Embed Size (px)
DESCRIPTION
Annotating genomes using proteomics data. Andy Jones Department of Preclinical Veterinary Science. Overview. Genome annotation Current informatics methods Experimental data How good are we at annotating genomes? Proteome data for genome annotation Study on Toxoplasma Challenges - PowerPoint PPT Presentation
Citation preview

Annotating genomes using proteomics data
Andy Jones
Department of Preclinical Veterinary Science

Overview
• Genome annotation– Current informatics methods– Experimental data– How good are we at annotating genomes?
• Proteome data for genome annotation– Study on Toxoplasma– Challenges– Proposed solutions

Summary: 780 “completed” genomes; 734 “draft” assembly; 842 “in progress”Total: 2356 (1996 prokaryote, 360 eukaryote)
Genome sequencing is just a starting point to understanding genes / proteins

Annotating eukaryotic genomes
• Genome annotation:– Find start codons / transcriptional initiation– Recognise splice acceptor and donor sequences– Stop codon– Predict alternative splicing...
Start codon
Exon 1 Exon 2 Exon 3 Exon 4
Stop codon
Genomic DNA
mRNA

Computational gene prediction
• De novo prediction – single genome– Trained with “typical” gene structures - learn exon-intron
signals, translation initiation and termination signals e.g. Markov models
– Many different predictions scored based on training set of known genes
• Multiple genome– Compare confirmed gene sequences from other species– Coding regions more highly conserved conservation
indicates gene position– Pattern searching: Higher mutation rate of bases separated
in multiples of three (mutations in 3rd position of codons are often silent)
• Experimental data also contribute to many genome projects
• New methods weigh evidence from a variety of sources
– Attempting to reproduce how a human annotator would work
Brent, Nat Rev Genet. 2008 Jan;9(1):62-73

Experimental corroboration of models
• Expressed Sequence Tags– Simple to obtain large volumes of data – sequence
randomly from cDNA libraries– Problems:
• Data sets can contain unprocessed transcripts (do not always confirm splicing)
• Rarely cover 5’ end of gene• Generally “low-quality” sequences
• High-throughput sequencing– “Next-generation” sequencers capable of directly
sequencing mRNA– Likely to become more widely used in the future
• Proteome data (peptide sequence data)

How good are gene models?
• Plasmodium falciparum (causative agent malaria)– genome sequenced in 2002, undergone considerable
curation of gene models
• Recent article: cDNA study of P. falciparum• Suggests ~25% of genes in Plasmodium
falciparum are incorrect (85 genes out of 356 sampled)
• Majority of errors are in splice junctions (intron-exon boundaries)
• What does this mean for other genomes...?– Likely that high percentage of gene sequences are
incorrect!
BMC Genomics. 2007 Jul 27;8:255.

Proteome data for genome annotation
• Motivation for genome annotation:– Can rule out that transcripts are non protein-coding– Large volumes of proteome data often collected for other
purposes– Certain types of proteome data able to confirm the start
codon of genes (difficult by other methods)– Even where considerable ESTs / cDNA sequencing has
been performed, proteins can be detected with no corresponding EST evidence

Proteogenomic study of Toxoplasma gondii
• Proteome study of Toxoplasma gondii using three complementary techniques– parasite of clinical significance related to Plasmodium
Study aims:• Identify as many components of the proteome as possible• Relate peptide sequence data back to genome to confirm genes• Relate protein expression data to transcriptional data (EST / microarray)

2D gel electrophoresis
1D gel electrophoresis
Cut bandsTrypsin digestion
Cut gel spotTrypsin digestion
Trypsin digestionFractions
Mass spectrometry
Sequence database search(compare with theoretical spectra predicted for each peptide in DB)
Liquid chromatography
Peptides

Database search strategy
ToxoDB
60MB genome sequence
“Official” gene models
Alternative gene models predicted by gene finders
= DNA sequence database
= amino acid sequence database
ORFs predicted in a 6 frame translation
Concatenate databases
Search all spectra
Identify peptides and proteins
Align peptide sequences back to corresponding genomic region

