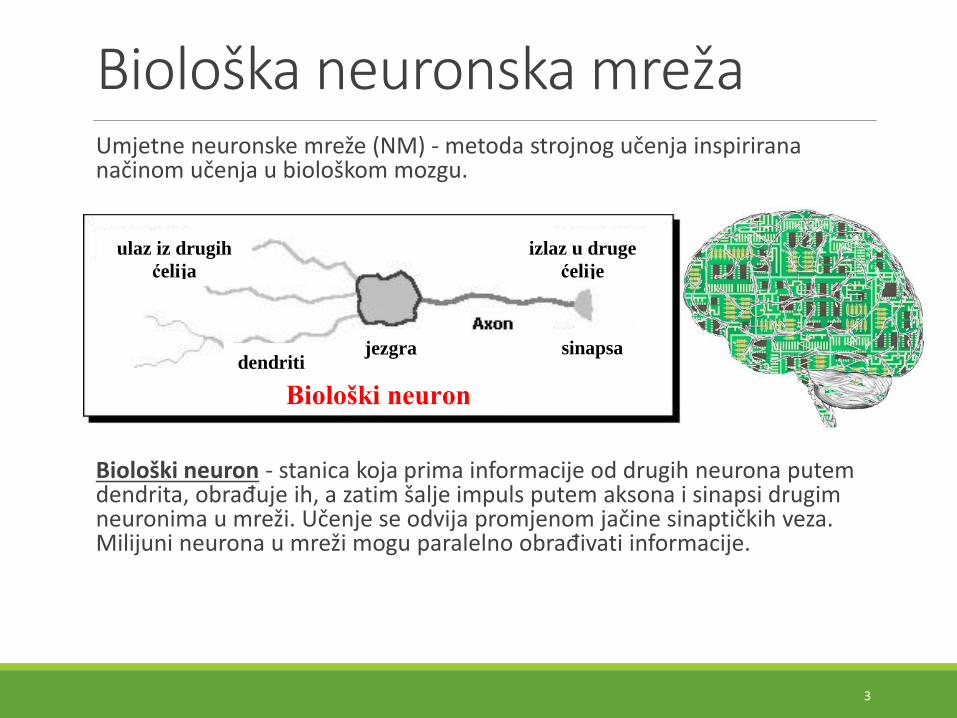
Biološka neuronska mrežaUmjetne neuronske mreže (NM) - metoda strojnog učenja inspirirana načinom učenja u biološkom mozgu.
Biološki neuron - stanica koja prima informacije od drugih neurona putemdendrita, obrađuje ih, a zatim šalje impuls putem aksona i sinapsi drugimneuronima u mreži. Učenje se odvija promjenom jačine sinaptičkih veza. Milijuni neurona u mreži mogu paralelno obrađivati informacije.
3
jezgra
izlaz u druge
ćelije
ulaz iz drugih
ćelija
dendritisinapsa
a
Biološki neuron
4
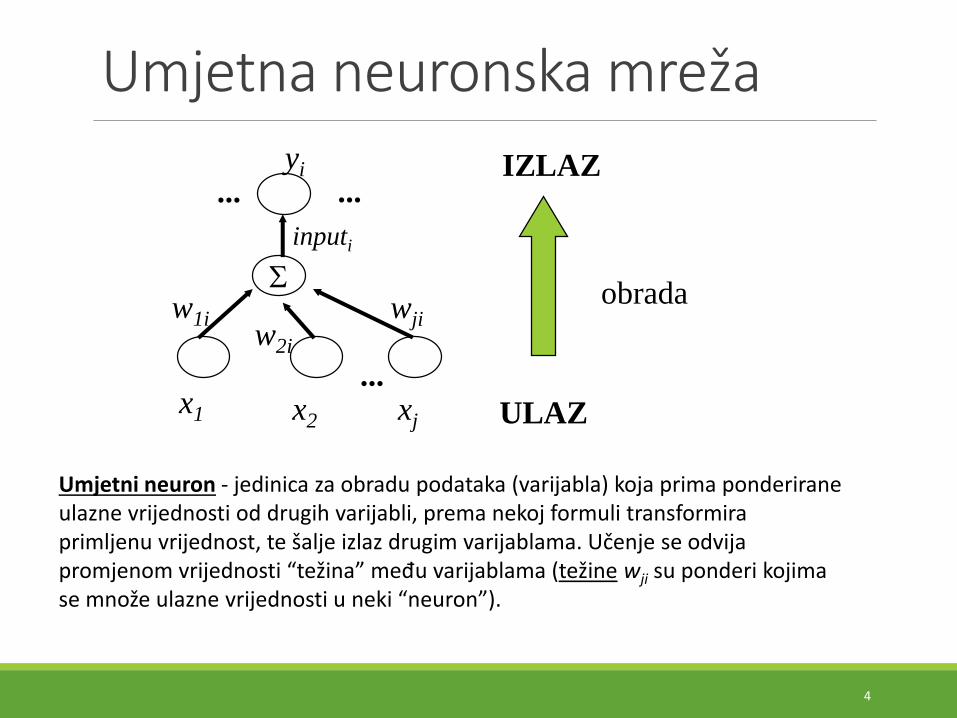
Umjetna neuronska mreža
...
wji
x1 x2 xj
...
w1iw2i
inputi
yi
...
ULAZ
IZLAZ
obrada
Umjetni neuron - jedinica za obradu podataka (varijabla) koja prima ponderiraneulazne vrijednosti od drugih varijabli, prema nekoj formuli transformiraprimljenu vrijednost, te šalje izlaz drugim varijablama. Učenje se odvijapromjenom vrijednosti “težina” među varijablama (težine wji su ponderi kojimase množe ulazne vrijednosti u neki “neuron”).

5
Definicija umjetne NMUmjetne neuronske mreže su programi ili hardverski sklopovi kojiiterativnim postupkom iz prošlih podataka nastoje pronaći vezu izmeđuulaznih i izlaznih varijabli modela, kako bi se za nove ulazne varijabledobila vrijednost izlaza (ili drugim riječima, uče na primjerima) (Zahedi, 1993).
NM su jedna od metoda strojnog učenja koja postaje sve popularnija u prediktivnoj analitici i u BigData platformi.
Standardne NM uče na podacima iz baza podataka i sastoje se od nekoliko slojeva, dok su u okviru BigData platformi razvijene neuronske mreže koje imaju nekoliko stotina slojeva i uče na brzim računalima velike obradbene moći, što se danas naziva duboko učenje (engl. DEEP LEARNING).
Deep learning se koristi za probleme prepoznavanja slika, govora, prevođenje, analizu sentimenta i druge analize društvenih mreža, te druge obrade.

Primjer upotrebe NM
6
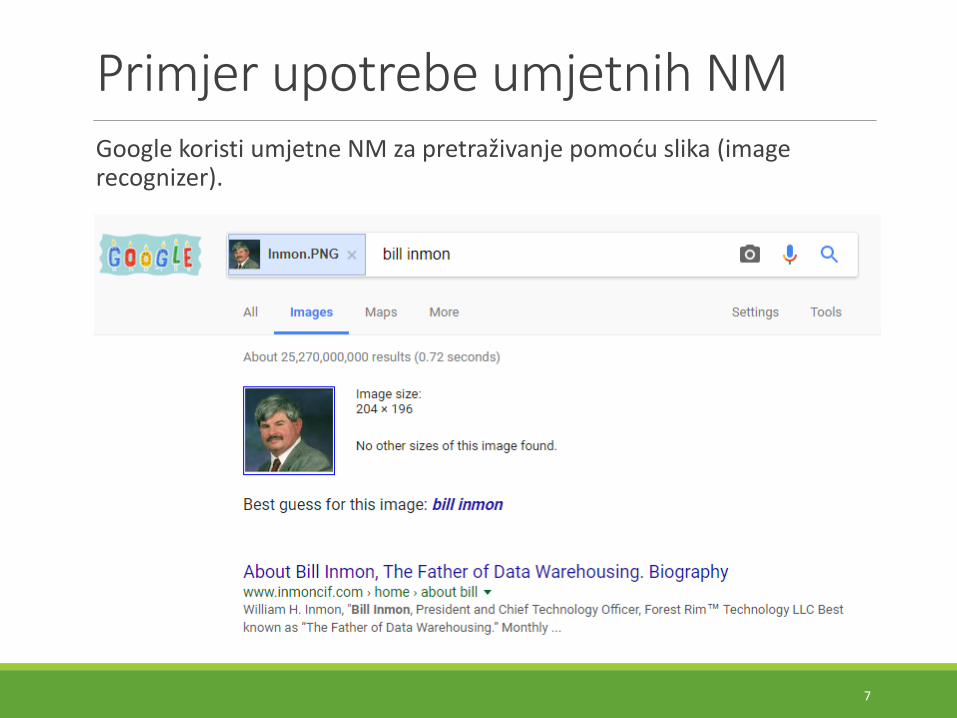
Primjer upotrebe umjetnih NMGoogle koristi umjetne NM za pretraživanje pomoću slika (image recognizer).
Primjer:
7

