Embed Size (px)
DESCRIPTION
A New Algorithm for Evaluating Ordered Tree Pattern Queries. Yangjun Chen Dept. Applied Computer Science, University of Winnipeg 515 Portage Ave. Winnipeg, Manitoba, Canada R3B 2E9. Outline. Motivation Algorithm for tree pattern query evaluation based on ordered tree matching - PowerPoint PPT Presentation
Citation preview

A New Algorithm for Evaluating Ordered Tree Pattern Queries
Yangjun Chen
Dept. Applied Computer Science,
University of Winnipeg
515 Portage Ave.
Winnipeg, Manitoba, Canada R3B 2E9

Outline
Motivation Algorithm for tree pattern query
evaluation based on ordered tree matching- Tree encoding- Algorithm description
Experiment results Summary
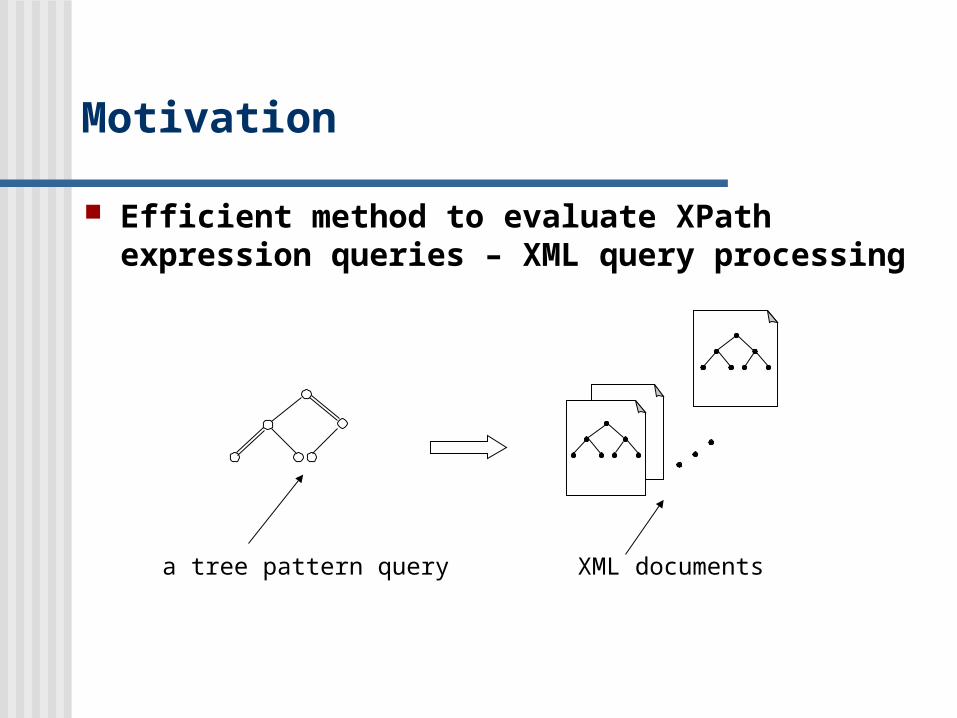
Efficient method to evaluate XPath expression queries – XML query processing
XML documentsa tree pattern query
Motivation

