Embed Size (px)
DESCRIPTION
Adaptive Multi-Robot Team Reconfiguration using a Policy-Reuse Reinforcement Learning Approach. Ke Cheng 1 , Raj Dasgupta 1 and Bikramjit Banerjee 2 1 Computer Science Department, University of Nebraska, Omaha 2 Computer Science Department, University of Southern Mississippi - PowerPoint PPT Presentation
Citation preview

Adaptive Multi-Robot Team Reconfiguration using a Policy-Reuse
Reinforcement Learning Approach
Ke Cheng1, Raj Dasgupta1 and Bikramjit Banerjee2
1Computer Science Department, University of Nebraska, Omaha2Computer Science Department, University of Southern Mississippi
Autonomous Robots and Multi-robot Systems (ARMS) 2011 WorkshopMay 2, 2011

Distributed Multi-robot Coverage
• Enable a group of robots to cover an initially unknown environment – Unmanned search and rescue– Robotic de-mining– Explore an extra-terrestrial surface (Mars, Moon)– Explore an engineering structure like a airplane’s
turbine-blade or a bridge for anomalies (e.g., cracks)
– Robotic lawn-mowing, vacuum cleaning

Distributed Multi-robot Coverage
• Efficiency is measured in time and space– Time: reduce the time required to cover the environment– Space: avoid repeated coverage of regions that have
already been covered
• Use a set of robots to perform complete coverage of an initially unknown environment in an efficient manner
The region of the environment that passes under the swathe of the robot’s coverage tool is considered as covered
• Using an actuator (e.g., vacuum) or a sensor (e.g., camera or sonar)
Robot’s coverage tool
Tradeoff in achieving both simultaneously
Source: Manuel Mazo Jr. and Karl Henrik Johansson, “Robust area coverage using hybrid control,”, TELEC'04, Santiago de Cuba, Cuba, 2004

Major Challenges
• Distributed – no shared memory or map of the environment that the robots can use to know which portion of the environment is covered
• Each robot has limited storage and computation capabilities– Can’t store map of the entire environment
• Other challenges: Sensor and encoder noise, communication overhead, localizing robots

Related Work: Multi-robot Coverage• Deterministic Approaches
– mSTC (Multi-robot Spanning Tree Coverage) [Agmon, Kaminka 2008]• Environment modeled as a
connected graph• Each robot does depth first search
within a sub-graph• Sub-graphs covered by each robot
made disjoint– Multi-robot Boustrophedon
[Rekleitis et al. 2009]• Robots determine disjoint regions;
cover each region using ladder search
• Record ‘holes’ in regions; uses auction protocol to allocate robot to fill holes
• Emergent Approaches– Potential field based [Batalin,
Sukhatme 2002, Parker 2002]• Robots exert repelling force on
each other when in vicinity – disperses robots away from each other
– Ant-coverage based • Pheromone based[Koenig et al.
2001] – Coverage marked with
pheromone, centralized map used to record all robots’ pheromones, robots LRTA* to choose next cell to visit
• Frontier-based [Bruckstein et al. 1998, 2007]
Complete coverage emerges, not provable
Complete coverage provable
Complete coverage provable

Multi-robot coverage: Individually coordinated robots using swarming
Global Objective: Complete coverage of
environment

Multi-robot coverage: Individually coordinated robots using swarming
Global Objective: Complete coverage of
environment
Local coverage rule of robot ......
...
Local coverage rule of robot
Local coverage rule of robot
Local coverage rule of robot
Local coverage rule of robot
Local coverage rule of robot
Multi-robot coverage: Individually coordinated robots using swarming
Global Objective: Complete coverage of
environment
Local coverage rule of robot ......
...
Local coverage rule of robot
Local coverage rule of robot
Local coverage rule of robot
Local coverage rule of robot
Local coverage rule of robot
Local interactions between robots

Multi-robot coverage: Individually coordinated robots using swarming
Global Objective: Complete coverage of
environment
Local coverage rule of robot ......
...
Local coverage rule of robot
Local coverage rule of robot
Local coverage rule of robot
Local coverage rule of robot
Local coverage rule of robot
Local interactions between robots
How well do the results of the local interactions translate to achieving the global objective?
Done empirically
References: 1. K. Cheng and P. Dasgupta, "Dynamic Area Coverage using Faulty Multi-agent Swarms" Proc. IEEE/WIC/ACM International Conference
on Intelligent Agent Technology (IAT 2007), Fremont, CA, 2007, pp. 17-24.2. P. Dasgupta, K. Cheng, "Distributed Coverage of Unknown Environments using Multi-robot Swarms with Memory and
Communication Constraints," UNO CS Technical Report (cst-2009-1).