8
Povijest razvoja NM
•1958. Perceptron - prva neuronska mreža (Frank Rosenblatt), učenje se odvija samo u dva sloja, nije mogla rješavati probleme klasifikacije koji nisu linearno djeljivi (npr. XOR problem)
• 1969. Minsky i Papert objavljuju rad u kojem oštro kritiziraju nedostatkePerceptrona, što uzrokuje prestanak ulaganja u istraživanja neuronskih mreža.
•1974. višeslojna perceptron mreža - MLP (Paul Werbos)- prva verzija Backpropagation mreže, prevladava nedostatak perceptrona uvođenjem učenja u skrivenom sloju
•1986. Backpropagation mrežu usavršuju Rumelhart, Hinton, Williams, i ona vraćaugled neuronskim mrežama, jer omogućuje aproksimiranje gotovo svih funkcija irješavanje praktičnih problema
•… - otada se razvijaju brojni algoritmi za NM koji s pomoću različitih pravila učenja, ulaznih i izlaznih funkcija rješavanju probleme predviđanja, klasifikacije iprepoznavanja uzoraka.
9
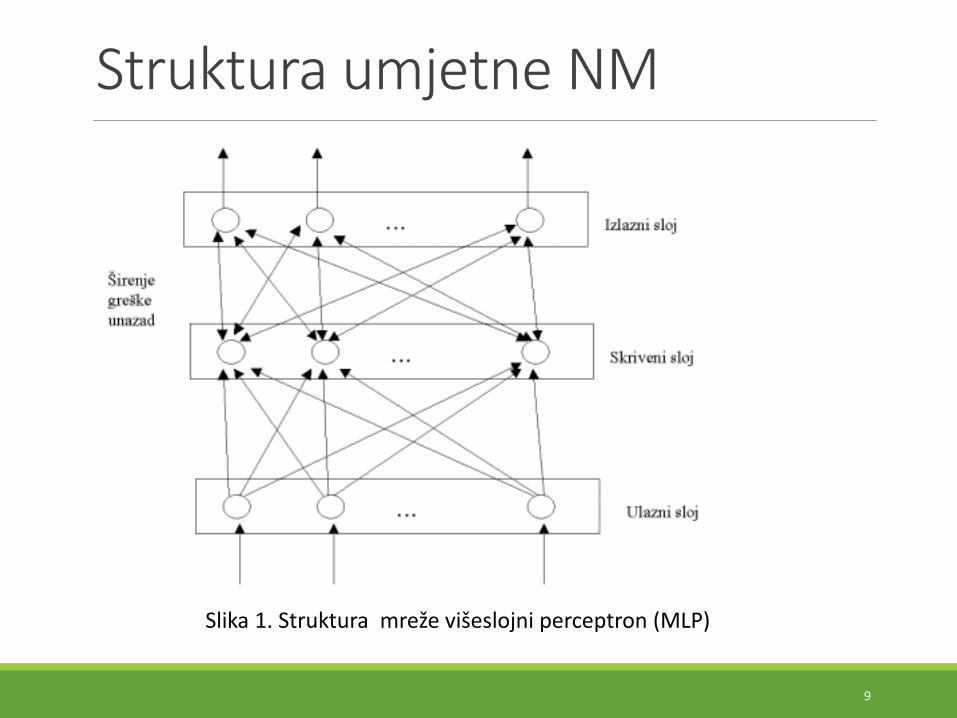
Struktura umjetne NM
Slika 1. Struktura mreže višeslojni perceptron (MLP)
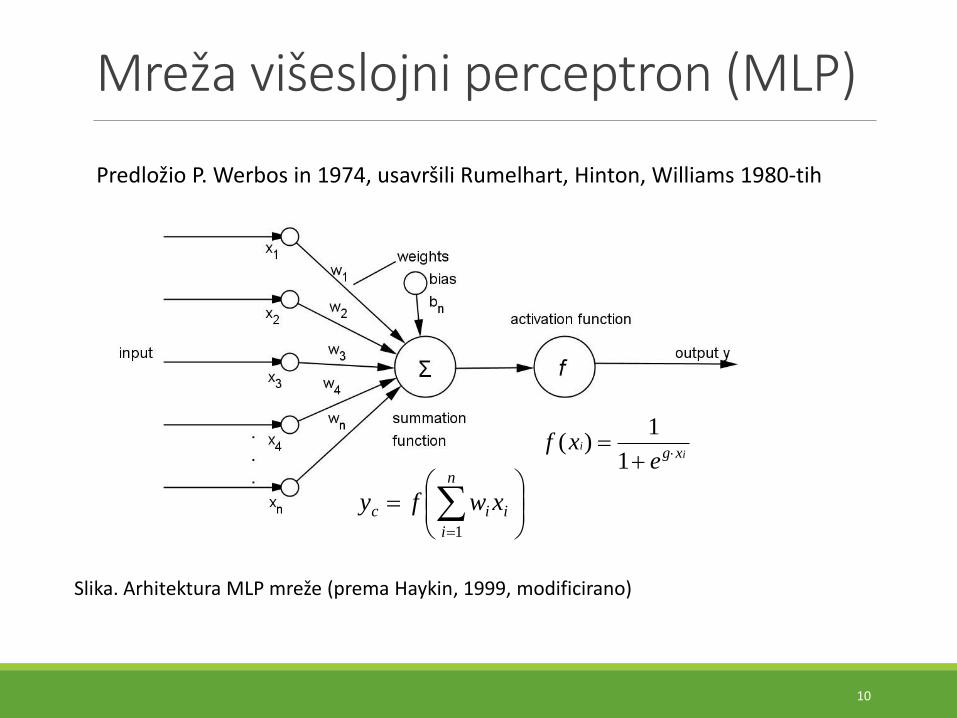
Mreža višeslojni perceptron (MLP)
Predložio P. Werbos in 1974, usavršili Rumelhart, Hinton, Williams 1980-tih
Slika. Arhitektura MLP mreže (prema Haykin, 1999, modificirano)
n
i
iic xwfy1
ii
xgexf
1
1)(
10
11
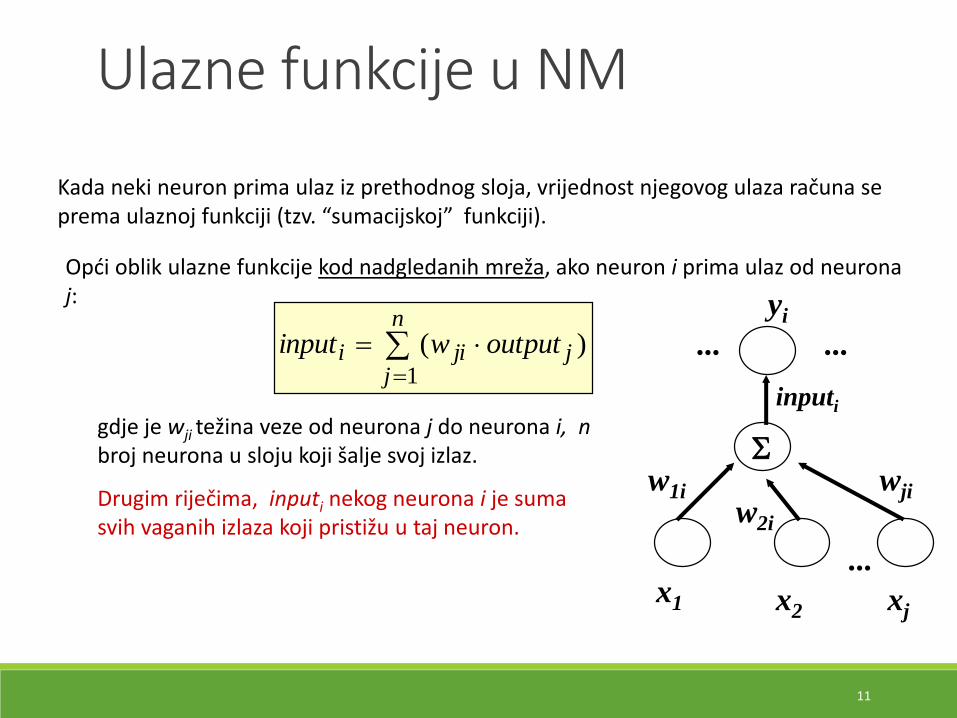
Kada neki neuron prima ulaz iz prethodnog sloja, vrijednost njegovog ulaza računa se prema ulaznoj funkciji (tzv. “sumacijskoj” funkciji).
Opći oblik ulazne funkcije kod nadgledanih mreža, ako neuron i prima ulaz od neuronaj:
n
jjjii outputwinput
1
)(
gdje je wji težina veze od neurona j do neurona i, n broj neurona u sloju koji šalje svoj izlaz.
Drugim riječima, inputi nekog neurona i je sumasvih vaganih izlaza koji pristižu u taj neuron.
...
wji
x1 x2 xj
...
w1i
w2i
inputi
yi
...
Ulazne funkcije u NM

Računanje u MLP mrežiSvaka jedinica (neuron) skrivenog sloja prima sumu svih ponderiranih inputa, a zatim
primjenjuje aktivacijsku funkciju da bi se dobio izlaz neurona skrivenog sloja:
gdje je f aktivacijska funkcija odabrana od strane kreatora modela, a može biti sigmoidna
(logistička), tangens hiperbolna, eksponencijalna, linearna ili dr. Formula logističke funkcije
je (Masters, 1995):
gdje je g parametar koji određuje gradijent funkcije. Output ove funkcije je u intervalu [0,1].
Izračunati output mreže yc uspoređuje se sa stvarnim ouputom ya, i razlika između njih je
lokalna greška ε. Greška se zatim koristi za podešavanje pondera (težina) u ulaznom sloju
prema nekom pravilu učenja, npr. Delta pravilu: ∆wi=η·yc·ε , gdje je ∆wi razlika između stare
i nove težine, η je koeficijent učenja, ε je greška NM.
n
i
iic xwfy1
ii
xgexf
1
1)(
12

