Embed Size (px)
Citation preview

Accelerating the Core of the CloudJuly 2015
OSCON
Greg Bentley
Intel Corporation

2
Agenda
• Core software optimization as a strategy
• Case study: OpenStack
• Notes from the LAMP stack
• Invitation to join us

Core software optimization: a strategy
July 2015

4
How to make systems run fast
• Performance analysis and improvement rarely taught in school
• Sometimes attempted in graduate level coursework
• Developers pressured to come up with features quickly
• We *should* write efficient algorithms
• We’re usually debugging or adding late features
• Besides, aren’t CPUs getting faster all the time?
• Thanks to Moore’s law they are
• But it takes time, and we can do better!

5
CPUs do get faster every generation
• Example: “5th Generation Core” processor (Broadwell)
• Runs existing code faster
• CPU design decisions based on tracing workloads
• Compiler developers are also improving things
• Is there a quicker way to get improvements?

6
The “core software” strategy
Don’t just speed up the program, speed up the compiler (or runtime) at the core
• Find a workload which is representative of real usages
• Analyze system behavior using the best tools possible (develop the tools if you have to)
• Modify the compiler or runtime, rather than the application
• If the workload is representative of broad usages, you should speed up a lot of things, not just the application you are optimizing
• Lather, rinse, repeat!

7
Examples at Intel for core software optimization
Existing practices – 20+ years
• C/C++ Compiler – both gcc and the Intel C Compiler
• Java (OpenJDK)
Emerging practices
• Python
• PHP / HHVM
• Go and Node.js

Case Study: OpenStack
July 2015

9
OpenStack: Open source cloud software
• Open source software for creating private and public clouds
• Infrastructure as a Service, basis for several usages
• Software Defined Infrastructure
• Software Defined Networking – with Open-daylight
• Software Defined Storage
• Intel is very involved in making OpenStack great:
• Platinum member of the OpenStack Foundation board of directors
• Employee on the technical committee (Dean Troyer)
• Top 10 contributor

10
OpenStack core software: Python
• 70% or more of OpenStack is written in Python –
• good candidate for core software focus
• Python is being taught to new CS students, significant use in HPC, machine learning, systems programming
• Swift – object storage in OpenStack
• Benchmarks: COSBench (Common Object Storage Benchmark, developed by Intel) and ssbench
STORAGE NODES
PROXYCOSBench
AUTH

11
Python performance on Openstack Swift Storage Node
• COSBench/Swift workload spends ~95% of cycles on the storage node (Xeon processor, Codenamed “Haswell”)
1. ~62% of cycles is Python (which is at user level)
2. ~30% cycles is at kernel level
Swift Performance on HSW-EP Storage Node
Python Module
Lots of opportunity for improvement!

