Embed Size (px)
Citation preview

AICS Café – 2013/01/18
AICS System Software teamAkio SHIMADA


Outline
• Self-introduction• Introduction of my research– PGAS Intra-node Communication towards Many-
Core Architectures (The 6th Conference on Partitioned Global Address Space Programming Models, Oct. 10-12, 2012, Santa Barbara, CA, USA)

Self-introduction
• Biography– AICS RIKEN System software team (2012 - ?)
• Research and develop the many-core OS– Key word: many-core architecture, OS kernel, process / thread
management
– Hitachi Yokohama Laboratory(2008 – present)• in Dept. of the storage product
– Research and develop the file server OS– Key word: Linux, file system, memory management, fault tolerant
– Keio university (2002 – 2008)• Obtained my Master’s degree in Dept. of the Computer
Science– Key word: OS kernel, P2P network, secutiry

• Hobby– Cooking– Football

PGAS Intra-node Communication towards Many-Core Architecture
Akio Shimada, Balazs Gerofi, Atushi Hori and Yutaka Ishikawa
System Software Research TeamAdvanced Institute for Computational Science
RIKEN

Background 1: Many-Core Architecture
• Many-Core architectures are gathering attention towards Exa-scale super computing– Several tens or around an hundred cores– The amount of the main memory is relatively small
• Requirement in the many-core environment– The intra-node communication should be faster
• The frequency of the intra-node communication can be higher due to the growth of the number of cores
– The system software should not consume a lot of memory• The amount of the main memory per core
can be smaller

Background 2: PGAS Programming Model
• Partitioned global array is distributed onto the parallel processes
• Intra-node ( ) or Inter-node ( ) communication takes place when accessing the remote part of the global array
Node 0
Process 0 Process 1 Process 2 Process 3 Process 4 Process 5
array[0:9]
array[10:19]
array[20:29]
array[30:39]
array[40:49]
array[50:59]
Node 1 Node 2
Core 0 Core 1 Core 0 Core 1Core 0 Core 1
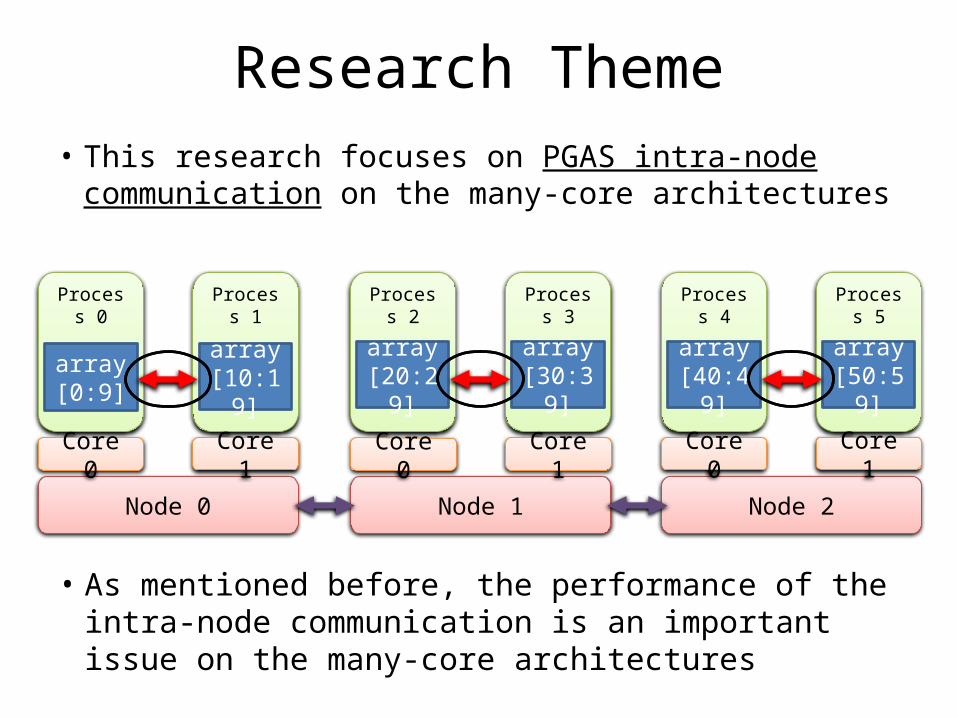
Research Theme• This research focuses on PGAS intra-node
communication on the many-core architectures
Node 0
Process 0 Process 1 Process 2 Process 3 Process 4 Process 5
array[0:9]
array[10:19]
array[20:29]
array[30:39]
array[40:49]
array[50:59]
Node 1 Node 2
• As mentioned before, the performance of the intra-node communication is an important issue on the many-core architectures
Core 0 Core 1 Core 0 Core 1Core 0 Core 1

