Embed Size (px)
Citation preview

i
An Intelligent Mashup that includes Personalisation in an
Interactive NewsreaderFaisal Akhtar
BSc Computer ScienceSession (2006/2007)
The candidate confirms that the work submitted is their own and the appropriate credit has been given where reference has been made to the work of others.
I understand that failure to attribute material which is obtained from another source may be considered as plagiarism.
(Signature of student)______________________________

i
Summary
The primary objective of this project was to develop an intelligent mashup web application that
incorporated personalisation techniques. An interactive news reader was the chosen application to
develop that would include these techniques. Research into the fields of mashup web applications and
personalisation had to be conducted in order to obtain sufficient background knowledge to
successfully understand the problem. As mashups are classed as upcoming Web 2.0 based
applications, research into this was also required. Investigation into a wide range of development
methodologies was essential. One of the methodologies was selected and the project development was
built around the chosen methodology, allowing for a more structured approach to tackling the
problem. The system was designed and implemented based on the specification set in advance. The
final system was then evaluated with end users, measuring how satisfied they were with the
personalised news reader.

ii
Acknowledgements
I would like to thank my Project supervisor, Dr Vania Dimitrovia for all the support provided to me
during the project. The feedback returned by the project assessor, Dr Roy Ruddle, during the progress
meeting and mid project report was extremely helpful and this is much appreciated. I am very
grateful to all the users that took part in the evaluation, I thank you for the time you took out to help
me with my project evaluation.

iii
Table of Contents
Chapters Page Numbers
1 Project Outline 1
1.1 Problem Definition 1
1.2 Project Aim and Objectives 1
1.3 Minimum Requirements 1
2 Methodology 2
2.1 Introduction 2
2.2 Methodologies Overview 2
2.3 Methodology Reviews 3
2.3.1 Agile Unified Process (AUP) 4
2.3.2 Adaptive Software Development (ASD) 5
2.3.3 Dynamic Systems Development Method (DSDM) 5
2.4 Conclusion 7
3 Background Research 8
3.1 Web 2.0 8
3.2 Mashups 10
3.2.1 Mashups Background 10
3.2.2 Intelligent Mashups 10
3.2.3 Existing Solutions 11
3.2.4 Summary and Project Implications 13
3.3 Personalisation 14
3.3.1 What is Personalisation? 14
3.3.2 Personalisation in Web Based Environment 14
3.3.3 Personalisation Techniques Overview 14
3.3.4 Possible Personalisation Techniques 15
3.3.5 Personalisation Summary 17

iv
4 Design 18
4.1 Data Sources 18
4.2 Tools and Applications 20
4.2.1 Programming Environment 20
4.2.2 Web Environment 21
4.2.3 Database Management Environment 21
4.2.4 Really Simple Syndication (RSS) 22
4.3 Architecture Designs 23
4.3.1 Iteration One System Architecture 23
4.3.2 Iteration Two System Architecture 24
4.3.3 Iteration Three System Architecture 24
4.3.4 System Components Sequence Diagram 25
4.4 Design Summary 26
5 Implementation 27
5.1 Iteration One 27
5.1.1 System Environment 27
5.1.2 Gathering News from Sources 28
5.1.3 Displaying Suitable Content 29
5.1.4 Implementation of User Profiles 30
5.1.5 Matching Categories and User Interests 31
5.1.6 Return of Filtered Content 31
5.2 Iteration Two 33
5.2.1 Implementation of Mashup Structure 33
5.2.2 Development of User Stereotypes 35
5.2.3 Statistical Article Recommendation 35
5.2.4 Stereotype Ranking Recommendation 36
5.3 Iteration Three 36
5.3.1 Implementation of a User-User Recommender 37
5.4 Summary of Implementation Chapter 38

v
6 Pilot Studies and User Evaluation 39
6.1 Pilot Studies 39
6.1.1 Problems Identified and Solutions 39
6.2 User Evaluation 41
6.2.1 User Evaluation Criteria 41
6.2.2 Evaluation Study Form 42
6.2.3 User Interviews 42
6.2.4 Feedback Analysis 43
6.2.5 Conclusion 48
6.2.6 Evaluation Summary 49
6.2.7 Further Work 49
7 Project Conclusion 50
Reference List 51
Appendices 54
Appendix A: Personal Reflections 54
Appendix B1: Initial Project Plan 56
Appendix B2: Final Project Plan 57
Appendix C: Stereotype Derivation Methods 58
Appendix D: Stereotype Rankings per Category 59
Appendix E: Evaluation Study Form 60
Appendix F: Cumulative User Feedback 62

1
Chapter 1. Project Outline
1.1 Problem Definition
Viewing news on the web is a popular activity performed by many people. Web based news sources
display to every news reader the exact same articles, meaning that articles of no interest to a particular
user are also displayed. The news sources only include a limited amount of news that a user will want
to read, from the users perspective it can become frustrating to continually search for these articles.
This approach of viewing news is not really intelligent and hinders the users overall experience.
Taking advantage of current Web 2.0 moves of web development will help to provide users a richer
environment in order to access news of interest. A mashup is one such application that is part of the
Web 2.0 paradigm. Presenting users with multiple sources of news information will further expand
the overall choices and variety of news offered, with the intention of improving usability and
satisfaction. Personalisation is a method that can provide news readers a more efficient way of
viewing articles of interest, but has not been widely incorporated within current mashup offerings.
1.2 Project Aim and Objectives
The aim of this project is to illustrate an application of personalisation techniques within intelligent
mashups. For this, a prototype of a personalised interactive newsreader that integrates multiple
sources of data and provides users with access to news they are interested in will be implemented.
The project must consider various personalisation issues associated with how news is constructed and
how end users can take advantage of any personalised options available. To satisfy the aims of the
project the following objectives are to be completed: -
Identify appropriate software engineering methodology
Identify sources of data to be included in the prototype and familiarise a way of querying data
Identify appropriate personalisation techniques to be included in the prototype
Design an interactive newsreader that can be adapted for particular users and offers news
depending on what topics the user is interested in
Develop a prototype of an interactive newsreader
Evaluate the prototype considering user satisfaction
1.3 Minimum Requirements
The minimum aims to be completed for the project are:-
Design of a personalised interactive newsreader
A web-based prototype that retrieves news from one source and provides basic
personalisation (e.g. User Profiles)

2
Chapter 2. Methodology
2.1 Introduction
A methodology is a set framework of tasks that are to be followed in order for the overall project to be
a success. Therefore a solid methodology is a crucial aspect of any project development cycle in
general, and is critical for the completion of this project.
This chapter is set out to show a possible software development methodology approach with
the project specifically in mind, taking into account the specific characteristics that this particular
project possesses. Several methodologies will be discussed and contemplated upon as to which would
be best suited for the development process to align the structure of tasks to.
Each project has different characteristics based on several conditions, such as requirements,
task force and time constraints. With such conditions taken into consideration, the specific
characteristics of this project are: -
Lack of specific user groups in mind, so need for scenario-based approach for defining
requirements
Creative and opportunistic design dependant on the availability of data, hence the task design
set should be easy to manipulate
Prototype design style would be of definite benefit during development of this system, the
methodology should allow this to be integrated
Single developer conducting the project, the methodology should be adaptable as to allow
them to perform each work step on their own
With these characteristics set in place we will select a methodology for this project based on these. It
is often difficult to find the perfect methodology that suits all characteristics, so it may be the case that
the final methodology chosen has to be modified as to fully satisfy the characteristics.
2.2 Methodologies Overview
There are numerous types of methodologies currently in wide-use. Every development team uses a
varying type of methodology, but no two are generally the same overall as no two projects are exactly
the same. Some past development methodologies will be discussed here making the benefits and
down sides of each methodology clear.
With no definite consumer set, it is possible for the developer to lay out the requirements
based around a predetermined problem scenario; this situation is described as a Plan-driven approach.
This approach is best suited for developers that can ‘determine the requirements in advance and when
the requirements remain relatively stable throughout’ (Boehm, 2002). There exist plan-driven
approaches such as the various Waterfall Models and Rational Unified Process ̧these are both plan-

3
driven as they show a general sequential style of development going from one step to the next to an
eventual final product. However, such methods would be inappropriate to use for this project as it is
impossible to tell what issues the developer would face during certain stages of the project cycle.
These frameworks would not allow modifications to certain areas of the system without causing
disruption to another due to the strict sequential structures readily in place. Without heavily
modifying a plan-driven approach, which in turn would no longer render it plan-driven, the sequential
structuring style would be unsuitable for use within this project.
There are also iterative methods to consider such as the well known Spiral Model and various
Agile approaches. William and Cockburn (2003) mention that such methods count on and recognise
that the ‘only constant is change’. This means that such methodologies are undertaken in order to
allow developers to be prepared for making changes to requirements and other aspects of the
development with relative ease and minor disruption to progression.
Agile methods allow the developer to incorporate iterative techniques and display
evolutionary methods that are based upon such practices as the opportunistic development process.
These techniques allow more structured freedom in the sense that each iteration on the development
cycle has a clear goal to be achieved. Agile methodologies appear to be the most appropriate for use
within this project as they will allow the developer to work around the characteristics set, so an agile
approach will be undertaken. However, there are many varieties of agile techniques and so a set of
them will be reviewed in greater depth in order to see which of them are most suited for the project.
2.3 Methodology Reviews
There are many agile techniques that have been researched and considered but most of them are
specifically driven towards specific roles of working, but three possible methodology choices stood
out for consideration. Agile techniques to be reviewed are: -
Agile Unified Process
Adaptive Software Development
Dynamic Systems Development Method
The reason why this subset of well known agile techniques have been listed is because of the nature of
each of them in that they closely relate to the type of project undertaken. Each of these methods have
very similar conceptual ideas and provide developers an iterative approach during implementation of
the system. They do though vary greatly in the way that each transitional phase is set out. Each of the
proposed techniques will be analysed in greater depth as to see which of these would be most
appropriate to embark upon.

4
2.3.1 Agile Unified Process (AUP)
The Agile Unified Process methodology is developed around four main development phases as
proposed by Ambler (2005). These being, (a) Inception, The life-cycle objectives are stated in the
inception phase, this includes identifying the scope of the system and requirements. (b) Elaboration,
software architecture is laid out in this phase, the problem domain is analysed around how the system
will be built. An analysis is delivered showing what the final product should become and how it will
get there. (c) Construction, during this phase the majority of the actual project development is
undertaken, taking into account the details gained from the past phases. (d) Transition, A finalised
system is publicly deployed in which it is then evaluated by the target audience.
These four phases are also accompanied by seven work flow disciplines: -
Model, ensuring requirements are successfully addressed throughout
Implementation, work is done developing the system itself
Test, an objective evaluation to ensure quality
Deployment, plan for the delivery of the system
Configuration Management, tracking development changes
Project Management, direct the activities taking place on the project
Environment, ensuring that developer requirements are met
Each of the workflow disciplines is reviewed at each one of the four phases, allowing the developer to
review each task during each phase. This ensures that they are not leading away from the original
project idea and are fulfilling requirements throughout the development cycle.
Figure 2.1: Illustration of the Agile Unified Process Methodology, (Ambler, 2005)
For the relevance of this project the AUP workflow disciplines must be modified, as it is currently not
suitable for the project as there exist extra steps that would be outside the current project scope. The
work flow disciplines that should be omitted from the AUP are ‘configuration management, project
management and deployment’ these are not required within the current scope of the characteristics.
The remaining phases would definitely be of use within the project. Most project methodologies
include model, implementation and some form of testing. AUP also ensures that the developer has
the necessary tools and other requirements from the offset and so will not be concerned with such

5
dilemmas in the future. The modified AUP methodology would allow the developer to construct the
system and satisfy all initial characteristics proposed.
2.3.2 Adaptive Software Development (ASD)
ASD largely focuses on the development of very large and often complex systems, but greatly
encourages incremental, iterative development with constant prototyping (Highsmith, 2002). ASD is
carried out in three – phase cycles. These are, (a) Speculate, Initial requirements and product
adaptation techniques depending on the situation are looked at during this phase. (b) Collaborate, The
implementation is done during this phase but it is heavily focused on a team based environment. (c)
Learn, This phase looks at the current issues with the system and relays methods on how to fix them.
Figure 2.2: Illustration of the Adaptive Software Development Methodology, (Highsmith, 2002)
ASD strives on continual incremental updates, each iteration of such a system is always an
improvement of the last, as problems are identified early and possible solutions are then proposed.
This style therefore satisfies the project characteristics regarding prototyping and would allow
requirements and other criteria to be constantly modified with ease. This is evident within Figure 2.2,
as the iterations cover each aspect of speculate, collaborate and learn. A concern with this
methodology is that it appears to be heavily focused around team oriented scenarios, and would need
to be modified if it were to be used within this project to be appropriate for a single developer.
2.3.3 Dynamic Systems Development Method (DSDM)
The DSDM technique is a very user oriented methodology, but once user requirements have been
gathered it sticks to them and develops the system according to them using various iterative
techniques. DSDM consists of Five Phases, these are, (a) Feasibility Study, The suitability of the
proposed model based on the project is given here so as to find out whether DSDM can function
properly within the project. (b) Business Study, after the project is deemed feasible to use under
DSDM, this is the phase in which all the user requirements and project structure is finalised. (c)
Functional Model Iteration, determines the functionalities to be implemented in the prototype. (d)
Design and Build Iteration, An initial system is built during this phase that satisfies the minimum set

6
of requirements; further iterations here continually improve on past developments. (e)
Implementation, This phase allows proposed users to test the current system and the requirements are
analysed again at this phase.
The Feasibility and Business studies are compiled just the once, whilst the Final three stages are both
iteratively and incrementally undertaken. The DSDM approach can provide a solid platform for the
development cycle, in that the details such as the requirements and tools to be used need only be
defined once. This results in the developer having more time and freedom as to how the actual
software needs to function without constant pressure from user requirements. For this project the
requirements would remain static so this methodology would be beneficial in this case. However, a
problem exists in that this methodology has a very user centred approach whereas the project has no
specific users as labelled by the characteristics. Therefore this methodology would have to be
modified to cater for this. The whole implementation phase must be removed as it is only concerned
about how the end users use the system.
Figure 2.3: Illustration of the Dynamic Systems Development Method Methodology, (Stapleton, 1997)

7
2.4 Conclusion
After conducting reviews around these three methodologies, the most suitable agile technique to use
within this project is the modified Agile Unified Process. This modification excludes 3 workflow
disciplines, deployment, configuration management and project management, and solely concentrates
on the remaining phases. This methodology now is capable of satisfying all proposed project
characteristics and is adaptable to other scenarios that may be faced during the development cycle.
The reasons as to why ASD was not chosen was mainly due to the fact that to get the most out
of the methodology the project must be completed under a team based environment due to the
collaborative step. This cannot be the case under this project and as collaboration is a large part of
ASD it is not feasible to modify it and still remain with an ASD methodology, hence why ASD was
not selected.
DSDM is a very effective methodology when worked with during a project, however for this
to be the case it is seriously reliant upon user based communication. This cannot be achieved within
this project but it would be possible to modify the DSDM implementation phase so to conform to the
project characteristics, however like ASD to attain the maximum benefit of this methodology heavily
modifying a core part of it will have a negate effect overall.
The Agile Unified Process technique is therefore the most appropriate methodology to use
within the scope of this project. The project schedule (Appendix B1 and B2) reflects each phase of
the AUP technique (Inception, Elaboration, Construction and Transition), showing how each task
required can successfully be mapped around this particular methodology.