Multi-robot coverage: Team-based robots using swarming
Global Objective: Complete coverage of
environment
Local coverage rule of robot-team ......
...
Local coverage rule of robot-team
Local coverage rule of robot-team
Local coverage rule of robot-team
Local coverage rule of robot-team
Local coverage rule of robot-team
Flocking technique to
maintain team formation

Multi-robot coverage: Team-based robots using swarming
Global Objective: Complete coverage of
environment
Local coverage rule of robot-team ......
...
Local coverage rule of robot-team
Local coverage rule of robot-team
Local coverage rule of robot-team
Local coverage rule of robot-team
Local coverage rule of robot-team
Flocking technique to
maintain team formation
Local interactions between robot teams
How well do the results of the local interactions translate to achieving the global objective?
Done empirically
Relevant publications: 1. K. Cheng, P. Dasgupta, Yi Wang ”Distributed Area Coverage Using Robot Flocks”, Nature and Biologically Inspired Computing (NaBIC’09), 2009.2. P. Dasgupta, K. Cheng, and L. Fan, ”Flocking-based Distributed Terrain Coverage with Mobile Mini-robots,” Swarm Intelligence Symposium 2009.

Flocking-based Controller for Multi-robot Teams
12
Works with physical characteristics such as wheel speed, sensor reading, pose, etc.
ControllerLayer (uses flocking)

Multi-robot teams for area coverage• Theoretical analysis: Forming teams gives a significant speed-up
in terms of coverage efficiency • Simulation Results: The speed-up decreases from the theoretical
case but still there is some speed-up as compared to not forming teams
• Based on Reynolds’ flocking model
• Leader referenced
• Follower robots designated specific positions within team

Coverage with Multi-robot TeamsSquare
Corridor
Office
20 robots in different sized teams, in different environments over 2 hours

Dynamic Reconfigurations of Multi-robot Teams
• Having teams of robots is efficient for coverage• Having large teams of robots doing frequent
reformations is inefficient for coverage• Can we make the modules change their
configurations dynamically– Based on their recent performance: If a team of
robots is doing frequent reformations (and getting bad coverage efficiency), split the team into smaller teams and see if coverage improves

Layered Controller for Dynamically Reforming Multi-robot Teams
16
Works with agent utility, agent strategies,
equilibrium points, etc.
Works with physical characteristics such as wheel speed, sensor reading, pose, etc.
Coalition GameLayer (uses WVG)
ControllerLayer (uses flocking)
Mediator
Map from agent strategy to robot action, sensor reading to agent utility, maintain data structure
for mapping

Coalition game-based Team Reconfiguration
• Coalition games provide a theory to divide a set of players into smaller subsets or teams
• We used a form of coalition games called weighted voting games (WVG)– N: set of players – Each player i is assigned a weight wi
– q: threshold value called quota– Solution concept: What is the minimum set of players whose
weights taken together can reach q
subject to S wi >=q for all S subset of Nminimize |S|
i e S

Coalition game-based Team Reconfiguration
• Coalition games provide a theory to divide a set of players into smaller subsets or teams
• We used a form of coalition games called weighted voting games (WVG)– N: set of players– Each player i is assigned a weight wi
– q: threshold value called quota– Solution concept: What is the minimum set of players whose
weights taken together can reach q
subject to S wi >=q for all S subset of Nminimize |S|
i e S
Minimum Winning Coalition (MWC)

