Embed Size (px)
Citation preview

Advances in Engineering Software 45 (2012) 272–280
Contents lists available at SciVerse ScienceDirect
Advances in Engineering Software
journal homepage: www.elsevier .com/locate /advengsoft
A genetic algorithm application using fuzzy processing timesin non-identical parallel machine scheduling problem
Pelin Alcan ⇑, Hüseyin Bas�lıgilYıldız Teknik Üniversitesi, Makine Fakültesi, Endüstri Müh. Bölümü, Yıldız, _Istanbul, Turkey
a r t i c l e i n f o a b s t r a c t
Article history:Received 6 March 2009Received in revised form 22 March 2010Accepted 4 October 2011Available online 27 October 2011
Keywords:Job schedulingNon-identical parallel machinesHeuristicsFuzzy logicGenetic algorithm (GA)Fuzzy processing times
0965-9978/$ - see front matter � 2011 Elsevier Ltd. Adoi:10.1016/j.advengsoft.2011.10.004
⇑ Corresponding author. Tel.: +90 2123832922; faxE-mail address: [email protected] (P. Alcan).
There are many scheduling problems which are NP-hard in the literature. Several heuristics and dispatch-ing rules are proposed to solve such hard combinatorial optimization problems. Genetic algorithms (GA)have shown great advantages in solving the combinatorial optimization problems in view of its charac-teristic that has high efficiency and that is fit for practical application [1]. Two different scale numericalexamples demonstrate the genetic algorithm proposed is efficient and fit for larger scale identical parallelmachine scheduling problem for minimizing the makespan. But, even though it is a common problem inthe industry, only a small number of studies deal with non-identical parallel machines. In this article, akind of genetic algorithm based on machine code for minimizing the processing times in non-identicalmachine scheduling problem is presented. Also triangular fuzzy processing times are used in order toadapt the GA to non-identical parallel machine scheduling problem in the paper. Fuzzy systems are excel-lent tools for representing heuristic, commonsense rules. That is why we try to use fuzzy systems in thisstudy.
� 2011 Elsevier Ltd. All rights reserved.
1. Introduction we respectively present a brief survey of the literature concerning
Scheduling is an essential function in production management.Scheduling determines what is going to be made, when, where andwith what resources. Production scheduling is an important deci-sion making in operational level and it is a difficult problemdepending on the number of calculations required to obtain ascheduling that optimizes the chosen criterion [2].
Production scheduling seeks optimal combination of short man-ufacturing time, stable inventory, balanced human and machineutilization rate, and short average customer waiting time. Variousheuristic and adaptive solutions have been proposed for miscella-neous production scheduling problems [3]. In many manufacturingsystems, production jobs have to go through several stages, and ineach stage there are several parallel machines with different pro-cessing power to handle the jobs. Among the many proposed jobscheduling solutions, heuristic rules and adaptive algorithms arefrequently used.
The reason for genetic algorithms success at a wide and evergrowing range of scheduling problems is a combination of powerand flexibility. The power derives from the empirically proven abil-ity of evolutionary algorithms to efficiently find globally competi-tive optima in large and complex search spaces [4].
Considerable research has already been conducted in the field offuzzy logic and genetic algorithms. In the subsequent subsections,
ll rights reserved.
: +90 2122585928.
the applications of fuzzy logic and GA in the scheduling arena.First of all, the proposed genetic algorithm has been tested
against a standard GA on the problem of designing fuzzy logic con-trollers in the paper of Pham and Karaboga [5]. This work describesa simple GA based on the idea of cross breeding ‘chromosomes’ fromdifferent solution populations. In their article, Hong et al. [6] utilizefuzzy concepts in the LPT algorithm for managing uncertain sched-uling. Also, in developing a fuzzy inference system to construct sev-eral configurations for mapping programs to parallel machines,Torra and Sodan [7] address some aspects that are not usually pres-ent in fuzzy knowledge based systems. Litoiua and Tadei [8] investi-gate the fuzzy scheduling models on real time systems and the mainmethodologies that solve these models on task scheduling. Wanget al. [9] study a ready time scheduling problem with fuzzy job pro-cessing times in their article. On the other hand, Yun [10] proposes anew genetic algorithm with fuzzy logic controller (FLC) for dealingwith preemptive job-shop scheduling problems (p-JSP) and non-preemptive job-shop scheduling problems (np-JSP). Kacem et al.[11] propose a Pareto approach based on the hybridization of fuzzylogic (FL) and evolutionary algorithms (EAs) to solve the flexible job-shop scheduling problem (FJSP). Kim et al. [12] develop a hybrid ge-netic algorithm (hGA) with fuzzy logic controller (FLC) to solve theresource-constrained project scheduling problem (rcPSP) which isa well-known NP-hard problem in their article. In their paper, Ang-lani et al. [2] formulate a fuzzy mathematical programming modelfor solving the scheduling problem of parallel machines with se-quence dependent set-up costs.

