Embed Size (px)
Citation preview

The Pennsylvania State University The Graduate School
Capital College
A Simple Web-enabled System for Database Management
A Master's paper in Computer Science
By Ping Wang
@2000 Ping Wang
December 2000

Abstract
A database management system (DBMS) is used to provide an environment that lets people store
and retrieve information conveniently and efficiently. The World Wide Web is the most popular and
widespread information service on the Internet. This paper describes a program that connects to a
database system and allows database managers and database users to collect and access data
through the Web. In our system, most complicated and redundant work is transparent to database
managers and users. Also, the system provides friendly interfaces. This allows people with limited
training to work with our database system. The system is a CGI application developed using the Perl
programming language.
Table of Contents
1. Introduction 1
2. System Description and Implementation 7
<2.1> General information about the implementation 7
<2.2> Running the CGI program on the Internet 13
<2.3> Implementation review 26
3. Conclusion 34

References 38
Table of Figures
Figure 1. Diagram of Qingru Zhang's system 3
Figure 2. Diagram of our system 4
Figure 3. Example of an input text file 11
Figure 4. Login page 13
Figure 5. Example of an error message page 14
Figure 6. Welcome page 15
Figure 7. Manager page 17
Figure 8. Create table page 18
Figure 9. Create query page 29
Figure 10. Result page from deleting a query 20
Figure 11. User page 22
Figure 12. Table value input page 23
Figure 13. Query result page 24
Figure 14. Query variable entry page 25

- 1
1. Introduction
Web-enabled applications provide solutions for education, business, entertainment and many other
application areas. For example, global education allows students around the world to take the
same class on the Web. In most such applications, a Web browser provides a front end to existing
database systems. Web servers are responsible for the other end of the connection, listening for
incoming requests and transmitting the desired document back to the browser. Web documents
often correspond to real, physical files stored on one of the server's disks. When a request comes
in, the server finds the corresponding document on its disk drive and sends it off. However, Web
documents don't have to be static files. To deal with dynamic documents, Common Gateway
Interface (CGI) scripts are used on the server's side. These allow designers of Web sites to create
dynamic documents that change every time they are accessed or in response to different user
requests [Harr99].
ODBiC (Open Database Internet Connector) is an example [Harr99]. It has many unique built-in
functions to simplify some common requirements. For example:
• Automatic HTML table generation from database queries.
• Automatic "query by example" queries generated from an input.
• Automatic HTML forms and SQL statements for database INSERT and UPDATE
operations.

- 2
• Automatic HTML "pull-down choice lists" with choices selected from the database.
• Easy "loop" processing for multiple rows selected by a query.
• Easy multiple-level "master/detail" or "category" grouping of query results.
In addition to database access, ODBiC provides many other functions for creating dynamic Web
pages. It is a consumer product for Web-enabled database management.
Database interface is the primary purpose of such applications, and is fundamental to today’s
booming electronic B2C (Business to Customer) and B2B (Business to Business) marketplaces.
This paper introduces a Web-enabled database management system -- a CGI application
implemented using Perl. Our system is a simple and easy to use database Internet connector. It is
similar to ODBiC and is based on a system developed by Qingru Zhang. In Zhang's paper "A
system to generate a simple and reusable Web-enabled solution for database queries"[Zhang00],
she explained how to implement a specific system that generates a CGI program for database
users (shown in Figure 1). To use her system, one needs to do the following:
1. Create an input text file that contains table and query information
2. Run a translation program that reads this text file and generates a target CGI program
and a standard file (called, for example, Xfile) which contains statements for creating
tables
3. Create the tables in the database (for example, using the DB2 command "db2 -f

- 3
Xfile").
4. Use the target program to provide a user-friendly interface to add values and execute
queries on the Internet
Run generating program
Access target CGI program
Create tables
Add records
Execute queries
Database
Figure 1. Diagram of Qingru Zhang's system
Zhang's system works well if the database is very stable, which means the tables and queries in the
database file do not need to be changed after they are created. Otherwise, to make changes, the
text file has to be regenerated, the old tables must be dropped from the database and the new
tables must be created in the database. Then the target CGI program can be run. This process is
Create text file

