Embed Size (px)
Citation preview

An Emulation-based Evaluation ofTCP BBRv2 Alpha for Wired Broadband
Elie F. Kfourya, Jose Gomeza, Jorge Crichignoa, Elias Bou-Harbb
aIntegrated Information Technology Department, University of South Carolina, USA.bThe Cyber Center For Security and Analytics, University of Texas at San Antonio, USA.
Abstract
Google published the first release of the Bottleneck Bandwidth and Round-trip Time (BBR) congestion control algorithm in 2016.Since then, BBR has gained a widespread attention due to its ability to operate efficiently in the presence of packet loss and inscenarios where routers are equipped with small buffers. These characteristics were not attainable with traditional loss-based con-gestion control algorithms such as CUBIC and Reno. BBRv2 is a recent congestion control algorithm proposed as an improvementto its predecessor, BBRv1. Preliminary work suggests that BBRv2 maintains the high throughput and the bounded queueing delayproperties of BBRv1. However, the literature has been missing an evaluation of BBRv2 under different network conditions.
This paper presents an experimental evaluation of BBRv2 Alpha (v2alpha-2019-07-28) on Mininet, considering alternative activequeue management (AQM) algorithms, routers with different buffer sizes, variable packet loss rates and round-trip times (RTTs),and small and large numbers of TCP flows. Emulation results show that BBRv2 tolerates much higher random packet loss rates thanloss-based algorithms but slightly lower than BBRv1. The results also confirm that BBRv2 has better coexistence with loss-basedalgorithms and lower retransmission rates than BBRv1, and that it produces low queuing delay even with large buffers. When a TailDrop policy is used with large buffers, an unfair bandwidth allocation is observed among BBRv2 and CUBIC flows. Such unfairnesscan be reduced by using advanced AQM schemes such as FQ-CoDel and CAKE. Regarding fairness among BBRv2 flows, resultsshow that using small buffers produces better fairness, without compromising high throughput and link utilization. This observationapplies to BBRv1 flows as well, which suggests that rate-based model-based algorithms work better with small buffers. BBRv2 alsoenhances the coexistence of flows with different RTTs, mitigating the RTT unfairness problem noted in BBRv1. Lastly, the paperpresents the advantages of using TCP pacing with a loss-based algorithm, when the rate is manually configured a priori. Futurealgorithms could set the pacing rate using explicit feedback generated by modern programmable switches.
Keywords: Active queue management (AQM), bandwidth-delay product (BDP), Bottleneck Bandwidth and Round-trip Time(BBR), BBRv2, congestion control, Controlled Delay (CoDel), CUBIC, round-trip time unfairness, router’s buffer size.
1. Introduction
The Transmission Control Protocol (TCP) [1] has been thestandard transport protocol to establish a reliable connectionbetween end devices. One of the key functions of TCP is con-gestion control, which throttles a sender node when the networkis congested and attempts to limit the TCP connection to its fairshare of network bandwidth [2].
The principles of window-based congestion control were de-scribed in late 1980s by Jacobson and Karels [3]. Since then,many enhancements have been proposed [4]. Traditional con-gestion control algorithms rely on the additive increase multi-plicative decrease (AIMD) control law [5] to establish the sizeof the congestion window, which in turn regulates the send-ing rate. These algorithms include Reno and its multiple vari-ants such as CUBIC [6] (the default algorithm used in multi-ple Linux distributions and in recent versions of Windows and
Email addresses: [email protected] (Elie F. Kfoury),[email protected] (Jose Gomez), [email protected] (JorgeCrichigno), [email protected] (Elias Bou-Harb)
MacOS), HTCP [7], and others. Most traditional algorithmsare loss-based, because a packet loss is used as a binary signalof congestion. The well-known TCP macroscopic model [8]demonstrated that traditional algorithms cannot achieve highthroughput in the presence of even a modest packet loss rateand large round-trip times (RTTs); the model states that thethroughput of a TCP connection is inversely proportional to theRTT and the square root of the packet loss rate. Essentially, thetime needed for TCP to recover from a packet loss is significant,as the congestion window is only increased by approximatelyone Maximum Segment Size (MSS) every RTT [9].
In a TCP connection, congestion occurs at the bottlenecklink. Usually, the router with the bottleneck link multiplexespackets received from multiple input links to an output link.When the sum of arrival rates exceeds the capacity of the out-put link, the output queue grows large and the router’s bufferis eventually exhausted, causing packet drops. Loss-based con-gestion control algorithms only indirectly infer congestion.
The router’s buffer plays an important role in absorbing traf-fic fluctuations, which are present even in the absence of con-gestion. The router avoids losses by momentarily buffering

packets as transitory bursts dissipate. When the router has asmall buffer, packets may be dropped even though the link maybe largely uncongested. With traditional loss-based algorithmssuch as Reno and CUBIC, packet losses lead to a low through-put as a consequence of the AIMD rule. While traditional loss-based algorithms were adequate in the past for applications re-quiring low throughput (e.g., Telnet, FTP), they face limita-tions for applications demanding high throughput, such as high-resolution media streaming, grid computing / Globus’ gridFTP[10], and big science data transfers [9].
The Bottleneck Bandwidth and Round-Trip Time (BBRv1)algorithm [11] has been the first scheme to estimate the bot-tleneck bandwidth. BBRv1 is a rate-based congestion controlalgorithm that periodically estimates the bottleneck bandwidthand does not follow the AIMD rule [11]. It uses pacing to setthe sending rate to the estimated bottleneck bandwidth. Thepacing technique spaces out or paces packets at the sender node,spreading them over time. This approach is a departure from thetraditional loss-based algorithms, where the sending rate is es-tablished by the size of the congestion window, and the sendernode may send packets in bursts. Thus, traditional algorithmsrely on routers to perform buffering to absorb packet bursts.
While BBRv1 has improved the throughput of a TCP con-nection, the literature [12] has reported some behavioral issues,such as unfairness and high retransmission rates. Recently,BBR version 2 (BBRv2) [13] has been proposed to addressthese limitations. BBRv1 uses two estimates to establish thesending rate of a connection: the bottleneck bandwidth and theRTT of the connection. BBRv2 enhances this approach by alsoincorporating Explicit Congestion Notification (ECN) and esti-mating the packet loss rate to establish the sending rate.
1.1. Contribution and FindingsAlthough some preliminary evaluations of BBRv2 have been
reported [13, 14], the literature is still missing a comprehen-sive evaluation of it. Thus, this paper presents an experimen-tal evaluation of BBRv2 under various scenarios designed totest the features of BBRv2. Scenarios include alternative activequeue management (AQM) algorithms, routers with differentbuffer sizes, variable packet loss rates and RTTs, and small andlarge numbers of TCP flows. Experiments are conducted withMininet using a real protocol stack in Linux, and provide thefollowing findings:
1. BBRv2 tolerates much higher random packet loss rates thanCUBIC but slightly lower than BBRv1.
2. In networks with small buffers, BBRv2 produces high Jain’sfairness index [15] while maintaining high throughput andlink utilization. On the other hand, in networks with largebuffers, the fairness index is significantly reduced. Thus,BBRv2 works better with small buffers. This observationalso applies to BBRv1 and indicates that small buffers re-duce the delay in the TCP control loop, which produces bet-ter outcomes.
3. The retransmission rate of BBRv2 is very low when com-pared with that of BBRv1. Although the retransmission rate
of CUBIC is lower than that of BBRv2, the throughput isalso lower. Additionally, the high retransmission rate notedin BBRv1 can be reduced by using an AQM algorithm suchas Flow Queue Controlled Delay (FQ-CoDel) [16].
4. The excessive delay or bufferbloat problem [17], noted intraditional congestion control algorithms when the buffersize is large, is not manifested in BBRv2. Instead, BBRv2exhibits a queueing delay that is loosely independent of thebuffer size, even when routers implement a simple Tail Droppolicy.
5. BBRv2 shows better coexistence with CUBIC than BBRv1,measured by the fairness index. Additionally, as the numberof flows in the network increases, the aggregate throughputobserved in BBRv2 is more consistent than that of BBRv1,independently of the buffer size. Thus, selecting the correctbuffer size is no longer essential when using BBRv2.
6. BBRv2 enhances the coexistence of flows with differentRTTs, mitigating the RTT unfairness problem observed inBBRv1. Such problem can be also corrected by using FQ-CoDel [16], regardless of the buffer size.
7. A simple Tail Drop policy leads to unfair bandwidth allo-cation among BBRv2 and CUBIC flows, in particular whenthe buffer size is large. On the other hand, advanced AQMpolicies such as FQ-CoDel [16] and Common ApplicationsKept Enhanced (CAKE) [18] produce fair bandwidth allo-cations.
8. Pacing [19] helps improve the fairness and the performanceof CUBIC when the rate is known a priori. Although dy-namically applying pacing with CUBIC to predefined rateswas solved in newer Linux versions, results suggest that fu-ture congestion control algorithms could consider the useof pacing and more explicit feedback signals from routers.As new-generation programmable switches are now becom-ing accessible, network operators could implement in-bandnetwork telemetry and other dataplane features to provideexplicit feedback control to adjust the pacing rate.
The rest of the paper is organized as follows: Section 2presents a brief background on BBRv2 and the AQM algo-rithms used in the experiments. Section 3 discusses relatedwork. Section 4 presents the experimental setup and the re-ported metrics, and Section 5 presents the evaluation results.Section 6 concludes the paper.
2. Background
2.1. BBRv2
BBRv2 is a rate-based, model-based congestion control al-gorithm. Fig. 1 depicts its high-level architectural design. Thealgorithm measures the bandwidth, the RTT, the packet lossrate, and the ECN mark rate. The measurements are used toestimate the bandwidth-delay product (BDP) and to model theend-to-end path across the network, referred to as the network
2

