Embed Size (px)
Citation preview

An Unsupervised Connectionist Model of Rule Emergence in
Category Learning
Rosemary Cowell & Robert FrenchLEAD-CNRS, Dijon, France
EC FP6 NEST Grant. 516542

Rule
No. of features attended to
“Eureka moment”
2
20
F
dt
“No Eureka moment”

Goal: To develop an unsupervised learning system from which simple rules emerge.
• Young infants do not receive “rule instruction” for category learning.
• Animals have even less rule instruction than human infants.
• We are not claiming that ALL rule learning occurs in this manner, but rather that some, especially for young infants, does.

w11
w12
w31
w21 w22
w32w13
w23w33
Kohonen Network
Category A Category B Category C
(w11, w21, w31) ?Is (f1, f2, f3) closest to
f1 f2f3New Object

w11
w12
w31
w21 w22
w32w13
w23w33
Kohonen Network
Category A Category B Category C
f1 f2f3New Object
(f1, f2, f3) is closest to (w11, w21, w31) or
(w12, w22, w32) ?

w11
w12
w31
w21 w22
w32w13
w23w33
Kohonen Network
Category A Category B Category C
f1 f2f3New Object
Is (f1, f2, f3) closest to (w11, w21, w31) or
(w12, w22, w32) or
(w13, w23, w33) ?

w11
w12
w31
w21 w22
w32w13
w23w33
Kohonen Network
Category A Category B Category C
f1 f2f3New Object
Is (f1, f2, f3) closest to (w11, w21, w31) or
(w12, w22, w32) or
(w13, w23, w33) ?If this is the winner, we modify (w13, w23, w33) to be a little closer to (f1, f2, f3) than before.

No. of calories consumed per day
Life expectancy
Weight vectors
(w11, w21, w31)
(w12, w22, w32)
(w13, w23, w33)
No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancy

No. of calories consumed per day
Life expectancyThe new weight
vectorsare now the centroids
of each category.

Let’s see how we could extract rules from this kind of system.

A first idea
Kohonen Network
Competitive learning network
A copy of the Kohonen network watches….
…the weights of the original Kohonen network.
w11
w12
w13
w21 w22
w32w13
w23w33
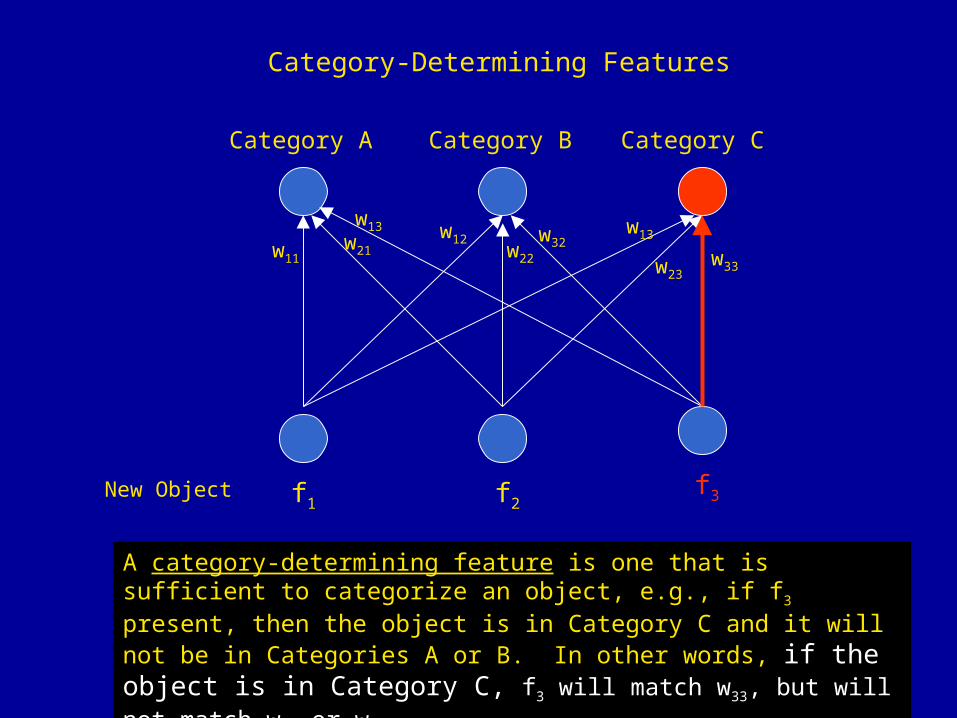
Category-Determining Features
Category A Category B Category C
f1 f2f3New Object
A category-determining feature is one that is sufficient to categorize an object, e.g., if f3 present, then the object is in Category C and it will not be
in Categories A or B. In other words, if the object is in Category C, f3 will match w33, but will not match w31 or w32.

