Embed Size (px)
Citation preview

UNIVERSIDAD DEL PAÍS VASCO FACULTAD DE INFORMÁTICA
ALGORITHMS FOR COMPOSING PERVASIVE
APPLICATIONS AND TWO CASE STUDIES
Author _______________________________________
Jon Imanol Durán Glz. de Monasterioguren
Supervisor _______________________________________
Prof. Jukka Riekki
Date _______/_______2008
Grade ___________________________________

Durán González de Monasterioguren, J. I. (2008) Algorithms for composing pervasive applications and two case studies. University of the Basque Country,
Computer Engineering Faculty of San Sebastian. Master’s Thesis, 76 p.
ABSTRACT
Component-based applications are becoming popular in information processing
technologies. Areas of application such as adaptive distributed systems, web
services, or grid computing are being closely influenced by this phenomenon.
Components interrelate to run the application by calling other component
methods or services. Depending on the application area, the system architecture
has to tackle with the problem of allocating the application components onto
computational hosts, each one with its own qualitative and quantitative
constraints, automatically and at run-time, especially in user dynamic
applications. These systems should have algorithms being able to select and
optimize the component allocation across the network nodes, without violating
any node constraints and satisfying all the component requirements, and also
taking into account user preferences to offer them the best possible QoS.
Moreover, in applications based on components resource constrained devices
can share their capabilities and take advantage from others’ resources with the
aim of becoming them into functional and potential machines. Moreover, this
kind of application based on components could become a very constrained
device into a functional and potential machine by sharing their capabilities and
taking advantage from others’ resources. A correct component allocation could
also improve the performance of the whole application, decrease resource
requirements, prevent device overloading and offer a better service to its users.
The task of allocating components in an optimal way is called an application
allocation problem.
The contribution of this thesis is to create two new algorithms for tackling
with the application allocation problem. These algorithms are done in co-
operation with Oleg Davidyuk and István Selek. The main goal is to use them in
ubiquitous computing environments. They improve actual existing solutions
results, while they are also generic with the purpose of using them in wide
application domains. Their goal is to maximize the allocation quality according
to given, easily modifiable criteria, such as minimizing hardware requirements
or maximizing application QoS. This thesis also analyzed the performance of
these algorithms by testing them in simulated environments, even in extreme
situations. Finally, the research concludes by presenting two innovative
applications that are developed in co-operation with Oleg Davidyuk and Iván
Sánchez. The algorithms developed were included in these applications, and the
allocation of the application components is made at run-time depending on the
user requirements. User feedback collected during user testing is also discussed.
Keywords: Ubiquitous computing, pervasive computing, task-based computing,
application allocation problem.

Durán González de Monasterioguren, J. I. (2008) Algorithms for composing pervasive applications and two case studies. Universidad del País Vasco, Facultad
de Informática de San Sebastian. Proyecto fin de carrera, 76 p.
RESUMEN
Día a día las aplicaciones basadas en componentes son más populares entre las
tecnologías de la información. Este fenómeno influencia sobre áreas como
sistemas distribuidos, servicios web o computación en grid. Los componentes se
interrelacionan entre sí llamando a métodos o servicios de otros componentes.
En ciertas áreas de aplicación, la arquitectura del sistema deberá abordar el
reto de asignar los componentes de la aplicación en nodos computacionales
(cada uno con sus propias restricciones cualitativas y cuantitativas) de forma
automática y en tiempo real. Aún más, tratándose de aplicaciones que
involucren a personas y traten de mantener las características dinámicas del
usuario. Este sistema debería contar con algoritmos capaces de decidir y
optimizar la asignación de componentes en los dispositivos de la red, todo ello
sin violar ninguna restricción de los nodos y satisfaciendo los requerimientos de
los componentes. Siempre teniendo en cuenta las preferencias del usuario con el
compromiso de ofrecer la mejor calidad de servicio. Además, este tipo de
aplicaciones basadas en componentes podrían hacer de un dispositivo con
limitaciones, una máquina potencial y funcional; únicamente compartiendo sus
capacidades y obteniendo ventajas de los recursos de otros dispositivos. Una
correcta asignación de componentes es esencial ya que mejoraría
considerablemente el rendimiento de toda la aplicación, reduciría los requisitos
de los recursos, prevendría el colapso de nodos y ofertaría un mejor servicio a
los usuarios. La asignación de componentes de un modo óptimo se denomina
problema de asignación de aplicaciones.
Este proyecto fin de carrera pretende contribuir por medio de la creación de
dos nuevos algoritmos que aborden el problema de asignación de aplicaciones.
Dichos algoritmos se realizaron con la cooperación de Oleg Davidyuk e István
Selek. El objetivo principal radica en emplearlos en entornos de computación
ubicua. Permiten ser usados en un amplio rango de aplicaciones porque además
de mejorar las soluciones existentes, son genéricos. Llevarán acabo su función
teniendo siempre presente el objetivo de maximizar la calidad de la asignación
dependiendo de un criterio fácilmente modificable. Por ejemplo, minimizando
los requisitos hardware o maximizando la calidad del servicio. También se
analiza el rendimiento de los algoritmos realizando pruebas en entornos
simulados, incluso en situaciones extremas. Para finalizar, el proyecto concluye
presentando dos aplicaciones innovadoras, desarrolladas en cooperación con
Oleg Davidyuk e Iván Sánchez. En ellas, se incluyeron los algoritmos y la
asignación de componentes de la aplicación se realiza en tiempo real en base a
los requisitos del usuario. Las reacciones y opiniones de los usuarios obtenidas
en las pruebas de las aplicaciones son expuestas junto con las principales
conclusiones.
Palabras clave: Computación ubicua, computación pervasiva, inteligencia
ambiental, problema de asignación de aplicaciones.

TABLE OF CONTENTS
ABSTRACT
RESUMEN
TABLE OF CONTENTS
ABBREVIATIONS
ACKNOWLEDGEMENTS
1. INTRODUCTION ................................................................................................. 7
2. RELATED WORK ................................................................................................ 9
2.1. Algorithms for application allocation......................................................... 9
2.2. Frameworks for pervasive computing ...................................................... 12
2.3. Frameworks for application composition in task-based computing ......... 16
2.4. Summary .................................................................................................. 17
3. APPLICATION ALLOCATION PROBLEM .................................................... 18
3.1. Application Model .................................................................................... 18
3.2. Platform Model......................................................................................... 19
3.3. Mathematical Details of the Application Allocation Problem ................. 21
3.4. Objective .................................................................................................. 22
3.5. Summary .................................................................................................. 24
4. ALGORITHMS FOR THE ALLOCATION PROBLEM ................................... 25
4.1. Data representation ................................................................................... 25
4.2. Basic algorithm......................................................................................... 26
4.3. New Algorithms ....................................................................................... 28
4.3.1. The three-phase validation schema ........................................... 28
4.3.2. Genetic Algorithm ..................................................................... 32
4.3.3. Evolutionary Algorithm ............................................................. 34
4.4. Summary .................................................................................................. 35
5. EXPERIMENTS AND ANALYSIS ................................................................... 36
5.1. BRITE graph generator ............................................................................ 36
5.2. Experiment 1: Performance of the algorithm ........................................... 38
5.3. Experiment 2: Quality of the algorithm ................................................... 40
5.4. Experiment 3: Robustness of the algorithm ............................................. 42
5.5. Summary .................................................................................................. 44
6. APPLICATIONS ................................................................................................. 45
6.1. Ubiquitous Multimedia Player Application ............................................. 45
6.1.1. Scenario ..................................................................................... 45
6.1.2. Design ........................................................................................ 47
6.1.3. User experiments ....................................................................... 50
6.2. Newsreader Application ........................................................................... 52
6.2.1. Scenario ..................................................................................... 52
6.2.2. Design ........................................................................................ 55
6.2.3. User experiments ....................................................................... 60
6.3. Summary .................................................................................................. 61
7. DISCUSSION ..................................................................................................... 62
8. CONCLUSIONS ................................................................................................. 64
9. REFERENCES .................................................................................................... 65
APPENDICES ............................................................................................................ 71

ABBREVIATIONS
AAP The Application Allocation Problem.
AI Artificial Intelligence.
AmI Ambient Intelligence.
API Application Programming Interface
BRITE Boston University network topology tool.
CPU Central Processing Unit.
EA Evolutionary Algorithm.
GA Genetic Algorithm.
GPRS General Packet Radio Service.
GUI Graphic User Interface.
HTTP HyperText Transfer Protocol.
JNI Java Native Interface.
MGA Micro-Genetic Algorithm.
NP Non-Deterministic Polynomial-time.
OS Operating System.
OWL Ontology Web Language.
PDA Personal Digital Assistant.
QoS Quality of Service.
REACHeS Remotely Enabling and Controlling Heterogeneous Services.
RFID Radio Frequency IDentification.
RSS Really Simple Syndication.
SAT Boolean Satisfaction Problem.
SMP Symmetric MultiProcessing.
SSD Semantic Service Description
TFT Thin Film Transistor-Liquid Crystal Display.
TSP Traveling Salesman Problem.
UMTS Universal Mobile Telecommunications System.
UI User Interface.
WLAN Wireless Local Area Network.
XML Extensible Markup Language.

ACKNOWLEDGEMENTS
This master’s thesis was done for the Ubilife project at MediaTeam Group,
Department of Electrical Engineering, University of Oulu, Finland. I would like to
thank my advisor Oleg Davidyuk for his guidance during all this year. Without it, the
resolution of this master’s thesis would have been impossible to achieve. I would
also like to thank prof. Jukka Riekki for his help in writing the thesis. Thanks both
for valuing my work.
Second, I would also like to thank all the friends I made during this year in Oulu.
Thanks for all the good moments we had during all the year together. I have a special
mention to all my Spanish friends, especially to those who helped me during all my
life and helped me to get this master degree.
I would like to mention my family, in particular. I wish to thank my parents for all
their support during all my life, for teaching me the values that have made me who I
am. Thanks also to my brother for giving me the opportunity to grow up with a
person like you.
Finally, I really would like to thank my girlfriend Zoë for helping me writing this
thesis, and most importantly, for all his support during this hard year for both of us.
Without you, my life has no meaning!
Oulu, 5th
of September 2008
Jon Imanol Durán

7
1. INTRODUCTION
Pervasive computing is a category of human-computer interaction model that has
been thoroughly introduced into everyday human life. Nowadays computational
devices are everywhere, even embedded ones are installed in unsuspected places,
such as cars, fridges, etc. It was unbelievable few years ago. Moreover, with every
passing day having Internet connection in these devices is more common due to the
appearance of wireless connections. Pervasive computing involves all computational
devices and systems simultaneously surrounding the user. Thus, this type of
applications is composed across different nodes of the network. This is possible
because of the existence of many communication protocols and interfaces between
devices. Resource limited devices get advantage using this kind of computing; they
become functional and potential machines within these environments by sharing their
capabilities and taking advantage from others’ resources. Furthermore, building
applications by allocating components in different devices facilitates the
computational load distribution; really useful in application areas such as grid
computing.
Developing a system that tackles the component allocation task is challenging.
There are many difficulties to be taken into account in order to have a good system,
which satisfies all the application components requirements, while the QoS offered
to users is maximized. It requires an optimal configuration onto network hosts in
order to avoid unnecessary device resource overconsumption and overload problems.
Even, having a correct configuration allows sending less data in component
communication and being able to allocate more components in the same host set. On
the other hand, it should be noted that handheld devices are mobile; the whole
application status could change due to a user entrance or departure from the
environment. Moreover, the user requirements could change and a completely
different configuration could be better, even for the same application. The
application allocation onto network hosts has to be done at run-time, preferable
quickly and automatically in order to prevent the user becoming increasingly
overloaded with distractions of managing their system configurations; they could opt
not to use the capabilities offered by the systems. After all, the most important
objective of these environments is to benefit the users. Furthermore, the task of
composing applications should include as many application types as possible. This
task cannot be focused only on a certain application variety.
Research in this area can be divided into three different categories: dynamic
component-based systems, frameworks supporting the composition of applications,
and systems for task-based computing. The first group research focuses on
component-based systems that take into account resource alteration with the aim of
adapting their conduct to the available resources in the environment. The second
group is concerned with creating frameworks that aim to minimize user distractions
by adapting to context changes automatically without involving them. The last group
research works on frameworks that allow users to introduce their task descriptions
into the system, with the purpose of satisfying their requirements by binding their
tasks to available network resources.
This thesis has several contributions. First, and most importantly, it offers two
algorithms capable of being introduced into an architecture for dynamic application
composition. The design of these algorithms were carried out by Oleg Davidyuk,
and István Selek – who implemented the algorithms – and the author of this thesis,

8
Jon Imanol Durán who also did the testing and performance experiments. Second, it
tests the algorithms in a real system with a view to study their capabilities in real
situations. The thesis also includes a related work analysis in order to avoid weak
points of other researches. Then, the application allocation problem (AAP) is
examined before presenting the two above-mentioned new algorithms for solving it.
The AAP is the problem of allocating software components onto available hosts in
the environment. Each component has its own requirements that must be fulfilled by
its host, while no resource constraints are violated. The new solutions are based on
genetic and evolutionary computing, and they are characterized by a very fast
convergence and good quality solution properties. They allocate components
according to an optimization criterion, for example, one such criterion could be to
minimize hardware requirements, load balancing or maximize the application quality
of service. The goal can be easily modified, just changing the commented
optimization condition. The reason for designing them in this way was to build the
two solutions as generic as possible, not to restrict the application to a certain
domain, and to facilitate an extensive use of the presented approaches. The solutions’
performance and quality were tested in simulated environments, some of them
exceptionally big, with the aim of testing the algorithms in extreme situations.
Finally, as mentioned above, these solutions’ allocation ability was tested through a
user experiment. Two applications were implemented with the aim of fulfilling user
real-time requirements in co-operation with Iván Sánchez.
This thesis is organized as follows: in chapter 2 the related work focused on
application composition is examined in three different groups: first, algorithms for
application allocation, second, frameworks for pervasive computing, and finally,
frameworks for application composition in task-based computing. Chapter 3
introduces the application allocation problem. Chapter 4, in its turn, describes the
two new algorithms. Chapter 5 demonstrates algorithms’ experiment results. Chapter
6 presents two case studies of the algorithms in real user-oriented applications.
Chapter 7 states discussion and future work. Finally, chapter 8 gives a conclusion of
the thesis.