Bandwidth RTT Loss rate ECN
Input: measurements from network traffic
Network path
modelState machine
BBRv2: model-based congestion control
Rate
Output: control parameters
Volume Quantum
Transport sending engine
Application data
Packets to the network
Figure 1: High-level architectural design of BBRv2.
path model. Based on the current network path model, the algo-rithm transitions among states of a finite state machine, whichincludes probing for bandwidth and RTT. The state machinegenerates three control parameters: rate, volume, and quantum.The rate is the pacing rate that will be used by the sender. Thevolume is the amount of data or bits that can be inside the pathas they propagate from the sender to the receiver, also referredto as in-flight volume. The quantum is the maximum burst sizethat can be generated by the sender. The control parameters areused by the transport protocol sending engine, which segmentsthe application data into bursts of quantum size before sendingthe data to the network as packets. Although packet loss rateand ECN signals are inputs of the model, BBRv2 does not sim-ply always apply a multiplicative decrease for every round tripwhere packet loss occurs or an ECN signal arrives.
BBRv2 maintains short-term and long-term estimates of thebottleneck bandwidth and maximum volume of in-flight data.This is analogous to CUBIC, which has a short-term slow startthreshold estimate (ssthresh) and long term maximum con-gestion window (W max). BBRv2 spends most of the connec-tion time in a phase where it can quickly maintain flow balance(i.e., the sending rate adapts to the new bottleneck bandwidth /
bandwidth-delay product), while also attempting to leave unuti-lized capacity in the bottleneck link. This spare capacity, re-ferred to as headroom capacity, enables entering flows to grabbandwidth. Therefore, BBRv2 maintains a short-term bw lo
and inflight lo estimates to bound the behavior using thelast delivery process (loss, ECN, etc.). The basic intuition inthis case is to maintain reasonable queueing levels at the bottle-neck bandwidth by inspecting the recent delivery process.
BBRv2 also periodically probes for additional bandwidthbeyond the flow balance level. It maintains a long-termtuple (bw hi and inflight hi) that estimate the maximumbandwidth and in-flight volume that can be achieved, consistentwith the network’s desired loss rate and ECN mark rate.
BBRv2 Research Focus and Goals. According to the IETFproposal [13], BBRv2 has the following goals:
1. Coexisting with loss-based congestion control algorithmssharing the same bottleneck link. The literature [12], [20]has shown that when the router’s buffer size is below 1.5BDP,BBRv1 causes constant packet losses in the bottleneck link,leading to successive multiplicative decreases in flows using
loss-based algorithms. When the router’s buffer size exceeds3BDP, loss-based algorithms steadily claim more bandwidth inthe bottleneck link, leading to a decrease in the bandwidth allo-cated to BBRv1. BBRv2 aims at improving the fairness index[21] when competing with loss-based algorithms, in particularin the above scenarios.
2. Avoiding the bufferbloat problem. BBRv2 aims at hav-ing no additional delay when a router’s buffer is large (up to100BDP). At the same time, BBRv2 aims at having low packetloss rate when a router’s buffer is small.
3. Minimizing the time to reach an equilibrium point wherecompeting flows fairly share the bandwidth. BBRv2 attemptsto solve the RTT bias problem observed in BBRv1: whena router’s buffer is large, flows with large RTTs have largebandwidth-delay product / in-flight volume and use much ofthe buffer, thus claiming more bandwidth than flows with smallRTTs.
4. Reducing the variation of the throughput by making the“PROBE RTT” phase less drastic.
Life Cycle of a BBRv2 Flow. The state machine of BBRv2 issimilar to that of BBRv1, alternating between cycles that probefor bandwidth and for round-trip time. A simplified life cy-cle of a flow is shown in Fig. 2. Initially, a flow starts at theSTARTUP phase (a), which is similar to the traditional slow-start phase. During the STARTUP phase, the algorithm attemptsto rapidly discover the bottleneck bandwidth by doubling itssending rate every round-trip time. If the packet loss rate orECN mark rate increases beyond their respective thresholds,the inflight hi is set as an estimation of the maximum in-flight volume. The flow exits the STARTUP phase when contin-uous bandwidth probes reach either a stable value (plateau) orthe inflight hi is set. The flow then enters the DRAIN phase(b) which attempts to drain the excessive in-flight bits and thequeue, which may have been formed at the bottleneck link dur-ing the previous phase, by setting a low pacing (sending) rate.The flow exits this phase when the in-flight volume is at or be-low the estimated bandwidth-delay product.
The flow spends most of the remainder of its life into theCRUISE phase (c), where the sending rate constantly adapts tocontrol queueing levels. The {bw, inflight} lo tuple is updatedevery round-trip time, using also packet loss and ECN signals.Afterwards, during the PROBE BW:REFILL phase (d), the flowprobes for additional bandwidth and in-flight capacity. The goalof this phase is to increase the in-flight volume (which was pre-viously reduced) by sending at the estimated capacity (bottle-neck bandwidth) for one round-trip time. Note that the expec-tation in this phase is that queues will not be formed, as thesending rate is not beyond the estimated bottleneck bandwidth.Also, if the routers have small buffers, packet losses that are notdue congestion may occur. To avoid a reduction in the sendingrate, which would negatively impact the throughput, the algo-rithm tolerates up to loss thresh losses every round-trip time.
During bandwidth probing PROBE BW:UP phase, ifinflight hi is fully utilized then it is increased by an
3

inflig
ht
Time
STARTUP
inflig
ht
Time
Inflight_hi
inflig
ht
Time
Inflight_lo
PROBE_BW: CRUISE inflig
ht
Time
Inflight_hi
PROBE_BW: REFILL
(a) (b) (c) (d) (e)
Inflight_hi
PROBE_BW: UPBDPBDPBDP
inflig
ht
Time
BDPInflight_hi
PROBE_BW: DOWN
DRAIN
Figure 2: Life cycle of a BBRv2 flow and its five phases: (a) STARTUP, (b) DRAIN, (c) PROBE BW: CRUISE, (d) PROBE BW: REFILL and PROBE BW: UP,and (e) PROBE BW: DOWN.
amount that grows exponentially per round (1, 2, 4, 8 ...packets). On the other hand, if the loss rate or the ECNmark rate is too high, then the inflight hi is reduced tothe estimated maximum safe in-flight volume. The flow exitsthe PROBE BW:UP phase when the inflight hi is set, or theestimated queue is high enough (in-flight volume > 1.25 ·estimated BDP). Finally, the flow enters the PROBE BW:DOWN
phase (e) to drain the queue recently created, and leavesunused headroom. The flow exits this phase when both of thefollowing conditions are met: the in-flight volume is belowa headroom margin from the inflight hi and the in-flightvolume is at or below the estimated bandwidth-delay product.
2.2. Active Queue Management and Bufferbloat
AQM encompasses a set of algorithms to reduce networkcongestion and queueing delays by preventing buffers from re-maining full. AQM policies help to mitigate the bufferbloatproblem [17, 22–24], which not only excessively increases thelatency but also decreases the aggregate network throughputand increases the jitter.
Several schemes have been proposed to mitigate thebufferbloat problem, such as regulating the sending rate at enddevices (e.g., BBRv1/BBRv2) and implementing AQM poli-cies at routers to signal imminent congestion. AQM policiesinclude Controlled Delay (CoDel) [25], Flow Queue CoDel(FQ-CoDel) [16] and Common Applications Kept Enhanced(CAKE) [18].
FQ-CoDel. CoDel [25] is a scheduling algorithm thatprevents bufferbloat by limiting the queue size. CoDel mea-sures the packet delay in the queue, from ingress to egressthrough timestamps. It recognizes two types of queues: 1)good queue, which has a small sojourn time; and 2) badqueue, which has a high sojourn time. When the bad queue ismanifested, the bufferbloat problem emerges. CoDel does notrely on estimating RTT or link rate; instead it uses the actualdelay experienced by each packet as a criterion to determineif a queue is building up. Thus, CoDel can adapt dynamicallyto different link rates without impacting the performance.FQ-CoDel [16] combines fair queueing scheduling and CoDel,attempting to keep queues short and to provide flow isolation.The queue used for a flow is selected by using a hashingfunction that maps the packets’ flow to the selected queue.The scheduler selects which queue to be dequeued based on adeficit round-robin mechanism.
CAKE. This scheduling algorithm is an extension of FQ-CoDel, designed for home gateways [18]. CAKE uses aneight-way set-associative hash instead of a direct hash functionas in FQ-CoDel. CAKE provides bandwidth shaping withoverhead compensation for various link layers, differentiatedservice handling, and ACK filtering.
3. Related Work
Previous studies focused on BBRv1 and provided an in-depth analysis of its behavior under various network condi-tions. Scholz et al. [26] explored features such as bottle-neck bandwidth overestimation, inter-protocol behavior withCUBIC, inter-flow synchronization, RTT unfairness, and oth-ers. Ma et al. [27] conducted an experimental evaluation andanalysis of the fairness of BBRv1. The researchers focused onthe RTT unfairness and proposed BBQ, a solution that providesbetter RTT fairness without deviating from Kleinrock’s optimaloperating point. Fejes et al. [28] performed experiments thatcombined different AQMs and congestion control algorithmsto analyze fairness and coexistence of flows. The authors con-cluded that fairness is poor as the assumptions used during thedevelopment of AQMs do not typically hold in real networks.While the authors tested some congestion control algorithmsand AQMs, they did not report results with FQ-CoDel [16] andCake [18]. Their experiments did not consider metrics and net-work conditions such as RTT, queueing delays, flow completiontime (FCT), retransmission rates, and RTT unfairness. Tahil-iani et al. [29] studied the differences in perceiving congestion,from the viewpoint of end systems, between networks that donot provide explicit feedback and AQMs, and those that providefeedback and AQMs. They demonstrated that simple feedbackgenerated at the point of congestion eliminates the congestionambiguities faced by end-systems. The authors tested BBRv2and DCTCP-style ECN [30], and showed that BBRv2 achieveshigher throughput when ECN is enabled in routers. Zhang [14]conducted experiments on BBRv1 variations, controlling pa-rameters used to improve the throughput. The tests focused onthe life cycles of BBRv1 variations.
Recent work includes in-network TCP feedback with new-generation switches [19, 31]. While these protocols cannot beused without replacing the legacy routers currently used in theInternet, their results suggest future research directions. Kfouryet al. [19] proposed a scheme based on programmable switchesto dynamically adjust the rates of competing TCP flows, ac-cording to the number of flows sharing the bottleneck link. The
4

