Embed Size (px)
Citation preview

An Experimental Approach to French
Attributive Adjective Syntax
Juliette Thuilier
In this paper, we study the alternation of adjective position in the noun
phrase. We postulate that this phenomenon is in�uenced by various
factors interacting in a complex way and favoring one position over
the other. Thus we use an experimental approach in order to deter-
mine which factors are indeed involved in the choice and how they
interact. Our approach is based on a corpus data modeling and a ques-
tionnaire experiment.
Keywords: word order, corpus, questionnaire, statistical modeling
1 Introduction
In French, as well as in other Romance languages, attributive adjectives can appear both before
or after the noun, as shown in example (1).
(1) a. une
a
agréable
nice
soirée
evening
(prenominal position)
b. une
a
soirée
evening
agréable
nice
(postnominal position)
The postnominal position is generally considered the canonical position because (i) adjectives
appear more frequently in this position, both in terms of lemmas and tokens (Forsgren 1978,
Wilmet 1981, Thuilier et al. 2010, among others),1
(ii) most of the new adjectives created in the
language appear in postnominal position (Noailly 1999). However, although it is not as frequent
as the postnominal position, the prenominal position appears to be the preferred position for
short and frequently occurring adjectives. Moreover, it will be shown in this paper that the
adjectives that appear in both positions in corpus data seem to occur more frequently before
the noun.
In this paper, we focus on the lexical and syntactic aspects of adjective position alternation.
We postulate that this phenomenon is in�uenced by various factors interacting in a complex
way and favoring one position over the other. Thus we need an experimental approach in or-
der to determine which factors are indeed involved in the choice and how they interact. Our
approach is based on experiences using corpus data and questionnaires. It has been inspired
by the work by Bresnan et al. (2007), Bresnan (2007) and Bresnan and Ford (2010) on the da-
tive alternation in English. It also follows up on previous works by Thuilier et al. (2010) and
Thuilier et al. (2012), which are corpus studies based on written data extracted from a newspa-
per corpus and comparing the e�ect of several factors on adjective position by using statistical
modeling. In comparison to these previous works, the present paper relies on (i) speech data
I thank the following people for their help and/or comments at di�erent stages of this work: Anne Abeillé,
Christophe Benzitoun, Benoît Crabbé, Laurence Danlos, Sarra El Ayari, Gwendoline Fox, Margaret Grant, Delphine
Tribout. I also thank the anonymous reviewer as well as the editor of the present volume, Christopher Piñon.
1For instance, in the corpus study by Thuilier et al. (2010), 71.9% of the adjective occurrences appear after the
noun, and 84.5% of the adjectival lemmas are only found in postnominal position.
EISS 10Empirical Issues in Syntax and Semantics 10, ed. Christopher Piñón, 287–304
http://www.cssp.cnrs.fr/eiss10/
© 2014 Juliette Thuilier 287

288 juliette thuilier
in addition to written data; (ii) more accurately annotated data, in particular concerning the
potentially homonymous adjectives (cf. section 3.1); (iii) a comprehension experiment investi-
gating the link between the results of the corpus data modeling and the metalinguistic choices
of speakers.
The paper is organized as follows: section 2 is dedicated to describing the semantic, syntac-
tic, and lexical aspects of the alternation phenomenon; in section 3, we will present the corpus
data and the multifactorial statistical modeling; section 4 will discuss a questionnaire exper-
iment showing that the results of the statistical modeling correlate with speaker preferences
about adjective position.
2 The Phenomenon
The alternation of noun-adjective ordering is a long-debated issue in French linguistics and
has generated a huge literature (Blinkenberg 1933, Reiner 1968, Waugh 1977, Forsgren 1978,
Wilmet 1981, Delbecque 1990, Bouchard 1998, Abeillé and Godard 1999, Noailly 1999, Thuilier
et al. 2012, among others). Without reviewing all of the literature, we will give the main factors
that have been mentioned and that we will study on the basis of corpus data.
2.1 Semantic Aspects
The semantics of adjectives as well as the semantics of noun-adjective combinations is a com-
plex problem, as shown by the literature: Kamp (1975), McNally and Kennedy (2008), among
many others. In French, this semantic problem interacts with the two possible positions of the
adjective, which adds complexity to the problem. Given that establishing an exhaustive review
of this problem is beyond the scope of this article, we will give a brief overview of the links
between position and semantics.
The general idea is that preposed adjectives tend to be subsective, as petite in (2), or inten-
sional, as vrai in (3), whereas the postposed ones are inclined to be intersective (or predicative),
as fragile in (4).
(2) une
a
petite
small
souris
mouse
(3) un
a
vrai
true
complot
plot
(4) un
a
vase
vase
fragile
fragile
Some linguists postulated that the alternation of position is a purely semantic phenomenon. In
broad outline, Waugh (1977) and Bouchard (1998) considered that preposed adjectives modify
internal components of the noun, whereas postposed ones assign the noun referent a property
that cannot be assigned to a sub-component of the noun. This approach leads to postulating
that there is a systematic di�erence of meaning between the preposed and the postposed ver-
sion of the same adjective. However, this generalization appears to be false. First, as pointed
out by Abeillé and Godard (1999), there are noun-adjective sequences with the same meaning
regardless of the position of the adjective. In (5), both NPs mean ‘a charming boy’, without any
possible variation in interpretation.

an experimental approach to french attributive adjective syntax 289
(5) a. un
a
charmant
charming
garçon
boy
b. un
a
garçon
boy
charmant
charming
Second, we observe semantic e�ects linked to the position of the adjective in the case of
some speci�c adjective-noun combinations. For instance, the adjective gros ‘fat’ can acquire an
intensifying value when it is preposed to agentive nouns, such as fumeur ‘smoker’ in (6), but
this value is not present with other agentive nouns, such as coi�eur ‘hairdresser’ in (7).
(6) a. un
a
gros
fat
fumeur
smoker
‘a heavy smoker’
b. un
a
fumeur
smoker
gros
fat
‘a fat smoker’
(7) a. un
a
gros
fat
coi�eur
hairdresser
b. un
a
coi�eur
hairdresser
gros
fat
Moreover, Abeillé and Godard (1999) pointed out that in the case of un gros fumeur, the prenom-
inal position is compatible with both interpretations: a person who smokes a lot or a person who
is a fat smoker. This means that this is not the position that requires a speci�c interpretation,
but the adjective-noun combination itself.
Thus, following Abeillé and Godard (1999), we consider that there is no semantic property
categorically associated with one position. We assume that the semantics does not account for
the entire phenomenon (contra Bouchard 1998 and Waugh 1977) and that the choice of the
position is mainly driven by lexical properties and syntactic constraints.
2.2 Lexical Aspects
Adjectives show individual preferences which are shaped by formal properties: length, fre-
quency, and morphological properties.
The length of words and constituents plays a role in word order and alternation phenomena
(Hawkins 1994). SVO languages as French tend to prefer the short-before-long order. In the case
of adjectives, Wilmet (1981), Forsgren (1978), and Thuilier (2012) noticed that what matters is the
length of the adjective itself,2
with the following tendency: short adjectives �rst, long adjectiveslast. These corpus studies showed that most of the monosyllabic adjectives are preposed, while
adjectives containing more than two syllables are more frequently postposed.