P. Alcan, H. Bas�lıgil / Advances in Engineering Software 45 (2012) 272–280 273
Besides, Petrovic and Duenas [13] present a new fuzzy logicbased decision support system for parallel machine scheduling/rescheduling in the presence of uncertain disruptions. In their pa-per, Yimer and Demirli [14] present a mixed-integer fuzzy pro-gramming model and a GA based solution approach to ascheduling problem of customer orders in a mass customizing fur-niture industry. Also, Muhuri and Shukla [15] consider fuzzy tim-ing constraints by modeling the realtime tasks with fuzzydeadlines and fuzzy processing times with different membershipfunctions.
Introduced in the 1970s by Holland, GA has been used to solve avariety of problems. GA tries to mimic the genetic behavior of aspecies. The primary difference between GA and other meta-heu-ristics (such as Tabu Search and Simulated Annealing) is that GAmaintains a population of solutions rather than a unique solution.Holland [16] propose the GA that imitate the natural evolution pro-gress, including the selection, crossover, and mutation. Schaffer[17] propose Vector Evaluated Genetic Algorithm (VEGA) to solvethe Pareto-optimal solution of multi-objective problem. Murutaand Ishibuchi [18] employe the structure of genetic algorithm insearching the multi-objective problem, and the algorithm is namedMOGA (Multi Objective Genetic Algorithm).
Furthermore, in their article, Min and Cheng [19] present a kindof genetic algorithm based on machine code for minimizing themakespan in identical machine scheduling problem. In their paper,Liu and Wu [20] apply evolutionary programming method to theidentical parallel machine production line scheduling problem ofminimizing the number of tardy jobs, which was a very importantoptimization problem in the field of research on CIMS and indus-trial engineering, and researches on problem formulation, expres-sion of feasible solution, methods for the generation of the initialpopulation, the mutation and improvement on the local searchability of evolutionary programming. Cochran et al. [21] proposea two-stage multi-population genetic algorithm (MPGA) to solveparallel machine scheduling problems with multiple objectives.Hop and Nagarur [22] develop a composite genetic algorithm tosolve the multi-objective problem. Moreover, Jou [3] propose aGA with Sub-indexed Partitioning genes (GASP) to allow more flex-ible job assignments to machines in the article. Çakar et al. [23] usea genetic algorithm to schedule jobs having precedence constraintswith the objective of minimizing the mean tardiness on identicalparallel machines.
This paper addresses the problem of scheduling independentjobs on non-identical parallel machines with total completion timecriterion. There are n independent jobs, each of which have a def-inite processing time and are allowed to be processed on any of them non-identical parallel machines. Each machine has a differentvelocity denoted by Vi. In this article, processing times have beentaken randomly and then have been adapted to non-identical par-allel machine scheduling problem. Besides, triangular fuzzy pro-cessing times are used in order to adapt the genetic algorithm tonon-identical parallel machine scheduling problem in the article.Fuzzy systems are excellent tools for representing heuristic, com-monsense rules. That is why we try to use fuzzy systems in thisstudy. The paper is structured as follows: Section 2 presents prob-lem formulation; Section 3 discusses scheduling non-identical par-allel machines using GA; Section 4 features the formulation of thestarting times of jobs on machines; Section 5 shows the numericalapplication and discusses related work; Section 6 concludes thepaper and points future work.
2. Problem formulation
In this paper, a set of n jobs is to be processed on m non-iden-tical parallel machines. The job j can be processed by either of
the machines i. Each machine has a different velocity (Vi) and canprocess only one job at a time. Each job is to be processed withoutinterruption. Processing time of job j on machine i is denoted byt(i, j). It is desired to find a schedule for which the maximum com-pletion time (makespan) is minimized.
x(i, j) is the boolean variable which determines whether job j isprocessed by machine i (if x(i, j) = 1) or not (if x(i, j) = 0). The matrixX is composed of variables x(i, j) and has the following properties:
– All elements are equal to ‘‘0’’ or ‘‘1’’, x(i, j) 2 {0, 1}.– Each column has only one element valued ‘‘1’’,Pm
i¼1xði; jÞ ¼ 1; j ¼ 1; . . . ;n.– The number of elements valued ‘‘1’’ is n,
Pnj¼1
Pmi¼1xði; jÞ ¼ n.
Processing time of a job j on different machines can be ex-pressed by the following equation:
tði; jÞ � V1 ¼ tði; jÞ � V2 ð1Þ
The maximum completion time (makespan) is equal to:
Cmax ¼maxm
i¼1
Xn
j¼1
xði; jÞ � tði; jÞ( )
ð2Þ
Thus, the objective function can be formulated as follows:
min Cmax ¼maxm
i¼1
Xn
j¼1
xði; jÞ � tði; jÞ( )
ð3Þ
3. Scheduling non-identical parallel machines using GA
Genetic algorithms are search algorithms which are based onnatural selection and natural genetic mechanism [19]. Geneticalgorithms have shown great advantages in solving the combinato-rial optimization problem in view of its characteristic that has highefficiency and that is fit for practical application [1]. From the viewpoint of the working principle, genetic algorithms firstly needs thecoding of the problem with the condition that it should be fittingwith the GA [23]. After coding process, GA operators are appliedon chromosomes. It is not guaranteed that the obtained new off-springs are good solutions by the working of crossover and muta-tion operators. Feasible solutions are evaluated, and others are leftout of evaluation. The feasible ones of the obtained offsprings aretaken and new populations are formed by reproduction processusing these offsprings [24]. During each iteration step (or called‘‘generation’’), genetic operations, that is, crossover, mutation andnatural selection are applied in order to search potential bettersolutions. Crossover combines two chromosomes to generatenext-generation chromosomes preserving their characteristics.Mutation reorganizes the structure of genes in a chromosome ran-domly so that a new combination of genes may appear in the nextgeneration. Reproduction is to copy a chromosome to the next gen-eration directly so that chromosomes from various generationscould cooperate in the evolution and the ‘‘quality’’ of the popula-tion may be improved after each generation [22].