h100
h1
R1
(Loss/delay
emulator)
R2
(Rate limiting
and AQM)
R3
00
Sender
h200
h101
Receiver
Bottleneck link
Figure 3: Topology used for evaluations.
scheme uses a custom protocol that is encapsulated inside theIP Options header field and requires programmable switches toparse such header. Li et al. [31] developed High Precision Con-gestion Control (HPCC), a new congestion control protocol thatleverages in-network telemetry (INT) to obtain precise link loadinformation. The authors showed that by using programmableswitches and INT, HPCC quickly converges to an equilibriumpoint while avoiding congestion and maintaining small queues.
4. Experimental Setup
Fig. 3 shows the topology used to conduct the experiments.The topology consists of 100 senders (h1, h2, ..., h100), eachopening a TCP connection to a corresponding receiver (h101,h102, ..., h200). The hosts in the experiments are networknamespaces in Linux. The AQM policy used in routers is thesimple Tail Drop, unless another policy is explicitly stated. Theemulation is conducted on Mininet [32], a lightweight mecha-nism for isolating network resources. The virtual machine usedfor the experiment runs a light Ubuntu (Lubuntu 19.04) distri-bution and the kernel version is 5.2.0-rc3+. The scripts usedfor the emulation are available in the following GitHub reposi-tory [33]. The emulation scenario was carefully designed, andsufficient resources were allocated (8 Xeon 6130 cores operat-ing at 2.1 GHz, with 8GB of RAM) to avoid over-utilization ofresources (e.g., the usage of CPUs was at all times below pru-dent levels), thus avoiding misleading results. The version ofBBRv2 used in the experiments can be found at [34]. Specif-ically, the “v2alpha-2019-07-28” release was used. The FairQueue (fq) queuing discipline (qdisc) was used on the send-ing hosts to implement pacing.
Latency/Loss Emulation. The router R1 is used to configurethe propagation delay and random packet loss rate, on the linkconnected to router R2. The Network Emulator (NetEm) tool[35] is used to set these values. All tests are configured with atotal propagation delay of 20ms, unless otherwise specified.
Rate Limitation and Buffer Size. Another importantfactor studied in this paper is the impact of the buffer size onthe bottleneck link. The topology of Fig. 3 uses the Linux’sToken Bucket Filter (TBF) for limiting the link rate and hence
for emulating a bottleneck in the network. TBF is also used tospecify the buffer size on the interface of the router R2, facingthe router R3. The bottleneck bandwidth (link R2-R3) is setto 1Gbps, unless otherwise specified. All other links have acapacity of approximately 40Gbps.
Metrics Collection. The tool used to perform the mea-surements between devices is iPerf3 [36]. Performance metricsand variables include throughput, retransmission rate, size ofcongestion window, RTT, and others. The queue occupancyon the interface connecting to the bottleneck link is measuredusing Linux’s traffic control (tc). The estimated bottleneckbandwidth in BBRv2, pacing rate, and other internal variablesare measured using Linux’s ss command. The retransmissionrate is calculated using netstat. The Jain’s fairness index iscomputed to measure fairness, as described in RFC 5166 [15]:
F =
(n∑
i=1Ti
)2
n ·n∑
i=1(Ti)2
, (1)
where Ti is the throughput of flow i. For example, in an scenariowith 100 simultaneous flows, n = 100 and i = 1, 2, ..., 100. Theresults report the fairness index in percentage, which is givenby multiplying Eq. (1) by 100.
Each test was executed for 300 seconds, unless otherwisespecified. The size of the TCP send and receive buffers(net.ipv4.tcp wmem and net.ipv4.tcp rmem) on the end-hosts (senders and receivers) was set to 10 times the bandwidth-delay product.
5. Results and Evaluation
This section presents the results obtained by running tests indifferent network conditions. Every experiment is repeated 10times and results are averaged for more accuracy.
5.1. Multiple Flows and Buffer SizesThese tests measure the throughput of a flow and the link
utilization of the bottleneck link. Each test consists of 100 flowsrunning the same congestion control algorithm: CUBIC, BBR,or BBRv2. The throughput of each flow over the duration of thetest (300 seconds) is calculated, which produces 100 samples.As the test is repeated 10 times, the Cumulative DistributionFunction (CDF) of the throughput is constructed with the 1000samples. The link utilization for a test is obtained by addingthe throughput of the 100 flows corresponding to that test anddividing this aggregate throughput by the capacity of the link,1Gbps. The CDF of the link utilization is constructed with the10 samples.
Fig. 4 shows the CDFs of the throughput when no randompacket losses are emulated, considering various buffer sizes.Fig. 5 shows their corresponding CDFs of the link utilization.Figs. 4(a)-(b) and 5(a)-(b) show the results when the buffer sizeis small, 0.01BDP and 0.1BDP, respectively. BBRv2’s aver-age throughput exceeds CUBIC, and is closely similar to that
5

0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=6.2=0.6=99.0
BBRv1=9.4=1.4=97.8
BBRv2=9.4=0.6=99.6
(a) Buffer size: 0.01BDP.
0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=9.1=0.6=99.6
BBRv1=9.5=1.7=96.9
BBRv2=9.4=0.7=99.4
(b) Buffer size: 0.1BDP.
0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=9.3=0.6=99.6
BBRv1=9.5=3.6=87.5
BBRv2=9.3=7.8=59.1
(c) Buffer size: 1BDP.
0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=9.5=3.2=89.8
BBRv1=9.6=16.9=24.3
BBRv2=9.4=7.0=64.3
(d) Buffer size: 10BDP.
0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=9.5=9.5=50.4
BBRv1=9.6=16.9=24.3
BBRv2=9.4=6.8=65.7
(e) Buffer size: 100BDP.
Figure 4: Cumulative distribution function of the throughput of CUBIC, BBRv1, and BBRv2, with various buffer sizes and no random packet loss.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=61.9=0.5
BBRv1=94.5=0.2
BBRv2=93.7=0.1
(a) Buffer size: 0.01BDP.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=91.2=0.9
BBRv1=95.5=0.6
BBRv2=94.0=0.2
(b) Buffer size: 0.1BDP.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=92.6=0.0
BBRv1=94.6=0.6
BBRv2=93.2=0.5
(c) Buffer size: 1BDP.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=94.8=0.1
BBRv1=95.6=0.3
BBRv2=93.7=0.5
(d) Buffer size: 10BDP.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=95.5=0.4
BBRv1=95.7=0.3
BBRv2=93.9=0.4
(e) Buffer size: 100BDP.
Figure 5: Cumulative distribution function of the link utilization of CUBIC, BBRv1, and BBRv2, with various buffer sizes and no random packet loss.
of BBRv1. CUBIC presents lowest throughput and link uti-lization due to the constant AIMD cycles emerging from fre-quent packet losses, caused by the small buffer. For BBRv1and BBRv2, the standard deviation of the throughput is smalland the bottleneck link’s bandwidth is evenly distributed amongthe simultaneous flows. Thus, the fairness index is high.
Fig. 4(c) and Fig. 5(c) show the results when the buffer size isincreased to 1BDP. Although the average throughput of BBRv2is similar to that of CUBIC, its standard deviation is increased,which indicates that some flows are grabbing more bandwidththan others, and hence, the fairness index decreases.
Fig. 4(d) shows the results when the buffer size is increasedto 10BDP. The throughput and the link utilization of CUBICslightly increase while its fairness index decreases to 89.8%.Although the throughput and link utilization of BBRv1 andBBRv2 remain high, their fairness indices are only 24.3% and64.3%. Thus, for BBRv1 and BBRv2, increasing the buffer sizeto 1BDP and above only reduces the fairness.
Figs. 6 and 7 show the results obtained with 1% packet lossrate. Initially, the same tests were executed with 0.01% packetloss rate instead of 1%, but the results were very similar to Figs.4 and 5 due to having a small loss rate distributed among the100 flows. Thus, 1% loss rate was chosen. With packet losses,BBRv1 and BBRv2 achieve much higher throughput and linkutilization than CUBIC, independently of the buffer size. How-ever, when the buffer size is large, 10BDP and 100BDP, see Fig.6(d)-(e), the fairness index produced by BBRv1 and BBRv2 de-creases to low levels.
Summary: with small buffers, BBRv1 and BBRv2 produce afair bandwidth allocation and high throughput and link utiliza-tion. With large buffers, the high throughput and the link uti-lization remain but the fairness decreases significantly. Thesetwo observations indicate that BBRv1 and BBRv2 work bet-ter with small buffers, as the TCP control loop becomes faster.
Both BBRv1 and BBRv2 have better performance than CUBIC,especially with random packet losses and small buffers.
5.2. Retransmissions with Multiple Flows
These tests compare the retransmission rate of CUBIC,BBRv1, and BBRv2 as a function of the number of compet-ing flows. The buffer size is 0.02BDP and no random packetlosses are introduced. The duration of each test is 300 secondsand the emulated propagation delay is 100ms.
Fig. 8 shows that the retransmission rate of BBRv1 is signifi-cantly high with any number of flows. With a single flow, the re-transmission rate of BBRv1 is around 2.5%, while CUBIC andBBRv2’s retransmission rates are below 0.1%. When the num-ber of flows increases to 10, the retransmission rate of BBRv1increases to approximately 18%, while BBRv2’s retransmissionrate is approximately 2.5%. CUBIC’s retransmission rate re-mains low at 0.5%. As the number of flows increases, BBRv1’sretransmission rate continues to increase and is significantlyhigher than that of BBRv2. Although the retransmission rateof CUBIC is lower than that of BBRv2, the throughput is alsolower, see Figs. 4 and 6.
Summary: the retransmission rate of BBRv2 is significantlylower than that of BBRv1. Thus, BBRv2 successfully reducesthe excessive number of retransmissions of BBRv1. Althoughthe retransmission rate of CUBIC is low, its throughput is alsolow.
5.3. Queueing Delay with Large Buffers
These tests measure the queueing delay when the router’sbuffer size is large. Experiments are analogous to those reportedby the BBRv2’s IETF presentation [13]. The duration of eachtest is 300 seconds and the total propagation delay and the band-width are 30ms and 1Gbps respectively. Various buffer sizes are
6

0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=5.2=0.4=99.4
BBRv1=9.4=1.4=97.8
BBRv2=9.4=0.6=99.6
(a) Buffer size: 0.01BDP.
0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=6.1=0.7=98.6
BBRv1=9.5=1.7=96.9
BBRv2=9.4=0.7=99.4
(b) Buffer size: 0.1BDP.
0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=6.2=0.8=98.5
BBRv1=9.5=3.4=88.5
BBRv2=9.3=3.2=89.5
(c) Buffer size: 1BDP.
0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=6.0=0.8=98.2
BBRv1=9.7=16.2=26.4
BBRv2=9.7=17.2=24.1
(d) Buffer size: 10BDP.
0 10 20 30 40 50 60Throughput [Mbps]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=6.0=0.8=98.3
BBRv1=9.6=19.4=19.8
BBRv2=9.7=17.6=23.4
(e) Buffer size: 100BDP.
Figure 6: Cumulative distribution function of the throughput of CUBIC, BBRv1, and BBRv2, with various buffer sizes and a random packet loss rate of 1%.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=51.9=0.5
BBRv1=94.4=0.3
BBRv2=93.6=0.1
(a) Buffer size: 0.01BDP.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=61.1=1.0
BBRv1=94.6=0.8
BBRv2=93.6=0.1
(b) Buffer size: 0.1BDP.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=62.0=1.1
BBRv1=95.2=0.9
BBRv2=92.7=0.3
(c) Buffer size: 1BDP.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=60.4=1.4
BBRv1=96.7=0.6
BBRv2=96.9=1.1
(d) Buffer size: 10BDP.
20 40 60 80 100Link utilization [%]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=60.1=1.1
BBRv1=96.4=0.4
BBRv2=97.0=0.5
(e) Buffer size: 100BDP.
Figure 7: Cumulative distribution function of the link utilization of CUBIC, BBRv1, and BBRv2, with various buffer sizes and a random packet loss rate of 1%.
used and samples of RTTs are averaged into a smoothed round-trip time (SRTT).
Fig. 9(a) shows the RTT results, which is the sum of thequeueing delay plus the propagation delay, when two flows arepresent. When the buffer size is 1BDP, the queueing delay issmall and packets experience a slight increase above the prop-agation delay (30ms) with BBRv2. When the buffer size is10BDP, the RTT of CUBIC increases to approximately 300ms.On the other hand, the RTTs of BBRv1 and BBRv2 are signifi-cantly lower, approximately 60ms. As the buffer size increasesto 50BDP and 100BDP, the RTT of CUBIC increases to ap-proximately 1000ms and 2000ms, respectively. The RTTs ofBBRv1 and BBRv2 remain approximately constant at 60ms.
Figs. 9(b)-(d) show the latency results, when 10, 25, and 50flows use the same congestion control algorithm. The RTT ofCUBIC decreases as the number of flows increases, especiallywith large buffers. With more simultaneous flows, CUBIC’scongestion window is relatively small and the throughput perflow decreases, which reduces the buffer occupancy. BBRv1and BBRv2 maintain low RTTs, between 50-75ms.
100 101 102
Number of flows
0
5
10
15
20
25
30
Retra
nsm
issio
n ra
te [%
] CUBICBBRv1BBRv2
Figure 8: Retransmission rate as a function of the number of flows. The buffersize is 0.02BDP.
Summary: BBRv1 and BBRv2 maintain relatively lowqueueing delay, independently of the number of flows and thebuffer size. CUBIC has a high queueing delay with largebuffers, in particular when the number of simultaneous flowsin the network is small.
5.4. Throughput and Retransmissions as a Function of PacketLoss Rate
These tests measure the throughput and the retransmissionrate of a single TCP flow as a function of the packet loss rate,using CUBIC, BBR, and BBRv2. Tests with buffer sizes of0.1BDP and 1BDP are conducted. The total propagation delayis 100ms.
Fig. 10(a) shows that BBRv1 and BBRv2 achieve higherthroughput than CUBIC when the buffer size is 0.1BDP. Whenthe packet loss rate is lower than 1%, BBRv1 and BBRv2 havea steady throughput of approximately 900Mbps. At that rate,the throughput of BBRv2 decreases to 600Mbps while that ofBBRv2 remains at 900Mbps. When the packet loss rate in-creases to 10%, the throughput of BBRv2 collapses while thatof BBRv1 decreases to 600Mbps. Although BBRv1 has ahigher throughput than BBRv2, its retransmission rate is alsohigher, as shown in Fig. 10(b). BBRv1 is loss-agnostic, whichleads to a higher retransmission rate, in particular when thebuffer size is small. On the other hand, BBRv2 uses the packetloss rate as a signal to adjust the sending rate, as shown in Fig.1.
Fig. 10(c) shows the throughput when the buffer size is1BDP. The throughput of BBRv2 decreases to 800Mbps whenthe packet loss rate is 1%, and collapses as the rate increasesfurther. BBRv1 achieves a better throughput than BBRv2 whenthe packet loss rate exceeds 0.1%. Both BBRv1 and BBRv2significantly outperform CUBIC in throughput. Fig. 10(d)
7