Since Zipf’s (1932) work, we know that there is a strong correlation between length and
frequency, such as the more frequent the word, the shorter it tends to be. Given the above men-
tioned short �rst and long last preference, corpus data display the expected tendency: frequent
adjectives are inclined to be preposed, whereas rare ones tend to be postposed (Wilmet 1981,
2In corpus data (Forsgren 1978, Thuilier 2012), the relative length of the noun and the adjective does not appear
to be as relevant as the length of the adjective itself. Thuilier (2012:142-145) showed that the slight e�ect of the
relative length observed in corpus data can be understood as the result of the e�ect of adjective length.

290 juliette thuilier
Table 1Lexical properties and adjective position
Prenominal position Postnominal position
short long
frequent rare
morphologically simple morphologically complex
Thuilier 2012). Besides the relation between length and frequency, the e�ect of frequency on
adjective position may be explained by an hypothesis on the diachronic evolution of adjective
syntax. Following Bybee (2006), we consider that highly frequent words and word sequences
are strengthened in their morphosyntactic structure and are resistant to change. In Old French,
the most frequent order was ‘adjective noun’, and some contexts allowed the adjective to be
postposed (Buridant 2000). We can hypothesize that the postposing default rule developed in
Modern-French did not a�ect highly frequent adjectives, because these were resistant to change.
The morphological complexity of the adjective seems to a�ect its position: derived adjec-
tives tend to be postposed. Apart from adjectives derived by conversion, complex adjectives are
generally longer than simple ones, which favors their postposition. Despite this length e�ect,
other properties have been identi�ed as playing a role in their preference for the postnomi-
nal position. In particular, part of the deverbals and denominals can be substituted by relative
clauses, as shown in (8) and (9). The ability of derived adjectives to be replaced by syntactically
more complex and obligatorily postposed sequences correlates with a signi�cant proportion of
occurrences of derived adjectives in postnominal position.
(8) Deverbal
a. une
a
décision
decision
contestable
questionable
b. une
a
décision
decision
que
that
l’on
one
peut
can
contester
contest
(9) Denominal
a. les
the
résultats
results
semestriels
semiannual
b. les
the
résulats
results
du
of-the
semestre
semester
In sum, previous works on corpus data showed that a bundle of formal lexical properties con-
verges at each position, as summarized in Table 1.
2.3 Syntactic Aspects
The alternation of position is a�ected by the internal structure of the adjective phrase (AP) and
the noun phrase (NP). We will present �ve syntactic factors based on the following elements:
post-adjectival dependent, pre-modi�ed adjective, coordination of adjectives, other noun de-
pendent in the NP, and type of determiners introducing the NP.
First, adjectives followed by a dependent must be postposed to the noun (Thuilier 2012,
Abeillé and Godard 1999, Blinkenberg 1933), as shown in (10). This is the only categorical con-
straint. The other syntactic constraints do not impose, but rather favor one position over the

an experimental approach to french attributive adjective syntax 291
other.
(10) a. une
a
musique
music
agréable
nice
à
to
écouter
hear
b. *une
a
agréable
nice
à
to
écouter
hear
musique
music
Pre-modi�ed adjectives can be both preposed and postposed to the noun, as in (11).
(11) a. une
a
très
very
agréable
nice
soirée
evening
b. une
an
soirée
evening
très
very
agréable
nice
However, the presence of a modi�er makes the AP longer, thereby favoring its postposition.
Forsgren (1978: 159) observed that among 559 pre-modi�ed adjectives in his corpus data, 73.4%
are postposed, whereas only 66% of single adjectives are in this position. This suggests that in
addition to the length of the adjective, the length of the AP also plays a role in the alternation.
Furthermore, if an adjective with a very strong preference for one position is pre-modi�ed,
its preference becomes less strong by means of the modi�er (Wilmet 1981, Abeillé and Godard
1999). For example, the adjective bon ‘good’ strongly prefers the prenominal position (the NP in
(12b) sounds odd), but can easily be postposed to the noun when it is pre-modi�ed, as in (12c).
(12) a. un
a
bon
good
poulet
chicken
b. ?un
a
poulet
chicken
bon
good
c. un
a
très
very
bon
good
poulet
chicken
/
/
un
a
poulet
chicken
très
very
bon
good
Likewise, the adjective familial ‘family’ has a strong preference for postnominal position, as in
(13a-b), but can be preposed if it is pre-modi�ed, as in (13c).
(13) a. une
a
berline
sedan
familiale
family
b. ?une
a
familiale
family
berline
sedan
c. une
a
berline
sedan
très
very
familiale
family
/
/
une
a
très
very
familiale
family
berline
sedan
Both the prenominal position and the postnominal position are also possible for coordi-
nated adjectives, as shown in (14). As has been observed for pre-adjectival modi�ers, coordina-
tion tends to favor the postnominal position because of the length of the AP. Forsgren (1978)
found around 73% of coordinated adjectives, and around 67% of noncoordinated adjectives in
postnominal position.
(14) a. un
a
petit
small
et
and
confortable
comfortable
canapé
sofa

292 juliette thuilier
b. un
a
canapé
sofa
petit
small
et
and
confortable
comfortable
Moreover, coordination is comparable to pre-modi�cation insofar as it allows adjectives with
strong lexical preferences to have more �exibility. For instance, grand ‘big’ and calme ‘quiet’
sound better, respectively, in prenominal position and in postnominal position, as in (15a-b).
Once coordinated, these adjectives can be naturally either preposed or postposed to the noun,
as in (15c).
(15) a. un
a
grand
big
appartement
apartment
b. un
an
appartement
apartment
calme
quiet
c. un
a
grand
big
et
and
calme
quiet
appartement
apartment
/
/
un
an
appartement
apartment
grand
big
et
and
calme
quiet
The e�ect of coordination is also observable when both adjectives have a strong preference
for the same position. For example, Abeillé and Godard (1999) draw attention to the case of
two intensional adjectives, vrai ‘true’ and false ‘false’, which sound very odd when they are
postposed, as in (16b) and (17b). However, the coordination of these adjectives can occur either
before or after the noun, as in (18).
(16) a. des
some
vrais
true
coupables
culprits
b. ?des
some
coupables
culprits
vrais
true
(17) a. des
some
faux
false
coupables
culprits
b. ?des
some
coupables
culprits
faux
false
(18) a. des
some
vrais
true
ou
or
faux
false
coupables
culprits
b. des
some
coupables
culprits
vrais
true
ou
or
faux
false
Grevisse and Goosse (2007) mentioned a tendency to produce, in planned and written dis-
course, “balanced NPs,” with material before and after the head noun in order to avoid the
accumulation of postnominal dependents. For example, when the NP contains a prepositional
phrase (PP), which cannot be preposed to the noun, placing the adjective before the noun avoids
separating the noun from its complement, as shown in (19c).
(19) a. un
a
recueil
collection
[de
of
textes
texts
grecs]PP
Greek
b. un
a
recueil
collection
récent
recent
[de
of
textes
texts
grecs]PP
Greek
c. un
a
récent
recent
recueil
collection
[de
of
textes
texts
grecs]PP
Greek

an experimental approach to french attributive adjective syntax 293
More generally, the presence of dependents postposed to the noun, as relative clauses, PPs, or
other adjectives, tends to favor the prenominal position of adjectives:
(20) a. l’air
the-tune
habituel
usual
[que
that
Paul
Paul
joue]RC
plays
b. l’habituel
the-usual
air
tune
[que
that
Paul
Paul
joue]RC
plays
(21) a. un
a
animal
animal
étrange
strange
[indomptable]A
untameable
b. un
a
étrange
strange
animal
animal
[indomptable]A
untameable
According to Forsgren’s (1978) corpus study, the nature of the determiner introducing the
NP in�uences the position of the adjective. This author observed that de�nite determiners, for
example, demonstratives, possessives or de�nite articles, favor the prenominal position. For
each NP, the inde�nite counterpart in (b) sounds less natural.
