Embed Size (px)
DESCRIPTION
新世代計算機概論. 第 3 章 電腦的系統單元. 3 -1 系統單元. 電腦的系統單元 (system unit) 包含中央處理器 (CPU) 與主記憶體兩個部分。. 范紐曼 (John von Neuman) 架構. 傳統電腦採用的范紐曼架構,包含有三部份:系統單元、儲存單元、及輸出和輸入單元。所以其特色為 (1) 具有內儲程式概念 (2) 指令的執行是循序的 (3) 用記憶體的位址來存取資料 (4) 指令的執行是由程式流程所控制 (5) 瞬間只有一個程式在執行. 不同形式的系統單元. 機殼內的元件: 主機板 (motherboard) 視訊卡 - PowerPoint PPT Presentation
Citation preview

新世代計算機概論新世代計算機概論第第 33 章 電腦的系統單元章 電腦的系統單元
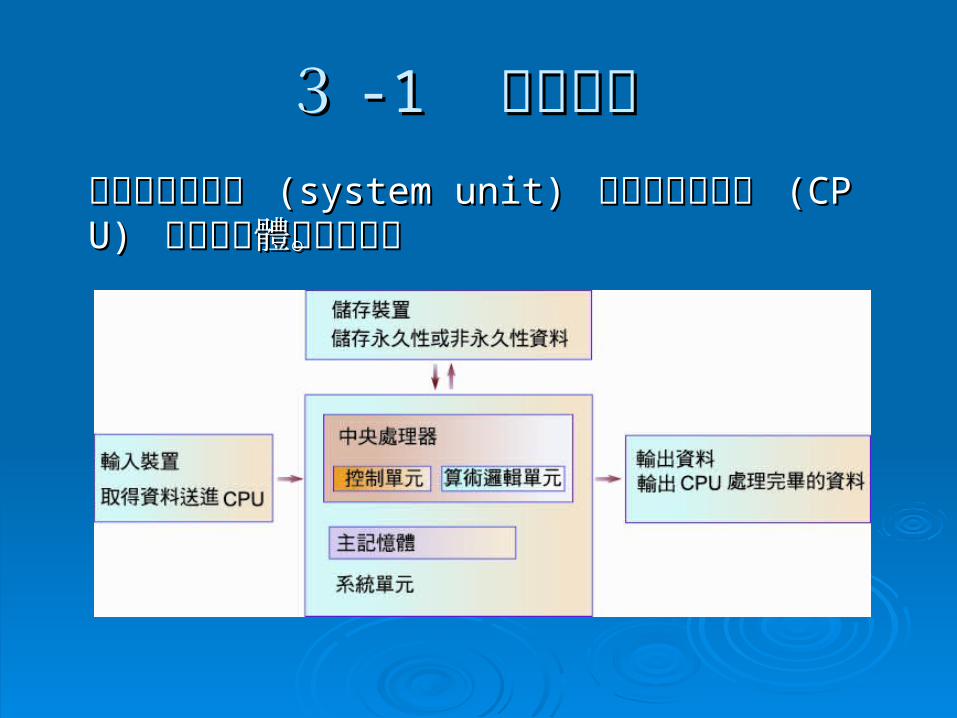
33 -1-1 系統單元 系統單元 電腦的系統單元 電腦的系統單元 (system unit) (system unit) 包含中央處理器 包含中央處理器 (CPU) (CPU) 與主記憶體兩個部分。與主記憶體兩個部分。

范紐曼范紐曼 (John von Neuman)(John von Neuman) 架構架構 傳統電腦採用的范紐曼架構,包含有三部份:系統傳統電腦採用的范紐曼架構,包含有三部份:系統單元、儲存單元、及輸出和輸入單元。所以其特色單元、儲存單元、及輸出和輸入單元。所以其特色為為 (1)(1) 具有內儲程式概念具有內儲程式概念
(2)(2) 指令的執行是循序的指令的執行是循序的 (3)(3) 用記憶體的位址來存取資料用記憶體的位址來存取資料 (4)(4) 指令的執行是由程式流程所控制指令的執行是由程式流程所控制 (5)(5) 瞬間只有一個程式在執行瞬間只有一個程式在執行

不同形式的系統單元不同形式的系統單元

機殼內的元件:機殼內的元件: 主機板 主機板 (motherboard)(motherboard) 視訊卡視訊卡 網路卡 網路卡 電源供應器 電源供應器 (power su(power su
pply) pply) 散熱風扇 散熱風扇 (cooling fa(cooling fa
n) n) 固定架 固定架 (drive bay) (drive bay) 連接埠 連接埠 (ports)(ports) ::::::機殼與其他元件選購考慮機殼與其他元件選購考慮因素因素 ?? ??

購買主機板注意事項購買主機板注意事項 選擇選擇 CPUCPU 所適合的主機板所適合的主機板 選擇可支援自己所要的選擇可支援自己所要的 RAMRAM 種類的主機板種類的主機板 選擇適合的晶片組選擇適合的晶片組 主機板的擴充性主機板的擴充性 主機板與其他硬體裝置的相容性主機板與其他硬體裝置的相容性
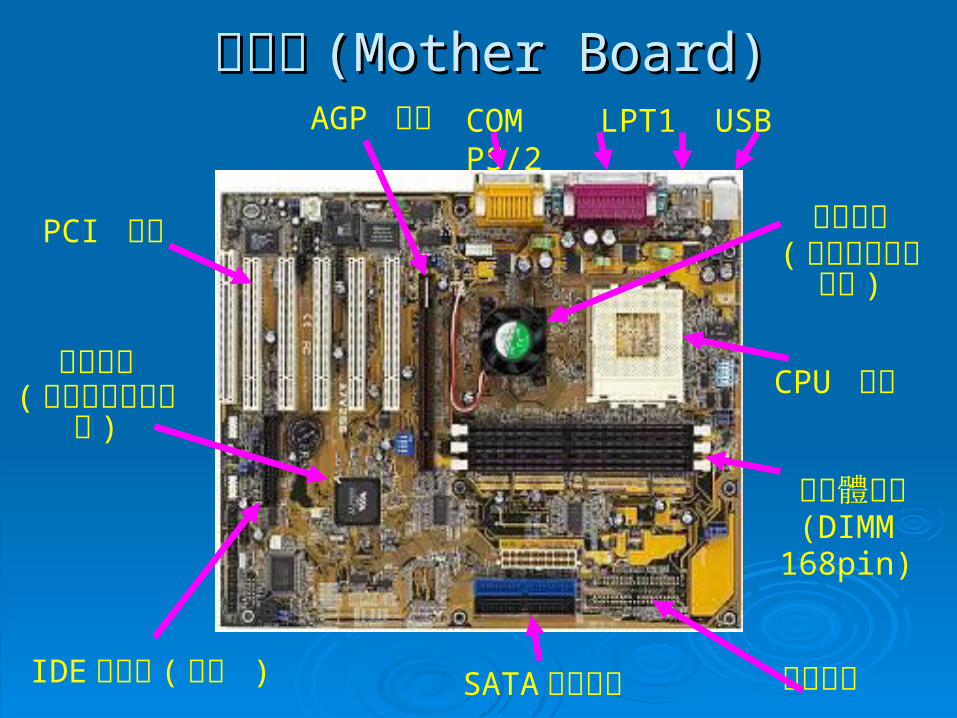
主機板主機板 (Mother Board)(Mother Board)
PCI 插槽
AGP 插槽 COM LPT1 USB PS/2
記憶體插槽(DIMM168pin)
CPU 插槽
IDE 連接埠 ( 軟碟 )
南橋晶片( 負責低速介面處理 )
北橋晶片( 負責高速介面處理 )
電源插槽SATA 硬碟插槽

因為因為 CPUCPU 是無法直接與是無法直接與 Main MemoryMain Memory 及及 PCIPCI 、、 ISAISA匯流排上的設備溝通,所以必須借助不同的暫存器匯流排上的設備溝通,所以必須借助不同的暫存器及解碼器等;而經過及解碼器等;而經過 IntelIntel 的設計,這些暫存器和的設計,這些暫存器和解碼器等已經整合在兩片不同的晶片內,就是南橋解碼器等已經整合在兩片不同的晶片內,就是南橋和北橋了。和北橋了。
北橋晶片主要控制北橋晶片主要控制 CPUCPU 與與 Main MemoryMain Memory 以及以及 PCIPCI 匯匯流排之間的訊號傳輸,現今的北橋晶片更加有流排之間的訊號傳輸,現今的北橋晶片更加有 AGP AGP (Accelerated Graphic Port)(Accelerated Graphic Port) 圖形加速匯流排的控圖形加速匯流排的控制工能;而南橋晶片則空制制工能;而南橋晶片則空制 ISAISA 匯流排及匯流排及 PCIPCI 匯流匯流排上速度較慢的週邊設備。南橋和北橋都是主機板排上速度較慢的週邊設備。南橋和北橋都是主機板上用來為上用來為 CPUCPU 及記憶體作週邊協調頻率或工作的兩及記憶體作週邊協調頻率或工作的兩片控制晶片。片控制晶片。
其中一顆晶片配置在主機板的上方,而另一顆晶片其中一顆晶片配置在主機板的上方,而另一顆晶片則配置在另一方,所以被稱為北橋則配置在另一方,所以被稱為北橋 (North Bridge) (North Bridge) 和南橋和南橋 (South Bridge )(South Bridge ) 。。
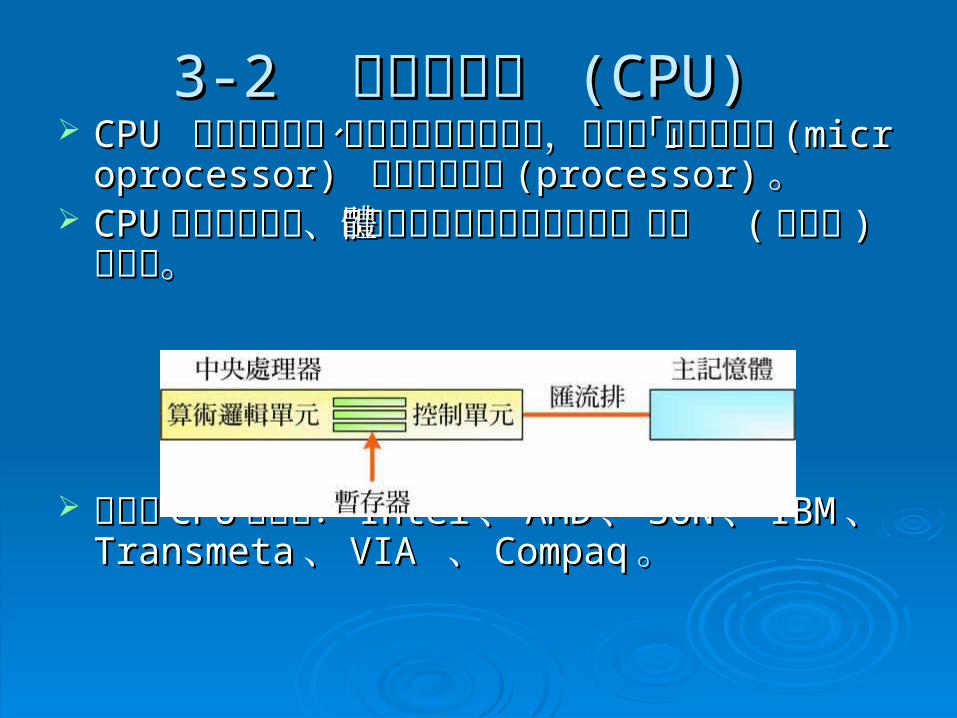
3-23-2 中央處理器 中央處理器 (CPU)(CPU) CPU CPU 負責算術運算、邏輯運算與程式執行,又稱負責算術運算、邏輯運算與程式執行,又稱
為「微處理器」為「微處理器」 (microprocessor) (microprocessor) 或「處理器」或「處理器」(processor)(processor) 。。
CPUCPU 是由控制單元、算術邏輯單元及部分的記憶是由控制單元、算術邏輯單元及部分的記憶體單元 體單元 (( 暫存器暫存器 ) ) 所組成。所組成。
知名的知名的 CPUCPU製造商製造商:: IntelIntel 、、 AMDAMD 、、 SUNSUN 、、 IBIBMM 、 、 TransmetaTransmeta 、、 VIA VIA 、、 CompaqCompaq 。。
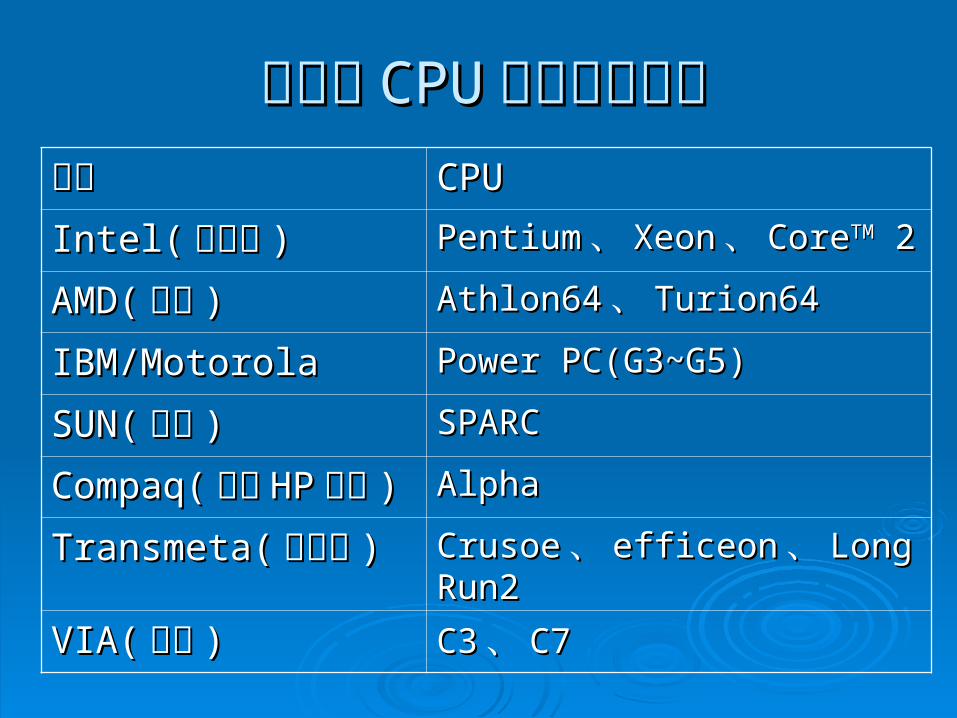
公司公司 CPUCPU
Intel(Intel( 英特爾英特爾 )) PentiumPentium 、、 XeonXeon 、、 CoreCoreTMTM 2 2
AMD(AMD( 超微超微 )) Athlon64Athlon64 、、 Turion64 Turion64
IBM/MotorolaIBM/Motorola Power PC(G3~G5)Power PC(G3~G5)
SUN(SUN( 昇陽昇陽 )) SPARCSPARC
Compaq(Compaq( 合併合併 HPHP 惠惠普普 ))
AlphaAlpha
Transmeta(Transmeta( 全美達全美達 )) CrusoeCrusoe 、、 efficeonefficeon 、、 LongRuLongRun2n2
VIA(VIA( 威盛威盛 )) C3C3 、、 C7C7
知名的知名的 CPUCPU 製造商與產品製造商與產品

