Embed Size (px)
Citation preview

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
A CORPUS-BASED STUDY OF THE USE
OF ADVERBIAL INTENSIFIERS
WITH SEMANTIC PROSODY
BY
MISS SIRIPORN GAMPAENGGAEW
AN INDEPENDENT STUDY PAPER SUBMITTED IN PARTIAL
FULFILLMENT OF
THE REQUIREMENTS FOR THE DEGREE OF
MASTER OF ARTS IN CAREER ENGLISH FOR
INTERNATIONAL COMMUNICATION
LANGUAGE INSTITUTE, THAMMASAT UNIVERSITY
ACADEMIC YEAR 2016
COPYRIGHT OF THAMMASAT UNIVERSITY

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
A CORPUS-BASED STUDY OF THE USE
OF ADVERBIAL INTENSIFIERS
WITH SEMANTIC PROSODY
BY
MISS SIRIPORN GAMPAENGGAEW
AN INDEPENDENT STUDY PAPER SUBMITTED IN PARTIAL
FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE
OF MASTER OF ARTS IN CAREER ENGLISH FOR
INTERNATIONAL COMMUNICATION
LANGUAGE INSTITUTE, THAMMASAT UNIVERSITY
ACADEMIC YEAR 2016
COPYRIGHT OF THAMMASAT UNIVERSITY


Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
(1)
Independent Study Paper Title A CORPUS-BASED STUDY OF THE USE OF
ADVERBIAL INTENSIFIERS WITH SEMANTIC
PROSODY
Author Miss Siriporn Gampaenggaew
Degree Master of Arts
Major Field/Faculty/University Career English for International Communication
Language Institute
Thammasat University
Independent Study Paper Advisor Assistant Professor Supakorn Phoocharoensil, Ph.D.
Academic Years 2016
ABSTRACT
In the use of English, word choice is probably one of the most important
keys to accomplishing effective communication. As the words carry not only
denotative meaning but also connotative and attitudinal meaning; therefore, it is
necessary, in particular, for L2 learners to be capable of applying words properly for
the correct and natural use of the language. This paper is thus aimed at investigating
the semantic prosody of the adverbial intensifiers really, certainly and clearly by
examining their adjective and verb collocations when in use and through observing
the authentic data of concordance lines from a language corpus which is the Corpus of
Contemporary American English (COCA). One thousand concordance lines of each
target word were analyzed by categorizing its prosodies of their adjective and verb
collocations. The results showed that these three adverbial intensifiers carry a stronger
positive semantic prosody than negative prosody as they are frequently applied to
intensify positive words, especially the words relating to states of mind, general
evaluation and description. Also, it was found that each AI has a particular set of
adverbs and verbs that it tends to co-occur with. Thereby, English learners should be
aware of using the AIs in accordance with their semantic prosodies for naturalness in
the use of English.
Keywords: adverbial intensifier, semantic prosody, collocation, corpus-based data

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
(2)
ACKNOWLEDGEMENTS
The completion of this study is a result of the support and encouragement
from several people. I would like to express my deep gratitude and appreciation to
them for their precious help and support.
Firstly, I would like to express my sincere gratitude to my admirable
advisor Asst. Prof. Supakorn Phoocharoensil for the continuous support and
motivation and for his comments and suggestions during the study. Besides my
advisor, I would like to thank all of the instructors at the Language Institute of
Thammasat University for providing me with extensive knowledge and useful
guidance, which helped me conduct this research study.
My sincere thanks also go to my CEIC classmates, in particular my close
ones, who always encouraged and helped me solve the problems which occurred
during the study; and the administrators of the Master of Arts Program in Career
English for International Communication at LITU for their prompt support and
coordination. Without their precious support, it would not be possible for me to
complete this study.
Finally, I must express my very profound gratitude to my family
including my mother, my father, my younger brother and all of my aunts, uncles and
cousins for their understanding, unfailing support and continuous encouragement
throughout my years of study. In addition, I would like to give a million thanks to Ms.
Pimsai Lertanugrom who is like my real sister. She is the one who has been inspiring
me and introduced me to study here. During the study, she always supported,
encouraged and soothed me.
This accomplishment would not have been possible without all of them.
Thank you very much.
Miss Siriporn Gampaenggaew

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
(3)
TABLE OF CONTENTS
Page
CHAPTER 1 INTRODUCTION 1
1.1 Background 1
1.2 Research Questions 4
1.3 Objectives of the Study 4
1.4 Definition of Terms 4
1.5 Scope of the Study 5
1.6 Significance of the Study 6
1.7 Limitations of the Study 7
1.8 Organization of the Study 7
CHAPTER 2 LITERATURE REVIEW 8
2.1 Corpus Linguistics 8
2.1.1 Definition and Characteristics 8
2.1.2 Types of Language Corpora 9
2.1.3 Corpus Processing Techniques 11
2.1.4 Use of Corpora 14
2.2 Adverbial Intensifiers 15
2.2.1 Definition and Types of Adverbial Intensifiers 15
2.2.2 Use of Intensifiers 18
2.3 Semantic Prosody 20
2.3.1 Background and Definition of Semantic Prosody 20
2.3.2 Main Features and Categories of Semantic Prosody 23
2.3.3 Semantic Prosody and Semantic Preference 24
2.4 Relevant Research 24

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
(4)
CHAPTER 3 RESEARCH METHODOLOGY 27
3.1 Target Adverb Intensifiers 27
3.2 Corpora 27
3.3 Procedures 27
3.3.1 Research Design 27
3.3.2 Selection of Target Adverbial Intensifiers 28
3.3.3 Data Collection 28
3.4 Data Analysis 31
CHAPTER 4 RESULTS 32
4.1 The Results of the Adjective and Verb Collocations 32
of the Adverbial Intensifier Really in COCA
4.2 The Results of the Adjective and Verb Collocations 35
of the Adverbial Intensifier Certainly in COCA
4.3 The Results of the Adjective and Verb Collocations 38
of the Adverbial Intensifier Clearly in COCA
CHAPTER 5 CONCLUSION, DISCUSSION AND RECOMMENDATION
44
5.1 Summary of the Findings and Discussion 44
5.2 Conclusion 47
5.3 Recommendations for Further Research 47
REFERENCES 49

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
(5)
LIST OF TABLES
Tables Page
1.1 Top 10 emphasizing adverbs in COCA 6
2.1 The most frequent words: ten-million-word corpus (CIC) 12
2.2 Frequency of expressions with time 13
4.1 Example of concordance lines of really collocating with top three 32
pleasant adjectives in COCA
4.2 Example of concordance lines of really in the sentence patterns S. + 34
Auxiliary V. + not + really + Main V., and S. + really + Auxiliary V. +
not + Main V. in COCA
4.3 Example of concordance lines of certainly collocating with frequent 35
positive adjectives in COCA
4.4 Example of concordance lines of certainly collocating with adjectives 36
ending with –able and –ible, comparative and superlative adjectives,
and proper adjectives in COCA
4.5 Example of concordance lines of certainly collocating with modal verbs 37
in COCA
4.6 Example of concordance lines of certainly collocating with main verbs 38
that express the meaning of ‘requirement’ in COCA
4.7 Example of concordance lines of clearly collocating with the top five 39
adjectives in COCA.
4.8 Example of concordance lines of clearly collocating with adjectives 39
ending with –able and –ible in COCA
4.9 Example of concordance lines of clearly collocating with unfavorable 40
adjectives in COCA
4.10 Example of concordance lines of clearly collocating with positive 41
verbs in COCA
4.11 Example of concordance lines of the top five verbs found with clearly 42
in COCA

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
(6)
4.12 Example of concordance lines of clearly collocating with verbs 42
that express the meaning of ‘to show’ and ‘to say’ in COCA

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
(7)
LIST OF FIGURES
Figures Page
2.1 Concordance lines for the word population generated by Antconc 11
2.2 Distribution of amplifiers across three periods 20
3.1 Extracted screen of the search for 1,000 concordance lines of 29
the adverb clearly when it collocates with adjectives
3.2 Extracted screen of the search for 1,000 concordance lines of 29
the adverb certainly when it collocates with verbs
3.3 Examples of the word clearly collocating with adjectives 30
in the concordance lines from COCA
3.4 Examples of the word certainly collocating with verbs 30
in the concordance lines from COCA
4.1 Percentage of the adjective collocations of the AI really 33
in three semantic prosody groups
4.2 Percentage of the verb collocations of the AI really 34
in three semantic prosody groups
4.3 Percentage of the adjective collocations of the AI certainly 35
in three semantic prosody groups
4.4 Percentage of the verb collocations of the AI certainly 37
in three semantic prosody groups
4.5 Percentage of the adjective collocations of the AI clearly 38
in three semantic prosody groups
4.6 Percentage of the verb collocations of the AI clearly 41
in three semantic prosody groups

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
1
CHAPTER 1
INTRODUCTION
1.1 BACKGROUND
In English language study, it has been widely agreed that words are one of
the most important components which language learners must master in order to
comprehend not only their denotative meaning but also connotative meaning
including other necessary aspects such as their patterning and grammar in use. Two
main types of words that play important roles in English are content words and
function words. Linguistically, it is explained that a function word, sometimes called
a grammatical word or a closed class word, is a word that contains little lexical
meaning or has no meaningful meaning, but expresses a grammatical or structural
relationship with other words in a sentence (Hartmann & Stork, 1972; Quirk,
Greenbaum, Leech, & Svartvik, 1985; Au-Yeung, Howell & Pilgrim, 1998;
Hartsuiker, Bastiaanse, Postma & Wijnen, 2005). Function words include
prepositions, pronouns, determiners, conjunctions, auxiliary verbs, modals, particles
and quantifiers. In contrast to the function word, a content word or a lexical word or
an open-class word, is referred to as a word that has meaning itself and function to
carry the content of a sentence. According to Carter, McCarthy and O’Keeffe (2011),
English has four classes of content words, namely nouns, verbs, adjectives, and
adverbs.
At the word level, for the selection of words in use, English native
speakers heavily rely on their intuition. Davies (1991) and Stern (1983) claimed that
the individual has intuitive knowledge of the language, whereas L2 learners mostly
depend on dictionaries and strictly follow the grammar rules and structures, and
strategies prescribed because it is believed that these would lead to the correct use of
English.
However, using English is not only related to language in terms of
denotative meaning nor grammatical rules but also collocation, semantics and
pragmatics; supported by Sinclair (1991) expressing that denotative meaning and
grammar are not enough to allow the learners capable to reach English

