Embed Size (px)
Citation preview

Journal of Symbolic Computation 61–62 (2014) 100–115
Contents lists available at ScienceDirect
Journal of Symbolic Computation
www.elsevier.com/locate/jsc
A tool for evaluating solution economy ofalgebraic transformations ✩
Rein Prank
Liivi Str 2, Institute of Computer Science, University of Tartu, 50409 Tartu, Estonia
a r t i c l e i n f o a b s t r a c t
Article history:Received 9 April 2013Accepted 14 June 2013Available online 18 October 2013
Keywords:Algebraic transformationsDisjunctive normal formExercise environmentSolution stepsSolution economy
In this paper we consider student solutions to tasks on theconversion of propositional formulas to disjunctive and conjunctivenormal forms. In our department, students solve such exercisesusing a computerized environment that requires correction ofevery direct mistake but does not evaluate suitability of the steps.The paper describes implementation of an additional tool foranalyzing these steps. This tool compares the students’ steps withan “official algorithm” and possible simplification operations andchecks for 20 deviations from the algorithm. The tool is appliedto solutions from two student sessions and the paper analyzes thedata on algorithmic mistakes.
© 2013 Elsevier B.V. All rights reserved.
1. Introduction
In this paper we consider solutions to algebraic tasks where the student transforms an expression,step by step, to some required form. Our concrete topic will be transformation of formulas of propo-sitional logic to normal form but in its essence the topic of the paper is elementary algebra. Manyalgorithmic tasks from many school algebra and university calculus topics (operations with fractions,operations with polynomials, differentiation, and integration, but also solution of equations and equa-tion systems) follow the same solution pattern and the same problems arise.
When a teacher checks a student’s written solutions to an expression transformation task, threequestions are the most important:
✩ Current research is supported by Targeted Financing grant SF0180008s12 of the Estonian Ministry of Education.E-mail address: [email protected]: http://vvv.cs.ut.ee/~prank/.
0747-7171/$ – see front matter © 2013 Elsevier B.V. All rights reserved.http://dx.doi.org/10.1016/j.jsc.2013.10.014

R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115 101
(1) Are the steps “correct”?(2) Are the steps reasonable?(3) Has the required final state been reached?
The first question is mostly meant to check whether the result of each conversion is equivalentto the previous expression. The second question should help to clarify whether the steps follow thealgorithm of the actual task type (if such exists) or “brings us closer to the answer.” In case of anunfinished solution, the third question can be modified to: “What stage is reached in the solution?”.
Algebraic transformations often contain many lines of symbols and each line contains many details.Checking them is very labor intensive, and computers seem to be better suited than human teach-ers for checking at least the most formal aspects. In addition, a computer can require correction ofmistakes immediately and this forces the student to correct his/her misunderstandings of the subjectbefore making the same mistake next time.
Progress in the creation of computerized exercise environments for algebraic transformations hasbeen slow. There are currently many small software pieces in existence for narrow subject scopes(mostly for elementary technical exercises). Three bigger programs – MathXpert (MathXpert, no date;Beeson, 1998), APLUSIX (Aplusix, no date; Nicaud et al., 2004) and T-algebra (T-algebra, 2007; Issakovaet al., 2006; Prank et al., 2007) – cover significant parts of school or university algebra and calculus.The solution environment that is the object of this article is designed for expression transformationexercises in propositional and predicate logic (Prank and Vaiksaar, 2003).
Solution step dialogs of existing environments allow us to speak about input-based and rule-basedsystems for algebraic conversions. This division is similar to the White Box and Black Box stagesof teaching in the paper of B. Buchberger (1990). In input-based systems the result of every stepis entered by the student. For example, in APLUSIX the student can create a copy of the previousexpression/equation/system and then edit it until the desired result of the step is reached. In someother systems the user marks a subexpression and enters an expression that will replace the markedpart. In input-based systems algorithmic decisions and technical work are both performed by thestudent.
For a step in the MathXpert rule-based system, the student marks a subexpression of the existingexpression and selects a conversion rule from the menu. The program performs the conversion au-tomatically (if the rule is applicable to the selected subexpression). Using Computer Algebra Systemscommands for performing conversion steps can also be considered as work in a rule-based system.In rule-based systems the student makes only the algorithmic decisions. The technical correctness ofsteps is the program’s responsibility.
The main benefit of using an input-based dialog is automation of checks required for answer-ing Question 1 above and the possibility for quick feedback. Programs like APLUSIX or T-algebra andmany others check equivalence with the previous line immediately as an expression is entered. Thestudent should correct the errors before the next step. An input-based dialog is quite natural for initialtraining of new mathematical techniques such as arithmetic operations in elementary grades, for col-lection of similar terms in middle grades, or for differentiation of expressions in secondary school. Theinput-based working mode seems also be unavoidable in testing and assessment of technical skills.The existing exercise environments that check equivalence cover rational expressions or propositionallogic topics, but not trigonometry or predicate logic. To answer Question 1, a program should be ableto verify equivalence of expressions that are allowed in the actual task type.
In most implementations free input allows the user to choose an arbitrary length for conversionsteps. This can be beneficial when students have different skill levels and some of them are able tocreate longer steps. Long steps, however, make it harder to recognize the reasons for nonequivalence(to give helpful feedback on Question 1) and to computerize the checks required to answer Question 2.
If a step is made in the rule-based mode then correctness is guaranteed and Question 1 becomesirrelevant. A rule-based dialog enables considerably quicker conversions to be made than direct input.It allows the user to ignore low-level details and to concentrate on learning the textbook algorithm(for example, for linear equations or systems) or on developing the learner’s own manner of solutionby solving more original tasks. However, it also makes it possible for the students to find the solutioncomparatively quickly through trial and error (instead of thinking about how to solve the task) or