8
Chapter 3. Background Research
This section is set out to discuss Web 2.0 and mashups, specifically intelligent mashups. Discussions
regarding various existing mashups that specifically involve news based content will also be evaluated
based on personalisation content offered to users. During the evaluations of the mashups an outline of
the intelligence of the mashups will be analysed. An in-depth overview of personalisation techniques
shall also be investigated, and the chosen techniques for the project shall be illustrated.
3.1 Web 2.0
The goal of this section is to provide a detailed breakdown into what exactly Web 2.0 actually
represents and how it reflects into the project. Details listed here will display the origins of Web 2.0,
the concepts behind it, and what it represents for the general web user. Web 2.0 is not an incremental
update to the web, as the ‘2.0’ may initially suggest. It is more of a base set of underlying principles,
which lead to a more communal web offering generating what is fast becoming a social phenomenon,
appealing to both users and developers alike.
The term Web 2.0 was brought about during a brainstorming conference between O’REILLY1
and MediaLive International. It was noted that the web was playing a larger part in societal
interaction than it had ever done in the past, such as the usage of web based commercial businesses
like Amazon2. This acknowledgement of a new level of human computer interaction defined a
turning point for the current status of the web. This societal change is what Web 2.0 is about and how
the web is experienced from all types of users. For this change to be experienced there must exist a
clear definition and goal for what exactly Web 2.0 is trying to achieve. Sigal (2005) states that ‘At the
core, Web 2.0 is an applied service model’, essentially this is true but this must be expanded upon as
to provide an in depth view of this ‘service model’. The underlying service model has been listed as
seven principle features that resemble what the architecture of Web 2.0 should incorporate,
(O’REILLY, 2005): -
Services, not packages software, with cost-effective scalability
Control over unique, hard-to-recreate data sources that get richer with more usage
Trusting users as co-developers
Harnessing collective intelligence
Leveraging the long tail through customer self-service
Software above the level of a single device
Lightweight user interfaces, development models and business models1
1 http://www.oreily.com2 http://www.amazon.com

9
From this set of principles it becomes clear that one of the most important factors of Web 2.0 is how it
integrates user interactivity within its architecture. End-users are an intricate part of the operations
behind the mind set of Web 2.0 design and development, as all the listed principles provide evidence
of the users being the main acting figures of Web 2.0.
By developing a system with these principles in mind, it becomes possible to provide a ‘Rich
User Experience’ based environment, that becomes more useful to users when there exists a larger
community base that continually provide input to the system. There have been many applications
produced that have the Web 2.0 principles behind them and these can be categorised into four
different areas, (Dang et al, 2006): -2
Mashups (Applications that collect and integrate information and services from multiple sources)
Social Community (People oriented information including their respective thoughts and opinions)
Social Media (User Contributed multi-media content)
Desktop-like web applications3 (Applications on the web that provide desk-top like experience)
These areas have been explored by several current Web 2.0 applications, a few of them being,
YouTube4, Wikipedia5 and Flickr6. These systems fall into the Social Media Web 2.0 genre due to the
functionality present in allowing users to contribute their own content. Social Community
applications, such as 43 Things7, provide its users with a variety of methods to communicate with
other members. Sharing user views and opinions is primarily how such a system operates.
These applications are classed as Rich Internet Applications, and are oriented around the user
community. Relying on users to add value to the current content on the applications, this means to
add content that is meaningful in one way or another to other users. This trust in end-users has led to
the overall success of rich internet applications and hence is one of the reasons of the vast popularity
associated with them. Tapscott (2006) mentions that, ‘Harnessing mass collaboration of users and
treating them as co-creators provides value to any system’. The examples listed show a deep level of
understanding of the Web 2.0 underlying principles. With the development of the project in mind,
such principles must be adhered to in order to successfully produce a Web 2.0 application that
provides a rich user experience.
This project will be focusing on the Mashups field of Web 2.0 applications. However, it is
important to recognise the characteristics of the other aforementioned Web 2.0 application areas, and
to obtain an understanding of how applications in the other fields operate. The following background
research will be specific to mashups in general so to obtain a greater understanding of the term and its
propositions.
3 An example of a desktop-like application is calendar.google.com4 http://www.youtube.com5 http://www.wikipedia.org6 http://www.flickr.com7
http://www.43things.com

10
3.2 Mashups
The goal of this section is to provide details and definitions about mashups, what they are and what
they bring to web users. Specific details will be elaborated upon what an intelligent mashup is and
how intelligence will be measured for the course of the project.
3.2.1 Mashups Background
Mashups ‘combine separate stand-alone technologies into a novel application’, (ELI, 2006). These
stand-alone technologies are system Application Programming Interfaces (API), that are made
publicly available to developers and allow them to build their applications with several sources of
data. Mashups are one of the Web 2.0 categories that are changing how users view and make use out
of the web today. These are systems developed with the combination of multiple sources brought
together to produce a more useful solution to web users. Defining what information is classed as
useful depends exactly on who the users are. But with the project, the proposed mashup does not
have any particular users to concentrate the development upon, so the mashup must provide a method
of differentiating between users. This is where the intelligence aspect of the proposed mashup will
come into play.
3.2.2 Intelligent Mashups
Taking a definition for intelligent, ‘…involves the ability to reason, plan, solve problems, think
abstractly, comprehend complex ideas, learn quickly and learn from experience’ (Gottfredson, 1997).
This definition of intelligence when mapped to a mashup context makes it possible to differentiate
between, static based content and the content that make use out of intelligent functionality. This
functionality is found between the collaboration of the system and its users. This in turn resolutely
provides a new breed of web applications that are not only useful to users but also makes them
enjoyable to work alongside. This allows users to control the way they perceive information.
For a web based solution to be classed as intelligent in the context of this project and beyond,
it should be shown to display some form of automated ability that is transparent from its users.
Displaying automated ability is a large field of study, and in the context of this project only a fraction
of such techniques shall be undertaken for further analysis, this being personalisation. This kind of
intelligence on web based solutions can be viewed as the system presuming what information users
wish to view before they actually select to view the specific information themselves. An example
related to this project could be, users that tend to view the same specific news content often, will
automatically receive similar content based on their past behaviour without them having to search
through extra details in order to find such content.
To obtain a further understanding into mashups and specifically intelligence a review of
current existing solutions shall be conducted.

11
3.2.3 Existing Solutions
The goal of this section is to view current mashup offerings, especially those that relate specifically to
‘news’ content as to keep within the scope of the project, and to decide on the personalisation level of
these news based mashups. Three news based mashups will be explored that give an overview of the
functionality and features of what users would expect from news mashups. These are found at the
programmableweb8 mashup archive: -
BBC news and Google maps
Associated Press news with geocoding by Yahoo and mapping from Google
Global News Now, a web-based News RSS reader
BBC News Mashup9
This is a mashup that displays news related information specifically for the UK. There does not
appear to be any extra functionality offered to users that visit this mashup, and the content is
indistinguishable between each other in that news relating to sport and business are displayed in the
same manner. A categorisation feature is non existent so it becomes very difficult for users to
effectively use this particular design to view news and the level of the amount of news displayed is
uncontrollable.
Summarising this particular mashup, it does not appear to offer any forms of user
personalisation, as any detail viewed from this mashup will be exactly the same when displayed to
any and all users.
3
8 http://www.programmableweb.com9 http://benedictoneill.com/content/newsmap
Figure 3.1: Screenshot of the BBC news mashup applications

12
Associated Press Mashup10
This mashup is very similar to the BBC news based mashup in that it provides news stories to specific
location on a map. Distinctively, AP news mashup gives users an 4option as to which news category
they wish to read information upon. The colour markers on the map of these news locations are
different from other category markers making the differences of news content much easier for users to
view. This mashup offers customisation to users so they have the option of viewing a select section of
the news offered. However, it should be noted that this is not exact personalisation, as essentially all
users will still receive the same news. If this mashup expanded on the categorisation option it has
available, and provided such filtering traits specific to individual users then, it would be evident that a
personalisation function would exist. But currently this is not the case within this mashup, further
analysis of personalisation and specific information regarding filtering will be analysed within the
next research area.
Figure 3.2: Screenshot of the Associated Press Mashup Applications
GlobalNewsNow Mashup11
The final news mashup under review is from GlobalNewsNow. Unlike the other mashups discussed
this does not include a map based user interface. One of the major differences between this mashup
and the others is that it offers a members section, once in this section users are able to personalise the
news they wish to view. This style of user personalisation is more user preference based rather than
system automation, once the preferences are set in place a filtering system is setup so only the data
sources to which the user has opted to view news from will be displayed. This mashup successfully
displays personalisation techniques in that it provides the possibility for individualised viewing of
news pages, via the profile of the user based on a filtering system. However, it should be noted that as
a user must specifically identify the filtering that they require, this mashup does not incorporate a
flexible method of providing specific information to its users, such as transparently displaying news
10 http://www.81nassau.com/apnews11 http://www.globalnewsnow.info

13
content that other users may have recommended. This mashup could be expanded to include such a
technique to further advance the level of personalisation offered to the users.
Figure 3.3: Screenshot of the GlobalNewsNow Mashup Application
3.2.4 Summary and Project Implications
To conclude, it is believed that a mashup displays a certain degree of intelligence due to the
personalisation techniques made available to the users. There are clear differences between the
mashups that are deemed intelligent and those that are not. By indulging into the method of how
information is provided to the users, and the advancements made with the content offered in terms of
personalisation, it becomes simpler to separate those that, for the scope of this project, are seen as
intelligent mashups.
With the existing solutions evaluated only the GlobalNewsNow mashup offered users any
scope of personalisation options, whilst the AP news mashup could be further expanded to provide
some form of personalisation, as previously noted. With the review of the BBC news mashup, the
difference between a mashup and an intelligent mashup becomes clearer, if we look into the
advancements made with the content offered to users, this mashup does not allow much room for
advancement into including some form of personalisation to be present. However, in comparison the
AP news mashup does have the scope for the inclusion of personalisation traits by expanding upon the
categorised filtering option provided.
From this research, a deeper level of understanding of mashups and in particularly intelligent
mashups has been obtained. With the reviews of a selection of existing solutions, a fundamental
understanding of guidelines into the development of such mashups and where personalisation is
present or lacking can be taken into consideration when beginning the development phase of the
project. Further elaboration into personalisation is required in order to fully comprehend the core
personalisation issues to be addressed within the scope of the project.

14
3.3 Personalisation
In this section a definition of personalisation will be provided specifically towards the nature of the
project. Personalisation techniques will be researched and examined as to which techniques would be
the most appropriate for use within this project.
3.3.1 What is Personalisation?
Jameson (2003) acknowledges that the term ‘personalisation’ is a very broad term and is currently in
wide use within commercially developed systems. He goes on to define such systems as ‘user-
adaptive systems’. It is therefore clear that personalisation is a characteristic provided to a user.
Jameson (2003) goes further on to define such user-adaptive systems as, ‘An interactive system that
adapts its behaviour to individual users on the basis of processes of user model acquisition and
application that involve some form of learning, inference, or decision making’. So when regarding
personalisation techniques within this research field we will be taking this particular definition of a
user adaptive system into consideration.
3.3.2 Personalisation in a Web Based Environment
When discussing personalisation in web environments it is vital to explain what customisation is in
this context also. These two phrases are often used interchangeably and since the overall web
functionality between the two may seem similar to end users, it is clear to see why there may exist
some confusion between the two. Nielsen (1998) briefly defines customisation as to when, ‘the user
is in direct control and is able to explicitly select options’. By the definition provided previously of
personalisation techniques (user adaptive systems) by Jameson (2003), it is safe to say that for
personalisation in a web based environment, the underlying system needs to incorporate a method of
monitoring users’ actions. Such as acquiring some form of data about them, in order for the system to
provide any sort of personalised delivery. An example of such a system can be found on Amazon,
where after a user browses through a few items an automated list of recommended items is displayed.
For a personalised news based mashup there must exist some personalisation techniques
within the system that are capable of providing users relevant information to suit their individual
needs. These techniques will now be analysed.
3.3.3 Personalisation Techniques Overview
A personalisation technique is required to provide users with individual news related content. Such
techniques must be capable of functioning successfully in a mashup scenario, in where there could
potentially exist ‘incomplete and noisy data’ (Dang et al, 2006). This could result in incorrect and
inappropriate information being returned to the user. Techniques that should be considered are those
that will add value to a system. Jameson (2003) states that techniques such as ‘filtering and
recommendations’ can be very beneficial in such scenarios. These two approaches are capable of

15
being mapped onto a news based system. We have seen an example of the filtering technique
incorporated by the GlobalNewsNow mashup, in that only a selection of news related information are
to be displayed to the user depending on their individual choices. Therefore we know that it is
possible to apply such a technique to a news mashup.
A recommender technique does exactly what the name suggests in that items are ‘advised’ to
users. This therefore makes it possible to display to users only content that they frequently view, such
as the method applied by Amazon and their respective sales items. A recommender technique saves
users time by providing suggestions, as they do not need to navigate through the system in order to
find information that they may potentially be interested in. Therefore it appears that the most
appropriate personalisation technique to be applied within the project is that of filtering and
recommendations, as they fit in perfectly within mashup scenarios. However these techniques hold
broad boundaries respectively, so must be narrowed down onto specific personalisation techniques
that incorporate the idea of filtering and recommendations.
3.3.4 Possible Personalisation Techniques
There exist several personalisation techniques that involve filtering and recommendations, it has been
identified that the most common in use today in terms of web services is content-based filtering and
collaborative filtering. A brief discussion regarding each of these techniques shall be displayed and a
final selected technique for the project shall be chosen.
Content Based Filtering
Content Based Filtering is a popular recommender technique in which ‘content’ is displayed to users
as to what the system believes they would be interested in. These recommendations are based on the
‘correlation between the content of the material and the users preferences’ (Meteren and Someran,
2000). A problem exists in how information regarding user preferences should be gathered, there are
two popular methods used for information gathering in content based systems, these being User
Profiles and User Stereotypes.
An example of how preferences are gathered through a User Profile has previously been
displayed within the GlobalNewsNow mashup, in which users manually input their filtering
requirements. To advance from this, a user profile filtering system may involve an automated feature
that stores information regarding users past experience with the content viewed and showing related
information to them at a later date.
User stereotyping are ‘representations of common attitudes among a group of similar users’
(Sollenborn and Funk 2002). This in turn means that users that share similar interests as others will
also share similar content. In terms of the project regarding news, if two users are viewing two
different business related articles, the system will recommend to them the business article the other

16
user was reading. An issue arises with this, in that if there exist many users viewing similar articles it
can become tricky for the system to offer the right item to the right user (Gil and Garcia, 2003).
This diagram illustrates the mechanics behind content-based filtering: -
It can be seen that for both user profile and user stereotype the same architecture is used, as they work
off the same functional content. This diagram displays how content is passed to a recommender that
in turn is accessed and compared by a specific user profile. This is where in the case of the project the
news related articles would be sorted and stored as an item that a user may be interested in. A user
can then access these items through an interface that will display to them the stored recommended
items.
Collaborative Filtering
Collaborative Filtering methods look for ‘similarities between users to make predictions as to what
content other users may find interesting’ (Pazzani, 1999). It involves information ranking techniques
that are then used to judge what content certain users would find appealing. The ranking of the
content is performed by other users, hence the collaboration aspect of the technique. These user
rankings allow the system to find similar characteristics of other users, and generate a larger dataset of
content that similar users may find interesting. Collaborative filtering techniques can be very useful
in a system where there exist many users actively taking part to rank items. Although this can
potentially lead to a dilemma with this particular technique, as the benefits are only found when there
exists an actively contributing user base. So if one such community does not exist then the level of
recommendations provided by the system will be very limited. This style of providing user
recommendations is effectively applied in many web based shopping services, such as Amazon, that
do have a very large user base.
Figure 3.4: Content Based Filtering Architecture (Dimitrova, 2005)

