Embed Size (px)
Citation preview

Vanessa Sofia Martins Lopes
Master of Science
A Computer-Based Therapy Game with a
Dynamic Difficulty Adjustment Model for
Childhood Dysphonia
Dissertation submitted in partial fulfillment
of the requirements for the degree of
Master of Science in
Computer Science and Informatics Engineering
Adviser: Prof. Dr. Sofia Cavaco,
Assistant Professor, Faculdade de Ciências e Tecnologia da
Universidade Nova de Lisboa
Examination Committee
Chairperson: Prof. Dr. Pedro Medeiros
Raporteur: Prof. Dr. Aníbal Ferreira
Member: Prof. Dr. Sofia Cavaco
December, 2018


AComputer-BasedTherapyGamewith aDynamicDifficultyAdjustmentModel
for Childhood Dysphonia
Copyright © Vanessa Sofia Martins Lopes, Faculty of Sciences and Technology, NOVA
University Lisbon.
The Faculty of Sciences and Technology and the NOVA University Lisbon have the right,
perpetual and without geographical boundaries, to file and publish this dissertation
through printed copies reproduced on paper or on digital form, or by any other means
known or that may be invented, and to disseminate through scientific repositories and
admit its copying and distribution for non-commercial, educational or research purposes,
as long as credit is given to the author and editor.
This document was created using the (pdf)LATEX processor, based in the “novathesis” template[1], developed at the Dep. Informática of FCT-NOVA [2].[1] https://github.com/joaomlourenco/novathesis [2] http://www.di.fct.unl.pt


Acknowledgements
This work was supported by the Portuguese Foundation for Science and Technology un-
der the projects BioVisualSpeech (CMUP-ERI/TIC/0033/2014) and also NOVA-LINCS
(PEest/UID/CEC/04516/2013).
First, I would like to express my gratitude to my advisor, Prof. Dr. Sofia Cavaco,
for her knowledge, support, and motivation, during the last year. For the exceptional
supervision that helped me achieve the work presented in this thesis. It was a great
pleasure to work with her.
I also want to thanks to Ines Jorge, for the fantastic designs produced. The final result
is perfect and would not be the same without her commitment.
A special thanks to all the therapists that participated directly or indirectly in the
furtherance of this project. Specifically, to Diana Lança, Cátia Pedroso, Sónia de Jesus
Lima and Nuno Silva for the availability, guidance, and knowledge during this last year.
I want to highlight the disponibility of the nursery school Alfredo da Mota in Castelo
Branco and the therapist Liliana for allowing me to validate the game platform with
children, which contributed a lot to the accomplishment of this work.
I also want to thankmy lab colleges, David, Flavio, Ivo, Gustavo andAndré for helping
me during the last year, for the great moments, philosophical discussions and all the
kindness and fun brought to the office. That lab has no identity without them!
To my special friends Daniela, Joana Silva, Joana Tavares, Joana Lopes, Frederico and
Catarina. For their friendship during the past 5 years and for being always there for me.
Also, to my nerd friends Pedro, Luis, Eduardo, and Daniel for the companion, support,
and friendly advices.
To my beloved, crazy and handsome friends André Pontes and Gonçalo Marcelino...
It was a long journey, that would not be so fun and memorable without them. For whom
I would like to tell, um bem haja.
To my best friend, Iana Lyckho, who was always prompt for support, advice... and
everything. For giving me so many good moments not only during the last year but also
through the remaining ones. We will always be partners in "crime."
To my uncle, a special thanks for his guidance and inspiration to overcome myself.
For being always supportive throughout the past 5 years.
Lastly, to my dad, my mom and my brother for being my home, my support and,
specially, for the effort along the past 5 years. This would never be possible without them.
v


Abstract
Problems in vocal quality are present in 4 to 12-year-old children, which may affect their
health as well as their social interactions and development process. Speech therapy has
a central role in their recovery and vocal re-education. Throughout the therapy sessions
with children, it is essential to keep them motivated and with the will to learn. With
the current digital advances, characterized by the increasing consumption of computer
devices, we seek to find new ways to practice the exercises included in the traditional
therapy sessions. These exercises should be adapted to the capabilities of each child so
that their experience follows a course without frustration nor boring moments.
For this purpose, we propose a computer-based therapy game that offers a new pow-
erful and engaging way of practicing the sustained vowel exercise. This interactive tool
was developed taking into account a set of scenarios and characters with an infant theme,
coupled with a gamification strategy to reward a player’s success. Additionally, to auto-
matically adapt the difficulty of the challenges in response to the child’s performance, we
created a novel dynamic difficulty adjustmentmodel. To measure the child’s performance,
the model uses parameters that are relevant to the therapy treatment.
Moreover, to allow an intensive training outside sessions, we developed an automatic
recognition system for the Portuguese vowels. The model is composed of the best combi-
nation of sound features extraction algorithms and classification algorithms. The merge
of these game components endeavors to challenge the child to practice the exercises with
higher performance and to prompt, in the long term, a healthy and stimulating therapy
process.
Keywords: Dysphonia, Sustained vowel exercise, Automatic sound recognition, Loud-
ness, Maximum phonation time, Dynamic difficulty adjustment model.
vii


Resumo
Os problemas na qualidade vocal estão presentes, sobretudo, em crianças entre os 4 e
os 12 anos e afetam as suas interações sociais e o seu processo de desenvolvimento, além
da saúde dos mesmos. A terapia da fala tem um papel fulcral na recuperação e reeducação
vocal, tanto a nível das patologias da voz, como da fala. Ao longo das sessões de terapia
com a criança, é importante manter a mesma motivada e suscetível à aprendizagem. Num
mundo tecnológico caracterizado pelo consumo crescente de dispositivos móveis e de
computadores, é fundamental encontrar exercícios alternativos que complementem as
sessões de terapia tradicionais, e que possam recorrer dos avanços tecnológicos atuais
para esse efeito. Por sua vez, esses exercícios devem ser adaptados às dificuldades de cada
criança para que a mesma não se sinta frustrada com a incapacidade de resolução das
tarefas ou que se aborreça com a facilidade das mesmas.
Desta forma, propõe-se um jogo sério para uso para complemento de terapia da fala,
que ofereça uma nova forma desafiante de praticar o exercício da vogal sustentada. Esta
ferramenta interativa foi desenvolvida tendo em consideração um conjunto de cenários
e personagens envolvidos num tema infantil, associado a uma estratégia de gamificação
com brindes conquistados a cada desafio ultrapassado com sucesso. Adicionalmente, de
forma a adaptar automaticamente a dificuldade dos desafios à performance da criança,
desenvolvemos um novo modelo dinâmico de ajuste da dificuldade. A medição da perfor-
mance da criança tem por base variáveis relevantes no contexto de terapia.
Ainda assim, de forma a permitir um treino intensivo fora das sessões de terapia,
desenvolvemos também um sistema de reconhecimento para vogais do português euro-
peu. Este modelo é composto pela melhor combinação de features extraídas do som com
algoritmos de classificação. A junção destas funciononalidades num único jogo, permite
estimular a criança a praticar o exercício com maior desempenho e a aumentar, a longo
prazo, os resultados do tratamento.
Palavras-chave: Disfonia, Exercício da vogal sustendada, Reconhecimento automático
de som, Frequência, Amplitude, Modelo dinâmico de ajustamento da dificuldade.
ix


Contents
List of Figures xiii
List of Tables xv
Acronyms xvii
1 Introduction 1
1.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Objectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Proposed Solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.5 Document structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Fundamental concepts 7
2.1 Speech Therapy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 The sound . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.2 The voice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.3 Classification of voice disorders . . . . . . . . . . . . . . . . . . . . 13
2.1.4 Treatments for voice disorders . . . . . . . . . . . . . . . . . . . . . 15
2.2 Speech processing and Machine Learning . . . . . . . . . . . . . . . . . . 16
2.2.1 Spectrum Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2.2 Speech processing and extraction . . . . . . . . . . . . . . . . . . . 16
2.2.3 Additional Sound Features . . . . . . . . . . . . . . . . . . . . . . . 18
2.2.4 Classification algorithms . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 Player-adaptability models . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3 State of Art 21
3.1 Tools for speech therapy . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.1 Without sound recognition . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.2 With unspecified phoneme recognition . . . . . . . . . . . . . . . . 23
3.1.3 With identification of specific phonemes . . . . . . . . . . . . . . . 24
3.2 Tools with a DDA model . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3 Tools comparison . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
xi

CONTENTS
4 Game and Architecture 29
4.1 Proposed game . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.1.1 The sustained vowel exercise . . . . . . . . . . . . . . . . . . . . . 30
4.1.2 Game scenarios and gamification strategy . . . . . . . . . . . . . . 30
4.1.3 Visual feedback . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.1.4 Game parametrization . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.2 Platform architecture, design and structure . . . . . . . . . . . . . . . . . 34
4.2.1 System architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.2.2 Game’s storyboard . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5 A Novel Dynamic Difficulty Adjustment model 41
5.1 The DDA model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
5.1.1 Maximum phonation time . . . . . . . . . . . . . . . . . . . . . . . 43
5.1.2 Speech intensity level . . . . . . . . . . . . . . . . . . . . . . . . . . 45
6 Automatic Sound Recognition System 51
6.1 Data set characterization . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
6.2 Automatic recognition system of vowels . . . . . . . . . . . . . . . . . . . 53
6.2.1 Feature extraction techniques . . . . . . . . . . . . . . . . . . . . . 53
6.2.2 Data preprocessing and analysis . . . . . . . . . . . . . . . . . . . . 55
6.2.3 Data visualization and feature analysis . . . . . . . . . . . . . . . . 57
6.2.4 Model estimation methodology . . . . . . . . . . . . . . . . . . . . 58
6.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
6.3.1 Comparison between different classifiers . . . . . . . . . . . . . . . 59
6.3.2 Effect of varying the number of MFCCs . . . . . . . . . . . . . . . 60
6.3.3 Effect of varying the train and test sets . . . . . . . . . . . . . . . . 61
6.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
7 Feedback and Validation 67
7.1 Feedback from SLP(s) and heterogeneous audiences . . . . . . . . . . . . 67
7.2 Validation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
7.2.1 User testing sessions . . . . . . . . . . . . . . . . . . . . . . . . . . 69
7.2.2 Questionnaire to SLTs . . . . . . . . . . . . . . . . . . . . . . . . . 72
7.2.3 Validation conclusions . . . . . . . . . . . . . . . . . . . . . . . . . 76
8 Conclusion and future work 79
8.1 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
8.2 Future work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
Bibliography 83
xii

List of Figures
1.1 A child practicing an exercise from our proposed solution. . . . . . . . . . . . 4
1.2 Proposed game platform. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1 Sinusoidal wave. Source: [43] . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Main places of articulation in the vocal tract. Source: [21] . . . . . . . . . . . 12
2.3 Broadband spectograms of nine standard EP oral vowels produced by a female
speaker. Source: [31] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4 Mel filters in a 8000 Hz signal. Source: [14] . . . . . . . . . . . . . . . . . . . 18
2.5 Flow model proposed by Csikszentmihalyi [42]. . . . . . . . . . . . . . . . . . 20
3.1 Training game with phonemes for articulation problems. Source: [51] . . . . 22
3.2 Falar a brincar game. Source: [23] . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.3 Scenarios of the robust gamewith voice exercises for speech therapy. Source: [10] 23
3.4 Scene from the serious game for sustained vowel Source: [29] . . . . . . . . . 24
3.5 Screenshot from the sPeAK-MAN interface. Source: [48] . . . . . . . . . . . . 24
3.6 Tool with virtual therapist for aphasia treatment. Source: [39] . . . . . . . . . 25
3.7 Screenshot from the Interactive Game for the training of portuguese vowels.
Source: [7] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.1 The figure illustrates the interaction between the character and the target in a
scene context. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.2 Scenarios available for the exercise page. . . . . . . . . . . . . . . . . . . . . . 31
4.3 Set of characters available, representing both genders and four different ethnies. 32
4.4 Available rewards. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.5 Add child basic info scene. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.6 Character’s falling feedback. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.7 Client-server architecture. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.8 Activity diagram of the game platform. . . . . . . . . . . . . . . . . . . . . . . 36
4.9 Start page scenario. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.10 Choose characters (left) and see rewards (right) scenarios. . . . . . . . . . . . 38
4.11 Add child basic info scene. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.12 Treatment editable parameters. . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.13 SLP and children’ game options. . . . . . . . . . . . . . . . . . . . . . . . . . . 39
xiii

List of Figures
5.1 Scheme for updating MPTe. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.2 Allowed variation intensity level intervals, ∆L. The figure illustrates a case
with Lm = 50 dB, LM = 70 dB, and Le = 60 dB. The orange line illustrates the
time-varying speech intensity level achieved by the child, La(t). . . . . . . . . 46
5.3 Scheme for updating ∆L, with the influence of MPT variable. . . . . . . . . . 48
6.1 Comparative samples with 100 ms from the sustained phonemes /a/, /i/ and
/u/, with pitch and formants marked as blue and red, respectively. . . . . . . 53
6.2 Steps in the development of our vowel ASR system. . . . . . . . . . . . . . . . 54
6.3 Comparative samples from the sustained phonemes /a/, /i/ and /u/, with 40
filter banks and 13 MFCCs. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
6.4 Radial visualization of the data set 1. . . . . . . . . . . . . . . . . . . . . . . . 57
6.5 Comparative dimensionality reduction for two features, with PCA e LDA tech-
niques. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.6 Classifiers’ performance comparison regarding different train and test split-
ting methods. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
6.7 Classifier performance for the kernel SVM and the randon split, regarding the
number of MFCCs and different data sets. . . . . . . . . . . . . . . . . . . . . 61
6.8 Classifier performance for the kernel SVM with different data sets. . . . . . . 62
6.9 Comparative features distribution with radial visualization for each data sets
with FB. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
6.10 Vowel detection confusion matrices. . . . . . . . . . . . . . . . . . . . . . . . 65
7.1 Game presentation in the European Congress of Speech and Language Ther-
apy, May 2018. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
7.2 Basic information regarding the participants. . . . . . . . . . . . . . . . . . . 69
7.3 The setup used for the recordings. . . . . . . . . . . . . . . . . . . . . . . . . 70
7.4 Children’s performance during the experiment. . . . . . . . . . . . . . . . . . 71
7.5 Results regarding the SLPs and children interactions with the game platform. 73
7.6 Answers regarding the question Q10. . . . . . . . . . . . . . . . . . . . . . . . 74
7.8 Answers about the question Q15. . . . . . . . . . . . . . . . . . . . . . . . . . 76
xiv

List of Tables
2.1 Ages for each gender of children in the study. Source: [50] . . . . . . . . . . . 10
2.2 MPT for children between 4 and 12 years producing the sustained vowel / a
/. Source: [50] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3 Parameters of GRBAS scale. Source: [36] . . . . . . . . . . . . . . . . . . . . . 11
3.1 Comparative table that summarizes the described tools for Speech Therapy. . 27
5.1 Allowed intensity levels and intensity interval sizes in dB (SPL). . . . . . . . 42
5.2 Evolution of child’s performance during four trials. . . . . . . . . . . . . . . . 49
6.1 Number of samples for each vowel. . . . . . . . . . . . . . . . . . . . . . . . . 52
6.2 Total number of children that perform the records from both datasets . . . . 52
6.3 Number of samples in the data sets 1-6. . . . . . . . . . . . . . . . . . . . . . 63
xv


Acronyms
APQ Amplitude Perturbation Quotient.
ASR Automatic Sound Recognition.
BVS BioVisualSpeech.
CPP Cepstral Peak Prominence.
DCT Discrete Cosine Transform.
DDA Dynamic Difficulty Adjustment.
EP European Portuguese.
ETMPT Emission Technique in Maximum Phonation Time.
FB Filter Bank.
FFT Fast Fourier Transform.
HNR Harmonic-Noise Ratio.
LDA Linear Discriminant Analysis.
LSVT Lee Silverman Voice Treatment.
MFCC Mel-Frequency Cepstral Coefficients.
MPT Maximum Phonation Time.
PCA Principal Component Analysis.
PhoRTE Phoneme Resistance Training Exercise.
PLVT Pitch Limiting Voice Treatment.
PPQ Pitch Perturbation Quotient.
QDA Quadratic Discriminant Analysis.
RF Random Forest.
xvii

ACRONYMS
SLP Speech and Language Pathologists.
SOVT Semi-Occluded Vocal Tract.
SSD Speech Sound Disorders.
SVE Sustained Vowel Exercise.
SVM Support Vector Machine.
xviii

Chapter
1Introduction
We speak not only to tell other people what we think, but to tell ourselves what we think. Speech
is a part of thought.
- Oliver Sacks
1.1 Overview
Speech is one of the most important ways to communicate in current societies. Many
children have speech sound disorders (SSD) that may affect not only their health but also
their social interactions and development process [19].
Deviations in the quality of an individual’s voice are known as dysphonia. These can
be identified through vocal quality parameters, such as the perception of the frequency
produced (pitch) or the intensity of the sound emitted (loudness) [21]. Childhood dyspho-
nia cases can occur as a result of an inappropriate vocal behavior or due to neurological,
physiological or social factors, among others. Studies on vocal analysis with children
between the ages of 2 to 12 years, report that voice disorders affect from approximately 4
to 38% of children, with hoarseness and breathy voice as the most frequent problems [11,
36, 49].
Dysphonia occurs more often in boys than in girl [36], possibly because of the vocal
effort and their personality traits. Until the entrance to primary education, the parame-
ters of vocal quality (the Chapter 2 addresses this concept) in children are very similar,
regardless of gender, and only tends to diverge when vocal changes occur in boys.
On the other hand, a speech disorder is associated with a problem in the articulation
of the sound [21], through the incorrect use of several articulators - throat, teeth, tongue,
lips, among other muscles and organs. These failures might be expressed in the exchange
of some sounds, the omission of phonemes in words, among other disturbances more or
1

CHAPTER 1. INTRODUCTION
less explicit.
In some cases, voice and speech pathologies can be naturally corrected while children
grow up [5, 21]. In other cases, the child may need to attend speech therapy for recovery
and vocal re-education, both concerning voice and speech pathologies. To detect and
treat dysphonia symptoms, speech and language pathologists (SLPs) in therapy sessions
with children commonly focus on pitch or loudness training, as well as, in the maximum
phonation time exercise, through the use of the sustained vowel exercise (SVE) [3, 12, 33,
47]. The goal of this exercise is to say a vowel for as long as possible while maintaining
the voice intensity level stable. The SVE is widely used in therapy sessions to evaluate the
patient’s voice quality, detect the existence of dysphonia, the severity of the pathology,
as well as to complement the treatment for dysphonia. For instance, it may be used to
correct hoarse voices. Additionally, this exercise is used with voice professionals like
actors and journalists, who make a constant vocal effort and need to learn how to put
the voice correctly. This exercise is also commonly used in therapy with patients with
Parkinson’s disease [12, 47].
In traditional therapy, dysphonic children usually attend speech therapy sessions only
once per week, and as a consequence they might have a slow progress curve, giving that
they do not repeat them with the desired frequency and cumulative intervention inten-
sity [19, 52]. With a portable solution to practice the exercises without the need for
supervision, it would be possible to perform therapy more often. With more frequent
sessions per week, which is known as intensive training, the results are considerably im-
proved. Repeating the vocal exercises used to correct voice problems may be monotonous
and tiring [5, 13]. Therefore, SLPs usually try to create more appealing sessions through
the use of several techniques, such as board games. Some SLPs even build PowerPoint an-
imations or try to adapt computer games that can be controlled manually: when the child
does the therapy exercise correctly, the SLP uses the powerpoint animations or makes the
game progress to motivate the child on doing the exercises.
The possibility of developing this type of tool, combined with a strategy of gamifica-
tion with rewards, introduces a positive stimulus for the child [13]. It induces the child
to practice to follow the regular training program with a stronger will and improve their
results. Such games should fit heterogeneous groups, where each child has capacities and
needs that grow while she is performing the exercises within the treatment. Moreover,
since different children have different needs, computer games and challenges for speech
and language therapy should adapt the difficulty of the tasks to the children needs and
capabilities.
Moreover, children are naturally motivated to use interactive displays. Thus, tak-
ing advantage of the current technological advances, several computer and mobile games
have been developed to complement traditional speech therapy techniques [13, 19]. Some
of these games can assist SLPs on keeping the children motivated on doing the therapy
exercises, such as the set of applications from the LittleBeeSpeech [23], Falar a Brin-
car [51], and sPeAK-MAN [48], which focus on articulation problems, alternatively,
2

1.2. OBJECTIVES
Flappy voice [28] and the Interactive Game for the training of Portuguese vowels [7]
which focus on problems like apraxia and vowels recognition, respectively.
Here we propose a platform that uses the sustained vowel exercise, usually performed
in the traditional therapy sessions. The tool incorporates a player-adaptable system,
to automatically adjust the exercise’s difficulty according to the player’s performance.
Additionally, the tool includes a gamification strategy with UI elements involved in a
childhood theme. Lastly, we present an automatic sound recognition system to identify
the produced vowel.
1.2 Objectives
This dissertation is part of the BioVisualSpeech project, which includes the partnership of
the Faculty of Sciences and Technologies of NOVAUniversity, Carnegie Mellon University,
INESC-ID, the company Voice Interaction, as well as institutes specialized in speech, the
School of Health of Alcoitão, and the Hospital Center of Lisbon. The project BioVisual-
Speech aims to investigate interaction mechanisms that aid speech therapy with children
and complement traditional therapy sessions with exercises tailored to the children’ needs.
Therefore, the project has developed a game focus on the treatment of voice and speech
pathologies, based on the European Portuguese (EP) language. Our solution purpose is to
contribute with a tool for the treatment of voice disorders and seek to improve the voice
quality of children between 5-9 years-old, to balance the values of maximum phonation
time (MPT) and loudness. As a contribution to improving the motivation of children on
performing the SVE, we have developed a serious computer game for this exercise.
Regarding the heterogeneous children’ situations, therapists might use different types
of age-appropriate exercises so that therapy is as effective as possible. It is also important
to consider the level of difficulty appropriate to the patient. Easy activities may not
sufficiently challenge the child, while overly strenuous activities can become frustrating
for the patient and limit their progress in treatment. Establishing the appropriate level
to the child’s abilities results in better performance and better treatment outcomes. Thus,
the principles of this treatment should begin with a level that allows the child to be
successful, gradually increasing the level of difficulty until the approximate results of
natural communication are achieved, with the minimization or total correction of the
disorder.
Additionally, it is important to include visual feedback and a gamification strategy
with prizes which can contribute to the creation of an interactive game environment,
with a motivational impact and reinforcement of the player’s focus and performance. The
game should allow intensive training, with a platform that automatically recognizes the
utterances produces by the child outside the therapy environment. In Figure 1.1 we
present a child practicing at home our solution, and so, she can perform the therapy task
with the SVE outside the traditional therapy sessions. The aspects reported so far lead
3

