Embed Size (px)
Citation preview

An Overview of Parallel Computing

Software Issues
• The idea of a process is a fundamental building block in most paradigms of parallel computing
• A process is an instance of program• A program is parallel if it can comprise more than one
process during execution• For parallel programs, processes must be specified,
created, and destroyed. Also, the interprocess interaction must be coordinated

Shared-Memory Programming
• Conventionally in a shared-memory system, processors have equal access to all the memory locations
• Perfectly reasonable to emulate shared memory with physically distributed memory if we have a mechanism to create a global address space
• Therefore, possible to program a distributed-memory system using shared-memory programming primitives
• Shared-memory systems typically provide both static (at the beginning of the program) and dynamic (during execution of the program) process creation
• Best know-know dynamic process creation function is fork

Fork Example
• #include <stdio.h>#include <unistd.h>
• int main(int argc, char **argv){ printf("--beginning of program\n");
• int counter = 0; pid_t pid = fork();
• if (pid == 0) { // child process int i = 0; for (; i < 5; ++i) { printf("child process: counter=%d\n", ++counter); } } else if (pid > 0) { // parent process int j = 0; for (; j < 5; ++j) { printf("parent process: counter=%d\n", ++counter); } } else { // fork failed printf("fork() failed!\n"); return 1; }
• printf("--end of program--\n");
• return 0;}
--beginning of programparent process: counter=1parent process: counter=2parent process: counter=3child process: counter=1parent process: counter=4child process: counter=2parent process: counter=5child process: counter=3--end of program--child process: counter=4child process: counter=5--end of program--

Shared-Memory Programming
• Use fork to start another process, child• Coordination among processes is managed by three
primitives 1. Specifies variables that can be accessed by all the
processes
2. Prevents processes from improperly accessing shared
resources
3. Provides a means for synchronizing the processes

Shared-Memory Programming
Example: Each process has computed a private int private_x. The program should compute the sum of the private ints.
Solution: Define a shared variable sum
int private_x
shared int sum=0;
However, we cannot simply have each process compute
sum=sum+private_x;

Shared-Memory Programming
When add is performed, the following sequences of instructions:
fetch sum into register A
fetch private_x into register B
add contents of register B to register A
store contents of register A in sum

Shared-Memory Programming
• We should ensure that only one process can execute a certain sequence of statement at a time, this is called mutual exclusion
• The sequence of statements is called a critical section• One of the simplest approaches is a binary semaphore• Use a shared variable s. If it is 1, the section is free; if s
is 0, the region cannot be accessed shared int s=1;
while (!s); /*wait until s=1 */
s=0; /*close down access */
sum=sum+private_x; /*critical section */
s=1; /* reopen access */

Shared-Memory Programming
• The problem is that the operations are not atomic• In addition to the shared variable, a binary semaphore
consists of two special functions
void P(int* s);
void V(int* s);• V sets s to 1, but it does this atomically using system
dependent mechanism. The simple solution is that machine commands lock and unlock. When a variable is locked, only the process that locked it can write to it

Share-Memory Programming
• The final issue is that how a process knows that all other processes complete the sum operation
• Use another shared variable count to maintain the number of processes that update the sum
• This is usually carried out with a somewhat high level abstraction called a barrier
• It is implemented as a function. Once a process called the function, it will not return until every other process has called it
• If a barrier after the sum, process 0 will know that additions have been completed once it returns from the call to the barrier

Shared-Memory Programming
int private_x;
shared int sum=0;
shared int s=1;
.
/*Compute private_x */
.
.
P(&s);
sum=sum+private_x;
V(&s);
barrier();
if (I am process 0)
printf(“sum=%d\n”, sum);

Shared-Memory Programming
• The concepts of shared variables and barriers is quite natural and appealing to programmers
• The idea of a binary semaphore is not so appealing
• It is somewhat error-prone and forces serial execution of the critical region
• Monitors provide a high-level alternative , which encapsulate shared data structures and the operations that can be performed on them
• The shared data structures are defined in the monitor and critical regions are functions of the monitor
• When a process calls a monitor function, the other processes are prevented them calling the function