102 R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115
to compose (quickly) very long solutions containing many aimless steps. The checks for Question 3do not depend on the working mode for making the steps. The requirements for the final answerare usually formulated in formal syntactical terms that can be easily verified by a program. Usuallythe solution window of exercise environments contains a special button for presenting the result ofa finished step as the final answer. After this button is pressed the program performs the checks toanswer Question 3.
Computerized environments for transformations do not usually monitor whether steps of a solu-tion are expedient or not (with respect to the actual task type). There is one commonly known algebraenvironment, APLUSIX, where the authors try to give some feedback about the student’s progress insolving the task. APLUSIX uses for this purpose some indicators of general properties of expressionsthat have an important role for many problem types (Nicaud et al., 2004): factored, expanded, reduced,sorted. The program displays (on the window status bar) the ratio of what part of the goal has al-ready been reached and what part remains. For some task types the authors of APLUSIX have alsoimplemented a measure of the integral property solved. The publications do not describe in detailhow these ratios are calculated, but their changes give the student some feedback about the progress.It is desirable to have similar features in other programs and also to have programs that compile andexpress more explicit judgments about the suitability of the steps.
This paper describes our attempt to construct a program that evaluates the expediency of steps insolutions to algorithmically nontrivial tasks. Our starting point is a solution environment for algebraictransformations in propositional logic. This main program guarantees that solution steps preserveequivalence with the initial formula; however, it does not evaluate whether a step is reasonable ornot. Our project creates an additional tool for analyzing expediency of steps in recorded solutions. Thetool annotates solution steps and seeks 20 types of deviations from the algorithm. It collects statisticsfor each solution, the entire solution file, and a group of students. We discuss our analyzer’s design,present results of an analysis of solutions received from two groups of students (162 and 43 students)and discuss how such data on mistakes can be used. To the knowledge of the author, this work is thefirst trial on computerization of explicitly formulated automated analysis of solution step expediencyand also the first tool for collection of corresponding data.
Section 2 of the paper provides a general description of the environment where our students solvethe tasks. Section 3 characterizes the educational situation that caused us to launch the analyzerproject. Sections 4–6 describe the implementation details for conversion rules of the main program,the normal form algorithm as we teach it to our students, and the information that is recorded insolution files. Section 7 describes the design of our additional tool for analyzing the solutions in files,which starts with a provisional list of deviations from the algorithm and describes the error typesthat were added after investigation of the analysis files from the first version. Section 8 analyzes theresults of application of the final version to solutions of two student groups. Section 9 investigatesthe correlations between the number of steps and numbers of different types of mistakes. Section 10summarizes the results of the project and discusses some further work.
2. History and general features of our formula transformation environment
Students in our department have solved most of the exercises for the third-term course, Intro-duction to Mathematical Logic, on computers since 1991 (Prank, 1991, 2006). Our program packagecontains exercise environments for truth-table exercises, propositional and predicate formula transfor-mation, evaluation of predicate formulas on finite models, formal proofs in propositional calculus andpredicate calculus, and for Turing Machines. While working with our programs, the student enters thesolution step by step. The program checks the correctness of each step and completion of the task.
Our first Formula Manipulation Assistant was implemented in MS DOS in 1989–1991 by H. Viira-Tamm for expression of propositional formulas using {&,¬}, {∨,¬} or {⊃,¬} and disjunctive normalform (Prank and Viira, 1991). (Note that in our course we use &, ⊃ and ∼ for conjunction, implicationand biconditional.) Each conversion step consisted of two substeps. At the first substep the studentmarked a subformula to be changed. For the second substep the program had different modes. In In-put mode the student entered a subformula that replaced the marked part. In Rule mode the studentselected a conversion rule from the menu and the program applied it.

R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115 103
Fig. 1. Solution window of the main program. Last three rules can be applied to conjunctions and disjunctions. The student hasperformed three steps and marked a subformula for moving the negation inside.
At the first substep the program checked that the marked part was a syntactically correct propersubformula (including checking the order of operations). At the second substep in Input mode theprogram checked syntactical correctness of entered subformula and equivalence issues (the enteredformula should be equivalent with the marked part and enclosed in brackets if necessary). In Rulemode the program checked whether the selected rule is applicable to the marked part. In case of anerror the program issued a corresponding message and required correction. The program counted er-rors in syntax, order of operations, equivalence, misapplications of rules, and presentation of formulaas the final answer. After a few years of using the program our use of modes stabilized. Exercises onexpression of formulas using given connectives were solved in Input mode and exercises on normalform in Rule mode. In the first case students should learn concrete equivalencies, and in the secondcase the conversion algorithm.
During our first software project, our approach to the design of exercise software was iterative. Westarted with minimal input from the students’ side and with minimal intervention from the programs’side. If necessary, we added details to the input and checking procedures. In case of algebraic conver-sions we started in 1989 with an environment where the student simply entered the next line (witha possibility to copy parts of the previous formula) and the program checked the equivalence with theprevious line. We saw that with such an interface the students who misinterpreted the order of opera-tions did not understand the reasons for messages about nonequivalence. Adding the marking substepmade the conversion mechanism explicit and after that we had no reason for further changes. Alge-braic formula manipulation in propositional logic was a comparatively easy part of the course of logic.Exercises on expression through given connectives and on normal form have textbook algorithms andonly the students who had missed exercise labs or homework sometimes had difficulties with tests.
In 2003 the program was rewritten in Java but we did not change the principles of the solutionstep dialog and did not add more support for students. We only extended the application area by tasktypes for conjunctive normal form and for predicate logic (Prank and Vaiksaar, 2003).
Fig. 1 demonstrates a disjunctive normal form exercise in Rule mode. The upper panel containscounters of direct errors, formulation of the task (‘Transform to FDNF’) and instruction (‘Mark

