Embed Size (px)
Citation preview

Amazon
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes,
Robert E. GruberGoogle, Inc.OSDI 2006

Introduction
What is Amazon? Amazons provides a e-commerce platform
for millions of customers Data centers all over the world Reliability is important since it impacts
customer trust

Overview
Founded in 1994; Didn’t make a profit until 2001
Headquarters in Seattle, Washington USA
Started as an on-line bookstore Today it offers various products and
services including: music, DVDs, videos, electronics, camera and photography, clothing apparel, shoes, etc.
US’s largest on-line retailer

Overview
In 1999 it offered its own auction service eBay had too much momentum
Offered AmazonFresh in 2007 Grocery store service
Attracted 615 million users in 2008 which is twice that of Walmart
50 million US users a month

Overview
Amazon makes 40% of its money from third parties
Features include: one-click shopping, customer review and e-mail order verification

Overview
Amazon has many Data Centers: Hundreds of services Thousands of commodity machines Millions of customers at peak times Performance + Reliability + Efficiency = $$
$$$ Outages are bad
• Customers lose confidence , Business loses money
Accidents happen

Requirement
Need a distributed storage system: Scale Simple: key-value Highly available Guarantee Service Level Agreements (SLA)

System Assumptions and Requirements
Query Model: Simple read and write operations to a data
item that is uniquely identified by a key.
ACID Properties: Atomicity, Consistency, Isolation, Durability. Weak consistency Permits only single key updates

System Assumptions and Requirements
Efficiency: Latency requirements which are in general
measured at the 99.9th percentile of the distribution.
Other Assumptions: Operation environment is assumed to be
non-hostile and there are no security related requirements such as authentication and authorization.

Design Consideration
Sacrifice strong consistency for availability
Conflict resolution is executed during read instead of write, i.e. “always writeable”.
Other principles: Incremental scalability. Symmetry. Decentralization. Heterogeneity.
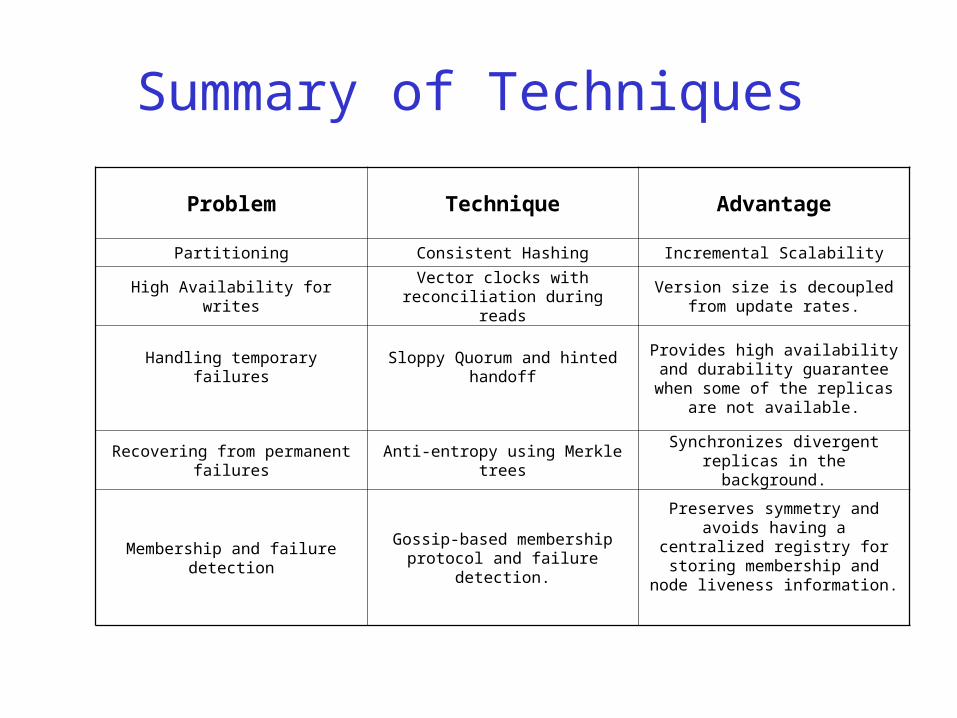
Summary of Techniques
Problem Technique Advantage
Partitioning Consistent Hashing Incremental Scalability
High Availability for writesVector clocks with reconciliation
during readsVersion size is decoupled from
update rates.
Handling temporary failures Sloppy Quorum and hinted handoff Provides high availability and durability guarantee when some of
the replicas are not available.
Recovering from permanent failures
Anti-entropy using Merkle treesSynchronizes divergent replicas in
the background.
Membership and failure detectionGossip-based membership
protocol and failure detection.
Preserves symmetry and avoids having a centralized registry for storing membership and node
liveness information.