- 4
inconvenient and must be done by a database manager.
We wanted to design a system that makes changing the database and querying easier. Also, we
want our system to be portable, transparent, simple and easy to use. A diagram of our system is
shown in Figure 2. We have integrated the database management part into our system. Compared
to Zhang's system, our system includes several new features as follows:
CGI program
Welcome page
Manager page
User page
Create and delete tables
Create and delete queries * Grant and revoke privileges
Add records
Execute queries Display results
Database

- 5
Figure 2. Diagram of our system (* no connection to the database)
1. A database manager does not need to generate a target CGI program. Our program itself is
a CGI program.
2. A database manager does not need to generate a standard file that contains statements for
creating tables. Also, he doesn't need to create tables in the database. Our system does this
automatically.
3. A database manager can create and delete tables, create and delete queries in an existing
input text file.
4. A database manager can create a new input text file.
5. A database manager can grant and revoke privileges to users.
6. A database user can select values for records while adding data and for variables while
executing queries.
Our system is portable. The connection from the program to a database system is implemented
using the database interface (DBI) package. DBI makes calls to modules called DBDs (database
drivers), which are specific to a database vendor and drive the native vendor API (Application
Programming Interface) for a particular database system. The reason we chose DBI is that DBI is
not related to any one specific database. It serves as an intermediary between a program and one

- 6
or more DBD driver modules. The DBI package API completely isolates the application from the
internal implementation of the underlying databases. One can connect to different database systems
using a different DBD driver module [Husa96]. For example, our system uses the DBI and
DBD::DB2 combination, but could use any DBD driver module needed to port to a different
database system.
Our system is relatively easy to implement. This is due to using a scripting language, which means
the program does not have to deal with complex formatting or function/procedure or
object/method structures to accomplish its task. Scripting languages provide quick turnaround,
dynamic user interfaces, good facilities for text handling, run-time evaluation, and good connections
to database and networks [Srin97].
Our system is designed to be easy to use and learn. The interface between our system and the
database system is transparent to both managers and users. Our system provides friendly interfaces
for both database managers and users. People who have limited training can handle our system
without significant difficulties.
There are several issues we needed to consider during the design of our system. The main issues
included how to build dynamic hash tables from an input text file, how to connect to an existing
database system, how to design a friendly interface, how to deal with the variables in the queries

- 7
and how to make the system transparent to both database managers and users. These issues will
be described in the following sections of this paper.

- 8
2. System Description and Implementation
<2.1> General information about the implementation
There are several programming languages that can be used as scripting languages. Scripts are
external programs that the server runs in response to a browser's request. When a user requests a
URL that points to a script, the server executes it. Any output that the script produces is returned
to the user's browser for display. We chose Perl as our scripting language because it is easy to
learn and because it is optimized for text processing.
Perl is an interpreted language optimized for scanning arbitrary text files, extracting information
from those text files, and printing reports based on that information [Stei97]. The key to Perl's
power over text is its implementation of regular expression. A regular expression is a pattern that
describes a set of strings. A job done using a single pattern match in Perl can cost lines of code in a
different language. "Pattern matches, especially when combined with Perl's handling of strings and
lists, provide capabilities that are very difficulty to mimic in other programming languages"
[Brow99]. Perl is available for most operating systems and Perl's code is far more compact than
most other languages.
Our system is Web-enabled, which means it is an HTML-based application. In such an interactive
HTML-based application, a client program, such as a browser, sends information to an HTTP

- 9
server using the HTTP protocol, and vice versa. An HTTP server handles requests in different
ways. If the requested resource is a file, the server locates the file and sends it back to the client, or
sends a relevant error message if the file is unavailable. If the requested resource is complex, such
as an access to a database, servers do not do this processing themselves. Because such tasks are
largely customized to the applications running on a particular Web site, most servers let other
programs handle such complex tasks. Those programs are called gateway programs. They are
designed for special processing and run separately from the HTTP server. The communication
protocol between HTTP servers and these gateway programs is called the Common Gateway
Interface (CGI) [Grah97]. It defines three basic ways (environment variables, standard input,
command line) that information can be passed from a server to a program and one way (print
statements) that information can be passed from the program to the server [Patc98]. Perl is the
most popular language for writing CGI programs.
Our system is implemented to handle <FORM> HTTP requests, which use standard input to pass
the information from the server to the program. HTTP forms are used to store feedback
information, send simple or complex queries to a specific database, and deliver query results
[Titt96].
Several methods can be used by programs to receive data, such as GET, HEAD and POST. Our
CGI program uses the POST method. Compared to other methods, the POST method is more

