Embed Size (px)
Citation preview

A Method of BP Network Learning by Expanding the
Distribution of Category
Naoki Tanaka
Chair of Information Systems Engineering, Kobe University of Mercantile Marine, Kobe, Japan 658-0022
Toshiaki Koreyeda
Department of Personal Communications, Kyocera, Tanakura, Fukushima, Japan 963-5692
Takeshi Inoue
Chair of Information Systems Engineering, Kobe University of Mercantile Marine, Kobe, Japan 658-0022
Koji Kajitani
Department of Science and Technology, Kinki University, Higashi-Osaka, Japan 577-8502
SUMMARY
In backpropagation networks, unlearned regions are
left between categories if the learning samples are compara-
tively small. Such unlearned regions are one of the reasons
for the degradation of network generalization ability. To
improve the generalization ability, it is preferable that the
boundaries of the categories are more accurately reflected
by the pattern distribution. This article presents the method
of expansion of the category distribution by adding dis-
placements proportional to the distance from the center of
gravity of the category to learning samples, and a back-
propagation (BP) learning method using given learning
samples and those displaced samples. The method is ap-
plied to the recognition of handwritten Kanji characters. We
confirm increased generalization abilities as a result of
increased recognition performance of unlearned samples in
comparison to the normal learning method. © 1999 Scripta
Technica, Syst Comp Jpn, 30(12): 16�24, 1999
Key words: Character recognition; neural net-
work; backpropagation learning method; generalization
ability.
1. Introduction
In pattern recognition, getting learning samples
which reflect the shape of each category distribution gov-
erns the recognition performance. If learning samples are
quantitatively insufficient, their distribution does not reflect
the shape of categories correctly, which results in leaving
unlearned regions between them. To improve the generali-
CCC0882-1666/99/120016-09
© 1999 Scripta Technica
Systems and Computers in Japan, Vol. 30, No. 12, 1999Translated from Denshi Joho Tsushin Gakkai Ronbunshi, Vol. J81-D-II, No. 2, February 1998, pp. 293�300
16

zation ability, it is required for the boundary to fall almost
in the middle of the category distribution [1]. However, in
backpropagation (BP) networks it cannot be guaranteed [2].
This is one of the main factors impeding the improvement
of the generalization ability. In avoiding unlearned regions,
the number of learning samples must be sufficiently large.
But in general, sample collection is limited, and there is no
guarantee for quantitative expansions to be always con-
nected to qualitative improvement. Further, the increase of
learning samples requires an increase of learning time, so a
quantitative increase of learning samples is not required
from this point of view. Instead of the quantitative increase
of learning samples, we can attempt to improve already
existing samples quantitatively. Namely, the category dis-
tribution is expanded by displacing the existing samples.
Kayama and Abe proposed a method that adds random
numbers to the learning samples [3] and reported remark-
able improvement in the generalization ability when the
number of learning samples was very insufficient. Although
this method can be applied to various problems, in the case
of a sample with extremely large dimensions (several hun-
dred to several thousand dimensions), such as handwritten
characters, it is difficult to decide the pattern and/or amount
of added noise. Further, an appropriate expansion of the
category distribution is expected to be carried out, but this
point is not taken into account in the method. In this article,
instead of adding randomness, the learning samples are
moved outward proportionally to the distance from the
center of gravity of the category [4]. It becomes possible to
expand the sample distribution effectively, and the expan-
sion is in response to the extent of the distribution. If the
expansion becomes excessive and when the error exceeds
the threshold value, the expansion is reduced gradually. The
proposed method is applied to recognition of handwritten
characters according to the BP network, and its effective-
ness is confirmed.
2. Problems in Generalization Capabilities
of BP Learning
Let us consider the boundary formation of BP net-
works. Figure 1 shows the boundaries formed by the normal
BP learning method, where A and E represent training
samples of category A and B, respectively. The unlearned
samples of the corresponding categories are shown by ! and
". The BP network has three-layer structure: a two-unit
input layer, a four-unit middle layer, and a two-unit output
layer. The output corresponding to category A unit is de-
noted Oa and that corresponding to category B unit is
denoted Ob; the boundary between regions Oa ! Ob and
Oa � Ob is shown by the thick line. As seen, the boundary
is a straight line and is not the midline between categories.
Therefore, unlearned samples (! and ") placed outside of
the learning samples are not correctly recognized, which
degrades the generalization capability. In this way, it can be
anticipated that boundaries formed in unlearned regions are
not necessarily optimized in normal BP learning.
3. BP Training Method Reflecting Pattern
Distribution
In overcoming the problem of unlearned regions
discussed in Section 2, it is effective to extend learning
regions by increasing learning points. For this purpose, the
method of sample displacement in response to the distance
from the category center of gravity is proposed [4].
3.1. Training algorithm of proposed method
(EXPAND method)
The learning samples of a given category c are de-
noted by ipc. The expanded pattern position ip
cc displaced
outward proportionally to the distance from the center of
gravity of given learning samples gc is formed according to
where l pc�t� is the expansion coefficient defined by Eq. (2)
and t is the number of reduction steps. As a result of learning
sample displacements, category regions overlap where their
distances are small. In order to avoid excessive expansion,
the expansion coefficient is gradually reduced. It is difficult
to detect directly the overlap of category distributions. But,
in the case of category overlaps, the error of the output unit
is believed to become large; hence, the maximum error of
the output unit is used as the index. That is, a relatively large
expansion coefficient is applied initially [initial expansion
coefficient l(0)], and when the maximum error (Omax) ex-
Fig. 1. Boundary formed by the normal BP method.
(1)
17