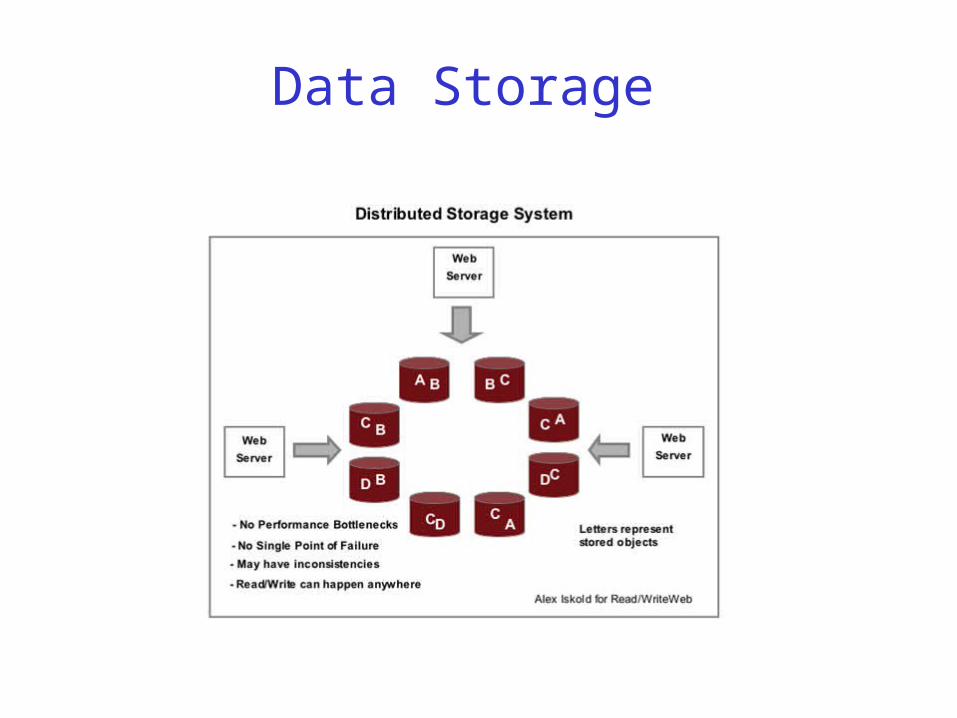
Data Storage
Dynamo is a distributed storage system It stores information to be retrieved It does not store the data into tables The data stored for an object is
relatively small GFS /Bigtable assume large amounts of data
Instead all objects are stored and looked up via a key

Data Storage
Let’s say that you go to the web page of the “Catcher in the Rye” that has the URL
http://www.amazon.com/Catcher-Rye-J-D-Salinger/dp/0316769177/ref=pd_sim_b_1 What do you see:
Description Customer reviews Related books etc

Data Storage
To create, Amazon’s infrastructure has to perform many database lookups
Example: It grabs information about the book from its URL or from its ASIN which the unique identifier that Amazon provides to a product (0316769177)
Data Storage

