Embed Size (px)
Citation preview

6th/June, ISCA2005, 1/30NEC Corporation
An Integrated Memory Array Processor Architecture for Embedded Image Recognition
Systems
*1 Shorin KYO*1 Shin'ichiro OKAZAKI
*2 Tamio ARAI
*1 Media and Information Research Laboratories, NEC Corporation*2 School of Engineering, University of Tokyo

6th/June, ISCA2005, 2/30NEC Corporation
1. Challenges of Embedded Image Recognition Systems
2. Integrated Memory Array Processor (IMAP) Architecture
3. Programming Language and Compiler Design
4. Evaluations
5. Summary
Outline
6th/June, ISCA2005, 3/30NEC Corporation
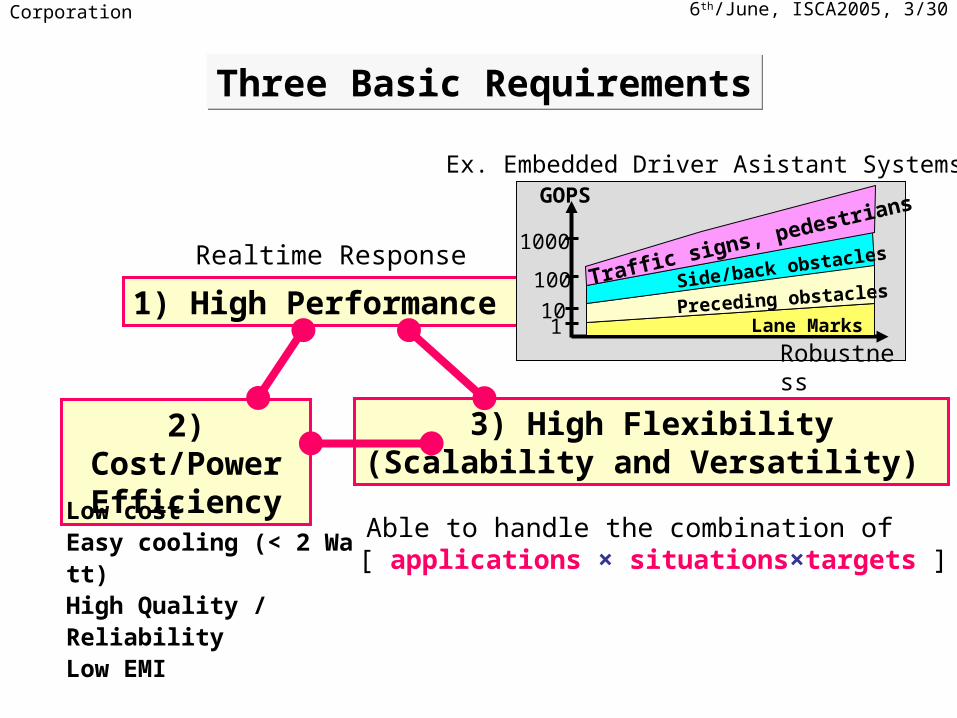
Three Basic RequirementsThree Basic Requirements
1) High Performance
2) Cost/Power Efficiency
3) High Flexibility(Scalability and Versatility)
Low costEasy cooling (< 2 Watt)High Quality / ReliabilityLow EMI
Able to handle the combination of [ applications × situations×targets ]
101
100
1000
Robustness
GOPS
Lane MarksPreceding obstaclesSide/back obstacles
Traffic signs, pedestrians
Ex. Embedded Driver Asistant Systems
Realtime Response

6th/June, ISCA2005, 4/30NEC Corporation
Applications × Situations × TargetsApplications × Situations × Targets
Dynamic Back Up Aid
Cross Traffic WarningFollowing Distance Warning
Park Slot Measurement
Backup Parking AssistStop&Go
Side Pre-CrashCut-In
Front Pre-Crash
Lane Change Assist
Pedestrian Protection
Blind Spot Detection
Drownsinesswarning
Traffic Sign Recognition

6th/June, ISCA2005, 5/30NEC Corporation
Control circuit
Cost ( Die size / power consumption )
Operation circuit
(peak) performanceFlexibility
100
100
ItaniumSparc64
SPE(CELL)FR1000
FR500IMAP-CE, IMAPCAR
CODEC LSI
a) Desktop/Server CPU (GPPs)
b) MIMDs (Multi-Cores)
c) DSPsd) Highly parallel SIMDs
e) Special purpose LSI
% o
f Con
tro
l Cir
cuitr
y
% of Operational Circuitry
(Fle
xib
ilit
y)
(Performance)
COR: Control versus Operational circuit RatioCOR: Control versus Operational circuit Ratio
1) Performance (higher)1) Performance (higher)
2) Cost (lower)2) Cost (lower)
3) Flexibility (higher)3) Flexibility (higher)
Trading-off items
6th/June, ISCA2005, 6/30NEC Corporation
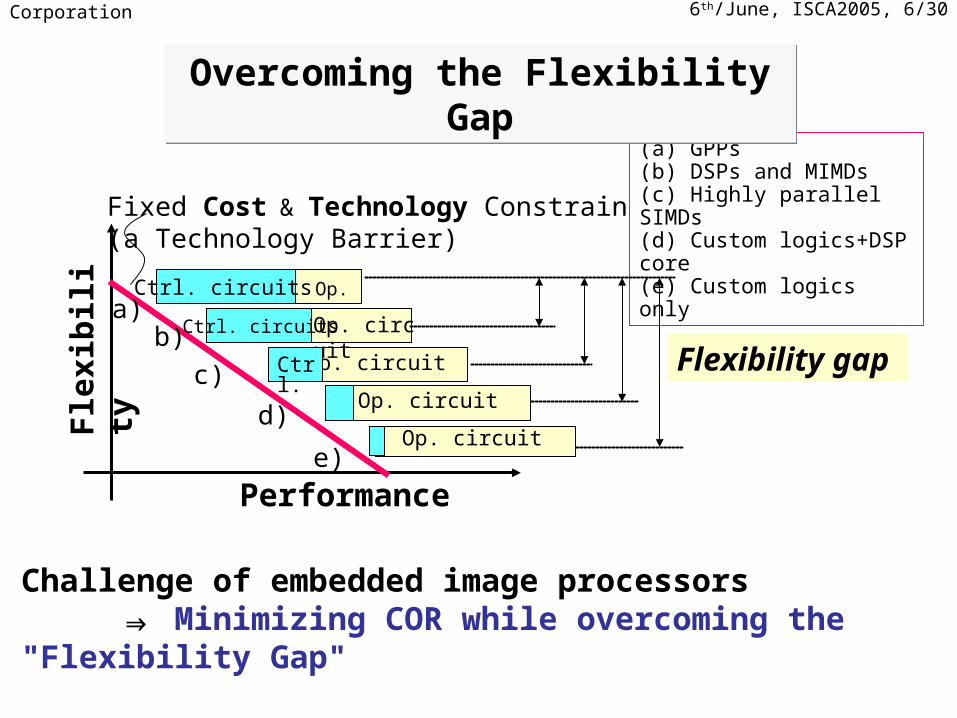
(a) GPPs(b) DSPs and MIMDs(c) Highly parallel SIMDs(d) Custom logics+DSP core(e) Custom logics only
Fle
xib
ilit
y
Performance
a)b)
c)
d)
e)
Ctrl. circuits
Op. circuit
Ctrl. circuits
Op.