Problems of the PGAS Intra-node Communication
• The conventional schemes for the intra-node communication are costly on the many-core architectures
• There are two conventional schemes– Memory copy via shared memory• High latency
– Shared memory mapping• Large memory footprint in the kernel space
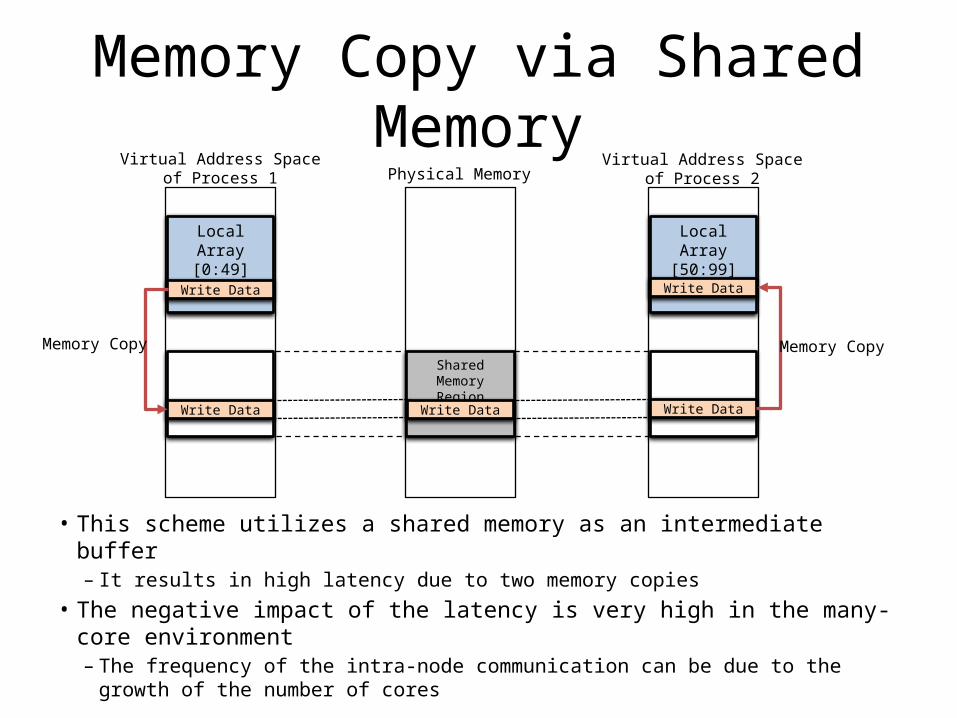
Memory Copy via Shared Memory
• This scheme utilizes a shared memory as an intermediate buffer– It results in high latency due to two memory copies
• The negative impact of the latency is very high in the many-core environment– The frequency of the intra-node communication can be due to the growth of
the number of cores
Virtual Address Spaceof Process 1
Virtual Address Spaceof Process 2Physical Memory
Local Array[0:49]
Local Array[50:99]
Write Data
Shared Memory Region
Write Data
Write Data Write DataWrite Data
Memory Copy Memory Copy
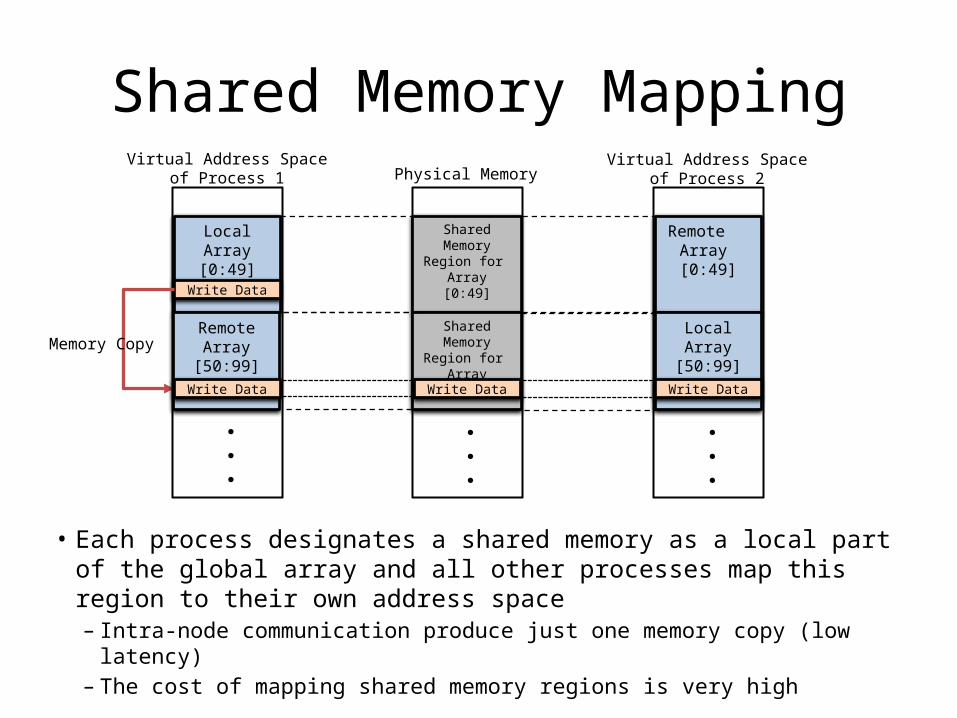
Shared Memory Mapping
• Each process designates a shared memory as a local part of the global array and all other processes map this region to their own address space– Intra-node communication produce just one memory copy (low latency)– The cost of mapping shared memory regions is very high
