Embed Size (px)
Citation preview

A State Machine Architecture for High-Efficiency, Low-Latency SS Media
Performance Extraction
Bret S. Weber DataDirect Networks
Flash Memory Summit 2012 Santa Clara, CA
1

The Real Issue
• Want SSD Performance & Latency • Need Enterprise Redundancy • Use Commodity Flash Products
• Non Proprietary • Customer Replaceable • No Technology “Lock In” • Lowest $/TB
• Allow Seamless Levels of Storage • Low $/TB • Low $/IOP
2

SSD Small Block IOPs
3

SSD Large Sequential
4

Flash Performance Takeaways
► Flash Performance is All over the Map ► The Technology Changes Fast ► Tradeoffs between Cost, Performance and Life ► Investment Protection
5

Typical Controller IOPs Throttling
6
0
200,000
400,000
600,000
800,000
1,000,000
1,200,000
1,400,000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Small Block IOPs
SSD Capability Typical Storage Controller Capability

Typical Controller BW Throttling
7
0
2000
4000
6000
8000
10000
12000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Bandwidth (MB/S)
SSD Capability Typical Storage Controller Capability

Storage Fusion Architecture History
► Previous Experience with Silicon-Based RAID-3 Arrays • High Bandwidth • Very consistent Quality of Service (Bandwidth and Latency)
► Ground Up “Blank Sheet of Paper” Architecture in 2007 • Typical Five Year Maturity Cycle
► Address Emerging Applications • HPC • Data-Intensive Cloud Applications • Big Data Analytics
► Address the Emerging Technologies • Multi-Core Processors • High IOP Non Volatile Memory Technologies • Server Virtualization • Scale Out
Ground-Up Design Big Data Optimized

SFA – Details
► Ground Up Design Exploiting Emerging Technologies ► Optimized for Ultra-High IOPs & Bandwidth
• Application Space Code • Kernel Bypass for all IO Operations • Real-Time NUMA Scheduler Minimizes Latency • Built to Exploit All Available CPU Cores • BW, IOPs and Mixed Workload Configurations
► Fully Parallel I/O Execution Engine • No Lock Architecture
► Portable Code • Rapid Time To Market • Optimizations around Linux architectures
► Highest levels of Performance & QoS ► DDN device drivers accelerate I/O ► Optional Server Virtualization Brings Big Data Closest to Processing
240Gb/s Cache Link
32-64GB High-Speed Cache
32-64GB High-Speed Cache
SFA Interface Virtualization SFA Interface Virtualization
960Gb/s Internal SAS Storage Management Network
16 x FDR InfiniBand Host Ports
SFA RAID 5,6
RAID 5,6
SFA RAID 1
1 2 3 4 5 6 7 8 P
RAID 5,6
Q RAID 6
1 2 3 4
1 1m
Q RAID 6
P RAID 5,6
Internal SAS Switching
Internal SAS Switching

Typical Approaches
10
User Application
GNU C Library
System Call Interface
Kernel-Level Engine
Architecture Dependent Kernel Code
User Space
OS Kernel
Kernel Level Implementation
Data Path
Sys
tem
Man
agem
ent
Data Path
Storage Application
GNU C Library
System Call Interface
Kernel
Architecture Dependent Kernel Code
User Space
OS Kernel
Typical User Space Implementation
Sys
tem
Man
agem
ent
Kernel Context Switches Add Significant Latency
In-Kernel Dependencies Prohibit Easy Portability

Low Latency – No Context Switching
User Application
GNU C Library
System Call Interface
Kernel-Level Engine
Architecture Dependent Kernel Code
User Space
OS Kernel
Kernel Level Implementation
Data Path
Sys
tem
Man
agem
ent
Data Path
DDN SFA Application
GNU C Library
System Call Interface
Kernel
Architecture Dependent Kernel Code
User Space
OS Kernel
DDN User Space Implementation
Sys
tem
Man
agem
ent
Data Path
Storage Application
GNU C Library
System Call Interface
Kernel
Architecture Dependent Kernel Code
User Space
OS Kernel
Typical User Space Implementation
Sys
tem
Man
agem
ent
► No Context Switching ► Low Latency IO ► Predictable Performance ► High Speed Routing
Architecture

A Scalable & Abstractable I/O Delivery Architecture
12
Front-End Services Abstraction
Back-End Services Abstraction
SFA JIPC: Non-Preemptive
I/O Routing System
InfiniBand RDMA Driver Fibre Channel Driver Memory DMA Driver
Internal VM Clients External Block-Based Applications
User Space I/O Scheduler
Owns The Kernel & Prohibits Disruption
(State Machine)
I/O Routing, RAID Services, Cache Management & Disk Virtualization
Com
plet
e St
orag
e O
S
Scale Scale

SFA12K Architecture
► 40GB/S Throughput ► 1.4M IOPs to SSD ► DirectFlash Caching
Acceleration
State Machine
Scale Up To Any # Of CPU Cores Today: 8/Socket
Scale Out To Any # Of CPU Sockets
Today: 4 Sockets