- 10
secure and can deal with unlimited length URLs [Deep96].
The DBI package API is designed specifically for use with Perl. Our system uses the DBI package
to connect to a database system.
$dbh = DBI->connect ($databasename, $username, $password);
DBI->connect( ) returns a database handle, which represents the connection to a specific
database. There are several other functions we use to execute our basic SQL queries, such as:
$sth = $dbh->prepare( $sql_query); # send the query $sth->execute( ); # execute the query
$sth->bind_param($id, $value); # bind values to variables within the query
Once a statement is prepared and executed, the DBI package stores the information as attributes
of the statement handle. For example:
$sth->{NUM_FIELD} # the number of fields returned $sth->{NAME} # column names returned by the query
All DBI statements return undef on failure. The error strings can be obtained from
$dbh->errstr, which contains the errors from the last executed DBI statement [Srin97].
The cgi-lib.pl library is the standard library for creating CGI scripts in the Perl language. We

- 11
use the &ReadParse() function from the cgi-lib.pl library to help us get the value of a
variable from its name.
require 'cgi-lib.pl'; &ReadParse ( ); <input type="text" name=$input_name value=$in{$input_name}>
$input_value = $in{$input_name};
We pass a parameter to &ReadParse( ), for example &ReadParse(*array), in order to
use a different variable as the hash table name, such as "%array", instead of "%in" which is
the default hash table name.
Our system is designed to create, read and modify the input text file. The input text file is used to
store and retrieve information about the tables in the database and the queries on these tables. The
format of the file is based on Zhang's input text file. We modified Zhang's file and made it simpler
and more transparent. Figure 3 is an example of our text file format.
user pxw138 dbname qxz110 table people attri Identity, SSN, integer, yes, yes attri Name, name, char(20), yes, no attri BirthDay, birthday, date, yes, no attri Address, address, char(20), no, no attri PhoneNo, phoneno, char(20), no, no @ table position attri JobID, jobid, char(10), yes, yes

- 12
attri Location, location, char(20), yes, no attri Title, title, char(20), yes, no attri Department, department, char(20), yes, no attri RoomNo, roomno, char(10), yes, no attri EmployeeID, SSN, integer, yes, no attri AdviserName, adviser, char(20), no, no @ query Find all information in table people select * from pxw138.people @ query Find all information in table position select * from pxw138.position @ query Find person by name and birthday select * from pxw138.people where name =:name and birthday =:day @ query Find all information about a person by adviser select * from pxw138.people, pxw138.position where adviser = :ad and people.SSN = position.SSN @
Figure 3. Example of an input text file
The first line in the file contains a user's account name. This account name is used to indicate that all
the tables specified in this file are created by that user. The second line contains the database name.
This specifies which database the program uses. The rest of the file is filled with table and query
specifications.

- 13
For each table, the format is as follows:
The first line is the keyword "table " followed by "table_name".
The last line is the character "@".
The rest of the lines define table attributes. Each line has the format:
"attri description_attr, attr_name, type, yes/no, yes/no"
This part has the same format as Zhang's text files[Zhang00]. The "description_attr" is a description
of the attribute. It is not necessary but provides more information about the attribute. The
"attr_name" stands for attribute name. The first yes/no is to indicate if this attribute can be null or
not. If the attribute can be null, the value is no; otherwise, it is yes. The second yes/no is to indicate
if the attribute is a primary key attribute or not. If the attribute is part of the primary key, the value
is yes.
For each query, the format is as follows:
The first line is the keyword "query " followed by "query_name".
The last line is the character "@".
The rest of the lines are a standard SQL query.
This part is simpler and more transparent than Zhang's. If the query has variables, the character ":"