Document:<Purchase>
<Seller><Name>dell</Name><Item>
<Manufacturer>IBM</Manufacturer><Name>part#1</Name><Item>
<Manufacturer>Intel</Manufacturer></Item>
</Item><Item>
<Name>Part#2</Name></Item><Location>Houston</Location>
</Seller><Buyer>
<Location>Winnipeg</Location><Name>Y-Chen</Name>
</Buyer></Purchase>
P
S B
I I L L NN
I
M
M N N
IBM Part#1 Part#2
Dell Houston Winnipeg Y-Chen
Intel
Motivation
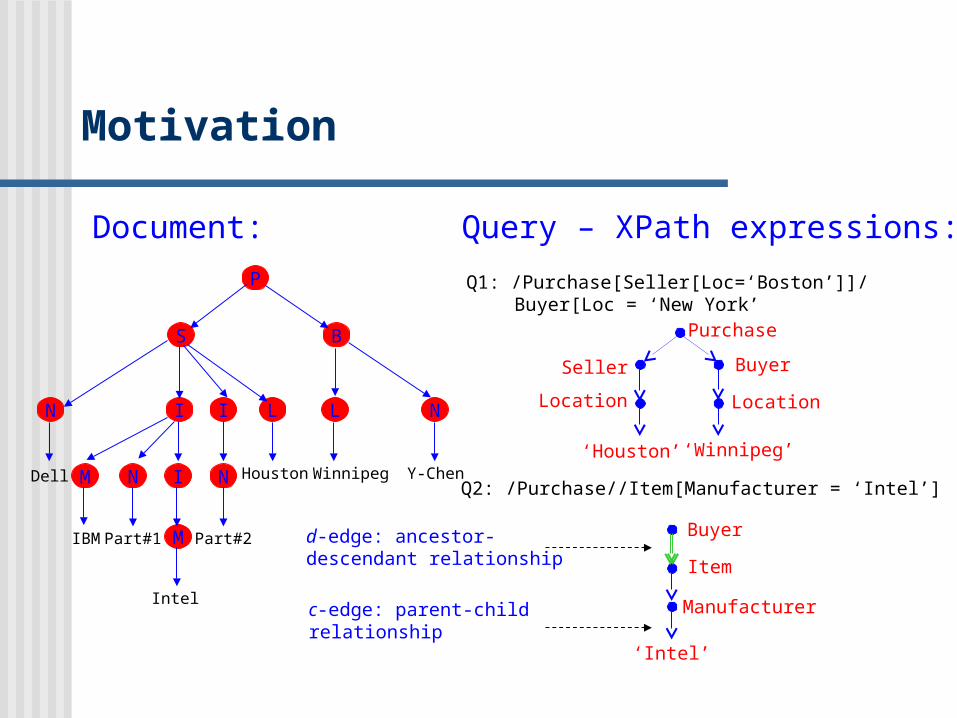
Motivation
Document: Query – XPath expressions:
Q1: /Purchase[Seller[Loc=‘Boston’]]/Buyer[Loc = ‘New York’
Q2: /Purchase//Item[Manufacturer = ‘Intel’]
Purchase
Seller Buyer
Location Location
‘Houston’ ‘Winnipeg’
Buyer
Item
Manufacturer
‘Intel’
d-edge: ancestor-descendant relationship
c-edge: parent-childrelationship
P
S B
I I L L NN
I
M
M N N
IBM Part#1 Part#2
Dell Houston Winnipeg Y-Chen
Intel

Motivation
- XPath expression
a[b[c and .//d]]/b[c and e//d]
book[title = ‘Art of Programming’]//author[fn = ‘Donald’ and
ln = ‘Knuth’]
a
b b
c d c e
d
title
Art of Programming
book
author
fn ln
KnuthDonald
<document><book>
<title>Art of Programming
</title><author>
<fn>Donald Knuth</fn>… …
XPath evaluation against XML documents

- Evaluation based on unordered tree matching:Definition An embedding of a tree pattern Q into an XML document T is a mapping f: Q T, from the nodes of Q to the nodes of T, which satisfies the following conditions:
(i) Preserve node label: For each u Q, label(u) matches label(f(u)).
(ii) Preserve parent-child/ancestor-descendant relationships: If u v in Q, then f(v) is a child of f(u) in T; if u v in Q, then f(v) is a descendant of f(u) in T.
Motivation XPath evaluation against XML documents
a
b c
Q: q3
q1 q2
a
b c
c b
b
T:
v1
v2
v3
v4 v5
v6

Motivation XPath evaluation against XML documents
- Evaluation based on ordered tree matchingXPath expression:
s/vp[v = “reads” and /following-sibling::n = “book” and /following
sibling::adv]s
vp
v n adv
“reads”“book”
s
np vp
det n v np adv
“The” “student”“reads” det adj n
“the”“interesting” “book”
“carefully”

Motivation XPath evaluation against XML documents
- Evaluation based on ordered tree matching:Definition An embedding of a tree pattern Q into an XML document T is a mapping f: Q T, from the nodes of Q to the nodes of T, which satisfies the following conditions:
(i) Preserve node label: For each u Q, label(u) matches label(f(u)).(ii) Preserve parent-child/ancestor-descendant relationships: If u v in Q,
then f(v) is a child of f(u) in T; if u v in Q, then f(v) is a descendant of f(u) in T.
(iii) Preserve sibling order: For any two nodes v1 Q and v2 Q, if v1 is to the left of v2, then f(v1) is to the left of f(v2) in T.
a
b c
Q: q3
q1 q2
a
b c
c b
b
T:
v1
v2
v3
v4 v5
v6

