Embed Size (px)
Citation preview

WHITE PAPER
Author: Sanhita Sarkar, Western Digital Corporation
An Analytics System Complementing HGST Object Storage SystemsEnabling Manufacturing Process Optimizations at a Low Cost
Author: Sanhita Sarkar, Western Digital Corporation
MAY 2017

1
WHITE PAPER AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
Executive Overview
Complex systems like enterprises, social networks, biological and physical systems, smart cities, smart homes and financial systems comprise of complex business processes that generate massive amounts of data in real time. This data is usually stored or archived as event logs, and analysis of this data through multiple stages leads to the discovery of properties of one or more processes. The challenge that businesses face today is to have an insight into the process data, process metadata and process semantics associated with the incoming event data, early on in the data pipeline, before it becomes history. An early insight can lead to an actionable mitigation of business process risks, take advantage of new opportunities and improve ROI.
This paper highlights the need of data archiving to include process archiving. Analytics involving data discovery, data mining and machine learning methodologies should involve optimizations and mining on the archived processes. This leads to a software-defined smart archive, introduced in this paper. Having an insight into the business processes associated with the archived data improves the efficiency of process optimizations as a part of process mining. As “Quality in time at the least cost” remains the mission statement for the continuously changing business environments on the third platform, it is imperative to emphasize on process archiving and process optimizations leading to Continuous Process Improvement (CPI), Total Quality Management (TQM) and Six Sigma.
This paper describes how an analytics system combined with an HGST Object Storage System can enable smart process archiving and process optimizations for a manufacturing workload to bring forth the desired quality in time in production. The paper describes best practices to deploy the solution for the most optimal performance and price/performance. The paper also demonstrates a lower Total Cost of Ownership (TCO) while executing the solution in a data center on premise, compared to a public cloud.

2
WHITE PAPER AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
1. IntroductionThe growth of a digital universe connecting people, processes, organizations, devices and things results in generating lots of events. These events which may be transactions, messages or activities are captured and stored as event logs. Machine learning algorithms are applied to these event logs to extract knowledge about the events, leading to discovery of new process models. Checking reality versus history leads to process conformity, and enhancing process models through machine learning allows for smarter business metrics. All these are standard process mining techniques (Figure 1a). However, in addition to recording and storing event logs, a prior knowledge of process data, metadata and process semantics should allow for an enhanced and actionable process mining methodology. This paper introduces software-defined smart archive with the capability for process archiving in order to retain process data, metadata and process semantics in addition to data archiving. Event logs as a function of archived processes can carry more information about the business process workflows and process hierarchy and can enable efficiency in process optimizations and process mining (Figure 1b). The paper applies this concept to a privately hosted manufacturing workload which otherwise executes in production in a public cloud. It solves a real-world problem of corporate business users who are challenged with a 24-48 hour lag in detecting device anomalies, thus impacting quality in time in production. The challenge surges with a bigger population of manufacturing event data.
In the current state of art, Big Data and advanced analytics are used for streamlining manufacturing value chains by finding the core determinants of process performance, and then taking action to constantly improve them. Manufacturing firms are integrating advanced analytics across the Six Sigma DMAIC (Define, Measure, Analyze, Improve and Control) framework to fuel continuous improvement. For more details, please refer to http://www.mckinsey.com/business-functions/operations/our-insights/how-big-data-can-improve-manufacturing. Figure 3 shows how advanced big data analytics involving machine learning is used for process optimizations within manufacturing for continuous improvement.
This paper describes how the software-defined smart archive executes Big Data analytics on archived process data from manufacturing and improves business ROI.
The software-defined smart archive executing on premise uses an analytics compute system connected to an HGST Object Storage System through the S3A connector (Figure 2). Manufacturing data generated from the shop floors at multiple site locations along with process metadata and semantics, for example, the site where the process has executed, transaction process group, precise date (end date) of archival, etc., are continuously archived into the HGST Object Storage System. As the data arrives, queries using Apache Hive™ user defined functions (UDF) which analyze device defect patterns are executed on the compute cluster connected to the HGST Object Storage System through S3A connector.
