Embed Size (px)
Citation preview

An Information Architecture for Hadoop
Mark Samson – Systems Engineer, Cloudera

2© Cloudera, Inc. All rights reserved.
Background
• The trend is for organisations to build business-wide Hadoop implementations
• Enterprise Data Hub / Data Lake / Hadoop as a Service• Many data sources• Many lines of business• Many use cases• Many engines and tools available to process and analyse data• Need to meet SLAs for data consumers
• How do I organise my information architecture within Hadoop to cope with this variety?
• Need a Logical Information Architecture for Hadoop!

3© Cloudera, Inc. All rights reserved.
What are the requirements?
• Ingest data in its full fidelity, in as close to its original, raw form as possible
• Provide a data discovery and exploration facility for analysts and data scientists
• Bring together and link multiple data sets• Serve data efficiently to business users and applications –
meeting SLAs

4© Cloudera, Inc. All rights reserved.
DataConsumers
Where does an Enterprise Data Hub fit?
DataSources
EnterpriseData Hub
Data consumers can be:• Analysts• Data Scientists• Business Users (Reports)• Applications
Data Sources can be:• Databases / DWs• File Sources• Machines, Sensors (IoT)• Internet (Social Media etc)• Mobile
Enterprise Data Hub sits in between!
(but it’s not the only thing in between)
5© Cloudera, Inc. All rights reserved.
DataConsumers
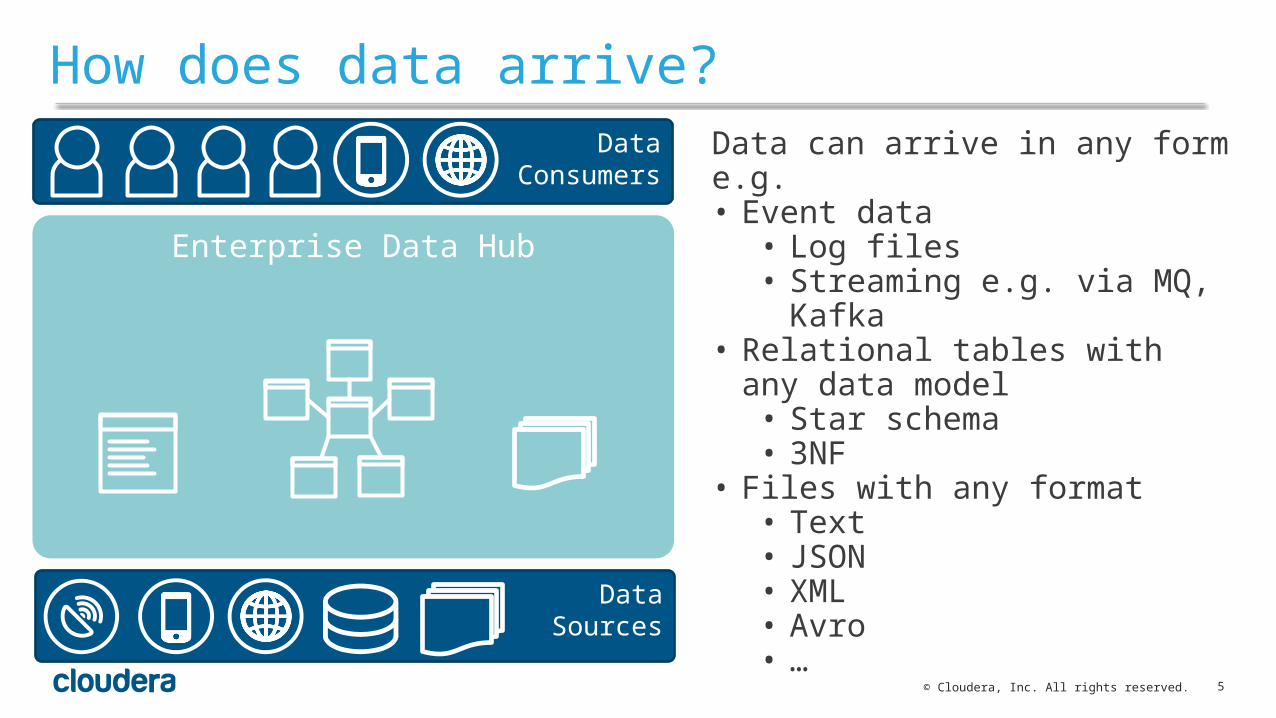
How does data arrive?