Virtual Address Spaceof Process 1
Virtual Address Spaceof Process 2Physical Memory
Local Array[0:49]
Remote Array [0:49]
Write Data
Shared Memory Region for Array [0:49]
Memory CopyRemote
Array[50:99]
Local Array[50:99]
Shared Memory Region for
Array [50:99]
Write Data Write Data Write Data
・・・
・・・
・・・
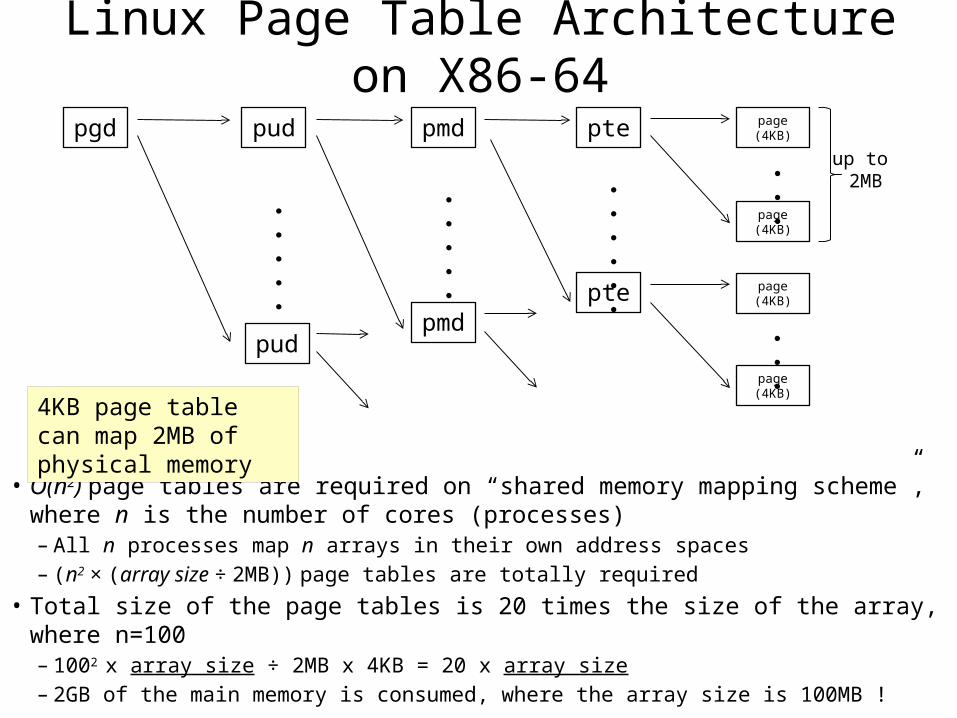
Linux Page Table Architecture on X86-64
• O(n2) page tables are required on “shared memory mapping scheme”, where n is the number of cores (processes)– All n processes map n arrays in their own address spaces– (n2 × (array size ÷ 2MB)) page tables are totally required
• Total size of the page tables is 20 times the size of the array, where n=100– 1002 x array size ÷ 2MB x 4KB = 20 x array size– 2GB of the main memory is consumed, where the array size is 100MB !
pgd pud pmd pte page(4KB)
page(4KB)
page(4KB)
・・・
pte
・・・・・・
page(4KB)
・・・
up to 2MB
4KB page table can map 2MB of physical memory
・・・・・・
・・・・・・ pmd
pud

