Embed Size (px)
DESCRIPTION
cours analyse numérique
Citation preview

Introduction
Analyse NumeriqueSANS AU CU N E DIFFICULTE
Sidi [email protected]
Version duDerniere mise a jour sur :
http://sites.google.com/site/sidimadjid/Home


Sommaire
1 Notion d’erreur 31.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 Chiffres significatifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.4 Notion de chiffres exactes . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Approximation aux Moindres Carres 72.1 Position du probleme d’approximation . . . . . . . . . . . . . . . . . . 72.2 Minimum d’une fonction reelle a plusieurs variables . . . . . . . . . . 82.3 Approximation dans le cas discret . . . . . . . . . . . . . . . . . . . . . 92.4 A.M.C. : Cas continu . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Interpolation 173.1 Position du probleme d’interpolation . . . . . . . . . . . . . . . . . . . 173.2 Premier polynome d’interpolation de Newton . . . . . . . . . . . . . . 173.3 Deuxieme polynome d’interpolation de Newton . . . . . . . . . . . . . 213.4 Polynome d’interpolation de LAGRANGE . . . . . . . . . . . . . . . 213.5 Estimation de l’erreur . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4 Integration Numerique 274.1 Les Principes Generaux . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.2 Les methodes de Newton-Cotes . . . . . . . . . . . . . . . . . . . . . . 284.3 Methode de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5 Systemes Lineaires 355.1 Les methodes directes : . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.2 Algorithme d’elimination de Gauss . . . . . . . . . . . . . . . . . . . . 365.3 Programme d’elimination de Gauss, sans pivot . . . . . . . . . . . . . 375.4 Methode de Gauss-Jordan : . . . . . . . . . . . . . . . . . . . . . . . . . 39
3


Introduction
UNE des preoccupations majeures d’un chercheur en face d’un phenomene phy-sique, est : comment mettre en equation ce phenomene tout en prenant en conside-ration tous les details qui l’accompagnent. Une fois cette etape effectuee, vient alorsla preoccupation suivante qui est : comment resoudre ces equations et obtenir unresultat, qui va servir a concretiser son travail de recherche.
Supposant maintenant que les equations sont posees, dans certains cas leurssolutions peuvent se calculer analytiquement, alors que dans d’autres cas ceci estimpossible. Alors, la solution sera effectuee en utilisant une methode numerique.Ces dernieres sont des methodes approximatives de resolution des problemes ma-thematiques. Ce qui signifie qu’elles ne donnent pas la solution exacte mais unesolution approchee. Ces methodes sont en general a caractere iteratif. En plus, lenombre d’iteration a effectuer est d’autant plus grand que la precision rechercheeest grande. Ainsi, La resolution d’un probleme de grande taille manuellement prendbeaucoup de temps a cause du nombre d’operations a effectuer.
L’avenement de l’informatique a eu un effet positif sur les utilisateurs des me-thodes numeriques. En effet, l’ordinateur a reduit considerablement les temps decalculs et a augmenter la precision des resultats obtenus. De nos jours, la mise enoeuvre des methodes de calculs numeriques sous-entend automatiquement l’utilisa-tion d’outils informatiques et particulierement un langage de programmation.
Le module analyse numerique a pour but en premier lieu d’exposer les methodesnumeriques de fac on claire, et en second lieu de montrer comment les traduire sousforme de programmes informatiques prets a l’utilisation.
1


Sommaire
1.1 Introduction1.2 Définitions1.3 Chiffres significatifs1.4 Notion de chiffres exactes
Chapitre
1Notion d’erreur
1.1 Introduction
Traditionnellement, les mathematiques nous familiarisent avec des theories etdes methodes qui permettent de resoudre de facon analytique un certain nombre deproblemes, comme c’est le cas notamment des techniques d’integration et de resolu-tion d’equations. Les differentes methodes, pour un probleme donne, permettent detrouver le resultat exact. En analyse numerique, les resultats obtenus sont differentscar les methodes utilisees dependent de certains parametres qui influent sur la pre-cision du resultat.Une partie importante de l’analyse numerique consiste donc a contenir les effets deserreurs ainsi introduites, qui proviennent de trois sources principales :
1. Les erreurs de modelisation : Les erreurs de modelisation proviennent de l’etapede mathematisation du phenomene physique auquel on s’interesse. Si le pheno-mene observe est tres complexe, il faut negliger ses composantes qui paraissentmoins importantes. Ces erreurs peuvent aussi se produire a cause d’imperfec-tion dans les mesures physiques.
2. Les erreurs d’arrondissement (ou de representation sur ordinateur) : La se-conde categorie d’erreurs est liee a l’utilisation de l’ordinateur. En effet, larepresentation sur ordinateur (sur un nombre fini de bits) des nombres intro-
duit souvent des erreurs. Par exemple, la fraction13
n’a pas de representation
binaire exacte, car elle ne possede pas de representation decimale finie.
3. Les erreurs de troncature : Les erreurs de troncature proviennent des methodesnumeriques elle-meme qui utilisent parfois des approximations des problemesposes par d’autres problemes plus simples.
Tout d’abord, un peu de terminologie est necessaire pour eventuellement quantifierles erreurs.
3

1
4 Notion d’erreur
1.2 Définitions
Definition 1
Soit x un nombre et x∗ une approximation de ce nombre. L’erreur absolue estdefinie par :
∆x = |x− x∗| (1.2.1)
Definition 2
Soit x un nombre et x∗ une approximation de ce nombre. L’erreur relative estdefinie par :
Er(x)= |x− x∗||x| = ∆x
|x| (1.2.2)
En pratique, il est difficile d’evaluer les erreurs absolue et relative, car on ne connaıtgeneralement pas la valeur exacte de x et on n’a que x∗. Dans le cas de quanti-tes mesurees dont on ne connaıt que la valeur approximative, il est impossible decalculer l’erreur absolue ; on dispose en revanche d’une borne superieure pour cetteerreur qui depend de la precision des instruments de mesure utilises. Cette borne estquand meme appelee erreur absolue, alors qu’en fait on a :|x−x∗|6∆x. Ce qui peutegalement s’ecrire : x = x∗±∆x. L’erreur absolue donne une mesure quantitative del’erreur commise alors que l’erreur relative en mesure l’importance.Cela nous amene a parler de precision et de chiffres significatifs au sens de la defini-tion suivante.
1.3 Chiffres significatifs
Definition 3
Si l’erreur absolue verifie : ∆x6 0,5.10n alors le chiffre correspondant a la nieme
puissance de 10 est dit significatif et tous ceux a sa gauche (correspondants auxpuissances de 10 superieures a n ) le sont aussi.
Exemple 1
On obtient une approximation de π (x = π= 3,141592...) au moyen de la quan-
tite :227
(x∗ = 227
= 3,142857...). On en conclut que :
∆x = |π− 227| = 0,001265...
Puisque l’erreur absolue est plus petite que : 0,5∗10−2 le chiffre des centiemesest significatif et on a en tout 3 chiffres significatifs (3,14).

1.4 Notion de chiffres exactes 5
1
Remarque 1
Inversement, si un nombre est donne avec n chiffres significatifs, cela signifieque l’erreur absolue est inferieure a 0,5 fois la puissance de 10 correspondantau dernier chiffre significatif.
1.4 Notion de chiffres exactes
Soit A un nombre theorique c’est a dire exact, a un nombre approche de A,dont la representation decimale prise de gauche a droite est:
a =αm10m +αm−110m−1 +·· ·+αm−n+110m−n+1 +αm−n10m−n +·· ·+αk10k
Ou :αm : premier chiffre significatif 10m : rang du premier chiffre significatifαm−1 : deuxieme chiffre significatif 10m−1 : rang du deuxieme chiffre significatif· · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · · ·αm−n+1 : nieme chiffre significatif 10m−n+1 : rang du nieme chiffre significatif
Notons ∆a = |A−a| l’erreur absolue du nombre approche a.
Definition 4
Les n premiers chiffres significatifs de a sont dits exacts si l’erreur absolue dea ne depasse pas la moitie du rang du nieme chiffre significatif, c’est a dire :
∆a = |A−a|6 12
10m−n+1
Exemple 2
A = 35.97, a = 36.00 ici m = 1 car a = 3.101 +6.100
∆a = |A−a| = 0.03< 0.05= 12
10−1 ⇒ m−n+1=−1⇒ n = 3a est une approximation de A avec 3 chiffres exacts.
La notion de chiffre exact est purement mathématiques, elle ne veut pas dire que lesn premiers chiffres significatifs de a coïncident avec n premiers chiffres significatifs
de A, l’exemple ci - dessus l’illustre bien.