Contents1. Introduction …………………………… 2
2. Description of the Problem and Its Solution …………………… 4
3. Implementation Details ………… 5
3.1. Specifications ……………………… 5
3.2. Performance Characterization and Results …………………………… 5
3.2.1 Performance of Compute intensive Analytical Query ……6
3.2.2 Performance of I/O-Intensive Analytical Query ……………………6
3.2.3 Network Throughput for Compute and I/O-intensive Queries …………………………………… 7
3.2.4 Performance of Mixed Analytical Query …………………… 7
3.2.5 Summary of Performance Results ……………8
4. Best Practices ………………………… 8
5. Total Cost of Ownership ……… 9
6. Summary ………………………………… 9
7. Appendix ……………………………… 10

3
WHITE PAPER AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
Results are stored in a Hive table, and accessed by the Impala query engine to display device defect quality metrics and sigma deviations from standard baseline, on a Tableau® visualizer. Predictive analytics is performed using a K-means clustering machine learning algorithm enabled by an IBM® SPSS® engine that classifies the defect patterns and detects any new patterns as a part of unsupervised learning (Figure 5).
Process archiving within software-defined smart archive has allowed for performance improvements in Hive queries by locating the data and metadata faster while reading them from an HGST Object Storage System through the S3A connector, followed by faster pattern recognitions, visualizations, and anomaly detections within a few minutes, compared to hours. This enhancement, further accompanied by an hourly dashboard, has been able to deliver an actionable solution demonstrating “quality-in-time” metrics, much desired by the business users.
The paper also calculates and conveys a lower TCO for operating the solution on premise compared to a public cloud. The on premise solution uses a compute cluster reading from and writing to an HGST Object Storage System through an S3A connector during analytical query executions. This eliminates the need for maintaining a large, static Apache™ Hadoop® cluster configured with a large number of disks per data node. Users can grow the compute and storage independently depending on their growing needs. Thus the overall solution can deliver “quality-in-time at a low cost” as an enhanced metric for business users.
While the process optimizations can be ultimately applied to the solution executing in the public cloud by making the required design changes, the lower TCO attained by deploying the solution on premise within a data center further resolves the challenges of business users.
Enhancement
SpecifiesConfiguresImplementsAnalyzesModels,
Metrics
Records process data, events,e.g., messages, transactions,activities, etc.
Hardware and software systems,implementing real-time business
processes
Machine
LearningSm
art Analytics
Supports / Controls“World”
PeopleThingsDevices
Business processesMachinesOrganizations
Process Mining
Discovery
ConformanceProcess Models
HGST Object Storage Systems
Software-defined smart archive
Archived Process= F1(Process data, Process metadata,
Process semantics)Event Logs
= F2 (Archived Process) = F2 F1 (process_id, phase_id, data_element,
timestamp, source_id, destination_id,…)
Figure 1 (b): Enhanced process mining using process archiving
Business Process Models and Workflows
Software-defined smart archive
Analytics ComputeEngine
Continuous data collection from Business Processes A, B, C, D, E....
• Massive data store• Process Archive• Durable• Recovery Time Objective (RTO) meeting SLAs for Data Centers• Low Access Time• Digitization• Tape replacement• Back up
HGST ObjectStorage System
• Streaming data capture/ multi-level transformations for business processes, Metadata creation/ Management, Indexing, Searching, Querying, Visualizing for analysis• Machine Learning, Predictive Modeling, Process Optimization, Process Mining for CPI, TQM, Six Sigma• Poly-interface to 3rd party apps
Software-defined infrastructure
BusinessProcess A
BusinessProcess B
BusinessProcess C
BusinessProcess D
BusinessProcess E
S3AReads data,
metadata, computesand writes
back results
Figure 2: Software-defined smart archive
Process P7
PredictiveMaintenance
Telematics forPreventive
Maintenance
PredictingSupplier
Performance Over Time
DemandForecasting
TotalQuality
Management
ContinuousProcess
Improvement
Six Sigma
RecommendImprovements
QuantifyFinancial
Performance
Process P6
Risk Analysis and
Regulation
Process P5Start event
Component Process P1
Component Process P2
Component Process P3
Component Process P4
Figure 3: Advanced Big Data analytics for manufacturing process optimizations, process mining and continuous improvement
Enhancement
Process Mining
Discovery
Conformance
Supports / Controls
SpecifiesConfiguresImplementsAnalyzesModels,
Metrics
Records events, e.g. messages, transactions,activities, etc.
