Embed Size (px)
Citation preview

PNAS
Supporting Information
Genomic and transcriptomic analyses of the medicinal fungus
Antrodia cinnamomea for its metabolite biosynthesis and
sexual development.
Lu et al.
Supplementary figures and text.
Supplementary text Supplementary methods
Supplementary Figure S1 De novo genome assembly, gene annotation and transcriptomic analysis.
Supplementary Figure S2 Blastp search for protein homologues with E-value at 1e-05 in NCBI nr database.
Supplementary Figure S3 Differential gene expression analysis of the four transcriptomes.
Supplementary Figure S4 Clusters of triterpenoid and P450 genes and domain organization of polyketide syntethases.
Supplementary Figure S5 tRNA predictions using tRNA Scan-SE.
Supplementary Figure S6 Inter-strain variants identified between strains S27 and S32.
Supplementary Figure S7 S27 and S32 are pure monokaryons.
Supplementary Figure S8 Representative secondary metabolites and biosynthesis pathways of triterpenoids and antrocamphin.
Supplementary Table S1 Summary of the Roche 454 and Illumina data used for assembling the S27 genome.
Supplementary Table S2 Summary of the NGS data obtained for the various A. cinnamomea strains for transcriptome analyses.
Supplementary Table S3 Metrics of the transcriptome assembly of mycelium tissues from two Antrodia strains.
Supplementary Table S4 Statistics of the raw PE-reads from preprocessing to transcriptome single reads mapping.
Supplementary Table S5 Stats of the gene models of A. cinnamomea genome with various functional and expression support.
Supplementary Table S6 The core meiotic genes in the genome of A. cinnamomea.
Supplementary Table S7 Genes and enzymes in KEGG pathways.
Supplementary Table S8 Triterpenoid biosynthesis related enzymes in A. cinnamomea S27 genome.
Supplementary Table S9 Classification of 96 putative CYP proteins into 39 families.
Supplementary Table S10 Sequences of the putative CYP protein coding genes.
Supplementary Table S11 Enzymes for ubiquinone biosynthesis.
Supplementary Table S12 Number of genes in different functional category related to terpenoid biosynthesis.
Supplementary Table S13 Functional description of the genes uniquely expressed in AT and AM.
Supplementary Table S14 Clusters of gene counts of differential expressed genes of triterpenoid pathway.
Supplementary Table S15 IDs and definitions of the GO terms enriched in only one DEG cluster of triterpenoid pathway.
Supplementary Table S16 The number of genes of GO terms which are enriched within the differential expressed gene cluster of triterpenoid genes.
Supplementary Table S17 Classification of putative carbohydrate metabolism proteins of A. cinnamomea based on CaZy database.
Supplementary Table S18 rRNA and tRNA prediction of A. cinnamomea and comparison with G. lucidum.

Supplementary Table S19 A. cinnamomea S27 ribosomal RNA loci and conservation regions.
Supplementary Table S20 Statistics of repeat sequence of the S27 scaffolds from RepeatModeler.
Supplementary Table S21 Statistics of the genomic Illumina reads after pre-processing steps.
Supplementary Table S22 SNP analysis and occurrence of SNPs in genes uniquely expressed in S27 and/or S32.
Supplementary Table S23 Expression of the triterpenoid pathway and P450 genes in the six clusters identified on different scaffolds.

Supplementary methods.
Methods of DNA/RNA extraction. The genomic DNA of S27 was extracted using
a protocol of Chang et al. (1) with modifications. Briefly, frozen tissue was ground to
fine powder in liquid nitrogen. Samples were combined into 2g of powder per
extraction in 20ml of pre-warmed extraction buffer at 60℃, and incubated for 1 hr
with occasional mixing. The solution was subjected to two rounds of chloroform
extraction, and DNA was precipitated by cold isopropanol. The pellet was
resuspended in 3ml of SSTE and treated with RNaseA (total 3mg) at 37℃ overnight.
The suspension was then treated with Proteinase K (3mg) at 50℃ for 30 min, and
extracted once with phenol:chloroform:isoamyl alcohol (25:24:1) and again with
chloroform. DNA was then precipitated by ethanol and the pellet was dissolved in TE.
The genomic DNA was further purified by using AMpure XP beads (Agencourt) to
remove residual RNA. The final samples were checked for purity and quality by
NanoDrop and gel electrophoresis, and quantification was measured by Qubit
(Invitrogen).
Total RNA samples of S27 and S32 were extracted from frozen mycelia, using
the Hot Acidic Phenol method (2) with modifications. The finely ground mycelium
powder was added with 10ml pre-warmed TES buffer and equal volume of acidic
phenol (pH4.3). The mixture was incubated at 65℃ for 1 hr with occasional shaking.
After chilling on ice for 5 min, the solution was centrifuged and aqueous phase was
extracted twice with equal volume of phenol:chloroform:isoamylalcohol, followed by
final extraction with chloroform. RNA was then precipitated with ethanol and the
pellet was water containing RNaseOUT (Invitrogen), and added with DNaseI (New
England Biolabs, 2U/μl) to digest residual DNA. The RNA solution was subjected to
two rounds of phenol:chloroform extraction and one round of chloroform extraction.
RNA was precipitated by isopropanol in the presence of high salt precipitation
solution (0.8M Sodium citrate and 1.2M NaCl) at -20℃. The derived RNA pellet was
then dissolved in water with RNAseOUT at 37℃ for 15 min and stored in aliquots at
-80℃.
Annotation of non-protein coding genes. rRNAs were identified by using
RNAmmer (3) software v. 1.2 with E-value cutoff at 1x10-5. Prediction of tRNA
regions and structures was carried out by tRNAscan-SE (4) software v 1.3.1 with
strict parameter and relaxed cutoff (-32.1) of EuFindtRNA parameter.
Transcriptome analysis and differential gene expression. The raw sequence
reads were trimmed for low quality bases and adapter by Trimmomatic v0.30 (5) with

minimum length 36 bp. For transcriptome profiling by RNA-seq analysis (6), we
aligned reads to the S27 reference genome by Bowtie2 v2.1.0 (7) and TopHat v2.0.8b
(8, 9). Quantification of gene expression was conducted using Cufflinks v2.1.1 (10)
(http://cufflinks.cbcb.umd.edu/) to calculate RPKM (6) (reads per kilobase gene
length per million mapped reads) for all gene models. We quantified the expression
level of S27 from reads by Cufflinks v2.1.1 and normalized it by upper-quartile. A
gene will not be considered as expressed gene if all RPKMs of the four samples are
less than 0.5. Only the expressed genes of the normalized datasets from different
RNA samples were analyzed for differential gene expression using NOISeq (11) of
the Bioconductor package for q=0.8
(http://www.bioconductor.org/packages/2.12/bioc/html/NOISeq.html).
Repeat analysis. Genome repeat sequence analysis was conducted using
RepeatModeler version open-1.0.7 (12) on the S27 scaffolds.
Genome variations between S27 and S32. For genomic mapping, the first
bases of the Illumina PE reads were used as input. The S27 and S32 reads were
preprocessed by Trimmomatic-3.0 to remove the adapters and read bases with quality
< 15. The trimmed reads with length < 36 were removed. For variation identification,
we used the BWA aligner version 0.6.2 (13) for Illumina paired-end reads of the S27
and S32 samples, generating a mapping rate > 93% (SI Appendix, Table S18). We
employed SAMtools-0.1.18 (14) to detect single nucleotide polymorphisms (SNPs)
and small INDELs, using two criteria: (a) read depth > 60 % of average depth, and (b)
allele frequency =1. In addition, the SNP/INDEL sites present in the S27 background
and those located in repeat sequences were removed. The remaining S32-specific
mutations were then subjected to functional analysis using snpEff (15).
References
1. Chang S. PJ, and Cairney J (1993) A simple and efficient method for isolating RNA from
pine trees. Plant Molecular Biology Reporter 11(2):4.
2. Kohrer K & Domdey H (1991) Preparation of high molecular weight RNA. Methods in
enzymology 194:398-405.
3. Lagesen K, et al. (2007) RNAmmer: consistent and rapid annotation of ribosomal RNA
genes. Nucleic acids research 35(9):3100-3108.
4. Schattner P, Brooks AN, & Lowe TM (2005) The tRNAscan-SE, snoscan and snoGPS
web servers for the detection of tRNAs and snoRNAs. Nucleic acids research 33(Web
Server issue):W686-689.
5. Bolger AM, Lohse M, & Usadel B (2014) Trimmomatic: a flexible trimmer for Illumina
sequence data. Bioinformatics 30(15):2114-2120.
6. Mortazavi A, Williams BA, McCue K, Schaeffer L, & Wold B (2008) Mapping and

quantifying mammalian transcriptomes by RNA-Seq. Nature methods 5(7):621-628.
7. Langmead B & Salzberg SL (2012) Fast gapped-read alignment with Bowtie 2. Nature
methods 9(4):357-359.
8. Kim D & Salzberg SL (2011) TopHat-Fusion: an algorithm for discovery of novel fusion
transcripts. Genome Biol 12(8):R72.
9. Kim D, et al. (2013) TopHat2: accurate alignment of transcriptomes in the presence of
insertions, deletions and gene fusions. Genome Biol 14(4):R36.
10. Trapnell C, et al. (2013) Differential analysis of gene regulation at transcript resolution
with RNA-seq. Nature biotechnology 31(1):46-53.
11. Tarazona S. F-TP, Ferrer A. and Conesa A. (2012) NOISeq: Exploratory analysis and
differential expression for RNA-seq data.), 2.0.0.
12. Smit A, Hubley, R (2008-2010) RepeatModeler Open-1.0. p
(http://www.repeatmasker.org).
13. Li H & Durbin R (2009) Fast and accurate short read alignment with Burrows-Wheeler
transform. Bioinformatics 25(14):1754-1760.
14. Li Heng et. al. 2009. The sequence alignment/map format and SAMtools. Bioinformatics,
25 (16) : 2078 – 2079.
15. Cingolani P, et al. (2012) A program for annotating and predicting the effects of single
nucleotide polymorphisms, SnpEff: SNPs in the genome of Drosophila melanogaster
strain w1118; iso-2; iso-3. Fly 6(2):80-92.