ceeds the given threshold value Th, the expansion coeffi-
cient lpc�t� is reduced by
where t represents the number of reduction steps and tmax is
the given maximum number of t. Hence, when the reduction
is applied tmax times, lpc�t� becomes 1. As tmax becomes
larger, the speed of reduction changes to become more
moderate. The initial expansion coefficient l(0) is a parame-
ter setting the extent of the distribution. When t tmax and
lpc�t� 1, no further reduction is applied to the expansion
coefficient. The expansion coefficient is determined at each
learning sample. Taking a specific sample into account, at
first it is expanded maximally by coefficient l(0), and in
learning process, with reference to the maximum error Omax
of the output unit, only when Omax ! Th and 0 � t � tmax, t ischanged to t + 1 and Eq. (2) is applied. Otherwise, expan-
sion coefficients are maintained at the same value as in the
previous iteration. Category distribution generated by such
pattern displacements extends outward, but in its internal
region, sample density becomes sparse. There is the possi-
bility that expanded regions of adjacent categories invade
into such sparse regions. To avoid this, the original pattern
ipc and the expanded pattern ip
cc are mutually trained. In
regard to a specific sample ip1c (reduced at each iteration)
and ip2c (not reduced in the first several iterations) are
learned sequentially according to
The reduction of the expansion coefficient of expanded
pattern is reflected in the next iteration. The method of
learning the expanded pattern proposed here is called the
�EXPAND� method, and the usual learning method is
called the �NORMAL� method.
3.2. Simulation on two dimensions
In the case of one dimension, the boundary formation
in the EXPAND method is shown conceptually in Figs. 2
and 3. As shown in Fig. 2, in the case of no overlap between
adjacent category distributions, the boundary is formed
somewhere in the black region. In this regard, in expansion
of the pattern distribution by the EXPAND method, as
shown in Fig. 3 (expansion of the distribution shown by the
dotted curve to that shown by the solid curve), the gap
between categories is reduced, and in the case of temperate
expansion, it becomes possible to fill the gap. Therefore,
(2)
Fig. 2. Boundary for the original pattern distribution.
Fig. 3. Boundary for the expanded distribution.
Fig. 4. Boundary formed by the EXPAND method.
18