w11
w12
w13
w21 w22
w32w13
w23w33
Category-Irrelevant Features
Category A Category B Category C
f1 f2f3New Object
A category-irrelevant feature is one that is not sufficient to categorize an object because it is shared by objects in two or more categories. e.g., if f3 present, then the object may in Category A or C. In other words, f3 matches both w31 and w33.

A concrete example:A Cat-Bird-Bat categorizer
BirdCat Bat
eyes wings beakInput stimulus
Category Nodes

BirdCat Bat
eyes wings beak
A category-determining feature is one that is sufficient to categorize an object, e.g., if ‘beak’, then ‘bird’ and not ‘bat’ or ‘cat’.
Input stimulus
Category Nodes

BirdCat Bat
eyes wings beak
A category-irrelevant feature is one that is not sufficient to categorize an object because it is shared by two or more categories, e.g., if ‘wings’, then ‘bird’ or ‘bat’.
Input stimulus
Category Nodes

BirdCat Bat
beak
BirdCat Bat
wings
BirdCat Bat
eyes
How do we isolate the category-determining features from category-irrelevant features?

One answer: competition between the weights in a separate network – the Rule Network -- that is a copy of the Kohonen network.

The Rule Network
The Rule Network is a separate competitive network with a weight configuration that matches that of the Kohonen network. It “watches” the Kohonen Network to find rule-determining features. How?

BirdCat Bat
beak
BirdCat Bat
wings
BirdCat Bat
eyes
We consider the weights coming from each feature are in competition.

BirdCat Bat
beak
BirdCat Bat
wings
BirdCat Bat
eyes
The results of the competition.
These weights in the Rule Network have been pushed down by mutual competition
This weight in the Rule Network has won the competition and is now much stronger

BirdCat Bat
beak
BirdCat Bat
wings
BirdCat Bat
eyes
The network has found a category-determining feature for birds

Yes, but in a biologically plausible model, what could it possibly mean for “synaptic
weights to be in competition” ?

We will implement a mechanism that is equivalent to weight-competition
using noise.

Revised architecture of the model, without weight
competition
Kohonen Network
Extension layers
… are echoed in the extension layers.
The activations in the primary part of the network …
Forms category representations on the basis of perceptual similarity
Extracts rules, by discovering which of the stimuli’s features are sufficient to determine category membership.

The neurobiologically plausible Kohonen Network

w11
w12
w31
w21 w22
w32w13
w23w33
Kohonen Network: a spreading activation, biologically plausible
implementation
(f1.w11 + f2.w21 + f3.w31) Is Cat A node most active ?
f1 f2f3Input stimulus
Output Nodes
Category A Category B Category C

w11
w12
w31
w21 w22
w32w13
w23w33
Kohonen Network
(f1.w11 + f2.w21 + f3.w31) Is Cat A node most active ?
f1 f2f3Input stimulus
Output Nodes
Category A Category B Category C
(f1.w12 + f2.w22 + f3.w32) Or, is Cat B node most active ?

w11
w12
w31
w21 w22
w32w13
w23w33
Kohonen Network
(f1.w11 + f2.w21 + f3.w31) Is Cat A node most active ?
f1 f2f3Input stimulus
Output Nodes
Category A Category B Category C
(f1.w12 + f2.w22 + f3.w32) Or, is Cat B node most active ?
(f1.w13 + f2.w23 + f3.w33) Or, is Cat C node most active ?

w11
w12w21 w22
w32w13
w23w33
f1 f2f3
If
w31
Kohonen Network
(f1.w12 + f2.w22 + f3.w32) is the largest, Cat B node is the winner.
Category A Category B Category C
Input stimulus
Output Nodes

f1 f2 f3
… …
• Winner activates itself highly• … activates its near neighbours a little• … inhibits distant nodes• Learning is Hebbian depends on activation of sending
and receiving nodes.• Next time a similar stimulus is presented, same output
node wins.