Op. circuit
Op. circuit
Op. circuit
Fixed Cost & Technology Constrain(a Technology Barrier)
Flexibility gap
Challenge of embedded image processors ⇒ Minimizing COR while overcoming the "Flexibility Gap"
Overcoming the Flexibility GapOvercoming the Flexibility Gap
Ctrl.

6th/June, ISCA2005, 7/30NEC Corporation
1. Challenge of Embedded Image Recognition Systems
2. Integrated Memory Array Processor (IMAP) Architecture
3. Programming Language and Compiler Design
4. Evaluation
5. Summary
Outline
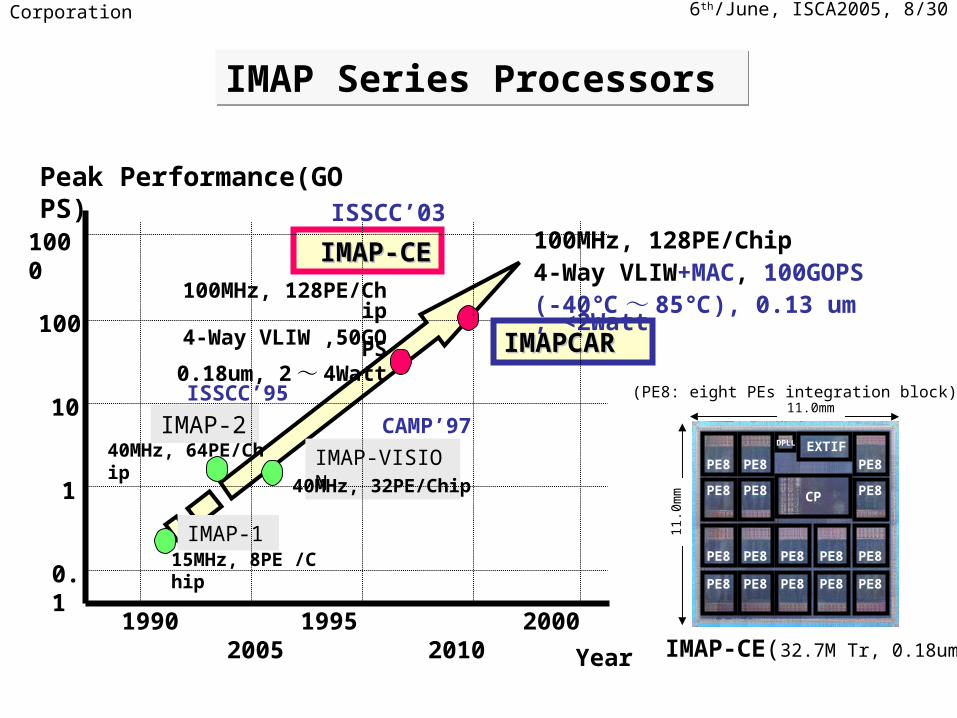
6th/June, ISCA2005, 8/30NEC Corporation
IMAP-CEIMAP-CE
IMAP-1
IMAP-VISION
1990 1995 2000 2005 2010
1
0.1
10
100
40MHz, 32PE/Chip
15MHz, 8PE /Chip
Peak Performance(GOPS)
100MHz, 128PE/Chip4-Way VLIW ,50GOPS
0.18um, 2 ~ 4Watt
IMAP-240MHz, 64PE/Chip
IMAPCARIMAPCAR
100MHz, 128PE/Chip4-Way VLIW+MAC, 100GOPS(-40℃ ~ 85 ), 0.13 um, <2Watt ℃
1000
IMAP Series Processors IMAP Series Processors
ISSCC’03
ISSCC’95
Year
11.0mm
11.0
mm
PE8 PE8 PE8 PE8 PE8
PE8 PE8 PE8 PE8 PE8
PE8 PE8 PE8
PE8 PE8 PE8
CP
EXTIFDPLL
IMAP-CE(32.7M Tr, 0.18um)
(PE8: eight PEs integration block)
CAMP’97
6th/June, ISCA2005, 9/30NEC Corporation
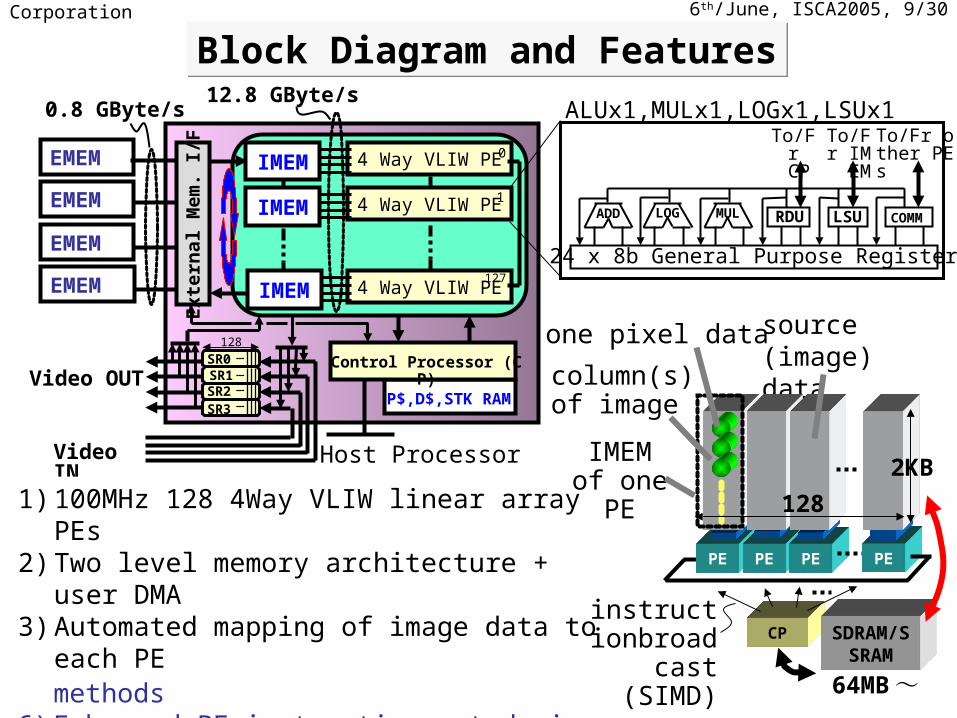
Block Diagram and FeaturesBlock Diagram and Features
Video IN
Video OUTP$,D$,STK RAM
EMEM
Host Processor
Control Processor (CP)
4 Way VLIW PE
4 Way VLIW PE
4 Way VLIW PE
SR0 SR1SR2
IMEM
IMEM
IMEMExt
ern
al M
em.