limitations are imposed on the freedom in formation of the
boundary, and it becomes possible to form the boundary at
desirable positions.
In order to verify the effectiveness of the EXPAND
method, the problem explained in section 2 is exercised and
the results are depicted in Fig. 4. Compared with the results
shown in Fig. 1, the boundary is formed near the middle of
categories and the sample distribution is better reflected. As
a result, unlearned samples at the outer parts of the learning
samples are correctly recognized. The network structure is
the same as that in Section 2, and the initial expansion
coefficient l(0), tmax, and Th are taken to be 2.0, 100, and
0.4, respectively.
4. Experiments on Recognition of
Handwritten Characters by EXPAND
Method
In order to verify the effectiveness of the EXPAND
method, experiments are carried out to recognize handwrit-
ten characters.
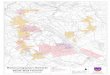
4.1. Character data of experiments
The ETL8-B2 handwritten character database com-
piled by Electrotechnical Laboratories is used in the experi-
ments. The K-th category of ETL8-B2 is inscribed as No.
K, and in all experiments (except that in Section 4.3.5) the
categories continued from No. 76 are used. For example,
[50 category] includes from No. 76 to No. 125 (shown in
Fig. 5). In each category, the odd-number patterns from the
head are used as learning samples while the 40 even-num-
ber patterns are used as unlearning samples.
4.2. Feature extraction of character images
As to the feature extraction method, the method using
the high-order autocorrelation function proposed by
Kanaya and colleagues [5] is adopted. In this extraction
method, at first autocorrelation masks are applied to local
regions of the character patterns [6] and the primitive
feature vector is obtained. Each local region is taken to be
10 u 10 in size where by sliding 4 pixels in the vertical and
horizontal directions, in regards to the 64 u 64 original
image; 256 local regions (16 u 16) are obtained. The
generation method of the primitive feature vector is de-
scribed here. The image is expressed by f�r�, r � R2, and
when N displacements a1, . . . , aN � R2 are taken, the N-th
order autocorrelation function is defined as
Limiting the displacement within 3 u 3 mesh and excluding
the redundant ones in regard to translations, 25 primitive
mask patterns (Fig. 6) are obtained up to the second order.
This mask is applied to an image, then a 25-dimension
vector in which each element is the number of matches with
the mask is obtained. This vector is called the primitive
feature vector. By adding the primitive feature vector of an
image and that of the reversed image and multiplying by
Fig. 5. Fifty categories of the ETL8-B2.
(3)
Fig. 6. Autocorrelation masks.
19

the emphasis factor, modified primitive feature vectors are
obtained, denoted by x �x1, . . . , x25�T. Further, the modi-
fied primitive feature vector is normalized. x1 corresponds
to the 0-th mask representing the area of characters;
x2, . . , x25 are normalized to x1; and x1 itself is normalized
to the overall area s of the image. The normalized modified
primitive feature vector xc is expressed by
xc is almost insensitive to character linewidth.
Next, the directive characteristic vector is obtained
by using a BP network that takes the normalized feature
vector as input and is trained to output eight directions 22.5°
apart. Hence, a directive characteristic vector of 16 u 16 u
8 dimensions is obtained. In order to achieve dimension
compression and vignetting, 5 u 5 Gaussian filtering is
applied to the directive vector. Finally, to emphasize the
directivity and to achieve more compression, a directive 6
u 6 Gaussian filter is applied and a 392 (7 u 7 u 8)-dimen-
sion directive characteristic vector is obtained.
4.3. Recognition experiments
4.3.1. Learning convergence
In order to observe the learning convergence of the
EXPAND method, recognition experiments of 50 catego-
ries are carried out. The three-layer network, which has 392
input units, 100 middle layer units, and 50 output units, is
used in these experiments. The learning and inertia coeffi-
cients are 0.1 and 0.9, respectively. The parameters of the
proposed method of initial expansion l(0), tmax, and Th are
taken to be 3.0, 3.5, and 0.4, respectively. Figure 7 shows
the corresponding recognition rate in relation to training
iterations (both the original pattern set and the expanded
pattern set are counted once). The dotted and adjacent solid
curves show the results for the NORMAL and EXPAND
methods, respectively. The thin solid curve shows the rec-
ognition rate of the training samples, while the thick curves
indicate that of the untrained ones. Corresponding to about
40 iterations will convergence in the NORMAL method; 60
iterations are required in the EXPAND method. This is due
to the increase in the number of learning samples produced
by expanding the sample distribution in the EXPAND
method. The recognition rate of untrained samples is 98.9%
in the EXPAND method (terminated at 100 iterations),
which is improved 1.5% in comparison to that of the
NORMAL one. In the following experiments, the training
is terminated after 100 iterations in the case of converged
while it is terminated after 200 iterations in the case of not
converged after 100 iterations (in some of 80 category
experiments). As to the recognition criteria, maximum out-
put unit corresponding to a correct category is used.
4.3.2. Experiments related to parameters
As described in Section 3.1, the EXPAND method
has parameters of initial expansion coefficient l(0), maxi-
mum number of reduction tmax, and threshold error value
Th. Figure 8 shows the recognition rate of unlearned sam-
ples when l(0) and tmax are varied and Th is taken to be 0.4.
C30P40, for example, indicates that the number of catego-
ries is 30 with 40 learning samples. The numbers of cate-
gories are taken to be 30, 50, and 80 while the numbers of
learning samples are 10, 15, 20, 30, 40, and 80. Figures 8(a)
to 8(c) show variations of the recognition rate with respect
to tmax at l(0) = 2.0, 3.0, and 4.0 when more than 30 learning
samples are treated. Figure 8(d) shows variations with
respect to l(0) when more than 30 learning samples are
treated and tmax is taken to be 35. From Figs. 8(a) to 8(d),
except for C80P30, recognition rates reach a maximum or
close to a maximum when the value of l(0) = 3.0 and tmax =
35. In regard to learning samples less than 20, the results
are shown in Fig. 8(e) where tmax = 35 and l(0) is varied
between 2 and 14. As seen, at 10 learning samples and
C80P15, recognition rates are increased until large l(0), and
maximum recognition rate results at l(0) = 12.0 in C30P10,
l(0) = 11.0 in C50P10, l(0) = 8.0 in C80P10, and l(0) = 11.0
in C80P15. Excepting C80P15, at learning samples of 15
and 20, the maximum is seen in the range l(0) = 4.0 to 8.0,
but the curve shapes are rather flat and the increase of
recognition rates is small in comparison to the case of 10
learning samples. Variations against tmax are also verified,
with the result that for learning samples in excess of 30, tmax
= 35 corresponds to the optimum value.
(4)
Fig. 7. Training curve of the EXPAND method.
20

