Embed Size (px)
Citation preview

This article was downloaded by: ["University at Buffalo Libraries"]On: 10 October 2014, At: 22:39Publisher: RoutledgeInforma Ltd Registered in England and Wales Registered Number: 1072954Registered office: Mortimer House, 37-41 Mortimer Street, London W1T 3JH, UK
AphasiologyPublication details, including instructions for authors andsubscription information:http://www.tandfonline.com/loi/paph20
A computational semantics approachto aphasic sentence comprehensionDavid Glenn Clark aa University of Alabama at Birmingham and the BirminghamVeteran's Affairs Hospital , ALPublished online: 28 Nov 2008.
To cite this article: David Glenn Clark (2009) A computational semantics approach to aphasicsentence comprehension, Aphasiology, 23:1, 33-51, DOI: 10.1080/02687030701657226
To link to this article: http://dx.doi.org/10.1080/02687030701657226
PLEASE SCROLL DOWN FOR ARTICLE
Taylor & Francis makes every effort to ensure the accuracy of all the information (the“Content”) contained in the publications on our platform. However, Taylor & Francis,our agents, and our licensors make no representations or warranties whatsoeveras to the accuracy, completeness, or suitability for any purpose of the Content. Anyopinions and views expressed in this publication are the opinions and views of theauthors, and are not the views of or endorsed by Taylor & Francis. The accuracyof the Content should not be relied upon and should be independently verifiedwith primary sources of information. Taylor and Francis shall not be liable for anylosses, actions, claims, proceedings, demands, costs, expenses, damages, and otherliabilities whatsoever or howsoever caused arising directly or indirectly in connectionwith, in relation to or arising out of the use of the Content.
This article may be used for research, teaching, and private study purposes. Anysubstantial or systematic reproduction, redistribution, reselling, loan, sub-licensing,systematic supply, or distribution in any form to anyone is expressly forbidden. Terms& Conditions of access and use can be found at http://www.tandfonline.com/page/terms-and-conditions

# 2007 Psychology Press, an imprint of the Taylor & Francis Group, an Informa business
http://www.psypress.com/aphasiology DOI: 10.1080/02687030701657226
A computational semantics approach to aphasic
sentence comprehension
David Glenn Clark
University of Alabama at Birmingham and the Birmingham Veteran’s Affairs Hospital,
AL, USA
Background: Patients with brain damage often exhibit difficulty understandingsentences, with certain grammatical constructions posing more of a problem thanothers. Differences between sentences that are ‘‘hard’’ or ‘‘easy’’ to process have beencharacterised in terms of modern syntactic theory, leading to a number of insightfulproposals regarding the nature of sentence comprehension problems in aphasia.However, little attention has been devoted to the semantic aspects of aphasic sentencecomprehension.Aims: The primary aim of this research is to validate the use of a computationalsemantic approach for modelling aphasic sentence comprehension.Methods & Procedures: The model presented here is an extension of natural languageprocessing software designed by Blackburn and Bos (2006). The original program parsesa natural language expression by means of a simple definite clause grammar, assigning asemantic representation to each node in the parse tree. The final result of a successfulparse is a sentence from first-order logic that describes the meaning of the naturallanguage sentence. The program was made relevant for the study of aphasia byextending the grammar to parse 14 sentences that present variable degrees of difficultyto aphasic patients. In addition, each constituent in the grammar was endowed with anintegrity feature that contained an integer with a maximum value of 100. This numberconstituted the percent chance that the node would be successfully realised and wasreduced in proportion to the node’s height in the syntactic tree. The constant ofproportionality was then manipulated to simulate various degrees of aphasia severity.Qualities of the model’s performance were compared to qualities of aphasic patientperformance on four key sentences. The model’s quantitative performance on 12sentences was compared to that of 46 patients with left hemisphere lesions.Outcomes & Results: There was a significant correlation between the performance of themodel and that of the patients (r 5 .85, p , .001). Sentence length was not significantlycorrelated with patient performance (r 5 2.52, ns). The probabilistic output of themodel resembles variability in performance by aphasic patients.Conclusions: A computational semantics approach to aphasic sentence comprehensionmay provide a means for explaining continuous variation in degrees of aphasia severityas well as qualitative patterns of agrammatic comprehension.
Keywords: Agrammatism; Aphasia; Natural language processing; Semantics; Syntax.
Address correspondence to: David Glenn Clark, Sparks Center, 360C 1720 7th Ave S., Birmingham,
AL 35294, USA. E-mail: [email protected]
APHASIOLOGY, 2009, 23 (1), 33–51
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

APHASIC SENTENCE COMPREHENSION
Aphasic speakers of English often exhibit poor comprehension of semantically
reversible sentences with noncanonical word order despite apparently good
comprehension of sentences with canonical word order. For example, these patients
generally perform ‘‘at chance’’ when selecting pictures that depict the action
described in passive voice sentences, such as (1), and sentences with embedded
object-relative clauses, such as (2). Nevertheless, they often perform above
chance on the same task when presented with simple, active voice sentences, such
as (3), or sentences in which semantic cues and deductive processes facilitate
interpretation (4) (Caramazza & Zurif, 1976). Although patients who exhibit this
pattern of comprehension failure perform well when interpreting the thematic
roles assigned to the embedded verb in a subject-relative sentence, such as (5),
they perform poorly when attempting to interpret the verb in the matrix clause
(Hickok, Zurif, & Canseco-Gonzalez, 1993). That is, in the case of (5), patients
in the Caramazza and Zurif (1976) study typically knew that the cat scratched
the girl, but often selected a picture showing that the girl, rather than the cat, was
angry.
(1) The man is pushed by the boy.
(2) The cat that the girl scratched is angry.
(3) The man pushed the boy.
(4) The apple was eaten by the boy.
(5) The cat that scratched the girl is angry.
This pattern of deficits depends on the syntactic structure of sentences. Accordingly,
there have been many attempts to characterise the lesion in terms of syntax. The
term ‘‘agrammatism’’, which had originally been applied to a defect of language
production (Goodglass, 1993, pp. 103–106), has been applied to these comprehen-
sion deficits as well. Some effort has been put forth to link syntax to Broca’s area,
and Broca’s aphasia to agrammatism (Grodzinsky, 2000b). However, studies that
have investigated the relationship between clinical aphasia syndrome, lesion
localisation, and sentence comprehension have suggested that sentence processing
is not necessarily associated with a particular clinical subtype of aphasia, and is
supported by a large-scale neurocognitive network involving at least five regions of
the left hemisphere, with possible participation by the right hemisphere and
cerebellum (Caplan, Hildebrandt, & Makris, 1996; Dick et al., 2001; Dronkers,
Wilkins, Van Valin, Redfern, & Jaeger, 2004; Kaan & Swaab, 2002; Marien et al.,
1996).
Although some of the hypotheses that have been advanced have been couched
in cognitive psychological terms (Bates, Friederici, & Wulfeck, 1987; Caplan &
Waters, 1999), most have been phrased in terms of syntactic theory (Druks &
Marshall, 1995; Friederici & Gorrell, 1998; Grodzinsky, 2000b; Hickok et al.,
1993; Mauner, Fromkin, & Cornell, 1993; O’Grady & Lee, 2001, 2005), with the
‘‘lesion’’ defined as damage to some more or less abstract theoretical device,
such as Case, access to tree structures, or traces. One potential problem with
this approach is that a theory that defines a lesion in terms of loss of one of
these theoretical constructs makes discrete predictions about patient perfor-
mance, rather than predictions that accommodate a continuous spectrum of
performance.
34 CLARK
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