9
2. RELATED WORK
There have been multiple attempts to develop systems supporting service
composition. Such systems focus on dynamic composition, provide the functionality
to adapt to user mobility, and changes in the environment. Supporting dynamic
composition of application requires assigning the application components on the fly
while the application is running. It offers a possibility for users to execute their tasks
without any previous knowledge about the network services. This can be achieved by
an algorithm which finds proper application configurations according to specific
objectives. Adaptation to user mobility offers users the best service configuration in
each situation and place. Finally, the adaptation to changes in the environment allows
the system to continue offering services in case any component goes down.
Everything has to be done automatically in order to prevent the user becoming
increasingly overloaded with distractions of managing their system configurations;
they could opt not to use the capabilities of their environments.
As mentioned above, the related work on service composition can be divided in
three different categories: first, algorithms for application allocation, second,
frameworks for pervasive applications, third, frameworks for application
composition in task-based computing. The first category covers algorithms that
decide, from a set of components, where to allocate them onto hosts according to
user task preferences and platform constraints. The second is concerned with
frameworks that aim to minimize users’ distraction by sensing and automatically
adapting to the changing context, without involving the user in maintenance tasks.
The last one is similar to the second, the main difference being attachment of
importance to users’ preferences. That is, the user provides a description of his/her
needs and the system aims to get the best configuration in order to improve the QoS
of the offered service.
2.1. Algorithms for application allocation
Many algorithms for the AAP have been presented since the paradigm of creating
applications from composing components from different devices was presented.
These components must be allocated onto available hosts of the environment.
Besides, these hosts have also properties that must not be exceeded in order to have
an optimal system. The AAP is the problem of finding a valid allocation of software
components onto the environment resources. A detailed description of AAP is
founded in chapter 3. The commented algorithms aim to find an optimal, or at least a
valid, allocation of different components into hosts for the application based on
different criterion, such as minimizing the hardware requirements [13], maximizing
system availability [8], or maximizing user preferences, as suggested in [29].
The algorithms for solving the AAP can be divided into two categories:
decentralized and centralized algorithms. The decentralized solutions assume that
information about the state of the whole system is not available. These solutions are
used when there are resource-restricted devices that cannot perform heavy
computational tasks. Moreover, decentralized solutions are applicable when the
environment is very dynamic because the update of the whole system state is not
necessary in each state modification. Centralized solutions are used when the state of
the system is available to all the devices. These systems are better when the

10
allocation has to be calculated for all the hosts at the same time. As a rule,
centralized solutions yield better quality solution than decentralized ones. That is
because all the hosts and its constraints are known each time the allocation has to be
calculated, so the system can improve the solution before continuing with the next
step, namely the allocation of the components in hosts. As mentioned above, in
decentralized algorithms, information of the whole system is not available and the
improvement cannot be done. Besides, decentralized solutions cause an increase of
the communication between the hosts that are taking part in the algorithm; the
performance of this kind of systems depends directly on the quality and speed of the
links between hosts. Even when the system is not fully connected, some nodes’ links
could be overloaded if they are responsible for sending a message from one place to
another of the system. Anyway, researches as PCOM [41] have demonstrated that
depending on the available devices the use of one type of algorithms can be a better
choice than the other.
First of all, partitioning bin-packing algorithms are important to mention, as
presented by de Niz and Rajkumar [13]. The objective of this research is to pack a set
of software components into a minimum number of bins, referring to hardware
nodes. In other words, they aim to minimize hardware requirements. According to
them, each application has functional and non-functional characteristics that can be
partitioned into different component-parts. This partitioning inserts a communication
code into partitioned components. Then, the pieces are assigned to available
machines using the bin-packing algorithm. Nevertheless, component partitioning
increases the use of network resources, decreasing the performance, in terms of
response time, of the application. Because of that, the algorithms presented in this
thesis do not take into account the partitioning.
Regarding centralized solutions, the following are the most significant ones in the
related work found: an approach such as AIRES [4] uses branch-and-bound and
forward mechanisms for getting the solutions. This approach uses a modeling
method based on graphs, such as the one used in this thesis, presented in chapter 3.
Computation and memory resource consumptions are modeled as node weights and
the communication resource consumptions as links’ weights. Anyway, this solution
offers a few possibilities; it takes into consideration only a few constraints, such as
CPU, memory, and link constraints. One of the main disadvantages is, apart from the
one mentioned above, that it is not able to make an adaptive change of the
configuration when in the system something changes, for example any of the hosts
goes down.
Sekitei [5] uses algorithms based on AI planning techniques. This model allows
the specification of a variety of network and application properties and restrictions.
The authors aim to get a good load balancing between hosts, satisfy QoS
requirements, and get a great system performance with respect to dynamical service
components deployment. Experiments show this approach gets very good results,
also in very hard cases. The weak spot of this system is that, when the network has a
bigger number of low-bandwidth insecure links between stubs compared with others,
the algorithm constructs and checks many logically correct plans that fail during
symbolic execution due to resource restrictions. Then, the performance of the
algorithm decreases considerably. There is also a modified version of this system,
called modified Sekitei [6]. The main difference of this system as compared with the
previous one is in using discrete resource levels instead of continuous variables. It
makes the searching of the solution easier, improving the converge speed.

11
In the research of Autonomic Pervasive Computing based on Planning [11],
researchers are presenting GAIA, a prototype planning system for pervasive
computing systems. The system presented allows users (through a GUI) to specify
their goals in an abstract manner and let the environment decide how best to achieve
these goals. Application developers can use this system as well by using its APIs.
The main idea of the algorithm is in getting the goal state with associated templates,
writing the rules for getting them in Prolog. Then the system finds values of some
variables in order to improve the final state. However, this system does not take into
account the optimization of the application QoS, although it tries to build adaptable
applications according to user goals.
Karve et al. [12] present another centralized solution. This approach is based on
three different phases: residual placement, incremental placement, and rebalancing
placement. The first one places an application with the highest memory requirement
compared to its CPU demand. The second combines the first part with the maximum
flow computation to solve the placement problem while the number of placement
changes is minimized. The last one aims to modify the solution proposed by the
incremental algorithm, such that a better load balancing across nodes can be
achieved. One of the best ideas presented in this paper is related to the application
placement, which is done by starting and stopping the application servers as needed.
This technique prevents from having a potentially time-consuming application
deployment, besides it saves time on configuring servers.
Davidyuk et al. [14] present a micro genetic algorithm based on a simple genetic
algorithm presented in [15]. These solutions take multiple platform constraints into
account. They also optimize component allocation to satisfy application QoS by
finding the correct deployment of the application, even having the advantage of
continuing computing the solution in order to make it better. The improvements
added to the micro genetic algorithm result in a lower computational load and the
fastest convergence property. The main difference between them is that the micro
genetic uses an external memory and an internal population with reinitialization. The
external memory is used for having a more varied population and for storing the best
individual founded before as well. As mentioned above, the main performance
difference is the faster convergence as compared with the previous genetic algorithm.
Having the ability to add more constraints properties into account without changing
its design makes these algorithms feasible solutions parsing them with other
presented solutions.
Related to decentralized solutions, the following are the most significant ones:
Graupner et al. [7] introduce two algorithms based on this kind of design pattern.
Those were designed with the aim of being generic enough to support new objectives
without fundamental changes. The first algorithm is based on Ant Colony
Optimization [46]. It is a probabilistic technique for solving computational problems,
which can be reduced to finding good paths through graphs. They are inspired by the
behavior of ants in finding paths from the colony to food. This technique is based on
a centralized solution, but the authors made modifications in order to get the
advantages of decentralized ones. The other presented algorithm took ideas from
Broadcast of Local Eligibility [47], which is used in the coordination of robots, in
this case for the placement of services. These solutions take advantages of
decentralized solutions explained above, that is, use more machines in the system
with the aim of reducing the computational needs by increasing the amount of

12
messages trough the network. Even so, analyzing the performance of these designs in
real environments is not possible because they are not implemented yet.
DecAp [8] is another decentralized solution for the AAP. This algorithm is based
on auctioning. When a component is going to be auctioned, the process continues as
follows: the auctioneer announces an auction of a component and it starts receiving
bids from the bidders within its domain. Finally, the auctioneer determines the
winner according to the offer that best adapts its requirement. The main problem
with this system is that they do not take into account load balancing, that is, there
might be hosts overloaded and others could be free. Besides, this system takes into
account few constraints, probably too few of them for being a good solution for the
AAP. The algorithms that will be presented in section 4 are generic, i.e. they are
capable of finding a solution when there are many constraints and resource properties
in the problem to be processed.
Ben-Shaul, Gidron and Holder [9] present a decentralized solution. This method
follows a negotiation using a 2-phase deployment protocol. The model has been
implemented as part of Hadas [48], an environment for dynamic composition of
distributed applications. The reason of this protocol is because the negotiation
succeed is not guaranteed. So a small object (negotiator object) is sent from the
components’ site to the target hosts. That prevents from sending unnecessarily the
full object in case of a negotiation failure. After a succeed negotiation they “sign a
contract” and the negotiator is sent back to the source host. It analyzes which source
host has offered a better “contract” according to the component requirements. Then,
the framework proceeds to send the entire object from the source component to the
destination host, according to the better “contract” obtained. However, HADAS and
DecAp [8], discussed in the previous paragraph, present a problem. Its performance
is completely dependant on the behavior of the agents carrying out the negotiation or
auctioning, which makes this type of applications unsuitable for dynamic
environments where the adaption should be as fast as possible.
Finally, ConAMi [10] is the last solution presented in the related work based on
decentralized designs. This method is implemented by every device, which is
interested to perform content adaption in a collaboration mode. For composing
services, a content adaption tree construction algorithm is presented. It puts in order
services in a colored tree to consider the dynamicity of the services where each color
in the tree has its own meaning; finally, it takes the best path depending on the colors
of the tree. Experiments show that the performance of the algorithm is similar to
other graph construction algorithms, but not enough when there are many tasks and
platforms involved in the system. This solution is not valid for finding a valid
solution for larger systems than the tested in the presented experiments.
2.2. Frameworks for pervasive computing
Pervasive computing aims to minimize users’ distractions by sensing and adapting to
context changes automatically without involving users in maintenance tasks. In other
words, these environments perform actions and take decisions on behalf of the user.
One of the main advantages is that they are able to distribute the computational load
between different hosts in order to prevent the situation of an overloaded machine,
while others are free of computational charge. This characteristic is very important in
this kind of computation where most of the devices are resource-constrained [44],
such as limited battery power, the CPU capacity is much smaller than normal

13
computers, the storage capacity is limited (some devices have flash memories instead
of hard disk), etc. Furthermore, these smart-spaces should be able to deploy
applications in devices with many different characteristics, from desktop computers
to handheld devices. Being aware of contextual needs of the user and being able to
adapt to context changes is also important. For example, applications should have an
ability to be adapted to different device capabilities, as well as to be moved from one
device to another with a view to provide to the user mobile the best possible QoS.
That is, they may focus on serving functionalities for applications in smart spaces
such as mobility, adaptation, context-awareness, and dynamic binding. As mentioned
above, this type of frameworks seldom asks users for taking that type of decisions;
the main target of this type of computing is allowing users to use services inside a
ubiquitous computing environment without interrupting them. In this section, many
different frameworks with these characteristics will be presented.
Gaia OS [11] [37] is a middleware operating system that provides the previously
explained functionalities. Some prototypes based on Gaia OS have been
implemented, such as ARIS [20]. This is an interactive window manager that allows
users to relocate application windows through different shared screen devices. This
relocation is done using an interface that represents a map of the interactive space.
The main objective of the application is to improve how users share information in a
collaborative work. In this prototype, users do the relocation of application windows
manually – supported by Gaia middleware functionalities. Gaia also provides the
information about the presence of users, devices and applications in the space.
Román, Ziebart and Campbell [36] present the Application Bridge prototype built
on top of Gaia OS, which provides a mechanism to define application composition
interaction rules that program the behavior of active spaces. These rules describe
how changes in the context affect the execution of other applications. Anyway, ARIS
and the Application Bridge aim to define smart spaces’ behavior, which is not where
this work focuses on.
Xiao and Boutaba [17] present a framework for autonomic network service
composition. They aim to create a framework with mechanism for QoS-aware
service composition and adaptation of end-to-end network service for autonomic
communication. These frameworks require an efficient method for service
composition and adaptation in order to achieve self-management intelligence. This is
done abstracting the domain into a graph. This way, the domain composition is
reduced to the classic k-multiconstrained optimal path with the aim of using any
designed solutions for solving these kinds of problems. Even so, these solutions are
inadequate and inefficient; they are not enough to carry out this problem. Because of
that, they have developed a set of new algorithms for QoS-aware service composition
and adaptation.
Personal Router [18] is an autonomous cognitive personal agent for wireless
access service selection. It chooses transparently and continuously a network service
through available ones based on user needs and preferences. Presented experiments
show, as they supposed, that the system might learn user preferences and select
services effectively. However, this system is not designed for composing
applications. It chooses the best service by selecting directly it; they do not aim to
create the service by composing it from different components.
IST-Context [21] is a framework that offers the service of getting aware of context
information, such as location, time, and device capabilities. They propose an
approach for taking decisions regarding the selection of the correct sources according

14
to user requests. The framework uses a heuristic algorithm for determining the best
combination of the context sources. Anyway, this approach is different from the
solutions presented in chapter 4. It models context services as monolithic entities,
that is, they cannot be allocated in different devices because separating them is not
possible. This is an essential feature that all frameworks designed for working with
pervasive applications should have.
Johanson et al. [23] present the Event Heap framework. It offers a mechanism
where users, machines, and applications can interact simultaneously. This software is
designed to offer for interactive workspaces what the event queue offers for single
user systems. That is, the framework offers multiple users a possibility to control
multiple network resources simultaneously. These resources are static host machines
that are controlled by events sent by user devices. This framework only focuses on
enabling the communication of many users with the previously composited services,
so there is no dynamic composition, as the approach of this thesis assumes.
Canfora et al. [24] present an approach for QoS-Aware service composition that
uses genetic algorithms for finding the optimal QoS estimation. An algorithm to
anticipate the re-planning decisions during the execution is also presented. That re-
planning action is launched when the difference between the estimated QoS and the
measured QoS is above a threshold. An alternative approach is discussed for cases
when QoS optimality is more relevant than performance, such as scientific
computations.
In the Composition Trust Binding (CTB) [25], the system aims to assure the
trustiness of software components. It is an extension of digitally signed software that
is used to provide software component trust. The problem is that remote applications
do not have visible the components they want to invoke services from. The CTB is a
set of rules which guarantee that the components are allowed in the combinations for
implementing a service or processing a specific content. In this thesis, security issues
are not the main objective. However, some rules could be defined by using affinity
constraints to force a component to be allocated in an authorized node. Affinity
constraints are a special restriction type, which are defined in later chapters.
Song, Labrou and Masuoka [27] present the technologies applied for dynamic
service discovery, creation, management, and manipulation of services. Service
discovery basically refers to the discovery of the Semantic Service Description
(SSD) of a service. SSD is used to describe services at the semantic level, in this
approach it is encoded in OWL-S. The services are made creating web services and
returning their semantic object. Then, a SSD for the recently created service is
generated. Anyway, this research is basically focused on service discovery and the
used technologies for doing it properly. This is not the research topic of this thesis.
The Ubiquitous Service Oriented Network (USON) architecture [31] aims at the
provision of services in the ubiquitous-computing context. It takes user preferences
and context into account. The system supplies services in two phases. The first one is
a service composition where the service elements are combined on the basis of
service templates. In the second, the template is obtained based on the history of
usage of service elements and templates. For the service composition, the system
uses a matching technique of XML templates and the use of a distributed dictionary
engine for the parameter resolution. This method, however, does not support generic
objectives, new device, or application restrictions without a system redesigning. A
generic approach for solving the AAP is one of the objectives of the algorithms
presented in the following chapters.

15
Kaefer et al. [33] present a framework for dynamic resource constrained
composition. Its main objective is to manage the permanent changing environment of
mobile and ad hoc networks. It provides two functionalities: first, the framework
supplies automatic execution of dynamic compositions for end-to-end functional
descriptions, second, it does component’s resource optimization. The algorithm for
the dynamic service composition is based on tree generation methods. In the first
phase, all the resources are placed on a tree, then, the branch that satisfies better the
requirements asked is chosen. An additional method exists for improving the
performance of the framework; it employs already founded compositions to generate
new ones.
Preuveneers and Berbers [34] present a context-driven composition infrastructure
to create compositions of services, customizing them to the preferences of the user
and the devices available in the system. They have designed a context ontology,
based on OWL, that has all the information about user, platform, service, and the
environment. An algorithm uses this information in order to find a minimal
composition of component instances. It is a centralized algorithm based on
backtracking. Therefore, this algorithm do not optimize its obtained solutions, it only
focuses on resource constraint satisfaction. In contrast, this thesis proposes a solution
which is capable of both functionalities: constraint satisfaction and optimization.
Related to their previous work, in [38] the above mentioned researchers present a
context-awareness infrastructure for context-driven adaptation of component-based
mobile services based on the context ontology presented in [34].
The Context-Aware Service Enabling (CASE) platform [35] is a solution for the
dynamic adaption of composite context-aware services that combines service
discovery and composition. The service discovery presented differs from other works
in using context information during the discovery phase. It gets firstly the references
to relevant context sources and then accesses to these context sources for obtaining
the actual context information. This kind of discovery reduces the number of
candidates for compose the service, in this context there might be many services
available and the reduction of the useless ones can increase the performance of the
composition. Moreover, the composited service is based on semantic matching and
OWL-S. In comparison with the algorithms presented in section 4, this platform does
not offer any functionality for QoS optimization of composited services. Thus, the
CASE platform does not optimize structure of services and limits composition of
services to resource matching.
SYNTHESIS [39] is a tool for assembling correct and distributed component-
based systems. It takes as input a high level description for the entire amount of
components that are going to be included in the system. The tool is based on the
technique of using adaptors, which are software modules that work as a bridge of the
components that are going to be assembled in the system. An adaptor acts as a simple
router and each request or notification is strictly delegated to the right component by
taking into account the specification of the desired behavior that the composed
system must exhibit. This tool automatically generates an adaptor for the components
of the system. After building it, the tool checks the adaptor for finding any problems
in relation to deadlocks or violations of the specified behavior. The task of
assembling components is not the main topic of this thesis.
Galaxy [40] is a shape-based service framework. There, service programmers
describe the capability of services in XML templates. This procedure is called shape;
because of this the shape-based nomenclature. End-users also specify their