104 R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115
a subformula and apply appropriate conversion’). The counters of direct errors showone error for marking a syntactically incorrect word and two errors for selection of inapplicable rules.The right column contains counters for errors in understanding the order of operations and in givinganswers.
The solution window already contains five solution steps:
(1) elimination of (negated) implication (rule 12);(2) elimination of biconditional (rule 15);(3) removing brackets (rule 1);(4) absorption of conjunction (rule 25);(5) multiplication (distributive law 21).
For the next step, the student has marked the disjunction in brackets.
3. Problems with first-term students
The current research was initiated when we used our formula transformation environment withanother category of students and experienced serious difficulties. Two changes occurred after 2003:the number of students admitted to computer science increased year by year and the knowledge andskill level of weaker students is now lower than before; and secondly, some years ago we startedteaching the introductory part of propositional logic in the first-term course, Elements of DiscreteMathematics, to allow better preparation for database and programming courses. We then saw thatapart from students who solved our computerized exercises very quickly, there were others who werein real trouble.
The character of their troubles was different for different types of exercises. In the first two com-puter labs (truth-table exercises and expression of formulas using given connectives) the difficultieswere caused mainly by the novelty of the material. The students had to execute new operations thathad new “multiplication tables,” take into account their order of priority and use about 20 differ-ent new equivalencies in conversion steps. Correspondingly, the students made frequent direct errors:the wrong truth-value, wrong order of operations, or nonequivalence with the previous line. How-ever, the solution principles of the task types were very straightforward and the error messages wereunderstandable.
With gradually increasing understanding of the necessary facts the messages disappeared and thestudents solved the exercises. Of course, there were also students who regularly used lecture notesand did not strive to memorize the equivalencies. The observable outcome of such behavior was thatlab exercises and homework were solved but the students were unable to solve a corresponding taskduring the test. Nevertheless, we did not consider such cases as signs of serious deficiencies in thework of instructors or in our exercise environments.
The case of normal form exercises is more complex. For computer science students the normalform exercises are a good example of processing the data by means of an algorithm containingseveral stages of different character. The student should successively express implication and bicon-ditional through negation, conjunction and disjunction, use De Morgan’s laws for pushing negationsdown to variables, expand the formula using distributive law, leave out false conjunctions and re-dundant copies of variables, etc., until obtaining the normal form. In normal form exercises it iscrucial first to determine what stage of the algorithm should be executed and only after that to applyappropriate conversion. Execution of the right steps in the wrong order can increase the length ofsolution by a considerable degree; however, students of the computer age prefer pushing buttons tothinking: The solution files of many students appeared to be 3–4 or more times longer than neces-sary.
Upon first reaction, we excluded the conjunctive normal form from the syllabus of the first-termcourse because the choice between two reciprocal uses of distributive law obviously confused weakerstudents. We also tried to speak more about the need to follow the algorithm, but this did not solvethe whole problem. In our final test, one of the tasks was always transformation of a formula tofull DNF. The formula was generated randomly and contained 3 variables and one conjunction, one

R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115 105
disjunction, one implication and one biconditional. In autumn term 2011 the two longest (successful!)transformations had lengths of 269 and 263 steps. Many transformations were between 50 and 80steps, instead of the normal 15–25 steps at most.
If we want to assess students’ learning of an algorithm properly then we must be able to under-stand individual solutions and their conformity to the algorithm. Grading solutions to the test provedthat we are not able to analyze such volumes of computer-created material by hand. If we want toimprove instruction or our exercise environment then we must be able to find out what the students’most typical algorithmic faults are and what causes such remarkable lengthening of solutions. Toachieve this, the author of this paper decided to program an additional software tool. Before descrip-tion of the tool, we will describe the necessary properties of the main program and also the object ofteaching – the normal form algorithm.
4. Some implementation details of conversion rules
The current version of our formula transformation environment was written in Java by V. Vaiksaaras his bachelor thesis in 2003 (Prank and Vaiksaar, 2003). He used our earlier DOS program as aprototype, with many design principles derived from our earlier project (Prank and Viira, 1991).
The student creates the solutions step by step. Each step consists of two substeps:
(1) The student marks a subformula to be changed;(2) The student enters the formula for replacing the marked part (in Input mode) or selects from the
menu a conversion rule to be applied to the marked part (in Rule mode).
For each task the working mode (Rule or Input) is fixed in the task file and the student cannotchange it. We describe here only the details of the Rule mode because this paper analyzes solutionsof normal form tasks that were solved in Rule mode.
At the first substep the program checks whether the marked part itself is a syntactically cor-rect formula and then whether it is a proper subformula of the whole formula. These two cases areconsidered separately because the respective mistakes have differing reasons. Marking a syntacticallyincorrect part of an expression is not a very serious error – usually it is a result of careless work withthe mouse or careless counting of parentheses in a complex formula. In our final tests we usuallyassign zero penalties for syntax errors. Marking a string of symbols that is itself a formula but not asubformula of the whole expression, however, is usually a misinterpretation of the order of operationsand we take such errors into account in grading.
For tasks with propositional formulas the main program offers the following menu of conversionrules:
1. (X) →← X 16. ¬(X ∼ Y ) →← X&¬Y ∨ ¬X&Y
2. ¬¬X →← X 17. X ∼ Y →← (X ⊃ Y )&(Y ⊃ X)
3. X&Y →← ¬(¬X ∨ ¬Y ) 18. ¬(X ∼ Y ) →← ¬(X ⊃ Y ) ∨ ¬(Y ⊃ X)
4. ¬(X&Y ) →← ¬X ∨ ¬Y 19. X →← X&Y ∨ X&¬Y
5. X ∨ Y →← ¬(¬X&¬Y ) 20. X →← (X ∨ Y )&(X ∨ ¬Y )
6. ¬(X ∨ Y ) →← ¬X&¬Y 21. X&(Y ∨ Z) → X&Y ∨ X&Z
7. X&Y →← ¬(X ⊃ ¬Y ) 22. X ∨ Y &Z → (X ∨ Y )&(X ∨ Z)
8. ¬(X&Y ) →← X ⊃ ¬Y 23. ¬X&X ∨ Y → Y
9. X ∨ Y →← ¬X ⊃ Y 24. X ∨ X&Y → X
10. ¬(X ∨ Y ) →← ¬(¬X ⊃ Y ) 25. (¬X ∨ X)&Y → Y
11. X ⊃ Y →← ¬(X&¬Y ) 26. X&(X ∨ Y ) → X
12. ¬(X ⊃ Y ) →← X&¬Y 27. X ⊕ Y → Y ⊕ X
13. X ⊃ Y →← ¬X ∨ Y 28. X ⊕ X → X

