Embed Size (px)
Citation preview

Adaptive Query Processing with Eddies
Amol Deshpande
University of Maryland

Roadmap
Adaptive Query Processing: Motivation
Eddies [AH’00]
STAIRs [DH’04] and SteMs [RDH’03]
Experimental Study
Implementation in PostgreSQL [Des’03]
Continuous queries [MSHR’02] (very briefly)
Open problems

Query Processing in Database Systems
Database System
Declarative Query
Results
We will focus on traditional select-project-join queries

Query Processing: Example
Database System
Students Enrolled Courses
Name Level
Joe Junior
Jen Senior
Name Course
Joe CS1
Jen CS2
Course Instructor
CS2 Smith
select *from students, enrolled, courseswhere students.name = enrolled.name and enrolled.course = courses.course

Query Processing: Example
Name Level
Joe Junior
Jen Senior
Name Course
Joe CS1
Jen CS2
Course Instructor
CS2 Smith
select *from students, enrolled, courseswhere students.name = enrolled.name and enrolled.course = courses.course
Students Enrolled
Name Level Course
Joe Junior CS1
Jen Senior CS2
Enrolled Courses
Students Enrolled
Courses
Name Level Course Instructor
Jen Senior CS2 Smith

Example Query: Execution Plans
Students Enrolled
Courses
E C
S E
A Query Execution Plan
S E
C
SE
SEC
Courses Enrolled
Students
E S
C E
An alternate Execution Plan
C E
S
CE
SEC

Cost-based Query Optimization
Students Enrolled
Courses
E C
S E
A Query Execution Plan
S E
C
SE
SEC
Estimate cost of each plan and choose the best
Cost = f(|S|, |E|, R)
Runtime Parameters
Input sizesCost = g(|SE|, |C|, R)
Cost (Plan)
=
+

Cost-based Query Optimization
DeclarativeQuery
Results
Query Optimizer
Query Executor
CompiledQuery Plan
Disk(s)

Cost-based Query Optimization
DeclarativeQuery
ResultsN
etwork
Query Optimizer
Query Executor
CompiledQuery Plan
Disk(s)
Wide area data sources: e.g. remote tables, web data sources

Cost-based Query Optimization
DeclarativeQuery
ResultsN
etwork
Query Optimizer
Query Executor
CompiledQuery Plan
Disk(s)
Streaming data e.g. Stock tickers Network logs Sensor networks

Estimation Errors
Students Enrolled
Courses
E C
S E
A Query Execution Plan
S E
C
SE
SECCost = g(|SE|, |C|, R)
Input sizes may not be availableErroneous estimation of intermediateresult sizes

Effect on the cost function maybe unpredictable
Estimation Errors
Students Enrolled
Courses
E C
S E
A Query Execution Plan
S E
C
Cost = g(|SE|, |C|, R)
Unknown runtime parametersSE
SEC

How to solve this problem ?
More sophisticated estimation techniques Sophisticated summary structures
e.g. MHists [PI’97], Wavelets [VWI’98] Feedback loop in the optimization process
e.g. [SLMK’01, BC’02]
Adaptive query processing Can’t always build and maintain synopses Runtime environments can be very unpredictable So…adapt query plans mid-way during execution

Eddies: Extreme Adaptivity
Telegraph & TelegraphCQ (at UC Berkeley) Eddies [AH’00] SteMs [RDH’03] Continuous queries [MSHR’02, CF’02, C+’03, K+’03] Implementation in PostgreSQL [Des04] Fault-tolerance and load balancing [SHB’04] STAIRs [DH’04]
Other work Distributed eddies, Content-based Routing [BB’05]
Dynamic QEP,Parametric,Competitive
staticplans
latebinding
inter-operator
per tuple
TraditionalDBMS
Query Scrambling,MidQuery
Re-opt
EddiesXJoin, DPHJConvergent
QP
intra-operator

Roadmap
Adaptive Query Processing: Motivation
Eddies [AH’00]
STAIRs [DH’04] and SteMs [RDH’03]
Experimental Study
Implementation in PostgreSQL [Des’03]
Continuous queries [MSHR’02] (very briefly)
Open problems