A"
B"

Figure S1. De novo genome assembly, gene annotation and transcriptomic analysis. A, Flowcharts of the de novo genome assembly pipeline for assembling the scaffolds of the single nucleated genome of A. cinnamomea strain S27. B, Pipeline of gene model integration. C, The first integration classified GeneMark and FgeneSH models by genome position. Overlapping gene model carried out by applying the filter score of the isotig alignment and blast score. Unique gene set is selected either with blast hits or RPKM > 1. D, Second integration. Classifying the first integrated gene set and MARKER genes by overlapping region share more than 10% of shorter one. Selected MAKER genes if same blast hits within overlapping pair; otherwise, selected both genes. Unique genes selected by blast hits with E-value threshold 1e-05. E, Transcriptome analysis workflow of RNA-seq data. Reads with base quality score lower than Q15 are removed by Trimmomatic-v0.3.0, and trimmed reads shorter than 36nt are discarded. Bowie2-v2.1.0, Tophat2-v2.0.8b and Cufflinks-v2.1.1 are used to calculate RPKMs. The RPKMs are normalized by up-quartile analysis. The genes with a normalized RPKM <0.5 in all four samples are considered non-expressed and removed. We only analyzed the genes differentially expressed between any two of the four samples determined by NOIseq (q = 0.8).�
C" D"
E"

0" 500" 1,000" 1,500" 2,000" 2,500" 3,000" 3,500" 4,000"
others"Macrophomina"phaseolina"
Plasmodium"yoelii"Tuber"melanosporum"
Grifola"frondosa"Methanobrevibacter"ruminan@um"
Nematostella"vectensis"Len@nula"edodes"Dacryopinax"sp."
Rhizoctonia"solani"Auricularia"delicata"
Piriformospora"indica"Schizophyllum"commune"Fomi@poria"mediterranea"
Agaricus"bisporus"Phanerochaete"chrysosporium"
Punctularia"strigosozonata"Taiwanofungus"camphoratus"
Coniophora"puteana"Coprinopsis"cinerea"
Laccaria"bicolor"Stereum"hirsutum"
Phanerochaete"carnosa"Serpula"lacrymans"
Moniliophthora"perniciosa"Dichomitus"squalens"Trametes"versicolor"
Pos@a"placenta"Ceriporiopsis"subvermispora"
Fibroporia"radiculosa"
Top$Hit(species(distribu0on(
BLAST(Top$Hits(
87"104"
4,257"4,611"
6,528"6,552"6,745"6,939"7,077"7,170"7,183"7,329"
7,696"7,776"
0" 1,000" 2,000" 3,000" 4,000" 5,000" 6,000" 7,000" 8,000"
Ganoderma"lucidam"Taiwanofungus"camphoratus"Moniliophthora"perniciosa"
Pos@a"placenta"Laccaria"bicolor"
oniophora"puteana"Coprinopsis"cinerea"
Ceriporiopsis"subvermispora"Stereum"hirsutum"
Phanerochaete"carnosa"Serpula"lacrymans"
Dichomitus"squalens"Trametes"versicolor"
Fibroporia"radiculosa"
A"
Figure S2. Blastp search for protein homologues with E-value at 1e-05 in NCBI nr database. A, Distribution of counts of top-hit species from Bast2GO. B, One-to-one hit distribution on the species above Taiwanofungus in Fig S2A plus Ganoderma lucidum.�
B"
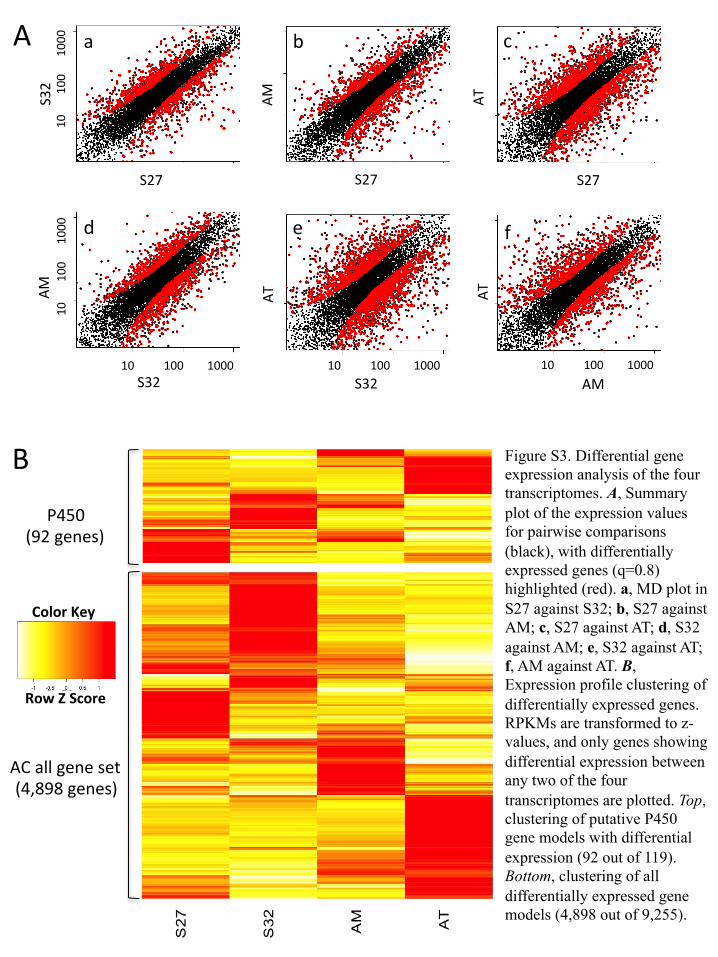
P450%%(92%genes)%
AC%all%gene%set%(4,898%genes)%
Color%Key%%
Row%Z%Score%
a b c
d e f�
''''''''''''''''10''''''''''100''''''''1000�
AM�
AT�
AT�
AT�
S27� S27� S27�
S32� S32� AM�
'''''''''''10'''''''10
0''''''100
0 �S32�
'''''''''''10'''''''10
0''''''100
0 �AM�
''''''''''''''''10''''''''''100''''''''1000� ''''''''''''''''10''''''''''100''''''''1000�
A%
B% Figure S3. Differential gene expression analysis of the four transcriptomes. A, Summary plot of the expression values for pairwise comparisons (black), with differentially expressed genes (q=0.8) highlighted (red). a, MD plot in S27 against S32; b, S27 against AM; c, S27 against AT; d, S32 against AM; e, S32 against AT; f, AM against AT. B, Expression profile clustering of differentially expressed genes. RPKMs are transformed to z-values, and only genes showing differential expression between any two of the four transcriptomes are plotted. Top, clustering of putative P450 gene models with differential expression (92 out of 119). Bottom, clustering of all differentially expressed gene models (4,898 out of 9,255).�

scaf4&
26.6$Kb$
scaf14&91$Kb$
scaf17&12.7Kb$
P450&genes&on&forward&strand&Triterpenoid&pathway&genes&on&forward&strand&P450&genes&on&reverse&strand&Triterpenoid&pathway&genes&on&reverse&strand&
scaf2&67.3$Kb$ 17.8$Kb$
scaf5&6.4$Kb$ 8.7$Kb$ 7$Kb$
A&
scaf24&
53$Kb$
ACg003224 ACg005327 ACg005636 ACg008849
ACg003224&
ACg005327&
ACg005636&
ACg008849&
B&
Figure S4. Clusters of triterpenoid and P450 genes and domain organization of polyketide syntethases. A, Triterpenoid pathway and P450 gene clusters in the A. cinnamomea genome. Red arrows and green arrows show P450 genes and triterpenoid biosynthetic (non-P450) pathway genes, respectively. Solid and open arrows represent the forward strand and on the backward strand, respectively. B, Prediction of the domain organization of four putative multi-modular polyketide synthases in the A. cinnamomea genome. All four proteins contain acyl-carrier protein domains.�

tRNA%of%A.%cinnamomea%S27%
Ala$(9)$Gly$(15)$Pro$(6)$Thr$(7)$Val$(8)$Ser$(9)$Arg$(10)$Leu$(9)$Phe$(5)$Asn$(5)$Lys$(7)$Asp$(8)$Glu$(7)$His$(3)$
Figure S5. tRNA predictions using tRNA Scan-SE. A total of 134 tRNA genes and 14 pseudogenes were predicted.
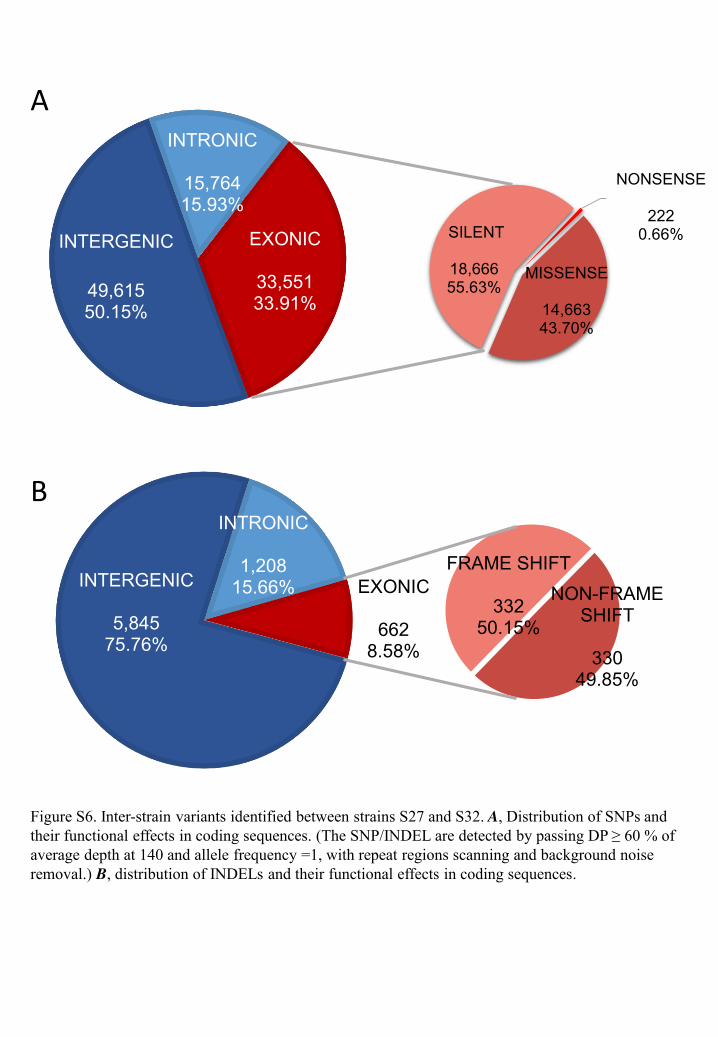
INTERGENIC
49,61550.15%
INTRONIC
15,76415.93%
EXONIC
33,55133.91%
MISSENSE
14,66343.70%
SILENT
18,66655.63%
NONSENSE
2220.66%
INTERGENIC
5,84575.76%
INTRONIC
1,20815.66% EXONIC
6628.58%
FRAME SHIFT
33250.15%
NON-FRAME SHIFT
33049.85%
A
B
Figure S6. Inter-strain variants identified between strains S27 and S32. A, Distribution of SNPs and their functional effects in coding sequences. (The SNP/INDEL are detected by passing DP ≥ 60 % of average depth at 140 and allele frequency =1, with repeat regions scanning and background noise removal.) B, distribution of INDELs and their functional effects in coding sequences.

10.7% 13.7%
155.4%
297.3%
0%50%100%150%200%250%300%350%
S27% S32% AM% AT%
RPKM%of%clp1%
Strain%
A%
B%
Figure S7. S27 and S32 are pure monokaryons. A, Photos of mycelia of the dikaryon B496 and the monokaryons S27 and S32. Arrowheads indicate clamp or pseudoclamp structures. B, Expression of the clamp formation genes clp1 was much higher in AT and AM compared to in S27 and S32.
B496%Dikaryon� S27�
S32�

Figure S8. Representative secondary metabolites and biosynthesis pathways of
triterpenoids and antrocamphin. Representative secondary metabolites of A.
cinnamomea. (1) Ubiquinone: antroquinonol; (2) Benzenoids:
1,4-dimethoxy-2,3-methylenedioxy-5-methylbenzene; (3) maleic anhydride
derivatives: antrocinnamomins C; (4) lanostane-type triterpenoids: dehydroeburicoic
acid; (5) ergostane-type triterpenoids: antcin C; and (6) polyketides: antrocamphin A
!