- 14
is placed just before each variable's name. This will help our CGI program find the variables in the
query.
We will talk more about the implementation detail later in section <2.3>.
- 15
<2.2> Running the CGI program on the Internet
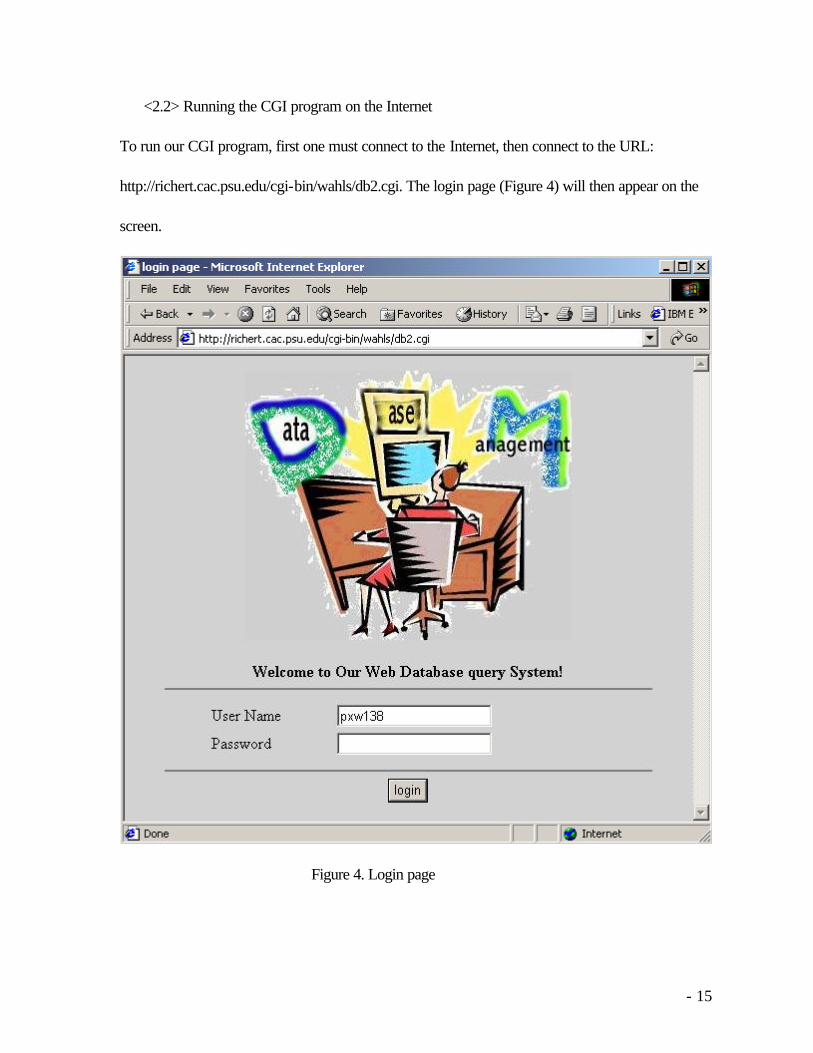
To run our CGI program, first one must connect to the Internet, then connect to the URL:
http://richert.cac.psu.edu/cgi-bin/wahls/db2.cgi. The login page (Figure 4) will then appear on the
screen.
Figure 4. Login page

- 16
Here, richert.cac.psu.edu is the hostname for the Web server and the location of our program.
Generally, our system can be placed on any suitable server.
On the login page, the user name and password should be entered. If the account information is
valid for the database (such as DB2 in our system), the login succeeds. Otherwise, an error
message page will appear (as shown in Figure 5).
Figure 5. Example of an error message page

- 17
Figure 6. Welcome page
The first page after login is the welcome page (Figure 6). On this page, one should type the name
of the input text file, and then select either "Manager" or "User" to use the input file chosen.

- 18
If the input text file entered does not exist, two different things can happen. If one selects
"Manager", the system will create a new input file as named. Also, there is a message that appears
at the top of the manager page (Figure 7) as below:
"$file_name is a New Input Text File." If one selects "User", the warning message below will appear and reentry is allowed.
"! ! ! The Input Text File You Entered Does Not Exist. Try Again! Please Enter a Correct File Name."
While on the manager page (Figure 7), one has the opportunity to create and delete tables, create
and delete queries and grant and revoke privileges to other users. For example, to create a table
with 5 attributes, one should enter the number of attributes, then click the "create new table"
button. The "create table" page (Figure 8) will appear.
In the "create table" page, one would then enter the table name and attribute information, then click
"Finish". If well defined, the table is stored into the database system and into the input text file, and
the program goes back to the manager interface. Otherwise an error page similar to that shown in
Figure 5 will appear.