Category A

Category B

Now, let’s focus on the features

The Rule Units are a separate layer of nodes whose activation echoes that in the Kohonen network. The Rule Units learn to map input stimuli onto category representations using only rule-determining features. How?

features
categories

features
categories

features
categories

features
categories

Training Protocol
1. Present Stimulus to Input Layer2. Pass activation through the various layers3. Perform Hebbian Update
4. Pass ‘Noise Burst’ through a single input unit, chosen randomly
5. Pass activation through the various layers6. Perform Hebbian Update
Repeat for
~200 training
items

A category-determining feature:
A noise burst is applied to an input unit at random
features
categories

A category-determining feature:
features
categories
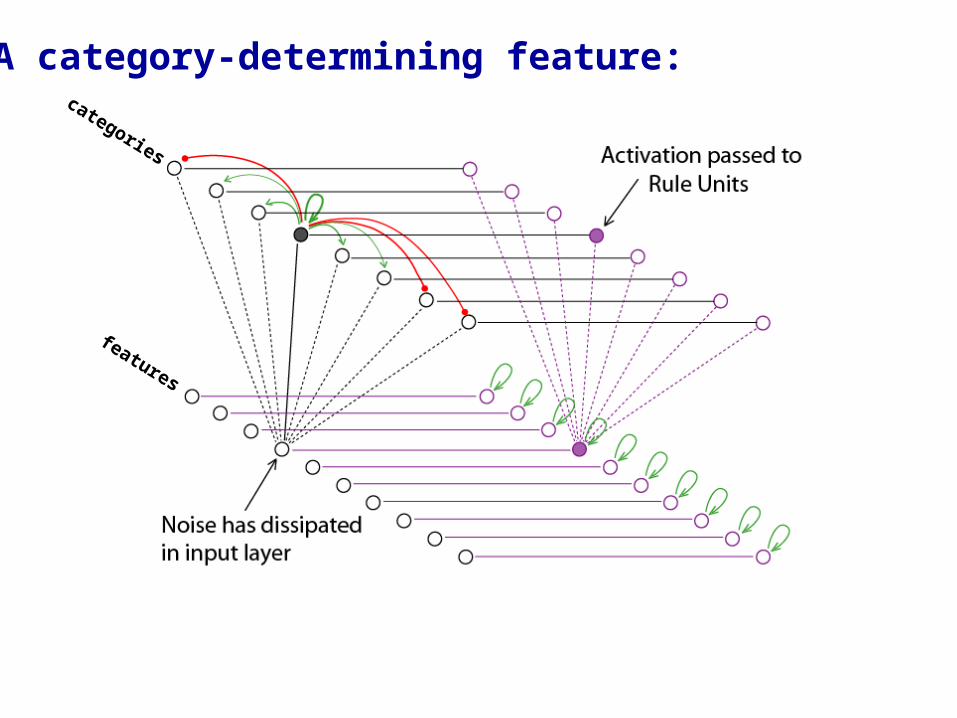
A category-determining feature:
features
categories