•Five exon gene; incomplete agreement between different gene models•Peptide evidence for all 5 exons and 2 introns out of 4•Note: Can only provide positive evidence, no peptides matched to 5’ and 3’ termini of gene model
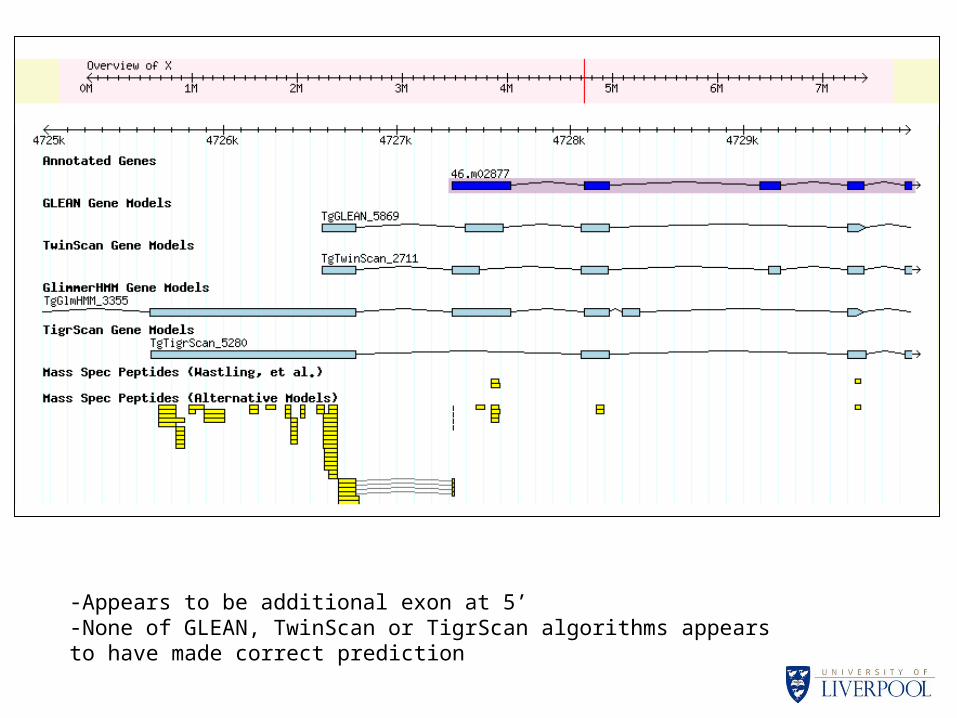
-Appears to be additional exon at 5’-None of GLEAN, TwinScan or TigrScan algorithms appears to have made correct prediction

ORF/ part of TgGlimmerHMM sequence:VVGGFSSNFLSFFSVIITSVKMSDAEDVTFETADAGASHTYPMQAGAIKKNGFVMLKGNPCKVVDYSTSKTGKHGHAKAHIVGLDIFTGKKYEDVCPTSHNMEVPNVKRSEFQLIDLSDDGFCTLLLENGETKDDLMLPKDSEGNLDEVATQVKNLFTDGKSVLVTVLQACGKEKIIASKEL
50.m5694 sequence:MVEGVYSSFEAMIFSLPHACRTVTRTDLPSVKRFLTCVATSSKFPSESLGSIKSSFVSPFSRSSVQKPSSDKSINWNSDLFTFGTSML
- All peptides matched to gene models on opposite strand

Study outcomes• Protein evidence for approximately 1/3 of predicted
genes (2250 proteins)• Around 2500 splicing events confirmed
– Peptides aligned across intron-exon boundaries• Around 400 protein IDs appear to match alternative
gene models• Genome database (ToxoDB) hosts peptide sequences
aligned against gene models
• Can we use informatics to improve this strategy...?
Xia et al. (2008) Genome Biology,9(7),pp.R11

Challenges of proteogenomics• Main informatics challenge:
– A protein can usually only be identified if the gene sequence has been correctly predicted from the genome
– In effect, would like to use MS data directly for gene discovery– But... searching a six frame genome translation is problematic
• All peptide and protein identifications are probabilistic– False positive rate is proportional to search database size
• On average only ~10-20% of spectra identify a peptide– Need methods that can exploit the rest of the meaningful spectra
• When gene models change, protein identifications are out of date– No dynamic interaction between proteome and genome data

Automated re-annotation pipeline
Planned improvements to the informatics workflow:
1. Re-querying pipeline– each time gene models change, all mass spectra are automatically re-
queried2. Integrate peptide evidence directly into gene finding
software3. Maximising the number of informative mass spectra4. Attempt to optimise algorithms for de novo sequencing of
peptides5. N-terminal proteomics
- Could be used to confirm gene initiation point