17
This diagram illustrates the mechanics behind collaborative filtering: -
The overall architecture in comparison to a content-based system has some major differences. As
collaborative filtering looks for similarities between multiple users, the data passed along the system
from those users expands to the general content, the recommender system and a shared user profile
space. So the collaborative architecture has a much more expansive set of underlying principles to
work from when compared to the content-based architecture. Also it should be noted that an
individual user profile no longer runs through the recommender system directly in order to configure
which items to display to the users, this has already been achieved with the inclusion of the user base
that in turn pass their results to the recommender system.
3.3.5 Personalisation Summary
After analysing the appropriate personalisation techniques, it has been decided to make use out of a
recommendation technique when developing the personalisation aspect of the mashup. However, as
the recommendation scope is also large the developer will be narrowing this technique down to only
issuing a content-based approach during the development of the news mashup. With the restrictions
in place and the limitations of the project, such as the lack of a vast user environment, it is believed
that the content-based approach in filtering and recommending news related information to its users
would therefore be the most suitable for use within this project. The developer acknowledges that if
there is sufficient time and resources available that collaborative filtering may be included into the
final system. With the details regarding the specifics behind such an approach being further
expressed in the second semester module GI32, there will be an opportunity available to experience
such personalisation techniques and more background information regarding these within this module.
Therefore, during the development of the system it would be possible to obtain a deeper
understanding behind the principles and techniques in the ways that they are applied.
Figure 3.5: Collaborative Based Filtering Architecture (Dimitrova, 2005)

18
Chapter 4. Design
This section is set out to discuss possible data sources that can be implemented into the news reader,
tools and applications that shall be used and system architecture designs outlining what is intended to
be achieved after each iteration of development.
4.1 Data Sources
When attempting to look for suitable data sources there are many factors that come into play such as
how often a source updates the news content and the reliability of the source for providing accurate
information. As news content constantly changes over time, potential data sources must update
content on a regular basis so as not to display outdated news to system users.
When searching for online news sources it is important to distinguish a commonality between
them, as this will help to allow the mashup architecture to be integrated seamlessly within the system.
A similarity found between such sources was that many of them had content structured using “RSS”
(Really Simple Syndication) feeds, denoted by the symbol . The importance of obtaining suitable
sources of data is very significant within this scenario. Many sources of news listings contain users
views and opinions, an example of such unsuitable news sources would be those with user Blogs
related to certain articles. Blogs often hold bias opinions on several news matters. Therefore the
credibility of the source shall be deemed unsuitable for many users and will not be included as
possible data sources within the system.
There exist many popular and trustworthy news authors offering RSS services, here is a list of
potential news sources considered for use within the project: -
Televised Newspaper Solely Web BasedBBC News Guardian Unlimited Google UKSky News The Independent ZDNET
Reuters UK Daily Mail -Channel 4 News Financial Times -
Sky Sports The Times -EuroSport - -
Figure 4.1: Potential News Sources categorised via initial user viewing manner
These credible data sources have RSS feeds available but the content within them show some
differences. When looking at the XML tags within the source code of each RSS feed it can be seen
that a few news sources have structured the feed with the inclusion of a <category> tag that contains
the name of the category that a particular article falls into. This appears to be suitable to base
personalisation functionality upon. As content-based filtering can be designed to filter out news
content that does not fall into a pre-selected user interest that is matched to a category found on the
data source. News sources from the initial list were reduced, due to the fact that many sources did not
incorporate a category tag. For the prototype development a sample set of categories will be included,
19
so system scalability concerns will not be apart of the problem. The selected categories are, Front
Page News, Business, Sports, Technology, and Entertainment. The list of sources that include
suitable category tags for selected categories within the RSS feed are: -
Data Source Front Page Business Sports Technology EntertainmentBBC12 Y Y Y Y Y
Reuters UK13 Y Y Y N YGoogle14 Y N N N N
EuroSport15 N N N N NZDNet16 N N N N N
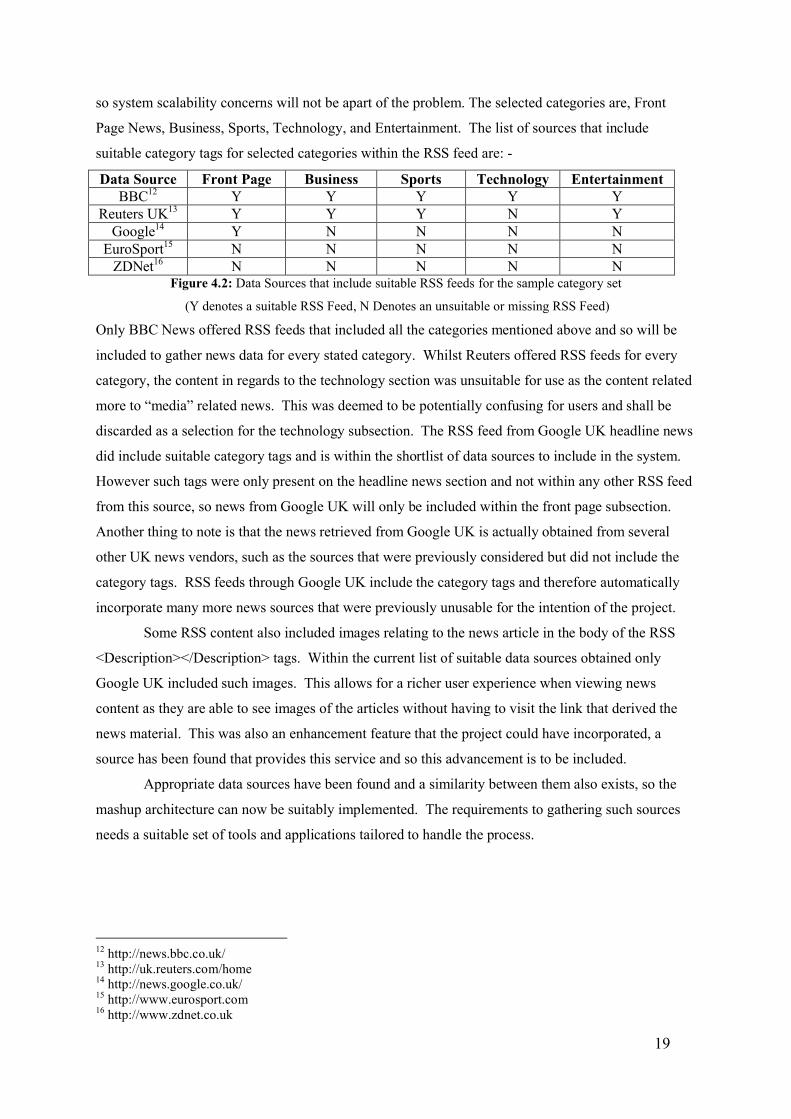
Figure 4.2: Data Sources that include suitable RSS feeds for the sample category set
(Y denotes a suitable RSS Feed, N Denotes an unsuitable or missing RSS Feed)
Only BBC News offered RSS feeds that included all the categories mentioned above and so will be
included to gather news data for every stated category. Whilst Reuters offered RSS feeds for every
category, the content in regards to the technology section was unsuitable for use as the content related
more to “media” related news. This was deemed to be potentially confusing for users and shall be
discarded as a selection for the technology subsection. The RSS feed from Google UK headline news
did include suitable category tags and is within the shortlist of data sources to include in the system.
However such tags were only present on the headline news section and not within any other RSS feed
from this source, so news from Google UK will only be included within the front page subsection.
Another thing to note is that the news retrieved from Google UK is actually obtained from several
other UK news vendors, such as the sources that were previously considered but did not include the
category tags. RSS feeds through Google UK include the category tags and therefore automatically
incorporate many more news sources that were previously unusable for the intention of the project.
Some RSS content also included images relating to the news article in the body of the RSS
<Description></Description> tags. Within the current list of suitable data sources obtained only
Google UK included such images. This allows for a richer user experience when viewing news
content as they are able to see images of the articles without having to visit the link that derived the
news material. This was also an enhancement feature that the project could have incorporated, a
source has been found that provides this service and so this advancement is to be included.
Appropriate data sources have been found and a similarity between them also exists, so the
mashup architecture can now be suitably implemented. The requirements to gathering such sources
needs a suitable set of tools and applications tailored to handle the process.5
12 http://news.bbc.co.uk/13 http://uk.reuters.com/home14 http://news.google.co.uk/15 http://www.eurosport.com16 http://www.zdnet.co.uk

20
4.2 Tools and Applications
The goal of this section is to review and select a set of tools and applications that is to be used during
system development. With the introduction of data sources to be included a question arises as to how
such data will be implemented within the system. There is therefore a need to find suitable methods
of successfully retrieving the news content on the system. The news articles will need to be integrated
in a manner that will allow manipulation of the content, so that they can be handled as desired for
functionality required within the project development. To incorporate personalisation techniques
within the system user profiles will need to be created and stored. The most suitable way of storing
and querying such profiles is via the use of a Database Management System. Tools and applications
required include a suitable programming language and database management system. An overview of
RSS will be included detailing the elements of the sources deemed relevant for system development.
4.2.1 Programming Environment
The goal of this phase is to decide upon a suitable programming environment to be used for system
development. The chosen programming language should be capable of retrieving content from news
sources in a manner that includes XML parsing, as RSS source code is developed under XML. It has
been decided that the news content will be represented on a web based platform, and so the language
selected must make it possible to interact with a browser interface to display suitable output to an end
user. The chosen language must include support for object-oriented implementations. Booch (1998)
stated that ‘Each object can be viewed as an independent little machine with a distinct role or
responsibility’. Implementing via object oriented principles would allow for more fluent message
passing through each system component. High-level Programming functionality must also be a trait
of the chosen language, as the flexibility introduced within such programming methods make more
complex programming tasks simpler to code than low-level programming languages. This is
important with the time limitations of the project in place. Another issue to consider is the level of
portability offered by the chosen language as it is intended for the developer to ensure that the system
is capable of functioning on any machine that it is installed upon. Allowing the programmer to
develop the system at multiple locations if required. There are many languages currently available
that are capable of meeting this criteria, however the developer has only had experience with two of
these candidates, these being Python and Java.
‘Python is a portable, interpreted, object-oriented programming language’ (Python
Documentation, 2006). It is developed in the C programming language and is classed as an
interpretive language where no compilation is required to take place. Python utilises simpler syntax in
comparison to Java and therefore results in a quicker and generally more convenient method of
systems development. Being an interpretive language has its advantages and disadvantages, code
written in an interpretive language can be used on any system that supports an interpreter for it and so
has good portability options. A downside is that due to the fact that when the program is loaded into

21
system memory the code is executed as soon as it is read, there does not exist any time for code
optimisation to take place. This unfortunately renders an interpretive language to be much slower
than compiled languages. 6
Java (Developed by Sun Microsystems17) is also a popular high-level language. It is classed
as an interpretive language just as Python, however Java code also requires compilation into Java byte
code to enable efficient portability and optimisation of source code. Java code in comparison to that
of Python is more complex in terms of the number of lines required to achieve the same functionality.
Both programming language toolkits are available to the developer so accessibility is not a
concern for language selection. However a major driving force to any individual developer when
selecting a programming language under strict time constraints would be the level of experience and
familiarity that they have with the programming language. In the context of the project the developer
has little past experience with Python when compared to the level of knowledge attained in Java,
although both languages offer very competitive ideals and both would allow for suitable development
of the proposed system. Java has therefore been selected for development for this reason.
Java code can be represented through JSP (Java Server Pages), this allows the dynamic
generation of HTML and other web based documents that incorporate Java functionality on them. So
this satisfies the initial requirement of selecting a programming language that is capable of displaying
content on a web based platform.
4.2.2 Web Environment
The aim of this section is to finalise a suitable web environment to display the content of the
newsreader. With the decision made in regard to the programming language and web interface to be
used, there is a requirement of ensuring that the Java code is actually implemented onto the Java
server pages, so that the functionality of the Java code is visible. A web container is required to
achieve this task that will set up a runtime environment for the execution of Java code. Apache
Tomcat is one such web container that implements the Java Server Pages and provides a hosted
environment for the Java code to run in cooperation with the system. Apache Tomcat has been used
previously by the developer (through the module SY33: Building Distributed Systems) in
implementing Java Server Pages so, familiarity between Apache Tomcat and the developer exists.
Therefore a suitable tool that ensures the Java functionality on a web browser has been found.
4.2.3 Database Management Environment
As previously mentioned, the system requires a Relational Database Management system in order to
store and retrieve relevant user information to handle the personalisation methods to be included.
There are many Relational Database Management Systems that are available to the developer, but the
17 http://www.sun.com/java

22
developer has only had previous experience with two of them, these being Microsoft SQL Server
2005 (MSSQL) and MySQL 5.0.
MySQL is an open-source developed DBMS that boasts ‘fast performance, high reliability
and ease of use’ (Why MySQL, 2007). These traits are desirable for any system developer and due to
the past experience with this DBMS it can be confirmed that these desirables are indeed true.
MSSQL is a proprietary DBMS developed by Microsoft specifically for enterprise business
applications in mind and includes a graphical user interface for ease of database development. This
was missing in MySQL but can be initiated with a third party GUI front-end.
As Java is the selected programming language for the development there is a need to connect
Java to the database in order to retrieve stored data. This can be achieved with a relevant Java
Database Connectivity (JDBC) driver, which both DBMS have compatibility for. MSSQL includes a
built in graphical user interface, however it can often be a hindrance to the developer as it includes
many functions that are of no use in the context of this project. Speed was another factor taken into
consideration. The initial loading times of the DBMS varied significantly where MySQL offered a
simple start-up procedure that allows the developer to perform queries very quickly. MSSQL has a
rather lengthy start-up procedure and the clunky interface makes it rather difficult to navigate around
and perform simple queries. As compatibility issues is not a constraint for the project, either DBMS
would therefore suffice for project development. But with the imposing differences in speed and user
interactivity between the DBMS the most appropriate DBMS for use within the project is MySQL.
MySQL has therefore been selected due to the simple setup and light weight infrastructure provided.
4.2.4 Really Simple Syndication (RSS)
RSS is ‘a format for delivering regularly changing web content’ (What is RSS, 2007). As discussed
in the data sources section above RSS will be the most suitable method of gathering news content for
use within the development of the mashup due to the fact that it handles constantly changing content.
RSS is developed under XML (Extensible Mark-up Language) and so the content on the source is
separated with adequate tags, labelling a specific attribute of the news feed. The XML tags found (in
bold) within the system and an example of the type of data represented between these tags are listed: -
<item><title> Wealthy donor backs UKIP</title><description> An anonymous backer has promised to donate cash to
UKIP if a legal challenge over funding fail.</description> <link>http://news.bbc.co.uk/go/rss/hi/uk_politics/645161.stm</link> <pubDate> Wed, 14 Mar 2007 17:59:21GMT</pubDate> <category> Politics </category></item>
Figure 4.3: Sample XML news structure found in RSS Feeds (BBC Politics, 2007)
Each article is packaged under the <item> set of tags and each news attribute is displayed between
these tags. The example shows that each article from the RSS feed contains details regarding the
article title, brief description, a hyperlink to the full article, the published date of the article and the