12
Python’s performance challenges
• Significant gap to other languages
• Interpreted language with rich eco-system of add-ons
• Common solution: Create a Just in Time (JIT) compiler
• Structural changes to the interpreter break compatibility with libraries
• There is a JIT version (Pypy) but adoption is low due to library incompatibility
Workload Java7Python 2.7.8 PyPy
K-Nucleotide (1Thread) 1 7.5 6.7K-Nucleotide (Multi-thread) 1 8.3 14.2Binary Trees 1 53.7 17.3Reverse Complement 1 3.4 4.3Josephus OO 1 115.2 3.0Josephus List Reduction 1 63.6 6.2Josephus Recursion 1 19.1 7.6Function Calls 1 1392.9 11.4
Performance normalized on Java 7Lower is better!
Source: http://benchmarksgame.alioth.debian.org/
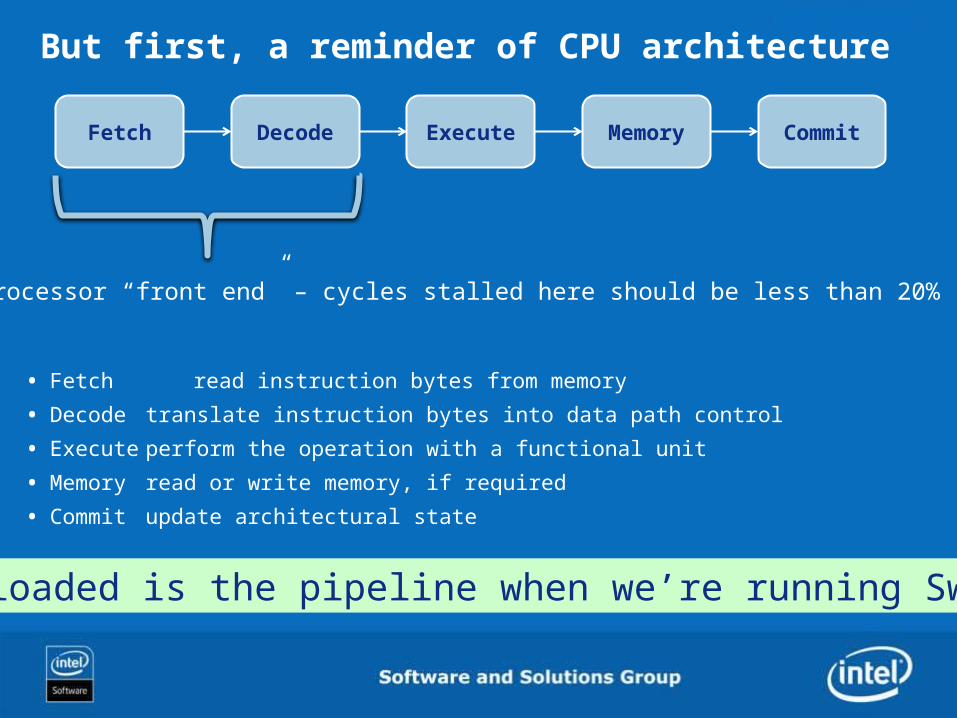
But first, a reminder of CPU architecture
• Fetch read instruction bytes from memory
• Decode translate instruction bytes into data path control
• Execute perform the operation with a functional unit
• Memory read or write memory, if required
• Commit update architectural state
Fetch Decode Execute CommitMemory
Processor “front end” – cycles stalled here should be less than 20%
How loaded is the pipeline when we’re running Swift?

14
Architecture awareness
Shows Vtune data for Swift Object Server.
Python / Swift is Front-end bound (42%)!

15
Front-end bound causes
Typical causes of front-end bound execution:
• Large code footprint
• Misses in the Instruction Translation Lookaside Buffer (ITLB)
• Misses in the instruction cache
• Branch misprediction
All are good candidates for optimization!

16
Let the compiler handle optimization!• PGO is helping in reducing FE issues. With PGO, the FE metric for
Python2.7 module was reduced by up to ~13% for Swift
• PGO on ssbench/Swift:
• ~10% boost on Xeon(BDW) Proxy + Atom(AVT) Storage node
• ~2.25% boost on Xeon (HSW) Proxy and Xeon(HSW) Storage node
• PGO gives ~10% boost for HPC oriented language workloads on both Xeon(HSW) and Atom (AVT)
1. HPC Workloads:2. K-nucleotide3. N-body4. Spectral-norm5. Binary-trees(Workloads 1-5 taken from Language Benchmarks Game http://benchmarksgame.alioth.debian.org/u64/python.php )6. Josephus Problem https://github.com/dnene/josephus
• List reduction• Object oriented• Element-recursion
PGO giving considerable benefit

17
Python PGO Adoption
• Idea: add (and maintain) an auto-FDO generated profile to the upstream Python project sources
• “Train” the compiler using Swift/ssbench
• Generate a profile using the training
• Submit the profile upstream to be used in compiling Python by default
• Commit to maintaining the profile long term
• Current status:
• Data collected showing significant improvement
• No known regressions
• Pull requests being created for both Python 2.7 and 3.5
• Potential downside: profile becomes “stale” with source changes
• Next step: a patch which adds our training profile to the git repo