Shared-Memory Programming
• Monitors do nothing to solve the serialization problem• The obvious solution is extremely complicated since they
introduce other shared variables and critical regions

Message Passing
• The most commonly used method of programming distributed-memory MIMD system is message passing, or its some variant
• In basic message passing, the processes coordinate their activities by explicitly sending and receiving messages
• For example send function int MPI_Send (void* buffer, int count, MPI_Datatype datatype, int destination, int tag,
MPI_Comm communicator)
• Receive function int MPI_Recv(void* buffer, int count, MPI_Datatype datatype, int source, int tag,
MPI_Comm communicator, MPI_Status status)

Message Passing
• Each processors has a unique rank in the range of 0, 1, 2, …, p, where p is number of processors
• If processor 0send float x to processor 1 MPI_Send(&x, 1, MPI_FLOAT, 1, 0, MPI_COMM_WORLD);
• Processor 1 calls MPI_Recv to receive the message MPI_Recv(&x, 1, MPI_FLOAT, 0, 0, MPI_COMM_WORLD, &status);
• To properly receive the message, it needs to match the tag and communicator augments, and the memory available to for receiving the message specified by buffer, count, and datatype
• Status parameter returns information on such thing as actual size of the received message

Message Passing
• To decide who will send and receive if (my_processor_rank==0)
MPI_Send(…);
else if (my_procesor_rank==1)
MPI_Recv(…);
• This approach to programming MIMD system is called single-program, multiple-data (SPMD)
• In SPMD programs, use conditional branches to run different programs, the common approach to program MIMD systems

Buffering
• 0 sends a “request to send” to1 and wait until it receives “ready to receive” message, then begin to transmit
• Alternatively, the system software can buffer the message
• The contents of the message can be copied and 0 can continue executing. When 1 is ready to receive, the system simply copies the buffered message into the appropriate memory controlled by 1
• The first is synchronous communication, and the second is buffered communication

Buffering
• The clear advantage of buffered communication is that the sending process can continue to do useful work if the receiving process isn’t ready
• Disadvantages are that it uses up system resources that otherwise wouldn’t be needed
• If the receiving process is ready, the buffered communication take longer because of copying
• Most systems provide some buffering. Some attempt to buffer all messages, others buffer only small messages,
• Others allows users to decide whether to buffer messages and how much space should be set

Buffering
• Some buffer messages on sending nodes, some on receiving nodes• In a buffered communication, if process 0 executes a send, but process 1
doesn’t execute a receive. We shouldn’t cause the program to crash. The message will simply sit in the buffer until the program ends
• In a synchronous communication, process 0 will probably hang, will wait forever
• In SIMD system, process 0 doesn’t incur overhead since it knows process 1 is ready to receive

Blocking and Nonblocking Communication
• Process 1 executes receive, but process 0 doesn’t execute send until some late time, the function MPI_Recv is blocking
• In synchronous communication, process 0 will send once it has the permission to send; however, process 0 is not necessary to wait to send
• Most systems provide an alternative, nonblocking receive operation. In MPI, its called MPI_Irecv. The process returns immediately from the call
• It has one more parameter: a request
• It will return to perform other work and check back later to see if the message had arrived

Blocking and Nonblocking Communication
• The use of nonblocking communication can be used to provide dramatic improvements in the performance of message passing program
• If a node of parallel system has the ability to simultaneously compute and communicate, the overhead due to communication can be substantially reduced

Data-Parallel Languages
• One of the simplest approaches to programming parallel systems is called data parallelism• A data structure is distributed among processors, and individual processors executes the
same instructions on their parts of the data• Extremely suited to SIMD systems, also quite common to MIMD systems• HPF is a set of extensions to Fortran to make it easy to write highly efficient data parallel
programs

Data-Parallel Languages
• An example
• Specify a collection of 10 abstract processors
• ALIGN specifies that y should be mapped to the processors in the say way that x is
• Second ALIGN has a similar effect on z
• DISTRIBUTE specifies which elements of x will be mapped to which abstract processors

