Embed Size (px)
Citation preview

9.523/6.861: Aspects of a Computational Theory of
Intelligence
Shimon Ullman + Tomaso Poggio
Gemma Roig + Chia-Jung Chang

9.523/6.861: Aspects of a Computational Theory of
Intelligence
Class 4, Part A

• Human Brain –1010-1011 neurons (~1 million flies) –1014- 1015 synapses
Vision:whatiswhere
• Ventral stream in rhesus monkey –~109 neurons in the ventral stream
(350 106 in each emisphere) –~15 106 neurons in AIT (Anterior
InferoTemporal) cortex
• ~200M in V1, ~200M in V2, 50M in V4
Van Essen & Anderson, 1990

Desimone & Ungerleider 1989
ventral stream
Theventralstream
Source: Lennie, Maunsell, Movshon

[software available online]Riesenhuber & Poggio 1999, 2000; Serre Kouh Cadieu Knoblich Kreiman & Poggio 2005; Serre Oliva Poggio 2007
HMAX is in the family of “Hubel-Wiesel” models such as
Hubel & Wiesel, 1959: Fukushima, 1980, Oram & Perrett, 1993; Wallis & Rolls, 1997; Riesenhuber & Poggio, 1999; Thorpe, 2002; Ullman et al., 2002; Mel, 1997; Wersing and Koerner, 2003; LeCun et al 1998; Serre et al., 2007; Freeman and Simoncelli, 2011….
Convolutional networks such as HMAX
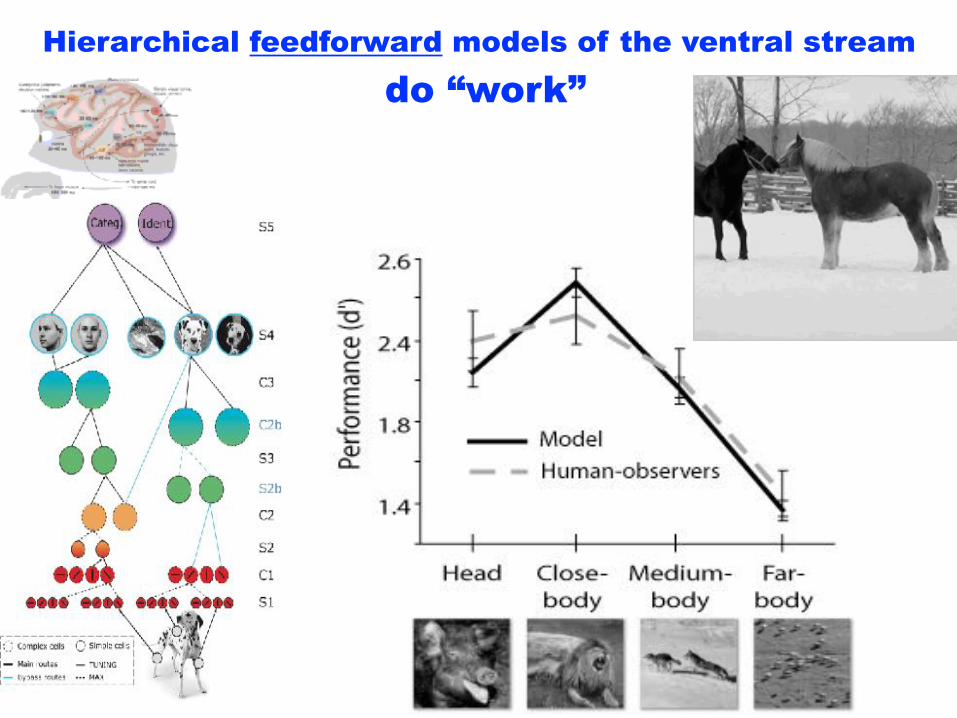
Hierarchical feedforward models of the ventral stream do “work”

Computational Model based on Deep Learning
Figure 1: HCNNs as models of sensory cortex.Using goal-driven deep learning models to understand sensory cortex. Daniel Yamins & James DiCarlo.
Nature Neuroscience(2016)

A key aspect of hierarchical models is
invariance to viewpoint

Theorem (transla)on case) Consider a space of images ofdimensions pixelswhichmayappearinanyposi5onwithin a window of size pixels. The usual imagerepresenta5on yields a sample complexity ( of a linearclassifier) oforder ;the oracle representa5on(invariant)yields(becauseofmuchsmallercoveringnumbers)a--muchbeBer--samplecomplexityoforder
9
moracle = O(d2 ) =
mimage
r2
d × drd × rd
m = O(r2d 2 )
poggio, rosasco
Theorem: invariance can significantly reduce sample complexity

10
Empiricaldemonstra5on:invariantrepresenta5onleadstolowersamplecomplexityforasupervisedclassifier

Thus a new hypothesis
A main computational goal of the feedforward ventral stream hierarchy — and of vision — is to compute a representation for each incoming image which is invariant to transformations previously experienced in the visual environment (in general, transformations of other objects).