MODELS OF APHASIC SENTENCE COMPREHENSION
All attempts to model agrammatic comprehension computationally have utilised an
explicit, symbol-manipulating component (i.e., a parser—see, for example,
Haarman, Just, & Carpenter, 1997; Kolk, 1995; Vosse & Kempen, 2000). In general,
this has been combined with connectionist elements, such as activation states for
lexical items and trees, and connection strengths. The models were then ‘‘lesioned’’
by manipulating one or more parameters that affected their ability to integrate
information. This approach has seen important advances, most notably by Haarman
et al. (1997) and by Vosse and Kempen (2000). The central hypothesis behind the
model proposed by Haarman et al. (1997) is that variation in the language
performance of normal adults and aphasic patients is determined by individual
differences in syntactic working memory capacity. The model consisted of three
components: a lexicon, a parser, and a system that used activation states in the
parser to compute the activation states of thematic role representations. With this
third component it was possible to calculate how well the model ‘‘understood’’
various sentence structures. By manipulating the syntactic working memory capa-
city the authors were able to fit the model’s comprehension accuracy (i.e., thematic
role activation) to the average performance of a group of aphasic patients on
nine sentence types. The authors pointed out that the model performed somewhat
better than aphasic patients on dative constructions, and worse than the patients on
cleft object constructions. The authors also made an effort to demonstrate the
model’s capacity to account for variation in patient data by running the model
with two different levels of syntactic working memory capacity impairment. The
interaction between sentence complexity and severity of impairment was shown to be
similar between the model and the performance of two patients, but the authors
indicated that such an interaction did not appear to be a general property of
the model, with certain sentence complexity contrasts exhibiting the opposite
interaction.
Vosse and Kempen (2000) presented a model based on unification grammar that
reproduced a number of findings from psycholinguistic studies of normal sentence
processing. In addition they made an effort to model the same pool of aphasic
sentence comprehension data used by Haarman et al. (1997). In this case, however, it
was necessary to search a space of five variables in order to fit the model to the
patient data. While the Spearman correlation between the lesioned model and the
patient data was high, it is possible that a model this powerful is capable of fitting
patterns that are not observed among aphasic patients, and the five variables are not
easily related to any particular neural structures or cognitive operations. To account
for a range of patient performance data, the authors evaluated the model’s
performance at various degrees of degradation. This was done by manipulating the
values of the five variables along a continuous line between those resulting in good
performance and those resulting in agrammatic performance. At low levels of
degradation the model exhibited increasingly frequent failure to generate a full parse
for object-relative sentences, while at higher levels of degradation subject-relative
sentences were also degraded. The authors did not demonstrate a continuous range
of performance for other sentence structures, such as passives. In addition, this
model did not include a semantic component. Thus, sentence comprehension deficits
were viewed only in terms of parse failure, with no attempt to derive meaning from
any parse.
COMPUTATIONAL SEMANTICS AND COMPREHENSION 35
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

MOTIVATIONS FOR THE CURRENT MODEL
A parsimonious representational explanation for the typical syntactic dissociation
that may occur in aphasia has been elusive (Kean, 1995), but inspection of the
literature readily identifies several qualities that would be desirable for any new,
putative account of the data. First, with regard to aphasic sentence production, recent
work indicates that the accuracy with which patients produce affixes depends on the
position at which the affix is introduced into the syntactic phrase marker tree, with
higher levels in the tree being affected more severely (Friedmann, 2001; Friedmann &
Grodzinsky, 1997; Hagiwara, 1995; Izvorski & Ullman, 1999). Although this view is
sometimes presented alongside the trace deletion hypothesis (see Grodzinsky,
2000a), there is no clear reason why two such different phenomena (i.e., trace
deletion and tree pruning) would be linked by a single brain lesion. Friedmann
(2006) has recently proposed a hypothesis of sentence comprehension that more
closely resembles the tree-pruning hypothesis. Although dissociations between
sentence comprehension and production clearly occur, an approach that has the
capacity to characterise both types of syntactic deficits in terms of a single type of
computational problem is clearly desirable. That is, although the brain regions
supporting sentence comprehension and production might be only partially
overlapping, it seems theoretically more parsimonious to propose similar syntactic
mechanisms for both processes.
Second, as discussed above, a hypothesis that accommodates a range of
impairments, rather than predicting a single, discrete pattern of performance, would
be a step forward for the field. Moreover, recent evidence suggests that individual
patients do not perform consistently on repeat testing, and that an explanation of
aphasic sentence comprehension might require the invocation of random ‘‘noise’’ in
the comprehension system (Caplan, DeDe, & Michaud, 2006; Caplan, Waters,
DeDe, Michaud & Reddy, 2007). Third, although characterisations of sentence
comprehension deficits in terms of linguistic theory are not without fault, all of the
accounts that have been put forth are insightful and seem to be presenting important
facets of language breakdown. It would therefore be useful to propose a common
(preferably computational) basis for these accounts.
Fourth, previous accounts have generally focused on syntax, without paying very
much attention to mappings from syntax to semantics (but see O’Grady & Lee, 2001,
2005; Saddy, 1995; also Thompson, Tait, Ballard, & Fix, 1999, who raise the issue
briefly). Since the patients have deficits of comprehension, and comprehension must
involve a mapping from sound to meaning, it stands to reason that some variability
in patient performance could be accounted for by giving some consideration to the
meanings themselves.
The research presented here is a demonstration of a new hypothesis with the
strengths outlined above. The hypothesis is that the probability of successfully
realising a syntactic constituent is reduced in proportion to the node’s height in the
syntactic tree. Failure of comprehension can be characterised by formally evaluating
the meanings of the constituents that are successfully realised during a parse. As
suggested by the tree-pruning hypothesis, the model (when lesioned) maintains the
ability to build syntactic structure in the lower parts of the tree, and has increasing
difficulty as higher nodes are projected. This is accomplished by assigning every
constituent a feature of integrity. This feature is meant to represent the quality of the
neural representation of that constituent (perhaps as hypothesised by Pulvermuller,
36 CLARK
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

