-
A Framework for Mining Hybrid Automata from
Input/OutputTraces
Ramy Medhat1, S. Ramesh2, Borzoo Bonakdarpour3, Sebastian
Fischmeister11University of Waterloo, Canada. 2GM R&D, United
States. 3McMaster University, Canada.
{rmedhat,sfichme}@uwaterloo.ca, [email protected],
[email protected]
ABSTRACTAutomata-based models of embedded systems are useful and
at-
tractive for many reasons: they are intuitive, precise, at a
high levelof abstraction, tool independent and can be simulated and
analyzed.They also have the advantage of facilitating readability
and systemcomprehension in the case of large systems. This paper
proposesan approach for mining automata-based models from
input/outputexecution traces of embedded control systems. The
models mined byour approach are hybrid automata models, which
capture discrete aswell as continuous system behavior. Specifically
this paper proposesa framework for analyzing multiple input/output
traces by identifyingsteps like segmentation, clustering,
generation of event traces, and au-tomata inference. The framework
is general enough to admit multipletechniques or future
enhancements of these steps. We demonstratethe power of the
framework by using some specific existing methodsand tools in two
case studies. Our initial results are encouraging andshould spur
further research in the domain.
1 IntroductionAutomata-based specifications are useful for
specifying behavioral
descriptions of complex embedded control systems. They are
intu-itive and precise, abstract and high level, and more
importantly theyare tool-neutral. Further, automata-based models
allow simulation,testing, debugging and sometimes even rigorous
formal verification.In the case of legacy systems and physical
systems, the automata spec-ifications can help developers migrate
to model based development.Unfortunately, legacy systems often lack
such models. Further, forlarge systems, one could focus on specific
aspects of the system andbuild precise and compact automata
specifications capturing thoseaspects for better comprehension,
debugging and testing.
For embedded control systems, a suitable automata-based modelis
the hybrid automata model [16]. Hybrid automata are extensionsof
traditional finite state machines capturing discrete states and
tran-sitions as well as continuous behavior using differential
equations.Hybrid automata have the advantage of visualizing system
statesand how control transitions between them, allowing for an
abstractconceptual understanding of the system.
This paper presents a framework for learning hybrid automata
mod-els from black-box implementations of embedded control systems
bymining their input/output traces. For instance, consider a legacy
sys-tem for which there exists no model or documentation. Our
objectiveis to design a framework that uses input/output traces
collected fromexecuting such a system, and recovers a hybrid
automaton that modelsthe behavior present in the collected traces.
To that end, we proposea general framework for mining by clustering
multiple input/outputtraining traces, translating the clustered
traces to event sequences,and constructing automata based upon the
input/output correlation.To demonstrate how to use the framework,
we populate it with someconcrete methods and tools of clustering,
segmentation, automataconstructions and perform some
experiments.
The specific contributions of the paper include:
• A formalized framework for mining hybrid systems
specifica-tions. The formalization precisely describes the
assumptionsand expectations of the various components required for
min-ing. This helps incorporate future evolutions and refinementsof
the components into the framework.• A set of algorithms and
heuristics for the suggested framework
that have proven to work for the evaluated case studies.• A
quantitative evaluation framework for future work, so follow-
up work can compare the results to this and other approaches.•
Case studies demonstrating the application of the proposed
framework to different control systems.Recently, the works in
[12, 18, 23] attempted to construct models
from black-box systems using only execution traces. However,
thatline of work requires some level of understanding of formal
logic,hence it is less accessible to engineers. Whether the
objective issystem comprehension, simulation, or integration with
other systems,it is challenging for an engineer to decipher
properties in formal logic.In contrast, automata-based models are
easily visualized to aid intheir comprehension.
The remainder of the paper is structured as follows: Section
2introduces a motivating example of the use of the proposed
framework.Section 3 formalizes the problem and introduces some
terminology.Section 4 introduces the proposed framework and
discusses its steps,as well as the concrete models and tools used
to build our case studies.Section 5 discusses the case studies we
implement to experimentwith the proposed framework. Section 6
discusses related work,Section 7 discusses the limitations of the
proposed framework, andfinally Section 8 presents the conclusion of
the paper and future work.
2 Motivating ExampleConsider the traces in Figure 1, which are
extracted from an engine
timing control system. The topmost trace is the output engine
speed.The middle trace is the input throttle speed. The bottom
trace is theinput load torque. The control system is responsible
for actuating theinput throttle and minimizing the effect of
changes in load torque.
time
3000
2000
3000
2000
25
20
Engine Speed
time
Input Throttle
time
Input Torque
StableSpeed
RampUp
CounterDrop
Throttle ↑
Torque ↓
CounterJump
Torque ↑
Figure 1: Running example traces (left) and an example
abstractautomaton (right).
1
-
The objective of the proposed framework is to construct a
hybridautomaton that models and abstracts the behavior of such a
controlsystem. On the right-hand-side of Figure 1 is an example of
a man-ually constructed automaton that models the trace on the
left. Theautomaton realizes the following behavior:• The system
starts at a stable speed.• If the torque drops, the transition
labelled “Torque ↓” is taken.
The engine speed experiences a bump while the controller
isattempting to negate the effect of the torque drop. This can
beseen in the engine speed trace.• The system returns to a stable
speed after some time ∆t.• If the throttle rises, the system
transitions to the “Ramp Up”
state where it gradually increases the engine speed.• The system
returns to a stable speed after some time ∆t .• Similar to torque
drop, if the torque rises the engine speed
experiences a dip, which is rectified by the controller and
thespeed returns to stability once again.
For the rest of the paper, we will use this example to
illustratethe different stages of the proposed framework to produce
a hybridautomaton model from the I/O traces of a system.
3 Problem DefinitionWe attempt a formal definition of the
general framework which fo-
cuses on the requirements including the assumptions of the
interfaces,abstracting out the details of the specific algorithms
used for differentsteps of the mining algorithm. This helps in
accommodating futureversions or refinements of the different
components like clustering,segmentations, etc. employed in the
proposed work.
3.1 Input/Output TracesOur objective is to construct a hybrid
automaton using input/outputtraces of a hybrid system. Naturally,
the hybrid system receives a setof input signals and produces a set
of output signals. First, we definea sampled trace of any such
signal.
DEFINITION 1 (SAMPLED TRACE). A sampled tracewS of sig-nal S is
a finite sequence of pairs of timestamps and values (t1, v1)(t2,
v2) · · · (tp, vp) such that:
– ti ∈ R≥0, ∀i ∈ [1, p] : ti < ti+1 (strict monotonicity),–
∀i ∈ [2, p] : ti − ti−1 = c where c is the sampling period,– ∀i ∈
[1, p] : vi ∈ D(S) where D(S) is the domain of signalS sampled
values.
A sub-trace of wS is indicated as wS [ti, tj ] where ti is the
firsttimestamp in the sub-trace and tj is the last timestamp.
time
value
0 15 19 22
2000
3000
39 46 50 55 69 74 79 95Figure 2: Visualization of a sampled
trace.
Figure 2 demonstrates a visualization of an engine speed signal
thathas been sampled to construct a trace w. The speed is seen
starting at2000 rpm and rises to 3000 rpm as the input throttle
increases.