Old neural data: IT neurons can be selective and invariant

Background: recording sites in Anterior IT
Logothetis, Pauls & Poggio 1995
…neurons tuned to faces are intermingled
nearby….

Neurons tuned to object views, as predicted by model!
Logothetis Pauls & Poggio 1995

12 7224 8448 10860 12036 96
12 24 36 48 60 72 84 96 108 120 132 168o o o o o o o o o o o o
-108 -96 -84 -72 -60 -48 -36 -24 -12 0-168 -120
Distractors
Target Views60
spi
kes/
sec
800 msec
-108 -96 -84 -72 -60 -48 -36 -24 -12 0-168 -120 oo o o o o o o o oo o
Logothetis Pauls & Poggio 1995
A very selective “view-tuned” cell in IT

View-tuned cells: scale invariance (one training view only) !!!
Logothetis Pauls & Poggio 1995

How neurons may compute an invariant signature

18
Algorithm that learns in an unsupervised way to compute invariant representations
ν
P(ν )
νµkn(I) = 1/|G|
|G|X
i=1
�(I · gitk + n�)

...
Our basic machine: a HW module (dot products and histograms/moments for image seen through RF)
• The cumulative histogram (empirical cdf) can be be computed as
• This maps directly into a set of simple cells with threshold
• …and a complex cell indexed by n and k summating the simple cells
µnk (I ) = 1
|G |σ ( I ,git
k + nΔ)i=1
|G |
∑
nΔ
The nonlinearity can be arbitrary for invariance, if optimal selectivity is not required

20
Invariant signature from a single image of a new object

21
Invariant signature from a single image of a new object
...
< x,t >
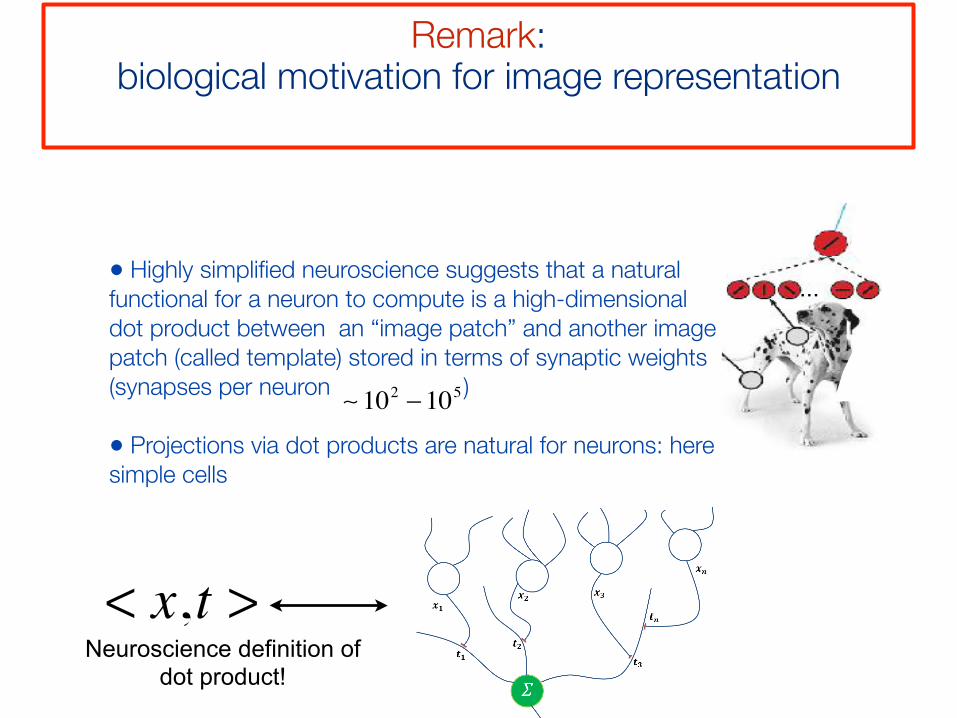
• Highly simplified neuroscience suggests that a natural functional for a neuron to compute is a high-dimensional dot product between an “image patch” and another image patch (called template) stored in terms of synaptic weights (synapses per neuron )
• Projections via dot products are natural for neurons: here simple cells
∼ 102 −105
Neuroscience definition of dot product!
Remark: biological motivation for image representation