Algorithm for query evaluation Tree encoding
Let T be a document tree. We associate each node v in T with a quadruple (DocId, LeftPos, RightPos, LevelNum), where DocId is the document identifier; LeftPos and RightPos are generated by counting word numbers from the beginning of the document until the start and end of the element, respectively; and LevelNum is the nesting depth of the element in the document.
<A><B>
<C></C><B>
<C></C><C></C><D></D>
</B></B><B></B>
</A>
(1, 1, 11, 1)
(1, 10, 10, 2)B v8
A v1
(1, 7, 7, 4)
(1, 6, 6, 4)
T:
(1, 5, 5, 4)
(1, 3, 3, 3)
B v2
v3 C B v4
D v7v5 C
(1, 4, 8, 3)
(1, 2, 9, 2)
v6 C
12
3
43
5
65
6
77
891010
11

Tree encoding
Let T be a document tree. We associate each node v in T with a quadruple (DocId, LeftPos, RightPos, LevelNum), denoted as (v), where DocId is the document identifier; LeftPos and RightPos are generated by counting word numbers from the beginning of the document until the start and end of the element, respectively; and LevelNum is the nesting depth of the element in the document.
(i) ancestor-descendant: a node v1 associated with (d1, l1, r1, ln1) is an ancestor of another node v2 with (d2, l2, r2, ln2) iff d1 = d2, l1 < l2, and r1 > r2.
(ii) parent-child: a node v1 associated with (d1, l1, r1, ln1) is the parent of another node v2 with (d2, l2, r2, ln2) iff d1 = d2, l1 < l2, r1 > r2, and ln2 = ln1 + 1.
(iii)from left to right: a node v1 associated with (d1, l1, r1, ln1) is to the left of another node v2 with (d2, l2, r2, ln2) iff d1 = d2, r1 < l2.

A: (1, 1, 11, 1)
B: (1, 2, 9, 2) (1, 4, 8, 3), (1, 10, 10, 2)C: (1, 3, 3, 3) (1, 5, 5, 4), (1, 6, 6, 4)
D: (1, 7, 7, 4)
Data streams:
Algorithm for query evaluation Tree encoding
(1, 1, 11, 1)
(1, 10, 10, 2)B v8
A v1
(1, 7, 7, 4)
(1, 6, 6, 4)
T:
(1, 5, 5, 4)
(1, 3, 3, 3)
B v2
v3 C B v4
D v7v5 C
(1, 4, 8, 3)
(1, 2, 9, 2)
v6 C
sorted by LeftPos values
<A><B>
<C></C><B>
<C></C><C></C><D></D>
</B></B><B></B>
</A>
12
3
43
5
65
6
77
891010
11

Algorithm for query evaluation Algorithm description
• Our algorithm works bottom-up. Therefore, we need to sort XMLstreams by (DocID, RightPos) values.
• Each time a query Q is submitted to the system, we will associateeach query node q with a data stream L(q) such that foreach v L(q) label(v) = label(q), in which each query node isattached with a list of matching nodes of the document tree.
{v1}
A q1
q2 B B q5
q3 C C q4
L(q1)Q:
L(q2) L(q5)
L(q4)L(q3)
L(q1 ) = (1, 1, 11, 1) -
L(q2 ) = L(q5) = (1, 4, 8, 3), (1, 2, 9, 2) (1, 10, 10, 2) -
L(q3) = L(q4) = (1, 3, 3, 3) (1, 5, 5, 4), (1, 6, 6, 4) -
{v4, v2, v8}
{v3, v5, v6}
sorted by RightPos values
T: Q:

Algorithm for query evaluation Algorithm description
1. First, we will number the nodes of Q in postorder. So the nodes inQ will be referenced by their postorder numbers. Additionally,we set a virtual node for Q, numbered 0, which is considered to beto the left of any node in Q.
A q1
B q5
C q4
q2 B
q3 C
(q1)
(q2)
2. For each node q of Q, a link from it to the left-most leaf node inQ[q], denoted by (q), is established. For a leaf node q’, (q’) = q’.
5
3
A q1
B q5
C q4
q2 B
q3 C
Q :
1 2
40
virtual node