3-2-13-2-1 控制單元 控制單元 (CU)(CU) 控制單元控制單元 (control unit)(control unit) 是負責控制資料流向與是負責控制資料流向與
指令流向的電路,它可以讀取並解釋指令,然後產指令流向的電路,它可以讀取並解釋指令,然後產生訊號控制生訊號控制 ALUALU 、暫存器等、暫存器等 CPUCPU 的內部元件完成工的內部元件完成工作。作。
控制單元的製作方式有下列兩種:控制單元的製作方式有下列兩種: 硬體線路控制 硬體線路控制 (hardwired control)(hardwired control) :速度快:速度快但缺乏彈性。 但缺乏彈性。
微程式控制 微程式控制 (microprogrammed control)(microprogrammed control) :微:微程式碼通常存放在程式碼通常存放在 EEPROMEEPROM 或快閃記憶體。執行或快閃記憶體。執行速度相對較慢,但修改彈性高。速度相對較慢,但修改彈性高。

3-2-23-2-2 算術邏輯單元 算術邏輯單元 (ALU)(ALU)
算術邏輯單元 算術邏輯單元 (arithmetic/logic unit) (arithmetic/logic unit) 是負是負責算術運算與邏輯運算的電路。責算術運算與邏輯運算的電路。
電腦的機器指令有下列三種類型:電腦的機器指令有下列三種類型: 資料傳送類型資料傳送類型:如:如 LOADLOAD、、 STORESTORE指令。指令。 算術邏輯類型算術邏輯類型:如加、減、:如加、減、 ANDAND、、 SHIFTSHIFT指令。指令。
控制類型控制類型:如:如 JUMPJUMP 、、 BRANCHBRANCH。。

3-2-33-2-3 暫存器 暫存器 暫存器 暫存器 (register) (register) 是位於是位於 CPUCPU 內部的記憶體,內部的記憶體,
用來暫時存放目前正在進行運算的資料或目前正好用來暫時存放目前正在進行運算的資料或目前正好運算完畢的資料。當運算完畢的資料。當 CPUCPU 要進行運算時,控制單元要進行運算時,控制單元會先讀取並解譯指令,將資料存放在暫存器,然後會先讀取並解譯指令,將資料存放在暫存器,然後啟動算術邏輯單元,針對暫存器內的資料進行運算,啟動算術邏輯單元,針對暫存器內的資料進行運算,完畢後再將結果存在暫存器。完畢後再將結果存在暫存器。
要注意的是暫存器和主記憶體不同,暫存器位於要注意的是暫存器和主記憶體不同,暫存器位於 CPCPUU 內部,主記憶體位於內部,主記憶體位於 CPUCPU外部,中間透過匯流排外部,中間透過匯流排來存取,匯流排 來存取,匯流排 (bus) (bus) 是主機板上面的鍍銅電路,是主機板上面的鍍銅電路,負責傳送電腦內部的電子訊號。 負責傳送電腦內部的電子訊號。

暫存器通常分成兩大類,其一是程式設計人暫存器通常分成兩大類,其一是程式設計人員能夠存取的可見暫存器,其二是程式設計員能夠存取的可見暫存器,其二是程式設計人員無法存取的控制與狀態的特殊暫存器。人員無法存取的控制與狀態的特殊暫存器。
可見暫存器又分成下列幾種:可見暫存器又分成下列幾種: 通用暫存器 通用暫存器 (general purpose register)(general purpose register) ::存放資料、指令或位址,數目越多,存放資料、指令或位址,數目越多, CPUCPU 執行執行效率越佳,成本越高。效率越佳,成本越高。
資料暫存器 資料暫存器 (data register) (data register) 位址暫存器 位址暫存器 (address register) (address register) 條件碼暫存器 條件碼暫存器 (condition code register)(condition code register) ::用來存放指令執行的狀態。 用來存放指令執行的狀態。

控制與狀態暫存器又分成下列幾種: 控制與狀態暫存器又分成下列幾種: 程式計數器 程式計數器 (program counter)(program counter) :用來存放:用來存放下一個要執行的指令在主記憶體的位址。 下一個要執行的指令在主記憶體的位址。
指令暫存器 指令暫存器 (instruction register)(instruction register) :將:將指令由記憶體取出,進入指令由記憶體取出,進入 CPUCPU準備要執行之準備要執行之前的暫存處。前的暫存處。
記憶體位址暫存器 記憶體位址暫存器 (memory address regist(memory address register)er) :記憶目前所要存取記憶體的位址,其長:記憶目前所要存取記憶體的位址,其長度通常與位址匯流排寬度相同。度通常與位址匯流排寬度相同。
記憶體緩衝暫存器 記憶體緩衝暫存器 (memory buffer registe(memory buffer register)r) :對記憶體進行讀寫時暫時存放資料的地:對記憶體進行讀寫時暫時存放資料的地方。 方。
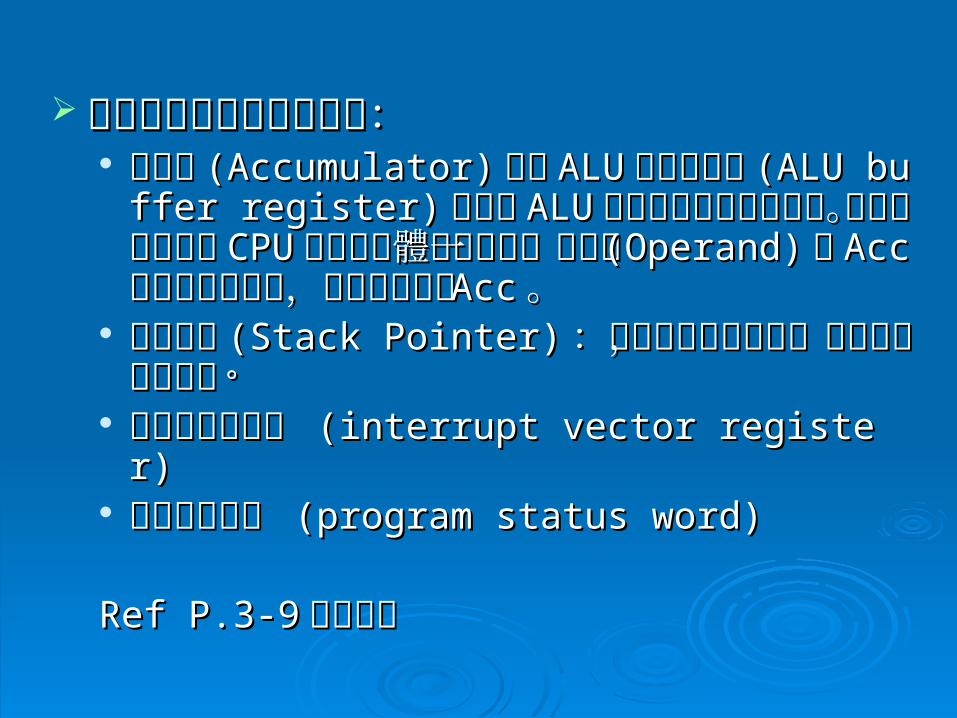
控制與狀態的特殊暫存器: 控制與狀態的特殊暫存器: 累加器累加器 (Accumulator)(Accumulator) 或稱或稱 ALUALU緩衝暫存器緩衝暫存器 (AL(ALU buffer register)U buffer register) :存放:存放 ALUALU 計算結果的特計算結果的特定暫存器。在計算進行時,定暫存器。在計算進行時, CPUCPU會從記憶體中取會從記憶體中取出另一運算元出另一運算元 (Operand)(Operand) 與與 AccAcc 之內容進行運算,之內容進行運算,其結果再存回其結果再存回 AccAcc 。。
堆疊指標堆疊指標 (Stack Pointer)(Stack Pointer) :記錄堆疊頂端位址,:記錄堆疊頂端位址,用來進行堆疊運算。 用來進行堆疊運算。
中斷向量暫存器 中斷向量暫存器 (interrupt vector registe(interrupt vector register) r)
程式狀態字組 程式狀態字組 (program status word) (program status word)
Ref P.3-9Ref P.3-9 詳細說明詳細說明

3-2-43-2-4 電腦的效能 電腦的效能 反應時間 反應時間 (response time) (response time) 是一個工作從開始是一個工作從開始做到結束所花費的時間做到結束所花費的時間
工作量 工作量 (throughput) (throughput) 是在固定時間內所能完成是在固定時間內所能完成的工作的工作
CPUCPU時間 時間 (CPU time) (CPU time) 是是 CPUCPU 執行一個程式執行一個程式所花費的時間,不包括等待輸入所花費的時間,不包括等待輸入 // 輸出或執行其輸出或執行其它程式的時間它程式的時間
CPUCPU時脈週期 時脈週期 (CPU clock cycle) (CPU clock cycle) 是是 CPUCPU 執執行一個程式所花費的時脈週期行一個程式所花費的時脈週期CPUCPU時間 時間 = CPU= CPU時脈週期 時脈週期 * * 時脈週期時間 時脈週期時間

時脈時脈 (clock)(clock) 是電腦內部一個類似時鐘的裝置,它是電腦內部一個類似時鐘的裝置,它每計數一次,稱為一個時脈週期每計數一次,稱為一個時脈週期 (clock cycle)(clock cycle) ,,電腦就可以完成少量工作。電腦就可以完成少量工作。
時脈速度時脈速度 (clock rate)(clock rate) 指的是時脈計數的速度,單指的是時脈計數的速度,單位為位為 MHz(MHz(百萬赫茲百萬赫茲 )) 或或 GHz(GHz(十億赫茲十億赫茲 )) ,也就是每,也就是每秒鐘幾百萬次或每秒鐘幾十億次,而時脈每計數一秒鐘幾百萬次或每秒鐘幾十億次,而時脈每計數一次所經過的時間稱為時脈週期時間次所經過的時間稱為時脈週期時間 (clock cycle ti(clock cycle time)me)
。換言之,。換言之, 1MHz1MHz、、 1GHz1GHz所對應的時脈週期時間分所對應的時脈週期時間分別為別為 10-610-6 秒秒 ((μμss 微秒微秒 )) 、、 10-910-9 秒秒 (ns(ns 奈秒奈秒 )) 。 。
電腦的效能取決於時脈速度、電腦的效能取決於時脈速度、 CPICPI 和指令數目等因素 和指令數目等因素
例如完成一個指令需要例如完成一個指令需要 3clocks3clocks,且,且 CPUCPU 頻率為頻率為 600MH600MHzz,則指令速度為,則指令速度為 600/3=200MIPS600/3=200MIPS 。。
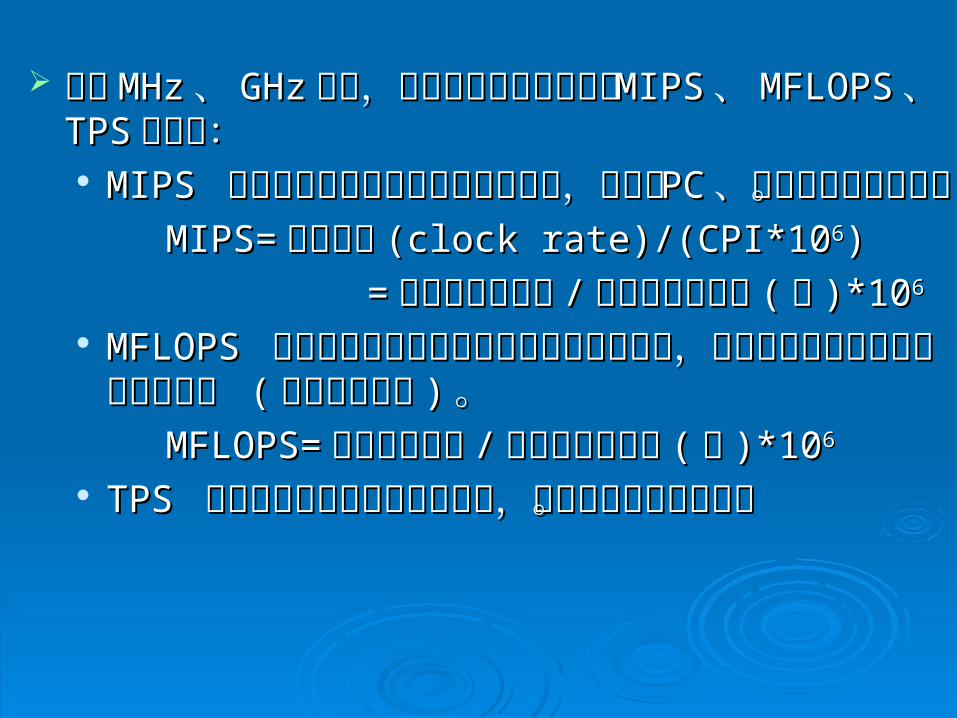
除了除了 MHzMHz 、、 GHzGHz 之外,電腦的速度也可以使用之外,電腦的速度也可以使用 MIPSMIPS 、、MFLOPSMFLOPS 、、 TPSTPS 來描述:來描述: MIPS MIPS 意指每秒鐘可以完成幾百萬個指令,適用於意指每秒鐘可以完成幾百萬個指令,適用於 PP
CC 、工作站或大型主機。、工作站或大型主機。 MIPS=MIPS=時脈速度時脈速度 (clock rate)/(CPI*10(clock rate)/(CPI*1066))
== 程式的指令個數程式的指令個數 // 程式的執行時間程式的執行時間 ((秒秒 )*10)*1066
MFLOPS MFLOPS 意指每秒鐘可以完成幾百萬個浮點數運算,意指每秒鐘可以完成幾百萬個浮點數運算,適用於需要大量浮點數運算的機器 適用於需要大量浮點數運算的機器 ((例如超級電腦例如超級電腦 )) 。。
MFLOPS=MFLOPS=浮點運算個數浮點運算個數 // 程式的執行時間程式的執行時間 ((秒秒 )*10)*1066
TPS TPS 意指每秒鐘可以完成幾個交易,適用於商業交意指每秒鐘可以完成幾個交易,適用於商業交易機器。 易機器。
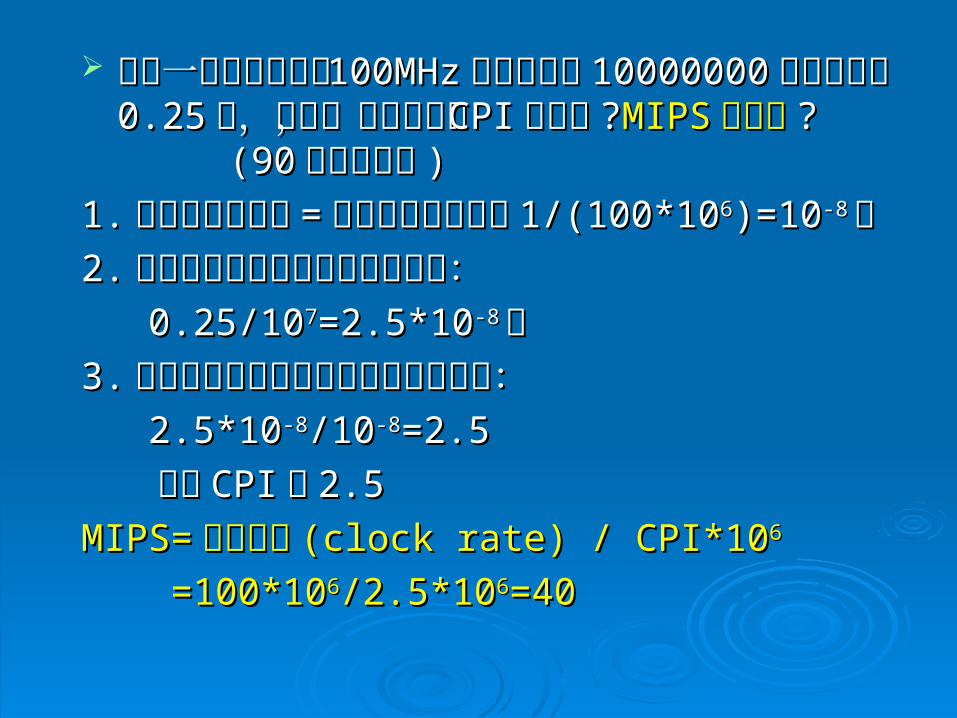
假設一部時脈速度為假設一部時脈速度為 100MHz100MHz的電腦執行的電腦執行 1000001000000000個指令需要個指令需要 0.250.25秒,試問,這部電腦的秒,試問,這部電腦的 CPICPI是多少是多少 ??MIPSMIPS 是多少是多少 ? (90? (90 台科電通台科電通所所 ))
1.1.電腦的時脈週期電腦的時脈週期 == 時脈速度的倒數:時脈速度的倒數: 1/(100*101/(100*1066)=10)=10-8-8秒秒
2.2.計算執行每個指令需要多少時間:計算執行每個指令需要多少時間: 0.25/100.25/1077=2.5*10=2.5*10-8-8秒秒3.3.計算執行每個指令需要多少時脈週期:計算執行每個指令需要多少時脈週期: 2.5*102.5*10-8-8/10/10-8-8=2.5=2.5 所以所以 CPICPI 為為 2.52.5MIPS=MIPS= 時脈速度時脈速度 (clock rate) / CPI*10(clock rate) / CPI*1066 =100*10=100*1066/2.5*10/2.5*1066=40=40