13
Kriteriji za razlikovanje algoritama NM
▪ broj slojeva,
▪ tip učenja,
▪ tip veze između neurona,
▪ veza između ulaznih i izlaznih podataka,
▪ ulazne i prijenosne funkcije,
▪ sigurnost ispaljivanja,
▪ vremenske karakteristike,
▪ vrijeme učenja.
14
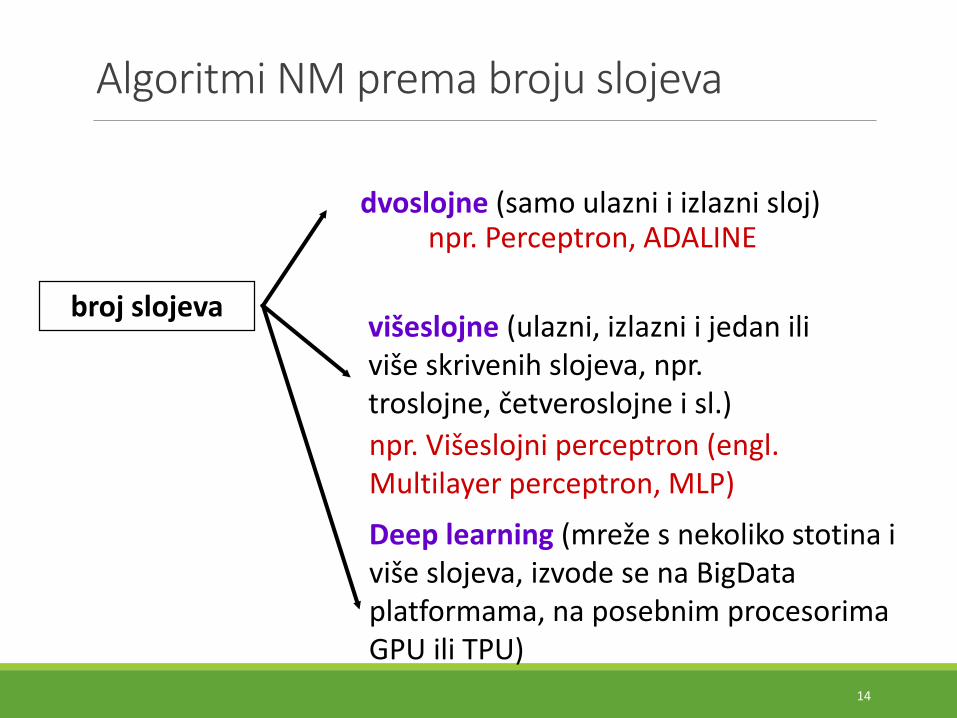
Algoritmi NM prema broju slojeva
broj slojeva
dvoslojne (samo ulazni i izlazni sloj)
višeslojne (ulazni, izlazni i jedan iliviše skrivenih slojeva, npr. troslojne, četveroslojne i sl.)
npr. Perceptron, ADALINE
npr. Višeslojni perceptron (engl. Multilayer perceptron, MLP)
Deep learning (mreže s nekoliko stotina i više slojeva, izvode se na BigData platformama, na posebnim procesorima GPU ili TPU)

15
Algoritmi NM prema tipu učenja
tip učenja u mreži
nadgledano (supervised) - poznate su vrijednostiizlaznih varijabli na skupu podataka za učenje mreže(Višeslojni perceptron (MLP), Radial Basis Function, Modularna, General Regression, LVQ, Probabilistička)
nenadgledano (unsupervised) - nisu poznate vrijednosti izlaznih varijabli na skupu podataka za učenje mreže (Kohonenova samoorganizirajuća, ART mreža)
Primjeri problema:
• predviđanje bankrota poduzeća sa znanjem da li je neko poduzeće bankotiralo u prošlosti (nadgledano) ili bez tog znanja (nenadgledano),
• ocjena kreditne sposobnosti sa znanjem da li je kredit u prošlosti vraćen ili nije(nadgledano),
• ponašanje kupaca u odnosu na neki proizvod s poznatim prošlim akcijamakupaca (nadgledano) ili bez poznatih akcija (nenadgledano)
Usporedba: učenje za ispit s točnim odgovorima i bez njih

16
Izlaz neurona računa se prema tzv. prijenosnoj funkciji (transfer function).Nekoliko najčešće korištenih prijenosnih funkcija su:
• funkcija koraka (step funkcija),• signum funkcija,• sigmoidna funkcija,• hiperboličko-tangentna funkcija,• linearna funkcija,• linearna funkcija s pragom.
Najčešće korištene funkcije su sigmoidna i hiperboličko-tangentna, jer najbliže oponašaju stvarne nelinearnepojave.
Izlazne (prijenosne) funkcije u NM
17
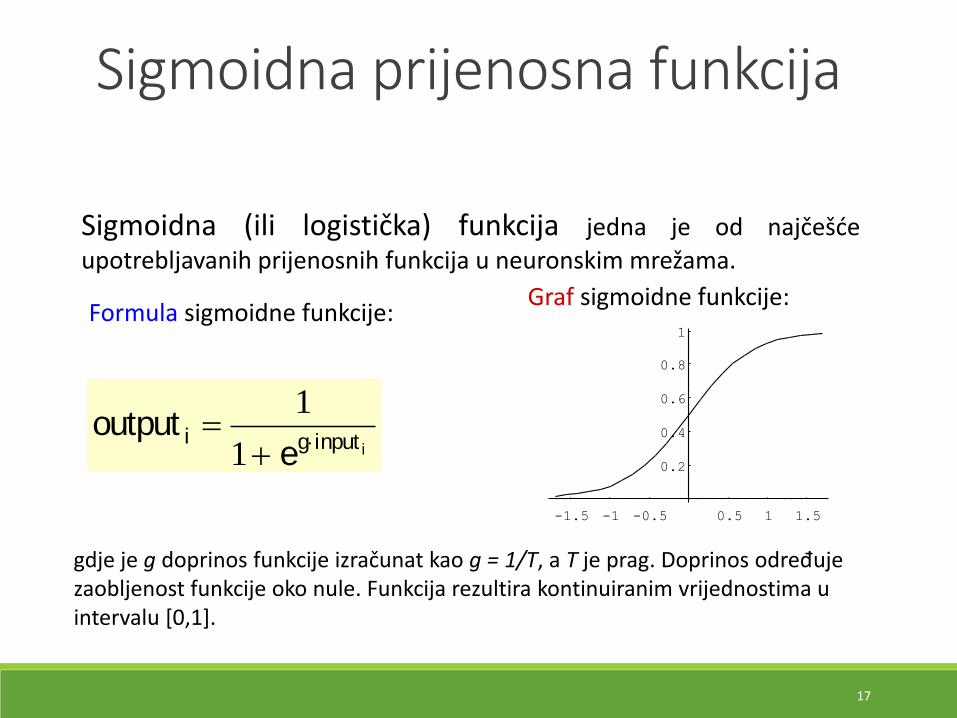
Sigmoidna (ili logistička) funkcija jedna je od najčešće
upotrebljavanih prijenosnih funkcija u neuronskim mrežama.
outpute
i g input i
1
1
gdje je g doprinos funkcije izračunat kao g = 1/T, a T je prag. Doprinos određujezaobljenost funkcije oko nule. Funkcija rezultira kontinuiranim vrijednostima u intervalu [0,1].
Formula sigmoidne funkcije:Graf sigmoidne funkcije:
-1.5 -1 -0.5 0.5 1 1.5
0.2
0.4
0.6
0.8
1
Sigmoidna prijenosna funkcija
18
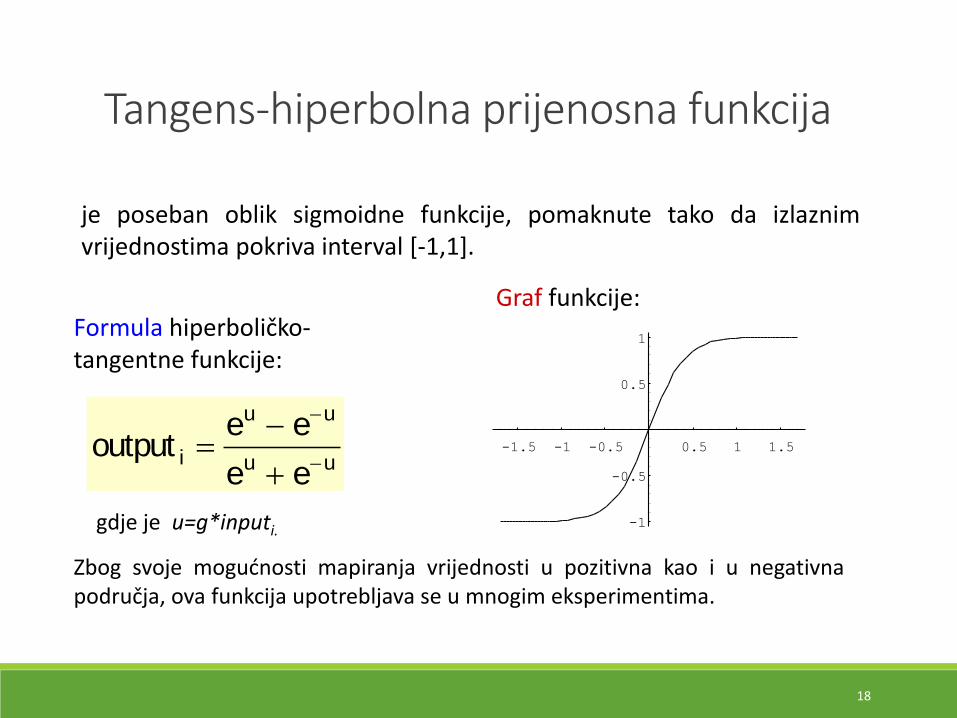
je poseban oblik sigmoidne funkcije, pomaknute tako da izlaznimvrijednostima pokriva interval [-1,1].
gdje je u=g*inputi.
Formula hiperboličko-tangentne funkcije:
Graf funkcije:
outpute e
e ei
u u
u u
-1.5 -1 -0.5 0.5 1 1.5
-1
-0.5
0.5
1
Zbog svoje mogućnosti mapiranja vrijednosti u pozitivna kao i u negativnapodručja, ova funkcija upotrebljava se u mnogim eksperimentima.
Tangens-hiperbolna prijenosna funkcija