Data Storage
Dynamo offers a simple put and get interface
Features Physical nodes are thought of as organized a
a ring Virtual nodes are created by the system
mapped to physical nodes so that hardware can be swapped for maintenance and failure
The partitioning algorithm (ala Chord-like) specifies which nodes will store an object
Every object is replicated to N nodes
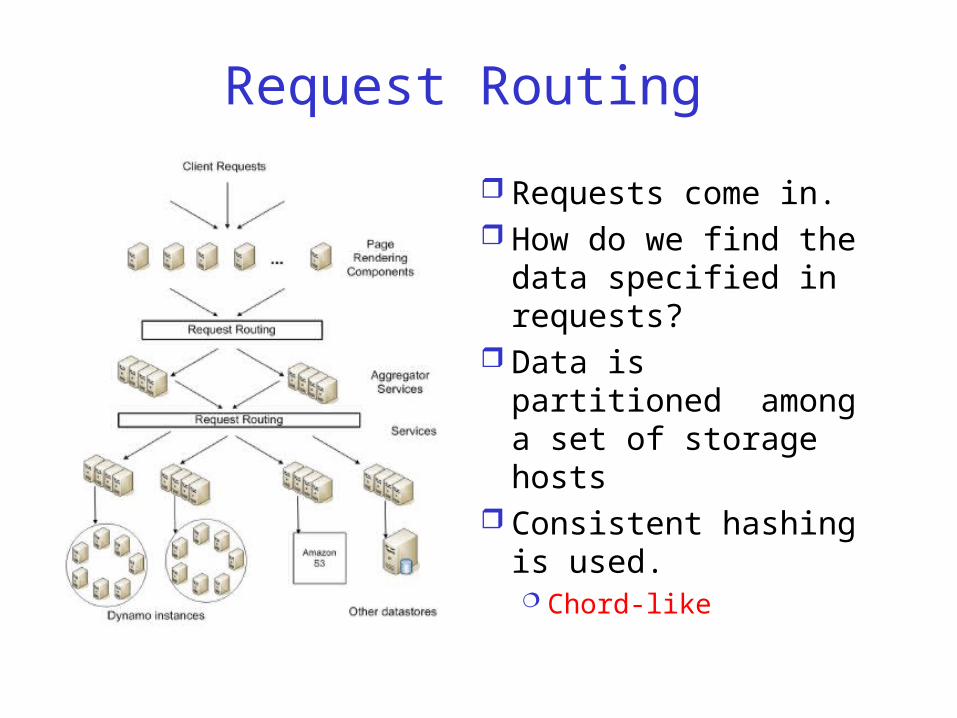
Request Routing
Requests come in. How do we find
the data specified in requests?
Data is partitioned among a set of storage hosts