假設有兩部指令集相同的電腦假設有兩部指令集相同的電腦 AA 、、 BB ,其中,,其中,AA 的時脈週期時間為的時脈週期時間為 10ns10ns,, CPICPI 為為 22 ,, BB 的時的時脈週期時間為脈週期時間為 20ns20ns,, CPICPI 為為 1.51.5 。試問,同。試問,同一個程式在一個程式在 AA 執行較快執行較快 ?? 還是在還是在 BB 執行較快執行較快 ??快多少快多少 ?(?(假設程式中的指令數目為假設程式中的指令數目為 N)N)
1.1.計算計算 AA 的的 CPUCPU時脈週期,也就是時脈週期,也就是 CPI*N=2NCPI*N=2N2.2.計算計算 BB 的的 CPUCPU時脈週期,也就是時脈週期,也就是 CPI*N=1.5N CPI*N=1.5N 3.3.計算計算 AA 的的 CPUCPU時間,也就是時間,也就是 CPUCPU時脈週期時脈週期 ** 時時脈週期時間脈週期時間 =2N*10=20N=2N*10=20N
4.4.計算計算 BB 的的 CPUCPU時間,也就是時間,也就是 CPUCPU時脈週期時脈週期 ** 時時脈週期時間脈週期時間 =1.5N*20=30N=1.5N*20=30N
所以所以 AA 的執行速度較快,快了的執行速度較快,快了 30N/20N=1.530N/20N=1.5倍倍

AmdahlAmdahl ,, s Laws Law 電腦的效能評估,除前述各項數值外,亦可電腦的效能評估,除前述各項數值外,亦可利用利用 AmdahlAmdahl ,, s Laws Law 了解某系統,經過改進了解某系統,經過改進一部份效能後,整個系統效能提升的情形。一部份效能後,整個系統效能提升的情形。
改良後的執行時間改良後的執行時間 =(=( 被改良部分的執行時間被改良部分的執行時間// 改良多少倍改良多少倍 )+)+ 未被改良部分的執行時間未被改良部分的執行時間
或是系統加速多少倍或是系統加速多少倍 (Speedup)=1/﹛((Speedup)=1/﹛( 被改被改良的部份佔多少良的部份佔多少 % / % / 增快多少倍增快多少倍 )+)+ 未被改未被改良的部份佔全部多少良的部份佔全部多少 %﹜ %﹜


假設某一應用程式,它全部執行時間為假設某一應用程式,它全部執行時間為 100100秒,其中秒,其中 CPUCPU時間佔了時間佔了 8080 秒,其餘是秒,其餘是 I/OI/O 時時間。如果未來五年內,其間。如果未來五年內,其 CPUCPU 速度總共快了速度總共快了44倍,但倍,但 I/OI/O 時間都沒有改進,試問執行該時間都沒有改進,試問執行該程式在五年後能變快多少程式在五年後能變快多少 ??
Speedup=1/﹛(Speedup=1/﹛( 被改良的部份佔多少被改良的部份佔多少 % / % / 增快增快多少倍多少倍 )+)+ 未被改良的部份佔全部多少未被改良的部份佔全部多少 %﹜%﹜
所以 所以 Speedup=1/﹛(0.8/4)+0.2﹜=2.5Speedup=1/﹛(0.8/4)+0.2﹜=2.5倍倍也就是雖然也就是雖然 CPUCPU快了快了 44倍,若倍,若 I/OI/O 未改進,將未改進,將影響程式執行效能。影響程式執行效能。

3-2-53-2-5 CPUCPU 相關規格相關規格 外頻:外頻: CPUCPU 與外界(主機板)進行資料傳輸與外界(主機板)進行資料傳輸的頻率速度,也就是的頻率速度,也就是 CPUCPU 存取主記憶體與晶存取主記憶體與晶片組的速度,單位為片組的速度,單位為 MHzMHz 。頻率越高,速度。頻率越高,速度越快。目前以越快。目前以 400400 、、 533533 、、 800800 、、 1066MHz1066MHz為主。為主。
倍頻:倍頻: CPUCPU 核心所採用的頻率通常是外頻的核心所採用的頻率通常是外頻的倍數,而這個倍數就叫做倍數,而這個倍數就叫做倍頻倍頻。如。如 Intel P4 Intel P4 640640 的外頻為的外頻為 800MHz800MHz ,內頻為,內頻為 3.2GHz3.2GHz ,所以,所以倍頻為倍頻為 44 。。
內頻:內頻:內頻內頻是是 CPUCPU 內部的實際運作速度,也內部的實際運作速度,也就是倍頻乘上外頻。就是倍頻乘上外頻。
就英特爾處理器而言,在就英特爾處理器而言,在 Pentium IIIPentium III 之前,系之前,系統外頻跟前端匯流排速度是相同的,於是一般也統外頻跟前端匯流排速度是相同的,於是一般也就認定外頻等於前端匯流排速度,而直接稱前端就認定外頻等於前端匯流排速度,而直接稱前端匯流排為外頻。匯流排為外頻。不過,這樣的情況對不過,這樣的情況對 Pentium 4Pentium 4 處理器來說,卻處理器來說,卻是行不通的,由於現今處理器及主機板能支援的是行不通的,由於現今處理器及主機板能支援的前端匯流排前端匯流排 ((前端匯流排前端匯流排 (FSB)(FSB) 是連結所有電腦是連結所有電腦元件與晶片組及主記憶體,讓數據由電腦的一部元件與晶片組及主記憶體,讓數據由電腦的一部份傳送至另一部份的線路。份傳送至另一部份的線路。 )) 速度已經遠高於處速度已經遠高於處理器外頻,廠商便開始不再強調外頻,而只講前理器外頻,廠商便開始不再強調外頻,而只講前端匯流排速度,例如端匯流排速度,例如 Pentium 4Pentium 4 支援支援 400MHz400MHz的前的前端匯流排頻率端匯流排頻率 ((甚至可以到甚至可以到 533MHz)533MHz) ,然而其外,然而其外頻只有頻只有 100MHz100MHz,以,以 Pentium 4 1.8GHzPentium 4 1.8GHz來看,其來看,其運算時脈應為運算時脈應為 100MHz100MHz 外頻乘外頻乘 18x18x 倍頻,而不是一倍頻,而不是一般所謂的般所謂的 400MHz400MHz 外頻乘外頻乘 4.5x4.5x 倍頻。 倍頻。
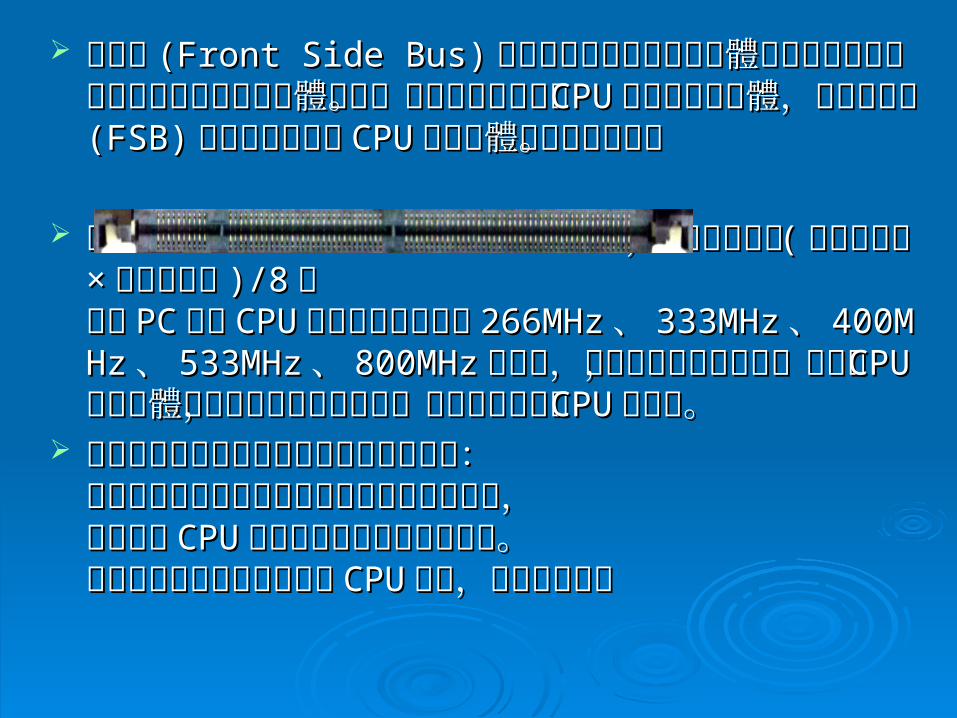
匯流排匯流排 (Front Side Bus)(Front Side Bus) 是將電腦微處理器與記憶體是將電腦微處理器與記憶體晶片以及與之通信的設備連接起來的硬體通道。前端晶片以及與之通信的設備連接起來的硬體通道。前端匯流排負責將匯流排負責將 CPUCPU 連接到主記憶體,前端匯流排連接到主記憶體,前端匯流排 (FSB)(FSB)頻率則直接影響頻率則直接影響 CPUCPU 與記憶體資料交換速度。與記憶體資料交換速度。
資料傳輸最大帶寬取決於同時傳輸的資料的寬度和傳資料傳輸最大帶寬取決於同時傳輸的資料的寬度和傳輸頻率,即資料帶寬=輸頻率,即資料帶寬= (( 匯流排頻率匯流排頻率 ××資料位元寬資料位元寬 )/)/88 。。目前目前 PCPC 機上機上 CPUCPU 前端匯流排頻率有前端匯流排頻率有 266MHz266MHz 、、 333MHz333MHz 、、400MHz400MHz 、、 533MHz533MHz 、、 800MHz800MHz 等幾種,前端匯流排頻率等幾種,前端匯流排頻率越高,代表著越高,代表著 CPUCPU 與記憶體之間的資料傳輸量越大,與記憶體之間的資料傳輸量越大,更能充分發揮出更能充分發揮出 CPUCPU 的功能。 的功能。
外頻與前端匯流排頻率的區別與聯繫在於:外頻與前端匯流排頻率的區別與聯繫在於:前端匯流排的速度指的是資料傳輸的實際速度,前端匯流排的速度指的是資料傳輸的實際速度,外頻這是外頻這是 CPUCPU 與主板之間同步運行的速度。與主板之間同步運行的速度。大多數時候前端速度都大於大多數時候前端速度都大於 CPUCPU 外頻,且成倍數關係 外頻,且成倍數關係

封裝:封裝: CPUCPU 其實是一個晶片 其實是一個晶片 (chip)(chip) ,需要將它包裝起來以,需要將它包裝起來以玆保護,並提供腳座與外界溝玆保護,並提供腳座與外界溝通,這個包裝的過程就叫做封通,這個包裝的過程就叫做封裝。封裝方式有很多種,例如裝。封裝方式有很多種,例如DIPDIP 、、 PGAPGA 、、 FCPGAFCPGA 、、 SECCSECC 、、LGALGA 。。 Micro-FCPGAMicro-FCPGA壓縮的壓縮的 CPUCPU由於採用了和台式電腦由於採用了和台式電腦 CPUCPU 相相似的似的 ZIP(ZIP(零拔插力零拔插力 )) 插座,因插座,因此陞級是可行的,也是所有封此陞級是可行的,也是所有封裝中陞級最為方便的。大部分裝中陞級最為方便的。大部分情況下,用戶隻需一把螺絲刀情況下,用戶隻需一把螺絲刀即可完成對即可完成對 CPUCPU 的更換。 的更換。 封裝廠如日月光、矽品…封裝廠如日月光、矽品…

插槽腳位:插槽腳位決插槽腳位:插槽腳位決定了定了 CPUCPU如何安插在主如何安插在主機板的機板的 CPUCPU 插槽,不同插槽,不同的腳位有不同的插槽,的腳位有不同的插槽,針腳數目各異。如早期針腳數目各異。如早期的的 Slot 1 Slot 1 、、 Slot A Slot A 為卡為卡匣式匣式,, P4 5P4 5xxxx 、、 6xx6xx 為為LGA775LGA775 ,, Athlon64Athlon64 、、OpteronOpteron 為為 Socket754Socket754 。。