106 R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115
14. ¬(X ⊃ Y ) →← ¬(¬X ∨ Y ) 29. X ⊕ (Y ⊕ Z) → (X ⊕ Y ) ⊕ Z
15. X ∼ Y →← X&Y ∨ ¬X&¬Y
Rules 1–20 can be applied in both directions but rules 21–29 only from left to right. Rules 27–29can be applied to conjunctions and disjunctions.
Conversions do not work in “pure rewrite rule” style. We have tried to enable conversion steps thatare similar to paper and pencil transformations; therefore the equivalencies behind rules 1–29 areimplemented in quite generalized manner (which is similar to usual work with sums and products inalgebra). We now describe the most important features added to avoid an excessive number of formalsteps. In our text, if the number of a rule is shown as negative, it denotes that the rule is appliedfrom right to left.
(1) Conjunctions and disjunctions are treated as connectives that can have two or more arguments.Rules 3. . . 10, 21. . . 22, 27 and 29 (and rules −3. . . −6, −11. . . −18) can be applied to conjunctionsand disjunctions with an arbitrary number of members. It is also permissible for the marked partto be part of a longer conjunction or disjunction. If a rule converts a disjunction or conjunction toimplication or biconditional (rules 7. . . 10, −11. . . −14, −15. . . −18) and the marked conjunctionor disjunction has more than two members, then the user is asked which conjunction/disjunctionsign should be treated as the main connective of the marked part. Rule 1 allows canceling andadding brackets around an arbitrary part of a conjunction or disjunction.
(2) The distributive rule 21 can be applied to any conjunction where at least one member is a dis-junction (having an arbitrary number of members). However, at one step the distributive law isapplied only to one disjunction. If the marked part is a conjunction that contains more than onedisjunction then the user is asked which disjunction should be used for expanding. Rule 22 worksin a dual way.
(3) Rules 19–20 allow for adding to X one or more variables that occur in the initial formula of theactual task but do not occur in X (X can be an arbitrary formula).
(4) Rules 23–26 and 28 allow for excluding some members from a disjunction or conjunction. Themarked disjunction/conjunction should have two or more members. The program asks the studentto mark the members that should be excluded. At least one member should remain unmarked. Forrules 23 and 25 the members marked for exclusion should contain two contrary literals (but cancontain more members). For rules 24, 26 and 28 the marked members should be in certain re-lation with some unmarked member (for 24, conjunction of some unmarked member with someother subformula, etc.). Each rule allows exclusion of members only for the reason that is spe-cific to this rule (only contradictory conjunctions, only conjunctions containing some unmarkedmember, etc.).
(5) Rule 27 allows for reordering members of arbitrary conjunction or disjunction. The user is askedto select the first, second, etc., member of the resulting formula.
To take advantage of features 1–5 the students should know that they exist; however, many stu-dents of the computer age prefer to push buttons without reading manuals or listening to lectures andinstructions. Such students convert the formula (A ∨ B)&C first to C&(A ∨ B) and then apply rule 21because the label on the button is X&(Y ∨ Z) → X&Y ∨ X&Z but not (Y ∨ Z)&X → Y &X ∨ Z&X .In historical perspective this does not mean that educational use of rule-based environments is im-possible because the full content of rules cannot be written to the button. We hope that after some(dozens of?) years the choice and behavior of algebraic rules will stabilize and the buttons will haveuniversally recognizable icons.
5. Our version of the full DNF algorithm
In our course we teach the following six-stage version of algorithm for conversion of formulas tofull disjunctive normal form:
(1) Eliminate implications and biconditionals from the formula;(2) Move negations inside until the only negations stand immediately before variables;