16
requirements in a XML. The composition of services is made by a service lookup by
matching XML templates. This framework bases its service composition in the
service discovery by, as commented, matching some templates. Service discovery
methods for service composition are out from the scope of this thesis.
2.3. Frameworks for application composition in task-based computing
The pervasive computing paradigm has recently evolved into task-based computing.
The main change is that users can supply the system with their tasks’ descriptions.
They have to specify their preferences and expected functionality in order to indicate
to the system how to satisfy their needs. The frameworks for task-based computing
assume that the user provides a description of his/her needs directly into the system
via some interface. The description contains also requirements related to the task’s
QoS, resource constraints and other preferences, for example, the user does not want
to wait too much before the application is started. Then, the system dynamically tries
to satisfy user requirements by binding their tasks to available network resources. In
some systems presented in the related work, such as The Event Heap [23] or the
work presented by Perttunen et al. in [22], researchers suggest doing the specification
by a UI with a view to help users specifying their requirements.
Ben Mokhtar et al. [19] focus on allowing users entering into the ambient
intelligence (AmI). That is, giving the possibility to users to perform a task by
composing available network services on the fly. They introduce a suitable QoS
specification of services that each user has to have in his/her device. Their proposal
solution is based on semantic Web services. The behavior of services and tasks are
described as OWL-S processes. They use a matching, match QoS specifications with
services and tasks descriptions, algorithm and evaluate it with and without taking
QoS-awareness into account. Results show that the introduction of QoS constraints
improves the performance. This is because the matching results decrease, thus the
algorithm does not take much time in parsing solutions. This thesis does not focus on
building a system that takes system preferences into account. However, the
algorithms can handle user preferences having a correct configuration of the input
data.
Perttunen et al. [22] propose a QoS-based model for service composition. The
concept of QoS in this approach refers to the degree of matching between the user’s
requisites and the properties of the composed service. When the system has the
requirements of users, the service assembly interprets it and composes a custom
service composition with the objective of maximizing user tasks’ QoS. This
assembling is validated using different criteria depending on the context. Therefore,
they distinguish between static and dynamic QoS. The first concept refers to the
degree of matching between the requirements of the user’s task, as well as qualities
and capabilities of service composition. The dynamic extends the static by taking
into account the state and availability of the resources.
COCOA [26] is a framework for composing user tasks on the fly. This work
focuses on workflow application composition, where each application is a workflow,
consisting of a set of required services in a required order. COCOA uses a semantic
language for specifying services and tasks, a service discovery mechanism, and the
ability of QoS attribute matching. It has a matching algorithm based on conversation,
which matches application's workflow with the services from the environment. User
tasks are modeled as service conversations in order to match them with available

17
services. This framework can only improve the QoS, but the improvement is done
matching QoS attributes. This means that the framework does not optimize the
application structure.
Aura [29] project focuses on enabling self-adapting task-based applications. The
applications are composed taking into account user’s needs and his/her criteria. The
decisive factor taken into account for composing applications is, for example, quality
preferences defined by the user. This data is provided to the system via special
interfaces specifically designed for this purpose. These requirements provided by the
user are abstracted into a model similar to the Knapsack [56] problem. Thus, an
algorithm designed for solving this problem can be used to maximize user task
feasibility in the specific context. In this thesis, there are no tools to let users specify
their preferences, although the algorithms presented are able to find solutions
according to those user requirements with the corresponding constraint
configuration. That is, the algorithms use an objective function that is possible to be
customized for getting different objectives, also user preferences. More details about
it will be described in further sections.
2.4. Summary
This chapter was divided into three different categories: algorithms for application
allocation, frameworks for pervasive applications, and frameworks for application
composition in task-based computing. The first category is about algorithms that
decide from a set of components where to allocate them onto hosts according to user
task preferences and platform constraints. The second is about frameworks that aim
to minimize user’s distraction by sensing and adapting automatically to the changing
context, without involving the user in maintenance tasks. The last one is similar to
the previous one differing from it in attaching importance to user’s preferences.
In this chapter, related work on systems that support service composition is
presented. These systems aim to compose applications at run-time, provide the
functionality to adapt to user mobility, and to changes in the environment. These
systems have to work automatically in order to prevent the user becoming
increasingly overloaded with distractions of managing their system configurations;
they could opt not to use the capabilities of their environments. The related works do
not take into account characteristics that are essential in these environments,
however, such as being dynamic. Or they do not optimize the QoS of the obtained
composition or they have a small number of constraints taken into account, and
adding more constraints implies a design change.
The following chapters present the AAP, analyze the complexity of this problem
and solutions for solving it, while an attempt is made to have a generic dynamic
solver capable of optimizing the QoS.

18
3. APPLICATION ALLOCATION PROBLEM
The following chapter presents the AAP, its definition, and main characteristics.
Since the component-based software design methods became a popular manner of
software designing, the habit of creating applications by composing components has
increased. The AAP is described as a task of finding an assignment of application
components onto networking hosts. This assignment is subject to multiple
requirements and optimization criteria. It is argued that under certain conditions the
problem becomes hard to solve, it is a NP-complete problem. This issue and other
mathematical properties are going to be explained as well. Moreover, the chapter
formally describes how the problem can be modeled, the application and platform
models, which compose the AAP, as well as its affinity constraints. These models are
rendered using a set of properties that specify functional and non-functional
characteristics. Finally, the chapter concludes by explaining what the objectives of
the algorithm are and how one solution can be distinguished from another.
3.1. Application Model
The application model describes the application: the components that make it up,
their properties and links. In software engineering, the component term refers to a
functional or logical part inside the application with well-defined interfaces.
Component abstraction is considered as a higher-level abstraction in comparison
with objects.
The applications are modeled using graph theory. These graphs, which have to be
connected but not necessary fully connected, represent the application’s topology. It
means that it is possible to go from each node going to the rest of them by following
links; there are no islands in the graph. With a view to simplify the model, undirected
links are used. The affinity constraints are also important to mention. These
constraints force the problem solver to find an allocation to a component when not
all the hosts available are able to allocate it.
Each node of the graph represents an application component. It has requirements
that have to be also represented, such as CPU and memory consumption, security
level, hard disc consumption, etc. Besides, application components may
communicate with others. As mentioned above, this feature is modeled with links
between graphs’ nodes. As well as application components, their links have also its
own properties that have to be abstracted in the graph, such as bandwidth
requirement or security level. In terms of nodes and links, security level means if
nodes and links are secure devices.
In this abstraction model, multiple properties that have to be fulfilled by the
platform can be abstracted, as many as the designer wants. Although having more
properties specifies better the application resource behavior, it implies an increase in
the computational load and memory consumption of the algorithm. Anyway, in the
user applications that are implemented and explained in chapter 6, no more than five
properties have been used in order to specify the details of the system. This amount
of properties is enough for having a good specification of the created environment.
Properties can be functional, such as monitor size or speaker quality, or non-
functional, such as energy efficiency or usability [53].

19
Properties can be expressed as a Boolean value or a number. The number must be
non-negative float or integer. The task of setting the properties of the application
components is important for the correct functioning of the algorithm, but this thesis
is not focused on this issue. Anyway, it can be done monitoring the performance of
application in different environments, different workloads, etc. This task can be done
with tools as DeSi [42].
An example of an application model is illustrated in Figure 1. It is composed by
six application components and eight links. The application is specified by five
properties, memory, CPU and bandwidth resource consumption, as well as link and
node security properties.
Figure 1. An example of application model.
There could be situations where some application components can only be
allocated in some devices. For example, the user interface that is specifically made
for a handheld device has to be allocated in these kinds of devices. This is difficult to
define using the general properties discussed above. For these cases, affinity
constraints are used. These constraints are also utilized when a user requires a
specific service. For example, the user is listening to music by load-speakers and he
needs to change the music reproduction to his/her earphones. Then, he/she touches
an RFID tag or a button, and the system automatically set the affinity constraints for
forcing the algorithm to choose the earphones instead other audio-devices. Affinity
constraints are also useful if a component requires access to specific material that is
only available at a unique platform node. For example, a component has trust
requirements and an explicit trust binding between the components that may
participate in the service composition are needed [25].
3.2. Platform Model
The platform model describes the real execution environment. It is modeled using
graph theory as well. In this case, the nodes of the graph represent a real
computational host and the links between them are their network connections. Unlike
the application model (which is just connected), the platform model is always a fully

20
connected graph. That is, all the hosts are able to communicate with the rest of them.
In terms of graph theory, this means that every node is connected to each other in the
graph.
A computational host is a device inside a real network environment. It has the
capability of allocating more than one software component in the case of its resource
restrictions are not violated. As mentioned above, the communication channel
between two devices is represented by a link between two nodes. The device and
connection constraints are detailed in the graph, as well as in application models.
These constraints, in the case of nodes, could be the maximum memory, computation
capacity, or if the device is secure. In the case of links, they could be the maximum
network connection capacities or if the link is secure.
Both kinds of properties can be represented as a Boolean, non-negative float or
integer number. Besides, these constraints must represent the same constraints as in
the application model but, in this case, they are restrictions instead of being
requirements.
The differences between two models’ constraints, application and platform, is that
application models’ properties represent, in the case of being a float properties, the
minimum value the host has to fulfill, and in platform models, they represent the
maximum capacity for its kind of constraint the device can support. In the case of
being Boolean properties, a “True” value means the obligation of being allocated in a
node that has the feature this property is representing. In contrast, if it has the “False”
value, it can be allocated in any device of the environment.
An example of a platform model is illustrated in Figure 2. It consists of eight
devices and its correspondent links. In this case, as it has to be fully connected, there
are 28 links. The platform model has the same number of properties (necessary
condition) as the previous application model example.
Figure 2. An example of platform model.

21
3.3. Mathematical Details of the Application Allocation Problem
The Application Allocation Problem is a combinatorial optimization problem. As
most of this kind of problems, it is a NP-complete problem. To cope with this,
approximation algorithms are used in order to find solutions close to the optimal. It is
just a hypothesis because it is impossible to know which the global optimal value is.
In these kinds of problems, some characteristics and examples of this problem will
be presented.
NP-complete problems are problems that cannot be solved in a polynomial time.
NP itself means non-deterministic polynomial-time. Therefore, finding the optimal
solution implies an exponential computational complexity, which is too high for
practical use. All problems of this type have a peculiarity, all of them are equivalents
[3]. It means that if one of them has an efficient algorithm for solving it (i.e. in P),
then, all NP-complete problems have efficient algorithms. Incidentally, if a solution
is in the set P, it means that it can be solved in a polynomial time. Nevertheless, there
are no discovered methods for solving these problems in P.
The AAP has also the uncorrelated property. When a problem has the property of
being uncorrelated, it means that the probability of getting a solution has no effect on
the probability of getting another one. That is, the structure of the search space does
not contain any information about the order of how solutions will be sampled.
Theoretically, it means that the covariance of two random real-valued variables is
zero; there is no linear relationship between these two variables. This property makes
these problems hard to solve, mainly to find the optimal solution, because insofar as
one gets solutions, they have no relation between them. Thus, the algorithm cannot
make any assumptions on the distance to the optimal solution.
Many famous NP-complete problems are under research, such as Boolean
satisfaction problem (SAT), knapsack problem, traveling salesman problem (TSP),
or graph coloring problem. There are different techniques to obtain high-quality
solutions in a polynomial time, such as approximation, randomization,
parameterization, or heuristic. Anyway, as mentioned above, if the solution is the
optimal one is impossible to know when these kinds of methods are used. Search
techniques such as genetic algorithms are also employed in order to find or to
approximate to good solutions in these high computational problems.
As mentioned above, the AAP is a NP-complete problem. It was proved in [43].
That is, there are not any solutions to solve them in a polynomial-time. In fact, the
solutions presented on this thesis are based on one of the above-mentioned
techniques to solve NP-complete problems, genetic algorithms. More details will be
presented in section 4.
One example of an uncorrelated problem, which is also a NP-complete problem, is
the previously mentioned knapsack problem [56]. It is a combinatorial optimization
problem. The main objective is to maximize the value of the items to be carried in
one bag without exceeding the maximum weight. That is, determine which item
should be included in a collection so that the total cost is less than a given limit and
the total value of the items is as large as possible. Figure 3 shows an overview of the
problem.

22
Figure 3. Example of one-dimensional (constraint) knapsack problem.
The AAP has also the property of being uncorrelated. The possible solutions do
not have any relation between them and the probability of finding a solution is not
influenced by the probability of finding others. Because of that, with respect to
designing the algorithm, there have to be some tools for comparing the solutions
obtained in order to find as good solutions as possible.
3.4. Objective
In this section, the objectives of the algorithms proposed for solving the AAP are
presented. The AAP is a very generic problem and is not tailored to a certain kind of
application type or application domain; therefore, it should support several objectives
at the same time. For example, in load balancing applications, such as grids where a
good distribution of the execution weight could involve into a faster problem
resolution, the main factor is the variance of the computational load among all the
platform nodes. In pervasive computing, it aims to find the best configuration for the
composed applications, in web services, the QoS of the available services, and
finally, in task based computing, fulfilling user tasks in the best way.
An objective function that allows our algorithms to compare the solutions will also
be explained. The aim of this function is to evaluate the solutions. One solution
related to the allocation problem of the previously presented models will be
presented, with a view to have an example for understanding better what is measured
in the objective function.
As mentioned above, the AAP could have many different goals, depending on the
context where is going to be used. Having a good objective function can improve the
applicability of the problem solver, improving the performance or the usability of the
system where is used at. The ideal would be that algorithms for solving the AAP
could support different kinds of goals; therefore algorithms use a generic objective

23
function, which supports new objectives without handling algorithm’s code. The
algorithms presented in this thesis use the following function: the lower the value,
the better the quality of the solution. The function is used for finding a configuration
that minimizes the network traffic and uses as less devices as possible, while the
variance of the free capacity in the hosts after the allocation is within a desired range.
The importance of one or another objective can be easily increased or decreased
using weighting coefficients. Anyway, in this thesis all the objectives were equally
important, so the coefficient values were 1. In case the application context changes,
the objective of the problem or its importance would be easily adapted to a new
situation by changing the mentioned objective function or weighting coefficient:
Fobj = fB + fD + fV,
where
• fB is the ratio of the network link bandwidth used in the allocation to the sum of
the bandwidths required by all the component links in the application. This value
decreases when some components are allocated onto the same device, thus, the
network communication requirements of the system decrease.
• fD is the ratio of the number of devices used in the allocation to the total number
of application components in the task. This feature minimizes the time needed for the
actual deployment of components.
• fV is the variance of processing capacity usage among the devices, that is, the
variance of free capacity of the hosts after allocating the components. In other words,
it balances the server load, with the intention that the utilization of each host is
within a desired range.
One possible solution combining the application model presented in section 3.1
and the platform model in 3.2 could be to allocate components with security property
in devices with that feature, for example, C1 to D2, C4 and C5 to D3. The rest of
them could go, for example, C2 to D1, C3 and C6 to D7. Figure 4 models the CPU
and Figure 5 the memory load according to the configuration presented.
Figure 4. CPU load balancing example.

24
Figure 5. Memory load balancing example.
On the one hand, these charts show that in this solution the load balancing do not
get a good result. Load balancing measures that the computational load is as uniform
as possible along the devices of the network; some devices are nearly full, while
others are completely free. But on the other hand, this configuration decreases the
latency of communication because less network links are used and minimizes the
time needed for the deployment of components. Due to the benefit that all mentioned
features provide to the AAP, all of them are considered together in the objective
function.
3.5. Summary
In this chapter, the AAP is described. It is the problem of allocating components in
devices according to their own properties, as well as trying to improve the QoS of the
corresponding allocation. The device where a component is allocated has to fulfill all
its requirements. There could be affinity constraints that have to be satisfied as well.
It has been explained how this problem can be modeled into a computational
problem, the application, and platform models. They are two models for representing
applications’ topology and its execution environments by using connected graphs. It
is argued that under certain conditions the problem becomes hard to solve, it is a NP-
complete problem and uncorrelated. Other problems with those mathematical
properties have been presented, as well as some algorithms discussed for solving
them properly.
With the aim of evaluating and comparing solutions of the problem, an objective
function is necessary. The reason for using a function for comparing solutions is that
the solution solvers should be as generic as possible, that is, without changing the
design of the algorithm; it should carry out different objectives. In this case, the
following algorithms can be used for many different objectives, only by changing the
presented function. For example, they could find an optimum computational load
between devices by focusing on the variance, or finding the best configuration for the
composed applications in order to fulfill user tasks in the best way.