3.2 Presegmented TracesBy breaking down traces into segments, we
can correlate changes inthe inputs to changes in the outputs in a
piece-wise manner, whichis essential in mining the behavior of the
digital aspect of the hybridsystem. Signal segmentation heavily
relies on the type of signal, andmultiple methods are successful
within the scope of their target signaltype. Hence, we assume
traces are pre-segmented using some signalsegmentation method that
is not in the scope of this work, since weare not attempting to
contribute to the science of signal processing.Therefore, a trace
of an input or output signal is segmented or split at
points where some segmentation algorithm detects abrupt change
inthe signal values. Ideally, these points – referred to as
change-points– are selected by the segmentation algorithm to mirror
changes inthe system’s state. However, the quality of the
segmentation processdepends on the quality of the segmentation
algorithm and the inputs itreceives. Different algorithms [3, 7,
34] are more accurate for specifictypes of signals. For instance,
detecting change-points in a sinusoidalsignal depends on changes in
frequency, amplitude, or phase shift,whereas a boolean signal
exhibits change-points only when it toggles.We refer to these
various characteristics as features.
DEFINITION 2 (FEATURE). A feature is a function
φ : W → V
where W is the domain of all sampled traces, and V is the domain
offeature vectors extracted from the input trace. V is also
referred to asthe feature space, for which the similarity relation
∼ is defined.
An example of a feature is a linear fitting feature φl, which
con-structs a linear fit to the values of the signal in the trace.
Such afeature returns a vector 〈m, b〉 where m and b are parameters
of thelinear fit equation (y = mx+ b).
For instance, consider the signal in Figure 2, specifically
thesamples at times 0, 15, and 19. These three points form two
sub-traces: w[0, 15] and w[15, 19]. Let feature φs be a feature
extract-ing the slope of the linear fit of the values in the
segment. Ac-cording to the trace in the figure, φs(w[0, 15]) =
〈0.0〉, whileφs(w[15, 19]) = 〈1.0〉. Let the similarity relation for
the featurespace of φs be defined as follows:
φ(w) ∼ φ(w′) iff∥∥φ(w)− φ(w′)∥∥ ≤ 0.1
According to such definition, φs(w[0, 15]) 6∼ φs(w[15, 19]).
Thesimilarity relation is normally more complicated. The work in
[28,32] introduces different methods to cluster feature vectors
based onsimilarity.
Hence, a signal is processed by some segmentation algorithm.
Thisalgorithm uses knowledge of the feature(s) that indicate change
ofstate in the signal to identify change-points. We formally
definechange-points as follows:
DEFINITION 3 (CHANGE-POINT VECTOR). Given– a sampled trace wS =
(t1, v1) · · · (tp, vp) of signal S,– a set of features ϕ = {φ1, ·
· · , φq}
a change-point vector πwS ,ϕ is a vector of time stamps that
indicatea significant change in feature vectors, and is defined as
follows:
πwS ,ϕ = 〈τ1, τ2, · · · , τl〉
such that– ∀i ∈ [1, l] : τi ∈ {tj | j ∈ [1, |wS |]},– τ1 = t1
indicating the time of’; the first sample of the signal,
and τl = tp indicating the time of the last sample of the
signal,– each change-point τk, where k ∈ [2, l − 1], indicates a
sig-
nificant change in the feature vector produced by at least
onefeature when applied to the left side sub-trace ws[τk−1,
τk]versus the right side sub-trace ws[τk, τk+1]. That is
∀k ∃j : ws[τk−1, τk]φj
6∼ ws[τk, τk+1]
where j ∈ [1, q] andφj∼ is a similarity relation defined for
feature φj .
Recall the trace in Figure 2, and feature φs which given a
sub-tracereturns the slope of the linear fit of all values in that
sub-trace. Asindicated in the figure by the samples with circles on
top, these arepoints where the slope shows significant change
between the left hand
2
-
side segment and the right hand side segment. Thus, for this
trace,ϕ = {φs}, and consequently the change-point vector is
πwS ,ϕ = 〈0, 15, 19, 22, 39, 46, 50, 55, 69, 74, 79, 95〉 (1)
A hybrid system is a system where continuous-time
dynamicsinteract with discrete-event dynamics. For a hybrid system
S, letI = {I1, I2, · · · , In} be a set of input signals to the
system, andO = {O1, O2, · · · , Om} be a set of output signals
produced by thesystem. We now define an input/output sampled trace
as an extensionto Definition 1.
DEFINITION 4 (INPUT/OUTPUT TRACE). Given a set of inputsignals
I, and a set of output signals O, an input/output trace wI,Ois a
finite sequence of tuples:
wI,O = 〈t0, µ0, ν0〉〈t1, µ1, ν1〉 · · ·
such that– ti follows the same conditions as in Definition 1,–
µi is a vector of values of input signals I at time ti. That is,µi
= 〈u0,i, u1,i, · · · , un,i〉 where uk,i is the sampled value
ofinput signal Ik at time ti,
– νi is a vector of values of output signals O at time ti. That
is,νi = 〈v0,i, v1,i, · · · , vn,i〉 where vk,i is the sampled value
ofinput signal Ok at time ti.
Finally, we introduce the definition of a segmented I/O
trace.
DEFINITION 5 (SEGMENTED I/O TRACE). A segmented I/Otrace is a
tuple ψ = 〈wI,O,ΦI ,ΠI ,ΦO,ΠO〉 where
– wI,O is an input/output trace,– ΦI is a vector of sets of
features associated with each input
signal:
ΦI = 〈ϕI1 , ϕI2 , · · · 〉
where ϕIi is the set of features associated with input signal
Ii.– ΠI is a vector of change-point vectors for each input
signal:
ΠI = 〈πwI1 ,ϕI1 , πwI2 ,ϕI2 , · · · 〉
where πwIi ,ϕIi is the change-point vector of input signal
Iigiven its associated feature set.
– Similarly, ΦO and ΠO are defined for output signals.
3.3 Formal ProblemBased on the definitions introduced in the
previous sections, theformal problem definition is as follows:
Given two sets of segmented traces: a training setΨr = {ψr1 ,
ψr2 , · · · }, and test set Ψt = {ψt1 , ψt2 , · · · }
Construct a hybrid automaton A that models the behaviour ofthe
system exhibited in the training set traces Ψr such thatupon
simulating the input test traces on A, the average errorbetween the
output test traces and the generated output from Ais minimized:
e =1
|Ψt|
|Ψt|∑i=1
‖A(ψti .wI)− ψti .wO‖ (2)
where ψti .wI and ψti .wO are the sets of input (output)
tracesin the segmented trace ψti (respectively),A(ψti .wI) is the
out-put of automaton A given the input traces, and the
subtractionoperator calculates some predefined distance metric
betweentwo signals.
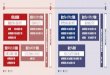
4 Proposed FrameworkThis section discusses a high-level overview
of the proposed frame-
work and details how different components can be replaced to
allowmore optimized system-centric modifications. Figure 3 presents
theframework we propose to construct a hybrid automaton for a
singleoutput from segmented traces. We decompose a system with
multipleoutputs by building an automaton for each output signal.