Hardware and software systems,implementing real-time business
processes
Machine
LearningSm
art Analytics
“World”PeopleThingsDevices
Business processesMachinesOrganizations
Process Models
Event Logs
Figure 1 (a): Process mining in a real-time digital world

4
WHITE PAPER AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
2. Description of the Problem and Its Solution
This section describes a Big Data platform that is hosted in a public cloud and used as a back-end for manufacturing process analytics by various corporate business users. Manufacturing event data in binary format is ingested daily from multiple factory sites to the Big Data platform at the rate of 600GB/day. About 85% of the total volume of data comprise of complex binary files from Asia-Pacific (APAC) regions and analyzing this data to capture defect patterns in a timely manner is critical to business.
This Big Data platform on the public cloud uses a standard Hadoop infrastructure to analyze the binary event data which is constantly growing and
becomingmassive. It also takes 24-48 hours to analyze the data from all sites. Ideally, the daily defects should be analyzed in near-real time in 10’s of secs and visualized on a dashboard to maintain a “quality in time” in production (Figure 4).
The solution involves a prototype for a software-defined smart archive, which comprises of an HGST Object Storage System and an analytics compute system connected to the HGST Object Storage System through the S3A connector. The manufacturing data, process metadata, and process semantics from multiple APAC sites are ingested, archived and optimized for analysis by the software-defined smart archive. The solution optimizes the manufacturing process to provide an hourly dashboard and is able to detect the defect patterns in an actionable manner. This solution has been implemented on premise in a data center. Figure 5 shows the total workflow for the
manufacturing processes starting from ingestion to analytics and visualization.
The process semantics archived in the HGST Object Storage System have allowed for proper mapping of the Hive table partitions and faster query executions. For example, the site executing the process, process group per product and the precise date (yyyymmdd format) of capture process are all stored in HGST Object Storage System along with the actual manufacturing data as {Site, Product, Process-grp, enddt(‘yyyymmdd’ format), binary-data} instead of just storing the same data as {Product, Process-grp, Year, month, binary-data}.
Following up on the example above, the Hive table to be queried after reading process data from the HGST Object Storage System can be partitioned in a way so that it can be mapped to the archived process data as follows:
PARTITION BY (`site` string,`product` string,`trxgroup` string,`enddt` (‘yyyymmdd’ format) int) (1)
instead of
PARTITION BY (`product` string,`process_group` string,`year` int,`month` int) (2)
Note, the Hive partition in (2) has no ‘site’ information, no precise ‘date’, but just the information about the ‘year’ and ‘month’. So the Hive queries executed to detect defect patterns in case 2, will need to first parse the incoming event data to decipher the information about the ‘site’ for each ‘product’, followed by analyzing the full month of data to get to the daily data. Additional processes like de-duplication takes extra time. The Hive partition in (1) is able to avoid the parsing altogether and complete the analysis within a few minutes to derive results from daily data analysis. The de-duplication has been done prior to storing the data in the HGST Object Storage System in case (1). The performance of overall process flow in case (1) leading to predictions and visualizations do benefit out of these optimizations and allows for delivering an hourly dashboard with minimal changes.
This serves as a real-world example of process archiving leading to enhanced process optimizations and newer process models as a part of process mining approach.
Hadoop It takes 24-48 hoursto analyze the binary data
from all sites.Data is GROWINGand getting HUGE
Using an optimizedanalytics platform
complementing HGSTObject Storage Systemis a potential solution.
Ideally, daily defects should beanalyzed in near-real time in 10’s of secs and visualized on
a dashboard to maintain a“quality in time” in production.
Can we achieve this goal?
Figure 4: The end user problem to detect defect patterns in manufacturing data which is analyzed on a Hadoop infrastructure hosted in a public cloud

5
AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
3. Implementation Details This section describes the implementation details and the performance results from the execution of the manufacturing workflow on premise.
3.1. SpecificationsThe hardware specifications used for the implementation are as follows (Figure 6).
• 1 HGST Object Storage System with EasiScale™ 4.1.1 (the HGST Active Archive System was used for this implementation).
• HGST Analytics System:
- 16 Data/Worker nodes each with 24 cores /48 vcpus (Intel® Xeon® E5-2680 V3), 24 drives, 512 GB memory
- 3 Master Nodes - 4 Edge Nodes - Dual 48-port 10GbE switches for data network - 48-port Management switch
Figure 6 shows a prototype implementation of the software-defined smart archive comprising of an analytics compute system connected to an HGST Object Storage System through the S3A connector, and optimized for process archiving, process optimizations and process mining.
The software specifications used for the implementation are shown in Table 1.