25
4. ALGORITHMS FOR THE ALLOCATION PROBLEM
In this chapter, the algorithms for solving the AAP are presented. The chapter shows
how the problem can be represented, the application and platform models, into data
structures. The design of the basic algorithms is presented and analyzed, and finally,
the new algorithms based on theory of evolutionary and genetic computing are
explained, as well as the innovative three-phase validation schema.
4.1. Data representation
This section shows data structures for representation of AAP. Data representation is
important because it affects the design phase of the algorithm and a better design
involves a better performance. Speaking about a better performance means more
rapidity in obtaining the solution from the algorithm. This section also shows some
examples.
The AAP can be represented as a set of tables (see Table 1). Tables are easy to
understand and computers use them efficiently. That makes them an ideal data
structure for having an efficient algorithm design.
The application model's table is shown in Table 1. It describes the application
model that was presented before (see Figure 1). An example of the platform model is
not shown because it has the same structure as this one; it is similar to the application
model because the properties of the resources and requirements are the same. The
only difference is that it has more rows for representing more data because the model
is larger. It is obvious that adding new constraints is very easy just by adding new
columns.
Table 1. Application model graph representation
Affinity constraints, which restrict certain components to be assigned onto certain
nodes, can also be represented using a table. The following example demonstrates
how affinity constraints are represented for the application model presented in Figure
1 and the platform model presented in Figure 2. The constraints are the following:
Node Representation
ID CPU MEM Security
C1 13 9 �
C2 12 7 �
C3 8 12 �
C4 14 12 �
C5 10 9 �
C6 5 7 �
Link Representation
Source Dest. Band. Security
C1 C3 5 �
C1 C4 7 �
C2 C4 9 �
C2 C5 7 �
C3 C4 12 �
C4 C5 12 �
C4 C6 10 �
C5 C6 5 �

26
• C2 must be allocated in D1, D4 or D5.
• C3 must be allocated in D7 or D8.
• C6 must be allocated in D7 or D8.
Table 2 shows how affinity constraints are represented in the AAP solvers
presented in this chapter. In this case, a component’s column represents an array of
the same size of the software components quantity. Every array cell contains another
array inside that save the index of the devices where these components could be
executed. In case, the first position is -1, means that the correspondent component
can be executed in any device. These arrays are the system’s device number minus
one size.
Table 2. Affinity constraints representation
Component 1 2 3 4 5 6 7
C1 -1
C2 D1 D4 D5
C3 D7 D8
C4 -1
C5 -1
C6 D7 D8
4.2. Basic algorithm
This section is related to the original algorithm, which the algorithms developed in
this thesis is based on. It is called micro-genetic algorithm (MGA) [14] and it is
based on a particular class of evolutionary algorithms, specifically in genetic
algorithms; it uses operators that are commonly used in these kinds of algorithms,
such as mutation, crossover, etc. These operators will be mentioned in this section.
Some of them are also used in the two new algorithms of section 4.3, where more
detailed explanations will be presented. The section also reveals the advantages and
disadvantages of this basic algorithm as well as its design.
As mentioned above, the algorithm is based on basic genetic algorithms, and it is
built with the aim to improve the solution presented in [15]. As pointed out above,
the AAP is a NP-complete and uncorrelated problem. Many approaches have been
tried using genetic algorithms in order to solve this kind of problems.
First of all, what genetic algorithms are must be explained: they are search
algorithms motivated on mechanics of natural selection and natural genetics. They
use operators that are also carried out by natural evolution, such as crossover,
mutation, and selection. By using crossover in every generation, new individuals are
created on the basis of the fittest individuals of the previous generation. However,
some structures are sometimes randomly modified in order to provide new genetic
information to the evolution process, in other words, to increase the search space.
This is done with the mutation operator. More details about algorithms like that can
be founded in [1].

27
Figure 6. The flowchart of micro-genetic algorithm.
The main difference between MGA and the approach presented in [15] is that it
uses an external memory. This memory is used as a source of population diversity
and to store the best individuals founded. The use of this memory allows the
algorithm to work with a smaller population (internal population) with
reinitialization that implies a lower computational load. The internal population size
is less than ten individuals.
The flowchart of the MGA is presented in Figure 6. Most of the steps correspond
to standard genetic operators; a larger explanation of tools of this type can be
founded in Eiben and Smith [2]. The following enumeration gives a general idea of
the operators used in the MGA. In Davidyuk et al. [14], further explanations of the
MGA and its operators can be founded.
• Initialization: The initial population of the external memory is generated
randomly. The initialization of every MGA-cycle is done picking half of
the internal population with randomly selected individuals from the
external memory. The rest of the internal population initialization is
generated completely arbitrarily.

28
• Selection: Binary tournament selection.
• Crossover: Depending on the individual feasibility, different crossover
operators are used. If the individual is infeasible, a standard one-point or a
uniform schema with a 50% probability is used. In the case of being
feasible, an operator based on a succession of ordered copies between
parents or a uniform schema operator are used, also with a 50%
probability.
• Mutation: It changes randomly few gens of the individual with a certain
probability, in this case 30% probability.
• Elitism: It saves the individuals with the highest fitness value in the
internal memory without considering individuals with a higher fitness of
the external memory.
• Memory handler: When the internal population arrives to nominal
convergence (similar genotype), it replaces the two worst individuals
from the external memory with the two best ones from the internal
memory, obviously if they are better.
Although this kind of genetic algorithm implies to define more than the habitual
parameters on standard genetic algorithm, such as micro population size, external
memory size, and micro-cycle size, MGA is characterized by a faster convergence.
Different performance can be obtained by modifying these parameters, for example,
having a bigger external memory implies to decrease the algorithm convergence
rapidity. Anyhow, this convergence speed was not enough in order to use this
algorithm in a real time environment. It took too much time for being integrated in a
framework that builds applications on the fly. Users could get exasperated waiting
until the system offers their requested service. Besides, the algorithm had a big
restriction; it was not able to find any valid solution when big size problems were
treated. In addition, the quality of the solution was not as good as expected. With the
aim of solving all these MGA drawbacks, the decision of designing and creating new
algorithms to resolve the AAP was taken.
4.3. New Algorithms
In this section, a fitness function based on the so-called clustering method will be
presented. The function aims to identify whether the individual is feasible or not
before starting with the optimization phase. Then, two new algorithms for solving the
AAP will be presented. Their flowcharts and how the algorithms’ operators work
will be included. The algorithms are: genetic algorithm and evolutionary algorithm.
4.3.1. The three-phase validation schema
An evaluation schema plays an important role in the design of the algorithms. The
schema aims to keep the computational load of the algorithms low by avoiding
calculating the objective function values for infeasible individuals. In addition, the

29
schema is used to calculate the fitness value for infeasible individuals; an individual
is used to denote points from the space of possible solutions [2]. It is also called
candidate solution or phenotype, as well as more technical words like chromosome.
Feasible and infeasible denotations refer to whether the solution fulfills all the
problem requirements or not. It does not matter if the mentioned solution is an
optimal solution, only its validity. The schema is used to guide the genetic operators
in terms of evolutionary computing.
As mentioned above, the performance of algorithms is directly related with
algorithms’ design. Having a good data representation helps in the task of algorithm
design. In this section, the representation of the candidate solutions is presented.
These ones are represented with a direct representation [2]. Figure 7 shows an
example of this representation plus the validation vector explained in the next
paragraph. This figure refers to the representation of the solution of the problem
presented in section 3. It contains six application components and eight hosts
although only four are actually used. As the figure shows, the length of the individual
is equal to the total number of application components in the task description.
Therefore, the number in the ith
position means the host identity where the ith
application component has to be allocated according to the current solution. For
example, in this case, the 2nd
application component should go in the device
identified by number 1.
To each individual is assigned a bit string, which is also called a validation vector.
A bit set to 1 indicates that the application component is badly allocated in the
current host; set to 0 indicates a correct allocation. The vector specifies how feasible
the individuals are, with more bits in 0, the more feasible the individual is. The
validation vector of the example shown in Figure 7 means that the individual is
feasible; it has all the bits in 0. It obviously has the same number of positions as the
individual it has been assigned to. This vector is very important in the algorithm’s
design; it decreases the problem complexity and it also helps the algorithms by
guiding their crossover and mutation operators.
Figure 7. The representation of an individual with its correspondent validation
vector.
Before starting with the three-phase validation, the validation vector must be
initialized. That is, all the bit positions must be set as 0. After that, the violation
detections can be started and the correspondent bits are set to 1 when suitable. Figure
8 shows a small flowchart of the three-phase validation process. As its own name

30
indicates, this process is divided into three different phases. It always starts from the
first phase, then if the individual is feasible, through the rest two steps. The following
paragraphs show more details about these phases:
Figure 8. The three-phase validation schema.
• Phase 1: In this phase, the validation method only checks if node
constraints are satisfied by the solution. It is divided into two steps.
o Step A: In this step, individual node violations are checked. That
is, it checks if any of the application components violate host
constraints without taking into account if other components are
allocated in the same node (group violations). This is done in the
next step. When this happens, the algorithm set the correspondent
bit of the validation vector to 1. If no violations have been
detected, all the application components of the candidate solution
can be allocated in these nodes if all the components are allocated
in different sites, without having taken into account link
constraints yet.
o Step B: Here, it is checked if groups of components from the
candidate solution violate any node constraints. That is, the
algorithm sums all the resource requirements of the components
that are supposed to be allocated in the same host and it checks if

31
this sum exceeds its constraints. If any constraint is violated, the
algorithm set the position of the last components that has caused
that constraint violation to 1. If the validation vector has all its
positions in 0, that is, there are no node violations, the algorithm
proceeds to the second phase. Otherwise the validation of the
candidate solution ends and its fitness function value is calculated.
• Phase 2: In this phase, link-related constraints are only considered. It
checks if there are platform link constraints violations by allocating the
application components as the candidate solution proposes. When a link
constraint is violated, a bit from the vector of one involved application
component in the violation has to be set to 1. The algorithm chooses one
of them randomly. If the violation vector has any bit set to 1 after the
verification of all the constraints, the algorithm stops the evaluation and
calculates the candidate solution fitness function value. In case no
violations are detected, the algorithm proceeds to the third phase.
• Phase 3: In this last phase, the fitness function value is calculated
according to the following equation. This value is very important to
transact the objective function optimization:
fitness =
− 4 −I
A if calculated in phase 1
− 2 −I
A if calculated in phase 2
− Fobj if calculated in phase 3,
where
• I is the number of components that violate any constraints.
• A is the amount of components in the application.
• Fobj is the objective function defined in section 3.4.
The fitness function presented above is based on the so-called clustering method.
The algorithm defines which the individual phase is according to the value obtained
from the mentioned function. For example, if the fitness value is in the interval [-5, -
4), the individual where this value has been obtained from belongs to feasibility
phase 1. However, if the value is in the interval [-3, -2), the individual belongs to
feasibility phase 2, and finally, if the value is in [-1, 0], to feasibility phase 3. By
using this method, there are no possibilities to fall into other values out from these
intervals.
Knowing the phase each individual belongs to, helps the algorithm in saving
computation time; constraints satisfaction and optimization tasks are done separately.
For example, in optimization phase there is no necessity to have as many individuals
(population size) as in constraint satisfaction phase and the crossover points can be
decreased as well. Moreover, in this phase, the penalty function, which was used in
earlier versions, is not employed to distinguish feasible and infeasible candidates.

32
4.3.2. Genetic Algorithm
The flowchart of this algorithm is presented in Figure 9. It is similar to the flowchart
of the algorithm presented in the previous section 4.2; only a few differences can be
realized. In this case, the initial population is generated randomly and the algorithm
uses the explained three-phase evaluation schema for evaluating the individuals. In
the randomly population initialization, it takes into account if affinity constraints
exist for the current components. For this purpose, it chooses randomly a device for
each constrained component from their possible allocation hosts’ list. The rest of the
operators used in the algorithm cycle are similar to MGA.
Figure 9. The flowchart of the genetic algorithm.
The characteristics of the operators used are the following:
• Selection: It is used the most habitual selection operator in genetic algorithms,
tournament selection.
• Crossover: The crossover operator used is one of the operators that MGA used
for feasible individuals. It starts selecting randomly one of the two parents and it
takes the individual first gene for copying it into the first position of the new
individual. Then, the second gene is taken from the other individual and copied
it into the child’s second position. Both of the parents could have the same gene
value, in this case, the gene is copied to the child and the process starts again

33
from the next position. The process stops when there are no more positions to
fill. Figure 10 shows an example of this crossover method. The algorithm
applies this crossover operator only to individuals that belong to the same
validation phase. This is done by sorting the whole population by taking each
individual fitness value as a reference for the ordering.
Figure 10. Example of crossover method for feasible individuals.
• Mutation: The used mutation operator depends on the phase each individual
belongs to. These kinds of operators are used for introducing randomness in the
algorithm. They process individuals one by one and the modifications they lead
to the individual are not related to the context where the individual is involved
in. The mutation works as follows:
o Infeasible individuals (1
st phase): in this case, validation vector is
used for carrying out the mutation. All the genes that have their bit
denote a violation (the value in the validation vector is 1) are
mutated. An example is showed in Figure 11. Mutation operators
do not assure the correct configuration of mutated candidates. In the
example, there is a mutated gene that is still incorrectly according
to the validation vector. In this case, the data for saying whether it
is valid or not comes from the example of chapter 3.
Figure 11. An example of the mutation for the 1st
validation phase.
o Infeasible individuals (2nd
phase): Here, the mutation operator
changes randomly the value of few genes of the individual with a
certain probability. The mutation points are also taken randomly.
An example can be seen in Figure 12. This mutation style is used in
MGA as well; the difference is that in this case the mutation
percentage is variable. That is, when a vector has 30% or less

34
violation indications, the mutation percentage is set to 50%. If not,
the probability is set to 20%. These values were set empirically in
order to minimize the randomness of this operator.
Figure 12. An example of the mutation for the 2nd
validation phase.
o Feasible individual (3
rd phase): In this case, the mutation works
by copying one random gene into another that is chosen randomly.
Figure 13 shows an example of this mutation process.
Figure 13. Example of the mutation for the 3rd
validation phase.
• Elitism: a standard elitism operator is used. That is, it saves the individuals with
the highest fitness value in the new population.
• Stopping Criteria: This is the criterion the algorithm follows in order to know
if it should stop or not. In this case, it stops when a maximum number of
individual fitness evaluations are done or a limit of generations without fitness
improvement is reached.
4.3.3. Evolutionary Algorithm
The primary objective of this algorithm was to have an extremely fast performance
to the detriment of having higher quality solutions. For this purpose, the
computational overhead is reduced as much as possible, decreasing the amount of
operators until the algorithm is able to find valid solutions. The usage scenario of this
algorithm is different in comparison with the previous one. For example, the genetic
algorithm, which gets better solutions, could be used to find an initial application
allocation. Then, in case any reallocation has to be carried out, the EA could be used
for having a very fast performance. Having a configuration as close as possible to the
optimal implies that small reallocations should not produce huge changes in its
quality. In case both algorithms would be integrated into a framework, the
framework itself should elect the algorithm depending on its actual context, a faster
or a better quality solution.

35
This algorithm is quite simple: it only uses three operators in the evolutionary
cycle, namely the explained three-phase evaluation, mutation, and saving the best
solution till the current moment. In this case, the mutation operator used is the same
as the one presented in section 4.3.2. The initialization and the stopping criteria are
done in the same way as in the genetic algorithm. The flowchart of the evolutionary
algorithm is shown in Figure 14.
Figure 14. The flowchart of the evolutionary-based allocation algorithm.
In both algorithms, there are only two parameters to set: the population size and
the tournament size. The first is set to the length of the individuals and the second is
set to 2. These sets were defined empirically during the initial tests of the algorithms.
4.4. Summary
In this chapter, all the details about two solutions for solving the AAP are presented.
A good data representation design is suggested in order to provide an excellent basis
for the algorithm design task, which involves better performance results. A
preliminary algorithm has been explained, which the new algorithms are based on,
with a view to provide a general idea of the utilized methods in the latest algorithms.
Its operators accompany by a little explanation. The main reasons for designing new
solutions are explained. These reasons were also their objectives. A more intense
view of the new algorithms is showed: their flowcharts and operator details with
some explicative figures. As a great innovation, the three-phase validation tool is
offered. It improves the algorithm performance preventing them from making
unnecessary calculations that involve high computational loads.
The next chapter will present some experiments relating to the algorithms’
performance: rapidity, quality of the solutions, and robustness. Furthermore, the
results obtained will be shown when affinity constrains are used.