I/F
12.8 GByte/s0.8 GByte/s
0
1
127
SR3
128
EMEM
EMEM
EMEM
ADD MUL RDU
24 x 8b General Purpose Registers
To/Fr other PEs
To/Fr IMEM
LSU COMM
To/Fr CP
LOG
4) 128 individual RAM blocks configuration5) 1DC (One Dimensional C) + “Line methods”6) Enhanced PE instruction set design for 1DC
1) 100MHz 128 4Way VLIW linear array PEs2) Two level memory architecture + user DMA 3) Automated mapping of image data to each PE PE PE
one pixel data
IMEM of one PE
column(s) of image
source (image) data
PE PE
CPinstructionbroadcast
(SIMD)SDRAM/SSRAM
2KB
128
64MB ~
ALUx1,MULx1,LOGx1,LSUx1
6th/June, ISCA2005, 10/30NEC Corporation
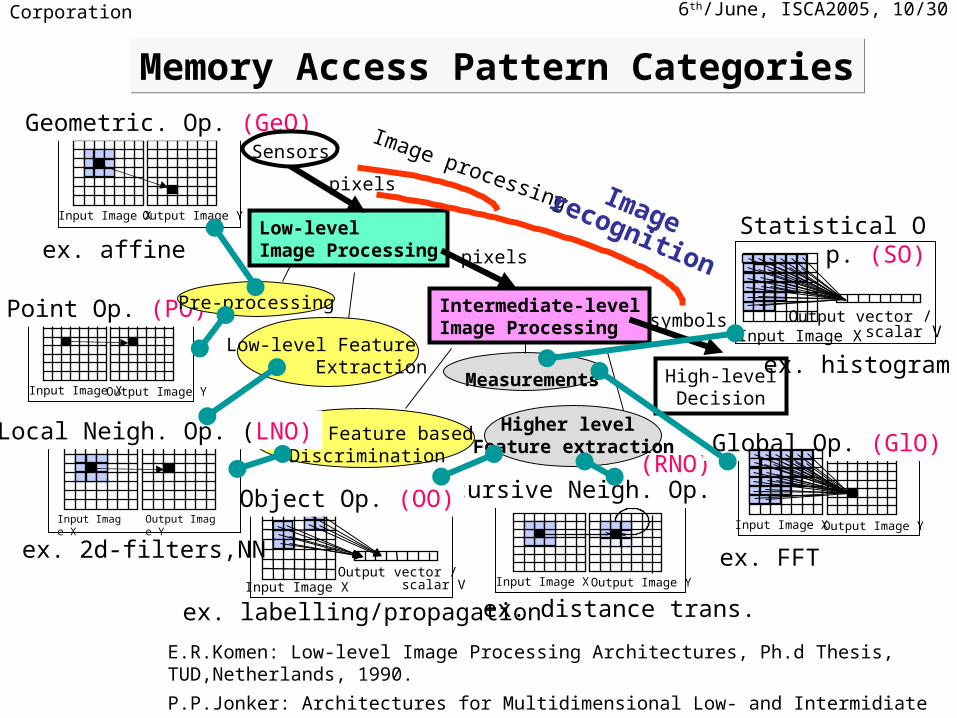
Memory Access Pattern CategoriesMemory Access Pattern Categories
Input Image X
(RNO)Recursive Neigh. Op.
Output Image Y
High-levelDecision
Local Feature basedDiscrimination
Measurements
Low-levelImage Processing
Intermediate-levelImage Processing
pixels
pixels
symbols
Output Image YInput Image X
Point Op. (PO)Input Image X
Output vector / scalar V
Statistical Op. (SO)
Input Image XOutput vector /
scalar V
Object Op. (OO)
Higher level Feature extraction
Low-level Feature Extraction
Output Image YInput Image X
Global Op. (GlO)
Output Image YInput Image X
Geometric. Op. (GeO)
Output Image YInput Image X
Local Neigh. Op. (LNO)
Pre-processing
SensorsImage processing Image
recognition
E.R.Komen: Low-level Image Processing Architectures, Ph.d Thesis, TUD,Netherlands, 1990.
