Embed Size (px)
Citation preview

An Iterative Approach to Extract Dictionaries from Wikipedia for Under-resourced Languages
G. Rohit BharadwajNiket Tandon
Vasudeva Varma
Search and Information Extraction LabLanguage Technologies Research Center
IIIT Hyderabad

Outline• Introduction• Model of our approach
– An example– Different steps– Scoring
• Dataset and Evaluation.– Dataset– Evaluation
• Results– Empirical Results– Coverage
• Discussion

Why CLIA?• Cross lingual information access.• Hindi-Wide Web and Telugu-Wide Web.• Bridge the gap between the information available and
languages known, CLIA systems are vital.
• Dictionaries form our first step in building such CLIA system.
• Built exclusively to translate/ transliterate user queries.
Why dictionaries?

Why Wikipedia ?
• Rich multi-lingual content in 272 languages and growing.
• Well structured.• Updated regularly.• All languages doesn’t have the privilege of
resources.Can harness Wikipedia structure instead.

How is it done?
• Exploit different structural aspects of the Wikipedia• Build as many resources from Wikipedia itself. • Extract parallel/comparable text from each structure using
the resources built.• Build dictionaries using previously built dictionaries and
resources.

Contd…• Extract maximum information using the structure of the articles
that are linked with cross lingual link.
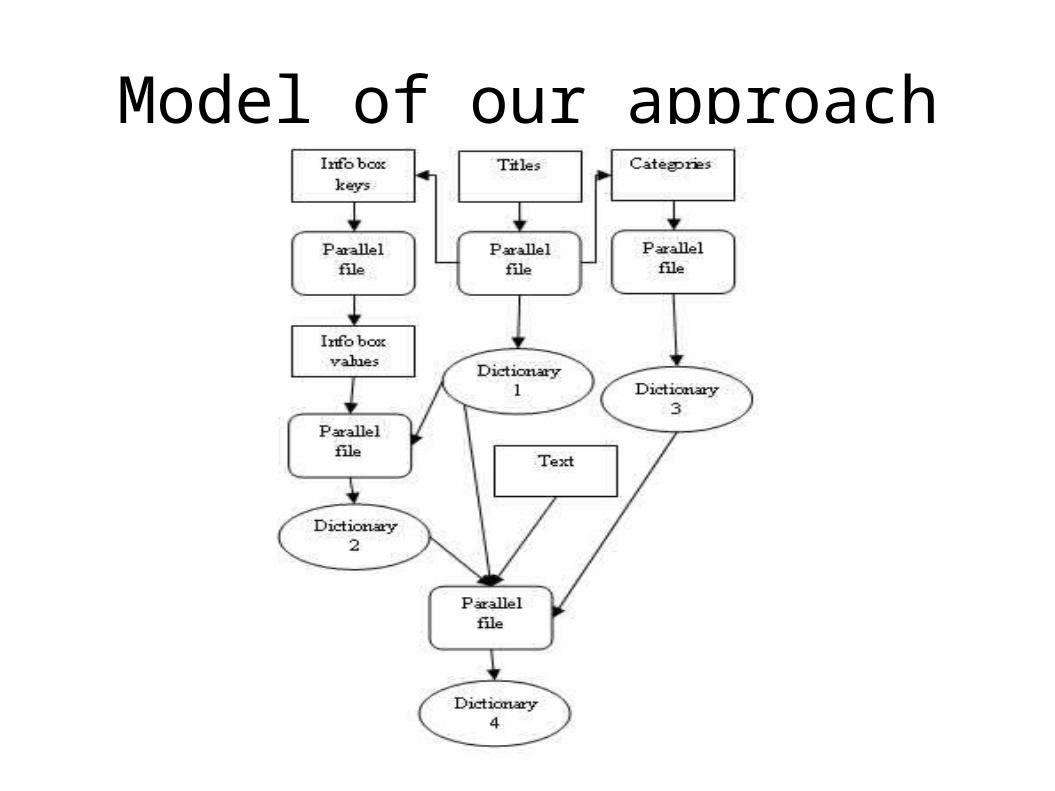
Model of our approach

Example…

Titles (dictionary1)• Titles of the articles form the parallel text to build dictionary.• Considered both directions for building parallel corpus
i.e.. English to Hindi and Hindi to English.
Infobox (dictionary2)• Contain vital information especially nouns. • Two step process
Keys Values
• Values of the mapped keys from the info boxes are considered as parallel text.
We reduce the number of words in the value pair by removing the highly scored word pairs in dictionary1 and stop words.