3.1. Methodology
The stages of the methodology are described like this:
1. Coding2. Generation of initial population3. Calculation of fitness values4. Reproduction5. Crossover6. Mutation7. Optimality criterion

274 P. Alcan, H. Bas�lıgil / Advances in Engineering Software 45 (2012) 272–280
In the next sections we will explain the stages of the methodol-ogy (see Fig. 1).
3.1.1. CodingThe raw i of the matrix X consists of jobs to be processed on ma-
chine i. Raws are called ‘‘genes’’ (g1, . . . ,gi, . . . ,gm) and they repre-sent jobs to be processed on each machine; jobs to be processedon machine i are given by elements non-zero of gene i(x(i, j) = 1).The completion time of each machine i, (Ci), is equal tothe sum of processing times of jobs to be processed on that ma-chine; it is called as the ‘‘value of gene i ’’ and it is defined by thefollowing function:
f ðgiÞ ¼Xn
j¼1
xði; jÞ � tði; jÞ i ¼ 1; . . . ;m ð4Þ
3.1.2. Generation of initial populationAs the matrix X represents the scheduling of n jobs on m ma-
chines, an initial solution can be obtained randomly by having onlyone non-zero element, x(i, j) 2 {0, 1}, in each column. Several initialsolutions can be obtained by repeating the same operation and eachinitial solution is called ‘‘chromosome’’. Chromosomes can be iden-tified by their order of creation, k 2 N. Initial population is the setconsisting of N chromosomes. The number of chromosomes, i.e.population size, is one of the important parameters of GA.
3.1.3. Calculation of fitness valuesAfter the generation of new population, fitness value of each
chromosome is calculated (Fk). The higher the fitness value, thebetter the performance of the chromosome (i.e. parent). Becausethe objective function is to minimize the makespan, fitness valuescan be obtained using the following function:
Fk ¼ a� e�b�CmaxðkÞ ð5Þ
where a and b are positive real number and Cmax(k) is the objectivefunction value (makespan) of the chromosome k.
Calculation of Fitness Values
Coding
Generation of Initial Population
Reproduction
Crossover
Mutation
Optimality criterion
Outputting
Fig. 1. The stages of the methodology.
3.1.4. ReproductionReproduction is the process in which parents copy themselves
according to the probabilities that are proportional to their fitnessvalues [1]. As a result, parents with higher fitness values will havehigher probabilities of producing their offspring in the next gener-ation. We make selection of parents according to the tournamentselection method in this paper. Tournament selection is one ofmany methods of selection in genetic algorithms which runs a‘‘tournament’’ among a few individuals chosen at random fromthe population and selects the winner (the one with the best fit-ness) for crossover. Selection pressure can be easily adjusted bychanging the tournament size. If the tournament size is larger,weak individuals have a smaller chance to be selected. Tournamentselection has several benefits: it is efficient to code, works on par-allel architectures and allows the selection pressure to be easilyadjusted. Tournament selection has become increasingly popularas it performs rank based selection using only local information.As it does not use the whole population, tournament selection doesnot require global population statistics [12].
3.1.5. CrossoverEach gene i consists of jobs to be processed on machine i,
x(i, j) – 0, j = 1, . . ., n) each chromosome contains m genes and con-stitutes on feasible solution. Crossover operator, described below,combines two genes of the same chromosome in a proper order,to obtain a new chromosome giving a better feasible solution.The first gene to combine, gi00 , is the one that indicates the machinewith maximum completion time:
f ðgi00 Þ ¼maxm
i¼1ff ðgiÞg ð6Þ
The job with the shortest processing time of gene gi00 is denoted by j00
and given by the equation below:
tði00; j00Þ ¼minn
j¼1ftði00; jÞg ð7Þ
Crossover operation is carried out by moving job j00 to another ma-chine. The new machine is represented by gene gA and is given bythe following equation:
ðf ðg00Þ � f ðgAÞÞ �VA
Vi00¼max
m
i¼1f ðgi00 Þ � f ðgiÞÞ �
Vi
Vi00
� �ð8Þ
The processing time of job j00 on machine A, tðA; j00Þ, can be calculatedby the equation below:
tðA; j00Þ ¼ tði00; j00Þ � Vi00
VAð9Þ
3.1.6. MutationIn genetic algorithms, mutation is a genetic operator used to
maintain genetic diversity from one generation of a population ofchromosomes to the next [15]. It is analogous to biological muta-tion. Mutation operator creates new chromosomes by causingsmall perturbations in genes. This operation prevents from gettingstuck on local suboptimal solutions and it is very helpful to main-tain the richness of the population in dealing with large scale prob-lems [1].
