Embed Size (px)
DESCRIPTION
A NEW FEATURE EXTRACTION MOTIVATED BY HUMAN EAR. Amin Fazel Sharif University of Technology Hossein Sameti, S. K. Ghiathi February 2005. Outline. Introduction Physiological basis in the human auditory system Modeling of the basilar membrane and hair cells Experimental results - PowerPoint PPT Presentation
Citation preview

A NEW FEATURE EXTRACTION MOTIVATED
BY HUMAN EAR
Amin Fazel
Sharif University of TechnologyHossein Sameti, S. K. Ghiathi
February 2005

Department of Computer Engineering 2/26Thursday, February 03, 2005
Introduction
Physiological basis in the human auditory system
Modeling of the basilar membrane and hair cells
Experimental results
Summary and conclusions
Outline

Department of Computer Engineering 3/26Thursday, February 03, 2005
Introduction Speech is #1 real-time communication
medium among humans.
Advantages of voice interface to machines: Hands-free operation Speed Ease of use

Department of Computer Engineering 4/26Thursday, February 03, 2005
Introduction Human is a
high-performance existence proof for speech recognition in noisy environments.
Wall Street Journal/Broadcast news readings, 5000 words
Untrained human listeners vs. Cambridge HTK LVCSR system

Department of Computer Engineering 5/26Thursday, February 03, 2005
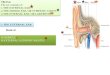
Physiological Basis

Department of Computer Engineering 6/26Thursday, February 03, 2005
Physiological Basis
The semicircular canals are the body's balance organs.
Hair cells, in the canals, detect movements of the fluid in the canals caused by angular acceleration
The canals are connected to the auditory nerve.
Semicircular Canals
Cochlea
Inner Ear

Department of Computer Engineering 7/26Thursday, February 03, 2005
Physiological Basis
The inner ear structure called the cochlea is a snail-shell like structure divided into three fluid-filled parts.
Two are canals (Scala tympani and Scala Vestibuli) for the transmission of pressure and in the third is the sensitive organ of Corti, which detects pressure impulses and responds with electrical impulses which travel along the auditory nerve to the brain
Semicircular Canals
Cochlea
Inner Ear

Department of Computer Engineering 8/26Thursday, February 03, 2005
Physiological Basis
The organ of Corti can be thought of as the body's microphone. Perception of pitch and perception of loudness is connected with this
organ.
It is situated on the basilar membrane in the cochlea duct It contains inner hair cells and outer hair cells. There are some 16,000 -20,000 of the hair cells distributed along the
basilar membrane.
Vibrations of the oval window causes the cochlear fluid to vibrate. This causes the Basilar membrane to vibrate thus producing a traveling
wave. This causes the bending of the hair cells which produces generator
potentials If large enough will stimulate the fibers of the auditory nerve to produce
action potentials The outer hair cells amplify vibrations of the basilar membrane
Semicircular Canals
Cochlea
Inner Ear

Department of Computer Engineering 9/26Thursday, February 03, 2005
Modeling of BM and Hair Cells
Different parts of basilar membrane and hair cells are sensitive to different frequencies of input signal.

Department of Computer Engineering 10/26Thursday, February 03, 2005
Modeling of BM and Hair Cells Since corporation of basilar membrane and hair
cells changes all frequencies of speech into mechanical energy, with good approximation, we can discretely represent basilar membrane and hair cells as forced damped oscillators with different natural frequencies.

Department of Computer Engineering 11/26Thursday, February 03, 2005
Modeling of BM and Hair Cells We stimulate these oscillators with input sound
In this simulation we have an oscillating particle which is always pulled by a force towards the center of oscillation
Displacement of the article from the center of oscillation is shown by x and the inward force is equal to –kx.
k is the constant for each oscillator
20mk
constant

Department of Computer Engineering 12/26Thursday, February 03, 2005
Modeling of BM and Hair Cells Since we have a foreign force (posed by sound),
we can no further use those standard equations which assume the energy of system is constant. If we don't consider the effect of friction, the energy of system will not decrease and it becomes instable. So we must add a force in opposite direction of movement. Since the direction of movement is determined by v (velocity), the friction force is –bv
Viewing each diapason as a filter
Q
mb 0
Bandwidth