Sommaire
2.1 Position du problème d’approximation2.2 Minimum d’une fonction réelle à plusieurs
variables2.3 Approximation dans le cas discret2.4 A.M.C. : Cas continu
Chapitre
2Approximation aux Moindres Carrés
2.1 Position du problème d’approximation
Soit X = {xi/i = 1..N} ⊂ [a,b] ⊂ R les xi peuvent etre par exemple des mesuresexperimentales, supposons qu’a chaque xi, on associe yi ∈ R comme resultat d’uneexperience et posons Y = {yi/i = 1..n}. On a donc le tableau suivant :
mesure i 1 2 · · · n
X x1 x2 · · · xn
Y y1 y2 · · · yn
En pratique, pour x ∈ [a,b]\X , on ne peut pas toujours connaitre la valeur y cor-respondante.
Probleme 1
Notre but est de modeliser la relation existante entre X et Y , ou encore detrouver f telle que Y = f (X ). Ceci nous permettra - sous certaines conditionssur f - de connaitre y pour tout x ∈ [a,b]\X (et dans certains cas x ∉ [a,b]).
Posons : {D = {(xi, yi) / i = 1..n}G = {(xi, f (xi)) / i = 1..n}
Supposons qu’on peut definir une distance entre D et G, notee d(D,G). Alors :
Definition 1
X Le probleme d’approximation consiste a trouver f d’un type choisi pourque d(D,G) soit minimale.
X Le probleme d’interpolation consiste a trouver f d’un type choisi telle queD ≡G.
7

2
8 Approximation aux Moindres Carrés
Remarque 1
On peut aussi approximer∫ b
a h(x)dx ou h′(x), x ∈ [a,b] ou tout autre operateurmathematique.
2.2 Rappel : Minimum d’une fonction dans Rn
Soit une fonction reelle a plusieurs variables reelles :
f : Rn →R
x = (x1, x2, . . . , xn) 7→ y= f (x) (2.2.1)
Ou n> 1 et f ∈C 2(Rn).
Gradient d’une fonctionOn rappelle que, si f est une fonction a plusieurs variables x = (x1, . . . , xn), legradient de f est le vecteur colonne
−−−→grad f (x)=−→∇ f (x)=
(∂ f∂x1
(x),∂ f∂x2
(x), · · · ,∂ f∂xn
(x))t
Matrice definie positiveSoit A une matrice symetrique reelle d’ordre n. Elle est dite definie positive si
∀x 6= 0Rn : (< Ax, x >)= xt Ax > 0
Ou bien, si toutes les valeurs propres de A sont strictement positives.
Definition 2
On dit qu’un point x∗ ∈ Rn est un minimum global de f si les deux conditionssuivantes sont verifiees :
1.−−−→grad f (x∗)= 0Rn
2. La matrice A = (ai j)16i, j6n, ou : ai j = ∂2 f∂xi∂x j
(x∗) est definie positive.
Cas particulierLe cas n = 1 est trivial, c’est a dire si f : R→ R, le gradient devient deriveepremiere et la matrice derivee seconde.

2.3 Approximation dans le cas discret 9
2
Proposition 1. Matrice definie positive
Si A est symetrique a diagonale positive alors A est definie positive.
2.3 Approximation dans le cas discret
Revenons aux ensembles D et G definis precedemment{D = {(xi, yi) / i = 1..n}G = {(xi, f (xi)) / i = 1..n}
Ou, le modele propose f : R 7→ R est d’un type prealablement choisi. Exemple demodeles :
f (t) = c (constante)f (t) = at+bf (t) = at2 +bt+ c· · · · · · · · · · · ·f (t) =
m∑i=0
ai ti
· · · · · · · · · · · ·Trouver le modele f revient a chercher les coefficients ai, i = 0, ..,n.
Notons par e i = yi − f (xi), i = 1, ..,n, l’erreur commise au point i (ou mesure i), onpose e = (e i)i=1..n ∈Rn.
Si f est un modèle parfait, alors e i = 0, ∀i = 1..n.
Definition 3
L’approximation (ou ajustement )aux moindres carres consiste a minimiser
‖e‖2 ”norme euclidienne”. C’est a dire : min(
n∑i=1
e2i
)ou le minimum est pris sur
les parametres de f ,
2.3.1 Étude d’un modèle simple : linéaire à 2 paramètres
Soit une fonction f definie par
f : R→R
t 7→ at+b
Et, l’ensemble D = {(xi, yi) ∈R2/i ∈ [1,n]}.L’approximation aux moindres carres revient a minimiser l’erreur d’approximationcomme suit :
min(a,b)∈R2
‖e‖22 = min
(a,b)∈R2
n∑i=1
[yi − (axi +b)]2
= min(a,b)∈R2
F(a,b)

2
10 Approximation aux Moindres Carrés
Avec F(a,b)=n∑
i=1[yi − (axi +b)]2 , F ∈C 2 (
R2)La premiere condition d’existence d’un minimum, nous donne le systeme :
∂F(a,b)∂a
= 0∂F(a,b)∂b
= 0⇒
n∑
i=1xi yi = a
n∑i=1
x2i +b
n∑i=1
xi
n∑i=1
yi = an∑
i=1xi +b
n∑i=1
1(2.3.1)
Verification de la deuxieme condition d’existence d’un minimum :La matrice
A =
n∑
i=1x2
i
n∑i=1
xi
n∑i=1
xi n
est symetrique a diagonale positive donc elle est definie positive.Le couple (a,b) cherche est deduit du systeme de deux equations a deux inconnues(2.3.1).
Exemple 1
Ajuster aux moindres carres les points
xi 0 1 2
yi 0 1 4
par le modele lineaire (droite) f (x)= ax+b
Solution
Sachant que :n∑
i=1xi yi = 9,
n∑i=1
x2i = 5,
n∑i=1
xi = 3 etn∑
i=1yi = 5
On a d’apres ce qui precede, le systeme lineaire de deux equations a deux inconnues :
{5a+3b = 93a+3b = 5
=⇒ a = 2
b =−13
Donc, f (x) = 2x− 13
est la droite qui realise le meilleure approximation de l’ensemble
des 3 points donnes par le tableau (voir le figure ci-dessous).
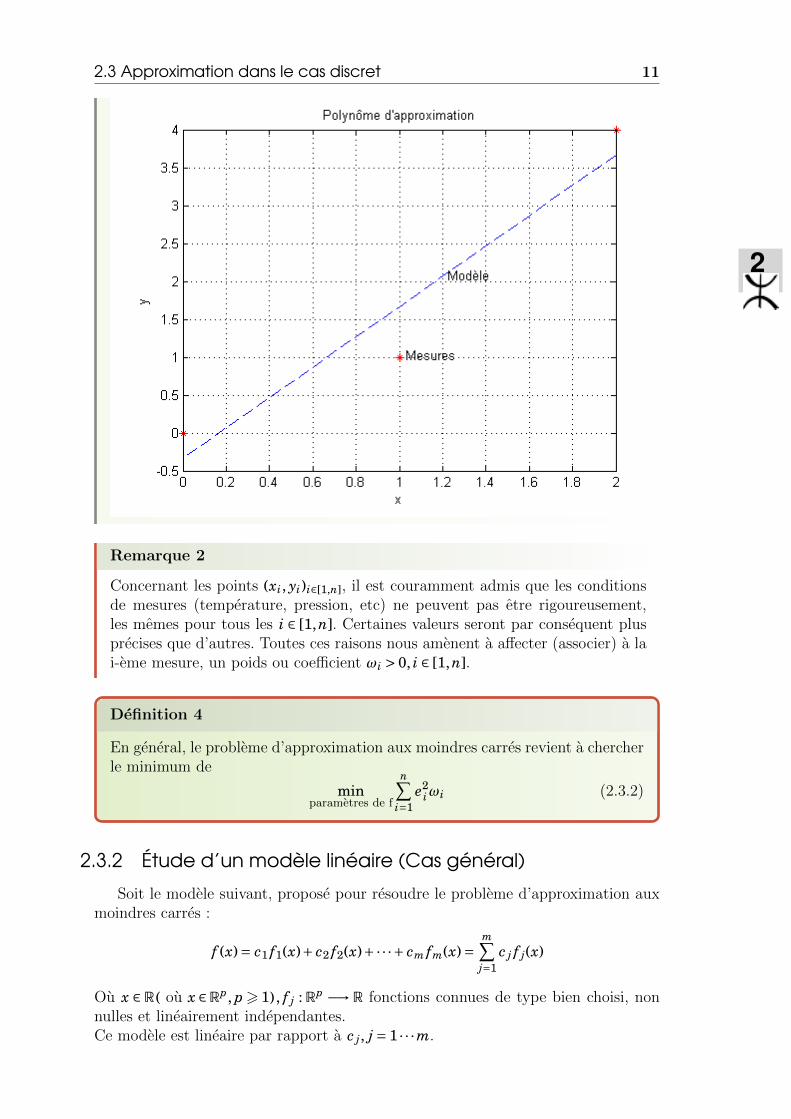
2.3 Approximation dans le cas discret 11
2
Remarque 2
Concernant les points (xi, yi)i∈[1,n], il est couramment admis que les conditionsde mesures (temperature, pression, etc) ne peuvent pas etre rigoureusement,les memes pour tous les i ∈ [1,n]. Certaines valeurs seront par consequent plusprecises que d’autres. Toutes ces raisons nous amenent a affecter (associer) a lai-eme mesure, un poids ou coefficient ωi > 0, i ∈ [1,n].
Definition 4
En general, le probleme d’approximation aux moindres carres revient a chercherle minimum de
minparametres de f
n∑i=1
e2iωi (2.3.2)
2.3.2 Étude d’un modèle linéaire (Cas général)
Soit le modele suivant, propose pour resoudre le probleme d’approximation auxmoindres carres :
f (x)= c1 f1(x)+ c2 f2(x)+·· ·+ cm fm(x)=m∑
j=1c j f j(x)
Ou x ∈ R ( ou x ∈Rp, p > 1) , f j : Rp −→ R fonctions connues de type bien choisi, nonnulles et lineairement independantes.Ce modele est lineaire par rapport a c j, j = 1 · · ·m.

