Embed Size (px)
Citation preview

4. Klassifikation

2
Inhalt§ 4.1 Motivation
§ 4.2 Evaluation
§ 4.3 Logistische Regression
§ 4.4 k-Nächste Nachbarn
§ 4.5 Naïve Bayes
§ 4.6 Entscheidungsbäume
§ 4.7 Support Vector Machines
§ 4.8 Neuronale Netze
§ 4.9 Ensemble-Methoden
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

3
4.1 Motivation§ Regressionsverfahren erklären metrisches Merkmal
anhand unabhängiger metrischer Merkmale
§ Beispiel: Sage Verbrauch (in l/100km) anhand Gewicht, PS, Hubraum, Zylinder, Beschleunigung und Jahr voraus
§ Klassifikationsverfahren erklären nominales Merkmalanhand unabhängiger metrischer Merkmale
§ Beispiel: Sage Herkunft (Europa, Japan, U.S.A.) anhandVerbrauch, Gewicht, Hubraum, Zylinder und Jahr voraus
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

4
Anwendungen von Klassifikationsverfahren§ Klassifikation von Zeitungsartikeln oder Blogposts
in Politik, Sport, Kultur, Reise und Auto
§ Klassifikation von E-Mailsin Spam und Nicht-Spam
§ Segmentierung von Kundenin Schnäppchenjäger, Normalos und Luxusliebhaber
§ Produktempfehlungen für bestimmten Kunden durch Klassifikation in Interessant und Nicht-Interessant
§ Handschrifterkennung auf Überweisungsträgern durch Klassifikation der gescannten Zeichen in Klassen 0-9
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

5
Überwachtes vs. unüberwachtes Lernen§ Verfahren des maschinellen Lernens lassen sich in
verschiedene Kategorien einteilen; zwei wichtige sind
§ überwachtes Lernen (supervised learning) mit Klassifikationsverfahren als typischem Beispiel nutzt Trainingsdaten (z.B. klassifizierte Datenpunkte) aus
§ unüberwachtes Lernen (unsupervised learning) mitClusteringverfahren als typischem Beispiel erkenntZusammenhänge in den gegebenen Daten
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

6
Überwachtes vs. unüberwachtes Lernen§ Beispiel: Betrachten wir Zeitungsartikel als Anwendung
§ Klassifikationsverfahren, als überwachtes Lernen, lernt anhand von bereits manuell klassifizierten Zeitungsartikeln, vorher unbekannte Zeitungsartikel in Politik, Sport, Kultur, Reise und Auto einzuteilen
§ Clusteringverfahren, als unüberwachtes Lernen, teilt eine gegebene Menge von Zeitungsartikeln anhand ihres Inhalts in möglichst homogene Gruppen (cluster) auf; diese Gruppen sind vorab nicht festgelegt und müssen nichtden manuell bestimmten Klassen Politik etc. entsprechen
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

7
Binäre vs. Mehrklassen Klassifikation§ Klassifikationsverfahren lassen sich nach der Ausprägung
des zu erklärenden nominalen Merkmals unterscheiden
§ binäre Klassifikationsverfahren (z.B. Spam vs. Nicht-Spam)wenn es zwei Werte des zu erklärenden Merkmals gibt
§ Mehrklassen Klassifikationsverfahren (z.B. Sport vs. Politik vs. Kultur) wenn es mehr als zwei Werte des zu erklärenden Merkmals gibt
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

8
Binäre vs. Mehrklassen Klassifikation§ Binäre Klassifikationsverfahren z.B.
§ logistische Regression
§ Support Vector Machines
§ Mehrklassen Klassifikationsverfahren z.B.
§ Entscheidungsbäume
§ k-Nächste Nachbarn
§ Naïve Bayes
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

9
Binäre vs. Mehrklassen Klassifikation§ Binäre Klassifikationsverfahren lassen sich durch „Trick“
zur Klassifikation in mehr als zwei Klassen einsetzen
§ bestimme für jede Klasse einen Klassifikator, der die Klassen von allen anderen Klassen unterscheidet(z.B. Sport vs. Nicht-Sport als Vereinigung anderer Klassen)
§ klassifiziere vorher unbekannten Datenpunkt mit jedem der zuvor bestimmten Klassifikatoren (z.B. Sport vs. Nicht-Sport, Politik vs. Nicht-Politik, Kultur vs. Nicht-Kultur)und weise dem Datenpunkt die Klasse des Klassifikatorsmit dem höchsten Konfidenz-Wert zu
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