Goal & Approach• Goal– Low cost PGAS intra-node communication on the many-
core architectures• Low latency• Small memory footprint in the kernel space
• Approach– Eliminating address space boundary between the
parallel executed processes• It is thought that the address space boundary produces the
cost for the intra-node communication– two memory copies via shared memory or memory consumption for
mapping shared memory regions
– It enables parallel processes to communicate with each other without costly shared memory scheme
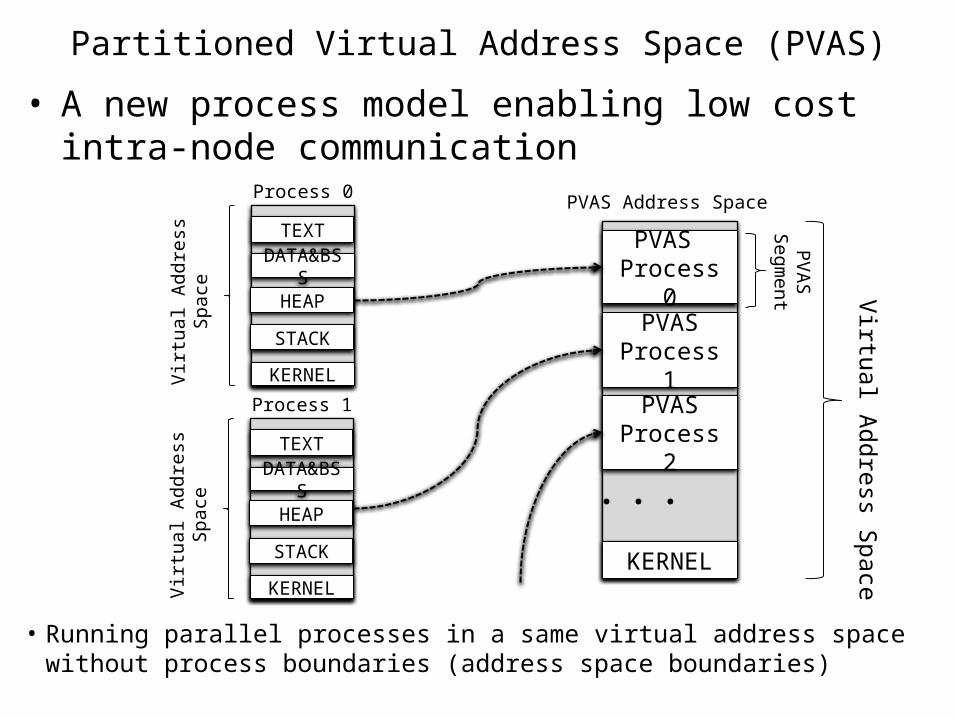
Partitioned Virtual Address Space (PVAS)
KERNEL
PVAS Process 0
PVASProcess 1
・・・
• A new process model enabling low cost intra-node communication
PVASProcess 2
• Running parallel processes in a same virtual address space without process boundaries (address space boundaries)
Process 0
TEXT
DATA&BSS
HEAP
STACK
KERNEL
PVAS Address SpaceVi
rtua
l Add
ress
Spac
e
Process 1
TEXT
DATA&BSS
HEAP
STACK
KERNEL
Virt
ual A
ddre
ssSp
ace
PVASSegm
ent Virtual Address Space
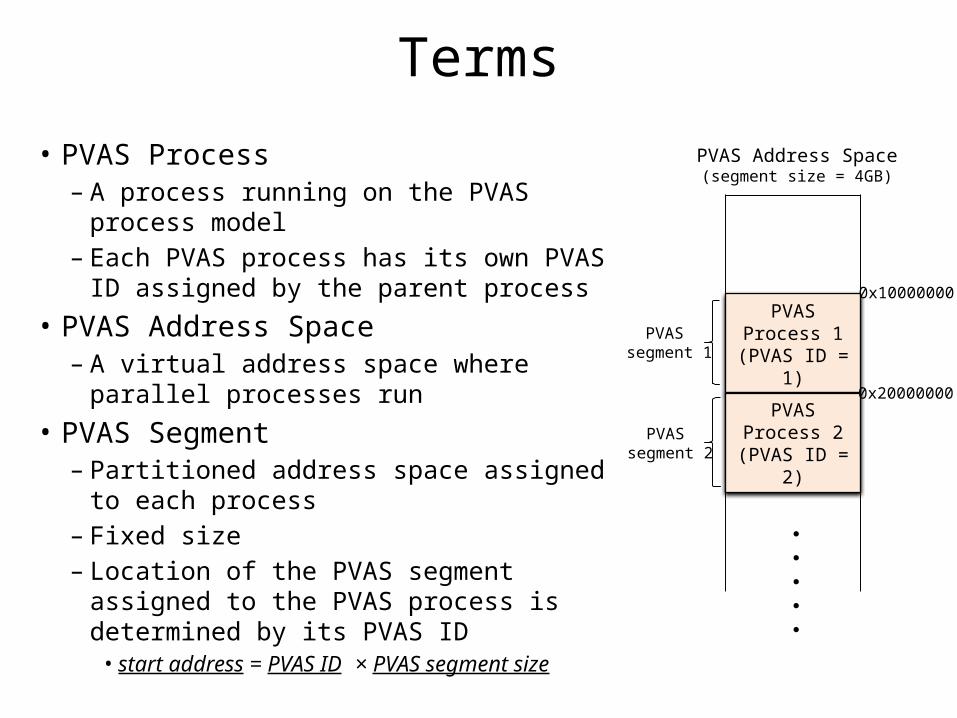
Terms
• PVAS Process– A process running on the PVAS process model– Each PVAS process has its own PVAS ID