3.1.7. Optimality criterionAfter mutation a new generation is obtained and an optimality
test is to be performed as the last step of the algorithm. Initially,completion time of each machine (value of genes, f(gi), using for-mula (4)) and the maximum completion time of each chromosome(makespan, Cmax(k), using formula (2)) have to be calculated. Theoptimality criterion to be used is given below:
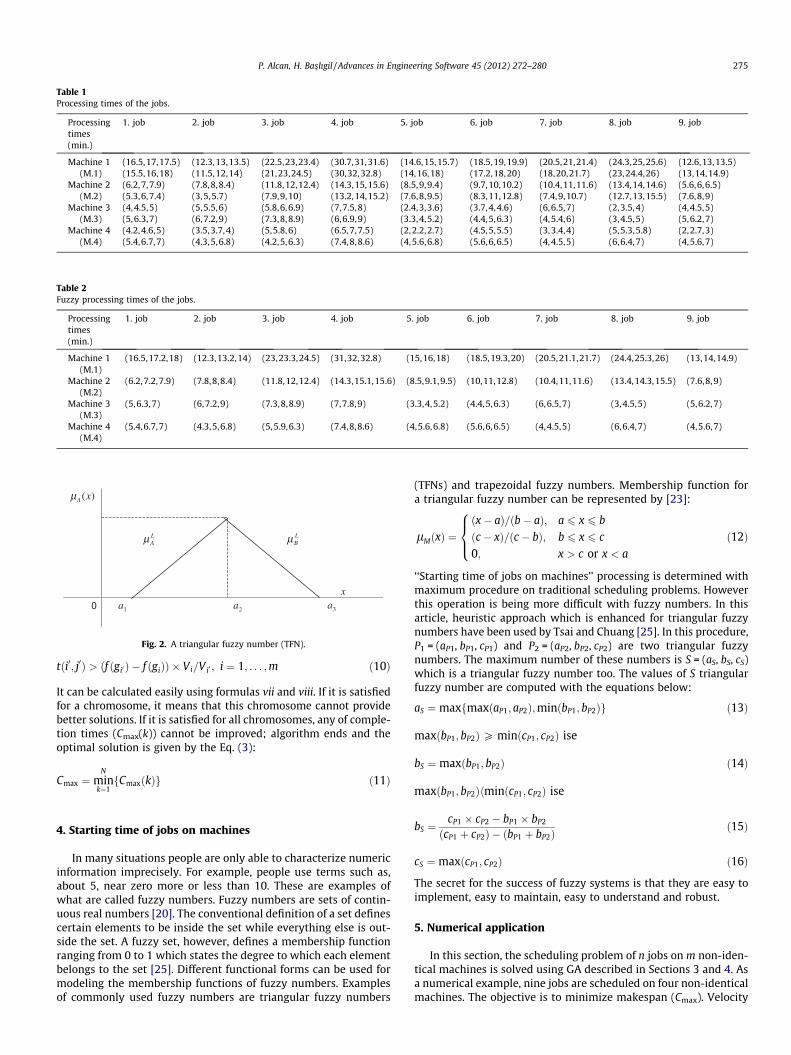
Table 1Processing times of the jobs.
Processingtimes(min.)
1. job 2. job 3. job 4. job 5. job 6. job 7. job 8. job 9. job
Machine 1(M.1)
(16.5,17,17.5)(15.5,16,18)
(12.3,13,13.5)(11.5,12,14)
(22.5,23,23.4)(21,23,24.5)
(30.7,31,31.6)(30,32,32.8)
(14.6,15,15.7)(14,16,18)
(18.5,19,19.9)(17.2,18,20)
(20.5,21,21.4)(18,20,21.7)
(24.3,25,25.6)(23,24.4,26)
(12.6,13,13.5)(13,14,14.9)
Machine 2(M.2)
(6.2,7,7.9)(5.3,6,7.4)
(7.8,8,8.4)(3,5,5.7)
(11.8,12,12.4)(7.9,9,10)
(14.3,15,15.6)(13.2,14,15.2)
(8.5,9,9.4)(7.6,8,9.5)
(9.7,10,10.2)(8.3,11,12.8)
(10.4,11,11.6)(7.4,9,10.7)
(13.4,14,14.6)(12.7,13,15.5)
(5.6,6,6.5)(7.6,8,9)
Machine 3(M.3)
(4,4.5,5)(5,6.3,7)
(5,5.5,6)(6,7.2,9)
(5.8,6,6.9)(7.3,8,8.9)
(7,7.5,8)(6,6.9,9)
(2.4,3,3.6)(3.3,4,5.2)
(3.7,4,4.6)(4.4,5,6.3)
(6,6.5,7)(4,5.4,6)
(2,3.5,4)(3,4.5,5)
(4,4.5,5)(5,6.2,7)
Machine 4(M.4)
(4.2,4.6,5)(5.4,6.7,7)
(3.5,3.7,4)(4.3,5,6.8)
(5,5.8,6)(4.2,5,6.3)
(6.5,7,7.5)(7.4,8,8.6)
(2,2.2,2.7)(4,5.6,6.8)
(4.5,5,5.5)(5.6,6,6.5)
(3,3.4,4)(4,4.5,5)
(5,5.3,5.8)(6,6.4,7)
(2,2.7,3)(4,5.6,7)
Table 2Fuzzy processing times of the jobs.