P.P.Jonker: Architectures for Multidimensional Low- and Intermidiate Level Image rocessing, Proc. of IAPR Workshop on Machine Vision Applications (MVA'90), pp.307--316, 1990.
ex. affine
ex. 2d-filters,NN
ex. labelling/propagation ex. distance trans.
ex. FFT
ex. histogram
6th/June, ISCA2005, 11/30NEC Corporation
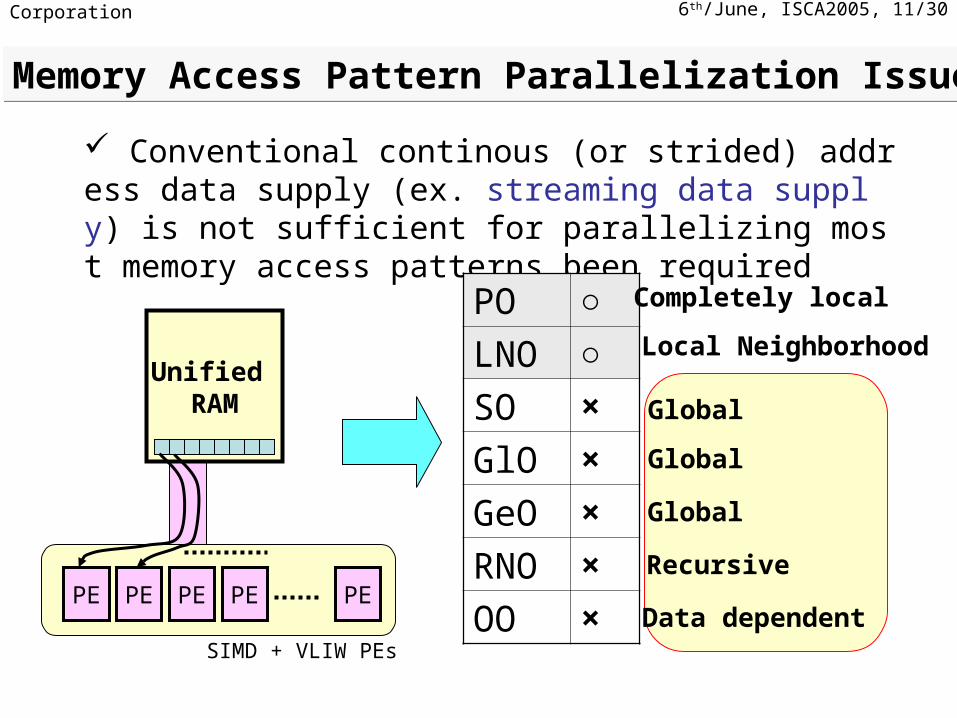
Recursive
Data dependent
Conventional continous (or strided) address data supply (ex. streaming data supply) is not sufficient for parallelizing most memory access patterns been required
PO ○
LNO ○
SO ×
GlO ×
GeO ×
RNO ×
OO ×
Global
Global
Global
Completely local
Local NeighborhoodUnified
RAM
PE PE PE PE PE
SIMD + VLIW PEs
Memory Access Pattern Parallelization IssueMemory Access Pattern Parallelization Issue
6th/June, ISCA2005, 12/30NEC Corporation
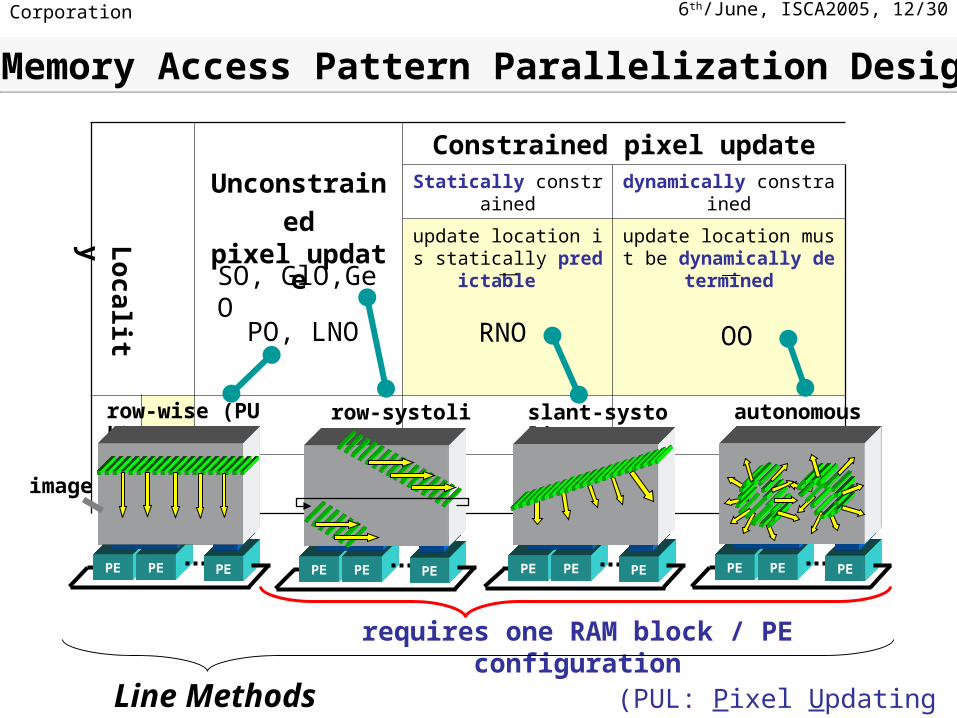
Unconstrainedpixel update
Constrained pixel updateStatically constrained dynamically constrained
update location is statically predictable
update location must be dynamically determined
No
Yes
SO, GlO,GeO -
PO, LNO RNO OO
-
Lo
calit
y
slant-systolic
PE PE PE
autonomous
PE PE PE
row-systolic
PE PE PE
row-wise (PUL)
PE PE PE
image
requires one RAM block / PE configuration
Memory Access Pattern Parallelization DesignMemory Access Pattern Parallelization Design
(PUL: Pixel Updating Line)Line Methods