4.3.3. Number of categories and recognition
rates
Figure 9 shows variation of the recognition rate when
the number of categories is varied from 20 to 90. Required
categories are selected according to the sequence collected
in ETL8-B2. The number of learning and unlearning sam-
ples of each category is 40, and l(0) = 3.0 and tmax = 35 are
used. The structure of the BP network is the following. The
number of units of the input layer is fixed at 392, that of the
output layer is the same as the number of categories, and
the number of middle layer units is twice that of the output
layer. For all numbers of categories, the recognition rates
of unlearned samples are higher in the EXPAND method
than in the NORMAL method. Further, for the number of
categories in the range of 30 to 80, the recognition rates are
Fig. 8. Recognition rate versus parameters l(0) and tmax.
21

more than 1% better than those in the NORMAL method,
and in this range, the improvement effects are remarkable.
In this regard, at 20 and 90 categories, the difference of the
recognition rates is slightly smaller in comparison to those
in the range of 30 to 80 categories. In the case of 20
categories, it is relatively easy to form the boundary be-
tween categories; therefore, even in the NORMAL method,
the recognition rate of unlearned samples is high. In the case
of 90 categories, the freedom in boundary formation is
limited and the advantages of the EXPAND method are
limited.
4.3.4. Relation of recognition rate to number
of learning samples
Figure 10 shows the recognition rate variations ver-
sus the number of samples; for 30, 50, and 80 categories,
the number of learning samples is varied as 10, 20, 30, 40,
and 80. tmax is taken to be 35, and l(0) is 7.0 in C30P15, 11.0
in C50P10, 4.0 in C50P15 and C50P20, 8.0 in C80P10, 11.0
in C80P15, 9.0 in C80P20, and 10.0 in C80P30. In the
others, it is always taken to be 3.0. As seen in Fig. 10, for
samples 15 (except in C30), 20, 30, and 40, the recognition
rate of the EXPAND method is two times better than the
number of samples of the NORMAL method. For example,
the recognition rate of the EXPAND method in C50P15 is
larger than that of the NORMAL method in C50P40. That
Fig. 9. Relationship between recognition rate and
number of categories.
Fig. 10. Relationship between recognition rate and
number of samples. Fig. 11. Five sets of categories.
22