36
5. EXPERIMENTS AND ANALYSIS
In this chapter, the performance and scalability experiments are presented. The goals
of the experiments were to measure the time each algorithm takes for finding a
solution. Knowing how good and reliable these solutions are is also important. For
this reason, the performance, the quality, and the robustness of the algorithms were
tested. In addition, they were tested using affinity constraints. The application and
platform models were synthesized using a third party graph generator, which has also
been used widely by the research community.
The mentioned graph generator that will be presented in this chapter is called
BRITE [45]. It was needed for testing scalability and performance of the algorithms.
These generated models were used for simulating real problems in order to give
some data to the algorithm for the testing in real situations.
Both the algorithms presented have been implemented in C++. The experiments
were performed until they found a valid solution or a maximum value of fitness
evaluations was done. If one of them found a solution, the experiment was restarted
after having rebuilt the application and platform models. The number of fitness
evaluations was limited to one million in order to get results within a reasonable
time. It means that the EA performs one million of cycles and in each cycle only one
individual is treated, in the case of the GA, the number of cycles is variable due to its
population size that is set to the application size, which depends on the problem. All
the data taken from these experiments was taken after 100 valid executions.
Moreover, the experiments were done for different sizes; the algorithms have been
tested in 15 different sizes, starting from an application model of size 15 increasing it
in five and a platform model of size 45, increasing it in 15 each iteration. The last
size used had 240 platform nodes. Although such a large application is hard to find, it
gives more detailed information about how the algorithm works when big models are
used.
Aside, all of them had been executed in machines with the same characteristics.
The CPU was an AMD Opteron 270 dual core machine with two chips, thus, it has
four cores in the same computer, although only one core was used for the execution
of each experiment. The OS was Red Hat 4.1.2 Linux.
5.1. BRITE graph generator
The Boston University network topology tool (BRITE) [45] is a graph generator tool,
which synthesized the application and the platform models used in the experiments.
The section presents its features and characteristics, as well as explains how the
BRITE tool was modified to comply with the AAP. Some examples of created files
will also be presented.
There are many independent generation models and topology generators. Having
many different kinds of topology generators in one tool is what BRITE focuses on. It
is a universal topology generator; in other words, it supports many generic topology
models.
For synthesizing the application and platform models, any network topology
generator available in BRITE is enough. It only has to generate a model with a
specified number of nodes and has to be able to link all the nodes with a certain
quantity of links. In these experiments, the application models have 70% of the links

37
from the fully connected approach. In contrast, the platform models must be fully
connected. Even so, as explained in the previous chapters, each node and link must
have each owns properties. This issue is not implemented yet in BRITE. Because of
that, for these experiments, a random property generator class has been included in
the graph maker. It adds the specified number of float and Boolean properties with
random values when the nodes and links are created. All the needed data by the
network generation tool, number of floats, and its value range, or Boolean, and its
truth probability, is taken from a text configuration file that is possible to be easily
modified.
As mentioned above, BRITE has the ability to create many different kinds of
network topologies. It also has the ability to export these topologies into many
different kinds of file formats in order to increase the facility of using this graph
generator. For example, SSF or ns that are discrete event simulators targeted at
networking research. Anyhow, these exportations add some information that is not
necessary for the following experiments. Because of that it was decided to create a
new kind of output file format, XML. This format is adequate because of being
easily understandable and legible. New property data can be also included in a
simply way. Figure 15 shows a part from the XML output file that represents the
application model of Figure 1.
Figure 15. An example of a XML output file.
The following enumeration describes what most important tags specify:
• NumberNodes & NumberEdges: These specify how many nodes and edges the
model has.
• NumberFloats & NumberBools, NumberLinkFloats & NumberLinkBools: These specify how many float and Boolean properties each model node and link
has.

38
• Node: It saves all the properties of each model node. ID specifies the
identification number of the node. P and B specify respectively the float and
Boolean property of the node.
• Link: It saves all the properties of each model link. The ID specifies the
identification number of the link. The SRC and DST specify which nodes it is
linking. P and B specify respectively the float and Boolean property of the node.
The bigger datasets used for experiments were generated with 80 and 240 sizes for
application and platform models, respectively; BRITE has the possibility of creating
models as big as the user needs. It also has the ability of showing the generated
model; Figure 16 shows an example of an application model with 30 nodes. Because
of the high value of links, something clear is difficult to appreciate. Making huge
network topologies is also possible. It is a good feature for testing the algorithms in
extreme situations. For example, for the experiments of the following sections,
models bigger than 240 nodes and 28680 links have been created.
Figure 16. Example of an application model with 30 nodes.
5.2. Experiment 1: Performance of the algorithm
This section presents the experiment that measures the computational overhead of the
algorithms while increasing the sizes of the application and platform models. It is
argued that the greater sizes of the problem will result in longer computational times.

39
A separate experiment studies how the affinity constraints affect the performance of
the algorithms.
The experiment uses the problems created by the graph generator. Table 3 defines
the parameters used in the experiments. The algorithms were launched until they
found 100 valid solutions. For each valid solution, how much time they took for
finding the first valid solution was written. Finally, the average time was calculated
with all the obtained computational times.
Table 3. Parameters of the graph generator
Float Node Float Link % Boolean
Nodes
% Boolean
Links
% Density
Application 10-25 10-25 0,3 0,3 0,70
Platform 80-100 80-100 0,75 0,75 1
Figure 17 demonstrates the computation time of the genetic algorithm and the
evolutionary algorithm. This figure shows the results for problems with six and ten
constraints, where 80% of the constraints were float and the rest Boolean constraints.
For example, GA6 means that the genetic algorithm was used for solving problems
with six constraints, four float and two Boolean; EA6 is analogous but using the
evolutionary algorithm, and so on.
Figure 17. Computational overhead of Genetic Algorithm, graphed on a logarithmic
scale.
As both graphs show, the genetic algorithm requires more time for finding a
solution, especially for big sizes, where the EA’s spent time is over ten times less
than the genetic one. It is due to its simplicity in comparison with the GA. For
example, as shown in chapter 4, in the EA some high computational operators are
omitted: the parents’ selection, which also involves the population sorting by their
fitness value and the correspondent crossover, and the elitism operator. Moreover,
the EA just works by mutating an individual and saving the best generated one
during all the procedure, while the GA has to tackle all the time with a bigger
population; it is set to the application size.

40
In general, analyzing the Figure 17 it can be observed how the computation time
for both algorithms increases while the problem size raises. It can also be
distinguished that the more properties the models have, the more computation time is
required.
In order to test affinity constraints, a middle size problem was used with six
constraints. Then affinity constraints were added to this problem. The experiment
starts by including four components with constraints; allocating each restricted
component in 25% from the total amount of platform devices was possible. The
quantity of constrained components was increased in four each iteration until all of
them have constraints at the end of the experiments. For every constrained
component, the restriction explained above was used.
Figure 18. Computation time of both algorithms using affinity constrained
components.
Figure 18 shows the computation time for both algorithms while affinity
constraints were included into the problem. EA demonstrates excellent performance
during the experiment; the used time is constant along the affinity constraint
addition. GA is very irregular; it is noteworthy that the same problems have been
used during the experiments for both of the algorithms. The use of so many operators
could influence the performance for solving problems with affinity constraints if the
results obtained in the current experiment are taken into account.
5.3. Experiment 2: Quality of the algorithm
The absolute quality of the solutions is usually measured by the distance between the
global optimum and the values of the objective function of the solutions; the smaller
the distance, the higher the quality of the solution. However, in the case of the AAP,
there is no information available about the global optimum. As mentioned above, it is
a NP-hard problem and there are no ways of knowing which the global optimum is.
Therefore, in the experiment the relative quality is measured. The relative quality is
the improvement in the objective functions value, that is, the difference between the
values of the first valid solution and the solution obtained after the optimization
phase. It is measured for both algorithms, the evolutionary and the genetic. How

41
affinity constraints affect the relative quality solution for both algorithms will also be
presented.
The experiment was done using models with ten properties, 80% of the properties
were float and the rest Booleans. Table 4 shows in detail how the parameters were
set for generating the models.
Table 4. Parameters of the graph generator
Float Node Float Link % Boolean
Nodes
% Boolean
Links
% Density
Application 10-25 10-25 0,3 0,3 0,70
Platform 80-100 80-100 0,75 0,75 1
Figure 19 demonstrates the percentage that means how much the first valid
solution found is optimized in both algorithms. As this figure is showing, the GA
always improves more the solution than EA, because the evolutionary solution only
uses a mutation operator that does not allow the exchange of information between
candidate solutions. It is noteworthy that the quality of the obtained solution
decreases while the model sizes increase. This is probably because of having fewer
cycles for optimization when the model is bigger, the optimization phase does not
start until the first valid solution is founded. They need more fitness evaluations for
finding the first valid solution and, as pointed out above, this parameter is restricted.
Besides, in the GA, more fitness evaluations have to be done for each cycle due to its
population size growth. Another motive is that the algorithm can examine less
percentage of the whole space due to an expanded search space to explore.
Figure 19. Quality comparison graph of the algorithms.
As well as in the performance experiment, a middle size problem was used with
ten constraints in order to test affinity constraints. Then, affinity constraints were
added to the problem. The experiment starts by including four components with
constraints; allocating each restricted component in 25% of the total amount of
platform devices was possible. The quantity of constrained components was
increased in four each iteration until all of them have constraints at the end of the
experiments.

42
Figure 20. A quality comparison graph of the algorithms by using affinity
constrained components.
The previous figure shows the distance between the first valid solution and the
solution obtained after the optimization phase for both algorithms while affinity
constraints were moderately included into the problem. The results obtained are quite
similar, although the GA always finds better solutions. In conclusion, analyzing the
data it can be said that the solutions’ quality of both algorithms are not affected when
the affinity constraints are presented; solutions when components are fully affinity
constrained have nearly the same quality as when no affinity constraints exist.
5.4. Experiment 3: Robustness of the algorithm
The robustness of the algorithms refers to how many times they are able to find a
solution for each application and platform sizes. This experiment is important
because it shows how reliable the algorithm is for each dimension in comparison
with the other one. In this case, the robustness is measured by the percentage of
experiments in which the algorithm fails to find a solution out of the total number of
experiments. If both of the algorithms fail, the execution is rerun. How affinity
constraints affect the performance of the algorithm will also be presented in terms of
robustness.
For this experiment, models with six and ten properties have been created. In this
case, also 80% of the properties are float properties. Table 5 shows the parameters
used for generating the models. The algorithms were run 100 times and then how
many times they had failed was counted. In case both algorithms failed for the same
model, the failure was not taken into account for the final result.
Table 5. Parameters of the graph generator
Float Node Float Link % Boolean
Nodes
% Boolean
Links
% Density
Application 10-25 10-25 0,3 0,3 0,70
Platform 80-100 80-100 0,75 0,75 1
Figure 21 shows the failure percentage of both algorithms when they try to find a
solution for the generated models with six and ten properties. As happened for
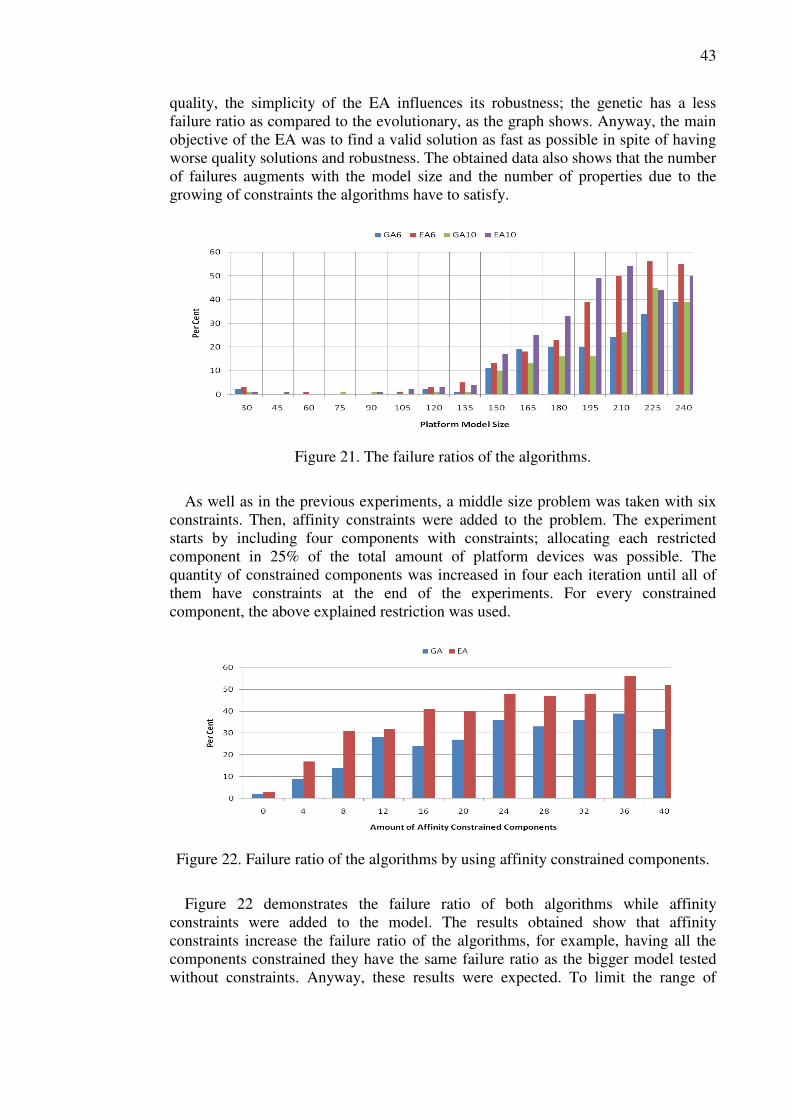
43
quality, the simplicity of the EA influences its robustness; the genetic has a less
failure ratio as compared to the evolutionary, as the graph shows. Anyway, the main
objective of the EA was to find a valid solution as fast as possible in spite of having
worse quality solutions and robustness. The obtained data also shows that the number
of failures augments with the model size and the number of properties due to the
growing of constraints the algorithms have to satisfy.
Figure 21. The failure ratios of the algorithms.
As well as in the previous experiments, a middle size problem was taken with six
constraints. Then, affinity constraints were added to the problem. The experiment
starts by including four components with constraints; allocating each restricted
component in 25% of the total amount of platform devices was possible. The
quantity of constrained components was increased in four each iteration until all of
them have constraints at the end of the experiments. For every constrained
component, the above explained restriction was used.
Figure 22. Failure ratio of the algorithms by using affinity constrained components.
Figure 22 demonstrates the failure ratio of both algorithms while affinity
constraints were added to the model. The results obtained show that affinity
constraints increase the failure ratio of the algorithms, for example, having all the
components constrained they have the same failure ratio as the bigger model tested
without constraints. Anyway, these results were expected. To limit the range of

44
possible components, makes the problem much harder to solve; it restricts the
possible solutions of the problem.
5.5. Summary
This chapter has presented the experiments for testing the algorithms developed and
their results. The goals were to measure the time each algorithm uses for finding the
first valid solution, the quality of the solution before and after the optimization phase
and their robustness. All these experiments demonstrate that the objectives for
improving previously created solutions have been satisfied. Moreover, affinity
constraints were used in some models in order to have a general idea of how
algorithms work in more constrained situations. For modeling the graphs that has
been used for simulating real application and platform models, a third graph
generator is presented, which has also been used widely by the research community.
The algorithms were integrated into a real time framework with the aim to show
the applicability of these solutions. The next chapter shows the details of the
applications, as well as the obtained user comments after a pertinent demo.

45
6. APPLICATIONS
In order to evaluate the applicability of the algorithm in real world, two concrete
applications were designed: the ubiquitous multimedia player and the newsreader.
Each subchapter will present the scenario of the application and its design. Small
user experiments were carried out and their results are also presented in this chapter.
6.1. Ubiquitous Multimedia Player Application
The chapter will present the scenario, its user interfaces, and the design details of the
application, as well as the obtained results from the user testing. This application
allows users to control a multimedia player on a wall display using a mobile phone.
The multimedia player streams audio and video content from a suitable server and it
is automatically played in a screen of the environment. The components that will
take part in the application, in this case the multimedia server and the screen, are
automatically allocated at run-time when the user chooses which video he/she wants
to watch. The algorithm is in charge of deciding, where the components of the
application have to be allocated.
6.1.1. Scenario
A user enters into a public place where many displays and different multimedia
contents are available, each one with its own characteristics. For example, different
size displays with their network connection and different multimedia content with its
own characteristics such as quality or resolution. The network connection could be
slow connections such as GPRS or UMTS, or faster connections such as WLAN or
Ethernet-LAN. Multimedia content characteristics could have different bit rate
quality, different resolution, or audio quality. This content is allocated in diverse
media servers. Figure 23 shows an overview of a platform model.
Figure 23. An example of the platform model.