Data-Parallel Lauguages
• BLOCK specifies that x will be mapped by blocks onto the processors
• Once the arrays are distributed and initialized, we can simply add the corresponding entries on the processors
• HPF does not provide a mechanism for specifying the mapping of abstract processors to physical processors
• It is done at execution time• Explicitly aligning the arrays in the HPF directives will
probably results in a more efficient executable program• The mapping from data to processors is difficult unless
the structure is static and regular

Data-Parallel Lauguages
• Data parallel is used in somewhat different way in other contexts
• Can be methodology for designing a parallel program
• Usually contrasted with control-parallel programming, in which parallelism is obtained by partitioning the control or instructions rather than data
• Most programs use both

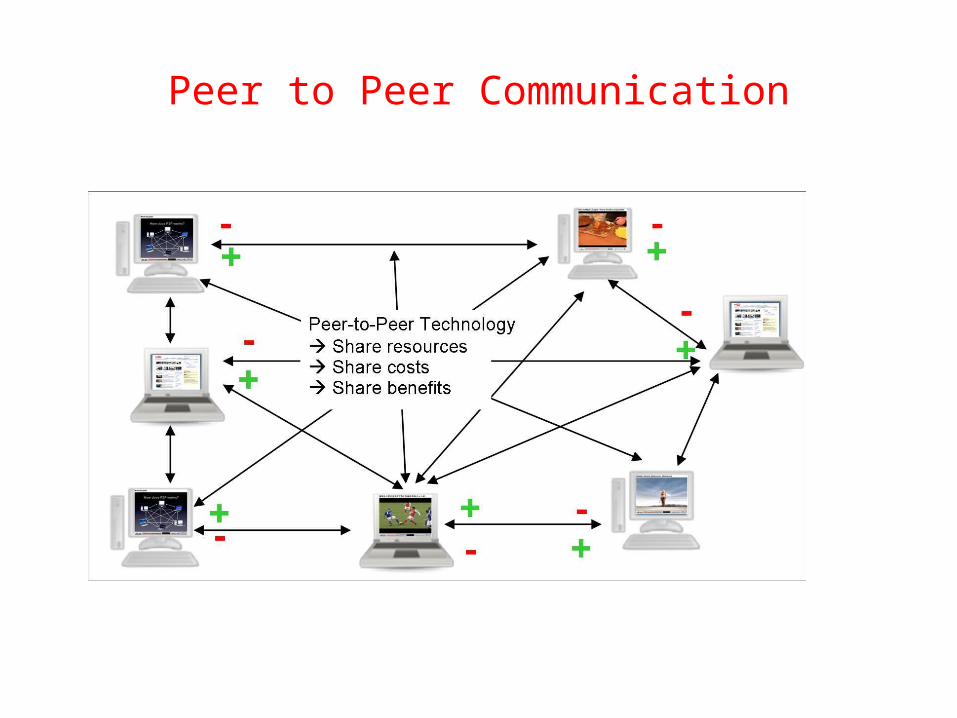
Peer to Peer Communication
Peer-to-peer (P2P) computing or networking is a distributed application architecture that partitions tasks or work loads between peers. Peers are equally privileged, equipotent participants in the application. They are said to form a peer-to-peer network of nodes.
• High degree of decentralization• Self-organization• Multiple administrative domains
Peer to Peer Communication