Eddies [AH’00]
Plans considered by the optimizer
pred2(S)S Output
select * from Swhere pred1(S) and pred2(S)
pred1(S)
pred1(S)S Outputpred2(S)
Decision made apriori based on statistics
Sort by (1-s)/c, where s = selectivity, c = cost
Once this decision is made, all tuples are processed using
the same order

Eddies [AH’00]
Executing the query using an Eddy
select * from Swhere pred1(S) and pred2(S)
pred2(S)
pred1(S)
EddyS Output
An eddy operator• Intercepts tuples from source(s) and output tuples from operators• Query executed by routing tuples between the operators• Uses feedback from the operators to route
Change routing ==> Change query execution plan used
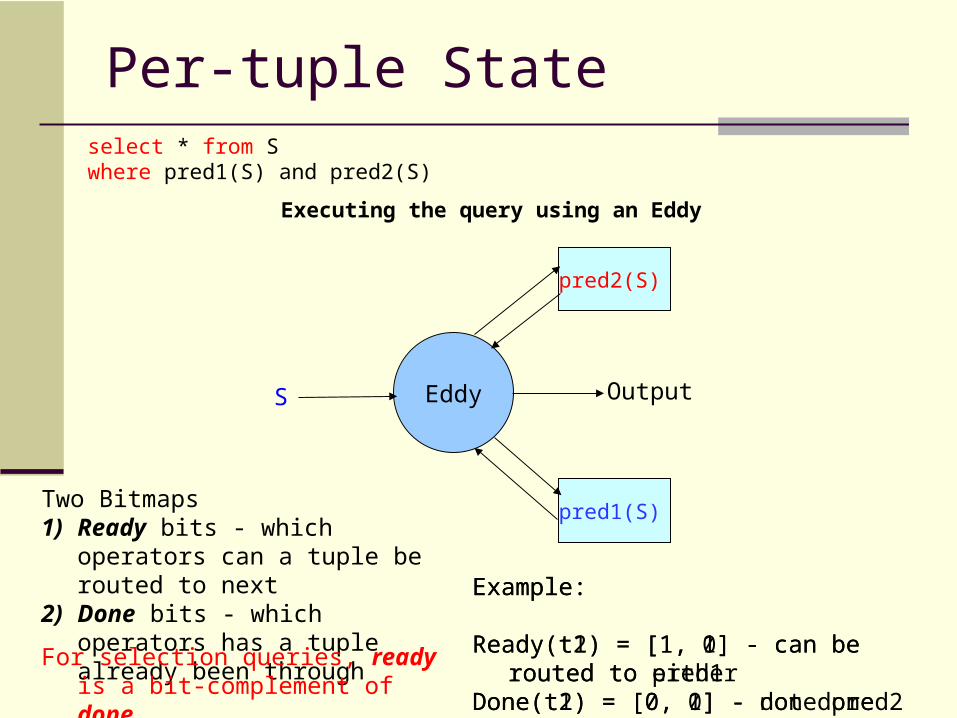
Per-tuple State
Executing the query using an Eddy
select * from Swhere pred1(S) and pred2(S)
pred2(S)
pred1(S)
EddyS Output
Two Bitmaps1) Ready bits - which operators can
a tuple be routed to next2) Done bits - which operators has a
tuple already been throughExample:
Ready(t1) = [1, 1] - can be routed to eitherDone(t1) = [0, 0] - not done either
Example:
Ready(t2) = [1, 0] - can be routed to pred1Done(t2) = [0, 1] - done pred2
For selection queries, ready is a bit-complement of done

Eddies: Routing Policy
Choosing which operator to route a given tuple to The brain of the eddy
Lottery Scheduling [Avnur 00]
Simplified Description
1. Maintain for each operator:
tuples sent
tuples returned
cost per tuple
2. Choose (roughly) based on the above
3. Explore by randomly sending tuples in
the wrong orders
sent = 100received = 2
sent = 30received = 20
Pred2 is more selectiveSend here 99% of the timeSend to the other operator 1% of the time
pred2(S)
pred1(S)
EddyS Output