3.2. Performance Characterization and Results
This section describes the performance characterization done for the manufacturing workload using three types of queries, in three different scenarios.
The three types of queries involve compute-intensive, I/O-intensive, and with a mixed compute and I/O operations, respectively.
The three scenarios of query execution are as follows:
Scenario 1: Hadoop HDFS for Input and Output files.
Scenario 2: HGST Object Storage System used for Input files and Hadoop HDFS for Output files.
Figure 6: A prototype implementation of the software-defined smart archive
Mgmt Switch
Edge NodeEdge NodeEdge NodeEdge Node10GbE Data Switch10GbE Data SwitchWorker Node 16
Worker Node 15
Worker Node 14
Worker Node 13
Worker Node 12
Worker Node 11
Worker Node 10
Worker Node 9
Worker Node 8
Worker Node 7
Worker Node 6
Worker Node 5
Worker Node 4
Worker Node 3
Worker Node 2
Worker Node 1
Master Node 1Master Node 2Master Node 3
42
383736353433
31 | 32
29 | 30
27 | 28
25 | 26
23 | 24
21 | 22
19 | 20
17 | 18
15 | 16
13 | 14
11 | 12
9 | 10
7 | 8
5 | 6
3 | 4
1 | 2
414039
HGST S3A Connector
Software-defined smart archive
HGST Analytics SystemHGST Object
Storage System
Table 1: Software components used for implementing a prototype for the software-defined smart archive
Figure 5: Software-defined smart active archive executing a manufacturing process workflow on premise
SPSSModeler for Visualization
Impala QueryEngine
Predictive Analytics with SPSS
Hadoop MapReduce
On-Premise
APAC MFG Shop Floors4 Sites: Singapore, China, Thailand, Japan
Con
tinuo
usBi
nary
Dat
a
APAC Object Storage Site Gateways
Tran
sfor
med
Las Vegas Object StorageSite Gateway• 700 GB+ Object size/day• 10,000+ Objects/day• 30 TB+ Total Object Size for 4 months• 500K+ Total number of objects HGST Object
Storage System
Store,persist,archive
Batch Layer
Batch queries, machine learning/scoring, visual dashboards for patternrecognition of disk defect maps.
Serving Layer
Tableau for Visualization
Batch Analytics & Visualization
S3A
Con
nect
or
VenusQ SerDe
VenusQ_MasterHive Table
Hive Querywith UDF
Decode binary data
External table for decoded binary data
Manufacturingdefect analytics
6
WHITE PAPER AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
Scenario 3: HGST Object Storage System used as a default Hadoop HDFS, for both Input and Output files.
The following sections provide a summary of the performance results.
3.2.1. Performance of Compute-intensive Analytical Query
This section summarizes the performance results for a compute-intensive analytical query (Figure 7).
• The performance of scenario 2 is similar or better compared to scenario 1 for all input file sizes ranging from 10 GB to 1 TB. The network bandwidth between the analytics system and HGST Object Storage System remains well below the maximum bandwidth (~3.5 GB/s) of the HGST Object Storage System, thus incurring no wait time for data from S3A.
• The performance of scenario 3 is a bit slower compared to scenarios 1 and 2, with an increase in the slowdown with larger input file sizes. The reason for this slowdown is as follows:
• Deletion and insertion of result files (while executing the ‘Insert overwrite’ SQL statement) takes longer in the object storage, compared to Hadoop HDFS, thus increasing the overall query execution time.
• With larger input file sizes, the number of output files to be updated in the HGST Object Storage System also increases, thus increasing the overall query execution time.