19
Pravilo učenja je formula koja se upotrebljava za prilagođavanjetežina veza među neuronima (wij). Najčešće korištena su narednačetiri pravila:
• Delta pravilo (Widrow/Hoff-ovo pravilo),• Poopćeno Delta pravilo,• Delta-Bar-Delta i Prošireno Delta-Bar-Delta pravilo,• Kohonen-ovo pravilo (koristi se za nenadgledane mreže).
Prošireno-Delta-Bar-Delta pravilo je najnaprednije među prva tri nabrojana, jer težine prilagođava lokalno za svaku vezu u mreži, a uključuje i momentum koji sprječava saturaciju. (Saturacija je ekstremno kretanje težina koje dovodi do blokade učenja).
Pravila učenja u NM

20
poznato je i kao pravilo najmanjih srednjih kvadrata, budući da ima za ciljminimizirati ciljnu funkciju određivanjem vrijednosti težina. Cilj jeminimizirati sumu kvadrata grešaka, gdje je greška definirana kao razlikaizmeđu izračunatog i stvarnog (željenog) izlaza nekog neurona za daneulazne podatke. Jednadžba za Delta pravilo je:
icjji yw gdje je staraji
novajiji www
ycj je vrijednost izlaza izračunatog u neuronu j , i je sirova greška izračunataprema:
dicii yy ydj je vrijednost stvarnog (željenog) izlaza neurona j, a je koeficijent učenja(learning rate).
Nova težina između neurona se, dakle, računa tako da se stara težinakorigira za vrijednost greške pomnožen s vrijednošću izlaza neurona j, tesa koeficijentom učenja.
Delta pravilo učenja u NM

21
1. Problem lokalnog minimuma pojavljuje se kada je najmanja greškafunkcije pronađena samo za lokalno područje te je učenje zaustavljenobez dostizanja globalnog minimuma.
2. Problem pretreniranja pojavljuje se jer nije moguće unaprijedodrediti koliko dugo treba učiti mrežu da bi ona mogla naučeno znanjegeneralizirati na novim podacima.
Koliko dugo onda trenirati mrežu? Što duže!??? NE!!!
predugotreniranje
mreža će naučiti i neke nebitne veze međupodacima za učenje, te ih primjenjuje napodacima za testiranje i tako proizvodi velikugrešku
Nedostaci Delta pravila
rješenje = optimirati duljinu treniranja

22
1. od ulaznog sloja prema skrivenom sloju: ulazni sloj učitava podatke iz ulaznogvektora X, i šalje ih u prvi skriveni sloj,2. u skrivenom sloju: jedinice u skrivenom sloju primaju vagani ulaz i prenose ga unaredni skriveni ili u izlazni sloj koristeći neku prijenosnu funkciju.Kako informacije putuju kroz mrežu, računaju se sumirani ulazi i izlazi za svakujedinicu obrade (neuron),3. u izlaznom sloju: za svaki neuron, računa se skalirana lokalna greška koja će seupotrebljavati za povećanje ili smanjenja težina pri daljenjm računanju ulaza uneurone,4. propagiranje unazad od izlaznog sloja do skrivenih slojeva: skalirana lokalnagreška, te povećanje ili smanjenje težina računa se za svaki sloj unazad, počevši odsloja neposredno ispod izlaznog sve do prvog skrivenog sloja, i težine sepodešavaju.5. Ponavljanje koraka 3 i 4 sve dok se ne dostigne željena greška ili određeni brojiteracija učenja
Kako radi MLP mreža?
23
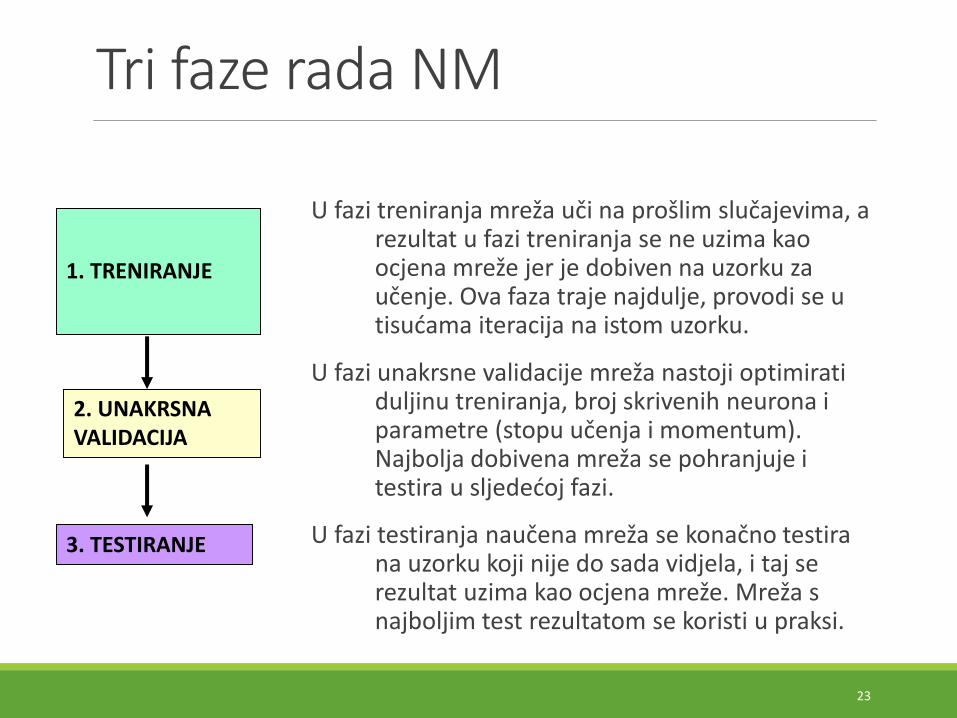
Tri faze rada NM
U fazi treniranja mreža uči na prošlim slučajevima, a rezultat u fazi treniranja se ne uzima kao ocjena mreže jer je dobiven na uzorku za učenje. Ova faza traje najdulje, provodi se u tisućama iteracija na istom uzorku.
U fazi unakrsne validacije mreža nastoji optimirati duljinu treniranja, broj skrivenih neurona i parametre (stopu učenja i momentum). Najbolja dobivena mreža se pohranjuje i testira u sljedećoj fazi.
U fazi testiranja naučena mreža se konačno testira na uzorku koji nije do sada vidjela, i taj se rezultat uzima kao ocjena mreže. Mreža s najboljim test rezultatom se koristi u praksi.
1. TRENIRANJE
2. UNAKRSNA VALIDACIJA
3. TESTIRANJE

24
Dizajniranje modela NM
izabrati algoritam - npr. Backpropagation (MLP), RBFN, Kohonen-ova mreža ili dr.)
odrediti strukturu mreže (topologiju)◦ broj slojeva (da li jedan skriveni sloj ili više), ◦ broj neurona u skrivenom sloju (proizvoljno ili korištenjem nekih od metoda
optimizacije broja skrivenih neurona (pruning, cascading i dr.)
izabrati funkcije i parametre u mreži◦ pravilo učenja (npr. Delta ili Delta-Bar-Delta)◦ prijenosnu funkciju (npr. sigmoidnu)◦ parametre: koeficijent učenja i momentum (veći koeficijent učenja znači
brže učenje, ali i mogućnost gubitka informacije o finijim vezama, momentum je najčešće 0.5)
izabrati mjerilo za ocjenjivanje mreže (kod problema predviđanja koristi se npr. srednja kvadratna greška (RMS), korelacija između željenog i izračunatogoutputa, a kod problema klasifikacije koristi se stopa klasifikacije, matrica konfuzije ili dr.)
izabrati željeni max. broj iteracija za učenje (npr. 100 000 ili više)

25
1. definirati model (ulazne i izlazne varijable)
2. prikupiti i urediti podatke (kodirati varijable koje nisu numeričke u kategorije iklase (npr. 1=NSS, 2=SSS, 3=VSS, itd.), izvršiti statističko preprocesuiranje podataka(detalji u pomoćnim materijalima)
3. uzorkovanje - odrediti koliki će se dio podataka koristiti za treniranje, validaciju i testiranje (npr. 70% za treniranje, 10% za validaciju, 20% za testiranje)
4. dizajniranje mreže - ako u programu koji se koristi ne postoji automatsko dizajniranje neuronske mreže, potrebno je odrediti dizajn mreže (detalji su na prethodnoj stranici)
5. odrediti željeni broj iteracija za učenje mreže (npr. 10000, može biti proizvoljan, a i optimiziran posebnim metodama)
Koraci u izgradnji NM
Mreža je spremna za učenje. Pokrenite je!!!