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
2
accomplishment, the matter of collocation, semantics, and pragmatics are also the
keys. This means that correctness is important, but the naturalness in actual use of
language should also be counted and considered, in particular in communication, as it
is the requirement of coherence and communicative effectiveness (Sinclair, 1991).
The importance of naturalness in language use is also confirmed by McCarthy (1998)
stating that naturalness resides everywhere, i.e. word, pairs of words (also known as
collocational pairs), phrases, clauses, and the naturalness is a property of text and
there should be the study of the text’s nature. Likewise, it was concluded that
naturalness is not an inherent quality of language but a characteristic of the
relationship between the reader and the text (Ramsey, 1987). Thus, it could be
claimed that naturalness is essential for the effective use of language and
communication in practice. And in pedagogy, the learners should be encouraged to be
able to use the language naturally (Widdowson, 1980).
Focusing on Thai L2 learners, it has often been found that a great number
of learners produce English language based on fixed grammar rules with the
ignorance of naturalness leading to ineffective communication in both written and
spoken English, which results in inappropriate or unnatural language use; for
example, applying substitute words expressing improper connotative meaning,
placing the words in the wrong position unintentionally, and overusing or underusing
certain words which lead to misinterpretation and misunderstanding.
Regarding the natural use of English, one well-known term that has raised
the interests and awareness of most linguists and language academics in the
pedagogical field to pay attention with wide discussion and concern is semantic
prosody. In summary, semantic prosody is a term used to describe the phenomenon in
which a word whose meaning in general is neutral can be perceived with positive or
negative meaning, especially its connotative or attitudinal meaning, or associated
through frequent occurrences with particular collocations (Sinclair, 1987; Louw,
1993; Stubbs, 1996; Partington, 1998). It has been widely addressed that semantic
prosody associates the meaning with a particular purpose in a contextual
communication. So, this term is related to the natural use of language and has become
important for several decades.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
3
The importance of semantic prosody is clearly stressed by Morley &
Partington (2009) who wrote that it helps maintain comprehensibility for the text
receiver and provides the receiver with an insight into the opinions and beliefs of the
text sender. They further emphasized that the awareness of semantic prosody can be
invaluable for the language learners in distinguishing among synonymous items for
the proper and natural word choice. Understanding the semantic prosody hidden in
language is important in order to maintain the connotational harmony and avoid
sending an ambiguous message (Morley & Partington, 2009). Hunston & Thompson
(2000, p.5) defined semantic prosody as “the speaker or writer’s attitude or stance
towards, viewpoint or feelings about the entities and propositions that he or she is
talking about”, in short, the “indication that something is good or bad”, in the aspect
of evaluative meaning. Apparently, there is a wide range of words that have semantic
prosody affecting their meaning in contexts. One of the well-known words is cause;
many studies show that cause actually has neutral meaning though it contains
negative prosody when it is applied in most contexts (Stubbs, 1995, 1996; Wei, 2002;
Xiao & McEnery, 2006; Limrosthip, 2013). Regarding the semantic prosody of
adverbs, the studies by Partington (2004) and Zhang (2013) confirmed that these
types of content words carry prominent semantic preference to some extent.
As naturalness is associated with semantic prosody, and this is confirmed
by many studies showing that a large number of words contains semantic prosody, the
study of semantic prosodic phenomenon occurring with adverbial intensifiers which
are also important to language production but often misused, overused or underused
by most Thai L2 learners and users, would enhance and improve the language use for
more natural and effective communication. Importantly, with more awareness on
semantic prosody, the learners’ comprehensibility would be highly developed.
In order to study the semantic prosody carried by words, a large amount
of data of authentic texts is needed to be able to explore the trend or phenomenon. For
this purpose, the data from corpora are extracted to be examined and analyzed. This is
to investigate how native speakers use intensifying adverbs in real situations and how
such adverbs commonly occur in texts.
The results of this study would enable Thai L2 learners to apply the most
appropriate words in a particular context naturally with the proper sense of

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
4
connotative and expressive meaning preventing misinterpretation or misunderstanding
to the receiver, and vice versa in receiving texts, in particular when communicating
with native speakers. More importantly, in pedagogical purpose, this study finding
would increase the awareness of learners to better use the adverbial intensifiers with
more comprehensibility and naturalness when necessary.
1.2 RESEARCH QUESTIONS
1.2.1 Which verbs and adjectives commonly collocate with the adverbial
intensifiers really, certainly and clearly?
1.2.2 What are the semantic prosodies of the adverbial intensifiers really,
certainly and clearly?
1.3 OBJECTIVES OF THE STUDY
The objectives of this study are the following:
1.3.1 To examine the frequent adjectives and verbs that collocate with the
adverbial intensifiers really, certainly and clearly.
1.3.2 To explore the semantic prosodies of the adverbial intensifiers
really, certainly and clearly.
1.4 DEFINITION OF TERMS
The definition of the terms of this study is as follows:
1.4.1. Adverbial Intensifier (AI) is an adverb that modifies an adjective, a
verb, or an adverb by adding stronger meaning and showing emphasis. It is a scaling
device that can intensify or weaken the meaning of words it modifies. The adverbial
intensifiers are classified into 3 main categories, namely emphasizer, amplifier and
downtoner.
1.4.2 Semantic prosody refers to the phenomenon in which certain
seemingly neutral words can be perceived with positive or negative meaning through
the habitually frequent occurrences with particular collocations.
1.4.3 Collocations refer to the words that are often used or co-occur with
another word, in the way that sounds correct to native English speaker. In corpus

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
5
linguistics, a collocation of a word co-occurs more often than would be expected by
chance (Kathleen, McKeown & Dragomir, 2000; Cunha & Manuela, 2009).
1.4.4 Corpus (plural, corpora) is a collection of written or spoken texts
that occur naturally in real use which is stored in computer-based readable format and
is available for qualitative and quantitative analysis (Sripichan, 2009). In this study,
the Corpus of Contemporary American English (COCA) is applied.
COCA is a freely-available corpus of English containing more than 520
million words of texts and it is equally divided into various genres, i.e. spoken,
fiction, magazine, newspaper, and academic.
1.4.5 Concordance line or key-word-in-context display is the line of texts
in which the searched items is presented in the middle. It is listed vertically to allow
reading outwards from the searched item.
1.4.6 Node word is the term used to describe the AIs that are selected to
be studied.
1.5 SCOPE OF THE STUDY
In this study, only the top three AIs, i.e. really, certainly and clearly were
investigated. These three words were selected as the target AIs because they are
intensifying adverbs and occur with the high frequency as ranked in the top 200
adverbs and top 5,000 words, in COCA (Figure 1.1). Another main reason is that they
are classified into the same category of AI emphasizer (Quirk et al. 1985).
Table 1.1
Top 10 Emphasizing Adverbs in COCA
No. Intensifying Adverb
(Emphasizer)
Top 200
Adverb
Top 5,000
Word Frequency
1 really 24 142 263414
2 actually 56 397 105155
3 simply 71 584 66712
4 certainly 74 664 59739
(Continue)

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
6
Top 10 Emphasizing Adverbs in COCA (Continued)
No. Intensifying Adverb
(Emphasizer)
Top 200
Adverb
Top 5,000
Word Frequency
5 clearly 87 849 45912
6 indeed 88 851 46184
7 obviously 112 1285 31299
8 definitely 164 2005 18214
9 surely 187 2434 13904
10 literally 189 2492 13425
Moreover, the node words were studied in a particular pattern where they
collocate with adjectives and verbs only. The other functions and perspectives, e.g.
grammatical patterns, discourse markers, were disregarded. In addition, the data
drawn for this study came from COCA, which represents American English.
However, the results should be sufficient to expose the sense of the use of AIs with
semantic prosody among all native speakers.
1.6 SIGNIFICANCE OF THE STUDY
In the global community in which English is used as a medium of
communication, using English in the positions of both sender and receiver with
comprehensibility is essential. Correctness in language use as well as naturalness is
necessary. In particular, among L2 learners, the awareness of natural use of language
should be raised in order that they become more aware of connotative and expressive
meaning or a word’s sense. Due to this reason, the study of semantic prosody of the
AIs really, certainly and clearly is beneficial. Furthermore, the main findings would
contribute to a more suitable pedagogical method for teachers in developing teaching
materials with regard to this concept. Additionally, the study also would be a
reference for further research concerning the use of other types of words with some
significant semantic preferences and semantic prosodies.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
7
1.7 LIMITATIONS OF THE STUDY
In this study of semantic prosody of target AIs, each word is examined by
investigating its occurrences in 1,000 concordance lines: the first 500 lines of
adjective collocations and another first 500 lines of verb collocations, so this amount
of data may not be sufficient to be generalized to all uses of AIs in American English.
Moreover, since the concordance lines are drawn from COCA only, the study results
cannot be generalized to other varieties of English such as British English or
Australian English.
Furthermore, since this research study is a small scale study and was
conducted under time limitation, the researcher is unable to examine the AIs actually
and simply, being ranked in the top three in COCO, because of their variety of
meanings.
In addition, the collocations of the target AIs were studied only when they
collocate with adjectives and verbs, while the other perspectives, e.g. grammatical
patterns and discourses functions were disregarded.
1.8 ORGANIZATION OF THE STUDY
The study of the use of adverbial intensifiers with semantic prosody in
this paper is divided into five chapters. The first chapter provides background
information projecting the overall picture of the study, research questions, objectives
of the study, definitions of terms involved in this study including scope, significance
and limitations of the study. Four main parts of literature, i.e. corpus linguistics,
adverbial intensifiers and semantic prosody together with the relevant research are
reviewed in the second chapter, while the third chapter displays the methodology
explaining the target AIs, corpora, research design, selection of target AIs and method
for data collection and analysis. The fourth chapter exhibits the results of the adjective
and verb collocations as well as the semantic prosodies of the AIs really, certainly and
clearly, in figures and description. In the end, the fifth chapter contains summary of
the findings, discussion, conclusion and recommendations for further research.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
8
CHAPTER 2
LITERATURE REVIEW
This chapter reviews the literature in four main areas: (1) corpus
linguistics, (2) adverbial intensifiers, (3) semantic prosody, and (4) relevant research.
2.1 CORPUS LINGUISTICS
2.1.1 Definition and Characteristics
In linguistics, a corpus (the plural form is corpora) that contains naturally
authentic texts is used as a methodology in language study and for a pedagogical
purpose (Kruger, 2002). According to O’Keeffe, McCarthy & Carter (2007, p. 1), “a
corpus is defined as a collection of texts which can be in the form of written or spoken
one, which is stored on a computer”. These electronically collected texts may vary in
size and length (Jones & Waller, 2015). Notably, a corpus is different from a general
text in terms of its purpose of use since it is created and collected to examine language
problems and to study particular perspectives of language (Hunston, 2002), It was
pointed out by Biber, Conrad & Reppen (1998) that a corpus is a principled collection
of texts which are available to be input for qualitative and quantitative analysis.
The abovementioned definitions represent three main features of the
corpus which are: a principled collection of written or spoken texts, as the corpus
must be designed in a principled way so that it represents data systematically; a
collection of electronic text stored on a computer which is usually large in size,
meaning that the large amount of texts can be stored and analyzed by using specific
software; available for qualitative and quantitative analysis, meaning that a corpus is
well planned in creation in order that it can be applied to study the language in various
aspects both qualitatively and quantitatively (O’Keeffe et al., 2007). Additionally,
another two distinctive features of a corpus are it is based on an empirical database
which contains authentic texts from various sources, so it represents the texts that
occur naturally in real use; and it is not very informative because it still needs
analysis, i.e. by human or software, for specific purposes of study (Sripicharn, 2009).

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
9
Regarding such definitions and characteristics, a corpus on the whole
could be summarized as “a principled collection of naturally-occurring written or
spoken texts in a computer-readable format which can be extracted and analyzed both
in qualitative and quantitative ways by using corpus analysis software” (Kennedy,
1998; McEnery & Wilson, 2001; Charles, 2002; Teubert & Cermakova, 2007).
2.1.2 Types of Language Corpora
Since the beginning of the time that corpus methodology has been
introduced (around 1960) and the first corpus named ‘Brown Corpus’ was created
(Lindquist, 2009), many types of language corpora have been established for language
study purposes.
Sripichan (2009) summarized that the categories of a corpus can be
divided into the following three major aspects. Firstly, a corpus can be categorized,
due to its communication mode, into written and spoken corpora. A written corpus
contains written texts, e.g. fiction, textbooks, news or students’ writing, and such texts
may be typed, scanned, or downloaded from websites and then entered into a
computer using corpus creation tools (O’Keeffe et al., 2007). Examples of solely
written corpora are Corpus of Global Web-based English (GloWbe), Brown Corpus,
International Corpus of Learner English (ICLE), and Longman Written American
Corpus. A spoken corpus consists of spoken language data, e.g. conversation in shops,
phone dialog, or radio interview, which are recorded, transcribed and changed into
electronic files to be stored in a computer and examples of spoken corpora are Bergen
Corpus of London Teenage Language (COLT), British Academic Spoken English
(BASE) Corpus, and Cambridge and Nottingham Corpus of Discourse in English
(CANCODE).
Secondly, corpora can be grouped in terms of data types or purpose in use
of data, into general and specialized corpora. A general corpus is often very large in
size; that is, it contains more than ten million words of a variety of language and data
so that the study and analysis from this kind of corpus may be somewhat generalized
(Bennett, 2010). Generalized corpora can be written-only corpus, spoken-only corpus
or the general corpus that contain both written and spoken language, for instance
American National Corpus (ANC), British National Corpus (BNC), Corpus of

