Embed Size (px)
Citation preview
Protein Folding 1Algorithms for Bioinformatics
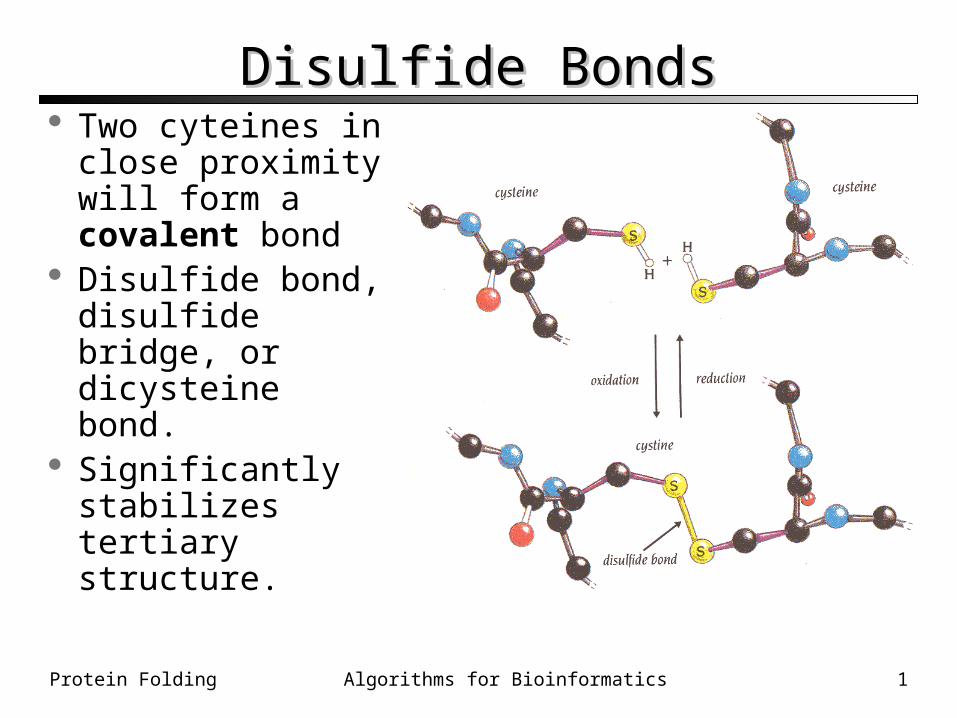
Disulfide BondsDisulfide Bonds Two cyteines in
close proximity will form a covalent bond
Disulfide bond, disulfide bridge, or dicysteine bond.
Significantly stabilizes tertiary structure.

Protein Folding 2Algorithms for Bioinformatics
Determining Protein StructureDetermining Protein Structure There are O(100,000) distinct proteins in the
human proteome. 3D structures have been determined for 14,000
proteins, from all organisms• Includes duplicates with different ligands bound,
etc.
Coordinates are determined by X-ray X-ray crystallographycrystallography

Protein Folding 3Algorithms for Bioinformatics
X-Ray CrystallographyX-Ray Crystallography
~0.5mm
• The crystal is a mosaic of millions of copies of the protein.
• As much as 70% is solvent (water)!
• May take months (and a “green” thumb) to grow.

Protein Folding 4Algorithms for Bioinformatics
X-Ray diffractionX-Ray diffraction
Image is averagedover:• Space (many copies)• Time (of the diffraction
experiment)