R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115 107
(3) Use distributive law to expand the conjunctions of disjunctions;(4) Exclude contradictory conjunctions (that contain the same variable with and without negation)
and redundant copies of literals;(5) Add missing variables to conjunctions;(6) Put the variables in conjunctions in alphabetic order and exclude redundant copies of conjunc-
tions.
For each stage of the algorithm, the lecture also points out the equivalencies that enable one toaccomplish the stage. For example, for stage 1 such equivalencies are
X ⊃ Y ≡ ¬X ∨ Y and X ∼ Y ≡ X&Y ∨ ¬X&¬Y ,
and for stage 2
¬(X&Y ) ≡ ¬X ∨ ¬Y , ¬(X ∨ Y ) ≡ ¬X&¬Y and ¬¬X ≡ X .
On the one hand, this provides proof of feasibility of the algorithm, and on the other it preparesthe students for finding the rules for execution of the stage. We also explain that the menu of ourexercise environment contains more than only these main equivalencies and in some circumstancesuse of some parallel rules can be an advantage. For example, if the biconditional stands under nega-tion, then we can eliminate it using rule 16 and get ¬(X ∼ Y ) ≡ X&¬Y ∨ ¬X&Y , instead of getting¬(X&Y ∨ ¬X&¬Y ) by rule 15.
When we present the algorithm, we underline that it is essential to execute the stages in theprescribed order. Our favorite example here is the case when the distributive law (stage 3) is appliedto a subformula that stands under negation, and after moving the negation inside we are forced toapply distributive law again in the opposite direction.
We also emphasize that execution of any expression transformation algorithm in mathematicsassumes continuous making of intermediate simplification steps, although this is not written in anexplicit way in descriptions of algorithms.
After demonstration of introductory examples and some independent work, we discuss more de-tailed aspects of execution of the algorithm that are not specified in the brief six-stage formulation:
(1) Stage 1 – Equivalencies for elimination of biconditional create two copies of the operands ofthis operation, and therefore it is better to eliminate the implication first (if it stands inside thebiconditional);
(2) Stage 2 – If there are embedded negations then it is better to process the outermost negationfirst (it eliminates the negations in its argument);
(3) Stage 3 – If a disjunction that will be multiplied using distributivity law contains tautologicallyfalse members then eliminate them before multiplication;
(4) Stage 4 – It is reasonable to eliminate tautologically false conjunctions without preceding elimi-nation of repeated literals in them;
(5) Stage 5 – Rule 19 permits adding more than one variable if necessary.
We also discuss the measures taken in the implementation of rules with the students to make thesolution steps similar to working with paper and pencil (issues 1–5 in Section 4).
6. Information in solution files
In this section we describe the input of our analysis tool. The main program is the product ofa bachelor thesis. Although the student in question was an extraordinarily strong programmer anda good mathematician, the time restraints of the bachelor thesis put limitations on what was imple-mented and what was not.
When a student starts solving tasks from a task file a new solution file is generated by the mainprogram. The fresh solution file contains data from the task file (tasks, solution modes, allowed num-bers of errors) and further the program adds data about the student’s attempts to solve tasks. Theallowed number of errors means that if the student makes more errors then the program does not
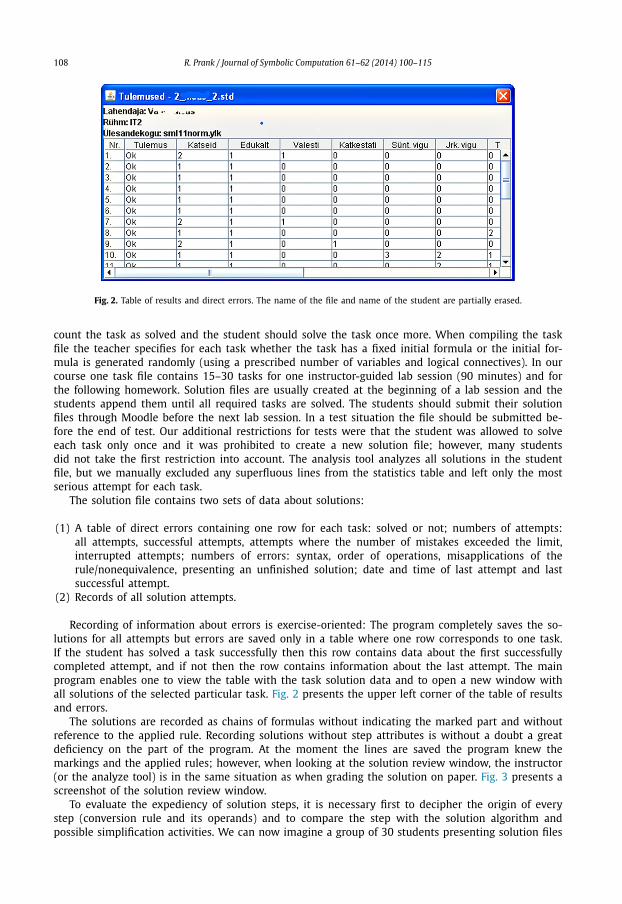
108 R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115
Fig. 2. Table of results and direct errors. The name of the file and name of the student are partially erased.
count the task as solved and the student should solve the task once more. When compiling the taskfile the teacher specifies for each task whether the task has a fixed initial formula or the initial for-mula is generated randomly (using a prescribed number of variables and logical connectives). In ourcourse one task file contains 15–30 tasks for one instructor-guided lab session (90 minutes) and forthe following homework. Solution files are usually created at the beginning of a lab session and thestudents append them until all required tasks are solved. The students should submit their solutionfiles through Moodle before the next lab session. In a test situation the file should be submitted be-fore the end of test. Our additional restrictions for tests were that the student was allowed to solveeach task only once and it was prohibited to create a new solution file; however, many studentsdid not take the first restriction into account. The analysis tool analyzes all solutions in the studentfile, but we manually excluded any superfluous lines from the statistics table and left only the mostserious attempt for each task.
The solution file contains two sets of data about solutions:
(1) A table of direct errors containing one row for each task: solved or not; numbers of attempts:all attempts, successful attempts, attempts where the number of mistakes exceeded the limit,interrupted attempts; numbers of errors: syntax, order of operations, misapplications of therule/nonequivalence, presenting an unfinished solution; date and time of last attempt and lastsuccessful attempt.
(2) Records of all solution attempts.
Recording of information about errors is exercise-oriented: The program completely saves the so-lutions for all attempts but errors are saved only in a table where one row corresponds to one task.If the student has solved a task successfully then this row contains data about the first successfullycompleted attempt, and if not then the row contains information about the last attempt. The mainprogram enables one to view the table with the task solution data and to open a new window withall solutions of the selected particular task. Fig. 2 presents the upper left corner of the table of resultsand errors.
The solutions are recorded as chains of formulas without indicating the marked part and withoutreference to the applied rule. Recording solutions without step attributes is without a doubt a greatdeficiency on the part of the program. At the moment the lines are saved the program knew themarkings and the applied rules; however, when looking at the solution review window, the instructor(or the analyze tool) is in the same situation as when grading the solution on paper. Fig. 3 presents ascreenshot of the solution review window.
To evaluate the expediency of solution steps, it is necessary first to decipher the origin of everystep (conversion rule and its operands) and to compare the step with the solution algorithm andpossible simplification activities. We can now imagine a group of 30 students presenting solution files

R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115 109
Fig. 3. Solution review window with a completed solution (11 steps) for a task with 2 variables.
with solutions for 20 tasks in a week. Some solutions are short – the average length is over 10 steps –and poor solutions contain 70 steps. At the same time, it is especially the poor solutions with theirunwise steps that call for the instructor’s comments.
7. Designing the analysis tool
The first part of the programming work was a module for deciphering the student’s steps. Thedeciphering module of the tool first finds the matching parts at the beginning and end of the initialand resulting formula of the step. The word between them in the initial formula is taken as a firstapproximation of the marked part. After that the analyzer finds the minimal subformula that containsthe changed part. Using this subformula as a candidate of being the marked part allows to determinethe applied conversion rule, except in cases where the step was made by abbreviation rules 23. . . 26or 28. However, in our context it is not necessary to determine which of the abbreviation rules wasused. It is quite natural to accept that all uses of them are reasonable steps. The tool also accepts anyuse of rules 1 and 2 in any situation.
To compare the student’s step with the algorithm the analyze tool also determines what operationshould be applied to the initial formula of the step according to the textbook algorithm.
If the conversion actually applied does not correspond to the algorithm then the analysis tool qual-ifies the step to one of the predefined classes of mistakes. The first list of error classes was compiledas an expert opinion about experienced student errors, hypothetical misapplications of conversionrules, applications of steps belonging to other task types and deviations from the algorithm. This gave15 classes (listed in the order of stages of the DNF algorithm):
(1) Conjunction or disjunction expressed through implication (rules 6. . . 12 applied in wrong direc-tion);
(2) New biconditional added (rules 15. . . 18 in the wrong direction);(3) Biconditional expressed through implication instead of conjunction and disjunction (rules 17. . . 18
used);(4) Negation moved inside before finishing stage 1;(5) Negation moved out of brackets (rules 3. . . 6 in the wrong direction);(6) Processing of negation that stands under another negation;(7) Distributivity used too early (before the end of stage 2);(8) Distributivity applied in the wrong direction (rule 22 instead of 21);(9) Members reordered too early;
(10) Reordering of members of a conjunction that should be removed;(11) Reordering in a conjunction that contains redundant members;