is, the EXPAND method is more effective when the number
of samples doubled in the NORMAL method.
4.3.5. Recognition rates of five sets of
categories
In order to investigate the capabilities of the EX-
PAND method, experiments on five sets of 50 categories
are carried out. Five sets of 50 category characters of
ETL8-B2 from No. 76 to No. 325 (shown in Fig. 11) are
chosen, and their experimental recognition rates are de-
picted in Fig. 12. Among these sets, the first one is the 50
category set treated so far. The parameters are set to be l(0)
= 3.0, Th = 0.4, and tmax = 35 with the number of samples
being 40. It is found that the average recognition rate of
unlearned samples in the EXPAND method is 99.11%
while that in the NORMAL method is 98.43%, which is
improved by 0.77%. As seen, the average value of the
recognition rate of all five sets is better than that of the first
set. Therefore, it can be said that the EXPAND method is
advantageous not only in the 50-category set treated in the
previous section, but also in other sets.
5. Conclusions
A learning method that learns given samples and
displaced patterns of given samples is proposed. The
method is intended to reduce unlearned regions between
categories by expanding category distributions. Learning
samples are displaced outward from the category center of
gravity. Experiments on recognition of handwritten charac-
ters are carried out, and the following results are confirmed.
(i) In the case of a small number of samples (10 to 20), the
recognition capability can be remarkably improved in com-
parison to that of the NORMAL method. In particular, in
cases where the number of samples is 10 and 15, the
recognition rates are significantly improved when a large
initial expansion coefficient is taken. (ii) In the case of 30,
40, and 80 samples, it is also possible to improve the
recognition capability. For example, in the case of 50 cate-
gories and 80 samples, in contrast to the 98.4% recognition
rate of unlearned samples in the NORMAL method, that in
the EXPAND method is increased to 99.4%. The following
subjects remain for future study: (1) investigation of the
variation of expansion coefficient l(0) in relation to the
value of the threshold Th in learning, (2) improvement of
recognition capability by devising a pattern variation
method (e.g., direction and/or magnitude of displacement),
(3) application to the number of categories in excess of 90,
and (4) application to similar categories. In the proposed
method, only the learning samples are modified and, hence,
the method is not limited to the applications described here
but can be used in other applications.
Acknowledgments. We thank Electrotechnical
Laboratories for supplying the handwritten character data-
base ETL8-B2. Further, we deeply thank students in the
Information Science Research Laboratory of Kinki Univer-
sity for help in developing programs and experiments.
REFERENCES
1. Abe S, Kayama M, Takenaga H. How neural net-
works for pattern recognition can be synthesized. J
Inf Process 1991;14.
2. Rumelhart DE, Hinton GE, Williams RJ. Learning
internal representations by error propagation. Paral-
lel distributed processing. Foundation; 1986. Vol. 1,
Chapter 8.
3. Kayama M, Abe S. Training neural net classifier for
improving generalization capability. Trans IEICE
1993;J76-D-II:863�872.
4. Koreyeda T, Tanaka N, Kajitani K. Method of learn-
ing BP network by which distribution of category is
considered. Tech Rep IEICE 1996;PRU95-208.
5. Kanaya T, Tanaka N, Kajitani K. Feature extraction
of images by a neural network using high-order auto-
correlation function, and its application to character
recognition. Tech Rep IEICE 1994;NC93-72.
6. Otsu N, Shimada T, Mori S. Feature extraction of
images by N-th order autocorrelation mask. Tech Rep
IEICE 1989;PRL78-31.
Fig. 12. Recognition rate for five sets of categories.
23

AUTHORS (from left to right)
Naoki Tanaka (member) received his B.S. degree in communication engineering from Osaka University in 1981 and his
D.Eng. degree from that university in 1986. He joined Kinki University in 1986 as an assistant and became an associate professor
at Kobe University of Mercantile Marine in 1990. He was a visiting associate professor at Washington University during 1992
and 1993. He is involved in research on pattern recognition, image processing, and so on.
Toshiaki Koreyeda (member) received his B.S. degree in electrical engineering in 1994 and his M.S. degree in 1996
from Kinki University. He joined Kyocera Co. in 1996. He is involved in research on pattern recognition and similar subjects.
Takeshi Inoue (member) received his B.S. degree in communication engineering in 1977 and his D.Eng. degree in 1982
from Osaka University. He then joined Toyohashi Technical University as an assistant. Following his services at Osaka University
as an assistant, he became an associate professor at Kobe University of Mercantile Marine in 1988. He is involved in research
on network control, image processing, and so on.
Koji Kajitani (member) graduated from the Defense Academy in 1962 and received his D.Eng. degree from Osaka
University in 1969. He became an instructor at Kinki University in 1969 and was promoted to associate professor in 1975. He
became a professor in 1983. He is involved in research on logic circuits, pattern recognition, and so on.
24