Protein Folding 5Algorithms for Bioinformatics
Electron Density MapsElectron Density Maps Resolution is
dependent on the quality/regularity of the crystal
R-factor is a measure of “leftover” electron density
Solvent fitting Refinement
Protein Folding 6Algorithms for Bioinformatics
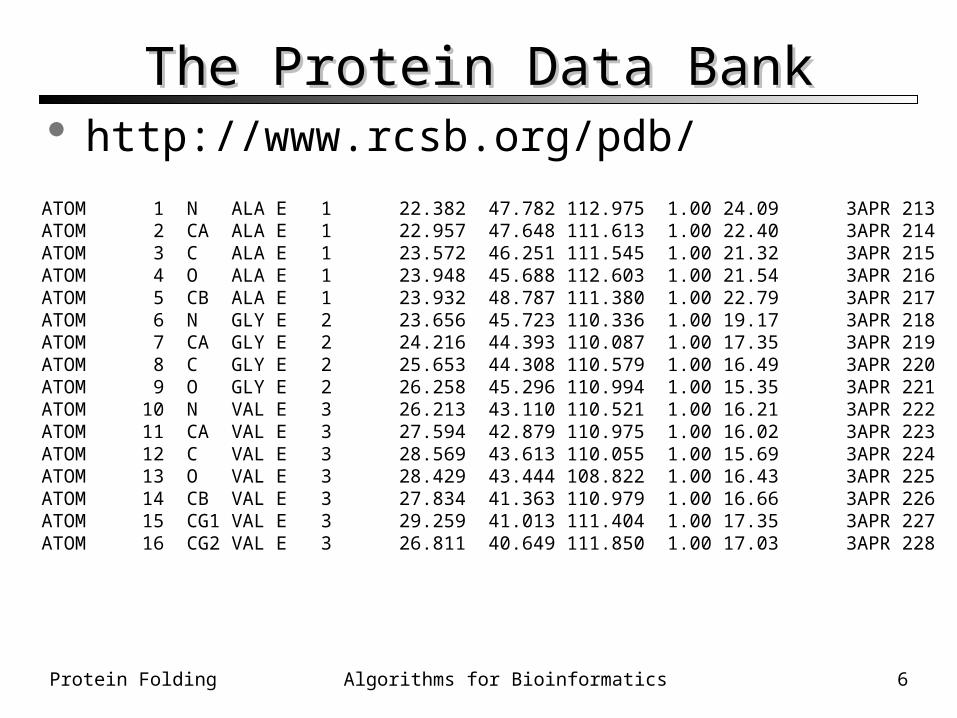
The Protein Data BankThe Protein Data Bank
ATOM 1 N ALA E 1 22.382 47.782 112.975 1.00 24.09 3APR 213ATOM 2 CA ALA E 1 22.957 47.648 111.613 1.00 22.40 3APR 214ATOM 3 C ALA E 1 23.572 46.251 111.545 1.00 21.32 3APR 215ATOM 4 O ALA E 1 23.948 45.688 112.603 1.00 21.54 3APR 216ATOM 5 CB ALA E 1 23.932 48.787 111.380 1.00 22.79 3APR 217ATOM 6 N GLY E 2 23.656 45.723 110.336 1.00 19.17 3APR 218ATOM 7 CA GLY E 2 24.216 44.393 110.087 1.00 17.35 3APR 219ATOM 8 C GLY E 2 25.653 44.308 110.579 1.00 16.49 3APR 220ATOM 9 O GLY