Table S1. Summary of the Roche 454 and Illumina data used for assembling the S27
genome. Data type No. of reads Read
length (bp) Fragment
length1 (bp)
No. of
bases (Mb) Coverage
2
(x) No.
of files
454 SR 715,689 571.8 NA 409 12.7 2
454 SR 392,462 325.8 NA 128 4 1
454 SR 450,780 391.7 NA 177 5.5 1
454 PE (20kb) 592,222 313.9 NA 186 5.8 1
GAIIx PE 52,242,470 151 221 7,888 245 2
GAIIx PE 61,066,692 151 475 9,221 286 2
GAIIx MP 62,876,846 80 3,672 5,030 156 2
GAIIx MP 65,609,524 80 5,424 5,249 163 2 1Evaluation of fragment length was based on mapping result.
2Coverage is calculated based on the estimated genome size of 32.2 Mb.
Abbreviations: SR: shotgun read; PE: paired end; LPE, long insert PE; MP: mate pair.

Table S2. Summary of the NGS data obtained for the various A. cinnamomea strains
for transcriptome analyses.
Strain Data type Total read counts Read length (bp) Fragment size (bp) Total bases (Mb)
S27 454 SE 1,005,759 448 NA 451
Hiseq PE 144,843,514 100 ~300 144,84
S32 454 SE 1,023,220 482 NA 493
HiSeq PE 166,670,862 100 ~300 16,667
AM HiSeq PE 147,671,870 100 ~300 14,767
AT HiSeq PE 171,657,456 100 ~300 12,763

Table S3. Metrics of the transcriptome assembly of mycelium tissues from two
Antrodia strains.
Input S27 S32
Number of reads 1,005,759 1,023,220
Number of bases 450,592,501 493,156,641
Number of reads trimmed 1,005,743 (100.00%) 1,023,197 (100.00%)
Number of bases trimmed 450,046,957 (99.90%) 492,278,798 (99.80%)
Isogroup# Metrics
Number of isogroups 7,503 7,541
Average contig count 1.9 2.9
Largest contig count 264 212
Number with one contig 5,558 4,230
Average isotig count 1.5 2.6
Largest isotig count 79 96
Number with one isotig 5,592 4,268
Isotig*
Metrics
Number of Isotigs 11,622 19,478
Average contig count 2.6 4.6
Largest contig count 16 16
Number with one contig 5,558 4,230
Number of bases 20,541,573 49,517,068
Average isotig size 1,767 2,542
N50 isotig size 2,105 3,329
Largest isotig 9,236 13,371
Large
Contig†
Metrics
Number of contigs 8,091 9,391
Number of bases 11,876,562 13,125,720
Average contig size 1,467 1,397
N50 contig size 1,721 1,656
Largest contig size 8,187 10,357
All
Contig†
Metrics
Number of contigs 14,135 22,225
Number of bases 12,972,625 15,371,737
Average contig size 918 692
†Contigs containing reads which are shared by other contigs. *Isotigs sharing reads may be splicing variants of a single gene region. #Isogroup may contain two or more isotigs.

Table S4. Statistics of the raw PE-reads from preprocessing to transcriptome single
reads mapping.
HiSeq Sequencing
stats S27 S32 AM AT
# Raw Reads
Sequencing read
length PE 2*100 PE 2*100 PE 2*100 PE 2*100
Read count 144,834,514 166,670,862 147,671,870 171,657,456
Total bases (bp) 14,483,451,400 16,667,086,200 14,767,187,000 17,165,754,600
# Read Trimming
(by Trimmomatic-
3.0)
Average
processed read
length 86 84 85 86
Read count
remained 94.85% 96.86% 95.86% 94.71%
Total bases
remained 86.97% 87.80% 91.05% 89.80%
# Mapping onto
S27 scaffold
genome
Input reads 140,070,951 161,433,327 13,749,113 158,330,798
Mapped 91.50% 87.31% 74.97% 69.63%

Table S5. Stats of the gene models of A. cinnamomea genome with various functional
and expression support.
Annotation category Counts Percentage
Total gene model 9,254 100.00%
Gene models with NR blast hit (e<10-5
) 8,911 96.29%
Gene models with NR blast hit (e<10-10
) 8,717 94.20%
Gene models with GO terms 6,396 69.12%
Gene models with EC numbers 1,135 12.26%
Gene models with Pfam support 6,226 67.28%
Gene models with CDD support 2,648 28.61%
Gene models with S27 isotig support 6,415 69.32%
Gene models with S32 isotig support 6,505 70.29%
Gene models with all isotig support 7,165 77.43%
Gene models considered "expressed"1 8,079 87.30%
Total number of gene models with support 9,248 99.94% 1Gene models with RPKM≥0.5 in at least one of the four RNA samples.

Table S6. The core meiotic genes in the genome of Antrodia cinnamomea. The search
of homologs was carried out using collection of query proteins (Ref. 1-4).
Gene Function A. cinnamomea
protein I.D. E values
IME1 Master inducer of meiosis in S. cerevisiae. - -
IME2 A serine/threonine protein kinase involved in activation of S.
cerevisiae meiosis. IME2 expression is positively regulated by
Ime1. ACg001560 2e-48
STE12 Mating transcriptional factor required for meiosis initiation in
S. cerevisiae. ACg003227 2e-48
SPO7 Putative regulatory subunit of Nem1p-Spo7p phosphatase
holoenzyme; required for normal nuclear envelope
morphology, premeiotic replication, and sporulation ACg007802 5e-04
SPO11 Meiosis-specific protein that catalytic meiotic DNA DSBs. ACg004129 4e-23
REC102 Spo11 accessory factor. - -
REC103 (SKI8)
Spo11 accessory factor. - -
REC114 Spo11 accessory factor. - -
MRE11 Nuclease subunit of the MRX complex for DSB resection &
DNA damage checkpoint activation. ACg007863 3e-80
RAD50 Subunit of the MRX complex ACg002432 e-161
XRS2 (NBS1)
Subunit of the MRX complex. Mutations in human NBS1, a
XRS2 homolog, are linked to the autosomal recessive disorder.
C. cinerea Nbs1 protein [AFN01892.1] ACg007172 e-116
SAE2 (COM1)
S. cerevisiae Sae2, Schizosaccharomyces pombe CtIP and
Cryptococcus neoformans Sae2 [JGI gene ID: 6285] are
involved in meiotic and mitotic DSB repair. ACg005805 6e-22
EXO1 Protein involved in DNA repair and processing of meiotic
DSB. ACg005778 2e-48
SGS1 A RecQ family nucleolar DNA helicase that forms a
heterodimer with Top3 and regulates chromosome synapsis
and meiotic joint molecule/crossover formation. ACg007726 e-128
DMC1 Meiosis-specific RecA-like strand exchange protein ACg002890 1e-91
RAD51 RecA-Like strand exchange protein ACg001504 e-119
HOP2 Meiosis-specific complexes with Mnd1 to promote Dmc1
function ACg006321 1e-05
MND1 Meiosis-specific, complexes with Mnd1 to promote Dmc1
function ACg003486 1e-12
RAD52 Protein that stimulates Rad51-meidated strand exchange & ACg006850 1e-47
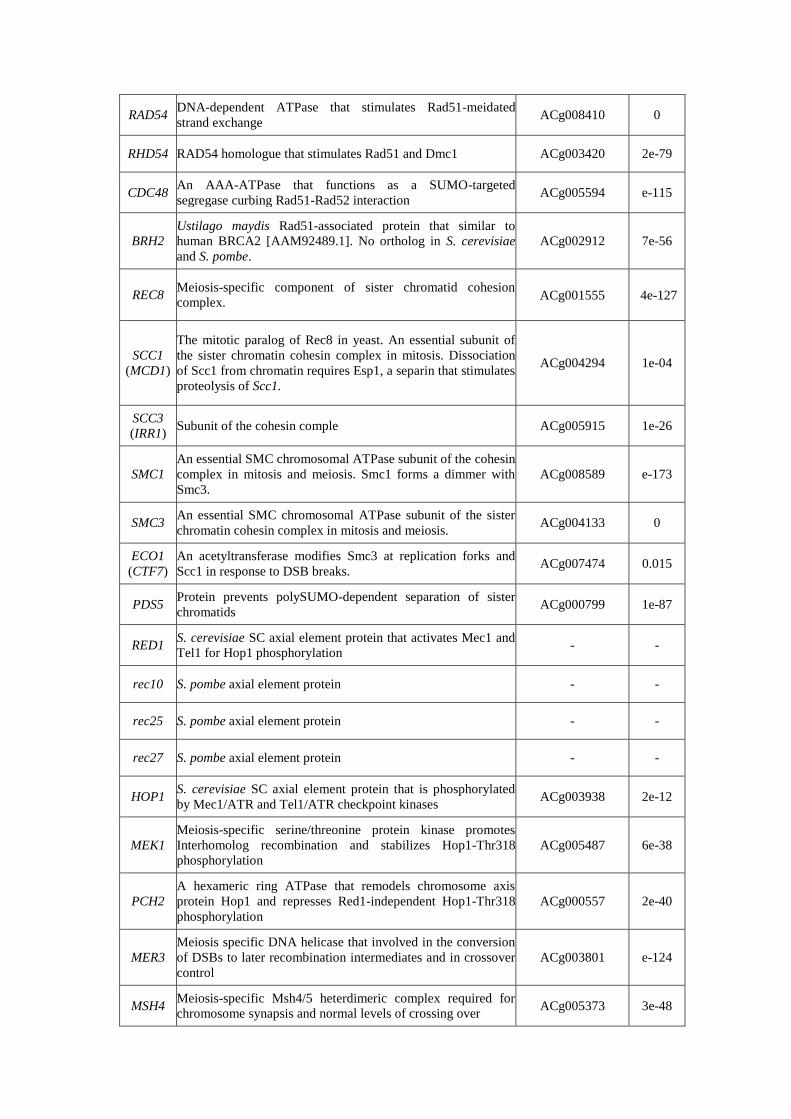
RAD54 DNA-dependent ATPase that stimulates Rad51-meidated
strand exchange ACg008410 0
RHD54 RAD54 homologue that stimulates Rad51 and Dmc1 ACg003420 2e-79
CDC48 An AAA-ATPase that functions as a SUMO-targeted
segregase curbing Rad51-Rad52 interaction ACg005594 e-115
BRH2 Ustilago maydis Rad51-associated protein that similar to
human BRCA2 [AAM92489.1]. No ortholog in S. cerevisiae
and S. pombe. ACg002912 7e-56
REC8 Meiosis-specific component of sister chromatid cohesion
complex. ACg001555 4e-127
SCC1 (MCD1)
The mitotic paralog of Rec8 in yeast. An essential subunit of
the sister chromatin cohesin complex in mitosis. Dissociation
of Scc1 from chromatin requires Esp1, a separin that stimulates
proteolysis of Scc1.
ACg004294 1e-04
SCC3 (IRR1)
Subunit of the cohesin comple ACg005915 1e-26
SMC1 An essential SMC chromosomal ATPase subunit of the cohesin
complex in mitosis and meiosis. Smc1 forms a dimmer with
Smc3. ACg008589 e-173
SMC3 An essential SMC chromosomal ATPase subunit of the sister
chromatin cohesin complex in mitosis and meiosis. ACg004133 0
ECO1 (CTF7)
An acetyltransferase modifies Smc3 at replication forks and
Scc1 in response to DSB breaks. ACg007474 0.015
PDS5 Protein prevents polySUMO-dependent separation of sister
chromatids ACg000799 1e-87
RED1 S. cerevisiae SC axial element protein that activates Mec1 and
Tel1 for Hop1 phosphorylation - -
rec10 S. pombe axial element protein - -
rec25 S. pombe axial element protein - -
rec27 S. pombe axial element protein - -
HOP1 S. cerevisiae SC axial element protein that is phosphorylated
by Mec1/ATR and Tel1/ATR checkpoint kinases ACg003938 2e-12
MEK1 Meiosis-specific serine/threonine protein kinase promotes
Interhomolog recombination and stabilizes Hop1-Thr318
phosphorylation ACg005487 6e-38
PCH2 A hexameric ring ATPase that remodels chromosome axis
protein Hop1 and represses Red1-independent Hop1-Thr318
phosphorylation ACg000557 2e-40
MER3 Meiosis specific DNA helicase that involved in the conversion
of DSBs to later recombination intermediates and in crossover
control ACg003801 e-124
MSH4 Meiosis-specific Msh4/5 heterdimeric complex required for
chromosome synapsis and normal levels of crossing over ACg005373 3e-48