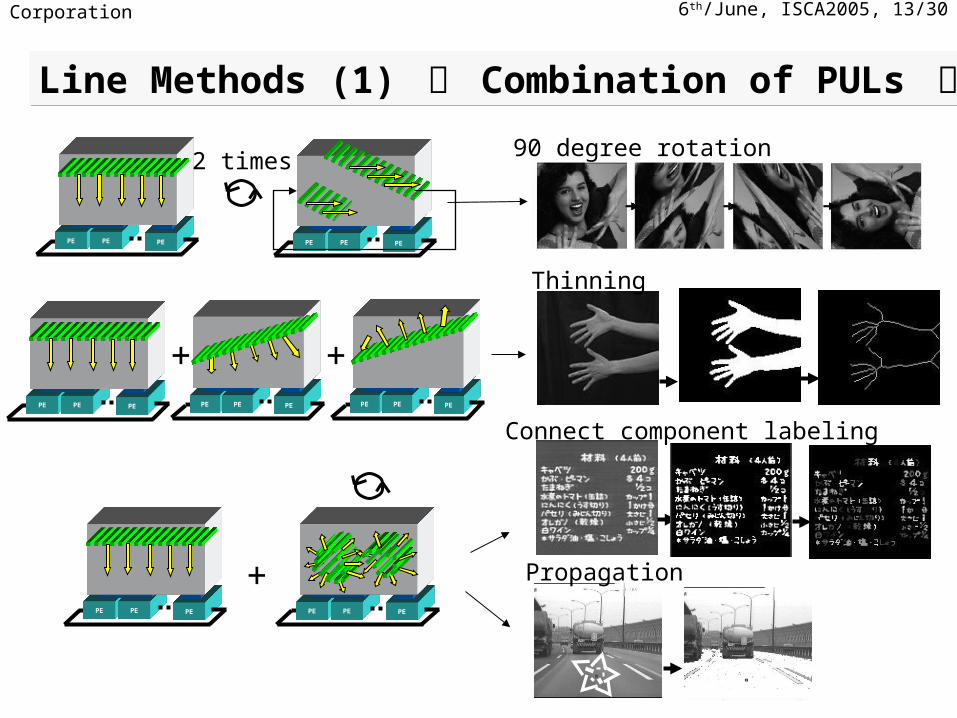
6th/June, ISCA2005, 13/30NEC Corporation
90 degree rotation
Thinning
Connect component labeling
Line Methods (1) ー Combination of PULs ーLine Methods (1) ー Combination of PULs ー
PE PE PE
PE PE PEPE PE PE
PE PE PE
+ Propagation
PE PE PEPE PE PE
+ +PE PE PE
2 times
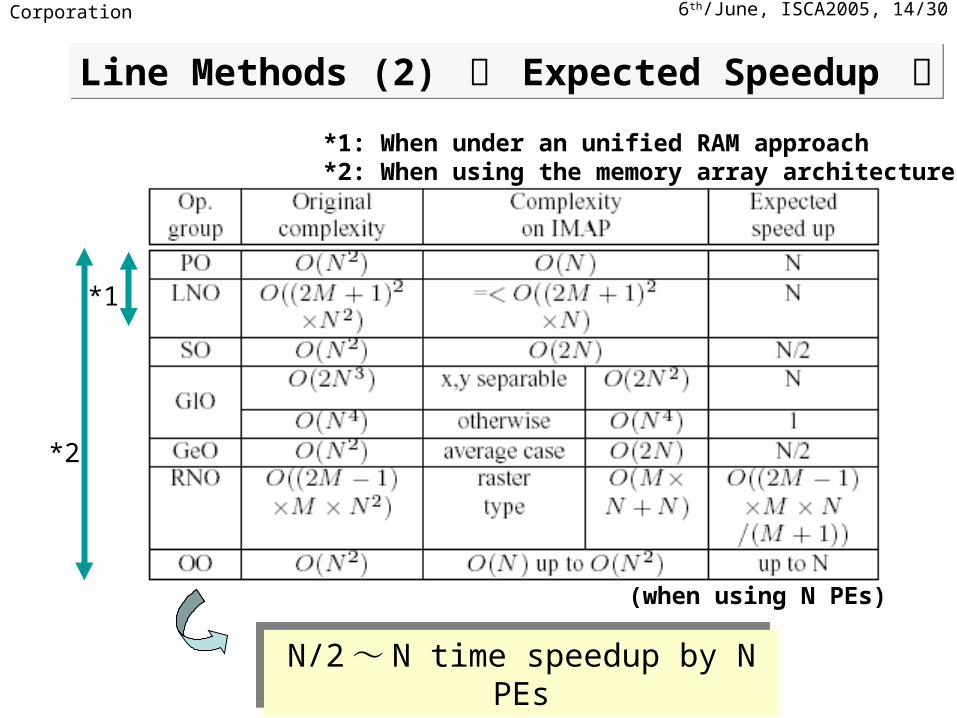
6th/June, ISCA2005, 14/30NEC Corporation
N/2 ~ N time speedup by N PEsN/2 ~ N time speedup by N PEs
*1
*2
*1: When under an unified RAM approach*2: When using the memory array architecture
Line Methods (2) ー Expected Speedup ーLine Methods (2) ー Expected Speedup ー
(when using N PEs)

6th/June, ISCA2005, 15/30NEC Corporation
1. Challenge of Embedded Image Recognition Systems
2. Integrated Memory Array Processor (IMAP) Architecture
3. Programming Language and Compiler Design
4. Evaluation
5. Summary
Outline

6th/June, ISCA2005, 16/30NEC Corporation
int d, e;sep char a,b;sep char c,ary[256];
One (vector like) data structure and six operators
1DC: An Extended C Language1DC: An Extended C Language
Correspondence between parallelizingtechniques and the 1DC syntax.
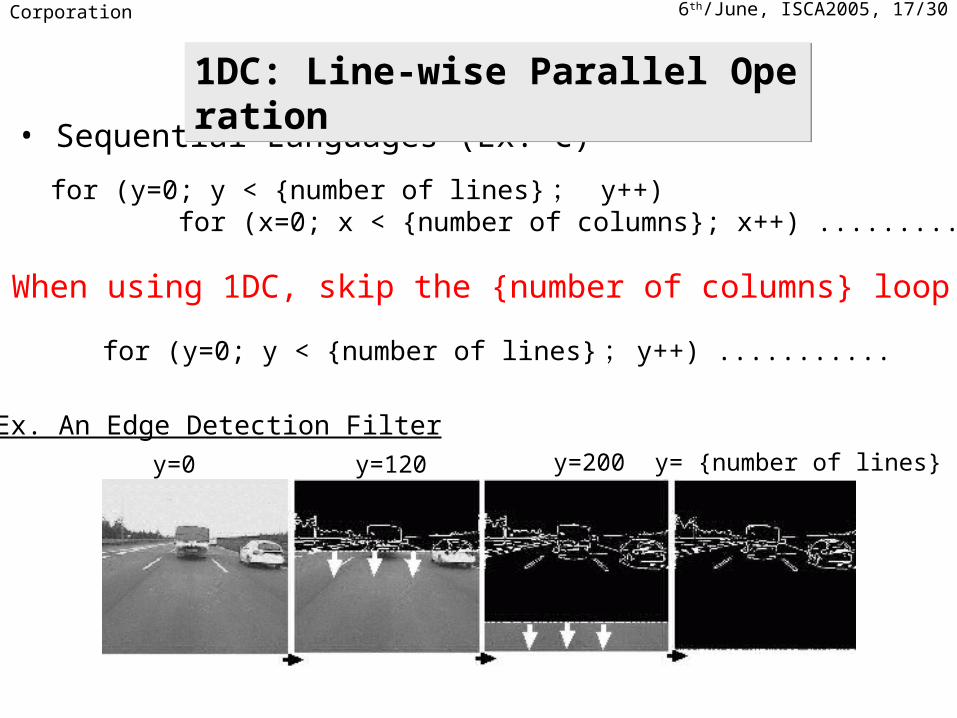
6th/June, ISCA2005, 17/30NEC Corporation
• Sequential Languages (Ex. C)
for (y=0; y < {number of lines} ; y++) for (x=0; x < {number of columns}; x++) .........
• When using 1DC, skip the {number of columns} loop
for (y=0; y < {number of lines} ; y++) ...........