2
12 Approximation aux Moindres Carrés
L’exemple numerique precedent etudie correspond a m = 2, f1(x)= x et f2(x)= 1.L’erreur commise par rapport au modele propose, a la mesure i, est
e i = yi − f (xi), i = 1..n (2.3.3)
= yi −m∑
j=1c j f j(xi), i = 1..n (2.3.4)
Definition 5
Nous definissons la meilleure approximation aux moindres carres comme etantcelle qui minimise l’erreur au sens de la norme euclidienne au-quelle on adjointle poids ωi, associe a la i-eme mesure (i = 1..n).
Probleme 2
Le probleme d’approximation aux moindres carres, revient donc a chercher leminimum de
minc=(c1,c2,...,cm)
F (c1, c2, . . . , cm)= minc=(c1,c2,...,cm)
n∑i=1
e2iωi (2.3.5)
Demonstration
La premiere condition que doit verifier c pour que F soit minimale est :
∂F∂ck
= 0, k = 1..m
c’est a dire :
∂
(n∑
i=1e2
iωi
)∂ck
= 0, k = 1..m
Donc :n∑
i=1e iωi
∂e i
∂ck= 0, k = 1..m (2.3.6)
Or :∂e i
∂ck=− fk(xi), i = 1..n, k = 1..m
L’equation 2.3.6 devient :
[n∑
i=1ωi
(yi −
m∑j=1
c j f j(xi)
)fk(xi)
]= 0
C’est a dire :m∑
j=1c j
n∑i=1
ωi f j(xi) fk(xi)=n∑
i=1ωi yi fk(xi)
Posons :
bk =n∑
i=1ωi yi fk(xi), ak j = a jk =
n∑i=1
ωi fk(xi) f j(xi) avec k = 1..n, j = 1..m

2.4 A.M.C. : Cas continu 13
2
On obtient :m∑
i= jc jak j = bk, k = 1..m
Ou, sous forme matricielle A.ct = b suivant
a11 a12 · · · a1 j · · · a1ma21 a22 · · · a2 j · · · a2m...
......
......
...ak1 ak2 · · · ak j · · · akm
......
......
......
am1 am2 · · · am j · · · amm
.
c1c2...c j...
cm
=
b1b2...
b j...
bm
(2.3.7)
Les quantites ak j = a jk sont connues car ωi, yi, f j(xi) le sont.
La matrice A est symetrique a diagonale positive car akk =[
n∑i=1
ωi f 2k (xi)
]> 0.
Donc, la matrice A est definie positive, c’est a dire que la deuxieme condition estverifiee.
ConclusionEn resume, l’approximation aux moindres carres de n points (xi, yi) par un
modele f (x) =m∑
j=1c j f j(x) se ramene a la resolution du systeme (2.3.7) lineaire
d’ordre m .
Remarque 3. Les types courants de modeles utilises
– Modele polynomial :
f (x) =m∑
j=1c j f j(x) ou f j(x)= x j−1
= c1 + c2x+·· ·+ cmxm−1
– Modele trigonometrique :
f j(x)= c j +a j cos jx+b j sin jx
– Modele exponentiel :f j(x)= a j eb j x
2.4 Cas continu :Approximation aux moindres carrés
Soit E un R-Hilbertien,M un sous espace vectoriel de E de dimension finie (com-plet, donc ferme). Soit f fixe (mais quelconque) dans E,

2
14 Approximation aux Moindres Carrés
Definition 6
La meilleure approximation aux moindres carres de f dans M - appelee aussiprojection orthogonale de f sur M - est un element g ∈ M telle que :
‖ f − g‖ =minh∈M
‖ f −h‖ ou ‖ f ‖2 =< f , f >
RappelOn rappelle que :
X ∀ f ∈ E,∃!g ∈ M telle que g est la meilleure approximation de f dans M.
X g est la meilleure approximation de f dans M ⇔< f − g,h >= 0,∀h ∈ M.
Dans tout ce qui suit, on suppose que E =C ([a,b]) muni du produit scalaire :
< f , g >=∫ b
af (x)g(x)dx
Qu’on generalise a :
< f , g >=∫ b
aω(x) f (x)g(x)dx (2.4.1)
Ou, la fonction poids ω : [a,b] → R , ω(x) > 0,∀x ∈ [a,b] a un nombre fini deracines, en pratique, on prend souvent : ω≡ 1.
2.4.1 Approximation par un modèle polynômial :
Soit M l’ensemble des polynomes reels de degre inferieur ou egal a n, c’est a diredim M = n+1, et f ∈C ([a,b])= E, (M est un convexe et ferme ).
Probleme 3
On cherche P ∈ M telle que P realise la meilleure approximation aux moindrescarres de f dans M.
Demonstration
P existe et il est unique, il verifie :
< f − P,P >= 0,∀P ∈ M
Posons,
P(x)=n∑
i=0aixi , P(x)=
n∑j=0
a jx j
Or, P est quelconque et{1, x, x2, . . . , xn}
est libre, on a alors :
< f (x)−n∑
i=0aixi, x j >= 0, ∀ j = 0,1,2, ..,n
Donc,n∑
i=0ai
∫ b
aω(x)xix jdx =
∫ b
aω(x) f (x)x jdx, ∀ j = 0,1,2, ..,n (2.4.2)
2.4 A.M.C. : Cas continu 15
2
Un systeme lineaire de (n+1) equations a (n+1) inconnues (a0,a1, . . . ,an), la solutionexiste et unique.
Exercice 1
Trouver le polynome de degre inferieur ou egal a 2 qui realise la meilleureapproximation aux moindres carres de f (x)= |x| sur [a,b]= [−1,+1] avec ω≡ 1.
Correction de l’exercice 1
En posant P(x)= a0 + a1x1 + a2x2, on trouve d’apres le systeme precedent :2a0 +0a1 +2
3 a2 = 10a0 +2
3 a1 +0a2 = 023 a0 +0a1 +2
5 a2 = 12
=⇒
a0 = 316
a1 = 0a2 = 15
16
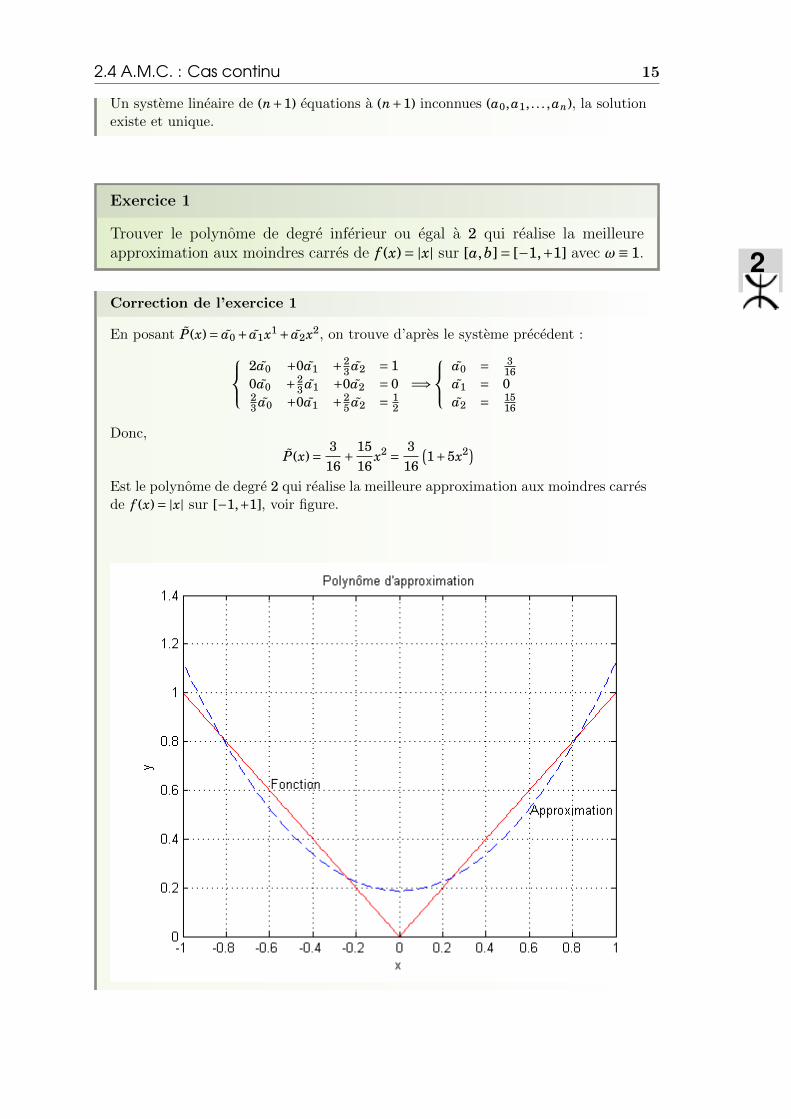
Donc,
P(x)= 316
+ 1516
x2 = 316
(1+5x2)
Est le polynome de degre 2 qui realise la meilleure approximation aux moindres carresde f (x)= |x| sur [−1,+1], voir figure.