MSH5 Meiosis-specific Msh4/5 heterdimeric complex required for
chromosome synapsis and normal levels of crossing over ACg002475 3e-24
ZIP1 S. cerevisiae central element protein of synaptonemal complex - -
ZIP2 S. cerevisiae meiosis-specific protein that involved in normal
synaptonemal complex formation and pairing between
homologous chromosomes during meiosis. - -
ZIP3 (CST9)
S. cerevisiae SUMO E3 ligase that required for synaptonemal
complex formation ACg003668 9e-04
ZIP4 (SPO22)
S. cerevisiae meiosis-specific protein essential for
synaptonemal complex assembly. ACg005454 5e-51
SPO16 S. cerevisiae meiosis-specific protein essential for chromosome
synapsis - -
Ecm11 S. cerevisiae meiosis-specific protein; component of the
synaptonemal complex (SC) along with Gmc2. - -
Gmc2 S. cerevisiae meiosis-specific protein; component of the
synaptonemal complex (SC) along with Ecm11 - -
TEL1 (ATM)
Yeast homolog of human ataxia-telangiectasia mutated (ATM)
protein kinase that controls the levels of meiotic DSBs, DSB
resection and interhomolog recombination ACg004775 1e-81
MEC1 (ATR)
Yeast homolog of human ATR protein kinase that controls
DNA recombination and cell cycle progression in mitosis and
meiosis ACg006123 e-123
RAD17
A component of the 9-1-1 complex (Ddc1-Mec3-Rad17) that
involved in the DNA damage and meiotic pachytene
checkpoints. Homolog of human and S. pombe Rad1 and U.
maydis Rec1 proteins.
ACg001217 1e-14 (Rec1)
RAD24 A subunit of a clamp loader that load the 9-1-1 complex onto
DNA ACg007076 3e-08
KU70 A subunit of the Ku70-Ku80 complex that binds DSB ends to
mediate nonhomologous end joining (NHEJ) and telomere
length maintenance ACg004653 0
KU80 A subunit of the Ku70-Ku80 complex ACg005396 0
LIG4 (DNL4)
The catalytic subunit of DNA ligase 4 complex (Lig4-Lif1-
Nej1) required for NHEJ ACg004756 2e-70
LIF1 (XRCC4)
A component of the DNA ligase IV that is homologous to
mammalian XRCC4 protein. ACg002996 0.035
DNA2 Protein involved in DNA repair and processing of meiotic
DNA double strand breaks ACg007097 e-135
FEN1 (RAD27)
Fen1 is multi-functional nuclease involved in processing
Okazaki fragments during DNA replication, base excision
repair and maintaining genome stability. ACg002509 e-111
MMS4 (Slx2)
A subunit of structure-specific Mms4p-Mus81p endonuclease
that mediates SC-independent class II crossover pathway. - -
MUS81 (Slx3)
The catalytic subunit of structure-specific Mms4p-Mus81p
endonuclease. - -

MLH1 The Mlh1/Pms1 and Mlh1/Mlh3 complex are required for
mismatch repair in mitosis and meiosis. The Mlh1-Mlh3
heterodimer is required for crossing over during meiosis. ACg000922 e-133
MLH3 The catalytic subunit of Mlh1/Mlh3 endonuclease complex
involved in DNA mismatch repair and meiotic recombination. ACg003290 e-160
PMS1 Pms1 forms a dimer with Mlh1. ACg006283 8e-71
YEN1 (GEN1)
Holliday junction resolvase ACg001983 9e-08
MPH1 A 3'-5' DNA helicase similar to FANCM human Fanconi
anemia complementation group protein that involved in error-
free bypass of DNA lesions to stimulate Dna2 and Rad27. ACg001734 1e-81
MSH2 Msh2 forms heterodimers with Msh3 and Msh6 that bind to
DNA mismatches to initiate the mismatch repair process, ACg000996 0
MSH3 Msh3 forms a dimer with Msh2. ACg001134 e-107
MSH6 Msh6 forms a dimer with Msh2. ACg005751 e-144
PMS1 Pms1 forms a dimer with Mlh1. ACg006283 8e-71
SLX1 The catalytic subunit of Slx1-Slx4 endonuclease complex
involved in DNA recombination and repair, functions overlaps
with that of the Sgs1-top3 complex. ACg005838 3e-04
SLX4 The accessory subunit of Slx1-Slx4 endonuclease. - -
SMC5
The Smc5-Smc6 complex, a novel non-structural maintenance
of chromosomes (SMC) component, perturbs meiotic joint
molecule formation and resolution without significantly
changing crossover or non-crossover levels.
ACg007949 0
SMC6 Smc6 forms a dimmer with Smc5 ACg002747 0
NDJ1 (TAM1)
Meiosis-specific telomere protein; required for bouquet
formation and telomere-led rapid prophase movement - -
CSM4 Meiosis-specific protein required for accurate chromosome
segregation during meiosis, bouquet formation and telomere-
led rapid prophase movement - -
MPS3
Nuclear envelope and SPB protein; required with Ndj1p and
Csm4p for meiotic bouquet formation and telomere-led rapid
prophase movement. Member of the SUN protein family,
including S. pombe Sad1.
- -
References
1. Burns C, et al. (2010) Analysis of the Basidiomycete Coprinopsis cinerea
reveals conservation of the core meiotic expression program over half a billion
years of evolution. (Translated from eng) PLoS Genet 6(9):e1001135.
2. Chi J, Mahe F, Loidl J, Logsdon J, & Dunthorn M (2014) Meiosis gene
inventory of four ciliates reveals the prevalence of a synaptonemal complex-
independent crossover pathway. (Translated from eng) Mol Biol Evol

31(3):660-672.
3. Holloman WK, Schirawski J, & Holliday R (2008) The homologous
recombination system of Ustilago maydis. (Translated from eng) Fungal
Genet Biol 45 Suppl 1(1):S31-39.
4. Schurko AM & Logsdon JM, Jr. (2008) Using a meiosis detection toolkit to
investigate ancient asexual "scandals" and the evolution of sex. Bioessays
30(6):579-589.

Table S7. Genes and enzymes in KEGG pathways. (A) Terpenoid backbone
biosynthesis. (B) Sesquiterpenoid and terpenoid biosynthesis. (C) Ubiquinone and
other terpenoid-quinone biosynthesis. (D) Metabolism of xenobiotics by cytochrome
P450. (E) Drug metabolism - cytochrome P450. (F) Fructose and mannose
metabolism. (G) Starch and sucrose metabolism. (G). Number of genes as total counts
vs counts of “expressed gene” (RPKM ≥ 0.5 in at least one transcriptome)
(A) Terpenoid backbone biosynthesis. (Total = 20)
Enzyme Ezyme ID Seqs of
Enzyme Seqs
acetyl-CoA acyltransferase ec:2.3.1.9 1 ACg000346
HMG-CoA synthase ec:2.3.3.10 1 ACg004857
reductase (NADPH) ec:1.1.1.34 1 ACg000822
Kinase ec:2.7.1.36 1 ACg002061
mevalonate phosphate kinase ec:2.7.4.2 1 ACg009255
Decarboxylase ec:4.1.1.33 1 ACg004385
delta-isomerase ec:5.3.3.2 1 ACg001555
geranyl-diphosphate synthase ec:2.5.1.1 2 ACg005547, ACg008849
synthase [geranyl-diphosphate specific] ec:2.5.1.84 1 ACg004020
diphosphate synthase ec:2.5.1.68 1 ACg004020
diphosphate synthase ec:2.5.1.10 1 ACg005547
synthase [(2E,6E)-farnesyl-diphosphate
specific] ec:2.5.1.31 2 ACg003004, ACg004020
diphosphate synthase ec:2.5.1.29 2 ACg007626, ACg008277
diphosphate synthase [geranylgeranyl-
diphosphate specific] ec:2.5.1.85 1 ACg004020
O-methyltransferase ec:2.1.1.100 7 ACg000386, ACg002078,
ACg003108, ACg006939,
ACg007070, ACg008408, ACg008797
(B) Sesquiterpenoid and terpenoid biosynthesis. (Total = 9)
Enzyme Ezyme ID Seqs of Enzyme Seqs
Squalene monooxygenase ec:1.14.13.132 1 ACg008894
sesquiterpene cyclase ec:4.2.3.6 7 ACg001223, ACg003119, ACg003147,
ACg003159, ACg004670, ACg005213,
ACg007731
squalene synthase ec:2.5.1.21 1 ACg004800
(C) Ubiquinone and other terpenoid-quinone biosynthesis. (Total = 7)
Enzyme Ezyme ID Seqs of Enzyme Seqs
methyltransferase ec:2.1.1.114 1 ACg004603
reductase (warfarin-sensitive) ec:1.1.4.1 1 ACg005537
dehydrogenase (quinone) ec:1.6.5.2 1 ACg001532

polyprenyltransferase ec:2.5.1.39 3 ACg007085, ACg007895, ACg008524
Transaminase ec:2.6.1.5 1 ACg006206
(D) Metabolism of xenobiotics by cytochrome P450. (Total = 24)
Enzyme Ezyme ID Seqs of
Enzyme Seqs
epoxide hydrolase ec:3.3.2.9 1 ACg005717
reductase (NADPH) ec:1.1.1.184 2 ACg002146, ACg005929
Dehydrogenase ec:1.1.1.1 2 ACg008552, ACg009092
dehydrogenase
[NAD(P)+] ec:1.2.1.5 5
ACg000306, ACg000817, ACg000847, ACg004671,
ACg007732
Transferase ec:2.5.1.18 10 ACg000589, ACg000736, ACg001212, ACg002721,
ACg005183, ACg005800, ACg007596, ACg008163,
ACg008167, ACg008769
Monooxygenase ec:1.14.14.1 4 ACg001959, ACg005537, ACg005671, ACg007676
(E) Drug metabolism - cytochrome P450. (Total = 22)
Enzyme Ezyme ID Seqs of
Enzyme Seqs
Dehydrogenase ec:1.1.1.1 2 ACg008552, ACg009092
Monooxygenase ec:1.14.13.8 1 ACg005678
dehydrogenase
[NAD(P)+] ec:1.2.1.5 5
ACg000306, ACg000817, ACg000847, ACg004671,
ACg007732
Transferase ec:2.5.1.18 10 ACg000589, ACg000736, ACg001212, ACg002721,
ACg005183, ACg005800, ACg007596, ACg008163,
ACg008167, ACg008769
Monooxygenase ec:1.14.14.1 4 ACg001959, ACg005537, ACg005671, ACg007676
(F) Fructose and mannose metabolism. (Total = 24)
Enzyme Ezyme ID Seqs of
Enzyme Seqs
phosphohexokinase ec:2.7.1.11 1 ACg001977
Isomerase ec:5.3.1.8 2 ACg007002, ACg008758