18
Python 2 Complications
• Core services of OpenStack are implemented in Python 2.7
• Porting to Python 3.4 is non-mechanical, a slow process
• “no new features in Python 2.7” – Guido van Rossum
• But … there is still considerable legacy code in Python 2 (like OpenStack)
• GOOD NEWS: Guido will allow performance patches to 2.7 so long as they don’t complicate maintenance
• First performance patch for 2.7 (computed GOTO) accepted in June 2015!
• Average improvement of 5% - ranging from -2% to +25% on GUPB (Grand Unified Python Benchmark)

19
Accelerating the core
Python is at the core
• We’re speeding up Python
• Which will speed up Swift
• Which (along with other pieces written in Python) will speed up OpenStack

The P in LAMP
July 2015

21
PHP acceleration• PHP has strong adoption as a
language:
• Most popular language for websites
• 80% of the 1.2B websites globally
• 5M PHP developers worldwide
• Similar performance challenges to Python
• No JIT, strong compatibility concerns for major changes
• Analysis showed function hotspots in allocating/freeing
• Zend addressed these and result was significant improvement
• PHP7 upcoming release
Zend Infographic:http://www.zend.com/en/resources/php7_infographic

22
HHVM optimization• HipHop VM, developed by Facebook
to accelerate their PHP code
• Several assembly-level optimizations have resulted in generous improvements in real customer workloads
• Facebook performance Lockdown in June
• Tried auto-FDO: 5% improvement
• Linker change to load hot functions together in the cache (2% improvement)
• Memory operations are 40% faster than glibc in some cases, drive improvements
WordPressImprovement observed on Haswell
Compile with AVX2 enabled
5%
Memset() assembly tuning
1.8%
Memcpy() assembly tuning
3% (generic)

23
HHVM optimization• Analysis of front-end bound turned up poor I-cache use by linker
generated shared library related code (PLTs)<__gmon_start__@plt+0>: jmpq *0x2c1bfe2(%rip) # 0x36e0ee8 <[email protected]>
<__gmon_start__@plt+6>: pushq $0x1
<__gmon_start__@plt+11>: jmpq 0xac4ee0
<_ZdlPv@plt+0>: jmpq *0x2c1bfda(%rip) # 0x36e0ef0 <[email protected]>
<_ZdlPv@plt+6>: pushq $0x2
<_ZdlPv@plt+11>: jmpq 0xac4ee0
• Separating the hot and cold portions of the code and packing together the hottest function calls resulted in a ~2% speedup of WordPress
jmpq *0x2de17da(%rip) # 0x38b1620 <[email protected]>
xchg %ax,%ax
jmpq *0x2dde08a(%rip) # 0x38aded8 <[email protected]>
xchg %ax,%ax
jmpq *0x2ddeaca(%rip) # 0x38ae920 <[email protected]>
xchg %ax,%ax
jmpq *0x2de267a(%rip) # 0x38b24d8 <[email protected]>
xchg %ax,%ax
• A pull request for binutils is being prepared
• This could yield an improvement for any executable that uses shared libraries heavily

24
Go optimization• Core language for many new cloud projects
• CloudFoundry, Kubernetes, Mesos, CoreOS/etcd, Docker server
• Core function in CloudFoundry makes heavy use of bytes.Compare() method
• Written in assembly language
• Optimized through refactoring, vectorization and loop unrolling techniques (SSE2 instructions – coming: SSE4)
• Results: Runtime performance improved from 3%-to-36% depending on the size of input data
• Upstream for Go 1.6 version
• Many opportunities for further optimization

25
How are we doing?
• Performance of master changes daily
• You can’t improve what you don’t measure
• Needed: a community resource to build and measure performance
• “0-Day” lab: daily build and benchmark
• Results emailed to the community mailing lists
• Demonstrates support for the community

Invitation to Join Us
July 2015

27
What’s next?
• Our work starts with representative workloads
• Python in particular is used in areas beyond OpenStack
• We need your ideas for workloads to optimize!
• Send your ideas to:
• python-dev mailing list
• groups.google.com/forum/#!forum/golang-dev
• github.com/facebook/hhvm

Thank you!

29
Thanks!





