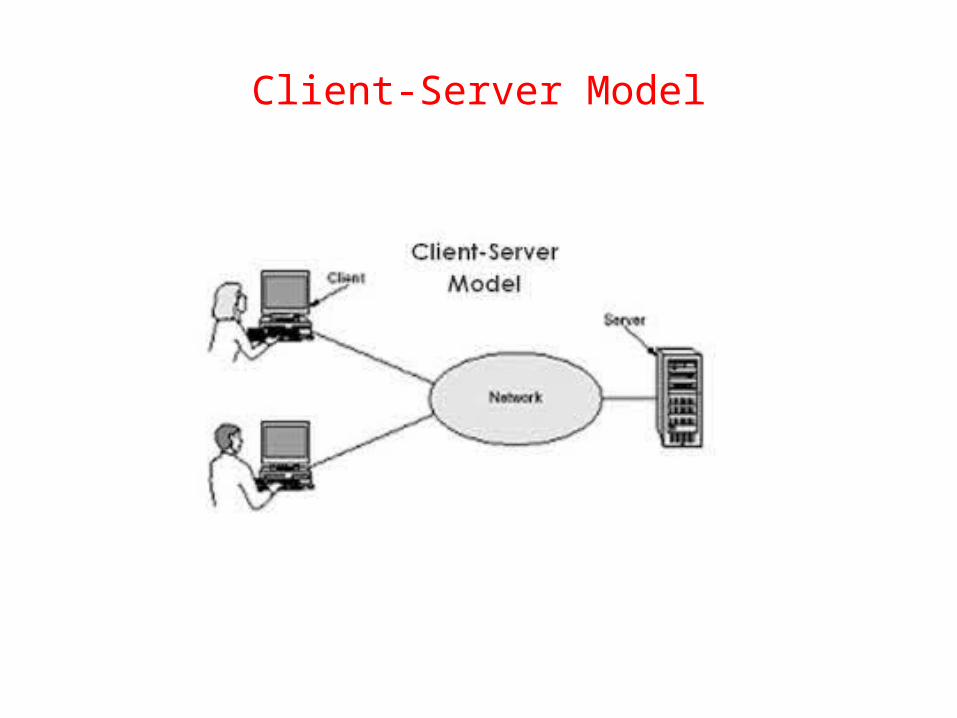
Client-Server Model
• The client–server model: a distributed application structure that partitions tasks or workloads between the providers of a resource or service, called servers, and service requesters, called clients.
• Often clients and servers communicate over a computer network on separate hardware, but both client and server may reside in the same system.
• A server host runs one or more server programs which share their resources with clients.
• A client does not share any of its resources, but requests a server's content or service function. Clients therefore initiate communication sessions with servers which await incoming requests.
Examples:• Email• network printing• World Wide Web.