110 R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115
Fig. 4. Analyzer output regarding the solution presented in Fig. 3. Black rectangles are bounds of the changed part of theformula. Steps 2, 3 and 8 are annotated by error messages.
(12) Reordering of members of a disjunction (as for conjunctive NF);(13) Variables added too early;(14) Variables added to a subformula that is not a conjunction of literals;(15) Variables added using rule 20 instead of 19 (as for conjunctive NF).
The current version of the analyzer is written in Free Pascal and has a very basic user interface. Itruns in a text window and displays the following information about the next step after each of theuser’s keystrokes:
• Number of the step, number of the stage in DNF algorithm, some further clue about the rule;• Specification of the applied rule and OK if the step was acceptable;• Error message in the form of a hint if the step was not acceptable;• The initial and resulting formula where the changed part and the resulting part are highlighted.
The same information is written in a text file to allow it to be read in less dynamic conditions. Aftereach solution attempt the analyzer displays statistics about this solution and the summarized statisticsat the end of solution file. Fig. 4 presents the lines of the analysis file that correspond to the solutionpresented in Fig. 3.
The analyzer also permits processing a set of solution files (for example, files of all participants ofone lab session). In addition to particular analysis files, we also get a text file with data of the group.Each line in this file contains data about one solution attempt: the name of the file, task type, numberof steps, number of steps taken back, what state was reached, overall number of mistakes, number of

R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115 111
Table 1Statistics received from version 1 of the analyzer. Diagnosed inexpedient steps in the FDNFtask for the final test in the autumn term 2011 (162 solutions, 7270 steps).
Deviation Mistakes Students
1. & or ∨ converted to implication 22 112. New biconditional added 1 13. Biconditional expressed through implication 8 84. Negation moved inside before finishing stage 1 61 365. Negation moved outside of brackets 142 436. Inner negation processed first 174 587. Distributivity used too early 153 538. Distributivity applied in wrong direction 21 129. Members reordered too early 330 6410. Members of a false conjunction reordered 82 2711. Reordering applied to redundant members 68 3212. Reordering applied to members of disjunction 30 1313. Variables added too early 147 4314. Variables added to a subformula of unsuitable form 5 315. Variables added using rule 20 instead of 19 5 4
mistakes by types. After copying the data from this file to a spreadsheet we can classify and sort thesolutions by various attributes and calculate statistics of solution lengths, numbers of mistakes andother quantities. For example, after separation of finished and unfinished solutions we discovered thatevery test participant who completed stage 3 in the algorithm also completed the entire FDNF task.
The author was not confident that the above-described design of the analyze tool, which isquite formal and syntax-driven, enables one to catch mistakes and to create intelligible error mes-sages/hints. To evaluate the first version, the analyzer was used for scanning solution files to thefinal test for Elements of Discrete Mathematics in the autumn term of 2011. Together with othertasks (truth-table tasks in another exercise environment, some written tasks) the test contained twoexpression manipulation tasks: expression of a formula using connectives {&,¬}, {∨,¬} or {⊃,¬}(different student groups had different sets) and conversion to full DNF. For both conversion tasksthe initial formula was generated randomly and contained 3 propositional variables, one occurrenceof each of the four binary connectives, and 2 negations. There were 185 test participants and 162 ofthem submitted a solution file. There were 132 completed and 30 partial solutions to the DNF taskreceived. The analyzer was used for checking the solutions to the DNF task.
The first version of the analyzer diagnosed a surprisingly large number of deviations from the al-gorithm: 1249 inexpedient steps of the 7270 steps made in the students’ solutions. However, a humananalysis of the output files of the analyzer showed that virtually all annotated steps were indeed atleast not the best choices for conversion. Table 1 displays the classes of diagnosed deviations togetherwith numbers of deviations and numbers of students who made that mistake.
The most frequent deviance from the official algorithm was usage of a conversion rule when aprevious stage of the algorithm had not yet been completed (lines 4, 7, 9, 13 of Table 1). This canhappen for different reasons. In some cases the formula really contains distinct parts that can beprocessed in any order. It is possible improve the diagnostics and avoid displaying error messages in(many of) these cases. The author is not sure that this is the right way to go. If we study severalchains of conversions of the same student then we see that some students simply do not know thealgorithm (even during the final test). They select from the menu arbitrary rules that happen to beapplicable, including the rules that make no sense in the DNF algorithm. A good example of this ismoving the negation out of brackets. Other students seem to ignore the prescribed order becausethey think that the order is not important. In both cases a more finely tuned analyzer would issuemessages about some deviations from the algorithm and “forgive” others. This would be didacticallyworse than the existing rough version of the analyzer. If we consider incorporating the analyzer (andits messages) in the main program then it seems to be appropriate to display the messages aboutdeviation from the algorithm every time the deviation exists. However, the program could give thestudent an opportunity to ignore the message or take the step back.