2002), and influences the function of the parse in the following manner. If node A
dominates node B in the phrase marker tree, and the integrity of node B is low, then
the integrity of node A will be even lower. Thus ‘‘noise’’ introduced into the system
propagates as higher structures are built, leading to faulty recognition and
interpretation of large constituents. Aphasic deficits of different severities can be
modelled by introducing different quantities of noise, but with repeated testing at
certain levels of noise the model’s performance might vary between extremes that
straddle any given cut-off score that is used to distinguish normal from abnormal
performance.
METHOD
The model
The program used for this research was modified from software written in Prolog by
Blackburn and Bos (2006), available as a free download from: http://www.cogsci.e-
d.ac.uk/,jbos/comsem/book1.html). Fundamentals of computational semantic
theory and the use of the software are detailed in a textbook from the same
authors. The syntactic theory used in the book, and for this model, involved a
fundamental ‘‘definite clause’’ grammar, also known as a context-free grammar.
Briefly, such a grammar consists of a set of rules of the form:
S R NP VP (i.e., a sentence is formed by a noun phrase followed by a verb phrase)
NP R Det N (a noun phrase is formed by a determiner followed by a noun)
VP R TV NP (a verb phrase is formed by a transitive verb followed by a noun phrase)
…
In computational semantics, all words are associated with a meaning that is
expressed using a blend of lambda calculus and first-order logic. The grammar
determines which groups of words may be constituents, and how these lambda
expressions are to be combined when new constituents are recognised (i.e., which
expression should act as the function and which as the argument). Parsing of a
natural language sentence results in simultaneous formation of a sentence from first-
order logic that expresses the meaning of the natural language sentence.
The Prolog software for basic sentence parsing and interpretation was modified
by expanding the definite clause grammar to recognise 14 sentence structures of
varying complexity. Appropriate modifications were made to the semantic
component of the program to accommodate these sentences. The sentences that
were added included a subset of those that were used for aphasia assessment by
Caplan et al. (1996). An example of each sentence type is listed in Table 1.
An integrity feature was added to the feature matrix of every potential constituent
in the definite clause grammar. Individual lexical items were given a default integrity
value of 100, which endowed them with a 100% chance of being realised during a
parse. A lower integrity value corresponded to a lower percent chance that a
constituent would be realised. Although word comprehension deficits are common in
aphasia, sentence and word comprehension deficits are dissociable. Since patients
with severe word comprehension problems were excluded from the Caplan et al.
(1996) study, it seems appropriate to endow the model with accurate word
comprehension.
COMPUTATIONAL SEMANTICS AND COMPREHENSION 37
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

TABLE 1Examples of each of the 14 sentence types
Sentence Minimal interpretation for accurate inference
Patient
data Model
(1) A boy that kissed a girl is happy. lq.’x.(GIRL(x) ‘ KISS(q,y)) [embedded verb only] – 409
(2) A boy that a girl kissed is happy. ’y.(BOY(y) ‘ ’x.(GIRL(x) ‘ KISS(x,y))) [embedded verb only] – 224
(3) A boy kissed a girl. lq.’x.(GIRL(x) ‘ KISS(q,x)) 92 328
(4) A boy was kissed by a girl. ’y.(BOY(y) ‘ KISS(,no agent.,y)) with lz.’x.(GIRL(x) ‘ z@x) 70 200
(5) A rabbit gave a cow to a goat. la.’p.(COW(p) ‘ ’g.(GOAT(g) ‘ GIVE(a,p,g))) 77 184
(6) A monkey scratched a rabbit and patted a frog. ly.’x.(RABBIT(x) ‘ ’z.(FROG(z) ‘ SCRATCH(y,x) ‘ PAT(y,z))) 69 168
(7) A frog patted a monkey and a rabbit. ly.’x.(RABBIT(x) ‘ ’z.(MONKEY(z) ‘ PAT(y,x) ‘ PAT(y,z))) 68 213
(8) A rabbit was patted. ’x.(RABBIT(x) ‘ PAT(,no agent.,x) 67 178
(9) It was a cow that a rabbit kissed. ’y.(COW(y) ‘ ’x.(RABBIT(x) ‘ KISS(x,y))) 70 239
(10) A monkey that a rabbit scratched shook a goat. ’y.(MONKEY(y) ‘ ’x.(RABBIT(x) ‘ SCRATCH(x,y)) ‘ ’z.(GOAT(z) ‘ SHAKE(y,z))) 37 58
(11) A goat hit a rabbit that kissed a cow. ’y.(GOAT(y) ‘ ’x.(RABBIT(x) ‘ HIT(y,x))) with ’x.(RABBIT(x) ‘ ’z.(COW(z) ‘KISS(x,z)))
49 134
(12) A monkey tickled a frog that a goat shook. ’y.(MONKEY(y) ‘ ’x.(FROG(x) ‘ TICKLE(y,x))) with ’x.(FROG(x) ‘ ’z.(GOAT(z) ‘SHAKE(z,x))))
42 123
(13) A frog that held a cow caught a rabbit. ’y.(FROG(y) ‘ ’x.(COW(x) ‘ HOLD(y,x)) ‘ ’z.(RABBIT(z) ‘ SHAKE(y,z))) 60 64
(14) A cow was hit by a monkey and a rabbit. ’x.(COW(x) ‘ HIT(,no agent.,x) with lw.’z.(RABBIT(z) ‘ ’y.(MONKEY(y) ‘ w@y)
‘ w@z)
65 165
Notes: Fourteen sentences for which the model’s behavior was assessed are listed in the leftmost column. The first four sentences have been considered the ‘core’ data of
agrammatism, while the last 12 of the 14 were used by Caplan, Hildebrandt, and Makris (1996) to assess comprehension in 46 subjects with left hemisphere lesions. The second
column lists the minimal amount of semantic information considered to result in accurate interpretation of each of the sentences. (For the first two sentences, only
interpretation of the embedded verb was considered, since these have been the focus of most research on aphasic sentence comprehension.) Patient data are percentages taken
from Table 1 of Caplan et al. (1996, p. 937). The model’s performance was quantified by counting the number of times that a successful interpretation occurred over a total of
420 runs of the sentence (20 runs at each of 21 levels of degradation). The ‘at’ symbol (@) represents application of a lambda expression to an argument.
38
CLA
RK
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