y=0 y=120 y=200 y= {number of lines}
Ex. An Edge Detection Filter
1DC: Line-wise Parallel Operation1DC: Line-wise Parallel Operation
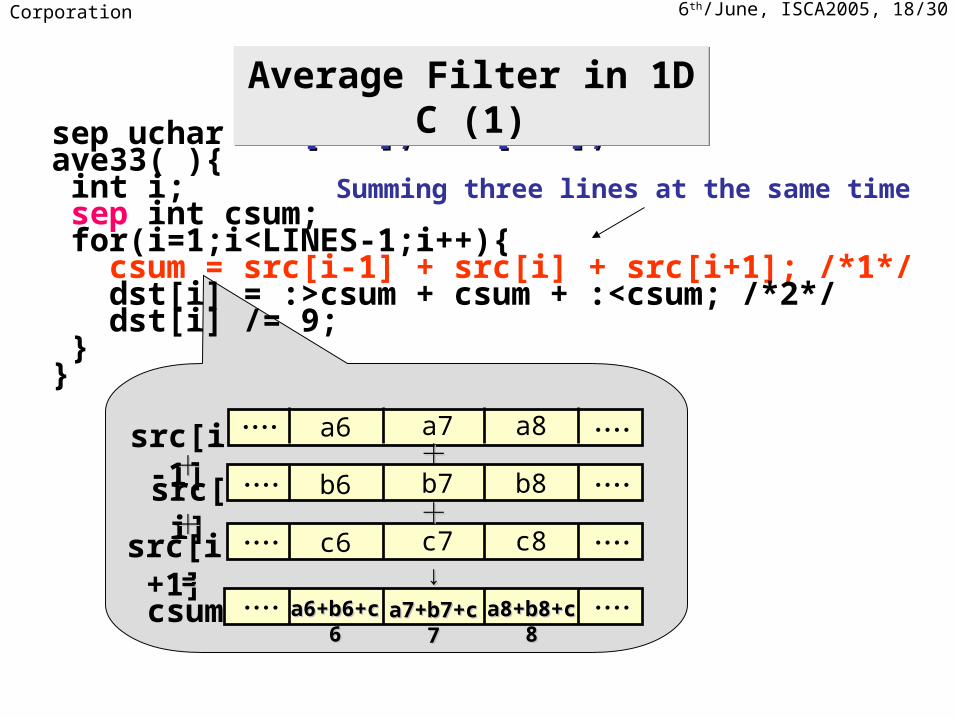
6th/June, ISCA2005, 18/30NEC Corporation
src[i]
src[i+1]
++a8a6・・・・ ・・・・
b7 b8b6・・・・ ・・・・
c7 c8c6・・・・ ・・・・
src[i-1] a7
++
・・・・ ・・・・a7+b7+c7a7+b7+c7
↓↓
csum a8+b8+c8a8+b8+c8a6+b6+c6a6+b6+c6
++
++
==
sep uchar src[256], dst[256];src[256], dst[256];ave33( ){ int i; sep int csum; for(i=1;i<LINES-1;i++){ csum = src[i-1] + src[i] + src[i+1]; /*1*/ dst[i] = :>csum + csum + :<csum; /*2*/ dst[i] /= 9; }}
Summing three lines at the same time
Average Filter in 1DC (1)Average Filter in 1DC (1)
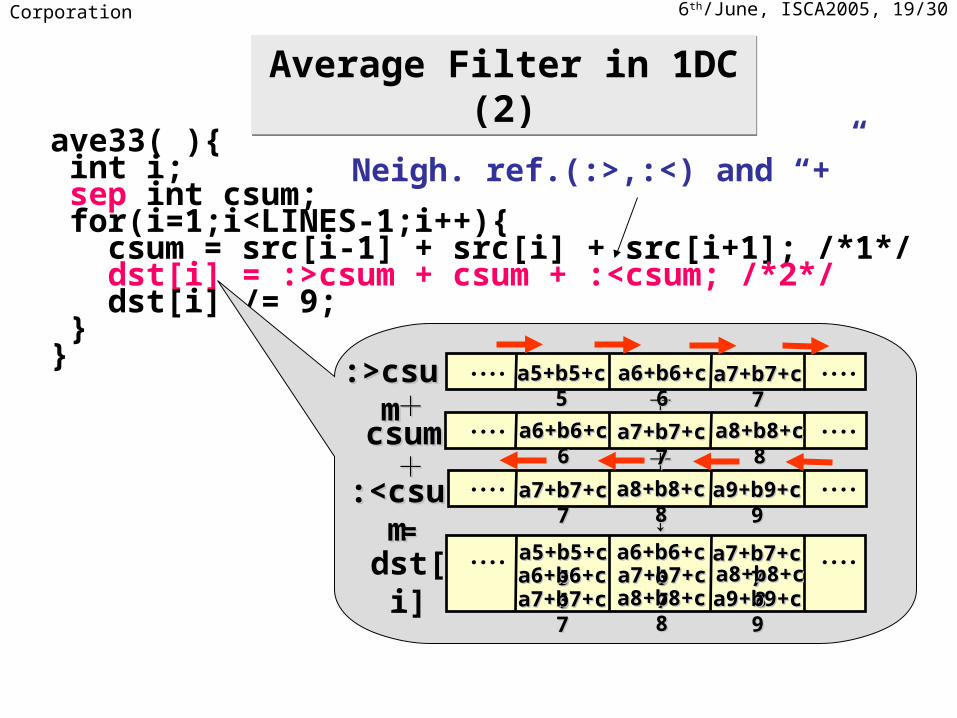
6th/June, ISCA2005, 19/30NEC Corporation
ave33( ){ int i; sep int csum; for(i=1;i<LINES-1;i++){ csum = src[i-1] + src[i] + src[i+1]; /*1*/ dst[i] = :>csum + csum + :<csum; /*2*/ dst[i] /= 9; }}
csumcsum
:<csum:<csum
++・・・・ ・・・・
・・・・ ・・・・
・・・・ ・・・・
:>csum:>csum
++
・・・・ ・・・・
↓↓
dst[i]
a9+b9+c9a9+b9+c9
a7+b7+c7a7+b7+c7a5+b5+c5a5+b5+c5 a6+b6+c6a6+b6+c6
a7+b7+c7a7+b7+c7 a8+b8+c8a8+b8+c8a6+b6+c6a6+b6+c6
a7+b7+c7a7+b7+c7 a8+b8+c8a8+b8+c8
a5+b5+c5a5+b5+c5a6+b6+c6a6+b6+c6a7+b7+c7a7+b7+c7
a7+b7+c7a7+b7+c7a6+b6+c6a6+b6+c6a7+b7+c7a7+b7+c7 a8+b8+c8a8+b8+c8
a9+b9+c9a9+b9+c9a8+b8+c8a8+b8+c8
++
++
==
Neigh. ref.(:>,:<) and “+”
Average Filter in 1DC (2)Average Filter in 1DC (2)
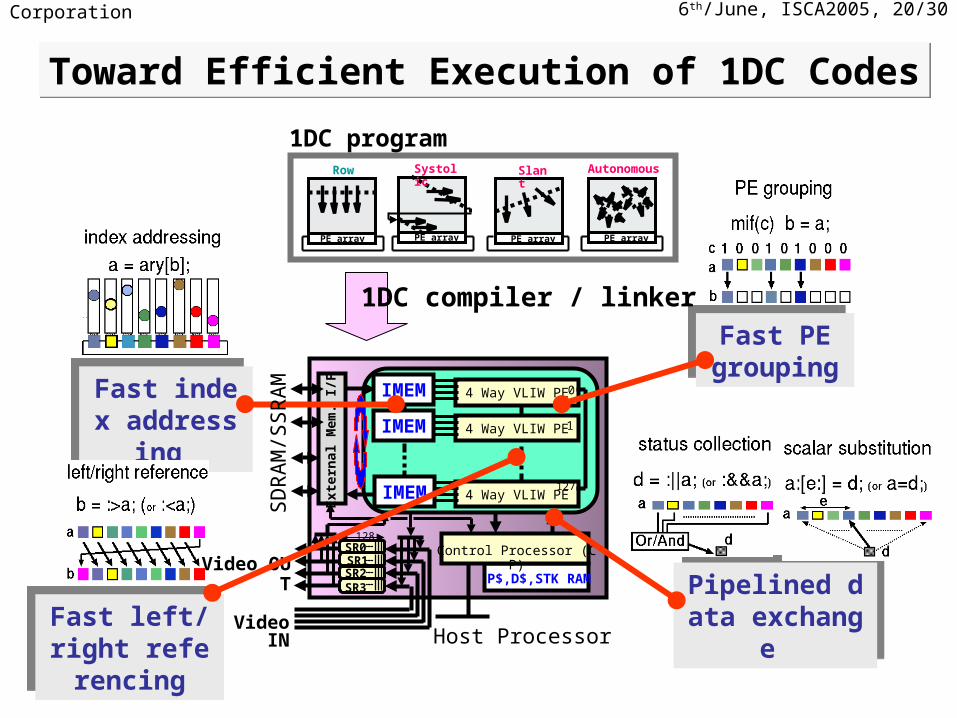
6th/June, ISCA2005, 20/30NEC Corporation
Fast PE grouping
Fast PE grouping
PE array
Systolic
PE array PE array
Slant Autonomous
PE array
Row
Toward Efficient Execution of 1DC CodesToward Efficient Execution of 1DC Codes
Pipelined data exchange
Pipelined data exchange Fast left/right
referencingFast left/right referencing
1DC program
1DC compiler / linker
Fast index addressing Fast index addressing
Video IN
Video OUT P$,D$,STK RAM
Host Processor
Control Processor (CP)
4 Way VLIW PE
4 Way VLIW PE
4 Way VLIW PE
SR0 SR1SR2
IMEM
IMEM
IMEMExt
ern
al M
em. I
/F 0
1
127
SR3
128
SD
RA
M/S
SR
AM
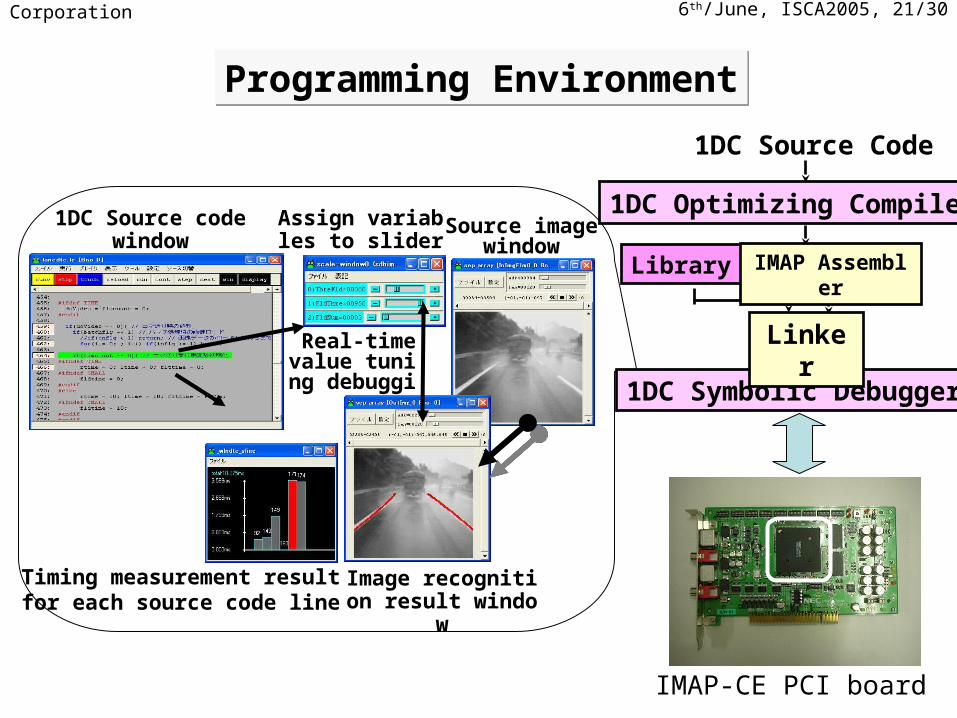