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
10
Contemporary American English (COCA), and International Corpus of English (ICE)
(Lindquist, 2009). A specialized corpus is typically smaller than the general one
(Sripicharn, 2009). This corpus is composed of specific genres or registers of texts or
specialized data from some particular areas such as academic, business, arts or
science; these texts and data are collected for the purpose of representing the language
of its specialization and answering very specific questions (Bennett, 2010). Examples
of specialized corpora are Michigan Corpus of Academic Spoken English (MICASE),
which contains only spoken American academic language from the University of
Michigan; International Corpus of Learner English (ICLE), which contains both
spoken and written language of learners at many levels, and the CHILDES Corpus
(MacWhinney, 1992), which contains children’s language use (Lindquist, 2009;
Bennett, 2010). In recent years, specialized corpora, e.g. learner corpora: a corpus of
writing and/or spoken language used by students who are currently learning language;
and pedagogic corpus: a corpus of language used in classroom including textbooks,
course materials and conversational language in educational setting, have been widely
used in language learning and teaching (Bennett, 2010) from the major point of view
that they represent the authentic language in real use. In Thailand, Thai Learner
English Corpus (TLEC) has been created (Wirote, 2009). TLEC contains essays
collected from undergraduate students from Chulalongkorn University and
Thammasart University, and is categorized into two levels that are intermediate
learners and advanced learners. It also comprises Thai journalists’ writings from two
English newspapers that are the Nation and Bangkok Post. Totally, the corpus size is
approximately 1,240,000 words
(source: http://www.arts.chula.ac.th/~ling/TLE/)
Lastly, corpora can be classified in terms of number of languages
collected, into a monolingual corpus and a bilingual or multilingual corpus. A
monolingual corpus consists of texts written in one language, while a bilingual or
multilingual collects texts of two or more language, or contains sets of two or more
monolingual corpora which are designed “on the basis of similar design criteria”
(Baker, 1995, p. 232).
In addition to the three main perspectives listed above, Jones and Waller
(2015) separate corpus types into open-access corpus and make-up corpus. An open-

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
11
access corpus is the online corpus available on the internet so that it can be freely
accessed by users, for instance BNC, COCA or MICASSE, whereas a make-up
corpus is a collection of data which is compiled and created by using corpus analysis
software such as AntConc (a freeware corpus analysis toolkit developed by Prof.
Laurence Anthony), which can be freely downloaded from
http://www.laurenceanthony.net/.
2.1.3 Corpus Processing Techniques
According to its features, a corpus can be used to conduct a data analysis
systematically through the following basic processing techniques.
A core tool in corpus linguistics is concordancing, which means applying
corpus software to search for a particular word or phrase everywhere it occurs in a
corpus (O’Keeffe et al., 2007). The item searched or node item is presented in the
middle of concordance lines that are known as key-word-in-context displays (KWIC
concordances) which are listed and shown vertically so that they can be read outwards
to left and right, from the center or searched items (O’Keeffe et al., 2007; Sripicharn,
2009).
Figure 2.1: Concordance lines for the word population generated by
Antconc

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
12
Another basic function that most corpus software can perform is a
calculation of words which may be number of tokens, i.e. number of all running
words or number of types, i.e. number of words with the same type in which the
repeated words are not counted, in a corpus (Sripicharn, 2009), for example, in the
sentence ‘I know you know what I mean’, this sentence has seven tokens but five
types. The corpus software can also make wordlists or word frequency counts, which
can be in order of alphabet or frequency and be made on single lexical items or
clusters of words. In the following sample tables (Table 2.1 and Table 2.2), the most
frequent words in ten-million words from the Cambridge International Corpus (CIC)
and most frequent cluster of the word time are presented respectively:
Table 2.1
The most frequent words: ten-million-word corpus (CIC)
Word Frequency
1 the 439,723
2 And 256,879
3 To 230,431
4 a 210,178
5 Of 194,659
6 I 192,961
7 you 164,021
8 it 150,707
9 in 142,812
10 that 124,250
11 was 107,245
12 yeah 86,092
13 he 78,932
14 Is 75,687
15 on 71,797
16 for 69,392
17 but 64,561
18 she 61,406
19 they 58,021
20 have 55,892
(O’Keeffe et al., 2007, p. 34)

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
13
Table 2.2
Frequency of expressions with time
Expressions Frequency
all the time 1,019
the first time 834
at the time 733
a long time 657
by the time 583
at the same time 460
in time 323
the last time 238
at a time 216
a good time 127
(O’Keeffe et al., 2007, p. 41)
For pedagogical purposes, this function is mainly used in identifying the
core vocabulary of English which can be an important tool for teaching English in
class. Also, Meunier (1998, p. 19) stated that “this facility is intended to support
stylistic comparison”, for instance the comparisons of various versions of translated
texts of the same story or articles on the same topic.
The other function that corpus software has is key word analysis, which is
performed by using a Keyness tool in order to compare key words between one
corpus and the other benchmark corpus (Sripicharn, 2009). This tool is helpful for
characterizing a register or a genre. For example, it is found that key words which are
found from an economic lecture relative to a general corpus of academic features are
tax, income, system, rate and supply (O’Keeffe et al., 2007). In addition to key word
analysis, the corpus technique can perform cluster analysis, that is to identify and list
the combinations of words or chunks as can be seen in Table 2.3 which shows the 20
most frequent 3-word combinations from 10-million words of CIC as follows:

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
14
Table 2.3
The 20 most frequent 3-word combination in ten-million-words from CIC
Word Frequency
1 I don’t know 588
2 a lot of 364
3 one of the 320
4 I don’t think 248
5 it was a 240
6 I mean I 220
7 the end of 198
8 there was a 193
9 out of the 190
10 do you think 177
11 a couple of 166
12 do you want 159
13 you have to 158
14 be able to 157
15 a bit of 155
16 you want to 153
17 and it was 148
18 it would be 142
19 do you know 138
20 you know what 137
(O’Keeffe et al., 2007, p. 14)
2.1.4 Use of Corpora
Regarding the techniques that corpus software can perform, it makes a
corpus useful for various language analysis and study purposes. According to
O’Keeffe et al. (2007), corpora have been used in many areas, e.g. lexicography:
corpora have been utilized to make dictionaries such as COBUID (Collins
Birmingham University International Language Database), one of the first corpora-
based dictionaries created by John Sinclair and his team in 1980; grammar:
significant grammatical patterns and frequency can be investigated through corpus
techniques; stylistics: corpora can be applied for the study of literature and style of the
language people use; forensic linguistics: corpus techniques are sometimes used in
law and crime investigations analyzing language in documents or discourse in

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
15
courtroom setting; sociolinguistics: the difference of sociolinguistic variables such as
age, gender, education, or socio-economic, that affects the use of language can be
explained through corpus analysis; translation: in translation, corpora can be either
compared to translate the same or similar texts or utilized as tools in translation by
humans and machines; semantics and pragmatics: since in real use, meanings defined
by dictionaries do not represent all meanings in real use, in this case corpora are
helpful by comparing sentence to sentence or text to text to understand the meaning of
a word or phrase when it is mentioned in specific context; and discourse study:
recently, corpus concept has been employed in discourse analysis, especially political
discourse and business discourse (Jones & Waller, 2015).
As remarked by Jones & Waller (2015), corpus methodology can be used
to explore language and reveal the perspectives of language usage and patterns that
might not have been explained or were misused, in particular in terms of grammatical
analysis, as the corpora can disclose the variations of grammatical patterns in specific
contexts including distinctive grammar of spoken English and lexico-grammatical
profiles. However, the intention or thought of a writer or speaker during the language
processing is unable to be discovered by a corpus, so the data interpretation is
necessary (Jones & Waller, 2015).
In terms of the use of corpora in language study, Biber, Conrad & Reppen
(1994) identified two important advantages, indicating that, with corpora, the
language analyses are based on a large empirical data of naturally-occurring texts and
corpora allow researchers to extract specific issues or to answer some questions.
2.2 ADVERBIAL INTENSIFIERS
2.2.1 Definition and Types of Adverbial Intensifiers
English mainly has four classes of content words, namely nouns, verbs,
adjectives and adverbs. Among these, the most frequent type of content words is
nouns while adverbs are the least; however, its importance is not less (Carter,
McCarthy & O’Keeffe, 2011). Adverbs are used to add more information to a verb, an
adjective, another adverb, a clause and a whole phrase or sentence, in particular to
indicate the time, manner, place, degree and frequency of something in order to make

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
16
the meaning stronger as well as play roles as discourse markers and short responses
(Carter et al., 2011). It is further stated that any adverbial words or phrases are not
necessary to the structure of the clause or sentence but only establishes an extra
meaning to it (Carter et al., 2011).
One of the most common types of adverbs is called ‘adverbial
intensifiers’ or ‘intensifiers’ (Suzuki & Yamagishi, 1999). The term intensifier has
been firstly defined by Bolinger (1972, p. 17) as “any device that scales a quality,
whether up or down or somewhere between the two”. Similarly, intensifiers have been
acknowledged as adverbs or adverbial groups of words or phrases that are the subset
of adverbs of degree, as claimed by Quirk, Randolph, Greenbaum, Leech & Svartvik
(1985), who categorized intensifiers under the group of degree modifiers that express
either high or low point or intensity degree.
In general, AIs have two main functions which are to increase or to
decrease the modified items’ meaning, as described in the book English Grammar
Today. The intensifiers are identified as the adverbs or adverbial phrases that add a
stronger meaning and show emphasis (Carter et al., 2011, p. 255). Likewise, Vasko
(2010, section 9.3.2) defined intensifiers as “scaling devices which have either an
intensifying or a weakening effect on the meaning of the word they modify”.
Overall, it seems that not only should the change in a modified item’s
meaning be concerning but also its intensity scale or degree must be focused on.
Strongly confirmed by Lorenz (1998), adverbial intensifiers have a major function to
increase the intensity of the word not its meaning. Likewise, Pichler (2016)
maintained that intensifiers can have an amplifying or diminishing influence on the
modified head specific word or phrase.
According to Backlund (1973), in terms of notions of degrees, adverbial
intensifiers are classified into eight sub-classes, which are:
1. Adverbs expressing the complete or partial absence of the concepts
denoted by their head words;
2. Adverbs expressing the minimum degree or degree just above the
non-presence;
3. Adverbs expressing the low degree;
4. Adverbs expressing the low degree of a positive idea;

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
17
5. Adverbs expressing the moderate degree;
6. Adverbs expressing the increasing degree;
7. Adverbs expressing the high degree; and
8. Adverbs expressing the highest degree.
Furthermore, Quirk et al. (1976) clearly classified intensifiers by and
large into three semantic categories, namely emphasizer, amplifier and downtoner, as
explained below.
Emphasizers, as defined by Quirk et al. (1985), have a reinforcing effect
adding to the force of the modified words or phrases; as such, they do not require a
gradable predicate in intensifying. Examples of emphasizers are actually, certainly,
clearly, definitely, indeed, obviously, plainly really, surely, frankly, honestly, literally,
simply. Reviewed by Baumgarten, Bois & House (2012), it is summarized that
emphasizers’ function is to reinforce truth value.
Amplifiers have their function to intensify or amplify a certain quality
(Plo-Alastrue & Perez-Llantada, 2015), and are subdivided into maximixers and
boosters. Maximizers, for instance absolutely, totally, completely, entirely, fully, quite,
thoroughly, and utterly, relate to the extreme degree or occupy the highest position on
the intensify scale and most commonly modify non-gradable words (Huddleston &
Pullum, 2002). Meanwhile, boosters, for instance very, really, terribly, badly, deeply,
greatly, heartily, only indicate that it is very intense but its degree of intensity can be
more, and modify fully gradable words (Huddleston & Pullum, 2002).
For the last category, downtoners, Quirk et al. (1973, 1985) considered
that the main function of downtoners are to diminish the modified item’s intensity
degree, and divided them into four sub-classes, namely approximators, expressing an
approximation to the force of verbs, which reveals more than is actually relevant, e.g.
almost, virtually, nearly, as good as; compromisers, can be used for ether extreme
maximizing or minimizing, depending on the item they modify, e.g. sort of, quite,
rather, enough; diminishers, having a lowering effect and basically mean “to a small
extent” (Quirk et al., 1985, p. 599), e.g. only, somewhat, partly, slightly, a little; and
minimisers, scaling downwards considerably, e.g. hardly, scarcely, barely. Regarding
its functions, it was stated that speakers use downtoners in order to weaken the
assertion and to ease the unwelcome effect (Urrea, 2006). Consequently this makes