CHAPTER 1. INTRODUCTION
to an engaging and challenging problem to deal with in a dissertation context and are
described in the following chapters.
Figure 1.1: A child practicing an exercise from our proposed solution.
1.3 Proposed Solution
This dissertation presents a game for the SVE practice, an exercise used in therapy sessions
with dysphonic children. Here we propose a new and motivating tool as a new way to
perform therapy. This game includes the primary characteristics described in Figure 1.2.
Two simpler versions of this game platform have previously been proposed [10, 29].
Diogo [10] developed a solution with a set of scenarios within a child theme, without
an automatic sound recognition system or parametrization allowed. Lopes et all. [29]’s
solution included two scenes where the child’s voice controls the game character and
allows manual parametrization through SLP. Both versions had some limitations, and so
we develop a full new version, and we recovered the scenarios used from the previous
work.
The game’s current version includes (1) a set of different scenarios andmain characters
which are controlled in real time with the child’s voice. In this way, we try to offer a
game platform interesting to children with different tastes and interests. On the other
hand, (2) the real-time feedback allows the child to become self-aware of the quality of
her utterance, to see her progress while she self-corrects her phoneme productions to
accomplish the game goals. Additionally, the game presents (3) gamification elements to
prompt a healthy and stimulating therapy process.
An essential characteristic of the game is that it can be adjusted to each child’s needs
through a set of customization parameters. We also propose (4) a dynamic difficulty
adjustment (DDA) model that allows the game to meet the child’s changing needs as
well as capabilities so that the child does not feel frustrated with the inability to solve
the tasks nor loses the motivation on doing the exercise when the tasks are too easy for
the child. For that, the game automatically adapts the difficulty of the challenge based
on the child’s performance during the previous trials. Moreover, we implemented (5)
a client-server architecture, to guarantee the practice of the game in the child’s mobile
4

1.4. CONTRIBUTIONS
Figure 1.2: Proposed game platform.
device. This architecture spares the load from the device side (client) and forwards it to
the server so that it can be appropriately analyzed and the accurate feedback returned in
real time during the child’s trial.
1.4 Contributions
• Research concerning the speech therapy area, specifically solutions with the SVE
for childhood dysphonia.
• A speech therapy tool with a gamification strategy with multiple scenes, characters
and rewards for children;
• A novel DDA model for children with dysphonia, based on the use of the therapy
variables: MPT and Loudness;
• An ASR system for vowels from the EP language, with the testing of distinct ma-
chine learning algorithms and the analysis of the combination of different features;
• A validation process including the target audiences of our game, children and ther-
apists;
5

CHAPTER 1. INTRODUCTION
Moreover, the dynamic difficulty adjustment model was presented in an accepted
scientific paper [30].
1.5 Document structure
For a description of the work performed during the dissertation, we propose the following
organization of this document:
Chapter 2 (Fundamental Concepts) This chapterwill discuss the introductory concepts
involving speech therapy, since the acoustic and auditory-perceptive characteristics
of sound and voice, through the analysis of the degree of severity of dysphonia in
children and, lastly, the treatments for these disorders. Additionally, we include
a description of the machine learning models explored, as well as, the dynamic
difficulty adjustment concept, in order to support the developed work.
Chapter 3 (State of Art) Chapter 3 will contain related work to our problem, specifi-
cally, tools that have already been developed for speech therapy with and without
identification of specific sounds and phoneme. Moreover, we present tools that
include a DDA model and a final comparison between the described tools.
Chapter 4 (Game and Architecture) This chapter will focus on all the details of the
game, from the type of exercises included in the structure - the story that intercon-
nects the scenarios - as well as the architecture of the game.
Chapter 5 (A novel Dymanic Difficulty Adjustment model) In this chapter we discuss
the DDA used in our game, which is a more complex model with two parameters to
measure the child’s performance and decides how to increase the game’s difficulty
based on this performance measure.
Chapter 6 (Automatic Sound Recognition System) This chapter focuses on the analysis
of the sound recognition system adopted for classification of sustained vowels. It
includes the extraction of the data for the preprocessing of the information to be
sent to the classifier, prepared through different training and test sets. Lastly, we
combine it with different classifiers and compare the respectively results;
Chapter 7 (Feedback and validation) Here we present the feedback received from het-
erogeneous audiences for the game developed. Furthermore, we describe the vali-
dation methodologies applied with the target audiences, children and SLPs;
Chapter 8 (Conclusion and future work) Here we present the final conclusion and few
ideas for future work.
6

Chapter
2Fundamental concepts
In this chapter, we present the definitions and terminologies on the theme of voice disor-
ders, concepts that were fundamental to support the elaboration of this dissertation. More
specifically, it was necessary to study sound, acoustic and perceptive-auditory analysis of
voice, as well as the analysis of voice problem and its solutions.
This chapter presents in the section 2.1 the definition of the main notions of sound,
voice and its articulators. More is added to the spectral analysis of the sound, in particular
the vowels, and techniques for treating problems with the use of sustained vowels, since
the exercises to be developed are based on this type of exercise. In the following section
(Section 2.2), we introduce the features extraction techniques that support the implemen-
tation performed as well as the classification algorithms that define our ASR system. In
the last section, Section 2.3, we present some related work regarding player-adaptable
models that we intend to follow.
2.1 Speech Therapy
It is necessary to understand for each child therapy process, the problem to be addressed
and its sources so that they can be approached with the appropriate tools for each situa-
tion. With this purpose, we present some introductory concepts regarding the area. Note
that, in this dissertation, we are exclusively focused on the treatment of voice disorders.
Thus, any reference to speech therapy problems and its solutions will be associated with
that.
2.1.1 The sound
The sound can be understood as the result of a mechanical disturbance caused by the
vibration of an object [31]. However, the sensation of hearing is not directly derived from
7

CHAPTER 2. FUNDAMENTAL CONCEPTS
this same vibration. The vibration of an object may cause the formation of a wave in
air or other medium, provided that it is elastic and inert, and whose properties allow
random oscillation of the particles in that atmosphere [53]. When an object vibrates in
a medium, consider the example of air, the particles tend to move in the direction along
which the object moves. Beginning with the particles closest to the object, energy and
motion are propagated to the adjacent particles and thereafter, from the vibrating source
to the receivers.
In this way, as long as an object has the properties of inertia and elasticity, it can vibrate
and, with this, be a sound source. When an object with mass begins its vibration and if
there is no friction to the movement, the oscillation continues infinitely. The execution
of a force on the object triggers its movement and consequently causes the output of its
equilibrium point, up to a given maximum distance, A. Therefore, the distance d(t) to
the point of equilibrium, θ, exhibits an oscillatory motion that stands between -A and A,
in a sinusoidal motion, as shown in figure 2.1.
Figure 2.1: Sinusoidal wave. Source: [43]
A sinusoidal wave can be characterized by two types of analysis: physical or percep-
tual. The parameters concerning the physical description of the wave are: amplitude,
frequency and start phase or equilibrium point. The amplitude of a sound wave is deter-
mined by the distance between the maximum pressure point and the minimum pressure
point of the wave [53]. Note that the larger the amplitude, the greater the amount of
energy that is carried. Frequency is another physical wave’s characteristic, it is measured
in Hertz (Hz) and is defined by the number of times a full cycle of vibration repeats for
one second. Lastly, the start phase is the relative position of an object at the moment the
movement or vibration begins. It is generally defined in terms of degrees of an angle.
The vibratory motion of an object is defined by the previous properties. As already
mentioned, it is also possible to characterize the physical stimulus, that is, the sine wave,
concerning the human perception of the previous parameters. Changes in the amplitude
of a sinusoidal are associated with the loudness. Moreover, the frequency variations
are associated with the pitch. The differences in the perception of the initial phase of
the wave by the two ears result in changes in the perceptual location of the beginning
8

2.1. SPEECH THERAPY
of the stimulus. The loudness concept corresponds to the individual perception of the
sound amplitude and the higher the intensity, the higher the sound is perceived, and vice
versa [44]. Additionally, Pitch is the human being perception of the sound frequency [45].
The higher the frequency, the higher the pitch is perceived. On the other hand, the lower
the frequency, the lower the pitch of the sound.
Fourier derived the theorem that shows that any vibration can be reduced to the sum of
several sinusoidal waves with their own amplitude, frequency and initial phases [53]. The
wave that results from this sum is called a complex wave. The representation of the wave
graphically can be made by means of a spectrum of magnitudes, when the magnitude of
each sinusoidal is represented as a function of its frequency. The graphical representation
of the initial phase of each sinusoidal component as a function of frequency is called
the phase spectrum. The graphical representation of the temporal domain exposes the
amplitude-frequency relation as a function of time. The graphical description according
to these relations results from the application of the Fourier theorem.
2.1.2 The voice
The voice can be understood as the sound produced from laryngeal activity, more specif-
ically, the result of the relation between the pressure and velocity of the exhaled air
flow, with the interaction between the articulators of the human respiratory system [21].
Through this interaction, the quality and suitability of the voice can be affected. Voice
quality is associated with common standards, while voice adequacy is associated with a
deviation / variation of these standards, without affecting quality.
2.1.2.1 Voice Measures
For diagnosis and choice of the appropriate treatment, it is necessary to evaluate the vocal
quality of the individual to perceive the degree of pathology, if it exists. The analysis of
these parameters can also be performed for the detection of a possible dysphonia or
laryngeal pathology.
Maximum phonation time (MPT) Maximum phonation time is the maximun time (in
seconds) a person can sustain a vocal sound (for example a vowel), after taking a
deep breath and producing the sound with a comfortable level of intensity [46]. The
values resulting from this measurement express the individual’s ability to control
their respiration [8]. To calculate the sound emission time, the following steps must
be followed:
1. Ask the patient to breathe deeply, and then say the sustained vowel /a/ for as
long as possible, at a comfortable vocal intensity and height. Use a stopwatch
(in seconds) during the exercise to measure the duration of the sustained vowel.
2. Repeat step 1 and record the results as step 2 for the same sustained vowel.
9

CHAPTER 2. FUNDAMENTAL CONCEPTS
3. Repeat step 1 and record the results again for the same vowel.
4. The MPT is the maximum length of the vowel of the steps 1, 2 and 3.
It is recommended the use of acute vowels /i/, grave /u/ and medium /a/. The type
of vocal register cord of each individual influences the MPT, with higher pitched
voices typically presenting lower MPT values [21, 46]. Note that, for very low values
of MPT, outside normal age and gender patterns, there might be present a vocal
dysfunction or laryngeal pathology (these disorders will be analyzed in the 2.1.3
section).
Table 2.1: Ages for each gender of children in the study. Source: [50]
Gender
Boy Girl TotalAge (y:mo) n % n % n %
4:0–6:11 185 47.56 aA 204 52.44 aB 389 1007:0–9:11 483 50.52 aA 473 49.48 aB 956 10010:0–12:00 156 49.52 aA 159 50.48 aB 315 100Total 824 49.64 836 50.36 1660 100
Table 2.2: MPT for children between 4 and 12 years producing the sustained vowel / a /.Source: [50]
Gender Boy Girl Total
Age(y:mo)
MPT/a/
MPT/a/
MPT/a/
4:0-6:11 6.02 ± 1.77 aA 6.22 ± 1.99 aA 6.12 ± 1.89 a7:0-9:11 8.05 ± 1.98 bA 7.90 ± 1.98 bA 7.98 ± 1.98 b10:0-12:00 9.22 ± 2.33 cA 9.05 ± 2.02 cA 9.14 ± 2.18 c
The values presented in the Tables 2.1 and 2.2 can be used as normative for a
comparison term with the samples obtained with the MPT of children concerning
the study in this dissertation.
Fundamental frequency (F0) The fundamental vocal frequency is defined as the fre-
quency of the sound produced by the vocal chords, i.e., it represents the vibration
of the vocal folds per unit of time [8]. Changes in F0 have been associated with
human growth and development. In general, there is a marked decrease in the first
two to three years of life, and from there a gradual decline to puberty. The study
cited in [21] has shown variation in F0 between vowels, more specifically:
• Vowel /u/ - 177,4Hz;
• Vowel /i/ - 174,9Hz;
• Vowel /a/ - 160,9Hz;
10

2.1. SPEECH THERAPY
The same authors put /u/ and /i/ in the category of the vowels [+ high] and /a/ in
the category of the vowels [+ lows]. Moreover, it can be identified a variability in
F0 of the sustained vowels, compared to the F0 resulting from speech production,
being lower in the latter case [21]. Regarding the analysis of F0 in voices with or
without dysphonia, the measurements obtained do not allow to distinguish signif-
icantly the majority of the individuals with pathological voice of the individuals
with the common voice patterns.
Frequency perturbation quotient (PPQ) The PPQ is a method of extraction of jitter
(fundamental frequency disturbance) and is calculated by averaging the frequency
perturbations for each cycle [36].
Amplitude perturbation quotient (APQ) The APQ is a method of extracting the shim-
mer (amplitude perturbation) and is calculated by averaging the amplitude pertur-
bations for each cycle [36].
Spectral noise measurements The Harmonic-Noise Ratio (HNR) is a measure of distur-
bance in noise, being calculated by the proportion of noise present in a spectrum in
relation to the proportion of harmonics in the same spectrum [36]. A more detailed
description of the vocal spectra is given in the 2.3 section.
GRBAS scale - Subjective method of vocal analysis The scale of GRBAS [36] measures
the set of dysphonia degrees through a scale that varies between the values pre-
sented in the first column of the 2.3 Table. These measures are analyzed subjectively
by the SLP, regarding four vocal alteration parameters.
Table 2.3: Parameters of GRBAS scale. Source: [36]
Overall degree of severity Perception-auditory characteristics
0 - normal or absent Roughness (R)1 - discrete Breathy voice (B)2 - moderate Asthenia (weak voice) (A)3 - severe Strain (S)
An example is the result G1R2S2A0S1, which is translated by the following dys-
phonia: discrete global degree, moderate roughness, moderate breathiness, absent
asthenia and discrete tension.
Cepstral peak prominence (CPP) The CPP is an acoustic measure that has shown to be
quite promising for the measurement of the degree of severity of the disturbances
in the voice [6, 17, 24]. This measure helps the definition of the level of harmonicity
in the voice. Voices with greater period of signal are considered voices more harmo-
nious. Voices with higher CPP values are considered as more harmonious voices.
The great advantage of CPP is that it does not depend on the quality of the sound
11

CHAPTER 2. FUNDAMENTAL CONCEPTS
recorded or the volume differences in it for measuring the parameters of interest.
Additionally, you do not need to analyze periodic or extended sound samples for a
valid production of the CPP result.
2.1.2.2 Phonation
When speech is produced, air is exhaled from the lungs, passing through the throat [53].
It is at the top of the throat, more specifically in the larynx, that the vocal folds that
vibrate in response to air expiration and under the control of the muscles. The vibration
of the strings in sound wave form causes resonance 1 in the vocal tract. Voiced sounds
are produced by the vibration of the vocal chords in their state of separation, while non
voiced sounds are produced with the vocal folds in the joint movement.
2.1.2.3 Articulation
The articulatory system is composed of several organs responsible for the production
of speech and are mostly located in the oral cavity [31]. The vocal tract is divided into
two zones: the anterior zone, which lies between the lips and the hard palate, and a
posterior zone, which encompasses the remaining articulators, represented in figure 2.2,
until to the posterior wall of the pharynx. The intervention of these articulators allows
the production of speech, characterized by distinct articulation modes that give rise to
the production of different sounds in the communication process.
Figure 2.2: Main places of articulation in the vocal tract. Source: [21]
2.1.2.4 Articulatory classification of the European Portuguese (EP) vowels
The articulatory classification is defined as a form of categorization of speech sounds 2 [31].
The tongue is the main articulator responsible for defining the vowels. More specifically,
the height of the dorsum of tongue (high, medium or low relative to the neutral position
in the oral tract) and the relation to the point of articulation (the dorsum of the tongue
1The resonance can be understood as an acoustic phenomenon, since the vibration originating in the vo-cal folds is transmitted to the adjacent cavities by the agitation of the air particles between the structures [21].
2All the dialectical phonetic variants of the vowels [31], which are the result, for example, of regionalisms,were excluded from this analysis.
12

2.1. SPEECH THERAPY
advances, maintains or retreats from the neutral position 3) are forms of differentiation
and distinction between the vowels.
It is necessary to take into account the role of other articulators for the classification
of the articulatory point of consonants. However, this dissertation does not focus on the
study on the production of EP consonants, only in the vowels.
2.1.2.5 Vowels Spectrum
A spectrogram is a representation of the acoustic signal, since it reflects in the spectrum
the properties of the sound produced [21]: (1) Time on the horizontal axis; (2) The
frequency on the vertical axis; (3) The amplitude perceptible by the intensity of the
horizontal bars produced by the spectrogram. As a representation of the complex sound
wave, its frequencies are produced separately, the fundamental frequency (first harmonic)
and its multiple frequencies (harmonics) [31]. For this decomposition to be possible at
the spectra level, narrow band and broadband filters are used. Broad band filters allow
a higher temporal resolution while narrow band filters increase the resolution of the
frequency.
For the distinction of phonemes, namely the vowels presented in the figure 2.3, we can
analyze the spectral patterns, called formants, which are dependent on the physical char-
acteristics of the supraglottal cavities [53]. The resonance properties of each component
of the vocal tract might intensify or weaken the acoustic signal, which is why the spectral
image produced by the respective vibrations denote different phonemes. Note that the
vowels have a well-defined pattern of formants [31]. Thus, they are easily distinguished
at the spectral level, as we ca see in figure 2.3.
The application of this technique in the analysis of the vocal signal and in the anal-
ysis of the spectral noise visible between the harmonics, can be used for analysis of
perturbations present there [21]. Noise in spectral images of sustained vowels allows the
measurement of different levels of dysphonia severity.
2.1.3 Classification of voice disorders
The incorrect and violent use of phonation structures, for instance, vocal abuse 4 can
cause organic changes in the vocal folds and attached musculature [21]. A voice dis-
turbance, dysphonia, occurs when voice quality, pitch or loudness vary inappropriately
from normal patterns for an individual of a given age, gender, cultural background, or
geographic location [1].
3Rest position of tongue [31], usually in a central position in the oral treatment.4Vocal abuse [21] encompasses a set of behaviors that impair vocal health such as smoking habits, medi-
cations or drugs, poor hydration, prolonged use of excessive vocal volume, or even the type of personality(anxiety or stress)
13

CHAPTER 2. FUNDAMENTAL CONCEPTS
Figure 2.3: Broadband spectograms of nine standard EP oral vowels produced by a femalespeaker. Source: [31]
2.1.3.1 Functional versus organic dysphonia
Dysphonia can be classified as organic when it has physiological origin, either due to a
disturbance in breathing or in the mechanisms / components of the vocal tract [2, 21].
Within this category, dysphonia may be structural or neurological. The first case applies
when there are physical changes in the mechanisms of the vocal tract, such as localized
mass lesions or tissue changes. A neurological dysphonia refers to problems with the
central and / or peripheral nervous system which affects the nerve connected to the
larynx, conditioning the voice normal function. For instance, those problems might be
visible through the trembling in the voice, spasmodic dysphonia or even paralysis of the
vocal folds. On the other hand, functional disorders are idiopathic, e.g., they are diseases
whose cause is unknown and for which no explanation can be found [2, 21]. In these
cases, the use of vocal folds and vocal tract mechanisms tends to be inappropriate or even
inefficient, even without structural changes.
2.1.3.2 Dysphonia based on the perceptual vs. acoustic phenomenon
The vocal disturbances can be perceived based on the human perception and acoustic
levels of the voice, by analyzing the pitch, loudness or resonance of the voice [21]. Pitch
problems are perceived in breathy, harsh, or hoarseness (the combination of the above).
14

2.1. SPEECH THERAPY
Physiologically, the vocal chords present an inefficient behavior compared to normal,
with low vibration of the same and that can be caused by several laryngeal diseases.
Concerning audible loudness problems, the cause is primarily a hearing or learning
deficit and the voice is, typically, monochrome - with no variation in the intensity and
speed of speech. Additionally, the perception of disturbance in the resonance can be a
consequence of incorrect postures in the language, dimension of the tract or problems of
nasal assimilation.
2.1.4 Treatments for voice disorders
Regarding type of disturbance in the child’s speech, different treatment categories may
be applied [3]: voice therapy at the physiological or symptom level. Since the area encom-
passes numerous types of treatments, only treatments based on the use of sustained vow-
els will be specified in this document. Within physiological voice therapy, the phoneme
resistance training exercise, the Lee Silverman technique (LSVT) treatment and the pitch
limitation treatment may be used.
Lee Silverman Voice Treatment (LSVT) This treatment was originally created for the
treatment of Parkinson’s diseases [3, 12, 47]. Although it is already being used for
therapy of other pathologies in the voice, for instance, dysfunctions in the breathing
and in the larynx. The LSVT may use exercises with the sustained vowel or with
small phrases. During treatment, patients should:
1. think loud / think shout,
2. initiate sound production through the most sustained vowel and
3. repeat the exercise at least once more.
This treatment should be intensive so that it has a long-term effect and allows
patients to recalibrate the loudness.
Pitch Limiting Voice Treatment (PLVT) PLVT is very similar to LSVT. This treatment
uses the same exercises for the proposed effect [47]. Additionally, it also allows lim-
iting the pitch increase and thus preventing vocal pressure. The phrase that serves
as a motto for patients is speak loud and low so that sustained sound production
follows this pattern.
Phoneme Resistance Training Exercise (PhoRTE) PhoRTE is another type of treatment,
which combines the treatment of loudness and pitch and has been applied to im-
prove vocal quality and decrease phonation effort [3]. The treatment should include
the following steps:
1. the sustained vowel production /a/ with the maximum intensity of the sus-
tained phoneme,
15

CHAPTER 2. FUNDAMENTAL CONCEPTS
2. the sustained vowel production /a/ with loudness increase and pitch along
sound production,
3. production of sentences with high loudness and high pitch, and
4. finally, production of the same sentences with high loudness and low pitch.
Emission Technique in Maximum Phonation Time (ETMPT) This technique was tested
in the field of spasmodic conduction dysphonia, a type of disturbance in the voice of
neurological origin [33]. This technique aims to promote glottic resistance, improve
phonatory stability and suit glottic coaptation. The treatment uses the sustained
vowel /a/, whose steps are similar to the execution of the LSVT.
Concerning symptomatic voice therapy with sustained vowel exercise, the straw
phonation exercise of the semi-occluded vocal tract (SOVT) exercise set can be per-
formed [3]. Therapy with SOVTs aims to maximize the interaction between the vocal
chords and the vocal tract, in order to facilitate the production of a resonant sound. The
straw phonation exercise is intended to increase the pressure on the vocal folds by keep-
ing them separate during the phonation time with the sustained vowel with the aid of a
straw or tube.
2.2 Speech processing and Machine Learning
2.2.1 Spectrum Analysis
The vowels can be classified based on the analysis of segments of the sound spectrum in
a stable state of the same [15]. As already mentioned in 2.1.2.5, the formants presented
in the respective spectra of each vowel define patterns that easily distinguish the vowels
from each other [4, 15, 35, 37]. These can be represented by the low-resonance peaks and
with the first two formants f1 and f2, that might be complemented with the information
in the third formant. However, there are limitations with the spectral analysis of the
formants, due to some particular characteristics in the child’s speech, in the phonemes
where the pitch is higher [27, 37]. This is due to the fact that in these situations, the dis-
tance between the harmonics of the sound produced tends to be higher and, consequently,
the harmonics are more likely to coincide with the central frequency of the formants.
2.2.2 Speech processing and extraction
As mentioned previously in section 2.1.1, the sound can be described based on physical
or acoustic parameters. The acoustic analysis is related to the way the human being
perceives the sound, which does not follow a linear scale. MFCCs are the sound features
mostly used today and which provide a robustness to the linguistic content produced and
an attenuation of the noise present in the signal. The MFCCs are a representation of the
parametrized acoustic signal and noise reduction present, based on the application of the
16