23
category that the article falls into. When retrieving news content from such RSS feeds the
information between the XML entity tags will be displayed on the web browser for users to view.
4.3 Architecture Designs
This section is set to show the flow of events to take place within the system during each iteration. A
diagram for each phase shall be shown to further express the functionality principles intended to be
achieved. A final sequence diagram shall also be displayed that illustrates exactly how and when each
component of the final system shall interact with another.
4.3.1 Iteration One System Architecture
The first iteration involves the development of a simple user profile that stores users interest sets upon
registration. The intended purpose of this iteration is to ensure that the content-based filtering of user
interests and the personalisation aspect from this functions appropriately. For this phase only a single
news source will be implemented here so there will exist no mashup structure through this iteration,
the reason for this is to allow for simpler testing of the functionality of the filtering mechanism.
Following the proposed structure through Figure 4.4: -
1. A user accesses the newsreader and instantiates the system to retrieve required data
2. Upon logging in, the interest set of a user is called through the user profile database.
3. The users interest set is passed onto a user modelling agent (that holds all details regarding a user)
which passes on the interest set onto a details manager.
4. The details manager holds all the information regarding user details.
5. News content from the news provider is passed onto the details manager. So the details
manager now contains all information about the users and the news content.
6. Once all the required details of a user and news are available, the filtering mechanism pulls out the
content that matches the users interest set and returns this set of articles back to the user.
Figure 4.4: Illustrating iteration one of development, showing component communication at this phase and how content is returned to a user
1
23
45
6

24
4.3.2 Iteration Two System Architecture
The second iteration includes all the functionality as the previous phase. This segment is intended to
expand and evolve upon what has been previously developed. This iteration will incorporate all the
news feeds integrated into a mashup structure, storing and handling the selected data sources in an
organised way. User stereotypes will be added to the system during this phase. Once user stereotypes
have been developed it will be possible for the system to observe what ‘similar’ users have selected
for their interests during registration, and then return back to users the most common selected interests
by all similar users. User stereotypes will also be used to predict what categories of news a user may
be interested in and pass on this news content onto them. This will be implemented by ranking each
category with a score out of 100 per stereotype, where the higher the value the more likely a particular
stereotype set will prefer a category. This iteration incorporates several news sources, and combines
them into an arrangement that when matched against both user interests and user stereotypes will
return a larger but more sophisticated set of news articles from the data sources that users may find
useful. Following the changes made in the second proposed architecture (Figure 4.5): -
2. As well as the interests, the user stereotype set is called through the user profile database.
3. The stereotype is also passed onto the user modelling agent.
4. With the inclusion of multiple data sources, the details manager now holds a vast set of content.
7. The news details from all the sources are organised in a single location in a suitable way. This is
the mashup collection of all news articles on the system.
4.3.3 Iteration Three System Architecture
The final development iteration aims to further provide functionality to users. Previous iterations
involved simply displaying news content through a filtering mechanism either derived via user
interests or user stereotypes. This phase incorporates a method that monitors how users make use of
Figure 4.5: Illustrating iteration two of development, Mashup of the News Sources and User Stereotypes have been added to the system. The new additions to the system have been highlighted
1
3
2
4
5
6
7

25
the system via the inclusion of a User-User recommender. The principles behind this mechanism is
that users currently viewing news articles can decide to recommend individual news articles to
‘similar’ users, these being users that fall into the same stereotype. The advantages of including such
a method is that users can interact more with the system and actually impact what other users will
receive. A user monitoring mechanism is to be added to handle this functionality. Following the
changes through this iteration (Figure 4.6): -
2. The new addition to the user profile database is the recommendations made by the user.
3. The ‘User-User Recommendations’ details are returned onto the User Modelling Agent.
4. The details manager now includes the user recommendation choices as retrieved from the profile
8. The ‘User Monitoring Mechanism’ is included and begins when a user logs onto the system.
4.3.4 System Components Sequence Diagram
This diagram shows the sequence of events performed in order for a user to retrieve their personalised
content via the system after the development of the final iteration. There are 9 phases in total
covering the sequence of events structured in time order (from top to bottom). This diagram provides
an extended overview of how and when each component of the final proposed system will interact
with each other to finally deliver suitable content to the user.
Figure 4.6: Illustrating iteration three of development, a user monitoring mechanism is to been added to allow users to recommend articles to each other. The new addition have been highlighted
1
3
2
4 5
6
7
8

26
4.4 Summary
The tools and applications have been decided and the sources of data have now been finalised. The
method to develop the system has been shown through each iteration and what the expected output of
each iteration shall be. The components required in order to successfully develop the system that will
return the desired results has also been decided. Implementation of the system can now begin,
keeping in mind the limitations in place of the tools and applications chosen.
Figure 4.7: A sequence diagram illustrating exactly how and when each component interacts with one another and what exactly is passed between them

27
Chapter 5. Implementation
The goal of this chapter is to display the steps taken to successfully implement the personalised
interactive news reader. The implementation chapter follows the construction phase through the
proposed methodology. This phase is broken into three iterations discussed in the design phase with
the system architecture diagrams, so this chapter will be structured following the three proposed
iterations. Appropriate figures shall be shown throughout illustrating exactly how and where certain
components are visible to the end users and how users interact with them.
5.1 Iteration One
The intention of the first iteration is to introduce simple personalisation functionality with the end
users. This iteration is very important as the future advancements of the development are built upon
the fundamentals implemented within this phase. The following objectives are set to be achieved
within the development of the first iteration: -
1. Creation of system development environment
2. Suitable method of acquiring news from a single source
3. Displaying the output to the users
4. Create user profiles upon user registration
5. Matching news categories to user interest sets
6. Returning this matching to the registered user
5.1.1 System Environment
The first step taken into project development is to ensure that the development environment is setup
and working properly. As Apache Tomcat was the chosen web container the requirements are to
ensure a successful runtime environment for the execution of Java code. Tomcat specific class paths
had to be setup in the system environment, so the system knows where to obtain the relevant class
files for Java execution on the JSP pages.
As the development required methods of connecting to a MySQL database a relevant JDBC
driver was required. A suitable driver was found (1) and so a classpath to this JAR file was required
to enable the system to find its location for execution. Tomcat required relevant JAR files (2 and 3)
for proper implementation of Java code on JSP pages, so classpath locations to these must also be
provided. The location to the classes generated from the Java source code is required (4).The relevant
JAR files were placed in the ‘lib’ directory ensuring proper organisation of system development.
1 <Tomcat directory>\webapps\rss\WEB-INF\lib\mysql-connector-java.5.0.4-bin.jar;2 <Tomcat directory>\webapps\rss\WEB-INF\lib\commons-httpclient.jar;3 <Tomcat directory>\webapps\rss\WEB-INF\lib\commons-beanutils.jar;4 <Tomcat directory>\webapps\rss\WEB-INF\classes\rss;
Figure 5.1: List of classpath locations required for the system environment

28
Once the class paths were setup the actual system implementation could now effectively begin. The
next step following the proposed objectives of this iteration is the development of suitably acquiring
news from a single source.
5.1.2 Gathering News from Sources
The goal of this section is to develop a method of retrieving news content from the data sources. The
news data source is in XML format, so relevant methods of XML parsing is required. The RSS
document is split into several tags, the exact tags can be seen in Figure 4.3. To gather the news details
from such sources a method is required to obtain the data within the relevant tags and in the end
successfully return the content to the system users. The exact flow of events to achieve this is: -
1. Retrieving news from the RSS documents
2. Hold this data on the system for appropriate manipulation
3. Returning this content suitably to the users
Following the list of events, the first objective is to develop a method to retrieve the news from the
sources. As the RSS document needs to be read into a Java Class file (Code: RssReader) it is possible
to check within this document for the required XML tags. The document can be split into smaller
sections based on these found tags, therefore the news details can be retrieved by searching through
the RSS document.
Each news article content is embedded within the <item> tags of the document. To retrieve
the news content the RSS document is scanned and searched for all <item> tags. When an <item> tag
has been found a method is called that then scans the content within <item></item>, pulling out the
details regarding each element of the contents (i.e. title, description, link, pubdate, category). Now all
the details for a single article have been retrieved, these details are passed onto a separate class file
(Code: RssItem) that analyses the content found with a filtering algorithm(2). This then returns the
content to the end user if it is deemed suitable, fulfilling the second event. If a filtering algorithm is
not to be initialised then all articles found within the RSS document will be returned to the user.
Figure 5.2: This figure illustrates the flow of document analysis required to successfully retrieve each article.
Analyse the RSS Document, Search all Item Tag Elements, Search and return all article details within Item tags
A suitable method of retrieving news content has been implemented. The next step is to ensure that
this content is displayed appropriately on screen to the end users. This follows on from step 3 of the
objectives to cover during this phase.
RSS Document Item Tag Element Article Detail Tags
Search for Search forand return
News Retrieval Method
Method Attempt to Analyse

29
5.1.3 Displaying Suitable Content
A suitable method of retrieving news content has successfully been found, the goal of this section is to
present this content appropriately onto a JSP web page. For this each article must be displayed onto
the web page, this means that as soon as the article is scanned and retrieved by the system it must also
be displayed onto the page before moving on to the next article set. To achieve this, each article was
called onto the JSP page via suitable ‘get’ methods for each element of the article, i.e. getTitle,
getDescription etc. Once all the article details were mapped onto the JSP page, the next article
(within the next item tag set) would be called and also mapped onto the webpage. The article detail
tags found are being mapped onto the JSP webpage so they are made visible to end users. The
contents of the article can be seen structured in the appropriate manner found within the RSS
document. From the XML based structure the details within each relevant tag is pulled out and
displayed in a suitable style to ensure ease of use and understanding when viewed by an end user.
Figure 5.3: On the left it can be seen how the XML based article description looks after it is implemented
onto the JSP page for user viewing purposes. On the right shows the same mapping in a simpler manner.
In addition to the XML representation, numerical tags were also included to each article so users can
distinguish between articles in a simpler manner.
To expand upon system usability when it comes to viewing full news articles currently when
a user clicks on an article link they are taken directly to the web page with the full article. Now an
issue arises if the user wishes to view another news topic, they would have to go back to the JSP page.
To avoid this scenario, rather than loading the article page in a new page the document would load
and appear on the same JSP webpage as the link presented. This was achieved by including an Iframe
below the full list of news articles. By introducing this navigation method a richer user experience
tool has been provided for end users: -
JSP Web Page
Article Detail Tags<item><title>N Korea nuclear deadline in doubt</title><description>Asian diplomats voice doubts North Korea will meet an April deadline to shut a nuclear plant, part of a landmark deal.</description><link>http://news.bbc.co.uk/go/rss/-/1/hi/world/asia-pacific /6525145.stm </link><pubDate>Wed, 04 Apr 2007 09:57:50 GMT</pubDate><category>Asia-Pacific </category></item>

30
Figure 5.4: The news viewing window allows viewing articles on the same page as the newsreader
The news content can now successfully be viewed by users on the JSP web page and so this objective
has been achieved. The next objective is to implement user profiles on to the system, so
personalisation techniques can be implemented.
5.1.4 Implementation of User Profiles
The aim of this section is to set suitable user profile requirements and develop a method to allow users
to register onto the system. Content based filtering was previously chosen as the main purpose of
personalisation techniques to include in the system. It was decided during the design of the system
that the category tags from the selected sources will be used for the filtering of news articles, this was
due to the fact that each selected source had this commonality between them. For user specific
filtering mechanisms to function appropriately user profiles must be created. A user profile must
contain sufficient details about them to ensure that the system is capable of returning personalised
news content. The personal details to store about users are: - Username, Password, Age, Gender, Job
field and Location. As well as these details user interests will also be selected by users upon
registration, the interest list presented to the users contain names of the categories found for each
article. The details regarding this category list are stored in a table (‘categories’) on the database.
This was done as adding and amending categories onto the list would be simpler than adding them
manually onto the registration page. Every user registered onto the system was also added onto
another table (‘user’) with an appropriate unique user id associated with them. When a user registers
onto the system, their interest set and associated user_id will be mapped onto another table (‘new’).
By doing this suitable manipulation with the users interests will be made possible, allowing for future
recommendation techniques to take place.

31
categories
category_id (int)title (varchar)
user
user_id (int)name (varchar)password (varchar)age (int)gender (varchar)location (varchar)job (varchar)
Figure 5.5: Database diagram showing the name and type of the fields included.
Foreign key mappings have also been shown.
The implementation of user profiles has been successfully implemented. The next step is to provide
simple content based filtering based upon the user interest set and related category lists.
5.1.5 Matching Categories and User Interests
The intention of this section is to filter news articles that fall in to the category set selected via users
upon registration when interests were selected. This phase illustrates the task required by the ‘News
Filtering’ object in Figure 4.4. To achieve this each article must be analysed and the category of the
articles are cross compared to the list of user interests. When a match is found the article is returned
to the user, eliminating all other articles that had categories that did not match the user interest set.
This allows for a more refined method of viewing news content. A filtering method is introduced that
looks at each article category and checks to see whether it matches any user interests, this is achieved
through a string comparison function (Code: RssItem). If an article category matches an interest the
article is returned to the user. Likewise, if the article category does not match an interest then the
article is omitted and the next category is analysed.
The filtering mechanism has successfully been implemented, with suitable methods that can
check whether an article would be suitable for a user based upon the interests set. The next step is to
show the functionality of the methods within the JSP web pages.
5.1.6 Return of Filtered Content
The goal of this section is to show a suitable way of returning filtered news content back to the users.
As articles can now be identified as those that match user interests and those that do not match user
interests, it is now possible to filter out the relevant news articles and display to users only those that
they would be interested in. In this example scenario, a user has registered within the system with the
following interest set: - ‘Africa, South Asia and Politics’. As these are the users own preference it is
apparent that the user would like to view this type of news content.
new
cat_id (int)
user_id (int)
Legend
Primary Key
Foreign Key
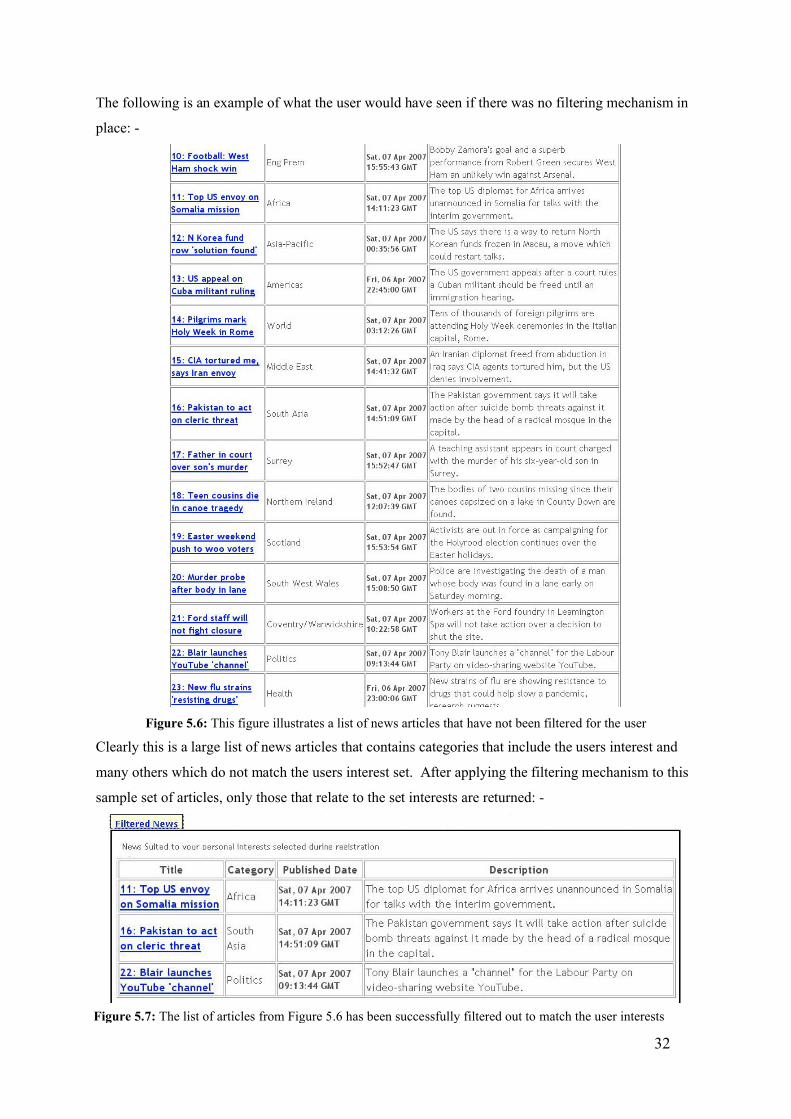
32
The following is an example of what the user would have seen if there was no filtering mechanism in
place: -
Figure 5.6: This figure illustrates a list of news articles that have not been filtered for the user
Clearly this is a large list of news articles that contains categories that include the users interest and
many others which do not match the users interest set. After applying the filtering mechanism to this
sample set of articles, only those that relate to the set interests are returned: -
Figure 5.7: The list of articles from Figure 5.6 has been successfully filtered out to match the user interests