Algorithm for query evaluation Algorithm description
3. Let q’ be a leaf node in Q. We denote by -1(q’) a set of nodes xsuch that for each q x (q) = q’.
A q1
B q5
C q4
q2 B
q3 C
(q1)
(q2)
-1(q3) = {q1, q2 , q3}
-1(q4) = {q4}
-1(q5) = {q5}

Algorithm for query evaluation Algorithm description
4. Each node v in T is associate it with an array Av of length |Q|,indexed from 0 to |Q| - 1. In Av, each entry is a query node or ,defined below:
q
Av:
Av[q]
x1
xj
Av[q] =
Max{x | x -1(q’) T[v] embeds Q[x]}, If there is a least leaf q’larger than q such that-1(q’) contains at leastone node x with Q[x]being embedded in T[v];
Otherwise.
q’
Q:

Algorithm for query evaluation Algorithm description
q
Av:
Av[q]
x1
xj
q’
Q:
• X1 is the largest ancestor of q’ such that T[v] contains Q[X1].
• q’ is the closest leaf node to the right of q.
In this way, both the subtree embedding and the left-to-rightordering can be recorded.

Algorithm for query evaluation
Setting values in Av
(i) If we find Q[x] can be embedded in T[v], we will set Av[q1], ...,Av[qk] to x, where each ql (1 l k) is a query node to the left ofx, to record the fact that x is the closest node to the right of ql
such that T[v] embeds Q[x].
5
3
A q1
B q5
C q4
q2 B
q3 C
Q :
1 2
40B v8
A v1T:
B v2
v3 C B v4
D v7v5 C v6 C
Av3:
0 1 2 3 4
Av3:
0 1 2 3 4
1

Algorithm for query evaluation
Setting values in Av
(ii) If some time later we find another node x’, which is to the rightof x, such that Q[x’] can be embedded in T[v], we will setAv[p1], ..., Av[ps] to x’, where each pl (1 l s) is to the left ofx’ but to the right of qk.
5
3
A q1
B q5
C q4
q2 B
q3 C
Q :
1 2
40B v8
A v1T:
B v2
v3 C B v4
D v7v5 C v6 C
Av3:
0 1 2 3 4
1 Av3:
0 1 2 3 4
1 2
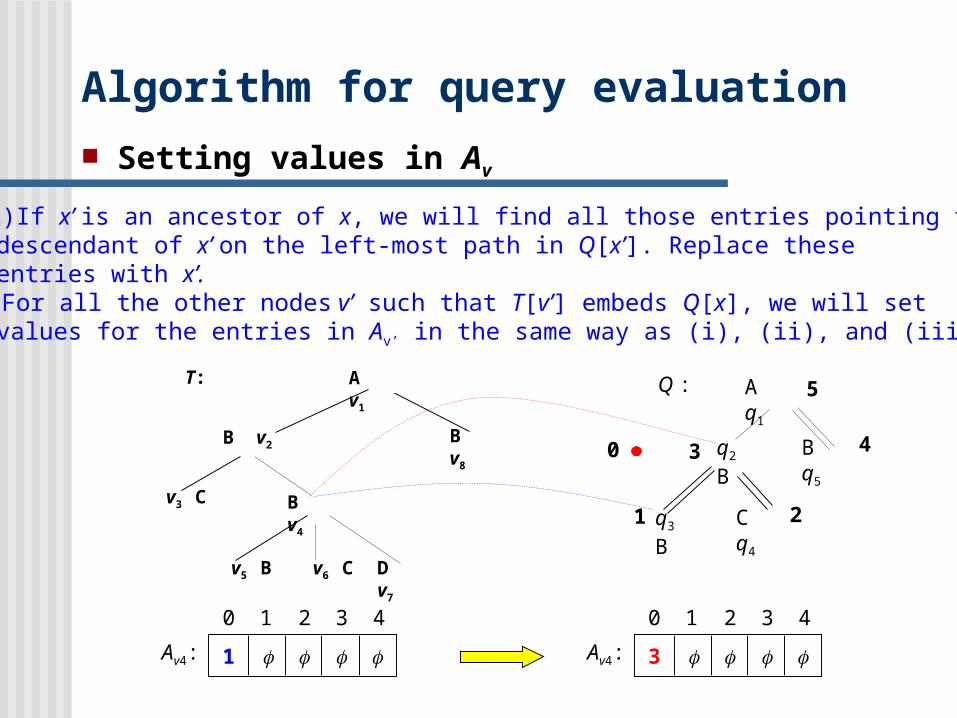
Algorithm for query evaluation
Setting values in Av
(iii) If x’ is an ancestor of x, we will find all those entries pointing to adescendant of x’ on the left-most path in Q[x’]. Replace theseentries with x’.
(iv) For all the other nodes v’ such that T[v’] embeds Q[x], we will setvalues for the entries in Av’ in the same way as (i), (ii), and (iii).
5
3
A q1
B q5
C q4
q2 B
q3 B
Q :
1 2
40B v8
A v1T:
B v2
v3 C B v4
D v7v5 B v6 C
Av4:
0 1 2 3 4
1 Av4:
0 1 2 3 4
3