SFA Controller IOPs – No Throttling
14
0
200,000
400,000
600,000
800,000
1,000,000
1,200,000
1,400,000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Small Block IOPs
SSD Capability Typical Storage Controller Capability
SFA with SSD
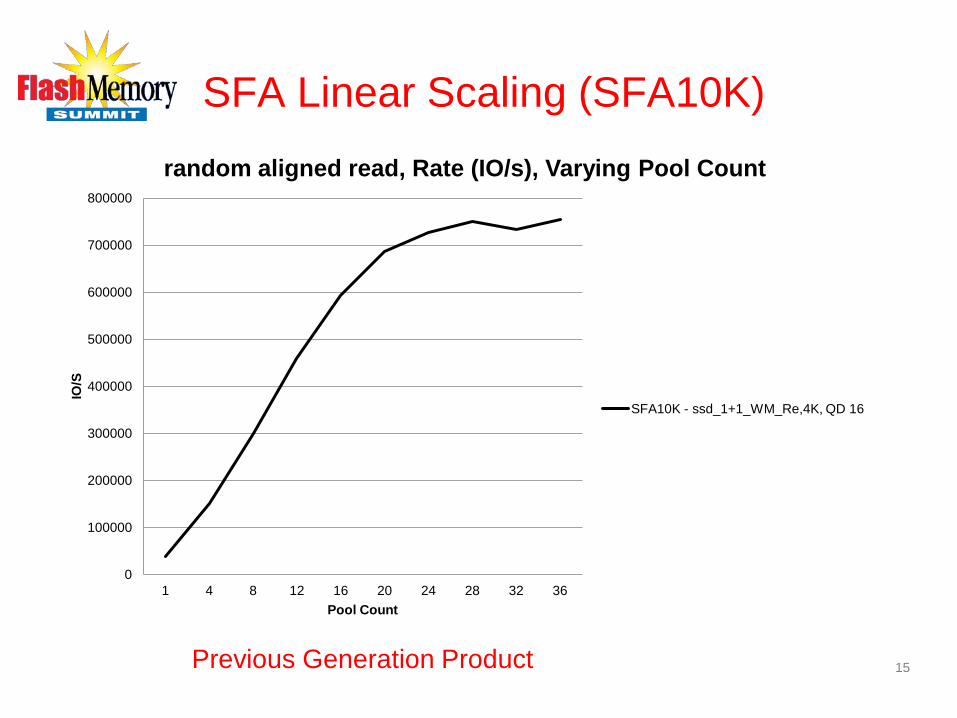
SFA Linear Scaling (SFA10K)
15
0
100000
200000
300000
400000
500000
600000
700000
800000
1 4 8 12 16 20 24 28 32 36
IO/S
Pool Count
random aligned read, Rate (IO/s), Varying Pool Count
SFA10K - ssd_1+1_WM_Re,4K, QD 16
Previous Generation Product

SFA Controller – No BW Throttling
16
0
2000
4000
6000
8000
10000
12000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Bandwidth (MB/S)
SSD Capability Typical Storage Controller Capability
SFA with SSD

SFA Linear Scaling (SFA10K)
17
0
2000
4000
6000
8000
10000
12000
14000
1 4 8 12 16 20 24 28 32 36 44 48 50 56
MB
/S
Pool Count
random aligned read, Rate (IO/s), Varying Pool Count
SFA 10K - ssd_1+1_WM_Re,64K, QD 16
Previous Generation Product

Our Surprise: 4KB I/O (SFA10K) Latency That Defies Convention
1 x 8+2: Pliant 800GB 1 x 4+1: Pliant 800GB QD Avg Latency (μs) Avg Latency (μs)
1 75.87 79.15 2 62.77 69.78 4 72.58 76.89 8 78.21 84.97
16 86.80 90.98 32 95.67 96.79 64 102.17 107.89
128 99.88 105.70
18
1 x 8+2: Pliant 800GB 1 x 4+1: Pliant 800GB QD Avg Latency (μs) Avg Latency (μs)
1 324.78 323.02 2 156.92 156.07 4 72.91 73.11 8 37.86 38.15
16 19.97 20.34 32 10.38 11.16 64 6.51 7.58
128 6.89 8.23
Ran
dom
Writ
e R
ando
m R
ead

Actual Case Studies
► Rich Imagery Processing Application
► GPFS File System ► Mix of Small & Large File
Requests (mostly small) ► SSD System Bake-Off ► DDN Selected Due To:
• Multi-Dimensional Performance • Low Latency & Wall Clock • Lowest Data Center Footprint
19
Leading U.S. Cloud-Based Applications
Provider
SFA10K-M Systems QDR InfiniBand Connected
114 x 800GB SSDs

Conclusions
► Get Performance and Redundancy ► SSDs Can Compete With The Right Architecture ► Lots Of Options: Don’t Lock Yourself In ► Don’t artificially limit your performance ► Big Data Requires All Varieties of Performance
• We don’t know what we don’t know…
7/27/2012 20

Questions ???
7/27/2012 21





