26
6. treniranje mreže – na uzorku za treniranje
7. testiranje mreže – na uzorku ostavljenom za testiranje
8. analiza rezultata dobivenih testiranjem (analiza veličine greške i grafičkogprikaza).
Ako je greška neprihvatljiva, vraćanje na neki od prethodnih koraka. Ako je
prihvatljiva, slijedi primjena mreže: faza opoziva (recall), a kod nekih mreža i
on-line učenje (stalno dodavanje novih podataka u uzorak za učenje)
Koraci u izgradnji NM - nastavak

27
Izbor mjerila ocjenjivanja NM
Ako se radi o problemu predviđanja, najčešće mjerilo za ocjenjivanje uspješnosti mreže je RMSE greška ili MSE greška
RMSE i MSE greške govore kolika su odstupanja između željenog outputa i outputa mreže. Raspon greške je (0,1). Cilj je dobiti što manju grešku (blizu O).
Druga korisna mjerila su npr. korelacija između željenog i stvarnog outputa, ostvaren profit itd.
1
0
2
1
0
2
)(1
)(1
n
i
ii
n
i
ii
otn
MSE
otn
ERRRMSRMSE = Root Mean Square Error
MSE = Mean Square Error

28
Izbor mjerila ocjenjivanja NM
Ako se radi o problemu klasifikacije, najčešće se koristi Stopa klasifikacije (% ili udio slučajeva koje je mreža dobro klasificirala). Stopa klasifikacije se izražava kroz matricu konfuzije.
U matrici se nalazi po jedan stupac i redak za svaku izlaznu klasu, podaci u recima su željene klase, a podaci u stupcima dobivene klase. Brojevi na dijagonali govore o % dobro klasificiranih slučajeva iz svake klase. Cilj je dobiti što veću ukupnu stopu klasifikacije.

29
Problem:
Predviđanje stope povrata na dionice IBM-a za naredni dan trgovanja.
Cilj je predvidjeti koliki će biti povrat na dionicu IBM-a narednog dana akose dionica proda po današnjoj cijeni zatvaranja (close price), a u svrhuOSTVARIVANJA PROFITA trgovanjem tim dionicama .
Povrat na dionicu računa se kao razlika u cijeni u odnosu na prošlo razdobljeuvećana za dividendu.
Pretpostavka je da se povrat na dionicu IBM-a može predvidjeti na temeljucijene dionice, financijskih pokazatelja tvrtke, makroekonomskih varijabli, itržišnih varijabli.
Podaci su prikupljeni s pomoću i-Soft Inc.(cijene dionica), te iz baza podatakana Internet mreži (Value Line i Economagic.com).
Primjer 1

30
IZLAZNA VARIJABLA (1):
- povrat na dionicu IBM-a za naredni dan
ULAZNE VARIJABLE (20):
Volumen dionice, Nepostojanost dionice, Beta, Povrat na ulaganje (ROI), Intenzivnost kapitala (CI), Financijska snaga (FL), Intenzivnost nenaplaćenih računa (RI), Intenzivnost zaliha (II), Tekući omjer (CR), Stanje novca (C), Stopa 30-godišnjeg hipotekarnog kredita (MR), Stopa 3-mjesečnog povećanja državnog trezora (TBR), Stopa primarnog zajma banke (BPLR), Stopa valutnog tečaja japanskog jena u odnosu na US dolar (ER), Stopa federalnih fondova (FFR), Stopa ukupnog povrata na S&P 500 indeks (S&P500 TRR), Indeks industrijske proizvodnje (IPI), Stopa nezaposlenosti (UR), Indeks vodećih indikatora (ILI), Indeks potrošačkih cijena (CPI)
Definiranje modela za Primjer 1

31
Ukupan uzorak sastoji se od 849 slučajeva (dnevni podaci).
Uzorak za treniranje i validaciju
prvih 594 slučajeva (70%)
pokrivajući razdoblje od 18. siječnja 1996. do 18.
rujna 1998
Uzorak za testiranje
ostalih 255 slučajeva
(30%)
pokrivajući ostalo razdoblje sve do 1. srpnja 1999.
Priprema ulaznih podataka zaPrimjer 1

32
Potrebno je kreirati ASCII datoteku (ili xls kod nekih mreža) u obliku slogova baze podataka, gdje će jedan red predstavljati jedan dan na trgovanja tom dionicom (najprije se u redu navode ulazne, a zatim izlazne varijable).
x1 x2 x3 x4 x5 x6 x7 … x32 y1 y2 y3 y4 y5
1.53 1.99 2.1 2.52 1.45 0 0 1 1 … 1 0 0 0 0
…. …...
Zatim se ta datoteka dijeli na 3 poduzorka: uzorak za treniranje, uzorak za unakrsno testiranje (kod optimizacije mreže) i uzorak za konačnu validaciju mreže.
Priprema ulazne datoteke za Primjer 1

33
• Backpropagation algoritam
• 20 ulaznih, 1 izlazni neuron, 4 skrivena neurona (premaMasters-ovoj formuli)
• Delta pravilo učenja, sigmoidna prijenosna funkcija
• koeficijent učenja 0.2, momentum 0.5
• epoha 10,
• RMS greška kao mjerilo ocjenjivanja mreže
• pokrećemo mrežu na 10 000 iteracija učenja
• testiramo mrežu, i analiziramo rezultat
Izbor parametara NM za Primjer 1

34
Budući da ne postoji pravilo po kojem je neka veličina greške minimalna kodneuronskih mreža, uspješnim rezultatom smatra se greška koja zadovoljava trenutnepotrebe korisnika.
Kako protumačiti veličinu greške? Npr. ako je RMS=0.09, to znači da je razlika između stvarnog (željenog) i izračunatog outputa 0.09 ako se outputi normaliziraju na interval [0,1], ili drugim riječima, odstupanje od stvarne vrijednosti outputa je 9%.
Na primjeru 1, to bi značilo da je razlika između stvarne i izračunate stope povrata na dionicu IBM-a oko 9%.
Analiza rezultata mreže
-15
-10
-5
0
5
10
15
1 25 49 73 97 121 145 169 193 217 241
Stvarni (zeljeni) output
Izracunati output
Grafička analiza rezultata kod predviđanja se provodi promatranjem kretanja stvarnog outputa i vrijednosti outputa dobivenog mrežom.

35
• gdje postoji mnogo prošlih reprezentativnih primjera (barem oko 100, a poželjno je što više)
• gdje nisu poznata pravila dolaženja do odluke (black box), tj. eksperata nema ili nisu dostupni
• gdje se varijable mogu kvantitativno izraziti (što je gotovo uvijek moguće)
• gdje standardne statističke metode nisu pokazale uspjeh, tj. pojava se ne može predstaviti nekim linearnim modelom
• gdje je ponašanje pojave često neizvjesno, podaci nepotpuni, te traže robustan alat
Na koje se vrste problema NM mogu primijeniti?

36
• kada nam je važno s matematičkom sigurnošću objasniti povjerenje u izlazni rezultat, jer NN ne daju podatak o pouzdanosti sustava
Primjeri:
- NN može izračunati da će sutrašnja cijena dionica porasti za 10%, ali ne može reći s kojom sigurnošću to tvrdi.
- NN može reći da kupci koji su vitki više jedu zdravu hranu, i da je greška u njezinoj procjeni 10% bila na podacima za testiranje, ali ne može reći kolika je greška na novim, budućim podacima.
- NN može reći da potrošač koji se bavi sportom pripada u skupinu koji će trošiti više deterdženta za iskuhavanje rublja, ali ne može reći koja je vjerojatnost
Na koje se vrste problema NM ne mogu primijeniti?

37
1. proizvodnja i operacije (53.5%)
2. financije i ulaganje (25.4%).
3. marketing i trgovina
Prema Wong, B.K., Bodnovich, T.A., Selvi, Y., Neural Network Applications in Business: A Review and Analysis of the literature (1988-95), Decision Support Systems, vol. 19, 1997, pp. 301-320. najčešća područja primjene neuronskih mreža u posljednjih 10 godina su:
Najčešća područja primjene NM u poslovanju

38
Procjena zajmova:hipotekarni krediti, prognoziranje kategorije rizika,potpisivanje zajmova i hipotekarnih kredita
Tržište dionica i obveznica:određivanje povoljnog trenutka kupovine i prodaje dionica,problem narudžbi za kupovanje i prodavanje, otkrivanje trokutatihuzoraka u cijenama dionica na tržištu dionica, prepoznavanjeuzoraka za kupovinu i prodaju žive stoke na tržištu budućih roba
Klasifikacija i rangiranje rizika:rangiranje obveznica, klasifikacija obveznica, klasifikacija povrata nadionice na visok ili nizak povrat,
Prognoze tržišta:predviđanje cijena dionica, prognoziranje cijena na tržištima budućih roba (futures), predviđanje mjesečnih kretanja cijena dionica, predviđanje povrata na tržištu dionica
Primjena u financijama i ulaganju

39
Segmentiranje potencijalnih kupaca u:grupe koje će vjerojatno kupiti ili neće kupiti robu (proizvod),grupe koje se razlikuju po ponašanju pri kupnji (sklonosti),grupe koje se razlikuju po tipu kupovanja,grupe koje se razlikuju po sklonosti riziku
Identificiranje novih tržišta:koje tržište odgovara našem tipu robe (proizvoda)
Veza kupac - prodavatelj:koji čimbenici utječu na uspješniji poslovni odnos
Ciljanje na potrošače putem pošte (target marketing, direct marketing):kojim potrošačima ovisno o njihovom profilu treba slati reklame putem pošte
Primjena u marketingu i trgovini