DataSources
Enterprise Data Hub
Data can arrive in any form e.g.• Event data• Log files• Streaming e.g. via MQ, Kafka
• Relational tables with any data model• Star schema• 3NF
• Files with any format• Text• JSON• XML• Avro• …
6© Cloudera, Inc. All rights reserved.
DataConsumers
DataSources
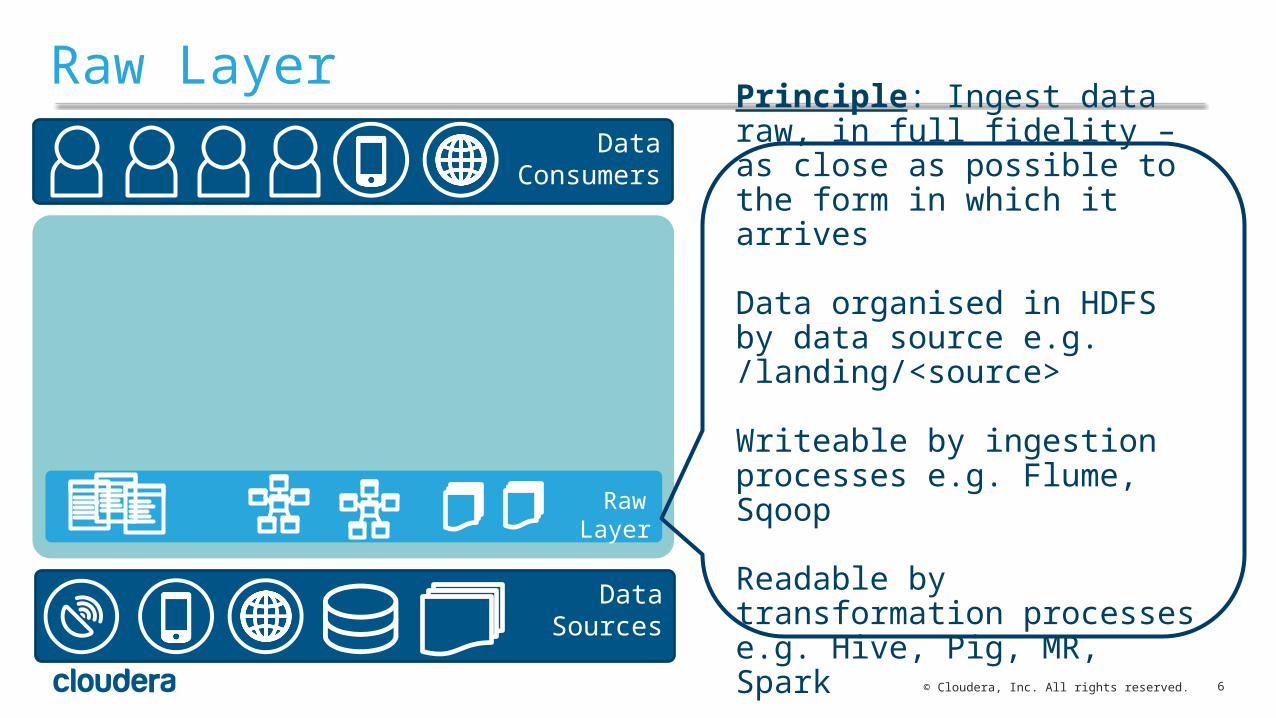
Raw Layer
RawLayer
Principle: Ingest data raw, in full fidelity – as close as possible to the form in which it arrives
Data organised in HDFS by data source e.g. /landing/<source>
Writeable by ingestion processes e.g. Flume, Sqoop
Readable by transformation processes e.g. Hive, Pig, MR, Spark
7© Cloudera, Inc. All rights reserved.