Consistent hashing is used. Chord-like
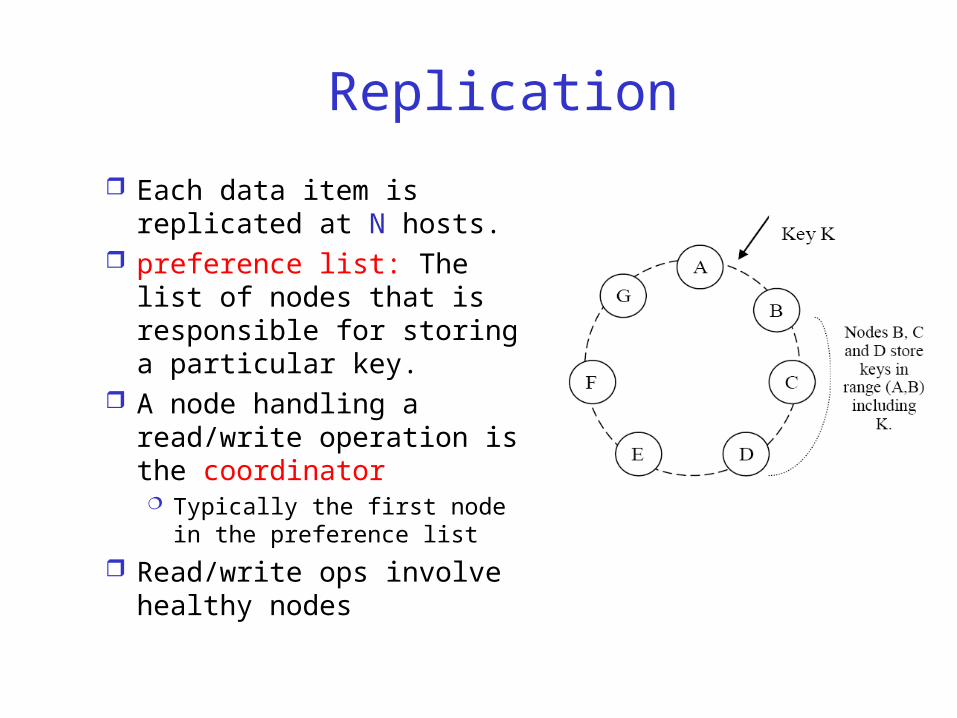
Replication
Each data item is replicated at N hosts.
preference list: The list of nodes that is responsible for storing a particular key.
A node handling a read/write operation is the coordinator Typically the first node in
the preference list
Read/write ops involve healthy nodes
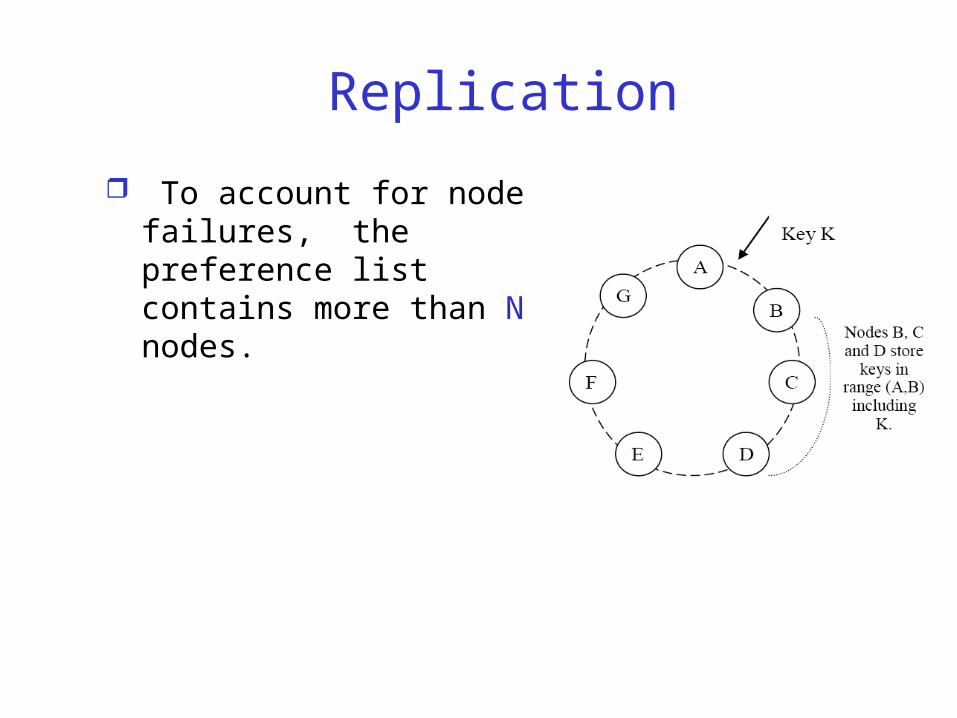
Replication
To account for node failures, the preference list contains more than N nodes.