Sommaire
3.1 Position du problème d’interpolation3.2 Premier polynôme d’interpolation de Newton3.3 Deuxième polynôme d’interpolation de Newton3.4 Polynôme d’interpolation de LAGRANGE3.5 Estimation de l’erreur
Chapitre
3Interpolation
3.1 Position du problème d’interpolation
Soit sur [a,b] un systeme de (n+1) points donnes (xi, yi), i = 0,1, ..,n tel que :a6 x0 < x1 < ·· · < xn 6 b et yi des valeurs associees a xi. Les points donnes peuventetre des mesures d’une experience ou des valeurs d’une certaine fonction inconnue fen ces points.
Probleme 1
Le but du probleme de l’interpolation consiste a chercher une fonction F (fonc-tion d’interpolation) qui appartient a une certaine classe connue et qui passepar les points Mi(xi, yi)i=0..n donnes, c’est a dire :
F(xi)= yi, i = 0..n
Ce procede nous permet d’estimer la valeur y∗ en un point x∗ 6= xi, i = 0..n, oux∗ ∈ [a,b]. Le probleme ainsi pose, peut avoir une infinite de solution ou pas desolution. Toutefois, le probleme admet une seule et unique solution si l’on cherchenon pas une fonction arbitraire mais un polynome Pn de degre inferieur ou egal an et verifiant :
P(xi)= yi, i = 0..n
Une interpolation est dite stricte si x ∈ [x0, xn], si x ∉ [x0, xn] c’est une extrapolation.
3.2 Premier polynôme d’interpolation de Newton
Soit un systeme de (n+1) points donnes (xi, yi), i = 0, ..,n..
Probleme 2
Notre but est de construire un polynome de degres inferieure ou egal a n notePn(x) qui s’ecrit sous la forme :
Pn(x)= a0+a1(x−x0)+a2(x−x0)(x−x1)+·· ·+an(x−x0)(x−x1) . . . (x−xn−1) (3.2.1)
17

3
18 Interpolation
Qui peut s’ecrire sous la forme :
Pn(x)=n∑
i=0αixi
Proposition 1
Les polynomes
1, (x− x0), (x− x0)(x− x1), . . . , (x− x0)(x− x1) . . . (x− xn−1)
sont une base de Newton associee aux points xi, i = 0..n.
Demonstration
Il existe (n+1) vecteurs et ils sont lineairement independants.
Avant de determiner les coefficients ai, i = 0..n, introduisons la notion de differencedivisee.
3.2.1 Notion de différences divisées
Definition 1
Soit un systeme de (n+1) points donnes (xi, yi), i = 0, ..,n et ∆xi = xi+1 − xi =hi 6= 0, i = 0..n. On definit les differences divisees du premier ordre par
∆[xi, x j]=yj − yi
x j − xi=∆[x j, xi] pour 06 i, j 6 n, i 6= j (3.2.2)
Et, les differences divisees du deuxieme ordre par
∆2[xi, x j, xk]= ∆[x j, xk]−∆[xi, x j]xk − xi
pour 06 i, j,k 6 n, i 6= j 6= k (3.2.3)
Par recurrence, on definit les differences divisees d’ordre superieur, a l’ordre n
∆n[x0, x1, . . . , xn]= ∆n−1[x1, x2, . . . , xn]−∆n−1[x0, x1, . . . , x(n−1)]
xn − x0(3.2.4)
Remarque 1
Les differences divisees sont symetriques, et elles sont independantes des la po-sition des points sur lesquels elles sont prises. Si σ est une permutation de{0,1,2, . . . ,k}, on a
∆k[x0, x1, . . . , xk]=∆k[xσ(0), xσ(1), . . . , xσ(n)]

3.2 Premier polynôme d’interpolation de Newton 19
3
Exemple 1
Donner la table des differences divisees des points suivants :
xi −1 0 1 2 3yi 1 0 −1 2 3
Solution
Sachant que :
∆0[xi] = yi
∆k[x0, . . . , xk] = ∆k−1[x1, . . . , xk]−∆k−1[x0, . . . , xk−1]xk − x0
, ∀k = 1,2,3,4
On etablit la table les differences divisees :
i xi yi ∆ ∆2 ∆3 ∆4
0 -1 1-1
02/3
- 5/121 0 0
-12
-12 1 −1
3-13 2 2
14 3 3
3.2.2 Coefficients du polynôme d’interpolation de Newton
Le polynome (3.2.1) defini precedemment doit verifier : Pn(xi)= yi, i = 0, ..,n.Si x = x0, on obtient Pn(x0)= a0 = y0 =∆0[x0]Si x = x1, on obtient Pn(x1)= y0 +a1(x1 − x0)= y1 ⇒ a1 = y1 − y0
x1 − x0=∆1[x0, x1]
Si x = x2, on obtient
P2(x2)=∆0[x0]+∆1[x0, x1](x2 − x0)+a2(x2 − x0)(x2 − x1)= y2 ⇒ a2 =∆2[x0, x1, x2]
En utilisant le meme procede, on generalise a l’ordre n, si x = xn on tire
an =∆n[x0, x1, . . . , xn]
Par consequent, le polynome Pn(x) s’ecrit
Premier PIN, aevc ∆xi = xi+1− xi = hi variable
Pn(x) = ∆0[x0]+∆1[x0, x1](x− x0)+·· ·+∆n[x0, x1, . . . , xn](x− x0) . . . (x− xn−1)
=n∑
j=0∆ j[x0, x1, . . . , x j]
n−1∏i=0
(x− xi) (3.2.5)
Exemple 2
Donner le polynome d’interpolation de Newton P4 de l’exemple 1 precedent.

3
20 Interpolation
Solution
De la table des differences divisees, on tire les coefficients du polynome
a0 = ∆0[x0]= 1
a1 = ∆1[x0, x1]=−1
a2 = ∆2[x0, x1, x2]= 0
a3 = ∆3[x0, x1, x2, x3]= 23
a4 = ∆4[x0, x1, x2, x3, x4]=− 512
D’ou, le polynome d’interpolation de Newton s’ecrit :
P4(x) =4∑
k=0∆k[x0, · · · , xk]
3∏i=0
(x− xi)
= 1− (x+1)+ 23
(x+1) x (x−1)− 512
(x+1) x (x−1)(x−2)
= −(
112
)x(5x3 −18x2 −5x+30
)
3.2.3 Notions de différences finies
Definition 2
Dans le cas ou les points donnes xi, i = 0, ..,n sont equidistants, c’est a dire que∆xi = xi+1 − xi = h 6= 0, ∀i = 0, ..,n, on definit les differences finies comme suit
∆[x1, x0]= y1 − y0
x1 − x0= y1 − y0
h(3.2.6)
∆2[x2, x1, x0]=y2 − y1
h− y1 − y0
h2!h
= y2 −2y1 + y0
2!h2 (3.2.7)
Par recurrence, on definit les differences divisees d’ordre superieur, a l’ordre n
∆n[x0, x1, . . . , xn]= 1n!hn
n∑k=0
(−1)kCkn f (x0 + (n−k)h) (3.2.8)
Dans le cas des differences finies, le polynome d’interpolation s’ecrit
Premier PIN, avec ∆xi = xi+1− xi = h constant
Pn(x)= y0 + y1 − y0
h(x− x0)+·· ·+ 1
n!hn
n∑k=0
(−1)kCkn f (x0 + (n−k)h)
n−1∏i=0
(x− xi)
(3.2.9)
La premiere formule d’interpolation de Newton est pratiquement incommodepour l’interpolation de la fonction dans la partie finale du tableau. Pour faire inter-venir ces points, on recourt a la deuxieme formule d’interpolation de Newton.

3.3 Deuxième polynôme d’interpolation de Newton 21
3
3.3 Deuxième polynôme d’interpolation de Newton
Soit un systeme de (n+1) points (xi, yi), i = 0, ..,n. Notre but est de construireun polynome de degres inferieure ou egal a n qui s’ecrit sous la forme :
Deuxieme PIN, avec ∆xi = xi+1− xi = hi variable
Pn(x)= a0 +a1(x− xn)+a2(x− xn)(x− xn−1)+·· ·+an(x− xn)(x− xn−1) . . . (x− x1)(3.3.1)
Dans le cas des differences finies ∆xi = xi+1 − xi = h 6= 0, i = 0, ..,n, Pn(x) s’ecrit
Deuxieme PIN, avec ∆xi = xi+1− xi = h constant
Pn(x)= yn + ∆yn−1
h(x− xn)+ ∆
2 yn−2
2!h2 (x− xn)(x− xn−1)+·· ·+ ∆n y0
n!hn
n∏i=1
(x− xi)
(3.3.2)
Remarque 2. Inconvenients de l’interpolation de Newton
1. On remarque que les points (xi, yi), i = 0, ..,n situes dans la partie finale (i =n, i = n−1, . . . ) n’interviennent que rarement dans le calcul des coefficientsdu premier polynome d’interpolation de Newton. Dans le cas du deuxiemepolynome d’interpolation de Newton c’est les points du debut qui serontles moins touches par l’operation d’interpolation.
2. Le calcul des differences divisees peut etre ardu (difficile) si le nombre depoints est relativement grand (en fait, meme pour n = 6,7,8,9, . . .).
Pour surmonter ces difficultes, on utilise le polynome d’interpolation de Lagrange.
3.4 Polynôme d’interpolation de LAGRANGE
Soit un systeme de (n+1) points (xi, yi), i = 0..n.
Probleme 3
Notre but est de construire un polynome de degres inferieur ou egal a n noteLn(x) tel que : Ln(xi)= yi,∀i = 0, ..,n.
Demonstration
Cherchons d’abord un polynome de d◦ 6 n, note L i(x) tel que pour i fixe sur [0,n]
L i(x j)= δi, j ={
1 i = j0 i 6= j
( δi, j symbole de Kronecker)
Le polynome L i(x) s’annule en x0, x1, · · · , xi−1, xi+1, · · · , xn, donc il s’ecrit sous la forme :
L i(x)= Ci(x− x0)(x− x1)(x− x2) · · · (x− xi−1)(x− xi+1) · · · (x− xn)