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
18
the terms downtoners and hedge able to be used interchangeably (Xiao & Tao, 2007).
However, Lakoff (1972) claimed that downtoners implicitly contribute to creating
fuzziness. As downtoners are very style-sensitive, it has been found that, “informal
downtoners (such as hardly, little and only) are rather frequent in informal spoken
discourse, whereas formal downtoners (such as nearly, merely and fairly) are
prevalent in academic writing” (Plo-Alastrue & Perez-Llantada, 2015). Furthermore,
in academic registers, downtoners are used to “specifying the amount of different”
(Biber et al., 1999, p. 567), and thus this type of intensifiers typically collocates with
an adjective different.
Similar to these groups classified by Quirk et al. (1985), Lorenz (1998)
categorized the intensifiers following the expression of their respective degrees,
namely maximizers, boosters, approximators, compromisers, dimininishers and
minimizers. It is explained that the maximizers and boosters work as intensifiers while
the other three groups function as downtoners (Lorenz, 1998).
2.2.2 Use of Intensifiers
Over many years, intensification in the use of natural language has been
studied in depth from many particular perspectives such as its common usage in the
real context, for example, a study found that “conversation uses a wider range of
common intensifiers than academic prose” (Biber, Johansson, Leech, Conrad &
Finegan et al., 1999). Not only its function, general application or pragmatic
viewpoints, but also the area of its semantics and usage in the social landscape have
been focused on broadly.
In terms of semantics, the recent findings (e.g. McCready & Kauffman,
2013; Bylinina, 2010; Irwin, 2013; Beltrama & Bochnak, 2013; McNabb, 2012) have
shown that the boosting impact of the intensification can occur through the various
semantic operations, and that the environments where intensification is found extend
well beyond the category of gradable expressions. For the social field factors, some
studies have revealed that the use of most intensifiers vary across the different social
categories and demographic categories, especially gender and age (Macaulay 2006,
Tagliamonte 2008, Tagliamonte & Roberts 2005). Affirmed by Beltrama (2014), the
intensification is often buried in “socially-conditioned variation” and the distribution

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
19
of intensifiers relates to the specific macro-social attributes of the speakers, in
particular their ages and to the specific communicative contexts. Concerning age, it
was found that intensifiers are commonly used more frequently among young
speakers, and on the contrary tend to decrease in use by older generations (Labov,
2001, Tagliamonte and D’Arcy, 2009, Kwon 2012). In a similar way, gender has also
been claimed to relate with intensifiers distribution as explored by Tagliamonte
(2008) presenting that some intensifiers such as so and pretty are predominantly used
by women in Toronto. Additionally, the education of the user affects the nature of
intensification; Ito & Tagliamonte (2003) observed the Northern English data from
York and noticed that the uneducated informants used fewer intensifiers than the
educated ones.
In addition to demographic and social categories, intensifiers have been
argued to be associated with specific genres. Biber (1988) examined the distribution
of intensifiers across different genres, i.e. news reports, academic writing, and fiction,
and found that intensifiers are most generally found in contexts where the speaker’s or
author’s intention is to express a high degree of personal involvement in the
communication. Furthermore, Xiao and Tao (2007) analyzed 33 English amplifiers,
supporting that intensifiers are used more in spoken registers than written ones.
Recently, Lim and Hong (2012) have investigated the use of intensifiers of Mandarin
Chinese, and result has been shown in the same direction, concluding that most
intensifiers are predominantly found in spoken genres.
In spite of the aforementioned variation in use of intensifiers, as same as
other types of main word classes which are nouns, verbs, adjectives and adverbs, the
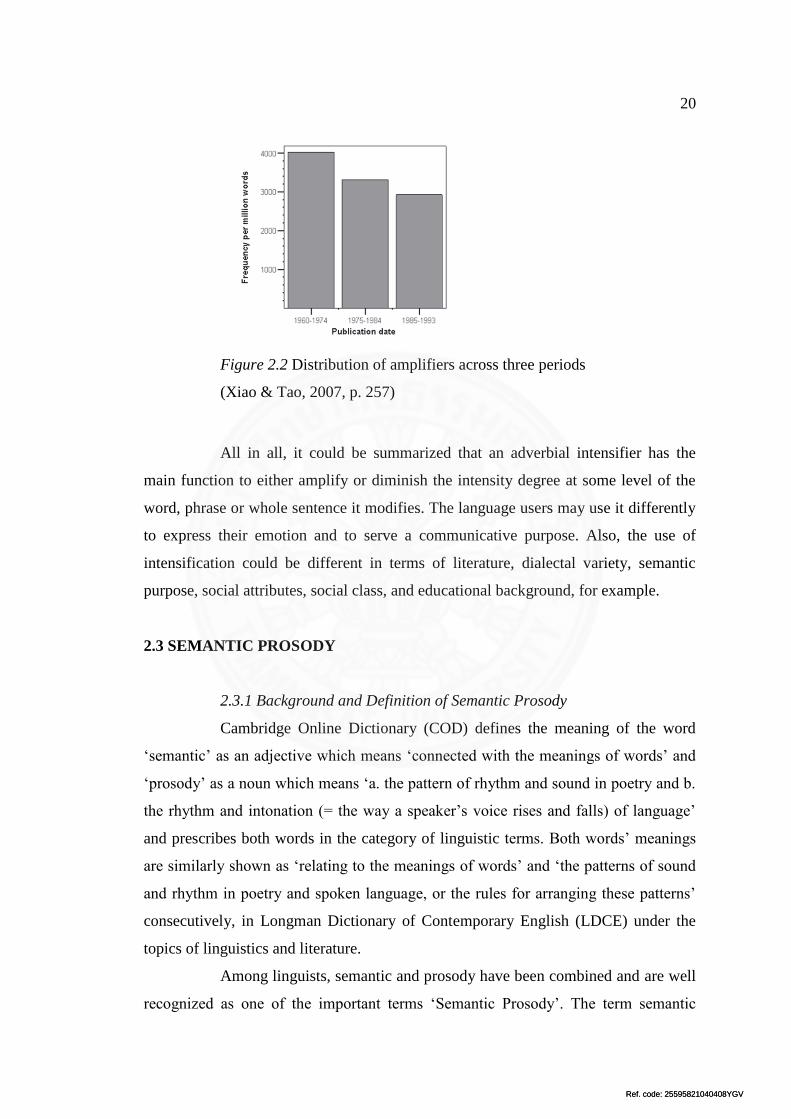
adverbial intensifiers face the phenomenon of the change in use over the time (Xiao &
Tao, 2007). Xiao & Tao (2007) studied the use of amplifiers analyzing the data from
BNC covering three decades from the early 1960s to the early 1990s by dividing into
three different times; and it can be seen (as shown in Figure 1.2) that the use of
amplifiers declined over the intervening three decades.
Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
20
Figure 2.2 Distribution of amplifiers across three periods
(Xiao & Tao, 2007, p. 257)
All in all, it could be summarized that an adverbial intensifier has the
main function to either amplify or diminish the intensity degree at some level of the
word, phrase or whole sentence it modifies. The language users may use it differently
to express their emotion and to serve a communicative purpose. Also, the use of
intensification could be different in terms of literature, dialectal variety, semantic
purpose, social attributes, social class, and educational background, for example.
2.3 SEMANTIC PROSODY
2.3.1 Background and Definition of Semantic Prosody
Cambridge Online Dictionary (COD) defines the meaning of the word
‘semantic’ as an adjective which means ‘connected with the meanings of words’ and
‘prosody’ as a noun which means ‘a. the pattern of rhythm and sound in poetry and b.
the rhythm and intonation (= the way a speaker’s voice rises and falls) of language’
and prescribes both words in the category of linguistic terms. Both words’ meanings
are similarly shown as ‘relating to the meanings of words’ and ‘the patterns of sound
and rhythm in poetry and spoken language, or the rules for arranging these patterns’
consecutively, in Longman Dictionary of Contemporary English (LDCE) under the
topics of linguistics and literature.
Among linguists, semantic and prosody have been combined and are well
recognized as one of the important terms ‘Semantic Prosody’. The term semantic

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
21
prosody has raised the interests and awareness of most language academics to pay
attention with broad discussion and exploration in depth for years, and is on the top of
language learning and teaching’s concern continually. The concept of semantic
prosody was originally noticed by J.R. Firth, the father of Firthian linguistics, in 1957
when he explored semantic interpretation in language utterance, and at that time it
was noted as ‘phonological prosody’. Later, in 1987, it was John Sinclair who firstly
coined the term ‘Semantic Prosody’ after he observed the phenomenon of semantic
prosody in the words’ habitual collocation. At last, semantic prosody was officially
introduced to the public by Bill Louw in 1993 by giving the first definition: “a
consistent aura of meaning with which a form is imbued by its collocates” (Louw,
1993, p. 157). His claim was that semantic prosodies are unable to easily be
recognized by human intuition or self-examination in using language and remain
hidden from the acknowledgement until John Sinclair initially studied lexis and
collocation with the machine driven lexicography from the large corpora.
Consequently, the evidence of semantic prosody can be discovered effectively using
corpora.
Sinclair (1996, p. 87) stated that “the initial choice of SP is the functional
choice which links meaning to purpose; all subsequent choices within the lexical item
relate back to the prosody”. It has been widely claimed that semantic prosody
associates the meaning with a particular purpose in a contextual communication. The
evidence was clearly shown in 1991 when Sinclair found that the lexical items
happen, break out, set in and bent on are all habitually linked to negative occurrences.
This concept is credited by Louw (2000), referring to semantic prosody as a form of
meaning developed through “the proximity of a consistent series of collocates”, which
are usually identified as positive or negative, and its function as the attitudinal
expressions of the message deliverer towards the pragmatic situation. Supported by
Stubbs (1996, p. 176), semantic prosody is referred to as “a particular collocational
phenomenon” in which two or more words are habitually co-occurring called
collocation. The classic word in the studies of semantic prosody which is cause was
initially investigated by Stubbs (1995, 1996). He observed the use of the word cause
in a corpus containing one million words, and found that almost 80% of occurrences
were negative (e.g. cause anxiety, cause errors, etc.), even a further study in another

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
22
corpus with 120 million words showed the same result of its negative prosody.
Furthermore, the term semantic prosody was explained in a new way by Alan
Partington in which he describes semantic prosody as an aspect of evaluative
meaning: “the spreading of connotational coloring beyond single word boundaries”
(Partington, 1998, p. 68). Partington (1998) as well supported the previously
mentioned linguists that corpus data reveals the statistical tendencies of the words or
phrases’ semantic prosodies since the language user’s intuition does not, as apparently
shown in his finding of the notion of the items timely, excessive, flabby which are said
to have a clearly favorable or unfavorable evaluation. In addition, Hunston and
Francis (2000) explained that if any word co-occurs typically with other words
holding a particular semantic set, such word may have a particular semantic prosody
correspondingly. Due to this view, semantic prosody is claimed as a phenomenon of a
node word frequently co-occurring with the lexical words or phrases under the same
semantic area (Hunston & Francis, 2000). Hunston (2002) further emphasized that the
sense of semantic prosody is able to be noticed only by the observation of “a large
number of instances of a word or phrase” because it is on the word or phrase’s use in
a typical way.
As the term semantic prosody has drawn the attention of most linguists,
its term’s concept, framework and definition have been endlessly studied and
extended. In 2005, William F. Whisitt offered a distinct concept of semantic prosody
which focuses on its pragmatic function. He also stated that “the essence of the
phenomenon of semantic prosody is, however, historical change: meaning being
transferred between terms which appear together frequently over time” (Whitsitt,
2005, p.294). Apparently, semantic prosody is closely associated with collocates or
collocation: the item’s affective or negative meaning does not show if it does not
occur along with the typical collocates in the context or it could be said that “the
semantic prosody of an item is the result of interplay between its typical collocates”
(Xiao and McEnery, 2006). This means that by only looking at the node items without
the consideration of the surrounding context and the frequent collocation is
impossible to extract the semantic prosody. This has been supported by Stubbs (2002,
p.225) observing that “there are always semantic relations between node and
collocates, and among the collocates themselves”, and Morley and Partington (2009,