Parsing began with a query to Prolog regarding whether an input was a sentence.
Prolog performed a left-to-right, depth-first search of the space of possible sentences
generated by the definite clause grammar. That is, for each context-free rule in the
grammar (e.g., S R NP VP), Prolog evaluated whether the input matched the
constituents listed to the right of the arrow in the rule, working from left to right as
long as each constituent was found in the input. If the first constituent was
recognised, Prolog would move on to the second constituent. Recognition of each
constituent usually involved satisfaction of additional context-free rules beforeProlog would move on to the next constituent. (This is why the order of evaluation is
considered to be ‘‘depth-first.’’ See the Appendix for an example.) In order to model
failure of comprehension, the parser was designed to occasionally reject con-
stituents that should have been permitted by the grammar. The chance that such a
rejection would take place at any given node in the tree was proportional to
the height of the node in the tree, and was determined by the integrity value for
that node. Each time the parser made an attempt to realise a constituent, the
integrity value of the new constituent was derived by selecting the lowest integrityvalue from among its daughter nodes and subtracting a constant (degradeconst).
Therefore, to put together an NP from the determiner ‘‘a’’ and the noun ‘‘girl’’,
the integrity value for each word would be accessed and compared. Since single
words always had an integrity of 100, the number 100 would be used to derive the
integrity for the new NP by subtracting degradeconst. If this constant were equal to
2, the integrity of the new NP would be 98. A random number between 1 and 100
was then selected and the constituent was accepted only if the random number was
lower than the integrity value for the constituent. Since only single words wereassigned integrity values initially, integrity values for all other nodes had to ‘‘trickle
up’’ the tree from the level of the word nodes. Aphasia severity was modelled by
varying the value of degradeconst. The Appendix contains a simplified trace of the
steps undertaken by the model when parsing a simple active sentence with
degradeconst set to 2.
Whenever the parser identified a constituent (any constituent, even a single word),
a semantic representation was computed for that constituent. For constituents
composed of two sub-constituents, this amounted to taking the lambda expressionassociated with one daughter node and applying it to the lambda expression for the
other daughter node. For every constituent the parser identified, the semantic
representation that was computed was written to a text file for later quantification.
Thus, even if the model had failed to parse an S from the input, it still might have
parsed the initial NP or the VP and the semantic representation for these
constituents would have been written to the file.
Procedure and analysis
The program was run 20 times for each sentence, with degradeconst set to each of 21
different values (0–20), for a total of 420 runs for the input sentences listed in
Table 1. The first four sentences listed have been considered to represent the ‘‘core’’
data of agrammatism (Dick et al., 2001; Hickok & Avrutin, 1995). The latter 12 of
the 14 sentences represent structures used by Caplan et al. (1996) for assessment of
46 patients with left hemisphere lesions.
Strings representing the semantic interpretations of certain key fragments ofsyntactic structure were counted in each output file. Some of these strings were
COMPUTATIONAL SEMANTICS AND COMPREHENSION 39
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

completely intact semantic interpretations of the input sentence. However, since
degradation of the model’s function resulted in incomplete parses, some attention
had to be directed to the quality of semantic interpretations of these incomplete
parses. Therefore, some a priori stipulation had to be made regarding the minimum
quantity of information that should lead to correct performance on tasks assessing
sentence comprehension. The definition of this minimum quantity of necessary
information was motivated partly by linguistic and partly by extra-linguistic
considerations. From a linguistic standpoint, Friederici and Gorrell (1998) notedthat when patients with typical agrammatic comprehension provide judgements of
sentence meaning, they exhibit a tendency to assign the Agent role to the highest NP
in the sentence structure. However, this behaviour is indistinguishable from the
behaviour one would see if aphasic participants assigned the Patient role to the lower
NP in the structure. Expressing Friederici and Gorrell’s observation in terms of the
lower NP is important to the interpretation of the model’s behaviour, since lower
NPs are more likely to be incorporated into the structure and thus to be available for
compositional interpretation.From an extra-linguistic standpoint, I presume only that aphasic participants
have an intact capacity for making two simple deductions. Deductive processes and
semantic world knowledge are known to influence sentence comprehension in
agrammatic participants, since these participants perform ‘‘above chance’’ when
interpreting semantically irreversible sentences, even if they are non-canonical (e.g.,
‘‘The apple was eaten by the boy.’’) The first of these two simple deductions is as
follows: if an aphasic listener gleans the following facts: (1) the speaker said
something about a boy, and (2) the speaker said someone hit a girl, then the listeneris very likely to infer that the boy was the one who did the hitting. Along with
Friederici and Gorrell’s observation, the capacity to make this inference raises the
possibility that a noun that has not been assigned a thematic role through normal
compositional mechanisms might be interpreted as the Agent of the event. For
purposes of this research, the model was considered to make such a deductive leap
under one circumstance: when the available semantic information included (1) a
lambda term for one N or NP that had not been assigned a thematic role (including
NPs composed of conjoined NPs), and (2) a VP (including those composed ofconjoined VPs) with one unassigned thematic role or undischarged lambda term. It
should be noted that such an inference leads to a correct interpretation only for
canonical sentences. The second deduction that patients might be expected to make
is even simpler. If a patient is able to interpret an utterance as containing an
assertion P and an assertion Q, then the patient can infer that the utterance contains
the assertion P & Q. The ability to make this deduction would facilitate the
interpretation of non-truncated passives and of sentences with relative clauses in
object position, but not those with relative clauses in subject position. This is due tothe fact that verbs in the former sentence types have a more local relationship with
their arguments than verbs in the latter type (see Table 1).
Performance of the model across sentence structures was evaluated. For the
first four sentences of Table 1, thematic role assignments were investigated in
detail and graphed. The model’s performance on these canonical and noncano-
nical sentences was compared with chi-square. The model’s performance on the
12 sentences from Caplan et al. (1996) was quantified for direct comparison to
the patient data. Following visualisation with a scattergram, a correlation wascomputed.
40 CLARK
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4
The influence of random noise on the model’s performance was evaluated by
running three sentences 20 times each for 10 consecutive runs with degradeconst set
to 8. The three sentence types were simple active, truncated passives, and full
passives. These structures were used by Caplan et al. (2007) as baseline and test
sentences. Performance by the model over the 10 runs was graphed.
RESULTS
Patterns of performance by the model closely matched those of actual patients on
the four sentences that constitute the ‘‘core’’ of agrammatic comprehension data.
The model performed relatively well (328/420 sentence presentations) with active
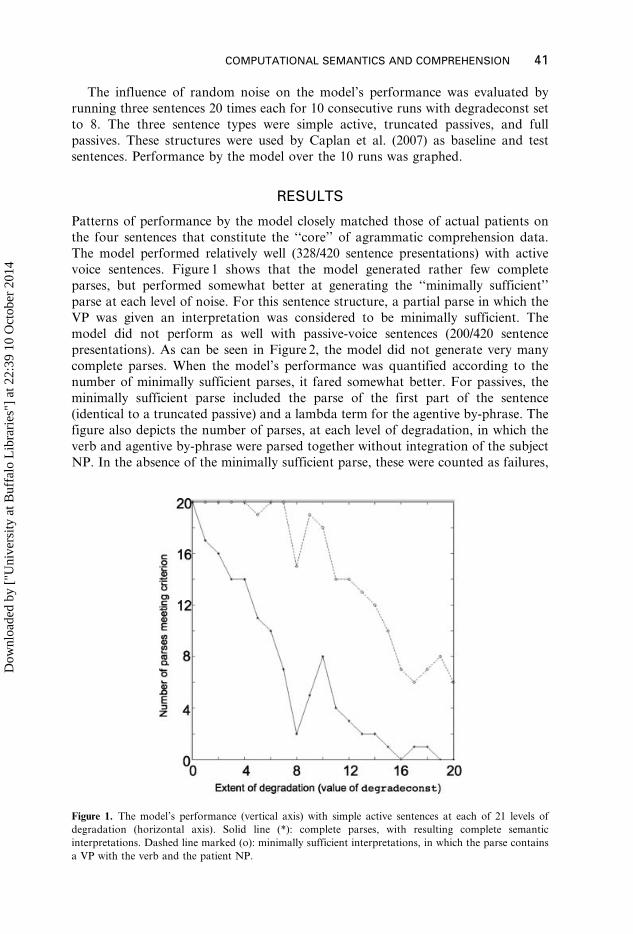
voice sentences. Figure 1 shows that the model generated rather few complete
parses, but performed somewhat better at generating the ‘‘minimally sufficient’’
parse at each level of noise. For this sentence structure, a partial parse in which the
VP was given an interpretation was considered to be minimally sufficient. The
model did not perform as well with passive-voice sentences (200/420 sentence
presentations). As can be seen in Figure 2, the model did not generate very many
complete parses. When the model’s performance was quantified according to the
number of minimally sufficient parses, it fared somewhat better. For passives, the
minimally sufficient parse included the parse of the first part of the sentence
(identical to a truncated passive) and a lambda term for the agentive by-phrase. The
figure also depicts the number of parses, at each level of degradation, in which the
verb and agentive by-phrase were parsed together without integration of the subject
NP. In the absence of the minimally sufficient parse, these were counted as failures,
Figure 1. The model’s performance (vertical axis) with simple active sentences at each of 21 levels of
degradation (horizontal axis). Solid line (*): complete parses, with resulting complete semantic
interpretations. Dashed line marked (o): minimally sufficient interpretations, in which the parse contains
a VP with the verb and the patient NP.
COMPUTATIONAL SEMANTICS AND COMPREHENSION 41
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