6th/June, ISCA2005, 21/30NEC Corporation
Programming EnvironmentProgramming Environment
Assign variables to sliders
Timing measurement result for each source code line
1DC Source code window
Real-time value tuning d
ebugging
Source image window
Image recognition result window
1DC Optimizing Compiler
1DC Symbolic Debugger
1DC Source Code
Library IMAP Assembler
Linker
IMAP-CE PCI board

6th/June, ISCA2005, 22/30NEC Corporation
1. Challenge of Embedded Image Recognition Systems
2. Integrated Memory Array Processor (IMAP) Architecture
3. Programming Language and Compiler Design
4. Evaluation
5. Summary
Outline

6th/June, ISCA2005, 23/30NEC Corporation
Operation Group Kernels Operation Group Kernels
Flexibility against various memory access patterns
Op. Grp.
Kernel Name IPC
PO Color format trans.
1.40
LNO 3x3 ave. filter 1.33
SO Histogram 1.66
GlO FFT 1.55
GeO 90 degree rotation
1.23
RNO Distance transform
1.52
OO Connected component labeling
1.400
1
2
3
4
5
6
7
8
PO LNO SO GlO GeO RNO OO (Ave.)0
20
40
60
80
100
120
140
GPPIMAP- CEParallelism
speedup parallelism (max.128)
IMAP-CE@100MHz, 1DC compiler codes
[email protected] , Intel C compiler codesOperation group kernels

6th/June, ISCA2005, 24/30NEC Corporation
name Purpose
Add2 dyadic arithmetic
GreyOpen3 3x3 grey morphology
Gauss5 5x5 filter
Mexican13 13x13 conv.
Var5Oct 5x5 texture analysis
Canny edge detection (3x3)
Smoothing edge preserving smoothing (7x7)
speed-up
PO
LNO
Processor Op.Freq.
PE # Peak Perf.
P4(SIMD) 2.4GHz 1PEx8x2 38.4GOPS
IMAP-CE 100MHz 128PEx4 51.2GOPS
IMAP-CE GPP x 1/24 x 32 x 1.33
Flexibility against algorithmic complexity
GOPS : in byte operation
Highly Parallel vs. Sub-Word SIMDHighly Parallel vs. Sub-Word SIMD
0123456789
10
Add2
Gre
yO
pen3
Gauss5
Mexic
an13
Var5
oct
Canny
Sm
ooth
ing
(Ave.) 0
2468101214161820
GPP(MMX)
IMAP-CE
Complexity
# of if-clause per pixel op.
IMAP-CE@100MHz, 1DC compiler codes
[email protected] , MMX codes
Benchmark kernels
Only PO,LNO kernels are used due to the nature of MMX inst.