3
22 Interpolation
D’ou {L i(x j) = 0 si i 6= jL i(xi) = 1= Ci(xi − x0)(xi − x1) · · · (xi − xi−1)(xi − xi+1) · · · (xi − xn)
On deduit la valeur de Ci :
Ci = 1(xi − x0)(xi − x1) · · · (xi − xi−1)(xi − xi+1) · · · (xi − xn)
Et, on tire :
L i(x)= (x− x0)(x− x1) · · · (x− xi−1)(x− xi+1) · · · (x− xn)(xi − x0)(xi − x1) · · · (xi − xi−1)(xi − xi+1) · · · (xi − xn)
(3.4.1)
Et, si l’on pose :
Ln(x)=n∑
i=0L i(x).yi =⇒ Ln(x j)=
n∑i=0
L i(x j).yi = yj (3.4.2)
Ln est un polynome de d◦ 6 n recherche et qui passe par les points (xi, yi)i=0,..,n.
Definition 3
Le polynome d’interpolation de LAGRANGE (P.I.L.) qui passe par les points(xi, yi)i=0,..,n, s’ecrit sous la forme
Ln(x) =n∑
i=0yi
n∏
j=0, j 6=i(x− x j)
n∏j=0, j 6=i
(xi − x j)
Lemme 1
Le polynome d’interpolation de Lagrange est unique.
Demonstration
Supposons qu’on a deux polynomes de Lagrange Ln et L′n telle que :
Ln(xi)= L′n(xi)= yi, i = 0, ..,n
Ces deux polynomes de d◦ 6 n passent par les memes points (xi, yi), i = 0, ..,n.Posons Qn(x) = Ln(x)− L′
n(x). Le polynome Qn est un polynome de d◦ 6 n et quis’annule en (n+1) points distincts xi , i = 0, ..,n.Alors Qn ne peut etre qu’un polynome nul.

3.5 Estimation de l’erreur 23
3
Lemme 2
Le polynome d’interpolation de Lagrange et le polynome d’interpolation deNewton sont deux formes differentes d’un meme polynome.
Demonstration
Il suffit de prendre le polynome L′n du lemme precedent comme etant le polynome
d’interpolation de Newton.
Exemple 3
On aP(x)= x2 −2x+3= 6+4(x−3)+ (x−3)2 = (x−1)2 +2
trois formes differentes d’un meme polynome.
Exemple 4
Soit la fonction f (x) = ln x dont on connait (on suppose) les valeurs qu’en troispoints :
i 0 1 2xi 1 4 6yi 0 1,386 1,791
1. Ecrire le polynome d’interpolation de Lagrange pour le systeme de points.
2. Estimer l’evaluation numerique de L2(2) et l’erreur relative associee sa-chant que ln2= 0.69315 - valeur supposee exacte -
3.5 Estimation de l’erreur
3.5.1 Erreur d’interpolation de LAGRANGE ( cas ou f est connue)
Supposons que pour i = 0, ..,n les points (xi, yi) soient associes a une fonction ftelle que yi = f (xi). Partant des points (xi, yi), i = 0, ..,n, on peut faire varier f entreces points sans changer de polynome d’interpolation.Par consequent, l’erreur d’interpolation ε(x)= f (x)−Ln(x) en un point x ∈ [a,b], oua 6 x0 < x1 < x2 < ·· · < xn 6 b n’a pas de sens puisque ne dependant pas seulementde x mais aussi de f ′′.Pour estimer ε(x), nous devons mieux connaitre f . Dans ce contexte, on a :

3
24 Interpolation
Theoreme 1
Si la fonction f est (n+1) fois continument differentiable sur [a,b], c’est a diref ∈ Cn+1[a,b]. Alors ∀x ∈ [a,b],∃ξ= ξx ∈ [a,b] telle que
ε(x)= 1(n+1)!
L(x) f (n+1)(ξx)
Ou
L(x)= (x− x0)(x− x1) · · · (x− xn)=n∏
i=0(x− xi)
Demonstration
cas 1 : S’il existe i ∈ [0,n] telle que x = xi ⇒ ε(x)= L(x)= 0
cas 2 : Si x 6= xi,∀i ∈ [0,n] considerons
F(t)= f (t)−Ln(t)− f (x)−Ln(x)L(x)
L(t)
Ou Ln est le PIL de dr6 n, t ∈ [a,b] et x fixe et x 6= xi, ∀i comme f est (n+1)fois continument differentiable sur [a,b] et L est un polynome d◦(n+1) donc Fest (n+1) fois continument differentiable sur [a,b].De plus, F(xi)= 0,∀i ∈ [0,n] et F(x)= 0=⇒ F a au moins (n+2) racines distinctesdans [a,b] (les (n+1) points plus le point x) alors d’apres le theoreme de Rolle,F ′ a au moins (n+1) racines dans [a,b], F" a au moins n racines dans [a,b],F (k) a au moins (n−k+2) racines dans [a,b], (06 k 6 n+1).Pour k = n+1, F (n+1) a au moins une racine dans [a,b], notons par ξx cetteracine, on a :
F (n+1)(t)= f (n+1)(t)−0− f (x)−Ln(x)L(x)
.(n+1)!
car Ln(t) est un PIL de d◦ 6 n donc de derivee (n+1) fois nulle.Et, pour t = ξx, on a F (n+1)(ξx)= 0, d’ou :
F (n+1)(ξx)= f (x)−Ln(x)L(x)
.(n+1)!
Or : f (x)−Ln(x)= ε(x), alors
ε(x)= 1(n+1)!
L(x). f (n+1)(ξx)
qui est l’egalite cherchee.
3.5.2 Erreur d’interpolation de NEWTON
De meme, que le theoreme precedent

3.5 Estimation de l’erreur 25
3
Theoreme 2
Si f ∈ Cn+1[a,b]. Alors ∀x ∈ [a,b],∃ξ= ξx ∈ [a,b] telle que
ε(x) = f (x)−Pn(x)
= ∆n+1(x, x0, x1, · · · , xn)n∏
i=0(x− xi)
On tire :
ε(x)= f (n+1)(ξx)(n+1)! .L(x)
Ou Pn est le Polynome d’Interpolation de Newton d◦ 6 n et L(x)=n∏
i=0(x− xi).
Demonstration: A faire comme exercice !
ConsidererF(t)= f (t)−Pn(t)−L(t).∆n+1(x, x0, x1, · · · , xn)
Consequence :On a :
|ε(x)| = 1(n+1)!
.|L(x)|| f (n+1)(ξx)|
Si on pose Mn+1 = Maxt∈[a,b]
| f (n+1)(t)|, alors
|ε(x)|6 Mn+1(n+1)! .|L(x)|
Remarque 3. Remarques importantes
1. Dans la pratique, f est rarement connue et quand elle l’est, son appar-tenance a Cn+1[a,b] n’est pas toujours realisee et a fortiori, si le nombre(n+1) de points (xi, yi)i∈[0,n] est grand.
2. Pour x donne, ξx est souvent difficile a trouver.
3. Dans les conditions ”ideales” f ∈ Cn+1([a,b]) et ξx est connu. Minimiser
|ε(x)| revient a faire de meme pour |L(x)|; et comme L(x)=n∏
i=0(x−xi), on a
interet a considerer des abscisses xi (i ∈ [0,n]) proches de x ( donc repartisde preference de part et d’autre de x).
4. Pour toutes ces raisons, l’erreur |ε(x)| est difficile a evaluer en pratique.La borne donnee, ci-dessus, reste donc purement theorique. Dans le casgeneral.