- 19
Figure 7. Manager page

- 20
Figure 8. Create table page

- 21
Figure 9. Create query page
As with the "create table" page, the "create query" page (Figure 9) is easy to use. One should type
the name of the query, and then implement the query using SQL. After one clicks "Complete", the
program will go back to the manager interface.
When creating queries, it is vital that the userid of the owner of a table (the person who created it)
be attached to the table name, i.e. select * from pxw138.people, where pxw138 is the

- 22
owner of the people table. Otherwise the query does not work if anyone except the creator runs it.
When comparing a variable with an attribute in an SQL query such as:
attribute_name =:variable_name
the attribute_name must be unique among all the tables specified in the input file. Otherwise, the
specific table name of this attribute must be added to this SQL query as follows:
table_name.attribute_name =:variable_name
Adding the table name to a non-unique attribute name makes it unique. Otherwise, the "select
variable value" function will not work. But one still can enter the variable value using priority choice,
as shown in Figure 14.
Figure 10. Result page from deleting a query

- 23
If one selects a table to delete and clicks "delete table", the following message will appear in the
"Result page from deleting a table" page:
Table "table_name" is deleted from the input file "file_name" and
from the database.
If one selects a query to delete and clicks "delete query", the following message will appear (Figure
10):
Query "query_name" is deleted from the input file "file_name".
Then one can click "Manager" to go back to the manager page.
While in the user page (Figure 11), one has the opportunity to insert values into tables (if this
privilege has been granted) and submit queries (this privilege is granted by default). This part is
similar to Zhang's system. We modified Zhang's interface and attempted to make it more friendly
for users.

- 24
Figure 11. User page
To insert a record, one simply selects the "table name" from the list, and then clicks the "insert table
value" button to get the "insert table value" page (Figure 12). We added the type of attribute after
the definition of the attribute name to help the user enter a correct value. Also, we added the select
feature that will show all the values of the attribute in the database. For frequently used values, such
as the name of states (for addresses), a department name, etc., the necessary value most likely
already exists in the database and can simply be selected. In this case, the "Enter value" field should
be left as "*empty*". Otherwise, the value entered will be the priority choice and the value selected
will be ignored.

- 25
After inputting or selecting the values, one should click "Done". If the value for each attribute is of
the correct type and the new record does not violate the primary key or not null constraints, the
record is successfully inserted into the selected table in the database system. The user page with
the message " Table values are successfully added to the database."
shows at the top will then appear. Otherwise, an error page will appear.
Figure 12. Table value input page
One can submit a query by selecting the query and clicking "submit query". The system checks
whether the query needs variables or not.

- 26
If the query is simple and no variables are needed, a result page (Figure 13) will appear.
Figure 13. Query result page
If the system finds that variables are needed, the variable definition page (Figure 14) will appear. In
the same way that one uses the record input page, one can either enter the variable value or select
the value from a list of values.

- 27
Figure 14. Query variable entry page
Actually, the situation here is more complex. In the record input page, all the record values for the
drop-down lists are from the same table. Here the variables may be compared with attributes
belonging to different tables.
If the same variable name is compared with more than one attribute, all the attributes' values can
be selected from the drop-down list of the variable. We explain the details of this in the next
section.

- 28
<2.3> Implementation review
In our CGI program we use many hash structures to store and retrieve data from the input text file.
Because the file may change frequently, generating these dynamic hashes becomes an important
issue.
Usually, a hash table is built in Perl with the format shown below (for creating a hash
%privileges to store the possible database privileges):
% privileges = qw{ 1 insert 2 update 3 delete 4 select
};
While generating dynamic hashes, we can not use this format. For example, our CGI program uses
dynamic hash tables to store and retrieve information from the input text file. Each time the CGI
program runs, the subroutine &make_hash in our program reads the input text file and generates
the hash tables that will be used later. The following code is used in our program to read the input
file and build the hash tables for the tables in the file:
while (<INPUT>){ $n = 1; if (/^table/i .. /\@/) { # recognize table definition part if ($_ =~ /^table\s+(\S+)/i){ # recognize table name