40
Usporedba sa statističkim metodama:
- kod većine radova točnost NN je veća od točnosti dobivene:
•regresijskom analizom (problemi predviđanja)
•diskriminantnom analizom (problemi klasifikacije)
•cluster analizom (problemi klasifikacije)
•ARIMA modelom (predviđanja vremenskih serija)
Uspješnost NM

41
Uspješnost NM - nastavakMjerenje uspješnosti NM ostvarenim profitom:
prosječan godišnji profit ostvaren trgovanjem na S&P500 s pomoću neuronskih mreža bio je više od 130% veći od trgovanja bez NM (Chenoweth, T., Obradovic, 1996)
British Telecom je upotrebom NM i drugih metoda datamining-a unaprijedio odgovor od reklame poštom za 100%),a prodaja i marketing su dobili listu najprospektivnijih mušterija)

42
Tipovi problema za rješavanje pomoću NM
•Regresijski problem – ili problem aproksimacije funkcije – kada je potrebno na temelju ulaznih varijabli procijeniti neku kontinuiranu vrijednost izlazne varijable (npr. cijenu, prihod, profit, ocjenu, itd.)
•Problem klasifikacije – sličan regresijkom, samo što je izlazna varijabla izražena u kategorijama (binarno), pa svaku ulaznu jedinicu treba razvrstati u jednu od kategorija (ili klasa)
•Problem predviđanja – kada su ulazne varijable praćene kroz neko vrijeme (vremenski nizovi), a potrebno je predvidjeti vrijednost izlazne varijable u nekom budućem vremenskom razdoblju (t+1) ili (t+n)
•Problem asocijacije – kada je potrebno prepoznati da je neki ulazni vektor (odn. pattern) jednak nekom od postojećih izlaznih vektora u bazi – ovdje je broj ulaznih varijabli jednak izlaznom
• Poseban slučaj ovog problema je klasifikacija uzoraka

43
Regresijski problem
•Cilj modela NM: procijeniti neku kontinuiranu vrijednost izlazne varijable (npr. cijenu, prihod, profit, ocjenu, temperaturu itd.) na temelju jedne ili više ulaznih varijabli
•Opći oblik je: Y=f(X), što bi se metodom regresijske analize rješavalo na način da se aproksimira funkcija f, npr. y= β1x1 + β2x2 + ... + βnxn tj. njezini parametri βi, pa se ovaj problem još zove i problem aproksimacije funkcije
•Neuronske mreže ne aproksimiraju jednu funkciju koja povezuje ulaze s izlazom, već se u više slojeva koriste izlazne (aktivacijske) funkcije, čime se postiže nelinearnost. Također se ne dobivaju parametri kao u regresijskoj analizi.

44
Primjer 1 – Određivanje vrijednosti kuća
Podaci: - housing_data (UCI Learning Machine Repository)
Model: na temelju 13 ulaznih varijabli procjenjuje se vrijednost kuća na području Bostona (SAD)
Ulazne varijable su izabrane na temelju pretpostavki da utječu na vrijednost nekretnina na tom području
Izvor:http://www.google.com

45
Primjer 1 – ulazne varijableStopa_kriminala
Udio_rezidencijalne zone
Udio_industrijske zone
Rijeka – da li je rijeka u blizini
Nitrat_oksid – udio nitrat-oksida u zraku
Broj_soba u nekretnini
Sarost_naselja
Udaljenost_centra
Indeks_pristupacnosti
Stopa poreza
Odnos_ucit_uc – broj učitelja/broj učenika
Udio_obojenog_stanovništva
Udio_nizeg_socijalnog_statusa
Izlazna varijabla
Srednja vrijednost nekretnine na tom području (izražena u tisućama dolara)

46
Primjer 1 – primjena modela
Primjena: ◦ U agencijama – ako brzo žele procijeniti tržišnu vrijednost nekretnine na
tom području
◦ Za privatne korisnike – ako su vlasnici nekretnine za koju žele procijeniti tržišnu vrijednost ili kupuju nekretninu
Limitiranost modela – s obzirom da su kao ulazne varijable izabrane one za koje se pretpostavlja da utječu na vrijednost nekretnina u području Bostona, model se ne može primijeniti za područja u kojima se ne prepostavlja da te ulazne varijable imaju utjecaj, tj. model je regionalno limitiran
Npr. u Hrvatskoj varijable poput:◦ Udjela obojenog stanovništva,
◦ Odnosa broja učitelja na broj učenika, i sl.
nemaju utjecaj na vrijednost nekretnina kao što to imaju u SAD.
Rješenje – napraviti posebne modele za pojedine regije ili države

47
Primjer 1 – kreiranje modela NMKoraci u kreiranju modela NM:
Priprema uzorka – uzorak se dijeli na tri dijela: treniranje, testiranje i validaciju, npr. 70%, 10%, 20%.
Izabire se algoritam – višeslojni perceptron ili drugi
Kreira se NM sa 13 ulaznih jedinica (neurona), 1 izlaznim neuronom
Eksperimentalno se prilikom modeliranja pronalazi najbolji broj skrivenih neurona
Izabire se željena izlazna (aktivacijska) funkcija za skriveni i izlazni sloj (npr. tangh za skriveni, linear za izlazni)
Izabiru se vrijednosti parametara učenja: stopa učenja i momentum
Određuje se maksimalni broj iteracija (ciklusa) učenja, npr. 1000

48
Primjer 1 – pokretanje mrežePokreće se treniranje (učenje) mreže – u toj fazi koristi se i uzorak za testiranje kako bi odredila najbolja duljina treniranja (broj iteracija)
Mreža se testira na uzorku za validaciju
Rezultat se promatra tablično i grafički (ako je raspoloživ) i donosi ocjena o uspješnosti modela NM

49
Mjerila za ocjenjivanje NM kod regresijskog tipa problema
Za regresijske probleme i probleme predviđanja, kao mjerilo uspješnosti NM preporuča se koristiti:
MSE – mean square error – srednju kvadratnu grešku, pokazuje kolika su prosječna odstupanja stvarnih od izračunatih vrijednosti na određenom uzorku (u mjernim jedinicama u kojima je izražen i output, tj. izlazna varijabla, ili
NMSE – normaliziranu srednju kvadratnu grešku – pokazuje kolika su odstupanja stvarnih od izračunatih vrijednosti ako se prije toga sve vrijednosti varijabli u modelu svedu na interval [0,1]. NMSE se može tumačiti kao prosječno postotno odstupanje stvarnih od izračunatih vrijednosti.
50
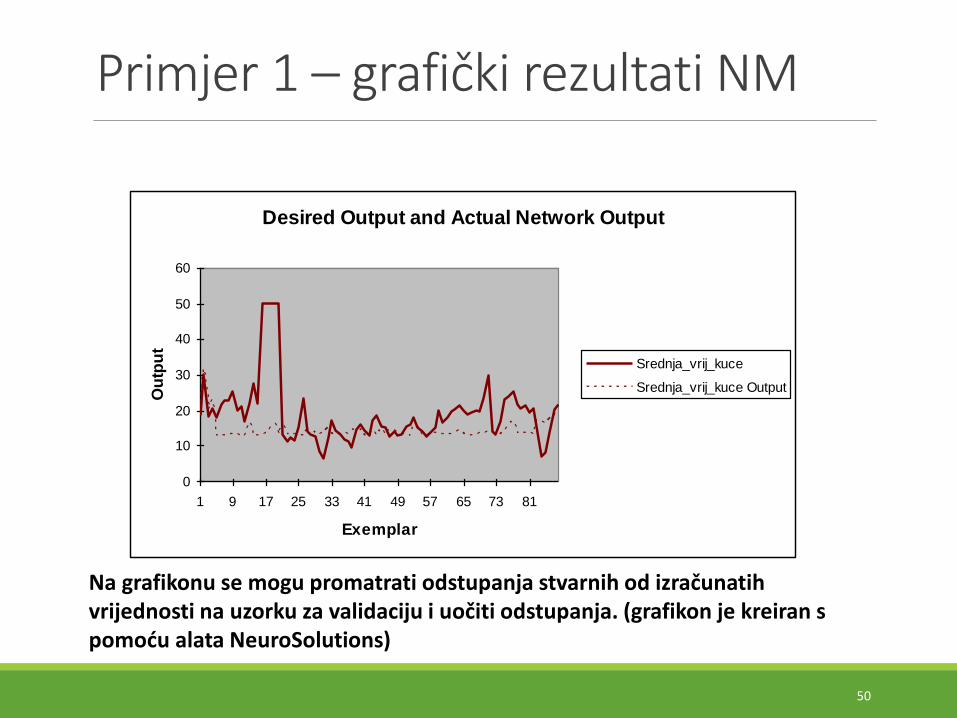
Primjer 1 – grafički rezultati NM
Desired Output and Actual Network Output
0
10
20
30
40
50
60
1 9 17 25 33 41 49 57 65 73 81
Exemplar
Ou
tpu
t
Srednja_vrij_kuce
Srednja_vrij_kuce Output
Na grafikonu se mogu promatrati odstupanja stvarnih od izračunatih vrijednosti na uzorku za validaciju i uočiti odstupanja. (grafikon je kreiran s pomoću alata NeuroSolutions)

51
Primjer 1 – tumačenje rezultata NM
Performance Srednja_vrij_kuce
MSE 10.0693901
NMSE 0.286981776
r 0.690981587
MSE – pokazuje da su prosječna odstupanja stvarnih od izračunatih vrijednosti nekretnina na području Bostona 10.06 tisuća dolara
NMSE – pokazuje da je prosječno postotno odstupanje stvarnih od izračunatih vrijednosti nekretnina na području Bostona 28.69% .
r = koeficijent korelacije između stvarnih i izračunatih vrijednosti – poželjno je da bude što bliži 1.
Dobiveni r iz tablice pokazuje da postoji jaka korelacija između stvarnih i izračunatih vrijednosti.