Categories (dictionary3)• Categories of articles linked by the ILL link form the parallel text.• Considered both directions for building parallel corpus
i.e.. English to Hindi and Hindi to English
Article text (dictionary4)• First paragraph of the text is generally the abstract of the article.• Sentence pairs are filtered by Jaccard similarity metric using the
dictionaries built.• Mapped words in any of the dictionaries and stop words in each
sentence pair are removed .

Scoring• The scoring of the words from parallel text is based on the formula
• are ith and jth words in English and Hindi wordlists respectively• are number of occurrences of respectively in
the parallel text • is the number of occurrences of in a single parallel text
instance.
WWWww i
E
j
H
i
Ej
H
i
EScore
)(),(
wwj
H
i
Eand
wwj
H
i
EandWW
j
H
i
Eand
WWj
H
i
E

Dataset
• Three sets of 300 English words each are generated from existing English-Hindi and English-Telugu dictionaries.
Existing dictionaries are provided by Language Technologies Research Center (LTRC, IIIT-H)
• Mix of most frequently used to less frequently used. Frequency determined using news corpus.
• POS tagged to perform the tag-based analysis.

• Precision and recall are calculated for the dictionaries built. precision is (ExtractedCorrectMappings) / (AllExtractedMappings) recall is (ExtractedCorrectMappings) / (CorrectMappingsUsingAvailableDictionary) Correctness of a mapping is determined in two ways
Automatic: Using an available dictionary Manual: We manually evaluate the correctness of the word
• Two methods are required because No language dependent processing (parsing, chunking etc). Different word forms (plural, tense etc) are returned. Different spellings in Wikipedia for the same word.
Evaluation
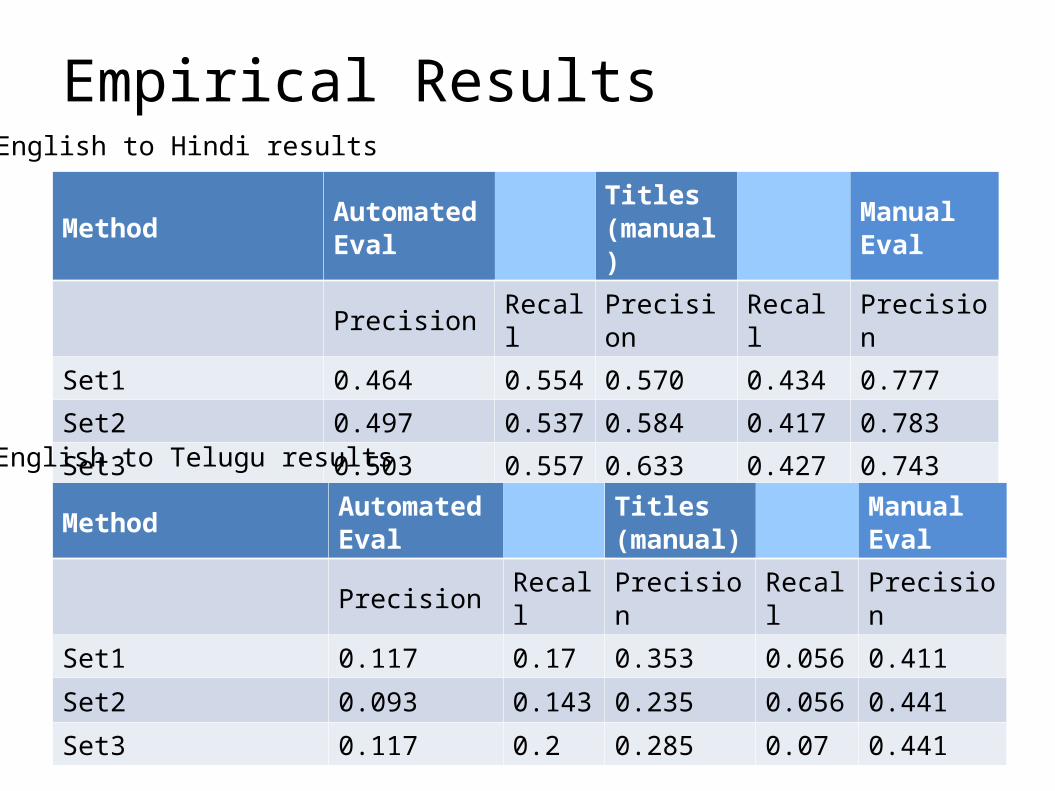
Empirical Results
MethodAutomated Eval
Titles (manual)
Manual Eval
Precision Recall Precision Recall Precision
Set1 0.464 0.554 0.570 0.434 0.777