E 2 26.258 45.296 110.994 1.00 15.35 3APR 221ATOM 10 N VAL E 3 26.213 43.110 110.521 1.00 16.21 3APR 222ATOM 11 CA VAL E 3 27.594 42.879 110.975 1.00 16.02 3APR 223ATOM 12 C VAL E 3 28.569 43.613 110.055 1.00 15.69 3APR 224ATOM 13 O VAL E 3 28.429 43.444 108.822 1.00 16.43 3APR 225ATOM 14 CB VAL E 3 27.834 41.363 110.979 1.00 16.66 3APR 226ATOM 15 CG1 VAL E 3 29.259 41.013 111.404 1.00 17.35 3APR 227ATOM 16 CG2 VAL E 3 26.811 40.649 111.850 1.00 17.03 3APR 228
http://www.rcsb.org/pdb/
Protein Folding 7Algorithms for Bioinformatics
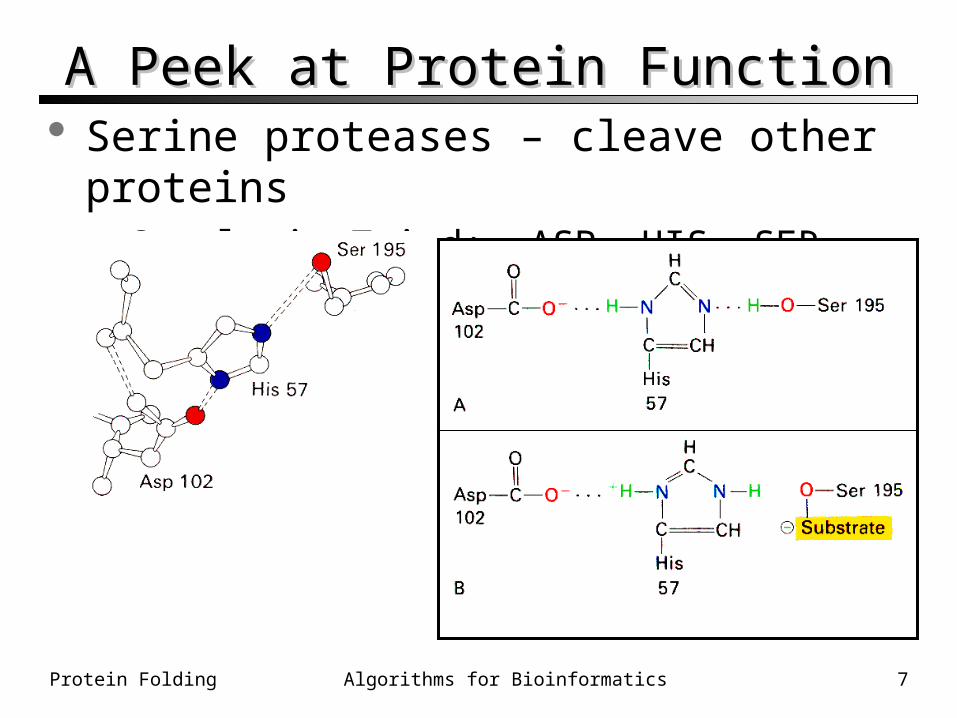
A Peek at Protein FunctionA Peek at Protein Function Serine proteases – cleave other proteins
• Catalytic Triad: ASP, HIS, SER
Protein Folding 8Algorithms for Bioinformatics
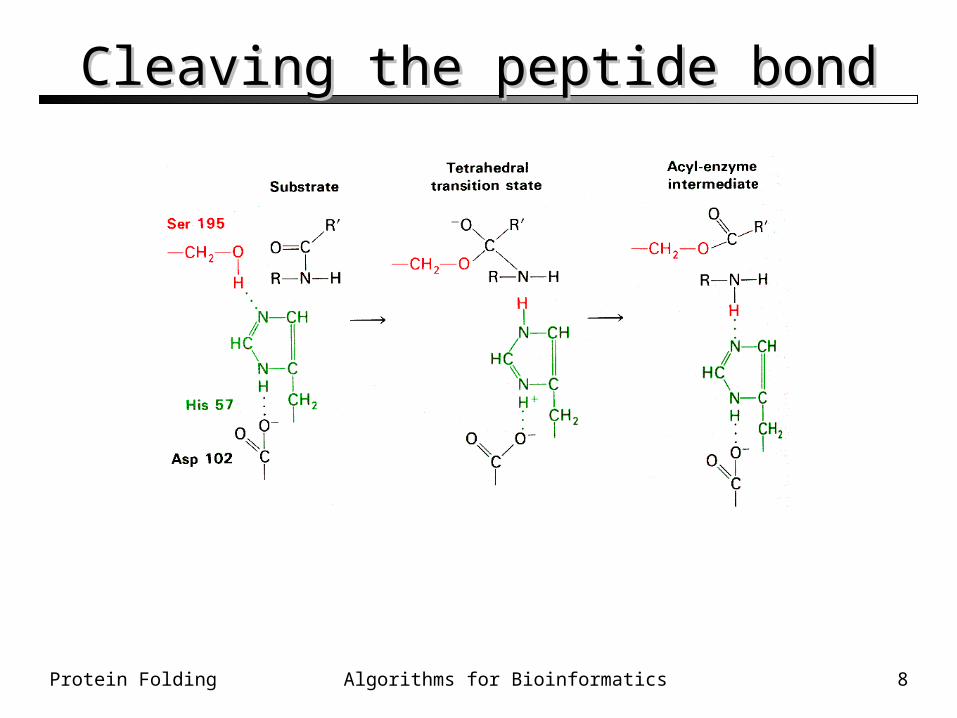
Cleaving the peptide bondCleaving the peptide bond