The processdescribed in the figure is repeated for each output
signal in the sys-tem, resulting in one hybrid automaton per output
signal. The finalautomaton for the entire system is computed as the
cross-product ofall single output automatons.
Cluster Output/Inputs SegmentsCluster Output/
Inputs SegmentsInfer Timing
RelationshipsInfer Timing
RelationshipsVerify Automaton
against Test TracesVerify Automaton
against Test Traces
Infer Flow Conditions & Initial Values
Infer Flow Conditions & Initial Values
Generate TraceStrings
Generate TraceStrings Infer AutomatonInfer Automaton
RefinementRefinement
1
2
6
3
5
4
Hybrid Automaton
Figure 3: Overview of the proposed framework.
4.1 Clustering SegmentsThe main purpose of clustering segments
is to identify which seg-ments potentially represent the same
internal state of a system. Wehave generalized clustering to be
independent of what type of featuresare extracted from segments
(see Definition 2), where it is stated thatthe similarity relation
is assumed to be defined for the feature space.Upon clustering
similar output segments, it is possible to hypothesizeabout the
states of the hybrid system, since it is exhibiting similarbehavior
during clustered segments. Clustering of similar input seg-ments
enables us to reason about the triggers that can possibly
causetransitions between output states. Note that what we can
observe iscorrelation between an input segment and a transition to
an outputstate. If this correlation is consistent across the
training set traces, itis hypothesized as a possible cause in the
output automaton.
Clustering is based on the feature vectors extracted by the
featuresassociated with signals. To this end, we compile a list of
featuresthat are indicative of state change we observe in our case
studies (seeTable 1). Obviously this list is incomplete, yet it
should converge asmore systems are studied.
Table 1: List of features and the returned feature vectors.
Feature Feature VectorValue 〈v〉Slope 〈m〉Range 〈a, b〉Linear Fit
〈m, b〉Higher-order Fit 〈c0, c1, · · · 〉Frequency 〈f, a〉Length
(time) 〈t〉
4.1.1 Input/Output Segment ClusteringClustering groups segments
in multiple traces of a signal according tosimilarity in the
feature space associated with the signal. This enablesour approach
to overcome small variation between traces and identifycommon
behavior of a specific signal across the entire training set.We use
K-Means clustering [15] on the feature spaces associatedwith the
signal, yet different clustering algorithms [19, 33] can beused
within the structure of the workflow. We selected K-Meanssince it
is widely available and simple to use. Since the optimumnumber of
clusters is not known a priori, we use the Davies-BouldinIndex
[11]. This approach is widely followed when the number ofclusters
is unknown. It is an iterative process of running the K-Means
3
-
clustering algorithm with a preset number of clusters,
calculating theDavies-Bouldin Index (DBI) for the output,
incrementing the presetnumber of clusters then repeating the
process. The final number ofclusters is the number of clusters for
which we observe the maximumDBI. The DBI is calculated as
follows:
DBI =1
N
N∑i=1
maxj,j 6=i
Si + Sjdij
(3)
where N is the number of clusters in the trial. Si is the
averagedistance between elements of cluster i and its centroid, and
dij isthe distance between the centroids of clusters i and j,
calculated asfollows:
Si =1
|Ci|∑x∈Ci
‖x−mi‖ (4)
dij = ‖mi −mj‖ (5)
where mi is the centroid of cluster Ci and |Ci| is the number
ofsegments in the cluster.
To demonstrate how clustering works, consider the sampled trace
inFigure 2, which is a trace of an output signal in our running
example.The change-points in the figure indicate change in the
slope featureφs, shown in Equation 1. Upon applying the clustering
processdescribed above to the feature vectors, namely the slopes of
eachsegment, the result is four clusters based on the highest DBI.
Thecluster assignments are listed below:
C1 = {w[0, 15], w[22, 39], w[55, 69], w[79, 95]}C2 = {w[15, 19],
w[46, 50], w[74, 79]}C3 = {w[19, 22], w[50, 55], w[69.74]}C3 =
{w[39, 46]}
(6)
4.1.2 Input Event DetectionThe purpose of input event detection
is to identify significant changesin the input as potential causes
for changes in the output. This isdistinguishable from input
segment clustering, which we perform tobe able to infer whether a
specific cluster of input segments is thecause for changes in the
output. To clarify this, consider a discreteinput signal that is
set to value a for a period of time, and then changesto b. At that
point of transition from a to b, the output experiences achange
that we observe. The change could be attributed to• The input
becoming b, meaning that value b specifically causes
the output to behave in the observed manner. That is, if
theinput was initially b, the output would have behaved in
theobserved manner from the start of the trace.• The differential
change in the input signal between a and b
causes the output to behave in the observed manner. That is,b− a
is the reason for the output to change.
Input event detection clusters changes in feature vectors
betweenconsecutive segments instead of clustering feature vectors.
For everychange-point τk in trace w of a signal I , the change in
the featurespace between segment w[k − 1, k] and w[k, k + 1] is
calculated asfollows:
δk = w[τk, τk+1]− w[τk−1, τk] (7)
Similar to the clustering process in Subsection 4.1.1,
clustering ofinput events is performed on the set of changes in
feature vectors:
∆ψI = {δ2, δ3, · · · , δl−1} (8)
where ∆ψI is the set of changes in feature vectors for signal I
in thesegmented trace ψ, and δk is the change in feature vectors
aroundchange-point τk.
To demonstrate how input event detection works, consider Figure
4,which shows a sampled trace wA of input signal A in our
running
time
value
0 15
25
20
69 95Figure 4: Sampled trace of an input signal.
example. The samples with black circles on top are detected
change-points. Assume the feature associated with this signal is φv
whichsimply extracts the constant value of the segment. This is
appropriatesince this signal is a digital signal and changes are
simply changesin value. The following are the resulting feature
vectors for eachsegment:
φv(wA[0, 15]) = 〈25〉φv(wA[15, 69]) = 〈20〉φv(wA[69, 95]) =
〈25〉
Clustering the input segments as per Subsection 4.1.1 results in
twoclusters: C1 = {wA[0, 15], wA[69, 95]} and C2 = {wA[15,
69]}.However, the set of changes in value vectors (see Equation 8)
is asfollows:
∆wA = {〈−5〉, 〈5〉}
which now results in two clusters: C′1 = {15} and C′2 = {69}.
Thus,the next steps of the proposed algorithm will utilize multiple
tracesto reason about whether the change in the output at 15 and 69
(seeFigure 2) is caused by C1 and C2 or C′1 and C′2.
4.2 Generating Trace StringsThe second step in the proposed
framework (see Figure 3) is togenerate trace strings. A trace
string is defined as follows:
DEFINITION 6 (TRACE STRING). Given a segmented trace w,its
associated change-point vector πw, and its cluster mapping
func-tion C which maps a segment to a cluster symbol. A trace
string is asequence of symbols that indicate the cluster to which
each segmentof a trace belongs. That is s = α1α2 · · ·αi where s is
a trace stringand αi is the symbol associated with the segment
w[τi, τi+1]. That isαi = C(w[τi, τi+1]).As mentioned earlier, we
focus on segmented and clustered traces forwhich there is one
output and possibly multiple inputs. Consider theexamples in
Figures 5 and 6, where all signal traces are segmentedand
clustered. The engine speed signal is an output signal, while
thethrottle and torque are inputs. The engine speed signal is
clustered asper Equation 6. The symbol assignment proceeds as
follows:
1. We assign a unique symbol to each cluster in the output
signal(a, b, c, d).