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
23
p.150) stating that the semantic prosody was referred to as a product of collocation
with the reason that the prosody tends to change according to the collocational
patterns of items in the context.
2.3.2 Main Features and Categories of Semantic Prosody
Apart from its definition and meaning, the semantic prosody’s features
and categories have been interestingly discussed and described. According to Sinclair
(1987), the semantic prosody was recognized as connotation, pragmatic meaning and
attitudinal meaning and three salient features, namely functionality: linguistic choices
and communicative purpose were proposed, (Sinclair, 1996). Louw (1993) explained
that semantic prosodies involve either negative/ unpleasant events or neutral/ positive/
pleasant events and serve the primary function to express the attitude or evaluation of
speaker or writer (Louw, 2000). Similarly, Stubbs (1996) distinctly categorized the
semantic prosody into three groups which are positive, neutral and negative, while
Partington (1998) separated it into favorable and unfavorable evaluations. From the
study, the semantic prosody’s phenomenon could be determined and observed from
two main perspectives which are the functional perspective and the collocative
meaning perspective, and could be summarily classified as positive/ pleasant/
favorable, negative/ unpleasant/ unfavorable and neutral/ mixed prosody (Zhang,
2010). And it is suggested that the knowledge and awareness of semantic prosody
should be taught and raised among second language learners in order that they will
use English more naturally.
There have also been more and more studies on semantic prosody
insisting on the importance of semantic prosody in language such as the study of more
than 25 English lexical items which proved that the words apparently carry either
negative or positive prosody (Xiao & McEnery, 2006); the finding which confirms
that the classic word cause has a stronger negative prosody (Wei, 2002). Even in other
languages, the concept of semantic prosody has been brought to consideration as to
whether it exists or not, for example, Gan (2015)’s study which explored the
collocational behavior and semantic prosody of the words ‘mianzi’ and ‘lian’ in
modern Chinese and found that these two words are likely to have opposite semantic
prosody especially when they are used in the same sentence.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
24
2.3.3 Semantic Prosody and Semantic Preference
On the other hand, there has been a dispute about the term semantic
prosody and the term semantic preference which are closely related to each other
whether they are the same or not. Sometimes, both terms are used to describe the
same phenomenon; however, it is argued that they should be considered differently at
other times. Stubbs (2002) referred to the semantic preference as the meaning
appearing from the shared semantic features of a given node word’s collocates.
Further explained, semantic prosody and semantic preference are not similar in terms
of operating scopes, semantic preference relates a node item to another item from a
particular semantic set and can be viewed as the collocates’ features; while the
semantic prosody affects broader stretches of text and can be viewed as the node
word’s feature (Partington, 2004, Xiao & McEnery, 2006). Partington (2004)
additionally noted that semantic prosody describes the phenomenon that a word or
phrase shows a preference to co-occur with surroundings that might be good or bad so
it can be explained as a sub-category of semantic preference.
2.4 RELEVANT RESEARCH
During the last two decades, the concept of semantic prosody has been
increasingly studied by many researchers and linguists (Hu, 2015). In order to analyze
the semantic prosodic behaviors in language, corpus methodology has been applied as
a main tool in observing and revealing the distinct semantic prosodies, especially in
near synonymous words (Xiao & McEnery, 2006). To date, there have been some
corpus-based studies exploring semantic prosodies in the use of words, as discussed
below.
Limrosthip (2013) investigated the semantic prosody of the words cause
and commit, collecting and exploring data from four selected language corpora, which
are British National Corpus (BNC), British News Corpus, Reuters Corpus and Corpus
of Contemporary American English (COCA). The results apparently revealed that
both cause and commit often occur in negative contexts, meaning that these words
carry negative semantic prosody. Additionally, the research showed that frequent
collocates of these words are also in negative sense, namely trouble, difficulty,
damage, cancer, injury and death. These findings supported the research of Wei

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
25
(2002), in that the word cause conveys a strong negative semantic prosody. In spite of
that, the further study by Wang & Wang (2005), comparing the English writing of
native speakers and Chinese learners, in the awareness of using lemma cause carrying
semantic prosodic meaning, showed that Chinese learners underuse the typical
negative semantic prosody and instead often overuse the atypical positive one, for
instance, development, progress and improvement.
Not only can words have semantic prosody but phrases also carry such
connotative meaning as proved by Begagic (2013) in the study on semantic prosody
of the collocation of a phrase make sense. The study was aimed at exploring the
behavior of make sense in COCA, focusing on its semantic prosody, and comparing
between the texts from newspapers and academic registers. It was found that make
sense often occurs in a negative environment and is in negative form, as well it is
more frequently found in a negative environment in newspaper genres than academic
one.
Recently, Hu (2015) compared the semantic preference and semantic
prosody with three synonymous adjective pairs, i.e. initial vs. preliminary, following
vs. subsequent, and sufficient vs. adequate. Such adjective pairs were selected from
3,000 core words in the Academic Vocabulary List (AVL), which is based on COCA
(Gardner and Davies), following clearly established criteria. The major findings
showed that an item may be involved with more than one group of semantic prosodies
and its particular semantic prosody could be noticed only when its collocates are
considerably scrutinized in the context and suggested that most of three synonymous
adjective pairs studied often carry neutral semantic prosody in academic registers.
However, it is suggested that more research in other types of texts such as
newspapers, magazines should be conducted to discover the differences as well.
Moreover, Xiao & McEnery (2006) conducted research to explore the
collocational behavior and semantic prosody of near synonyms, i.e. consequence
group, cause group, and price & cost group, from a cross-linguistic aspect, based on
data in English and Chinese. In their paper, it was emphasized that more than 25
lexical words in English have been shown to carry notably negative or positive
prosody. Their findings concluded that semantic prosody in Chinese can be noticed as
in English as well; consequently, it was clear that the importance of semantic prosody

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
26
should be explained to L2 learners to some extent. The findings were in line with
Zhang W. (2009), in that the ignorance of semantic prosody among ESL (English as a
Second Language) and EFL (English as a Foreign Language) learners are common,
and it was proposed that the concept of semantic prosody should be integrated into
ESL/ EFL vocabulary pedagogy in order that the learners’ communicative
competency will be improved.
Apart from the study of semantic prosody of verbs, adjectives and
synonyms as mentioned previously, a study in the case of adverbial intensifiers, in
terms of the change in semantic prosody, was conducted by Zhang, R. (2013). In the
study, Zhang examined four adverbial intensifiers that are terribly, awfully, horribly
and dreadfully by comparing their frequent collocational companies which may be
favorable or unfavorable words, drawn on historical corpus data: Bank of English
Corpus (BOE), and modern corpus data: Corpus of Late Modern English (CLME) as
the contrasted data, in order to study the semantic prosody change over different
period of times. The study showed that these four adverbial intensifiers, in the past,
carry the strong negative semantic prosody, especially negative emotional meaning;
however, over the centuries, their semantic prosodies have changed to be more neutral
or positive through their habitual collocation. This supports Louw (1993) who relates
semantic prosody to ‘contagion’ or ‘semantic transfer’. Another study of semantic
prosodic phenomenon in adverbial intensifiers was conducted by Partington (2004)
who examined seven amplifying intensifiers, namely absolutely, perfectly, entirely,
completely, thoroughly, totally and utterly. The finding revealed that the adverbial
intensifiers carry semantic prosody and semantic preference to some extent, and some
items have a stronger good or bad prosody than others.
This chapter reviews the related literatures in three main areas which are
corpus linguistics, adverbial intensifiers, and semantic prosody. Previous studies are
also presented and summarized, showing that words have particular sets of
collocations and carry semantic prosodies. Next, Chapter three reveals the
methodology including target adverbial intensifiers, corpora, procedures and data
analysis.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
27
CHAPTER 3
METHODOLOGY
3.1 TARGET ADVERBIAL INTENSIFIERS
The study investigated the use of the three adverbial intensifiers (AIs)
really, certainly and clearly and their verb and adjective collocates in authentic texts.
For this study, 3,000 concordance lines (1,000 lines for each AI) from the Corpus of
Contemporary American English or COCA were extracted for the analysis. Those
data are the language samples produced by native speakers of American English, in a
variety of genres, i.e. spoken text, fiction, magazine, newspaper and academic text, so
it presents the authentic language use.
3.2 CORPORA
In this study, the Corpus of Contemporary American English (COCA),
as a reliable source of data, was used in the process of data collection in order to show
the concordance lines of authentic texts.
Additionally, the researcher consulted Longman Dictionary of
Contemporary English (LDOCE), online version 2016 as a main reference in
checking the collocates that co-occur with node words, their meanings and examples
of use. This dictionary contains more than one million corpus examples and the
words’ collocations. It is also claims to be a comprehensive online vocabulary and
grammar resource.
3.3 PROCEDURES
This section describes the research design and procedure of data
collection.
3.3.1 RESEARCH DESIGN
This study is an exploratory study which was conducted using a corpus-
based approach. The concordance lines of the target AIs were drawn from COCA
showing real texts used by native speakers for investigating their semantic prosody

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
28
and exploring their connotative meaning. For the examination of the semantic prosody
of node words, their adjective and verb collocations were collected and analyzed.
3.3.2 SELECTION OF TARGET ADVERBIAL INTENSIFIERS
In this study, only three AIs that are found in COCA were studied. Two
main criteria for selecting the target AIs were:
1. The selected words must be intensifying adverbs and be classified
into the category of adverbial intensifier emphasizer (Quirk et al., 1985).
2. The selected words must be the emphasizers occurring with high
frequencies, found in the top three ranked in COCA.
As shown in Figure 1.1, the top three emphasizers found in COCA are
really, actually, and simply. However, from the pilot study, it was discovered that the
words actually and simply, which are ranked in the top three, do not function as only
intensifying adverbs, instead, they have many varieties of use. Most of the frequencies
show their use as in the meaning of ‘as a matter of fact’ for actually, and ‘only’ for
simply, so the frequencies shown might not represent its real data as the AIs. Thus, the
researcher decided to study the next words ranked in the fourth and fifth places
instead, which are certainly and clearly.
3.3.3 DATA COLLECTION
The researcher collected the data from COCA online website at
http://corpus.byu.edu/coca/, provided free by Brigham Young University. The
researcher used its search feature ‘KWIC’ to extract the concordance lines of the node
words as designed.
1,000 concordance lines of the adverbs really, certainly and clearly were
searched for and extracted. To take each node word that functions as adverb and
collocates with adjectives, the part-of-speech tags were selected as r* and j*
respectively, as shown in Figure 3.1.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
29
Figure 3.1 Extracted screen of the search for 1,000 concordance lines of
the adverb clearly when it collocates with adjectives
from http://corpus.byu.edu/coca/
Likewise, a similar method was used to collect the data of AIs’ verb
collocations. Only a part-of-speech tag was changed from adjectives, i.e. j*, to verbs,
i.e. v*, as shown in Figure 3.2.
Figure 3.2 Extracted screen of the search for 1,000 concordance lines of
the adverb certainly when it collocates with verbs
from http://corpus.byu.edu/coca/