(22) a. cet
this
éblouissant
dazzling
spectacle
show
(demonstrative)
b. un
a
éblouissant
dazzling
spectacle
show
(23) a. son
her
habituel
usual
refrain
record
(possessive)
b. un
a
habituel
usual
refrain
record
(24) a. le
the
traditionnel
traditional
thé
tea
(de�nite article)
b. un
a
traditionnel
traditional
thé
tea
2.4 Speci�c Combinations of Nouns and Adjectives
Given that we are interested in the factors a�ecting the placement of attributive adjectives with
respect to the noun, it is important to mention that the noun itself plays a role in a number of
cases.
First, some adjective-noun pairs are strongly collocational in the sense that the choice of the
adjective depends on the noun. For instance, the noun hommage ‘tribute’ is generally associated
with the adjective vibrant ‘vibrant’ in order to idiomatically refer to a big or intense tribute. Not
only does the collocational e�ect a�ect the selection of the adjective with respect to the noun,
but it also a�ects its position. Indeed, the adjective vibrant is inclined to be postposed to the
noun, as in (25), partly due to the fact that it is a derived adjective (cf. section 2.2). Nevertheless,
the noun hommage strongly favors its placement in prenominal position, as in (26).
(25) a. une
a
voix
voice
vibrante
vibrant
/
/
?une
a
vibrante
vibrant
voix
voice

294 juliette thuilier
b. un
a
ton
tone
vibrant
vibrant
/
/
?un
a
vibrant
vibrant
ton
tone
(26) un
a
vibrant
vibrant
hommage
tribute
Second, as mentioned in section 2.1, we observe that some adjective-noun combinations
convey a particular meaning when the adjective is preposed. (6) and (7) above show that in a
number of cases, the noun selects the adjective and its position. Thus not only is the position of
the adjective determined by its lexical properties, but it is also a�ected by the particular noun
the adjective combined with.
3 Corpus Data Modeling
By looking over the factors playing a role in adjective position alternation, we observed that a
variety of constraints in�uences the choice for one position. In order to better understand their
e�ects and to capture their relative importance, we conducted a corpus study. Using statistical
modeling, we tested most of the factors mentioned in the previous section with attested data
excerpted from speech and written corpora. We assume that, with statistical tools, we are able
to free ourselves from variations due to the sampling of the corpora.
3.1 Building the Database
The data were excerpted from two corpora:
• the French TreeBank (henceforth, FTB), which comprises 20,000 sentences (400,000 to-
kens) from the newspaper Le Monde fully annotated and manually validated for syntax
purposes (Abeillé et al. 2003, Abeillé and Barrier 2004).
• the French part of the spoken corpus C-ORAL-ROM (henceforth, CORAL), which com-
prises about 300,000 tokens (Cresti and Moneglia 2005)
We must make an initial observation concerning the adjective position alternation in the FTB
data. In this corpus, there are 1,750 adjectival lemmas in attributive position. These include
1,488 only-postposed adjectives and 92 only-preposed ones. These only-preposed and only-
postposed lemmas represent around 64% of the 13,399 adjectival occurrences. Thus, only 170
lemmas occur in both positions. These alternating adjectives represent 4,486 occurrences and
thus are the most frequent lemmas on average. These observations are summarized in Table 2.
So, even though we assume that alternation is possible for the entire adjective category, (i)
for a number of adjectives the alternation is very rare and the probability that we observe it in
a corpus is low; (ii) more that two �fths of the adjectives (747) in attributive position appear
only once in the corpus, thus making it impossible to regard alternation for them.
Table 2Attributive adjectives in the FTB corpus
Number of lemmas Number of occurrences
Only-preposed adjectives 92 (5.3%) 462 (3.3%)
Only-postposed adjectives 1,488 (85%) 8,485 (60.9%)
Adjectives in both positions 170 (9.7%%) 4,986 (35.8%)
Total 1,750 (100%) 13,933 (100%)

an experimental approach to french attributive adjective syntax 295
The fact that the proportion of nonalternating adjectives is so high means that for a large
part of the data, the identity of the adjective is enough to categorically determine its position
in the dataset. This kind of data distribution leads to convergence problems of estimation algo-
rithms with the statistical tools used here (see section 3.4).
Given that we are interested in the factors explaining the alternation and that including
nonalternating adjectives raises an issue of statistical soundness, we focus on adjectives that
do alternate in the FTB. In a sense, this methodological choice limits the scope of the present
corpus study because we don’t have a comprehensive picture of the entire category position
alternation. However, we made sure that the data and the statistical modeling are reliable.
To build our database, we �rst excerpted the attributive adjectives that appeared in both
positions in the FTB. Given that the presence of post-adjectival dependents categorically deter-
mines the position of the AP (cf. section 2.3), we left these adjectives aside. Then we excerpted
the same adjectives from CORAL.
We set apart two lemmas for each of the following potentially homonymous adjectives: an-cien ‘ancient/former’, propre ‘own/clean’, pur ‘pure’, seul ‘alone/single’, simple ‘simple/modest’.
For each adjective, both meanings are illustrated in examples (27)–(31).