Protein Folding 9Algorithms for Bioinformatics
Three Serine ProteasesThree Serine Proteases Chymotrypsin – Cleaves the peptide bond on
the carboxyl side of aromatic (ring) residues: Trp, Phe, Tyr; and large hydrophobic residues: Met.
Trypsin – Cleaves after Lys (K) or Arg (R)• Positive charge
Elastase – Cleaves after small residues: Gly, Ala, Ser, Cys

Protein Folding 10Algorithms for Bioinformatics
Specificity Binding PocketSpecificity Binding Pocket
Protein Folding 11Algorithms for Bioinformatics
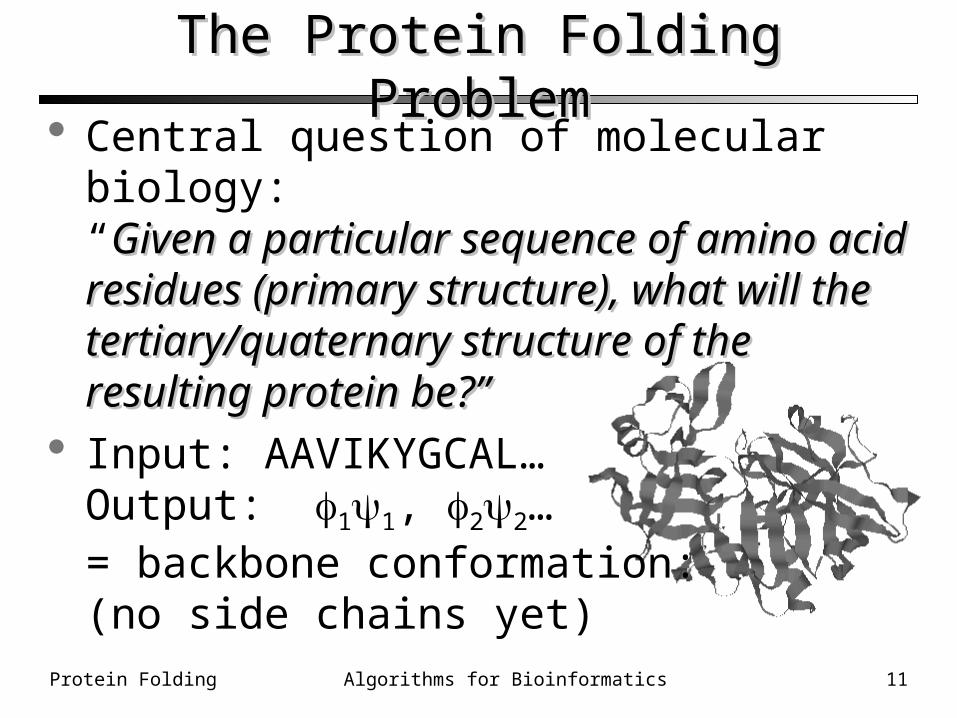
The Protein Folding ProblemThe Protein Folding Problem Central question of molecular biology:
“Given a particular sequence of amino acid Given a particular sequence of amino acid residues (primary structure), what will the residues (primary structure), what will the tertiary/quaternary structure of the resulting tertiary/quaternary structure of the resulting protein be?”protein be?”
Input: AAVIKYGCAL…Output: 11, 22…= backbone conformation:(no side chains yet)