快取記憶體快取記憶體 (Cache)(Cache) :快取記憶體是介於:快取記憶體是介於CPUCPU 與主記憶體之間的記憶體,存取速度與主記憶體之間的記憶體,存取速度較快,成本也較高。較快,成本也較高。 CPUCPU 需要資料時,先需要資料時,先到到 CacheCache 找找 (cache hit vs. cache miss)(cache hit vs. cache miss) ,,找不到再從主記憶體找,若仍然找不到找不到再從主記憶體找,若仍然找不到,,再從硬碟移至主記憶體。又分為二至三種再從硬碟移至主記憶體。又分為二至三種層次,稱為層次,稱為 L1L1 快取快取 (( 內建於內建於 CPUCPU 約約 8~1288~128KB)KB) 、、 L2L2 快取快取 (( 內建或外部約內建或外部約 256KB~4MB)256KB~4MB) 、、L3L3 快取快取 (( 獨立晶片獨立晶片 )) 。。
匯流排寬度匯流排寬度 匯流排匯流排 (bus)(bus) 是主機板上面的鍍銅電路。是主機板上面的鍍銅電路。 匯流排決定了電腦一次可以同時傳送多少匯流排決定了電腦一次可以同時傳送多少位元,電路愈多,匯流排寬度位元,電路愈多,匯流排寬度 (bus width) (bus width) 愈大,傳送速度愈快。愈大,傳送速度愈快。
字組大小:字組大小 字組大小:字組大小 (word size) (word size) 是是 CPUCPU 在固在固定時間內能夠解譯並執行多少位元,所謂定時間內能夠解譯並執行多少位元,所謂 88 、、1616 、、 3232 或或 6464 位元位元 CPUCPU 指的就是一次最多指的就是一次最多可以處理可以處理 88 、、 1616 、、 3232 或或 6464 位元的位元的 CPUCPU 。。
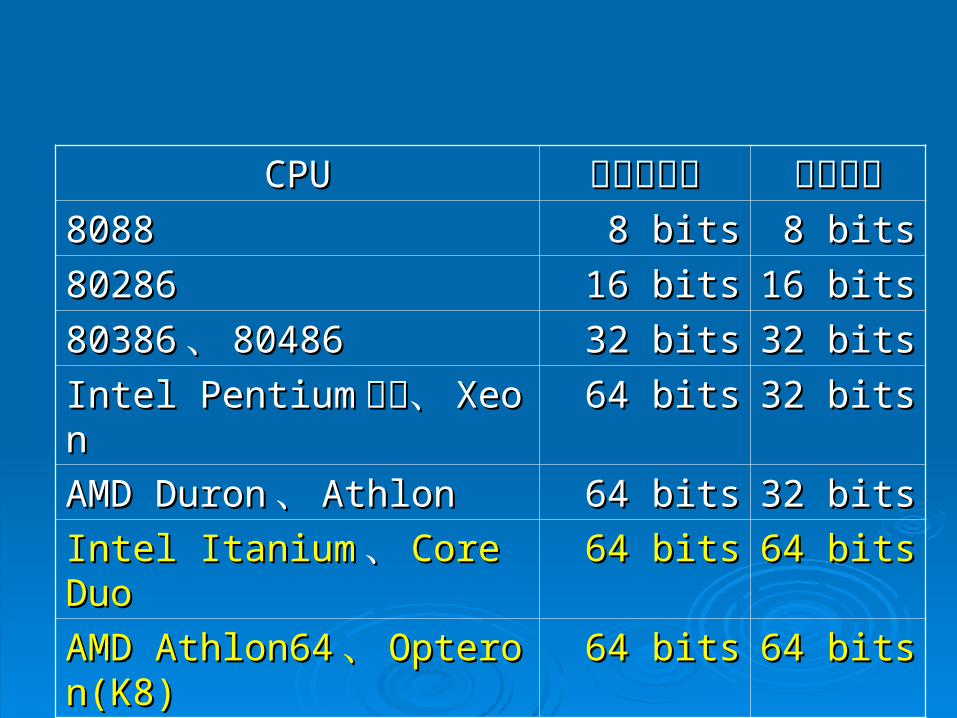
CPUCPU 匯流排寬度匯流排寬度 字組大小字組大小80888088 8 bits8 bits 8 bits8 bits
8028680286 16 bits16 bits 16 bits16 bits
8038680386、、 8048680486 32 bits32 bits 32 bits32 bits
Intel PentiumIntel Pentium 以上、以上、 XeonXeon 64 bits64 bits 32 bits32 bits
AMD DuronAMD Duron 、、 AthlonAthlon 64 bits64 bits 32 bits32 bits
Intel ItaniumIntel Itanium 、、 Core DuoCore Duo 64 bits64 bits 64 bits64 bits
AMD Athlon64AMD Athlon64 、、 Opteron(KOpteron(K8)8)
64 bits64 bits 64 bits64 bits

相容性:相容性: 傳統處理器設計方式中,由於暫存器的數量有限,傳統處理器設計方式中,由於暫存器的數量有限,當處理器手頭上仍有工作要處理時,就無法受理當處理器手頭上仍有工作要處理時,就無法受理其他指令所發出的需求,而是得乖乖排隊在後面其他指令所發出的需求,而是得乖乖排隊在後面等,而因為這個特點,處理器的效能變會因為指等,而因為這個特點,處理器的效能變會因為指令處理流程的影響而受到限制。令處理流程的影響而受到限制。
由於不同的由於不同的 CPUCPU各有唯一的指令集各有唯一的指令集 ((比較出名的比較出名的有有 IntelIntel 的的 MMXMMX、、 SSE4SSE4 系列,以及系列,以及 AMDAMD的的 3DNOW3DNOW !!技術技術 )) ,因此,廠商在推出新的,因此,廠商在推出新的 CPUCPU 晶片之前,晶片之前,必須考慮相容性 必須考慮相容性 (compatibility)(compatibility) ,特別是新的,特別是新的晶片能否與舊的晶片具有向下相容性。 晶片能否與舊的晶片具有向下相容性。

3-2-63-2-6 機器語言 機器語言 機器語言 機器語言 (machine language) (machine language) 是程式與是程式與電腦溝通的介面,定義了程式可以使用的電腦溝通的介面,定義了程式可以使用的指令與編碼方式。指令與編碼方式。
機器指令 機器指令 (machine instruction) (machine instruction) 的編碼方的編碼方式通常包含運算碼 式通常包含運算碼 (op-code) (op-code) 和運算元 和運算元 (operand) (operand) 兩個部分,其中運算碼是這個指兩個部分,其中運算碼是這個指令所要進行的運算,運算元是這個指令進令所要進行的運算,運算元是這個指令進行運算的對象。 行運算的對象。
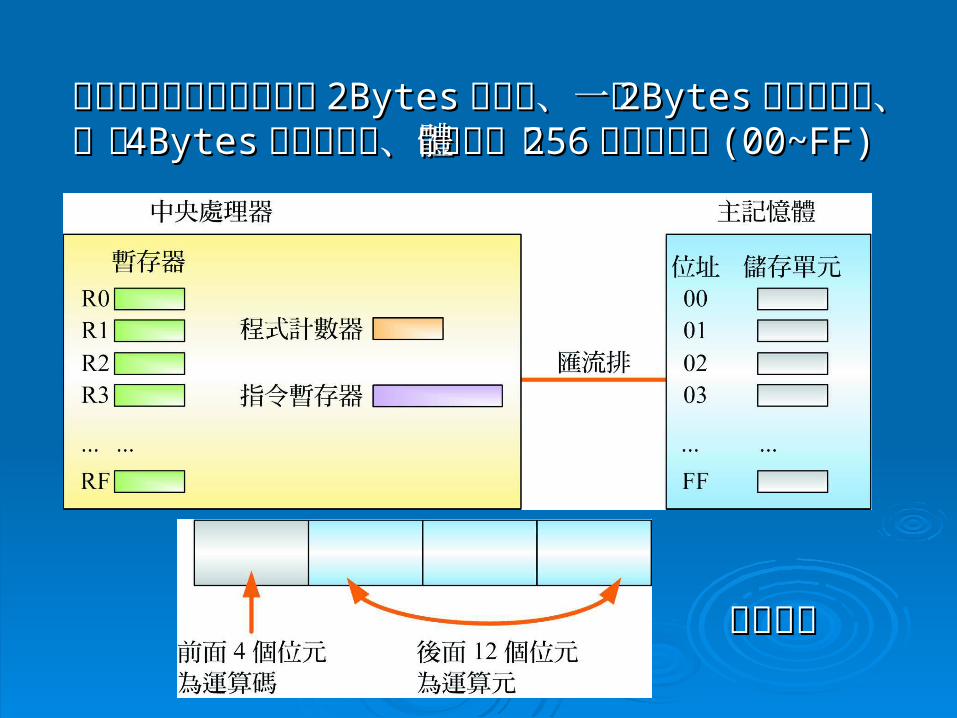
假設中央處理器有十六個假設中央處理器有十六個 2Bytes2Bytes 暫存器暫存器、一個、一個 2Byt2Byteses 程式計數器程式計數器、一個、一個 44BytesBytes 指令暫存器指令暫存器、主記憶體、主記憶體有有 256256個儲存單元個儲存單元 (00~FF)(00~FF)
指令格式指令格式

運算碼運算碼 運算元運算元 說 明說 明
11 RXY RXY LOADLOAD 指令,將主記憶體位址指令,將主記憶體位址 XYXY 的資料載入暫存器的資料載入暫存器 R R
22 RXY RXY STORESTORE 指令,將暫存器指令,將暫存器 RR 的資料儲存到主記憶體位址的資料儲存到主記憶體位址XY XY
33 RSTRSTADDADD 指令,將暫存器指令,將暫存器 SS 的資料與暫存器的資料與暫存器 TT 的資料相加,的資料相加,再將結果儲存到暫存器再將結果儲存到暫存器 R R
44 RST RST OROR 指令,將暫存器指令,將暫存器 SS 的資料與暫存器的資料與暫存器 TT 的資料進行的資料進行 OORR 運算,再將結果儲存到暫存器運算,再將結果儲存到暫存器 R R
55 RST RST ANDAND 指令,將暫存器指令,將暫存器 SS 的資料與暫存器的資料與暫存器 TT 的資料進行的資料進行ANDAND 運算,再將結果儲存到暫存器運算,再將結果儲存到暫存器 R R
66 RST RST XORXOR 指令,將暫存器指令,將暫存器 SS 的資料與暫存器的資料與暫存器 TT 的資料進行的資料進行XORXOR 運算,再將結果儲存到暫存器運算,再將結果儲存到暫存器 R R
77 RXYRXYJUMPJUMP 指令,若暫存器指令,若暫存器 RR 的資料與暫存器的資料與暫存器 R0R0 的資料相的資料相同,就跳到主記憶體位址同,就跳到主記憶體位址 XYXY去執行,否則依序執行 去執行,否則依序執行
88 000000HALTHALT 指令,使程式暫時停止執行,例如機器指令指令,使程式暫時停止執行,例如機器指令 80008000是將程式暫停 是將程式暫停

11BA11BA ((將主記憶體位址將主記憶體位址 BABA 的資料載入暫存器的資料載入暫存器 R1)R1)
12BB12BB ((將主記憶體位址將主記憶體位址 BBBB 的資料載入暫存器的資料載入暫存器 R2)R2)
33123312 ((將暫存器將暫存器 R1R1 的資料與暫存器的資料與暫存器 R2R2 的資料相加,的資料相加, 再將結果儲存到暫存器 再將結果儲存到暫存器 R3)R3)
23B023B0 ((將暫存器將暫存器 R3R3 的資料儲存到主記憶體位址的資料儲存到主記憶體位址 B0)B0)
10B010B0 ((將主記憶體位址將主記憶體位址 B0B0 的資料載入暫存器的資料載入暫存器 R0)R0)
73FF73FF ((若暫存器若暫存器 R3R3 的資料與暫存器的資料與暫存器 R0R0 的資料相同,的資料相同, 就跳到主記憶體位址 就跳到主記憶體位址 FFFF去執行,否則去執行,否則依序執行依序執行 ) )
運算碼運算元
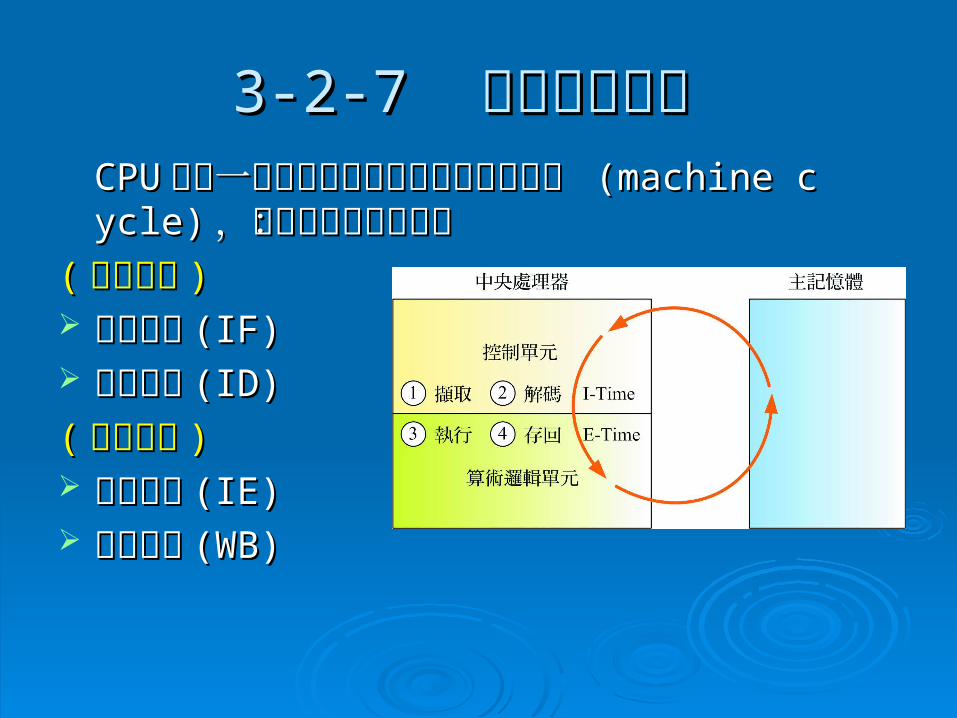
3-2-73-2-7 機器循環週期 機器循環週期 CPUCPU 執行一個指令的過程叫做機器循環週期 執行一個指令的過程叫做機器循環週期 (machine cycle)(machine cycle) ,包含下列四個步驟:,包含下列四個步驟:
(( 指令時間指令時間 )) 指令擷取指令擷取 (IF) (IF) 指令解碼指令解碼 (ID)(ID)
(( 執行時間執行時間 )) 指令執行指令執行 (IE)(IE) 結果存回結果存回 (WB)(WB)