Sommaire
4.1 Les Principes Généraux4.2 Les méthodes de Newton-Côtes4.3 Méthode de Gauss
Chapitre
4Intégration Numérique
”[...] j’aime les mathematiques pour elles-memes comme n’admettant pas l’hypocrisie et levague, mes deux betes d’aversion.”
Stendhal
..
Dans ce chapitre nous etudierons les methodes numeriques d’integration.Il est parfois difficile, voire impossible de calculer la valeur d’une integrale, parexemple, dans le cas ou on ne connaıt pas de primitive explicite.Le but de cette lecon est d’essayer de trouver une valeur approchee de cette integrale.Pour se faire on va considerer plusieurs methodes et evaluer a chaque fois l’erreurcommise.Ces methodes se repartissent en deux grandes categories : Les methodes composees(ou de Newton-Cotes)dans lesquelles la fonction f est remplacee par un polynomed’interpolation.Les methodes de Gauss fondees sur les polynomes orthogonaux pour lesquelles lespoints de la subdivision sont imposes.On supposera connu les notions sur les integrales ainsi que la formule de Taylor-Lagrange.
27

4
28 Intégration Numérique
4.1 Les Principes Généraux
Soit f une fonction continue sur un intervalle [a,b] de R. On se propose d’evaluer
l’integraleb∫a
f (x)dx en subdivisant l’intervalle d’integration
a = x0 < x1 < ......< xn = b
Alors, on a :
b∫a
f (x)dx =n−1∑i=0
xi+1∫xi
f (x)dx
Sur chaque intervalle partiel [xi, xi+1], on applique une methode d’integrationconsistant a remplacer f (x) par le polynome d’interpolation.l’integrale d’une fonction continue sur un intervalle borne [a,b] est remplacee par unesomme finie. Le choix de la subdivision de l’intervalle d’integration et des coefficientsqui interviennent dans la somme approchant l’integrale sont des criteres essentielspour minimiser l’erreur.
4.2 Les méthodes de Newton-Côtes
4.2.1 Méthode des rectangles à gauche et à droite
Principe
On remplace f par une fonctionen escalier, c’est a dire, par uneconstante sur chaque intervalle par-tiel [xi, xi+1] de la subdivision de[a,b], elle prend la valeur f (ξi) =f (xi) ou f (ξi) = f (xi+1) que l’on ap-plique la methode des rectangles agauche ou a droite.Cela revient a interpoler la fonctionf sur le segment [xi, xi+1] par le po-lynome de Lagrange de degre 0.
Proposition 1
La valeur approchee de l’integrale par la methode des rectangles sur [xi, xi+1]
xi+1∫xi
f (x)dx ' hi f (ξi), ξi ∈ [xi, xi+1] , hi = xi+1 − xi (4.2.1)

4.2 Les méthodes de Newton-Côtes 29
4
Et sur [a,b],b∫
a
f (x)dx =n−1∑i=0
hi f (ξi) (4.2.2)
Demonstration
Pour la methode des rectangles a gauche, il suffit d’ecrire que l’aire du rectangle sur[xi, xi+1] est (xi+1− xi) f (xi) avec xi+1− xi = hi et de sommer les aires des rectangles ...De meme pour rectangle a droite !
On reconnaıt la somme de Riemann, si f est Riemann integrable, on sait qu’elle
converge versb∫a
f (x)dx quand le pas de la subdivision h = maxhi06i6n−1
tend vers 0.
4.2.2 Évaluation de l’erreur
Theoreme 1. Rectangles a gauche ou a droite
si f est de classe C 1 sur [a,b], alors ∀n ∈N∗, on a∣∣∣∣∣∣xi+1∫xi
f (x)dx− (xi+1 − xi) f (xi)
∣∣∣∣∣∣6 h2i
2M1 ou M1 = max
a6x6b
∣∣∣ f′(x)
∣∣∣ (4.2.3)
Pour la formule composee avec pas h = b−an
constant :
∣∣∣∣∣∣b∫
a
f (x)dx−hn−1∑i=0
f (xi)
∣∣∣∣∣∣6 (b−a)2
2nM1, ou M1 = max
a6x6b
∣∣∣ f′(x)
∣∣∣ (4.2.4)
Demonstration . Pour la methode des rectangles a gauche
∣∣∣∣∣∣b∫
a
f (x)dx−n−1∑i=0
f (xi) (xi+1 − xi)
∣∣∣∣∣∣ =∣∣∣∣∣∣n−1∑i=0
xi+1∫xi
f (x)dx−n−1∑i=0
f (xi) (xi+1 − xi)
∣∣∣∣∣∣=
∣∣∣∣∣∣n−1∑i=0
xi+1∫xi
( f (x)− f (xi))dx
∣∣∣∣∣∣6n−1∑i=0
xi+1∫xi
| f (x)− f (xi)|dx
6n−1∑i=0
xi+1∫xi
|x− xi|M1dx d’apres le teeoreme des accroissements finis
6n−1∑i=0
xi+1∫xi
(x− xi) M1dx6n−1∑i=0
[(x− xi)2
2
]xi+1
xi
M1
6n−1∑i=0
h2
2M1 6 n
h2
2M1 = (b−a)2
2nM1
De meme, pour la methode des rectangles a droite !
4
30 Intégration Numérique
4.2.3 Méthode des rectangles du point milieu
Principe
De meme que precedemment, a ladifference pres qu’au lieu de prendrela valeur de f a l’extremite gaucheou droite du segment [xi, xi+1], onprend la valeur de f au milieudu segment, c’est a dire, f (ξi) =f( xi + xi+1
2
),
Proposition 2
La valeur approchee de l’integrale par la methode des rectangles du point milieusur [xi, xi+1] , 06 i 6 n−1
xi+1∫xi
f (x)dx ' hi f( xi + xi+1
2
), hi = xi+1 − xi (4.2.5)
Et sur le segment [a,b],
b∫a
f (x)dx =n−1∑i=0
hi f( xi + xi+1
2
)(4.2.6)
Demonstration
Meme principe que precedemment, il suffit de calculer l’aire des rectangles ...
4.2.4 Évaluation de l’erreur
Theoreme 2. Rectangles du point milieu
Dans ce cas, on obtient une methode d’ordre 1 exacte pour toute fonctionlineaire bien qu’on interpole par une constante, si f est de classe C 2 sur [a,b],
alors ∀n ∈N∗, on a la formule composee avec le pas h = b−an
constant :
∣∣∣∣∣∣b∫
a
f (x)dx−hn−1∑i=0
f (xi+1/2)
∣∣∣∣∣∣6 M2(b−a)
24h2 ou M2 = max
a6x6b
∣∣∣ f′′(x)
∣∣∣ (4.2.7)

4.2 Les méthodes de Newton-Côtes 31
4
Demonstration
On pose I =b∫a
f (x)dx valeur exacte de l’integrale et In =n−1∑i=0
f (ξi) (xi+1 − xi) sa valeur
approchee. Pour ξi = xi + xi+1
2= xi+1/2 et M2 = max
a6x6b
∣∣ f ′′(x)∣∣, on remarque que :
xi+1∫xi
(x−ξi) f ′(ξi)dx = 0 etb−a
nf (ξi)=
xi+1∫xi
(x−ξi) f ′(ξi)dx si xi+1 + xi = b−an
Donc, on a :
|en| = |I − In| =∣∣∣∣∣∣n−1∑i=0
xi+1∫xi
f (x)dx− b−an
f (ξi)
∣∣∣∣∣∣6n−1∑i=0
∣∣∣∣∣∣xi+1∫xi
f (x)dx− b−an
f (ξi)
∣∣∣∣∣∣6
n−1∑i=0
∣∣∣∣∣∣xi+1∫xi
(f (x)− f (ξi)− (x−ξi) f ′(ξi)
)dx
∣∣∣∣∣∣6
n−1∑i=0
xi+1∫xi
∣∣ f (x)− f (ξi)− (x−ξi) f ′(ξi)∣∣dx
∣∣ f (x)− f (ξi)− (x−ξi) f ′(ξi)∣∣ 6
M2
2(x−ξi)2 d’apres l’inegalite de Taylor Lagrange
|I − In| 6M2
2
n−1∑i=0
xi+1∫xi
(x−ξi)2 dx = M2
2
n−1∑i=0
((xi+1 −ξi)3
3− (xi −ξi)3
3
)
6M2
6
n−1∑i=0
(h3
8− (−h)3
8
)= nh3
24M2
Sachant que h = b−an
, alors
|I − In| =∣∣∣∣∣∣
b∫a
f (x)dx−n−1∑i=0
f (ξi) (xi+1 − xi)
∣∣∣∣∣∣6 (b−a)3
24n2 M2
Remarque: Dans le cas d’une subdivision reguliere h = xi+1 − xi = b−an
Suivant les choix de ξi, on a :– Rectangles a gauche : ξi = xi
b∫a
f (x)dx ' ( b−an
)n−1∑i=0
f (xi)
– Rectangles a droite : ξi = xi+1b∫a
f (x)dx ' ( b−an
)n−1∑i=0
f (xi+1)
– Rectangles du point milieu : ξi = xi + xi+1
2= xi+1/2