assigned by the parent process• PVAS Address Space
– A virtual address space where parallel processes run
• PVAS Segment– Partitioned address space assigned to each
process – Fixed size– Location of the PVAS segment assigned to the
PVAS process is determined by its PVAS ID• start address = PVAS ID × PVAS segment size
・・・・・
PVAS Process 1(PVAS ID = 1)
PVAS Process 2(PVAS ID = 2)
PVAS Address Space(segment size = 4GB)
0x10000000
0x20000000
PVAS segment 2
PVAS segment 1
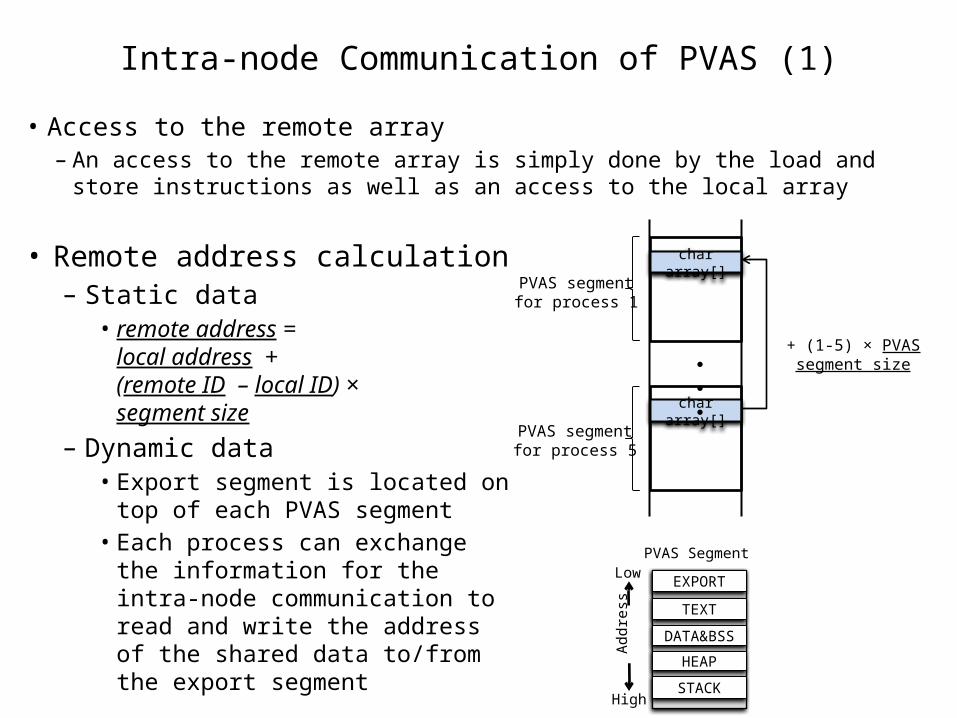
Intra-node Communication of PVAS (1)
• Remote address calculation– Static data
• remote address = local address + (remote ID – local ID) × segment size
– Dynamic data• Export segment is located on top
of each PVAS segment• Each process can exchange the
information for the intra-node communication to read and write the address of the shared data to/from the export segment
• Access to the remote array– An access to the remote array is simply done by the load and store
instructions as well as an access to the local array
TEXT
DATA&BSS
STACK
HEAP
PVAS Segment
EXPORT
Addr
ess
Low
High
char array[]PVAS segmentfor process 1
PVAS segmentfor process 5
char array[]
・・・
+ (1-5) × PVAS segment size