RawLayer
DataSources
DataConsumers
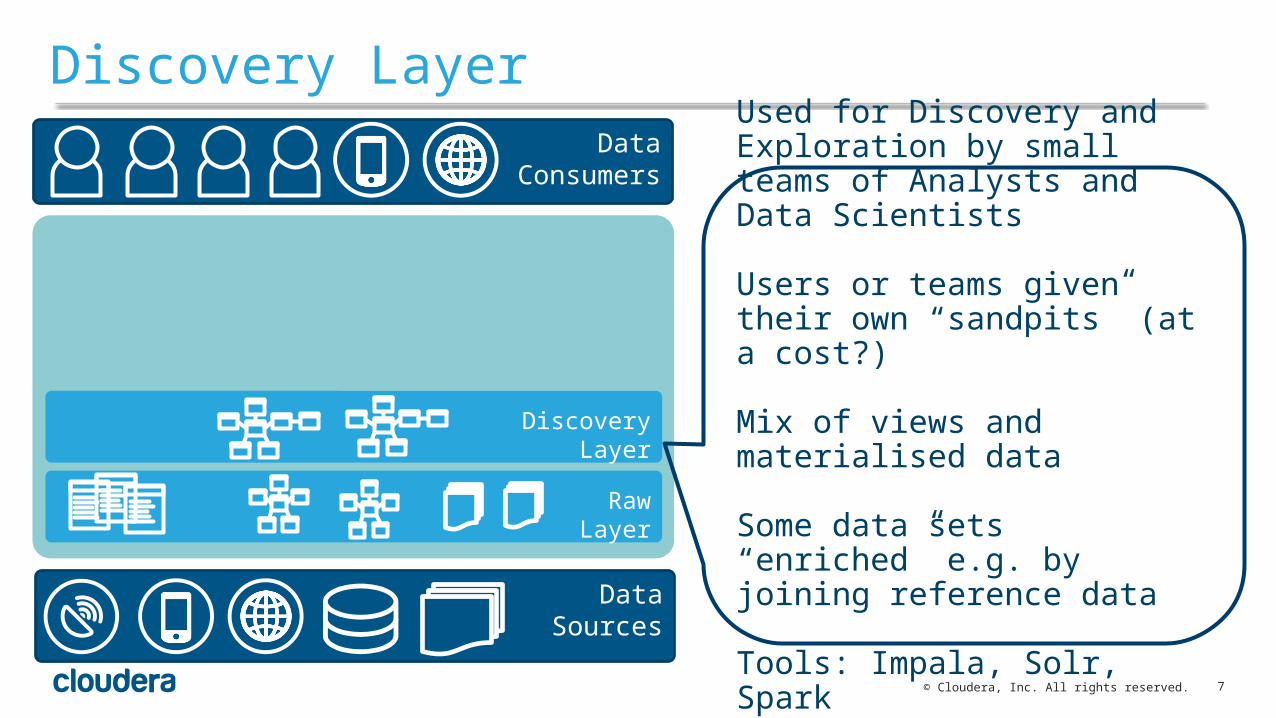
Discovery Layer
DiscoveryLayer
Used for Discovery and Exploration by small teams of Analysts and Data Scientists
Users or teams given their own “sandpits” (at a cost?)
Mix of views and materialised data
Some data sets “enriched” e.g. by joining reference data
Tools: Impala, Solr, Spark
8© Cloudera, Inc. All rights reserved.
RawLayer
DiscoveryLayer
DataSources
DataConsumers
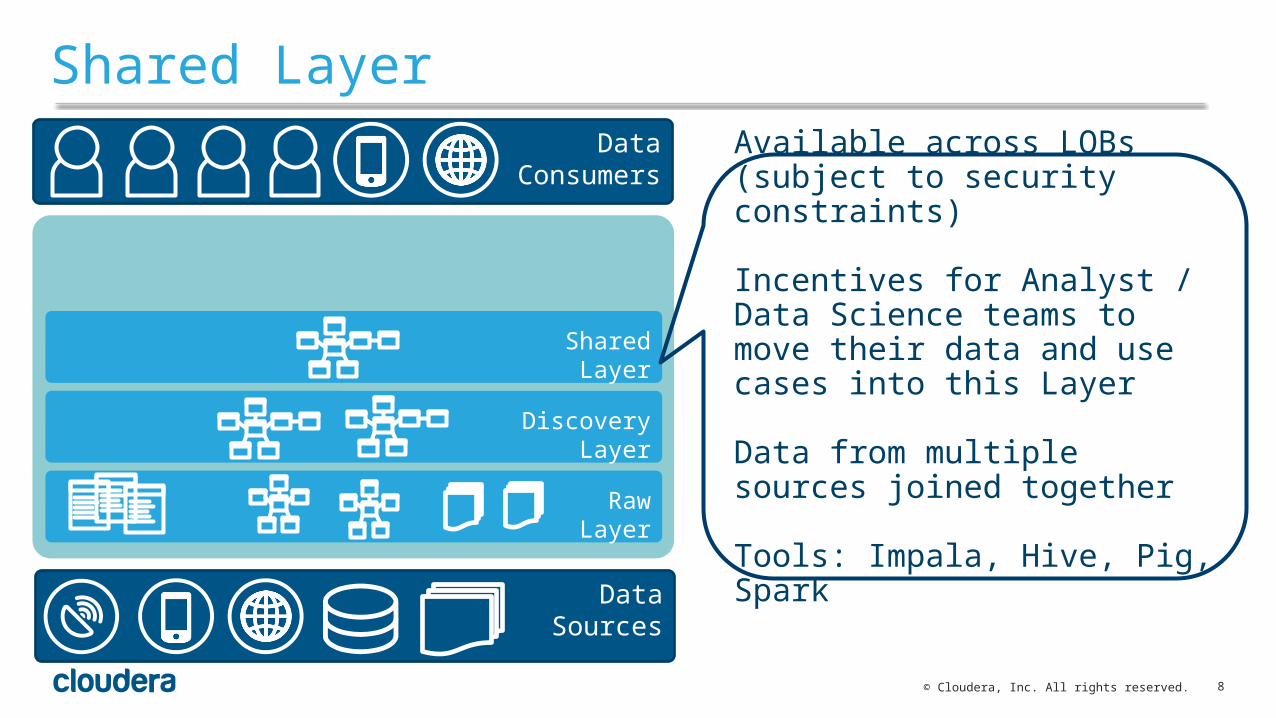
Shared Layer
SharedLayer
Available across LOBs (subject to security constraints)
Incentives for Analyst / Data Science teams to move their data and use cases into this Layer