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
30
After that, the program presented the concordance lines of the studied
words functioning as adverbs followed by adjectives and verbs, as shown in Figure
3.3 and 3.4, respectively.
Figure 3.3 Examples of the word clearly collocating with adjectives
in the concordance lines from COCA from http://corpus.byu.edu/coca/
Figure 3.4 Examples of the word certainly collocating with verbs
in the concordance lines from COCA from http://corpus.byu.edu/coca/
Then, the researcher scanned each line and removed the irrelevant data,
e.g. the concordance lines showing the target AIs functioning as discourse markers or
particles and mixed-up lines produced by automatic errors, to prevent
misinterpretation during investigation. Among these 1,000 lines of each node word,
the first 500 lines that met this criterion were selected for data analysis.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
31
3.4 DATA ANALYSIS
After the procedure of data selection and collection, the adjective and
verb collocations that co-occur with the targeted AIs in the COCA were categorized
into 3 classifications regarding their semantic prosodies, i.e. positive, negative and
other or mixed prosody, by consulting the LDOCE to check the definition and
possible meanings of a word.
The raw data as the members of each semantic prosody group were then
counted and calculated into percentages for a clearer picture of the results. Next, all
the data were analyzed and interpreted in a descriptive way in order to respond to the
research questions. Finally, the conclusion was summarized based on the findings and
discussed.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
32
CHAPTER 4
RESULTS
This chapter reveals the results of the adjective and verb collocations
of the adverbial intensifiers really, certainly and clearly, in COCA. Each AI’s
collocates were categorized into 3 semantic prosodies, i.e. positive, negative and
others. The adjective and verb collocations for which their sense of meanings present
as neither positive nor negative due to their meanings in use, or limited texts for
interpretation, were then classified into ‘others’.
4.1 THE RESULTS OF THE ADJECTIVE AND VERB COLLOCATIONS OF
THE ADVERBIAL INTENSIFIER REALLY in COCA
The results show that really occurs more often with positive adjectives,
such as great (9), cool (7), happy (7), glad (6), special (5), lucky (3), elegant (2),
brilliant (1), friendly (1), helpful (1), and smooth (1). Among those pleasant words,
the top three most frequent adjectives modified by really are good (68) followed by
important (18) and nice (15), as in Table 4.1.
Table 4.1
Example of concordance lines of really collocating with top three pleasant adjectives
in COCA.
1 So, I think that’s really good because it’s going to be a great balance…
2 -- you know, so far we feel really good about production.
3 my age ,made a good album, a really good album, last year, and I wouldn’t put it
4 They’re old, anyway, and people take really good care of them.
5 This is just a really important day where you celebrate the start of…
6 his television show, it was a really important phase in the development of country music…
7 One of us. Well, to me this is really important that the air gets clear, that we get rid of
8 And it’s just kind of a really nice luminescent effect again.
9 It’s going to be a really nice afternoon.
10 Now, it is really nice because I am at an age where I’ve done my

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
33
Nevertheless, really also collocates with negative adjectives, e.g. bad
(21), hard (10), difficult (5), serious (4), sorry (6), sad (4), low (2), and uncomfortable
(1), including other adjectives, e.g. early (1), local (1), similar (1), and substantive
(1), which cannot be classified into either positive or negative prosody due to
unspecified and limited context.
From the calculation into percentage, as shown in Figure 4.1, the positive
adjectives occur with really for 62.4%, while the use of really with negative and other
adjectives occur only 29.4% and 8.2% respectively.
Figure 4.1: Percentage of the adjective collocations of the AI really in
three semantic prosody groups
Through a close investigation of the individual significant collocates of
really, it was found that the adjectives typically occur with the node item relating to
emotions or state of mind such as happy (7), glad (6), sorry (6), tired (2),
embarrassed (1), satisfied (1), scared (1), and general evaluation such as good (68),
nice (15), hard (10), difficult (5), proud (5), confident (1). Significantly, size
adjectives such as big (14), small (1), huge (1) are also its common collocates.
In terms of verb collocations, the initial results do not show any
significant semantic preference. According to the limited context, most main verbs
that appear with really present neither negative nor positive sense of meaning, so they
were classified as others, as shown in Figure 4.2.
62.4%
29.4%
8.2%
PositiveNegativeOthers

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
34
Figure 4.2: Percentage of the verb collocations of the AI really in three
semantic prosody groups
From the data drawn, the top five most frequent verbs emphasized by
really are get (24), think (21), know (11), care (10) and look (10), respectively.
However, it can be notably seen that really typically occurs in the sentence patterns S.
+ Auxiliary V. + not + really + Main V.; and S. + really + Auxiliary V. + not + Main
V., as in Table 4.2.
Table 4.2
Example of concordance lines of really in the sentence patterns S. + Auxiliary V. +
not + really + Main V., and S. + really + Auxiliary V. + not + Main V. in COCA.
1 You know, they’re not really talking about it.
2 that you’ve now gathered that I hadn’t really heard before.
3 when she screamed “baby”. “I didn’t really think about it.”
4 Suddenly she didn’t really care about Joe Smith anymore.
5 they come back and start a fight. They are not really hating each other.
6 place, a smaller environment. We really weren’t doing anything different than we…
7 the phase of the campaign where voters really cannot recognize them, don’t know their…
8 and studying atoms in a way that really couldn’t be explained very simply.
9 Islamic fundamentalists, who really don’t owe their support to any particular
10 give us an instructive opinion, but really won’t put a period at the end of this
20.2%
20.2%59.6%
Positive
Negative
Others

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
35
4.2 THE RESULTS OF THE ADJECTIVE AND VERB COLLOCATIONS OF
THE ADVERBIAL INTENSIFIER CERTAINLY in COCA
The results of the adjective collocations of the AI certainly concerning
semantic prosody are similar to those of really. It shows that 66% of the adjectives
that co-occur with certainly have a pleasant sense of meaning, Figure 4.3.
Figure 4.3: Percentage of the adjective collocations of the AI certainly
in three semantic prosody groups
The top three most frequent positive adjectives that co-occur with
certainly are true (87), possible (13), right (10) and interested/ interesting (10); and
the other sample positive words that collocate with certainly are good (9), glad (3),
correct (2), happy (2), worthwhile (2), nice (2), useful (2), attentive (1), pretty (1),
supportive (1), for example, as in Table 4.3.
Table 4.3
Example of concordance lines of certainly collocating with frequent positive
adjectives in COCA.
1 at levels of leadership, which is certainly true and a good start.
2 …, I think, that it’s certainly possible for Barack Obama to carry Virginia.
3 But you’re certainly right that an editor is an essential part of…
(Continue)
66%
20%
14%
Positive
Negative
Others

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
36
Example of concordance lines of certainly collocating with frequent positive
adjectives in COCA.(Continued)
4 I’m certainly interested in fashion. I like pretty clothes, just…
5 acknowledging that they are certainly interesting and worth serious discussion.
6 You know, the environment is certainly good for broadcasters in general.
7 The definition is certainly useful and has been corroborated by the…
Furthermore, with a closer investigation, it was found that certainly
frequently co-occurs with ability adjectives ending with –able and –ible, e.g. audible
(1), capable (5), plausible (4), understandable (3), questionable (2), changeable (1),
sustainable (1); comparative and superlative adjectives, e.g. better (4), higher (3),
bigger (2), easier (2), greater (2), harder (1), older (1); and proper adjectives, e.g.
African-American (1), Asian (1), Kurdish (1), Russian (1), Syrian (1), as in Table 4.4.
Table 4.4
Example of concordance lines of certainly collocating with adjectives ending with –
able and –ible, comparative and superlative adjectives, and proper adjectives in
COCA.
1 ...to COTTLE but there are
already
certainly questionable images that are out there like “USA”…
2 She looks serene and pastoral, certainly capable of mercy. I take this for a good sign.
3 It is certainly plausible that one’s personality and emotional…
4 …perhaps not irrelevant, is certainly changeable in the fashion of Watt’s narration:…
5 …to the value of the property and certainly greater than the rents for many years to come,..
6 You know, it’s certainly easier in my time than it was when Bonnie…
7 …to complain. On camera, it’s certainly hardier for Mr. Clinton to be bold than it was...
8 …as old possibly as the land itself, certainly older than the colony, which had exited…
9 There are certainly Asian gangs, Jamaican possess.
10 Certainly Russian leaders are now trying to prevent…
Regarding verb collocations, it can be seen that certainly generally co-
occurs with verbs showing other semantic prosody, Figure 4.4.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
37
Figure 4.4: Percentage of the verb collocations of the AI certainly in
three semantic prosody groups
Remarkably, it was revealed that modal verbs, e.g. would (32), can (10),
could (9), should (3), must (2), frequently co-occur with certainly, as in Table 4.5.
Table 4.5
Example of concordance lines of certainly collocating with modal verbs in COCA.
1 “There certainly would be no harm in discussing that.
2 independent counsel, but he certainly can be swept up as part of something that…
3 …during the summer,, we certainly could have fought it longer.
4 The ship certainly should have awakened him if someone tried to…
5 …I think that AIDs patients certainly must be cared for, and doctors have an obligation
In addition, a large number of the main verbs co-occurring with certainly
express the meaning of ‘requirement’, e.g. want (19), need (5), ask (4), expect (3),
dream about (1), prefer (1), request (1), require (1), as in Table 4.6.
36.8%
20.5%
42.7%Positive
Negative
Others

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
38
Table 4.6
Example of concordance lines of certainly collocating with main verbs that express
the meaning of ‘requirement’ in COCA.
1 I certainly didn’t want to have one in front of an audience.
2 …security while the company certainly needs a degree of flexibility to change size,…
3 And I’ll certainly ask for their opinion as to where they…
4 We would certainly expect an accused stalker sample to show…
5 Research certainly requires funding, but just as important, the…
4.3 THE RESULTS OF THE ADJECTIVE AND VERB COLLOCATIONS OF
THE ADVERBIAL INTENSIFIER CLEARLY in COCA
In agreement with really and certainly, the results show that AI clearly as
well co-occurs with positive adjectives rather than negative or other items, as shown
in Figure 4.5, presenting the proportion in percentage.
Figure 4.5: Percentage of the adjective collocations of the word clearly
in three semantic prosody groups
The sample positive adjectives found with this AI are better (6),
important (6), greater (4), good (3), logical (1), powerful (1). The data reveals the top
49.7%
34.0%
16.3%
Positive
Negative
Others

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
39
five adjectives that are visible (38), evident (20), articulated (17), aware (12), and
audible (7) and identifiable (7), as in Table 4.7.
Table 4.7
Example of concordance lines of clearly collocating with the top five adjectives in
COCA.
1 A dozen ships were clearly visible from where she stood, and more…
2 This attitude is clearly evident in classical Greece.
3 …requires the development of clearly articulated goals and objectives.
4 The court’s majority was clearly aware of the perils of entering what one…
5 …a situation in which unusual clearly audible background utterances frequently go…
6 ...temples comprise communities clearly identifiable as autonomous civil association,…
Similar to certainly, it was revealed that ability adjectives ending with –
able and –ible, e.g. visible (38), audible (7), identifiable (7), discernible (6),
distinguishable (4), observable (3), applicable (2), definable (2), questionable (2),
recognizable (2), commonly occur with clearly, as in Table 4.8.
Table 4.8
Example of concordance lines of clearly collocating with adjectives ending with –able
and –ible in COCA
1 …mass, together with several clearly visible abdominal masses.
2 …before that when he barks, it is clearly audible at her house, even with her music on.
3 Strong remnants of both are clearly identifiable even today.
4 Her spine was clearly discernible as she bent, a string of walnut-sized…
5 …groups of mounds that are clearly distinguishable from other groups.
6 …and economic power is most clearly observable in ethnically heterogeneous countries…
7 …and thus become much more clearly applicable and engaged with the world of the…
8 …ways rather than falling along clearly definable boundaries.
9 …, in questionable circumstances, clearly questionable circumstances.
10 …automatically attributed to any clearly recognizable figure in a picture.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
40
However, there were a large number of unfavorable adjectives found.
Most of them are the words relating to unpleasant emotions or unfavorable states of
mind of people such as embarrassed (4), tired (3) annoyed (2), disappointed (2),
angry (1), confused (1), depressed (1), distressed (1), nervous (1), and worried (1);
and the adjectives with negative prefixes (dis- il-, im-, in-, un-), for example
uncomfortable (6), unhappy (4), illegal (4), inappropriate (2), unworkable (2),
unsuited (1), dissatisfied (1), impatient (1), impractical (1), incapable (1), inevitable
(1), unfamiliar (1), unfair (1), unstable (1), as in Table 4.9.
Table 4.9
Example of concordance lines of clearly collocating with unfavorable adjectives in
COCA
1 …students organizers were clearly embarrassed by the small turnout.
2 Melissa was clearly tired from work.
3 Eisner was clearly annoyed at his pushing, and at the increasing…
4 The mother was clearly disappointed at this outcome since she had wanted…
5 And he would be – and he is clearly angry about it.
6 Jimmy is clearly uncomfortable at the sight of these two.
7 But he’s clearly unhappy about the environment.
8 …since Watergate, that was clearly illegal and unconstitutional and yet the press...
9 …wrote, because a lot of it was clearly inappropriate and would be embarrassing if…
10 …is exceedingly unpopular, and clearly unworkable and remains unfair.
From the exploration of verb collocations, the results of clearly are
different from those of really and certainly, exhibiting that clearly more often co-
occurs with the verbs showing positive prosody, as the percentage result shown in
Figure 4.6.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
41
Figure 4.6: Percentage of the verb collocations of the AI clearly in
three semantic prosody groups
Sample positive verbs include understand (5), enjoy (4), establish (4),
remember (4), love (3), produce (3), recognize (3), benefit (2), admire (1), care (1),
improve (1), like (1), promote (1), as in Table 4.10.
Table 4.10
Example of concordance lines of clearly collocating with positive verbs in COCA
1 She clearly understands far more than she can respond to.
2 McCain clearly enjoyed being a prime candidate, and he has
3 … nature of a work of art, clearly establishes an important bond between the life…
4 …Achille Lauro in 1985, still clearly remembered by the industry.
5 Playing directly to the camera, he clearly loves being in the spotlight.
6 While student evaluations of faculty clearly produce a large quantity of data…
7 College GPA is clearly recognized as being the most important factor...
8 Obama has clearly benefited from being black through his…
9 ..tomorrow in Philadelphia, and he clearly admires a career like Springsteen’s.
10 China clearly cares about the decision.
It was revealed that top five verbs found with clearly are define (19), see
(10), show (9), mark (7) and reflect (7), as in Table 4.11.
43.4%
26.8%
29.8%Positive
Negative
Others