10
4.2 Evaluation§ Systematische Vorgehensweise, um die Güte eines
Klassifikationsverfahrens zu messen bzw. verschiedeneVerfahren miteinander zu vergleichen
§ Analog zur Evaluation von Regressionsverfahren, ist eine Aufteilung der manuell klassifizierten Daten in Trainings- und Testdaten ggf. mitKreuzvalidierung sinnvoll
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

11
Konfusionsmatrix§ Wenden wir einen Klassifikator auf unsere Testdaten an,
so erhalten wir als Ergebnis eine Konfusionsmatrix
§ Spalten entsprechen wirklichen Klassen der Testdaten; Zeilen geben Vorhersage des Klassifikators wieder
§ Beispiel: Klassifikation in Sport, Kultur und Politik
§ je Klasse wurden 10 von 20 Daten-punkten korrekt klassifiziert
§ 3 der Datenpunkte aus Politik wurdenfälschlicherweise als Sport klassifiziert
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
S K PS 10 4 3K 5 10 7P 5 6 10

12
Gütemaße§ Konfusionsmatrix bildet Grundlage zur Berechnung
verschiedener Gütemaße eines Klassifikators
§ Präzision (precision) als Maß der Fähigkeit,eine bestimmte Klasse genau zu erkennen
§ Ausbeute (recall) als Maß der Fähigkeit,alle Datenpunkte einer Klasse zu erkennen
§ F-Maß (f-measure) als harmonisches Mittelvon Precision und Recall
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

13
Präzision (precision)
§ Präzision (precision) eines Klassifikators für eine bestimmte Klasse ist definiert als
§ #TP (true positives) als Zahl der Datenpunkte aus der betrachteten Klasse, die korrekt in die betrachtete Klasse eingeordnet wurden
§ #FP (false positives) als Zahl der Datenpunkte aus anderen Klassen, die fälschlicherweise in die betrachtete Klasseeingeordnet wurden
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
Precision =
#TP
#TP + #FP
14
Präzision (precision)
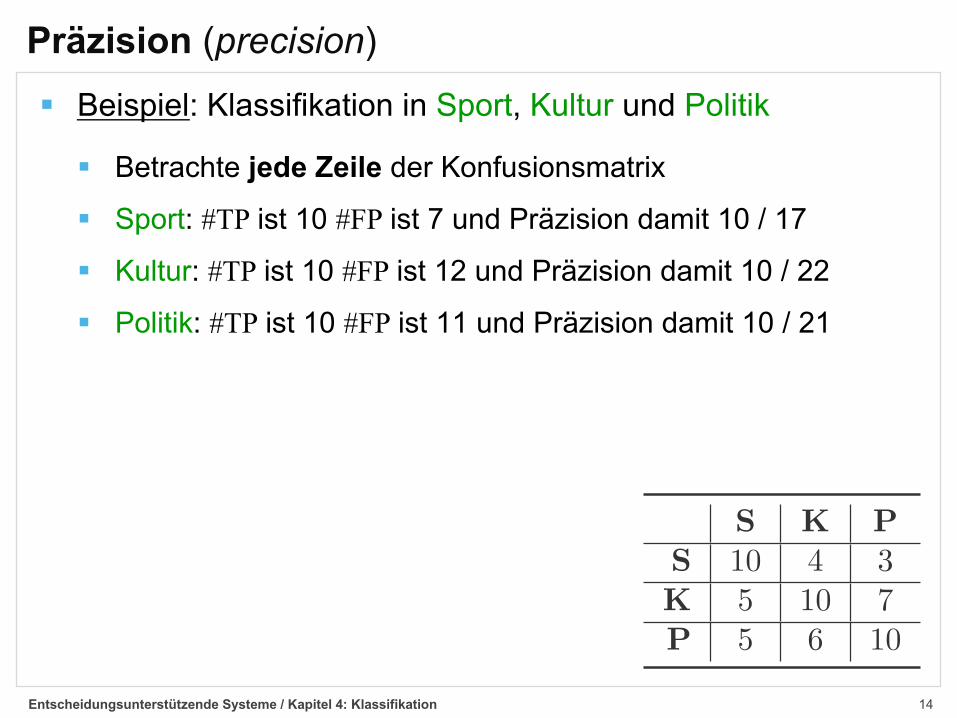
§ Beispiel: Klassifikation in Sport, Kultur und Politik
§ Betrachte jede Zeile der Konfusionsmatrix
§ Sport: #TP ist 10 #FP ist 7 und Präzision damit 10 / 17
§ Kultur: #TP ist 10 #FP ist 12 und Präzision damit 10 / 22
§ Politik: #TP ist 10 #FP ist 11 und Präzision damit 10 / 21
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
S K PS 10 4 3K 5 10 7P 5 6 10