(27) a. un
a
co�re
chest
ancien
old
‘an ancient chest’
b. un
a
ancien
old
co�re
chest
‘a former chest’
(28) a. son
her
propre
own
pantalon
pants
b. son
her
pantalon
pants
propre
clean
(29) a. un
a
pur
pure
produit
product
‘an archetypal product’
b. un produit pur
a product pure
‘a pure product’ (not mixed)
(30) a. un
a
seul
alone
homme
man
‘a single man’
b. un
a
homme
man
seul
alone
‘a lonely man’
(31) a. une
a
simple
simple
phrase
sentence
‘a mere sentence’
b. une
a
phrase
sentence
simple
simple
‘a simple sentence’
296 juliette thuilier
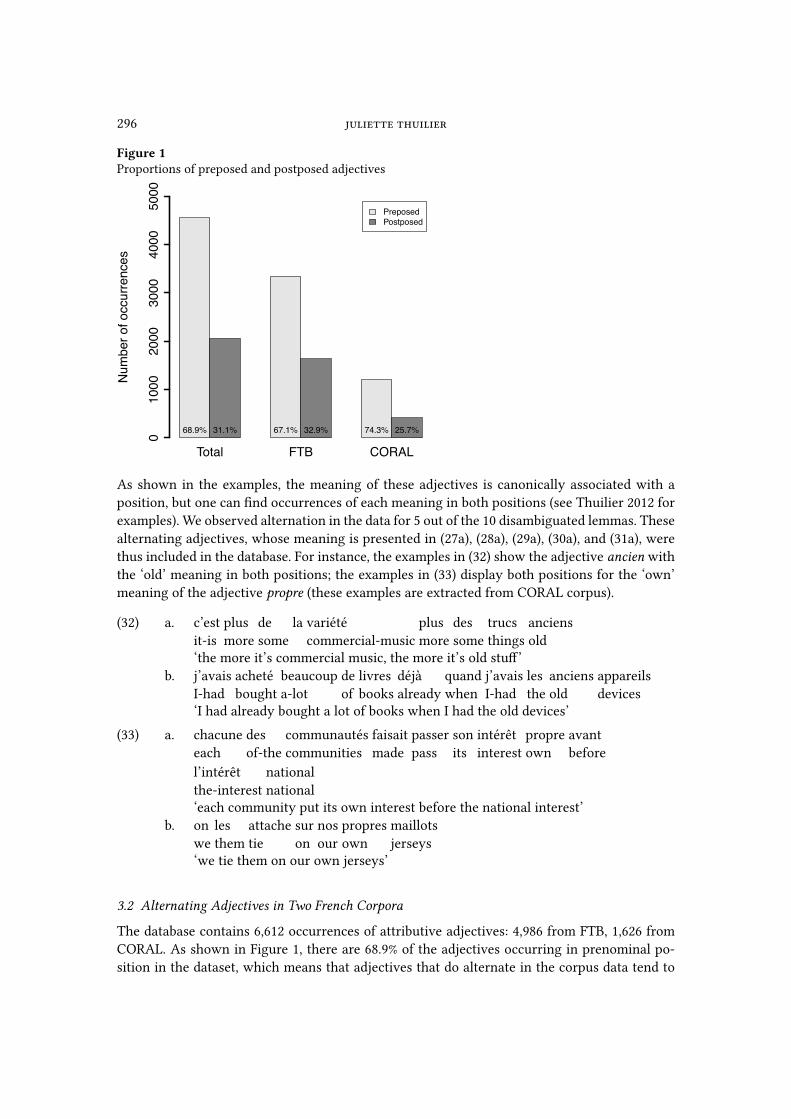
Figure 1Proportions of preposed and postposed adjectives
Total FTB CORAL
PreposedPostposed
Num
ber o
f occ
urre
nces
010
0020
0030
0040
0050
00
68.9% 31.1% 67.1% 32.9% 74.3% 25.7%
As shown in the examples, the meaning of these adjectives is canonically associated with a
position, but one can �nd occurrences of each meaning in both positions (see Thuilier 2012 for
examples). We observed alternation in the data for 5 out of the 10 disambiguated lemmas. These
alternating adjectives, whose meaning is presented in (27a), (28a), (29a), (30a), and (31a), were
thus included in the database. For instance, the examples in (32) show the adjective ancien with
the ‘old’ meaning in both positions; the examples in (33) display both positions for the ‘own’
meaning of the adjective propre (these examples are extracted from CORAL corpus).
(32) a. c’est
it-is
plus
more
de
some
la variété
commercial-music
plus
more
des
some
trucs
things
anciens
old
‘the more it’s commercial music, the more it’s old stu�’
b. j’avais
I-had
acheté
bought
beaucoup
a-lot
de
of
livres
books
déjà
already
quand
when
j’avais
I-had
les
the
anciens
old
appareils
devices
‘I had already bought a lot of books when I had the old devices’
(33) a. chacune
each
des
of-the
communautés
communities
faisait
made
passer
pass
son
its
intérêt
interest
propre
own
avant
before
l’intérêt
the-interest
national
national
‘each community put its own interest before the national interest’
b. on
we
les
them
attache
tie
sur
on
nos
our
propres
own
maillots
jerseys
‘we tie them on our own jerseys’
3.2 Alternating Adjectives in Two French Corpora
The database contains 6,612 occurrences of attributive adjectives: 4,986 from FTB, 1,626 from
CORAL. As shown in Figure 1, there are 68.9% of the adjectives occurring in prenominal po-
sition in the dataset, which means that adjectives that do alternate in the corpus data tend to
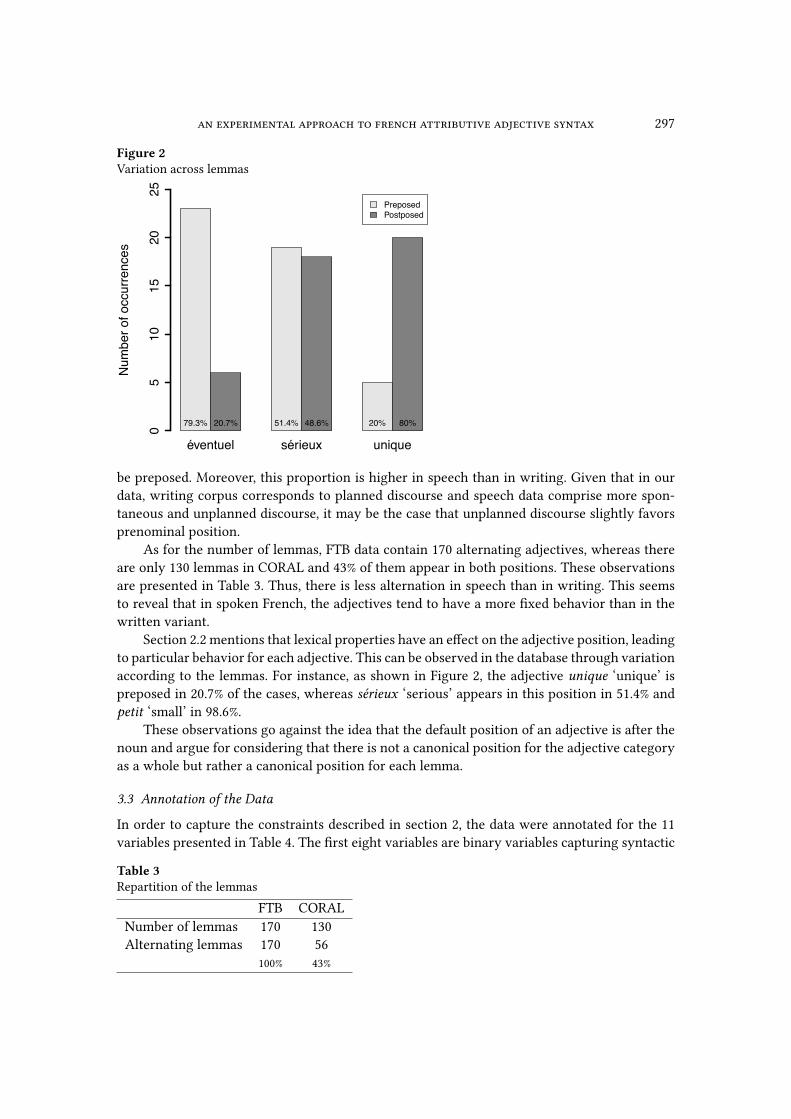
an experimental approach to french attributive adjective syntax 297
Figure 2Variation across lemmas
éventuel sérieux unique
PreposedPostposed
Num
ber o
f occ
urre
nces
05
1015
2025
79.3% 20.7% 51.4% 48.6% 20% 80%
be preposed. Moreover, this proportion is higher in speech than in writing. Given that in our
data, writing corpus corresponds to planned discourse and speech data comprise more spon-
taneous and unplanned discourse, it may be the case that unplanned discourse slightly favors
prenominal position.
As for the number of lemmas, FTB data contain 170 alternating adjectives, whereas there
are only 130 lemmas in CORAL and 43% of them appear in both positions. These observations
are presented in Table 3. Thus, there is less alternation in speech than in writing. This seems
to reveal that in spoken French, the adjectives tend to have a more �xed behavior than in the
written variant.
Section 2.2 mentions that lexical properties have an e�ect on the adjective position, leading
to particular behavior for each adjective. This can be observed in the database through variation
according to the lemmas. For instance, as shown in Figure 2, the adjective unique ‘unique’ is
preposed in 20.7% of the cases, whereas sérieux ‘serious’ appears in this position in 51.4% and
petit ‘small’ in 98.6%.