3-33-3 CPUCPU 的設計架構與技術的設計架構與技術 3-3-13-3-1 CISC V.S. RISC CISC V.S. RISC RISCRISC 所提供的指令較為精簡,每個指令的執所提供的指令較為精簡,每個指令的執行時間都很短,完成的動作也很單純,在一個行時間都很短,完成的動作也很單純,在一個時脈週期時脈週期 (clock cycle)(clock cycle) 內執行完畢內執行完畢。。若要做複若要做複雜的事情,就要由多個指令來完成。如雜的事情,就要由多個指令來完成。如 SUN SUN SPARCSPARC 、、 PowerPCPowerPC 、、 IBM RS/6000 IBM RS/6000
CISCCISC 則提供了豐富的指令,每個指令的執行則提供了豐富的指令,每個指令的執行時間較長,能夠完成的動作也較複雜。如時間較長,能夠完成的動作也較複雜。如 Intel Intel x86x86 、、 MOT 680x0MOT 680x0 。 。

比較項目比較項目 RISCRISC CISCCISC
指令集指令集提供較少的指令種類,指令功
能也較簡單,且指令長度固定,指令格式不具彈性,故 RISC 指令集較小且簡單。
提供較多的指令種類,指令功能較齊全,且指令長度可變,每種指令格式差異大較具彈性,故 CISC 指令集較大且複雜。
定址模式定址模式 提供的定址模式少 提供的定址模式多
控制單元控制單元 控制電路較簡單 控制電路較複雜
記憶體存取記憶體存取所有的運算元都在 CPU 暫存器
內執行,只有 load 和 store 兩個指令能存取記憶體,較不具彈性。
大部分的指令都能存取記憶體及暫存器的值。
通用暫存器通用暫存器 暫存器數目多 暫存器數目少
最佳化最佳化因指令長度固定,所以使用管
路 (pipeline) 執行效率佳,需配合編譯器使用
無
系統軟體系統軟體 需較複雜系統軟體,利用編譯器輔助以達成最佳化
不需特殊編譯器
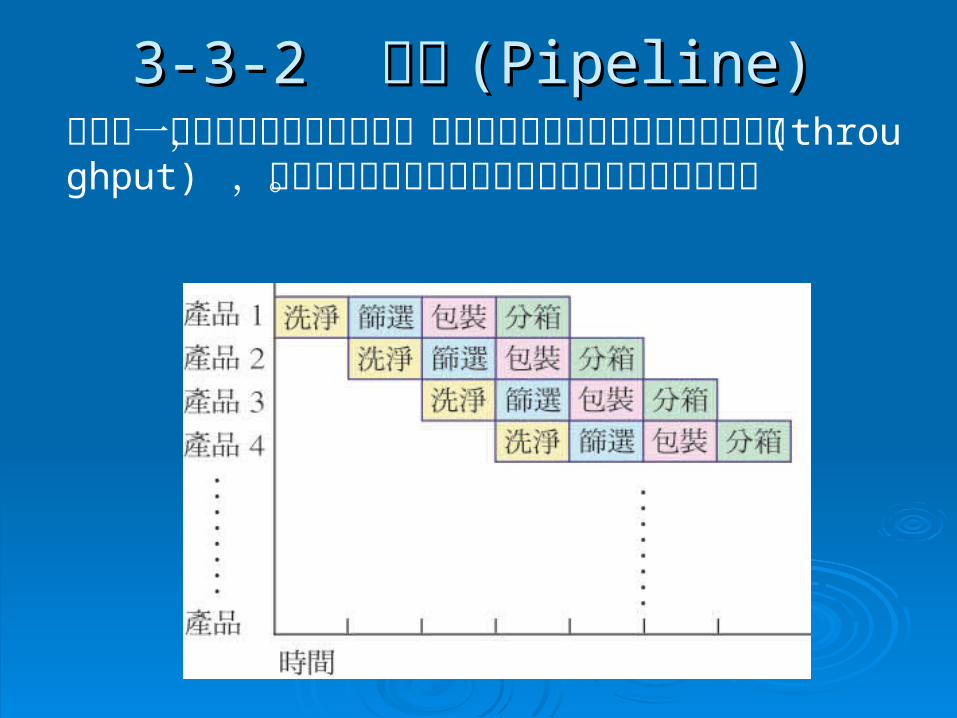
3-3-23-3-2 管線 管線 (Pipeline)(Pipeline)
管路是一種資料路徑的製作技巧,利用指令的重疊來增加指令的生產量 (throughput) ,也就是增加電腦在固定時間內所能完成的工作量。
管路是一種資料路徑的製作技巧,利用指令的重疊來增加指令的生產量 (throughput) ,也就是增加電腦在固定時間內所能完成的工作量。
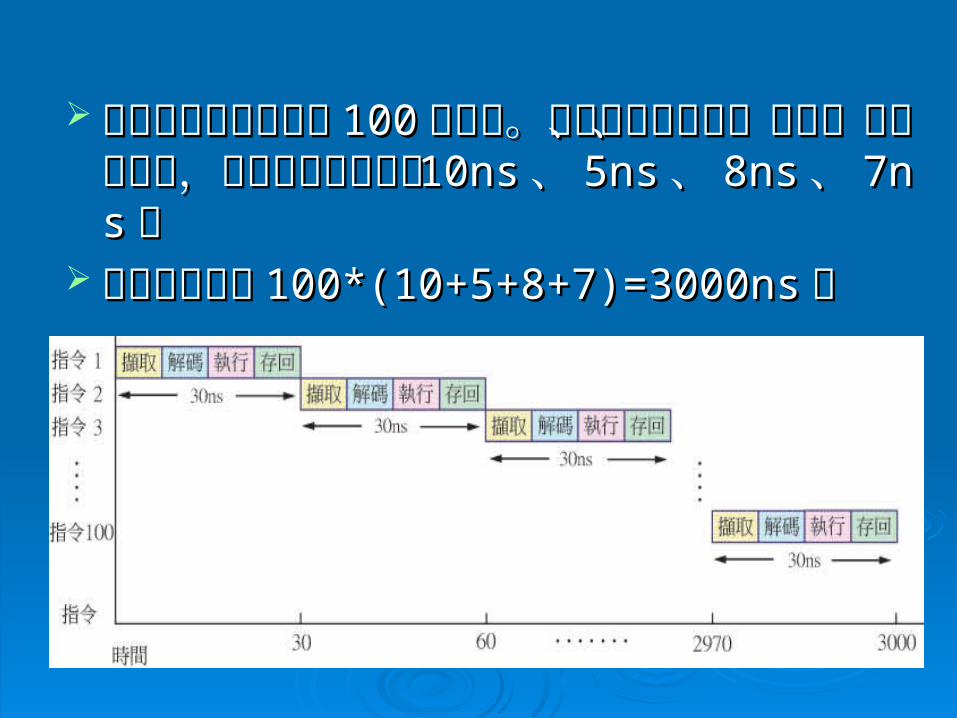
以傳統的做法來執行以傳統的做法來執行 100100 個指令。假設指令個指令。假設指令的擷取、解碼、執行與存回,各步驟所需時的擷取、解碼、執行與存回,各步驟所需時間為間為 10ns10ns 、、 5ns5ns 、、 8ns8ns 、、 7ns7ns 。。
執行總時間為執行總時間為 100*(10+5+8+7)=3000ns100*(10+5+8+7)=3000ns 。 。
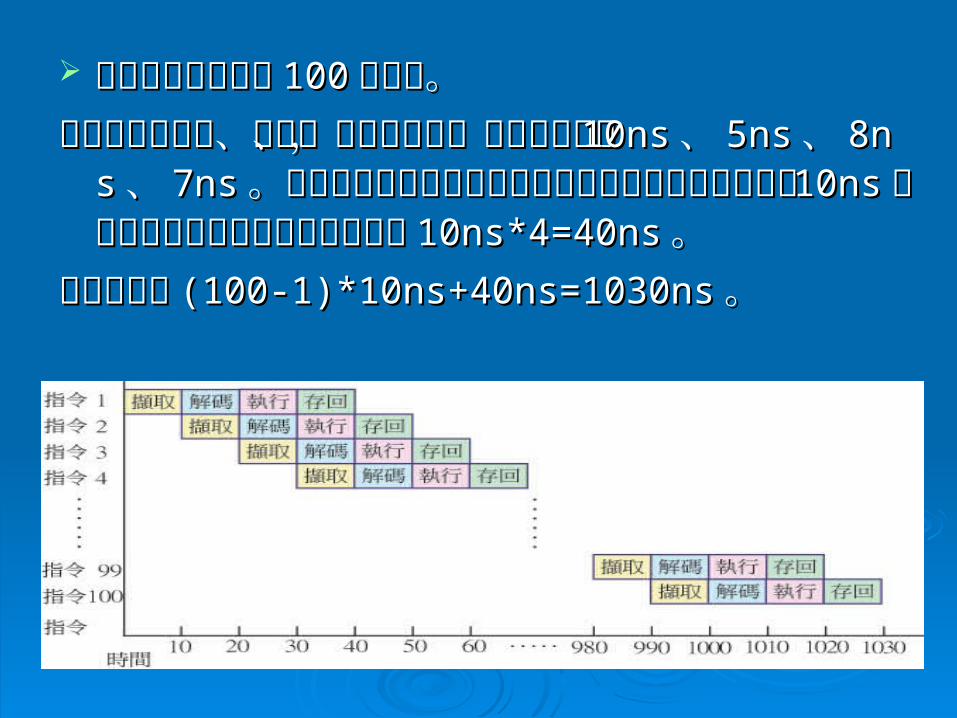
以管線技術來執行以管線技術來執行 100100個指令。個指令。由於指令的擷取、解碼、執行與存回,所需時間各由於指令的擷取、解碼、執行與存回,所需時間各為為 10ns10ns、、 5ns5ns、、 8ns8ns、、 7ns7ns。必須將各步驟所需。必須將各步驟所需的時間定義改為最長步驟使用時間的時間定義改為最長步驟使用時間 10ns10ns,所以完,所以完成一個指令所需時間變成成一個指令所需時間變成 10ns*4=40ns10ns*4=40ns。。
所需時間為所需時間為 (100-1)*10ns+40ns=1030ns(100-1)*10ns+40ns=1030ns。。

3-3-33-3-3 超純量處理器超純量處理器 (Superscalar)(Superscalar)
Superscalar describes a microprocessor design that makes it possible for
more than one instruction at a time to be executed during a single
clock cycle. In a superscalar design, the processor or the instruction
compiler is able to determine whether an instruction can be carried out
independently of other sequential instructions, or whether it has a
dependency on another instruction and must be executed in sequence with
it. The processor then uses multiple execution units to simultaneously carry
out two or more independent instructions at a time. Superscalar design is
sometimes called "second generation RISC."

管線管線 (Pipeline):(Pipeline): 管線的概念類似生產線管線的概念類似生產線 ,, 簡單來說簡單來說就是將一個指令的執行週期切割成多個階段就是將一個指令的執行週期切割成多個階段 ,,每個階每個階段由不同的電路負責段由不同的電路負責 ,,因此可以不用等待一個指令完因此可以不用等待一個指令完全執行完畢才執行下一個指令全執行完畢才執行下一個指令 ,,可以讓可以讓 CPUCPU 同時執行同時執行多個指令多個指令 ((也就是說第一個指令完成第一階段進行第也就是說第一個指令完成第一階段進行第二階段時二階段時 ,,第二個指令就可以開始進行第一階段的工第二個指令就可以開始進行第一階段的工作作 ),),這樣的設計可以提高各個模組電路的使用率這樣的設計可以提高各個模組電路的使用率 ,,進而提升程式的執行效率進而提升程式的執行效率 !!理論上理論上 ,,一個區分為一個區分為 NN 個個階段的管線可以讓階段的管線可以讓 CPUCPU 同時處理同時處理 NN 個指令個指令 !!
超純量超純量 (Superscalar):(Superscalar):在一個在一個 CPUCPU 中建立多個執行中建立多個執行單元單元 (Execution Unit),(Execution Unit),各個執行單元可以分別處各個執行單元可以分別處理不同的指令理不同的指令 !(!( 要注意的是每個執行單元可以做管要注意的是每個執行單元可以做管線化設計線化設計 ,,因此管線與超純量是不同的概念因此管線與超純量是不同的概念 ))

若一個系統將指令區分為若一個系統將指令區分為 66個階段個階段 (S1~S6),(S1~S6),其中其中 S4S4需需要要 22 個機器週期而其他階段僅需個機器週期而其他階段僅需 11 個機器週期個機器週期 ,, 討論執討論執行行 22 個指令的情況個指令的情況 ::
(1)(1)管線:管線: 99個週期個週期時間 1 2 3 4 5 6 7 8 9時間 1 2 3 4 5 6 7 8 9指令1 S1 S2 S3 S4 S4 S5 S6指令1 S1 S2 S3 S4 S4 S5 S6指令2 S1 S2 S3 等待 S4 S4 S5 S6指令2 S1 S2 S3 等待 S4 S4 S5 S6注意第二個指令執行完第注意第二個指令執行完第 33階段後階段後 ,,因為第一個指令的第因為第一個指令的第44階段尚未完成階段尚未完成 ,,因此須等第一個指令完成因此須等第一個指令完成 S4S4後第二個指後第二個指令才能進入令才能進入 S4S4階段階段 !!(2)(2)雙管線超純量:雙管線超純量: 77個週期個週期因為有兩個管線可以分開處理第一個跟第二個指令因為有兩個管線可以分開處理第一個跟第二個指令 ,,因因此此 ,,二個指令可以同時進行二個指令可以同時進行 ,, 故只需要故只需要 77個機械週期個機械週期 !!