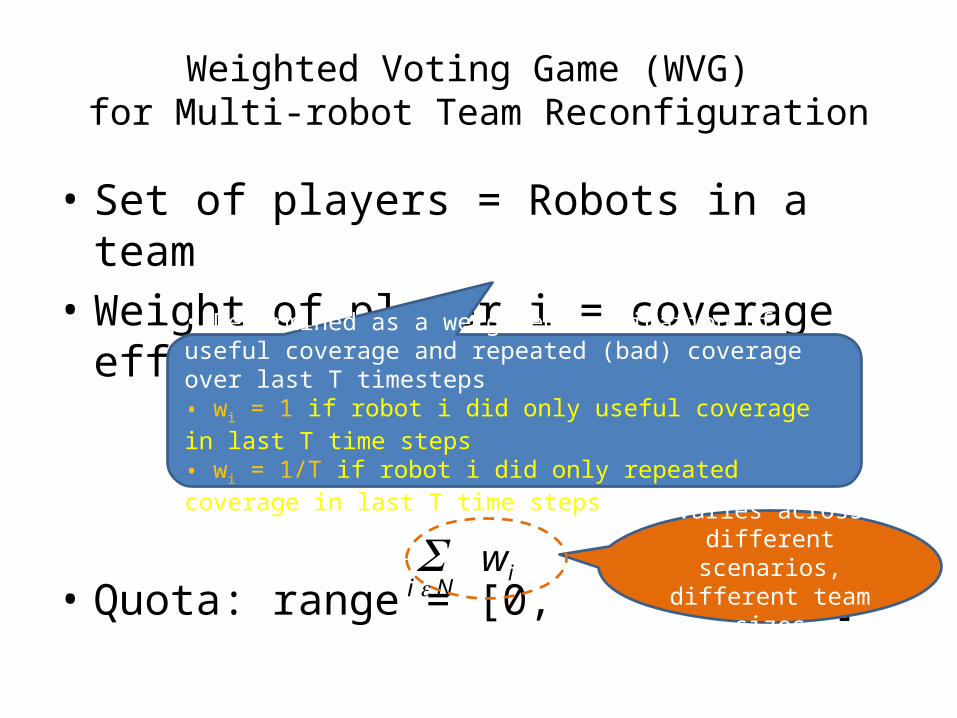
Weighted Voting Game (WVG) for Multi-robot Team Reconfiguration
• Set of players = Robots in a team• Weight of player i = coverage efficiency of
robot i• Determined as a weighted combination of useful coverage and repeated (bad) coverage over last T timesteps• wi = 1 if robot i did only useful coverage in last T time steps• wi = 1/T if robot i did only repeated coverage in last T time steps
Weighted Voting Game (WVG) for Multi-robot Team Reconfiguration
• Set of players = Robots in a team• Weight of player i = coverage efficiency of
robot i
• Quota: range = [0, ]
• Determined as a weighted combination of useful coverage and repeated (bad) coverage over last T timesteps• wi = 1 if robot i did only useful coverage in last T time steps• wi = 1/T if robot i did only repeated coverage in last T time steps
S wii e N
Varies across different scenarios, different
team sizes

Weighted Voting Game (WVG)for Multi-robot Team Reconfiguration
• Set of players = Robots in a team• Weight of player i = coverage efficiency of
robot i
• Quota: range = [0, ]– q = qf X , where qf e [0,1]
• Determined as a weighted combination of useful coverage and repeated (bad) coverage over last T timesteps• wi = 1 if robot i did only useful coverage in last T time steps• wi = 1/T if robot i did only repeated coverage in last T time steps
S wii e N
S wii e N
Varies across different scenarios, different
team sizes
Quota fraction

Example of WVG for Robot Team Reconfiguration
• 4 robots: N = {A, B, C, D}• wA = 0.45, wB = 0.25, wC = wD = 0.15• qf = 0.5 • Here = 1.0 and q = 0.5 X 1 = 0.5
• Find the MWC, i.e., min. set of players with S wi >= q• MWC = {A, B} {A, C} {A, D} {A, B, C} {A, B, D} {A, C, D} {B,
C, D} {A, B, C, D}• If we change qf to 0.76, MWC becomes {A, B, C} {A, B, D}
{A, B, C, D}
S wii e N

Example of WVG for Robot Team Reconfiguration
• 4 robots: N = {A, B, C, D}• wA = 0.45, wB = 0.25, wC = wD = 0.15• qf = 0.5 • Here = 1.0 and q = 0.5 X 1 = 0.5
• Find the MWC, i.e., min. set of players with S wi >= q• MWC = {A, B} {A, C} {A, D} {A, B, C} {A, B, D} {A, C, D} {B,
C, D} {A, B, C, D}• If we change qf to 0.76, MWC becomes {A, B, C} {A, B, D}
{A, B, C, D}
S wii e N
Changing the value of qf (quota) changes the solution (MWCs)
Our prior works refine the MWCs further to select one best MWC (BMWC) depending on the pose of the robots forming the team - P. Dasgupta and K. Cheng, "Robust Multi-robot Team Formations using Weighted Voting Games," 10th International Symposium on Distributed Autonomous Robotic Systems (DARS 2010), Lausanne, Switzerland, 2010