RPC and Active Messages
• Other approaches for programming distributed-memory systems are RPC (Remote Procedure Call) and active messages
• Their assumption is that the communication among processes should be more general than the simple transmission of data
• They provide constructs for processes to execute subprograms on remote processors
• RPC is essentially synchronous
• In order to call a remote procedure, the client process calls a stub procedure that sends an argument list to the server process.
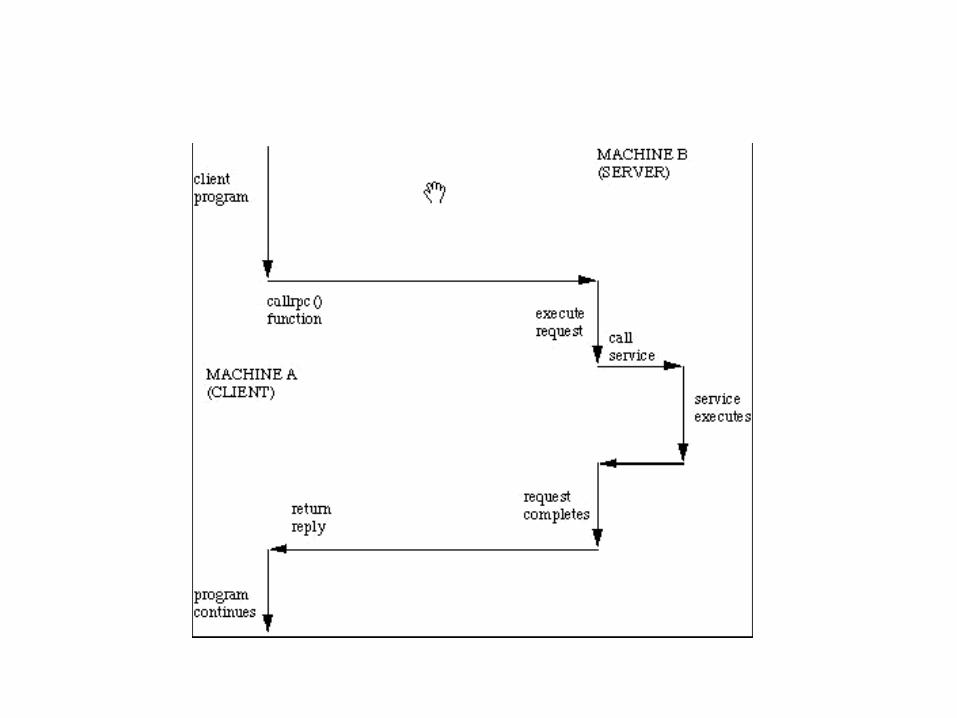
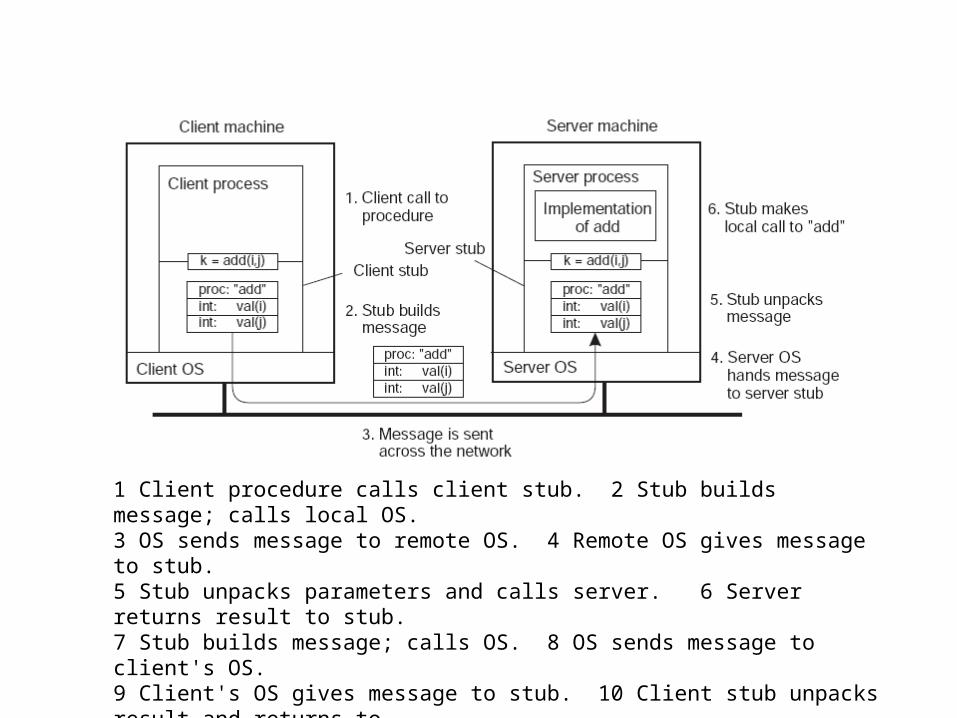
1 Client procedure calls client stub. 2 Stub builds message; calls local OS. 3 OS sends message to remote OS. 4 Remote OS gives message to stub. 5 Stub unpacks parameters and calls server. 6 Server returns result to stub. 7 Stub builds message; calls OS. 8 OS sends message to client's OS. 9 Client's OS gives message to stub. 10 Client stub unpacks result and returns to
the client

RPC and Active Messages
• The argument list is used by the server process in a call to the actual procedure• After completing the procedure, the arguments are returned to the client process• The client is idle when waiting for the results to be returned• Originally developed for use in distributed systems• Processors are run on different computers• Computers can execute other jobs when waiting. For processors, it will result in
inefficiency

RPC and Active Messages
• Active messages remedy this problem by eliminating the synchronous behavior of the process interaction
• The message sent by the source process contains, in this header, the address of a handler residing on the receiving process’s processor
• When the message arrives the receiving process is notified via an interrupt and it runs the handler
• The arguments of the handler are the contents of the message
• no synchronicity: the process deposits its message in the network and proceeds with its computations, whenever the message arrives, the receiving process interrupted