Isomerase ec:5.3.1.1 1 ACg007001
hexokinase type IV
glucokinase ec:2.7.1.1 1 ACg005983
endo-1,4-beta-mannosidase ec:3.2.1.78 3 ACg001443, ACg003497, ACg005772
Lyase ec:4.2.2.3 1 ACg001671
hexose diphosphatase ec:3.1.3.11 1 ACg003779
guanylyltransferase (GDP) ec:2.7.7.22 2 ACg003462, ACg007434
Synthase ec:1.1.1.271 1 ACg007872
Aldolase ec:4.1.2.13 1 ACg004401
phosphofructokinase 2 ec:2.7.1.105 2 ACg006912, ACg007738
Reductase ec:1.1.1.21 6 ACg000461, ACg005285, ACg005624,
ACg005631, ACg006938, ACg008158
2-dehydrogenase ec:1.1.1.14 1 ACg000383
mannose phosphomutase ec:5.4.2.8 1 ACg008678
(G) Starch and sucrose metabolism. (Total = 49) Enzyme Ezyme ID Seqs of
Enzyme Seqs
Phosphorylase ec:2.4.1.1 1 ACg000144
Isomerase ec:5.3.1.9 1 ACg008705
hexokinase type IV glucokinase ec:2.7.1.1 1 ACg005983
endo-1,4-beta-D-glucanase ec:3.2.1.4 1 ACg005614
1,4-alpha-glucosidase ec:3.2.1.3 1 ACg002651
Glycogenase ec:3.2.1.1 2 ACg007389, ACg007704
1,3-beta-glucosidase ec:3.2.1.58 8 ACg000047,ACg000185,
ACg001971,ACg002915,
ACg004862,ACg007444,
ACg007475,ACg008469 endo-1,3-beta-D-glucosidase ec:3.2.1.39 1 ACg001852
amylo-1,6-glucosidase ec:3.2.1.33 1 ACg004750
Trehalase ec:3.2.1.28 2 ACg001892, ACg005648
Gentiobiase ec:3.2.1.21 2 ACg004065, ACg007761
Maltase ec:3.2.1.20 2 ACg000270, ACg004084
pectin depolymerase ec:3.2.1.15 3 ACg005952, ACg005954,
ACg006785 Uridylyltransferase ec:2.7.7.9 2 ACg003321, ACg003322
glucose 6-phosphate phosphatase ec:3.1.3.9 2 ACg000754, ACg005727
4-alpha-galacturonosyltransferase ec:2.4.1.43 1 ACg000224
Synthase ec:2.4.1.34 11 ACg003679,ACg005906,
ACg006298,ACg006299,
ACg007479,ACg008254,
ACg008255,ACg008256,
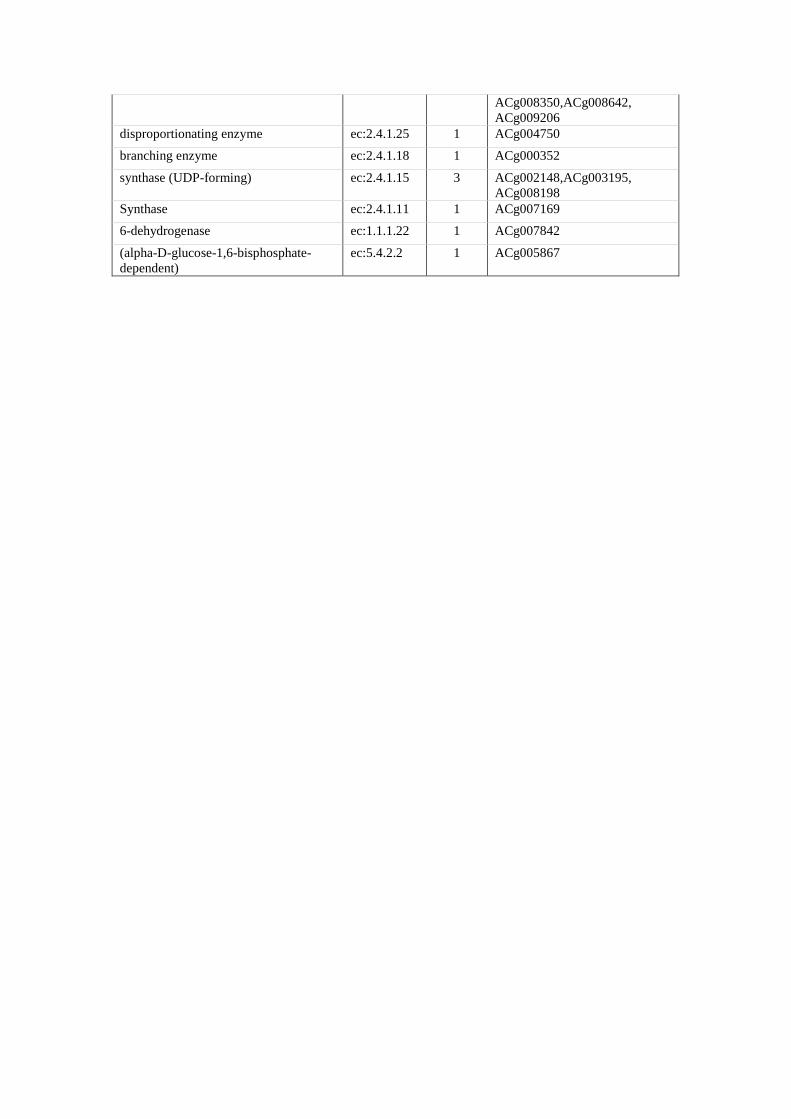
ACg008350,ACg008642,
ACg009206 disproportionating enzyme ec:2.4.1.25 1 ACg004750
branching enzyme ec:2.4.1.18 1 ACg000352
synthase (UDP-forming) ec:2.4.1.15 3 ACg002148,ACg003195,
ACg008198 Synthase ec:2.4.1.11 1 ACg007169
6-dehydrogenase ec:1.1.1.22 1 ACg007842
(alpha-D-glucose-1,6-bisphosphate-
dependent) ec:5.4.2.2 1 ACg005867

Table S8. Triterpenoid biosynthesis related enzymes in A. cinnamomea S27 genome. Num. of
sequences Triterpenoid biosynthesis related enzymes
1 AACT: acetyl-CoA acetyltransferase, [EC:2.3.1.9], K00626;
1 HMGS: 3-hydroxy-3-methylglutaryl-CoA synthase, [EC:2.3.3.10], K01641;
1 HMGR: 3-hydroxy-3-methylglutaryl-CoA reductase, [EC:1.1.1.34], K00021;
1 MVK: mevalonate kinase, [EC:2.7.1.36], K00869;
1 MPK: phosphomevalonate kinase, [EC:2.7.4.2], K00938;
1 MVD: pyrophosphomevalonate decarboxylase, [EC:4.1.1.33], K01597;
1 IDI: isopentenyl-diphosphate isomerase, [EC: 5.3.3.2], K01823;
2 GPPs: geranyl diphosphate synthase, [EC: 2.5.1.1], K00787, K00804;
1 FPPs: EC 2.5.1.68 (2Z,6E)-farnesyl diphosphate synthase
1 FPPs: farnesyl diphosphate synthase, [EC: 2.5.1.10], K00787, K00804;
2 GGPPs: geranylgeranyl diphosphate synthase; farnesyltransferase [EC 2.5.1.29]
1 SPS1/2: all-trans-nonaprenyl diphosphate synthase [geranylgeranyl-diphosphate specific][EC 2.5.1.85]
1 SPS2: all-trans-nonaprenyl-diphosphate synthase [EC 2.5.1.84]
7 STE14: protein-S-isoprenylcysteine O-methyltransferase [EC 2.1.1.100]
2 UPPs: Ditrans,polycis-undecaprenyl-diphosphate synthase ((2E,6E)-farnesyl- diphosphate specific) [EC 2.5.1.31]
1 SQS: squalene synthase, [EC: 2.5.1.21], K00801;
1 SE: squalene monooxygenase, Squalene epoxidase [EC:1.14.13.132] [KO:K00511]
1 OSC/LSS: Oxidoqsualene cyclase/Lanosterol synthase [EC:5.4.99.7] [ACg008680]
24 Mono-TPS: monoterpene synthase [EC:4.2.3.-]
7 sesquiterpene cyclase/ trichodiene synthase [EC: 4.2.3.6] [Q6WP50.1, P13513.1, 2OA6_A, 2OA6_B, 2OA6_C, 2OA6_D] {map00909} [ACg001223, ACg003119, ACg003147, ACg003159, ACg004670, ACg005213, ACg007731]
3 COQ2: 4-hydroxybenzoate polyprenyltransferase (EC:2.5.1.39) [ACg007085, ACg007895, ACg008524]
1 COQ3: polyprenyldihydroxybenzoate methyltransferase (EC2.1.1.114) [ACg004603] map00130
14 PKS: polyketide synthase [XP_001876029.1][EC:2.3.1.206] [ACP-domain containing: ACg003224, ACg005327, ACg005636 and ACg008449; no ACP domain: ACg000077, ACg000788, ACg000930, ACg002831, ACg003519, ACg003904, ACg005691, ACg006323, ACg008872, ACg009092]
1 OAC: Polyketide cyclase [EC:4.4.1.26] [ACg002677]
1 Lignin peroxidase [EC: 1.11.1.14] [ACg002413]
1 Manganese peroxidase [EC:1.11.1.13] [ACg008146]
2 Lactoperoxidase [EC: 1.11.1.7] [ACg004767, ACg007568]
1 Sterol 14-α-demethylase, CypX, CYP51F1 [ACg002141]