Data from multiple sources joined together
Tools: Impala, Hive, Pig, Spark

9© Cloudera, Inc. All rights reserved.
RawLayer
DiscoveryLayer
SharedLayer
DataSources
DataConsumers
Optimised Layer
OptimisedLayer
Build this when you need to operationalise the use case
Organised by data consumer and use case not by source
Data modeled to provide optimised performance• Often denormalised• Uses optimised storage formats
e.g. Parquet with partitioning, HBase
• Accessed by low latency query engines e.g. HBase, Impala, Solr
10© Cloudera, Inc. All rights reserved.
RawLayer
DiscoveryLayer
SharedLayer
DataSources
DataConsumers
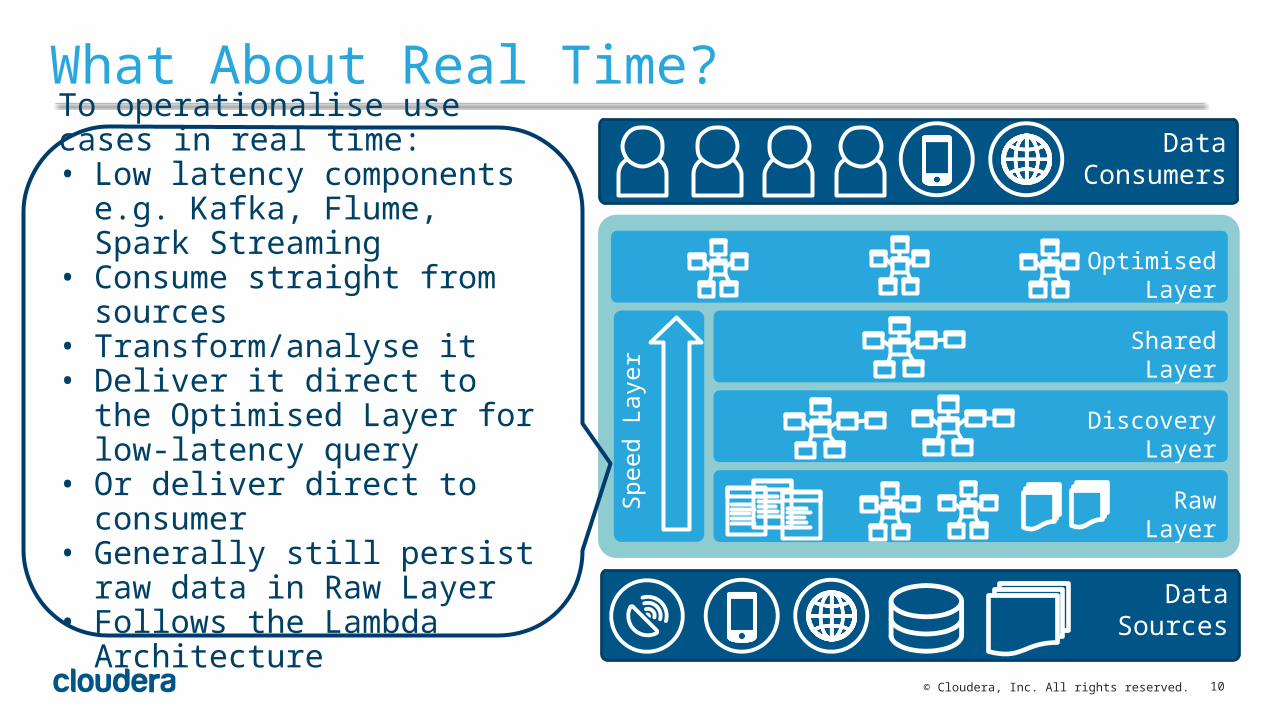
What About Real Time?