112 R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115
Table 2Diagnosed algorithmic deviations in a test of first-term students and in a session of third-term students.
Quantity/mistake DME IML FDNF FCNF NF
Number of students 162 43 43 43 43Tasks 1 26 12 10 4Steps 7270 20 718 7922 7675 5121Steps taken back 933 1536 537 628 371Errors 1481 3239 1227 1119 8931. & or ∨ converted to implication 23 45 12 28 52. New biconditional added 1 7 2 4 13. Biconditional converted to impl 8 34 26 0 84. Negation moved inside brackets at stage 1 56 280 77 100 1035. Negation moved outside of brackets 157 199 110 72 176. Inner negation processed first 219 204 134 41 297. Distributivity used too early 84 169 92 24 538. Distributivity applied in wrong direction 17 245 28 112 1059. Members reordered too early 327 807 239 357 21110. Members of a FALSE conj reordered 81 45 31 10 411. Reordering of redundant members 68 32 18 2 1212. Members of disj reordered in DNF/
members of conj reordered in CNF197 258 174 51 33
13. Variables added too early 147 319 117 202 014. Variables added to arbitrary subformula 5 11 9 2 015. Variables added to disj in DNF/conj in CNF 5 64 22 42 016. Only a part of conj/disj reordered 45 91 69 15 717. Only one variable added instead of two 3 28 15 13 018. Unnecessary brackets/negations added 33 44 19 14 1119. Addition of variables not required 0 208 0 0 20820. Formula is already in the required form 5 149 33 30 86
Observation of the analyzer’s output and analysis files convinced us that our provisional design ofthe analysis is usable. We saw that the analyzer’s messages could improve the performance of themain program. Even the first version gave us an idea of the number of mistakes and an indicationof more widespread mistakes. The search for mistakes and unwise steps that were not diagnosedby the first version gave us additional error categories 16–18 and 20. Line 19 is added for tasks onfinding non-full disjunctive or conjunctive normal form (without the requirement of adding variablesto conjunctions/disjunctions).
(16) All variables of conjunction can be sorted in one step.(17) All missing variables can be added in one step (in stage 5).(18) Unnecessary brackets or negations added.(19) Addition of variables is not necessary in this task type.(20) Formula is already in the required form.
Some programming errors were also corrected in the second version. In particular, diagnostics ofdeviation 12 was changed.
8. Comparison of first-term and third-term students
In this section we present Table 2 with the results of applying the second version of the anal-ysis tool to two sets of data. The first set contains the same solutions for the test from first-termstudents (column DME). The second set contains files from a second-week lab session and the fol-lowing homework for a third-term course, Introduction to Mathematical Logic, in the autumn termof 2011 (column IML). The task file contained 12 tasks of transformation to full disjunctive NF (col-umn FDNF), 10 tasks for full conjunctive normal form (FCNF) and 2 + 2 tasks on disjunctive andconjunctive normal form (NF, without the requirement to add variables to conjunctions and disjunc-tions).

R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115 113
In analyzing the data of younger and older students we can draw several conclusions:
• Numbers of algorithmic faults from both categories of students are high. The analysis of inex-pedient steps in solutions confirms that the alarm caused by the large size of solution files wasfounded.
• Already during the exercise lab the quality of solutions from third-term students is better thanthe quality of solutions from first-term students after training for FDNF tasks. Third-term studentsmade 0.16 mistakes per step and first-term students 0.20 mistakes. The number of steps that weretaken back are at nearly the same ratio.
• Working with both DNF and CNF task types confused the third-term students and resulted in anincrease of mistakes 8 and 15.
• Large numbers in the CNF column (357 on line 9 and 202 on line 13) are also caused by reorder-ing or adding members in conjunctions that are members of disjunctions, i.e., the students hadin mind the DNF pattern. The “too early” message would be only formally correct (reordering oraddition of a new variable took place before application of distributive law). However, the realreason seems to be confusion of CNF and DNF patterns.
• It seems that most students did not read the texts for the tasks and always solved the fullDNF/CNF task type. Almost 300 errors would be prevented on lines 19 and 20 if the solutionenvironment would give messages when the student solved the first non-full NF task.
9. Number of steps and numbers of mistakes
It is quite natural to ask what algorithmic deviations are typical for the students who composelong solutions. For this question we calculated correlation coefficients between the numbers of stepsand numbers of diagnosed errors of particular error types.
It is easy to guess that the number of steps in solutions stands in strong correlation with thenumber of steps taken back and the overall number of mistakes. These two quantities simply mea-sure how well the student knows what he/she should do. Even so, we had no expectations about theparticular deviation classes. The earlier impression was that different students could have rather vari-able “favorite” ways of erring. Table 3 is based on the same data discussed above from the final testof first-term students (DME) and practical session of third-term students (IML). The first and thirdcolumns contain summarized numbers of steps and numbers of different types of mistakes. The sec-ond and fourth columns are correlation coefficients between numbers of steps made by the studentsand numbers of concrete type of mistake.
In the case of the test, the students solved only one task where the initial formula was randomlygenerated. This randomness corrupts the statistics because for different initial formulas the minimallength of solution differs by about two times and the possibility of making specific mistakes dependson the initial formula (for example, the positions of the sign of biconditional and negations in theformula). Therefore, we primarily discuss the numbers in the last column here.
(1) The highest coefficient of 0.72 is associated with moving negation outside of brackets. The stu-dent is moving it directly in the opposite direction compared with the algorithm. This mistakedemonstrates that the student does not understand the ideas behind the algorithm and there isa high probability of other missteps as well.
(2) Despite the hope that the “too early” messages could appear without a real mistake (Section 7)we see a coefficient of 0.65 for early reordering and 0.57 for early adding of variables. The im-portance of these mistakes is also visible in column 2. The natural implication of this is thatdisplaying the corresponding error messages should be made obligatory when we incorporate theanalyzer in the main program.
(3) Application of distributive law in the wrong direction has a coefficient of 0.58. This mistake againmeans poor understanding of the goal (DNF or CNF). The best way to cope with the results ofthis mistake is just to take the step back. Other ways are more costly (in terms of steps).
(4) There is one more mistake with a high coefficient – processing of innermost negation beforeoutermost (0.54). This seems to be merely a technical detail regarding optimal usage of the algo-