Processingtimes(min.)
1. job 2. job 3. job 4. job 5. job 6. job 7. job 8. job 9. job
Machine 1(M.1)
(16.5,17.2,18) (12.3,13.2,14) (23,23.3,24.5) (31,32,32.8) (15,16,18) (18.5,19.3,20) (20.5,21.1,21.7) (24.4,25.3,26) (13,14,14.9)
Machine 2(M.2)
(6.2,7.2,7.9) (7.8,8,8.4) (11.8,12,12.4) (14.3,15.1,15.6) (8.5,9.1,9.5) (10,11,12.8) (10.4,11,11.6) (13.4,14.3,15.5) (7.6,8,9)
Machine 3(M.3)
(5,6.3,7) (6,7.2,9) (7.3,8,8.9) (7,7.8,9) (3.3,4,5.2) (4.4,5,6.3) (6,6.5,7) (3,4.5,5) (5,6.2,7)
Machine 4(M.4)
(5.4,6.7,7) (4.3,5,6.8) (5,5.9,6.3) (7.4,8,8.6) (4,5.6,6.8) (5.6,6,6.5) (4,4.5,5) (6,6.4,7) (4,5.6,7)
)(xAµ
x0 1a 2a 3a
LAµ L
Bµ
Fig. 2. A triangular fuzzy number (TFN).
P. Alcan, H. Bas�lıgil / Advances in Engineering Software 45 (2012) 272–280 275
tði0; j0Þ > ðf ðgi0 Þ � f ðgiÞÞ � Vi=Vi0 ; i ¼ 1; . . . ;m ð10Þ
It can be calculated easily using formulas vii and viii. If it is satisfiedfor a chromosome, it means that this chromosome cannot providebetter solutions. If it is satisfied for all chromosomes, any of comple-tion times (Cmax(k)) cannot be improved; algorithm ends and theoptimal solution is given by the Eq. (3):
Cmax ¼minN
k¼1fCmaxðkÞg ð11Þ
4. Starting time of jobs on machines
In many situations people are only able to characterize numericinformation imprecisely. For example, people use terms such as,about 5, near zero more or less than 10. These are examples ofwhat are called fuzzy numbers. Fuzzy numbers are sets of contin-uous real numbers [20]. The conventional definition of a set definescertain elements to be inside the set while everything else is out-side the set. A fuzzy set, however, defines a membership functionranging from 0 to 1 which states the degree to which each elementbelongs to the set [25]. Different functional forms can be used formodeling the membership functions of fuzzy numbers. Examplesof commonly used fuzzy numbers are triangular fuzzy numbers
(TFNs) and trapezoidal fuzzy numbers. Membership function fora triangular fuzzy number can be represented by [23]:
lMðxÞ ¼ðx� aÞ=ðb� aÞ; a 6 x 6 bðc � xÞ=ðc � bÞ; b 6 x 6 c
0; x > c or x < a
8><>: ð12Þ
‘‘Starting time of jobs on machines’’ processing is determined withmaximum procedure on traditional scheduling problems. Howeverthis operation is being more difficult with fuzzy numbers. In thisarticle, heuristic approach which is enhanced for triangular fuzzynumbers have been used by Tsai and Chuang [25]. In this procedure,P1 = (aP1, bP1, cP1) and P2 = (aP2, bP2, cP2) are two triangular fuzzynumbers. The maximum number of these numbers is S = (aS, bS, cS)which is a triangular fuzzy number too. The values of S triangularfuzzy number are computed with the equations below:
aS ¼maxfmaxðaP1; aP2Þ;minðbP1; bP2Þg ð13Þ
maxðbP1; bP2ÞP minðcP1; cP2Þ ise
bS ¼maxðbP1; bP2Þ ð14Þ
maxðbP1; bP2ÞhminðcP1; cP2Þ ise
bS ¼cP1 � cP2 � bP1 � bP2
ðcP1 þ cP2Þ � ðbP1 þ bP2Þð15Þ
cS ¼maxðcP1; cP2Þ ð16Þ
The secret for the success of fuzzy systems is that they are easy toimplement, easy to maintain, easy to understand and robust.
5. Numerical application
In this section, the scheduling problem of n jobs on m non-iden-tical machines is solved using GA described in Sections 3 and 4. Asa numerical example, nine jobs are scheduled on four non-identicalmachines. The objective is to minimize makespan (Cmax). Velocity

Machine
M.1
M.2
M.3
M.4
t(2,1)= 13.018
t(3,2)=11.881
t(6,3)=3.91 T(5,3)=2.819
14.489
C1=f(g1)=13.018
C2=f(g2)=11.881
C3=f(g3)=14.489
Time
t(8,3)=3.265
t(4,4)=6.950 t(7,4)=3.251 t(9,4)=2.284 C4=f(g4)=12.487
t(1,3)=4.48
Fig. 3. Gantt chart for job scheduling using Eclipse Europa Computer Programming (n = 100 iteration).