Protein Folding 12Algorithms for Bioinformatics
Protein Folding – Biological perspectiveProtein Folding – Biological perspective ““Central dogma”: Central dogma”: Sequence specifies structureSequence specifies structure Denature – to “unfold” a protein back to
random coil configuration-mercaptoethanol – breaks disulfide bonds• Urea or guanidine hydrochloride – denaturant• Also heat or pH
Anfinsen’s experiments• Denatured ribonuclease• Spontaneously regained enzymatic activity• Evidence that it re-folded to native conformation

Protein Folding 13Algorithms for Bioinformatics
Folding intermediatesFolding intermediates Levinthal’s paradox – Consider a 100 residue
protein. If each residue can take only 3 positions, there are 3100 = 5 1047 possible conformations.• If it takes 10-13s to convert from 1 structure to
another, exhaustive search would take 1.6 1027 years!
Folding must proceed by progressive stabilization of intermediates• Molten globules – most secondary structure formed,
but much less compact than “native” conformation.

Protein Folding 14Algorithms for Bioinformatics
Forces driving protein foldingForces driving protein folding It is believed that hydrophobic collapse is a key
driving force for protein folding• Hydrophobic core• Polar surface interacting with solvent
Minimum volume (no cavities) Disulfide bond formation stabilizes Hydrogen bonds Polar and electrostatic interactions

Protein Folding 15Algorithms for Bioinformatics
Folding helpFolding help Proteins are, in fact, only marginally stable
• Native state is typically only 5 to 10 kcal/mole more stable than the unfolded form
Many proteins help in folding• Protein disulfide isomerase – catalyzes shuffling of
disulfide bonds• Chaperones – break up aggregates and (in theory)
unfold misfolded proteins

Protein Folding 16Algorithms for Bioinformatics
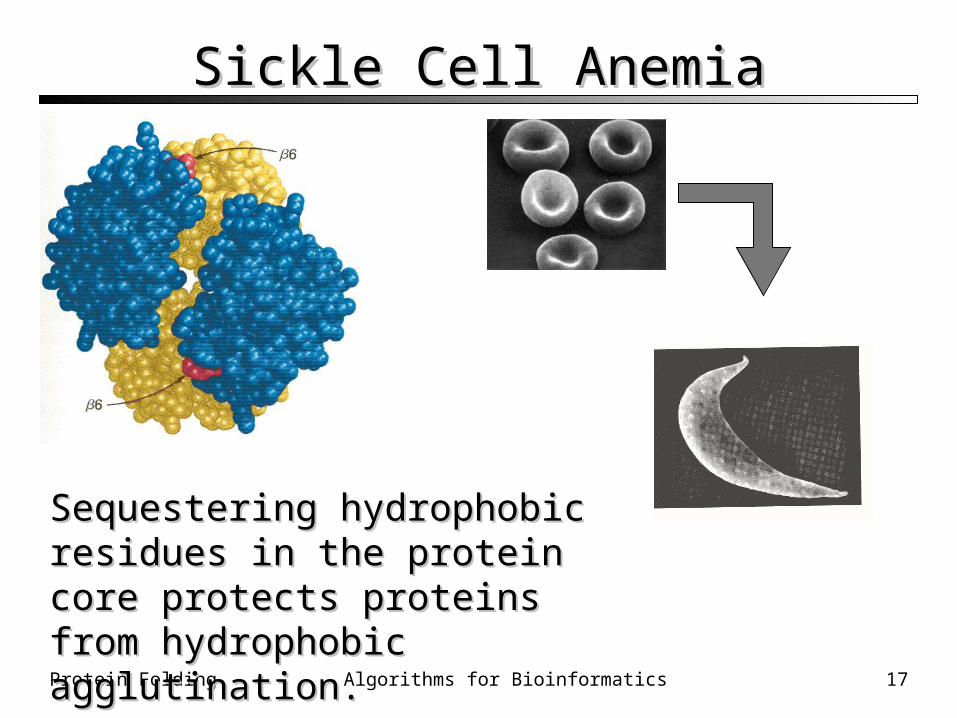
The Hydrophobic CoreThe Hydrophobic Core Hemoglobin A is the protein in red blood cells
(erythrocytes) responsible for binding oxygen. The mutation E6V in the chain places a
hydrophobic Val on the surface of hemoglobin The resulting “sticky patch” causes hemoglobin
S to agglutinate (stick together) and form fibers which deform the red blood cell and do not carry oxygen efficiently
Sickle cell anemia was the first identified molecular disease
Protein Folding 17Algorithms for Bioinformatics
Sickle Cell AnemiaSickle Cell Anemia
Sequestering hydrophobic residues in Sequestering hydrophobic residues in the protein core protects proteins from the protein core protects proteins from hydrophobic agglutination.hydrophobic agglutination.