4
32 Intégration Numérique
b∫a
f (x)dx ' ( b−an
)n−1∑i=0
f( xi+xi+1
2
)
4.2.5 Méthode des trapèzes
Principe
On remplace f par son interpole li-neaire sur chaque segment [xi, xi+1]de la subdivision, c’est a dire, par lesegment de droite qui relie (xi, f (xi))a (xi+1, f (xi+1)), qui represente le po-lynome de Lagrange de degre 1.
Proposition 3
La valeur approchee de l’integrale par la methode des trapezes sur chaque in-tervalle partiel [xi, xi+1] , 06 i 6 n−1 est de
xi+1∫xi
f (x)dx ' 12
hi ( f (xi)+ f (xi+1)) ,hi = xi+1 − xi (4.2.8)
Et sur l’intervalle [a,b], elle est de
Tn =b∫
a
f (x)dx 'n−2∑i=0
hi +hi+1
2f (xi+1)+ 1
2(h0 f (x0)+hn−1 f (xn)) (4.2.9)
Et dans le cas d’une subdivision reguliere hi = h = b−an
, ∀06 i 6 n−1
Tn =b∫
a
f (x)dx ' h
[n−2∑i=0
f (xi+1)+ 12
( f (x0)+ f (xn))
](4.2.10)
Demonstration
Rappel : l’aire d’un trapeze = hauteur .grande base + petite base
2Il suffit donc de calculer l’aire des trapezes sur chaque segment [xi, xi+1], qui est de
(xi+1 − xi).( f (xi)+ f (xi+1))
2puis de faire la somme pour les 06 i 6 n−1.
4.2.6 Évaluation de l’erreur
4.2 Les méthodes de Newton-Côtes 33
4
Theoreme 3. Methode des trapezes
Si f est de classe C 2 sur [a,b], alors ∀n ∈N∗, l’erreur pour h = b−an
constant
|en| =∣∣∣∣∣∣
b∫a
f (x)dx−Tn
∣∣∣∣∣∣6 (b−a)3
12n2 M2 ou M2 = maxa6x6b
∣∣ f ′′(x)∣∣ (4.2.11)
Demonstration
4.2.7 Méthode de Simpson
Principe
On interpole f aux points xi, xi+1 et ξi = xi+xi+12 par un polynome du second degre
definissant un arc de parabole passant par les points d’ordonnees f (xi), f (xi+1) etf (ξi), cette methode consiste donc a remplacer f par le polynome d’interpolationde Lagrange de degre 2 sur chaque segment [xi, xi+1] ayant les memes valeursque f aux bornes de l’intervalle et en son milieu.
Proposition 4
La valeur approchee de l’integrale par la methode de Simpson sur chaque inter-valle partiel [xi, xi+1] , 06 i 6 n−1 est pour hi = xi+1 − xi de
xi+1∫xi
f (x)dx ' 16
hi ( f (xi)+4 f (xi+1/2)+ f (xi+1)) (4.2.12)
Et sur l’intervalle [a,b], elle est de
Sn =b∫
a
f (x)dx 'n−2∑i=0
16
(xi+1 − xi)(f (xi)+4 f (
xi + xi+1
2)+ f (xi+1)
)(4.2.13)

4
34 Intégration Numérique
Dans le cas d’une subdivision reguliere, le pas h est constant,
Sn =b∫
a
f (x)dx ' h6
[f (x0)+ f (xn)+2
n−2∑i=0
f (xi+1)+4n−2∑i=0
f (xi+1/2)
](4.2.14)
Et, dans le cas d’une subdivision reduite a sa plus simple expression x0 = a,x1 = a+b
2 et x2 = b la formule precedente devient :
S =b∫
a
f (x)dx ' 16
(b−a)[
f (a)+ f (b)+4 f (a+b
2)]
(4.2.15)
4.2.8 Évaluation de l’erreur d’intégration
Theoreme 4. Methode de Simpson
si f est de classe C 4 sur [a,b], alors ∀n ∈N∗, pour h pas constant, on a
|En| =∣∣∣∣∣∣
b∫a
f (x)dx−Sn
∣∣∣∣∣∣6 (b−a)5 M4
2880 n4 ou M4 = maxa6x6b
∣∣∣ f (IV )(x)∣∣∣ (4.2.16)
La methode est exacte pour tout polynome de degre inferieur ou egal a 3.
Demonstration
4.3 Méthode de GaussPrincipe
Les methodes d’integration numerique de Gauss utilisent une subdivision par-ticuliere de l’intervalle [a,b], les points x j sont les racines d’une famille de po-lynomes orthogonaux qui ne sont pas regulierement espaces, contrairement auxmethodes composees. La fonction a integrer est approximee par une interpola-tion de Lagrange sur les points x j.Soit donc $ une fonction poids definie sur l’intervalle ]a,b[, c’est-a-dire une fonc-tion continue et strictement positive. On s’interesse aux methodes d’integrationapprochee du type :
b∫a
f (x)$(x)dx 'n∑
j=0ω j f (x j)dx, x j ∈]a,b[ (4.3.1)
Avec :
ω j =b∫
a
L j(x)$(x)dx

Sommaire
5.1 Les méthodes directes :5.2 Algorithme d’élimination de Gauss5.3 Programme d’élimination de Gauss, sans pivot5.4 Méthode de Gauss-Jordan :
Chapitre
5Systèmes Linéaires
En analyse numerique, la resolution des systemes lineaires se fait par deux me-thodes : Les methodes directes et les methodes iteratives.Soit un systeme de n equations a n inconnues
a11x1 +a12x2 +a13x3 +·· ·+a1nxn = b1a21x1 +a22x2 +a23x3 +·· ·+a2nxn = b2· · · · · · · · · · · · · · · · · · · · · · · · = · · ·an1x1 +an2x2 +an3x3 +·· ·+annxn = bn
(5.0.1)
Ecriture matricielle du systeme :
A.x = b (5.0.2)
Avec :
A =
a11 a12 · · · a1na21 a21 · · · a2n· · · · · · · · · · · ·an1 an2 · · · ann
; x =
x1x2· · ·xn
; b =
b1b2· · ·bn
5.1 Les méthodes directes :
5.1.1 La formule de Cramer
Si la matrice A est reguliere i.e det A 6= 0 ; le systeme (5.0.1) admet une solutionunique.
A.x = b ⇐⇒ x = A−1.b (5.1.1)
5.1.2 Méthode de Gauss :
La methode de Gauss consiste a transformer la matrice A de l’equation (5.0.1)en une matrice triangulaire superieure, si elle ne l’est pas, en effectuant une suited’operations elementaires donnant de nouveaux systemes lineaires ayant la memesolution que le systeme (5.0.1) de depart.
35

5
36 Systèmes Linéaires
5.1.3 Description de la méthode :
Soit A une matrice de dimension n×n,b ∈Rn.On pose A(1) = A, on definit par recurrence A(k+1) a partir de A(k) en effectuant lescombinaisons de lignes, si a(k)
kk 6= 0 :
l i ← l i −a(k)
ik
a(k)kk
lk (5.1.2)
Pour i > k, on obtient ainsi des 0 au dessous de la diagonale dans la colonne k, al’etape n on a un systeme triangulaire qu’on resout par remontee :
xn = 1ann
bn
· · · · · · · · · · · · · · · · · · · · · · · ·xi = 1
aii
(− ∑
j>iai jx j +bi
)· · · · · · · · · · · · · · · · · · · · · · · ·x1 = 1
a11
(− ∑
j>1a1 jx j +b1
)
5.1.4 Le nombre d’opération
La methode de Gauss necessite n(n−1)(2n+5)/6 multiplications, n(n−1)(2n+5)/6additions et n(n+1)/2 divisions soit au total
(4n3 +9n2 −7n
)/6 operations.
En utilisant la methode de Cramer (n+1)(n−1)n! multiplications, (n+1)(n!−1)additions et n divisions.
5.2 Algorithme d’élimination de Gauss
Entrees :La matrice A = (
ai j)16i, j6n et le second membre b = (bi)16i6n du systeme initial.
Sorties :La nouvelle matrice triangulaire superieure et du nouveau second membre.Triangularisation :
Algorithme
pour i = 1 a n
p = 1aii[
pour j = i+1 a nai j = p∗ai j
bi = p∗bipour k = i+1 a n[
pour j = i+1 a nak j = ak j −aki ∗ai j
bk = bk −aki ∗bi

5.3 Programme d’élimination de Gauss, sans pivot 37
5
p = 1ann
bn = p∗bn
5.2.1 Résolution du système triangulaire supérieur
On stocke la solution x du systeme dans la vecteur b pour economiser de l’espacedans la memoire de l’ordinateur pour i = n−1 a 1
bi = bi −n∑
j=i+1ai j ∗bi
le facteur de conditionnement γ d’un systeme lineaire Ax = b est
γ= |det A|n∏
j=1
(n∑
i=1a2
i j
)1/2
γ est compris entre 0 et 1, le systeme est dit bien conditionne si γ est voisin de1 (0,16 γ6 1), mal conditionne si γ¿ 1
5.3 Programme d’élimination de Gauss, sans pivot
Programme 1. Methode de Gauss sans pivot
function x = gauss(A,b) % Fonction de Gauss sans pivot
% description de la methode
[m,n] = size(A);
if m~=n, error(’La Matrice A doit etre carre’); end
nb = n+1; % la taille de A augmentee de b
Aug=[A b]; % matrice augmentee A du vecteur b
% Elimination de Gauss
for k = 1:n-1
for i = k+1:n
p = Aug(i,k)/Aug(k,k);
Aug(i,k:nb) = Aug(i,k:nb)-p*Aug(k,k:nb);
end
end
% Methode de remontee
x = zeros(n,1);
x(n) = Aug(n,nb)/Aug(n,n);
for i = n-1:-1:1
x(i) = (Aug(i,nb)-Aug(i,i+1:n)*x(i+1:n))/Aug(i,i);
end
end