1 10 50 100Buffer size [BDP]
101
102
103
104
RTT
[ms]
CUBICBBRv1BBRv2
(a) Round-trip time, 2 flows.
1 10 50 100Buffer size [BDP]
101
102
103
104
RTT
[ms]
CUBICBBRv1BBRv2
(b) Round-trip time, 10 flows.
1 10 50 100Buffer size [BDP]
101
102
103
104
RTT
[ms]
CUBICBBRv1BBRv2
(c) Round-trip time, 25 flows.
1 10 50 100Buffer size [BDP]
101
102
103
104
RTT
[ms]
CUBICBBRv1BBRv2
(d) Round-trip time, 50 flows.
Figure 9: Round-trip time experienced by packets with: (a) 2 simultaneous flows; (b) 10 simultaneous flows; (c) 25 simultaneous flows; and (d) 50 simultaneousflows in the network. The total propagation delay is 30ms.
shows the retransmission rate when the buffer is 1BDP. BBRv1and BBRv2 have similar retransmission rates.
Summary: BBRv2 can tolerate up to approximately 1%of random packet loss rate without a significant performancedegradation, which is much higher than the packet loss rate tol-erated by CUBIC but lower than that of BBRv1. On the otherhand, with a small buffer, the retransmission rate of BBRv2 issignificantly lower than that of BBRv1.
5.5. Coexistence and Fairness with CUBIC
These tests investigate the capabilities of BBRv1 and BBRv2to coexist with CUBIC, with different buffer sizes. Four typesof experiments are considered: 1) a single BBRv1 flow compet-ing with a single CUBIC flow; 2) 50 BBRv1 flows competingwith 50 CUBIC flows; 3) a single BBRv2 flow competing witha single CUBIC flow; and 4) 50 BBRv2 flows competing with50 CUBIC flows. Experiments with and without random packetlosses are conducted.
The middle and bottom graphs of Fig. 11(a) show thethroughput as a function of the buffer size. The top graph showsthe corresponding fairness index. When the buffer size is below1BDP, BBRv1 consumes approximately 90% of the bandwidth.On the other hand, BBRv2 shows a better coexistence with CU-BIC, in particular with a small buffer. When the buffer size ex-ceeds 1BDP, CUBIC starts consuming more bandwidth. Whenthe buffer is significantly large, 100BDP, the fairness index de-creases to approximately 60%.
Fig. 11(b) shows the results with a random packet loss rateof 0.01%. When the buffer size is below 1BDP, BBRv2 hashigher throughput than CUBIC, yet both achieve comparable
throughput. This result is reflected in the fairness index, whichis always above 80%. In contrast, when the buffer size is below1BDP, BBRv1 consumes most of the bandwidth, leading to apoor performance of the CUBIC flow. The corresponding fair-ness index is below 60%. This index increases to approximately100% only when the buffer size is very large, 100BDP.
Figs. 11(c) and 11(d) show the results with 50BBRv1/BBRv2 flows competing with 50 CUBIC flows, withand without random packet losses. BBRv2 achieves betterthroughput than CUBIC, independently of the buffer size, andthe fairness index is always above 80%. On the other hand,BBRv1 consumes most of the bandwidth, in particular when thebuffer size is below 1BDP. When no random packet losses areconfigured and when the buffer size is above 4BDP, the through-put of BBRv1 and CUBIC are similar and the fairness indexincreases.
Fig. 12 evaluates the impact of the number of competingflows on the throughput share per congestion control algorithm.The dashed lines represent the ideal fair share, while the solidlines represent the measured share. It can be seen that gener-ally BBRv2 flows claim more bandwidth than their fair shareswhen competing against CUBIC flows. Nevertheless, as thenumber of BBRv2 flows increases, CUBIC’s bandwidth shareapproaches the ideal share; for example, with 10 BBRv2 flowsand two CUBIC flows, the achieved share is exactly the fairshare.
Fig. 13 shows the heatmaps of the fairness index. The testsconsider two competing flows (CUBIC and BBRv2), differentbuffer sizes, without random packet losses and with 0.01% ran-dom packet loss rate. Each entry in a heatmap was generated by
10 4 10 3 10 2 10 1 100 101
Packet loss rate [%]
0
200
400
600
800
1000
1200
Thro
ughp
ut [M
bps]
CUBIC BBRv1 BBRv2
(a) Buffer size: 0.1BDP.
10 4 10 3 10 2 10 1 100 101
Packet loss rate [%]
10 3
10 2
10 1
100
101
102
Retra
nsm
issio
n ra
te [%
] CUBIC BBRv1 BBRv2
(b) Buffer size: 0.1BDP.
10 4 10 3 10 2 10 1 100 101
Packet loss rate [%]
0
200
400
600
800
1000
1200
Thro
ughp
ut [M
bps]
CUBIC BBRv1 BBRv2
(c) Buffer size: 1BDP.
10 4 10 3 10 2 10 1 100 101
Packet loss rate [%]
10 3
10 2
10 1
100
101
102
Retra
nsm
issio
n ra
te [%
] CUBIC BBRv1 BBRv2
(d) Buffer size: 1BDP.
Figure 10: Throughput and retransmission rate as functions of the packet loss rate. The buffer size is: (a), (b): 0.1BDP, and (c), (d): 1BDP.
8

0
100
Fairn
ess [
%]
CUBIC - BBRv1 CUBIC - BBRv2
0
1000 CUBIC BBRv1
10 1 100 101 102
Buffer size [BDP]0
1000
Thro
ughp
ut [M
bps]
CUBIC BBRv2
(a) No packet loss, 2 flows.
0
100
Fairn
ess [
%]
CUBIC - BBRv1 CUBIC - BBRv2
0
1000 CUBIC BBRv1
10 1 100 101 102
Buffer size [BDP]0
1000
Thro
ughp
ut [M
bps]
CUBIC BBRv2
(b) 0.01% packet loss rate, 2 flows.
0
100
Fairn
ess [
%]
CUBIC - BBRv1 CUBIC - BBRv2
0
1000 CUBIC BBRv1
10 1 100 101 102
Buffer size [BDP]0
1000
Thro
ughp
ut [M
bps]
CUBIC BBRv2
(c) No packet loss, 100 flows.
0
100
Fairn
ess [
%]
CUBIC - BBRv1 CUBIC - BBRv2
0
1000 CUBIC BBRv1
10 1 100 101 102
Buffer size [BDP]0
1000
Thro
ughp
ut [M
bps]
CUBIC BBRv2
(d) 1% packet loss rate, 100 flows.
Figure 11: Throughput and fairness index as functions of the buffer size. (a) 2 flows: one BBRv1 (middle graph) / BBRv2 (bottom graph) flow and one CUBICflow, with no random packet losses; (b) 2 flows: one BBRv1/BBRv2 flow and one CUBIC flow, with a random packet loss rate of 0.01%; (c) 100 flows: 50BBRv1/BBRv2 flows and 50 CUBIC flows, with no random packet losses; and (d) 100 flows: 50 BBRv1/BBRv2 flows and 50 CUBIC flows, with a random packetloss rate of 1%.
running 10 experiments, calculating the average fairness value,and coloring the entry according to that value. Additionally, anentry includes three values: the link utilization of the bottlenecklink in percentage (center top value), the percentage of band-width used by CUBIC (bottom left value), and the percentageof bandwidth used by BBRv2 (bottom right value). The rowsand columns correspond to the bandwidth of the bottleneck linkand the propagation delay respectively. For simplicity, the prop-agation delay is referred to as delay hereon.
Fig. 13(a)-(c) show the heatmap with no random packetlosses. When the buffer size is small, see Fig. 13(a), theheatmap illustrates a low fairness index. Even with small BDPvalues (upper left entries of the matrix), BBRv2 is allocatedmore bandwidth than CUBIC. The latter presents low band-width allocation because of the constant AIMD cycles emerg-ing from frequent packet losses due to the small buffer. Whenthe bandwidth (lower left entries), the delay (upper right en-tries), or both increase, the fairness index decreases further.This is clearly noted for large BDP values (lower right entries),where the bandwidth allocated to CUBIC collapses as that ofBBRv2 surges. As a traditional loss-based congestion controlalgorithm, CUBIC throughput is inversely proportional to theRTT and the square root of the packet loss rate [37]. Becauseof this relationship, its performance is poor with large BDP val-ues. On the other hand, the above relation does not apply to
1 2 3 4 5 6 7 8 9 10Number of CUBIC flows
0
20
40
60
80
100
Tota
l sha
re o
f CUB
IC fl
ows [
%] # BBRv2 flows
1 2 3 5 10
Figure 12: Bandwidth share for competing CUBIC and BBRv2 flows. Thedashed lines show the ideal fair share and the solid lines show the measuredshare.
BBRv2. Moreover, BBRv2 actively measures the propagationdelay and the available bandwidth to estimate the number ofpackets that can be in-flight, leading to a better utilization ofthe bandwidth. Note that when the bandwidth is 20Mbps andthe delay is 20ms, the buffer can only hold one packet, whichleads to a low link utilization.
When the buffer size is 1BDP, see Fig. 13(b), packet lossesdue to buffering at the router decrease. Consequently, CUBICutilizes more bandwidth and a better fairness index is observed.Increasing the buffer size further to 10BDP, however, results inlower fairness index, see Fig. 13(c). When the BDP is small(upper right entries), CUBIC fills the buffer and uses most ofthe bandwidth, while BBRv2 is allocated the remaining capac-ity. As the bandwidth (lower left entries) or the delay (upperright entries) increases, the bandwidth is more evenly allocated.When the BDP is large (lower right corner), the performanceof CUBIC deteriorates and BBRv2 utilizes the available band-width.
When random packet losses are injected, see Fig. 13(d)-(f),the fairness index is similar to the results observed in Fig. 13(a)-(c). A larger bandwidth allocation for BBRv2 is more evidentas the BDP increases (lower right corner) and CUBIC is unableto use its share of the bandwidth.
Summary: BBRv2 shows a better coexistence with CUBICthan BBRv1. Additionally, as the number of flows increases,the aggregate throughput observed in BBRv2 is more consistentthan that of BBRv1, independently of the buffer size. There-fore, when BBRv2 is used, selecting the correct buffer size isnot as important as it is when loss-based congestion control al-gorithms are used. Furthermore, as the number of BBRv2 flowsincreases when competing against CUBIC, the bandwidth shareof CUBIC approaches the ideal share. When the buffer sizeis 1BDP, BBRv2 demonstrates good coexistent with CUBIC.BBRv2 is also able to use the available bandwidth in networkswith small buffer size and in networks with large BDP. In suchscenarios, additional bandwidth is available because of the in-ability of CUBIC to use its share.
5.6. Round-trip Time UnfairnessThe literature has reported that BBRv1 suffers from RTT un-
fairness [27]. Unlike traditional congestion control algorithms,
9