A Join Query
Name Level
Joe Junior
Jen Senior
Name Course
Joe CS1
Jen CS2
Course Instructor
CS2 Smith
select *from students, enrolled, courseswhere students.name = enrolled.name and enrolled.course = courses.course
Students Enrolled
Name Level Course
Joe Junior CS1
Jen Senior CS2
Enrolled Courses
Students Enrolled
Courses
Name Level Course Instructor
Jen Senior CS2 Smith

Eddies [AH’00]A traditional query plan Query execution using an eddy
S E
E C
S E
Output
CEddy
S E
E C
SEC
Output
A key difference:
Tuples can’t be arbitrarily routed to any operator
E.g. S tuples can’t be routed to E Join C
Use ready bits to identify this

Eddies w/ Joins
Traditional join operators typically consume one relation entirely and then start reading the second relation E.g. hash join operator builds a hash table on one
relation first, and then reads in the other relation This is problematic for eddies An eddy needs to see tuples from different relations in
order to make its routing decisions Also, if the inner relations are pre-decided, not much
options left for adapting the join order
[Avnur, Hellerstein 00] discusses this issue in detail for traditional join operators

Symmetric Hash Join
We will use a new join operator called symmetric hash join operator Also called doubly pipelined Other variants include ripple joins, Xjoins (disk-based)
S E
HashTableS.Name
HashTableE.Name
S E
When a new S tuple arrives:(1) It is built into S.name
hashtable(2) Probed into E.name hash table
to find matches with already arrived E tuples
(3) Matches are immediately output
Symmetric Operation !!

Query Execution using Eddies
Eddy
SE
C
Insert with key hash(joe)Probe
to find matches
S E
HashTableS.Name
HashTableE.Name
E C
HashTableE.Course
HashTableC.Course
Joe Junior
Joe Junior
Joe Jr
No matches; Eddy processesthe next tuple
Output

Query Execution using Eddies
Eddy
SE
C
InsertProbe
S E
HashTableS.Name
HashTableE.Name
E C
HashTableE.Course
HashTableC.Course
Joe Jr
Jen Sr
Joe CS1
Joe CS1
Joe CS1
Joe Jr CS1
Joe Jr CS1Joe Jr CS1
Output
CS2 Smith

Query Execution using Eddies
Eddy
SE
COutput
Probe
S E
HashTableS.Name
HashTableE.Name
E C
HashTableE.Course
HashTableC.Course
Joe Jr
Jen Sr
CS2 Smith
Jen CS2
Joe CS1
Joe Jr CS1Jen CS2
Jen CS2
Jen CS2 Smith
Probe
Jen CS2 SmithJen CS2 SmithJen Sr. CS2 Smith
Jen Sr. CS2 Smith

Per-tuple State
Here also we need to keep track of what operators a tuple has already been through
Again use Ready bits - operators that can be applied
next Done bits - operators that have already been
applied
Unlike selections, these are not bit-complements of each other

Per-tuple State
Eddy
SE
C
S E
HashTableS.Name
HashTableE.Name
E C
HashTableE.Course
HashTableC.Course
Joe Junior
Output
S Join E E Join C
Ready 1 0
Done 0 0

Per-tuple State
Eddy
SE
C
S E
HashTableS.Name
HashTableE.Name
E C
HashTableE.Course
HashTableC.Course
Joe Jr
Jen Sr
Joe CS1Output
CS2 Smith
S Join E E Join C
Ready 1 1
Done 0 0

Per-tuple State
Eddy
SE
C
S E
HashTableS.Name
HashTableE.Name
E C
HashTableE.Course
HashTableC.Course
Joe Jr
Jen Sr
Joe CS1
Joe Jr CS1
Output
CS2 Smith
S Join E E Join C
Ready 0 1
Done 1 0

Execution Postmortem
Can we talk about what exactly the eddy did during the execution ? Yes !