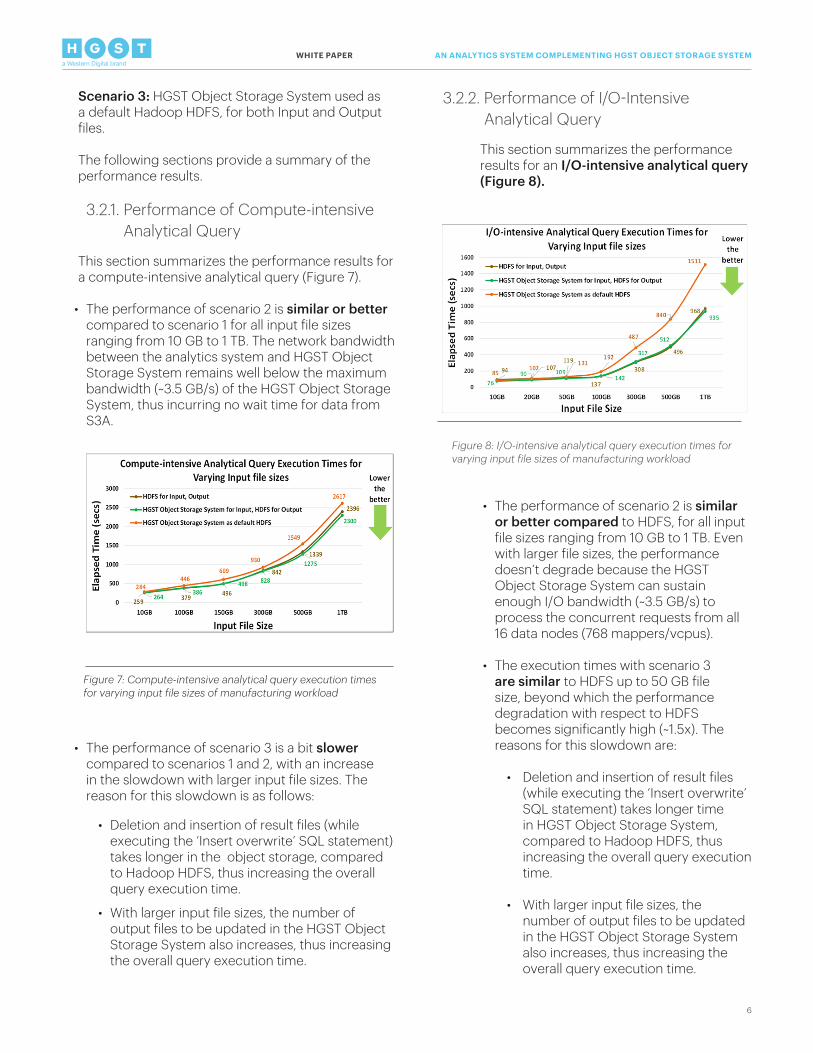
3.2.2. Performance of I/O-Intensive Analytical Query
This section summarizes the performance results for an I/O-intensive analytical query (Figure 8).
• The performance of scenario 2 is similar or better compared to HDFS, for all input file sizes ranging from 10 GB to 1 TB. Even with larger file sizes, the performance doesn’t degrade because the HGST Object Storage System can sustain enough I/O bandwidth (~3.5 GB/s) to process the concurrent requests from all 16 data nodes (768 mappers/vcpus).
• The execution times with scenario 3 are similar to HDFS up to 50 GB file size, beyond which the performance degradation with respect to HDFS becomes significantly high (~1.5x). The reasons for this slowdown are:
• Deletion and insertion of result files (while executing the ‘Insert overwrite’ SQL statement) takes longer time in HGST Object Storage System, compared to Hadoop HDFS, thus increasing the overall query execution time.
• With larger input file sizes, the number of output files to be updated in the HGST Object Storage System also increases, thus increasing the overall query execution time.
Figure 7: Compute-intensive analytical query execution times for varying input file sizes of manufacturing workload
Figure 8: I/O-intensive analytical query execution times for varying input file sizes of manufacturing workload

7
WHITE PAPER AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
3.2.3. Network Throughput for Compute and I/O-intensive Queries
This section describes the behavior of I/O-intensive and compute-intensive queries for scenario 2 as an example, related to the attained Network I/O throughput (Figure 9) between the analytics system and HGST Object Storage System.
Network impact for I/O-intensive analytical query:
• Simple analytical functions are performed on a chunk of input data, implying a lower number of CPU cycles and a smaller elapsed time (142 secs). Request for the next input chunk is quicker, thus incurring frequent requests and a higher I/O rate.
• As shown in the chart (Figure 9), for a 100 GB input file size:
• With 1 controller, the average network I/O reaches 900 MB/s, which is close to the maximum of 1.2 GB/s, hence the execution time takes longer (226 secs).
• With 3 controllers, the average network bandwidth reaches 1.9 GB/s (~2x of the above scenario), which is well below the maximum bandwidth of ~3.5 GB/s, hence the execution time (142 secs) is lower (almost half) compared to the case cited above (226 secs).
Network impact for compute-intensive analytical query:
• Here, complex analytical functions are performed on a chunk of input data, implying a higher number of CPU cycles and a larger elapsed time (386 secs). Request for the next input chunk takes longer, thus incurring a lower frequency of requests and a lower I/O rate.