15
Ausbeute (recall)
§ Ausbeute (recall) eines Klassifikators für einebestimmte Klasse ist definiert als
§ #TP (true positives) als Zahl der Datenpunkte aus der betrachteten Klasse, die korrekt in die betrachtete Klasse eingeordnet wurden
§ #FN (false negatives) als Zahl der Datenpunkte aus der betrachteten Klasse, die fälschlicherweise in eine andere Klasse eingeordnet wurden
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
Recall = #TP#TP + #FN

16
Ausbeute (recall)
§ Beispiel: Klassifikation in Sport, Kultur und Politik
§ Betrachte jede Spalte der Konfusionsmatrix
§ Sport: #TP ist 10 #FN ist 10 und Ausbeute damit 10 / 20
§ Kultur: #TP ist 10 #FN ist 10 und Ausbeute damit 10 / 20
§ Politik: #TP ist 10 #FN ist 10 und Ausbeute damit 10 / 20
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
S K PS 10 4 3K 5 10 7P 5 6 10
17
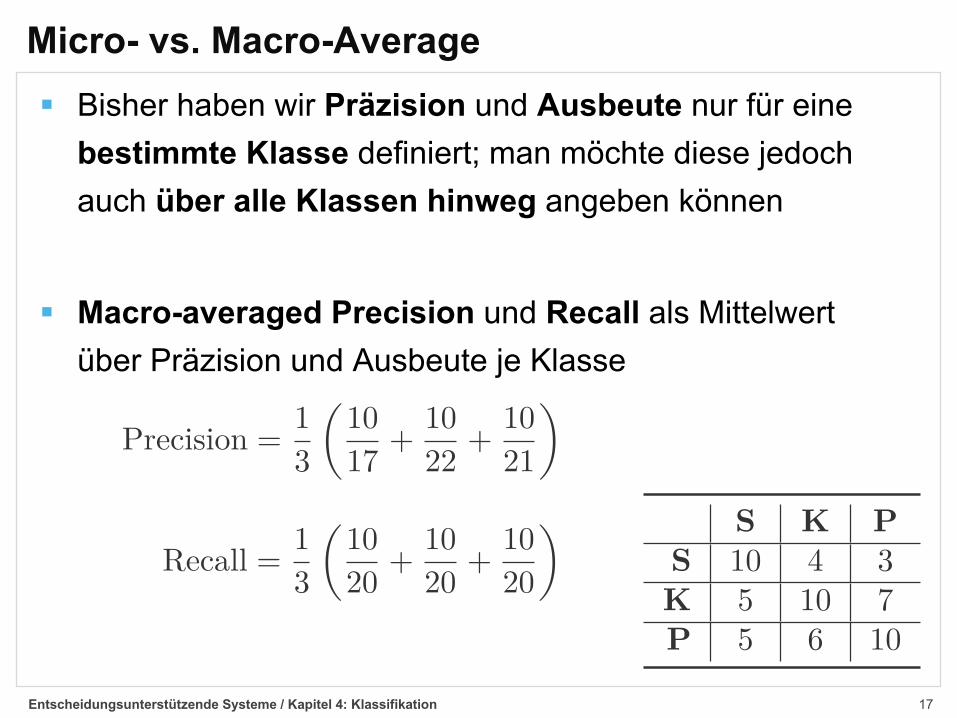
Micro- vs. Macro-Average§ Bisher haben wir Präzision und Ausbeute nur für eine