Execution Postmortem
Students Enrolled
Output
Courses
E C
S E
Courses Enrolled
Output
Students
E S
C E
Eddy executes different query execution plans for different parts of data
Course Instructor
CS2 Smith
Course Instructor
CS2 Smith
Name Course
Joe CS1
Name Level
Joe Junior
Jen Senior
Name Level
Joe Junior
Jen Senior
Name Course
Jen CS2

Execution Postmortem
Can we talk about what exactly the eddy did during the execution ? Yes !
Eddy executes different plans for different parts of data
This is where the adaptivity comes from

Routing policy Lottery scheduling unfortunately doesn’t work well with joins
Just because a join operator does not return tuples right now doesn’t mean it won’t return more tuples later
In other words, a join operator is state-ful Selection operators are state-less

Example: Delayed Data SourcesSETUP:
|S E|
|E C|
>>
E C
S E
S E
C
E S
C E
C E
S
Execution plan 1 Execution plan 2
Cost (Plan 1) > Cost (Plan 2)
SE
SEC
CE
SEC

SETUP:
E and C arrive early; S is delayed
Example: Delayed Data Sources
time
|S E|
|E C|
>>
S
E
C

S0
SETUP:
E and C arrive early; S is delayed
time
|S E|
|E C|
>>
S
E
C
E C
EddySEC
Output
S EHashTable
S.NameHashTable
E.Name
HashTableE.Course
HashTableC.Course
S0 E
CS0E
Eddy decides to route E to E CEddy learns the correct sizes
Too Late !!
S
SE
S –S0
(S –S0)E
sent and received suggested(so far) that S Join E is better option for E tuples

E C
EddySEC
Output
S EHashTable
S.NameHashTable
E.Name
HashTableE.Course
HashTableC.Course
S
SETUP:
E and C arrive early; S is delayed
|S E|
|E C|
>>
Query is executed using the worse plan.
E
C
Too Late !!
SE
E C
S E
S E
C
Execution Plan Used
State got embedded as aresult of earlier routing decisions

Joins and Lottery Scheduling
Lottery scheduling doesn’t work well with joins
Not clear how any routing policy can work without reasonable knowledge of future Whatever the current state in the join operators, an
adversary can send tuples to make it look very bad
Two possible solutions: Allow manipulation of state (STAIRs) [DH’04] Don’t embed state in the operators (SteMs) [RDH’03]

Roadmap
Adaptive Query Processing: Motivation
Eddies [AH’00]
STAIRs [DH’04] and SteMs [RDH’03]
Experimental Study
Implementation in PostgreSQL [Des’03]
Continuous queries [MSHR’02] (very briefly)
Open problems

STAIRs [DH’04]
Expose join state to the eddy
Provide state management primitives That guarantee correctness of execution That can be used to manipulate embedded
state in the operators Also allow support for cyclic queries etc

New Operator: STAIR
E C
EddySEC
Output
S EHashTable
S.NameHashTable
E.Name
HashTableE.Course
HashTableC.Course