6th/June, ISCA2005, 25/30NEC Corporation
Compared with Some Recent Media ProcessorsCompared with Some Recent Media Processors
PE PE
Image
128 bank memory
PE PE
(scratch pad memories)
SRF of Imagine (Stanford)
Frame Buffer of Morphosys (UC)
Local Store of SPE(CELL:Sony) 2KB
One to several banks
On chip vector partitioning & chaining
VIRAM (UCB), CODE (Stanford)
static vector partitioning
IMAP
1024 point 1D-FFT performance compared with other media processors
PE
Processor Name Cycle count Word Size Die-size Pwr(W) Tech(um)
Imagine(Float) 2176 16 12*12 4 0.15
Morphosys2 2636 16 16*16 4 0.13
IMAP-CE(IMAPCAR) 5000(3700) 8 11*11 4(2) 0.18(0.13)
VIRAM 5280 16 15*18 2 0.18
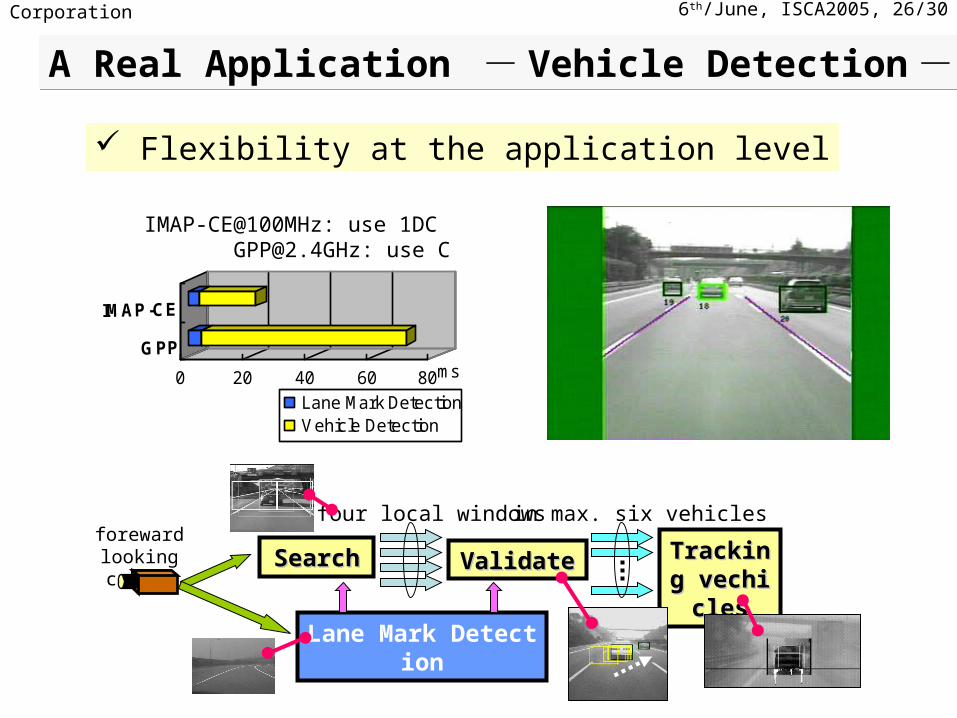
6th/June, ISCA2005, 26/30NEC Corporation
IMAP-CE@100MHz: use 1DC [email protected]: use C
0 20 40 60 80ms
Lane Mark DetectionVehicle Detection
A Real Application - Vehicle Detection -A Real Application - Vehicle Detection -
Flexibility at the application level
SearchSearch Tracking Tracking vechiclesvechicles
ValidateValidate
Lane Mark Detection
four local windows in max. six vehiclesforeward
looking camera

6th/June, ISCA2005, 27/30NEC Corporation
Processing time distribution
The Uneven Workload Issue The Uneven Workload Issue
Search
Search
Validate
Validate
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
IMAP-CE
GPP
PE
PE
PE
PE
PE
PE
PE
PE
PE
PE
PE array fullyutilized
Partial activation of PE array during sequential validatation of each candidate area
Search Validation

6th/June, ISCA2005, 28/30NEC Corporation
1. Challenge of Embedded Image Recognition Systems
2. Integrated Memory Array Processor (IMAP) Architecture
3. Programming Language and Compiler Design
4. Evaluation
5. Summary
Outline
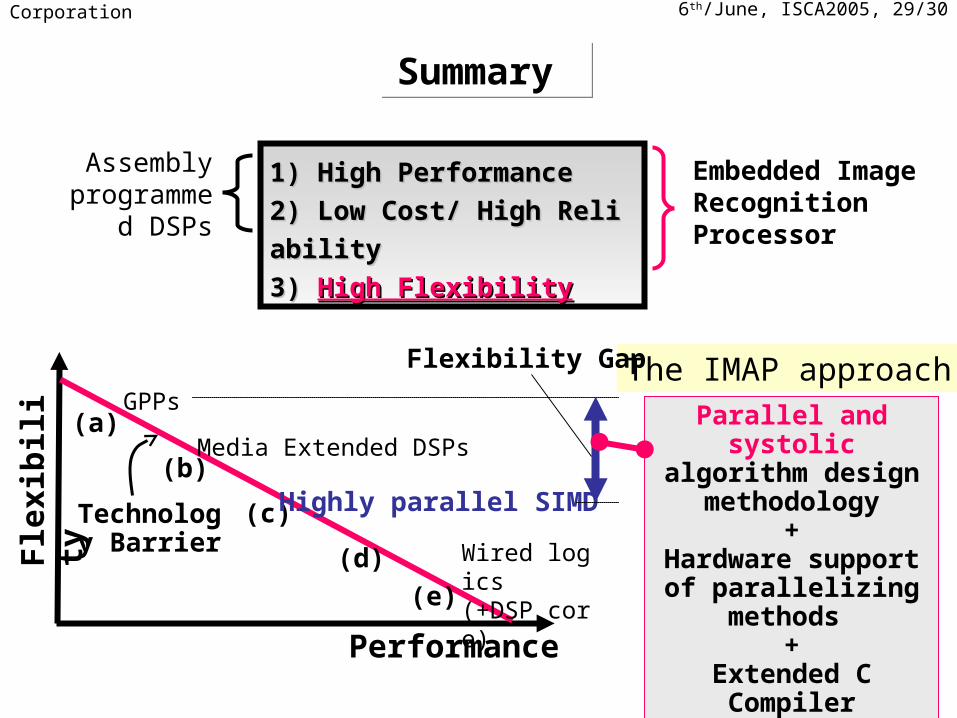
6th/June, ISCA2005, 29/30NEC Corporation
Summary Summary
Technology Barrier
(c)
(a)
(b)
(d)
GPPs
Highly parallel SIMD
Media Extended DSPs
Fle
xib
ilit
y
Performance
(e)
1) High Performance1) High Performance
2) Low Cost/ High Reliability2) Low Cost/ High Reliability
3) 3) High FlexibilityHigh Flexibility
Parallel and systolic algorithm design
methodology+
Hardware support of parallelizing methods
+Extended C Compiler
& GUI Debugger
The IMAP approach
Wired logics(+DSP core)
Assembly programmed
DSPs
Flexibility Gap
Embedded ImageRecognition Processor

6th/June, ISCA2005, 30/30NEC Corporation
The END
(Thank you for your attention)





