bestimmte Klasse definiert; man möchte diese jedoch auch über alle Klassen hinweg angeben können
§ Macro-averaged Precision und Recall als Mittelwertüber Präzision und Ausbeute je Klasse
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
S K PS 10 4 3K 5 10 7P 5 6 10
Precision =
1
3
310
17
+
10
22
+
10
21
4
Recall = 13
31020 + 10
20 + 1020
4
18
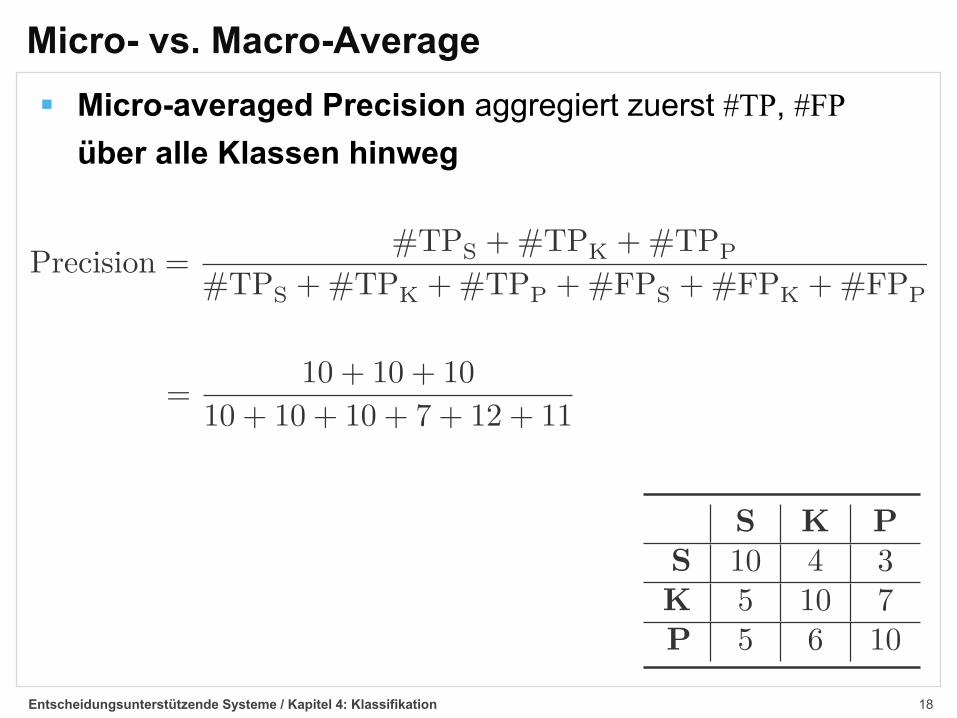
Micro- vs. Macro-Average§ Micro-averaged Precision aggregiert zuerst #TP, #FP
über alle Klassen hinweg
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
S K PS 10 4 3K 5 10 7P 5 6 10
Precision =
#TPS + #TPK + #TPP#TPS + #TPK + #TPP + #FPS + #FPK + #FPP
= 10 + 10 + 1010 + 10 + 10 + 7 + 12 + 11
19
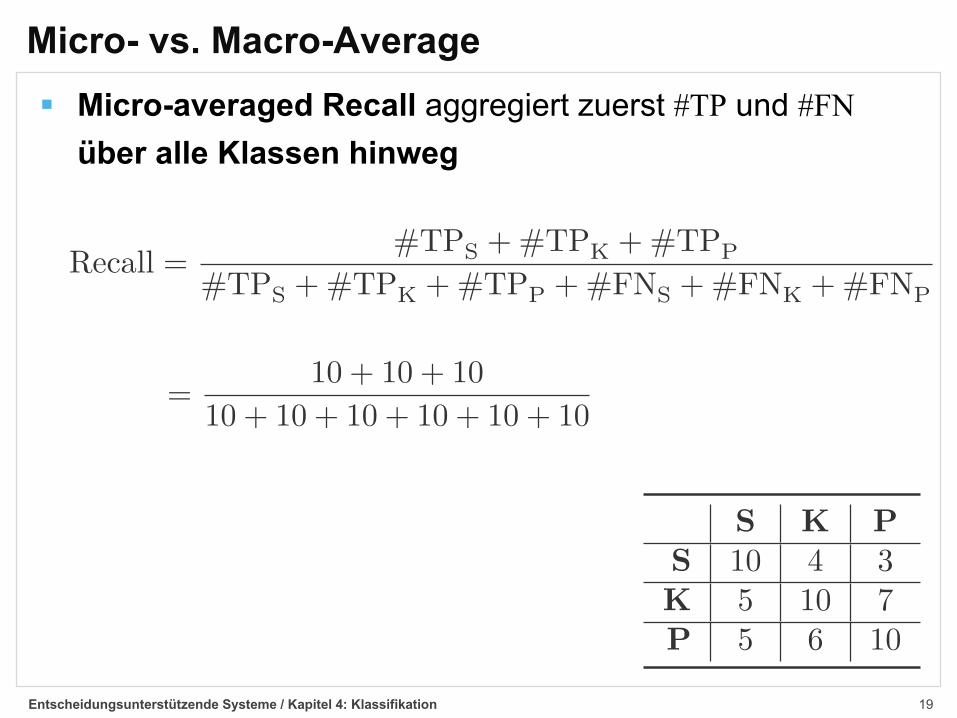
Micro- vs. Macro-Average§ Micro-averaged Recall aggregiert zuerst #TP und #FN
über alle Klassen hinweg
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
S K PS 10 4 3K 5 10 7P 5 6 10
Recall = #TPS + #TPK + #TPP#TPS + #TPK + #TPP + #FNS + #FNK + #FNP
= 10 + 10 + 1010 + 10 + 10 + 10 + 10 + 10