2.2. SPEECH PROCESSING AND MACHINE LEARNING
Fourier transform to each segment of the signal [20]. In addition, it involves the mapping
of the energy of the same through the filter of the mel scale of frequencies 5. They result
in a compressed and equalized short spectrum of short duration.
Setup and Pre-emphasis The pre-emphasis filter on the signal amplifies the high fre-
quencies [14]. It balances the frequency spectrum considering that lower frequen-
cies have higher magnitudes and vice-versa. The goal of pre-emphasis is to com-
pensate the high-frequency part that was suppressed during the sound production
mechanism of humans.
Framing In a sound signal, the frequencies change over time [20]. By slicing the signal
into frames, we can obtain the frequency contours of the signal. If the frame is too
short, it might not have enough samples to get a reliable spectral estimate. On the
other hand, if the frame is too long, the signal changes too much throughout the
frame.
Window After slicing, a window function is applied to deal with FFT limitations [34].
When the FFT is applied, it assumes that the data set is a continuous spectrum, one
period of a periodic signal. However, we might not have an a continuous time signal,
it might include sharp transition changes, discontinuities with spectral leakages.
Windowing reduces the amplitude of these discontinuities at the boundaries of the
frame taking into account. Each frame has to be multiplied with a Hamming or
Hanning window, to keep continuity of the first and last points in the frame.
Fourier-Transform and Power spectrum The Fourier transform deconstructs a time do-
main representation of a signal into a frequency domain components with discrete
values - bins. The computation of the power spectrum generate a periodogram
which allows the identification of the frequencies in the frame.
Filter Banks The mel frequency range was developed based on the observations of hu-
man perceptions regarding stimuli with variations in frequency tones [7]. The
mel scale is applied to simulate the gaps in human hearing sensitivity for different
frequency tones, which become more spaced with increasing frequency.
Take the logarithm of the filter banks A transformation in the filter bank vectors is ap-
plied because loudness is not perceived in a linear scale [14]. Using a logarithm
function allows us to use cepstral mean subtraction as a normalization technique.
Take the Discrete Cosine Transform (DCT) This function is normally used for data com-
pression since it concentrates the amount of information in the first few points [20].
5The mel scale of frequencies is based on the pitch perception. Since human auditory system doesnot interpret pitch in a linear way, the mel scale presents a scale that follows the humam perception offrequencies (linear in frequency range 0-1000 Hz and logarithmic above 1000 Hz) [20]
17

CHAPTER 2. FUNDAMENTAL CONCEPTS
Figure 2.4: Mel filters in a 8000 Hz signal. Source: [14]
Therefore, it uses the 26 log filterbank energies from the previous step and trans-
form them in 26 cepstral coefficients - Mel Filter Cepstral Coefficients. Usually,
for ASR purpose, only the lower 12-16 coefficients are used.
Mean normalization The mean of each coefficient from all frames might be applied in
order to balance the spectrum and improve Signal-to-Noise (SNR) 6.
2.2.3 Additional Sound Features
Delta - Differential Coefficients Represents the changes in coefficients between consec-
utive frames and the returned matrix has the same size and data type as the original
coefficients array.
Double Delta - Acceleration Coefficients Represents the changes in delta values from
one frame to another. The returned matrix has the same size and data type as the
original coefficients array.
2.2.4 Classification algorithms
The classification algorithms to be applied were chosen with support in previous studies
involving the classification of vowels [7, 10], for which high classification results were
obtained.
Quadratic discriminant analysis (QDA) The QDA is a classic classifier [38]. In partic-
ular, it can learn to make quadratic boundaries, is more flexible than linear ap-
proaches, since it manages to use more dimensions. For the QDA application, the
co-variance matrix of the extracted acoustic parameters is used and it is assumed
that these matrices are different for each category.
Support Vector Machine (SVM) The SVM is a supervised learning algorithm and can
be used for linear regression and classification between two classes [38]. When used
for classification, the algorithm seeks to maximize the margin between the classes
6The signal-to-noise ration is defined as the ratio between the power of the signal and the backgroundnoise, expressed in decibels. [20]
18

2.3. PLAYER-ADAPTABILITY MODELS
of interest, using vectors to define these margins. In the scope of this dissertation,
it is used as a classifier to separate the vowels /a/, /e/, /i/, /o/ and /u/, based on
the feature vectors that distinguish them.
In order for the algorithm to be able to classify not linearly separable sets, a kernel
function can be used and so, the training vectors can be extended to higher dimen-
sions. In the study that included the classification of vowels in children [10] the
same algorithm was used, with the kernel function Gaussian radial basis, with high
and reliable results.
Random Forest Classifier (RF) The RF algorithm works as a large collection of decorre-
lated N-tree decision trees, where N-tree is the number of estimators chosen [38].
Each decision tree is created according to hierarchic splits, where a split corresponds
to a leaf of the tree. In turn, each split tries to minimize the entropy between the
data. Thus, the optimal split, maximizes the number of different points in each one
of the leafs.
The RF is based on ensemble learning, regarding that, for a new data point, it makes
each one of the N-tree trees predict the category to which the data points belongs,
assigning the new data point to the category that wins the majority vote.
2.3 Player-adaptability models
There are several strategies that can be followed in order to implement a serious game
adaptability model [26]. These include approaches that control the state of the game by
varying global resources or specific exercise variables. The Rubber Banding technique is
generally used in racing games, as the Mario Karts game [26, 41]. The idea behind this
technique is based on the manipulation of the available resources in the game, so that the
performance of a player starts very limited, within a certain threshold. In the beginning,
the system offers a limited set of resources to the player, so he can progress in the game,
with forward and backward movements towards achieving the success. This technique
challenges the player to overcome new tasks until he reaches a maximum level, where
the resources are fully available. What happens in these cases is that the game presents
itself rather less accessible for novice players then for experienced players.
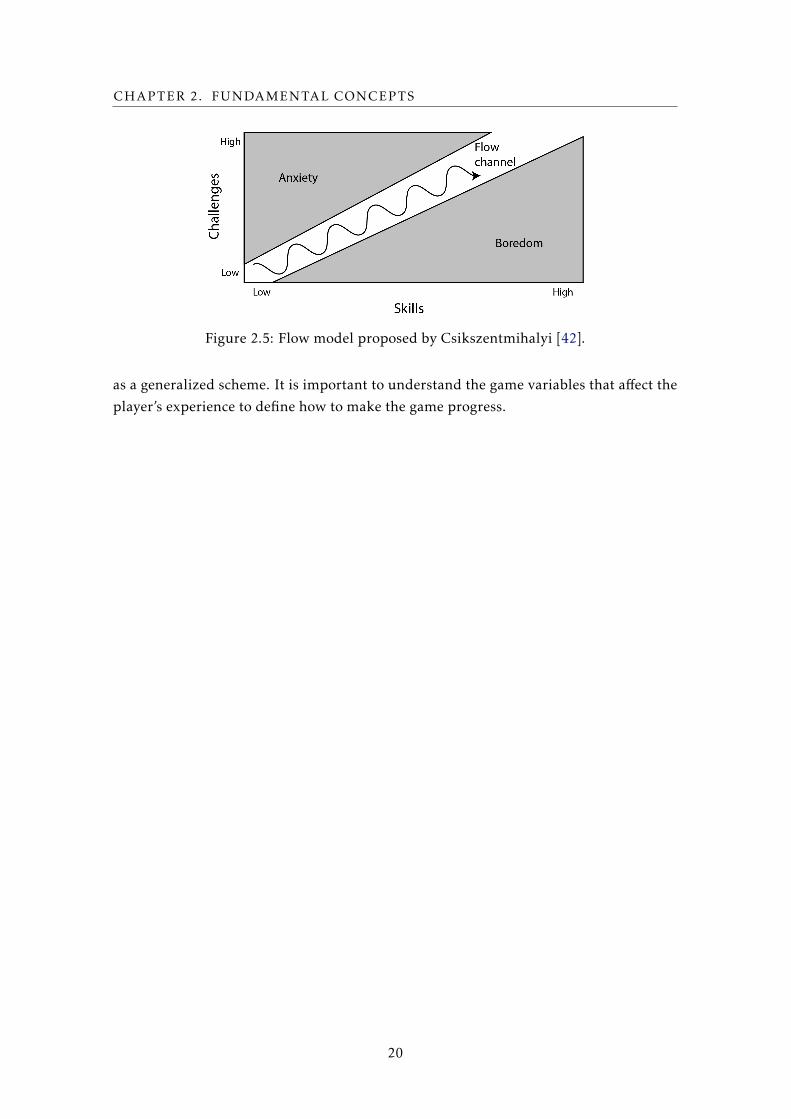
In addition to this approach, the flow model tends to be widely used (figure 2.5) [42].
This model controls the resources and variables of the game according to the player’s
experience with the game platform. More specifically, this control is achieved by bal-
ancing the proposed challenge with the player’s skills. In order for the user to maintain
interest in the game he must remain in a state limited to the flow channel as illustrated
in figure 2.5. The figure shows a repeating cycle of increasing challenges, until a thresh-
old is reached and the player receives a reward or some new resources to motivate him
to keep on playing. This state is followed by a less challenging period, until the game’
variables change again, taking the challenge to new heights. The flow model was defined
19
CHAPTER 2. FUNDAMENTAL CONCEPTS
Figure 2.5: Flow model proposed by Csikszentmihalyi [42].
as a generalized scheme. It is important to understand the game variables that affect the
player’s experience to define how to make the game progress.
20

Chapter
3State of Art
Computational therapeutic interventions have shown to be essential tools to complement
traditional therapy sessions since they can be used in an informal and comfortable learn-
ing environment. Among the tools available for therapeutic use, some focus on problems
in speech articulation and others on voice disturbance, and we present them throughout
this chapter. Concerning the fact that we want to develop a dynamic difficulty adaptable
model, we analyze other platforms with this functionality. Lastly, we summarize the
mainly differences between these systems.
3.1 Tools for speech therapy
Some of the tools we are presenting do not use acoustic analysis, and so, only offers
visual interaction with the game. These games will be briefly described in the 3.1.1
section. There are sound-aware tools, without the specification of any phonemes that are
introduced in section 3.1.2. Lastly, systems with specific phonemes detection are briefly
presented in section 3.1.3.
3.1.1 Without sound recognition
Some tools available for speech therapy does not include acoustic analysis and offer an-
other type of exercises to complement speech treatment. The Little Bee Speech website
offers a range of articulation training applications with English or Spanish language [51].
More specifically, the Articulation Station, as shown in figure 3.1, provides exercises
for practicing isolated words or phrases in the context of different stories, with the pos-
sibility of including optional exercises with reproduction of the presented sounds. It
allows the player to train any sound through an interactive and childlike environment.
However, since the app does not detect sound, it can not give feedback to the child if the
21

CHAPTER 3. STATE OF ART
sound reproduction requested was correct or not. This app does not focus on a particular
disturbance.
Figure 3.1: Training game with phonemes for articulation problems. Source: [51]
The tool Falar a brincar, illustrated in figure 3.2, provides an interactive interface
without sound feedback, whose exercises allow syllables to be counted and identified in
the word [23]. Giving that, there is no ASR system to recognize the sounds produced, the
practice of the exercises must be performed within the sessions with an SLT. Unlike the
previous game, Falar a brincar is intended for EP language.
Figure 3.2: Falar a brincar game. Source: [23]
The robust game with voice exercises in the field of speech therapy is included in
the BVS project and is focused on the practice of phonemes, based on a treasure map
theme, with gifts to conquer in each exercise [10]. For further mention, we call it BVS
tool 1. The figure 3.3 reveals some of the scenarios included in the game. The possibility
of winning rewards challenges the child to practice the set of available exercises, which
is an exciting gamification strategy. However, this tool can only be used in a session
environment since, through a specific key, the therapist must give the feedback in the
game if according to the child’s performance to produce the requested sound. Otherwise,
the system cannot display a response to the children’ behavior.
22

3.1. TOOLS FOR SPEECH THERAPY
Figure 3.3: Scenarios of the robust game with voice exercises for speech therapy.Source: [10]
The limitation of many of these games and systems, such as the set of the Little-
BeeSpeech exercises and Falar a Brincar, is the lack of automatic phoneme recognition.
They depend on the support of an adult to judge the child’s speech productions and
manually make the game progress. On the other hand, our proposed game automatically
responds to the child’s voice, and so, it overcomes this limitation.
3.1.2 With unspecified phoneme recognition
The serious game of the vowel sustained with adaptive difficulty for speech therapy
is included in the BVS project and focus on the practice of sustained phonemes [29]. For
further mention, we call it BVS tool 2. The game includes two scenarios involved in a
childhood theme, as we present in figure 3.4. In this case, it is possible to identify if the
sound is being produced sustainably. Additionally, it allows the therapist’s parametriza-
tion of the difficulty within each trial.
The Lee Silverman voice treatment (LSVT) companion system, is a computer tool
that uses the SVE exercise to complement treatment sessions and speech therapy assess-
ment [16, 22]. The tool focus on patients with Parkinson’s disease, and other neurological
pathologies, including children with dysarthria or cerebral palsy. The crucial feature in
this therapy program is the intensive voice treatment to improve voice quality, specifically
vocal loudness.
The tool allows practicing the SVE and other continuous speech exercises, while it
records the speech parameters of interest. Although children can use this software, it
does not offer an attractive interactive interface for them. It was designed to be a tool,
23

CHAPTER 3. STATE OF ART
Figure 3.4: Scene from the serious game for sustained vowel Source: [29]
not a game. Moreover, the tool does not allow real-time customization, and so, the tasks’
parameters must be chosen before each session starts, manually.
3.1.3 With identification of specific phonemes
Tools without sound analysis lack the flexibility to practice the exercises outside the ther-
apy session and, consequently, do not allow the strengthening of the exercises practiced
during the session. The following examples introduce sound recognition and solve part of
the problem. sPeAK-MAN, illustrated in figure 3.5, uses a popular and well-known game,
Pac-Man, to motivate the player to practice the vocalization of words usually performed
in a therapeutic environment [48]. The feedback of the player’s performance is delivered
in real time for each sound production.
Figure 3.5: Screenshot from the sPeAK-MAN interface. Source: [48]
In the case of VITHEA, illustrated in figure 3.6 a virtual therapist is available for the
24

3.1. TOOLS FOR SPEECH THERAPY
treatment of aphasia, especially for cases with difficulty in producing some words [39].
It includes automatic word recognition and prompts the user of the tool to pronounce
the visual or audible stimulus presented to you correctly. The disease under treatment,
aphasia, does not usually occur in children and so, the tool does not offer other types of
exercises focused on them.
Figure 3.6: Tool with virtual therapist for aphasia treatment. Source: [39]
The game Flappy Voice is adapted from a popular game, the Flappy Bird, but in this
version, the player’s voice controls the bird’s movement [28]. The initial position of the
bird is mapped according to the intensity of the child’s voice, who has to vary the sound
intensity so that the character does not collide against obstacles. This tool allows the
repetition of the exercise in terms of time and loudness thresholds. The therapist can
also define different levels of difficulty. The game offers an assisted mode, which limits
the user skills according to the therapeutic settings and the advanced mode where this
limitation does not exist.
Figure 3.7: Screenshot from the Interactive Game for the training of portuguese vowels.Source: [7]
The Interactive Game for the training of Portuguese vowels uses a simple car race
theme [7]. This game offers an interactive application, as we present in figure 3.7, entirely
controlled with the pronunciation of isolated vowels (a, e, i, o, u) which are classified
25

CHAPTER 3. STATE OF ART
with an ASR system. This game does not allow the therapist’s parameterization and does
not include a player-adaptable model to fit the child’s needs.
3.2 Tools with a DDAmodel
As we have mentioned, it is essential to keep the child motivated during the in-game
experience. Thus, a gaming platform should prepare different challenging scenarios, for
instance, through difficulty levels, to stimulate the player to improve his performance and
continuos playing. In a therapy context, this appealing environment should arouse the
evolution of the therapy’s variables and therefore, contribute to the treatment’s progress.
Some of the previous systems implement a basic parametrization method. Falar a
Brincar and sPeAK-MAN include predefined difficulty levels. The passage to the next
level involves hitting a set of tasks which become harder, level after level. Moreover, there
are are other systems where the player-adaptable concept can be parameterized through
the therapist, although they incorporate a simplistic approach.
For instance, the Articulation Station allows the therapist to customize the list of
words to use in the exercise and so, the level of difficulty, by choosing more complex
words. Flappy Voice can adapt the game to the needs of each child. Specifically, the SLP
can create new scenarios with an arbitrary number of obstacles, or adapt the difficulty of
the game through changing two parameters: the reaction time of the bird to the sound of
the input and the vertical distance between the obstacles, which allows the crossing of the
bird. The BVS tool 2 includes a manual parametrization approach with two variables: the
MPT variable and the intensity level. However, regarding the intensity level chosen, there
is no possibility to change the intensity interval. So, if the child oscillates her intensity
production, the system assumes it as correct.
Alternatively, Yun et. al. present a less simple methodology that automatically adjusts
the game difficulty using a profile-based adaptive difficulty system (PADS) [54]. They
want to improve the gaming experience by using player profiles to determine the best
difficulty level to each player. To create a player profile, they use a player’s prior gaming
experience and his preferences. Then, with these parameters they set the game difficulty
adjustment thresholds, and the PADS use a performance-based algorithm to adjust the
difficulty settings to the player. To do this, they transform the player’s performance
data into a point scale (these points are calculated using a predefined threshold system
depending on the player profile). The difficulty level changes whenever the thresholds
are crossed. If the output is greater than the positive threshold they increase the difficulty
level, on the other hand, if the output is less than the negative threshold they decrease
the difficulty level.
Another approach to give an appropriate challenge level to each player is presented
by Demediuk and colleagues [9]. They developed an adaptive training framework to
construct an opponent, whose strategies and behavior adapt to the progress of the player.
Their goal is to alter the level of challenge of the opponent according to the changes in
26

3.3. TOOLS COMPARISON
the player’s proficiency. More specifically, the player competes against the AI opponent
which adapts its level of challenge by using Dynamic Difficulty Adjustment, which means
change strategies based on the interaction in real time with the player. They present a
comparison between the behavior of the opponent against the player, and against fixed
difficulty levels. After that, it is necessary to relate player proficiency to the difficulty
level of the opponent. Finally, it monitors the player’s proficiency level and adjusts the
adaptive AI opponent when necessary.
With our DDA proposal, we offer a dynamic strategy to parametrize the game dif-
ficulty and we allow the initial choice of MPT value, intensity level and the intensity
variation from an easier/larger interval to a harder/ reduced interval, allowing the child
to stabilize her production in phase.
3.3 Tools comparison
Table 3.1: Comparative table that summarizes the described tools for Speech Therapy.
Tool Pathology Idiom Platform ASR DDAArticulation
stationArticulation En iPad, iPhone No Yes
Falar a brincarPhonologicalawareness
Pt Android Yes Yes
BVS tool 1Articulation andvoice disorders
Pt Computer No No
BVS tool 2 Dysphonia Pt Computer No No
LSVT Parkinson En Computer No No
sPeAK-MAN Articulation EnComputer
+ sensor KinectYes Yes
VITHEA Aphasia Pt Online Yes No
Flappy Voice Apraxia En Mobile Yes Yes
Interactive Gamefor the trainingof Portuguese
Vowels
Vowelsrecognition
Pt Computer Yes No
Proposedsolution
Dysphonia PtComputer,mobile
Yes Yes
The Table 3.1 summarizes the main differences between the therapy tools previously
described in section 3.1. These systems focus on different pathologies, idioms, and plat-
forms. We also highlight the existence of an ASR system, as well as, a DDA model. How-
ever, none of the tools fulfill the requisites we desire — specifically, our proposed solution
focuses on voice disorders for children with dysphonia. It should run in both computer
and mobile devices and incorporate an ASR system and a DDA scheme. Therefore, the
following chapters cover a detailed explanation of the game functionalities, including a
novel DDA and the complete methodology’s description to prepare the ASR system.
27


Chapter
4Game and Architecture
In this chapter, we present in greater detail our game based approach, as we previously
introduced in chapter 1. We start with a detailed description of the primary exercise,
the game functionalities, main theme, scenes, and transitions, the game architecture and
other details concerning the game’s implementation.
4.1 Proposed game
The solution addressed in this dissertation focuses on the practice of the sustained vowel
exercise towards the treatment of voice disorders. As mentioned before, it is essential
to develop a tool that helps speech therapists, in the session and outside the therapy
environment. In order to keep the children interested and to stimulate learning, the
therapy should be a motivating and relaxed process, appropriate to age, gender and tastes
of each child.
Computer-based sessions with interactive interfaces might fill these requirements,
with a stimulus that can be represented through gifts, collected throughout the practice
of the exercises. Additionally, depending on the characteristics of the child in therapy,
numerous parameters must be adapted appropriately to each situation that might arise
during the course of the therapy. The intensity of therapy sessions can affect the child’s
performance. A more significant number of sessions per week strengthens the positive
results of the exercises and tends to accelerate the child’s progress. In this way, having
a portable tool that can be used in different spaces and outside the traditional therapy
environment adds training moments to the treatment besides the advantages mentioned
above.
29

CHAPTER 4. GAME AND ARCHITECTURE
4.1.1 The sustained vowel exercise
In this dissertation project, we developed a game with the SVE, destined for the treatment
of childhood dysphonia. To perform the exercise, the child has to produce one of the
vowels /a/, /e/, /i/, /o/ or /u/ for as much time as possible. This time duration is
associated with the MPT, one of the variables in therapy. Moreover, the platform goal is to
move the character within the exercise scene, from a starting point to a final position. The
character movement is illustrated in Figure 4.1, where a target object represents the final
position. Through this feedback, the game instructs the child to continuous produce the
sustained vowel, until the character reaches the target. The initial distance between these
two scene’s elements is associated with the MPT expected duration. Thus, to challenge
the practice of the MPT, the game can change the initial distance between the character
and the target.
Figure 4.1: The figure illustrates the interaction between the character and the target in ascene context.
Additionally, the character’s movement depends on two aspects: loudness of the
sound produced and the sound itself. Specifically, the loudness is another variable in
therapy and must stand between specific thresholds. These thresholds and further infor-
mation regarding the variables in therapy are explained in chapter 5. On the other hand,
the sound produced must follow the SLP choice, from one of the vowels /a/, /e/, /i/, /o/
or /u/ whose recognition is responsibility of the ASR system introduced in chapter 6.
4.1.2 Game scenarios and gamification strategy
Since the game is intended for children, the scenarios focus on an infant theme, without
too much detail, and with appealing colors. Figure 4.2 represents the scenes for the SVE
exercise. These scenarios were created with the help of a visual artist and with images
from Freepik [18].
We decided to focus the game on a journey for the discovery of treasures, which are
gifts that the players, i.e. the children conquered at the end of each task. Additionally, the
children can choose a character that reflects their preferences and tastes. Since tendencies
differ according to age, gender and culture, the game offers four different ethnic options
for both genders, and so, to fulfill different child’s preferences. The figure 4.3 presents the
30