Algorithm for query evaluation
Using Av to check tree embedding
5. Let q in Q and v in T be the nodes encountered. Let v1, ..., vk bethe child nodes of v. Let q1, ..., ql be the child nodes of q. We firstcheck Av1 starting from Av1[h], where h = (q) - 1. We begin thesearch from (q) - 1 because it is the closest node to the leftof the first child of q. Let Av1[h] = q’. If q’ is not q1, nor an ancestorof q1, we will check Av2[h] in a next step. This process continuesuntil one of the following conditions is satisfied:(i) All Avj’s have been checked, or(ii) There exists vj such that Avj[h] is q1 or an ancestor of q1.
q
Av1:
h = (q) - 1
q1
?qv
label(v) = label(q)
q1 qlv1 vk

Algorithm for query evaluation
Using Av to check tree embedding
6. If all Avj’s are checked (case (i)), it shows that Q[q1] cannot beembedded in any subtree rooted at a child node of v. So T[v]cannot embed Q[v]. If it is case (ii), we know that T[vj] embedsQ[q1]. If q1 is a //-child, or both q1 and vj are /-children, we willcontinue to check Av(j+1)[g] against q2, where g = Avj[h].(Otherwise, we will continue to check Av(j+1)[h] against q1.)
q
Av1:
h = (q) - 1
q1
Av2:
q2
Av2:[q1]

Algorithm for query evaluation Algorithm description
Av3:
Av5:
Av6:
Av4:
Av2:
Av8:
Av1:
[2, 2, , , ]
[1, , , , ]
[2, 2, , , ]
[1, , , , ]
[1, , , , ]
[1, 4, 4, 4, ]
[5, , , , ]
[1, 4, 4, 4, ]
[3, , , , ]
[3, 2, , , ]
[5, 2, 4, 4, ]
[3, 4, 4, 4, ]
[3, 2, 4, 4, ]
[3, 2, 4, 4, ]

Algorithm for query evaluation Experiments
• We conducted our experiments on a DELL desktop PCequipped with Pentium(R) 4 CPU 2.80GHz, 0.99GB RAMand 20GB hard disk. The code was compiled usingMicrosoft Visual C++ compiler version 6.0, runningstandalone.
• Tested methodsIn the experiments, we have tested four methods:- TwigStack (TS for short) [3],- Twig2Stack (T2S for short) [10],- PRIX [30],- tree-embedding (discussed in this paper, TE for short).

• Tested methodsIn the experiments, we have tested four methods:- TwigStack (TS for short) [1],- Twig2Stack (T2S for short) [2],- PRIX [3],- tree-embedding (discussed in this paper, TE for short).
Algorithm for query evaluation Experiments
[1] N. Bruno, N. Koudas, and D. Srivastava, Holistic Twig Joins: Optimal XMLPattern Matching, in Proc. SIGMOD Int. Conf. on Management of Data,Madison, Wisconsin, June 2002, pp. 310-321.
[2] S. Chen, H-G. Li, J. Tatemura, W-P. Hsiung, D. Agrawa, and K.S. Canda,Twig2Stack: Bottom-up Processing of General ized-Tree-Pattern Queriesover XML Documents, in Proc. VLDB, Seoul, Korea, Sept. 2006,pp. 283-294.
[3] P. Rao and B. Moon, Sequencing XML Data and Query Twigs for FastPattern Matching, ACM Transaction on Data base Systems, Vol. 31,No. 1, March 2006, pp. 299-345.