due to the axiom that VPs with only one argument would be interpreted as verb +Patient.
The object-relative and subject-relative sentences used to compare the model’s
performance to the core data of agrammatism had only one transitive verb (within
the relative clause), while the matrix clause contained a predicate adjective. Although
comprehension (i.e., generation of an adequate semantic representation) of the
matrix verb was poor for both of the sentence types at higher levels of degradation,
comprehension of the transitive verb in the relative clause varied in the same mannerthat was observed for active voice and passive voice sentences. Measured according
to performance with the relative clause verb, the model performed relatively well
with subject-relative sentences (409/420). Figure 3 shows the model’s performance,
quantified over 20 iterations at each of 21 levels of degradation. Again, across all
levels of degradation, the model did not generate many complete parses, but often
formed a parse containing the minimally sufficient information for accurate
performance, i.e., at the very least a VP with the embedded verb and its Patient
NP. The model generated parses associated with adequate interpretations for 224/420 object-relative sentences (Figure 4). For these sentences, the model generated
even fewer complete parses and minimally sufficient parses. For object-relative
sentences, a parse was considered minimally sufficient if it contained the embedded
verb and both of its arguments. The figure also depicts the number of parses in which
the embedded verb was parsed with only the lower NP, resulting in faulty
interpretation of this argument as Patient. When the model’s semantic interpreta-
tions were judged as adequate or inadequate on these grounds, the model was
accurate on 87.7% of canonical sentences, but only on 50.5% of non-canonicalsentences (x25271.4, p,.001).
Figure 2. The model’s performance (vertical axis) with passive voice sentences at each of 21 levels of
degradation (horizontal axis). Dashed line (o): complete parses, with resulting complete semantic
interpretations. Dash-dot line (*): adequate interpretations, i.e., either a complete parse or a parse with
both truncated passive and the agentive by-phrase. Solid line (D): Incomplete parses containing a VP with
the agentive by-phrase but without the subject (Patient) NP.
42 CLARK
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

The model was tested on 12 of the sentence types used by Caplan et al. (1996),
some of which contain ‘‘empty’’ referential dependencies. The sentences with relative
clauses used for this part of the experiment contained two transitive verbs. The task
employed by Caplan et al. (1996) required enactment of each sentence with stuffed
animals or puppets. This task should have been quite unforgiving, since an error with
either verb would have interfered with the participant’s enactment of a given
sentence. For these sentences, only a parse in which all thematic roles were correctly
assigned was considered to be adequate for comprehension by the model, since the
aphasic patients were required to comprehend both verbs. It is important to note
that for sentences with a relative clause in the subject NP this required a complete
parse, but for sentences with a relative clause in the object NP it was sufficient to
have two simultaneous parses, each of which contained a semantic representation of
one of the transitive verbs along with appropriate thematic role assignments (see
Table 1). The derivation of an accurate interpretation from these two simultaneous
partial parses requires the use of the second of the two extra-linguistic deductions
described in the Method section. The correlation between the model’s performance
and patient performance was significant (r5.85, p,.001; see Figure 5). The
correlation between patient performance and sentence length was not significant
(r52.52, ns).
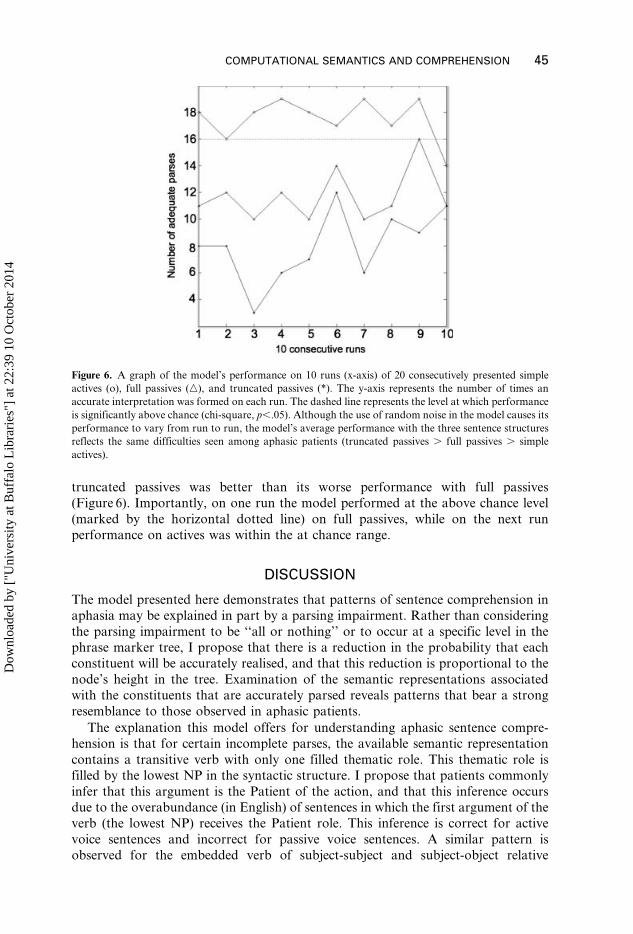
Repeated testing of the model at a single level of degradation revealed overlap
between quantifications of the model’s performance on active and passive voice
sentence structures. Specifically, the model’s best performance with full passives was
better than its worst performance with actives, and its best performance with
Figure 3. The model’s performance (vertical axis) with subject-relative sentences at each of 21 levels of
degradation (horizontal axis). Solid line (o): complete parses, with resulting complete semantic
interpretations. Solid line (*): complete interpretations of the embedded verb, regardless of the matrix
verb interpretation. Solid line (D): minimally sufficient interpretations. For subject relatives with predicate
adjectives in the matrix clause, this requires formation of a parse containing the embedded verb with the
appropriate Patient argument.
COMPUTATIONAL SEMANTICS AND COMPREHENSION 43
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