Problems with Fixed qf
• 4 robots: N = {A, B, C, D}• wA = wB = wC = wD = 1
• qf = 0.5 • q = 0.5 X 4 = 2• MWC: Any two players• But the team of 4 was giving useful
coverage only! (each robot’s wi = 1)• Team split was unnecessary
• First T time steps – 5 robots: N = {A, B, C, D, E}– wA = wB = wC = wD = wE =1
– qf = 0.9 (q = 0.9 X 5 = 4.5)– MWC: all 5 robots stay together…
good!• Next T time steps
– 5 robots: N = {A, B, C, D, E}– wA = 0.9, wB = 0.8, wC = 0.7, wD = wE =
0.6– qf = 0.9 (q = 0.9 X 3.6 = 3.24)– MWC: all 5 robots stay together
again…bad! They should have split• Team did not split when it was
necessary

Problems with Fixed qf
• 4 robots: N = {A, B, C, D}• wA = wB = wC = wD = 1
• qf = 0.5 • q = 0.5 X 4 = 2• MWC: Any two players• But the team of 4 was giving useful
coverage only! (each robot’s wi = 1)• Team split was unnecessary
• First T time steps – 5 robots: N = {A, B, C, D, E}– wA = wB = wC = wD = wE =1
– qf = 0.9 (q = 0.9 X 5 = 4.5)– MWC: all 5 robots stay together…
good!• Next T time steps
– 5 robots: N = {A, B, C, D, E}– wA = 0.9, wB = 0.8, wC = 0.7, wD = wE =
0.6– qf = 0.9 (q = 0.9 X 3.6 = 3.24)– MWC: all 5 robots stay together
again…bad! They should have split• Team did not split when it was
necessary
Depending on operating
conditions, (e.g., cov. eff. in team),
dynamically adapt qf
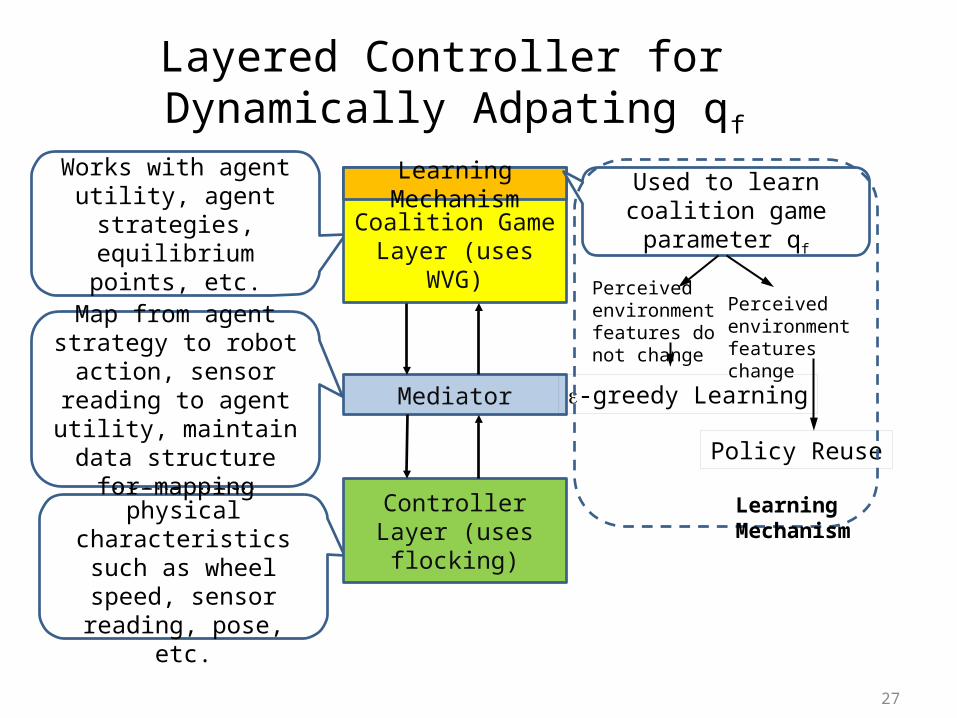
Layered Controller for Dynamically Adpating qf
27
Works with agent utility, agent strategies,
equilibrium points, etc.
Works with physical characteristics such as wheel speed, sensor reading, pose, etc.
Coalition GameLayer (uses WVG)
ControllerLayer (uses flocking)
Mediator
Map from agent strategy to robot action, sensor reading to agent utility, maintain data structure
for mapping
Learning Mechanism Used to learn coalition game parameter qf
Perceived environment features do not change
e-greedy Learning
Policy Reuse
Learning Mechanism
Perceived environment features change