Algorithm for query evaluation Experiments
• Theoretical computational complexities
methods Query time Runtime space usage
TwigStack O(|D||Q|) O(|D||Q|)
Twig2Stack O(|D||Q|2+|subTwig-Results|
O(|D||Q|)
PRIX O(|T||Q|) O(|T| + |Q|)
TE O(|T|leafQ) O(leafTleafQ)
• Indexes
XB-trees used for TwigStack, Twig2Stack, TE.Trie structure used for PRIX

Algorithm for query evaluation Experiments
• Data sets
The TreeBank dataset is a real data set with narrow and deeply recursivestructure that includes multiple recursive elements.(U. of Washington, The Tukwila System, available fromhttp://data.cs.washington.edu/integration/tukwila/.)
Data size: 82 MBNum. of nodes: 2.43 millionMax/average tree depth: 36/7.9
• Queries
Q1: //VP[DT]//PRP_DOLLAR
Q2: //S/VP/PP[IN]/NP
Q3: //S/VP//PP[NP/VB]/IN
Q4: //VP[.//PP/IN]//NP/*//JJ
Q5: //S[CC][.//PP]//NP[VBZ][IN]//JJ

Algorithm for query evaluation Experiments
• Test results
0
50
100
150
200
250
300
350
Q1 Q2 Q3 Q4 Q5
PRIX T2S TE TS
Pag
e n
um
bers
For all the experiments, the buffer pool size was fixed at 2000 pages. Thepage size of 8KB was used. For each data set, all the tag names are storedin a single list and then each tag name is represented by its order numberin that list during the evaluation of queries. In our implementation, eachDocId occupies 4 bytes while a number in a Prüfer sequence, a LeftPos ora RightPos occupies 2 bytes. A levelNum value takes only 1 byte. I
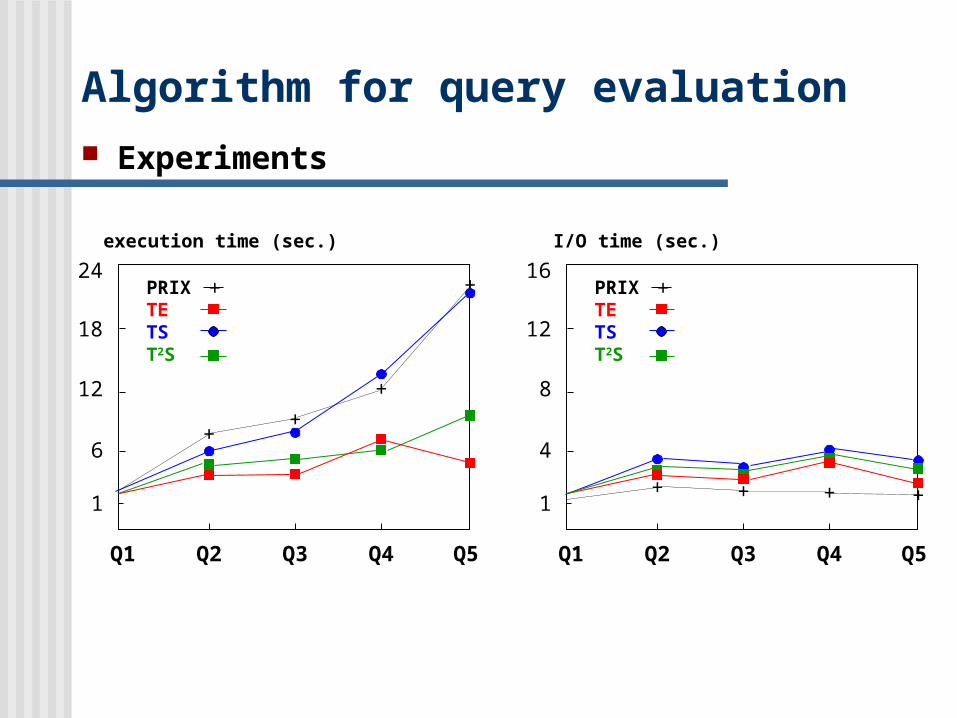
Algorithm for query evaluation Experiments
Q1 Q2 Q3 Q4 Q5
24
18
12
6
1
execution time (sec.)
PRIXTETST2S
+
++
+
+
Q1 Q2 Q3 Q4 Q5
16
12
8
4
1
I/O time (sec.)
PRIXTETST2S
+
+ + + +

Summary
• An efficient method for evaluating ordered tree pattern queries in XML document databases- parent/child and ancestor/descendant relations- from-left-to-right relations
• Computational complexity- O(|T|leafQ) time- O(leafTleafQ) space
• Experiments- TreeBank database - I/O time and CPU processing time

Thank you.





