Figure 5. A scattergram depicting the strong linear relationship between the model’s performance
(horizontal axis) and patient performance (vertical axis) on 12 of the sentence structures used by Caplan
et al. (1996). The coefficient of correlation is .85 (p,.001).
Figure 4. The model’s performance with object-relative sentences (vertical axis) at each of 21 levels of
degradation (horizontal axis). Dashed line (o): complete parses, with resulting complete semantic
interpretations. Dash-dot line (*): minimally sufficient interpretations. For object-relatives these result
either from a complete parse or a parse in which the embedded verb is associated with both the Agent and
Patient arguments. Solid line (D): incomplete parses in which the verb was paired with only one argument.
Although this argument should have been interpreted as an Agent, since no other argument was available
it was instead interpreted as Patient.
44 CLARK
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4
truncated passives was better than its worse performance with full passives
(Figure 6). Importantly, on one run the model performed at the above chance level
(marked by the horizontal dotted line) on full passives, while on the next run
performance on actives was within the at chance range.
DISCUSSION
The model presented here demonstrates that patterns of sentence comprehension in
aphasia may be explained in part by a parsing impairment. Rather than considering
the parsing impairment to be ‘‘all or nothing’’ or to occur at a specific level in the
phrase marker tree, I propose that there is a reduction in the probability that each
constituent will be accurately realised, and that this reduction is proportional to the
node’s height in the tree. Examination of the semantic representations associated
with the constituents that are accurately parsed reveals patterns that bear a strong
resemblance to those observed in aphasic patients.
The explanation this model offers for understanding aphasic sentence compre-
hension is that for certain incomplete parses, the available semantic representation
contains a transitive verb with only one filled thematic role. This thematic role is
filled by the lowest NP in the syntactic structure. I propose that patients commonly
infer that this argument is the Patient of the action, and that this inference occurs
due to the overabundance (in English) of sentences in which the first argument of the
verb (the lowest NP) receives the Patient role. This inference is correct for active
voice sentences and incorrect for passive voice sentences. A similar pattern is
observed for the embedded verb of subject-subject and subject-object relative
Figure 6. A graph of the model’s performance on 10 runs (x-axis) of 20 consecutively presented simple
actives (o), full passives (n), and truncated passives (*). The y-axis represents the number of times an
accurate interpretation was formed on each run. The dashed line represents the level at which performance
is significantly above chance (chi-square, p,.05). Although the use of random noise in the model causes its
performance to vary from run to run, the model’s average performance with the three sentence structures
reflects the same difficulties seen among aphasic patients (truncated passives . full passives . simple
actives).
COMPUTATIONAL SEMANTICS AND COMPREHENSION 45
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

sentences. Since the task employed by Caplan et al. (1996) involved enacting two
events described by transitive verbs in sentences with relative clauses in the subject
(one embedded verb and one matrix verb), participants would need to form a
complete parse of these sentences in order to fill all the thematic roles, and only
complete parses by the model were counted as successful. In contrast, piecemeal
comprehension of sentences with relative clauses in an object NP seems feasible,
owing to the fact that both verbs have local relationships with their arguments, while
the matrix verb in subject-subject and subject-object relative sentences isdisconnected from its agent argument by the intervening relative clause.
There is increasing evidence in the psycholinguistic literature that normal listeners
rely on a combination of ‘‘heuristic’’ strategies and strict compositional interpreta-
tion (Ferreira, Bailey & Ferraro, 2002; Ferreira & Patson, 2007), and that these
processes might compete during normal sentence interpretation, often leading to
sentence misinterpretation. Although the authors refer to the heuristic processes as
being non-compositional, it is clear that the meanings derived through the heuristics
are composed from meanings of words in the sentences. The meanings are only non-compositional in the sense that listeners do not derive them from a global syntactic
structure, but instead rely on other cues to derive thematic relationships. These other
cues include semantic background knowledge, anticipated argument structures, and
locality of verbs and potential NP arguments. These findings are relevant to the
study of aphasic sentence comprehension, and provide a preliminary explanation for
Friederici and Gorrell’s (1998) Structural Prominence Hypothesis: the observation
that aphasic listeners assign the Agent role to the most structurally prominent NP.
For purposes of this model I have rephrased the structural prominence hypothesis asa tendency to assign the Patient role to the lowest NP, since these two
complementary cognitive operations cannot be dissociated on the basis of the
behavioural data. In terms of the work by Ferreira and her colleagues, this tendency
arises from occasional failure to compute a global syntactic structure for complete
compositional interpretation. In the absence of the complete global syntactic
structure, other cues (such as string locality) prevail in thematic role assignment.
Perhaps this competition between local and global compositional processes will
prove to be useful for understanding the apparent greater difficulty of non-canonicalsentences, as measured by fMRI (Cooke et al., 2001), and for understanding
conflicting observations regarding structural vs linear thematic role assignment
(Beretta, 2001; Law, 2000).
The main reason for adopting this approach to explaining features of aphasic
sentence comprehension is that the lesion introduced may be characterised in neural
terms, i.e., as reduced priming, activation, or coherence in a neural sequence detector
that supports syntactic (and possibly semantic) processing (Pulvermuller, 2002). For
this reason, the approach may be considered to be similar to those that attributesentence comprehension deficits to a deficiency in some kind of resource (Caplan &
Waters, 1999; Haarman et al., 1997). However, it is important to note that certain
aspects of sentence complexity (particularly with regard to relative clauses) are
merely stipulated by the current model. Functional imaging research indicates that
the processing of object-relative sentences is associated with larger increases in left
frontal blood flow than the processing of subject-relative sentences (Cooke et al.,
2001; Just, Carpenter, Keller, Eddy, & Thulborn, 1996). It is reasonable to infer that
these differences relate to the dissociations seen among aphasic patients.Syntacticians often give more complex derivations to object-relative sentences. For
46 CLARK
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