These observations go against the idea that the default position of an adjective is after the
noun and argue for considering that there is not a canonical position for the adjective category
as a whole but rather a canonical position for each lemma.
3.3 Annotation of the Data
In order to capture the constraints described in section 2, the data were annotated for the 11
variables presented in Table 4. The �rst eight variables are binary variables capturing syntactic
Table 3Repartition of the lemmas
FTB CORAL
Number of lemmas 170 130
Alternating lemmas 170 56
100% 43%

298 juliette thuilier
Table 4Variables annotated in the database
Variables Description
1 coord the adjective is coordinated or not
2 mod the adjective is pre-modi�ed or not
3 demDet the NP is introduced by a demonstrative determiner or not
4 possDet the NP is introduced by a possessive determiner or not
5 defArt the NP is introduced by a de�nite article or not
6 PP the NP contains a PP or not
7 rel the NP contains a relative clause or not
8 postAdj the NP contains a postposed or not
9 collocAN collocation score for A+N bigram (log(χ 2))
10 collocNA collocation score for N+A bigram (log(χ 2))
11 modality the modality is speech (s) or writing (w)
constraints mentioned in the literature. Variables 9 and 10 (collocAN and collocNA) were
designed in order to take into account the in�uence of the noun combined with the adjective
(cf. section 2.4). Their values correspond to χ 2scores (Manning and Schütze 1999)
3calculated
with data from the Est-Républicain corpus4
and they estimate the strength of the association
of the noun and the adjective in a given position. Finally, in order to know whether the way
data were produced a�ects the adjective position, we included the modality variable (variable
number 11 in the table).
3.4 Multifactorial Statistical Modeling
The statistical modeling of adjective position alternation was done using mixed-e�ects logistic
regression (Agresti 2007, Gelman and Hill 2006). This statistical tool allows one to model the
behaviour of a binary variable. More precisely, in our case, it estimates the probability that the
adjective will be preposed to the noun as a function of the predictive variables presented in
Table 4. One advantage of the mixed-e�ects logistic regression model is that it is predictive, in
the sense that one can build a model on a set of data and use this model to predict the choice
between prenominal position and postnominal position on new data. This way, we can assess
how well the model generalizes from the training set.
The construction of the model consists in estimating the coe�cients that are associated
with each variable. Each coe�cient can be interpreted as the preference of its variable: in the
case of a variable having only positive values, a positive coe�cient indicates a preference for
3Using contingency tables (2-by-2 tables) such as the ones presented below, “[t]he [χ2
] statistic sums the dif-
ferences between observed and expected values in all squares of the table, scaled by the magnitude of the expected
values” (Manning and Schütze 1999:169).
Noun = hommage Noun , hommagePre-adj = vibrant 152 8607
Pre-adj , vibrant 238 2797624
Noun = hommage Noun , hommagePost-adj = vibrant 10 8749
Post-adj , vibrant 380 4578757
In other words, the χ2statistic is an estimation of the distance between the observed frequencies and the expected
frequencies for independent variables. So, the more greater the distance, the higher the χ2and the stronger the
association of the noun and the adjective.
4It is a newspaper corpus comprising 148 million words and downloadable from http://www.cnrtl.fr/corpus/
estrepublicain/.
an experimental approach to french attributive adjective syntax 299
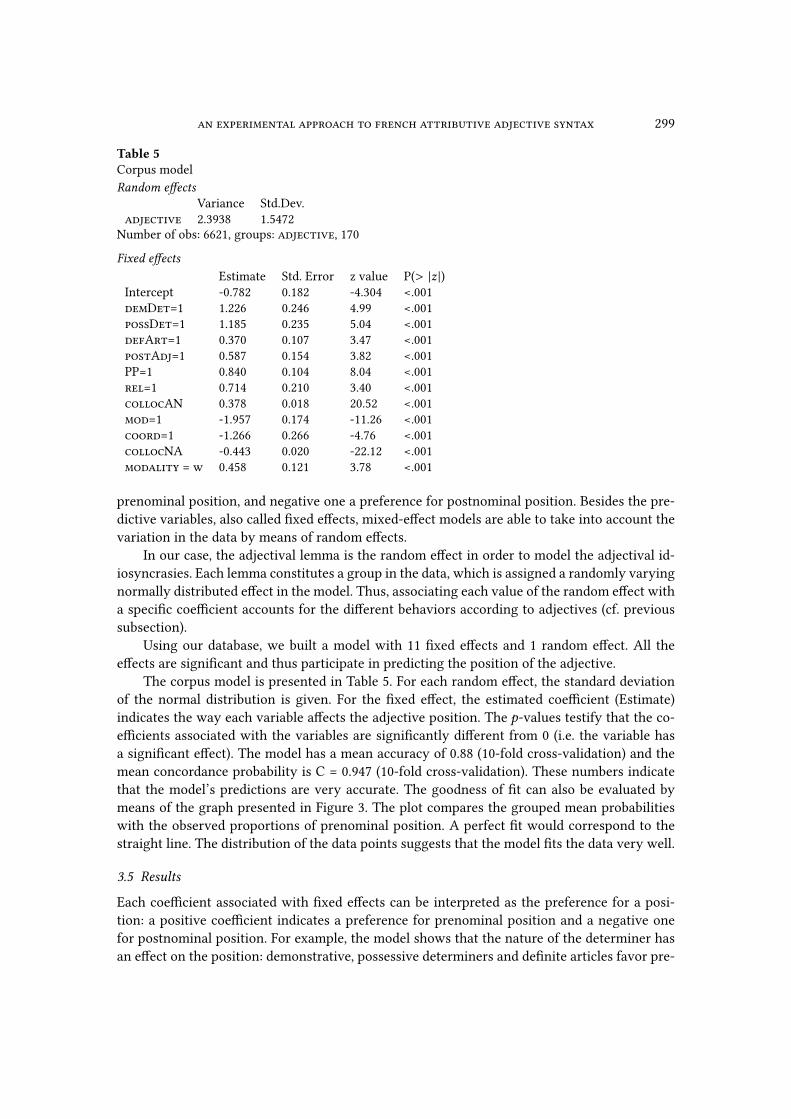
Table 5Corpus model
Random e�ectsVariance Std.Dev.
adjective 2.3938 1.5472
Number of obs: 6621, groups: adjective, 170
Fixed e�ectsEstimate Std. Error z value P(> |z |)
Intercept -0.782 0.182 -4.304 <.001
demDet=1 1.226 0.246 4.99 <.001
possDet=1 1.185 0.235 5.04 <.001
defArt=1 0.370 0.107 3.47 <.001
postAdj=1 0.587 0.154 3.82 <.001
PP=1 0.840 0.104 8.04 <.001
rel=1 0.714 0.210 3.40 <.001
collocAN 0.378 0.018 20.52 <.001
mod=1 -1.957 0.174 -11.26 <.001
coord=1 -1.266 0.266 -4.76 <.001
collocNA -0.443 0.020 -22.12 <.001
modality = w 0.458 0.121 3.78 <.001
prenominal position, and negative one a preference for postnominal position. Besides the pre-
dictive variables, also called �xed e�ects, mixed-e�ect models are able to take into account the
variation in the data by means of random e�ects.
In our case, the adjectival lemma is the random e�ect in order to model the adjectival id-
iosyncrasies. Each lemma constitutes a group in the data, which is assigned a randomly varying
normally distributed e�ect in the model. Thus, associating each value of the random e�ect with
a speci�c coe�cient accounts for the di�erent behaviors according to adjectives (cf. previous
subsection).