3-3-33-3-3 超純量處理器超純量處理器 (Superscalar)(Superscalar)(( 續續 ))
Superscalar 加上pipeline技術

在一個管線計算機在一個管線計算機 (Pipeline Computer)(Pipeline Computer) 中有三中有三個管個管 (Pipe)(Pipe) ,其處理某一運算所需時間分別為,其處理某一運算所需時間分別為 33 、、66、、 44 ,則全部計算完,則全部計算完 1010個此種運算所需時間為?個此種運算所需時間為?(82(82二技管理類四二技管理類四 ))
SolSol :依計算公式:依計算公式 Max(3,6,4)Max(3,6,4)** 1010++ (3,6,4(3,6,4 中除最大值外的其中除最大值外的其餘 餘
值之和值之和 )) == 66** 1010++ (3(3++ 4) 4) == 6767

3-3-43-3-4 平行處理 平行處理 根據根據 FlynnFlynn 電腦架構分類電腦架構分類簡稱簡稱 指令流指令流 資料流資料流 架構架構 例子例子
SISDSISD 11 11 單處理機單處理機Von neumanVon neuman
PCPC
SIMDSIMD 11 MM 陣列處理機陣列處理機向量處理機向量處理機管線電腦管線電腦
TMC CM-5TMC CM-5 CRAY T3DCRAY T3D
MISDMISD MM 11 無無 無無
MIMDMIMD MM MM 多處理機平多處理機平行處理電腦行處理電腦
CRAY CRAY X/MPX/MP

Thinking Machine Corp. CM-2(8K CPUs Thinking Machine Corp. CM-2(8K CPUs 1bit) and Data Vault1bit) and Data Vault
CRAY T3D(Massively Parallel Processing)CRAY T3D(Massively Parallel Processing)
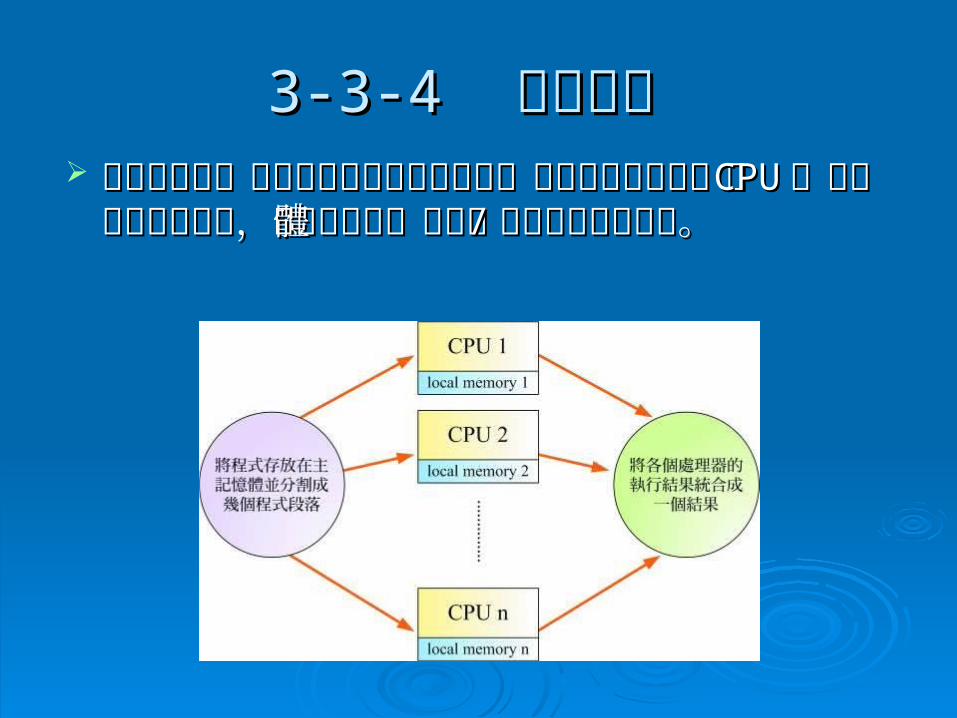
3-3-43-3-4 平行處理 平行處理 平行處理是一部電腦裡面有多個處理器,每個處平行處理是一部電腦裡面有多個處理器,每個處
理器都像一個理器都像一個 CPUCPU ,可以獨立執行工作,至於,可以獨立執行工作,至於主記憶體及輸入主記憶體及輸入 // 輸出裝置則是共用。 輸出裝置則是共用。
3-43-4 記憶體 記憶體 3-4-13-4-1 記憶體的種類 記憶體的種類 記憶體有記憶體有 RAM (RAM (隨機存取記憶體,電源消失,資料隨機存取記憶體,電源消失,資料
就消失就消失 )) 與與 ROM(ROM(唯讀記憶體,資料錄存後永遠保唯讀記憶體,資料錄存後永遠保存 存 )) 兩種。兩種。
RAMRAM又分成下列兩種:又分成下列兩種: DRAM(dynamic RAMDRAM(dynamic RAM ,動態隨機存取記憶體,動態隨機存取記憶體 )) SRAM(static RAMSRAM(static RAM ,靜態隨機存取記憶體,靜態隨機存取記憶體 )) :存:存取速度快,成本高,作為取速度快,成本高,作為 CacheCache 用。 用。
ROMROM又分成下列三種:儲存又分成下列三種:儲存 BIOSBIOS 用用 PROM(programmable ROM) PROM(programmable ROM) EPROM(erasable PROM) EPROM(erasable PROM) EEPROM(electronically EPROM) EEPROM(electronically EPROM) 目前,目前, BIOSBIOS 儲存在快閃記憶體儲存在快閃記憶體 (Flash Memory)(Flash Memory) 內內
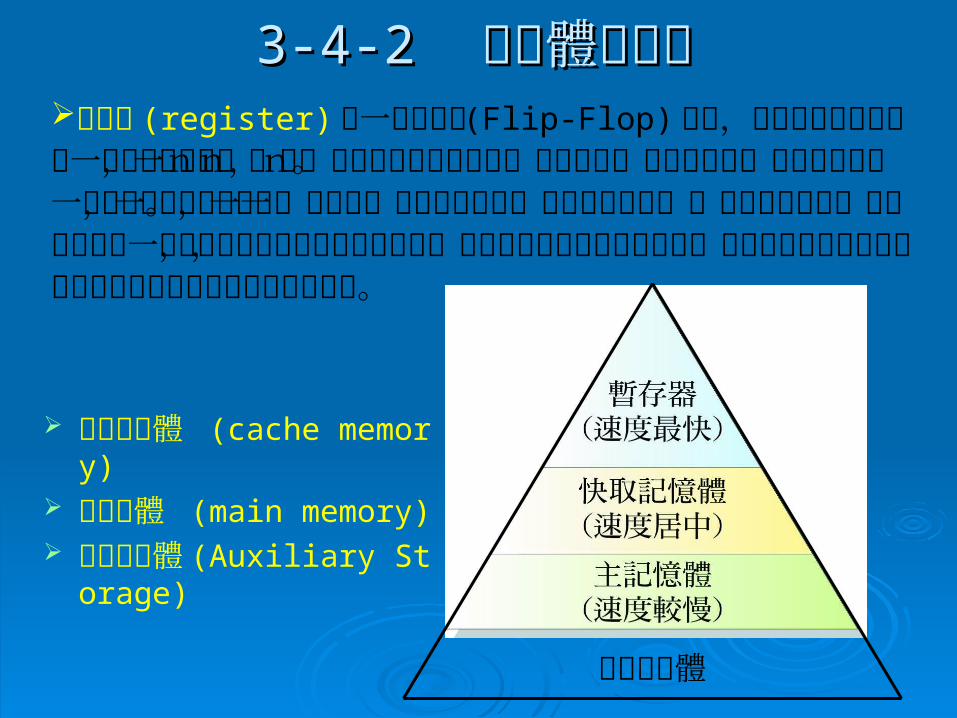
3-4-23-4-2 記憶體的階層 記憶體的階層
輔助記憶體
快取記憶體 (cache memory)
主記憶體 (main memory) 輔助記憶體 (Auxiliary S
torage)
暫存器 (register) 由一群正反器 (Flip-Flop) 組成,每個正反器可以儲存一個位元的資料,一個n位元的暫存器便包含n個正反器,而可以儲存n位元的資料。一個暫存器除了正反器外,還包含一些組合邏輯閘。廣義的定義中,一個暫存器包含一群正反器以及一些會影響他們狀態改變的邏輯閘,正反器用來保存二進位資料,而其他的輯閘則用來控制新資料於何時及如何轉移到暫存器。

何謂『何謂『 BIOSBIOS』 』 ref P.3-31ref P.3-31BIOSBIOS 是『是『 Basic Input Output System-Basic Input Output System-基本輸出入控基本輸出入控制系統』。專責系統中各式參數設定,是放在主機板制系統』。專責系統中各式參數設定,是放在主機板上一顆小小的快閃上一顆小小的快閃 EEPROMEEPROM 記憶體模組中,這個一種唯記憶體模組中,這個一種唯讀的記憶體,需使用特殊工具和技術才可以修改或重讀的記憶體,需使用特殊工具和技術才可以修改或重新編譯裡面內容,電腦一啟動,處理器會第一優先自新編譯裡面內容,電腦一啟動,處理器會第一優先自動執行存放在動執行存放在 BIOSBIOS 中的程式。因為它是將硬體方面的中的程式。因為它是將硬體方面的控制程式利用機器燒錄至唯讀記憶體『控制程式利用機器燒錄至唯讀記憶體『 ROMROM』裡面,』裡面,所以所以 BIOSBIOS 就是屬於硬體的東西,但是裡面的程式又是就是屬於硬體的東西,但是裡面的程式又是屬於軟體,因此綜括起來就統之稱為『韌體』,由於屬於軟體,因此綜括起來就統之稱為『韌體』,由於這是專做硬體控制用的角色,所以可以稱這是專做硬體控制用的角色,所以可以稱 BIOSBIOS 是硬體是硬體的『監督程式』。 的『監督程式』。
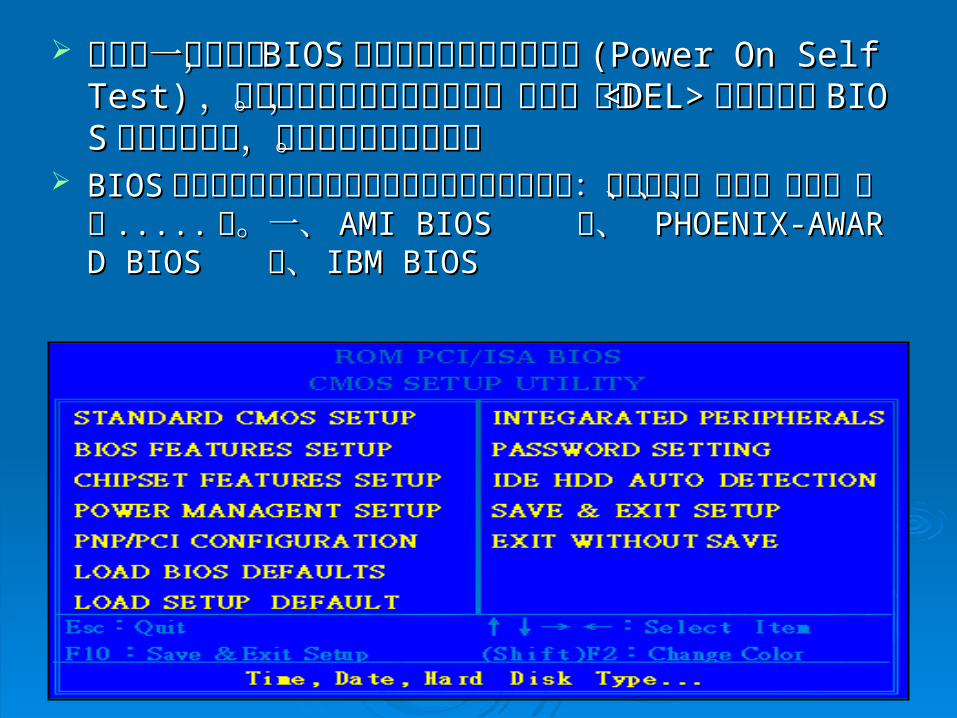
在系統一開機時,在系統一開機時, BIOSBIOS 會進行開機時的檢測工作會進行開機時的檢測工作 (Po(Power On Self Test)wer On Self Test) ,以確定系統組件的基本組態。,以確定系統組件的基本組態。此時,按下此時,按下 <DEL><DEL> 鍵即可進入鍵即可進入 BIOSBIOS 設定的主畫面,設定的主畫面,你可以調整各個細項。 你可以調整各個細項。
BIOSBIOS 控制著主機板上所有的輸出及輸入的訊號與控制:例控制著主機板上所有的輸出及輸入的訊號與控制:例如硬碟、軟碟、鍵盤、滑鼠如硬碟、軟碟、鍵盤、滑鼠 ..........等。一、等。一、 AMI BIOS AMI BIOS 二、 二、 PHOENIX-AWARD BIOS PHOENIX-AWARD BIOS 三、三、 IBM BIOSIBM BIOS
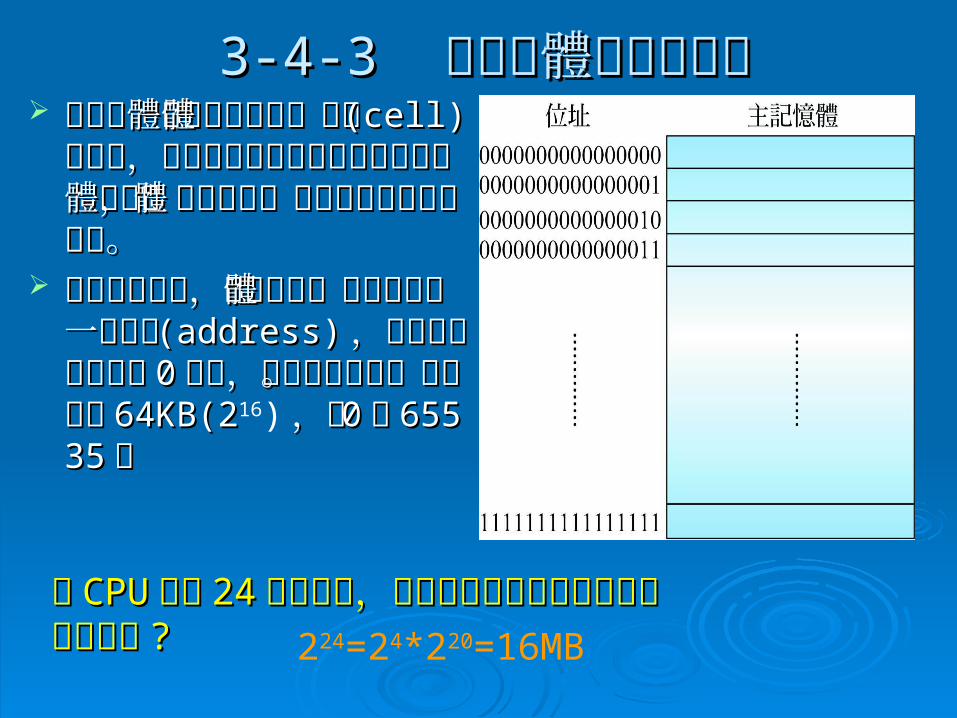
3-4-33-4-3 主記憶體的定址方式 主記憶體的定址方式 主記憶體是由許多記憶體主記憶體是由許多記憶體
單元單元 (cell)(cell) 所組成,不同所組成,不同機器可能有不同數目的記機器可能有不同數目的記憶體單元,而且記憶體單憶體單元,而且記憶體單元的大小也不盡相同。元的大小也不盡相同。
為了加以辨識,每個記憶為了加以辨識,每個記憶體單元都有唯一的位址體單元都有唯一的位址 (ad(address)dress) ,同時這些位址是,同時這些位址是從從 00 開始,依照順序編號。開始,依照順序編號。圖示容量圖示容量 64KB(264KB(216) ,從,從 00到到 6553565535 。 。 某某 CPUCPU 含有含有 2424條位址線,請問他可直接定址到多大的條位址線,請問他可直接定址到多大的記憶空間記憶空間 ?? 224=24*220=16MB