New Operator: STAIRStorage, Transformation and Access for Intermediate Results
HashTable
E.Name STAIR
HashTable
S.Name STAIR
HashTable
E.Course STAIR
HashTable
C.Course STAIR
EddySEC
Output
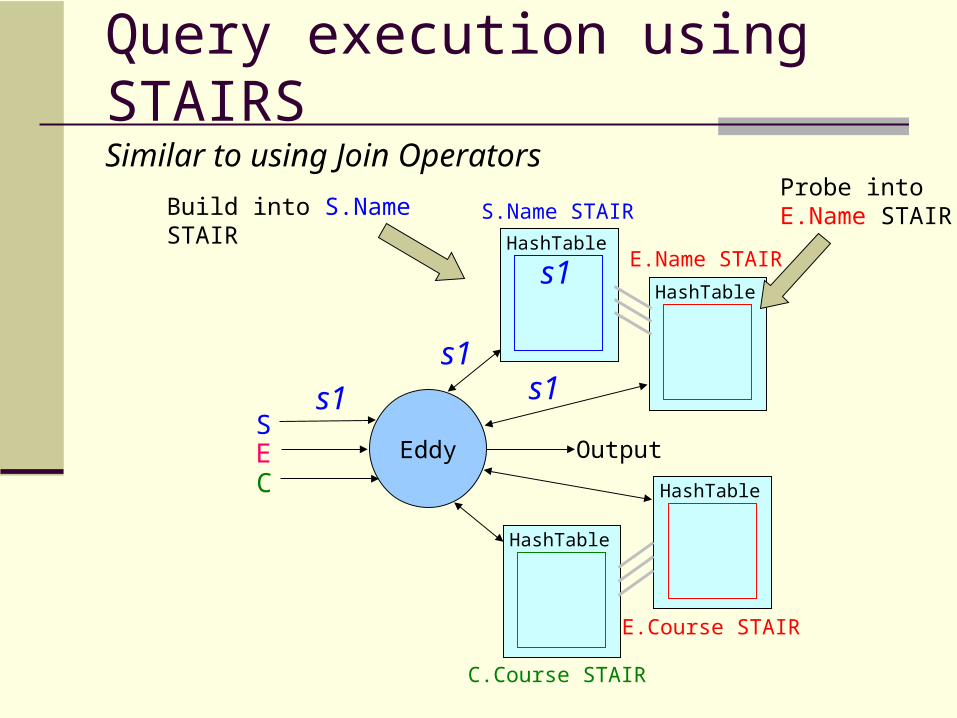
HashTable
E.Name STAIR
HashTable
S.Name STAIR
HashTable
E.Course STAIR
HashTable
C.Course STAIR
EddySEC
Output
Query execution using STAIRS
Similar to using Join Operators
s1s1
s1
Probe into E.Name STAIRBuild into S.Name
STAIR
s1

STAIR: Operations
Build (insert): Insert the given tuple into the STAIR
Probe (lookup): Find matching tuples for the given tuple
State Management Operations: Demotion Promotion

State Management Primitive: Demotion
Replace a tuple in a STAIR with a projection of that tuple
HashTable
E.Name STAIR
Eddy
S
E
C
Output
HashTable
S.Name STAIR
HashTable
E.Course STAIR
HashTable
C.Course STAIR
s1
s1e1e2
e2c1
c1
e1e1
e1
e2e2
Demoting e2c1 to e2
e2
Can be thought of as undoing work
e2c1e2c1
s1e1s1e1

e1c1
e1c1
State Management Primitive: Promotion
Replace a tuple in a STAIR with the result of joining it with other tuples
HashTable
E.Name STAIR
Eddy
S
E
C
Output
HashTable
S.Name STAIR
HashTable
E.Course STAIR
HashTable
C.Course STAIR
s1
s1e1e2
e2c1
c1
e1
Two arguments:• A tuple• A join to be used to promote this tuple
Can be thought of as precomputation of work
Promoting e1 using E C
e1
e1e1
e1e1c1

STAIRs: Correctness
Theorem: For any sequence of applications of the state management operations, STAIRs will produce the correct query output. STAIRs will produce every result tuple There will be no spurious duplicates

Lifting Burden of History: Delayed Data Sources

SETUP:
E and C arrive early; S is delayed
time
|S E|
|E C|
>>
S
E
C
E C
EddySEC
Output
S EHashTable
S.NameHashTable
E.Name
HashTableE.Course
HashTableC.Course
S0
S0 E
CS0E
Eddy decides to route E to E CEddy learns the correct selectivities

SETUP:
E and C arrive early; S is delayed
time
|S E|
|E C|
>>
S
E
C EddySEC
Output
S0
HashTable
S0
S.Name STAIR
HashTable
E
E.Name STAIR
HashTable
S0E
E.Course STAIR
HashTable
C
C.Course STAIR
Eddy decides to route E to E CEddy learns the correct selectivitiesEddy decides to migrate E
EC
ECE
E
E
EC
E
By promoting E using E C

SETUP:
E and C arrive early; S is delayed
time
|S E|
|E C|
>>
S
E
C EddySEC
Output
HashTable
S0
S.Name STAIR
HashTable
E.Name STAIR
HashTable
S0E
E.Course STAIR
HashTable
C
C.Course STAIR
EC
E
S
S –S0S –S0
(S –S0) E C