Using our database, we built a model with 11 �xed e�ects and 1 random e�ect. All the
e�ects are signi�cant and thus participate in predicting the position of the adjective.
The corpus model is presented in Table 5. For each random e�ect, the standard deviation
of the normal distribution is given. For the �xed e�ect, the estimated coe�cient (Estimate)
indicates the way each variable a�ects the adjective position. The p-values testify that the co-
e�cients associated with the variables are signi�cantly di�erent from 0 (i.e. the variable has
a signi�cant e�ect). The model has a mean accuracy of 0.88 (10-fold cross-validation) and the
mean concordance probability is C = 0.947 (10-fold cross-validation). These numbers indicate
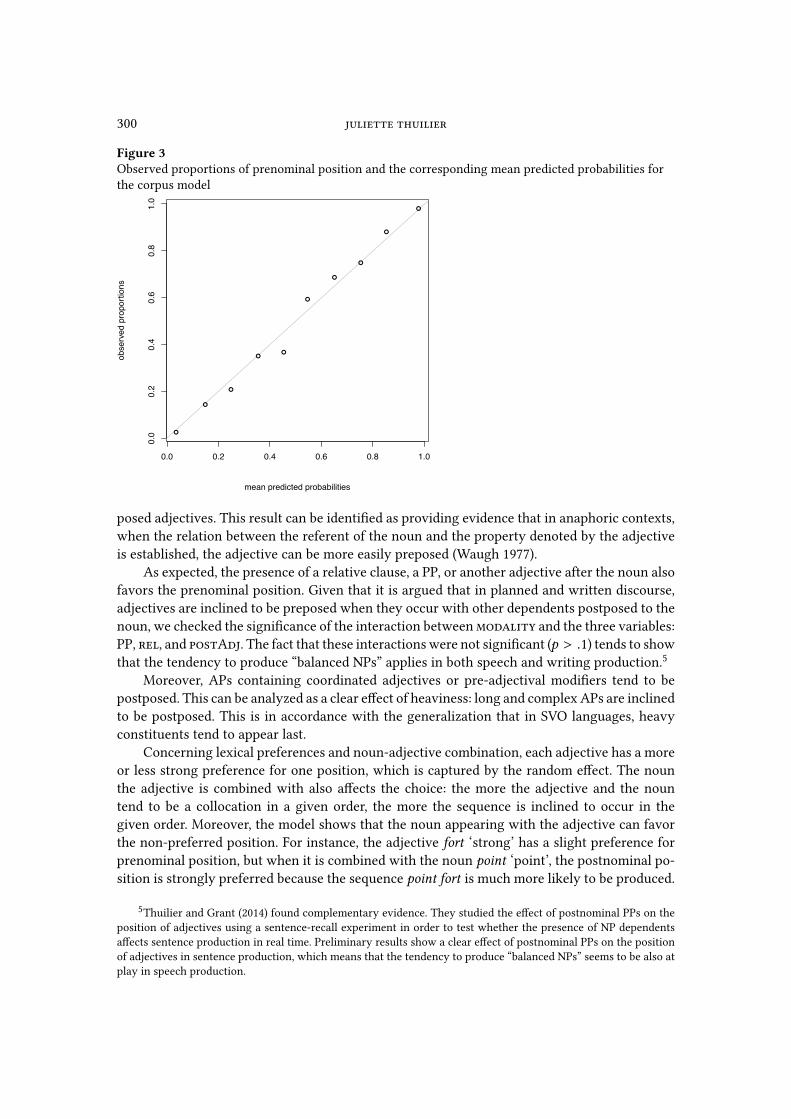
that the model’s predictions are very accurate. The goodness of �t can also be evaluated by
means of the graph presented in Figure 3. The plot compares the grouped mean probabilities
with the observed proportions of prenominal position. A perfect �t would correspond to the
straight line. The distribution of the data points suggests that the model �ts the data very well.
3.5 Results
Each coe�cient associated with �xed e�ects can be interpreted as the preference for a posi-
tion: a positive coe�cient indicates a preference for prenominal position and a negative one
for postnominal position. For example, the model shows that the nature of the determiner has
an e�ect on the position: demonstrative, possessive determiners and de�nite articles favor pre-
300 juliette thuilier
Figure 3Observed proportions of prenominal position and the corresponding mean predicted probabilities for
the corpus model
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.2
0.4
0.6
0.8
1.0
mean predicted probabilities
obse
rved
pro
porti
ons
!
!
!
!!
!
!
!
!
!
R−squared: 0.99
posed adjectives. This result can be identi�ed as providing evidence that in anaphoric contexts,
when the relation between the referent of the noun and the property denoted by the adjective
is established, the adjective can be more easily preposed (Waugh 1977).
As expected, the presence of a relative clause, a PP, or another adjective after the noun also
favors the prenominal position. Given that it is argued that in planned and written discourse,
adjectives are inclined to be preposed when they occur with other dependents postposed to the
noun, we checked the signi�cance of the interaction between modality and the three variables:
PP, rel, and postAdj. The fact that these interactions were not signi�cant (p > .1) tends to show
that the tendency to produce “balanced NPs” applies in both speech and writing production.5
Moreover, APs containing coordinated adjectives or pre-adjectival modi�ers tend to be
postposed. This can be analyzed as a clear e�ect of heaviness: long and complex APs are inclined
to be postposed. This is in accordance with the generalization that in SVO languages, heavy
constituents tend to appear last.
Concerning lexical preferences and noun-adjective combination, each adjective has a more
or less strong preference for one position, which is captured by the random e�ect. The noun
the adjective is combined with also a�ects the choice: the more the adjective and the noun
tend to be a collocation in a given order, the more the sequence is inclined to occur in the
given order. Moreover, the model shows that the noun appearing with the adjective can favor
the non-preferred position. For instance, the adjective fort ‘strong’ has a slight preference for
prenominal position, but when it is combined with the noun point ‘point’, the postnominal po-
sition is strongly preferred because the sequence point fort is much more likely to be produced.
5Thuilier and Grant (2014) found complementary evidence. They studied the e�ect of postnominal PPs on the
position of adjectives using a sentence-recall experiment in order to test whether the presence of NP dependents
a�ects sentence production in real time. Preliminary results show a clear e�ect of postnominal PPs on the position
of adjectives in sentence production, which means that the tendency to produce “balanced NPs” seems to be also at
play in speech production.