10 20 30 40 50 60 70 80 90 100 200
20
40
60
80
100
200
400
600
800
1000
2000
Bottl
enec
k ba
ndwi
dth
[Mpb
s]
Propagation delay [ms]
Fairn
ess [
%]
98 1
9127 64
9231 61
9336 57
9329 64
9340 53
9332 61
9334 59
9323 70
9320 73
929 83
9317 76
9428 66
9239 53
9233 59
9230 62
9223 69
9222 70
9215 77
9115 76
9012 78
927 85
9231 61
9236 56
9241 51
9341 52
9129 62
9223 69
9118 73
9116 75
9215 77
9010 80
9113 78
9138 53
9236 56
9236 56
9237 55
9127 64
9119 72
9116 75
9116 75
9113 78
9116 75
917 84
9132 59
9141 50
9131 60
9238 54
9128 63
9116 75
9116 75
9116 75
9212 80
9018 72
9111 80
8936 53
9030 60
9334 59
9439 55
9126 65
9220 72
9119 72
9221 71
9120 71
8918 71
8718 69
9232 60
9136 55
9119 72
9232 60
8923 66
9123 68
9128 63
9215 77
9218 74
8912 77
8927 62
943 91
9212 80
9112 79
8913 76
9011 79
9310 83
905 85
9113 78
913 88
906 84
893 86
9315 78
9213 79
9112 79
906 84
892 87
926 86
896 83
927 85
918 83
893 86
893 86
8840 48
9323 70
906 84
902 88
916 85
915 86
906 84
913 88
917 84
904 86
871 86
9330 63
925 87
916 85
912 89
892 87
922 90
903 87
922 90
903 87
892 87
840 84 50
60
70
80
90
100
(a) Buffer size: 0.1BDP.
10 20 30 40 50 60 70 80 90 100 200
20
40
60
80
100
200
400
600
800
1000
2000Bo
ttlen
eck
band
widt
h [M
pbs]
Propagation delay [ms]
Fairn
ess [
%]
9550 45
9659 37
9664 32
9562 33
9558 37
9660 36
9662 34
9570 25
9559 36
9562 33
9562 33
9563 32
9565 30
9567 28
9670 26
9555 40
9552 43
9558 37
9561 34
9553 42
9558 37
9557 38
9558 37
9563 32
9556 39
9559 36
9561 34
9662 34
9559 36
9555 40
9561 34
9652 44
9555 40
9661 35
9560 35
9660 36
9557 38
9556 39
9658 38
9556 39
9558 37
9556 39
9554 41
9559 36
9561 34
9564 31
9661 35
9548 47
9657 39
9562 33
9651 45
9659 37
9641 55
9552 43
9555 40
9565 30
9557 38
9660 36
9564 31
9665 31
9559 36
9648 48
9552 43
9539 56
9548 47
9556 39
9566 29
9648 48
9571 24
9556 39
9556 39
9668 28
9649 47
9554 41
9552 43
9546 49
9550 45
9563 32
9563 32
9649 47
9561 34
9562 33
9560 35
9653 43
9537 58
9559 36
9556 39
9553 42
9564 31
9664 32
9650 46
9543 52
9567 28
9657 39
9659 37
9558 37
9552 43
9662 34
9558 37
9567 28
9663 33
9559 36
9565 30
9558 37
9562 33
9556 39
9549 46
9666 30
9548 47
9662 34
9665 31
9562 33
9567 28
9566 29
9658 38
9555 40
9662 34
9556 39
9662 34
9567 28
9319 74 50
60
70
80
90
100
(b) Buffer size: 1BDP.
10 20 30 40 50 60 70 80 90 100 200
20
40
60
80
100
200
400
600
800
1000
2000
Bottl
enec
k ba
ndwi
dth
[Mpb
s]
Propagation delay [ms]
Fairn
ess [
%]
9678 18
9586 9
9680 16
9685 11
9580 15
9579 16
9578 17
9570 25
9571 24
9581 14
9675 21
9675 21
9577 18
9573 22
9672 24
9580 15
9680 16
9574 21
9574 21
9570 25
9674 22
9570 25
9581 14
9564 31
9570 25
9576 19
9676 20
9570 25
9572 23
9566 29
9567 28
9567 28
9667 29
9571 24
9559 36
9564 31
9664 32
9565 30
9565 30
9562 33
9663 33
9657 39
9558 37
9659 37
9563 32
9666 30
9564 31
9564 31
9571 24
9555 40
9656 40
9567 28
9566 29
9564 31
9559 36
9673 23
9556 39
9666 30
9670 26
9555 40
9561 34
9565 30
9564 31
9655 41
9655 41
9555 40
9567 28
9553 42
9657 39
9660 36
9653 43
9660 36
9554 41
9558 37
9551 44
9560 35
9556 39
9565 30
9674 22
9560 35
9576 19
9565 30
9568 27
9559 36
9562 33
9660 36
9559 36
9553 42
9568 27
9654 42
9570 25
9562 33
9557 38
9656 40
9565 30
9662 34
9555 40
9561 34
9646 50
9667 29
9565 30
9558 37
9662 34
9656 40
9661 35
9568 27
9658 38
9658 38
9555 40
934 89
9561 34
9565 30
9559 36
9560 35
9559 36
9559 36
4925 24
9640 56
945 89
934 89
912 89 50
60
70
80
90
100
(c) Buffer size: 10BDP.
10 20 30 40 50 60 70 80 90 100 200
20
40
60
80
100
200
400
600
800
1000
2000
Bottl
enec
k ba
ndwi
dth
[Mpb
s]
Propagation delay [ms]
Fairn
ess [
%]
87 1
9128 63
9229 63
9334 59
9331 62
9238 54
9431 63
9331 62
9322 71
9320 73
937 86
9321 72
9332 61
9234 58
9231 61
9333 60
9221 71
9221 71
9216 76
9313 80
9012 78
917 84
9329 64
9238 54
9138 53
9237 55
9126 65
9219 73
9115 76
9115 76
9116 75
9211 81
909 81
9137 54
9240 52
9135 56
9230 62
9123 68
9216 76
9116 75
9114 77
9215 77
9111 80
918 83
9138 53
9143 48
9132 59
9129 62
9023 67
9120 71
9014 76
9114 77
9112 79
9110 81
898 81
8349 34
8611 75
9144 47
9019 71
8816 72
9226 66
9110 81
9211 81
9013 77
8915 74
898 81
8331 52
8530 55
9016 74
8829 59
9012 78
9116 75
887 81
884 84
9014 76
8612 74
884 84
7859 19
8926 63
8328 55
9018 72
9124 67
9311 82
908 82
898 81
909 81
8217 65
869 77
8931 58
8213 69
9122 69
903 87
9011 79
927 85
913 88
904 86
893 86
893 86
875 82
8630 56
8520 65
916 85
884 84
886 82
903 87
893 86
911 90
904 86
894 85
882 86
8835 53
8112 69
913 88
903 87
891 88
911 90
902 88
902 88
912 89
882 86
863 83 50
60
70
80
90
100
(d) Buffer size: 0.1BDP.
10 20 30 40 50 60 70 80 90 100 200
20
40
60
80
100
200
400
600
800
1000
2000
Bottl
enec
k ba
ndwi
dth
[Mpb
s]
Propagation delay [ms]
Fairn
ess [
%]
9548 47
9562 33
9560 35
9566 29
9560 35
9556 39
9660 36
9553 42
9658 38
9660 36
9559 36
9561 34
9666 30
9658 38
9556 39
9658 38
9555 40
9552 43
9655 41
9659 37
9557 38
9551 44
9560 35
9557 38
9551 44
9557 38
9640 56
9638 58
9554 41
9650 46
9656 40
9543 52
9549 46
9562 33
9667 29
9556 39
9555 40
9556 39
9652 44
9543 52
9553 42
9547 48
9544 51
9544 51
9560 35
9652 44
9547 48
9557 38
9655 41
9556 39
9555 40
9634 62
9545 50
9549 46
9535 60
9561 34
9548 47
9560 35
9351 42
9556 39
9542 53
9653 43
9649 47
9532 63
9535 60
9644 52
9550 45
9557 38
9661 35
9657 39
9547 48
9646 50
9556 39
9529 66
9635 61
9545 50
9532 63
9657 39
9538 57
9542 53
9531 64
9425 69
9629 67
9529 66
9114 77
9542 53
9527 68
9529 66
9566 29
9650 46
9552 43
9536 59
8029 51
9541 54
9521 74
9451 43
9536 59
9524 71
9530 65
9664 32
9464 30
8946 43
9234 58
9538 57
9641 55
9640 56
9333 60
9535 60
9419 75
9529 66
9545 50
7630 46
6528 37
9641 55
6327 36
9230 62
9533 62
946 88
9416 78
9211 81
837 76 50
60
70
80
90
100
(e) Buffer size: 1BDP.
10 20 30 40 50 60 70 80 90 100 200
20
40
60
80
100
200
400
600
800
1000
2000
Bottl
enec
k ba
ndwi
dth
[Mpb
s]
Propagation delay [ms]
Fairn
ess [
%]
9667 29
9675 21
9669 27
9578 17
9667 29
9577 18
9658 38
9563 32
9559 36
9669 27
9558 37
9677 19
9579 16
9580 15
9558 37
9572 23
9654 42
9557 38
9550 45
9565 30
9556 39
9657 39
9576 19
9563 32
9560 35
9558 37
9559 36
9552 43
9655 41
9656 40
9552 43
9659 37
9534 61
9679 17
9559 36
9550 45
9566 29
9668 28
9661 35
9648 48
9559 36
9653 43
9543 52
9558 37
9575 20
9651 45
9660 36
9580 15
9548 47
9554 41
9643 53
9558 37
9542 53
9552 43
9554 41
9548 47
9557 38
9563 32
9654 42
9661 35
9649 47
9551 44
9545 50
9554 41
9541 54
9659 37
9558 37
9553 42
9655 41
9554 41
9544 51
9555 40
9642 54
9655 41
9535 60
9561 34
9520 75
9679 17
9538 57
9537 58
9544 51
9541 54
9641 55
9524 71
9541 54
9651 45
9512 83
9518 77
9548 47
9552 43
9547 48
9550 45
9648 48
9542 53
9526 69
9639 57
9510 85
9536 59
9527 68
9557 38
9575 20
9360 33
9643 53
9629 67
9526 69
9517 78
9533 62
9525 70
9536 59
937 86
9640 56
9640 56
9525 70
9548 47
9410 84
9537 58
9415 79
9516 79
9528 67
9524 71
869 77 50
60
70
80
90
100
(f) Buffer size: 10BDP.
Figure 13: Fairness index visualized in a heatmap for CUBIC and BBRv2 flows. Each entry in a heatmap includes three numbers: the percentage of the linkutilization at the bottleneck link (center top) and the percentage of bandwidth used by the CUBIC flow (bottom left) and the BBRv2 flow (bottom right). (a)-(c) Nopacket loss. (d)-(f) 0.01% packet loss rate.
which favor flows with small RTTs, BBRv1 allocates morebandwidth to flows with large RTTs. According to [27], thisbias presents a tradeoff between low latency and high deliveryrate and therefore violates the engineering efforts of minimiz-ing latency. It also disrupts the concept of finding a route withthe minimum RTT.
These tests compare the RTT unfairness of BBRv1 andBBRv2, and investigate whether this limitation is mitigated byBBRv2. The tests incorporate one flow with a propagation de-lay of 10ms competing with another flow with a propagationdelay of 50ms. The tests are executed 10 times and the aver-age is reported. Four types of experiments are considered: 1)two competing BBRv1 flows. Router R2 implements a sim-ple Tail Drop policy; 2) two competing BBRv2 flows. RouterR2 implements a simple Tail Drop policy; 3) two competingBBRv1 flows. Router R2 implements FQ-CoDel policy; and4) two competing BBRv2 flows. Router R2 implements FQ-CoDel policy. The severity of RTT unfairness is also related tothe buffer size. Thus, the throughput and fairness are reportedas a function of the buffer size. Fig. 14(a) shows the throughputof BBRv1 flows, for experiment 1. When the buffer size is be-low 1BDP, the two flows receive similar amounts of bandwidthand the fairness index is approximately 100%. When the buffersize increases above 1BDP, the flow with 50ms RTT receivesmore bandwidth than the flow with 10ms RTT; at 3BDP and
above, the flow with 50ms RTT receives approximately 85% ofthe bandwidth and the fairness index remains at approximately60%.
Fig. 14(b) shows the throughput of BBRv2 flows, for experi-ment 2. At the tested buffer sizes, the two flows receive similaramounts of bandwidth and the fairness index is always above85%. Figs. 14(c) and 14(d) show that by using FQ-CoDel, theRTT unfairness is eliminated and the fairness index is 100% forboth BBRv1 and BBRv2.
Fig. 15 shows the average retransmission rates generated byBBRv1 and BBRv2 (i.e., the average of the retransmission ratesobserved in both flows, the one with propagation delay of 10msand the one with propagation delay of 50ms), with Tail Dropand FQ-CoDel policies. The results indicate that the retrans-mission rate generated by BBRv2 is low, independently of thequeue management algorithm and the buffer size. On the otherhand, the retransmission rate generated by BBRv1 is high whenthe Tail Drop policy is used and when the buffer size is below1BDP, see Fig. 15(a). Applying FQ-CoDel helps to reduce theretransmission rate of BBRv1, see Fig. 15(b).
Summary: BBRv2 enhances the coexistence of flows withdifferent RTTs, mitigating the RTT unfairness problem. Also,by using an AQM algorithm such as FQ-CoDel to manage thebuffer delay, oversized buffers are made irrelevant, without neg-atively impacting the bottleneck link utilization. The AQM al-
10