Protein Folding 18Algorithms for Bioinformatics
Computational Problems in Protein FoldingComputational Problems in Protein Folding
Two key questions:• Evaluation – how can we tell a correctly-folded
protein from an incorrectly folded protein? H-bonds, electrostatics, hydrophobic effect, etc. Derive a function, see how well it does on “real” proteins
• Optimization – once we get an evaluation function, can we optimize it?
Simulated annealing/monte carlo EC Heuristics We’ll talk more about these methods later…

Protein Folding 19Algorithms for Bioinformatics
Fold OptimizationFold Optimization Simple lattice models (HP-
models)• Two types of residues:
hydrophobic and polar• 2-D or 3-D lattice• The only force is hydrophobic
collapse• Score = number of HH
contacts

Protein Folding 20Algorithms for Bioinformatics
H/P model scoring: count noncovalent hydrophobic interactions.
Sometimes:• Penalize for buried polar or surface hydrophobic
residues
Scoring Lattice ModelsScoring Lattice Models

Protein Folding 21Algorithms for Bioinformatics
What can we do with lattice models?What can we do with lattice models? For smaller polypeptides, exhaustive search can
be used• Looking at the “best” fold, even in such a simple
model, can teach us interesting things about the protein folding process
For larger chains, other optimization and search methods must be used• Greedy, branch and bound• Evolutionary computing, simulated annealing• Graph theoretical methods
Protein Folding 22Algorithms for Bioinformatics
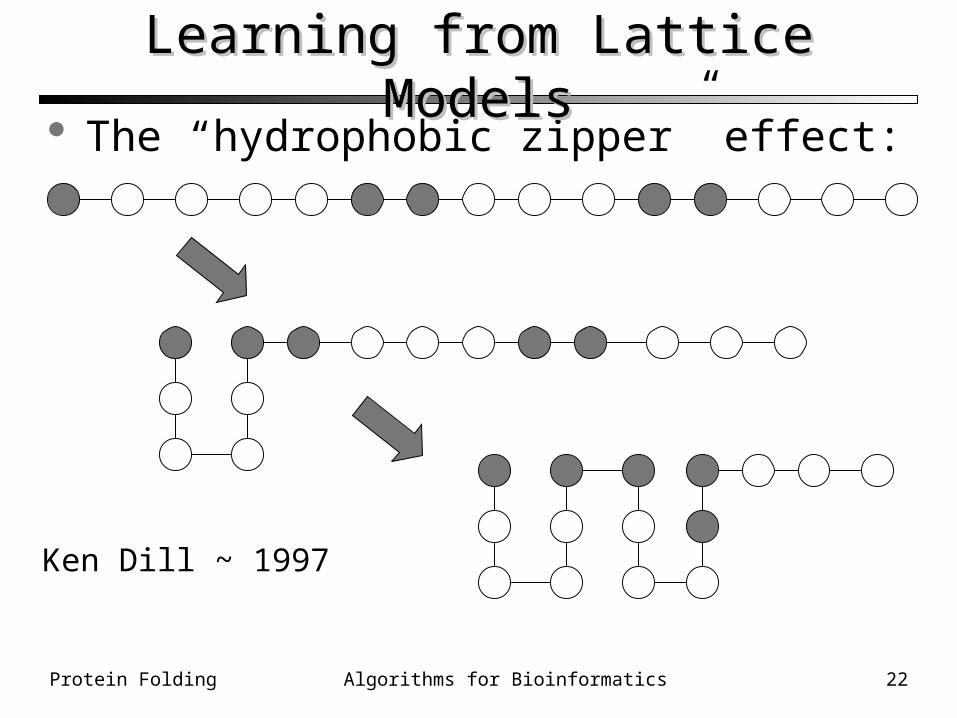
The “hydrophobic zipper” effect:
Learning from Lattice ModelsLearning from Lattice Models
Ken Dill ~ 1997