5
38 Systèmes Linéaires
5.3.1 Élimination de Gauss avec changement de pivot :(Stratégie de pivot)
Comme nous venons de le voir, la methode de Gauss ne peut etre execute que siles pivots successifs sont non nuls a(k)
kk 6= 0, c’est a dire que toutes les sous matricesprincipales de A sont regulieres.Si le pivot est tres petit, l’algorithme conduit a des erreurs d’arrondi importantes.C’est pourquoi des algorithmes qui echangent les elements de facon a avoir le pivotle plus grand possible ont ete developpes.La methode du pivot partiel consiste a intervertir les lignes a chaque etape de facona mettre comme pivot (le coefficient diagonal) le terme de coefficient le plus elevede la ligne en valeur absolue.
a(k)ik = max
p=k,..,n
∣∣∣a(k)pk
∣∣∣ (5.3.1)
La methode du pivot total consiste a intervertir les lignes et les colonnes a chaqueetape de facon a mettre comme pivot (le coefficient diagonal) le terme de coefficientle plus eleve de la matrice en valeur absolue.
a(k)i j = max
p,q=k,..,n
∣∣∣a(k)pq
∣∣∣ (5.3.2)
Le nombre d’operation est de l’ordre de n2 pour le pivot partiel et de n3 pourl’ordre total. Ce dernier est rarement utilise.
5.3.2 Programme d’élimination de Gauss avec choix du plusgrand pivot :
Entrees : La matrice A et le second membre b du systeme lineaire original.Sorties : La solution contenue dans le vecteur x.
Programme 2. Methode de Gauss avec pivot
function x = GaussPivot(A,b)
% x = GaussPivot(A,b): Gauss elimination with pivoting.
% input:
% A = coefficient matrix et b = right hand side vector
% output: x = solution vector
[m,n]=size(A);
if m~=n, error(’Matrix A must be square’); end
nb=n+1;
Aug=[A b];
% forward elimination
for k = 1:n-1
% partial pivoting
[big,i]=max(abs(Aug(k:n,k)));
ipr=i+k-1;
if ipr~=k
Aug([k,ipr],:)=Aug([ipr,k],:);
end

5.4 Méthode de Gauss-Jordan : 39
5
for i = k+1:n
factor=Aug(i,k)/Aug(k,k);
Aug(i,k:nb)=Aug(i,k:nb)-factor*Aug(k,k:nb);
end
end
% back substitution
x=zeros(n,1);
x(n)=Aug(n,nb)/Aug(n,n);
for i = n-1:-1:1
x(i)=(Aug(i,nb)-Aug(i,i+1:n)*x(i+1:n))/Aug(i,i);
end
5.3.3 Résolution du système triangulaire supérieur
On stocke la solution x du systeme dans la vecteur b pour economiser de l’espacedans la memoire de l’ordinateur. pour i = n−1 a 1
bi = bi −n∑
j=i+1ai j ∗bi
5.4 Méthode de Gauss-Jordan :
De meme, La methode de Gaus-Jordan consiste a transformer la matrice A del’equation (0.2) en une matrice identite, en effectuant une suite d’operations elemen-taires.
Exemple 1 2 8 42 10 61 8 2
x1x2x3
=1
11
On obtient, apres calcul, le systeme suivant :1 0 00 1 00 0 1
x1x2x3
= 1/4
1/8−1/8
5.4.1 Cucul de la matrice inverse :
Le meme algorithme est utilise pour calculer l’inverse d’une matrice. On ecrit Asous la forme AI et on applique a l’identite I toutes les operations elementaires quesubit A, i.e : AI → I A−1
Meme exemple que precedemment :
AI =2 8 4
2 10 61 8 2
1 0 00 1 00 0 1

5
40 Systèmes Linéaires
apres une suite d’operation, on trouve :
I A−1 =1 0 0
0 1 00 0 1
7/4 −3 −1/2−1/8 1 1/4−3/8 −1/2 −1/4
D’ou
A−1 = 7/4 −3 −1/2−1/8 1 1/4−3/8 −1/2 −1/4
Le nombre d’operation : La methode de Gauss-Jordan necessite n(n2−1)/2 mul-
tiplications, n(n2 −1)/2 additions et n(n+1)/2 divisions.
5.4.2 Description de la méthode :
Soit A une matrice de dimension nxn,b ∈Rn.
5.4.3 Systèmes mal conditionnés :
Soit le systeme :{4.218613 x1 +6.327917 x2 = 10.5465303.141592 x1 +4.712390 x2 = 7.853982 (5.4.1)
Systeme regulier, de solution : x1 = x2 = 1Soit un autre systeme{
4.218611 x1 +6.327917 x2 = 10.5465303.141594 x1 +4.712390 x2 = 7.853980 (5.4.2)
Systeme regulier, de solution : x1 =−5, x2 =+5
5.4.4 Conclusion :
Bien que les systemes (3.1) et (3.2) sont proches leurs solution sont tres differentes.On dit que les systemes sont mal conditionnes.

Table des matières
1 Notion d’erreur 31.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Definitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 Chiffres significatifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.4 Notion de chiffres exactes . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Approximation aux Moindres Carres 72.1 Position du probleme d’approximation . . . . . . . . . . . . . . . . . . 72.2 Minimum d’une fonction reelle a plusieurs variables . . . . . . . . . . 82.3 Approximation dans le cas discret . . . . . . . . . . . . . . . . . . . . . 9
2.3.1 Etude d’un modele simple : lineaire a 2 parametres . . . . . . 92.3.2 Etude d’un modele lineaire (Cas general) . . . . . . . . . . . . 11
2.4 A.M.C. : Cas continu . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132.4.1 Approximation par un modele polynomial : . . . . . . . . . . 14
3 Interpolation 173.1 Position du probleme d’interpolation . . . . . . . . . . . . . . . . . . . 173.2 Premier polynome d’interpolation de Newton . . . . . . . . . . . . . . 17
3.2.1 Notion de differences divisees . . . . . . . . . . . . . . . . . . . 183.2.2 Coefficients du polynome d’interpolation de Newton . . . . . 193.2.3 Notions de differences finies . . . . . . . . . . . . . . . . . . . . 20
3.3 Deuxieme polynome d’interpolation de Newton . . . . . . . . . . . . . 213.4 Polynome d’interpolation de LAGRANGE . . . . . . . . . . . . . . . 213.5 Estimation de l’erreur . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.5.1 Erreur d’interpolation de LAGRANGE ( cas ou f est connue) 233.5.2 Erreur d’interpolation de NEWTON . . . . . . . . . . . . . . . 24
4 Integration Numerique 274.1 Les Principes Generaux . . . . . . . . . . . . . . . . . . . . . . . . . . . 284.2 Les methodes de Newton-Cotes . . . . . . . . . . . . . . . . . . . . . . 28
4.2.1 Methode des rectangles a gauche et a droite . . . . . . . . . . 284.2.2 Evaluation de l’erreur . . . . . . . . . . . . . . . . . . . . . . . . 29
41

5
42 Table des matieres
4.2.3 Methode des rectangles du point milieu . . . . . . . . . . . . . 304.2.4 Evaluation de l’erreur . . . . . . . . . . . . . . . . . . . . . . . . 304.2.5 Methode des trapezes . . . . . . . . . . . . . . . . . . . . . . . . 324.2.6 Evaluation de l’erreur . . . . . . . . . . . . . . . . . . . . . . . . 324.2.7 Methode de Simpson . . . . . . . . . . . . . . . . . . . . . . . . 334.2.8 Evaluation de l’erreur d’integration . . . . . . . . . . . . . . . . 34
4.3 Methode de Gauss . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5 Systemes Lineaires 355.1 Les methodes directes : . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.1.1 La formule de Cramer . . . . . . . . . . . . . . . . . . . . . . . 355.1.2 Methode de Gauss : . . . . . . . . . . . . . . . . . . . . . . . . . 355.1.3 Description de la methode : . . . . . . . . . . . . . . . . . . . . 365.1.4 Le nombre d’operation . . . . . . . . . . . . . . . . . . . . . . . 36
5.2 Algorithme d’elimination de Gauss . . . . . . . . . . . . . . . . . . . . 365.2.1 Resolution du systeme triangulaire superieur . . . . . . . . . . 37
5.3 Programme d’elimination de Gauss, sans pivot . . . . . . . . . . . . . 375.3.1 Elimination de Gauss avec changement de pivot :
(Strategie de pivot) . . . . . . . . . . . . . . . . . . . . . . . . . 385.3.2 Programme d’elimination de Gauss avec choix du plus grand
pivot : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 385.3.3 Resolution du systeme triangulaire superieur . . . . . . . . . . 39
5.4 Methode de Gauss-Jordan : . . . . . . . . . . . . . . . . . . . . . . . . . 395.4.1 Cucul de la matrice inverse : . . . . . . . . . . . . . . . . . . . . 395.4.2 Description de la methode : . . . . . . . . . . . . . . . . . . . . 405.4.3 Systemes mal conditionnes : . . . . . . . . . . . . . . . . . . . 405.4.4 Conclusion : . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40

Introduction aA nal y
s e N ume ri q u e
N° ISBN : 978-2-35209-149-3N° EAN : ?
Acheve d’imprimer en France pour le compte d’InLibroVeritas.net en 2013





