• As shown in the chart, the average network bandwidth remains well below the maximum network bandwidth (~3.5 GB/s) of the HGST Object Storage System. Hence the query performance for scenario 2 remains similar or better, compared to Hadoop HDFS.
3.2.4. Performance of Mixed Analytical Query
This section summarizes the performance results for an analytical query executing a mixed compute and I/O operations (Figure 10).
Considering the daily average binary manufacturing data with an input file size of 50GB* for 13 products from 4 manufacturing sites:
• Analytical query using the HGST solution to get daily defect patterns for scenario 1 is ~17x faster when compared to the solution hosted in the public cloud (projected from reported data). The projection for public cloud is calculated for best case scenario. The worst case scenario on the public cloud is reported to be ~24-48 hrs.
Figure 10: HGST analytics solution running a mixed compute and I/O workload from manufacturing, for a fixed input file size
Analytical Query Execution Times for Detecting Daily Defect Patterns
Elap
sed
Tim
e (s
ecs) 4500
262 260 284
Lower thebetter
10000
1000
100
10
1Analytic Platform
on Public Cloud(Reported)
HGST Analytic Solution:
HDFS for both Inputand Output Files
(Scenario 1)
HGST Analytic Solution:
HGST Object Storage System forInput Files, HDFS for Output Files
(Scenario 2)
HGST Analytic Solution:
HGST Object Storage as a default HDFS for both Input
and Output Files(Scenario 3)
Figure 9: Network I/O throughput between the analytics system and HGST Object Storage System while executing the I/O and compute-intensive queries

AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
8
WHITE PAPER
• Analytical query using the HGST solution to get daily defect patterns for scenarios 2 and 3 is pretty much similar in performance, compared to scenario 1.
• The price/performance benefits of scenarios 2 and 3 over scenario 1 is a driving factor for customers while making purchase decisions because they don’t need to maintain a large static Hadoop cluster, but can leverage HGST Object Storage System, instead.
* Out of 500 -600 GB data ingested per day to the Big Data platform on the public cloud, 50 GB is the size of average daily binary manufacturing data which is being used by the analytical query.
3.2.5. Summary of Performance Results
Through various process optimizations, the HGST analytics solution implemented on premise is able to deliver up to ~17x better performance over the solution executing in the public cloud. The solution analyzes product anomalies as a part of a manufacturing process, and solves a real-world problem for corporate business users who are challenged with a 24-hr lag on public cloud, impacting the “quality in time” for production.
Table 2 summarizes a case study demonstrating the performance characteristics of an HGST Object Storage System for compute-intensive and I/O-intensive workloads with varying input file sizes.
Please refer to the Appendix for a list of parameters tuned for the manufacturing workload to get the best possible results.
4. Best Practices This section describes the best practices for deploying an analytics system connected to an HGST Object Storage System through the S3A connector.
• HGST Object Storage System as an external storage for input data files, can be used very well with an analytics system.
• HGST Object Storage System as a default HDFS, may be used for certain types of Big Data workloads for price/performance benefits.
• For optimal performance, an analytics compute cluster needs to maintain a small static HDFS that
stores and incrementally updates the output files from continuously running analytical queries. The HDFS can be built out of a small number of SSDs for fast writes.
• Output files in HDFS can be aggregated in large batches and written back to an HGST Object Storage System during off-peak hours without impacting query execution times in production.
• A dynamically provisioned analytics compute cluster working with an HGST Object Storage System will allow for flexibility of configuring multiple input data sizes, on demand.
Figure 11: 5-year relative TCO for operating the manufacturing analytics solution on the public cloud and on premise
5-Year Relative TCO for operating the Manufacturing Analytics solutions
1.25
1
0.75
0.5
0.25
o
TCO IS 1/4th ofpublic cloud
Public Cloud On premise
Table 2: Performance characterization of compute-intensive and I/O-intensive workloads for varied input file sizes: Scenario 2 vs. Scenario 1 and Scenario 3 vs. Scenario 1
Input File size (considering 3.5GB/s as network bandwidth, 768 vcpus, 1 mapper/vcpu)
Similar Similar
Performance of HGST Object Storage System as an external storage for input files (Scenario 2) VS. HDFS (Scenario 1)
Performance of HGST Object Storage System as a default HDFS (Scenario 3) VS. HDFS (Scenario 1)
Workload Type Parameters tuned
I/O-intensive analytical workloads
Similar (for 10-20 output file updates)
Similar or Better (20%)
Compute-intensive analytical workloads
Similar or Better (5%)
I/O-intensive analytical workloads
Similar Lower at a 50% mini-mum (may not matter for public cloud customers, when considering price/per-formance benefit for not having to maintain a large static Hadoop cluster)
1) Increased the AAproxy port time out value from 50s to 180s to avoid connection timeout errors for compute- intensive queries;
2) HAProxy Load Balancer configured for 24 threads and each thread a�initized to a vcpu.