Spectra
Multiple database search
engines
Official gene set
Confirmed official model
Multiple database search
engines
Modified de novo
algorithms
Novel ORF, splice junction
Promote alternative model
Stage 1
Stage 2
Gene Finder
Proteomic evidence
Alternative gene models
Genome sequence
• Spectra searched in series• Peptide evidence confirming official gene, alternative model, new ORF:
• Direct flow back to modified gene finder• Produce new set of predictions
• Iteratively improve number of spectra identified• In each iteration, fewer spectra flow on to stage 2 and 3
Stage 3
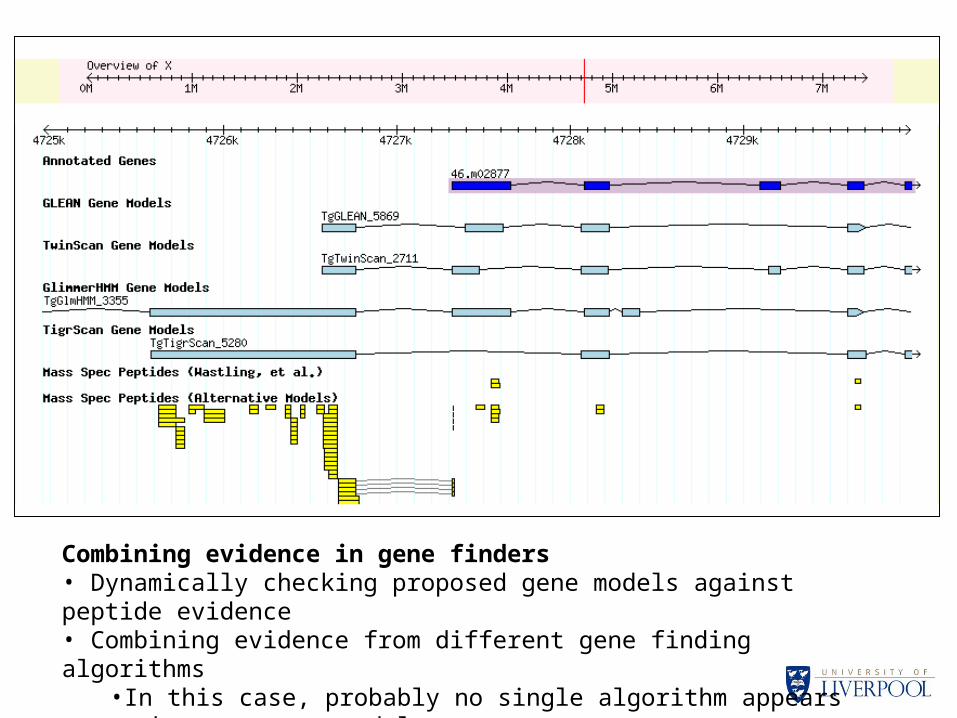
Combining evidence in gene finders• Dynamically checking proposed gene models against peptide evidence • Combining evidence from different gene finding algorithms
•In this case, probably no single algorithm appears to have correct model

Query spectra using different search engines
Jones et al. Improving sensitivity in proteome studies by analysis of false discovery rates for multiple search engines. PROTEOMICS, in press (2008)
• Each search engine produces a different non-standard score of the quality of a match • Developed a search engine independent score, based on analysis of false discovery rate
• Identifications made more search engines are scored more highly• Can generate 35% more peptide identification than best single search engine
Omssa
X!Tandem
MascotPeptides
Combined list
Peptides
Peptides
Omssa X!Tandem
Mascot
Peptide identifications
RescoringAlgorithm
(FDR)

Conclusions
• Proteome data is able to confirm gene models are correct– Currently data under-exploited
• Challenges searching mass spec data directly against the genome for gene discovery
• Build re-querying pipeline– Iteratively improve gene models– Improve capabilities for using multiple search engines– Integrate peptide evidence directly into gene finders

Acknowledgments
• Data from Wastling lab:– Dong Xia, Sanya Sanderson, Jonathan Wastling
• ToxoDB at Upenn– David Roos, Brian Brunk
Email: [email protected]





