- 29
$tables{$n} = $1; # build hash %tables $n++; $tablename =$1; } # recognize attribute name if ($_ =~ /attri\s+(\S+),\s*(\S+),\s*(\S+),\s*(\S+),\s*(\S+)/) { $$tablename{$2} = $3; # build hash %$tablename } }#for table .. @ }
This code builds dynamic hash tables containing the table information from the input text file. These
hash tables include a %table that contains all the tables in the file with keys from 1 to n and values
of each table name. It has the same functionality as the regular static hash table shown below.
%table = qw (
1 table_name_1 2 table_name_2 … n table_name_n );
Also each table has a hash table %$tablename that contains keys with actual attribute name and
values with the type of the attribute.
These hash tables provide an efficient data structure for storing data about tables and allow our
CGI program to retrieve this data easily. For example, there are many drop-down lists in our
interface that can be built from these hash tables as follows:
print "<TD><SELECT NAME=TABLE_INDEX>"; print "<OPTION VALUE=" ">select your table";

- 30
foreach $table (sort keys (%tables)) { print"<OPTION VALUE = \"$table\"> $useraccount.$tables{$table}\n"; } print "</SELECT> </TD>";
The code above builds a drop-down list of all table names. If the keyword "sort" appears before
keys or values, the list is in sorted order. Otherwise, the list is in no specific order.
In our implementation, we use Perl's powerful regular expressions to retrieve information from the
text file and to add/delete specific statements into/from the text file. Perl's regular expressions are
not difficult to learn but not easy to master. The more one learns about regular expressions, the
more one feels their power and the less one feels helpless.
In Perl's regular expressions, the "^" character is guaranteed to match at only the beginning of the
string, the "$" character is guaranteed to match at only the end (or before the new line at the end),
and Perl does certain optimizations with the assumption that the string contains only one line.
Below are two examples of using "^" and "$".
Our CGI program uses the pattern "/^table\s+(\S+)/i../\@/" to find the table
name to build hash %tables. Without the "^" character in the pattern, there may be more
matches than expected. For example, the word "table" in a query statement would be selected.
The reason is that the word "table" within the query statement matches the pattern.

- 31
Also, without the "$" character in the pattern
"/^query\s*$query_name\s*$/i../\@/" that is used to find the query
statement, there may be more than one match. For example, executing the "delete query"
operation with the query statement "Find all flies" will delete both "Find all flies by name and color"
and "Find all flies", because both query statements contain "Find all flies".
In order to make a friendly interface for users to add records to the database and to submit
queries with variables, we designed our system to give users the opportunity to either select or
enter the values of records/variables.
In the beginning, we tried to design the system to let users select frequently used values, such as
state names and the department names. The problem is that we did not know what kinds of values
would be needed because the system allows database managers to create input text files and
tables. We can build some hashes with fixed information such as Countries, States and Oceans.
But most information in the database is not fixed. In order to provide users with a convenient
interface, our system retrieves all the values from appropriate records already in the database and
lets users select from these values or enter their choice.
This design is convenient for users but more time is needed by the system to retrieve all previously

- 32
entered values from the database and then to build hash tables for storing and retrieving the data,
especially when dealing with a database that has many records.
On the record input page, all the information needed is within a specific table. It is relatively easy to
retrieve the record for an attribute of the table using the SQL query:
"select distinct $attribute_name from $useraccount.$table_name" # $useraccount is the table creator's account name
On the variable entry page, things are more complex. The variables may be compared with
attributes belonging to different tables, so we don't have a specific table name as used in the
previous SQL query. The SQL query used to retrieve the values for the attribute that is compared
with the variable is more complex. The basic SQL query is:
"select distinct $attribute_name from $alltables" # $alltables is the join of all the tables
and below is the code to build the from clause above with the variable $alltables.
$alltables = "";
foreach $table ( keys (%tables)) { if ($alltable eq ""){
$alltables = "$useraccount.$tables{$table}"; }
else { $alltables .= ", $useraccount.$tables{$table}";
} }

- 33
If the variable is compared with an attribute that is not unique (some other table has an attribute
with the same name), one should add the table name to this attribute name when defining the query
(we mentioned this before in how to create queries on page 23). Otherwise, the query is illegal.
If the same variable is compared with different attributes, all attributes' values can be selected from
the drop-down list. To implement this part, first we attempted to use attribute names as keys to
retrieve the corresponding variables. This did not work. Using attributes as keys provides more
than one input or selection for one variable if the variable is compared with more than one
attribute. The reason is that our CGI program uses &ReadParse(*array) to get the input
data. This way, we input or select the same variable's value more than one time. All values for that
variable are concatenated, and so do not match any values in the database correctly. For example,
if we have a variable compared with two attributes:
# variable1 compared with attribute1 and attribute2 # get variable1's value from input or select # (assume the value is a string "red") $array{'attribute1'} = "red"; $array{'attribute2'} = "red"; # system retrieves the wrong variable value as below $array{'variable1'} = "redred";
That is why we use variables as the key to get values. The easy way is to build a hash table that
stores variables and associated attributes. When the variables are used as the key to retrieve the
corresponding attributes and build a drop-down list, only one of the attribute's values appear on

