Embed Size (px)
Citation preview

A BIOINFORMATIC GENE HUNTING

E-learning"Tools and tips for science
teachers"
http://ariel.ctu.unimi.it/corsi/bioteach/home

Bioinformatics
When biology meets informatics

What is bioinformatics?
•Creation and maintenance of databases to store biological information
•Development of mathematical and statistical tools for analysis, interpretation and continuous updating of biological information
•Development of new tools to assess relationships among members of large data sets in order to obtain a comprehensive picture of normal cellular activities and their alterations
•Data sharing

Bioinformatics includes:
1. Databases collecting
experimental data generated in
research laboratories
2. Software for navigating
databases

Where does bioinformatics stem from?
Human Genome Project
Experimental efforts to determine structure
and function of biologicalmolecules
Production of large data sets
Molecular biology databases(genes and proteins)
Interpretation
Techniques, tools, algorithmsfor analysis, comparison, classification,interpretation

The global approach to the study of biological data refers to the possibility for analysis and
comparison of:
• Genomes ( the whole genetic information of a given organism)
• Transcriptomes ( the full set of RNAs of a given organism )
• Proteomes ( the full set of proteins of a given organism)

Applications of bioinformatics analysis
MEDICINE
AGRICULTUREPHARMACEUTICS

A database is a collection of information.
Databases are made of “entries”.
Databases

Biological databases •A biological database is a large collection of information and data derived from laboratory studies (in vitro and in vivo analysis), from bioinformatics (in silico analysis) and from the scientific literature.
•Data are structured so to enable efficient user access and management of different types of information.

Bioinformatics was essential to obtain the complete sequence of
the human genome
Genomic DNA
Random long (5-20 kb) and short (0.4-1.2 kb) fragments derived from mechanical breakage of DNA were cloned in
vectors and sequenced.
Bidirectional automated sequencing
Computerized reconstruction of genomic sequence
Whole genome shotgun

Primary and specialized
databases
Primary databases collect nucleotide sequences (DNA , RNA) or protein sequences containing general information for the retrieval of sequences, and to identify species of origin and function.
Specialized databases collect large sets of homogeneous records (taxonomic, functional, literature, etc. etc...), with additional annotations and specific information.

---ATGTTGAAGTTCAAGTATGGT---
--MLKFKYG--
Nucleotide sequence database
Amino acid sequence database
3D structures database
Genetic diseases database
Gene expression database

How to extract information from a
database
We can combine different criteria by means of Boolean operators to intersect (operator AND), add (operator OR) or exclude (operator BUT NOT) information. More Boolean operators are available for more sophisticated searches (IN, NEAR and WITH).
By entering a text in a box (like with a search engine, i.e. google) or filling in a given form
AND
OR
BUT NOT

Algorithms in bioinformatics
Algorithms to compare sequences:- to assess similarities - to study molecular evolution and phylogenesis
Algorithms to predict:- genes- regulatory elements (promoters, etc.)- RNA structures- protein structures

Some important results obtained by bioinformatics:
• Search for homologous genes in the same and in different species
• Identification of genes and genetic markers
• Identification of disease-associated genes
• Prediction of three-dimensional structures of proteins
• Design of new drugs
• Data sharing


Genetic-based differences in the response to drugs
Comparing two human genomes, single base differences are found, on average, every 1200-1500 base pairs
Each individual is unique
A new “omics” discipline: PHARMACOGENOMICS

What is pharmacogenomics for?
Patient with genetic defect
reduced dose of drug
standard drug
1/10 thiopurine