RPC and Active Messages
• The handler invoked, and the receiving process continues its work
• Active messages provide features of both RPC and nonblocking message passing

Data Mapping
• Data locality is a critical issue in the programming of both distributed-memory systems and nonuniform memory access (NUMA) shared-memory systems
• Communication is much more expensive than computation• It is a commonplace that instructions that access memory are much slower than
operations that only involve the CPU• This difference in cost is even more dramatic if the memory is remote

Data Mapping
• Load balancing is to assign the same amount of work to each processor, or else will be wasting our computation resources
• Any mapping must take into consideration both load balance and data locality
Example: Map a linear array to a collection of nodes in a distributed-memory system. Suppose the array is A=(a0, a1, …an-1), the processors as a linear array: P=(q0, q1, …qp-1). Assume that the amount of computation associated with each array element is about the same

Data Mapping
• If the number of processors p is equal to the number of array elements n
ai→qi
• If p evenly divides n, a block mapping partitions the array into blocks of consecutive entries, for example,
• The other “obvious” mapping is a cyclic mapping. It assigns the first element to the first processor, the second element to the second, and so on.

Data Mapping
• Block-cyclic mapping. It partitions the array into blocks of consecutive elements. The blocks are not necessarily of size n/p.
• The blocks are then mapped to the processors in the way that elements are mapped in the cyclic mapping
• Block size of 2
• Real possibilities: p don’t‘ evenly divide n; high-dimensional arrays or trees or general graphs, the problems will be more complex

Speedup Factor

Maximum Speedup
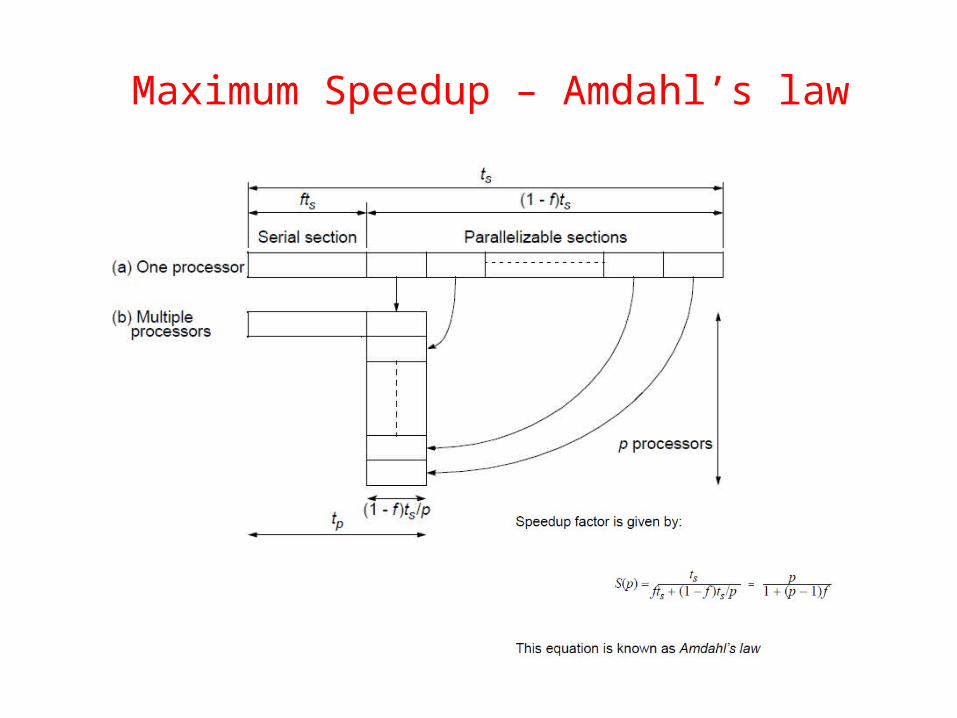
Maximum Speedup – Amdahl’s law