Intra-node Communication of PVAS (2)
• Performance– The performance of the intra-node communication of
the PVAS is comparable with that of “shared memory mapping”
– Both intra-node communication produce just one memory copy
• Memory footprint in the kernel space– The total number of the page tables required for the
intra-node communication of PVAS can be fewer than that of “shared memory mapping”
– Only O(n) page tables are required since one process maps only one array

Evaluation
• Implementation– PVAS is implemented in the kernel of Linux version 2.6.32– Implementation of the XcalableMP coarray function is
modified to use PVAS intra-node communication• XcalableMP is an extended language of C or Fortran, which
supports PGAS programming model• XcalableMP supports coarray function
• Benchmark– Simple ping-pong benchmark– NAS Parallel Benchmarks
• Evaluation Environment– Intel Xeon X5670 2.93 GHz (6 cores) × 2 Sockets

XcalableMP Coarray
・・・#include <xmp.h>
char buff[BUFF_SIZE];char local_buff[BUFF_SIZE];
#pragma xmp nodes p(2)#pragma xmp coarray buff:[*]
int main(argc, *argv[]) {int my_rank, dest_rank;
my_rank = xmp_node_num();dest_rank = 1 – my_rank;
local_buff[0:BUFF_SIZE] = buff[0:BUFF_SIZE]:[dest_rank];
return 0;}
• Coarray is declared by xmp coarray pragma
• The remote coarray is represented as the array expression attached :[dest_node] qualifier
• Intra-node communication takes place when accessing the remote coarray located on the intra-node process
Sample code of the XcalableMP coarray