What do you need to know to “surf among the genomes”
without being submerged by the waves !!!
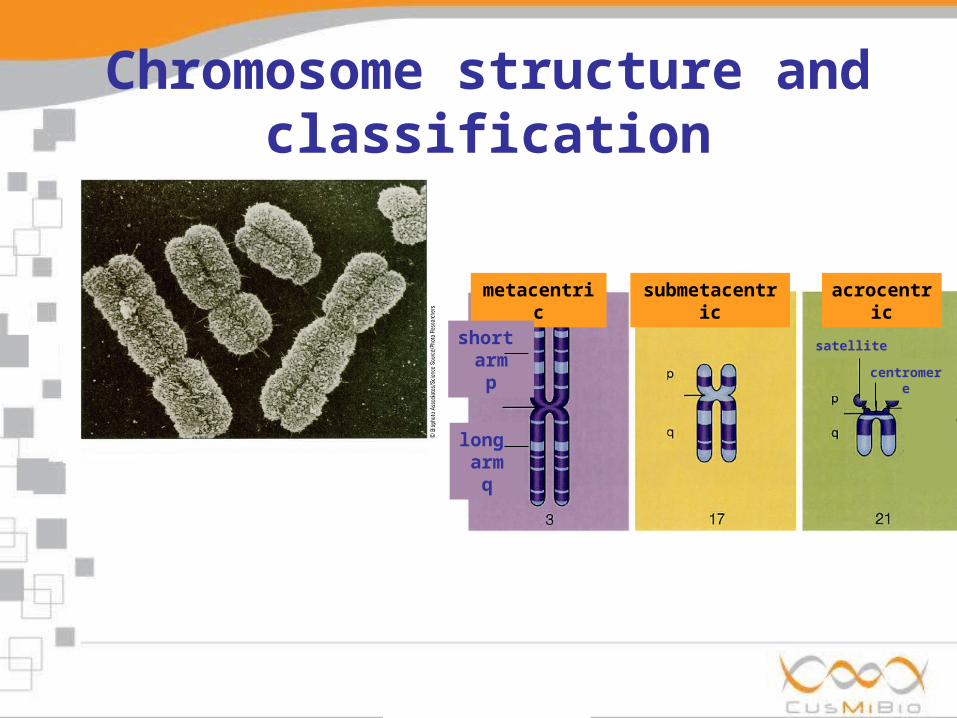
Chromosome structure and classification
metacentric acrocentricsubmetacentric
long arm
q
short arm
p
satellite
centromere

Human karyotype and chromosome map

Chromosome banding
Karyotype: Q banding
Karyotype: G banding

Each chromosomehas a specific
banding pattern

Chromosomes mutations
Fig.10.2.1 Mutazioni cromosomiche
delezione
traslocazione
inversione
Basi perse
GAC-AAA-GGA-TGA-CTG original sequence
GAC-AAA-CGA-TGA-CTG substitution
GAC-AAA-TGG-ATG-ACT-G insertion
GAC-AA~G-GAT-GAC-TG deletion
Gene mutations or point mutations

Identification of genes and genetic
markers

Identification of disorder-
associated genes

From gene to protein
Exon 1 Exon 2 Exon 3 Exon 4
Intron 1 Intron 2 Intron 3
Starttranscription
Endtranscription
H2N
Transcription
COOH
5’UTR
3'
5'3'
3'5'
Maturation
Translation
DNA
preRNA
mRNA
protein
5'
3’UTR

Prediction of genes within a genomic region
• Internal exons (---exon---gt---intron---ag---exon---)• First exon (5’ UTR sequence)• Last exon (3’ UTR sequence)• Unique exons• Alternative splicing sites• Promoters (TATA e CAAT boxes)• Polyadenylation signals (AAUAAA)• start codon ATG• STOP codon

splice sites

Splicing

Alternative splicing

Alternative splicing

Here is a comprehensive view of what you should find among the
genome waves .… enjoy your surfing!!

QuickTime™ and a TIFF (Uncompressed) decompressor are needed to see this picture.
Finding the Genes
Dr. Blat helping a gene find itself.

Chromosomes mutations
Fig.10.2.1 Mutazioni cromosomiche
delezione
traslocazione
inversione
Basi perse
GAC-AAA-GGA-TGA-CTG original sequence
GAC-AAA-CGA-TGA-CTG substitution
GAC-AAA-TGG-ATG-ACT-G insertion
GAC-AA~G-GAT-GAC-TG deletion
Gene mutations or point mutations

Bioinformatics uses algorithms
Algorithms to compare sequences:- to assess similarities - to study molecular evolution and phylogenesis
Algorithms to predict:- genes- regulatory elements (promoters, etc.)- RNA structures- protein structures

Genome sequence
Sequence Similarity Searches
Genome sequerce
Ganome sequence
Genome spequence
Genetic variability
Genme sequence
mutations

•Evolution implies the generation of morphological
and molecular variants.•At the molecular level, variants are created by
errors (mutations) during DNA replication not
corrected by DNA repair systems. •Introduction of mutations (single aa substitutions,
deletions, insertions) imply that DNA segments
with the same function in different organisms don’t
share exactly the same sequence.
Sequences conservation and
evolution

Sequence alignment programs to study variability
Sequence alignment establishes a biunivocal relationship between two sequences (or parts of them) so minimizing the number of operations necessary to transform one sequence into the other.