Table S9. Classification of 96 putative CYP proteins into 39 families.
CYP_family A. cinnamomea G.lucidum P. placenta P. chrysosporium
CYP51 1 2 1 1
CYP53 2 1 7 1
CYP61 0 1 1 1
CYP63 6 6 5 7
CYP66 1 0 0 0
CYP502 0 1 4 1
CYP504 10 0 0 0
CYP505 5 4 2 7
CYP512 6 22 14 14
CYP530 1 0 0 0
CYP537 1 1 2 0
CYP539 1 0 0 0
CYP609 1 0 0 0
CYP619 1 0 0 0
CYP620 1 0 0 0
CYP642 0 1 0 0
CYP645 2 0 0 0
CYP5027 0 0 9 0
CYP5035 1 16 3 13
CYP5036 0 0 0 5
CYP5037 6 6 13 5
CYP5053 1 0 0 0
CYP5065 0 1 0 0
CYP5082 1 0 0 0
CYP5136 3 7 0 5
CYP5137 0 1 6 2
CYP5138 1 1 1 1
CYP5139 3 7 8 1
CYP5140 3 1 1 1
CYP5141 1 2 4 7
CYP5142 0 0 0 7
CYP5143 0 0 0 2
CYP5144 6 3 3 34
CYP5145 1 0 0 3
CYP5146 2 0 0 6
CYP5147 0 0 0 6
CYP5148 0 2 1 2
CYP5149 1 0 1 1
CYP5150 12 36 25 6
CYP5151 2 1 1 1

CYP5152 1 1 2 2
CYP5153 1 0 0 1
CYP5154 2 0 0 1
CYP5155 0 0 0 1
CYP5156 1 1 1 1
CYP5157 1 0 0 1
CYP5158 2 1 2 1
CYP5205 2 0 0 0
CYP5293 1 0 0 0
CYP5339 0 0 2 0
CYP5340 0 2 1 0
CYP5341 0 2 3 0
CYP5342 0 0 1 0
CYP5343 0 0 1 0
CYP5344 0 0 3 0
CYP5345 0 0 1 0
CYP5346 0 0 1 0
CYP5347 0 1 2 0
CYP5348 0 3 34 0
CYP5349 0 1 2 0
CYP5350 0 0 11 0
CYP5351 0 1 1 0
CYP5352 0 0 1 0
CYP5353 0 0 1 0
CYP5354 0 0 2 0
CYP5355 0 0 1 0
CYP5356 0 0 1 0
CYP5357 0 2 0 0
CYP5358 0 1 0 0
CYP5359 0 47 0 0
CYP5360 0 1 0 0
CYP5361 0 1 0 0
CYP5362 0 1 0 0
CYP5363 0 1 0 0
CYP5364 0 3 0 0
CYP5365 0 1 0 0
CYP5366 0 1 0 0
CYP6001 1 0 0 0
CYP6004 1 0 0 0
CYP6005 0 2 0 0

Table S10. Sequences of the putative CYP protein coding genes.
CYP family E-value Hit coverage Query coverage Gene ID
CYP512G2 2.00E-116 85.74% 93.99% ACg000015
CYP5139A1 3.00E-164 85.34% 100.21% ACg000090
CYP504E5 1.00E-07 33.43% 34.12% ACg000167
CYP5136A2 6.00E-53 97.86% 67.72% ACg000189
CYP504E5 5.00E-08 38.12% 38.58% ACg000299
CYP505K1 4.00E-26 25.45% 24.59% ACg000657
CYP53A15 1.00E-177 97.29% 105.70% ACg000810
CYP5037B2 7.00E-176 46.26% 85.29% ACg000830
CYP5158A1 6.00E-153 86.57% 77.31% ACg001138
CYP5037B2 3.00E-111 89.08% 86.59% ACg001139
CYP5150A1 1.00E-179 96.02% 90.46% ACg001140
CYP5150A1 3.00E-177 96.00% 89.95% ACg001143
CYP5152A1 3.00E-134 90.79% 55.10% ACg001165
CYP5153A1 5.00E-68 95.89% 47.21% ACg001266
CYP5144C5 6.00E-140 95.05% 95.93% ACg001456
CYP5037 7.00E-12 85.98% 26.06% ACg001608
CYP645A1 1.00E-09 53.98% 22.73% ACg001635
CYP5150B1 5.00E-169 99.09% 88.15% ACg001953
CYP5150A1 2.00E-177 95.35% 87.39% ACg001957
CYP5150A1 4.00E-169 97.59% 96.76% ACg001959
CYP51F1 9.00E-162 91.32% 99.09% ACg002141
CYP512A1 1.00E-143 99.05% 104.41% ACg002478
CYP512A1 9.00E-180 99.40% 99.80% ACg002480
CYP5205A1 1.00E-57 90.30% 53.95% ACg002607
CYP5144C3 9.00E-136 98.04% 92.75% ACg002666
CYP63A3 9.00E-172 96.97% 94.44% ACg002691
CYP504E5 2.00E-07 51.51% 45.70% ACg002752
CYP5035C1 3.00E-175 92.01% 95.41% ACg002804
CYP512A1 1.00E-172 99.01% 100.00% ACg002875
CYP512A1 2.00E-178 98.39% 98.00% ACg003106
CYP5157A1 6.00E-85 85.26% 72.91% ACg003117
CYP5205A3 1.00E-42 97.45% 48.11% ACg003260
CYP5145A3 2.00E-117 97.29% 95.99% ACg003266
CYP504E5 1.00E-07 40.58% 41.54% ACg003550
CYP63A1 8.00E-99 95.07% 62.31% ACg003854
CYP63A3 2.00E-159 95.01% 106.06% ACg003857
CYP512A1 2.00E-103 92.28% 98.20% ACg004532
CYP6001C16 8.00E-180 97.75% 91.32% ACg004767
CYP5146A3 1.00E-11 80.90% 13.00% ACg004856
CYP5144C3 3.00E-116 98.92% 102.60% ACg005005

CYP5136A1 2.00E-150 98.53% 98.89% ACg005042
CYP5150A5 5.00E-179 97.04% 93.30% ACg005224
CYP5151B1 1.00E-27 95.95% 47.70% ACg005237
CYP5037B3 5.00E-142 98.46% 95.18% ACg005326
CYP63C1 3.00E-157 98.98% 97.33% ACg005354
CYP5037B1 6.00E-75 95.97% 85.77% ACg005358
CYP504E5 5.00E-08 45.45% 43.03% ACg005478
CYP5154A1 6.00E-91 99.12% 88.58% ACg005537
CYP504E5 9.00E-16 50.00% 43.62% ACg005609
CYP5150A2 3.00E-179 57.54% 88.63% ACg005625
CYP5150A5 2.00E-169 97.87% 92.46% ACg005628
CYP537B1 9.00E-94 99.05% 88.03% ACg005634
CYP5151A2 0 95.69% 89.28% ACg005641
CYP5138A1 4.00E-127 94.26% 90.73% ACg005664
CYP5150C1 2.00E-11 90.70% 34.21% ACg005670
CYP5150A2 2.00E-58 98.98% 31.96% ACg005671
CYP504E5 2.00E-15 52.07% 44.81% ACg005697
CYP5150A4 8.00E-138 95.44% 93.91% ACg006042
CYP5141A2 1.00E-178 88.97% 95.91% ACg006201
CYP5144C1 9.00E-140 98.38% 87.91% ACg006355
CYP5053C1 3.00E-07 63.48% 11.57% ACg006373
CYP5150A4 3.00E-100 89.97% 84.78% ACg006374
CYP619D1 2.00E-95 92.09% 76.74% ACg006376
CYP5144C3 2.00E-151 95.43% 93.12% ACg006474
CYP5139A1 2.00E-159 86.59% 103.11% ACg006484
CYP5149A1 8.00E-11 10.32% 10.98% ACg006496
CYP5139B2 5.00E-77 90.30% 80.51% ACg006818
CYP5156A1 1.00E-147 89.06% 65.73% ACg006835
CYP505D5 4.00E-45 98.73% 22.00% ACg006872
CYP505D4 7.00E-17 92.24% 9.64% ACg006873
CYP505D6 1.00E-36 92.23% 16.84% ACg006874
CYP5037B4 2.00E-146 94.56% 90.19% ACg006982
CYP5154A1 3.00E-67 84.52% 81.69% ACg007044
CYP63C1 2.00E-170 98.98% 97.50% ACg007189
CYP6004A2 1.00E-149 80.88% 72.92% ACg007568
CYP539E1 7.00E-32 18.08% 25.95% ACg007616
CYP620H5 4.00E-92 91.30% 80.98% ACg007671
CYP5136A2 3.00E-58 96.78% 94.81% ACg007676
CYP5158A1 1.00E-122 93.08% 89.30% ACg007677
CYP5146B1 3.00E-125 25.83% 82.59% ACg007686
CYP66A1 3.00E-38 86.50% 56.40% ACg007885
CYP530A3 5.00E-76 87.66% 86.37% ACg007894