4.1. PROPOSED GAME
Figure 4.2: Scenarios available for the exercise page.
31

CHAPTER 4. GAME AND ARCHITECTURE
Figure 4.3: Set of characters available, representing both genders and four different eth-nies.
Figure 4.4: Available rewards.
available characters and figure 4.4 shows the possible gifts. In total, we offer 15 rewards,
that the child can collect after a successful trial.
The primary purpose of these game’s UI elements lies in the importance of holding
the child engaged and satisfied so that she sees therapy not as a hassle but as a fun
and challenging experience. With this stimulus, our game tries to prompt the child to
practice the exercise continuously with motivation. After the child completes a task, she
can choose a reward and starts its rewards collections. In this way, these interactive
elements are combined in a gamification strategy that pretends to keep the child engage
to play.
4.1.3 Visual feedback
The children motivation to continue playing occurs due to an interactive game platform
where the child can see her progress. Thus, with the right visual feedback from the
exercise scene, the child can recognize her failures and improve her utterances produc-
tion until she accomplishes the exercise goal. During the trial, the game shows distinct
32

4.1. PROPOSED GAME
(a) Try again message. (b) Congratulations message.
Figure 4.5: Add child basic info scene.
(a) Fall of the flying carpet. (b) Fall of the train.
Figure 4.6: Character’s falling feedback.
feedbacks according to the child’s performance. Figure 4.5b presents the game visual
feedback in the case of success. Otherwise, if the character achieves the game margins,
the game presents the message illustrated in figure 4.5a.
Moreover, if the child exhibits a correct production, the game reacts through the char-
acter’s movement to the right. In the opposite situation, the character stops the movement
and begins to fall, until her production reaches the expected values. These movement’s
variations are supposed to be intuitive to the child and encourage her to improve her
performance. However, since the exercise scenarios have different characteristics, the
same movement may be appropriate in some scenarios and inadequate in other. The fol-
lowing figures 4.6 show different scenes for the SVE. In the 4.6a is adequate the fall of the
flying carpet. Nonetheless, in the scene 4.6b is almost unbearable to let the train decline.
To avoid these situations, we could adapt the character’s animation easily. Nevertheless,
we consider best to have similar behaviors in the furtherance of intuitiveness. Besides,
children have a vast imagination, and so, it should not be a problem.
4.1.4 Game parametrization
Since each child has a unique pathological situation, their treatment should focus on their
needs. Thus, before the child interacts with the platform, a set of parameters must be
established to ensure the ideal level of difficulty. Note that, different children deal in
33

CHAPTER 4. GAME AND ARCHITECTURE
different ways with a new stimulus. According to information from therapists, for an
autistic child, for example, the platform should include a reduced number of scenarios,
since these children are more comfortable with repetitive exercises. On the other hand,
hyperactive children prefer a game with more appealing and challenging UI elements.
Therefore, the therapist is able to choose the scenes in the "treasure hunt".
Each child can have a different performance throughout the treatment, and thus, the
difficulty level should be fit her abilities. For instance, the current level may be harder
than the child’s capacities and frustrate her, or be extremely simple and prove to be less
challenging and boring. Thus, each exercise must be adapted to the current level of
treatment and the child to find a balance between the degree of motivation and challenge.
The game difficulty variables can be chosen manually by the therapist or automatically
with our DDA scheme, further described in chapter 5.
For this purpose, the therapist can choose the corresponding parameters in therapy,
the MPT and the loudness variables. The therapist is also able to select the scenarios that
she considers most appropriate for the child. On the other hand, when the child interacts
with the game, the custom map should already be available with the parametrization
of the therapist. Since each platform focus on one particular child, the SLP can also
introduce the child’s basic information. This information includes the name, age, gender
and relevant additional description.
To sum up, the therapist can set the following information and parametrization:
• child’s basic info;
• the scenarios that are available for the child’ treatment;
• the intensity level - low, medium or high - regarding the purpose of the therapy;
• difficulty adaptation mode (manual or automatic);
• the established time for the child to complete the exercise (MPT);
• the loudness expected intervals;
• the vowel to identify during the SVE.
4.2 Platform architecture, design and structure
4.2.1 System architecture
The game is designed to run on computer or mobile devices. As we previously mentioned,
our platform includes an ASR system, responsible for the preprocessing and analysis of
the child’s utterances produced in real time, during the SVE. Depending on the device on
which the executable will run, resource limitation may be an obstacle to processing the
data received. Regarding the type of algorithm adopted for an ASR system, it is necessary
to assure its real-time interaction response with the child.
34

4.2. PLATFORM ARCHITECTURE, DESIGN AND STRUCTURE
To ensure the best performance of the software, we used a client-server architecture,
in which the system forwards the most complex processing to the server. In this way, the
tool is not limited by its resources and its future use is muchmore flexible. The processing
on the server must be performed in real time so that the feedback can be returned to the
child during her attempt. The data exchange between client and server is presented in
the figure 4.7 and is followed by a brief description of the responsibilities of each part of
the system.
Figure 4.7: Client-server architecture.
The client represents the part of the system responsible for the game actions, graphics
organization, recording of child’s utterances and sending them to the server. After his
response, the client generates the right feedback to the child through the game elements.
The server is responsible for all processing in the ASR system. Therefore, it receives
the segments of sound produced from the client side and deals with the proper extrac-
tion and data processing so that they can be analyzed, and classified using the trained
algorithm. For that, it is necessary to consider which algorithm to choose, so that the
processing time is as low as possible without penalizing the correct classification of the
phoneme.
For the development of the platform, we used the Unity game engine, regarding its
advantages. First, Unity is cross-platform, which means that through a single develop-
ment process and the same code, we can launch it on different platforms. On the other
hand, it is free, quite intuitive and has an extended community of platform users which
facilitates and supports the rapid implementation of the tool.
4.2.2 Game’s storyboard
In order to integrate the functionalities for both therapist and child, the game platform
presents the following structure: (1) initial page, (2) choose character page, (3) fill child
basic info page, (4) choose scenarios page, (5) add exercise parameters page, (6) SLP
choose options page, (7) map page, (8) prizes page, and (9) the exercise page (The char-
acter, the scene, and the target vary according to the scenario chosen). These scenes
35
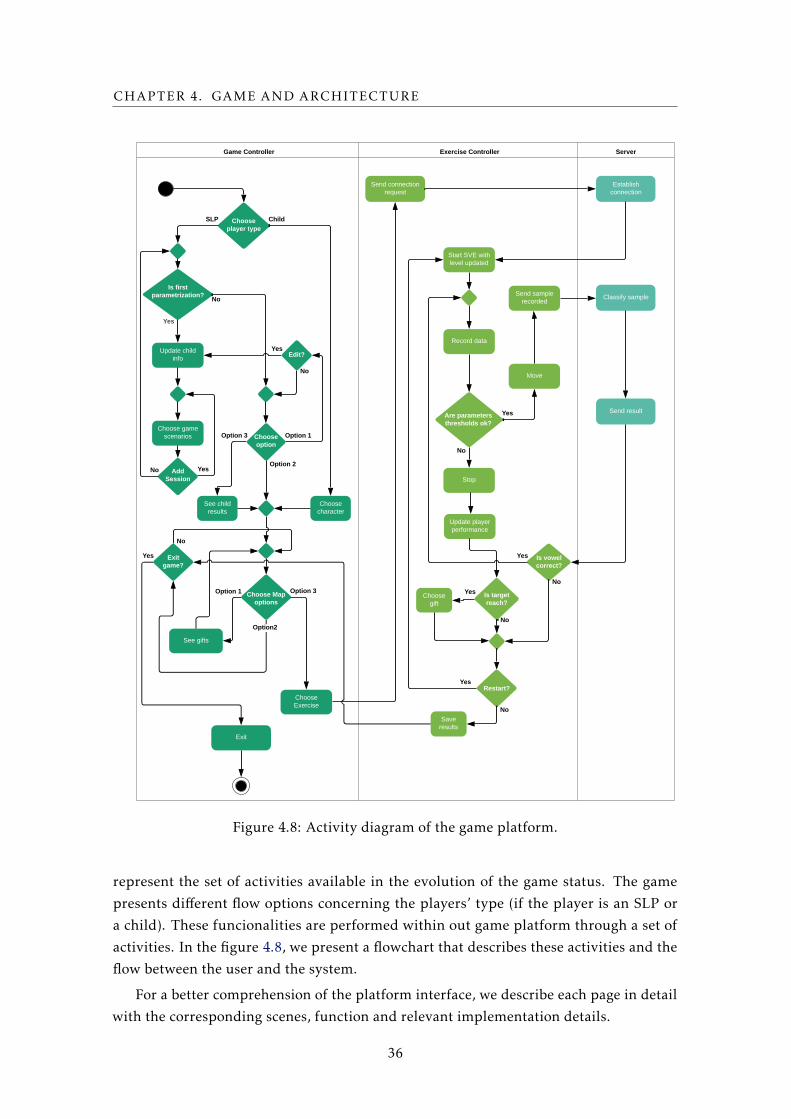
CHAPTER 4. GAME AND ARCHITECTURE
Customer ATM Machine Bank
Exit
Update child info
Choose game scenarios
Game Controller
Is first parametrization?
Yes
Edit?
Add Session
No
Child
Exercise Controller Server
Choose character
See gifts
Exit game?
Yes
Send connection request
Text
Establish connection
Are parameters
thresholds ok?
Stop
Move
No
Classify sample
Send result
Send sample recorded
Yes
Is vowel correct?
Is target reach?
Start SVE with level updated
Record data
No
Restart?Yes
No
Yes
Yes
No
No
Choose Exercise
Option 1
Option2t
Option 3
Option 1
Option 2
Update player performance
No
Yes
SLP Choose player type
Choose option
Choose Map options
Choose gift
Yes
Save results
No
See child results
Option 3
Figure 4.8: Activity diagram of the game platform.
represent the set of activities available in the evolution of the game status. The game
presents different flow options concerning the players’ type (if the player is an SLP or
a child). These funcionalities are performed within out game platform through a set of
activities. In the figure 4.8, we present a flowchart that describes these activities and the
flow between the user and the system.
For a better comprehension of the platform interface, we describe each page in detail
with the corresponding scenes, function and relevant implementation details.
36

4.2. PLATFORM ARCHITECTURE, DESIGN AND STRUCTURE
1. Initial page
The game starts with the presentation of this page, as illustrated in figure 4.9, and
it offers to the player two possible flows, one if the player is a therapist and another
the player is the child, with a different path for each case.
Figure 4.9: Start page scenario.
2. Choose character page
The choose character page is the following scene in the child’s flow if we choose
the correspondent button on the start page. The figure 4.10a illustrates the page
responsible for changing the available characters from figure 4.3.
3. Fill child basic info page
The game introduces a set of three pages for the steps in the game configuration
process, to add information about the child in treatment. The first parametrization
page - fill child basic info page - allows the therapist to add the elemental informa-
tion about the child, as shown in figure 4.11a. More specifically, the name, gender,
age and a field to fill with extra information, for example, the description of the
pathology to treat. This scene concerns the therapist flow. These parameters are
validated before the user proceeds to the next page, as shown in figure 4.11b. Note
that, if the therapist already added the child’s information, the game will not show
this page. Instead, the platform will present the choose options scene 4.13a.
4. Choose scenarios page
The choose scenarios page is the second parametrization step and allows the SLP
to choose the most appropriate scenarios to the child in treatment, as illustrated in
figure 4.12a.
5. Parameters page
Regarding the child’s needs, it is essential to include the possibility to parametrize
37

CHAPTER 4. GAME AND ARCHITECTURE
(a) Choose character page scenario. (b) Rewards pages.
Figure 4.10: Choose characters (left) and see rewards (right) scenarios.
(a) Add basic info page (b) Basic info validation
Figure 4.11: Add child basic info scene.
.
(a) Choose scenes page (b) Choose parameters page
Figure 4.12: Treatment editable parameters.
the exercise variables, as presented in figure 4.12b. This scene corresponds to the
third step in the configuration process.
The therapist is allowed to choose the adequate parameters to each case. Besides
the scenes, the intensity level (low, medium or high) and a variable that indicates
if the difficulty adjust level is automatic or manual. If the SLP chooses the manual
parametrization option then, there are appended the options MPT level (from 2s
to 10s) and intensity index (easy for a larger loudness interval, moderate for an
intermediate range or hard for a small interval).
38

4.2. PLATFORM ARCHITECTURE, DESIGN AND STRUCTURE
(a) Therapist game options page. (b) Map scenes available to the child.
Figure 4.13: SLP and children’ game options.
6. Therapist choose options page
After the therapist adds the child’s first parametrization, the therapist will see the
choose options page, as illustrated in figure 4.13a. From there, the therapist can edit
the child profile, and the treatment information, as seen in figure 4.12. Otherwise,
the SLP can see the map with the scenes previously chosen.
7. Map page
In the map scene, the child is allowed to choose the session with the therapist’s
configuration. Otherwise, without previous parametrization, the child can perform
in a random exercise. Besides selecting the task, the kid can see his conquered
prizes or exit the game. In this last case, the platform saves the current status
in a serializable object which contains the player information, his performance
concerning his trials, as well as, the treatment situation. The figure 4.13b illustrates
the map scene.
8. Rewards page
Te page to choose a reward is achievable when the child completes the exercise
selects the rewards button. The figure 4.10b presents the page where the child can
interact through drag and drop with the rewards present in figure 4.4.
9. Exercise page
This scene has three main elements: the character, the scenario, and the target and
they vary according to the scene selected in the map available scenarios and the
chosen player in the choose character page. This page focus on the practice of the
SVE.
Overall, the game’s goal is to make the main character reach a target, for each of the
proposed SVE scenarios. To make the main character move, the child has to produce a
sustained vowel and achieve the values expected in the speech parameters of interest to
the therapy exercise: the phonation time and the intensity level. In the course of following
chapter 5, we discuss how do the therapy variables are measured in the game, during the
39

CHAPTER 4. GAME AND ARCHITECTURE
SVE, and how do we pretend to update them regarding the child’s performance, which
results in the development of a dynamic difficulty adjustment model (DDA).
40

Chapter
5A Novel Dynamic Difficulty Adjustment
model
Our SVE serious game is controlled by the child’s voice in real-time and offers several
scenarios based on an infant theme that aims to keep the child interested. During the
therapy sessions, the SLP can update the treatment variables so that the game’s difficulty
follows the child’s performance. However, without the presence of a therapist, if the
child is struggling with the asset, she may feel frustrated for the incapacity to succeed.
Otherwise, she would be bored with an effortless task. Thus, here we propose a player
adaptable difficulty model, so that she sees the therapy not as a hassle but as a fun and
challenging experience.
The models described in chapter 3 may be appropriate to the respective game, but
inadequate for other applications. For our problem, we suggest an innovative scheme,
where the player’s experience should result in a balance between challenge and relish,
through the influence of the variables relevant to therapy.
5.1 The DDAmodel
Some of the scenarios for the SVE are illustrated in Figure 4.2. During the SVE, the child
has to produce a vowel for as long as possible. The maximum phonation time (MPT) is an
important measure of voice quality [8]. It helps evaluating the child’s ability to control
the breathing while producing a sound at the requested intensity level. The analysis
of this variable can be used both for assessing the individual’s aerobic capacity and for
vocal treatment, for example, for stabilizing the intensity of the sound produced [3]. The
repetition of the SVE will help the child improve her MPT and control her voice intensity
and stability.
The proposed game allows the SLP to parameterize the expected MPT, that is, the
41

CHAPTER 5. A NOVEL DYNAMIC DIFFICULTY ADJUSTMENT MODEL
Table 5.1: Allowed intensity levels and intensity interval sizes in dB (SPL).
intensity level Le L1m L1M L2m L2M L3m L3mhigh 85 80 90 70 100 50 100
medium 60 50 70 47.5 75 45 80
low 40 35 45 30 50 30 55
MPT that the child should reach, and which we call MPTe. In the game’s graphics, MPTe
is the time that the main character needs to move (walk, fly, swim, etc.) to reach the game
target. We use the expression MPTe(r) to refer to MPTe of trial run r.
Depending on the pathology, the child may need to train the SVE with different
intensity levels. Children who usually speak very low, must train speaking at higher
intensities, whereas children who tend to increase the volume and, as a consequence,
strain their vocal cords, must practice speaking at softer intensities. In order to correct
these behaviors, the child can practice the SVE according to his needs. The game allows
the SLP to choose the intensity level to be practiced from three possible values (one value
for low intensity, one for medium and another for high intensity) [29]. We call this the
expected intensity level (or expected loudness), Le.
The child may have difficulties in stabilizing the requested intensity and obviously, it
is not expected that the child achieves a perfectly constant intensity level. Thus small vari-
ations in intensity should be allowed and it is essential to establish the allowed variation
interval. The algorithm uses a minimum and maximum threshold, Lm and LM , around Le
to define this interval:
∆L = [Lm,LM ] , (5.1)
where Le ∈ [Lm,LM ]. We use the expressions ∆L(r) and Le(r) to refer to the intensity
level interval and expected intensity of trial run r, but we will often drop the variable
r for simplicity. Table 5.1 shows the possible expected intensity levels and the allowed
intensity intervals. The SLP has the possibility of manually adjusting these values. To
choose these values we consulted an SLP and related work [16]. The values were adjusted
empirically with children in the aimed age group.
The game’s difficulty depends onMPTe and∆L. The game offers five different possible
values for MPTe: 2, 4, 6, 8 and 10 seconds as the MPT estimated for children is 10 sec-
onds [40]. On the other hand, while the game’s first version used a fixed ∆L size [29], we
now defined three intensity level intervals for ∆L, such that different difficulty levels use
different intensity interval sizes (∆Ln = [Lnm,LnM ] with n ∈ 1,2,3). The lowest difficulty
level allows the widest ∆L, while the highest difficulty level allows the narrowest ∆L.
Combining the different possibilities for the values ofMPTe and ∆L sizes, the game offers
15 different difficulty levels (for each Le, that is, for the low, medium and high intensity
values). Note that the expression ∆L(r) = ∆Ln means that trial run r uses the n-th intensity
level interval size.
Here we propose a new dynamic difficulty adjustment model that aims to keep the
42

5.1. THE DDA MODEL
child motivated on playing. The game’s current version offers the option of adapting
the game’s difficulty manually or automatically. In the latter case, the SLP chooses the
initial difficulty level (defined through an initial value for MPTe and an initial ∆L), and
afterwards, the game runs an algorithm for adapting the difficulty level before each new
trial, that is, the game adapts the values of MPTe and ∆L.
Difficulty adjustments should take into account the player’s performance, and the
player’s performance should be a measure of the parameters to be improved in therapy:
the maximum phonation time and the voice’s intensity and stability. If the child achieves
the expected values for these parameters, the child is ready to access a more demanding
level, with more ambitious expected values. Otherwise, if the values achieved are lower
than what is expected, it means that the child had a poor performance in the game and
the challenge difficulty should be decreased.
Below we first discuss a simpler adaptation model that measures the child’s perfor-
mance only in terms of the MPT achieved by the child (section 5.1.1), and then we
discuss the proposed DDA model, which is a more complete model that measures per-
formance both in terms of the achieved MPT and speech production intensity stability
(section 5.1.2).
5.1.1 Maximum phonation time
When the child starts playing, the SLP should parameterize the expected MPT, that is,
MPTe. The actual MPT achieved by the child, MPTa(r), is measured at each trial run r. It
is intended that during the task the child obtains MPTa(r) =MPTe(r). For simplicity, we
sometimes refer to these fucntions simply as MPTa and MPTe.
If the child is not able to reach the expected MPT (because MPTa <MPTe), the main
character will not reach the target. If this happens for several trials, the child can feel
frustrated with the game. In these situations, the child’s achieved performance is below
the expected performance. Thus, it is important to define a lower value forMPTe. On the
other hand, if the child is achieving a positive performance, that is, obtaining MPTa =
MPTe in successive trials, she may be ready for a higher difficulty level, since she has
already stabilized the aerobic capacity requested for the respective degree of difficulty.
Figure 5.1: Scheme for updating MPTe.
It is important to define when to decrease or increase MPTe. There are situations in
43

CHAPTER 5. A NOVEL DYNAMIC DIFFICULTY ADJUSTMENT MODEL
which the child achievesMPTe andwe should not increase the expectedMPT immediately.
A difficulty level enhancement should be difficult to achieve in order for the child to
stabilize his performance with the current degree of difficulty. On the other hand, a lower
level should be easier to achieve to avoid frustration when the level is not appropriate to
the child’s ability. Also, if the child fails once, it is not necessarily good to decrease MPTe
immediately. In some cases, we should give the child another chance and let her try again.
For instance, if the child does not reach MPTe but MPTe −MPTa is small, we should let
her try again. However, if MPTe −MPTa is large, we should soon decrease the value of
MPTe. We use a threshold of 13MPTe. This scheme is represented in figure 5.1 and can be
summarized as follows:
1. If MPTe <MPTa we will shortly increase MPTe but first we let the child play a few
more trials with this MPTe so that the child stabilizes his performance with the
current MPTe.
2. If 13MPTe < MPTa ≤MPTe we let the child try again a few more trial runs before
changing MPTe.
3. If MPTa ≤13MPTe we will soon decrease MPTe. The achieved MPT was much
smaller than the expetect MPT, which means that the exercise is too difficult for the
child with this MPTe value.
In order to define when and how to change MPTe, we use a cumulative value that
measures the time-evolving child’s performance in terms of the MPT, which we call
PMPT (r), and where r represents the trial run. The value of PMPT increases (that is,
PMPT (r) > PMPT (r − 1)) when the child has a good performance, and decreases otherwise.
We increase or decrease the value of MPTe by 2 seconds depending on the value of PMPT .
PMPT of the current trial r is updated as follows:
PMPT (r) =
PMPT (r − 1) +MPTa(r) , if MPTe(r) ≤MPTa(r)
PMPT (r − 1)−MPTe(r)MPTa(r)
, if 13MPTe(r) <MPTa(r) ≤MPTe(r)
−13MPTe(r) , if MPTa(r) ≤
13MPTe(r)
(5.2)
with PMPT (0) = 0 (the initial value of PMPT before the start of the first trial).
In addition to defining the function’s behavior, it is necessary to establish the limits
between which the PMPT may vary before there is an update of the value of MPTe. The
interval ]− 13MPTe(r), 2MPTe(r)[ determines the possible variation for PMPT (r). Thus,
MPTe(r +1) =
MPTe(r)− 2 , if PMPT (r) ≤ −13MPTe(r)∧MPTe(r) ≥ 4
MPTe(r) + 2 , if PMPT (r) ≥ 2MPTe(r)∧MPTe(r) ≤ 8
MPTe(r) , otherwise
(5.3)
44