52
Problem klasifikacijeCilj: razvrstati promatrane jedinke u skupine (ili kategorije, ili klase) pri čemu je unaprijed poznat broj klasa
U tu svrhu koriste se posebni algoritmi za klasifikaciju, kao npr.◦ Višeslojni perceptron sa dodanom Softmax funkcijom u izlazni sloj
kako bi se na izlazu dobile vjerojatnosti pripadanja u neku klasu
◦ Mreža s radijalno zasnovanom funkcijom – također sa Softmax funkcijom u izlaznom sloju
◦ Mreža učeće vektorske kvantizacije (LVQ)
◦ Vjerojatnosna mreža (eng. probabilistic network) i dr.

53
Primjer 2 – Klasifikacija rakova
Podaci: NeuroSolutions data samples (raspoloživi uz alat)
Model: na temelju 6 ulaznih varijabli procjenjuje se da li je neki rak ženka ili mužjak
Ulazne varijable su izabrane na temelju pretpostavki da utječu na odluku o spolu raka
Izvor: http://www.coolinarka.com
54
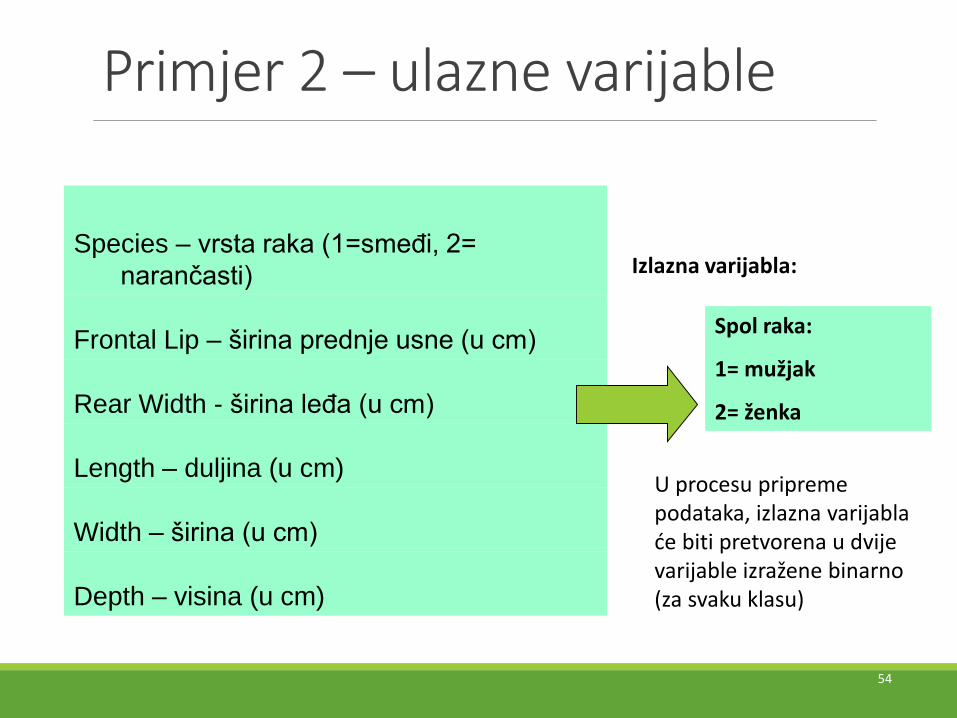
Primjer 2 – ulazne varijable
Species – vrsta raka (1=smeđi, 2=
narančasti)
Frontal Lip – širina prednje usne (u cm)
Rear Width - širina leđa (u cm)
Length – duljina (u cm)
Width – širina (u cm)
Depth – visina (u cm)
Spol raka:
1= mužjak
2= ženka
Izlazna varijabla:
U procesu pripreme podataka, izlazna varijabla će biti pretvorena u dvije varijable izražene binarno (za svaku klasu)

55
Primjer 2 – primjena modela
Primjena: ◦ U biologiji – za selektivne procese i izbor metoda uzgoja rakova
Limitiranost modela – ovaj model sadrži mali broj ulaznih varijabli, pa je u tom smislu limitiran. U slučaju da NM pokaže veliku grešku na promatranom modelu, jedan od načina poboljšanja modela je proširiti skup ulaznih varijabli

56
Primjer 2 – kreiranje modela NMKoraci u kreiranju modela NM:
Priprema uzorka – uzorak se dijeli na tri dijela: treniranje, testiranje i validaciju, npr. 70%, 10%, 20%.
Izabire se algoritam – višeslojni perceptron ili drugi
Kreira se NM sa 6 ulaznih jedinica (neurona), 2 izlazna neurona (za svaku klasu po 1)
Eksperimentalno se prilikom modeliranja pronalazi najbolji broj skrivenih neurona
Izabire se željena izlazna (aktivacijska) funkcija za skriveni i izlazni sloj (npr. tangh za skriveni, linear za izlazni)
Izabiru se vrijednosti parametara učenja: stopa učenja i momentum
Određuje se maksimalni broj iteracija (ciklusa) učenja, npr. 1000

57
Primjer 2 – pokretanje mrežePokreće se treniranje (učenje) mreže – u toj fazi koristi se i uzorak za testiranje kako bi odredila najbolja duljina treniranja (broj iteracija)
Pokreće se testiranje mreže na uzorku za validaciju
Rezultat se promatra tablično i grafički (ako je raspoloživ) i donosi ocjena o uspješnosti modela NM

58
Mjerila za ocjenjivanje NM kod klasifikacijskog tipa problema
Za probleme klasifikacije, kao mjerilo uspješnosti NM preporuča se koristiti:
Matricu konfuzije – ona pokazuje broj slučajeva (jedinki u uzorku) koje je NM svrstala u ispravnu i u pogrešnu klasu
Stopu klasifikacije – postotak ispravno klasificiranih slučajeva – za svaku klasu posebno i prosječnu stopu za sve klase
Output /
Desired Male Female
Male 20 1
Female 2 17
Percent Correct 90,90908813 94,44444275
Matrica konfuzije za Primjer 2.

59
Primjer 2 – tumačenje rezultata NM
Matrica konfuzije sa prethodne slike pokazuje slijedeće:
• U stupcima je prikazan stvarni broj slučajeva koji su pripadali u pojedinu klasu ili kategoriju (u ovom slučaju broj mužjaka i ženki) u uzorku za validaciju . Ukupno je bilo 22 mužjaka u tom uzorku, te 18 ženki.
• Od ukupno 22 mužjaka, njih 20 je svrstano ispravno u klasu mužjaka, dokje njih 2 mreža pogrešno svrstala u klasu ženki. Broj ispravno klasificiranihmužjaka prikazan je u zadnjem retku donje tablice (Percent Correct – Male): 90.90%.
• U uzroku za validaciju je bilo ukupno 18 ženki, od kojih je njih 17 mrežauspjela dobro klasificirati u ženke, dok je 1 pogrešno svrstana u mužjake. U postocima to iznosi 94.44%.

60
Problem asocijacije
Asocijacija ili prepoznavanje uzoraka je karakterističan tip problema po tome što obično ulazni vektor čini digitalizirana slika, a također i izlazni vektor – NM nastoji prepoznati koji ulazni vektor odgovara kojem izlaznom
Ponekad u izlaznom vektoru nije slika, nego kategorije (klase), pa se takav problem zove: klasifikacija uzoraka
Slike se prikazuju na način da se izraze matricom piksela, a zatim svakom pikselu dodijeli vrijednost i prikaže u datoteci s podacima
Model NM za klasifikaciju hrv. novčanica –izradili studenti FER-a i dobili Rektorovu nagradu za najbolji seminarski rad 2001/02.
61
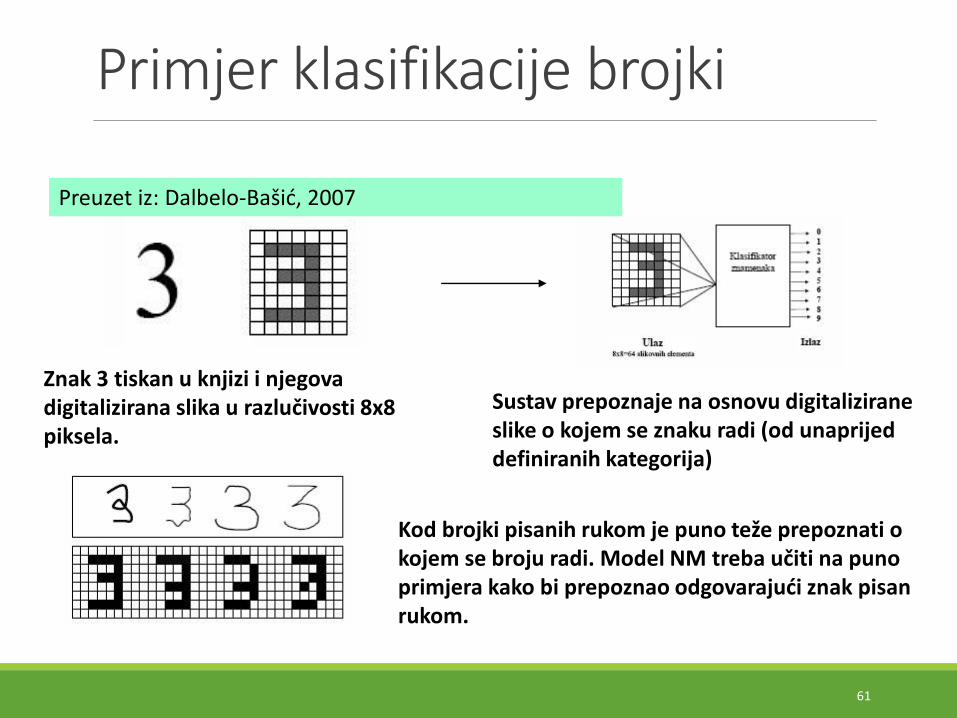
Primjer klasifikacije brojki
Kod brojki pisanih rukom je puno teže prepoznati o kojem se broju radi. Model NM treba učiti na puno primjera kako bi prepoznao odgovarajući znak pisan rukom.
Znak 3 tiskan u knjizi i njegova digitalizirana slika u razlučivosti 8x8 piksela.
Sustav prepoznaje na osnovu digitalizirane slike o kojem se znaku radi (od unaprijed definiranih kategorija)
Preuzet iz: Dalbelo-Bašić, 2007

