Embed Size (px)
Citation preview
Realtime
Batch
Legenda
Apache Hadoop�prostředí pro distribuované zpracování velkých datwww.trigama.eu
atriga
KDY POUŽÍT HADOOP?Ke zpracování je potřeba vysoký výpočetní výkon … data mining, statistické metody
Data přibývají velmi rychle (desetitisíce zpráv za sekundu) … analýzy dat v reálném čase
Celkový objem dat k uložení je velký (desítky TB) … spolehlivé, dostupné úložiště
BIG DATA A HADOOPApache Hadoop je programové prostředí, které umožňuje
paralelní běh big data aplikací v rámci výpočetního clusteru. Zahrnuje sadu nástrojů pro distribuované
pořizování, ukládání a zpracování velkých dat.
Je to open-source systém volně dostupný i pro komerční použití, podobně jako třeba webový server Apache. Existují ale
také komerční distribuce, součástí jejichž licence je i provozní podpora (např. Hortonworks, Cloudera, MapR).
DATABÁZE vs. HADOOPTabulky vs. souboryData v Hadoopu mohou být uložena ve zdrojové
struktuře i formátu. Systém HDFS zajistí bezpečné
a efektivní uložení souborů libovolné velikosti
(limitem je pouze kapacita celého clusteru).
Pevné schéma vs. volná strukturaV Hadoopu se data ukládají jako soubory a
struktura se definuje až při jejich použití.
Transakčnost vs. dostupnosta škálovatelnostHadoop upřednostňuje rychlost odpovědi před
úplností (např. při výpadku části clusteru).
Spolehlivost je zajištěna redundancí – každý uzel
clusteru je kdykoli nahraditelný.
Flume
Fronta zpráv (aplikační logy)
HDFS (uložení vstupních dat)
MapReduce (parsování zpráv)
HBase (NoSQL DB v HDFS)
Alerty
HIVE(analytický přístup)
Analýzy a reporty
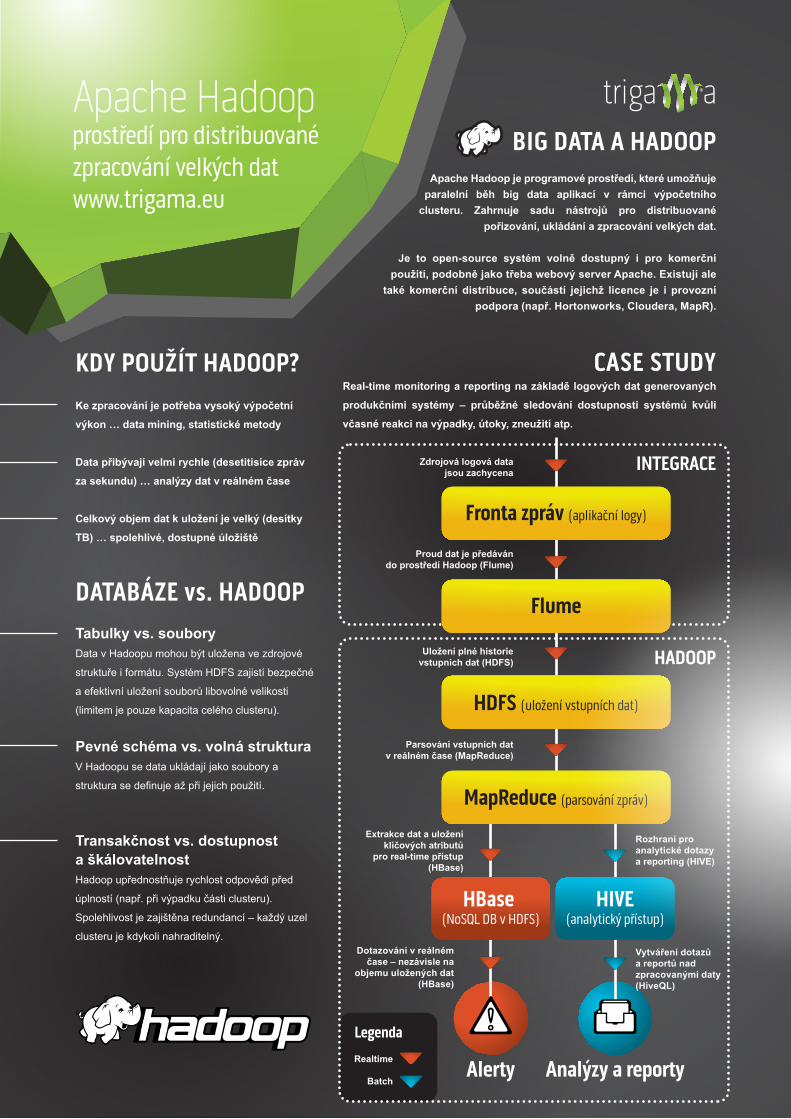
Zdrojová logová data jsou zachycena
Proud dat je předáván do prostředí Hadoop (Flume)
Uložení plné historie vstupních dat (HDFS)
Parsování vstupních dat v reálném čase (MapReduce)
Rozhraní pro analytické dotazy a reporting (HIVE)
Extrakce dat a uložení klíčových atributů
pro real-time přístup (HBase)
Vytváření dotazů a reportů nad zpracovanými daty (HiveQL)
Dotazování v reálném čase – nezávisle na
objemu uložených dat (HBase)
INTEGRACE
HADOOP
CASE STUDYReal-time monitoring a reporting na základě logových dat generovaných produkčními systémy – průběžné sledování dostupnosti systémů kvůli včasné reakci na výpadky, útoky, zneužití atp.