- 34
the list, because Perl chooses only one if there are multiple identical keys. This will miss other
attributes' values in the drop-down list but will still provide the select feature.
To solve this problem and make all attributes' values appear in the drop-down list, we build two
hash tables instead of one. One hash table stores the variables with unique numbers as keys, and
the other stores the corresponding attributes with the same unique numbers as keys. Every variable
appearing in the query has a list containing its corresponding attribute (the attribute it is compared
with). For example, if the variable name "SSN" appears twice in the query, there should be two
original lists:
@varattr2 = ($attri_name{2}); # list for variable "SSN" @varattr4 = ($attri_name{4}); # list for variable "SSN" # %attri_name is the hash table that stores the attributes
Then we compare the variable values with the information retrieved from the hash table that stores
the variables. If two identical values are found, the corresponding attribute is removed from one
variable's list and put into the other variable's list. For example, after comparing the variable values,
the above two lists would become:
@varattr2 = ($attri_name{2},$attri_name{4}); @varattr4 = ( ); # two list for variable "SSN"
Using these lists, the system can retrieve all the appropriate attributes' values and build a drop-

- 35
down list without missing any values.
We now show some code from our CGI program that builds hash tables for queries having
variables. To do this, we give each query a unique number, and if the query has variables, we use
this unique number to build hash tables for this query to store the attribute names and the variable
names.
if ($_ =~ /^query\s+(\S+)/){ # recognize description sentence
... $m++; # a unique number for this query $num = 1; # to order attributes and variables } if ($_=~/\.*:\.*/){ #find variable $c=$m-1; $attri_name = attrname.$c; #define hash name $var_name = varname.$c; @and=split(/\s+and\s+/, $_); #split between "and" foreach $and(@and){ if ($and=~/\.*(\S+)\s*[\=\>\<][\=]*\s*\:(\S+)/){ $$attri_name{$num} = $1; $$var_name{$num} = $2; #add hash contains $num++; } @or=split(/\s+or\s+/,$and); #split between "or" foreach $or(@or){ if ($or =~ /\.*(\S+)\s*[\=\>\<][\=]*\s*\:(\S+)/
and $or ne $or[0]){ $$attri_name{$num} = $1; $$var_name{$num} = $2; $num++; } } } }
The split of "and" and "or" above helps the system to get all the variables in the query. Using these

- 36
dynamic hash tables, the program creates a list for each variable containing its corresponding
attributes.
$numb = 0; foreach $z (keys %var_name){ # $z is a unique number $varattr = varattr.$z; @$varattr = ($attri_name{$z}); # create original list $numb++; }
After comparing with every variable's value, all the attributes compared with the same variable are
put into the same list (in the code shown below). All the values of those attributes appear in the
drop-down list for that variable.
for ($x = 1; $x < $numb; $x++){
for ($y = $x+1; $y <= $numb; $y++){ if ($var_name{$x} eq $var_name{$y}){ $varattr = varattr.$x; $varattr2 = varattr.$y; if ($#$varattr >= 0){ push (@$varattr, $attri_name{$y}); pop (@$varattr2); } } } }
3. Conclusion

- 37
In this paper we introduced a simple Web-enabled system for database management. In our
system, the CGI program handles the various tasks as much as possible. Our program builds drop-
down lists that eliminate redundant work such as entering repeated values in table, and provides a
friendly interface for both database managers and users. The main work which database managers
and users do is simply to select and submit.
The following sequence of events shows the flow of our CGI program and how HTML pages are
created when a client (database manager or user) requests operations.
1. Clients use a Web browser to select the operations by clicking on a link or pressing a button.
These operations include the following:
• Login and logout
• Create/open input text files
• Create and delete tables
• Create and delete queries
• Grant and revoke privileges
• Add records
• Submit queries
2. The program accepts these requests for operation execution on behalf of the Web server and
handles the requests. The operations can modify the input text file and send SQL queries and