2. We assign a unique symbol to each cluster in the input
signals(f, g, h, i).
3. We assign a unique symbol to each transition from one
inputsegment to another (f → g = j, h→ i = k, and i→ h = l).
4. We assign a unique symbol to each cluster of input events
(seeSubsection 4.1.2).
5. Finally, we assign a unique symbol to each unique
combinationof concurrently changing inputs or concurrent input
events. Forinstance, if the throttle in Figure 5 transitions from f
to g atthe same time the torque transitions from h to i, this event
isassigned a unique symbol. This scenario occurs at the
initialpoint in the traces in Figures 5 and 6, and is assigned
thesymbols m for when f and h occur concurrently, and n forwhen f
and i occur concurrently.
4
-
Note that step 3 and 4 cannot be used concurrently, in the
sensethat a transition in the input trace can either be assigned a
symbol thatrepresents a change from the previous input segment to
the next inputsegment (step 3), or assigned a symbol that
represents the cluster towhich the change belongs (step 4). The
symbol assignment we makein step 5 relies on whether we select the
symbol from step 3 or step4. Initially we select the choice that
results in a lower number ofsymbols, however this is later modified
in the feedback loop of ourframework, where we refine specific
states based on their error values.This is detailed in Subsection
4.6.1.
As mentioned earlier, we assume that the effect of a change
inthe input will appear instantaneously in the output trace. This
canbe achieved by assuming that the sampling period is larger than
thepropagation delay of the input signal through the system. This
as-sumption simplifies the problem of determining causality, and
resultsin perfectly synchronized traces as seen in Figures 5 and
6.
The result is an I/O trace string pair, which is defined as
follows:
DEFINITION 7 (I/O TRACE STRING PAIR). An I/O trace stringpair is
a pair of trace strings sI = α1α2 · · ·αi and sO = β1β2 · · ·βisuch
that the segment αi occurs concurrently with the occurrence ofthe
input event combination βi. For any βi and βi+1, if αi = αi+1and αi
6= ∆, αi+1 = ∆.
where ∆ indicates that while there is detectable change in
theoutput, there is no change in the input. This can be
demonstrated byobserving the trace in Figure 5, for which the I/O
trace string pair isas follows:
Table 2: I/O Trace string for the trace in Figure 5.sO a b c a d
b c a c b asI m k ∆ ∆ j ∆ ∆ ∆ l ∆ ∆
In case of the trace in Figure 6, the I/O trace string pair
is:
Table 3: I/O Trace string for the trace in Figure 6.sO a c b a d
b c a b c asI n l ∆ ∆ j ∆ ∆ ∆ k ∆ ∆
time
Engine Speed
time
Input Throttle
time
Input Torque
a
f j
g
a
d
b c
b
b
c
ca a
h
m
k lih
Figure 5: The first example of a segmented, clustered
Input/Outputtrace in our running example.
4.3 Automaton InferenceThe automaton inference step in our
framework receives a set ofinput/output trace string pairs as shown
in the previous section, andproduces an automaton that models these
traces. Since we are dealingwith input/output traces, the produced
automaton is a Mealy automa-ton. Mealy automata inference has been
rigorously studied in variouswork [35,38]. The algorithms in most
of the work on Mealy inferenceare based on Angluin’s L∗ algorithm
[2]. Note that as mentionedearlier, our framework supports
plug-and-play components to replacethe inference step; as long as
the component receives input/outputtrace string pairs and produces
Mealy automata.
time
Engine Speed
time
Input Throttle
time
Input Torque
j
l k
a a
d
b c
c
c
f
g
ih
i
b
ba a
n
Figure 6: The second example of a segmented, clustered
Input/Outputtrace in our running example.
4.3.1 Modification of Mealy InferenceMealy inference algorithms
based on L∗ assume there is a systemfor which we want to produce a
Mealy automaton. To produce suchautomaton, these algorithms rely on
two oracles: a membership oracleand an equivalence oracle:•
Membership Oracle. This oracle receives an input string and
returns the output string produced by the system.• Equivalence
Oracle. This oracle checks whether the automa-
ton and the system are equivalent. If not, the oracle returnsa
counterexample in which the output of the system does notmatch the
output of the automaton.
Unfortunately a membership oracle is often unavailable. This
isspecially true, if the traces are recorded live and not through
simula-tion, requiring an engineer to rerun the system every time
the Mealyinference algorithm requests a membership query. An
equivalenceoracle is even harder to achieve, since it requires a
formal model ofthe original system, which is not available in the
first place. Variouswork has tackled this problem using different
approaches [17,37]. Wepropose a similar approach that fits within
our framework: namelymodified membership oracles and equivalence
oracles.• Modified Membership Oracle. This membership oracle
searches through the training set of traces and finds the
longestmatch. It returns the output corresponding to that match. If
theinput is longer than the longest match, the rest of the outputis
set to an error state. For example, consider the traces inTables 2
and 3. Assume the input is mk, the output will be abas per the
trace in Table 2. Now assume the input is mkl, theoutput will be
ab⊗, indicating an error occurring on passingin the third input
symbol (m).• Modified Equivalence Oracle. This equivalence oracle
sim-
ply searches for a counterexample using the training set
traces.That is, it runs every input trace in the training set
through theproduced Mealy automaton, and checks whether the
outputmatches the output in the training set. Granted, this does
notprove formal equivalence, yet since our objective is to
producean abstract model of the system, strict equivalence is
unneces-sary.
We have used Learnlib [31] as the basis of our implementation.
Wehave extended the built-in Mealy membership and equivalence
oraclesto rely on the training set of traces instead of an actual
automaton.
4.3.2 Automaton Post ProcessingAfter the automaton is inferred
using LearnLib and our modifiedoracles, it is processed to ensure
that no state has multiple incomingedges that produce different
outputs. This is to prevent confusionwhen generating the flow
condition for such state.
4.4 Infer Flow Conditions and Initial ValuesInitial values are
functions that define the initial value of a variablewhen the
system enters a specific state in the hybrid automaton.Flow
conditions are functions associated with a state in the hybrid
5
-
automaton that describe how a variable changes while the system
is inthat state. The purpose of inferring initial values and flow
conditionsis to produce functions that given input values return
accurate outputvalues as per the training set. Since our framework
produces oneautomaton per output signal, each state is associated
with a functionthat returns the initial value of the output signal
upon entering thestate, and a function that describes the change of
the output signalwhen the system resides in that state.
To this end, we propose a heuristic to infer flow conditions
andinitial values that is based on simple statistical methods such
asstandard correlation and linear regression. As mentioned
earlier,the plug-and-play design of the framework allows for
replacing theproposed heuristic with different methods in the
future. An overviewof the heuristic is presented in Algorithm 1.