Modification to the Implementation of the XcalableMP Coarray
• XcalableMP coarray utilizes GASNet PUT/GET operations for the intra-node communication– GASNet can employ two schemes as mentioned before
• GASNet-AM : “ Memory copy via shared memory”• GASNET-Shmem : “ Shared memory mapping”
• Implementation of the XcalableMP coarray is modified to utilize PVAS intra-node communication– Each process writes the address of the local coarray in its
own export segment– Processes access the remote coarray confirming the
address written in export segment of destination process
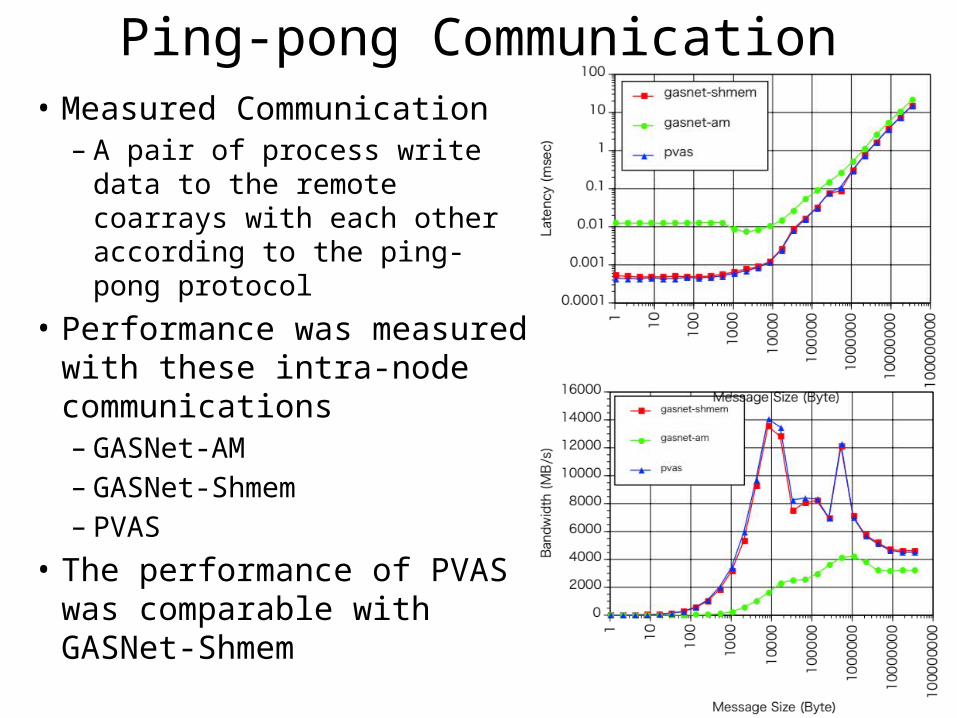
Ping-pong Communication• Measured Communication– A pair of process write data to
the remote coarrays with each other according to the ping-pong protocol
• Performance was measured with these intra-node communications– GASNet-AM– GASNet-Shmem– PVAS
• The performance of PVAS was comparable with GASNet-Shmem
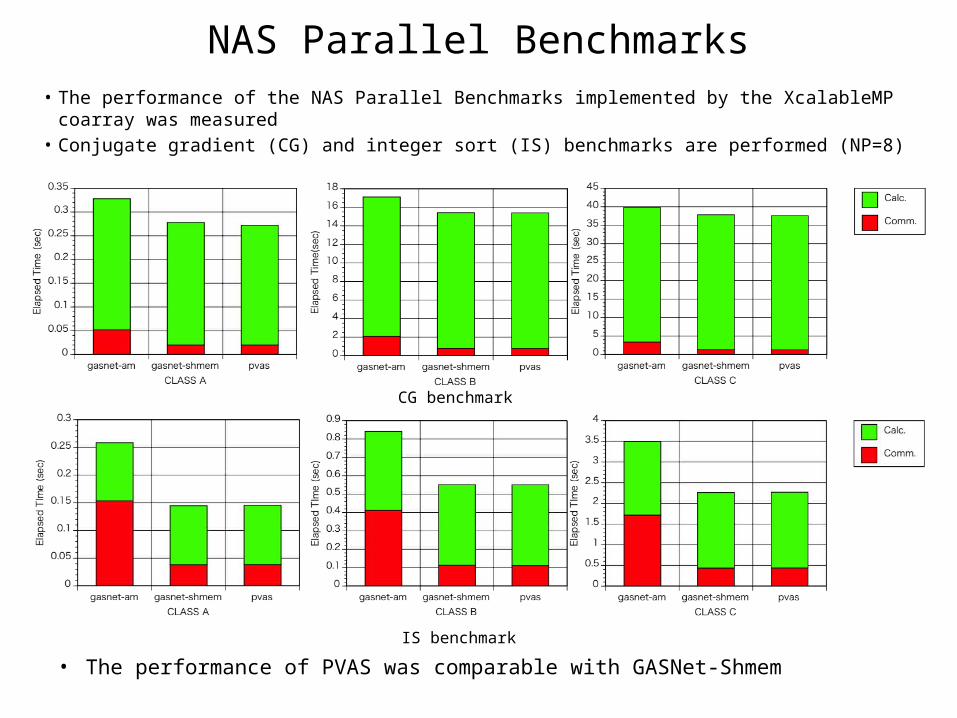
NAS Parallel Benchmarks• The performance of the NAS Parallel Benchmarks implemented by the
XcalableMP coarray was measured• Conjugate gradient (CG) and integer sort (IS) benchmarks are performed (NP=8)
• The performance of PVAS was comparable with GASNet-Shmem
CG benchmark
IS benchmark