5.1. THE DDA MODEL
Note that when the level change is reached, the current performance is reset, that is,
it is reduced to 0. Thus, we add the following first line to equation 5.2:
PMPT (r) =
0 , MPTe(r − 1) ,MPTe(r)∨ r = 0
PMPT (r − 1) +MPTa(r) , if MPTe(r) ≤MPTa(r)
PMPT (r − 1)−MPTe(r)MPTa(r)
, if 13MPTe(r) <MPTa(r) ≤MPTe(r)
−13MPTe(r) , if MPTa(r) ≤
13MPTe(r)
(5.4)
Let us see a few examples.
Example 1 Let us suppose that MPTe(1) = 6 s. Then, while
PMPT ∈ ]− 2, 12[ s, MPTe will remain with the same value.
If MPTa(1) = MPTa(2) = MPTa(3) = 4 s, then
PMPT (1) = −6/4 = −1.5 s, PMPT (2) = −6/4 × 2 = −3, and MPTe(3) decreases, that is,
MPTe(3) = 4 s.
Example 2 Let us suppose that we still have MPTe(1) = 6 s but MPTa(1) = 2 s. In this
case, the difficulty will decrease faster. PMPT (1) = −6/2 = −3, and MPTe decreases
immediately, that is, MPTe(2) = 4 s.
Example 3 Now let us suppose that the child can achieve the expectedMPTwithMPTe(1) =
6 s. That is, MPTa(1) = MPTa(2) = 6 s, then PMPT (1) = 6 s, and PMPT (2) = 12 s.
Thus, the level increases after two trial runs, that is MPTe(3) = 8 s.
5.1.2 Speech intensity level
While it is important to consider the MPTa by the child at trial run r to decide the value
of MPTe of the next trial, it is also important to consider how the speech production
intensity varies during the trial. When the game starts, the SLP chooses an appropriate
expected intensity level, Le. While performing the SVE, one must keep the intensity
level as stable as possible and as close to Le as possible. Thus, the sound intensity level
achieved by the child, La, is one of the variables measured by our algorithm.
The intensity of the speech production, La, is allowed to fluctuate within the interval
∆L. The speech intensity level achieved by the child is a time-varying function, La(t)
(figure 5.2). During the game, the main character moves towards the target, exclusively,
when the speech production intensities (La(t0), La(t1), La(t2), . . .) are within the defined
thresholds, that is, within ∆L.
As explained above, different difficulty levels use different intensity interval sizes ∆L.
Figure 5.2 illustrates the three allowed interval sizes. The first trial run always starts with
the widest intensity interval size, ∆L(1) = ∆L3.
Now let us analyze how the difficulty of the game changes in reaction to La, that is,
how MPTe and ∆L of the next trial are updated. Like in the previous section, here we
also measure the child’s performance to determine when to change the game’s difficulty.
45
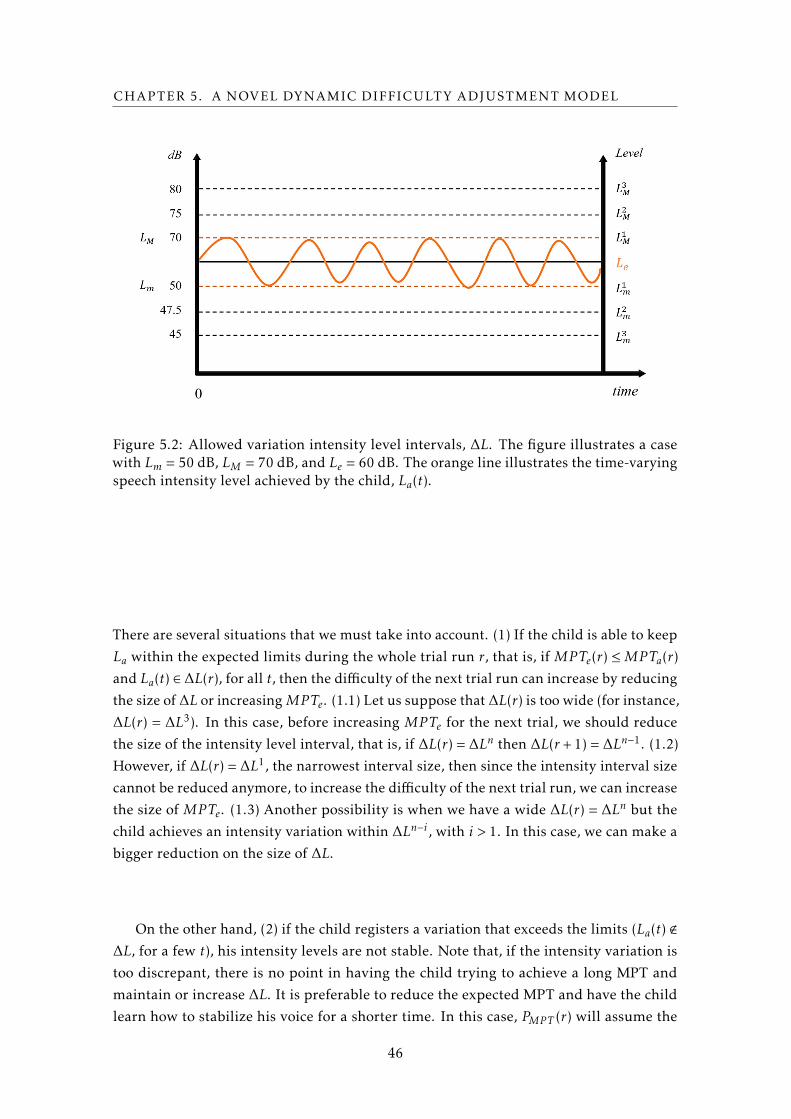
CHAPTER 5. A NOVEL DYNAMIC DIFFICULTY ADJUSTMENT MODEL
Figure 5.2: Allowed variation intensity level intervals, ∆L. The figure illustrates a casewith Lm = 50 dB, LM = 70 dB, and Le = 60 dB. The orange line illustrates the time-varyingspeech intensity level achieved by the child, La(t).
There are several situations that we must take into account. (1) If the child is able to keep
La within the expected limits during the whole trial run r, that is, if MPTe(r) ≤MPTa(r)
and La(t) ∈ ∆L(r), for all t, then the difficulty of the next trial run can increase by reducing
the size of ∆L or increasingMPTe. (1.1) Let us suppose that ∆L(r) is too wide (for instance,
∆L(r) = ∆L3). In this case, before increasing MPTe for the next trial, we should reduce
the size of the intensity level interval, that is, if ∆L(r) = ∆Ln then ∆L(r +1) = ∆Ln−1. (1.2)
However, if ∆L(r) = ∆L1, the narrowest interval size, then since the intensity interval size
cannot be reduced anymore, to increase the difficulty of the next trial run, we can increase
the size of MPTe. (1.3) Another possibility is when we have a wide ∆L(r) = ∆Ln but the
child achieves an intensity variation within ∆Ln−i , with i > 1. In this case, we can make a
bigger reduction on the size of ∆L.
On the other hand, (2) if the child registers a variation that exceeds the limits (La(t) <
∆L, for a few t), his intensity levels are not stable. Note that, if the intensity variation is
too discrepant, there is no point in having the child trying to achieve a long MPT and
maintain or increase ∆L. It is preferable to reduce the expected MPT and have the child
learn how to stabilize his voice for a shorter time. In this case, PMPT (r) will assume the
46

5.1. THE DDA MODEL
value 13MPTe(r). The expression for PMPT (r) now reflects all these cases:
PMPT (r) =
0 , MPTe(r − 1) ,MPTe(r)∨ r = 0
PMPT (r − 1) +MPTa(r) , if MPTe(r) ≤MPTa(r)∧
∀t La(t) ∈ ∆L1
PMPT (r − 1)−MPTe(r)MPTa(r)
, if 13MPTe(r) <MPTa(r) ≤MPTe(r)
−13MPTe(r) , if MPTa(r) ≤
13MPTe(r)∨
∧ ∃t La(t) < ∆Ln+1 ,n < 3
(5.5)
MPTe(r) is still defined by equation 5.3 but PMPT (r) is now defined by equation 5.5.
Note that there are slight differences between the old definition of PMPT (r) (equation 5.4)
and its new definition (equation 5.5).
In order to decide when to update ∆L we use another measure of performance that
takes into account both the achieved MPT and intensity variation. We call this measure
P∆L:
P∆L(r) =
0 if ∆L(r − 1) , ∆L(r) ∨ r = 0
∨MPTe(r − 1) ,MPTe(r)
P∆L(r − 1) +1
|∆La(r)|if MPTe(r) ≤MPTa(r) ∧ ∀t La(t) ∈ ∆L(r)
P∆L(r − 1)−|∆La(r)||∆L(r)|
if |∆La(r)| > |∆Ln|where∆L(r) = ∆Ln
P∆L(r − 1) otherwise
(5.6)
where |∆La| measures the achieved intensity variation. |∆La| = Lamax − Lamin, where
Lamax ≥ La(t) and Lamin ≤ La(t) for every La(t) in trial run r. Note that if the difficulty level
changes (because there is a reduction on the size of the allowed intensity interval or in
the value of MPTe) the performance P∆L is reset to 0. The performance P∆L increases for
situation (1) above. On the other hand, it should decrease for situation (2) when ∆La(r)
exceeds ∆Ln. Considering a trial, where the MPTe increased, the ∆L(r) = ∆L1. If the
child experienced a bad performance during consecutive trials, the game should give the
change to try with the next larger ∆L. However, if the child’s performance remains low,
the PMPT decrements and the MPTe will decrease.
As mentioned above, the game starts with the widest interval size. Once the child
starts to achieve a good performance with this interval size, the interval size decrements.
As mentioned above, it is possible to have big decrements on the size of ∆L when the
intensity variation achieved by the child is much smaller than |∆L|. On the other hand,
once the child has reached the narrowest interval size (∆L1), it is possible to increase the
difficulty level by increasing MPTe. If with this new value of MPTe the child’s intensity
variation is wider than |∆L1|, then we increase the interval size a bit, to give the child
47

CHAPTER 5. A NOVEL DYNAMIC DIFFICULTY ADJUSTMENT MODEL
some more time to stabilize his voice for this longer MPT. In this case, we increase the
interval to ∆L2 but we will not increase it further than that, because the child has already
achieved a smaller interval size for a shorter MPT. The following expression reflects how
and when to change ∆L:
∆L(r +1) =
∆L2 , if ∆L(r) = ∆L1 ∧P∆L(r) ≤ 0
∆Ln−i , if ∆L(r) = ∆Ln ∧P∆L(r) >2
|∆L(r)|∧ n > 1
∆L(r) , otherwise
(5.7)
where i determines the size of the decrement on ∆L and is defined as follows: 1 ≤
i ≤ n− 1 and i = n− n′ where |∆La| ≤ |∆Ln′ | and (n′ = 1∨ |∆La| > |∆L
n′−1|), with n′ < n. For
instance, if ∆L(r) = ∆L3 and the child is able to make a correct sound production with
|∆La| ≤ |∆L1|, then ∆L(r + 1) can be updated to ∆L1. The combined behavior with our
variables in therapy is presented in figure 5.3.
Figure 5.3: Scheme for updating ∆L, with the influence of MPT variable.
Example 4 Supposing thatMPTe(1) = 2s. Then, while PMPT ∈]−23 ,4[s,MPTe will remain
with the same value.
When focusing in ∆L variable, we started the first trial r = 1 with ∆L(1) = ∆L4,
which means that was expected the largest ∆L.
Consider that, for each trial r ∈ 1,2,3,4 ,MPTe(r) = 2s and thatMPTa(r) >MPTe(r).
The PMPT will not be updated until the player achieves ∆L1. An exemplified behav-
ior is present next in figure 5.2:
After the trial r = 4, the MPTe will be updated and, as follow, the difficulty will be
increased. Additionally,
∆L will remain the same, unless the child’s performance decrease and she cannot
achieve the target for the expected ∆L thresholds.
The proposed model was developed taking in consideration all the variables in the
therapy process and our main goal. This was finding the right balance between the child’s
skills and the game challenges, with a correlation that must stand within the flow channel.
48

5.1. THE DDA MODEL
Table 5.2: Evolution of child’s performance during four trials.
Trial 1 Trial 2 Trial3 Trial 4MPTa(1) = 2 MPTa(2) = 2 MPTa(3) = 2 MPTa(4) = 2
PMPT (1) = 0 PMPT (2) = 0 PMPT (3) = 2 PMPT (4) = 4
∆L(r) = ∆L3 ∆L(r) = ∆L3 ∆L(r) = ∆L1 ∆L(r) = ∆L1
∆L(1) = [52,69] ∆L(2) = [54,65] ∆L(3) = [53,64] ∆L(4) = [55,64]
P∆L(1) = 0+0,054 P∆L(2) = 0,145 P∆L(3) = 0+0,091 P∆L(4) = 0,2022
|∆L(r)|= 0,057 2
|∆L(r)|= 0,057 2
|∆L(r)|= 0,1 2
|∆L(r)|= 0,1
Thus, it was imperative to analyze how to manipulate the game difficulty according to
the performance in the task’s variables, whose behavior was presented in the (1)-(7)
equations. In cases wherever the player’s performance is low for a specific variable, the
correspondent performance is decremented. Otherwise, if he performs correctly the task
then, the variables’ performances are positively updated.
Additionally, when the performance of a variable reaches a lower or upper boundary,
the variable’s parameters become easier or harder, respectively. These thresholds were
carefully defined to avoid that, in any moment, the child’s experience moves her out of
the flow channel neither triggers a feeling of anxiety or boredom with the game-play
experience.
49


Chapter
6Automatic Sound Recognition System
As we previously discussed, the game platform should detect the child’s failures in pro-
ducing the desired phoneme for the task. In order to be able to identify the sound
produced by the child, it is necessary to implement an ASR system. This system requires
a process of extracting the features of each received sample and processing them through
an automatic learning algorithm.
In this chapter, we discuss the development of an ASR system for vowels. There-
fore, we start with a description of the dataset preprocessing and the feature extraction
techniques to provide the right information of each sound and create a robust classifier.
Furthermore, we describe the results of the combination of the classification algorithms
to improve the accuracy test results. Lastly, we propose a final solution to build the model
that best fits our data.
6.1 Data set characterization
For the practice of the game’s exercises, the child will be asked to produce the sustained
vowel, which can be /a/, /e/, /i/, /o/ or /u/ sustained. To train our ASR model, we used
2 data sets, (A) vowels /a/, /e/, /i/, /o/ and /u/ from the data set created by Aníbal J.
S. Ferreira, and presented in [15]. These records have a 32kHz sampling of the speech
sound with 100 ms, corresponding to the most common EP vowels. Additionally, we
used (B) BioVisualSpeech’s sustained vowels data set, which includes files with 48kHz
sampling and around 4 seconds of the speech sound. The data set includes exclusively
the sustained vowels /a/, /i/ and /u/ [10].
The description regarding each data set is presented in the tables 6.1 and 6.2. Due
to the difference between the two data sets - the sampling frequency and the file length -
we needed to perform a few changes in the original data sets. Giving the differences in
51
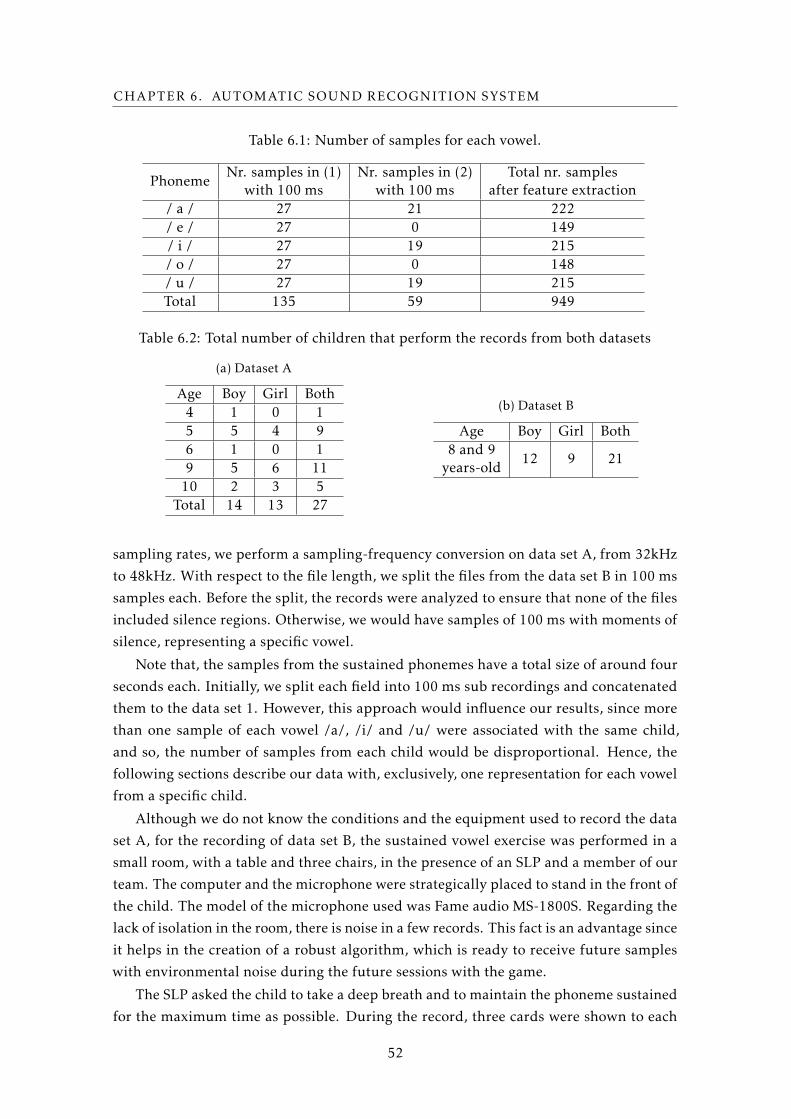
CHAPTER 6. AUTOMATIC SOUND RECOGNITION SYSTEM
Table 6.1: Number of samples for each vowel.
PhonemeNr. samples in (1)
with 100 msNr. samples in (2)
with 100 msTotal nr. samples
after feature extraction
/ a / 27 21 222
/ e / 27 0 149
/ i / 27 19 215
/ o / 27 0 148
/ u / 27 19 215
Total 135 59 949
Table 6.2: Total number of children that perform the records from both datasets
(a) Dataset A
Age Boy Girl Both
4 1 0 1
5 5 4 9
6 1 0 1
9 5 6 11
10 2 3 5
Total 14 13 27
(b) Dataset B
Age Boy Girl Both
8 and 9years-old
12 9 21
sampling rates, we perform a sampling-frequency conversion on data set A, from 32kHz
to 48kHz. With respect to the file length, we split the files from the data set B in 100 ms
samples each. Before the split, the records were analyzed to ensure that none of the files
included silence regions. Otherwise, we would have samples of 100 ms with moments of
silence, representing a specific vowel.
Note that, the samples from the sustained phonemes have a total size of around four
seconds each. Initially, we split each field into 100 ms sub recordings and concatenated
them to the data set 1. However, this approach would influence our results, since more
than one sample of each vowel /a/, /i/ and /u/ were associated with the same child,
and so, the number of samples from each child would be disproportional. Hence, the
following sections describe our data with, exclusively, one representation for each vowel
from a specific child.
Although we do not know the conditions and the equipment used to record the data
set A, for the recording of data set B, the sustained vowel exercise was performed in a
small room, with a table and three chairs, in the presence of an SLP and a member of our
team. The computer and the microphone were strategically placed to stand in the front of
the child. The model of the microphone used was Fame audio MS-1800S. Regarding the
lack of isolation in the room, there is noise in a few records. This fact is an advantage since
it helps in the creation of a robust algorithm, which is ready to receive future samples
with environmental noise during the future sessions with the game.
The SLP asked the child to take a deep breath and to maintain the phoneme sustained
for the maximum time as possible. During the record, three cards were shown to each
52

6.2. AUTOMATIC RECOGNITION SYSTEM OF VOWELS
(a) /a/ (b) /i/ (c) /u/
Figure 6.1: Comparative samples with 100 ms from the sustained phonemes /a/, /i/ and/u/, with pitch and formants marked as blue and red, respectively.
child, with the words "Ave", "Iva"and "Uva", since they should perform the MPT exercise
without any adulterate factor. Additionally, for each child, the sequence of the MPT
exercises was randomly selected. In the Figure 6.1 three samples are shown representing
each of the sustained vowels recorded. As observed in Figure 6.1 each vowel presents
different spectrum characteristics. When observing the formant plot, we are completely
able to separate the shown vowels. However, as we previous analyzed, the children’s
pitch tends to affect the formants pattern, and so, in some cases these features are not
capable of completely separate the vowels [15, 27, 37].
6.2 Automatic recognition system of vowels
In order to develop the ASR system, we combine several techniques to find the solution
that best fits our purpose, regarding the possible solutions analyzed in section 2.2. The
development of our system is described in the following subsections and illustrated in
the figure 6.2.
6.2.1 Feature extraction techniques
The ASR system needs to train the classifier with information that characterizes each
sound data of interest, to adequately distinguish the phonemes produced. Besides the
analysis of the data set characteristics, we had to choose the features that represent each
phoneme and capture important perceptual cues, that allows our model to distinguish
them. In chapter 2, section 2.2, we show the most popular features in sound data analysis.
The previous spectral analysis approach was replaced for the MFCCs analysis.
Among other details, the mel frequency cepstral coefficients are obtained through the
application of a mel-filter in the signal frames and further applying of the DCT func-
tion. Despite the popularity of MFCCs, some studies tried to analyze if the process of
decorrelating the Mel-filter banks through DCT method is necessary to improve perfor-
mance. Otherwise, it may be an unnecessary step if it discards important information
53

CHAPTER 6. AUTOMATIC SOUND RECOGNITION SYSTEM
Figure 6.2: Steps in the development of our vowel ASR system.
from the original speech signal [25]. Consequently, we perform the extraction of MFCCs
features and we complement their analysis with the filter bank features. Figure 6.3 shows
a comparison between the FB and MFCCs from the sustained phonemes /a/, /i/ and /u/.
The MFCCs are produced in the format of feature vectors. Each vector defines a frame
from one input signal, with 26 Mel-filter cepstral coefficients on it. Usually, for ASR,
only the coefficients 2-13 are maintained. Depending on the problem, i.e., the sound
to decompose in the ASR system, the number of coefficients may change. For instance,
other vowel recognition researchers used 12 and 16 MFCCs [10, 15]. In our project, we
needed to find the best number of coefficients to use, and so we trained our classifier using
from 5 to 16 coefficients. For the extraction process, we used the Librosa python library,
which performs audio and music signal analysis [32]. This library includes, among other
functionalities, the computation of the filter banks, MFCCs with customized parameters
and derivation features - delta and double delta.
The Librosa solution includes the steps described in section 2.2. These steps and the
correspondent parameters are described below:
1. Preprocessing: In the beginning, we convert ".wav"files into float arrays.
2. Framing and Windowing: For this step, we had to choose the size to split our
sample into a stack of frames. It is usual to take 20-40 ms frames with partial
overlap between consecutive frames. In our implementation, we used 20 ms and 10
ms of overlap. For example, for the dataset A with a sampling rate of 32kHz, the
first 640 samples starts at sample 0, the next 640 samples start at frame 320 until
the end of speech is reached. The hamming windows are applied to each frame.
54