Reinforcement Learning forUpdating qf
• Problem formulated as a Markov Decision Process (MDP) = <S, A, T, R>
Depending on coverage efficiency in team, dynamically
adapt qf
• Recall that coverage efficiency e [1/T, 1]• Discretize the coverage efficiency: [0.1, 0.2, …, 0.9, 1.0] • Each of these discretized values are denoted by S1, S2, S3,
….S9, S10
State Space

Action Space of MDP• qf e [0, 1] – discretize this space too• AL: qf = 0.9 (90% of combined wts.) - robots having very poor coverage efficiency are
dropped, if at all• AM: qf = 0.5 (50% of combined wts.) - robots having below average coverage efficiency
are likely to be dropped• AS: qf = 0.2 (20% of combined wts.) - robots having best coverage efficiency are likely to
be retained ActionSpace

Action Space of MDP
Obstacle
Robots
Comm. range
Five robot team trying to stay together, but impeded by a long obstacle
• qf e [0, 1] – discretize this space too• AL: qf = 0.9 (90% of combined wts.) - robots having very poor coverage efficiency are
dropped, if at all• AM: qf = 0.5 (50% of combined wts.) - robots having below average coverage efficiency
are likely to be dropped• AS: qf = 0.2 (20% of combined wts.) - robots having best coverage efficiency are likely to
be retained ActionSpace

Action Space of MDP
Obstacle
Robots
Comm. range
Five robot team trying to stay together, but impeded by a long obstacle
Probabilities representing uncertainties with actions AL and AM
• qf e [0, 1] – discretize this space too• AL: qf = 0.9 (90% of combined wts.) - robots having very poor coverage efficiency are
dropped, if at all• AM: qf = 0.5 (50% of combined wts.) - robots having below average coverage efficiency
are likely to be dropped• AS: qf = 0.2 (20% of combined wts.) - robots having best coverage efficiency are likely to
be retained ActionSpace

Domain Action Effect Transition0% of perceived environment has obstacles
AL Improves coverage efficiency (reward) by 10% T(Si, AL) Si+1
AM Reduces coverage efficiency (reward) by 40% T(Si, AM) Si-4
AS Reduces coverage efficiency (reward) by 70% T(Si, AS) Si-7
20% of perceived environment has obstacles
AL Reduces coverage efficiency (reward) by 10% T(Si, AL) Si-1
AM Improves coverage efficiency (reward) by 20% T(Si, AM) Si+2
AS Reduces coverage efficiency (reward) by 60% T(Si, AS) Si-6
40% of perceived environment has obstacles
AL Reduces coverage efficiency (reward) by 40% T(Si, AL) Si-4
AM Reduces coverage efficiency (reward) by 20% T(Si, AM) Si-2
AS Improves coverage efficiency (reward) by 10% T(Si, AS) Si+1
Transition Function of MDP

Domain Action Effect Transition0% of perceived environment has obstacles
AL Improves coverage efficiency (reward) by 10% T(Si, AL) Si+1
AM Reduces coverage efficiency (reward) by 40% T(Si, AM) Si-4
AS Reduces coverage efficiency (reward) by 70% T(Si, AS) Si-7
20% of perceived environment has obstacles
AL Reduces coverage efficiency (reward) by 10% T(Si, AL) Si-1
AM Improves coverage efficiency (reward) by 20% T(Si, AM) Si+2
AS Reduces coverage efficiency (reward) by 60% T(Si, AS) Si-6
40% of perceived environment has obstacles
AL Reduces coverage efficiency (reward) by 40% T(Si, AL) Si-4
AM Reduces coverage efficiency (reward) by 20% T(Si, AM) Si-2
AS Improves coverage efficiency (reward) by 10% T(Si, AS) Si+1
Transition Function of MDP

Domain Action Effect Transition0% of perceived environment has obstacles
AL Improves coverage efficiency (reward) by 10% T(Si, AL) Si+1
AM Reduces coverage efficiency (reward) by 40% T(Si, AM) Si-4
AS Reduces coverage efficiency (reward) by 70% T(Si, AS) Si-7
20% of perceived environment has obstacles
AL Reduces coverage efficiency (reward) by 10% T(Si, AL) Si-1
AM Improves coverage efficiency (reward) by 20% T(Si, AM) Si+2
AS Reduces coverage efficiency (reward) by 60% T(Si, AS) Si-6
40% of perceived environment has obstacles
AL Reduces coverage efficiency (reward) by 40% T(Si, AL) Si-4
AM Reduces coverage efficiency (reward) by 20% T(Si, AM) Si-2
AS Improves coverage efficiency (reward) by 10% T(Si, AS) Si+1
Transition Function of MDP