Alignment is obtained by comparing
sequences in a pairwise fashion
Each comparison is given a score which is
a measure of the degree of similarity

E V D Q K I S - - K W D| | | | | | |E V - K K I T R P K W D
SA= E V D Q K I S K W D
SB= E V K K I T R P K W D
gap mismatchmatch
Alignment:
When sequences are not identical, the alignment must contain gaps and mismatches

Identity, Similarity and HomologyIdentityThe extent to which two sequences are invariant
SimilarityQuantitative parameter defined by the alignment score
HomologyOrigin from a common ancestor sequence

Homologous Sequences
ATA GAAKAVALVLPNLKGKLNGIALRVPTPNVSVVDLVVQVSKK-TFAEEVNAAFRDSAEK-- 328ATB GAAKAVSLVLPQLKGKLNGIALRVPTPNVSVVDLVINVEKKGLTAEDVNEAFRKAANG-- 351HS GAAKAVGKVIPELNGKLTGMAFRVPTANVSVVDLTCRLEKP-AKYDDIKKVVKQASEG-- 268MM GAAKAVGKVIPELNGKLTGMAFRVPTPNVSVVDLTCRLEKP-AKYDDIKKVVKQASEG-- 266XL GAAKAVGKVIPELNGKITGMAFRVPTPNVSVVDLTCRLQKP-AKYDDIKAAIKTASEG-- 266DM GAAKAVGKVIPALNGKLTGMAFRVPTPNVSVVDLTVRLGKG-ASYDEIKAKVQEAANG-- 265CE GAAKAVGKVIPELNGKLTGMAFRVPTPDVSVVDLTVRLEKP-ASMDDIKKVVKAAADG-- 274SP GAAKAVGKVIPALNGKLTGMAFRVPTPDVSVVDLTVKLAKP-TNYEDIKAAIKAASEG-- 268ATC GAAKAVGKVLPALNGKLTGMSFRVPTVDVSVVDLTVRLEKA-ATYEEIKKAIKEESEG-- 272OS GAAKAVGKVLPDLNGKLTGMSFRVPTVDVSVVDLTVRIEKA-ASYDAIKSAIKSASEG-- 270SC GAAKAVGKVLPELQGKLTGMAFRVPTVDVSVVDLTVKLNKE-TTYDEIKKVVKAAAEG-- 266ECA GAAKAVGKVLPELNGKLTGMAFRVPTPNVSVVDLTVRLEKA-ATYEQIKAAVKAAAEG-- 266HI GAAKAVGKVLPALNGKLTGMAFRVPTPNVSVVDLTVNLEKP-ASYDAIKQAIKDAAEGKT 268ECC GAAKAIGLVIPELSGKLKGHAQRVPVKTGSVTELVSILGKK-VTAEEVNNALKQATTN-- 266
Homologous sequence comparison helps in:
•identifying important structural and functional domains of a given protein•identifying aa residues responsible for common features and those responsible for different features of a given protein

Degree of Sequences Conservation • In sequence alignment both sequence identity
and degree of conservation of different aa residues in positions where the two sequences differ are taken into consideration.
• Molecules with similar primary aa sequence tend to have similar secondary and tertiary structures
• If two proteins share 50% of their sequence, the probability that they have superimposable 3D structures is very, very high
Conservative (two aa with similar chemical properties) substitutionsSemi-conservative substitutionsNon-conservative substitutions

Genes in evolutionHomologous genes are those evolved from a common ancestral precursor gene:
•orthologous genes: genes in different species that have evolved directly from an ancestral gene, generally maintaining the same function.
•paralogous genes: two genes or clusters of genes at different chromosomal locations in the same organism that have structural similarities and have diverged from the parent copy by duplication. In general, their function is different although correlated with that of the ancestral precursor gene.

The three-letter and one-letter amino acid code

Amino acid polarity
polar aanon polar aa
+ -

Sequence conservation during evolution
• Evolution doesn’t work on DNA sequences or on primary structures of proteins, but only on 3D structures of proteins
• As a consequence of this and of the degeneration of the genetic code, 3D structure of proteins is more conserved than primary structure, which in turn is more conserved than the nucleotide coding sequence
-ATGTTGAAGTTT-- M L K F -
-ATGTTGAAGTTT-- M L K F -
-ATGTTGAAGTTT-- M L K F -
-ATGTTGAAGTTC-- M L K F -aa sequence identity
-ATGTTGAAGTAT-- M L K Y -
Different aa sequence, conserved
structure
-ATGTTGAAGGTT-- M L K V -
Different aa sequence, altered 3D
structure

Model organismsModel organisms
Zebrafish Danio rerio
Mouse Mus musculus30.000 geni19.000 geni
Nematode Caenorhabditis elegans
Fruit flyDrosophila melanogaster
30,000 genes
13.600 geni

Unknown Function
The specific function of the major part of the human genome is unknown





