Execution of put()/get()
For a put() operation the coordinator: Generates the vector clock for the new
version and writes the new version locally Sends the new version (with the new vector
clock) to the N highest-ranked reachable nodes
If at least W-1 nodes respond to the write is considered successful
A put() call may return to its caller before the update has been applied at all the replicas

Execution of put()/get() For a get() operation the coordinator:
Coordinator requests all existing versions of data for that key from the N highest-ranked reachable nodes in the preference list for that key
Waits for R responses before returning the result to the client
If the coordinator ends up gathering multiple versions of the data, it returns all the versions it deems to be causally unrelated
The divergent versions are reconciled and the reconciled version is written back (more later)

Execution of put()/get()
Two configurable parameters: R, W R is the minimum number of nodes that
must participate in a successful read operation
W is the minimum number of nodes that participate in a successful write operation

Data Versioning
Updates are propagated to all replicas asynchronously
A put() call may return to its caller before the update
A subsequent get() operation may return an object that does not have the latest updates

Data Versioning
Ok. Why do we reconcile with reads and not writes
Dynamo wants an always writable data store Rejecting customer updates could result in a
poor customer experience Do we want a shopping car that we have to
often wait on (the answer it turns out is no). The advantage of reconciling different
versions at the read end is that this can be done based on the application needs

Data Versioning Example: Shopping cart
Add to Cart operation can never be forgotten or rejected
If the most recent state of the cart is unavailable and a user makes a change to an older version of the cart then the change is considered meaningful and should be preserved
It should not supersede the currently unavailable state of the cart
Add to cart and delete item from cart operations are translated into Dynamo put operations

Data Versioning When a customer wants to add/remove from a cart
and the latest is not available the item is added/removed from the version it has
Most of the time new versions subsume the previous version
Version branching may happen resulting in conflicting versions of the object
The client application must perform the reconciliation in order to collapse multiple branches back into one Adds are preserved Deleted items can resurface
Dynamo uses vector clocks

Data Versioning
Associate a vector clock with a value Versioned value is a (value, vector clock)
tuple Multiple versioned values can exist for a key We can use a vector clock to determine
causality If two versioned values aren’t causally
related, allow application to reconcile

Data Versioning
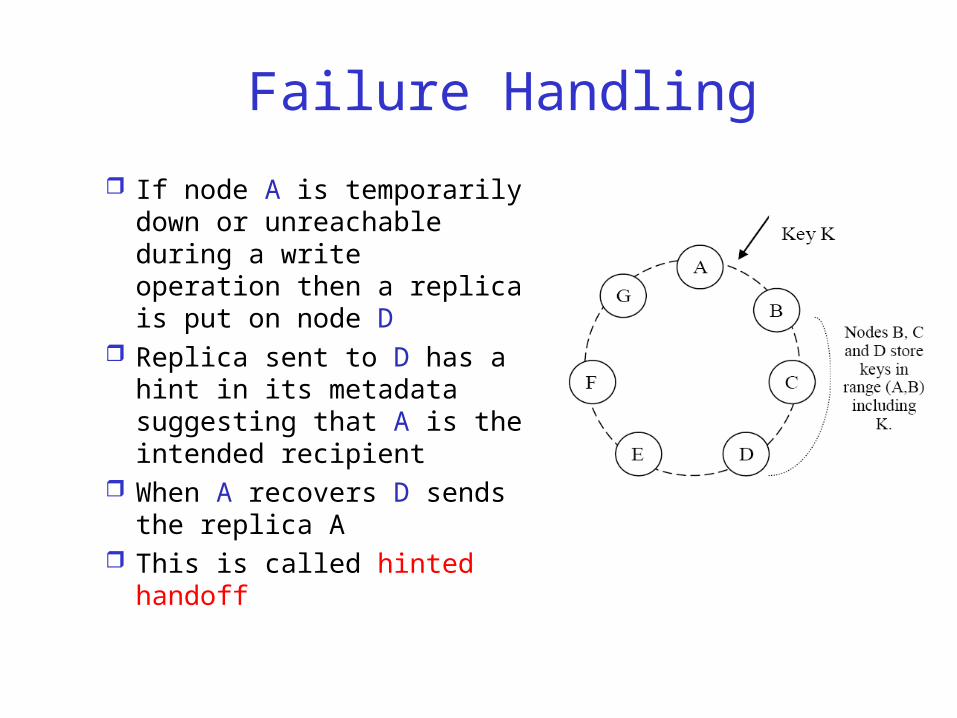
Failure Handling
If node A is temporarily down or unreachable during a write operation then a replica is put on node D
Replica sent to D has a hint in its metadata suggesting that A is the intended recipient
When A recovers D sends the replica A
This is called hinted handoff