Table 3Scheduling table with Eclipse Europa Computer Programming (n = 100 iteration).
Machines Scheduled jobs Ci
M1 Job 2 13.01M2 Job 3 11.88M3 Job 6 Job 5 Job 8 Job 1 14.48M4 Job 4 Job 7 Job 9 12.48
276 P. Alcan, H. Bas�lıgil / Advances in Engineering Software 45 (2012) 272–280
of machines are given as (V1, V2, V3, V4) = (1, 2, 3, 4). Processingtimes of the jobs are summarized in Table 1. and fuzzy processingtimes of the jobs are given in Table 2. Fuzzy processing times ofjobs are computed from the formulas given in Section 5.
A triangular fuzzy number (TFN), x is shown in Fig. 2. A TFN isdenoted simply as(a1, a2, a3).The parameters a1; a2; and a3; respec-tively, denote the smallest possible value, the most promising
Fig. 4. Eclipse
value, and the largest possible value that describe a fuzzy event.Each TFN has linear representations on its left and right side suchthat its membership function can be defined as;
lAðxÞ ¼
0; x < a1x�a1
a2�a1; a1 � x � a2
a3�xa3�a2
; a2 � x � a3
0; x > a3
8>>>><>>>>:
ð17Þ
The objective function value, completion time of the last job (make-span), obtained using Eclipse Europa computer programming is14.489 min. Scheduling results are shown as a Gantt chart inFig. 3. This Gantt chart shows the results of the iterations(n = 100) which are applied in the programming. Scheduling resultsare given in Table 3.
The same scheduling problem is solved with GA using EclipseEuropa Computer Programming as a Gantt chart in Fig. 8 for 782
platform.

Fig. 5. ‘‘Creat Time Java’’ computer screen.
Fig. 6. ‘‘Create Population Java’’ computer screen.
P. Alcan, H. Bas�lıgil / Advances in Engineering Software 45 (2012) 272–280 277
iterations. Although Eclipse is written in Java and its most popularuse is as a Java IDE, it is language neutral. Support for Java devel-opment is provided by a plug-in component, and additional plug-ins are available for other languages, such as C/C++, Cobol, andC#. At the most fundamental level, Eclipse is the Eclipse Platform.The Eclipse Platform’s purpose is to provide the services necessaryfor integrating software development tools, which are imple-mented as Eclipse plug-ins.
Firstly, data input should be done in this platform. In Fig. 4. wepresent the work space of the Eclipse Europa Computer Program-ming. In here, ‘‘Pelin folder’’ is defined as a project. Initially, whenthe program is opened, the suitable project has to be chosen fromthe folder.
The workspace is responsible for managing the user’s resources,which are organized into one or more projects at the top level. Eachproject corresponds to a subdirectory of Eclipse’s workspace

Fig. 7. ‘‘Machine completion time’’ computer screen.
Table 5The whole scheduling tables with Eclipse Europa Computer Programming.
Machines Scheduled jobs Ci
Iteration 100M1 Job 2 13.01M2 Job 3 11.88M3 Job 6 Job 5 Job 8 Job 1 14.48M4 Job 4 Job 7 Job 9 12.48
Iteration 250M1 Job 1 12.27M2 Job 4 Job 9 12.28M3 Job 6 Job 3 Job 8 14.23M4 Job 7 Job 5 Job 2 12.72
Iteration 496M1 Job 2 13.01M2 Job 3 Job 4 11.32M3 Job 6 Job 7 Job 8 14.11M4 Job 1 Job 5 Job 9 13.38
Iteration 500M1 Job 3 12.77M2 Job 2 Job 4 12.45M3 Job 6 Job 5 Job 8 14.08M4 Job 1 Job 7 Job 9 12.87
Iteration 782M1 Job 2 13.01M2 Job 3 Job 4 11.88M3 Job 6 Job 5 Job 8 13.43M4 Job 1 Job 7 Job 9 12.48
278 P. Alcan, H. Bas�lıgil / Advances in Engineering Software 45 (2012) 272–280
directory. Each project can contain files and folders; normally eachfolder corresponds to a subdirectory of the project directory, but afolder can also be linked to a directory anywhere in the filesystem.The workspace maintains a low-level history of changes to each re-source. The workspace is also responsible for notifying interestedtools about changes to the workspace resources.
In the program, the subclasses of project can be defined below:
� Genetic Java� Compute Fitness Java� Main Java� Program running Java� Data Input 1 Java� Create Population Java� Create Time Java
Figs. 5–7 show the stages of the Eclipse Europa Computer Pro-gramming in our paper.
Besides, as a result of 782 iterations, completion time of the lastjob is 13.439 min. Scheduling results are given in Table 4 andshown as a Gantt chart in Fig. 8.