...
Our basic machine: a HW module (dot products and histograms/moments for image seen through RF)
• The cumulative histogram (empirical cdf) can be be computed as
• This maps directly into a set of simple cells with threshold
• …and a complex cell indexed by n and k summating the simple cells
µnk (I ) = 1
|G |σ ( I ,git
k + nΔ)i=1
|G |
∑
nΔ

Pooling

Dendrites of a complex cells as simple cells…
Active properties in the dendrites of the complex cell

Invariance explains a puzzle
• what is visual cortex computing?
• function and circuits of simple-complex cells
• how does the face network work?
• what is the computational reason for the eccentricity-dependent size of RFs in V1, V2, V4?
poggio, anselmi, rosasco, tacchetti, leibo, liao

RF size depends on eccentricity in a special way

Note:wefocusonthesamplinglayoutoftheretinalganglioncells(RGCs)-theoutputsoftheretina.

Desimone & Ungerleider 1989
ventral stream
Theventralstream
Source: Lennie, Maunsell, Movshon

Retinalsamplingisnonuniform
• Thumbnailatarm’slength=1degree• By+/-1degree,resolutionhasdroppedby½• Mostcommonexplanation:
– Fullresolutioneverywherewouldrequireanopticnervethethicknessofyourneck,andvisualcortexthesizeofasmallcar(*)
– Solution:asmallpatchofhighresolutionthatyoucanmovearound
• However:theparticularsamplingstrategytheretinahaschosensuggeststhereismoretothestory
(*)calculationsareapproximate

An application of i-theory: translation and scale invariance implies
a specific model of eccentricity-dependent RFs in cortex
Hubel and Wiesel, 1971
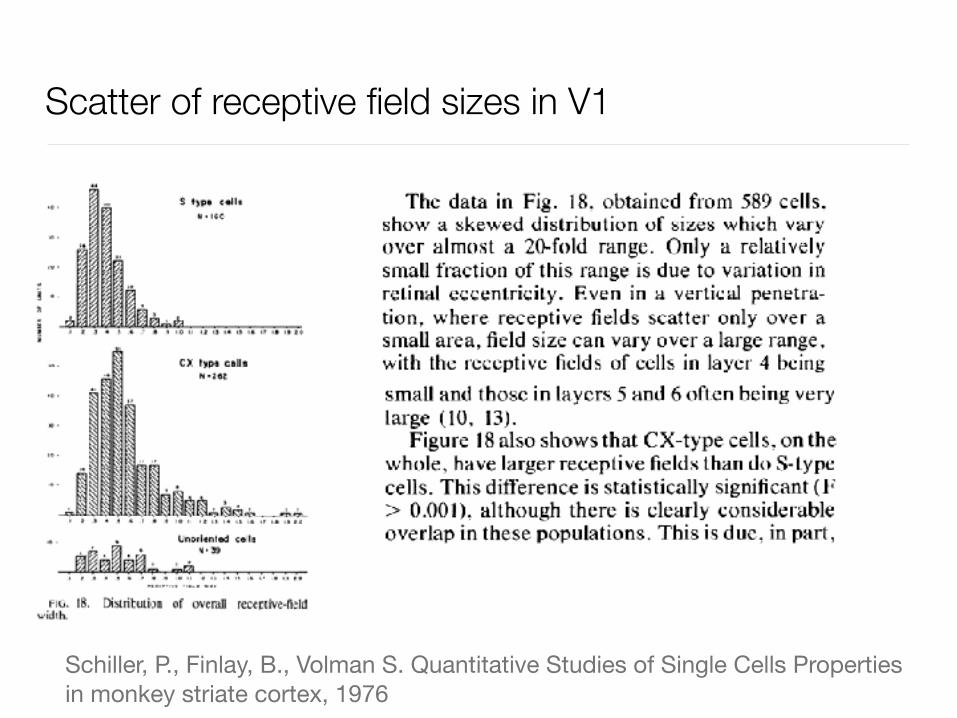
Scatter of receptive field sizes in V1
Schiller, P., Finlay, B., Volman S. Quantitative Studies of Single Cells Properties in monkey striate cortex, 1976