33
The filtering algorithm for the first iteration has been shown to successfully function. It is capable of
returning back to users those articles that only relate to their interests, showing a straightforward
example of content based filtering. Mining out the irrelevant categories provides users with a more
agile method of viewing news categories that they would like to see, without having to exhaustively
search for the categories themselves.
The initial objectives set for this phase have been successfully implemented concluding the
first iteration of development. The second iteration is to expand upon what the first iteration has
developed. This includes adding upon the personalisation techniques to offer and the number of news
data sources to include within the system.
5.2 Iteration Two
The first iteration included the relevant structure to develop the system upon. Following the system
architecture the mashup of the data sources and user stereotypes are to be developed during this phase.
With the inclusion of user stereotypes, there are two personalisation techniques that can be
introduced, both of these techniques are recommendations based upon user stereotype sets. So for this
iteration the following objectives are to be achieved: -
1. Implementation of Mashup Structure
2. Development of User Stereotypes
3. Statistical Article Recommendations
4. Stereotype Ranking Recommendations
5.2.1 Implementation of Mashup Structure
The goal of this section is to successfully implement a mashup environment onto the system. With the
inclusion of a single news source the basic functionality of the news reader has been developed.
However a mashup environment requires multiple data sources coherently functioning together in a
method that is transparent to system users.
To incorporate multiple data sources into the web application the exact same principles were
applied as the single data source idea, the only variant being the exact location of the RSS XML
document. This step was fairly straight forward as the XML layouts in the RSS documents were very
similar. A problem arisen from including multiple data sources would be how to represent the amount
of content from all the data sources on the web page. This problem was tackled by including a tabbed
navigation system that is capable of splitting the news articles by category and source. The inclusion
of the tabbed feature makes it possible to incorporate many data sources without over populating the
web page.

34
An example of the tabbed navigation system: -
Figure 5.8: The ‘BBC’ tab is selected with the sports news feed. Users are notified of which source they are
viewing with the highlighted tab
Figure 5.9: When a user selects the ‘EuroSport’ news source they are shown the relevant news articles from
this source. News displayed is similar between each source, but the descriptions and article details are different.
The challenge now faced is that users interest sets should now be checked amongst every other data
source and return the relevant article matching. This was successfully implemented via the same
methodology introduced with the inclusion of the first filtering method from the first iteration.
However the larger the pool of data sources the longer it took to scan the full set of details to return
the final filtered content. This was one of the reasons why during the design phase only a small
selection of news categories was chosen to include within the project development.
The mashup environment has successfully been implemented and functions appropriately
with the content based filtering mechanism, the downsides of the inclusion of many data sources have
also been illustrated. The next step is to expand upon user control over personalisation of news
content with the inclusion of user stereotypes.

35
5.2.2 Development of User Stereotypes
The goal of this section is to decide upon the user stereotypes to include in the system and the data
required to derive users into the specific stereotypes. User stereotyping allows the grouping of similar
users into sets and appropriate management of a larger set of users can be appropriately achieved.
The data required for the development of the stereotypes is obtained from the user profile. Some of
the stereotypes introduced have been adapted from those researched during the GI32 module, the
complete list of stereotypes used during the project is: -
Sports PersonProfessional Finance ReaderYoung TravellerTechyPolitically Engaged AdultTeen News ReaderManWoman
Figure 5.10: List of stereotypes to include in the system
The final two stereotypes (Man, Woman) were created as ‘safety nets’ so as to ensure that every user
registered onto the system is apart of at least one user stereotype set. The system will therefore
recognise these users and be capable of recommending news to them. The full list of stereotypes
accompanied with the user details required to derive them can be found in Appendix C.
With the user stereotypes developed it becomes possible to provide other methods of
returning news to the users other than simple content based filtering that has already been included.
Following the plan of this iteration the addition of a statistical method of article recommendations is
next to be included in the development of the system.
5.2.3 Statistical Article Recommendations
The objective of this recommendation technique is to return to users news related to the most common
selected user interests of a particular stereotype. As the user stereotypes and the list of interests
selected by every user were saved onto the system database, it was possible to count the number of
occurrences of every single news category selected by users of a particular stereotype. From this the
three most commonly selected user interests were easily calculated, and all news articles that matched
these three categories are returned to the user for viewing. Essentially this is like saying, ‘Others like
you are interested in the following news categories, maybe you will be too’. This expands upon the
personalisation aspect of the system by displaying to users news content that they otherwise may not
notice and realise they may be interested in. Unlike the previous personalisation method included this
recommendation technique was in fact a collaborative filtering method as the recommendations were
brought upon by the calculation of results based upon several user profiles.

36
For example, Jill has registered onto the system and has been assigned onto a particular stereotype
based upon their user profile. Jill falls into the stereotype ‘professional finance reader, woman’. now
the system scans through all users that also fall into the same stereotype and computes the three most
popular categories selected by these users. The interest list for Jill is 'Football and Education', but the
three most commonly selected categories of this stereotype are 'Health, Tennis and Golf'. Jill
therefore has a larger range of articles to view with an added incentive to hold interest in them as they
were the most popular selected categories for users ‘like’ her. Statistical article recommendations has
been implemented successfully, the next recommendation technique to include is Stereotype Ranking
Recommendations.
5.2.4 Stereotype Ranking Recommendations
The purpose of this recommendation technique is to predict what type of news categories a user will
be interested in based upon the stereotype they are assigned to. To achieve this each stereotype was
given a relative score between 0 and 100 for each category, where receiving a higher score means this
particular user is likely to hold more interest in this category. Generally users fall into multiple
stereotype sets and so the scores for the categories are averaged out between them. Once the final
scores have been found, the top three news categories that end up with the highest results are
forwarded onto the user. A list of rankings based upon categories and stereotypes can be found in
Appendix D. An example will now be shown using the same user example as before. Jill falls into
the stereotype ‘professional finance reader, woman’, effectively two stereotypes. When calculating
the top three results each category is analysed, since Business received a score of 100 for
‘Professional Finance Reader’ and a score of 50 for ‘Woman’ the total score for the Business category
was (100 + 50) / 2 = 75. The division applied in this formula is related to the number of stereotypes a
user falls into, in this case 2. With the same formula applied throughout the category list for this
example the top three categories are, Business with 75, UK and Politics both with 65. More different
recommendations are made to this user. This recommendation technique is a more advanced
application of content based filtering.
The objectives for iteration 2 have been completed. The third and final iteration of
development is set to further expand upon what has already been done and include another
personalisation technique for use within the system.
5.3 Iteration Three
The final proposed development iteration requires the addition of a user monitoring system to be
implemented. The intention of this inclusion is to allow users to recommend news articles that they
may find interesting to other similar users, therefore expanding the overall experience that users of the
system will receive. The single task required to fulfil the intention for this iteration is: -
1. Development of a User-User Recommender

37
5.3.1 Implementation of a User-User Recommender
The goal of this section is to successfully develop the recommendation technique that allows for users
to recommend certain articles to each other. The differences between this recommendation technique
and those that have been previously developed through the first two iterations is that users now have
more control of articles other similar users will see. Also this recommendation technique is more
refined in that the articles returned to users are not of all one single category, instead a single article
recommended by a user is returned.
To develop this, the numerical values added to each article during the first iteration were
taken advantage of. It was possible to differentiate between news articles with these tags so this was
the best option in place to achieve individual article recommendations. A requirement now is to
configure how to enable users to physically recommend articles to other users.
In order to achieve this, check boxes were added onto a separate column for every news
source with which users are able to select articles they wish to ‘save’ for other users to read. An
example of the addition of the article recommendations section: -
Figure 5.11: This figure illustrates the suitable location of the recommend news options right next to the news
articles listed. Articles 2 and 5 have been selected for recommendation here.
The next task for this recommendation technique is to enable users to ‘save’ the selected articles.
When users check the box of an article to recommend, this article ID is stored in a temporary location
as users may often change their mind over what articles they wish to recommend. Once they have
finalised their decision they can select a ‘save recommendations’ option that stores the article IDs
onto the user profile data base. This allows the system to calculate which users of a stereotype have
set recommendations for particular articles.
With the recommendation values stored, when a user logs onto the web page, the system will
scan through all entries for saved articles by users of the same stereotype. Once all values have been
found by the system an attempt to match up the values of the articles to those on the recommendations
list is made. When a match has been found the individual article is returned to the end users.

38
Following the Figure 5.11 above, the saved articles are now shown in a separate suitable location to
another user under the personalised news section: -
Figure 5.12: This figure shows the recommended articles under a suitable tabbed heading within the
personalised news section of the web page. Articles 2 and 5 are returned, these were selected in Figure 5.11.
The user-user recommendation technique is an example of a more user controlled collaborative
filtering method. The objectives for this iteration have been successfully completed, concluding the
development of the system.
5.4 Summary of Implementation Chapter
The overall development of the project design has been done following the proposed system
methodology and architecture concepts. The implementation phase ran through three iterations and
introduced the tasks that were completed throughout each phase. The methods used to develop news
recommendations allowed for the straight forward addition of collaborative filtering techniques.
Collaborative filtering methods were not expected to be included in the system unless there was
sufficient time available. However as the methods for introducing collaborative filtering was simple
to implement it was of best interest of the system to take advantage of this and apply these techniques
onto the system. Problems faced during the development were more towards how the data was to be
represented. As articles from many data sources was to be included it was rather difficult to think of a
suitable method to place the amount of data on the page and ensuring that the system will still be
satisfactorily usable. However, this dilemma was sorted out with the inclusion of the tabbed
navigation method. Overall the development of the system went rather well, following the
development diagrams created beforehand made it possible to easily construct the set of tasks required
in order to successfully complete the goals for each iteration.
Thorough evaluations of the project with prospective end users will be made through the next
chapter, allowing the developer to retrieve feedback regarding the implementation of the final system.

39
Chapter 6. Pilot Studies and User Evaluation
This chapter is set to evaluate the project development. Before actual user based evaluation takes
place it is of best interest for quality evaluative purposes to initially conduct suitable pilot studies. A
user based evaluation will also be demonstrated illustrating methods used and the justification for the
choices made throughout. Set criterion is to be shown as to what the aims of the evaluation
subsections are exactly.
6.1 Pilot Studies
Before user evaluation the developer has decided that initial pilot studies should be performed.
Pilot studies are set for the developer to find potential usability and functionality flaws within the
system, this type of testing is classed as a ‘small trial run of the main study’ (Preece et al, 2002). Due
to the time limitations of the project a full-scale study cannot be performed. Performing a well
structured pilot study before user based evaluation was chosen, the developer is able to identify clear
usability problems in advance and amend them. Had such issues still remained prior to user
evaluation the feedback received would not be as useful for the developer for future revisions of the
system, as multiple evaluators would provide comments on the same issues. So by introducing pilot
studies to find and fix problems, the quality of the user evaluations should be much higher than
without a pilot study in place. However, ‘Pilot studies do not guarantee success, but does increase the
likelihood’ (Teijlingen and Hundley, 2001). With this in mind suitable criteria shall be developed to
ensure the highest quality evaluation feedback.
6.1.1 Problems Identified and Solutions
The goal of this section is to find and amend as many system problems as possible under the strict
time constraints. The reason for this is that by fixing tedious usability and functionality issues the
users will respond more to issues concerning the actual system criteria.
During navigation of the system, the developer noticed a few issues that hinder the overall
system usability. When a user has successfully registered with their desired details, they are taken to
a ‘success’ page acknowledging their successful registration. The user is now required to return to the
home page and login with their details to access personalised news. They currently they see: -
Figure 6.1 A figure showing the ‘Successful Registration Page’

40
There is a hyper link on this page allowing the user to return to the home page (‘Click Here’), but
evidently this is very difficult to find as it does not stand out above the remainder of the text. To
appropriately fix this issue it was decided to convert the text link to an image link so users can more
easily navigate their way back to the home page: -
Figure 6.2 An Image has been included so users can easily navigate back to the home page
The same issue was found on the user article recommendation success page and so the appropriate
amendment was also made in regards to this.
Currently the homepage of the system attempts to collect all the data from the data sources
and map them onto the system. This process takes approximately 10 seconds, depending on data
availability and web traffic. Now if a user selects any news tab before completion the page would
reload itself and gather news from the data sources again. This appears to be an issue in regards to the
method used for retrieving the news, as the more sources there are the longer it takes for the page to
load. Waiting 10 seconds is a long time for a page to load without any notifications. As modifying the
data collection code at this stage could become erroneous and time consuming it was decided to
provide a suitable notification to the user clearly showing them when the page is loading and when the
page has fully loaded: -
Figure 6.3 This figure illustrates the notification to the user whether the page is loading or has loaded and is
ready for use without any problems. Notifications are added below the header so are easily visible for all users.
Once a user has logged in they are able to view personalised news content. Currently the system does
not show them the details picked out for them, such as what stereotype set that they fall into and
categories recommended to them by similar users. This issue is relatively simple to solve as the
details stored about the users should be displayed back to the users themselves. The most appropriate
position on the page to display this information is immediately above the news section: -

41
Figure 6.4: The details returned to the users have been highlighted making it easier to view.
Now users will be able to view exactly what stereotype they are placed in and the news categories that
are recommended to them.
This concludes the pilot study phase, a few problems have been noted and suitable solutions
have been provided for them. User evaluation can now take place and the feedback received should
be more useful in regards to the overall content and functionality of the system as tedious usability
issues have been resolved.
6.2 User Evaluation
The plan for user evaluation is to monitor the overall user satisfaction of their experience with the
system. Obtaining and measuring user satisfaction is rather difficult as it involves many different
aspects in relation to the users overall practice and understanding of the system. It was decided that
the best evaluative method for obtaining feedback that would allow for user satisfaction analysis
would be holding user interviews. User interviews involve the system developer cooperating and
receiving feedback from the interviewee. One of the main reasons why this method of user evaluation
was selected was because direct feedback from end users could be immediately received and
discussions can be held. Also as the system is only available on a local machine, this is the only
available method for external user to gain access. A downside to this method is that holding
individual interviews can become a ‘very time consuming process’ (Liou, 1992). However as the
evaluation phase is to take place during the Easter period the developer felt that this interval was more
than enough to successfully perform such an evaluative method on a suitable scale. To make each
interview session fair amongst all evaluators it is essential to ensure that they each have the exact
same experience whilst using the newsreader. To achieve this, an ‘Evaluation Study Form’
(Appendix E) is to be provided that breaks down the tasks required for each user to go through. Once
they have completed the tasks the system developer shall formally hold the interview.
6.2.1 User Evaluation Criteria
As previously mentioned, overall user satisfaction within the system is to be analysed. However the
term ‘user satisfaction’ is overly generalised so must be broken down into smaller elements. With the
use of the study form users can comment on their experiences with certain areas of the system.
Explicit questions shall be asked to them that concentrate on the personalisation aspect of the news