Evaluation Result
• The performance of the PVAS is comparable with GASNet-Shmem– Both of them produce only one memory copy for
the intra-node communication– However, memory consumption for the intra-node
communication of the PVAS can be in theory smaller than that of GASNet-shmem• Only O(n) page tables are required on the PVAS, in
contrast, O(n2) page tables are required on the GASNet-Shmem
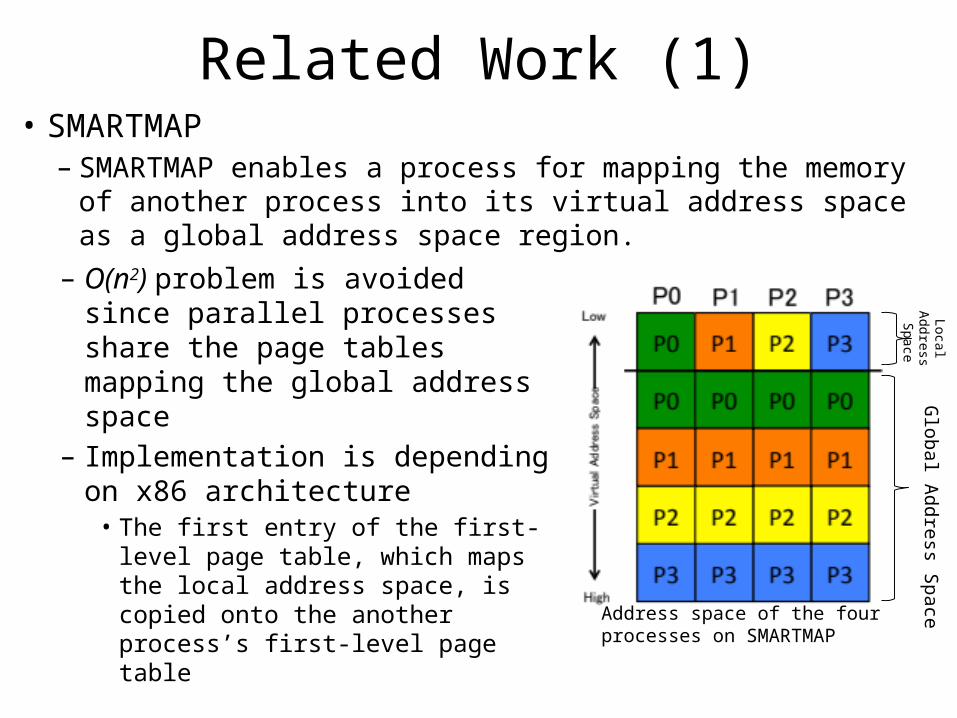
Related Work (1)• SMARTMAP– SMARTMAP enables a process for mapping the memory of another
process into its virtual address space as a global address space region.– O(n2) problem is avoided since
parallel processes share the page tables mapping the global address space
– Implementation is depending on x86 architecture• The first entry of the first-level page
table, which maps the local address space, is copied onto the another process’s first-level page table
Address space of the four processes on SMARTMAP
Global Address Space
Local Address Space

Related Work (2)
• KNEM– Message transmission between two processes takes
place via one memory copy by the kernel thread– Kernel-level copy is more costly than user-level copy
• XPMEM– XPMEM enables processes to export its memory
region to the other processes– O(n2) problem is effective

Conclusion and Future Work• Conclusion– PVAS process model which enhances PGAS intra-node
communication was proposed• Low latency• Small memory footprint in the kernel space
– PVAS eliminates address space boundaries between processes– Evaluation results show that PVAS enables high-performance
intra-node communication • Future Work– Implementing PVAS as Linux kernel module to enhance
portability– Implementing MPI library which utilizes the intra-node
communication of the PVAS










![[Morita Akio] Akio Morita and Sony(BookFi)](https://img.pdfslide.net/doc/110x75/56d6bf251a28ab3016950cd3/morita-akio-akio-morita-and-sonybookfi.jpg)


