an experimental approach to french attributive adjective syntax 301
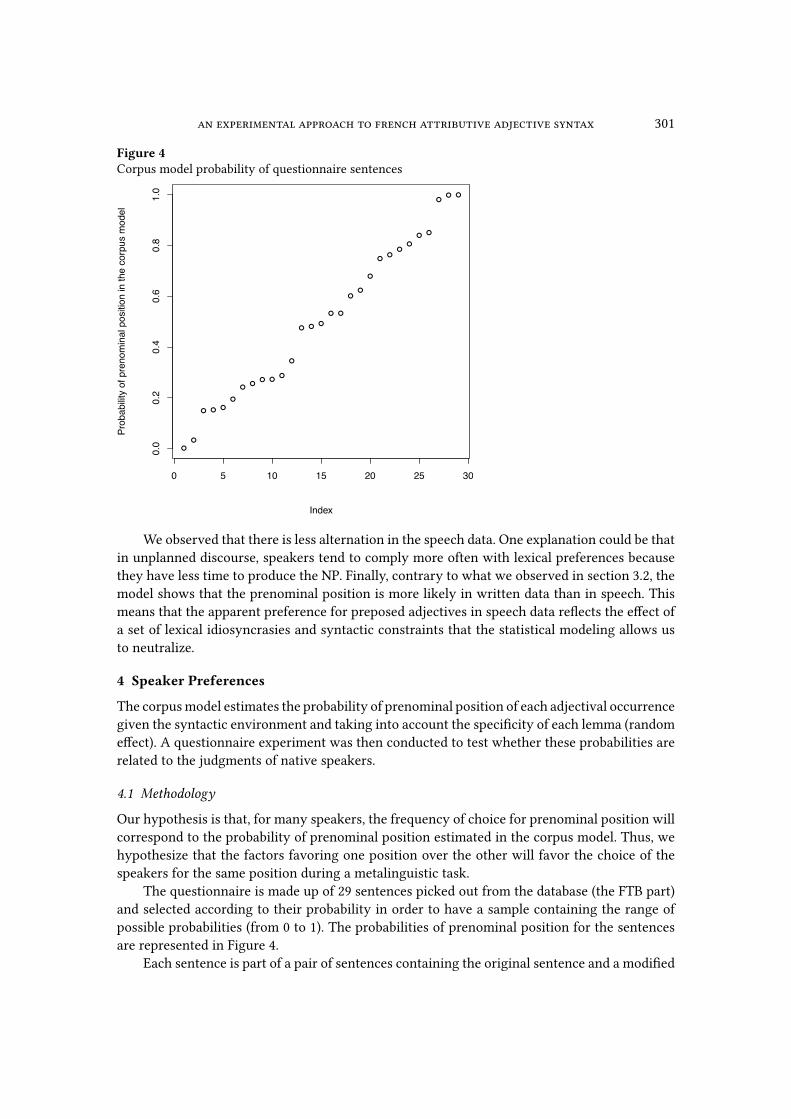
Figure 4Corpus model probability of questionnaire sentences
!
!
! ! !
!
!!
! !!
!
! !!
! !
!!
!
!!
!!
! !
!! !
0 5 10 15 20 25 30
0.0
0.2
0.4
0.6
0.8
1.0
Index
Prob
abilit
y of
pre
nom
inal
pos
ition
in th
e co
rpus
mod
el
We observed that there is less alternation in the speech data. One explanation could be that
in unplanned discourse, speakers tend to comply more often with lexical preferences because
they have less time to produce the NP. Finally, contrary to what we observed in section 3.2, the
model shows that the prenominal position is more likely in written data than in speech. This
means that the apparent preference for preposed adjectives in speech data re�ects the e�ect of
a set of lexical idiosyncrasies and syntactic constraints that the statistical modeling allows us
to neutralize.
4 Speaker Preferences
The corpus model estimates the probability of prenominal position of each adjectival occurrence
given the syntactic environment and taking into account the speci�city of each lemma (random
e�ect). A questionnaire experiment was then conducted to test whether these probabilities are
related to the judgments of native speakers.
4.1 Methodology
Our hypothesis is that, for many speakers, the frequency of choice for prenominal position will
correspond to the probability of prenominal position estimated in the corpus model. Thus, we
hypothesize that the factors favoring one position over the other will favor the choice of the
speakers for the same position during a metalinguistic task.
The questionnaire is made up of 29 sentences picked out from the database (the FTB part)
and selected according to their probability in order to have a sample containing the range of
possible probabilities (from 0 to 1). The probabilities of prenominal position for the sentences
are represented in Figure 4.
Each sentence is part of a pair of sentences containing the original sentence and a modi�ed
302 juliette thuilier
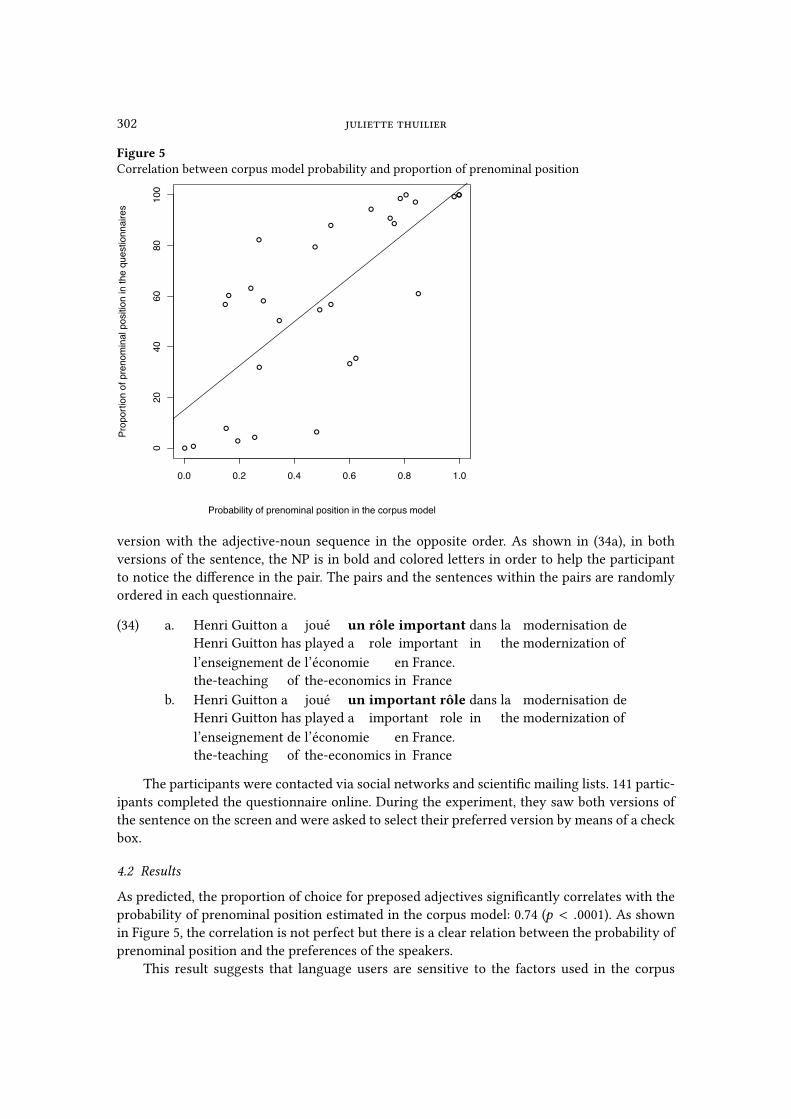
Figure 5Correlation between corpus model probability and proportion of prenominal position
! !
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!
!!
!
!!
!!
!
!
!!!
0.0 0.2 0.4 0.6 0.8 1.0
020
4060
8010
0
Probability of prenominal position in the corpus model
Prop
ortio
n of
pre
nom
inal
pos
ition
in th
e qu
estio
nnai
res
version with the adjective-noun sequence in the opposite order. As shown in (34a), in both
versions of the sentence, the NP is in bold and colored letters in order to help the participant
to notice the di�erence in the pair. The pairs and the sentences within the pairs are randomly
ordered in each questionnaire.
(34) a. Henri
Henri
Guitton
Guitton
a
has
joué
played
una
rôlerole
importantimportant
dans
in
la
the
modernisation
modernization
de
of
l’enseignement
the-teaching
de
of
l’économie
the-economics
en
in
France.