20
F-Maß (f-measure)
§ F-Maß (f-measure) als harmonisches Mittel zwischenPrecision und Recall kombiniert die beiden Maße
und nimmt einen Wert in [0,1] an
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
F1 = 2 · Precision · Recall
Precision + Recall

21
4.3 Logistische Regression§ Logistische Regression ist ein Klassifikationsverfahren,
welches auf linearer Regression aufbaut, jedochein binäres nominales Merkmal erklärt
§ Rückblick: Multiple lineare Regression erklärt abhängiges metrisches Merkmal y als lineare Kombination unabhängiger metrischer Merkmale x(,j)
mit Vorhersage
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
yi = —0 + —1x(i,1) + —2x(i,2) + . . . + —mx(i,m)
yi œ R

22
Logistische Regression§ Daten stehen in Form von n Beobachtungen zur Verfügung
§ Jeder Datenpunkt (x(i,1), …, x(i,m), yi) besteht aus
§ als Werte der unabhängigen Merkmale x(,j)
§ als Wert des abhängigen Merkmals y
§ Logistische Regression verwendet eine lineare Kombination der unabhängigen Merkmale,transformiert den Wert der Vorhersagejedoch derart, dass er in [0,1] liegt
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
(x(1,1), . . . , x(1,m), y1), . . . , (x(n,1), . . . , x(n,m), yn)
yi œ {0, 1}
x(i,j) œ R
23
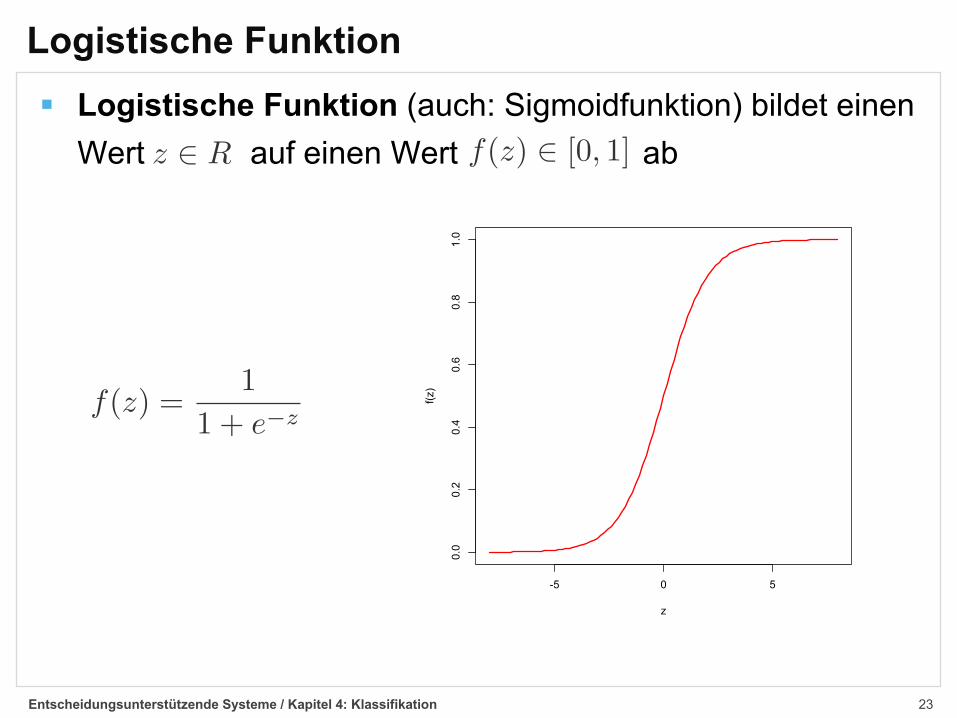
Logistische Funktion§ Logistische Funktion (auch: Sigmoidfunktion) bildet einen
Wert auf einen Wert ab
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
z œ R f(z) œ [0, 1]
f(z) = 11 + e≠z
-5 0 5
0.0
0.2
0.4
0.6
0.8
1.0
z
f(z)