A category-determining feature:
features
categories
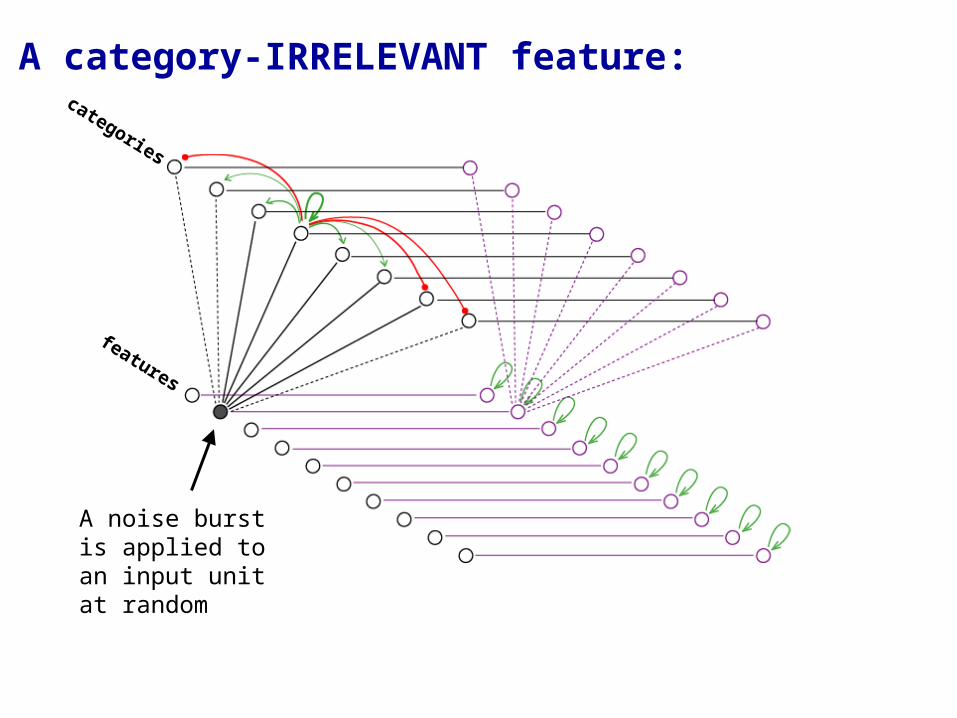
A category-IRRELEVANT feature:
A noise burst is applied to an input unit at random
features
categories

A category-IRRELEVANT feature:
features
categories

A category-IRRELEVANT feature:
features
categories
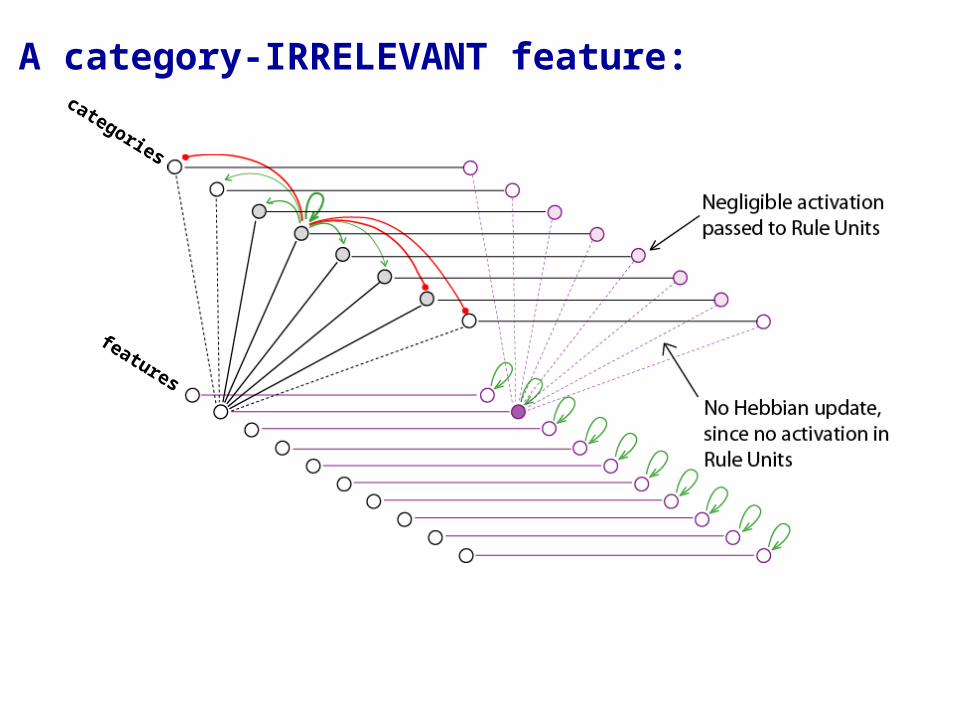
A category-IRRELEVANT feature:
features
categories