The heuristic receives asinput the following:• Automaton A, which
is the automaton produced by the previ-
ous step in the framework (see Figure 3).• Training set of
traces Ψr ,• Cluster mappings C which maps each segment in the
trace to a
symbol. This mapping should be readily available after
tracestrings are generated (see Figure 3).
The heuristic proceeds as follows:• Line 2 declares a map
between states in the automaton and
traces.• The loop at Line 3 iterates over the training set, and
foreach
segmented trace, calls SPLIT which breaks down the tracesinto
input/output segments defined by the change-points in thetrace.
SPLIT then returns a vector of all the segments in thetrace.• The
automaton is reset to its initial state, and then the loop at
Line 6 iterates over each input/output segment in the trace.•
For each segment, the symbol of the associated input cluster
is retrieved (Line 7). The automaton then advances to the
nextstate given the input symbol.• The segment is then associated
to the current state of the au-
tomaton (Line 9).• Next, for each state in the automaton, a
standard correlation
matrix is built using a normalized version of all the
segmentsassociated to that state. The matrix expresses the
correlationbetween the output signal and the input signals. Note
thattime is also considered an input. It is readily available as
thetimestamp of each sample in the segment.• The matrix is then
filtered for significant relationships only
(relationships for which there is strong positive or
negativecorrelation between the output and input). The filter
thresholdcan be configured, for instance to allow only
relationships withcorrelation coefficient |c| > 0.5.• A linear
regression is then constructed for the output versus
significant inputs, and the resulting coefficients are assigned
tovariable c.• The initial condition assigned to the state is a
linear function
in the input variables and the coefficients c in the form c1x1
+c2x2 . . . (Line 16).• Finally, the flow condition is set to the
derivative of the above
linear function with respect to time.Consider the automaton in
Figure 7, which a subset of the automa-
ton we achieve through learning from traces of our running
example.As can be seen, the input symbols m and n direct control to
states q1and q2 respectively, while both producing the output a.
This directlymaps to the two traces in Figures 5 and 6.
q0 q1q2 q3m∣∣ an ∣∣ a k ∣∣ b
Figure 7: A subset of the states in the automaton inferred for
ourrunning example. q0 is the initial state.
Now let us focus on state q1. Upon executing the first for loop
in
Algorithm 1 Infer Flow Conditions.1: INPUT: Automaton A,
Training set traces Ψr , Cluster mappings
C2: declare traces mapping T3: for ψ ∈ Ψr do4: W ← SPLIT(ψ.wI,O
,ψ.ΠI ,ψ.ΠO)5: RESET(A)6: for ω ∈ W do7: s← C[ωI ]8: v ←
PROCESSSTRING(A,s)9: APPEND(T[v],ω)
10: end for11: end for12: for State v ∈ A do13: r ←
CORRELATION(T[v])14: I ← FILTER(R)15: c← REGRESSION(I)16: v.init←
c17: v.flow← dc
dt18: end for
Algorithm 1, the state will be associated with all segments
where ini-tially the input throttle is low and the torque is high,
which constitutesinput event m (refer to Figure 5). To clarify
this, Figure 8 demon-strates seven instances of the output signal
taken from seven differenttraces while the system is in state q1.
We concatenate these seveninstances to form one vector for the
purpose of studying correlation.
0 500 1000 1500 2000 2500
1900
2000
2100
Index
Engi
ne S
peed
Figure 8: Concatenated output traces for segment a. The
x-axisrepresents the index of the concatenated data frame.
Next, we study the correlation of the output signal with the
inputs:namely time, input throttle and input torque. The following
are theresulting correlation coefficients:
Time Input Torque Input Throttle0.079 0.014 0.997 ≈ 1.0
Time and input torque are insignificant with respect to the
output,as observed by their low correlation coefficient. Input
throttle howeveris strongly correlated with the output. This
results in y = x1 where yis the output and x1 is the input
throttle. Since time is insignificantto the output at state q1, the
flow condition of q1 is ẏ = dx1dt = 0,resulting in no change in
output since the input when the system isin that state does not
change with time. The updated automaton isshown in Figure 9.
To further clarify flow conditions, let q3 be the state that
representsthe system when segment b first occurs after segment a
(see Figure 5).Upon studying the correlation of the output in that
state against theinputs, it is obvious that time is contributing
factor, since the outputexhibits a steady rise as time passes. In
that case, the derivative ofthe initial condition (based on the
regression coefficients) will be asfollows:
ẏ = ct + c1dx1dt
+ c2dx2dt
where ct is the regression coefficient of the input time
variable.
6
-
q0q1
ẏ = dx1dt
q2 q3m, y = x1n
∣∣ a k ∣∣ bFigure 9: q1 updated with its flow condition and
initial condition.
4.5 Inferring Timing RelationshipsA time-based condition (time
guard) is added to a transition in ahybrid automaton to illustrate
that the transition may be taken whenthe condition is satisfied.
Recall that in our I/O trace strings we usedthe notation ∆ to
signify that the output changes while no changeoccurs in the input.
Naturally this can be caused due to a change in ahidden internal
state of the system, or due to some time limit elapsing.Since we
cannot postulate about a hidden unobservable system state,we
attempt to model all such transitions as time-based
transitions.
The amount of time spent in a specific output segment is
measur-able through trace timestamps. By analyzing multiple traces
we canattempt to infer an average time which must pass before the
transitionoccurs, or try to deduce a relationship between the
previous changein the input and timed change in the output.
Consider the followingsubset of the automaton inferred from our
running example.
q1 q3 q4 q5k∣∣ b ∆ ∣∣ c ∆ ∣∣ a
The states in this example map to states observed in the trace
inFigure 5. The two timed transitions are q3 → q4 and q4 → q5.
Weintroduce the notion of a closest input events, which are the
latestinput events to occur before a time transition is taken. In
the case ofboth transitions in the above automaton, the closest
input event is k.
We now follow a process similar to the inference of flow
conditionsand initial values in Subsection 4.4. To that end, we
distinguishbetween two different scenarios:
1. The time between the two states surrounding a timed
transitionacross all traces is normally distributed. In such a
case, weassign the average time to the transition time guard. Note
thatother statistical techniques might yield more accurate
results,such as survival analysis. However, a normality test is
sufficientfor an initial heuristic and can be replaced later within
theframework.
2. The time between two states surrounding a timed transition
hasa high correlation to one or more inputs at the closest
inputevent, and we hence build a linear regression and assign
theexpression c1x1 + c2x2 . . . to the transition guard, where
ciare regression coefficients.
To test for normality, we use D’Agostino and Pearson’s tests
ofnormality that combine skewness and kurtosis [6, 9].
To clarify how we infer timing relationships, let us apply the
pro-posed technique to our running example. Assume we have
collectedthe time it takes the system to transition from q3 to q4
across eighttraces. If the ∆ dataset passes the normality test,
then the transitionis assigned the average time as a
time-guard.
By assigning time guards to the appropriate transitions, we
com-plete the final step in preparing the hybrid automaton. The
automatoncan now be verified against test traces to quantify its
accuracy, asdetailed in the next section.