0
50
100
Fairn
ess [
%]
Fairness
10 1 100 101 102
Buffer size [BDP]0
500
1000
Thro
ughp
ut [M
bps]
10 ms 50 ms
(a) BBRv1 with Tail Drop policy.
0
50
100
Fairn
ess [
%]
Fairness
10 1 100 101 102
Buffer size [BDP]0
500
1000
Thro
ughp
ut [M
bps]
10 ms 50 ms
(b) BBRv2 with Tail Drop policy.
0
50
100
Fairn
ess [
%]
Fairness
10 1 100 101 102
Buffer size [BDP]0
500
1000
Thro
ughp
ut [M
bps]
10 ms 50 ms
(c) BBRv1 with FQ-CoDel policy.
0
50
100
Fairn
ess [
%]
Fairness
10 1 100 101 102
Buffer size [BDP]0
500
1000
Thro
ughp
ut [M
bps]
10 ms 50 ms
(d) BBRv2 with FQ-CoDel policy.
Figure 14: Throughput and fairness index as functions of the buffer size, for two competing flows: one flow has 10ms RTT and another has 50ms RTT. (a) Flowsuse BBRv1 and the router R2 implements a simple Tail Drop policy. (b) Flows use BBRv2 and the router R2 implements a simple Tail Drop policy. (c) Flows useBBRv1 and the router R2 implements FQ-CoDel policy. (d) Flows use BBRv2 and the router R2 implements FQ-CoDel policy.
gorithm also helps to reduce the retransmission rate of BBRv1.
5.7. Flow Completion Time (FCT)
These tests compare the flow completion times (FCTs) us-ing different congestion control algorithms, considering severalbuffer sizes. Five types of experiments are conducted: 1) 100flows using the same congestion control algorithm (CUBIC,BBRv1, and BBRv2); 2) 50 flows using CUBIC and 50 flowsusing BBRv2; 3) 50 flows using CUBIC and 50 flows usingBBRv1; 4) the same composition of flows as in experiment 2,but incorporating a random packet loss rate of 1%; and 5) thesame composition of flows as in experiment 3, but incorporatinga random packet loss rate of 1%. Each experiment is repeatedten times and the average is reported.
Fig. 16 shows the results for experiment 1, where each flowcompletes a data transfer of 10 Gigabytes (GB). Consider firstthe case when no random packet losses are introduced, Fig.16(a). When the buffer size is 0.1BDP, the completion time offlows using CUBIC increases considerable with respect to thoseflows using BBRv1 and BBRv2, as frequent packet losses occurat the router and the bottleneck link is poorly utilized. When thebuffer size is 0.2BDP and larger, the completion time is approx-imately 90s in all cases, independently of the congestion controlalgorithm. Note that although relatively small when comparedwith the rule-of-thumb, 1BDP, a buffer size of 0.2BDP is ac-ceptable for these experiments, because the number of flows islarge, 100. This result is aligned with the buffer size rule pro-
10 1 100 101 102
Buffer size [BDP]
10 2
10 1
100
101
102
Retra
nsm
issio
n ra
te [%
] BBRv1 BBRv2
(a) Retransmissions, Tail Drop.
10 1 100 101 102
Buffer size [BDP]
10 2
10 1
100
101
102
Retra
nsm
issio
n ra
te [%
] BBRv1 BBRv2
(b) Retransmissions, FQ-CoDel.
Figure 15: Retransmission rate generated by BBRv1 and BBRv2, with: (a)a simple Tail Drop policy implemented at router R2, and (b) with FQ-CoDelpolicy implemented at router R2.
posed by Appenzeller et al. [38], who stated that a buffer size of(RTT·bottleneck bandwidth)/
√N bits is sufficient for a full uti-
lization of the bottleneck link, where N is the number of flows.Consider now Fig. 16(b). In the presence of a packet loss rateof 1%, the completion time of flows using BBRv1 and BBRv2is still approximately 90s. Meanwhile, the completion time offlows using CUBIC increases substantially. Thus, BBRv1 andBBRv2 have a better performance than CUBIC, as they are lesssensitive to random packet losses.
Fig. 17 shows the results for experiment 2, where each flowcompletes a data transfer of 100 Megabytes (MB). When thebuffer size is 0.1BDP, see Fig. 17(a), the completion timeof flows using BBRv2 is approximately between 50s and 60s,whereas the completion time of flows using CUBIC is approx-imately between 80s to 90s. As the buffer size increases to0.5BDP and 1BDP, see Figs. 17(b) and 17(c), the gap be-tween the completion time of flows using BBRv2 and CUBICis slightly reduced. As the buffer size increases to 10BDP and100BDP, see Figs. 17(d) and 17(e), the variability of the com-pletion time of flows using both BBRv2 and CUBIC increases,and values vary between 20s and 70s for BBRv2, and between18s and 80s for CUBIC.
Fig. 18 shows the results for experiment 3, where each flowcompletes a data transfer of 100 Megabytes (MB). Similar toBBRv2, BBRv1 has a smaller FCT than CUBIC, independentlyof the buffer size. BBRv1’s FCT is smaller than BBRv2 due itsaggressiveness when competing with CUBIC.
Fig. 19 shows the results for experiment 4, where the sce-
10 1 100 101 102
Buffer size [BDP]
0
50
100
150
200
250
FCT
[sec
onds
]
CUBIC BBRv1 BBRv2
(a) No random packet losses.
10 1 100 101 102
Buffer size [BDP]
0
50
100
150
200
250
FCT
[sec
onds
]
CUBIC BBRv1 BBRv2
(b) 0.01% random packet loss rate.
Figure 16: Flow completion time as a function of the buffer size with: (a) norandom packet losses; and (b) random packet loss rate of 0.01%.
11

0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC= 85.2= 1.3
BBRv2= 57.2= 1.4
(a) Buffer size: 0.1BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC= 84.1= 1.3
BBRv2= 69.9= 2.1
(b) Buffer size: 0.5BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC= 83.1= 1.5
BBRv2= 66.3= 4.7
(c) Buffer size: 1BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC= 73.6= 10.2
BBRv2= 50.1= 10.9
(d) Buffer size: 10BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC= 71.2= 13.8
BBRv2= 49.5= 7.6
(e) Buffer size: 100BDP.
Figure 17: Cumulative distribution function of the flow completion time, for 50 flows using CUBIC and 50 flows using BBRv2, with various buffer sizes and norandom packet losses.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=84.7=6.8
BBRv1=41.4=2.5
(a) Buffer size: 0.1BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=84.4=2.5
BBRv1=40.0=3.2
(b) Buffer size: 0.5BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=83.9=2.1
BBRv1=39.0=3.4
(c) Buffer size: 1BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=75.7=9.7
BBRv1=56.0=11.9
(d) Buffer size: 10BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=72.4=19.0
BBRv1=54.3=15.1
(e) Buffer size: 100BDP.
Figure 18: Cumulative distribution function of the flow completion time, for 50 flows using CUBIC and 50 flows using BBRv1, with various buffer sizes and norandom packet losses.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC= 127.9= 2.4
BBRv2= 56.3= 1.2
(a) Buffer size: 0.1BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC= 119.4= 4.1
BBRv2= 58.8= 2.4
(b) Buffer size: 0.5BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC= 121.9= 3.5
BBRv2= 55.5= 3.4
(c) Buffer size: 1BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0CD
F
CUBIC= 125.2= 4.5
BBRv2= 44.0= 10.1
(d) Buffer size: 10BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC= 124.2= 3.3
BBRv2= 44.0= 10.4
(e) Buffer size: 100BDP.
Figure 19: Cumulative distribution function of the flow completion time, for 50 flows using CUBIC and 50 flows using BBRv2, with various buffer sizes and arandom packet loss rate of 1%.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=154.6=9.9
BBRv1=41.2=2.6
(a) Buffer size: 0.1BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=153.2=10.4
BBRv1=39.8=3.1
(b) Buffer size: 0.5BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=150.8=10.0
BBRv1=38.8=3.1
(c) Buffer size: 1BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=141.5=10.8
BBRv1=39.9=13.6
(d) Buffer size: 10BDP.
0 40 80 120 160 200 240Flow completion time [seconds]
0.0
0.2
0.4
0.6
0.8
1.0
CDF
CUBIC=142.5=10.0
BBRv1=38.2=12.8
(e) Buffer size: 100BDP.
Figure 20: Cumulative distribution function of the flow completion time, for 50 flows using CUBIC and 50 flows using BBRv1, with various buffer sizes and arandom packet loss rate of 1%.
nario is similar to experiment 2, with the addition of a packetloss rate of 1%. The completion time of flows using BBRv2is similar to that observed in experiment 2, where no randompacket losses were introduced. BBRv2 is not affected by suchpacket loss rate and correctly estimates the bottleneck band-width and sending rate. On the other hand, the flow completiontime of flows using CUBIC substantially increases, indepen-dently of the buffer size, to values between approximately 100sand 135s.
Fig. 20 shows the results for experiment 5, where the sce-nario is similar to experiment 3, with the addition of a packet
loss rate of 1%. Similar to BBRv2, BBRv1 has a shorter FCTthan CUBIC, independently of the buffer size. BBRv2’s FCTis larger than that of BBRv1, as it incorporates the packet lossrate in the network path model, see Fig. 1.
Summary: BBRv2 is not affected by random packet loss ratesbelow 1-2% and correctly estimates the bottleneck bandwidthand sending rate, leading to a full utilization of the bottlenecklink. The corresponding flow completion times are reducedwith respect to those of CUBIC. On the other hand, as a loss-based algorithm, CUBIC erroneously decreases the sending ratewhen random packet losses occur, leading to a poor utilization
12