6.2. AUTOMATIC RECOGNITION SYSTEM OF VOWELS
3. Compute the STFT: Here we compute the N-point FFT on each frame to calculate
the frequency spectrum. In our case, the number of FFTs is 1024. The computation
of the power spectrum follows this step.
4. Compute Mel-Filterbank energy features: In this step, we used 40 filters, which
is the standard choice in the ASR context.
5. Take the log of the features: Here we calculate the logarithm of the features, which
gives us the filter banks features.
6. Apply DCT: We apply the Discrete Cosine Transform of type 2, which gives us the
cepstral coefficients.
7. Normalization: We normalize the final feature vectors obtained.
After this step, we compute the delta and double delta features.
6.2.2 Data preprocessing and analysis
To use the computed features to train the classifier, we create multiple data sets with
different combinations of features. We establish 6 possible data sets, combining Filter
Banks or MFCCs in the following cases:
1. MFCCs for all frames;
2. MFCCs with delta and double delta for all frames;
3. MFCCs with delta and double delta for the mean and standard deviation of all
frames;
4. MFCCs for the mean and standard deviation of all frames;
5. Filterbanks for all frames;
6. Filterbanks for the mean and standard deviation of all frames;
Moreover, after defining our data sets, we need to train the model while we try to find
the right balance, without overfitting and underfitting the data. To adjust the relationship
between the predictions of our model and the correct values and the generalization of
our model, we need to train the model with a more substantial portion of the data set,
multiple times and with different train and test sets distribution. For this purpose, we
apply the following techniques:
• Random split
For this option, we use a random split to create both training and test sets. Note that,
with this splitting method it is more likely to have samples from the same child in
both subsets which can cause a bias in our classification process. Thus, randomize
the data might not be enough;
55

CHAPTER 6. AUTOMATIC SOUND RECOGNITION SYSTEM
(a) FB from a file with label /a/. (b) MFCCs from a file with label /a/.
(c) FB from a file with label /i/. (d) MFCCs from a file with label /i/.
(e) FB from a file with label /u/. (f) MFCCs from a file with label /u/.
Figure 6.3: Comparative samples from the sustained phonemes /a/, /i/ and /u/, with 40filter banks and 13 MFCCs.
• One Child Out experiment
Instead of using the previous naive approach, we separate the data set in a specific
number of subsets with an approach of leaving one child out for the test set. So,
56
6.2. AUTOMATIC RECOGNITION SYSTEM OF VOWELS
(a) Data set 1
Figure 6.4: Radial visualization of the data set 1.
we run n tests, where n is the number of children in our data set. In each test, the
test data must only contain the data from one child, while the training set uses the
remaining data. With this technique, we ensure that our model is not biased with
samples in both train and test sets from the same child since in future prediction it
classifies unseen data;
• Cross validation split
For the CV-split, we separate the children using the stratified k-folds. Using strati-
fied folds, we ensure that each subset includes the equal number of samples of each
class. Considering that, we have a slightly class imbalance, a randomly selected fold
may not represent a minor class adequately. Moreover, using the cross-validation
technique, we process out training and test sets multiple times, with different dis-
tributions.
6.2.3 Data visualization and feature analysis
In order to analyze the problem complexity and verify if the features’ correlation with
each label is appropriate to our problem-solving, we tried to visualize our data. Giving
that our data is multidimensional, we use radial viz, which is a multi-dimensional visu-
alization technique. The figure 6.4 presents the result of this first approach without any
data processing. Our data instances /a/, /e/, /i/, /o/ and /u/ are presented as anchor
points. If they are close to a set of variable anchors, they have higher values for these
variables than for others. However, as we can see in the figure 6.4, this projection is not
perceptible neither useful.
Therefore, we apply a methodology of dimensionality reduction and multidimen-
sional data preprocessing using Principal Component Analysis (PCA) and Linear Dis-
criminant Analysis (LDA) techniques and we perform visualization through scatter plots.
Specifically, the PCA allows the mapping of the features information into n principal
57
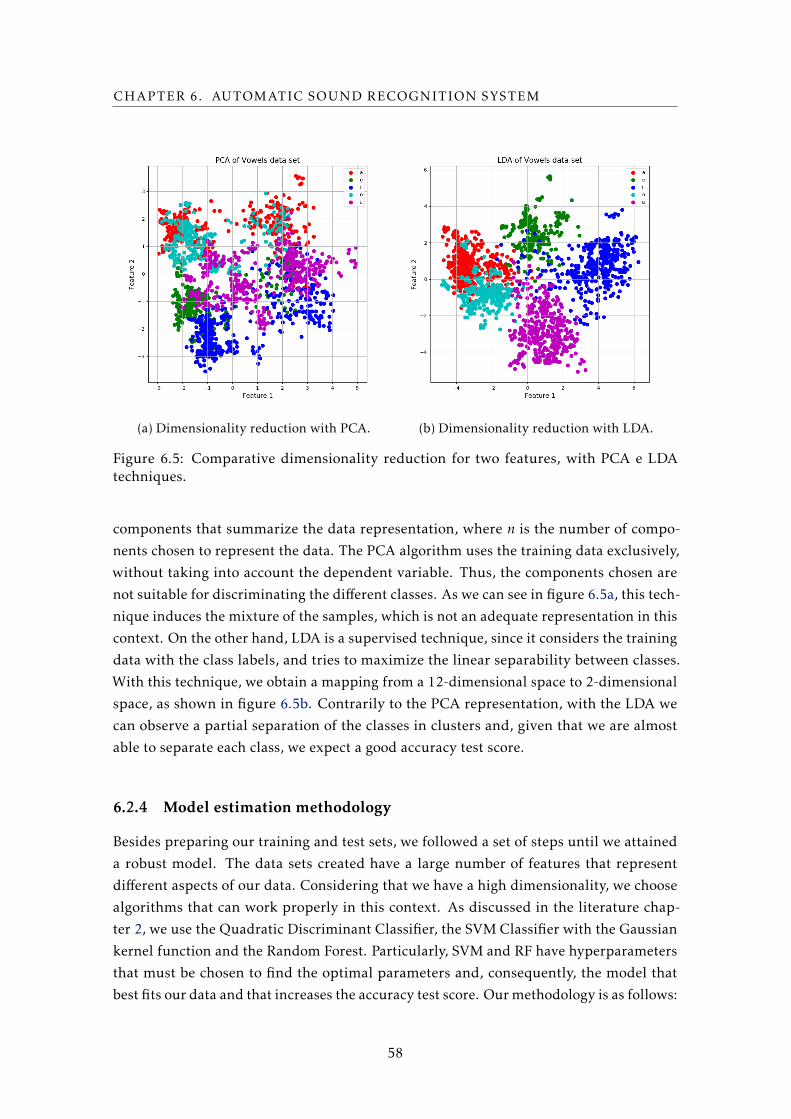
CHAPTER 6. AUTOMATIC SOUND RECOGNITION SYSTEM
(a) Dimensionality reduction with PCA. (b) Dimensionality reduction with LDA.
Figure 6.5: Comparative dimensionality reduction for two features, with PCA e LDAtechniques.
components that summarize the data representation, where n is the number of compo-
nents chosen to represent the data. The PCA algorithm uses the training data exclusively,
without taking into account the dependent variable. Thus, the components chosen are
not suitable for discriminating the different classes. As we can see in figure 6.5a, this tech-
nique induces the mixture of the samples, which is not an adequate representation in this
context. On the other hand, LDA is a supervised technique, since it considers the training
data with the class labels, and tries to maximize the linear separability between classes.
With this technique, we obtain a mapping from a 12-dimensional space to 2-dimensional
space, as shown in figure 6.5b. Contrarily to the PCA representation, with the LDA we
can observe a partial separation of the classes in clusters and, given that we are almost
able to separate each class, we expect a good accuracy test score.
6.2.4 Model estimation methodology
Besides preparing our training and test sets, we followed a set of steps until we attained
a robust model. The data sets created have a large number of features that represent
different aspects of our data. Considering that we have a high dimensionality, we choose
algorithms that can work properly in this context. As discussed in the literature chap-
ter 2, we use the Quadratic Discriminant Classifier, the SVM Classifier with the Gaussian
kernel function and the Random Forest. Particularly, SVM and RF have hyperparameters
that must be chosen to find the optimal parameters and, consequently, the model that
best fits our data and that increases the accuracy test score. Ourmethodology is as follows:
58

6.3. EVALUATION
• Standardize the data;
• Choose the best parameters for each classifier algorithm, if needed. For the SVM
with RBF kernel, the correspondent parameters C and gammawere carefully chosen
with the grid-Search cross-validation. In the case of the Random Forest classifier,
we tested different combinations for the number of estimators and the maximum
depth. This function iterates over the given parameters and indicates, after a cross
validation process, the optimal parameters to our problem;
• Compare the accuracy test score for each classifier, for each data set, combined with
different training and test sets techniques;
• Select the best model, i.e., the one that has the best accuracy results, which will
predict the future samples.
6.3 Evaluation
6.3.1 Comparison between different classifiers
After defining the model preparation steps, we are going to start our evaluation by ana-
lyzing different classifiers’ performance, according to the train and test splitting methods
previously mentioned. Figure 6.6 presents this comparison, where SVM classifier has the
highest accuracy test score, for all training and test sets. On the other hand, although
QDA can create quadratic boundaries in our data, it performs the worse when compared
with the remaining classifiers. Concerning the Random Forest classifier, the performance
is slightly lower, around 2% for all training and test sets. When comparing the training
and test sets, we observe in figure 6.6, that the One Child Out approach has a worst per-
formance, which is due to the fact that it uses one child data as the test set. Thus, if the
chosen child data represents an outlier, it will influence the classifier results negatively.
This behavior is further analyzed in section 6.3.3.
The three classifiers are inherently multiclass. To choose the hyperparameters for
the SVM and RF classifiers, we used grid-search with cross-validation, a method that
performs an exhaustive search over the parameters provided for our estimators. This
method outputted the values 1.0 and 0.1 as the optimal values for C and gamma parame-
ters, respectively, for SVM with RBF kernel. In the case of the Random Forest classifier,
we trained the number of estimators and maximum depth, for which we obtained the
optimal values 200 and 8, respectively. QDA does not need to fine tune any parameter.
The QDA performance is lower than the remaining algorithms. This classifier is
based in the assumption that the data follows a Gaussian distribution. In the presence of
outliers that do not follow this normal distribution, the model has a worse performance.
The performance degrades even more with One Child Out approach. Additionally, since
the model does not have hyperparameters to tune, there is no possibility to adjust the
model to the data characteristics.
59

CHAPTER 6. AUTOMATIC SOUND RECOGNITION SYSTEM
Figure 6.6: Classifiers’ performance comparison regarding different train and test split-ting methods.
The RF results from the bagging of multiple decision trees. These trees are created
based on sub-optimal splits that are made by introducing randomness. Regarding the
high dimensionality of our data, it is plausible that less relevant features are selected
over each split, and so the result can be slightly worst. In a way, the hyperparameters
can be tuned to fit better our model and to generate soft linear boundaries at the model’s
decision surface.
Nevertheless, SVM with the RBF kernel maximizes the margins and generates a curve
as the non-linear boundary which depends on the value of C and gamma. C is a regu-
larization parameter therefore, higher values make the decision surface smooth. On the
other hand, the gamma value controls how sensitive the model would be to outliers. It
follows that distant points influence the creation of the decision boundary. Considering
the values 1.0 and 0.1 for C and gamma, respectively, our model produces a high accuracy
score without overfitting and taking into account a few outliers. Since the SVM with RBF
kernel produces the best results, we decided to use it through the remaining experiments
performed in the context of this thesis.
6.3.2 Effect of varying the number of MFCCs
Besides analyzing the classifiers’ performance, we need to choose the number of MFCCs
to use, as it influences the algorithm’s results. In fundamental concepts chapter 2, par-
ticularly, in Carvalho et al., the original data set 6.2a was tested with 12 MFCCs. In our
classification problem, after testing in the range from 5 to 25 coefficients, we reach other
results. The extracted MFCCs were combined with the SVM estimator, for each proposed
60
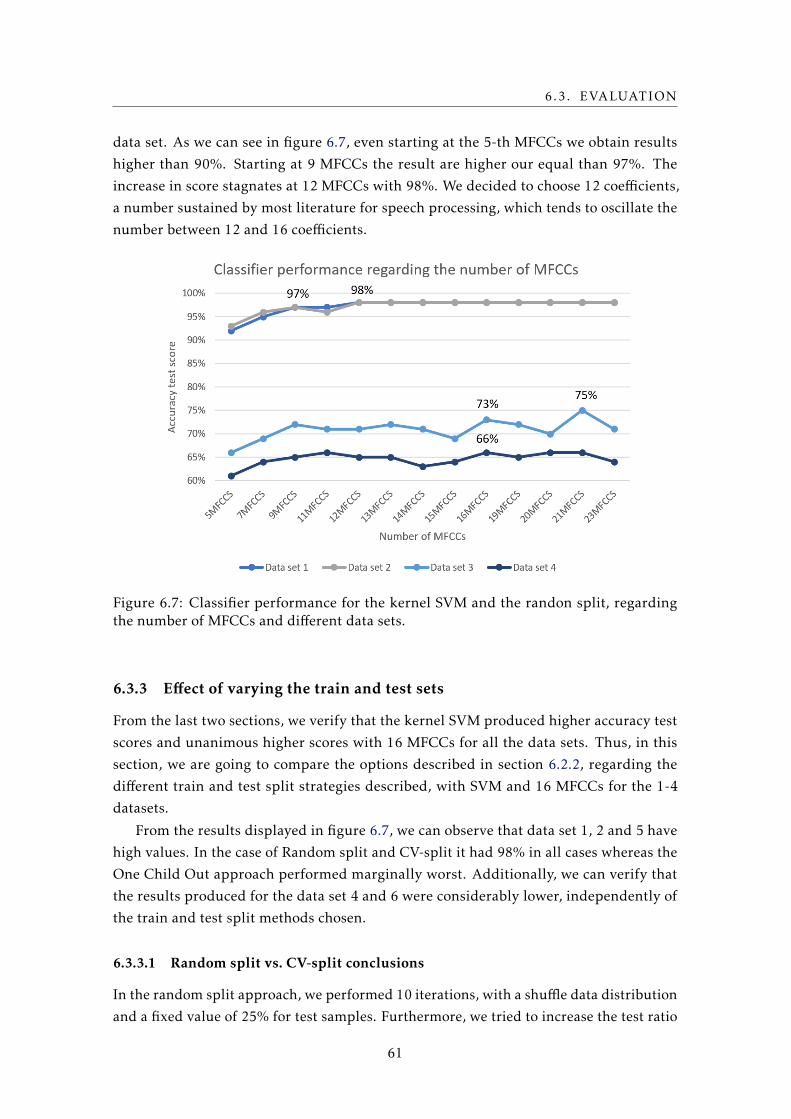
6.3. EVALUATION
data set. As we can see in figure 6.7, even starting at the 5-th MFCCs we obtain results
higher than 90%. Starting at 9 MFCCs the result are higher our equal than 97%. The
increase in score stagnates at 12 MFCCs with 98%. We decided to choose 12 coefficients,
a number sustained by most literature for speech processing, which tends to oscillate the
number between 12 and 16 coefficients.
Figure 6.7: Classifier performance for the kernel SVM and the randon split, regardingthe number of MFCCs and different data sets.
6.3.3 Effect of varying the train and test sets
From the last two sections, we verify that the kernel SVM produced higher accuracy test
scores and unanimous higher scores with 16 MFCCs for all the data sets. Thus, in this
section, we are going to compare the options described in section 6.2.2, regarding the
different train and test split strategies described, with SVM and 16 MFCCs for the 1-4
datasets.
From the results displayed in figure 6.7, we can observe that data set 1, 2 and 5 have
high values. In the case of Random split and CV-split it had 98% in all cases whereas the
One Child Out approach performed marginally worst. Additionally, we can verify that
the results produced for the data set 4 and 6 were considerably lower, independently of
the train and test split methods chosen.
6.3.3.1 Random split vs. CV-split conclusions
In the random split approach, we performed 10 iterations, with a shuffle data distribution
and a fixed value of 25% for test samples. Furthermore, we tried to increase the test ratio
61
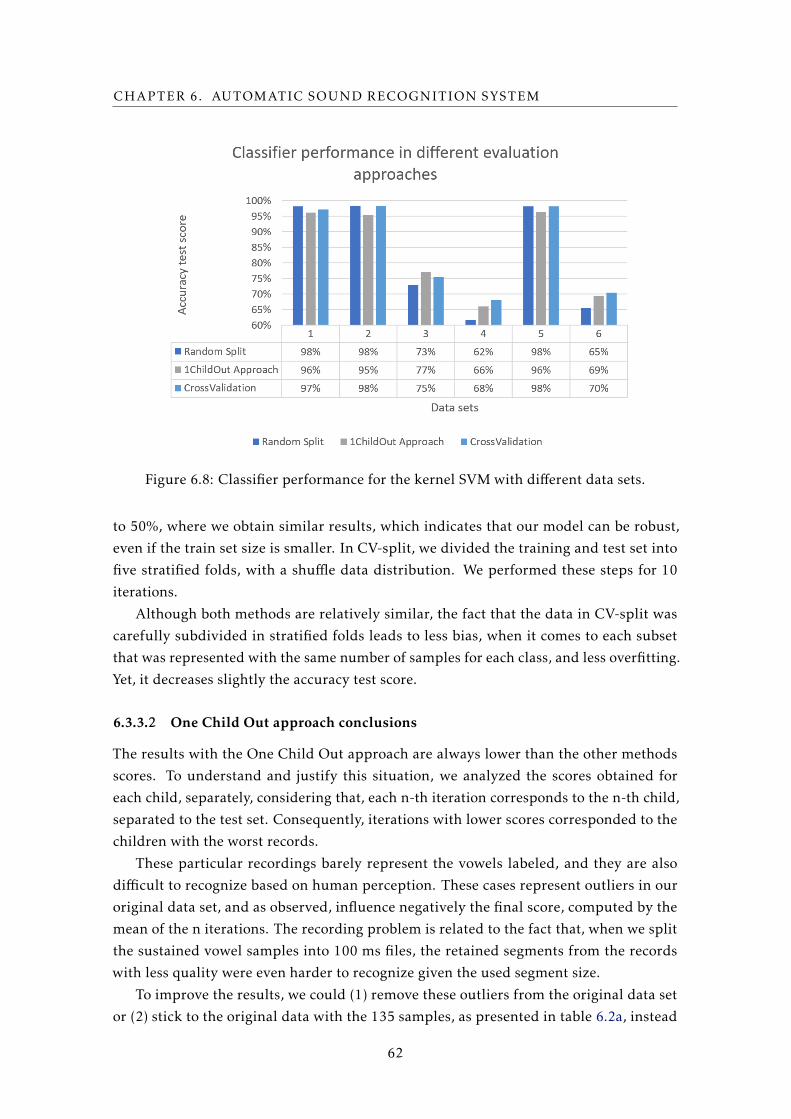
CHAPTER 6. AUTOMATIC SOUND RECOGNITION SYSTEM
Figure 6.8: Classifier performance for the kernel SVM with different data sets.
to 50%, where we obtain similar results, which indicates that our model can be robust,
even if the train set size is smaller. In CV-split, we divided the training and test set into
five stratified folds, with a shuffle data distribution. We performed these steps for 10
iterations.
Although both methods are relatively similar, the fact that the data in CV-split was
carefully subdivided in stratified folds leads to less bias, when it comes to each subset
that was represented with the same number of samples for each class, and less overfitting.
Yet, it decreases slightly the accuracy test score.
6.3.3.2 One Child Out approach conclusions
The results with the One Child Out approach are always lower than the other methods
scores. To understand and justify this situation, we analyzed the scores obtained for
each child, separately, considering that, each n-th iteration corresponds to the n-th child,
separated to the test set. Consequently, iterations with lower scores corresponded to the
children with the worst records.
These particular recordings barely represent the vowels labeled, and they are also
difficult to recognize based on human perception. These cases represent outliers in our
original data set, and as observed, influence negatively the final score, computed by the
mean of the n iterations. The recording problem is related to the fact that, when we split
the sustained vowel samples into 100 ms files, the retained segments from the records
with less quality were even harder to recognize given the used segment size.
To improve the results, we could (1) remove these outliers from the original data set
or (2) stick to the original data with the 135 samples, as presented in table 6.2a, instead
62