Category A
1 2 3 4 5 6 7 8 9 10
Category B
1 2 3 4 5 6 7 8 9 10
Category C
1 2 3 4 5 6 7 8 9 10
Training Stimuli


Model Weights After Training
Cat A
Cat B
Cat C
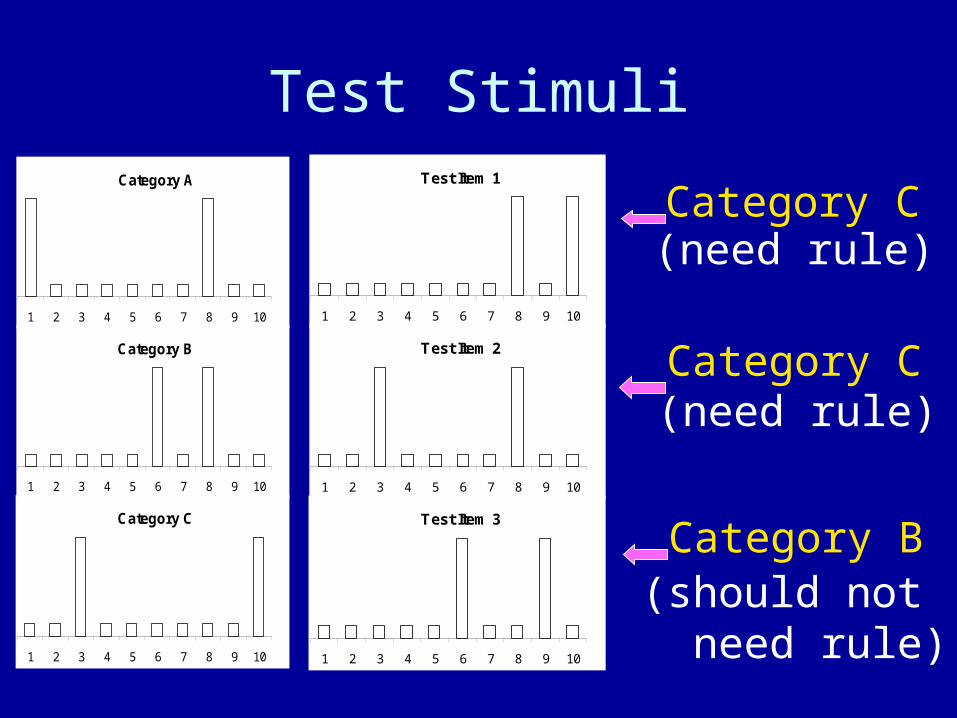
Test StimuliTest Item 1
1 2 3 4 5 6 7 8 9 10
Test Item 2
1 2 3 4 5 6 7 8 9 10
Test Item 3
1 2 3 4 5 6 7 8 9 10
Category C(need rule)
Category C(need rule)
Category B(should not need rule)
Category A
1 2 3 4 5 6 7 8 9 10
Category B
1 2 3 4 5 6 7 8 9 10
Category C
1 2 3 4 5 6 7 8 9 10

Simulation ResultsTesting with Distorted Category Exemplars
0
10
20
30
40
50
60
70
80
90
100
Test 1 Test 2 Test 3
Per
cen
t C
orr
ect
Kohonen Only
Kohonen + Rule

Why did the Rule+Statistical network do better than the Kohonen Network alone?
• Statistical-learning networkCategorises according to any features consistently present in stimuli.
• Rule-learning networkCategorises according to only diagnostic features present in stimuli.

Reaction Times: This network can be successfully produce RT data. When there is a conflict between the Rule Network answer and the Statistical Network answer, the will still get the right answer, but it will take longer than in the case where the Rule Network and the Statistical Network are in agreement.
Supervised Learning: By (occasionally) artificially activating category nodes, we can significantly speed up category learning. So, we can address the Poverty of the Stimulus problem.
Modeling Reaction Times and Supervised Learning

Conclusions
• We have developed an unsupervised network (that can also be used to do supervised learning) that extracts the rule from knowledge about statistics of perceptual features
• Successfully integrates conceptual and perceptual mechanisms of categorization.
• Biologically plausible (two components potentially map onto areas in the brain)





