Domain Action Effect Transition0% of perceived environment has obstacles
AL Improves coverage efficiency (reward) by 10% T(Si, AL) Si+1
AM Reduces coverage efficiency (reward) by 40% T(Si, AM) Si-4
AS Reduces coverage efficiency (reward) by 70% T(Si, AS) Si-7
20% of perceived environment has obstacles
AL Reduces coverage efficiency (reward) by 10% T(Si, AL) Si-1
AM Improves coverage efficiency (reward) by 20% T(Si, AM) Si+2
AS Reduces coverage efficiency (reward) by 60% T(Si, AS) Si-6
40% of perceived environment has obstacles
AL Reduces coverage efficiency (reward) by 40% T(Si, AL) Si-4
AM Reduces coverage efficiency (reward) by 20% T(Si, AM) Si-2
AS Improves coverage efficiency (reward) by 10% T(Si, AS) Si+1
Transition Function of MDP
Summary• Across different environments• S and A are unchanged• T changes• <S, A, T> is called a domain D

Reward Function of MDP• R(Si) – r X actual coverage efficiency received
in state Si
Summary• Across different environments• S and A are unchanged• T changes• <S, A, T> is called a domain D
• Reward changes: different domains have different awards• Taken together a domain and its corresponding rewards define a task W = <D, RW>

Iterated policy selection strategy• Used within each domain (MDP is fixed)– Follow policy for MDP with probability e– Explore (choose an action not recommended by policy)
with probability 1-e

Policy Reuse Algorithm• If domain has changed, which policy to use?– At certain intervals (called episodes)• If discounted reward from current policy is low
– Store (current policy, current domain) in pollicy library L along with discounted reward
– Probabilisitically select a (policy, domain) from policy library L that has highest value of discounted rewards (excluding current domain)
• Else continue to use current policy
Both iterated policy selection and policy reuse algorithm are run by a robot team’s leader
01 2
3 4
a
u
dsep
F. Fernandez and M. Veloso, “Probabilistic Policy Reuse in Reinforcement Learning Agent,” Proc. 5th Intl. Joint Conference on Autonomous Agents and Multi-Agent Systems (AAMAS), 2006

Experimental Results on Webots• Simulated models of e-puck robot• Wheel speed: 2.8 cm/sec• Wireless comms, IR sensors for obstacle avoidance• Simulated on-board GPS•Robot size = Grid cell size = 7 cm X 7 cm• Results averaged over 10 runs, each run is 30 min – 2 hrs
Test environment: 2 m X 2 m arena• with no obstacles• with 10% of the arena’s area occupied by obstacles• with 20% of the arena’s area occupied by obstacles

Average Reward per Episode
20% of environment occupied by obstacles
10% of environment occupied by obstacles
No obstacles in environment
Learning algorithm parameters:• Iterated Policy Selection• Learning rate, a = 0.05• e- greeedy strategy: e0 = 0, De = 0.001
• Policy reuse algorithm• No. of time steps per episode, H = 100• Reward discount factor, g = 0.95
More obstacles, allows more policy reuse – library built faster, and convergence happens faster

Percentage of Environment Covered
Up to 2 hours 20 robots, divided into 5 robot teams, 20% of environment
occupied by obstacles
Different no. of robots {5, 10, 15, 20}, 20% of environment occupied
by obstacles, 2 hours
• Adapting qf using our reinforcement learning algorithm improves the percentage of environment covered by 4-10% w.r.t. a setting where qf is fixed

Video demo on the Webots with learning

Conclusions, Ongoing and Future Work• Learning the quota fraction parameter, qf, using
reinforcement learning + policy reuse improves the coverage performance of robot teams– By allowing them to reconfigure more efficiently
• Improving learning algorithm:– Learning across multiple teams– Apply principles from transfer learning, keep-away soccer
domain– Modeling partially observed information (environment
features) in existing algorithm• Implementation on physical robots

Acknowledgements• We are grateful to the sponsors of our
projects:– COMRADES project, Office of Naval Research– NASA Nebraska EPSCoR Mini-grant
For more information please visit our C-MANTIC lab’s Website http://cmantic.unomaha.edu
THANK YOU





