6.3. EVALUATION
of including the data set 6.2b with the sustained vowels. Still, none of the options are
good. We know that a robust machine learning model needs a large data set, otherwise
the model will not have enough data to learn from. On the other hand, if we remove these
few outliers from the data set, our model has no idea how to adjust to these cases and
will fail the task, when the samples recorded have a lower quality. Considering this, we
choose to include these outliers since that training the model with variations in the data
set prepare it for future predictions.
6.3.3.3 Comparative analysis between data sets
Each data set has particular characteristics, regarding the features and the number of
features in each data set:
• The number of samples is summarized in the table 6.3:
Table 6.3: Number of samples in the data sets 1-6.
VowelData set1, 2 and 5
Data set3, 4 and 6
/a/ 222 48
/e/ 149 27
/i/ 215 46
/o/ 148 27
/u/ 215 46
• The data set 1 only has 13 MFCCs, while the data set 2 has 13 MFCCs, 13 Deltas
(D) and 13 Double Deltas (DD) which results in 39 features. Since the accuracy test
score is the same in both data sets, we conclude that, in this particular case, the
extra features, D and DD, do not contribute to increase the classification results;
• The data sets 3 and 4 contain the same features in data sets 1 and 2, respectively,
although we applied the mean and standard deviation of all frames, which reduce
the number of total samples for each vowel. When we compare the results shown
in figure 6.8, we see that with the data set 3, the model achieved better results
than with data set 4. This case suggests that the derivative features from MFCCs,
provided important information, that increased the accuracy test scores by 10%;
• The data set 5 has 40 FB, while the data set 6 has 40 FB and, in this last case, the
frames were reduced to its mean and standard deviation. Thus, the number of
samples for each vowel is lower than the total size in the data set 5. As we can
see in figure 6.9, the feature distribution and shape of each data set is the same,
although the number of samples is significantly lower in data set 6. This difference
is reflected in the classification results, hence the lower number of samples in data
set 6 penalizes drastically the final score;
63
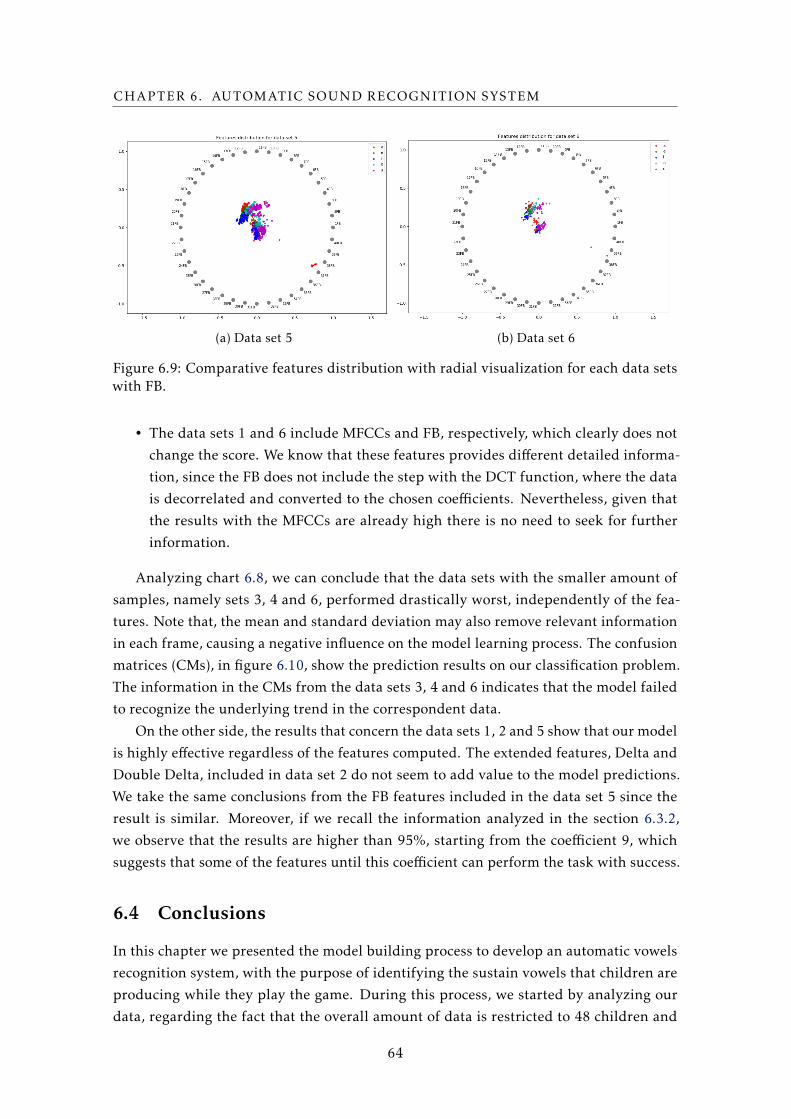
CHAPTER 6. AUTOMATIC SOUND RECOGNITION SYSTEM
(a) Data set 5 (b) Data set 6
Figure 6.9: Comparative features distribution with radial visualization for each data setswith FB.
• The data sets 1 and 6 include MFCCs and FB, respectively, which clearly does not
change the score. We know that these features provides different detailed informa-
tion, since the FB does not include the step with the DCT function, where the data
is decorrelated and converted to the chosen coefficients. Nevertheless, given that
the results with the MFCCs are already high there is no need to seek for further
information.
Analyzing chart 6.8, we can conclude that the data sets with the smaller amount of
samples, namely sets 3, 4 and 6, performed drastically worst, independently of the fea-
tures. Note that, the mean and standard deviation may also remove relevant information
in each frame, causing a negative influence on the model learning process. The confusion
matrices (CMs), in figure 6.10, show the prediction results on our classification problem.
The information in the CMs from the data sets 3, 4 and 6 indicates that the model failed
to recognize the underlying trend in the correspondent data.
On the other side, the results that concern the data sets 1, 2 and 5 show that our model
is highly effective regardless of the features computed. The extended features, Delta and
Double Delta, included in data set 2 do not seem to add value to the model predictions.
We take the same conclusions from the FB features included in the data set 5 since the
result is similar. Moreover, if we recall the information analyzed in the section 6.3.2,
we observe that the results are higher than 95%, starting from the coefficient 9, which
suggests that some of the features until this coefficient can perform the task with success.
6.4 Conclusions
In this chapter we presented the model building process to develop an automatic vowels
recognition system, with the purpose of identifying the sustain vowels that children are
producing while they play the game. During this process, we started by analyzing our
data, regarding the fact that the overall amount of data is restricted to 48 children and
64

6.4. CONCLUSIONS
(a) Data set 1 (b) Data set 2 (c) Data set 3
(d) Data set 4 (e) Data set 5 (f) Data set 6
Figure 6.10: Vowel detection confusion matrices.
the number of recordings from /e/ and /o/ is about half the number of the remaining
classes. Moreover, part of the samples had just 100 ms which includes a small amount
of information from the correspondent vowel. Therefore, we seek to extract features
that mainly represent our data, enough to distinguish the classes of interest, and so, we
prepared the training of 6 different solutions. As we concluded in the last subsection,
part of the features extracted are less significant for this classification problem, and the
data set 1 is adequate and enough to train our model.
Additionally, we presented the results of each classifier. QDA produced results lower
than 94%. Random Forest classifier, achieved a maximum accuracy test score of 97%, for
which we used the optimal values 200 and 8 for the number of estimators and maximum
depth, respectively. SVM algorithm with RBF kernel produced accuracy test scores of
98%, with the hyperparameters C equals 1 and gamma with the value of 0.1. As we
previously concluded, the SVM with RBF kernel obtain the best accuracy test results,
independently of the train and test sets.
At the same time, each classifier were tested, varying the number of MFCCs (in the
case of data set 1-4) and considering the different train and test splitting methods. Con-
cerning the number of MFCCs, with a reduced number of features, it is possible to achieve
accuracy test results higher that 90%. After testing from 5 to 25 MFCCs, we verified that
9 MFCCs and 12 MFCCs produced 97 and 98% respectively, with the Random split tech-
nique and for the data set 1, 2 and 5. After the 12-th coefficient, the accuracy test score
65

CHAPTER 6. AUTOMATIC SOUND RECOGNITION SYSTEM
stagnate. Thus, the 12 MFCCs were chosen as a component of our final solution.
Moreover, if we consider, exclusively, the accuracy test score achieved through each
train and test split methods, we would choose the Random split. In this technique, we
used different test sizes, from 25 to 50%, with which the algorithm maintained the high
accuracy score of 98%. Therefore, this method does not overfit our data set and so, provide
low bias. On the other hand, we experimented the CV-split, which produces good results
as well, and it performs through more iterations, over the 5 stratified folds created in
each iteration, which ensures the same class distribution in each fold. Nevertheless, both
methods do not separate the samples from the same child that are in both train and test
sets, and so, it will bias the model.
This problem is solved with the One Child Out approach, although it produced less
significant results, around 2% lower than what was observed in the previous experiments,
which is related to the quality of the samples used in the test set. The lack of quality is due
to the fact the sustain vowel recordings contain silence zones, low volume segments or
noise. The segments with these problems were causing the incorrect classification and so,
they performed a negative influence in the final score. We could remove these outliers and
then produce a score as high as in the previous techniques. However, these cases allow the
model to capture small variations in the data set and for future predictions, considering
that, we will certainly have future recording with noise, and children’ productions with a
lower volume.
Therefore, we created our best model, regarding our previous conclusions. The SVM
is the classifier chosen with the parameters C equals to 1.0 and gamma equals to 0.1.
For the train and test split method, we opted by the One Child Out approach. Lastly,
we decide to choose the data set 1, with 12 MFCCs, considering that, it is adequate to
generate a high accuracy test score.
66

Chapter
7Feedback and Validation
Before the proposed game can be used to complement speech therapy sessions, it is impor-
tant to receive SLP’s feedback and test the implemented functionalities with the target
audiences. During the platform development, we received feedback from therapists,
students and teachers to whom we were able to demonstrate our platform.
Besides that, after the game development process, to acknowledge and evaluate whereas
the functionatities fulfill the game’s objectives, we applied user tests with children. Dur-
ing the course of this chapter we present the experiment procedure and conclusions
according to the results observed. Moreover, in order to collect information regarding the
SLP’s opinion, we also applied questionnaires with them. The questions’ results are fur-
ther analyzed. Lastly, we take the overall conclusion of the application of both validation
methodologies.
7.1 Feedback from SLP(s) and heterogeneous audiences
During the development of our solution, we were able to demonstrate the game at Expo
FCT NOVA 2018 and the European Congress of Speech and Language Therapy 2018.
Each event focused on a different target audience, which allowed us to received diversi-
fied feedback from both groups. The Expo FCT NOVA 2018 is an open day at FCT NOVA
which receives high school students and their teachers from all over the country, to see
each department offers, with demonstrations of the work developed at the university.
Therefore, we were there to demonstrate the BioVisualSpeech project which includes the
worked performed in this dissertation. At the time of the demonstration, the game plat-
form was already developed with the main scenes and functionalities, without the ASR
system included. The players, both students, and teachers produced sustained phonemes
that had to stand within the defined intensity thresholds. We received their feedback in
67

CHAPTER 7. FEEDBACK AND VALIDATION
respect to the interface intuitiveness and usability, as well as, the game functionalities.
Figure 7.1: Game presentation in the European Congress of Speech and Language Ther-apy, May 2018.
Besides the demonstration described previously, the BioVisualSpeech team members
were present in the 10th CPLOL Congress - European Congress of Speech and Language
Therapy in Estoril, Portugal. The congress involved the participation of other researchers
and SLP(s) from all over the world, for whom we were able to demonstrate our game,
as illustrated in figure 7.1. At the time of that demonstration the complete game as
presented in this dissertation was not finished. We used a simpler version that did not
include the ASR system. Only the ASR system was not integrated with the game platform.
The participants practiced the SVE and tested the main functionalities for which they
gave their total approval. Additionally, to the feedback received during those events, we
received professional opinions from voice disorders specialists.
7.2 Validation
After the game development is essential to perform a platform’s evaluation to ensure that
the game fulfills the objectives proposed. Therefore, we were able to perform two types
of evaluation: user testing sessions with children and questionnaires with SLPs.
In this study, we pretend to analyze the following aspects:
• The feasibility and intuitiveness of the platform and the adaptability regarding
different children needs;
• The software design, specifically, the scenarios, scenes transitions, characters and
rewards;
• The software functionalities;
• The impact of the gamification strategy;
• The children’s opinion regarding the user tests;
• The SLPs’s opinion according to the information collected through the question-
naires.
68

7.2. VALIDATION
7.2.1 User testing sessions
In order to ensure the quality of our system, we deployed a testing methodology lever-
aging in field experiments with children. This study was not designed to determine if
the game platform improved the children conditions. Instead, we evaluate if the game is
appealing, intuitive and feasible for the children.
7.2.1.1 Participants
This experiment took place in the nursery school Alfredo da Mota, in Castelo Branco. The
program included the SLP from the institution and 14 children between 4 and 5 years-old.
As we can see in figure 7.2, most of the children have 5 years-old and are female.
(a) Age of children. (b) Gender of children. (c) Number of children with dys-phonia.
Figure 7.2: Basic information regarding the participants.
Concerning the children voice analysis, we had three participants with 5 years-old
and diagnosed dysphonia. To further identify and analyze the results from each child,
we use numerations. Thus, child 14 present rough voice, child 3 has asthenia (weak
voice) and child 9 has abnormal loudness/ unsteady volume. The SLP performed the
auditory-perceptual quality evaluation of these children.
7.2.1.2 Experiment procedure
We performed user test sessions, individually for each child in a quiet room, with the
presence of the SLP. The equipament used is illustrated in the figure 7.3.
The children were submitted to the same conditions, with the following steps:
1. We introduce them the idea of the game, a journey with different characters where
they can be rewarded with gifts if they conclude the tasks.
2. The SLP asks the child to perform the SVE, as long as possible. During the child’s
production, we recorded the sound and we measured the MPT achieved. For the
recording we used Audacity 2.3.0. At the time, the children did not see the game;
69

CHAPTER 7. FEEDBACK AND VALIDATION
Figure 7.3: The setup used for the recordings.
3. The SLP starts the game, inserts the basic information concerning child and she
choose the scenes and the exercise parameters;
4. Afterwards, we show the game to the child, allowing her to choose the character
and the scenario;
5. When the child enters the scene, the SLP tell her to produce the chosen vowel, until
the character reaches the target. As so, the child practice the SVE;
6. In the end of the trial, we measure the MPT achieved and child chooses a reward;
7. We repeat the process one more time for each child, in order to register two perfor-
mances during the in-game experience. For the next time, we update the exercise
parameters in 3, if the child performed the exercise without breaks. Otherwise, we
start the process from step 4.
For the first game trial, the therapist increment 4s 1 to the expected MPT, according to
the MPT obtained in the recording. For the second game trial, if the child performed the
exercise with success, the therapist increments the expected MPT with more 4s 1, until
the maximum (10s). Otherwise, she maintains the previous parametrization.
Note that, for the recording and the first game trial, the SLP instruct the child to
produce the vowel /a/. In the second game trial, she asked the child to choose another
vowel. We start with the vowel /a/, since the SLP considered the /a/ the easier vowel to
perform the SVE.
7.2.1.3 Experiment results
Figure 7.4 present the children’s results from 1 to 14. If we compare each child’s perfor-
mance, we realize that most of the children improved progressively until trial 2. During
the first recording, they were less motivated and consequently achieving a lower MPT
1Note that, for a child with dysphonia, the increments is just 2s.
70
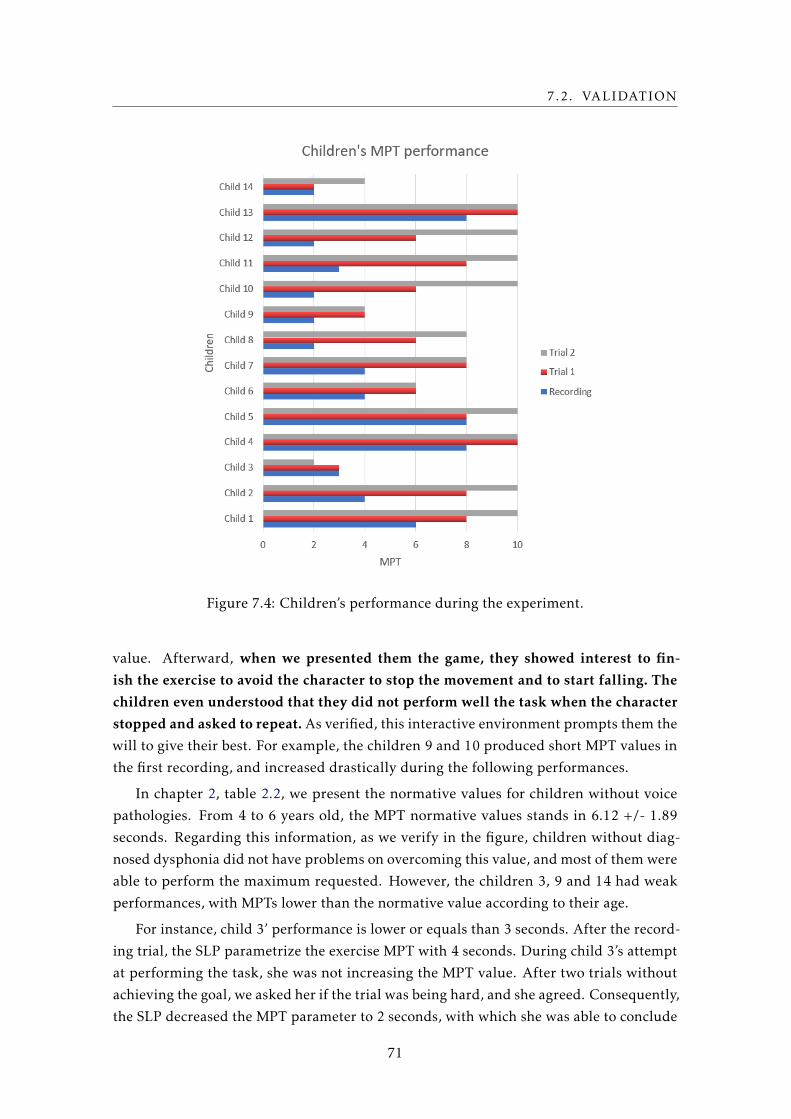
7.2. VALIDATION
Figure 7.4: Children’s performance during the experiment.
value. Afterward, when we presented them the game, they showed interest to fin-
ish the exercise to avoid the character to stop the movement and to start falling. The
children even understood that they did not perform well the task when the character
stopped and asked to repeat. As verified, this interactive environment prompts them the
will to give their best. For example, the children 9 and 10 produced short MPT values in
the first recording, and increased drastically during the following performances.
In chapter 2, table 2.2, we present the normative values for children without voice
pathologies. From 4 to 6 years old, the MPT normative values stands in 6.12 +/- 1.89
seconds. Regarding this information, as we verify in the figure, children without diag-
nosed dysphonia did not have problems on overcoming this value, and most of them were
able to perform the maximum requested. However, the children 3, 9 and 14 had weak
performances, with MPTs lower than the normative value according to their age.
For instance, child 3’ performance is lower or equals than 3 seconds. After the record-
ing trial, the SLP parametrize the exercise MPT with 4 seconds. During child 3’s attempt
at performing the task, she was not increasing the MPT value. After two trials without
achieving the goal, we asked her if the trial was being hard, and she agreed. Consequently,
the SLP decreased the MPT parameter to 2 seconds, with which she was able to conclude
71

CHAPTER 7. FEEDBACK AND VALIDATION
the task with success. In this situation, we used the manual parametrization option to
update the game’s difficulty to the child’s capacities. With an automatic parametrization,
it would not be necessary. In the case of child 9’s performance, while she was trying
to achieve the target with the MPT requested, she was also dealing with an unsteady
loudness. On the other hand, child 14’s has a rough voice, which made it difficult for him
to perform the task.
With respect to the game’ UI elements, the children choose the character most similar
to them. On the other hand, the rewards’ choice was random. In the case of the SVE
scenarios, the approval was unanimously. Overall, they asked to keep playing and to
conquer more rewards.
7.2.1.4 User tests conclusions
• In most of the cases, children improve MPT immediately, as they start the game tri-
als, which indicates that the game UI elements, with the character moving through
a target, motivate them to endeavor the task with commitment;
• At the end of each user test, the children’s feedback was positive and unanimous.
We concluded that the UI elements suit our purpose. The children wanted to keep
on playing to conquer rewards and play with different scenarios;
• A key aspect of maintaining the child engaged in keep on playing is to provide
challenges according to her needs. In the case of child 3, her experience was moving
her out the flow channel and can trigger frustration feelings. Thus, manual or
automatic parametrization in the game was proved to be an essential functionality.
Moreover, automatic parametrization allows the child to play the game at home,
without going through this problem;
• Children with dysphonia struggled more in achieving the MPT requested than chil-
dren without this pathology. Child 14 increase his performance in trial 2, and child
9 increased after the recording task. Nevertheless, child 3 needed to stabilize the
MPT value in 2 seconds, before the increment. Otherwise, she would be frustrated.
7.2.2 Questionnaire to SLTs
The questionnaire focus on the evaluation of the following aspects:
• Interaction of the child with the game, in which the child practices the exercises
with difficulty parameterized manually:
1. Maximum phonation time predefined in the therapist’s area;
2. Predefined intensity interval for voice pathologies intervention;
3. Control the character with the keys A (forward), S (stop + fall).
72

7.2. VALIDATION
(a) Answers within the question Q1. (b) Answers about the question Q2.
Figure 7.5: Results regarding the SLPs and children interactions with the game platform.
• Interaction of the child with the character and the reward system to assess whether
the interactive elements of the game capture the child’s interest;
• Integration of scenarios, scenario transition, and child theme adequacy;
• Usability, clarity, and goals of the game;
• Global game feedback;
7.2.2.1 Participants
The questionnaire involved the participation of three SLPs, where one of them is special-
ized in voice disorders. Before answering the questionnaire, the SLPs tested the platform
with at least one patient, a child between 4 and 10 years-old with speech sound disorders.
7.2.2.2 Software design: scenarios and transitions
In order to evaluate the game’s scenarios and transitions between scenes, we prepared the
following questions:
• Q1: (Concerning interaction with the therapist) From 1 to 5 how clear and practical
is the game?
• Q2: (Concerning interaction with the child) From 1 to 5 how clear and practical is
the game?
• Q3: Do you consider the transition of scenarios clear and objective, from the initial
page toward the exercise page?
• Q4: Do you consider the scenarios appealing and suitable for children?
• Q5: Do you consider the scenarios inappropriate for the SVE?
• Q6: Are there any scenarios in the therapist settings that are not appropriate?
Through the questions’ results shown in figures 7.5a and 7.5b, we can understand if
the platform structure and design fits our goals. The SLPs considered, unanimously, that
73

CHAPTER 7. FEEDBACK AND VALIDATION
Figure 7.6: Answers regarding the question Q10.
the game transitions are intuitive and appealing for children, and none of them rejected
the scenes for the exercise page. Besides, they considered the set of operations for the
therapist are adequate and useful, and so, we consider these UI elements appropriate for
therapists and children.
7.2.2.3 Software design: Characters, rewards and other interactive UI elements
In order to evaluate the game’s UI elements, we introduced the following questions:
• Q7: Do you consider the rewards system to be capable of engaging the child ih the
game?
• Q8: Has the child ever been disinterested in the presented rewards?
• Q9: Do the characters’ variety, with different ethnicities for each gender, contribute
to the child’s satisfaction?
Considering both characters’ and rewards’ diversity, we can suit different children
tastes and, as confirmed by the SLPs, it contributes to the child’s satisfaction. Specifically,
the rewards stimulate and involve the children in the task, boosting their therapeutic
effects while they keep on playing.
• Q10:Did you find the visual cues in Bio Visual Speech adequate? (E.g.: the character
stops and begins to fall when the child produces the sound with a different intensity
than the requested)
Nevertheless, according to the answers presented in chart 7.6 about the characters’
movement, one of the three SLPs acknowledge that the falling of the figure does not suit
the theme under specific scenarios. In an open question, the same therapist proposed
an adaptation of the movement for different scenes. In the case of the train scene, the
SLP suggested a backward movement to substitute the fall of the figure, although it stills
appropriate in the bird and desert scenes.
74

7.2. VALIDATION
(a) Answers about Q13. (b) Answers about the question Q14.
These results oppose the feedback we received during the game development process.
We tried to find a visual cue that would be clear enough to represent the child’s wrong
behavior. According to the feedback received, the movement should be consistent for all
the scenarios in furtherance of intuitiveness.
7.2.2.4 Software functionalities
Besides the platform design, we will further detail the results concerning the game func-
tionalities:
• Q11: Did you find the therapist’s environment to add the child’s basic information
with appropriate fields (name, age, gender, and pathology description)?
• Q12: Did you consider that the therapist’s editing parameters are appropriate for
therapy with children (expected sound intensity - low, medium, high, MFT and
intensity range expected for manual parametrization of difficulty)?
Regarding the child’s basic information and the treatment parameters, the SLPs col-
lectively agree that the fields are relevant to complement the therapy task. On the other
hand, concerning the editable parameters within the treatment, the therapist of voice
disorders suggests the addition of the pitch parameter.
• Q13: In the manual parametrization state, did you have to change the parameters
in therapy until the child can complete the exercise without stopping?
• Q14: In the manual parametrization state, did you have to change the parameters
in therapy at least once so that the child would feel challenged to complete the
exercise?
• Q15: In the manual parameterization state, did you have to use the A key so the
child could complete the exercise?
• Q16: (In case of using manual control, keys A and S) Did the child realize that the
therapist could control the characters?
75