Explaining the puzzle

34
Computational reason for eccentricity dependence of RFs size
ν
P(ν )
νµkn(I) = 1/|G|
|G|X
i=1
�(I · gitk + n�)

to compute invariant representation
Recipe:
• memorize a set of images/objects called templates and for each template memorize observed transformations as images
• to generate an invariant signature - compute dot products of transformations with image - pool, e.g. compute histogram of the resulting values
35

36
Geometry of scaling

37
Sampling in the window

38
Magic window in V1
5 degree! total 40x40 units
25’ !!! total 40x40 units

Qualitative predictions

• Very small foveola ~25’
• In the center of fovea “full” scale invariance, little position invariance
• Position invariance proportional to spatial frequency
• Anstis
• Bouma’s law for peripheral crowding d= b x (role of V2 b=0.5)
• Prediction: crowding in the fovea at less than d=2’40” in fovea
Qualitative predictions

Anstis, 1974
“Prediction” of Anstis observation

Computational model

V
D
SV = 2 * arctan (S/(2D))
D= 50.39 cm
…
…
…
…… … … …
… …
… …
5 degrees - 4.4 cm - 224 px
0.63 degrees - 0.55 cm - 28 pxtemplate smaller resolutiontemplate 2nd smaller resolution
template larger resolutiontemplate 2nd larger resolution
Eccentricity dependent model for quant predictions
0 eccentricity (deg)
scale

smallest res
largest res
orig
inal
imag
ew
hat t
he m
odel
“see
s”
(sam
plin
g ph
otor
ecep
tors
)…
……
…
… … … …
… ………
…
……
…
… … … …
… ………
…
……
…
… … … …
… ………
…
……
…
… … … …
… ………
Gemma Roig

Smallest scale
largest scale
original image
what the model “sees” (sampling photoreceptors)Gemma Roig

V
D
S
V = 2 * arctan (S/(2D))
D= 50.39 cm
template larger scale - convolutiontemplate 2nd larger scale - convolution
template smaller scale - convolutiontemplate 2nd smaller scale - convolution
1st layer- model with 4 scales
input crops at 4 scales input image
…
…
…
…… … … …
… …
… …
input crops at 4 scales what the model sees
5 degrees - 4.4 cm - 224 px
0.63 degrees - 0.55 cm - 28 px

Psychophysical experiments

Experimental question: is the window of visibility…
…the same as the window of invariance to scale and shift for novel, unfamiliar objects, never seen before
(as predicted by i-theory)?
window of visibility
scale
eccentricity0 deg
window of invariance
scale
eccentricity0 deg
?Gemma Roig
Yena Han

Notice: published data (refs…) are inconclusive and inconsistent
Question: is the window of visibility…
Gemma RoigYena Han

50
Examples

51
Example

52

ExperimentsPhase 1
check parameters of the visual window
psychophysics experiments with very familiar letters:
recognition of letters at different eccentricities and sizes we have seen letters in all positions: no need for training
sanity check
Gemma RoigYena Han

A
Phase 1 experiments
A A
A
A
A
recognize familiar letters of different sizes at different eccentricities
visual window:
scale
eccentricity0 deg
Gemma RoigYena Han

ExperimentsPhase 2
check position invariance with unfamiliar characters (Chinese letters) psychophysics experiments with Chinese letters:
training phase: learn few new letters at one eccentricity, testing phase: is the letter recognizable at other eccentricities? (same/different? task)
is the visual window the same as the window of invariance?
Gemma RoigYena Han

Phase 2 experiments
learn a novel character (never experienced before) at a eccentricity and scale, test recognition of the character at other eccentricities and /or scales
train (show once): test:
visual window:
scale
eccentricity0 deg
ecc. (deg.)ecc. (deg.)0 0
scale scale

Psychophysics Experiment • Stimuli: Korean Letters. Should be unfamiliar to subjects.
• Same/Different Discrimination Task
• Scale Invariance: Present target letter and test either the target or a distractor letter at the center. The letters vary in size.
• Position Invariance: Present target letter at one eccentricity and test either the target or a distractor letter at another eccentricity
• Presentation time 33 ms
• Letter size 1 deg
모 보==
모 == 모
Gemma RoigYena Han

Position Invariance
Scale Invariance
Gemma RoigYena Han

Next Question(experiments and simulations)
Which kind of pooling?In V1 and V2 and V4?

Next Question(experiments and simulations)
Crowding predictions depending on pooling

Psychophysics Experiment
Volunteers?

http://cbmm.mit.edu/eit/join-us
Engineering Intelligence Teams
Sound engineering practices for cutting-edge Machine Learning research
Psychophysics
Deep Learning
Web Interfaces





