CYP504E5 2.00E-06 8.26% 33.83% ACg007905
CYP5140A1 4.00E-162 95.03% 98.92% ACg007979
CYP504E5 5.00E-07 12.14% 32.64% ACg007984
CYP5140A1 4.00E-154 88.25% 105.17% ACg007985
CYP5140A1 2.00E-153 88.76% 95.26% ACg008012
CYP504E5 3.00E-07 46.69% 45.99% ACg008209
CYP5144C4 1.00E-31 99.26% 26.37% ACg008523
CYP53C2 2.00E-160 99.60% 90.81% ACg008539
CYP645A1 9.00E-08 60.90% 24.40% ACg008558
CYP505A16 3.00E-13 17.66% 22.53% ACg008683
CYP609A1 7.00E-60 83.08% 84.20% ACg008700
CYP63A1 1.00E-180 99.12% 86.62% ACg008739
CYP5082B1 2.00E-91 88.17% 76.57% ACg008853
CYP5293A1 8.00E-85 93.46% 85.11% ACg008858
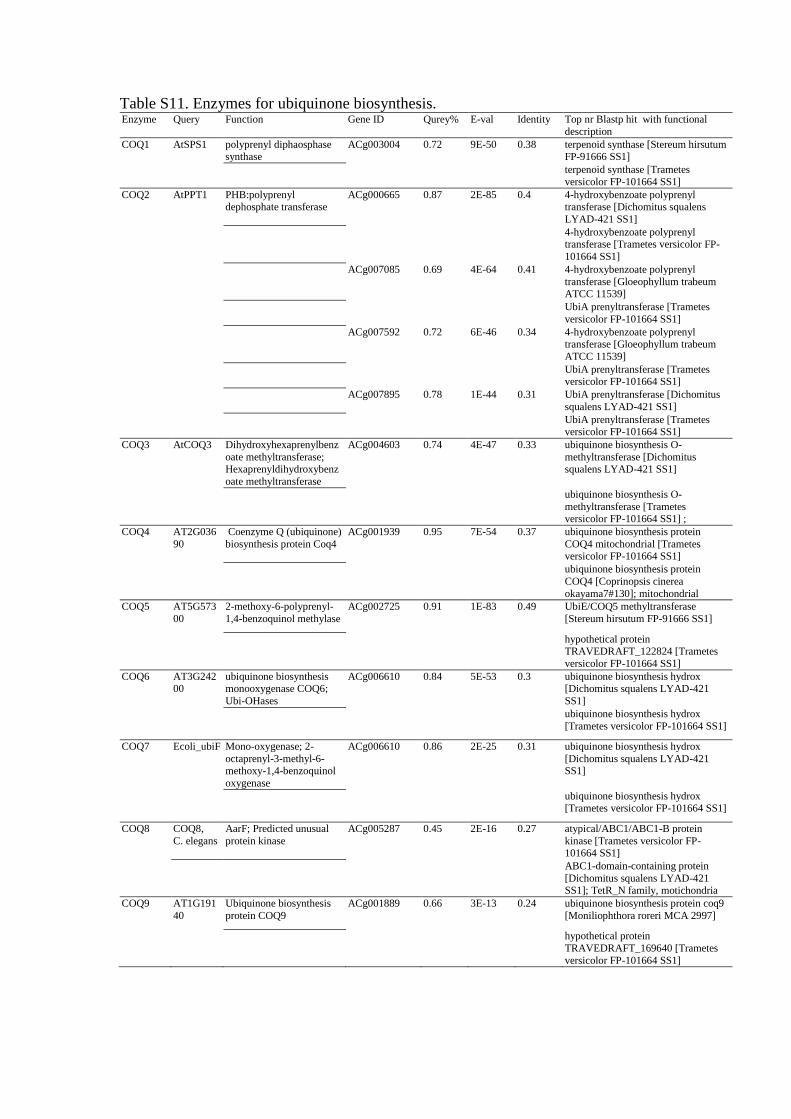
Table S11. Enzymes for ubiquinone biosynthesis. Enzyme Query Function Gene ID Qurey% E-val Identity Top nr Blastp hit with functional
description COQ1 AtSPS1 polyprenyl diphaosphase
synthase ACg003004 0.72 9E-50 0.38 terpenoid synthase [Stereum hirsutum
FP-91666 SS1] terpenoid synthase [Trametes
versicolor FP-101664 SS1] COQ2 AtPPT1 PHB:polyprenyl
dephosphate transferase ACg000665 0.87 2E-85 0.4 4-hydroxybenzoate polyprenyl
transferase [Dichomitus squalens
LYAD-421 SS1]
4-hydroxybenzoate polyprenyl
transferase [Trametes versicolor FP-
101664 SS1]
ACg007085 0.69 4E-64 0.41 4-hydroxybenzoate polyprenyl
transferase [Gloeophyllum trabeum ATCC 11539]
UbiA prenyltransferase [Trametes
versicolor FP-101664 SS1]
ACg007592 0.72 6E-46 0.34 4-hydroxybenzoate polyprenyl
transferase [Gloeophyllum trabeum
ATCC 11539] UbiA prenyltransferase [Trametes
versicolor FP-101664 SS1]
ACg007895 0.78 1E-44 0.31 UbiA prenyltransferase [Dichomitus
squalens LYAD-421 SS1] UbiA prenyltransferase [Trametes
versicolor FP-101664 SS1] COQ3 AtCOQ3 Dihydroxyhexaprenylbenz
oate methyltransferase; Hexaprenyldihydroxybenz
oate methyltransferase
ACg004603 0.74 4E-47 0.33 ubiquinone biosynthesis O-
methyltransferase [Dichomitus squalens LYAD-421 SS1]
ubiquinone biosynthesis O-
methyltransferase [Trametes versicolor FP-101664 SS1] ;
COQ4 AT2G036
90 Coenzyme Q (ubiquinone)
biosynthesis protein Coq4 ACg001939 0.95 7E-54 0.37 ubiquinone biosynthesis protein
COQ4 mitochondrial [Trametes versicolor FP-101664 SS1]
ubiquinone biosynthesis protein
COQ4 [Coprinopsis cinerea
okayama7#130]; mitochondrial COQ5 AT5G573
00 2-methoxy-6-polyprenyl-
1,4-benzoquinol methylase ACg002725 0.91 1E-83 0.49 UbiE/COQ5 methyltransferase
[Stereum hirsutum FP-91666 SS1]
hypothetical protein TRAVEDRAFT_122824 [Trametes
versicolor FP-101664 SS1] COQ6 AT3G242
00 ubiquinone biosynthesis monooxygenase COQ6;
Ubi-OHases
ACg006610 0.84 5E-53 0.3 ubiquinone biosynthesis hydrox [Dichomitus squalens LYAD-421
SS1] ubiquinone biosynthesis hydrox
[Trametes versicolor FP-101664 SS1]
COQ7 Ecoli_ubiF Mono-oxygenase; 2-
octaprenyl-3-methyl-6-methoxy-1,4-benzoquinol
oxygenase
ACg006610 0.86 2E-25 0.31 ubiquinone biosynthesis hydrox
[Dichomitus squalens LYAD-421 SS1]
ubiquinone biosynthesis hydrox [Trametes versicolor FP-101664 SS1]
COQ8 COQ8,
C. elegans AarF; Predicted unusual
protein kinase ACg005287 0.45 2E-16 0.27 atypical/ABC1/ABC1-B protein
kinase [Trametes versicolor FP-101664 SS1]
ABC1-domain-containing protein
[Dichomitus squalens LYAD-421 SS1]; TetR_N family, motichondria
COQ9 AT1G191
40 Ubiquinone biosynthesis
protein COQ9 ACg001889 0.66 3E-13 0.24 ubiquinone biosynthesis protein coq9
[Moniliophthora roreri MCA 2997]
hypothetical protein
TRAVEDRAFT_169640 [Trametes
versicolor FP-101664 SS1]

Table S12. Number of genes in different functional category related to terpenoid
biosynthesis. Only the genes with RPKM ≥ 0.5 in at least one of the four
transcriptomes are considered as expressed genes. The DEGs are derived by NOISeq
of bioconductor package with q = 0.8.
Description Expression Gene counts
A. cinnamomea str. S27 all genes 9,254
RPKM≥0.5 8,079
DEGs 4,898
Terpenoid related genes all genes 486
RPKM≥0.5 481
DEGs 314
Triterpenoid pathway genes all genes 242
RPKM≥0.5 242
DEGs 185
P450 all genes 119
RPKM≥0.5 119
DEGs 92
Terpenoid backbone biosynthesis (KEGG map: 00900)
all genes 20
RPKM≥0.5 20
DEGs 17

Table S13. Functional description of the genes uniquely expressed in AT and AM. (A)
The genes uniquely expressed in AT. (B) The genes uniquely expressed in both AT
and AM. (C) The genes uniquely expressed in AM. The function of the uniquely
expressed genes are determined by BLASTp hit with E-value <10-10
and three criteria:
(1) The best hit of the hit genes with known protein function.
(2) The best hit of the hit genes with hypothetical function definition, if none of
the hit genes with known protein function.
(3) The best hit of the hit genes if none of the hit genes with known protein
function of hypothetical function definition.
(A) The genes uniquely expressed in AT.
Gene ID Function Hit species
ACg004031 NAD-binding protein Fomitiporia mediterranea
ACg004725 BTB domain-containing protein Rhizoctonia solani
ACg004753 putative mitochondrial carrier C8C9,12c Rhizoctonia solani
ACg005279 ankyrin repeat protein Aspergillus fumigatus
ACg006161 GPI-anchored domain-containing protein Rhizoctonia solani
ACg008058 other/FunK1 protein kinase Coprinopsis cinerea okayama
ACg000902 hypothetical protein TRAVEDRAFT_84145, partial Trametes versicolor
ACg002837 hypothetical protein PHACADRAFT_206652 Phanerochaete carnosa
ACg000033 - No blast hit
(B) The genes uniquely expressed in both AT and AM.
Gene ID Function Hit species
ACg000962 expressed protein Schizophyllum commune
ACg002403 alpha/beta-hydrolase Trametes versicolor
ACg002720 MRP-L20 domain-containing protein Rhizoctonia solani
ACg005652 PREDICTED: von Willebrand factor-like Ciona intestinalis
ACg006297 expressed protein Agaricus bisporus var.
bisporus ACg006365 MFS general substrate transporter Trametes versicolor
ACg006501 sure-like protein Dichomitus squalens
ACg007569 DNA/RNA polymerase Auricularia delicata
ACg007886 terpenoid synthase Stereum hirsutum
ACg004778 hypothetical protein TRAVEDRAFT_94269, partial Trametes versicolor
ACg007584 predicted protein Postia placenta ACg005863 - No blast hit
(C) The genes uniquely expressed in AM.
Gene ID Function Hit species
ACg002543 TPA_exp: reverse transcriptase/ribonuclease H Coprinopsis cinerea
ACg005055 NAD(P)-binding protein Coniophora puteana
ACg005761 DUF1769-domain-containing protein Trametes versicolor
ACg008306 hypothetical protein TRAVEDRAFT_83667, partial Trametes versicolor

Table S14. Clusters of gene counts of differential expressed genes of triterpenoid
pathway.
C1 C2 C3 C4 Total
Triterpenoid 34 36 67 48 185
P450 14 22 28 28 92

Table S15. IDs and definitions of the GO terms, which are enriched in only one DEG
cluster of triterpenoid pathway. There are 34, 36, 67, and 48 genes enriched for the
cluster C1, C2, C3, and C4, respectively.
GO ID GO Definition Enriched
Cluster
GO:0006696 Ergosterol biosynthetic
process
The chemical reactions and
pathways resulting in the
formation of ergosterol, (22E)-
ergosta-5,7,22-trien-3-beta-ol, a
sterol found in ergot, yeast and
moulds.
C1
GO:0051762 Sesquiterpene
biosynthetic process
The chemical reactions and
pathways resulting in the
formation of sesquiterpenes, any of
a class of terpenes of the formula
C15H24 or a derivative of such a
terpene.
C1
GO:0071770 DIM/DIP cell wall layer
assembly
The aggregation, arrangement and
bonding together of a set of
components, including
(phenyl)phthiocerol,
phthiodiolone, phthiotriol
dimycocerosate and
diphthioceranate, to form the
DIM/DIP layer of the
Actinobacterium-type cell wall
C2
GO:0004364 Glutathione transferase
activity
Catalysis of the reaction: R-X +
glutathione = H-X + R-S-
glutathione. R may be an aliphatic,
aromatic or heterocyclic group; X
may be a sulfate, nitrile or halide
group.
C3
GO:0006537 Glutamate biosynthetic
process
The chemical reactions and
pathways resulting in the
formation of glutamate, the anion
of 2-aminopentanedioic acid.
C4
GO:0016712
Oxidoreductase activity,
acting on paired donors,
with incorporation or
reduction of molecular
oxygen, reduced flavin or
flavoprotein as one donor,
and incorporation of one
atom of oxygen
Catalysis of an oxidation-reduction
(redox) reaction in which
hydrogen or electrons are
transferred from reduced flavin or
flavoprotein and one other donor,
and one atom of oxygen is
incorporated into one donor.
C4