24
Logistische Regression§ Logistische Regression erklärt das abhängige nominale
Merkmal anhand der unabhängigen metrischenMerkmale als
§ Vorhersage kann als Wahrscheinlichkeit P[yi=1|xi]interpretiert werden dass der Datenpunkt xi
zur Klasse yi = 1 gehört und lässt sichdurch Runden in einen binären Wertin {0,1} transformieren
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
yi
= 11 + e≠(—0+—1x(i,1)+—2x(i,2)+...+—mx(i,m))
yi

25
Logistische Regression§ Logistische Regression als Optimierungsproblem
§ Optimaler Parametervektor β ist mittels stochastischem Gradientenverfahren bestimmbar
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
arg min
—
nÿ
i=1≠ (yi · log(yi) + (1 ≠ yi) · log(1 ≠ yi))

26
Logistische Regression in R§ Beispiel: Binäre Klassifikation von Autos nach Herkunft
U.S.A vs. Japan/Europa anhand aller anderen Merkmale
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
1 # Modell ausgeben
2 autos $HK <- 03 autos $HK[ autos$ Herkunft == "U.S.A."] <- 14
5 # Trainings - (70%) und Testdaten (30%) erzeugen
6 train <- sample (nrow(autos), 0.7*nrow(autos ))7 autos. train <- autos[train ,]8 autos.test <- autos[-train ,]9
10 # Logistische Regression
11 fit <- glm(HK ˜ Gewicht +PS+ Verbrauch + Beschleunigung +Jahr+ Zylinder +Hubraum ,12 data=autos.train , family = binomial ())13
14 # Vorhersagen auf Testdaten berechnen
15 prob <- predict (fit , autos.test , type=" response ")16 pred <- factor (prob > 0.5, levels =c(FALSE ,TRUE), labels =c("0","1"))17
18 # Konfusionsmatrix berechnen
19 perf <- table(pred , autos.test$HK , dnn=c(" Vorhersage "," Daten"))

27
Logistische Regression in R
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
1 # Konfusionsmatrix ausgeben
2 perf3
4 Daten5 Vorhersage 0 16 0 42 127 1 3 618
9 # Modell ausgeben
10
11 fit12
13 Call: glm( formula = HK ˜ Gewicht + PS + Verbrauch + Beschleunigung +14 Jahr + Zylinder + Hubraum , family = binomial (), data = autos.train)15
16 Coefficients :17 ( Intercept ) Gewicht PS18 -23.689858 -0.011688 -0.00622119 Verbrauch Beschleunigung Jahr20 0.523234 0.193104 0.28884121 Zylinder Hubraum22 -1.878439 7.271401

28
Logistische Regression§ Parameter βj können bezüglich der Chancen (odds)
interpretiert werden
§ Erhöhung des Merkmals x(,j) um eine Einheit verändertdie Chance, dass der Datenpunkt zur Klasse yi = 1 gehörtum einen Faktor exp(βj)
§ Beispiel: Auto mit einem Liter höheren Hubraum stammt mitum Faktor 1438 = exp(7.2714) höheren Wahrscheinlichkeitaus U.S.A.
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
P [yi = 1]P [yi = 0] = P [yi = 1]
(1 ≠ P [yi = 1])

29
Zusammenfassung§ Klassifikationsverfahren haben viele Anwendungen
§ Binäres Klassifikationsverfahren auch zur Klassifikation in mehr als zwei Klassen verwendbar
§ Konfusionsmatrix stellt Vorhersagen und Daten gegenüber und erlauft Berechnung von Präzision,Ausbeute und F-Maß als Gütemaße
§ Logistische Regression zur binären Klassifikation basierend auf linearer Regression
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation

30
Literatur[1] L. Fahrmeir, R. Künstler, I. Pigeot und G. Tutz:
Statistik – Der Weg zur Datenanalyse,Springer 2012
[2] R. Kabacoff: R In Action,Manning 2015 [Kapitel 17]
[3] N. Zumel und J. Mount: Practical Data Science with R,Manning 2014 [Kapitel 7]
Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation





