EddySEC
Output
HashTable
S.Name STAIR
HashTable
E.Name STAIR
HashTable
SE
E.Course STAIR
HashTable
C
C.Course STAIR
EC
E
S
S0 E
C
E C
S E
UNION
E C
S – S0
S E
E C
Most of the data isprocessed using thecorrect plan

Further Motivating Adaptive State Management Eager pre-computation for faster response
times Query scrambling [UFA’98] Partial results [RH’02]
Selective caching of intermediate results Continuous queries over streams
Cyclic queries Adapting the join spanning tree used

Making State Migration Decisions
Another policy question
Optimal migration decisions Requires knowledge of future selectivities and the
sizes of relations

Roadmap
Adaptive Query Processing: Motivation
Eddies [AH’00]
STAIRs [DH’04] and SteMs [RDH’03]
Experimental Study
Implementation in PostgreSQL [Des’03]
Continuous queries [MSHR’02] (very briefly)
Open problems

Alternative: SteMs [RDH’03]
Don’t embed the state in the operators at all
Note: Not the original motivation for SteMs Focus was on increasing opportunities for
adaptivity by breaking up the join operators
We will focus on a very simplistic version of the operator

Query Execution using SteMs
Eddy
SE
C
S SteM
E SteM
C SteM
Store S tuplesAllow probes using E tuples ie. If an E tuple is routed to it, find matching S tuplesCould use any indexing technique to find matches
Store E tuplesAllow probes using S and C tuplesNeed to build two internal indexes

Query Execution using SteMs
Eddy
SE
C
Insert
Probe
S SteM
Joe Jr
Jen Sr
Joe CS1
CS2 Smith
E SteM
C SteM
Jen CS2
Jen CS2 Smith
Jen Sr. CS2 SmithJen CS2Jen CS2
Jen CS2
Jen CS2
Jen CS2 Smith
Jen Sr. CS2 Smith
Probe

Query Execution using SteMs
State inside the operators is independent of previous
routing decisions Because no intermediate tuples are ever stored
Doesn’t have the same problem as the join or STAIR
operators
Optimal routing policy easy to write down Similarities to queries with only selections
But not storing intermediate results increases the
computation cost significantly

SteMs: Drawbacks
Recomputation of intermediate result tuples
Constrained plan choices Available plans depend highly on the arrival
order

EddySEC
S SteM
E SteM
C SteM
S0
SETUP:
E and C arrive early; S is delayed
time
|S E|
|E C|
>>
S
E
C
S0
E
C
S –S0can only be routedto E SteM for probingand is forced to be executedas (S Join E) Join C
Under the mechanism, there is no way to execute the other plan for this setup

SteMs: Drawbacks
Recomputation of intermediate result tuples
Constrained plan choices Available plans depend highly on the arrival
order
Though more subtle, the second drawback might be the more important one

Recap
An eddy operator Can affect the query execution plan(s) used by
routing different tuples differently Eddy w/ Selections:
Well understood Even if selections are correlated
Babu, Munagala et al [SIGMOD 2004, ICDT 2005]

Recap
Eddies for multi-way joins Opportunities for adaptivity depend on the join operators
used Higher adaptivity tends to push logic into the eddy ==>
Routing policies very important
Similarities toselections
Sort-mergeHybrid-Hash
Index-nestedloop joins
Nested-loopJoins
SteMs/STAIRs
Blocking opeatorsLittle adaptivity
See [AH’00] Suffers from state accumulation
problems
Pipelined/SymmetricHash Join
Policy issues not well-understood

Roadmap
Adaptive Query Processing: Motivation
Eddies [AH’00]
STAIRs [DH’04] and SteMs [RDH’03]
Experimental Study
Implementation in PostgreSQL [Des’03]
Continuous queries [MSHR’02] (very briefly)
Open problems