example, in at least one variant of transformational grammar, object-relative clauses
contain two traces, while subject-relative clauses contain only one (Hickok et al.,
1993). Combinatory categorial grammar (Steedman, 2001) requires type-raising and
function composition operations in the derivation of object-relatives that are not
necessary for subject-relatives. The grammar used by this model is no different, since
parsing of an object-relative is associated with introduction of a ‘‘gap’’ that adds a
computational step to the derivation. Thus, this model’s performance with object-
relative sentences arises in part from their greater ‘‘complexity’’, and in part from thefact that accurate interpretation of the object-relative clause requires assimilation of
a greater number of words into a single constituent. Yet the model does not include
any explanation (in neural terms) for the greater complexity of object-relative
sentences. Thus, it is possible that the variable manipulated in this model does not
represent all of the factors that result in differing degrees of difficulty with sentence
interpretation. Perhaps more of the variation can be accounted for with the addition
of one variable representing a form of working memory, possibly implemented as an
activation level for individual lexical items (or their meanings) that undergoesspontaneous decay. On the other hand, this is hardly conceptually different from the
‘‘integrity’’ value manipulated by current model—the main difficulty lies in
developing a grammatical analysis that hasn’t already incorporated the fact that
object-relative sentences are more difficult to process.
There are several other reasons to adopt this approach to understanding aphasic
comprehension deficits. First, since the constant of proportionality (degradeconst)
that determines the reduction in the parser’s accuracy at each node can be varied, it is
possible to account for many degrees of sentence-level comprehension impairment.Second, the model provides a first approximation for conceptualising the interaction
between global and local processes of sentence interpretation. The hypothesis is
therefore aligned with previous hypotheses that posit a structural interpretation
strategy—notably the Structural Prominence Hypothesis of Friederici and Gorrell
(1998) and the Double Dependency Hypothesis of Mauner et al. (1993). In addition
to compositionality, however, the possibility of using ‘‘good-enough’’ representa-
tions or simple logical deductions in the absence of a globally correct parse was taken
into account while quantifying the model’s performance. Third, defining the defect interms of recursive processing (i.e., either tree structure building or systematic
recombination of semantic representations) opens the possibility of unifying
characterisations of agrammatic comprehension with those of agrammatic produc-
tion (cf. the tree-pruning hypothesis of Friedmann). A final reason to use this
approach is that it may be used to make predictions of patient performance on other
sentence structures, such as active and passive voice sentences with coordinated
subjects or sentences with adjectives or other modifiers.
This research has a number of limitations. Hickok et al. (1993) have reported thataphasic patients often mis-assign the Agent role of verbs in the matrix clause of
subject-subject relative sentences. That is, given sentence (5), patients believe that the
girl is the one who is angry. The current model could not produce this parse due to
the highly constrained nature of the definite clause grammar. A grammar permitting
a more parallel approach to parsing (such as a lexicalist grammar) could derive this
parse as well as its resulting semantic interpretation. The current model was not
designed to address the fact that agrammatic patients exhibit the relatively preserved
capability to detect many grammatical errors (Linebarger, Schwartz & Saffran,1983). However, more recent evidence suggests that the dissociation is not as strong
COMPUTATIONAL SEMANTICS AND COMPREHENSION 47
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

as once believed (Wilson & Saygın, 2004). The proposal that this dissociation arises
from an interaction between the relative utility and cost of interpreting cues (Dick
et al., 2001) is an important idea that may be integrated into future models. It is
important to note that the current model’s simple definite clause grammar does not
take into account some aspects of sentence processing that might be very important
for defining agrammatic comprehension, such as tense and agreement morphology.
These additional layers of recursive structure might be important for truly explaining
details of aphasic sentence comprehension (Friedmann, 2006). This model was not
designed to address aspects of agrammatic comprehension that have only begun to
be explored, such as the interpretation of wh-questions and quantifiers (Hickok &
Avrutin, 1995; Saddy, 1995; Thompson et al., 1999). However, it might be better to
approach such problems with the tools of computational semantics rather than with
those of syntax alone. This work is limited in scope to the interpretation of roles for
transitive verbs that take Agent and Patient arguments. However, some transitive
verbs take arguments with other thematic roles, such as Experiencer, Range, or
Theme.
Future work may address the question of whether the extra-grammatical deduc-
tive processes outlined here might lead to specific (correct or incorrect) assignments of
these other thematic roles. Finally, the current work pertains only to agram-
matism in speakers of English. Although one might expect the model to continue to
behave in accordance with Friederici and Gorrell’s Structural Prominence Hypothesis,
this will require empirical verification with other languages. Since the Structural
Prominence Hypothesis was motivated by observations of aphasia in speakers of
German, Japanese, and Dutch, attention will be directed next to these languages. The
availability of other cues in these languages, particularly richer grammatical
morphology, might reduce the impact of syntactic hierarchy on sentence interpretation
(Bates et al., 1987)—nevertheless, it is likely that syntactic structure will continue to
have greater explanatory value than raw word order or sentence length.
In summary this is a probabilistic hypothesis, couched in terms of computational
semantics, for the occurrence of sentence-level comprehension deficits in aphasia.
The hypothesis proposes that a defect of syntactic structure building propagates as
information is recombined, resulting in failure to integrate non-local syntactic
information into a unified representation that permits complete semantic inter-
pretation. The effects of brain damage were modelled by systematically reducing the
probability that a constituent would be realised in proportion to the constituent’s
height in the phrase marker tree. The model’s output closely resembles data from
patients with left hemisphere lesions. Further work is required to assess the utility of
this approach for languages other than English, especially those with richer
morphology.
Manuscript received 30 May 2007
Manuscript accepted 30 August 2007
First published online 27 November 2007
REFERENCES
Beretta, A. (2001). Linear and structural accounts of theta-role assignment in agrammatic aphasia.
Aphasiology, 15(6), 515–531.
48 CLARK
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

Bates, E., Friederici, A., & Wulfeck, B. (1987). Comprehension in aphasia: A cross-linguistic study. Brain
and Language, 32, 19–67.
Blackburn, P., & Bos, J. (2006). Representation and inference for natural language. A first course in
computational semantics. Stanford, CA: CSLI Publications.
Caplan, D., DeDe, G., & Michaud, J. (2006). Task-independent and task-specific syntactic deficits in
aphasic comprehension. Aphasiology, 20(9/10/11), 893–920.
Caplan, D., Hildebrandt, N., & Makris, N. (1996). Location of lesions in stroke patients with deficits in
syntactic processing in sentence comprehension. Brain, 119, 933–949.
Caplan, D., Waters, G., DeDe, G., Michaud, J., & Reddy, A. (2007). A study of processing in aphasia I:
Behavioral (psycholinguistic) aspects. Brain and Language, 101, 103–150.
Caplan, D., & Waters, G. S. (1999). Verbal working memory and sentence comprehension. Behavioral and
Brain Sciences, 22(1), 77–94.
Caramazza, A., & Zurif, E. B. (1976). Dissociation of algorithmic and heuristic processes in language
comprehension: Evidence from aphasia. Brain and Language, 3, 572–582.
Cooke, A., Zurif, E. B., DeVita, C., Alsop, D., Koenig, P., & Detre, J. et al. (2001). Neural basis for
sentence comprehension: Grammatical and short-term memory components. Human Brain Mapping,
15, 80–94.
Dick, F., Bates, E., Wulfeck, B., Utman, J. A., Dronkers, N., & Gernsbacher, M. A. et al. (2001).
Language deficits, localisation, and grammar: Evidence for a distributive model of language
breakdown in aphasic patients and neurologically intact individuals. Psychological Review, 108(4),
759–788.
Dronkers, N. F., Wilkins, D. P., Van Valin, R. D. Jr., Redfern, B. B., & Jaeger, J. J. (2004). Lesion
analysis of the brain areas involved in language comprehension. Cognition, 92, 145–177.
Druks, J., & Marshall, J. C. (1995). When passives are easier than actives: Two case studies of aphasic
sentence comprehension. Cognition, 55, 311–331.
Ferreira, F., Bailey, K. G. D., & Ferraro, V. (2002). Good-enough representations in language
comprehension. Current Directions in Psychological Science, 11, 11–15.
Ferreira, F., & Patson, N. K. (2007). The ‘‘good enough’’ approach to language comprehension. Language
and Linguistics Compass, 1(1–2), 71–83.
Friederici, A. D., & Gorrell, P. (1998). Structural prominence and agrammatic theta-role assignment: A
reconsideration of linear strategies. Brain and Language, 65, 253–275.
Friedmann, N. (2001). Agrammatism and the psychological reality of the syntactic tree. Journal of
Psycholinguistic Research, 30(1), 71–90.
Friedmann, N. (2006). Generalisations on variations in comprehension and production: A further source
of variation and a possible account. Brain and Language, 96, 151–153.
Friedmann, N., & Grodzinsky, Y. (1997). Tense and agreement in agrammatic production: Pruning the
syntactic tree. Brain and Language, 56, 397–425.
Goodglass, H. (1993). Understanding aphasia. San Diego, CA: Academic Press.
Grodzinsky, Y. (2000a). Overarching agrammatism. In Y. Grodzinsky, L. Shapiro, & D. Swinney (Eds.),
Language and the brain: Representation and processing – Studies presented to Edgar Zurif on his 60th
birthday (pp. 73–86). San Diego, CA: Academic Press.
Grodzinsky, Y. (2000b). The neurology of syntax: Language use without Broca’s area. Behavioral and
Brain Sciences, 23, 1–71.
Haarman, H. J., Just, M. A., & Carpenter, P. A. (1997). Aphasic sentence comprehension as a resource
deficit: A computational approach. Brain and Language, 59, 76–120.
Hagiwara, H. (1995). The breakdown of functional categories and the economy of derivation. Brain and
Language, 50, 92–117.
Hickok, G., & Avrutin, S. (1995). Representation, referentiality, and processing in agrammatic
comprehension: Two case studies. Brain and Language, 50, 10–26.
Hickok, G., Zurif, E., & Canseco-Gonzalez, E. (1993). Structural description of agrammatic
comprehension. Brain and Language, 45, 371–395.
Izvorski, R., & Ullman, M. T. (1999). Verb inflection and the hierarchy of functional categories in
agrammatic anterior aphasia. Brain and Language, 69(3), 288–291.
Just, M. A., Carpenter, P. A., Keller, T. A., Eddy, W. F., & Thulborn, K. R. (1996). Brain activation
modulated by sentence comprehension. Science, 274, 114–116.
Kaan, E., & Swaab, T. Y. (2002). The brain circuitry of syntactic comprehension. Trends in Cognitive
Sciences, 6(8), 350–356.
Kean, M-L. (1995). The elusive character of agrammatism. Brain and Language, 50, 369–384.
COMPUTATIONAL SEMANTICS AND COMPREHENSION 49
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