4.6 Verify Automaton Against Test TracesThe final step in our
framework is to verify the produced hybridautomaton. Our evaluation
technique proceeds as follows:
1. Given a segmented input/output trace ψ, for each input
assigneach segment to a cluster from the set of precomputed
clustersfor that input. This is done using a K-Means predictor.
2. Generate an input trace string using the same methodology
asthat used in Subsection 4.2.
3. Run the input string and the accompanying input traces
throughthe hybrid automaton and record the output.
4. Compare the output of the automaton to the original output
inthe segmented input/output trace and return the total
distance.The total distance is calculated as follows:
γA,ψ =1
L
L∑i=1
|wA[i]− ψ.wO[i]| (9)
where wA is the sampled output from the automaton, ψ.wO isthe
original output in the input/output trace, andL = max {|wA|,
|ψ.wO|}. If w[i] does not exist for eithertrace, it is assumed to
be zero.
The final error metric for the entire test set is the average γ
foreach individual trace in the test set:
e =1
Ψt
|Ψt|∑i
γA,ψi (10)
which is the error metric explained in Eq. 2. The objective of
theframework is to reduce the error through multiple iterations of
au-tomaton refinement. This is further explained in Subsection
4.6.1.
4.6.1 Automaton RefinementAutomaton refinement utilizes data
collected from the test runs toimprove the accuracy of the
automaton. Since test input traces are runthrough the automaton,
and the output of the automaton is comparedto the output traces
point by point, we can breakdown the error toevery state and
transition in the automaton. We plan to elaborate onrefinement in
our future work (Section 8).
5 Case StudiesThis section presents the case studies we use to
evaluate the appli-
cability of our framework to different systems. Obviously these
casestudies are not representative of the entire spectrum of hybrid
systems,yet this paper proposes a framework that can be further
enhancedin the future to support different types of systems and
evolve into arobust abstraction engine.
The case studies are based on systems for which there
alreadyexists a Simulink model. Our framework is designed to
support anyinput/output traces, whether their origin is simulation
or live execu-tion. However, having the models helped us in
producing noiselessinput/output traces which is beyond the scope of
the current work.Moreover, the Simulink models helped us in
validating the proposedapproach by generating test traces.
We implemented the framework using a mixture of Python, Java,and
R with various libraries associated with it. R was used for
seg-mentation, Java was used for automata inference based on
LearnLib,and Python was used for clustering, flow condition
inference andtiming condition inference.
5.1 Engine Timing ModelThis case study is based on the engine
timing model in the Simulinktoolbox examples (www.mathworks.com),
which is also the basis forour running example in Figure 1. The
system has two inputs: (1)input throttle, which is the desired
speed of the engine in rounds perminute (RPM), and (2) load torque
in joules per radian. The outputof the system is the engine speed
in RPM.
To test our approach, we collect eight traces of the model
inSimulink, which cover permutations of inputs as well as basic
states.We then segment them using the changepoint library in R
[22].At this point, we have the training set Ψr . Next, we feed
them throughthe framework outlined in Figure 3. The final output of
the frame-work is a hybrid automaton that models the behavior of
the system asobserved in the training traces. Figure 10 shows the
produced hybridautomaton.
To verify the output automaton, we use a test set of traces to
ensurethat the automaton can produce correct output to traces other
thanits training traces. The test traces have different values for
inputsand transition at different times. To that end, we run a set
of these
7
-
Figure 10: Hybrid automaton for the engine timing control
model.
Sample Index
Engi
ne S
peed
0 500 1000 1500 2000
2000
2200
2400
2600
2800
3000 Automaton
Test Trace
Figure 11: Comparison of automaton output versus test
output.
test input traces through the automaton and compare the outputs
tothe respective output test traces. Figure 11 shows the test
outputversus the automaton output. The dashed line shows the output
inthe test trace recorded from Simulink, and the solid line shows
theoutput of the hybrid automaton. As can be seen in the figure,
theautomaton output closely follows the test trace output, except
whenthe input throttle increases, where the automaton overshoots
beyondthe actual system. This is caused by inaccurate assessment of
theslope of the overshoot, which is in fact a function of the
change in thethrottle input. We plan to rectify this in future
work. Based on ourexperiments, increasing the number of traces that
cover the same usecase improves the fidelity of the model. Using
less than eight tracesin this case study results in an inaccurate
model, simply because thetraces do not cover the use cases shown in
the automaton in Figure 1.
The error γ, which is the average distance between the
automa-ton trace and the test trace in Figure 11, is 26.37 RPM per
sample.Knowing that the range of the output in the trace is between
2000RPM and 3000 RPM, this error amounts to 2.6%.
5.2 Fault-Tolerant Fuel Control SystemThe second case study we
conduct is based on the Simulink fault-tolerant fuel control system
(www.mathworks.com). The model con-tains both Simulink and
StateFlow components. The controller shouldregulate the fuel rate
without interruption in case of individual sensorfailure. Four
sensors are connected to the controller: throttle, speed,EGO, and
MAP. Failure in at most one sensor should not interruptfuel rate
control.
The training set traces record the output fuel rate control
signalin different combinations of sensor failures. Each
input/output traceconsists of four inputs (one for each sensor) and
one output. UsingSimulink, any sensor can be toggled to simulate
failure. The modelsimulates a failed sensor by producing readings
that are outside thevalid range for that sensor.
Although we require presegmented traces, the traces for this
casestudy were easy to segment automatically. We applied k-means
clus-tering to the values of the input traces (which are sensor
readings),and we were able to identify the periods in the traces
where a spe-cific sensor is turned off. For instance, as per the
Simulink model,the speed sensor normally provides readings between
300 and 700,whereas when it is off it reads 0 (see Figure 12).
Similarly for the
remaining three sensors, faulty readings are easily
identifiable. Theoutput trace is segmented according to the input
traces, meaning thatthe change-points in the output trace are the
union of all change-pointsin the input trace. Figure 13 shows a
concatenated output trace ofthe system when different sensors fail,
where change-points are blackcircles.
Upon applying our framework, we first cluster the output
segmentsinto four clusters based on the range feature (see Table
1). Eachcluster is assigned a symbol from a to d. For example, the
trace inFigure 13 is translated to the output trace string
abacabababdba. Theinput traces in Figure 12 are clustered using the
same technique usedfor our running example. Throttle is assigned
the symbols f and gfor when it is on (value above 10) and off
(value is zero) respectively.Similarly, Speed is assigned h and i,
EGO is assigned j and k, andMAP is assigned l and m. Note that
although we refer to a sensoras on or off, the framework is unaware
of that notion and only seestwo clusters per input signal that are
assigned two unique symbols.Since it never occurs in the training
set traces that two sensors fail atthe same time, there are no
symbols assigned to two or more sensorsfailing concurrently.
However, initially all sensors are on in all traces,and thus this
is assigned the symbol n.
Sample Index
Thro
ttle
0 10000 25000
010
Sample Index
Spee
d
0 10000 25000
020
0
Sample Index
EGO
0 10000 250000
612
Sample Index
MAP
0 10000 25000
0.0
0.6
Sample Index
Thro
ttle
0 10000 25000
010
Sample Index
Spee
d
0 10000 25000
020
0
Sample IndexEG
O0 10000 25000
06
12
Sample Index
MAP
0 10000 25000
0.0
0.6
Figure 12: The four input traces of the fuel rate
controller.