Implementation Details
In PostgreSQL Database System code base In the context of TelegraphCQ project
Highly efficient implementation [SIGREC’04] Eddy, SteMs, STAIRs export get_next() functions
Routing decisions are made per batch Can control batch size
Routing decisions made for all possible ready bitmaps
Decisions are encoded in arrays that are indexed with
ready bits Efficiently find the operator to route to

Results - Overheads (1)
All plans have identical costs, so adaptivity plays no role

Results - Overheads (2)

Policies used for experiments
Routing policy: Observe:
Selectivities of predicates on base tables Domain sizes of join attributes
Compute join selectivities and use them to route tuples Migration policy:
Tie state migration decisions to routing decisions Follow the routing policy decisions to make sure that
most tuples are routed correctly Caveats :
May end doing migrations late in the query execution May thrash

State Migration: Illustrative Example
select * from customer c, orders o, lineitem l where c.custkey = o.custkey and
o.orderkey = l.orderkey and c.nationkey = 1 and c.acctbal > 9000 and l.shipdate > date ’1996-01-01’
Setup:lineitem arrives sorted on shipdate==> selectivity(l.shipdate > …) very low initially==> orders routed to join with lineitem (bad)
No explicit delays introduced

Illustrative Example (1)

Illustrative Example (2)

Experiments: Synthetic Workload
Modeled after the Wisconsin Benchmark 20 Tables for varying sizes Randomly generated queries Environment
Rates proportional to table sizes; no delays or Random initial delays introduced or Random data rates

Traditional vs STAIRs

SteMs vs STAIRs
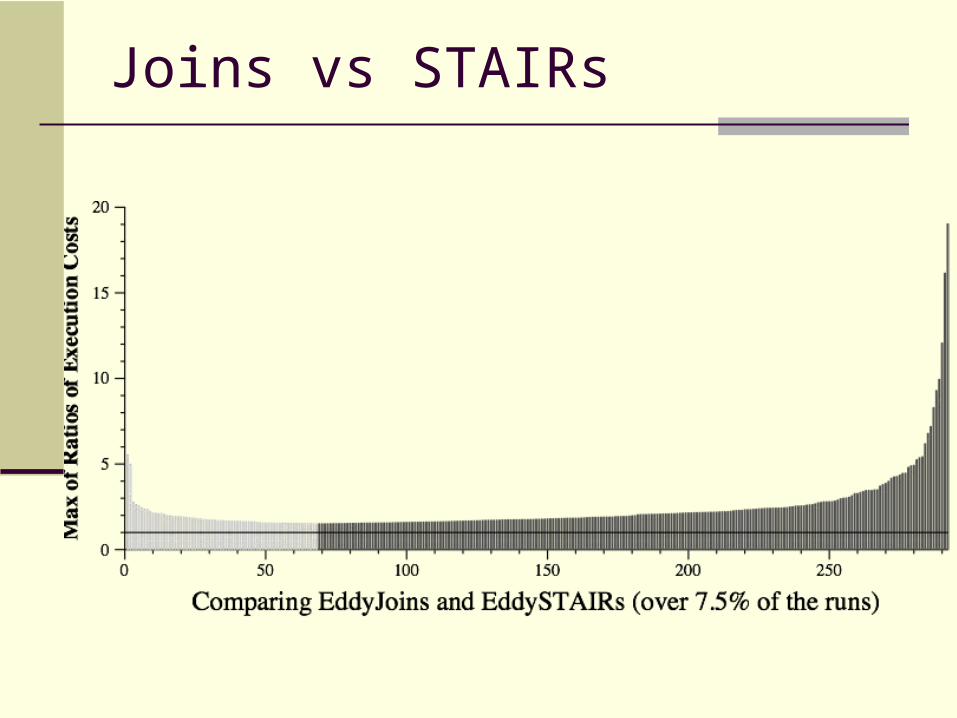
Joins vs STAIRs

Roadmap
Adaptive Query Processing: Motivation
Eddies [AH’00]
STAIRs [DH’04] and SteMs [RDH’03]
Experimental Study
Implementation in PostgreSQL [Des’03]
Continuous queries [MSHR’02] (very briefly)
Open problems