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
42
Table 4.11
Example of concordance lines of the top five verbs found with clearly in COCA
1 …depend on a group’s ability to clearly define itself as an entity, an in-group, and to…
2 The postauricular nerve can be clearly seen distal to the chorda tympani nerves, …
3 The reenactment, OK, it clearly shows a Georgia man used the phone in the…
4 The exits are clearly marked for you to walk of, as I stand here without
5 This high technology orientation is clearly reflected in American international trade data.
Additionally, by further examining the other collocations of clearly, it has
been revealed that clearly is often used with verbs that express the meaning of ‘to
show’ and ‘to say’, e.g. show (9), demonstrate (6), indicate (5), say (4), spell out (4),
express (3), illustrate (2), state (2), enunciate (1), expose (1), describe (1), display (1),
present (1), suggest (1), as in Table 4.12.
Table 4.12
Example of concordance lines of clearly collocating with verbs that express the
meaning of ‘to show’ and ‘to say’ in COCA
1 They clearly show a man that knows what he was doing…
2 …final three baseline data points clearly demonstrate a downward trend.
3 …, the results of the post-survey clearly indicated a high degree of satisfaction and…
4 Sandusky is clearly saying he did not abuse anyone.
5 Because the law clearly spells out the grounds for expulsion and sets…
6 Noa has so much character, clearly expressing her likes and dislikes.
7 …loan guarantees for Israel clearly illustrated congressional reluctance to work against..
8 ...in case of Global Grind, they clearly stated hip hop was their jumping-off point.
9 …she poses in a man’s suit which clearly exposes her breasts.
10 …three lots that clearly describe Boulions fashionable ornamental…
From the data drawn from COCA, the results of the adjective and verb
collocations of AIs really, certainly and clearly were revealed and categorized into 3
semantic prosodies showing the trend of their senses of meaning. Moreover, some
distinctive characteristics of the AIs’ collocates were also disclosed. Next, in Chapter

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
43
5, the findings will be summarized and discussed. Then, the conclusion will be
presented, followed by recommendations for further research.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
44
CHAPTER 5
CONCLUSION, DISCUSSION AND RECOMMENDATION
This chapter concludes this study. A summary of the research is
presented, and findings of the study are discussed and interpreted. The conclusion is
also drawn within the scope of this study. Finally, recommendations for further
research end the chapter.
5.1 SUMMARY OF THE FINDINGS AND DISCUSSION
This research studied the three adverbial intensifiers really, certainly and
clearly in terms of their semantic prosodies by examining the frequent adjectives and
verbs that collocate with them.
As shown in Chapter 4, the results reveal the frequent adjective and verb
collocations that co-occur with the AIs as follows:
Firstly, the study reveals the top three most frequent adjectives co-
occurring with the AI really are good, important and nice. It is also found that most of
the adjectives collocating with really are related to favorable states of mind and
pleasant evaluation, e.g. confident, easy, glad, good, happy, nice, proud, and satisfied,
as well as size adjectives such as big, huge and large. Considering its verb
collocations, it is shown that top five most frequent verbs emphasized by really are
get, think, know, care and look, respectively.
Secondly, the results show that certainly often co-occurs with positive
adjectives such as best, cool, famous, glad, good, happy, helpful, nice, and useful. Its
top frequent positive adjective collocations are true, possible, right and interested/
interesting. Moreover, it was discovered that certainly frequently co-occurs with
adjectives ending with –able and –ible, e.g. audible, capable, plausible, responsible,
and understandable; comparative adjectives, e.g. bigger, better, easier, greater and
higher; and proper adjectives, e.g. Asian, Kurdish, Russian and Syrian. In terms of its
verb collocations, the results show that certainly overwhelmingly collocates with
modal verbs, e.g. can, could, may, must, should, and would. Additionally, there are

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
45
plenty of verbs expressing the meaning of ‘requirement’, e.g. ask, expect, need,
request, require, and want found with certainly.
Thirdly, the study reveals that the top five adjectives collocating with the
AI clearly are visible, evident, articulated, aware and audible, respectively. Similar to
certainly, the adjectives ending with –able and –ible, e.g. applicable, audible,
definable, discernible, distinguishable, identifiable, recognizable, and visible,
commonly occur with clearly. However, many unfavorable adjectives relating to
unpleasant emotions or unfavorable states of mind such as angry, annoyed, confused,
depressed, disappointed, distressed, nervous, tired and worried, and the adjectives
containing negative prefixes, e.g. dissatisfied, illegal, impatient, impractical,
inappropriate, incapable, uncomfortable, unfamiliar, and unhappy, are also found.
From the investigation of verb collocations, the top five verbs found with clearly are
define, see, show, mark and reflect. The results show that clearly commonly co-occurs
with positive verbs such as admire, benefit, care, enjoy, establish, like, love, produce,
and promote. Remarkably, it reveals that clearly often co-occurs with verbs
expressing the meaning of ‘to show’ and ‘to say’, e.g. enunciate, express, define,
demonstrate, describe, display, present, say, show, state, and suggest.
Since this research aims at examining the frequent collocates of really,
certainly and clearly when they function as adverbial intensifiers, their adjective and
verbs collocations are mainly focused on. As summarized, the results show that AIs
have their habitual or common collocates, for example certainly overwhelmingly was
followed by the adjective true, while really tends to co-occur with the adjective good
very often, which supports the studies by Zhang (2013) showing that the adverbial
intensifiers terribly, awfully, horribly and dreadfully often intensify particular words,
especially unpleasant and unfavorable words. Likewise, the study of maximizers
absolutely, perfectly, entirely, completely, thoroughly, totally and utterly reveals a
similar result which displayed the common words’ collocations (Partington, 2004).
Additionally, according to the findings from Chapter 4, it could be
summarized that the studied AIs really, certainly and clearly are typically used to
intensify or emphasize good things since they tend to co-occur with positive
adjectives rather than negative or other ones, which can be interpreted as that they
possess positive senses of meaning. However, in terms of verb collocations