Using 17 training traces, the inferred hybrid automaton for
thesystem is shown in Figure 14. Note that we assume once a
sensoris faulty it cannot recover. The input events g, i, k, and m
indicatefailures in the throttle, speed, EGO, and MAP sensors
respectively. Asample run of the hybrid automaton against a test
trace (a trace not inthe training set) is plotted in Figure 15.
While the automaton mimicsthe oscillations of the original output,
it fails to replicate the amplitudeof these oscillations. This can
be improved by using other regressionmodels, namely for this case
study a sinosoidal regression modelwould produce more accurate
results. Since our framework allowsfor plug-and-play components,
one can replace linear regression withsinosoidal regression to
reduce error. Even with the use of simplelinear regression models,
the error percentage is 3.7%.
6 Related WorkMany researchers tackled the problem of
specification mining of
software systems [26], the work in [5, 10, 25, 36] being the
prominentadvances in the field. But none of these works deal with
the problemof mining specifications for control systems, where
analog and digital
8
-
Sample Index
Fuel
Rat
e C
ontro
l
0 5000 15000 25000 35000
0.0
0.5
1.0
1.5
2.0
Figure 13: Fuel rate control signal trace with
change-points.
Figure 14: The inferred hybrid automaton of the fuel rate
controller.
signals coexist. There are some works on generating API
specifica-tions [1, 39], yet control systems offer a new challenge
due to theneed to mine their input output relationship.
The work on invariant generation from traces has yielded
favourableresults and has proven to be versatile in mining basic
invariants onvariables in traces [8, 13]. Our work is capable of
breaking downtraces and constructing an automaton in which
different states canhold different invariants. Thus, an invariant
generation module canbe a pluggable component within our framework
to produce a moreaccurate hybrid automaton. Invariant generation
techniques can alsobe used to infer transition conditions along
with input event detection.
The work on behavioral model inference is close to the workin
this paper since it targets inference of behavior from
executiontraces [14, 24, 27, 29]. The objective is to produce a
model thatrepresents the system behavior. However, these works
target discretesystem behavior and can not be used for inferring
hybrid models.
The work on system identification is well established and
vari-ous robust tools exist to aid in the process [4, 20, 21, 30].
Systemidentification approaches produce complete models which would
belarge and complex. In contrast, our objective is to to focus on
certainaspects of the system and generate small and comprehensible
models,thus aiding in the comprehension of such system, its
integration withother components, and its simulation. Further, our
framework isgeneral enough to accommodate system identification
techniques andcombine them with other techniques of specification
mining to inferabstract accessible hybrid automata.
7 DiscussionMining hybrid automata from traces is a complex
problem with nu-
merous challenges. Here we identify the limitations of our
framework:(1) Although we were successful with automatically
segmenting thesignals in our case studies, the methods used may not
be applicableto all types of signals. The signals collected from
live systems posesome challenges. They are noisy and need to be
filtered and pro-cessed before being fed to our framework. (2) Any
hidden state thatcannot be observed in the traces cannot be
modelled. The modellingtechnique we use relies on correlating
inputs and outputs as observed
Sample Index
Fuel
Rat
e C
ontro
l Out
put
0 5000 10000 15000
0.0
0.5
1.0
1.5
2.0
Figure 15: A sample of the hybrid automaton output (solid)
versusthe original system output (dashed).
in the training set traces. If certain behavior is triggered by
an internalstate that is not observable through inputs and outputs,
the behaviorwill not be modelled, or the framework will model it
with faultyassumptions. (3) Some transition guards cannot be
modelled such asguards on output values, which will be addressed in
the future. (4)We assume that the propagation delay of a change in
the input to anobservable change in the output is instantaneous.
This allows consis-tent segmentation and synchronized trace
strings. In future work, thisassumption needs to be relaxed to
infer time-delayed responses.
8 ConclusionThis paper has presented a general framework for
inference of
hybrid automata models from black box system implementations
bymining their input/output traces. The framework outlines an
iterativeprocess for the inference and refinement of hybrid
automata. Wepresented specific techniques in our case studies for
the purpose ofdemonstration but the framework is general enough to
allow replace-ment/improvements of these techniques. We introduced
two casestudies that demonstrate the applicability of the approach
(and alsosome limitations). The results are highly encouraging and
we believewould spur more work on hybrid automata inference.
The framework allows for multiple directions of improvementfrom
within. As future work, we plan to explore enhancementssuch as
better preprocessing of data, improved segmentation, moreefficient
algorithms, support for more causality rules, and improvedautomata
inference. In parallel with these enhancements, we plan toelaborate
on automata refinement by experimenting with case studieswhere
automata refinement is necessary. We plan to explore
variousfeedback techniques to reduce the error of the produced
automatoniteratively and apply these techniques to case studies.
Finally, we planto explore modifying the framework to produce
constrained hybridautomata on which we can verify properties
formally.
9 AcknowledgementsThis research was sponsored as part of the
NECSIS project by
the Ontario Research Fund, the Natural Sciences and
EngineeringResearch Council of Canada, and associated industry
partners. Theauthors would like to thank NECSIS and General Motors
R&D fortheir generous support, without which this work would
not have takenshape. The authors would also like to thank Oleg
Sokolsky and theanonymous reviewers for their valuable
feedback.
10 References
[1] M. Acharya, T. Xie, J. Pei, and J. Xu. Mining API Patterns
asPartial Orders from Source Code: From Usage Scenarios
toSpecifications. In Proceedings of the ACM SIGSOFTSymposium on the
Foundations of Software Engineering, pages25–34. ACM, 2007.
[2] D. Angluin. Learning Regular Sets from Queries
andCounterexamples. Information and Computation, 75(2):87 –106,
1987.
[3] I. E. Auger and C. E. Lawrence. Algorithms for the
OptimalIdentification of Segment Neighborhoods. Bulletin of
9
-
Mathematical Biology, 51(1):39–54, 1989.[4] A. Bemporad, A.
Garulli, S. Paoletti, and A. Vicino. A
Bounded-error Approach to Piecewise Affine SystemIdentification.
IEEE Transactions on Automatic Control,50(10):1567–1580, 2005.
[5] I. Beschastnikh, Y. Brun, S. Schneider, M. Sloan, and M.
D.Ernst. Leveraging Existing Instrumentation to AutomaticallyInfer
Invariant-Constrained Models. In Proceedings of the 19thACM SIGSOFT
Symposium and the 13th European Conferenceon Foundations of
Software Engineering, pages 267–277. ACM,2011.
[6] K. Bowman and L. Shenton. Omnibus Test Contours
forDepartures from Normality Based on b1 and b2.
Biometrika,62(2):243–250, 1975.
[7] J. Chen and A. K. Gupta. Parametric Statistical Change
PointAnalysis: With Applications to Genetics, Medicine, andFinance.
Springer Science & Business Media, 2011.
[8] M. Cova, D. Balzarotti, V. Felmetsger, and G. Vigna.