Continous Query Processing
Eddies ideal for executing continuous queries over data
streams Dynamic runtime conditions make a static plan unsuitable
Queries typically executed over sliding windows Find average over last one week
Note: Continuous vs Multi-query processing Not identical
Data streams literature does not make this difference
explicit Application environments tend to have a large number of
simultaneous queries

Continuous Query Processing
CACQ [Madden et al 2002] Focus on sharing work as much as adaptivity Uses SteMs augmented with a deletion
operator To handle sliding windows
Also uses predicate indexes For handling a large number of queries on the
same set of streams but with different predicates
E.g. millions of stock alerts over a few streams

Roadmap
Adaptive Query Processing: Motivation
Eddies [AH’00]
STAIRs [DH’04] and SteMs [RDH’03]
Experimental Study
Implementation in PostgreSQL [Des’03]
Continuous queries [MSHR’02] (very briefly)
Open problems

Some open problems (1)
Eddies for continuous query processing Much work since CACQ, but not a solved problem E.g. computational inefficiency of SteMs Many other proposed CQ architectures face the
same problem MJoins (NiagaraCQ) Stanford STREAM processor (earlier version)
Later added intermediate result caches Note: These two don’t use eddies explicitly
Routing policies for CQ still an open question Different from routing policies for non-CQ queries

Some open problems (2)
Routing policies Whether eddies will succeed depends on the
routing policies Little work so far...
SteMs, STAIRs Theoretical analysis of optimization space,
and practical viability analysis needed Especially in the context of continuous query
processing

Some open problems (3)
Eddies for multi-query processing (non-CQ) SteMs may be sufficient for CQ processing, but
not for normal multi-query processing
Parallel, distributed environments, P2P, Grid..
Disk: Flexibility demanded by adaptive techniques at
odds against the careful scheduling typically done by DBMSs
XJoins Very little work on understanding this

Some open problems (4)
Optimization with expanded plan space Eddies can explore a plan space much larger
than traditional plan space They allow relations to be broken into pieces,
with each piece executed separately Can we explore this plan space in a non-
adaptive setting ? Recent work on:
Conditional Planning [Deshpande et al, ICDE 2005]
Content-based Routing [Babu et al, VLDB 2005]

Summary
Increasing need for adaptivity Eddy: A highly adaptive query processor
Executes queries by routing tuples through operators
SteMs, STAIRs New operators proposed to handle problems
with traditional join operators Very promising especially for continuous and
wide-area query processing Exciting research lies ahead…

The End
Questions ?

Fatal Flaw: Burden of Routing History
Eddy
SE
COutput
S E
HashTableS.Name
HashTableE.Name
E C
HashTableE.Course
HashTableC.Course
Joe Jr
Jen Sr
CS2 Smith
Joe CS1
Joe Jr CS1
Jen CS2
Jen CS2 Smith
Routing decisions get
embedded in the state
Future adaptibility is
severly constrained

Example: Delayed Data SourcesSETUP:
|S E|
|E C|
>>
E C
S E
S E
C
E S
C E
C E
S
Execution plan 1 Execution plan 2
Cost (Plan 1) > Cost (Plan 2)
SE
SEC
CE
SEC

SETUP:
E and C arrive early; S is delayed
Example: Delayed Data Sources
time
A plan may have to be chosen without any statistical information about the data
Earliest time sufficient information may be available to choose optimal plan
|S E|
|E C|
>>
S
E
C

Tricky State Configurations: 1
Want to undo the decision to route E1 to S E
E C
EddySEC
Output
S EHashTable
S.NameHashTable
E.Name
HashTableE.Course
HashTableC.Course
S0 E1
CS0E1 E2
E2C
Result S0ECalready produced

Eddy
SE
I
E C
HashTableE.Course
HashTableC.Course
C1SE1 E2
S EHashTable
S.NameHashTable
E.Name
S E1E2C1
C I
HashTableC.Intstructor
HashTableI.Instructor
I
C
E2C2I
C2I
C2SE1C1SE2C1
Tricky State Configurations: 2





