Protein Folding 23Algorithms for Bioinformatics
Absolute directions• UURRDLDRRU
Relative directions• LFRFRRLLFFL• Advantage, we can’t have UD or RL in absolute• Only three directions: LRF
What about bumps? LFRRR• Bad score• Use a better representation
Representing a lattice modelRepresenting a lattice model

Protein Folding 24Algorithms for Bioinformatics
Preference-order representationPreference-order representation Each position has two “preferences”
• If it can’t have either of the two, it will take the “least favorite” path if possible
Example: {LR},{FL},{RL},{FR},{RL},{RL},{FR},{RF}
Can still cause bumps:{LF},{FR},{RL},{FL},{RL},{FL},{RF},{RL},{FL}

Protein Folding 25Algorithms for Bioinformatics
““Decoding” the representationDecoding” the representation The optimizer works on the representation, but
to score, we have to “decode” into a structure that lets us check for bumps and score.
Example: How many bumps in: URDDLLDRURU?
We can do it on graph paper• Start at 0,0• Fill in the graph
In PERL we use a two-dimensional array

Protein Folding 26Algorithms for Bioinformatics
A two-dimensional array in PERLA two-dimensional array in PERL$configuration = “URDDLLDRURU”;$sequence = “HPPHHPHPHHH”;foreach $i (1..100) { foreach $j (1..100) { $grid[$i][$j] = “empty”; }}$x = 0;$y = 0;@moves = split(//,$configuration);@residues = split(//,$sequence);

Protein Folding 27Algorithms for Bioinformatics
Setting up the gridSetting up the gridforeach $move (@moves) { $residue = shift(@residues); if ($move = “U”) { $y_position++; } if ($move = “R”) { $x_position++; } etc…if ($grid[$x][$y] ne “empty”) { BUMP!} else { $grid[$x][$y] = $residue;}

Protein Folding 28Algorithms for Bioinformatics
More realistic modelsMore realistic models Higher resolution lattices (45° lattice, etc.) Off-lattice models
• Local moves• Optimization/search methods and /
representations Greedy search Branch and bound EC, Monte Carlo, simulated annealing, etc.

Protein Folding 29Algorithms for Bioinformatics
The Other Half of the PictureThe Other Half of the Picture Now that we have a more realistic off-lattice
model, we need a better energy function to evaluate a conformation (fold).
Theoretical force field:G = Gvan der Waals + Gh-bonds + Gsolvent + Gcoulomb
Empirical force fields• Start with a database• Look at neighboring residues – similar to known
protein folds?

Protein Folding 30Algorithms for Bioinformatics
Threading: Fold recognitionThreading: Fold recognition Given:
• Sequence: IVACIVSTEYDVMKAAR…
• A database of molecular coordinates
Map the sequence onto each fold
Evaluate• Objective 1: improve
scoring function• Objective 2: folding