Swaddler:An Approach for the Anomaly-based Detection of
StateViolations in Web Applications. In Recent Advances inIntrusion
Detection, pages 63–86. Springer, 2007.
[9] R. B. d’Agostino. An Omnibus Test of Normality for
Moderateand Large Size Samples. Biometrika, 58(2):341–348,
1971.
[10] V. Dallmeier, N. Knopp, C. Mallon, S. Hack, and A.
Zeller.Generating Test Cases for Specification Mining. In
Proceedingsof the 19th International Symposium on Software Testing
andAnalysis, pages 85–96. ACM, 2010.
[11] D. L. Davies and D. W. Bouldin. A Cluster Separation
Measure.IEEE Transactions on Pattern Analysis and
MachineIntelligence, PAMI-1(2):224–227, April 1979.
[12] A. Donzé, T. Ferrère, and O. Maler. Efficient
RobustMonitoring for STL. In Proceedings of the 25th
InternationalConference on Computer Aided Verification, pages
264–279,Berlin, Heidelberg, 2013. Springer-Verlag.
[13] M. D. Ernst, J. H. Perkins, P. J. Guo, S. McCamant, C.
Pacheco,M. S. Tschantz, and C. Xiao. The Daikon System for
DynamicDetection of Likely Invariants. Science of
ComputerProgramming, 69(1):35–45, 2007.
[14] C. Ghezzi, M. Pezzè, M. Sama, and G. Tamburrelli.
MiningBehavior Models from User-intensive Web Applications.
InProceedings of the 36th International Conference on
SoftwareEngineering, pages 277–287. ACM, 2014.
[15] J. A. Hartigan and M. A. Wong. Algorithm AS 136: AK-Means
Clustering Algorithm. Journal of the Royal StatisticalSociety.
Series C (Applied Statistics), 28(1):pp. 100–108, 1979.
[16] T. A. Henzinger. The Theory of Hybrid Automata.
InVerification of Digital and Hybrid Systems, volume 170 ofNATO ASI
Series, pages 265–292. Springer, 2000.
[17] H. Hungar, O. Niese, and B. Steffen.
Domain-specificOptimization in Automata Learning. In Computer
AidedVerification, pages 315–327. Springer, 2003.
[18] X. Jin, A. Donze, J. V. Deshmukh, and S. A. Seshia.
MiningRequirements from Closed-Loop Control Models. InProceedings
of the 16th International Conference on HybridSystems: Computation
and Control, pages 43–52. ACM, 2013.
[19] S. C. Johnson. Hierarchical Clustering
Schemes.Psychometrika, 32(3):241–254, 1967.
[20] A. L. Juloski, W. Heemels, G. Ferrari-Trecate, R. Vidal,S.
Paoletti, and J. Niessen. Comparison of Four Procedures forthe
Identification of Hybrid Systems. In Hybrid Systems:Computation and
Control, pages 354–369. Springer, 2005.
[21] A. L. Juloski, S. Weiland, and W. Heemels. A
BayesianApproach to Identification of Hybrid Systems.
IEEETransactions on Automatic Control, 50(10):1520–1533, 2005.
[22] R. Killick and I. Eckley. changepoint: An R Package
forChangepoint Analysis. Journal of Statistical
Software,58(3):1–19, 2014.
[23] Z. Kong, A. Jones, A. Medina Ayala, E. Aydin Gol, andC.
Belta. Temporal Logic Inference for Classification andPrediction
from Data. In Proceedings of the 17th InternationalConference on
Hybrid Systems: Computation and Control,pages 273–282. ACM,
2014.
[24] I. Krka, Y. Brun, D. Popescu, J. Garcia, and N.
Medvidovic.Using Dynamic Execution Traces and Program Invariants
toEnhance Behavioral Model Inference. In Proceedings of the32nd
ACM/IEEE International Conference on SoftwareEngineering - Volume
2, pages 179–182. ACM, 2010.
[25] W. Li, A. Forin, and S. A. Seshia. Scalable
SpecificationMining for Verification and Diagnosis. In Proceedings
of the47th Design Automation Conference, pages 755–760, 2010.
[26] D. Lo, S.-C. Khoo, J. Han, and C. Liu. Mining
SoftwareSpecifications: Methodologies and Applications. CRC
Press,2011.
[27] D. Lo, L. Mariani, and M. Pezzè. Automatic Steering
ofBehavioral Model Inference. In Proceedings of the ACMSIGSOFT
Symposium on the Foundations of SoftwareEngineering, pages 345–354.
ACM, 2009.
[28] P. Mitra, C. Murthy, and S. Pal. Unsupervised Feature
SelectionUsing Feature Similarity. IEEE Transactions on
PatternAnalysis and Machine Intelligence, 24(3):301–312, Mar
2002.
[29] T. Ohmann, M. Herzberg, S. Fiss, A. Halbert, M. Palyart,I.
Beschastnikh, and Y. Brun. Behavioral Resource-awareModel
Inference. In Proceedings of the 29th ACM/IEEEInternational
Conference on Automated Software Engineering,pages 19–30. ACM,
2014.
[30] S. Paoletti, A. L. Juloski, G. Ferrari-Trecate, and R.
Vidal.Identification of Hybrid Systems — a Tutorial.
EuropeanJournal of Control, 13(2):242–260, 2007.
[31] H. Raffelt, B. Steffen, and T. Berg. Learnlib: A Library
forAutomata Learning and Experimentation. In Proceedings of the10th
International Workshop on Formal Methods for IndustrialCritical
Systems, pages 62–71, 2005.
[32] T. Räsänen and M. Kolehmainen. Feature-Based Clustering
forElectricity Use Time Series Data. In M. Kolehmainen,P. Toivanen,
and B. Beliczynski, editors, Adaptive and NaturalComputing
Algorithms, volume 5495 of Lecture Notes inComputer Science, pages
401–412. Springer, 2009.
[33] J. Sander, M. Ester, H.-P. Kriegel, and X. Xu.
Density-BasedClustering in Spatial Databases: The Algorithm
GDBSCANand Its Applications. Data Mining and Knowledge
Discovery,2(2):169–194, June 1998.
[34] A. Scott and M. Knott. A Cluster Analysis Method
forGrouping Means in the Analysis of Variance. Biometrics,
pages507–512, 1974.
[35] M. Shahbaz and R. Groz. Inferring Mealy Machines. In
FM2009: Formal Methods, pages 207–222. Springer, 2009.
[36] S. Shoham, E. Yahav, S. J. Fink, and M. Pistoia.
StaticSpecification Mining Using Automata-based Abstractions.IEEE
Transactions on Software Engineering, 34(5):651–666,2008.
[37] B. Steffen and H. Hungar. Behavior-based Model
Construction.In Verification, Model Checking, and Abstract
Interpretation,pages 5–19. Springer, 2003.
[38] G. van Heerdt. Efficient Inference of Mealy
Machines.Bachelor thesis, Radboud University Nijmegen, June
2014.
[39] J. Yang, D. Evans, D. Bhardwaj, T. Bhat, and M.
Das.Perracotta: Mining Temporal API Rules from Imperfect Traces.In
Proceedings of the 28th International Conference onSoftware
Engineering, pages 282–291, 2006.
10