10 1 100 101 102
Buffer size [BDP]
0
20
40
60
80
100
Fairn
ess [
%]
CAKEFQ-CoDelTail DropFQ-CoDel with ECN
(a) 1 BBRv2 flow, 1 CUBIC flow.
10 1 100 101 102
Buffer size [BDP]
0
20
40
60
80
100
Fairn
ess [
%]
CAKEFQ-CoDelTail DropFQ-CoDel with ECN
(b) 1 BBRv2 flow, 10 CUBIC flows.
10 1 100 101 102
Buffer size [BDP]
0
20
40
60
80
100
Fairn
ess [
%]
CAKEFQ-CoDelTail DropFQ-CoDel with ECN
(c) 10 BBRv2 flows, 10 CUBIC flows.
10 1 100 101 102
Buffer size [BDP]
0
20
40
60
80
100
Fairn
ess [
%]
CAKEFQ-CoDelTail DropFQ-CoDel with ECN
(d) 50 BBRv2 flows, 50 CUBIC flows.
Figure 21: Fairness index as a function of the buffer size, produced with an even number of flows using BBRv2 and CUBIC. The following AQM policies areimplemented in the router R2: Tail Drop, CAKE, FQ-CoDel, and FQ-CoDel with ECN.
of the bottleneck link and high flow completion times.
5.8. Impact of AQM on Fairness
These tests compare the fairness index when flows usingBBRv2 and CUBIC are present in the network, and when dif-ferent AQM policies and buffer sizes are implemented on therouters. The tests consider the following AQM policies: simpleTail Drop, CAKE [18], and FQ-CoDel [16] with and withoutDCTCP-style ECN enabled [30]. The DCTCP-style ECN is en-abled by setting the ce threshold parameter of the fq codel
qdisc to 242us. Tests are executed with 2, 11, 20, and 100 flows,with even and uneven composition of flows using BBRv2 andCUBIC.
Fig. 21(a) shows the results for 2 flows: 1 BBRv2 flow and1 CUBIC flow. Consider first the results with Tail Drop policy(red curve). When the buffer size is 0.1BDP, the fairness in-dex is approximately 80%. This result is a consequence of theinability of CUBIC to fully utilize its bandwidth share whenthe buffer size is small. When the buffer size increases to val-ues between 0.5BDP to 10BDP, the fairness index using TailDrop improves to values close to 90%. However, when thebuffer increases further to 100BDP, the Tail Drop policy leadsto a poor fairness index of approximately 60%, because CUBICfills the buffer, increases the delay, and consumes most of thebandwidth. Consider now the results with more advanced AQMpolicies, CAKE and FQ-CoDel (with and without ECN). Thesepolicies produce better fairness indices, which approach 100%.These AQM policies are designed to solve the bufferbloat prob-lem and also prevent flows from consuming additional band-width beyond their share.
Fig. 21(b) shows the case when a BBRv2 flow and 10 CU-BIC flows are present. In this case, the fairness index remainsabove 80% when the Tail Drop policy is used. Similarly, ad-vanced AQM policies improve the fairness. Fig. 21(c) showsthe results when 10 BBRv2 flow and 10 CUBIC flows arepresent. With the Tail Drop policy, the results are similar tothose observed in Fig. 21(a), and the unfairness resulting fromCUBIC consuming most of the bandwidth is noted when thebuffer size is 100BDP. Fig. 21(d) shows the case when 50BBRv2 flows and 50 CUBIC flows are present. The fairnessindex is approximately 80% for any buffer size different than1BDP. On the other hand, advanced AQM policies produce bet-ter fairness indices, independently of the buffer size and the
number of flows.Summary: although very simple to implement, a simple Tail
Drop policy leads to unfair bandwidth allocation among BBRv2and CUBIC flows, in particular when the buffer size is large.On the other hand, advanced AQM policies such as FQ-CoDeland CAKE produce fair bandwidth allocations, independentlyof the buffer size and the number of flows.
5.9. The Effects of Fixed-rate Pacing on TCP CUBIC
TCP pacing is used by BBRv1 and BBRv2. It evenly spacespackets over time, so that packets are not sent in bursts. Pacingreduces the variance in the data rates at network bottlenecks,which in turn reduces the transient queues everywhere [8]. Asa result, congestion control algorithms can still achieve highthroughput with small buffers, as noted in previous sections.Motivated by such results, this section investigates whether pac-ing can have a positive impact on window-based congestioncontrol algorithms.
These tests investigate the throughput, fairness, and RTT offlows using CUBIC, with and without TCP pacing. The num-ber of flows is 100. The bottleneck bandwidth is 1Gbps and thetotal propagation delay of 20ms. The tests are executed with-out random packet losses and with a random packet loss rateof 1%. The experiments are executed 10 times and the averageis reported. When pacing is used, the pacing rate is manuallycomputed so that all flows have the same maximum bandwidthallocation. Thus, the pacing rate per flow is set to (1Gbps)/(100flows) - headroom = 10Mbps - 1.5Mbps = 8.5Mbps. The head-room of 1.5Mbps is used to keep the link utilization at approx-imately 85%, which avoids filling the buffer. Pacing is appliedthrough the fq qdisc in Linux using fq pacing maxrate
parameter when the sending hosts are configured with CUBIC.Note that these experiments emulate ideal scenarios where thenumber of flows is known in advance and each flow is con-figured with the correct pacing rate. Nevertheless, the resultsprovide insight into the success of new congestion control al-gorithms based on pacing.
Fig. 22(a) shows the aggregate throughput. When pacingis used and the network does not experience packet losses, thethroughput is high, constant at 850Mbps. When pacing is notused, and the network does not experience packet losses, thethroughput is slightly higher, peaking at 900Mbps. On the otherhand, when the network experiences packet losses, enabling
13

10 1 100 101 102
Buffer size [BDP]
0
200
400
600
800
1000Th
roug
hput
[Mbp
s]
w/o pacing w/o lossw/o pacing w/ lossw/ pacing w/o lossw/ pacing w/ loss
(a) Throughput.
10 1 100 101 102
Buffer size [BDP]
0
20
40
60
80
100
Fairn
ess [
%]
w/o pacing w/o lossw/o pacing w/ lossw/ pacing w/o lossw/ pacing w/ loss
(b) Fairness index.
10 1 100 101 102
Buffer size [BDP]
0
100
200
300
400
500
RTT
[ms]
w/o pacing w/o lossw/o pacing w/ lossw/ pacing w/o lossw/ pacing w/ loss
(c) Round-trip time.
Figure 22: Throughput, fairness index, and RTT as functions of the buffer size. The four curves represent the results of flows operating according to the followingconfigurations: CUBIC without enabling TCP pacing and no random packet losses (red); CUBIC without enabling TCP pacing and with a packet loss rate of 1%(yellow); CUBIC with TCP pacing and no random packet losses (green); and CUBIC with TCP pacing and with a packet loss rate of 1% (blue).
pacing improves the total throughput: the throughput of pacedflows is 700Mbps, while the throughput of non-paced flows isapproximately 600Mbps. The buffer size does not affect theaggregate throughput.
Fig. 22(b) shows the fairness results. When pacing is used,the fairness index is high, close to 100%, independently ofwhether the network experiences packet losses or not. Whenpacing is not used and the buffer size is below 5BDP, the fair-ness index is similar in both cases, with packet losses and with-out packet losses. When the buffer size increases to 5BDP andabove, the fairness index decreases rapidly. CUBIC withoutpacing is unable to avoid a very disproportionate bandwidth al-location, even when all flows use the same congestion controlalgorithm.
Fig. 22(c) shows the RTT results. When pacing is used,the RTT is almost constant and equal to the propagation delay.When pacing is not used and the network experiences packetlosses, the RTT is also almost constant and equal to the prop-agation delay. In this regard, the random packet losses have apositive effect on CUBIC, as they prevent the congestion win-dow to continue to increase, and sender nodes do not fill up thebuffer. On the other hand, when no losses occur and pacing isnot used, the bufferbloat problem is observed.
Summary: TCP pacing enhances the throughput of CUBICwhen the network experiences packet losses. It also improvesthe fairness among CUBIC flows and avoids the bufferbloatproblem when the buffer size is large. Although the scenar-ios described in this section are ideal (the pacing rate must beconfigured statically according to the number of flows. In pro-duction networks, estimating the number of flows in real timeis challenging), future research directions may explore the ca-pability of new-generation switches to obtain explicit feedbackfrom routers to estimate the pacing rates dynamically [19, 31].
6. Conclusion
BBRv1 represented a major disruption to the traditional loss-based congestion control algorithms. BBRv1 departed from theuse of binary signals -packet losses- to modify the sending rate.Instead, it relied on periodical measurements of the bottleneck
bandwidth and the RTT to set the pacing rate and the numberof bits to keep in-flight. Despite its success in improving thethroughput of a connection, BBRv1 has shown some issues, in-cluding a poor coexistence with other congestion control algo-rithms and a high retransmission rate. In this context, BBRv2has been recently proposed to address such issues.
This paper presented an emulation-based evaluation ofBBRv2, using Mininet. Results show that BBRv2 toleratesmuch higher random packet loss rates than CUBIC but slightlylower than BBRv1, has better coexistence with CUBIC thanBBRv1, mitigates the RTT unfairness problem, produces lowerretransmission rates than BBRv1, and exhibits low queuing de-lay even with large buffers. The results also show that withsmall buffers, BBRv2 produces better fairness without compro-mising the high throughput and the link utilization. This obser-vation was also noted in BBRv1 and suggests that model-based,rate-based congestion control algorithms work better with smallbuffers, which could have significant implications on networks.The paper also presented advantages of using AQM algorithmsand TCP pacing with loss-based algorithms.
Acknowledgements
This material is based upon work supported by the NationalScience Foundation under Grant Numbers 1925484, 1829698,and 1907821, funded by the Office of Advanced Cyberinfras-tructure (OAC). The authors are very grateful for the compre-hensive review conducted by the anonymous reviewers. Theirsuggestions and corrections helped improve the quality of thismanuscript.
References
[1] J. Postel, RFC 793: Transmission control protocol (TCP), September,1981.
[2] J. Kurose, K. Ross, Computer networking: a top-down approach, 7th Edi-tion, Pearson, 2017.
[3] V. Jacobson, M. Karels, Congestion avoidance and control, ACM SIG-COMM Computer Communications Review 18 (4) August, 1988.
[4] R. Al-Saadi, G. Armitage, J. But, P. Branch, A survey of delay-basedand hybrid TCP congestion control algorithms, IEEE CommunicationsSurveys & Tutorials, 21, (4), March, 2019.
14