- 38
statements to the database.
3. In the database, SQL statements and queries are executed.
4. A dynamic HTML page is created that includes the statement or query result.
5. The HTML page is returned to the Web server.
6. The Web server finishes the request by returning the page to the browser.
Our CGI program runs as a simple database management system. To make it more powerful and
more practical, there are several things we can do, including:
• Implementing a Web-enabled database monitor, which provides comprehensive information
about the database system.
• Implementing more database operations in the system. One example would be an operation to
add a column to an existing table using the SQL command:
"ALTER TABLE $table_name ADD COLUMN $attr_name type"
• Implementing a message send and receive feature within the system. The messages could be
either in a text file or dynamically selected from the database with a query. For example, the
query results can be sent to people who can not access our database but need some
information from the database.

- 39
• Implementing a Web-enabled database director, such as a graphical hierarchical tree structure
that can deal with more complex and heavy duty database management tasks.
The Internet has changed the way we manage databases. Software tools that simplify the
integration of SQL-based databases into Web sites that provide WWW access to the contents of
databases are becoming popular. There are more and more of these software tools being created,
such as WDB, a Web to Database Interface [Fres00] and ODBiC, Open Database Internet
Connector [Harr99].
As with our system, WDB and ODBiC are CGI programs that are executed by a Web server.
They all produce standard HTML web pages and interact with databases. They all have SQL
statements to SELECT, INSERT, or DELETE data in databases. WDB deals with a simple
database which stores addresses. ODBiC is more complex, as it produces both HTML formatted
text and JavaScript, and provides many other useful data processing functions in addition to its
SQL interface. Our system is simple but can deal with all of the basic operations on databases. In
comparison with WDB and ODBiC, the feature of selecting values and variables makes our
system easier to handle. The drop-down select lists provide an integrated view of the information
in the database and make it easy to insert values into the database and execute queries with
variables. Also our system is portable, transparent, and allows people with limited training to work

- 40
with a database management system.
With the rapid development of the Internet, Web-enabled applications have become the best
choice for many organizations. They provide a platform that enables an organization to work more
closely and efficiently with its customers, partners, and suppliers without the barriers of geography
and time differences. Our Web-enabled database management system is an example of such an
application. With a friendly interface and clear directions, it provides database managers and users
an easy way to access databases wherever and whenever they have Internet access.

- 41
References
[Brow99] Brown, M., Bellew, C., Livingston, D. Essential Perl 5 for Web Professionals. Prentice-Hall, Inc., 1999. 163p. [Cham1996] Chamberlin, D. Using the New DB2. Morgan Kaufmann Publishers, Inc., 1996. [Deep96] Deep, J., Holfelder, P. Developing CGI Applications with Perl. John Wiley & Sons, Inc., 1996. 299p. [Fres00] Frese, B. WDB - A Web to DataBase Interface, 2000 <http://www.i-con.dk/wdb/>. [Grah97] Graham, I. S. HTML Sourcebook. Third Edition. John Wiley & Sons, Inc., 1997. 620p. [Harr99] Harris, R. Open DataBase Internet Connector. Copyright ©1997-1999, <http://www.odbic.com/odbic/>. [Husa96] Husain, K., Breedlove, R. F. Perl5 Unleashed. Sams, 1996. 797p. [Patc98] Patchett, C., Wright, M. CGI/Perl Cookbook. John Wiley & Sons, Inc., 1998. 622p. [Srin97] Srinivasan, S. Advanced Perl Programming. Sebastopol, CA. O'Reilly, 1997. 161p. [Stei97] Stein, L. D. How to Set Up and Maintain a Web Site. Addison Wesley Longman, Inc., 1997. 793p. [Stei00] Stein, L. D. CGI.pm - a Perl5 CGI Library, Version 2.74, 2000, <http://stein.cshl.org/WWW/software/CGI/cgi_docs.html>. [Titt96] Tittel, E., Madden, M., Smith, D. B. Building Windows NT Web Servers. IDG Books Worldwide, Inc., 1996. 298p. [Zhang00] Zhang, Q. A System to Generate a Simple and Reusable Web-enabled Solution For database Queries. Master's paper, The Pennsylvania State University, 2000.