Protein Folding 31Algorithms for Bioinformatics
Secondary Structure PredictionSecondary Structure Prediction
AGVGTVPMTAYGNDIQYYGQVT…AGVGTVPMTAYGNDIQYYGQVT…A-VGIVPM-AYGQDIQY-GQVT…AG-GIIP--AYGNELQ--GQVT…AGVCTVPMTA---ELQYYG--T…
AGVGTVPMTAYGNDIQYYGQVT…AGVGTVPMTAYGNDIQYYGQVT…----hhhHHHHHHhhh--eeEE…----hhhHHHHHHhhh--eeEE…

Protein Folding 32Algorithms for Bioinformatics
Secondary Structure PredictionSecondary Structure Prediction Easier than folding
• Current algorithms can prediction secondary structure with 70-80% accuracy
Chou, P.Y. & Fasman, G.D. (1974). Biochemistry, 13, 211-222.
• Based on frequencies of occurrence of residues in helices and sheets
PhD – Neural network based• Uses a multiple sequence alignment• Rost & Sander, Proteins, 1994 , 19, 55-72

Protein Folding 33Algorithms for Bioinformatics
Chou-Fasman ParametersChou-Fasman ParametersName Abbrv P(a) P(b) P(turn) f(i) f(i+1) f(i+2) f(i+3)Alanine A 142 83 66 0.06 0.076 0.035 0.058Arginine R 98 93 95 0.07 0.106 0.099 0.085Aspartic Acid D 101 54 146 0.147 0.11 0.179 0.081Asparagine N 67 89 156 0.161 0.083 0.191 0.091Cysteine C 70 119 119 0.149 0.05 0.117 0.128Glutamic Acid E 151 37 74 0.056 0.06 0.077 0.064Glutamine Q 111 110 98 0.074 0.098 0.037 0.098Glycine G 57 75 156 0.102 0.085 0.19 0.152Histidine H 100 87 95 0.14 0.047 0.093 0.054Isoleucine I 108 160 47 0.043 0.034 0.013 0.056Leucine L 121 130 59 0.061 0.025 0.036 0.07Lysine K 114 74 101 0.055 0.115 0.072 0.095Methionine M 145 105 60 0.068 0.082 0.014 0.055Phenylalanine F 113 138 60 0.059 0.041 0.065 0.065Proline P 57 55 152 0.102 0.301 0.034 0.068Serine S 77 75 143 0.12 0.139 0.125 0.106Threonine T 83 119 96 0.086 0.108 0.065 0.079Tryptophan W 108 137 96 0.077 0.013 0.064 0.167Tyrosine Y 69 147 114 0.082 0.065 0.114 0.125Valine V 106 170 50 0.062 0.048 0.028 0.053

Protein Folding 34Algorithms for Bioinformatics
Chou-Fasman AlgorithmChou-Fasman Algorithm Identify -helices
• 4 out of 6 contiguous amino acids that have P(a) > 100
• Extend the region until 4 amino acids with P(a) < 100 found
• Compute P(a) and P(b); If the region is >5 residues and P(a) > P(b) identify as a helix
Repeat for -sheets [use P(b)] If an and a region overlap, the overlapping
region is predicted according to P(a) and P(b)

Protein Folding 35Algorithms for Bioinformatics
Chou-Fasman, cont’dChou-Fasman, cont’d Identify hairpin turns:
• P(t) = f(i) of the residue f(i+1) of the next residue f(i+2) of the following residue f(i+3) of the residue at position (i+3)
• Predict a hairpin turn starting at positions where: P(t) > 0.000075 The average P(turn) for the four residues > 100 P(a) < P(turn) > P(b) for the four residues
Accuracy 60-65%

Protein Folding 36Algorithms for Bioinformatics
Chou-Fasman ExampleChou-Fasman Example CAENKLDHVRGPTCILFMTWYNDGP CAENKL – Potential helix (!C and !N)
Residues with P(a) < 100: RNCGPSTY
• Extend: When we reach RGPT, we must stop• CAENKLDHV: P(a) = 972, P(b) = 843• Declare alpha helix
Identifying a hairpin turn• VRGP: P(t) = 0.000085• Average P(turn) = 113.25
Avg P(a) = 79.5, Avg P(b) = 98.25





