OptimisedLayer
To operationalise use cases in real time:• Low latency components e.g.
Kafka, Flume, Spark Streaming• Consume straight from sources• Transform/analyse it• Deliver it direct to the Optimised
Layer for low-latency query• Or deliver direct to consumer• Generally still persist raw data in
Raw Layer• Follows the Lambda Architecture
Spee
d La
yer
11© Cloudera, Inc. All rights reserved.
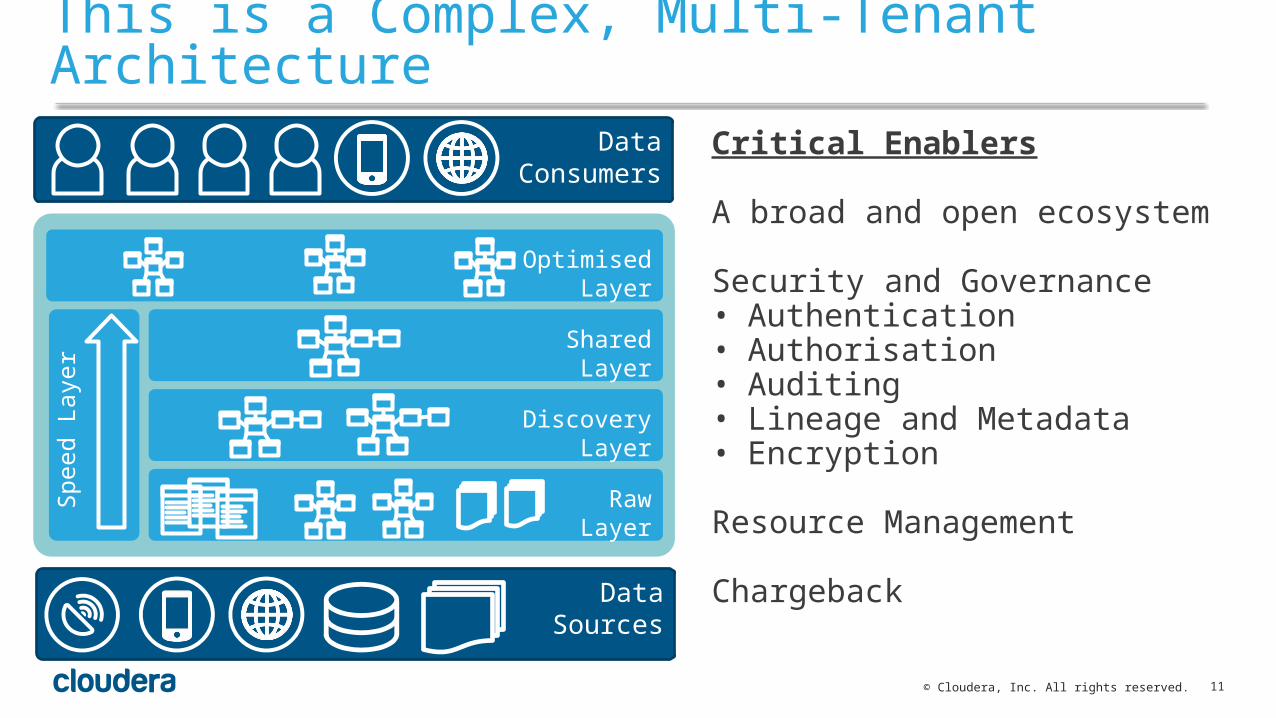
This is a Complex, Multi-Tenant ArchitectureCritical Enablers
A broad and open ecosystem
Security and Governance• Authentication• Authorisation• Auditing• Lineage and Metadata• Encryption
Resource Management
Chargeback
RawLayer
DiscoveryLayer
SharedLayer
DataSources
DataConsumers
OptimisedLayer
Spee
d La
yer

12© Cloudera, Inc. All rights reserved.