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
46
investigation, the results of really and certainly do not expose any particular semantic
preference except clearly as it is more commonly collocated with positive verbs such
as admire, care, enjoy, love, therefore seemingly being more positive in semantic
coloring. Therefore, the AIs really, certainly and clearly contain positive rather than
negative semantic prosody.
With regard to the literature reviews in this study, semantic prosody is the
term used to describe the phenomenon concerning a word whose meaning in general
is neutral but which can be perceived with positive or negative meaning or association
through frequent occurrences with some particular collocations (Louw, 1993;
Partington, 1998; Sinclair, 1987; Stubb, 1996). It has been widely agreed by many
linguists, e.g. Hunston & Francis (2000), Xiao and McEnery (2006), that a large
number of words carry this sense of meaning. The present study’s findings about
semantic prosody of selected AIs are confirmed by the study of the words set in,
happen, break out and bent by Sinclair (1991), revealing that they are all habitually
linked to negative occurrences. The present study also bears out Brown (1995) in that
some words seem to co-occur with words having negative meanings, e.g. cause
anxiety, cause errors.
Likewise, it can be seen from this study that the adverbial intensifiers also
carry semantic prosody exhibiting either a positive/ pleasant/ favorable or negative/
unpleasant/ unfavorable sense of meaning in context. The findings show that each
investigated AI has a tendency to co-occur with specific words so that a particular
semantic preference is perceived. The outcomes are in accordance with the study of
Partington (2004), who conducted research on the semantic prosody of the
maximizing adverbs absolutely, perfectly, entirely, completely, thoroughly, totally and
utterly, and confirmed that the adverbial intensifiers have particular semantic prosody
and semantic preference to some extent and some adverbs, for instance, really,
certainly and clearly, as shown in this study, have a stronger good prosody than others
in comparison.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
47
5.2 CONCLUSION
This study investigated the semantic prosody of three adverbial
intensifiers by examining their adjective and verb collocations within the data drawn
from COCA.
The key findings reveal that the three AIs in this study carry a stronger
positive semantic prosody rather than negative prosody since they are used to modify
and emphasize the good words relating to states of mind, general evaluation, and
description. The interesting findings exhibit sets of particular words occurring with
specific adverbs, namely adjectives relating to emotion and evaluation, e.g. difficult,
embarrassed, glad, good, hard, happy, and sorry, and size adjectives, e.g. big, huge,
and small, frequently occur with really, comparative and superlative, e.g. better,
easier, harder, older, and proper adjectives, e.g. Asian, Russian, Syrian, commonly
occur with certainly; ability adjectives ending with –able or –ible, e.g. audible,
capable, definable, possible, and visible, frequently collocated with both certainly and
clearly, and adjective relating to unfavorable states of mind, e.g. confused, depressed,
nervous, and worried, adjectives added with negative prefixes, e.g. dissatisfied,
impractical, inappropriate, and unhappy, are frequently found with clearly.
Regarding verb collocations, the initial investigation of verbs collocating
with the studied AIs really and certainly does not show any semantic preference.
However, it was revealed that clearly has an obvious positive prosody since it
frequently co-occur with verbs containing a positive sense of meaning, e.g. admire,
benefit, enjoy, love, and produce. It is also found that clearly typically occurs with
verbs that express the meaning ‘to show’ and ‘to say’, e.g. express, demonstrate,
describe, present, and state. In addition, the results indicate that really, certainly and
clearly typically co-occur with ‘verbs to be’ and ‘modal verbs’ as they
overwhelmingly appear in the COCA.
5.3 RECOMMENDATIONS FOR FURTHER RESEARCH
In this study, the researcher only focuses on the top three emphasizing
adverbs functioning as AIs found in COCA that are really, certainly and clearly, and
also studied only adjective and verb collocations. Further studies may examine other
AIs and explore other collocational aspects to discover additional semantic prosodies.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
48
Also, different corpora may be applied to study other varieties of English, such as
British English or New Zealand English.
Additionally, the corpus-based approach applied in this study can be
expanded to deeper exploration of the use of AIs in other perspectives such as
distributional placements, grammatical patterns, formal or informal use of them by
comparing the use from genre to genre. This approach can also be utilized to explore
Thai learners’ use of AIs, mainly with semantic prosody.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
49
REFERENCES
Ali, S.A., & Muhammed, L.N. (2008). The translation of downtoners in the literary
texts into arabic. Adab Al-Rafidayn, 63, 33-60.
Au-Yeung, J., Howell, P., & Pilgrim, L. (1998). Phonological words and stuttering on
function words. Journal of Speech, Language, and Hearing Research, 41,
1019-1030.
Backlund, ULF. (1973). The collocation of adverbs of degree in English. Uppsala
University: Acta Universitatis Upsaliensis.
Baumgarten, N., Bois, I. D., & House, J. (2012). Subjectivity in language and in
discourse. Bingley: Emerald Group Publishing Limited.
Begagic, M. (2013). Semantic preference and semantic prosody of the collocation
make sense. Jezikoslovlje, 14(2), 403-416.
Beltrama, A. (2014). This is totally interesting, intensifiers between formal semantics
and social indexicality. Michicagoan, Linguistics Department.
Beltrama, A., & Bochnak, M.R. (2013). To Appear: Intensification without degrees
cross-linguistically. Natural Language and Linguistic Theory.
Bennett, R. G. (2010). Using corpora in the language learning classroom: Corpus
linguistics for teachers. Michigan: University of Michigan Press.
Biber, D. (1988). Linguistic features: Algorithms and functions in variation across
speech and writing. Cambridge: Cambridge University Press.
Biber, D., Conrad, S., & Reppen, R. (1994). Corpus-based approaches in applied
linguistics. Applied Linguistics, 15, 169-189.
Biber, D., Conrad, S., & Reppen, R. (1998). Corpus linguistics: Investigating
language structure and use. Cambridge: Cambridge University Press.
Biber, D., Johansson, S., Leech, G., Conrad, S., & Finegan, E. (1999). Longman
grammar of spoken and written English. London: Longman.
Bolinger, D. (1972). Degree words. The Hague: Mouton.
Carter, R., McCarthy, M., Mark, G., & O’Keeffe, A. (2011). English grammar today:
An a-z of spoken and written grammar. Cambridge: Cambridge University
Press.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
50
Charles, F.M. (2002). English corpus linguistics: An introduction. Cambridge:
Cambridge University Press.
Cunha, C., & Manuela, M. (2009). Handbook of research on social dimensions of
semantic technologies and web services. Pennsylvania: IGI Global.
Davies, A. (1991). The native speaker in applied linguistics. Edinburgh: Edinburgh
University Press.
Firth, J.R. (1957). A synopsis of linguistic theory: Prosody. in F.R. Palmer (Ed.):
selected papers of J.R. Firth (pp. 1952-1959). London: Longman.
Gan, Y. (2015). Analysis on semantic prosody of ‘mianzi’ and ‘lian’: A corpus-based
study. In Lu, Q. Gao, H. (Ed.): Chinese lexical semantics. Lecture Notes in
Computer Science, 9332. Spinger, Cham.
Harsuiker, R.J., Bastiaanse, R., Postma, A., & Wijnen, F. (2005). Phonological
encoding and monitoring in normal and pathological speech. Hove:
Psychology Press.
Hartmann, RRK., & Stork, FC. (1972). Dictionary of language and linguistics.
London: Applied Science.
Hu, M. (2015). A semantic prosody analysis of three adjective synonymous pairs in
COCA. Journal of Language and Linguistic Studies, 11(2), 117-131.
Huddleston, R., & Pullum, G. K. (2002). The Cambridge grammar of the English
language. Cambridge: Cambridge University Press.
Hunston, S., & Francis, G. (2000). Pattern grammar: A corpus-driven approach to
the lexical grammar of English. Amsterdam: John Benjamins Publishing.
Hunston, S. (2002). Corpora in applied linguistics. Cambridge: Cambridge University
Press.
Irwin, P. (2014). So (Totally) Speaker-oriented: An analysis of “Drama SO”. In
Zanuttini, R. and Horn, L. R. (Ed.): Micro-syntactic variation in north
American English. Oxford: Oxford University Press
Jones, C., & Waller, D. (2015). Corpus linguistics for grammar: A guide for research.
London: Routledge.
Kennedy, G. (1998). An introduction to corpus linguistics. London: Longman.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
51
Kruger, A. (2002). Corpus-based translation research: Its development and
implications for general, literary and bible translation. Acta Theologica,
22(1), 70-106.
Kwon, S. (2012). Beyond the adolescent peak of Toykey. In 48th Meeting of the
Chicago Linguistic Society.
Labov, W. (2001). Principles of linguistic change. New-Jersey: Wiley-Blackwell.
Lakoff, R. (1973). Language and woman’s place. Language in Society, 2(1), 45-80.
Lim, N.E., & Hong, H. (2012). Intensifiers as stance markers: A corpus study on
genre variations in Mandarin Chinese. Chinese Language and Discourse,
3(2), 129 – 166.
Limrosthip, K. (2013). A corpus-based study of semantic prosody of the words cause
and commit. Thammasat University. Master’s Project, M.A. (English),
Thailand.
Lindquist, H. (2009). Corpus linguistics and the description of English. Edinburgh:
University Press
Liu, D., & Espino, M. (2012). Actually, genuinely, really, and truly: A corpus-based
behavioral profile study of near-synonymous adverbs. International Journal
of Corpus Linguistics, 17(2), 198-228.
Liu, G. (2014). Investigating Chinese college learners’ use of frequency adverbs: A
corpus-based approach. Journal of Language Teaching and Research, 5(4),
837-843.
Longman dictionary of contemporary English. (2016). Retrieved from
http://www.ldoceonline.com/
Lorenz, G. (1998). Overstatement in advanced learners’ writing: Stylistic aspects of
adjective intensification. In Granger, S. (Ed.): Learner English on computer.
London: Longman.
Louw, B. (1993). ‘Irony in the text or insincerity in the writer? The diagnostic
potential of semantic prosodies’. In Baker, M. and Tognini-Boneli, E. (Eds.)
Text and technology: in honor of John Sinclair. Amsterdam: John Benjamins,
157-176.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
52
Louw, B. (2000). ‘Contextual prosodic theory: bringing semantic prosodies to life’.
In C. Heffer, H. Sauntson, and G. Fox (Eds.): Words in context: A tribute to
John Sinclair on his retirement. Birmingham: University of Birmingham.
Louw, H. (2005). Really, too, very, much: adverbial intensifiers in black south
African English. North-West University, Potchefstroom Campus, South
Africa.
Macaulay, R. (2006). Pure grammaticalization: The development of a teenage
intensifier. Language Variation and Change, 18(3), 267–283.
MacWhinney, B. (1992). Transfer and competition in second language learning. In R.
Harris (Ed.): Cognitive processing in bilinguals. Amsterdam: Elsevier.
McCready, E., & Kauffman, M. (2013). Maximum intensify. Paper presented at the
Semantics Group, Keio University, 29 November.
McEnery, T., & Wilson, A. (2001). Corpus linguistics: An introduction. Edinburgh:
Edinburgh University Press.
McKeown, K.R., & Radev, D.R. (2000). Collocations. In Dale, R. Moisl, H. Somers,
H. (Ed.): Handbook of natural language procession. New York: Marcel
Dekker.
McCarthy, M. (1998). Spoken language and applied linguistics. Cambridge:
Cambridge University Press.
McNabb, Y. (2012). Cross-categorial modification of properties in Hebrew and
English. In Chereches, A. (Ed.): Proceedings of semantics and linguistic
Theory, 22, 365-382.
Morley, J.,& Partington, A. (2009). A few frequently asked questions about Semantic
– or evaluative prosody*. International Journal of Corpus Linguistics, 14(2),
139-158.
O’Keeffe, A., McCarthy, M., & Carther, R. (2007). From corpus to classroom:
Language use and language teaching. Cambridge: Cambridge University
Press.
Partington, A. (1998). Patterns and meanings: using corpora for English language
research and teaching. Amsterdam: John Benjamins.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
53
Partington, A. (2004). Utterly content in each other’s company: Semantic prosody and
semantic preference. International Journal of Corpus Linguistics, 9(1), 131-
156.
Phoocharoensil, S. (2010). A corpus-based study of English synonyms. International
Journal of Arts and Sciences, 3(10), 227-245.
Pichler, H. (2016). Discourse-pragmatic variation and change in English: New
methods and insights. Cambridge: Cambridge University Press.
Plo-Alastrue, R., & Perez-Llantada, C. (2015). English as a scientific and research
language, debates and discourses: English in Europe. Boston: De Gruyter
Mouton.
Quirk, R., & Greenbaum, S. (1973). A university grammar of English. London:
Longman.
Quirk, R., Greenbaum, S., Leech, G., & Svartvik, J. (1976). A grammar of
contemporary English. London: Longman.
Quirk, R., Greenbaum, S., Leech, G., & Svartvik, J. (1985). A comprehensive
grammar of the English language. London: Longman.
Ramsey, S.R. (1987). The languages of China. Princeton: Princeton University Press.
Sinclair, J.M. (1987). Looking up. London: Collins.
Sinclair, J.M. (1991). Corpus, concordance, collocation. Oxford: Oxford University
Press.
Sripicharn, P. (2009). A Study of collocation and language pattern of high-frequency
nouns, verbs, adjectives and adverbs in a corpus of English compository
writing by Thai students. Thammasat University, Thailand.
Suzuki, H., & Yamagishi, M. (1999). Licensing some kinds of degree adverbs in
English. Report of the Special Project for the Typological Investigation of
Languages and Cultures of the East and West, 735-754.
Stern, H.H. (1983). Fundamental concepts of language teaching. Oxford: Oxford
University Press.
Stubbs, M. (1995). Collocations and semantic profiles: On the cause of the trouble
with quantitative methods. Function of Language, 2(1), 1-33.
Stubbs, M. (1996). Text and corpus analysis: computer assisted studies of language
and culture. Oxford: Blackwell.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
54
Tagliamonte, S. R. (2005). So weird; so cool; so innovative: The use of intensifiers in
the television friends. American Speech, 80, 280–300.
Tagliamonte, S. (2008). So different and pretty cool!, recycling intensifiers in
Toronto, Canada. English Language and Linguistics, 12(02), 361–394.
Tagliamonte, S., & D’Arcy, A. (2009). Peaks beyond phonology: Adolescence,
incrementation, and language change. Language, 85, 58–108.
Teubert, W., & Cermakova, A. (2007). Corpus linguistics: A short introduction.
London: Continuum.
Uba, S.Y. (2015). A Corpus-based behavioral profile study of near-snynonyms:
important, essential, vital, necessary and crucial. International Journal of
English Language and Linguistics Research, 3(5), 9-17.
Vasko, A. L. (2010). Cambridgeshire dialect grammar: Studies in variation, contacts
and change in English 4. Helsinki: Research Unit for Variation, Contact and
Change in English.
http://www.helsinki.fi/varieng/series/volumes/04/chapter9.html
Wang, H., & Wang, T. (2005). A contrastive study on the semantic prosody of cause.
Modern Foreign Language, 28(3), 297-307.
Wei, N. (2002). Research methods in the studies of semantic prosody. Foreign
Language Teaching and Research, 34(4), 300-307.
Wei, N.X. (2006). A corpus-based contrastive study of semantic prosodies in learner
English. Foreign Language Research, 132, 50-54.
Whitsitt, S. (2005). A critique of the concept of semantic prosody. International
Journal of Corpus Linguistics, 10, 283-305.
Widdowson, H.G. (1980). Models and fictions. Applied Linguistics, 1(2), 165-170.
Xiao, R., & McEnery, A. (2006). Collocation, semantic prosody, a near synonymy: A
cross-linguistic perspective. Applied Linguistics, 27(1), 103-109.
Xiao, R., & Tao, H.Y. (2007). A corpus-based sociolinguistic study of amplifiers in
British English. Sociolinguistic Studies, 1(2), 241–273.
Zhang, C. (2010). An overview of corpus-based studies of semantic prosody. Asian
Social Science. 6(6), 190-194.
Zhang, R. (2013). A corpus-based study of semantic prosody change: The case of the
adverbial intensifier. Concentric: Studies in Linguistics, 39(2), 61-82.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
55
Zhang, W. (2009). Semantic prosody and ESL/EFL vocabulary pedagogy. TESL
Canada Journal, 26(2), 1-12. Beijing: Springer International Publishing.

Ref. code: 25595821040408YGVRef. code: 25595821040408YGV
56
BIBIOGRAPHY
Name Miss Siriporn Gampaenggaew
Date of Birth April 14, 1988
Educational Attainment
2009: Bachelor of Technology
(First Class Honors)
Work Position Senior Project Assistant
Project of Japan International Cooperation
Agency
Work Experiences (January 2010 - Present): Senior Project Assistant
Project of Japan International Cooperation,
Ministry of Public Health of Thailand





