46
Many different configurations are possible, but many of them are not correct with
the purpose of fulfilling user requirements. Running a high-quality video in a display
that is connected with GPRS could exasperate the user because of being a long time
waiting to visualize the video. Another bad configuration could be to run a very low-
quality video in a wall display; the video image is pixeled. If the user has to
configure manually the whole application composition, he/she can be overloaded
with distraction and opt not to use the possibilities offered by the system. Even so, in
a public place forcing users to assembly the application components is not a proper
way to attract them. Besides, users do not know the details of the network connection
of each display or content server. One of the presented allocation algorithms is used
for making the appropriate configuration for each situation in order to make an
automatic application allocation, depending on the content and the user selection. Its
objective was to get the higher user satisfaction by selecting the best available
devices avoiding all the device constraints. Each device has its own quality
properties and constraints. Displays have a quality property that refers to its size and
a network connection capacity constraint and media servers have their own
restrictions as computational capacity and network connection capacity.
In this chapter, a multimedia environment as the above explained is presented. In
this case, it has eight computers with wall or TFT displays and three media content
servers, all of them with different capabilities. A general view of the environment
can be seen in Figure 24. For screens, the network connection and the screen size are
measured, and for servers, the network connection and the computational capacity.
Figure 24. A general view of the environment.
For starting the application, the participant has to select a file touching a mobile
with an appropriate RFID reader to a RFID tag. There are four different tags attached
to the same multimedia content but in four different qualities. An example is shown
in Figure 25 [51]. Depending on the user selection, the assembly would be different.
When a participant starts the application, a display-computer pair is automatically
connected with a content server. The best display-server pair is chosen according to
the available devices and the selected multimedia file. The selected file is played
automatically in the chosen display. The user has the possibility to pause and replay
the file as many times he/she wants. A UI offering these possibilities appear

47
automatically in the user’s mobile. More details about the interfaces will be
explained in the design section.
Figure 25. A mobile and a RFID tag for starting the application.
6.1.2. Design
This section presents the design of the application. First, the used framework and the
developed classes for the communication with the algorithm are presented. Then, the
sequence diagram is showed. Finally, the user interfaces that appear in the user
mobile are presented.
The application was based on the REACHeS [49] platform. It is a server-based
application built in Java that is in charge of registering services and displays. A
mobile device controls services remotely. REACHeS has the capability of registering
displays for showing the user requested services, giving the possibility of modifying
their content dynamically. In this application, it is used for assembling the needed
devices of the application, the monitor with the correspondent media server. It also
has the ability of showing the suitable UI, which is used to control the service
through the mobile, in the user’s portable device.
Figure 26. REACHeS architecture.
Figure 26 [49] shows the system architecture. It consists of four different
components: the remote control, the user interface gateway, the service component,
and the system display control. The first is in charge of allowing the user to start and

48
to control the service. Any device capable of making HTTP requests to the user
interface gateway can be used; the remote controller has to perform an HTTP request
in order to send the requested command. The user interface gateway acts as a bridge
between the UI and the services. It works as an event router; it is responsible for
processing all the received events and sending them to the suitable component. It is
also in charge of carrying out some other tasks, such as error processing, register and
unregister displays, and to establish the connection between the displays and the
servers. Finally, the service component provides the services. Its allocation is
possible in a different server. The system display control connects external displays
with the system. A browser that supports JavaScript is just needed. After registering
a display, its browser charges all the necessary scripts that maintain the connection
with the server and change the webpage dynamically if necessary.
As mentioned in the previous chapter, the algorithms were implemented in C++.
With the aim to connect the framework with them, a Java class was created. That
class takes advantage of the XML parsing ability that was implemented in the
algorithms for their testing phase. REACHeS gives a list of available displays and
multimedia servers and it translates this data into a XML file understandable by the
algorithms. The wrapper only uses one of the implemented allocation algorithms,
concretely the GA. That is because the GA gets better quality solutions in
comparison with the EA. Although its slowness has been empirically demonstrated,
this application is not going to use a large amount of devices. Moreover, performance
was not an essential parameter in this application. Figure 27 shows the sequence
diagram of the application. In this application, the allocation is only done at the
application start-up, when the user selects the video he/she wants to watch.
Figure 27. Ubiquitous multimedia player sequence diagram.

49
The process is as follows:
1. All the services, displays and media servers, are registered into REACHeS.
2. The user touches the tag of the multimedia file he/she wants to watch. The
mobile reads the information needed for sending the request to REACHeS.
3. REACHeS sends to the wrapper all information related to the user request
and devices available in the system.
4. The wrapper creates the XML files understandable by the algorithm.
5. The wrapper launches the algorithm indicating which XMLs the algorithm
has to read.
6. The algorithm returns the obtained solution to the wrapper, and this one
indicates to REACHeS which devices are the most suitable ones according
to the user request.
7. REACHeS reserves the display that the algorithm indicated.
8. REACHeS sends to the ubiquitous multimedia player service the start
event and which multimedia server has to be used.
9. Ubiquitous multimedia player reads the video file from the multimedia
server.
10. The service component generates the UI, specifically the mobile phone UI
for controlling the application and the UI for showing the video in the
display.
11. REACHeS updates both UI according to the information received from the
service component. In this case, a multimedia flash player is loaded in the
external display.
12. When the user wants to do so, he/she selects the event to be sent to the
multimedia player, for example the play event.
13. REACHeS redirects the event to the ubiquitous multimedia player service
component.
14. The service component processes the event and updates both UI, the
external display, and the mobile phone.
15. REACHeS updates both UI according to the information received from the
service component. In this case, the flash player embedded in the external
display’s UI receives the order to start playing the file.
16. The user exits the application and the mobile send to REACHeS the close
event. REACHeS releases the external display and closes the connection
with the service component.
Figure 28 [50] shows the design of the mobile UI used in this application. It is
quite intuitive and easy to use. Everybody understands its icons and knows what the
application should do: play current video, pause current video, stop the current video,
go to the following video in the chosen playlist, or go to the previous video in the
chosen playlist. This interface is made using MIDlet technology. It is a Java program
made for embedded systems. It shows the suitable image in the mobile according to
the state of the application. For example, the UI on the left shows the image
corresponding to the initial state; the UI on the right is shown when the play button
has been pressed. Users can go through the interface using the arrow keys of the
mobile and press the press button for sending the command to the multimedia player
service.

50
Figure 28. A user interface to control the multimedia content.
6.1.3. User experiments
A user testing was carried out for evaluating the adequacy and feasibility of the
algorithm’s concept, especially the idea of having a system that takes decisions for
them. The application presented during this section was used in the testing. Users
utilized the application and tell what they think about the algorithm applicability and
in which context they would use it. All users filled a short questionnaire (Appendix
1) and they were interviewed after finishing the test. The details about user
comments are explained in following paragraphs.
The participants were ten students and researches of the Oulu University
Information Processing Laboratory, most of them were males (70%). As might be
expected, in using these people skills, the great majority of them had used an
assistant that made choices for them, at least once. For starting the application, they
were asked to choose a video clip from a set of different clips with different qualities.
Then, the system automatically allocated the application onto a media server and a
computer connected to a wall display. As mentioned in the scenario section, there
were eight computers with displays and three media servers. The main topic about
the formulated questions was about the comfort the system offered to them or if they
would have preferred additional control about the algorithm’s choice. They were also
asked to evaluate the usefulness and reliability of the application. Then, they were
solicited to suggest additional environments where this initiative would be useful.
Although application usability questions were not the main objective of the testing,
some comments related to this topic were also obtained.
A high percentage of the users would have liked to have had more control in the
algorithm’s choices, only one of them felt comfortable with the system. Figure 29
shows more information of the received comments. Some of them would have
preferred to have more notifications, they did not like that the system started playing
the file without any announcements. Others suggested aggregating the functionality
of asking for confirmation in the mobile phone to the system after telling which the
proposal of the algorithm was. In case they would have had another preference, the
system would offer another suggestion. These comments are common in
technological environments where people usually employ technology. For example,
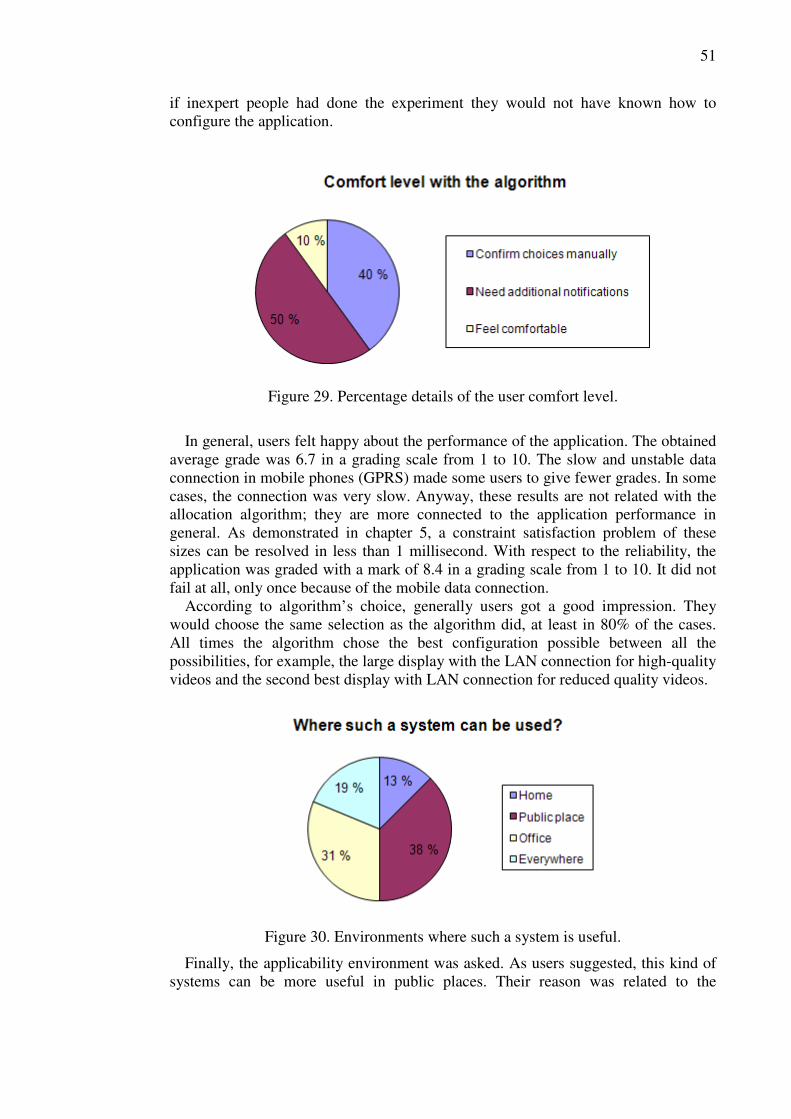
51
if inexpert people had done the experiment they would not have known how to
configure the application.
Figure 29. Percentage details of the user comfort level.
In general, users felt happy about the performance of the application. The obtained
average grade was 6.7 in a grading scale from 1 to 10. The slow and unstable data
connection in mobile phones (GPRS) made some users to give fewer grades. In some
cases, the connection was very slow. Anyway, these results are not related with the
allocation algorithm; they are more connected to the application performance in
general. As demonstrated in chapter 5, a constraint satisfaction problem of these
sizes can be resolved in less than 1 millisecond. With respect to the reliability, the
application was graded with a mark of 8.4 in a grading scale from 1 to 10. It did not
fail at all, only once because of the mobile data connection.
According to algorithm’s choice, generally users got a good impression. They
would choose the same selection as the algorithm did, at least in 80% of the cases.
All times the algorithm chose the best configuration possible between all the
possibilities, for example, the large display with the LAN connection for high-quality
videos and the second best display with LAN connection for reduced quality videos.
Figure 30. Environments where such a system is useful.
Finally, the applicability environment was asked. As users suggested, this kind of
systems can be more useful in public places. Their reason was related to the

52
difficulty to know which the device constraints are when you are supposed to use
devices that do not belong to you. Office could be another applicability environment
where this application would be useful. A minor amount of testers suggested using
the application at home. Figure 30 shows a detailed overview of the obtained results.
6.2. Newsreader Application
This chapter presents the scenario, its user interfaces, and the design details of the
newsreader application, as well as the obtained results from the user testing. This
application allows users to select a set of news taken from a RSS file. Then, this
news will be automatically read by a text-to-speech system. Some videos and photos
related to the selected news will also be showed in a wall display. As well as
happened in the previous application, the algorithm is in charge of making the
selection of the display, the speaker and the multimedia content server depending on
the best available devices in the environment. Then, the framework is responsible for
allocating the application components in the appropriate device. Moreover, taking
into account the previously obtained user comments and suggestions two new
selection modes are added to the system. Thus, three different operation ways are
offered: automatic, semi-automatic and manual.
6.2.1. Scenario
A user arrives home. There are many displays and sound systems available, probably
in different rooms and all of them with different characteristics. At first, in his/her
corridor, there is a monitor where a list of news is shown. He/she can select as many
news he/she is interested in. After the selection, the user has the possibility to select
the mode he/she is interested in to run the application at. There are three different
modes with the purpose of giving the full control to the user in the manual mode or
to the system in the automatic in order to explain to users the importance of the
algorithm; letting users to select the devices manually and then the algorithm makes
their previous work for them implicitly in the automatic mode. An intermediate mode
that mixes both modes also exists, the semi-automatic mode.
• Manual: The user can select the display and speaker that fulfills his/her
actual preferences best. Then, the system starts visualizing and playing the
user’s selected news in the preferred devices.
• Semi-automatic: The system offers three different display-speaker pairs.
They are sorted from the best option to the worse according to devices’
resource quality property. The user can select in which one he/she wants to
listen and visualize their news selection. Then, the system starts visualizing
and playing the user’s selected news in the chosen display-speaker pair.
• Automatic: The system selects the most suitable display-speaker pair of the
environment according to devices’ resource quality. Then, the system starts
visualizing and playing the user’s selected news in the automatically selected
devices.

53
In semi-automatic and automatic modes, the commented resource quality can be
modified depending on user preferences, for example, giving more weight to the
situation or the quality of the speaker/display. The system aims to maximize this
resource quality in order to get the best user satisfaction. Figure 31 shows an
example of the multimedia environment.
Figure 31. An example test environment of the newsreader application.
The algorithm’s objective is different in this application. Although all the available
display-speaker pairs are feasible in this application, the algorithm aims to maximize
the user satisfaction by selecting the best device according to their quality. There are
no constraints that can make a configuration infeasible; the unique requirement is to
select a display-speaker pair, selecting a pair containing the same kind of device is
not possible. Any device pair can be selected without creating a configuration that
violates the constraints. Because of this the manual mode is possible; the user can
perform any device selection without violating their constraints. As regards the
algorithm’s task, distinguishing between distinct devices is easy for humans but
difficult for a machine. It has to distinguish between displays and speakers and return
a valid display-speaker pair. In case there are no methods for distinguishing those
devices, a display-display or speaker-speaker could appear and return a non-valid
solution. Watching a video in a speaker or listening an audio in a display is not
possible. As mentioned above, the automatic mode selects the best option between
all the obtained and valid ones. In contrast, the semi-automatic mode returns three
different possibilities, if available, and lets the user choose the one that he/she prefers
the most.
In this chapter, an environment as the commented in the previous section is
simulated. In this case, it has six computers with wall or TFT displays and four
computers with speakers or headphones. A general view of the environment can be
seen in Figure 32. In the case of being a display, the resource quality property

54
indicates its size, and in the case of being a speaker, its property refers to the
speaker’s power. There is also a multimedia content server but in this application the
server is always the same. It is worth mentioning that the algorithm has the ability to
select also the best available server, although this feature has not been utilized in this
case.
Figure 32. A general view of the environment.
There is 1 RFID tag for starting the application. The participant has to approach a
mobile with an appropriate reader to the tag, as shown in Figure 25. Then, the news
list is showed in a display. The monitor shows the news the user has already chosen
and the others that have not been chosen yet. In the mobile, an appropriate UI is
shown for select or unselect more news. After finishing this task, the application
waits until the user selects the mode he/she wants to utilize. If the automatic mode is
selected, the system assemblies the needed devices and it starts automatically playing
the news and the videos or pictures. If the semi-automatic mode is selected, the
system shows three different display-speaker pairs and waits until the user selects the
choice he/she prefers the most. Once the user selects one, it connects the devices
with the correspondent multimedia files and start running them. In both modes, the
application allocation algorithm is used to select the best display-speaker available
pair in the automatic mode or to offer to the user the three best available pairs in the
semi-automatic. Anyhow, selecting the best display-speaker pair could not be the
best selection. For example, the quality of the video could be insufficient for the best
display. Finally, if the user selects the manual mode the system waits until the user
selects one by one the preferred devices. Once the display and the speaker are
selected, the application starts running the multimedia files in these devices. For all
the cases, when it starts playing the files, a UI appears in the user’s mobile he/she
can control the reproduction of the files with: play, replay, pause, next news,
previous news, stop, and more info about the news. More details about UI will be
presented in the design section.

55
6.2.2. Design
This section presents the design of the application. Information about the used
framework is not explained in this section, it can be founded in section 6.1.2. The
sequence diagram of the application is showed and, finally, the user interfaces that
appear in the user mobile are presented.
In this case, the GA is used as well. The algorithm was integrated in the
REACHeS [49] platform. As mentioned above, getting the finest solutions is better
in order to satisfy users’ requirements. This algorithm gets better quality solutions
although the computational load is higher. Anyway, as well as happened in the
previous application, the platform and application model are not big enough to
increase its slowness into a marked state. For this application, the GA was modified
to some extent; in this case, it has to return at least three different allocation
configurations if possible. The returned options were sorted from the best to the
worst according to their fitness value with the aim of letting users selecting the most
suitable configuration in the semi-automatic mode. The previously presented
algorithm wrapper class was also modified for having the ability to process the
returned results from the algorithm and forwarding them to REACHeS. Then, the
framework would use them depending on the user requirements. In this application,
the allocation is done only at the start-up. That is, once the news has begun to play
reallocating the components without restarting the application is not possible.
In this application, two different phases must be identified. Firstly, when the user
selects the news he/she wants to listen. There is no necessity for using the allocation
algorithm in this phase because the same devices are always used for the news
selection task. Figure 33 shows the sequence diagram of the first phase. Secondly,
when the application starts playing the selected news. In this case, the allocation
algorithm work is needed when the automatic or semi-automatic modes are selected
in order to specify which devices are the most suitable ones for satisfying the user. In
the first one, the devices used are the following: the user mobile device, a display,
and the RSS server. In the other phase: the user mobile device, as many displays as
available in the environment, as many speakers as available in the environment, and
the multimedia server that contains the audio, video, and pictures of the news. Figure
34 and Figure 35 show the sequence diagrams of the second phase depending on the
selected mode.