114 R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115
Table 3Correlation between the number of steps and the numbers of error types.
Quantity/mistake DME Correl IML Correl
Number of students 162 43Tasks 1 26Steps 7270 1.00 20 718 1.00Steps taken back 933 0.69 1536 0.55Errors 1481 0.66 3239 0.781. & or ∨ converted to implication 23 0.17 45 0.262. New biconditional added 1 0.06 7 −0.043. Biconditional converted to implication 8 −0.04 34 04. Negation brought into brackets at stage 1 56 0.20 280 0.295. Negation moved outside of brackets 157 0.11 199 0.726. Inner negation processed first 219 0.55 204 0.547. Distributivity used too early 84 0.27 169 0.308. Distributivity applied in the wrong direction 17 0.11 245 0.589. Members reordered too early 327 0.55 807 0.6510. Members of a FALSE conjunction reordered 81 0.05 45 0.1611. Reordering applied to redundant members 68 0.07 32 0.2112. Members of disj reordered in DNF/
members of conj reordered in CNF197 0.20 258 0.25
13. Variables added too early 147 0.38 319 0.5714. Variables added to arbitrary subformula 5 0.03 11 −0.0415. Variables added to disj in DNF/conj in CNF 5 −0.01 64 0.3216. Only a part of conj/disj reordered 45 0.06 91 −0.1317. Only one variable added instead of two 3 −0.08 28 0.0518. Unnecessary brackets or negations added 33 0.06 44 0.4219. Addition of variables not required 0 208 0.4220. Formula is already in the required form 5 0.12 149 0.17
rithm; however, statistics indicate that this is a mistake that characterizes poor transformationsand should consequently be annotated. This is confirmed by the number 0.55 in the second col-umn.
If we try to find a common denominator for issues 1–4 then it is probably the importance of under-standing the mathematical side of the algorithm. It seems that concrete details for using the rules ofthe exercise environment (like lines 16–17) in the table are much less important.
10. Conclusions and ideas for further work
This paper described a project for which we designed, implemented and tested on real data anadditional tool for annotating the solutions to normal form exercises in propositional logic. We candraw the following conclusions:
• Our rather formal approach to seeking and classifying errors proved to be useful and resulted ina program that helps instructors to check students’ solutions.
• We knew that large sizes of solution files are really caused by large numbers of duly recognizablemistakes.
• We collected quantitative data about the appearance of different types of algorithmic mistakes instudent solutions. We now know which mistakes appear frequently and which mistakes have astrong correlation with the length of solutions. This helps to improve our instruction.
• We have explained that in our course the main equivalencies are taught through exercises onexpression, using given connectives, while the normal form algorithm is taught through exerciseson normal form. Learning of equivalencies has been supported by feedback for the past 20 years.In addition, we now have a tool that composes feedback about the conformity with the normalform algorithm.
• We now have a tool that helps to measure the impact of future changes in our instruction.

R. Prank / Journal of Symbolic Computation 61–62 (2014) 100–115 115
It is clear that the numbers of mistakes, correlations and other characteristics depend on concreteteaching and on the students. We will repeat the calculations on the data of next years and alsoexamine our (unfortunately incomplete) data from the past.
We hope to have the main program upgraded by the autumn term of 2013. In 2012 we still usedthe exercise environment as it was created in 2003; however, we made the analyze tool available tostudents and required that they submit a solution file with a small number of algorithmic mistakes.We hope that this is a signal for the students to improve their skills.
Our project for rule-based conversions has also led to some progress towards evaluation of expe-diency in input-based modes. As described in Section 7 the solution files do not contain informationabout the applied conversion rules. The analyzer restores the rules using only the two successive for-mulas. What happens if the solution is composed in an input-based environment? We tested it withfiles containing solutions to tasks on expression of formulas via negation and one binary connective.Our students solve these tasks in the input-based mode. The most frequently inefficient step here isusing a third intermediate connective because the student does not know the direct conversion rule.The result was better than expected: Even without any correction of recognition of rules, almost allsteps were understood correctly. Although students have the possibility to make arbitrary steps, thereal data show that practically all steps are applications of only one conversion rule from the text-book. There is one widespread exception – additional removal of double negations from the result ofthe step. Fortunately, addition of the capability to handle this exception does not require considerableprogramming effort.
This study dealt with expression manipulation exercises in propositional logic. The author believesthat an expediency analyzer can also be created for many task types in elementary algebra.
References
Aplusix, no date. http://aplusix.com/. Last visited 1.04.2013.Beeson, M., 1998. Design principles of Mathpert: Software to support education in algebra and calculus. In: Computer-Human
Interaction in Symbolic Computation. Springer, pp. 89–115.Buchberger, B., 1990. Should students learn integration rules?. SIGSAM Bull. 24, 10–17.Issakova, M., Lepp, D., Prank, R., 2006. T-algebra: Adding input stage to rule-based interface for expression manipulation. Int. J.
Technol. Math. Educ. 13, 89–96.MathXpert, no date. http://www.helpwithmath.com/. Last visited 1.04.2013.Nicaud, J., Bouhineau, D., Chaachoua, H., 2004. Mixing microworld and CAS features in building computer systems that help
students learn algebra. Int. J. Comput. Math. Learn. 5, 169–211.Prank, R., 1991. Using computerised exercises on mathematical logic. In: Informatik und Schule. In: Inform.-Fachber., vol. 292.
Springer, pp. 34–38.Prank, R., 2006. Trying to cover exercises with reasonable software. In: Second International Congress on Tools for Teaching
Logic. University of Salamanca, pp. 149–152.Prank, R., Issakova, M., Lepp, D., Tõnisson, E., Vaiksaar, V., 2007. Integrating rule-based and input-based approaches for better
error diagnosis in expression manipulation tasks. In: Symbolic Computation and Education. World Scientific, pp. 174–191.Prank, R., Vaiksaar, V., 2003. Expression manipulation environment for exercises and assessment. In: 6th International Con-
ference on Technology in Mathematics Teaching. Volos-Greece, October 2003. New Technologies Publications, Athens,pp. 342–348.
Prank, R., Viira, H., 1991. Algebraic manipulation assistant for propositional logic. Comput. Logic Teach. Bull. 4, 13–18.T-algebra, 2007. http://math.ut.ee/T-algebra/. Last visited 1.04.2013.













![Transformations of Software Product Lineschechik/pubs/Models17-Category.pdfBuild on existing formal theories: category theory and theory of Algebraic Graph Transformations (AGT)[1]](https://img.pdfslide.net/doc/110x75/601beaa0b80c5043ab6ae9eb/transformations-of-software-product-chechikpubsmodels17-categorypdf-build-on.jpg)