Five iterations and their results are given in Table 5. Each one ofthem indicates a different schedule.
Furthermore, we showed the scheduling table of 1000 iterationsin Table 6. In this expression, we want to present that we ran theEclipse Europe Programming for 1000 times. But we found the bestsolution for n = 782 iterations.
Table 4Scheduling table with Eclipse Europa Computer Programming (n = 782 iteration).
Machines Scheduled jobs Ci
M1 Job 2 13.01M2 Job 1 Job 9 13.38M3 Job 6 Job 3 Job 8 13.43M4 Job 7 Job 5 Job 4 12.72
Table 6Scheduling table with Eclipse Europa Computer Programming (n = 1000 iteration).
Machines Scheduled jobs Ci
Iteration 1000M1 Job 2 13.01M2 Job 3 Job 4 11.88M3 Job 6 Job 5 Job 8 13.43M4 Job 1 Job 7 Job 9 12.48

Machine
M.1
M.2
M.3
M.4
t(2,1)= 13.018
t(1,2)=7.422
t(6,3) (3,3)=6.258
13.439
C1=f(g1)=13.018
C2=f(g2)=13.383
C3=f(g3)=13.439
Time
t(8,3)=3.265
t(7,4)
=3.915 T
=3.251 t(5,4)=2.522 t(4,4)=6.950 C4=f(g4)=12.724
t(9,2)=5.960
Fig. 8. Gantt chart for job scheduling using Eclipse Europa Computer Programming (n = 782 iteration).
P. Alcan, H. Bas�lıgil / Advances in Engineering Software 45 (2012) 272–280 279
Genetic algorithms have shown great advantages in solving thecombinatorial optimization problem in view of its characteristicthat has high efficiency and that is fit for practical application[19]. Simulated annealing (SA) and GA algorithms are proposedto obtain near-optimal solutions of the scheduling problems [26].Simulated annealing is a kind of search algorithm based on MonteCarlo interactive method, it introduces annealing equilibriumproblem of thermodynamics into problem solving. Its basicthought is to apply randomness of the algorithm and to increasefreedom of optimization of the algorithm and to accept bad solu-tion with a certain probability, thus escaping from local optimumand tending to global optimum [19].
Several different scale numerical examples demonstrate the ge-netic algorithm proposed is efficient and fit for larger scale parallelmachine scheduling problem for minimizing the makespan, thequality of its solution has advantage over heuristic method andSA method.
6. Conclusion and future work
A genetic algorithm (GA) is a search technique used in comput-ing to find exact or approximate solutions to optimization andsearch problems. Genetic algorithms are a particular class of evolu-tionary algorithms (also known as evolutionary computation) thatuse techniques inspired by evolutionary biology such as inheri-tance, mutation, selection, and crossover (also called recombina-tion) [9]. As many practical job shop and open shop schedulingproblems can be simplified as parallel machine scheduling prob-lems under certain conditions, the parallel machine schedulingproblem has received a great deal of attention in the academicand engineering circle.
There are many applications of GA to solve parallel machinescheduling problem; but, even though it is a common problem inthe industry, only a small number of them deal with non-identicalparallel machines. We therefore decided to concentrate our re-search effort on scheduling non-identical parallel machines usingGA. In order to expand the article, we propose a fuzzy logic tech-nique. A numerical application is presented to support the article.Inferential findings from this execution, in addition to its highcomputational speed, the GA proposed here is suitable for non-identical parallel machine scheduling problem of minimizing themaximum completion time. Another advantage of GA is the possi-bility of using several initial populations leading to discrepant re-sults. While most of the other heuristics give only one solution,GA maintains a cluster of solutions.
Nevertheless in the literature, there is a less number of re-searches which deal with the application of GA on ‘‘fuzzy schedul-ing problems’’. The GA described in this study is applied on non-identical parallel machine scheduling problem with fuzzy process-ing times. In this article, the GA is implemented in a Java Eclipse
Europa Software where The Eclipse platform’s purpose is to pro-vide the services necessary for integrating software developmenttools, which are implemented as Eclipse plug-ins. The workspaceis responsible for managing the user’s resources, which are orga-nized into one or more projects at the top level. In further research,GA can be applied to non-identical parallel machine schedulingproblem involving setup times, ready times and/or due dates in or-der to minimize the maximum flow time, number of tardy jobs ortotal tardiness.
References
[1] Chiu Nan-Chieh, Fang Shu-Cherng, Lee Yuan-Shin. Sequencing parallelmachining operations by genetic algorithms. Comput Indus Eng1999;36:259–80.
[2] Anglani Alfredo, Grieco Antonio, Guerriero Emanuela, Musmanno Roberto.Robust scheduling of parallel machines with sequence-dependent set-up costs.Eur J f Operat Res 2005;161:704–20.
[3] Jou Chichang. A genetic algorithm with sub-indexed partitioning genes and itsapplication to production scheduling of parallel machines. Comput Indus Eng2005;48:39–54.
[4] Montana David, Brinn Marshall, Moore Sean, Bidwell Garrett. Geneticalgorithms for complex, real-time scheduling. In: Proceedings of the IEEEnetwork operations and management symposium, vol. 1; 1998. p. 245–48.