3) Set the following parameters to avoid JVM “out of memory” errors for >= 500GB input file size
• Multipart size – 64MB• Multipart threshold size – 64MB • Multipart bu�er size – 4MB• S3A tasks – 2• S3A max threads – 4
Similar (for 10-20 output file updates)
Lower (9%) (for a larger number of output file updates)
Compute-intensive analytical workloads< 300GB
>= 300GB

AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
9
WHITE PAPER
• With a larger network bandwidth for the HGST Object Storage System, it is possible to support concurrent Big Data workloads on multi-rack server farms and multiple clients of an HGST Object Storage System (e.g., bandwidth ~10MB/s/compute-core + bandwidth for additional client jobs of the HGST Object Storage System).
5. Total Cost of Ownership This section compares the Total Cost of Ownership (TCO) for hosting the manufacturing production Big Data analytics platform in a public cloud with the TCO for hosting the HGST analytics solution on premise in a data center.
Calculations include the operational costs to host the HGST analytics solution in a data center and the depreciation cost of the hardware over 5 years. The cost of the production environment in the public cloud is based on typical/reported pricing for a similar configuration described in Section 3. The TCO for 5 years for both solutions is compared and shown in Figure 11.
6. SummaryThe paper demonstrates a prototype for a software-defined smart archive, comprising of an analytics compute platform connected to an HGST Object Storage System through the S3A connector, which has been able to:
• Leverage process archiving in an HGST Object Storage System for improving the quality of manufacturing business processes
• Deliver through process optimizations, a ~17x performance improvement over the public cloud for analyzing defect patterns
• Deliver an “hourly” dashboard for visualizing defect patterns, currently “not” available in production
• Accomplish a similar or better performance of analytical queries with the scenario where input files are retained in an HGST Object Storage System and analyzed by the compute platform through S3A, instead of moving them into Hadoop HDFS. It has also demonstrated the use of HGST Object Storage System as a default HDFS for price/performance benefits
• Demonstrate the 5-year TCO to be 1/4th of the solution hosted in the public cloud
The paper describes:
• A software-defined smart archive using Big Data analytics to solve a real-world manufacturing problem and transforming data to knowledge to wisdom
• Lower TCO of an on premise solution
• Reduction in time to capture and prevent defects leading to a reduction in the Defects-Per-Million-Opportunities (DPMO), and an increased Rolled Throughput Yield (RTY) for Continuous Process Improvement (CPI), Total Quality Management (TQM) and an improved Six-Sigma compliance
• Customer demand alignment by augmenting an existing HGST Object Storage System with an analytics system, so that the total solution can deliver “quality in time” metric through process improvement
• Manufacturing process optimizations, and process mining as a strategic use case for HGST products
A software-defined smart archive is most suitable for Manufacturing, Government and Defense, Social Media and Online Gaming, Genomics and Healthcare, and other commercial markets, where optimizing complex business processes at speed and scale to maintain and improve Total Quality Management and Six Sigma remains a continuous challenge.

AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
10
WHITE PAPER
Appendix1. Tunables for HGST Object Storage System Load
Balancer
1.1. HAProxy Load Balancer Tuning:
- Load balancer ‘haproxy’ is configured from single thread to multi-threaded, assigned threads to be equal to the number of vcpus
- Dedicated server is assigned to the Load balancer
- Each load balancer thread affinities to a physical core
- Timeout for client and server is increased to 3minutes
- Max connections increased to 8000 for front end
1.2. Edited or Added the following parameters in haproxy.cfg file (for a server with 24 vcpus)
maxconn 8000nbproc 23cpu-map 1 1cpu-map 2 2cpu-map 3 3cpu-map 4 4cpu-map 5 5cpu-map 6 6cpu-map 7 7cpu-map 8 8cpu-map 9 9cpu-map 10 10cpu-map 11 11cpu-map 12 12cpu-map 13 13cpu-map 14 14cpu-map 15 15cpu-map 16 16cpu-map 17 17cpu-map 18 18cpu-map 19 19cpu-map 20 20cpu-map 21 21cpu-map 22 22
defaults timeout client 6m timeout server 3m
front-end maxconn 8000 timeout client 3m bind-process 1 2 3 4 5 6 7 8 9 10 11
2. S3A parameters in core-site.xml
2.1. The following parameters are added for S3A connector in core-site.xml:
<property> <name>fs.s3a.impl</name> <value>org.apache.hadoop.fs.s3a.S3AFileSystem</value> </property> <property> <name>fs.AbstractFileSystem.s3a.impl</name> <value>org.apache.hadoop.fs.s3a.S3A</value> </property> <property> <name>fs.s3a.connection.maximum</name> <value>100</value> </property> <property> <name>fs.s3a.connection.ssl.enabled</name> <value>false</value> </property> <property> <name>fs.s3a.endpoint</name> <value>s3.hgst.com</value> </property> <property> <name>fs.s3a.proxy.host</name> <value>192.168.1.72</value> </property> <property> <name>fs.s3a.proxy.port</name> <value>9007</value> </property> <property> <name>fs.s3a.block.size</name> <value>67108864</value> <!-- 64MB --> </property> <property> <name>fs.s3a.attempts.maximum</name> <value>10</value> </property> <property> <name>fs.s3a.connection.establish.timeout</name> <value>500000</value> </property> <property> <name>fs.s3a.connection.timeout</name> <value>500000</value></property> <property> <name>fs.s3a.paging.maximum</name> <value>1000</value> </property> <property> <name>fs.s3a.threads.max</name>

AN ANALYTICS SYSTEM COMPLEMENTING HGST OBJECT STORAGE SYSTEM
11
<value>4</value> </property><property> <name>fs.s3a.threads.keepalivetime</name> <value>60</value> </property> <property> <name>fs.s3a.max.total.tasks</name> <value>2</value> </property> <property> <name>fs.s3a.multipart.size</name> <value>67108864</value> <!-- 64MB --> </property> <property> <name>fs.s3a.multipart.threshold</name> <value>67108864</value> <!-- 64MB * 6 --> </property> <property> <name>fs.s3a.multipart.purge</name> <value>true</value> </property> <property> <name>fs.s3a.multipart.purge.age</name> <value>86400</value> <!-- 24h --> </property> <property> <name>fs.s3a.buffer.dir</name> <value>${hadoop.tmp.dir}/s3a</value> </property> <property> <name>fs.s3a.fast.upload</name> <value>true</value> </property> <property> <name>fs.s3a.fast.buffer.size</name> <value>4194304</value> </property> <property> <name>fs.s3a.signing-algorithm</name> <value>S3SignerType</value> </property>
3. Operating System Kernel Parameters
3.1. The following entries are added to /etc/sysctl.conf
net.core.rmem_max = 33554432 net.core.wmem_max = 33554432net.ipv4.tcp_rmem = 4096 87380 33554432 net.ipv4.tcp_wmem = 4096 65536 33554432net.ipv4.tcp_window_scaling=1net.ipv4.tcp_timestamps=1 net.ipv4.tcp_sack=1net.ipv4.tcp_tw_reuse=1 net.ipv4.tcp_keepalive_intvl=30 net.ipv4.tcp_fin_timeout=30 net.ipv4.tcp_keepalive_probes=5 net.ipv4.tcp_no_metrics_save=1 net.core.netdev_max_backlog=30000 net.ipv4.route.flush=1 fs.file-nr = 197600 0 3624009 fs.file-max=10000000
3.2.The following entries are added to /etc/security/limits.conf file
* soft nofile 100000* hard nofile 100000
© 2017 Western Digital Corporation or its affiliates. All rights reserved. Western Digital, the HGST logo, and EasiScale are registered trademarks or trademarks of Western Digital Corporation or its affiliates in the U.S. and/or other countries. Amazon S3 is a trademark of Amazon.com, Inc. or its affiliates. Apache®, Apache Hadoop, Hive, and Hadoop® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks. All other marks are the property of their respective owners.
WHITE PAPER
11
WHITE PAPER





