Komponenty Hadoopekosystému
atriga
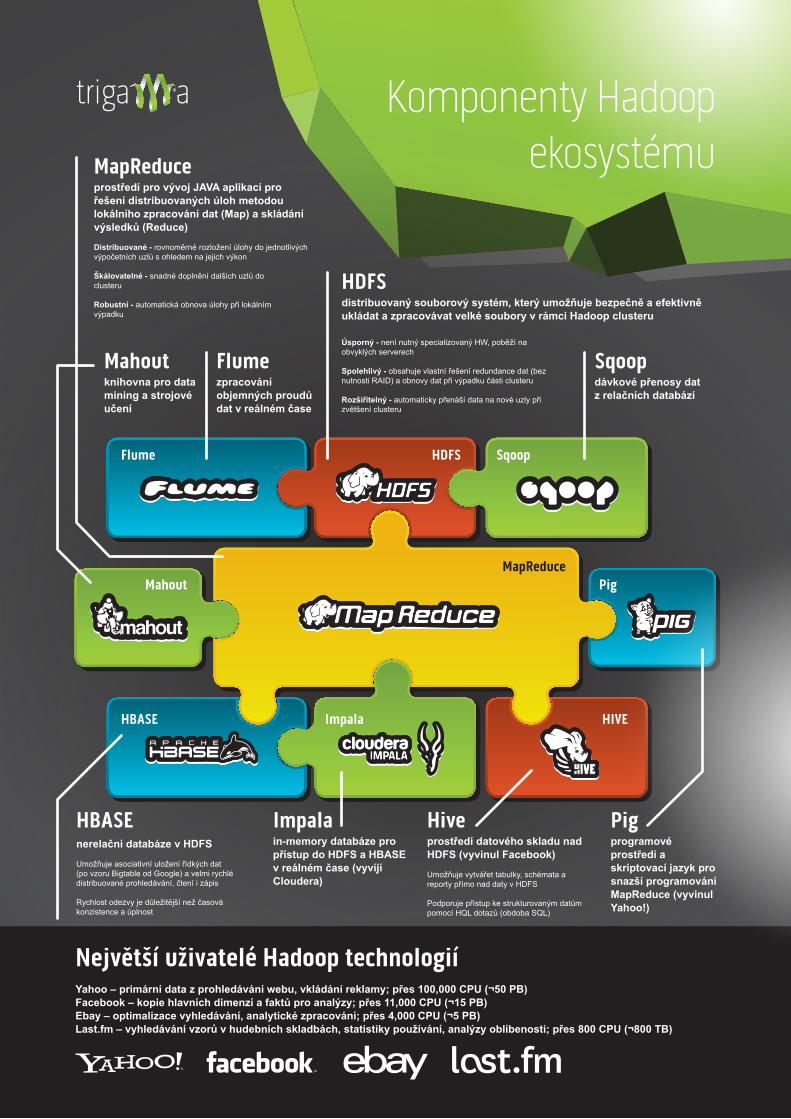
MapReduceprostředí pro vývoj JAVA aplikací pro řešení distribuovaných úloh metodou lokálního zpracování dat (Map) a skládání výsledků (Reduce)
Distribuované - rovnoměrné rozložení úlohy do jednotlivých výpočetních uzlů s ohledem na jejich výkon
Škálovatelné - snadné doplnění dalších uzlů do clusteru
Robustní - automatická obnova úlohy při lokálním výpadku
Flumezpracování objemných proudů dat v reálném čase
Sqoopdávkové přenosy dat z relačních databází
Pigprogramové prostředí a skriptovací jazyk pro snazší programování MapReduce (vyvinul Yahoo!)
Hiveprostředí datového skladu nad HDFS (vyvinul Facebook)
Umožňuje vytvářet tabulky, schémata a reporty přímo nad daty v HDFS
Podporuje přístup ke strukturovaným datům pomocí HQL dotazů (obdoba SQL)
Impalain-memory databáze pro přístup do HDFS a HBASE v reálném čase (vyvíjí Cloudera)
Mahoutknihovna pro data mining a strojové učení
HBASEnerelační databáze v HDFS
Umožňuje asociativní uložení řídkých dat (po vzoru Bigtable od Google) a velmi rychlé distribuované prohledávání, čtení i zápis
Rychlost odezvy je důležitější než časová konzistence a úplnost
HBASE Impala HIVE
Flume HDFS Sqoop
PigMahoutMapReduce
HDFSdistribuovaný souborový systém, který umožňuje bezpečně a efektivně ukládat a zpracovávat velké soubory v rámci Hadoop clusteru
Úsporný - není nutný specializovaný HW, poběží na obvyklých serverech
Spolehlivý - obsahuje vlastní řešení redundance dat (bez nutnosti RAID) a obnovy dat při výpadku části clusteru
Rozšiřitelný - automaticky přenáší data na nové uzly při zvětšení clusteru
Největší uživatelé Hadoop technologií Yahoo – primární data z prohledávání webu, vkládání reklamy; přes 100,000 CPU (¬50 PB)Facebook – kopie hlavních dimenzí a faktů pro analýzy; přes 11,000 CPU (¬15 PB)Ebay – optimalizace vyhledávání, analytické zpracování; přes 4,000 CPU (¬5 PB)Last.fm – vyhledávání vzorů v hudebních skladbách, statistiky používání, analýzy oblíbenosti; přes 800 CPU (¬800 TB)

![BIOMECHANIKA · jako součin hmotnosti a okamžité rychlosti hmotného bodu. p = m ×v [p] = kg ×m ×s–1 (kilogram metr za sekundu) Vektor hybnosti má stejný směr jako vektor](https://img.pdfslide.net/doc/110x75/5e4c1d99eb017a197026aa7d/biomechanika-jako-souin-hmotnosti-a-okamit-rychlosti-hmotnho-bodu-p-m.jpg)



