Kolk, H. (1995). A time-based approach to agrammatic production. Brain and Language, 50, 282–303.
Law, S. P. (2000). Structural prominence hypothesis and Chinese aphasic sentence comprehension. Brain
and Language, 74, 260–268.
Linebarger, M. C., Schwartz, M. F., & Saffran, E. M. (1983). Sensitivity to grammatical structure in so-
called agrammatic aphasics. Cognition, 13, 361–392.
Marien, P., Saerens, J., Nanhoe, R., Moens, E., Nagels, G., & Pickut, B. A. et al. (1996). Cerebellar
induced aphasia: Case report of cerebellar induced aphasic language phenomena supported by SPECT
findings. Journal of Neurological Sciences, 144(1–2), 34–43.
Mauner, G., Fromkin, V. A., & Cornell, T. L. (1993). Comprehension and acceptability judgments in
agrammatism: Disruptions in the syntax of referential dependency. Brain and Language, 45, 340–370.
O’Grady, W., & Lee, M. (2001). The isomorphic mapping hypothesis: Evidence from Korean. Brain and
Cognition, 46, 226–230.
O’Grady, W., & Lee, M. (2005). A mapping theory of agrammatic comprehension deficits. Brain and
Language, 92, 91–100.
Pulvermuller, F. (2002). The neuroscience of language. On brain circuits of words and serial order. New
York: Cambridge University Press.
Saddy, J. D. (1995). Variables and events in the syntax of agrammatic speech. Brain and Language, 50,
135–150.
Steedman, M. (2001). The syntactic process. Cambridge, MA: MIT Press.
Thompson, C. K., Tait, M. E., Ballard, K. J., & Fix, S. C. (1999). Agrammatic aphasic subjects’
comprehension of subject and object extracted wh questions. Brain and Language, 67, 169–187.
Vosse, T., & Kempen, G. (2000). Syntactic structure assembly in human parsing: A computational model
based on competitive inhibition and lexicalist grammar. Cognition, 75, 105–143.
Wilson, S., & Saygın, A. (2004). Grammaticality judgment in aphasia: Deficits are not specific to syntactic
structures, aphasic syndromes or lesion sites. Journal of Cognitive Neuroscience, 16, 238–252.
APPENDIX
This is a simplified trace showing the major steps that Prolog would take while
parsing a simple active sentence. The answer to any given question posed during the
query might depend on the answers to other questions, which are written (indented)
beneath the question that depends on them. For purposes of this demonstration, the
following definite clause grammar is assumed:
S R NP VPNP R Det N VP R V NP
Det R a N R girl, rabbit V R chased
50 CLARK
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4

It should be noted that if degradeconst had been higher, the integrity values wouldhave been lower. For example, if degradeconst had been 4, the integrity values would
have been 96, 96, 92, and 88. In addition, if the final random number generated
during this simulation had been any higher, the overall parse would have failed,
although semantic representations for the NP and VP would have been saved to the
output file.
Question asked by the parser
Integrity of
constituent Random number
Is the input an S?
Does the input begin with an NP?
Does the constituent begin with a Det?
Does the constituent begin with the word ‘‘a’’?
Yes, the constituent begins with the word ‘‘a’’. 100
Is the next word an N?
Is the word ‘‘girl’’?
Yes, the word is ‘‘girl’’. 100
What is the integrity of the putative NP? 10022598
Is a random number between 1 and 100 lower than the
integrity value?
32
Yes, the random number is lower.
Yes, the input begins with an NP.
Is the next constituent a VP?
Is the next word a V?
Is the next word ‘‘chased’’?
Yes, the word is ‘‘chased’’. 100
Is the next constituent an NP?
Does the next constituent start with a Det?
Does the next constituent start with ‘‘a’’?
Yes, the constituent starts with ‘‘a’’. 100
Is the next word an N?
Is the next word ‘‘girl’’?
No, the next word is not ‘‘girl’’.
Is the next word ‘‘rabbit’’?
Yes, the next word is ‘‘rabbit’’. 100
What is the integrity of the putative NP? 10022598
Is a random number lower than the integrity value? 71
Yes, the random number is lower.
Yes, the constituent is an NP.
What is the integrity of the putative VP? 9822596
Is a random number lower than the integrity value? 11
Yes, the random number is lower.
Yes, the second constituent is a VP.
What is the integrity of the putative S? 9622594
Is a random number lower than the integrity value? 93
Yes, the random number is lower.
Yes, the input is an S.
COMPUTATIONAL SEMANTICS AND COMPREHENSION 51
Dow
nloa
ded
by [
"Uni
vers
ity a
t Buf
falo
Lib
rari
es"]
at 2
2:39
10
Oct
ober
201
4





