Department of Computer Engineering 13/26Thursday, February 03, 2005
Modeling of BM and Hair Cells We model the state of each oscillator with
the pair [x v], where x is the displacement and v is the velocity of particle
Where ∆t is the inverse of sampling frequency
a
v
x
t
t
v
xold
old
new
new
10
01

Department of Computer Engineering 14/26Thursday, February 03, 2005
Modeling of BM and Hair Cells The particle is imposed by three forces:
The diapason itself pulls the particle by force –kx
The sound imposes a foreign force, say Fexternal
To compute Fexternal from the current sample we use the value of sample itself as the external force
The friction opposes to the movement by force –bv

Department of Computer Engineering 15/26Thursday, February 03, 2005
Modeling of BM and Hair Cells Now we can compute a, using the
following formula
For using this model in feature extraction After calculation of the energy for each of
these oscillators, we use them as feature vectors in ASR systems
m
kxbvFa prpr
22
2
1
2
1kxmvE

Department of Computer Engineering 16/26Thursday, February 03, 2005
Experimental results We transform a speech with our human based
model and compare it to spectrum domain of this speech
These two transformations have little differences

Department of Computer Engineering 17/26Thursday, February 03, 2005
Experimental results This comparing shows that this human
based model can be used impressively in ASR systems.
In addition, this method can be used as an effective and quick signal transformation instead of FFT or wavelet in various tasks.

Department of Computer Engineering 18/26Thursday, February 03, 2005
ASR Experiments The feature extraction algorithm proposed
for speech recognition were tested on a English digit database For training we use 1386 digit sequences
spoken by 18 speakers
In testing phase we use 200 digit sequences that uttered by speakers out of training database
The testing database split to four groups of 50 sequences and four types of noises added to these groups

Department of Computer Engineering 19/26Thursday, February 03, 2005
ASR Experiments Recognition is performed using HTK
16 emitting states and three mixture continuous HMM model
3-state silence model Single state inter-digit pause model
In the reference experiments, MFCC_0_D_A is used Consists of 13 standard cepstral coefficients including
C0 augmented with first and second derivations of them
MFCC features were generated by applying a Hamming window of size 25 ms and overlap 10 ms to the same pre-emphasized 23-channel Mel-scale filterbank.
The cepstral features were obtained from DCT of log-energy over the 23 frequency channels.

Department of Computer Engineering 20/26Thursday, February 03, 2005
ASR Experiments Car Noise
Comparing of MFCC and HEFE for Car Noise
0102030405060708090
100
20dB 15dB 10dB 5dB 0dB -5dBSNR. dB
Wo
rd e
rro
r R
ate
%
MFCC
HEFE

Department of Computer Engineering 21/26Thursday, February 03, 2005
ASR Experiments Exhibition Noise
Comparing of MFCC and HEFE for Exhibition Noise
0
20
40
60
80
100
20dB 15dB 10dB 5dB 0dB -5dBSNR. dB
Wo
rd e
rro
r R
ate
%
MFCC
HEFE

Department of Computer Engineering 22/26Thursday, February 03, 2005
ASR Experiments Babble Noise
Comparing of MFCC and HEFE for Babble Noise
0
20
40
60
80
100
120
20dB 15dB 10dB 5dB 0dB -5dB
SNR. dB
Wo
rd e
rro
r R
ate
%
MFCC
HEFE

Department of Computer Engineering 23/26Thursday, February 03, 2005
ASR Experiments Subway Noise
Comparing of MFCC and HEFE for Subway Noise
0
20
40
60
80
100
20dB 15dB 10dB 5dB 0dB -5dB
SNR. dB
Wo
rd e
rro
r R
ate
%
MFCC
HEFE

Department of Computer Engineering 24/26Thursday, February 03, 2005
ASR Experiments For all contaminated speech, HEFE shows
superior performance for all noise types at most SNR levels.
For babble noise, HEFE demonstrates significantly better performance than MFCC.
For subway noise, improvements by the HEFE are least significant, but still noticeable.

Department of Computer Engineering 25/26Thursday, February 03, 2005
Summary In this paper we have introduced a simple
model for basilar membrane and hair calls based on physiological basis
We use this model for feature extraction in ASR systems
These features significantly outperform MFCC features at babble noise

Thank you!