3-53-5 電腦與週邊通訊 電腦與週邊通訊 電腦內部的電子訊號是由匯流排進行傳送,由下列電腦內部的電子訊號是由匯流排進行傳送,由下列
三組電路所組成:三組電路所組成: 資料線資料線 (data line)(data line) 位址線位址線 (address line)(address line) 控制線控制線 (control line) (control line)
匯流排又分為下列兩種:匯流排又分為下列兩種: 系統匯流排系統匯流排 (system bus)(system bus) :負責傳送:負責傳送 CPUCPU 與主記與主記憶體之間資料憶體之間資料
擴充匯流排擴充匯流排 (expansion bus)(expansion bus) ::負責傳送負責傳送 CPUCPU 與與週邊之間資料週邊之間資料。。
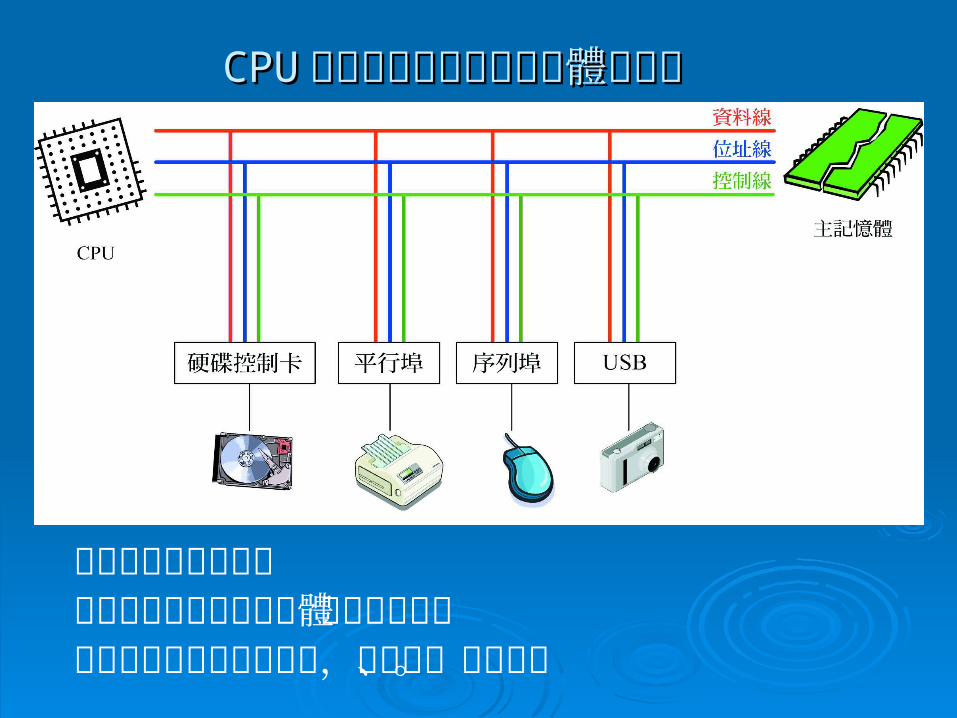
CPUCPU 透過匯流排連接主記憶體與週邊透過匯流排連接主記憶體與週邊
資料線負責傳送資料位址線負責存放主記憶體或週邊的位址控制線負責發出控制訊號,如讀取、寫入等。

PCPC 常見的擴充匯流排: 常見的擴充匯流排: ref P.3-32ref P.3-32 ISA (industry standard architecture) ISA (industry standard architecture)
MCA (microchannel architecture)MCA (microchannel architecture)
EISA EISA (extended industry standard architecture)(extended industry standard architecture)
VL (VESA local bus)VL (VESA local bus)
Graphics Card IBM XGA-2.

PCPC 常見的擴充匯流排常見的擴充匯流排 (( 續續 )) : : ref P.3-32ref P.3-32 PCI (peripheral component interconnect)PCI (peripheral component interconnect)
AGP (accelerated graphics port)AGP (accelerated graphics port)

PCI Express(2.5~4PCI Express(2.5~4 倍倍 )) 硬碟控制介面、軟碟控制介面、光碟控制硬碟控制介面、軟碟控制介面、光碟控制介面、介面、 Monitor portMonitor port
PS/2PS/2 埠埠 序列埠 序列埠 (serial port) (serial port) (COM 1) (COM 1) 平行埠 平行埠 (parallel port) (parallel port) (LPT 1) (LPT 1) USB (universal serial bus)USB (universal serial bus)
IEEE1394IEEE1394
SCSI-3
New SCA 80-pin

1616 條排線的電腦,其定址空間為:條排線的電腦,其定址空間為: 221616=2=266*2*21010=64KB=64KB
假設假設 80286 CPU80286 CPU 資料匯流排為資料匯流排為 1616 條線,位址條線,位址匯流排有匯流排有 2424 條線,其資料傳輸量與定址能條線,其資料傳輸量與定址能力各為何力各為何 ??
1.1. 此為此為 1616 位元的位元的 CPUCPU ,資料傳輸量為,資料傳輸量為 2Bytes2Bytes2.2. 定址能力為定址能力為 222424=2=244*2*22020=16MB=16MB

紅外線傳輸埠 紅外線傳輸埠 (IrDA) (IrDA) 其它擴充插槽其它擴充插槽
顯示器插槽顯示器插槽 網路卡插槽網路卡插槽 SCSISCSI 卡插槽卡插槽 音效卡插槽音效卡插槽 數據卡插槽 數據卡插槽
PS/2
USB
ParallelSerial port
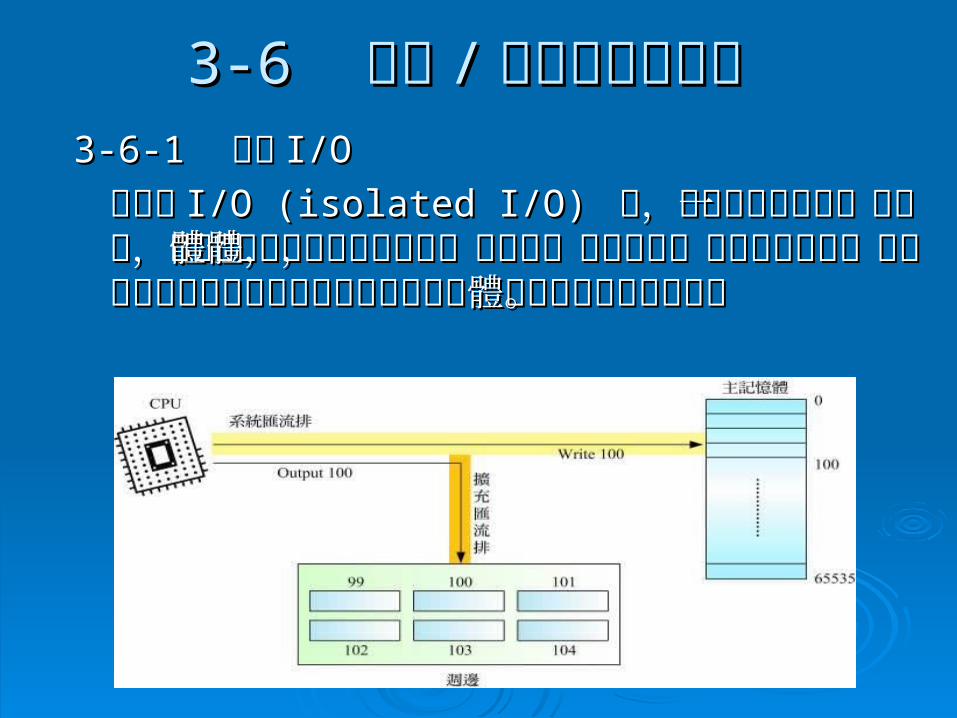
3-63-6 輸入 輸入 // 輸出的定址方式輸出的定址方式 3-6-13-6-1 隔離 隔離 I/O I/O
在隔離在隔離 I/O (isolated I/O) I/O (isolated I/O) 中,每個週邊均有唯一中,每個週邊均有唯一的位址,但這些位址卻可能和主記憶體的記憶體的位址,但這些位址卻可能和主記憶體的記憶體單元重複,為了避免混淆,於是得設計兩組不同單元重複,為了避免混淆,於是得設計兩組不同的指令來進行主記憶體的讀寫及週邊的讀寫。 的指令來進行主記憶體的讀寫及週邊的讀寫。
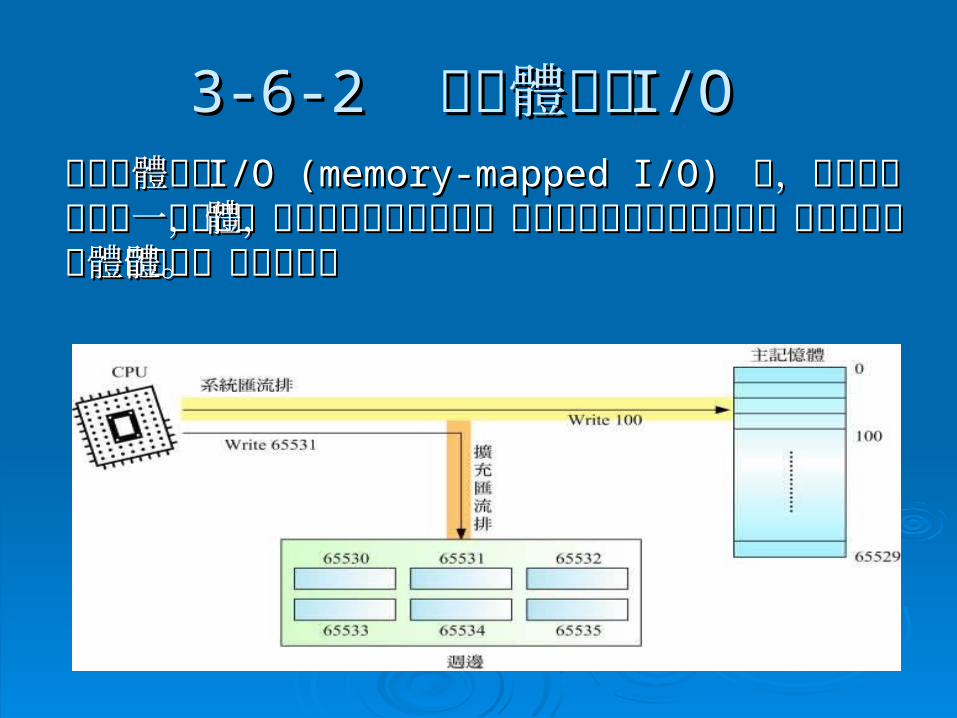
3-6-23-6-2 記憶體映射 記憶體映射 I/OI/O 在記憶體映射在記憶體映射 I/O (memory-mapped I/O) I/O (memory-mapped I/O) 中,每個中,每個週邊均有唯一的位址,這些位址是從主記憶體的部週邊均有唯一的位址,這些位址是從主記憶體的部分定址空間配置出來,不會和主記憶體的記憶體單分定址空間配置出來,不會和主記憶體的記憶體單元重複。元重複。
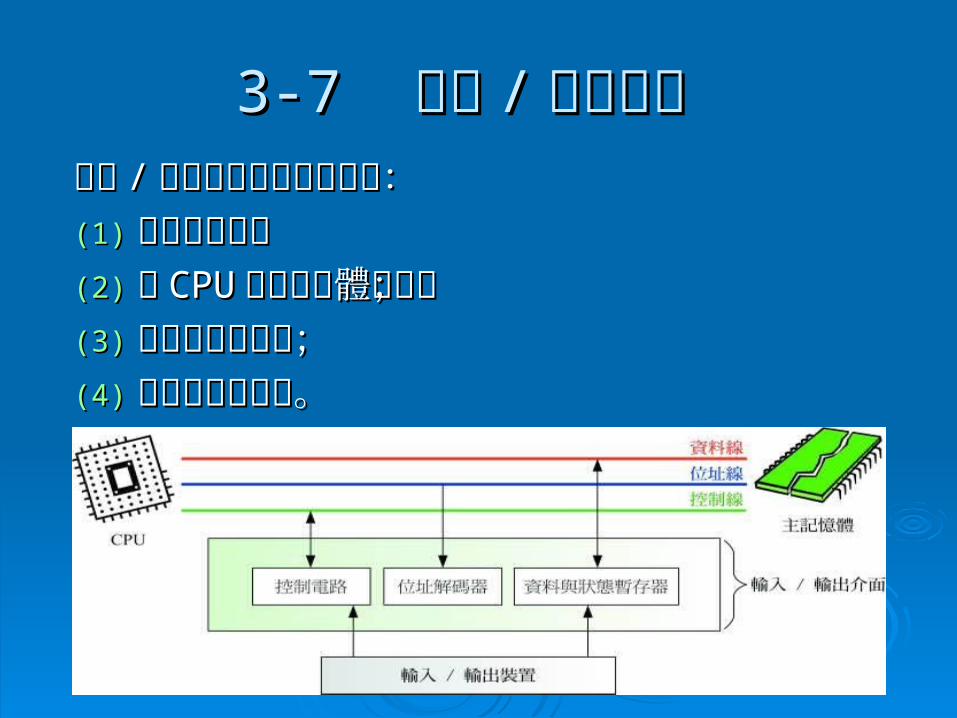
3-73-7 輸入 輸入 // 輸出介面輸出介面 輸入輸入 // 輸出介面主要的工作有:輸出介面主要的工作有:(1)(1) 與週邊溝通;與週邊溝通;(2)(2) 與與 CPUCPU 和主記憶體溝通;和主記憶體溝通;(3)(3) 做為資料緩衝區;做為資料緩衝區;(4)(4) 錯誤偵測與回報。 錯誤偵測與回報。