Table S16. The number of genes of GO terms which are enriched within the
differential expressed gene cluster of triterpenoid genes.
All gene set C1 C2 C3 C4
32 46 62 40
GO:0004497 Monooxygenase activity 19 5 6
GO:0008202 Steroid metabolic process 20 6 4
GO:0043231 Intracellular membrane-bounded
organelle 9 2 4
GO:0005506 Iron ion binding 83 21 10 15
GO:0009055 Electron carrier activity 70 18 10 9
GO:0045482 Trichodiene synthase activity 7 2 3
GO:0055114 Oxidation-reduction process 125 6 18 11
GO:0020037 Heme binding 92 5 21 9 15
GO:0016705 Oxidoreductase activity, acting on
paired donors, with incorporation
or reduction of molecular oxygen 51 4 19 8 9
GO:0071770 DIM/DIP cell wall layer assembly 7 2
GO:0019748 Secondary metabolic process 7 4
GO:0004364 Glutathione transferase activity 9 4
GO:0006790 Sulfur compound metabolic proces 14 3
GO:0016712
Oxidoreductase activity, acting on
paired donors, with incorporation
or reduction of molecular oxygen,
reduced flavin or flavoprotein as
one donor, and incorporation of
one atom of oxygen
6 2
GO:0006537 Glutamate biosynthetic process 7 2
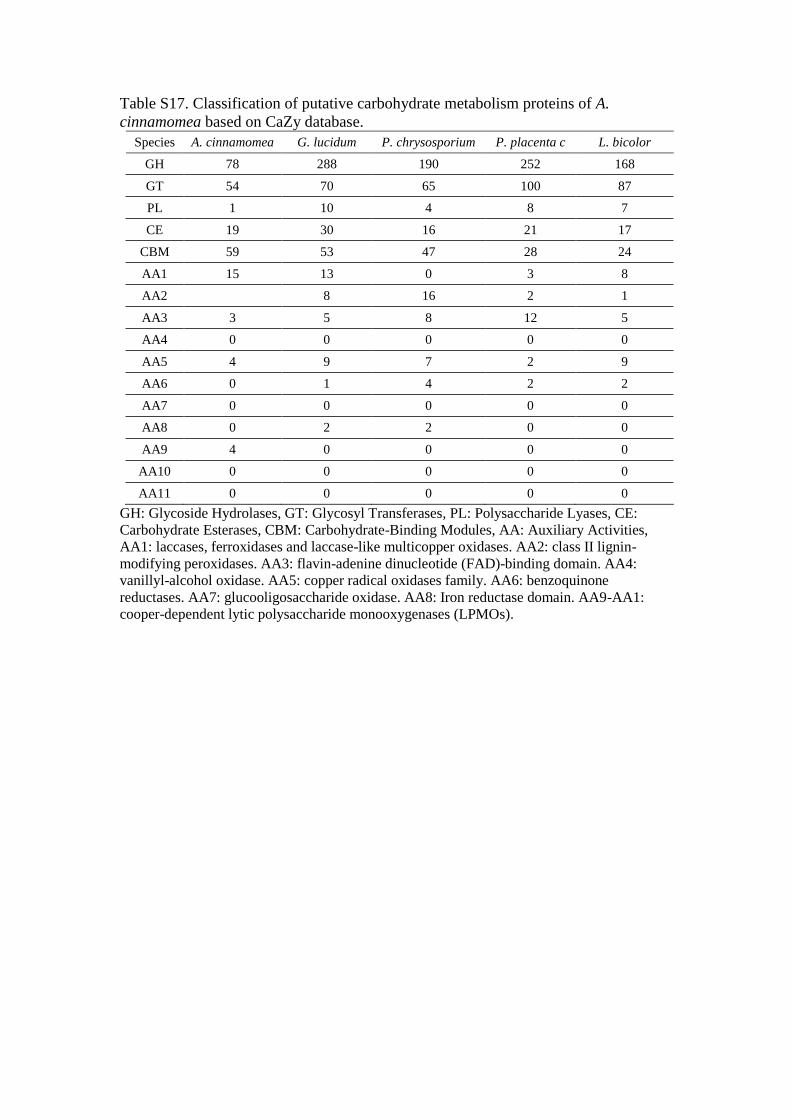
Table S17. Classification of putative carbohydrate metabolism proteins of A.
cinnamomea based on CaZy database.
Species A. cinnamomea G. lucidum P. chrysosporium P. placenta c L. bicolor
GH 78 288 190 252 168
GT 54 70 65 100 87
PL 1 10 4 8 7
CE 19 30 16 21 17
CBM 59 53 47 28 24
AA1 15 13 0 3 8
AA2 8 16 2 1
AA3 3 5 8 12 5
AA4 0 0 0 0 0
AA5 4 9 7 2 9
AA6 0 1 4 2 2
AA7 0 0 0 0 0
AA8 0 2 2 0 0
AA9 4 0 0 0 0
AA10 0 0 0 0 0
AA11 0 0 0 0 0
GH: Glycoside Hydrolases, GT: Glycosyl Transferases, PL: Polysaccharide Lyases, CE:
Carbohydrate Esterases, CBM: Carbohydrate-Binding Modules, AA: Auxiliary Activities,
AA1: laccases, ferroxidases and laccase-like multicopper oxidases. AA2: class II lignin-
modifying peroxidases. AA3: flavin-adenine dinucleotide (FAD)-binding domain. AA4:
vanillyl-alcohol oxidase. AA5: copper radical oxidases family. AA6: benzoquinone
reductases. AA7: glucooligosaccharide oxidase. AA8: Iron reductase domain. AA9-AA1:
cooper-dependent lytic polysaccharide monooxygenases (LPMOs).

Table S18. rRNA and tRNA prediction of A. cinnamomea and comparison with G.
lucidum.
A. cinnamomea
Input S27.v2.5.fasta
Genome Bases 32177404
Length in tRNA 14040
Length in rRNA 7895
# tRNA 148 (14 pseudo)
# rRNA 3
rRNA 8S, 18S, 28S

Table S19. A. cinnamomea S27 ribosomal RNA loci and conservation regions. We
predicted one ribosomal RNA cluster with 3 rRNAs: 8S, 18S and 28S by RNAmmer
v.1.2. The direction of the rRNA from 5’ to 3’ is 8S, 18S, and 28S with a total length
of 10Kb bases. RNAmmer predicts the ribosomal RNA sequences by doing the
structural alignment with the HMM model. It might over-estimate the rRNA
sequences since the structural folding of a sequence is determined by the sequence
length and content. In order to avoid the over-estimation, we used Blastn to find a
sequentially conserved region of 8S-18S-28S rRNA with 7Kb bases, which is similar
to the size of rRNA repeat cluster of Aspergillus fumigatus (1). Conserved regions (*)
represents those with significant alignment in Blastn.
Scaffold Start End Length Strand Conserved*
start end length
8S scaf10 1,156,450 1,156,563 114 - 1,156,450 1,156,563 114
18S scaf10 1,158,908 1,160,712 1,805 + 1,158,908 1,160,712 1,805
28S scaf10 1,160,933 1,166,911 5,979 + 1,160,933 1,163,715 2,783
References
1. Nierman, W. C., et al. (2005). Genomic sequence of the pathogenic and allergenic
filamentous fungus Aspergillus fumigatus. Nature 438(7071): 1151-1156.

Table S20. Statistics of repeat sequence from RepeatModeler. Total repetitive
sequence accounts for 17.7% of the S27 scaffolds.
Number of elements Length Occupied (bp) Percentage of sequence (%)
SINEs 0 0 0 ALUs 0 0 0 MIRs 0 0 0
LINEs 502 747,611 2.32 LINE1 0 0 0 LINE2 0 0 0 L3/CR1 0 0 0
LTR elements 1,384 2,245,758 6.98 ERVL 0 0 0 ERVL-MaLRs 0 0 0 ERV_classI 0 0 0 ERV_classII 0 0 0
DNA elements 274 199,816 0.62 hAT-Charlie 0 0 0 TcMar-Tigger 0 0 0
Unclassified 4,261 2,198,660 6.83 Total interspersed repeats 5,391,845 16.76 Small RNA 0 0 0 Satellites 0 0 0 Simple repeats 2,942 283,656 0.88 Low complexity 398 21,307 0.07 Total repetitive 5,695,889 17.7

Table S21. Statistics of the genomic Illumina reads after pre-processing steps.
S27 S32
# Raw Reads
Read length PE 2*100 PE 2*100
Read count 113,309,162 127,738,466
Total base (bp) 11,043,231,184 12,449,502,738
# Read Trimming (by Trimmomatic-3.0)
Total bases remained (%) 58.63 58.31
Sequence coverage 201 347
# Mapping onto s27v2.5 scaffold genome
Input reads 83,652,588 94,654,661
Mapped (%) 98.40 93.96
Genome coverage (%) 98.20 97.01

Table S22. SNP analysis and occurrence of SNPs in genes uniquely expressed in S27
and/or S32.
Regions Size (bp) SNP
counts
SNP density
(per kb)
Whole genome 32,177,404 98,930 3.07
Exonic regions 13,925,609 33,551 2.41
Non-exonic regions 18,251,795 65,379 3.58
Uniquely expressed genes (98) 90,729 235 2.59
S27 uniquely expressed genes (38) 44,766 60 1.34
S32 uniquely expressed genes (28) 24,336 30 1.23
Genes uniquely expressed in S27 AND S32 (32) 21,627 145 6.70

Table S23. Expression of the triterpenoid pathway and P450 genes in the six clusters
identified on different scaffolds shown in Figure S7.
P450
Cluster Gene ID S27 S32 AM AT
Scaf2
ACg000810 109.6 221 108.9 136.3
ACg000817 16.6 7.9 3.9 2.5
ACg000822 203 63.4 169.4 202.7
ACg000830 4.9 8 3.2 25.3
ACg001138 22.1 23.7 3.5 3.6
ACg001139 67 41.3 10.8 27.9
ACg001140 26 10.2 12.3 22.2
ACg001143 25.1 7.5 4.2 13.8
Scaf4
ACg001953 69.8 23 24.4 19.5
ACg001954 310.1 126.6 29.4 207.6
ACg001957 4.9 5.9 6.6 27
ACg001959 261.2 17.2 3.7 28.6
ACg001961 13.3 14.7 20.9 6.3
Scaf5
ACg002403 0.5 0.4 1.3 10.6
ACg002404 200.5 56.3 28.4 166.1
ACg002478 2 4.4 1.2 5.9
ACg002480 13.2 2.5 2 117.6
ACg002691 60.3 32.1 50.3 8.6
ACg002693 119.5 8.2 13.6 13.6
Scaf14
ACg005615 37.7 19.9 7.2 64.2
ACg005625 4.2 14.8 4.9 46.2
ACg005628 118.6 14.8 25 43.2
ACg005634 4.4 12.5 5.8 12.5
ACg005636 4.9 3.8 1.6 19.2
ACg005641 23.7 46.7 39.5 10.4
Scaf17
ACg006374 29 16.1 12.4 18.4
ACg006376 12.5 18.3 4 9.1
ACg006378 3.1 13 37.6 12.4
Scaf24
ACg007671 15 24.3 15 2.5
ACg007676 62.5 55.4 61.6 11.8
ACg007677 23.6 36.4 36.5 11.4
ACg007686 30.2 24 37.6 42.6





