42
reader, as this is what the overall aim was for the evaluation, but comparative questions shall also be
asked regarding the non personalisation elements.
Questions to be asked are set to achieve the overall benefits of personalisation in a news
reader and the negative aspects that come along with it. The questions to ask the users will initially
regard the system functionality with no personalisation aspects, and then questions about the
functionality concerning the addition of the personalisation features will be discussed.
The cumulative feedback into these areas will allow the developer to successfully analyse
whether overall user satisfaction of the personalisation elements introduced in the system was
successfully achieved.
The criteria to measure user satisfaction has been set, the next phase is to ensure a suitable
‘Evaluation Study Form’ that users go through to experience all sections of the system.
6.2.2 Evaluation Study Form
The aim of the evaluation study form was to ensure that the users evaluating the system all had the
same level of experience with the system. So an accurate set of results of the feedback can be
properly analysed without any bias towards certain elements of the system. The study form will go
through all the user interactive elements of the system. The evaluation study form consists of four
tasks, these four tasks were in place to provide users with enough applied practice with the system in
order to properly be ready for an interview. Each task ran through a phase of the system and consists
of a set of objectives which required users to manually interact with the system. Also included on the
form were visual guidance notes to users during the simulation of the tasks to make them aware of
certain elements of the objectives. The tasks performed were: - System Navigation, User
Registration, Accessing Personalised News and Recommending News to other users, the task form
can be found in Appendix E. The developer ensured to personally run through a pilot study of the
form to ensure that every task and objective has been illustrated in the simplest manner.
6.2.3 User Interviews
Interviews can be thought of as a ‘conversation with a purpose’ (Kahn and Cannell, 1957). The
intention of user evaluation with interviews was to ensure that user responses were focused towards
the set goals regarding satisfaction. Often it is required by the interviewer to ask for answers to these
specific questions so interviews were the best choice for this project.
The interview methodology to be used is ‘semi-structured’. As the goals for the evaluation is
to analyse user satisfaction it is very difficult to achieve this without having asked the same questions
to every user. A ‘structured interview style allows for the standardisation of results’ (Fontana and
Frey, 1994), as each user answers the same questions. But once the aims of the required questions
have been fulfilled a semi-structured interview would allow for the interviewer to further ask
questions that would benefit the overall summation of analysing user satisfaction. The evaluation

43
study form will be of great benefit under this interview scenario as it allows for further conversation
routes to take place. This will allow the interviewer to retrieve even more valuable information from
every user.
The following list of events is to take place during the interview sessions: -
1. The interviewer sets up the system so is ready for evaluation
2. The user is given the task form and starts the tasks to be completed
3. The interviewer will then ask the user questions concerning their experience with the system
4. Once the objective questions have been answered further questions are imposed about the
comments received to ensure highest quality feedback in all areas
5. The feedback of the evaluation is recorded for analysis
The users selected for the evaluation will be those that regularly access news information on the web.
This will further allow the developer to retrieve feedback to compare the user experiences with
viewing the news in this particular manner as opposed to their regular standards.
The user based evaluations can now properly take place. Once complete the results are to be
analysed and suitable calculations can take place to show whether user satisfaction was achieved and
to what standard.
6.2.4 Feedback Analysis
The goal of this section is to work out with the results and comments made by users whether they
were satisfied with the end result of the system.
To calculate user satisfaction the questions proposed to users will fall into two categories,
system usability without concerning any personalisation aspects, and system functionality with
personalisation introduced. The questions proposed will span the experiences that users have had
with each element of the system. With questions asked and suitable feedback received the method of
calculation involves analysing the number of users that answered favourably or unfavourably in each
section. Further comments made by users about each question set will also be taken into
consideration when deciding if users were overall satisfied with the system.
In total the number of evaluators to take part in the evaluation stage of the project was 34.
The individuals that took part were all known to the developer but had never seen the system before,
so each evaluator would have neutral opinions of the system direct from the start.
Questions regarding System Usability (non-personalised)
The questions proposed here are to discuss whether users were comfortable with using certain
elements of the system. Assessing standard system usability is very important in calculating user
satisfaction as this is what users will see in the system without the addition of personalisation content.
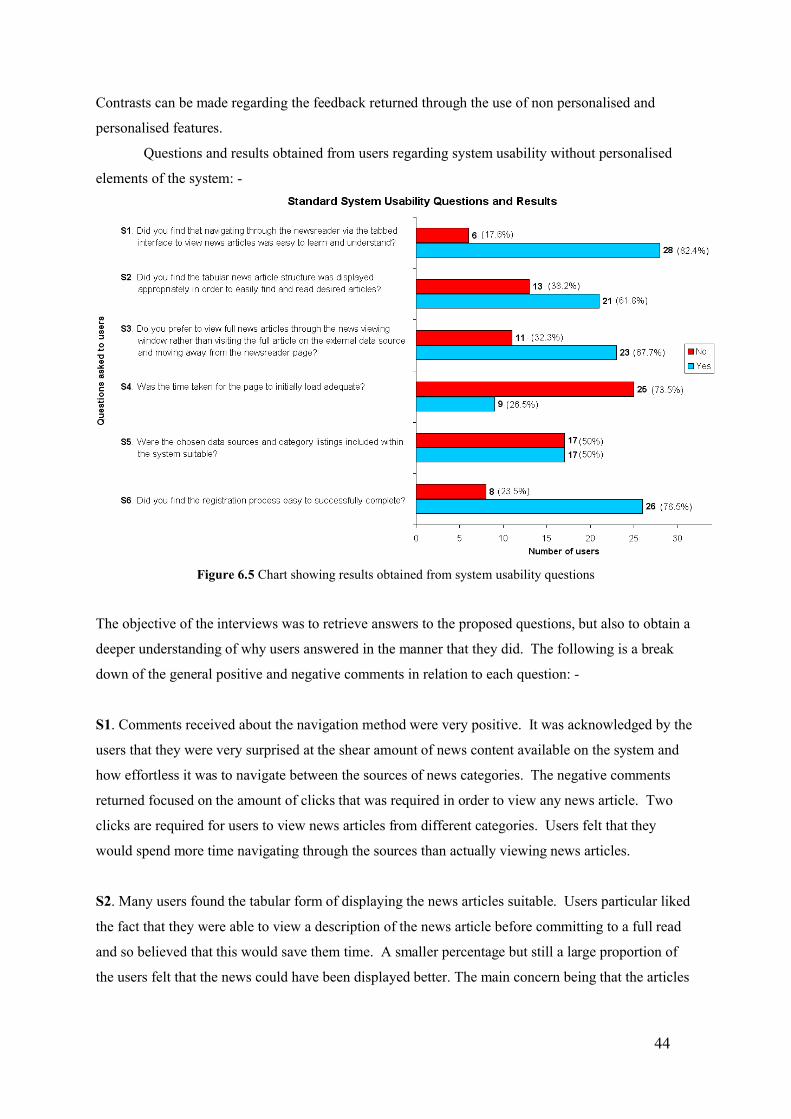
44
Contrasts can be made regarding the feedback returned through the use of non personalised and
personalised features.
Questions and results obtained from users regarding system usability without personalised
elements of the system: -
Figure 6.5 Chart showing results obtained from system usability questions
The objective of the interviews was to retrieve answers to the proposed questions, but also to obtain a
deeper understanding of why users answered in the manner that they did. The following is a break
down of the general positive and negative comments in relation to each question: -
S1. Comments received about the navigation method were very positive. It was acknowledged by the
users that they were very surprised at the shear amount of news content available on the system and
how effortless it was to navigate between the sources of news categories. The negative comments
returned focused on the amount of clicks that was required in order to view any news article. Two
clicks are required for users to view news articles from different categories. Users felt that they
would spend more time navigating through the sources than actually viewing news articles.
S2. Many users found the tabular form of displaying the news articles suitable. Users particular liked
the fact that they were able to view a description of the news article before committing to a full read
and so believed that this would save them time. A smaller percentage but still a large proportion of
the users felt that the news could have been displayed better. The main concern being that the articles

45
were listed one on top of another and were too clustered. So finding the article that they want to read
was made more difficult with this structure.
S3. Feedback received about the news viewing window was quite positive. Users felt that not having
to move away from the system page to view a news article at an external source was a good concept.
Although many users said that the news viewing window should have been positioned in a more
appropriate place, users generally did not like scrolling up and down the page of a small window.
They would much prefer to have the news articles listed with the viewing window side by side rather
than one on top of the other.
S4. Users generally felt that the amount of time that they had to wait for the system to fully load was
far too long. This was previously acknowledged during the initial pilot study but could not be solved
in time for the evaluation.
S5. There was a split decision on whether the system contained enough suitable news categories to
satisfy their viewing choices. The general consensus was that the more popular categories were
included with the data sources selected, however a wider variety should be included to cater for all
potential user interests.
S6. Mostly positive comments were returned regarding the registration process. Users felt that the
process was very simple and short. However a large proportion of them really did not like having to
be sent to another page after they had registered, only to be asked to go back to the home page. Many
comments returned said that the layout of the interests list should have been structured in a more clear
fashion rather than a big list of interests to one side of the page.
Looking back at the results and comments provided by the users it appears that the general system
functionality, not considering personalisation aspects, was much appreciated by the users. The overall
feel is that the system performed at a suitable standard and ensured that the understanding of the
system was appropriate. A lot of usability problems were identified through the comments returned,
showing that there is much room for improvement for the standard system functionality.
The next step is to determine whether users’ are satisfied with the personalisation addition
onto the newsreader.
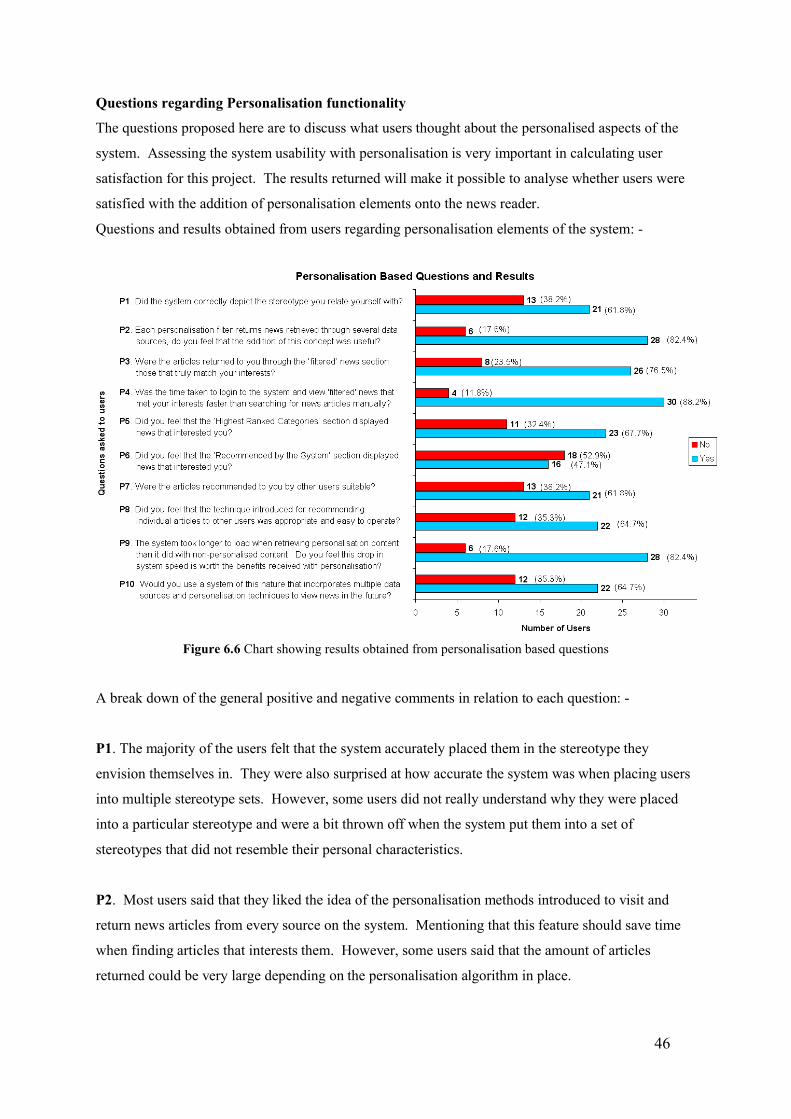
46
Questions regarding Personalisation functionality
The questions proposed here are to discuss what users thought about the personalised aspects of the
system. Assessing the system usability with personalisation is very important in calculating user
satisfaction for this project. The results returned will make it possible to analyse whether users were
satisfied with the addition of personalisation elements onto the news reader.
Questions and results obtained from users regarding personalisation elements of the system: -
Figure 6.6 Chart showing results obtained from personalisation based questions
A break down of the general positive and negative comments in relation to each question: -
P1. The majority of the users felt that the system accurately placed them in the stereotype they
envision themselves in. They were also surprised at how accurate the system was when placing users
into multiple stereotype sets. However, some users did not really understand why they were placed
into a particular stereotype and were a bit thrown off when the system put them into a set of
stereotypes that did not resemble their personal characteristics.
P2. Most users said that they liked the idea of the personalisation methods introduced to visit and
return news articles from every source on the system. Mentioning that this feature should save time
when finding articles that interests them. However, some users said that the amount of articles
returned could be very large depending on the personalisation algorithm in place.