56
Figure 33. Sequence diagram of the first phase.
The process of Figure 33 is as follows:
1. The news selector service, the display where the news will be showed and
the RSS server the news will be obtained from, are registered into
REACHeS.
2. The user touches the newsreader start tag. The mobile read the needed
information for sending the request to REACHeS.
3. REACHeS reserves the display for selecting the news.
4. REACHeS starts the news selector service.
5. The service accesses to the RSS server in order to get the information of
the news for preparing the interface for the display.
6. The service component generates the UI, specifically the mobile phone UI
for controlling the application and the UI for showing the video in the
display.
7. REACHeS updates both UI according to the information received from the
service component.
8. When the user wants to do so, he/she selects the event to be sent to the
multimedia player, for example the next news, previous news, or select
event.
9. REACHeS redirects the event to the news selector service component.
10. The service component processes the event and updates both UIs, the
display and the mobile phone.
11. REACHeS updates both UIs according to the information received from
the service component.
12. When the user finishes selecting the news, he/she presses the read button in
the mobile for sending to REACHeS the read event. REACHeS releases

57
the external display and asks the service component the list with the IDs of
the selected news.
13. REACHeS closes the connection with the service.
Figure 34. Sequence diagram of the second phase, manual mode.
The process of Figure 34 is as follows:
1. The news player service, the displays and the speakers where the news will
be played and the media server where the audio files, videos, and pictures
of the news will be obtained from are registered into REACHeS.
2. The user touches the manual mode tag. The mobile reads the needed
information for sending the request to REACHeS.
3. REACHeS updates the mobile UI. The UI specifies to the user that he/she
has to select a display and a speaker by touching the correspondent device
tag.
4. Once the user has finished selecting the devices, the MIDlet sends to
REACHeS the IDs of the selected devices.
5. REACHeS reserves the selected display and speaker.
6. REACHeS starts the news player service.
7. The service accesses to the media server in order to get the audio and
video, or picture files needed by the speaker and the display.
8. The service sends the UI information to REACHeS. The mobile phone UI
for controlling the application and in the display the UI for showing the
video.
9. REACHeS updates both UIs according to the information received from
the service component.
10. At this moment, the process continues as in the previous application player
after the 12th
step.

58
Figure 35. Sequence diagram of the second phase, automatic and semi-automatic
modes.
The process of Figure 35 is as follows:
1. The news player service, the displays and the speakers where the news will
be played and the media server where the audio files, videos, and pictures
of the news will be obtained from are registered into REACHeS.
2. The user touches the automatic or semi-automatic mode tag. The mobile
reads the needed information for sending the request to REACHeS.
3. REACHeS sends to the wrapper all the information related to the user
request and devices available in the system.
4. The wrapper creates the XML files understandable by the algorithm.
5. The wrapper launches the algorithm indicating which XMLs the algorithm
has to read.
6. The algorithm returns three possible solutions ordered from the best to the
worst to the wrapper. It sends to REACHeS the obtained solutions as well.
7. (Only in the semi-automatic mode) REACHeS updates the mobile UI. The
three obtained solutions from the algorithm are specified.
8. (Only in the semi-automatic mode) Once the user has decided in which
devices he/she wants to play the news, the MIDlet sends to REACHeS the
selection information.
9. REACHeS reserves the selected display and speaker.
10. REACHeS starts the news player service.
11. The service accesses to the media server in order to get the audio and
video, or picture files needed by the speaker and the display.

59
12. The service sends the UI information to REACHeS.
13. REACHeS updates both UIs according to the information received from
the service component, that is, the mobile phone UI for controlling the
application and the UI for showing the video in the display.
14. At this moment, the process continues as in the previous application player
after the 12th
step.
Figure 36. User interfaces to select the news.
Figure 36 shows the design of the mobile and display UI used in the first phase
and Figure 37 shows the used mobile UI in the second phase. Most of the icons in
both UI are very intuitive and easy to use. In the first phase, in the display the yellow
marked news is the current news. It can be selected or deselected accordingly, go to
the next news or the previous news. In the mobile, the available actions are: go to the
previous news, go to the following news, or select the actual news. In the second
phase, the icons are similar to the UI presented for the first application: go to the
previous news, start playing the news, go to the following news, read more
information about the news, and stop the news reading. Users can go through the
interfaces using the arrow keys of the mobile and press the main keypad button for
sending the command to the newsreader service.

60
Figure 37. A user interface to control the news reproduction.
6.2.3. User experiments
An initial user testing, with only two users, was carried out with the purpose of
evaluating the application allocation concept, basically its adequacy and feasibility.
The received comments from the previous application were taken into account in the
application design with the aim of getting different user comments. The testers used
the application recently presented. Then, they were asked about their feelings when
they used it. All the received comments are presented in this section.
The participants were researches of the Oulu University Information Processing
Laboratory; in this case, all of them were males. For starting the application, they
were asked to select the news they were interested in. After the selection, they chose
the mode they wanted to run the application. They were suggested to use the
application in different modes with a view to compare preliminary user feelings. The
first user used the manual and semi-automatic modes and the second the semi-
automatic and fully automatic modes. The main topic about the questions was the
comfort the system offered, if they would have liked additional control about the
algorithm’s choice (the selection criteria) if they can realize about the importance of
having an automatic system like this and they were asked to suggest additional
features that could be useful in further application versions.
The first user generally liked the three possibilities offered by the system in the
semi-automatic mode; the second user liked the selection made in the automatic
mode, as well as the suggested options in the semi-automatic. In many cases, the user
told that they would have chosen the same device. Anyway, both users suggested
adding a feature for changing their selection criterion. For example, the device
situation in the environment; in some situations enjoying the newsreader in a more
comfortable location could be better. It could also happen that a user does not want
to watch his/her selection in a big display if the selected content will show private
content, for example if the environment would be situated in a public place. The
system should also memorize the selections made in the manual mode or semi-
automatic mode in order to increase the importance of the selected devices for other
occasions. All proposed suggestions would add new criteria to take into account with
a view to maximize the comfort level.

61
Users emphasize the importance of the algorithm. In some cases, they were not
able to observe all the devices the environment offered to them. In this situation, if
they select the manual mode, they could not make their best possible configuration,
some hidden devices could have offered them a better opportunity. In the automatic
mode, where the algorithm selection is the most important, all the available resources
are taken into account although users do not realize about the existence of these
devices. When the application starts playing the news in the selected devices, the
user could realize about their existence.
6.3. Summary
In this chapter, two case studies of the developed allocation algorithms for
composing pervasive applications are presented. Concretely, they are two application
prototypes that are used for getting real user comments (the ubiquitous multimedia
player and the newsreader). The main objective is to obtain a general idea of what
people think about the idea of automatic application composition.
Firstly, general views of the application scenarios are presented, all the used
devices in the environment and small instructions of how the application works.
Secondly, their design details accompanies by their sequence diagram with their
details. Finally, some user experiments were carried out. After all, these experiments
were the main objective in order to get the necessary real user comments.
The obtained comments in the ubiquitous multimedia player application
emphasized the fact that the user should have more control in the application
allocation decision. Users do not really like to have a system that forces them to use
concretely devices; they would prefer to have an opportunity to influence the final
selection. With this main objective in mind, the second application was developed. In
the newsreader application, making a full manual application configuration or letting
the system suggest you some configurations was possible. In this case, the user
acceptation was better. For further versions, they suggested adding the possibility to
change the selection criteria and taking into account for the following selections of
the automatic and semi-automatic modes the user manually selected devices.

62
7. DISCUSSION
The main objective of this thesis was to design an algorithm to be integrated into an
automated system for application composition. The system had to be able to adapt
the applications to changing context and user needs. The main goal was to improve
the performance of previously presented solutions [1], keeping the same main
objective, getting a system as generic as possible preventing to be tailored to only
certain application types. For this purpose, the basics of a previous algorithm were
taken in order to develop different operators. Finally, two new algorithms, based on
genetic and evolutionary algorithms, were implemented for different situations. The
genetic algorithm is suitable to be used when an application has to be allocated for
the first time; the evolutionary solution due to its faster convergence property is
better to be used when small changes in the allocation have to be calculated. The
system should select and apply the best algorithm for each situation. To conclude, a
user testing was carried out in order to test the solutions implemented in real
situations.
Related work has outlined the difficulties in finding good solutions for the
application allocation problem. After all, few works had tested their solutions in
environments as big as the one presented in this thesis, perhaps, due to slow
convergence properties or the impossibility for finding solutions for these big
problems. Another problem was to find solutions capable of being used in different
applicability contexts, having generic solutions increase the appliance range. The
goal of this thesis was to prevent the weak points of the related work and testing the
adequacy and feasibility of these kinds of solutions with real users.
Due to the executed experiments, important information about the algorithms
behavior was obtained. Regarding the speed performance, the evolutionary
algorithms never take more than one second. However, the genetic algorithm takes
more than one second in problems with more than 150 platform nodes. The genetic
algorithm has better optimization properties; it gets an optimization up to 30% in
some cases. In contrast, the evolutionary algorithm only gets up to 20% of
improvement. On the other hand, the failure ratio is not considerable for problems
with many nodes (the failure ratio is not bigger than 30%). The genetic algorithm has
normally a less failure ratio than the evolutionary algorithm. Generally speaking, the
genetic algorithm could be considered as a better algorithm in getting solutions
although it is slower than the evolutionary algorithm.
With the purpose of getting a really optimum system, the algorithms were decided
to implement in C++. It is well known that compiled programming languages are
much faster than interpreted languages, such as Java. This is one of the differences in
which this work differs from others. Previous works were all implemented in Java.
This caused problems with the interoperability of the algorithms, and for example,
the frameworks they are going to be integrated in. Most of them are implemented in
languages such as Java. Moreover, algorithms actually are in a preliminary state, they
only admit the input data as XML files where the application and platform models
are described. It is not a good method for using the algorithms; at last, the obtained
improvement within the new design is lost in the procedure of creating and parsing
the XML files. It would be an interesting engineering design problem for future
work. The author of this thesis would recommend the use of JNI [55]. It allows the
integration of code written in languages such as C or C++ into a Java application.
After compiling the algorithms into a dynamic linking library, JNI technology allows

63
linking these kinds of libraries with a Java program. After adding a good interface to
the system, the problem could be transferred directly from the framework to the
algorithms without any waste of time in parsing.
The work has been important for the research community and some obtained
results during the realization of this thesis have been presented in various
conferences [16], [32]. The author also has been co-writer of the paper “A
Framework for Composing Pervasive Applications” presented in the workshop on
advances in methods of information and communication technology (AMICT 08)
[32]. His contribution in this paper was to participate in the development and also in
the framework implementation and its testing phase. In addition, he contributed in
the publication of “Algorithms for Composing Pervasive Applications” presented in
the International Journal of Software Engineering and its Applications [16]. The
algorithms introduced in this thesis were specifically presented.
There are still many important aspects to research, however. Although the
performance of the application allocation algorithms is good, the performance of the
models could be better in order to have a better system behavior in real-time
optimization tasks, also for bigger scale problems. In addition, resource models
should contain a new constrain type which allows partial constrain violations.
Adding this feature, the algorithms will be able to deal user preferences in a better
way.
Another interesting research direction would be to take advantage of the actual
CPU technology capabilities, especially those with SMP feature incorporated. That
is, using many CPUs at the same time in order to reduce the computation time or
increasing the solution qualities. Reducing time by using supercomputers is
complicated because the internal dependencies between cycles inside these kinds of
algorithms. A very large population size or an objective function with a really high
computational load would be needed. Because of that, focusing on the improvement
of the solution qualities would be more interesting. Having more CPUs working at
the same time, it is possible to explore more solutions of the solution space. Many
publications have been presented focusing on this research topic, such as Whitley
[52] or Ambrosio and Iovine [54]. A general view and some results in how many
CPUs working at the same time can improve a genetic algorithm solution are shown
in Appendix 2.
Davidyuk et al. [14] presented a micro genetic algorithm that uses an external
memory. The main performance was the faster convergence as compared to previous
solutions. With a view to increase the obtained performance or the solutions quality,
many parallel algorithms using the same external memory could be used. Next, two
methods are explained for two different objectives. The first method involves having
an external memory with fixed capacity but with more CPUs working on it. In the
following manner, the external memory would converge faster. In the second
method, the external memory capacity is increased, that is, the genetic search space
is augmented. The last method gets better quality solutions without decreasing the
rapidity due to the increase of the amount of CPUs.
According to user suggestions, another interesting feature for further versions of
the algorithm could be the learning capacity. The algorithm should take user
preferences into account. This characteristic could be interesting, for example, in
systems similar to the presented newsreader application where users could select
their own allocation configuration in some execution modes. For future
implementations, the user preference satisfaction should be one of the main goals.

64
8. CONCLUSIONS
In this thesis, an overview of pervasive computing was presented. Subsequently, a
related work review was presented where the actually existing solutions for this kind
of computing were shown. After a careful analysis, the requirements for pervasive
computing solutions and the weak points of other researches were extracted.
This thesis also presented the application allocation problem, where the new
solution finders focused on. The AAP is the problem of finding a component
allocation configuration for fulfilling all the component requirements by the network
hosts while none of their resource constraints are violated. With this target, two
algorithms that could be the basement of automated systems for application
composition were also presented. The two algorithms are based on genetic
algorithms (GA) and evolutionary algorithms (EA). Both solutions even optimize the
obtained solution with the aim of finding the optimal or the configuration closest to
the optimal. These solutions are generic; therefore they are not restricted to an
application field only. They can be used in many application areas, including
pervasive computing.
This thesis presented the results of the experiments carried out as well. The first
experiment measured the performance, the second the quality of the obtained
solutions, and finally, the robustness. All the experiments were presented
accompanied by the correspondent results of the same tests with affinity constraints.
These results show that these solutions can be integrated into pervasive computing
frameworks, because of their excellent qualities. The only inconvenience is that they
did not work properly in huge systems; anyway, having systems as big as the
simulated ones is difficult.
Finally, this thesis showed two case studies where the presented algorithms were
integrated: the ubiquitous multimedia player and the newsreader application. Both of
them were tested by real users who they told their feelings when they used the
application. The main objectives of the applications were to evaluate the adequacy
and feasibility of the main concept of this thesis.
From my point of view, these kinds of solutions are going to be useful when much
of the users have handheld devices with the possibility to use free wireless networks.
At that time, many applications based on components will be available for using with
devices like that. Pervasive computing popularity will increase and solutions for
getting good component allocations onto the networks will be absolutely necessary.

65
9. REFERENCES
[1] Ceberio, J. 2007. An Evolutionary Algorithm for Application Allocation.
Bachelor’s thesis. University of Oulu, Finland.
[2] Eiben, A. E. Smith, J. E. 2003. Introduction to Evolutionary Computing.
Springer.
[3] Wegener, I. 2005. Complexity Theory. Springer.
[4] Wang, S. Merrick, J. R. Shin, K. G. 2004. Component Allocation with
Multiple Resource Constraints for Large Embedded Real-Time Software
Design. Real-Time and Embedded Technology and Applications
Symposium. Proceedings (RTAS 2004). pp 219-226. Michigan University,
USA.
[5] Kichkaylo, T. Ivan, A. Karamcheti, V. 2003. Constrained Component
Deployment in Wide-Area Networks Using AI Planning Techniques.
Parallel and Distributed Processing Symposium. Proceedings.
International. pp 10. New York University, USA.
[6] Kichkaylo, T. Karamcheti, V. 2004. Optimal Resource-Aware Deployment
Planning for Component-based Distributed Applications. High
performance Distributed Computing, 2004. Proceedings. 13th
IEEE
International Symposium. pp 150-159. New York Univ., NY, USA.
[7] Graupner, S. Andrzejak, A. Kotov, V. Trinks, H. 2004. Adaptative Service
Placement Algorithms for Autonomous Service Networks. Engineering
self-organizing systems: methodologies and applications. pp 280-295.
Springer.
[8] Malek, S. Mikic-Rakic, M. Medvidovic, N. 2005. A Decentralized
Redeployment Algorithm for Improving the Availability of Distributed
Systems. Lecture Notes in Computer Science. pp 99-114. Springer.
[9] Ben-Shaul, I. Gidron, Y. Holder, O. 1998. A Negotiation Model for
Dynamic Composition of Distributed Applications. Database and Expert
Systems Applications. Proceedings. Ninth International Workshop on. pp
820-825. Vienna, Austria.
[10] Fawaz, Y. Negash, A. Brunie, L. Scuturici, V. 2007. ConAMi:
Collaboration – Based Content Adaption Middleware for Pervasive
Computing Environment. IEEE International Conference on Pervasive
Services. pp 189-192. Lyon, France.
[11] Ranganathan, A. Campbell, R. H. 2004. Autonomic Pervasive Computing
based on Planning. Autonomic Computing. Proceedings. pp 80-87.
International Conference.