Set2 0.497 0.537 0.584 0.417 0.783
Set3 0.503 0.557 0.633 0.427 0.743
English to Hindi results
MethodAutomated Eval
Titles (manual)
Manual Eval
Precision Recall Precision Recall Precision
Set1 0.117 0.17 0.353 0.056 0.411
Set2 0.093 0.143 0.235 0.056 0.441
Set3 0.117 0.2 0.285 0.07 0.441
English to Telugu results
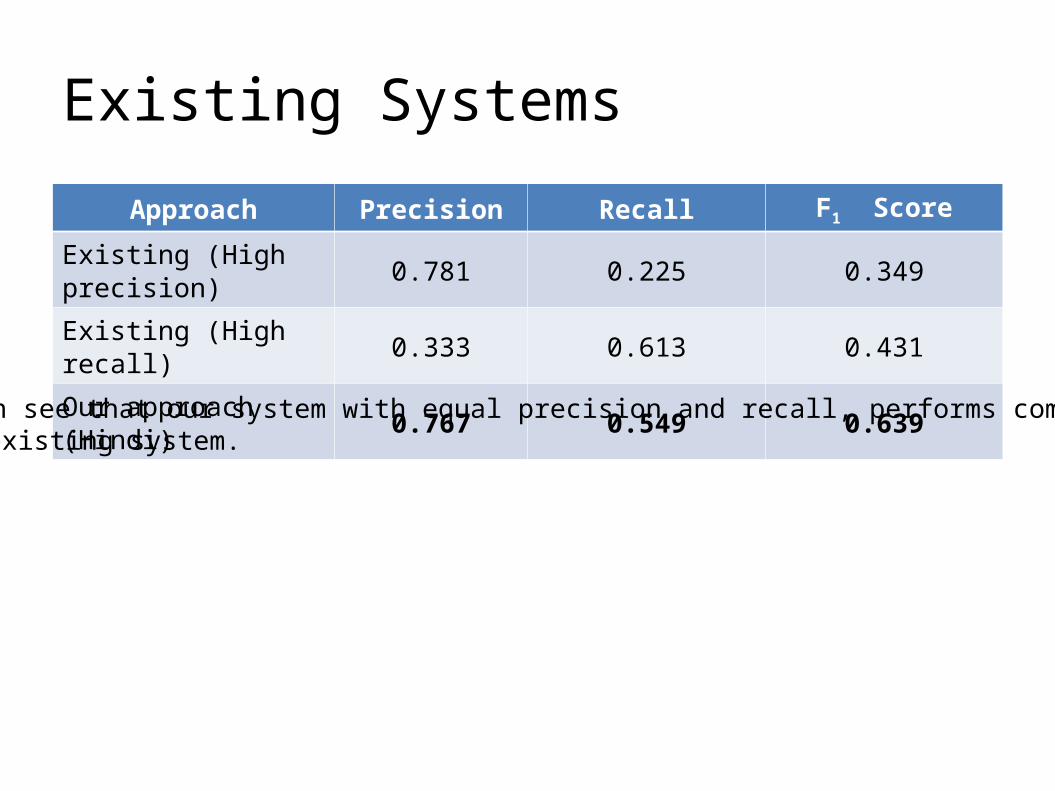
Existing Systems
Approach Precision Recall F1 Score
Existing (High precision) 0.781 0.225 0.349
Existing (High recall) 0.333 0.613 0.431
Our approach (Hindi) 0.767 0.549 0.639
We can see that our system with equal precision and recall, performs comparatively with the existing system.

Coverage• Number of Unique words that are added to the
dictionary from each structure
Structure(X-axis) Vs Unique word count (Y-axis)

Discussion
• Titles are considered as a baseline most of the existing CLIA systems over Wikipedia also consider
titles as baseline. • The precision is high when evaluated manually because
Various context-based translation for a single English word. Different word forms of the word returned and that present in
the dictionary. Different spelling for the same word. (different characters)
• Also the precision of dictionaries created are in the order Title > info box > categories > text

Cont..• Query formation in wiki-CLIA does not depend completely on
dictionaries and their accuracy.• The words returned by our dictionaries, if not exact
translations, are related words since they are present in a related wiki article.
• Words returned can be used to form the query.• The coverage of proper nouns that are generally not present in
dictionaries is high. Their values are
Precision Recall F-Measure (F1)
0.715 0.787 0.749

On-going Work
• Extract more parallel sentences using other structures to increase the coverage of dictionary• Image meta tags, • Body of the article and • Anchor text.
• Query Formation from these dictionaries.

Questions???
Thank you.





