47
P3. Comments returned here were encouraging. Most users felt that the filtering method through the
many data sources functioned well. Users found that being able to eliminate all articles that did not
meet their interests was a very valuable tool included in the system. Some users felt that the filtering
method seemed to be too strict in that only news matching their interests were returned via the name
of the news category. It was also noted that they would have liked the system to act smarter so that
similar categories that match their interests would also be returned to them, i.e. ‘Business’ categories
should possibly be linked to news with the category ‘Finance’.
P4. An overwhelming proportion of the users said that they felt that obtaining news from the content
based filtering mechanism was much faster than searching through all the data sources looking for
news that matched their interests. A drawback returned was that even if the filtering mechanism made
certain news articles faster and easier to find, it still may not return the exact articles users are
interested in. Another concern pointed out was that if many news articles were returned users will
still have to search a large list of articles to find what they would like to view.
P5. The majority of the users felt that the top three news categories that users of the same stereotype
selected as interests also appealed to them. They liked the fact that the system considered what other
users selected as interests and made decisions as to which users may like the same categories. A lot
of negative comments returned were that users did not know much about the other users besides their
stereotype. Several users did not agree with the stereotype set they were initially placed in and so did
not trust the recommendations made through this feature.
P6. Some users were pleasantly surprised as the system recommended them articles that they would
normally not think of viewing and did find them interesting. However, most of the users felt that the
system recommended them articles that they simply did not like. This is a possible problem with the
scores provided for each user stereotype per category, but also that the stereotypes users are placed
into may not be accurate.
P7. Users enjoyed reading articles that other users recommended to them. They said that if a similar
user has recommended them the article then that article must definitely be interesting, and largely this
was the case. When users read an article recommended by another user and did not find it interesting
they then doubted the credentials of the remaining recommended articles.
P8. Positive comments regarding this focused on the ease of being able to select individual news
articles and the suitable method used with the inclusion of checkboxes and the ‘Recommend’ column
to achieve this. The negative comments were that users found it difficult to remember which articles

48
they had selected if they went away to another section of the system to view other news articles.
Another problem was with the ‘successful recommendations’ page that users were sent to when
making recommendations. This issue was also noted with question S6. Users said that a simple
popup box to alert them of their recommendations would be a suitable replacement.
P9. Most users did not mind a performance hit on the system if it meant that they did not have to
manually find interesting articles themselves. They also mentioned that finding articles they would
not normally consider reading an added incentive for them to make use of personalised content. Some
users felt that rather than having to login and wait for the system to load that they would find the
articles they would like to view faster manually. These users stated that the content returned through
the methods introduced were not always accurate.
P10. Feedback received displayed that overall users thought the system would be useful to them for
viewing news. They liked that multiple data sources were incorporated allowing for a very large
variety of news content. Users were exceedingly pleased with the content based filtering mechanism
of the system and said they could definitely see some use with this feature in the future as it saves a
lot of time. But users also thought that the system needs to do more to gain their trust when
recommending articles.
6.2.5 Conclusion
The goal of this section is to analyse the total average results obtained from both set of questions
asked to the users. This will allow the developer to view the overall satisfaction users had with each
aspect of the system. The total averages for each section has been calculated: -
Figure 6.7 Chart showing the average results obtained from both question sets

49
It can be seen from the graph that for both question sets users voted favourably in terms of their
experiences with the system. Majority of the users therefore were satisfied with the system as a
whole. The feedback returned on the personalisation aspects introduced was very positive, meaning
that the algorithms applied in the newsreader appealed to end users. However, there were some clear
drawbacks discussed throughout illustrating that the personalised news reader is by no means perfect.
6.2.6 Evaluation Summary
The user interviews were completed successfully and the feedback returned has now been analysed.
From the evidence provided through the charts, the system overall succeeded in maintaining a high
user satisfaction rate throughout the set of questions asked. The user comments provided display that
no section of the system was totally liked by all users, this means that there exists a lot of room for
future improvement. Many system bugs and usability concerns were notified during the interviews
and these should be addressed in the future. The main concern with the personalisation aspect of the
system was that the algorithms that associate stereotypes to users seemed imprecise. This resulted in
negative feedback regarding some of the recommendations made to them through the personalisation
methods introduced. Looking at the cumulative feedback returned by the users (Appendix F), users
that did not like the stereotypes assigned to them generally did not like the future system
recommendations made by the system. This is something that should definitely be addressed for
future development plans. Overall positive comments returned about personalisation were focused on
method of obtaining filtered news from many sources of data.
The evaluation has looked at the user satisfaction of the overall system. The evaluation
provides sufficient evidence to ensure that personalisation techniques can successfully be applied to a
mashup environment and be appreciated by end users.
By looking at the results and the cumulative set of comments returned, the system evaluation
has shown that the personalised news reader has successfully satisfied a large population of the users
with the features and both non-personalised and personalised functionality included. The project aim
has been surpassed and each objective required for completion has been fulfilled.
6.2.7 Further Work
Whilst the software development met the initial requirements, there is always room for additional
components to implement onto the system that offer further enhancement. The comments made by
the users should be taken heavily into account when considering the next development stage for this
system. The main problem noted was the assignment of user stereotypes, and this must be addressed
to improve overall user satisfaction. Further work could include allowing users to modify their
chosen interests after registration, and also provide news from several regions. If there was additional
time and unlimited scope for the project a mapping interface could also be integrated, similar to the
previously encountered existing solutions, allowing users to view news in a more ‘richer’ manner.

50
Chapter 7. Conclusion
The goal of this chapter is to review a breakdown of the work done throughout the project as a whole.
This will help to assess what the project has achieved and how it could be improved in the future.
The methodology chosen for the development of the system was ‘Agile Unified Process’ and the
project schedule followed the methodology through each phase. The initial project schedule
(Appendix B1) was very accurately followed with the tasks to be done, it was noted however that the
evaluation phase was to take place before the Easter period. Due to the strict time restrictions and the
type of evaluation to pursue, this goal was unachievable at the time period initially selected. The
evaluation phase was pushed into the Easter period and this is reflected on the revised project
schedule (Appendix B2). The user interviews did take a very long time to complete and so this choice
in time change for the evaluation period has been justified.
System architecture diagrams were prepared during the design phase to illustrate the intention
of each development iteration. The inclusion of these diagrams was very useful when it came to
actual development. The developer could analyse step by step what the next objective to include onto
the system was, without problems surrounding which object of the system relates to another.
A few personalisation techniques have been included onto the system. The algorithms
developed to achieve them functioned successfully, however the accuracy of assigning user
stereotypes was questioned during evaluation. Therefore the choices of stereotype assignment will
need to be revised in the future.
With the limitations faced with the availability of the system there was a boundary to the
amount of user feedback that could have been returned. 34 users were interviewed in the end and the
results returned suitably justify the evaluation aims for the project. However, if this constraint was
eliminated better quantifiable feedback may have been attained with a larger variety of users.
The aim and objectives for the project have been surpassed. A prototype of a personalised
news reader mashup was successfully developed and appropriate evaluations were made to assess
how satisfied users were with the system. The tools and development methodologies chosen were
successfully put into practice during system implementation. On the whole the project has been a
success from both a development and personal point of view.

51
Reference List
1. Ambler, S. W. (2005). The Agile Unified Process, Ambysoft,
http://www.ambysoft.com/unifiedprocess/agileUP.html [Accessed 06/12/2006]
2. Ambler, S. W. (2002). Agile Modelling, New York: John Wiley & Sons
3. BBC Politics (2007). BBC News | Politics | UK Edition, http://newsrss.bbc.co.uk/rss/newsonline_uk_edition/uk_politics/rss.xml [Accessed 14/03/2007]
4. Boehm, B. (2002). A survey of Agile Development Methodologies, Laurie Williams 2004
5. Booch, G. (1998). Object-Oriented Analysis and Design with Applications. Addison-Wesley. ISBN: 0-8053-5340-2
6. Dang, M.T, Dimitrova, V and Djemame, K. (2006). Personalised Mashups: Opportunities
and Challenges, Technical Report, School of Computing, University of Leeds
7. Dimitrova, V. (2005). GI32: Personalisation and User Adaptive Systems, Lecture 4:
Recommender systems (Part 1), School of Computing, University of Leeds
8. ELI (2006). The EDUCAUSE Learning Initiative, 7 Things You Should Know About
Mapping Mashups, EDUCAUSE
9. Fontaina, A. and Frey, J. J. (1994). Getting Physical: what is fun computing in tangible
form? In: Computing and Fun 2, Workshop 20 Dec. York, UK
10. Gil, A., and Garcia, F. (2003). E-commerce Recommenders: Powerful tools for E-Business,
In: Crossroads Volume 10, Issue 2 (Winter 2003). ACM Press New York, NY, USA
11. Gottfredson, D. (1997). Intelligence and social policy. Intelligence, 24(1). P. 13
12. Highsmith, J. (2000). Adaptive Software Development A collaborative approach to
managing complex systems, New York, NY, Dorset House Publishing
13. Highsmith, J (2002). Agile Software Development Ecosystems. Boston, MA, Addison-
Wesley

52
14. Jameson, A. (2003). Adaptive Interfaces and Agents. Human-computer interaction
handbook, pp. 305–330, Mahwah, NJ: Erlbaum
15. Kahn, R., and Cannel, C. (1957) The Dynamics of Interviewing. New York: John Wiley &
Sons
16. Liou, M. I. (1992). Knowledge acquisition: issues, techniques and methodology, In: ACM SIGMIS Database, Volume 23, Issue 1 (Winter 1992). ACM Press New York, NY, USA
17. Meteren R., and M. Someren. (2000). Using Content-Based Filtering for Recommendation,
in: Proceedings of MLnet/ECML2000 Workshop, Barcelona, Spain, 30 May 2000
18. Nielsen, J. (1998). Personalization is over-rated, Jakob Nielsen’s Alertbox
www.useit.com/alertbox/981004.html [Accessed 10/12/2006]
19. Pazzani, M. J. (1999). A framework for collaborative, content-based and demo-graphic
filtering, in: Artificial Intelligence Review, Volume 13, Issues 5-6
20. Preece, J., Rogers, Y., and Sharp, H. (2002). Interaction Design: beyond human-computer interaction, New York: John Wiley & Sons
21. Python Documentation (2006). An Introduction to Pythonhttp://www.python.org/doc/Introduction.html [Accessed 20/04/2007]
22. Sigal, M (2005). What the hell is Web 2.0? The great web mashup begins, 16 Sept 2005.
http://www.oreillynet.com/digitalmedia/blog/2005/09/what_the_hell_is_web_20_the_gr.htm
l [Accessed 06/12/2006]
23. Sollenborn, M., and Funk, P. (2002). Category-Based Filtering and User Stereotype Cases
to Reduce the Latency Problem in Recommender Systems, Lecture Notes In Computer
Science; Vol. 2416, Proceedings of the 6th European Conference on Advances in Case-
Based Reasoning
24. Stapleton, J. (1997). Dynamic systems development method, The method in practice,
Addison Wesley
25. Tapscott, D. (2006) Wikinomics and Mass Collaboration, In: The Web 2.0 Summit, 7-9
November 2006, San Francisco, CA

53
26. Tim O’Reilly (2005). What is Web 2.0, Design patterns and business models for the next
generation of software, 30 Sept 2005
http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html
[Accessed 06/12/2006]
27. Teijlingen, E. and Hundley, V. (2001). Sociology at Surrey, Social Research Update, Issue 35, P.1
28. Williams, L. and Cockburn A. (2003). June Special Issue on Agile Methods,
IEEE Computer 36(3)
29. What is RSS (2007). What Is RSS? RSS Explained, http://www.whatisrss.com [Accessed 24/03/2007]
30. Why MySQL (2007). http://www.mysql.com/why-mysql [Accessed 20/04/2007]

54
Appendix A. Personal Reflections
With the development of the system complete I can truly say that I am very pleased with the final
outcome, both with the system development and the overall experience gained. Having never worked
on a project of this scale before, the development methodology followed allowed me to arrange my
time appropriately in order to successfully complete the system. Choosing a suitable methodology is
extremely important when planning the system development process. My advice to students would be
to initially set a list of conditions that you want the methodology to conform to for development
requirements. The most appropriate methodology will be the one that fully satisfied your initial
criteria. Development methodologies do not always follow strict guidelines as they are often over
generalised. As the project consists of single developer these can suitably be modified to suit their
individual needs.
I highly recommend that all future final year project students develop expected
implementation designs well in advance of actual development. This made the whole implementation
phase a lot easier in my case, and the total time taken was greatly reduced by pre-empting the design
of the final system. However, the time taken for actual development was still rather lengthy. As
acknowledged by the comments made by my assessor on the mid project report, the implementation
should begin as early as possible. I left the implementation onto the second semester and this resulted
in only having approximately seven weeks to complete the system. This is a very small period of time
to develop a fully working system from scratch, therefore most of my time during the semester was
spent developing the prototype. This meant having to initiate very long working sessions in order to
complete the functionality of the system for the progress review meeting. An advice to students
would be to plan the implementation stage early in order to allow for sufficient time for development.
Conducting an evaluation is a key component of the project. I had personally decided on the
evaluation style well before the completion of the implementation, but did not realise how limited the
amount of time available for evaluation was during the semester and so this had to be pushed further
back. The time taken to conduct the evaluation during Easter was extensive, in my scenario the more
user feedback received the better the overall result of the evaluation. However, the amount of users
that took part in the evaluation was limited and could have been expanded if the system was made
more widely available. Future students should realise well in advance the evaluation style they want
to commit to, and also try to obtain as much quality feedback as possible. I believe that user
interviews was the best choice for my project, as the further comments returned allowed me to gain a
deeper understanding of what the users felt about the system. If I had more time for this project, I
would have included more user involvement during implementation. This would have allowed a lot
of the negative comments received from the evaluation to be rectified in advance, resulting in more
user satisfaction for the final system.