66
[12] Karve, A. Kimbrel, G. Pacifici, M. Spreitzer, M. Steinder, M. Sviridenko,
M. and Tantawi, A. 2006. Dynamic Placement for Clustered Web
Applications. Proceedings of the 15th
international conference on World
Wide Web. pp 595-604. Edinburgh, Scotland.
[13] de Niz, D. Rajkumar, R. 2005. Partitioning Bin-Packing Algorithms for
Distributed Real-Time Systems. International Journal of Embedded
Systems. Special Issue on Design and Verification of Real-Time
Embedded Software.
[14] Davidyuk, O. Selek, I. Ceberio, J. and Riekki, J. 2007. Application of
Micro-Genetic Algorithm for Task Based Computing. Proceedings of
International Conference on Intelligent Pervasive Computing. pp 140-145.
Jeju Island, Korea.
[15] Davidyuk, O. Ceberio, J. Riekki, J. 2007. An Algorithm for Task-based
Application Composition. Procedings of the 11th
IASTED International
Conference on Software Engineering and Applications. pp 465-472.
Cambridge, Massachusetts, USA.
[16] Davidyuk, O. Selek, I. Durán, J.I. Riekki, J. 2008. Algorithms for
Composing Pervasive Applications. International Journal of Software
Engineering and Its Applications. pp 71-94. University of Oulu, Oulu,
Finland.
[17] Xiao, J. Boutaba, R. 2005. QoS-Aware Service Composition and Adaption
in Autonomic Communication. Selected Areas in Communications, IEEE
Journal. pp 2344-2360. University of Waterloo, Ontario, Canada.
[18] Lee, G. Faratin, P. Bauer, S. Wroclawski, J. 2004. A User-Guided
Cognitive Agent for Network Service Selection in Pervasive Computing
Environments. Pervasive Computing and Communications (PerCom 2004).
Proceedings of the Second IEEE Annual Conference. pp 219-228.
Cambridge, Massachusetts, USA.
[19] Ben Mokhtar, S. Liu, J. Georgantas, N. Issarny, V. 2005. QoS-aware
Dynamic Service Composition in Ambient Intelligence Environments.
Proceedings of the 20th
IEEE/ACM international Conference on
Automated software engineering. pp 317-320. Long Beach, CA, USA.
[20] Biehl, J. T. Bailey, B. P. 2004. ARIS: An Interface for Application
Relocation in an Interactive Space. Proceedings of Graphics Interface
2004. pp 107-116. London, Ontario, Canada.
[21] Chantzara, M. Anagnostou, M. Sykas, E. 2006. Designing a Quality-aware
discovery Mechanism for Acquiring Context Information. 20th
International Conference on Advanced Information Networking and
Applications (AINA'06). pp 211-216. School of Electrical & Computer
Engineering, NTUA, Greece.

67
[22] Perttunen, M. Jurmu, M. Riekki, J. 2007. A QoS Model for Task-Based
Service Composition. Proc. 4th
International Workshop on Managing
Ubiquitous Communications and Services. pp 11-30. Munich, Germany.
[23] Johanson, B. Fox, A. Hanrahan, P. Winograd, T. 1999. The Event Heap:
An Enabling Infrastructure for Interactive Workspaces. IEEE Intelligent
Systems. Stanford University, CA, USA.
[24] Canfora, G. Esposito, R. Di Penta, M. Villani, M. L. 2004. A Lightweight
Approach for QoS-Aware Service Composition. 2nd
International
Conference on Service Oriented Computing (ICSOC 2004). New York
City, NY, USA.
[25] Buford, J. Kumar, R. Perkins, G. 2006. Composition Trust Bindings in
Pervasive Computing Service Composition. 4th
IEEE International
Conference on Pervasive Computing and Communications Workshops
(PERCOMW 06). pp 261-266. Princeton, NJ, USA.
[26] Ben Mokhtar, S. Georgantas, N. Issarny, V. 2006. COCOA: Conversation-
Based Service Composition for Pervasive Computing Environments.
Pervasive Services, ACS/IEEE International Conference. pp 29-38. Le
Chesnay Cedex, France.
[27] Song, Z. Labrou, Y. Masuoka, R. 2004. Dynamic Service Discovery and
Management in Task Computing. Mobile and Ubiquitous Systems:
Networking and Services (MOBIQUITOUS 2004). pp 310-318. Fujitsu
Laboratory of America, College Park, MD, USA.
[28] Liu, Z. Ranganathan, A. Riabov, A. 2007. A Planning Approach for
Message-Oriented Semantic Web Service Composition. Twenty-Second
Conference on Artificial Intelligence (AAAI 2007). Watson Research
Center, Hawthorne, NY, USA.
[29] Sousa, J. P. Poladian, V. Garlan, D. Schmerl, B. Shaw, M. 2006. Task-
Based Adaptation for Ubiquitous Computing. Systems, Man, and
Cybernetics, Part C: Applications and Reviews, IEEE Transactions. pp
328-340. School of Computer Science, Carnegie Mellon University,
Pittsburgh, PA, USA.
[30] Tripathi, A. R. Kulkarni, D. Ahmed, T. 2005. A Specification Model for
Context-based Collaborative Applications. Pervasive and Mobile
Computing 1. pp 21-42. Department of Computer Science, University of
Minnesota, Minneapolis, USA.
[31] Takemoto, M. Oh-ishi, T. Iwata, T. Yamato, Y. Tanaka, Y. 2004. A
Service-Composition and Service-Emergence Framework for Ubiquitous-
Computing Environments. Applications and the Internet Workshops
(SAINT 2004). International Symposium. pp 313-318. NTT Network
Service System Laboratories, NTT Corporation, Japan.

68
[32] Davidyuk, O. Sanchez, I. Durán, J.I. Riekki, J. 2008. A Framework for
Composing Pervasive Applications. In Process of Workshop on Advances
in Methods of Information and Communication Technology (AMICT 08),
Petrozavodsk, Russia.
[33] Kaefer, G. Schmid, R. Prochart, G. Weiss, R. 2006. Framework for
Dynamic Resource-Constrained Service Composition for Mobile Ad Hoc
Networks. 8th
Annual Conference on Ubiquitous Computing (UbiComp
2006). California, USA.
[34] Preuveneers, D. Berbers, Y. 2005. Automated Context-Driven
Composition of Pervasive Services to Alleviate Non-Functional Concerns.
International Journal of Computing & Information Sciences. Leuven,
Belgium.
[35] Hesselman, C. Tokmakoff, A. Pawar, P. Iacob, S. 2006 Discovery and
Composition of Services for Context-Aware Systems. Discovery and
Composition of Services for Context-Aware Systems. pp 67-81. Springer.
[36] Román, M. Ziebart, B. Campbell, R. H. 2003. Dynamic Application
Composition: Customizing the Behavior of an Active Space. Pervasive
Computing and Communications. Proceedings of the First IEEE
International Conference. pp 169-176. Department of Computer Science,
Illinois, USA.
[37] Román, M. Hess, C. Cerqueira, R. Ranganathan, A. Campbell, R. H. and
Nahrstedt, K. 2002. Gaia: A Middleware Platform for Active Spaces. ACM
SIGMOBILE Mobile Computing and Communications Review. pp 65-67.
Department of Computer Science, University of Illinois at Urbana-
Champaign, USA.
[38] Preuveneers, D. Vandewoude, Y. Rigole, P. Ayed, D. Berbers, Y. 2006.
Context-aware adaptation for component-based pervasive computing
systems. The 4th
International Conference on Pervasive Computing. The
Burlington Hotel, Dublin, Ireland.
[39] Autili, M. Inverardi, P. Navarra, A. Tivoli, M. 2007. SYNTHESIS: a tool
for automatically assembling correct and distributed component-based
systems. 29th
International Conference on Software Engineering. pp 784-
787. Computer Science Department, University of L’Aquila, L’Aquila,
Italy.
[40] Nakazawa, J. Yura, J. Tokuda, H. 2004. Galaxy: A Service Shaping
Approach for Addressing the Hidden Service Problem. Software
Technologies for Future Embedded and Ubiquitous Systems. Proceedings
Second IEEE Workshop. pp 35-39. School of Media & Governance, Keio
University, Kanagawa, Japan.
[41] Handte, M. Hertmann, K. Schiele, G. Becker, C. 2007. Supporting
Pluggable Configuration Algorithms in PCOM. Pervasive Computing and

69
Communications Workshops, 2007. 5th
Annual IEEE International
Conference. pp 472-476. IPVS, Stuttgart Univ.
[42] Mikic-Rakic, M. Malek, S. Beckman, N. Medvidovic, N. 2004. Improving
Availability of Distributed Event-Based Systems via Run-Time Monitoring
and Analysis. Twin Workshop on Architecting Dependable Systems
(WADS 2004). Edinburgh, UK, and Florence, Italy.
[43] Weerdt, M. Zhang, Y. Klos, T. 2007. Distributed Task Allocation in Social
Networks. Delft University of Technology, Delft, The Netherlands.
[44] Satyanarayanan, M. 1996. Fundamental Challenges in Mobile Computing.
Symposium on Principles of Distributed Computing. pp. 1-7. School of
Computer Science, Carnegie Mellon University.
[45] Medina, A. Lakhina, A. Matta, I. Byers, J. 2001. BRITE: Universal
Topology Generation from a User's Perspective. The Boston University
Representative Internet Topology Generator. Boston University, Boston,
MA, USA.
[46] Dorigo, M. Stützle, T. 2004. Ant Colony Optimization. MIT Press.
[47] Werger, BB. Mataric, M. 2001. From Insect to Internet: Situated Control
for Networked Robot Teams. Springer.
[48] Ben-Shaul, I. Cohen, A. Holder, O. Lavva, B. 1997. HADAS: A Network-
Centric Framework for Interoperability Programming. 2nd
IFCIS
International Conference on Cooperative Information Systems. p. 120.
Israel Institute of Technology, Department of Electrical Engineering,
Haifa, Israel.
[49] Sánchez, I. Cortés, M. Riekki, J. 2007. Controlling Multimedia Players
using NFC Enabled mobile phones. In Proceedings of 6th
International
Conference on Mobile and Ubiquitous Multimedia (MUM07). Oulu,
Finland.
[50] Sánchez, I. Riekki, J. Pyykkönen, M. 2008. Touch & Control: Interacting
with Services by Touching RFID Tags. The 2nd
International Workshop on
RFID Technology (IWRT08). Barcelona, Spain.
[51] Riekki, J. Sánchez, I. Pyykkönen, M. Universal Remote Control for the
Smart World. The 5th
International Conference on Ubiquitous Intelligence
and Computing (UIC08). Oslo University College, Oslo, Norway.
[52] Whitley, D. 1994. A Genetic Algorithm Tutorial. Statistics and Computing.
Springer Netherlands. pp 65-85. Computer Science Department, Colorado
State University, USA.
[53] Chung, L. Nixon, B. Yu, E. Mylopoulus, J. 1999. Non-Functional
Requirements in Software Engineering. Springer.

70
[54] D’ Ambrosio, D. Iovine, G. 2003. Applying Genetic Algorithms in a
Parallel Computing Environment for Optimising Parameters of Complex
Cellular Automata Models: The Case of Sciddica S3HEX.
[55] Liang, S. 1999. The Java Native Interface. Addison-Wesley.
[56] Wikipedia, Knapsack problem,
http://en.wikipedia.org/wiki/Knapsack_problem (accessed June 2008).

71
APPENDICES
Appendix 1 Ubiquitous Multimedia Player user questionnaire
Appendix 2 Genetic Algorithms in Parallel Computing

72
Appendix 1: Ubiquitous Multimedia Player user questionnaire
General Questions
Gender: � Male � Female Age: ________
Occupation/Area of study (research): ____________________________________
How confident you are with Ubiquitous Computing (AKA Pervasive
Computing, AKA Calm/Ambient/Context-Aware Technology) Research? (1-10)
1 � 2 � 3 � 4 � 5 � 6 � 7 � 8 � 9 � 10 �
10 - I am an expert in the area
9 - Very comfortable: It is my area
8 - Comfortable: It is my area
7 - Moderate: I am aware of main trends
6 - Moderate: I have read key works
5- Satisfactory: I know about it
4 - Satisfactory: I have read/seen some papers/presentations
3 - I know a couple of examples
2 - Not confident, but I have heard about it
1 - Not confident: I have never heard about this area
Have you ever used any service (assistant) which provided you information for
your everyday activities? E.g., MS Office Assistant, GPS path finder, Automatic
mobile operator selector, Flight booking assistant, etc.
� � � � � Never used Used once Used few times Use often Use everyday

73
Imagine that you are in a public place and you need some equipment or service
to use for leisure (e.g., a printer, a wireless access point, a public display or a
media service). Would you feel comfortable, if an assistant (e.g., in your mobile
phone) automatically chose equipment for you?
We assume that you earlier created a policy permitting certain choices of services.
� No, I would rather prefer to find all services manually.
� Yes, but I want to confirm manually every choice the assistant makes.
� Yes, but it should explicitly inform me (e.g. with a blocking message on the
screen).
� Yes, but it should notify me without disturbing me (so I can later check the
choice if needed).
� Yes, I would feel very comfortable.
Where would you like to use such an assistant? (please choose multiple answers,
if necessary)
� At Home
� At Office
� In Public Places (airport, metro, shop, cafeteria, etc)
� At a Meeting or Conference
� Everywhere
� Your suggestion ___________________________________________________
Evaluation of the Demonstrated System
The system’s performance was
� � � � � � � � � �
Very slow Very Fast
Did the system function as you expected before using it?
� � No, I expected totally different result Yes! It worked as I expected!
Would you need more control when the system chooses monitors and media
servers?
� �
Yes, I’d definitely need No, Automatic selection is ok!
If yes, how do you want to control the system additionally? (Multiple choices are
possible)
� I want to have a list of alternative choices on my mobile device.
� I would like to receive additional notifications/confirmation messages.
� Other, what? ______________________________________________

74
Was the system reliable during the demonstration?
� � � � � � � � � �
Highly
unstable Very Reliable
Was it easy to use the system?
� � � � � � � � � �
Very Difficult Very Easy
Did you find such a system (which makes choices in the equipment for you)
useful?
� � � � Not Useful at all May be Useful Useful Very Useful
Miscellaneous
Are there any application areas, where you find such a system very useful?
Please comment, what advantages you see if using such a system?
Are there any disadvantages?
Was it easy to understand how does the system work?
� � � � � � � � � �
Very Difficult Very Easy
What was the most difficult part to understand?

75
Appendix 2: Genetic Algorithms in Parallel Computing
This appendix presents some genetic algorithms design methods and their
correspondent solution quality analysis. The main objective is not to reduce the
computation time, as it is usual in using this kind of machines; the main goal is to
increase the quality of the obtained solutions. The search space of the algorithms is
increased using parallel computers. Obviously, a higher number of CPUs involves
that the number of treated candidate solutions is higher without interfering in the
performance of the algorithms. A well-known NP-Problem is going to be tackled,
which has even been mentioned during this thesis, the knapsack problem.
1. Island model with star communication:
In this case the same genetic algorithm is run in different CPUs of the same
machine, the communication between the cores is done each 20% of the total number
of generations. Each CPU sends to the master core its best solutions in each
communication. Then, this master sends to the rest of the machines the best solutions
founded by all the CPUs. Appendix Figure 1 shows a general overview of the model.
Appendix Figure 1. An overview of the island model with star communication.
The following image indicates the solution quality with different amount of CPUs
(the higher – the better). It shows an increase in the quality of the solution; with more
CPUs, better quality.
Appendix Figure 2. Solution quality in the island model with star communication.

76
1. Island model with ring communication:
In this case the same genetic algorithm is run in different CPUs of the same
machine, the communication between the cores is done each 20% of the total number
of generations. Each CPU sends to its neighbor node its best solutions in each
communication. Finally, all of them send their best solution to a master node that
will show which is the best-founded solution. Appendix Figure 3 shows a general
overview of the model.
Appendix Figure 3. An overview of the island model with ring communication.
The following image indicates the solution quality with different amount of CPUs
(the higher – the better). It shows an increase in the quality of the solution in most of
the cases; with more CPUs, better quality. The difference between the single
processing model and the model with the maximum quantity of CPUs is even higher
than in the previously presented model.
Appendix Figure 4. Solution quality in the island model with ring communication.





