[5] Pham Dinh Tuan, Karaboga Dervis. Cross breeding in genetic optimisation andits application to fuzzy logic controller design. Artificial Intell Eng1998;12:15–20.
[6] Hong Tzung-Pei, Huang Cheng-Ming, Yu Kun-Ming. LPT scheduling for fuzzytasks. Fuzzy Sets Syst 1998;97:277–86.
[7] Torra Vicenç, Sodan Angela. A multi-stage system in compilationenvironments. Fuzzy Sets Syst 1999;105:49–61.
[8] Litoiua Marin, Tadei Roberto. Fuzzy scheduling with application to real-timesystems. Fuzzy Sets Syst 2001;121:23–535.
[9] Wang Chengyao, Wang Dingwei, Ip WH, Yuen DW. The single machine readytime scheduling problem with fuzzy processing times. Fuzzy Sets Syst2002;127:117–29.
[10] Yun Young Su. Genetic algorithm with fuzzy logic controller for preemptiveand non-preemptive job-shop scheduling problems. Comput Indus Eng2002;43:623–44.
[11] Kacem Imed, Hammadi Slim, Borne Pierre. Pareto-optimality approach forflexible job-shop scheduling problems: hybridization of evolutionaryalgorithms and fuzzy logic. Math Comput Simul 2002;60:245–76.
[12] Kim Kwan Woo, Gen Mitsuo, Yamazaki Genji. Hybrid genetic algorithm withfuzzy logic for resource-constrained project scheduling. Appl Soft Comput2003;2:174–88.
[13] Petrovic D, Duenas Alejandra. A fuzzy logic based production scheduling/rescheduling in the presence of uncertain disruptions. Fuzzy Sets Syst2006;157:2273–85.
[14] Yimer Alebachew D, Demirli Kudret. Fuzzy scheduling of job orders in a two-stage flowshop with batch-processing machines. Int J Approx Reason2007;50:117–37.
[15] Muhuri Pranab K, Shukla KK. Real-time task scheduling with fuzzy uncertaintyin processing times and deadlines. Appl Soft Comput 2008;8:1–13.
[16] Holland JohnH. Adaptation in natural and artificial systems: an introductoryanalysis with applications to biology control and artificial intelligence. 4thed. The University of Michigan in press; 1975.
[17] Schaffer JD. Multiple objective optimization with vector evaluated geneticalgorithms. In: Proceedings of first international conference on geneticalgorithms; 1985. p. 93–100. ISBN: 0-8058-0426-9.
[18] Muruta Tadahiko, Ishibuchi Hisao. MOGA: multi-objective genetic algorithm.In: Proceedings of second IEEE international conference on evolutionarycomputation, Australia, 1996. p. 289. ISBN: 0-7803-2759-4.

280 P. Alcan, H. Bas�lıgil / Advances in Engineering Software 45 (2012) 272–280
[19] Liu Min, Wu Cheng. A genetic algorithm for minimizing the makespan in thecase of scheduling identical parallel machines. Artificial Intell Eng1999;13:399–403.
[20] Liu Min, Wu Cheng. Scheduling algorithm based on evolutionary computing inidentical parallel machine production line. Robot Comput Integr Manuf2003;19:401–7.
[21] Cochran Jeffery K, Horng Shwu-Min, Fowler John W. A multi-populationgenetic algorithm to solve multi-objective scheduling problems for parallelmachines. Comput Operat Res 2003;30:1087–102.
[22] Hop Nguyen Van, Nagarur Nagendra N. The scheduling problem of PCBs formultiple non-identical parallel machines. Eur J Operat Res 2004;158:577–94.
[23] Çakar Tarık, Koker Rasit, Demir HIbrahim. Parallel robot scheduling tominimize mean tardiness with precedence constraints using a geneticalgorithm. Adv Eng Softw 2008;39:47–54.
[24] Damodaran Purushothaman, Manjeshwar Praveen-Kumar, SrihariKrishnaswami. Minimizing makespan on a batch-processing machine withnon-identical job sizes using genetic algorithms. Int J Prod Econ2006;103:882–91.
[25] Tsai YC, Chuang Tzung-Nan. A new max operator on triangular fuzzy sets. JChin Fuzzy Syst Assoc 1999;5:71–8.
[26] Kim Dong-Won, Na Dong-Gil, Jang Wooseung, Chen F-Frank. Simulatedannealing and genetic algorithm for unrelated parallel machine schedulingconsidering set-up times. Int J Comput Appl Technol 2006;26:28–36.

















![Priority based Fuzzy Decision Multi-RAT Scheduling ...paper.ijcsns.org/07_book/201912/20191210.pdf · in computing [4]. In this paper, we propose a novel Fuzzy scheduling called PFDMS](https://img.pdfslide.net/doc/110x75/5f0d8e137e708231d43af00d/priority-based-fuzzy-decision-multi-rat-scheduling-paper-in-computing-4-in.jpg)