[5] P. Hurley, J. Le Boudec, P. Thiran, Technical Report: A note on the fair-ness of additive increase and multiplicative decrease, Infoscience EPFLScientific Publications, 1990.
[6] S. Ha, I. Rhee, L. Xu, CUBIC: a new TCP-friendly high-speed TCP vari-ant, ACM SIGOPS Operating Systems Review, 42, (5), July, 2008.
[7] D. J. Leith, R. N. Shorten, H-TCP protocol for high-speed long distancenetworks, Second International Workshop on Protocols for Fast Long-Distance Networks, Chicago, IL, USA, February, 2004.
[8] M. Mathis, J. Mahdavi, Deprecating the TCP macroscopic model, ACMSIGCOMM Computer Communication Review, 49, (5), November, 2019.
[9] J. Crichigno, E. Bou-Harb, N. Ghani, A comprehensive tutorial on sci-ence DMZ, IEEE Communications Surveys & Tutorials, 21, (2), October,2018.
[10] K. Chard, I. Foster, S. Tuecke, Globus: Research data management as ser-vice and platform, 2017 Practice and Experience in Advanced ResearchComputing (PEARC) Conference, New Orleans, LO, USA, July, 2017.
[11] N. Cardwell, Y. Cheng, C. S. Gunn, S. H. Yeganeh, V. Jacobson, BBR:congestion-based congestion control, ACM Queue, 14, (5), September,2016.
[12] M. Hock, R. Bless, M. Zitterbart, Experimental evaluation of BBR con-gestion control, 2017 IEEE 25th International Conference on NetworkProtocols (ICNP), Toronto, Canada, October, 2017.
[13] N. Cardwell, Y. Cheng, S. H. Yeganeh, I. Swett, V. Vasiliev, P. Jha, Y. Se-ung, M. Mathis, V. Jacobson, BBRv2: a model-based congestion control,Presentation in the Internet Congestion Control Research Group (ICCRG)at IETF 105 Update, Montreal, Canada, July, 2019.
[14] S. Zhang, An evaluation of BBR and its variants, In Proceedings of ACMConference, Washington, DC, USA, July 2017.
[15] S. Floyd, RFC 5166: metrics for the evaluation of congestion controlmechanisms, March, 2008.
[16] T. Høiland-Jørgensen, P. McKenney, D. Taht, J. Gettys, E. Dumazet, RFC8290: The flow queue CoDel packet scheduler and active queue manage-ment algorithm, January, 2018.
[17] J. Gettys, Bufferbloat: dark buffers in the internet, IEEE Internet Com-puting, 15, (3), May, 2011.
[18] T. Høiland-Jørgensen, D. Taht, J. Morton, Piece of CAKE: a comprehen-sive queue management solution for home gateways, 2018 IEEE Inter-national Symposium on Local and Metropolitan Area Networks (LAN-MAN), Washington, DC, USA, October, 2018.
[19] E. Kfoury, J. Crichigno, E. Bou-Harb, D. Khoury, G. Srivastava, EnablingTCP pacing using programmable data plane switches, 42nd InternationalConference on Telecommunications and Signal Processing (TSP), Bu-dapest, Hungary, July, 2019.
[20] S. M. Claypool, Sharing but not caring-performance of TCP BBR andTCP CUBIC at the network bottleneck, Worcester Polytechnic Institute,March, 2019.
[21] R. Jain, A. Durresi, G. Babic, Throughput fairness index: an explanation,ATM Forum contribution, 99, (45), February, 1999.
[22] M. Allman, Comments on bufferbloat, ACM SIGCOMM Computer Com-munication Review, 43, (1), January, 2013.
[23] Y. Gong, D. Rossi, C. Testa, S. Valenti, M. D. Taht, Fighting thebufferbloat: on the coexistence of AQM and low priority congestion con-trol, Computer Networks, 65, (1), June, 2014.
[24] C. Staff, Bufferbloat: what’s wrong with the Internet?, Communicationsof the ACM, 55, (2), February, 2012.
[25] K. Nichols, V. Jacobson, Controlling queue delay, Communications of theACM, 10, (5), July, 2012.
[26] D. Scholz, B. Jaeger, L. Schwaighofer, D. Raumer, F. Geyer, G. Carle,Towards a deeper understanding of TCP BBR congestion control, 2018IFIP Networking Conference (IFIP Networking) and Workshops, Zurich,Switzerland, May, 2018.
[27] S. Ma, J. Jiang, W. Wang, B. Li, Towards RTT fairness of congestion-based congestion control, Computing Research Repository (CoRR), June,2017.
[28] F. Fejes, G. Gombos, S. Laki, S. Nadas, Who will save the internet fromthe congestion control revolution?, International Conference ProceedingSeries (ICPS) Proceedings of the 2019 Workshop on Buffer Sizing, PaloAlto, CA, USA, December, 2019.
[29] M. P. Tahiliani, V. Misra, K. Ramakrishnan, A principled look at the util-ity of feedback in congestion control, International Conference Proceed-ing Series (ICPS) Proceedings of the 2019 Workshop on Buffer Sizing,
Palo Alto, CA, USA, December, 2019.[30] S. Bensley, D. Thaler, P. Balasubramanian, L. Eggert, G. Judd, RFC 8257:
Data center TCP (DCTCP): TCP congestion control for data centers, Oc-tober, 2017.
[31] Y. Li, R. Miao, H. Liu, Y. Zhuang, F. Feng, L. Tang, Z. Cao, M. Zhang,F. Kelly, M. Alizadeh, M. Yu, HPCC: high precision congestion control,SIGCOMM 2019: Proceedings of the ACM Special Interest Group onData Communication, Beijing, China, August, 2019.
[32] R. De Oliveira, C. Schweitzer, A. Shinoda, R. Prete, Using mininetfor emulation and prototyping software-defined networks, 2014 IEEEColombian Conference on Communications and Computing (COLCOM),Bogota, Colombia, June, 2014.
[33] J. Gomez, E. Kfoury, Emulation scripts using BBRv2, [Online], Avail-able: https://github.com/gomezgaona/bbr2, July, 2020.
[34] google/bbr, TCP BBR v2 Alpha/Preview Release, [Online], Available:https://github.com/google/bbr/tree/v2alpha, July, 2019.
[35] S. Hemminger, et al., Network emulation with NetEm, Linux conf au,April, 2005.
[36] J. Dugan, S. Elliott, B. A. Mah, J. Poskanzer, K. Prabhu, iPerf3, toolfor active measurements of the maximum achievable bandwidth on IPnetworks, [Online], Available: https://github.com/esnet/iperf.
[37] M. Mathis, J. Semke, J. Mahdavi, T. Ott, The macroscopic behavior ofthe TCP congestion avoidance algorithm, ACM SIGCOMM ComputerCommunication Review 27 (3) July, 1997.
[38] G. Appenzeller, I. Keslassy, N. McKeown, Sizing router buffers, ACMSIGCOMM Computer Communication Review, 34, (4), August, 2004.
Elie F. Kfoury is a PhD student inthe College of Engineering and Com-puting at the University of South Car-olina (USC). Prior to joining USC, heworked as a research and teaching as-sistant in the Computer Science depart-ment at the American University of Sci-ence and Technology in Beirut. He haspublished several research papers and ar-
ticles in international conferences and peer-reviewed journals.His research focuses on telecommunications, network security,Blockchain, Internet of Things (IoT), Software Defined Net-working (SDN), and data plane programming.
Jose Gomez is a PhD student in the Col-lege of Engineering and Computing atthe University of South Carolina (USC)in the United States of America. Prior tojoining USC, he worked as a researcherand teaching assistant in the School ofEngineering at the Catholic Universityin Paraguay. His research focuses onP4 programming and congestion control
protocols.
15

Dr. Jorge Crichigno is an AssociateProfessor in the College of Engineer-ing and Computing at the University ofSouth Carolina (USC) and the directorof the Cyberinfrastructure Lab at USC.He has over 15 years of experience inthe academic and industry sectors. Dr.Crichigno’s research focuses on practicalimplementation of high-speed networks,
network security, TCP optimization, offloading functionality toprogrammable switches, and IoT devices. His work has beenfunded by U.S. agencies such as the National Science Founda-tion (NSF) and the Department of Energy. He received his PhDin Computer Engineering from the University of New Mexicoin 2009, and his bachelor’s degree in Electrical Engineeringfrom the Catholic University in Paraguay in 2004.
Dr. Elias Bou-Harb is the Associate Di-rector of the Cyber Center for Securityand Analytics at the University of TexasSan Antonio (UTSA), where he leads,co-directs and co-organizes university-wide innovative cyber security research,development and training initiatives. Heis also an Associate Professor at thedepartment of Information Systems and
Cyber Security specializing in operational cyber security anddata science as applicable to national security challenges. Pre-viously, he was a senior research scientist at Carnegie Mel-lon University (CMU) where he contributed to federally-fundedprojects related to critical infrastructure security and workedclosely with the Software Engineering Institute (SEI). His re-search and development activities and interests focus on oper-ational cyber security, attacks’ detection and characterization,malware investigation, cyber security for critical infrastructureand big data analytics.
16
![Apple ][ Emulation on an AVR Microcontroller Emulation ... · Apple ][ Emulation on an AVR Microcontroller Emulation eines Apple ][ auf einem AVR Mikrocontroller Maximilian Strauch](https://img.pdfslide.net/doc/110x75/5d494b4588c99334058bd1f6/apple-emulation-on-an-avr-microcontroller-emulation-apple-emulation.jpg)
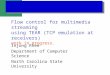















![Enhancing TCP Congestion Control for Improved Performance ... · scratch when introduced in wireless networks [17]. Wired TCP assumes packet losses are due to congestion in the path](https://img.pdfslide.net/doc/110x75/5f63c25cd97feb7bc64a52fa/enhancing-tcp-congestion-control-for-improved-performance-scratch-when-introduced.jpg)











![NS2 Wired With Tcp EXTRA[1]](https://img.pdfslide.net/doc/110x75/543f812bb1af9f520a8b4801/ns2-wired-with-tcp-extra1.jpg)