CHAPTER 7. FEEDBACK AND VALIDATION
Figure 7.8: Answers about the question Q15.
According to the manual parametrization questions, we inspect from the charts 7.7a
and 7.7b that the possibility to parametrize the variables in therapy is essential, regarding
the fact that children may have different capabilities and the game should fit them. On the
other side, none of the SLPs had to increase the game difficulty to challenge the child on
playing. Note that, the difficulty parametrization depends on the progress of the player.
Thus, during one or two trials the child may not be comfortable yet with the obstacles in
the game, and so, we can not collect enough data to make reliable conclusions.
Observing the chart 7.8, one SLP needed to use the keys A and S to manipulate the
character’s movement. In a consensual way, the child did not realized when the therapist
used it.
• Q17: Did the child improve his or her performance in the exercises regarding feed-
back with the movement of the character? (to move further, stop or to fall)
• Q18: From 1 to 5 how difficult was it for the child to perform the exercise success-
fully?
• Q19: From 1 to 5, how do you rate the use of this game to captivate the child’s
interest in therapy?
• Q20: From 1 to 5, how useful do you consider the use of this platform for voice
therapy with children?
Overall, the results showed that the children improved her performance, in respect to
the movement of the character, which can capture the interest of the children. Moreover,
we can observe that in the evaluation scenarios of two SLPs, the children considered the
task with a medium difficulty level, while the other considered it hard.
7.2.3 Validation conclusions
From the previous assessments, we can take the following conclusions:
• The software UI elements are adequate and appealing for children;
76

7.2. VALIDATION
• The professionals, unanimously, agreed that the parametrizable functionalities are
beneficial and useful for prompting an healthy and challenging therapy environ-
ment;
• Besides the exercise parameters, MPT and Loudness, we received the suggestion
to combine the Pitch variable, concerning its equal importance in the treatment of
voice disorders;
• In specific scenarios, the representative visual cue of the children’s error is not
adequate. However, establishing different character’s responses according to the
scenario’ theme may affect the intuitiveness of the exercise, since this user feedback
introduces non-consistent behaviors;
• In both validation methods, we verified that the SVE with the character moving
towards the target, challenge the children to increase their performance and so,
improve their therapy results;
• The gamification strategy with rewards and the game integration in a childhood
theme stimulates the children to keep on playing with different scenarios to conquer
new rewards;
• In regard to the questionnaires, the SLPs considered this game a valuable speech
therapy tool to complement therapy sessions with children.
77


Chapter
8Conclusion and future work
8.1 Conclusion
With the current advances in technology, computer-based therapy games have shown a
high potential to help to deliver therapy to children in a sophisticated encouragement
solution. These computer-assisted technologies must be designed to serve not only a
therapeutic purpose but also to be appealing and appropriate to the children’s cognitive
and emotional abilities as well as their age, gender and culture. Furthermore, these
platforms might increase the accessibility of speech therapy services for children with
SSDs, specifically voice disorders, and extend the time that they spend practicing the
addressed therapy tasks. The development of a speech therapy tool is a long-drawn and
complex journey inside the speech therapy field and where we can undoubtedly disperse
without the proper guidance from the SLPs. Thus, the development of these solutions
requires a interdisciplinary approach between computer engineers and clinicians.
Therefore, in this dissertation, we propose a computer platform that units game-like
features for children with a beneficial therapy exercise focus on voice disorders, the SVE.
In order to perform the exercise, the child must produce the sustained vowel /a/, /e/, /i/,
/o/ or /u/ from the European Portuguese language. Meanwhile, the child’s utterances
produced must stand between the thresholds associated to the variables in therapy. The
movement of a character towards a specified target in the scene represents the platform
feedback to the children’ performance. Thus, when the child correctly performs the vowel,
the character moves to the right. Otherwise, the character stops and starts falling until
the system receives a correct production.
Different children can have different levels of a specific pathology and children of
different ages accomplish singular performances during their in-game experience. There-
fore, it is desirable that the therapy games can be adjusted to each child situation. In
79

CHAPTER 8. CONCLUSION AND FUTURE WORK
response to their needs, we provide the possibility of manually adapting the difficulty,
by allowing the SLP to choose the desired maximum phonation time and intensity level.
Therefore, the SLP can customize the variables thresholds, according to the child needs.
Nevertheless, if the child is practicing the therapy task at home, this static parametriza-
tion model cannot deal with child’ improvements or struggles, since it does not imple-
ment a real-time adaptation. Therefore, to extend our parametrization functionality to
an effective intervention at home, we introduce a novel automatic difficulty adjustment
(DDA) model that evaluates the child’s performance in real-time and changes the state
of the game variables dynamically. This model relies on the basic principles of the flow
model, which measures performance based on specific parameters of interest to speech
therapy and allows the fluctuation between tense and release moments, keeping the child
engaged to hold on playing, while she increases her skills. This technique allows different
children to practice repetitive therapy exercises, within a flow channel that challenge
them and supports the creation of a fun and relaxing environment.
Besides this novel DDA scheme, we also implemented an ASR system for vowels
recognition. This system identifies the vocal utterances produced during the in-game
experience. With this functionality, the game is controlled with the child’s voice and can
be used outside the traditional therapy session, without the professional’ supervision to
validate the child’s utterances produced. To create the optimal model for our data, we
tested different model estimation methodologies. We built data sets with distinct features’
combinations, arranged in different train and test sets, as input to different classification
algorithms. In the end, our best model produces an accuracy test score of 96%. This
solution results from the data set with 12 MFCCs, where we applied the One Child Out
approach, which prepared the data to train the SVM classifier with the RBF kernel.
The aloft solution does not reflect the maximum score achieved during the evaluation
phase, regarding the lack of quality of a few segments from our data recordings. However,
these outliers support the creation of a robust algorithm considering that, for future
predictions, we can undoubtedly receive samples with noise or low volume. In this way,
we are preparing our model to deal with small variations in the data set and to improve
future predictions. Furthermore, even that the system produces a misplaced classification
for a correct child production, regarding the nature of the exercise (repeating the vowel
sustainable) and the low error ratio of ourmodel, that mistake should not have a revealing
consequence in the user feedback.
With both DDA and ASR models, we can accommodate a fulfilling experience that en-
sures that the child’s sustained vowels stand according to the previous therapist parametriza-
tion and, as follows, the child cannot produce the long task inefficiently and counterpole
the treatment’ progress. This system imports an extensive background preprocessing.
Thus, to load the game in low end-devices we created a client-server architecture. Hence,
we forward the ASR complex computation to the server side, while the client displays the
game platform.
Moreover, we focused on the validation of another main component of this project, the
80

8.2. FUTURE WORK
game UI for children and their SLPs, the target audiences of this game. This validation
process started with user tests with children, and questionnaires with therapists. Overall,
according to the validation results, the children improved their performances regarding
the game feedback. Specifically, the character movement as proved to be a easily inter-
pretable visual cue. When the character stops, the children realize they failed to move
the character without breaks as requested, and so, they seek to improve in the their next
trial. Moreover, through the user testing session, the children’ feedback was positive.
We verified the success of our gamification strategy proving it keep children motivated,
since they asked to keep playing, to collect rewards and try different scenarios. Finally,
according to the SLPs opinion, the game was considered a valuable speech therapy tool,
to integrate in therapy sessions for children with dysphonia.
Regarding the previous conclusions, we can highlight the following contributions:
• A game platform with the SVE for children;
• A gamification strategy with multiple scenes, characters and rewards;
• A novel DDA model for children with dysphonia;
• An ASR system for vowels from the EP language;
• A validation process with children and therapists;
There are also a few limitations of our game platform that must be taken into
account:
The development of a speech therapy tool is a complex journey. Numerous exercises
can be implemented, regarding each SSD, although not all of them can be designed in
a computer-based format. For example, dysphonia treatment is not efficient with exclu-
sively the SVE practice. In many dysphonia situations, besides the SVE, there are others
voice-producing mechanisms that include phonation, respiration, and musculoskeletal
function, to instruct a healthy vocal production. Thus, a limitation of our system concerns
the lack of exercises that our platform offers, and so, the utility for multiple application.
Moreover, according to the current implementation, the global game data is saved
locally in the client device. So, if the game is set up in the therapist device, the child
cannot perform the tasks at home. On the other side, if they install the game on child’s
device, during the in-game experience both child and parents may enter the therapist
mode and easily change the treatment parameters, without the SLP approval.
8.2 Future work
The area of therapeutic computer-based games is promising, despite the need for rigorous
outcome studies and applications. Besides the current functionalities of our tool, we can
81

CHAPTER 8. CONCLUSION AND FUTURE WORK
introduce new features, regarding the potential of the SVE. The proposed solution uses
the sound parameters maximum phonation time and vocal intensity. These are the most
relevant variables to the treatment of many dysphonia cases. However, there are plenty of
other sound features that may be extracted, analyzed and carefully included in a future
extension of the model. The right correlation between all variables must be ensured, as
well as, the evolution of an efficient and enthusiastic child’s learning curve in all of them,
independently.
The insurance that the player’s experience stands within the flow channel involves a
complex testing process. Our validation approach must include a long-term experiment
of the game-play. As future work, we should create a rigorous experimental design
with control groups and multiple groups baselines, to verify the efficacy of the different
platform functionalities.
82

Bibliography
[1] American Speech-Language-Hearing Association (ASHA) - Voice Disorders: Overview.
url: http://www.asha.org/Practice- Portal/Clinical- Topics/Voice-
Disorders/.
[2] American Speech-Language-Hearing Association (ASHA) - Voice Disorders: Overview.
url: https://www.asha.org/PRPSpecificTopic.aspx?folderid=8589942600Âğion=
Overview.
[3] American Speech-Language-Hearing Association (ASHA) - Voice Disorders: Treat-
ment. url: https : / / www . asha . org / PRPSpecificTopic . aspx ? folderid =
8589942600Âğion=Treatment.
[4] P. F. Assmann, T. M. Nearey, and J. T. Hogan. “Vowel identification: Orthographic,
perceptual, and acoustic aspects.” In: The Journal of the Acoustical Society of America
71.4 (1982), pp. 975–989. issn: 0001-4966. doi: 10.1121/1.387579.
[5] C. Bowen. “Childhood apraxia of speech.” In: Childrens Speech Sound Disorders.
2nd ed. John Wiley and Sons, L.td., 2015, 343–350.
[6] L. F. Brinca, A. P. F. Batista, A. I. Tavares, I. C. Goncalves, andM. L. Moreno. “Use of
Cepstral Analyses for Differentiating Normal From Dysphonic Voices: A Compar-
ative Study of Connected Speech Versus Sustained Vowel in European Portuguese
Female Speakers.” In: Journal of Voice 28.3 (2014), 282–286. doi: 10.1016/j.
jvoice.2013.10.001.
[7] M. Carvalho and A. Ferreira. “Real-Time Recognition of Isolated Vowels.” In:
vol. 5078. June 2008, pp. 156–167. doi: 10.1007/978-3-540-69369-7_18.
[8] R. H. Colton, J. K. Casper, and R Leonard. Understanding voice problem: A physiolog-
ical perspective for diagnosis and treatment: Fourth edition. 2011, pp. 202–205. isbn:
9781451123951. url: https://www.scopus.com/inward/record.uri?eid=2-s2.
0-84970002476\&partnerID=40\&md5=2d669bd30832ac856398981c707a739f.
[9] S. Demediuk, W. L. Raffe, and X. Li. “An Adaptive Training Framework for In-
creasing Player Proficiency in Games and Simulations.” In: Proceedings of the 2016
Annual Symposium on Computer-Human Interaction in Play Companion Extended
Abstracts - CHI PLAY Companion ’16 (2016). (Visited on 12/07/2016).
83

BIBLIOGRAPHY
[10] M. Diogo, M. Eskenazi, J. Magalhaes, and S. Cavaco. “Robust scoring of voice
exercises in computer-based speech therapy systems.” In: 2016 24th European Signal
Processing Conference (EUSIPCO) (2016). doi: 10.1109/eusipco.2016.7760277.
[11] M. C. Duff, A. Proctor, and E. Yairi. “Prevalence of voice disorders in African
American and European American preschoolers.” In: Journal of Voice 18.3 (2004),
pp. 348–353. issn: 08921997.
[12] A. El Sharkawi, L. Ramig, J. A. Logemann, B. R. Pauloski, A. W. Rademaker, C. H.
Smith, A. Pawlas, S. Baum, and C. Werner. “Swallowing and voice effects of Lee
Silverman Voice Treatment (LSVT®): A pilot study.” In: Journal of Neurology Neu-
rosurgery and Psychiatry 72.1 (2002), pp. 31–36. issn: 00223050. doi: 10.1136/
jnnp.72.1.31.
[13] E. Eriksson, O. Balter, O. Engwall, A.-M. Oster, and H. Kjellstrom. “Design Rec-
ommendations for a Computer-Based Speech Training System Based on End-User
Interviews.” In: 2005 (SPECOM) (2005).
[14] H. Fayek. Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cep-
stral Coefficients (MFCCs) and What’s In-Between | Haytham Fayek. 2016. url:
https://haythamfayek.com/2016/04/21/speech-processing-for-machine-
learning.html (visited on 09/11/2018).
[15] A. J. S. Ferreira. “Static features in real-time recognition of isolated vowels at high
pitch.” In: The Journal of the Acoustical Society of America 122.4 (2007), pp. 2389–
2404. issn: 0001-4966. doi: 10.1121/1.2772228.
[16] C. M. Fox and C. A. Boliek. “Intensive Voice Treatment (LSVT LOUD) for Children
With Spastic Cerebral Palsy and Dysarthria.” In: Journal of Speech Language and
Hearing Research 55.3 (2012), p. 930. issn: 1092-4388.
[17] R. Fraile and J. I. Godino-Llorente. “Cepstral peak prominence: A comprehensive
analysis.” In: Biomedical Signal Processing and Control 14.1 (2014), pp. 42–54. issn:
17468108. doi: 10.1016/j.bspc.2014.07.001.
[18] Freepik. url: https://www.freepik.com/ (visited on 11/11/2018).
[19] L. Furlong, S. Erickson, andM. E.Morris. “Review: Computer-based speech therapy
for childhood speech sound disorders.” In: Journal of Communication Disorders 68
(2017), pp. 50 –69. issn: 0021-9924.
[20] B. Gold, N. Morgan, and D. Ellis. Speech and audio signal processing: processing and
perception of speech and music. Wiley, 2011.
[21] I. Guimaraes. A ciencia e a arte da voz humana. 1st ed. ESSA, 2007.
84

BIBLIOGRAPHY
[22] A. E. Halpern, L. O. Ramig, C. E. C. Matos, J. A. Petska-Cable, J. L. Spielman, J. M.
Pogoda, P. M. Gilley, S. Sapir, J. K. Bennett, and D. H. McFarland. “Innovative
technology for the assisted delivery of intensive voice treatment (LSVT(R)LOUD)
for Parkinson disease.” In: American journal of speech-language pathology 21.4 (2012),
pp. 354–367. issn: 1558-9110.
[23] H. Hanks, C. Hanks, andM. Suman. Little Bee Speech. url: http://littlebeespeech.
com/articulation_station.php.
[24] Y. D. Heman-Ackah, R. T. Sataloff, G. Laureyns, D. Lurie, D. D. Michael, R. Heuer,
A. Rubin, R. Eller, S. Chandran, M. Abaza, K. Lyons, V. Divi, J. Lott, J. Johnson,
and J. Hillenbrand. “Quantifying the cepstral peak prominence, a measure of
dysphonia.” In: Journal of Voice 28.6 (2014), pp. 783–788. issn: 18734588. doi:
10.1016/j.jvoice.2014.05.005.
[25] G. Hinton, L. Deng, D. Yu, G. Dahl, A. R. Mohamed, N. Jaitly, A. Senior, V. Van-
houcke, P. Nguyen, T. Sainath, and B. Kingsbury. “Deep neural networks for acous-
tic modeling in speech recognition: The shared views of four research groups.” In:
IEEE Signal Processing Magazine (2012). issn: 10535888. doi: 10.1109/MSP.2012.
2205597. arXiv: 1207.0580.
[26] T Jonathan, B Bruno, and B Abdenour. “Understanding and implementing adaptive
difficulty adjustment in video games.” In: Algorithmic and Architectural Gaming
Design: Implementation and Development. 2012, pp. 82–106. isbn: 9781466616349.
doi: 10.4018/978-1-4666-1634-9.ch005.
[27] R. D. Kent. “Anatomical and Neuromuscular Maturation of the Speech Mecha-
nism: Evidence from Acoustic Studies.” In: Journal of Speech, Language, and Hearing
Research 19.3 (1976), pp. 421–447. doi: 10.1044/jshr.1903.421.
[28] T. Lan, S. Aryal, B. Ahmed, K. Ballard, R. Gutierrez-Osuna, R. Gutierez-osuna, and
A Texas. “Flappy Voice: An Interactive Game for Childhood Apraxia of Speech
Therapy.” In: Proceedings of the First ACM SIGCHI Annual Symposium on Computer-
human Interaction in Play 2.1 (2014), pp. 429–430. doi: 10.1145/2658537.2661305.
url: http://doi.acm.org/10.1145/2658537.2661305.
[29] M. Lopes, J. a. Magalhães, and S. Cavaco. “A Voice-controlled Serious Game for
the Sustained Vowel Exercise.” In: Proceedings of the 13th International Conference
on Advances in Computer Entertainment Technology. ACE ’16. Osaka, Japan: ACM,
2016, 32:1–32:6. isbn: 978-1-4503-4773-0. doi: 10.1145/3001773.3001807. url:
http://doi.acm.org/10.1145/3001773.3001807.
[30] V. Lopes, J. Magalhaes, and S. Cavaco. “A dynamic difficulty adjustment model
for dysphonia therapy games.” In: HUCAPP 2019 - 3rd International Conference on
Human Computer Interaction Theory and Applications (2018).
[31] M. H. M. Mateus, F. Isabel, and F. M. Joao. Fonetica e fonologia do portugues. 2nd ed.
Universidade Aberta, 2005.
85

BIBLIOGRAPHY
[32] B. McFee, M. McVicar, S. Balke, C. Thomé, V. Lostanlen, C. Raffel, D. Lee, O.
Nieto, E. Battenberg, D. Ellis, R. Yamamoto, J. Moore, WZY, R. Bittner, K. Choi,
P. Friesch, F.-R. Stöter, M. Vollrath, S. Kumar, nehz, S. Waloschek, Seth, R. Naktinis,
D. Repetto, C. F. Hawthorne, C. Carr, J. F. Santos, JackieWu, Erik, and A. Holovaty.
librosa/librosa: 0.6.2. Aug. 2018. doi: 10.5281/zenodo.1342708.
[33] L. A. A. Mota, C. M. B. Santos, J. M. d. Vasconcelos, B. C. Mota, and H. C. Mota.
“Applying the technique of sustained maximum phonation time in a female patient
with adductor spasmodic dysphonia: a case report.” pt. In: Revista da Sociedade
Brasileira de Fonoaudiologia 17 (2012), pp. 351 –356. issn: 1516-8034.
[34] National Instruments. Understanding FFTs and Windowing Overview. Tech. rep.,
p. 15. url: http://download.ni.com/evaluation/pxi/UnderstandingFFTsandWindowing.
pdf.
[35] T. M. Nearey. “Static, dynamic, and relational properties in vowel perception.” In:
The Journal of the Acoustical Society of America 85.5 (1989), pp. 2088–2113. issn:
0001-4966. doi: 10.1121/1.397861.
[36] R. C. Oliveira, L. C. Teixeira, A. C. C. Gama, and A. M. de Medeiros. “Análise
perceptivo-auditiva, acústica e autopercepção vocal em crianças.” In: Jornal da
Sociedade Brasileira de Fonoaudiologia 23.2 (2011), pp. 158–163. issn: 2179-6491.
doi: 10.1590/S2179-64912011000200013.
[37] S Palethorpe, R Wales, J. E. Clark, and T Senserrick. “Vowel classification in chil-
dren.” In: The Journal of the Acoustical Society of America 100.6 (1996), pp. 3843–
3851. issn: 00014966. doi: 10.1121/1.417240.
[38] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blon-
del, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau,
M. Brucher, M. Perrot, and E. Duchesnay. “Scikit-learn: Machine Learning in
Python.” In: Journal of Machine Learning Research 12 (2011), pp. 2825–2830.
[39] A. Pompili, A. Abad, and I. Trancoso. Vithea. url: https://vithea.l2f.inesc-
id.pt/wiki/index.php/Main_Page.
[40] R. J. Prater and R. Swift. Manual de Terapeutica de la voz. Masson-Litle, Brown,
1995.
[41] A. Rietveld, S. Bakkes, and D. Roijers. “Circuit-adaptive challenge balancing in
racing games.” In: Conference Proceedings - 2014 IEEE Games, Media, Entertainment
Conference, IEEE GEM 2014. 2015.
[42] J. Schell. The Art of Game Design: A Book of Lenses. San Francisco, CA, USA: Morgan
Kaufmann Publishers Inc., 2008. isbn: 0-12-369496-5.
[43] Simple harmonic motion. url: https://commons.wikimedia.org/wiki/File:
Simple_harmonic_motion.svg.
[44] SLPinfo - Loudness. 2017. url: https://www.sltinfo.com/loudness/.
86

BIBLIOGRAPHY
[45] SLPinfo - Pitch. 2017. url: https://www.sltinfo.com/pitch/.
[46] SLTinfo - Maximum Phonation Time (MPT). 2017. url: https://www.sltinfo.
com/maximum-phonation-time/.
[47] B. J. D. Swart, S. C. Willemse, B. Maassen, and M. W. Horstink. “Improvement of
voicing in patients with Parkinsons disease by speech therapy.” In: Neurology 60.3
(2003), 498–500. doi: 10.1212/01.wnl.0000044480.95458.56.
[48] C. T. Tan, A. Johnston, K. Ballard, S. Ferguson, and D. Perera-Schulz. “sPeAK-
MAN: towards popular gameplay for speech therapy.” In: Proceedings of The 9th
Australasian Conference on Interactive Entertainment: Matters of Life and Death. 2013,
p. 28. isbn: 978-1-4503-2254-6. doi: 10.1145/2513002.2513022. url: http:
//dl.acm.org/citation.cfm?id=2513022.
[49] E. L. M. Tavares, A. Brasolotto, M. F. Santana, C. A. Padovan, and R. H. G. Mar-
tins. “Epidemiological study of dysphonia in 4-12 year-old children.” In: Brazilian
Journal of Otorhinolaryngology 77.6 (2011), pp. 736–746. issn: 18088686.
[50] E. L. M. Tavares, A. G. Brasolotto, S. A. Rodrigues, A. B. B. Pessin, and R. H. G.
Martins. “Maximum Phonation Time and s/z Ratio in a Large Child Cohort.” In:
Journal of Voice 26.5 (2012). doi: 10.1016/j.jvoice.2012.03.001.
[51] J. Tavares, J. Lopes, M. Cunha, and R. Saldanha. Falar a brincar. 2017. url: https:
//falarabrincar.wordpress.com/2016/01/16/sobre-nos/.
[52] A. L. Williams. Intensity in phonological intervention: Is there a prescribed amount?
2012.
[53] W. A. Yost. Fundamentals of hearing: an introduction. 5th ed. Brill, 2013.
[54] C. Yun, P. Trevino, W. Holtkamp, and Z. Deng. “PADS: Enhancing Gaming Expe-
rience Using Profile-Based Adaptive Difficulty System.” In: Proceedings of the 5th
ACM SIGGRAPH Symposium on Video Games - Sandbox ’10. July. 2010, pp. 31–36.
isbn: 9781450300971.
87