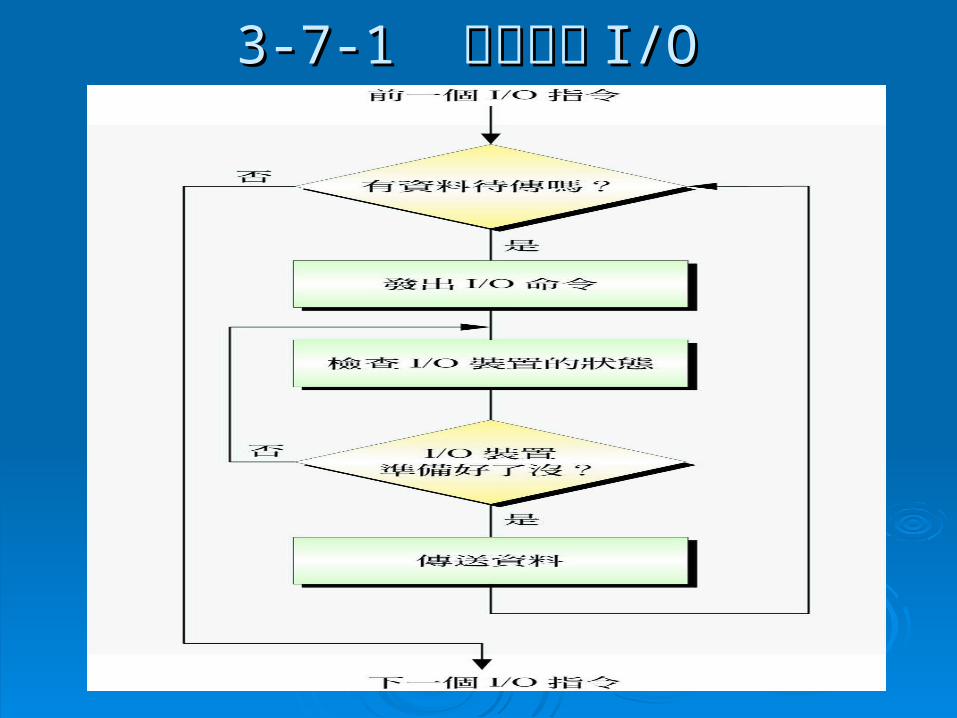
3-7-13-7-1 程式控制 程式控制 I/OI/O 程式控制程式控制 I/O (program-controlled I/O)I/O (program-controlled I/O) ,又稱,又稱
為輪詢式為輪詢式 I/O (polling I/O)I/O (polling I/O) ,當,當 CPUCPU 與週邊與週邊傳送資料時,輸入傳送資料時,輸入 //輸出介面並不會主動通知輸出介面並不會主動通知CPUCPU 其所要存取的週邊是否已經準備好需要的其所要存取的週邊是否已經準備好需要的資料,然後叫資料,然後叫 CPUCPU去拿下一筆資料,也不會主去拿下一筆資料,也不會主動通知動通知 CPUCPU 其所要存取的週邊是否已經消化完其所要存取的週邊是否已經消化完送來的資料,然後叫送來的資料,然後叫 CPUCPU送下一筆資料過去。送下一筆資料過去。
在這個過程中,在這個過程中, CPUCPU 必須一直詢問輸入必須一直詢問輸入 //輸出介面,輸出介面,才能掌握週邊的狀態,無法執行其他工作。如才能掌握週邊的狀態,無法執行其他工作。如下圖下圖
3-7-13-7-1 程式控制 程式控制 I/OI/O
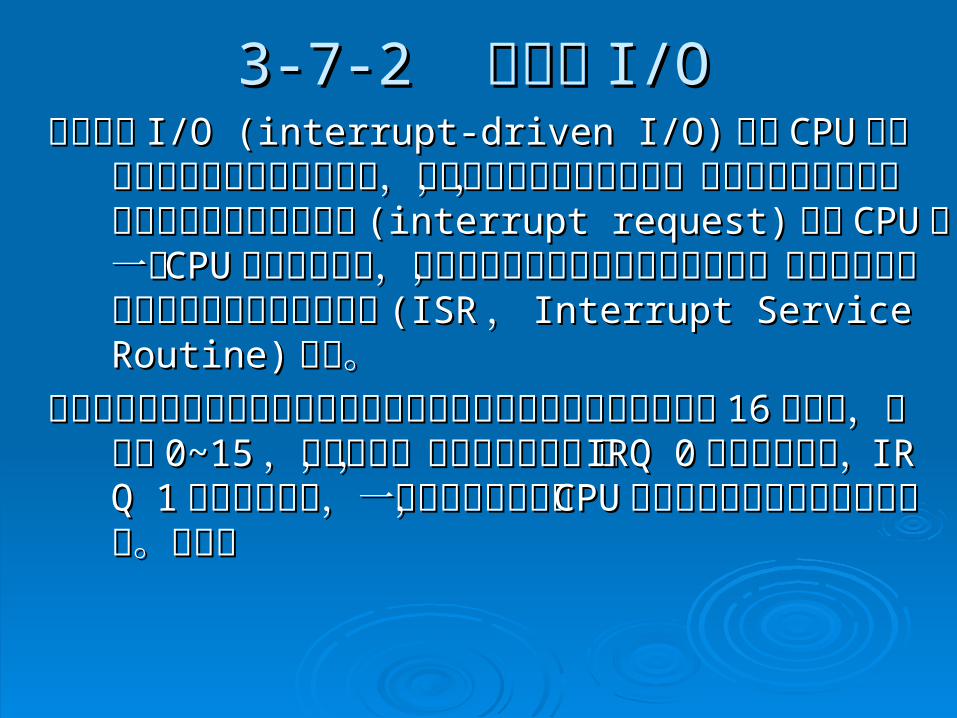
3-7-23-7-2 中斷式 中斷式 I/OI/O 在中斷式在中斷式 I/O (interrupt-driven I/O)I/O (interrupt-driven I/O) 中,中, CPUCPU會先會先
通知週邊即將開始傳送資料,之後便逕自執行其通知週邊即將開始傳送資料,之後便逕自執行其他工作,待資料傳送完畢後,週邊會發出一個中他工作,待資料傳送完畢後,週邊會發出一個中斷要求斷要求 (interrupt request)(interrupt request) 通知通知 CPUCPU ,一旦,一旦 CPUCPU收到中斷要求,就會暫時停止目前正在執行的工收到中斷要求,就會暫時停止目前正在執行的工作,改去執行中斷要求所指定的中斷服務程式作,改去執行中斷要求所指定的中斷服務程式 (IS(ISRR,, Interrupt Service RoutineInterrupt Service Routine)) 工作。工作。
目前處理中斷要求的控制晶片內建於主機板的晶片組,目前處理中斷要求的控制晶片內建於主機板的晶片組,中斷要求分為中斷要求分為 1616個層次,編號為個層次,編號為 0~150~15 ,數字越,數字越大,優先順序越低,如大,優先順序越低,如 IRQ 0IRQ 0式系統計時器,式系統計時器, IRQ IRQ 11 是鍵盤控制器,一旦發出中斷要求,是鍵盤控制器,一旦發出中斷要求, CPUCPU會先處會先處理系統計時器的中斷要求。如下圖理系統計時器的中斷要求。如下圖
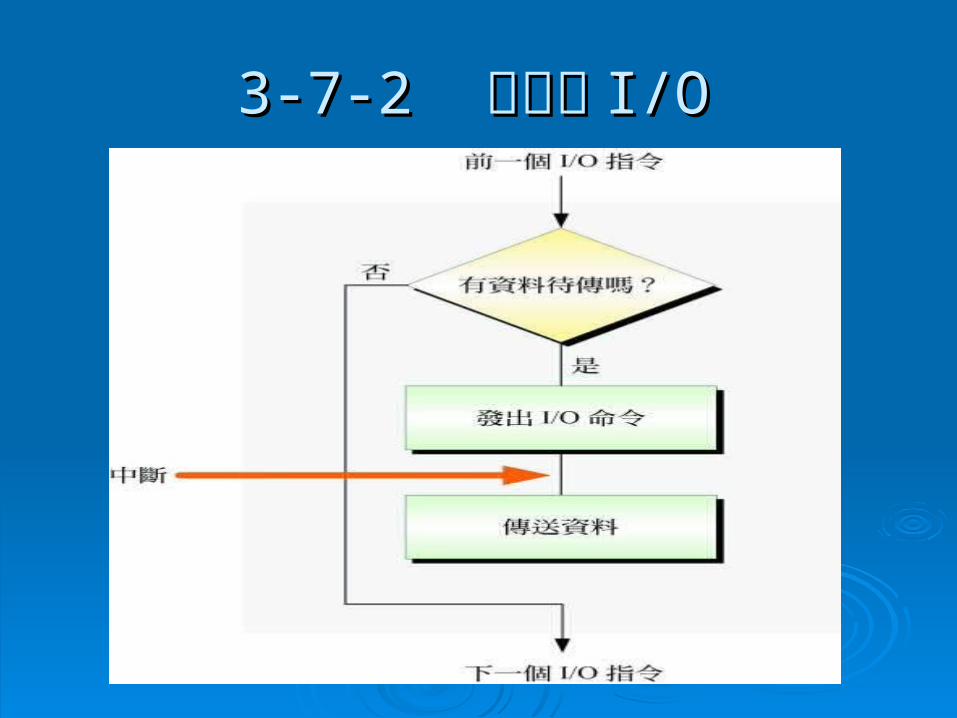
3-7-23-7-2 中斷式 中斷式 I/OI/O

3-7-33-7-3 直接記憶體存取 直接記憶體存取 (DMA)(DMA) 直接記憶體存取直接記憶體存取 (direct memory access)(direct memory access) 是應用在主是應用在主
記憶體與週邊之間的資料傳送,當主記憶體與週記憶體與週邊之間的資料傳送,當主記憶體與週邊之間要傳送資料時,邊之間要傳送資料時, CPUCPU 只要將傳送類型、位只要將傳送類型、位址、資料的位元組數目等訊息通知址、資料的位元組數目等訊息通知 DMADMA ,就可以,就可以執行其他工作,接下來便由執行其他工作,接下來便由 DMADMA 直接向週邊取得直接向週邊取得資料,然後傳送給主記憶體,不再打擾資料,然後傳送給主記憶體,不再打擾 CPUCPU ,電,電腦的效能自然會提升。如下圖腦的效能自然會提升。如下圖
不過,共用的匯流排在不過,共用的匯流排在 CPUCPU 、、 DMADMA 和主記憶體競相使和主記憶體競相使用的情況下仍會成為障礙,也就是所謂范紐曼瓶用的情況下仍會成為障礙,也就是所謂范紐曼瓶頸。現在的頸。現在的 1616位元位元 PCIPCI 匯流排有兩顆 匯流排有兩顆 DMADMA 控制控制晶片,可以提供八個晶片,可以提供八個 DMA(DMA(編號編號 0~7)0~7) 。。
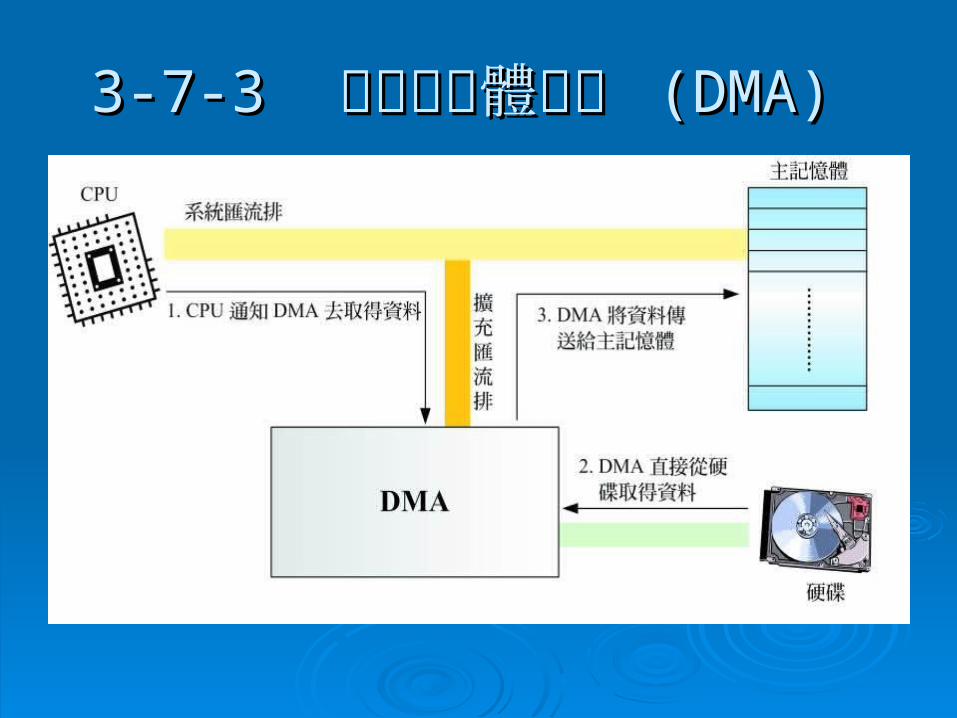
3-7-33-7-3 直接記憶體存取 直接記憶體存取 (DMA)(DMA)
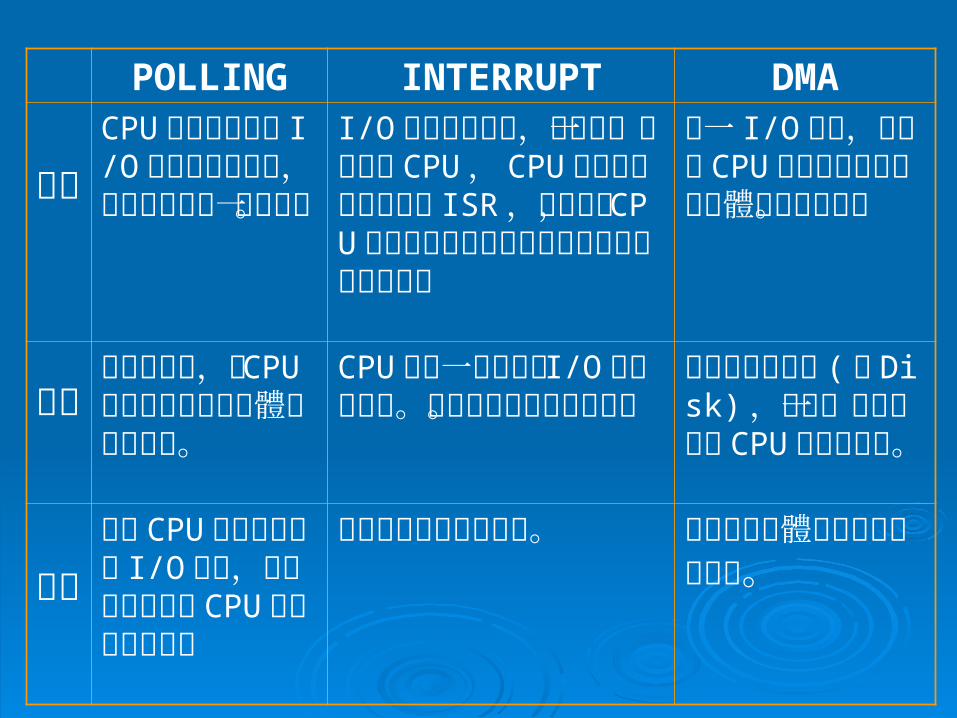
POLLING INTERRUPT DMA
意義
CPU 週期性的確認 I/O裝置的狀態位元,是否可進行下一個動作。
I/O裝置要動作時,會發出一個中斷給 CPU ,CPU停下原本的工作執行 ISR ,完成後, CPU再返回原本的工作位置繼續執行未完的工作。
為一 I/O介面,不透過 CPU 的暫存器直接與記憶體作資料傳輸。
優點
簡單易執行,且 CPU輪詢的順序可由軟體程式來改變。
CPU 不用一直去確認 I/O裝置的狀態。不會浪費時間在輪詢上。
適用於高速裝置(如 Disk) ,也是一種用中斷和CPU 溝通的方式。
缺點
因為 CPU 的速度遠快於 I/O裝置,所以會浪費許多 CPU時間在輪詢上。
程式上處理較複雜困難。程式的記憶體部分處理難度增加。