55
To summarise, I am extremely satisfied with the end result of the project. The skills that I have gained
during the development of the project, both technical and project management related, will stick with
me throughout my career. I am very grateful to have had this experience at the University of Leeds,
where I was surrounded by people that were very helpful to me throughout the project lifecycle. I
hope that future students will pay attention to the advice that I have given in relation to planning their
projects, as it will make future large scale system development a lot simpler. Students should not
hesitate to ask questions primarily to their supervisor and others, as the comments received will
always help them towards reaching their goals for their final year project.
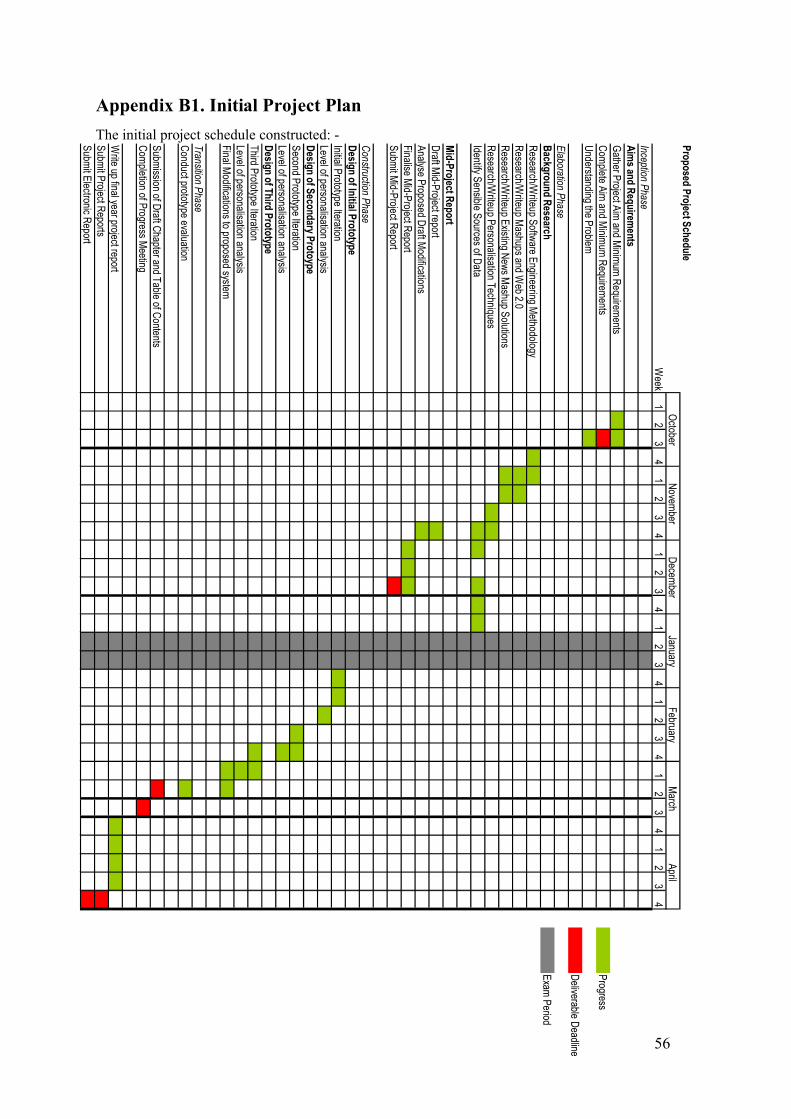
56
Appendix B1. Initial Project Plan
The initial project schedule constructed: - Proposed Project Schedule
Week
12
34
12
34
12
34
12
34
12
34
12
34
12
34
Inception PhaseAim
s and Requirem
entsG
ather Project Aim and M
inimum
Requirem
entsC
omplete Aim
and Minim
um R
equirements
ProgressU
nderstanding the ProblemD
eliverable Deadline
Elaboration PhaseB
ackground Research
Exam Period
Research/W
riteup Software Engineering M
ethodologyR
esearch/Writeup M
ashups and Web 2.0
Research/W
riteup Existing News M
ashup SolutionsR
esearch/Writeup Personalisation Techniques
Identify Sensible Sources of Data
Mid-Project R
eportD
raft Mid-Project report
Analyse Proposed Draft M
odificationsFinalise M
id-Project Report
Submit M
id-Project Report
Construction Phase
Design of Initial Prototype
Initial Prototype IterationLevel of personalisation analysisD
esign of Secondary ProtoypeSecond Prototype IterationLevel of personalisation analysisD
esign of Third PrototypeThird Prototype IterationLevel of personalisation analysisFinal M
odifications to proposed system
Transition PhaseC
onduct prototype evaluation
Submission of D
raft Chapter and Table of C
ontentsC
ompletion of Progress M
eeting
Write up final year project report
Submit Project R
eportsSubm
it Electronic Report
October
Novem
berD
ecember
AprilJanuary
FebruaryM
arch
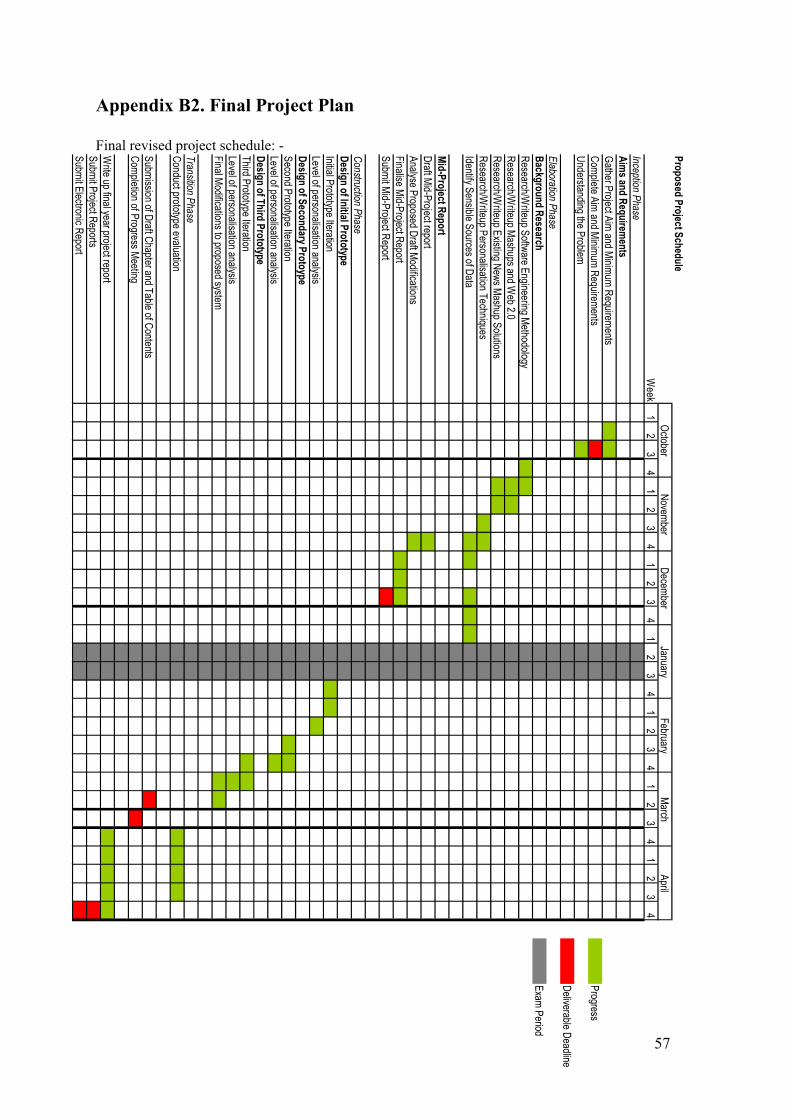
57
Proposed Project Schedule
Week
12
34
12
34
12
34
12
34
12
34
12
34
12
34
Inception PhaseAim
s and Requirem
entsG
ather Project Aim and M
inimum
Requirem
entsC
omplete Aim
and Minim
um R
equirements
ProgressU
nderstanding the ProblemD
eliverable Deadline
Elaboration PhaseB
ackground Research
Exam Period
Research/W
riteup Software Engineering M
ethodologyR
esearch/Writeup M
ashups and Web 2.0
Research/W
riteup Existing News M
ashup SolutionsR
esearch/Writeup Personalisation Techniques
Identify Sensible Sources of Data
Mid-Project R
eportD
raft Mid-Project report
Analyse Proposed Draft M
odificationsFinalise M
id-Project Report
Submit M
id-Project Report
Construction Phase
Design of Initial Prototype
Initial Prototype IterationLevel of personalisation analysisD
esign of Secondary ProtoypeSecond Prototype IterationLevel of personalisation analysisD
esign of Third PrototypeThird Prototype IterationLevel of personalisation analysisFinal M
odifications to proposed system
Transition PhaseC
onduct prototype evaluation
Submission of D
raft Chapter and Table of C
ontentsC
ompletion of Progress M
eeting
Write up final year project report
Submit Project R
eportsSubm
it Electronic Report
October
Novem
berD
ecember
AprilJanuary
FebruaryM
arch
Appendix B2. Final Project Plan
Final revised project schedule: -

58
Appendix C. Stereotype Derivation Methods
List of Stereotypes and user profile details used to derive them: -
Sports PersonAge > 16Job Field = ‘Sports’ or Interests include ‘Sports’ (including specific sports)
Professional Finance ReaderAge > 21 and age < 61Job = ‘Finance sector’ or Interests include ‘Business’
Young TravellerAge > 16 age < 30Interests includes ‘World’ (including specific world regions)
TechyAge > 19 and age < 41Interests include ‘Technology’ or ‘Hardware’ or ‘Software’ or ‘IT Management’
Politically Engaged AdultAge > 24 and age < 61Interests include ‘Politics’ or ‘Education’
Teen News ReaderAge > 12 and age < 20Interests include ‘Entertainment’
ManGender = ‘Male’
WomanGender = ‘Female’
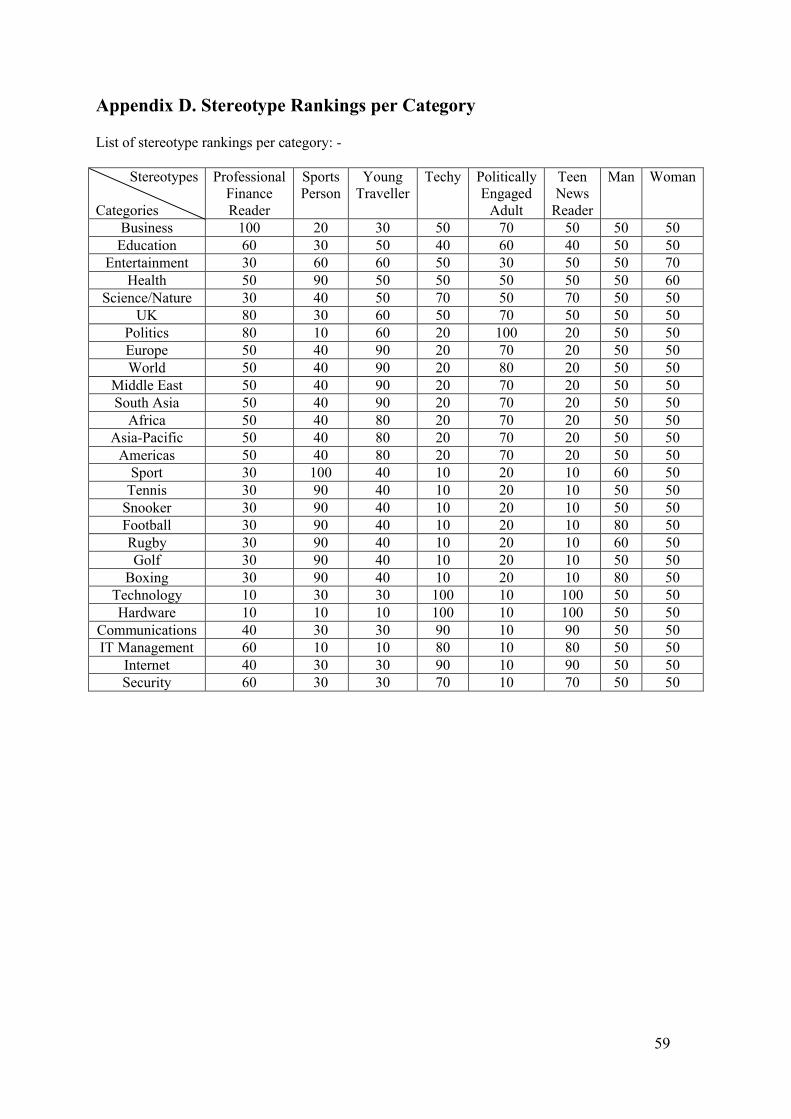
59
Appendix D. Stereotype Rankings per Category
List of stereotype rankings per category: -
Stereotypes Categories
Professional Finance Reader
Sports Person
Young Traveller
Techy Politically Engaged
Adult
Teen News
Reader
Man Woman
Business 100 20 30 50 70 50 50 50Education 60 30 50 40 60 40 50 50
Entertainment 30 60 60 50 30 50 50 70Health 50 90 50 50 50 50 50 60
Science/Nature 30 40 50 70 50 70 50 50UK 80 30 60 50 70 50 50 50
Politics 80 10 60 20 100 20 50 50Europe 50 40 90 20 70 20 50 50World 50 40 90 20 80 20 50 50
Middle East 50 40 90 20 70 20 50 50South Asia 50 40 90 20 70 20 50 50
Africa 50 40 80 20 70 20 50 50Asia-Pacific 50 40 80 20 70 20 50 50
Americas 50 40 80 20 70 20 50 50Sport 30 100 40 10 20 10 60 50
Tennis 30 90 40 10 20 10 50 50Snooker 30 90 40 10 20 10 50 50Football 30 90 40 10 20 10 80 50Rugby 30 90 40 10 20 10 60 50Golf 30 90 40 10 20 10 50 50
Boxing 30 90 40 10 20 10 80 50Technology 10 30 30 100 10 100 50 50Hardware 10 10 10 100 10 100 50 50
Communications 40 30 30 90 10 90 50 50IT Management 60 10 10 80 10 80 50 50
Internet 40 30 30 90 10 90 50 50Security 60 30 30 70 10 70 50 50

60
Appendix E. Evaluation Study Form
Personalised News Reader Mashup Evaluation Study
Thank you for taking part in this evaluation study. Please follow the tasks listed below, once
complete a short interview session will be held discussing your experiences through each task.
Denotes visual guidance and non system tasks Denotes a task to perform
Task 1 – System Navigation
You are presented with a simple user interface that contains titles of news categories
Select any news category tab you wish to view (Front Page, Sports, Entertainment etc)
Then select each of the news source tabs that appear in this section (‘BBC’, ‘Reuters’ etc)
Take a moment to familiarise with this method of navigation by selecting other categories
You should see a tabular format of current news articles displayed in numerical order
Click on the ‘Title’ of a news article (highlighted in blue) to view the article in the news window
below, you may need to scroll down the page to view the article in full
Once complete, continue onto the next task
Task 2 – User Registration
Click on the ‘Registration Page’ link to access the registration form
Now enter the required details and select a set of interests from the list on the left
Once complete click on the ‘Submit’ button to register your details
You will be taken to a ‘Registration Success’ page acknowledging that your registration was
successfully added onto the system
Click on the ‘Return to Home’ button to be taken back to the home page
You are now ready to access personalised news content, follow onto the next task

61
Task 3 – Accessing Personalised News
Type in your Username and Password in the appropriate fields, click the ‘Login’ button
You can see the stereotype set the system has placed you in and the categories recommended to
you under different scenarios above the tabbed news area
News content received now will be retrieved from every source included in the system
Select the ‘Personalised News’ tab
Select the ‘Filtered News’ tab, take a moment to view the articles
Select the ‘Highest Ranked Categories’ tab, take a moment to view the articles
Select the ‘Recommended Articles by the System’ tab, take a moment to view the articles
Select the ‘Recommended Articles by Similar Users’ tab and view the articles
Once complete, continue onto the final task
Task 4 – Recommending News to other users
Click on any news category tab and view the news articles
You can see a ‘recommend’ column and checkboxes relating to each news article
Select by clicking the check boxes of articles you feel similar users may be interested in
Once complete click on the ‘Save Recommendations’ button
You will be taken to a ‘Successful Recommendations’ page acknowledging that your
recommendations have been saved for other users of the same stereotype
Click on the ‘Return to Home’ button to go back to the home page
This concludes the tasks required for user evaluation
Your comments will be greatly appreciated

62
Appendix F. Cumulative User Feedback
All responses to each question proposed by the users during interviews, Y = Yes, N = No: -
Users S1 S2 S3 S4 S5 S6 P1 P2 P3 P4 P5 P6 P7 P8 P9 P10
User 1 Y N N Y Y Y N Y N Y N N N N Y N
User 2 Y Y Y N Y Y Y Y Y Y Y Y Y Y Y Y
User 3 N N Y N Y Y N Y Y Y N N N N Y N
User 4 N N Y N N N Y Y Y Y Y Y Y Y Y Y
User 5 Y N Y Y N Y Y Y Y Y Y Y Y Y Y Y
User 6 Y Y N N Y Y Y Y N Y Y N Y N N N
User 7 Y Y N N Y N N N Y Y N N N N Y Y
User 8 Y Y Y Y Y Y Y Y Y Y Y N N N Y Y
User 9 Y N Y N Y Y Y Y Y Y Y Y Y Y Y Y
User 10 Y Y N N N Y N Y Y Y Y N N N Y Y
User 11 Y Y Y Y N Y Y N N N Y Y Y N N N
User 12 Y Y N N N N Y Y Y Y Y Y Y Y Y Y
User 13 N N N Y N Y N Y Y Y N N N N Y N
User 14 Y Y N Y N Y Y Y Y Y Y Y Y Y Y Y
User 15 Y N Y N N Y Y Y N N Y N Y N N N
User 16 N Y Y N N N Y Y Y Y Y Y Y Y Y Y
User 17 Y N Y N Y Y N N Y Y N N N Y Y N
User 18 Y Y Y Y Y Y Y N N Y Y Y Y Y Y N
User 19 Y Y Y N Y N Y Y Y Y Y Y Y Y Y Y
User 20 Y N Y N N N N Y Y Y Y N Y N Y Y
User 21 Y Y N N Y Y Y Y Y Y Y Y Y Y Y Y
User 22 Y Y Y N N Y Y Y Y Y Y N Y Y Y Y
User 23 N Y Y N N Y Y Y N N Y Y Y Y N N
User 24 Y N N N N Y N Y Y Y N N Y Y Y Y
User 25 Y Y Y Y Y Y N Y Y Y N N Y Y Y Y
User 26 Y N Y N Y Y N Y N Y N N N Y Y N
User 27 Y Y Y N Y Y N Y Y Y N N N N Y Y
User 28 Y N Y N N N Y N Y Y Y Y Y Y Y Y
User 29 N N Y N Y N Y Y Y Y Y Y Y Y Y Y
User 30 Y Y Y N N Y N Y N N N N N Y N N
User 31 Y Y Y N Y Y N Y Y Y N N N Y N N
User 32 Y Y N N Y Y Y Y Y Y Y N N N Y Y
User 33 Y Y N Y N Y Y N Y Y Y Y N Y Y Y
User 34 Y Y Y N N Y Y Y Y Y Y Y Y Y Y Y





