France
b. Henri
Henri
Guitton
Guitton
a
has
joué
played
una
importantimportant
rôlerole
dans
in
la
the
modernisation
modernization
de
of
l’enseignement
the-teaching
de
of
l’économie
the-economics
en
in
France.
France
The participants were contacted via social networks and scienti�c mailing lists. 141 partic-
ipants completed the questionnaire online. During the experiment, they saw both versions of
the sentence on the screen and were asked to select their preferred version by means of a check
box.
4.2 Results
As predicted, the proportion of choice for preposed adjectives signi�cantly correlates with the
probability of prenominal position estimated in the corpus model: 0.74 (p < .0001). As shown
in Figure 5, the correlation is not perfect but there is a clear relation between the probability of
prenominal position and the preferences of the speakers.
This result suggests that language users are sensitive to the factors used in the corpus

an experimental approach to french attributive adjective syntax 303
model when they make metalinguistic choices. More precisely, if the context strongly favors
one position, the speakers tend to mostly choose this position, whereas when the context is
not clearly in favor of one position, a part of the speakers selects one position and the others
choose the other position. This result is in accordance with Bresnan’s (2007) experimental work
on the dative alternation in English. Her experiment (Experiment 1 in the paper) indicated that
subjects’ intuitions are a�ected by the same constraints as those that have an e�ect on the
probability of dative PP realization calculated in a corpus model.
Finally, this experiment is an argument in favor of the idea that the statistical modeling
proposed on the basis of usage data is an appropriate way of describing and accounting for a
rather complex syntactic phenomenon such as the alternation of attributive adjective position.
5 Conclusion
This paper presented an experimental approach to the alternation of adjective position in the
NP, combining the modeling of corpus data and a questionnaire experiment.
From the linguistic point of view, the results suggest that there are three levels of orga-
nization involved in the phenomenon. The �rst level is related to the lexicon insofar as each
adjective has a more or less strong preference for one position. In the model, this is captured
via the random e�ect. The second level concerns the combination of two lexical items: the noun
can strongly a�ect the position of the adjective as the collocation variables show in the model.
The third level is related to syntax and corresponds to the constraints concerning the structure
of the AP and the NP.
We have o�ered a very accurate modeling of the phenomenon, based on corpus data and
providing the probability of having a preposed adjective in a given context. The result of the
comprehension experiment showed that the probabilities estimated in the corpus model seem
to partly re�ect the speaker preferences. This is a further argument in favor of the idea that
what corpus data tell us is in accordance with a form of linguistic knowledge of language users.
References
Abeillé, Anne, and Nicolas Barrier. 2004. Enriching a French treebank. In Proceedings of LanguageRessources and Evaluation Conference, 2233–2236. Lisbon.
Abeillé, Anne, Lionel Clément, and François Toussenel. 2003. Building a treebank for French. In Tree-banks: Building and Using Parsed Corpora, 165–187. Dordrecht: Kluwer Academic Publishers.
Abeillé, Anne, and Danièle Godard. 1999. La position de l’adjectif épithète en français : le poids des mots.
Recherches Linguistiques de Vincennes 28:9–32.
Agresti, Alan. 2007. An introduction to categorical data analysis. Wiley.
Blinkenberg, Andreas. 1933. L’ordre des mots en français moderne. Deuxième partie. Copenhagen: Levin
& Munksgaard.
Bouchard, Denis. 1998. The distribution and interpretation of adjectives in French: A consequence of
bare phrase structure. Probus 10:139–183.
Bresnan, Joan. 2007. Is syntactic knowledge probabilistic? Experiments with the English dative alterna-
tion. In Roots: linguistics in search of its evidential base, ed. Sam Featherston and Wolfgang Sternefeld,
77–96. Berlin: Mouton de Gruyter.
Bresnan, Joan, Anna Cueni, Tatiana Nikitina, and R. Harald Baayen. 2007. Predicting the dative alter-
nation. In Cognitive foundations of interpretation, ed. G. Boume, I. Kraemer, and J. Zwarts, 69–94.
Amsterdam: Royal Netherlands Academy of Science.
Bresnan, Joan, and Marilyn Ford. 2010. Predicting syntax: Processing dative constructions in American
and Australian varieties of English. Language 86:186–213.

304 juliette thuilier
Buridant, Claude. 2000. Grammaire nouvelle de l’ancien français. Sedes.
Bybee, Joan. 2006. From usage to grammar: The mind’s response to repetition. Language 82:711–733.
Cresti, Emanuela, and Massimo Moneglia, ed. 2005. C-ORAL-ROM Integrated reference corpora for spokenRomance languages. Amsterdam, USA: John Benjamins.
Delbecque, Nicole. 1990. Word order as a re�exion of alternate conceptual construals in French and
Spanish. Similarities and divergences in adjective position. Cognitive Linguistics 1:349–416.
Forsgren, Mat. 1978. La place de l’adjectif épithète en français contemporain, étude quantitative et séman-tique. Stockholm: Almqvist & Wilksell.
Gelman, Andrew, and Jennifer Hill. 2006. Data Analysis using regression and multilevel/hierarchical mod-els. Cambridge University Press.
Grevisse, Maurice, and André Goosse. 2007. Le bon usage. 14ème édition: De Boeck Université.
Hawkins, John. 1994. A performance theory of order and constituency. Cambridge: Cambridge University
Press.
Kamp, Hans. 1975. Two theories about adjectives. In Formal semantics of natural language, ed. Edward
Keenan, 123–155. Cambridge: Cambridge University Press.
Manning, Christopher D., and Hinrich Schütze. 1999. Foundations of statistical natural language process-ing. Cambridge: MIT Press.
McNally, Louise, and Christopher Kennedy, ed. 2008. Adjectives and adverbs: Syntax, semantics and dis-course. Oxford University Press.
Noailly, Michèle. 1999. L’adjectif en français. Paris: Ophrys.
Reiner, Erwin. 1968. La place de l’adjectif épithète en français : théories traditionnelles et essai de solution.
Vienna et Stuttgart: W. Braumüller.
Thuilier, Juliette. 2012. Contraintes préférentielles et ordre des mots en français. Doctoral Dissertation,
Université Paris 7.
Thuilier, Juliette, Gwendoline Fox, and Benoît Crabbé. 2010. Fréquence, longueur et préférences lexicales
dans le choix de la position de l’adjectif épithète en français. In Actes du 2ème Congrés Mondialde Linguistique Française, ed. Franck Neveu, Valelia Muni Toke, Thomas Klingler, Jacques Durand,
Lorenz Mondada, and Sophie Prévost, 2197–2210. Nouvelle-Orléans.
Thuilier, Juliette, Gwendoline Fox, and Benoît Crabbé. 2012. Prédire la position des adjectifs épithètes
en français. Lingvisticae Investigationes 35:28–75.
Thuilier, Juliette, and Margaret Grant. 2014. In�uence of noun dependents on French adjective place-
ment in sentence production. Poster presented at International Workshop on Language Productionin Geneva.
Waugh, Linda R. 1977. A semantic analysis of word order: Position of the adjective in French. Leiden: E. J.
Brill.
Wilmet, Marc. 1981. La place de l’épithète quali�cative en français contemporain : étude grammaticale
et stylistique. Revue de linguistique romane 45:17–73.
Zipf, George Kingsley. 1932. Selected studies of the principle of relative frequency in language. Cambridge,
USA: Harvard University Press.
Université Rennes 2 and Laboratoire de Linguistique Formelle (CNRS/Paris 7)[email protected]




