62
Primjer prepoznavanja licaPreuzeto iz alata NeuroSolutions, Demos
Ulazna digitalizirana slika lica
Izlazna digitalizirana slika imena koje NM treba povezati s licem (na početku faze učenja)
Izlazna digitalizirana slika imena koje NM treba povezati s licem (u fazi testiranja)

63
Mjerila za ocjenjivanje NM kod problema asocijacije
Najčešće se koristi MSE greška
Mogu se koristiti i druga mjerila, npr. ◦ r – koeficijent korelacije između stvarnog i dobivenog outputa
◦ MAE – mean absolute error – srednja apsolutna greška, i dr.
◦ Stopa točnosti klasifikacije – ako su na izlazu klase (kategorije) u koje treba razvrstati ulazni uzorak
Iako se kod problema asocijacije mogu koristiti i algoritmi opće namjene (MLP, mreža s radijalno zasnovanom funkcijom, LVQ i dr.), postoje specijalizirani algoritmi NM za asocijaciju, npr:◦ Linear associator◦ ART mreže◦ Adaline/Madaline mreže i dr.

64
Primjena NM za asocijacijuU medicini (ultrazvučna dijagnostika, rentgenski snimci, i dr.)
U astronomiji - za prepoznavanje svemirskih tijela
U vojne svrhe – za prepoznavanje vojnih baza na temelju satelitskih snimki zemljine površine
U agronomiji – za prepoznavanje bolesti biljaka na temelju slika
U kriminalistici – za prepoznavanje lica, otisaka prstiju, i dr.
U biometrici – za identifikaciju korisnika na temelju otisaka prstiju, rožnice oka, glasa i dr.
U glazbi – za prepoznavanje glazbenih zapisa, i dr.
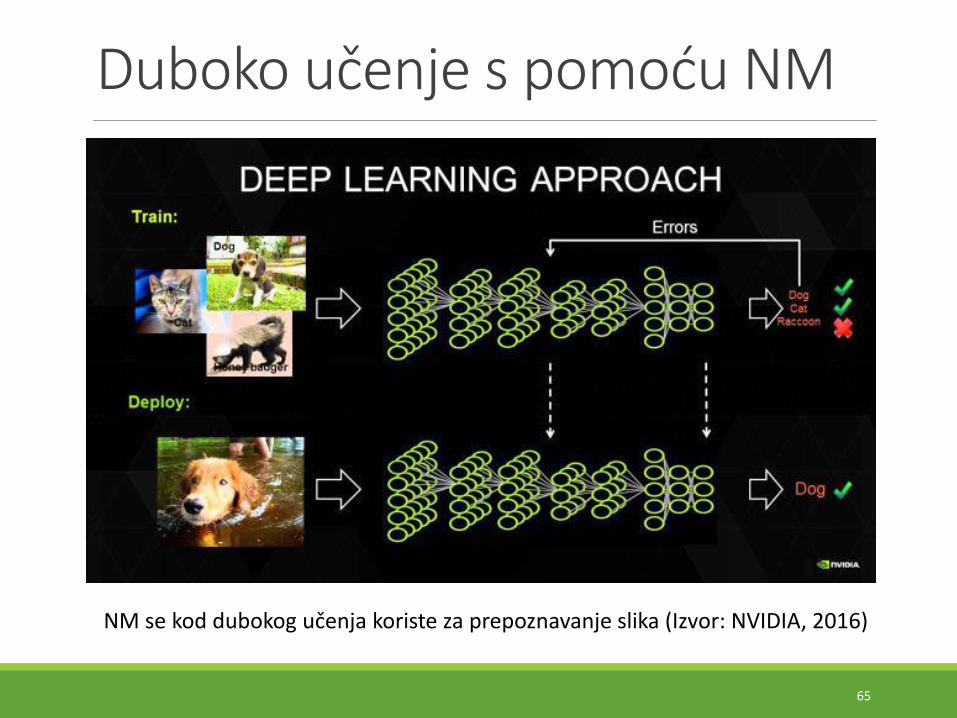
Duboko učenje s pomoću NM
65
NM se kod dubokog učenja koriste za prepoznavanje slika (Izvor: NVIDIA, 2016)
Razvoj strojnog učenja
66

67
ZaključakKod neuronskih mreža za regresiju predviđa se neka kontinuirana vrijednost izlazne varijable (npr. cijena, količina prodaje, starost, itd.)
Kao mjerilo za ocjenjivanje modela koristi se MSE greška ili NMSE greška, te koeficijent korelacije između stvarnih rezultata i rezultata koje je mreža trebala dobiti.
Kod neuronskih mreža za klasifikaciju model razvrstava slučajeve u više kategorija ili klasa.
Kao mjerilo za ocjenjivanje modela koristi se stopa točnosti klasifikacije (prosječna za sve klase).
Trend razvoja neuronskih mreža je u smjeru dubokog učenja (Deep Learning) u okviru BigData platformi.

Literatura▪ G. Klepac, L. Mršić, Poslovna inteligencija kroz poslovne slučajeve, Lider, Tim Press, Zagreb, 2006.
▪ Ž. Panian, G. Klepac, Poslovna inteligencija, Masmedia, Zagreb, 2003.
▪ V.Čerić, M., Varga, Informacijska tehnologija u poslovanju, Element, Zagreb, 2004., poglavlja 13-16.
▪ T. Hastie, R. Tibshirani, J. Friedman, The Elements of Statistical Learning, Data Mining, Inference, and Prediction, Springer, Second Edition, 2013.
▪ F. Provost, T. Fawcett, Data Science for Business, What You Need to Know about Data Mining and Data-Analytic Thinking, O'Reilly Media, 2013.
▪ S. J. Russell, P.Norvig, Artificial Intelligence: A Modern Approach, Prentice Hall; 2nd edition, 2002.
▪ I.H. Witten, E. Frank, Data Mining: Practical Machine Learning Tools and Techniques with Java Implementation. Morgan Kaufman Publishers, San Francisco, CA, 2000.
▪ C. Bishop, Neural Networks and Machine Learning, Springer Verlag, Berlin, 1998.
▪ D. Graupe, Principles of Artificial Neural Networks (2nd edition), Advanced Series in Circuits and Systems - Vol. 6, World Scientific, Singapore 2007.
▪ Zekić-Sušac, M., Has, A., Predictive analytics in Big Data platforms – comparison and strategies, MIPRO BIS 2016, Opatija, Hrvatska
68

Literatura - web izvori▪ NVIDIA, What’s the Difference Between Artificial Intelligence, Machine Learning, and Deep Learning?, https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/, 11.10.2017.
▪ B. Marr, The Amazing Ways Google Uses Deep Learning AI, https://www.forbes.com/sites/bernardmarr/2017/08/08/the-amazing-ways-how-google-uses-deep-learning-ai/#5ad4fc813204, Forbes, 08.08.2017.
▪ FinanceOnline, Pros and Cons of Grow BI: A Business Intelligence Solution for the Power User, https://financesonline.com/pros-cons-grow-bi-business-intelligence-solution-power-user/, 11.10.2017.
▪ Gartner, Business Intelligence (BI), http://www.gartner.com/it-glossary/business-intelligence-bi/, 11.10.2017.
▪ J. Heinze, Business Intelligence vs. Business Analytics: What’s The Difference?, https://www.betterbuys.com/bi/business-intelligence-vs-business-analytics/, 10.10.2017.
▪ W3Resource, MySQL Create Database, https://www.w3resource.com/mysql/creating-using-databases-tables/what-are-database-and-tables.php, 12.10.2017.
▪ SAS, Big Data Analytics, https://www.sas.com/en_us/insights/analytics/big-data-analytics.html, 10.10.2017.
▪ S. Russell, P. Norvig, AI on the web, http://aima.cs.berkeley.edu/ai.html, 14.11.2013.
69