ConsiderationsThis is not prescriptive
• There could be more or fewer layers, depending on use cases
This is a logical architecture
There may be multiple physical clusters due to non functional requirements e.g.• Compliance and security e.g. some
data can only be kept in EU• If there are tight SLAs, some engines
perform better on dedicated clusters e.g. HBase, Kafka
RawLayer
DiscoveryLayer
SharedLayer
DataSources
DataConsumers
OptimisedLayer
Spee
d La
yer
13© Cloudera, Inc. All rights reserved.
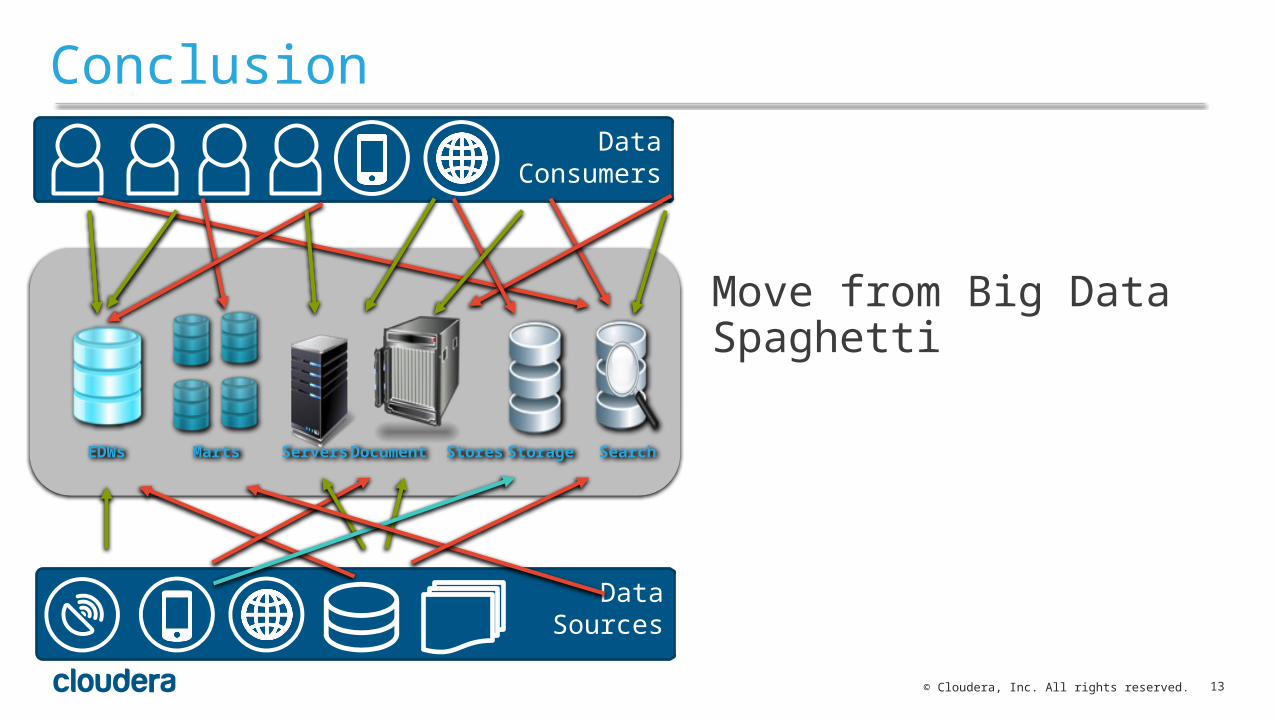
Conclusion
Move from Big Data Spaghetti
DataSources
DataConsumers
EDWs Marts SearchServers Document Stores Storage

14© Cloudera, Inc. All rights reserved.
Conclusion
RawLayer
DiscoveryLayer
SharedLayer
DataSources
DataConsumers
OptimisedLayer
Spee
d La
yer
Move from Big Data Spaghetti
…to Big Data Lasagne!

15© Cloudera, Inc. All rights reserved.
BOOK SIGNINGS THEATER SESSIONS
TECHNICAL DEMOS GIVEAWAYS
Visit us at Booth #101HIGHLIGHTS:
Apache Kafka is now fully supported with Cloudera
Learn why Cloudera is the leader for security & governance in Hadoop

Thank you





