Replica Synchronization What if a hinted replica becomes
unavailable before it can be returned to the original replica node
Dynamo implements an anti-entropy protocol
Use Merkle trees Leaves are hashes of keys
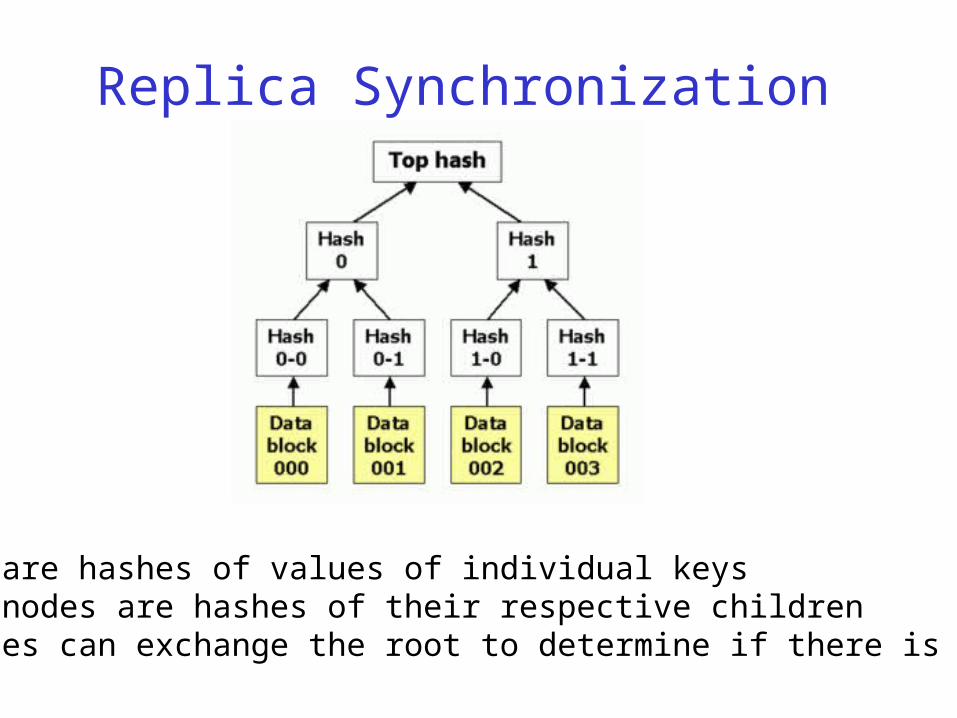
Replica Synchronization
•Leaves are hashes of values of individual keys•Parent nodes are hashes of their respective children•Two nodes can exchange the root to determine if there is a change

Replica Synchronization
Can compare trees incrementally, without transferring the whole tree
If a part the tree is not modified, the parent nodes’ hashes will be identical
So parts of the tree can be compared without sending data between two replicas
Only keys that are out of sync are transferred

Replica Synchronization
Each node maintains a Merkle tree for each key range it hosts Don’t forget a physical node hosts a set of
virtual nodes Each virtual node is associated with a key range Virtual nodes are replicated on other physical
nodes Let’s say that a node goes down
When it comes back up it can request from another node its Merkle tree
It compares the Merkle trees to determine if there is a difference

Summary
We will discuss the different algorithms and show how they fit within Amazon





























