Embed Size (px)
Citation preview

207 | P a g e
APPLICATION OF WEB DATA MINING
Durga Patel1 ,
Pallavi Sengar
2
1,2Information Technology Department Banasthali University, Niwai,Rajasthan, (India)
ABSTRACT
Data Mining has attracted a great deal of attention in the information industry and in the society as a whole in
recent years due to the wide availability of huge amounts of data and the imminent need for turning that data
into useful information and knowledge . There are many types of data mining based on the type of data being
extracted: Spatial data mining, Multimedia data mining ,Text data mining , Temporal data mining , and Web
data mining. Web data mining itself is an interdisciplinary field .Web data mining is extracting of data from the
world wide web. According to the survey report of Google of 2008 the number of web users is above 1 trillion .It
consist of Web structure mining, Web content mining and Web usage mining .As the number of web users are
increasing day by day so we have to implement methods so we can get the data accurately .When we search for
any particular topic on the web then we can get only the data that is similar to the original one and not the exact
data .So, we have to use some form of association to correlate with it.
Keywords: web mining,web usage mining,web content mining,web structure mining,apriori
algorithm,page ranking algorithm,weighted page ranking algorithm,hyper link induced topic
search(hits).
I. INTRODUCTION
World wide web is a huge and diverse in nature .It consist of semi –structured pages .web data mining is the
extraction of data from multiple source of information and converting it into our useful knowledge .The growth
of web has increased in the last years .The data can be converted using some preprocessing steps such as: data
cleaning, data integration, data selection, data transformation, data mining, pattern evaluation and knowledge
presentation. Web usage mining in this we identify the user behavior while interacting with the web. User
behavior can be identified by identifying the browsing pattern .Web structure mining it is used to link the
structure of web pages form of graph .Web content mining is related to more structured form of data by
indexing the web pages. It is represented in two views: information retrieval and database view.
II. LITERATURE REVIEW
2.1 Web Data Mining
Web data mining is the process of extracting the information automatically from the web pages or document. As
we have stated earlier that the data mining is a multidisciplinary field. In this, the information can be extracted
with the help of other areas such as neural network, fuzzy or rough set theory, knowledge representation .It is
also integrated with other technology such as information retrieval, pattern recognition, image analysis, signal

208 | P a g e
processing, bioinformatics or psychology, etc. Data mining system can be categorized according to the various
criteria[1]:
Classification on the basis of databases mined.
Classification on the basis of knowledge mined.
Classification on the basis of technology utilized.
Classification on the basis of application adopted.
We have reviewed some challenges in web mining:
Web is huge.
Web pages are semi-structured.
Web information stand to be diversity in meaning.
Quality of information extracted.
Knowledge from information extracted.
The tasks performed by web data mining:
Resource finding: It is the process of extracting the information from offline or online text resource
available on the web.
Information selection and pre-processing: It is the process of transforming the selected information to
convert into meaningful knowledge.
Generalization: It is the process of replacing the low level data or “primitive” data by high level data with
the help of concept hierarchies. Ex: Categorical attributes, like street, can be generalized to high -level
concepts, like city or country.
Analysis: It plays an important role of validation and help in pattern mining.
Web mining can be divided into three broad categories:
2.1.1 Web content mining:
According to Linoff and Berry (in 2001) defined this as “the process of extracting useful information from the
text , image and other forms of content that make up the pages” .With the advent of increase in WWW there are
billions of Html documents, pictures and other multimedia files available on the internet. As the information
available on the internet is vast how can a user find the exact information as the search engines are not of much
help. Most of the time the result displayed by the engines does not correspond to the original data but somewhat
correlate to it. Information extraction from the web is complex when working with static data bases, due to its
dynamic nature and large number of documents. As the web content mining can be represented in two views:[2]
Information Retrieval view: In this the data is in the form of unstructured and structured form. Data can be
extracted from the text documents and hypertext documents. It is represented in relational form. The
method used in extraction is Machine Learning and Statistical (include Natural Language Processing). The
application categories are Categorization, Clustering, finding extract rules and finding patterns in text.
Data Base view: The data is represented in the form of semi structured which consist of hypertext
documents. The method used is proprietary algorithms and association rules. The application categories are
finding frequent sub-structures and web site schema discovery. In this ,we will discuss two terms:
Association: Association rule implies the picking of the unrelated data and find out the relation between
them. It is also measured as the frequency of occurrence. It is represented in:

209 | P a g e
X=>Y
Example: Suppose ,if a person goes to buy a computer he/she had to definitely buy a software cd with it.
buys(x, “computer”)=>
buys(x, “software cd”)
In this the, value of support=1%
Support is defined as XUY.
Value of confidence =50%
which is defined as X |Y.
Correlation: To determine the correlation value of support and confidence is not enough but also the
relation between the item sets. It can be calculated by using the lift. In this the itemsets A and B are
independent of each other if,
P(X U Y)=P(X)P(Y)
Then, lift(X,Y)=P(X U Y)/P(X)(Y).
Apriori Algorithm
This algorithm is a seminal algorithm for mining frequent itemsets for Boolean association rule. This is the
important and basic algorithm given in 1994 by Agarwal and Srikant. This is known as the fastest algorithm for
finding out the frequent itemsets. In this we have to consider the value of minimum support count. It follows the
property:[3][4][5][6][7]
“All nonempty subsets of a frequent itemsets must also be frequent.”
Principles used in this are:
Generation of frequent itemsets.
Items having support>=min-support.
Each itemset have high confidence rules.
Working of Apriori Algorithm
In this there are two important steps:
1. Join Step: In the join step, there are a total number of n itemsets so the subset is n-1.
2. Pruning Step: Any (n-1)-itemsets that is not frequent cannot be a subset of a frequent n-1 itemset.
Get frequent things
Get frequent itemsets
Join Step: - Cn is generated by joining Ln-1 with itself.
Prune step: - Any (n-1) –itemset that is not frequent cannot be a subset of a frequent n-1 itemset
Where,
Cn: candidate itemset of size n
Ln:- frequent itemset of size n
L1={frequent items};
For (n=1; Ln! =Ø;n++)
do begin
Cn-1=candidates from Ln;
For each purchase p in database do

210 | P a g e
Increment the count of customers in Cn-1 that are contained in p
Ln-1 =candidates in Cn-1 with min-support
end
Return UnLn
Example:
Transaction ID Item ID’s
1 A,B,C,E
2 C,D,E
3 C,E
4 A,C,D
5 B,D
Step 1- Total no. of frequent item in the transactions to count support of each item.
TID Item ID’s Support Count
1 A 2
2 B 2
3 C 4
4 D 3
5 E 3
Step-2 Join the table with itself.
TID Item ID’s Support count
1 A,B 1
2 A,C 2
3 A,D 1
4 A,E 1
5 B,C 1
6 B,D 1
7 B,E 1
8 C,D 2
9 C,E 3
10 D,E 1
Step 3- Prune the above table on the basis of minimum support count i.e.2
TID Item ID’s Support count
1 A,C 2
2 C,D 2

211 | P a g e
3 C,E 3
Step 4-Join the table with itself.
TID Item ID’s Support count
1 A,C,D 1
2 C,D,E 1
So, in this table none of the satisfying the minimum support count. So, in this none of them is frequent itemsets.
But, there are a number of drawbacks associated with it.
Drawbacks of algorithm
Repetition of data is more.
Same support minimum threshold.
Difficulty to get rare occurring.
Time taking.
If data size is large then the number of candidate sets is large.
To overcome these disadvantage several authors have given their algorithm.
Intersection and record filter approach: In record filter approach, count the support of candidate set only in
the transaction record whose length is greater than or equal to length of candidate set. It consumes less time
but more optimization is needed.
Improvement based on set size frequency: In this the items whose frequency is less than the minimum
support count is removed initially and determine initial set size to get the highest set size whose frequency
can be greater than or equal to minimum support of set size. In this there is no fix criteria to determine the
size of key for pruning the data.
Utilization of attributes: In this all the unnecessary transaction should be cut down to increase I/O. As all
the data in the transaction are treated equally, so the data that is not present should not be considered. This
can be removed by using attributes such as frequency of items, quantity.
After this it has been concluded that the number of candidate set should be less in number.
Improved Apriori Algorithm
In this algorithm, another column have been introduced which is the size of transaction (SOT), which depicts the
number of individual items in the database .The deletion should be done on the basis of value k. If the value of
k, matches the value of SOT then, that value would be deleted in the database.
Input: transaction database DB; min-sup.
Output: the set of Frequent L in the database DB
Minimum support count =minimum support count *mode of data base
L1-candidates=find all one item set from the data base
L1={<Y1,TID-set(Y1)> L1-candidates |support-count&'()-support- count}
for (n=2; Ln-1#*+,--.!/0!1)
{ for each n-itemset (yi,TID-set(yi) Ln-1 do
for each n-itemset (yj,TID-set(yj) Ln-1 do
if (yi[1]=yj[1])!(yi[2]=yj[2])!…!(yi[n-2]=yj[n-2] then
{Ln-candidates.Yn= Yi* Yj;

212 | P a g e
Ln-candidates.TID-set(Yn) = TID-set(Yi) 234-set(Yj)
}
}
for each n-itemset<Yn,TID(Yn)> Ln-candidates do
sup-count=|TID-set|
Ln={<Yn,TID-set(Yn)> Ln-candidates|support-count&'()-support-count}
}
set-count=Ln.itemcount //updata set-count
return L="nLn;
Example: D
TID Items
1 A,C,G
2 B,C,G
3 A,B,C
4 B,C
5 B,C,D,E
6 B,C
8 B,C,D,F
9 A
10 A,C
Step- 1
TID Items SOT
1 A,C,G 3
2 B,C,G 3
3 A,B,C 3
4 B,C 2
5 B,C,D,E 4
6 B,C 2
7 A,B,C,D,F 5
8 B,C,D,F 4
9 A 1
10 A,C 2
Step-2 C1
Item Set Support count
A 5
B 7
C 9
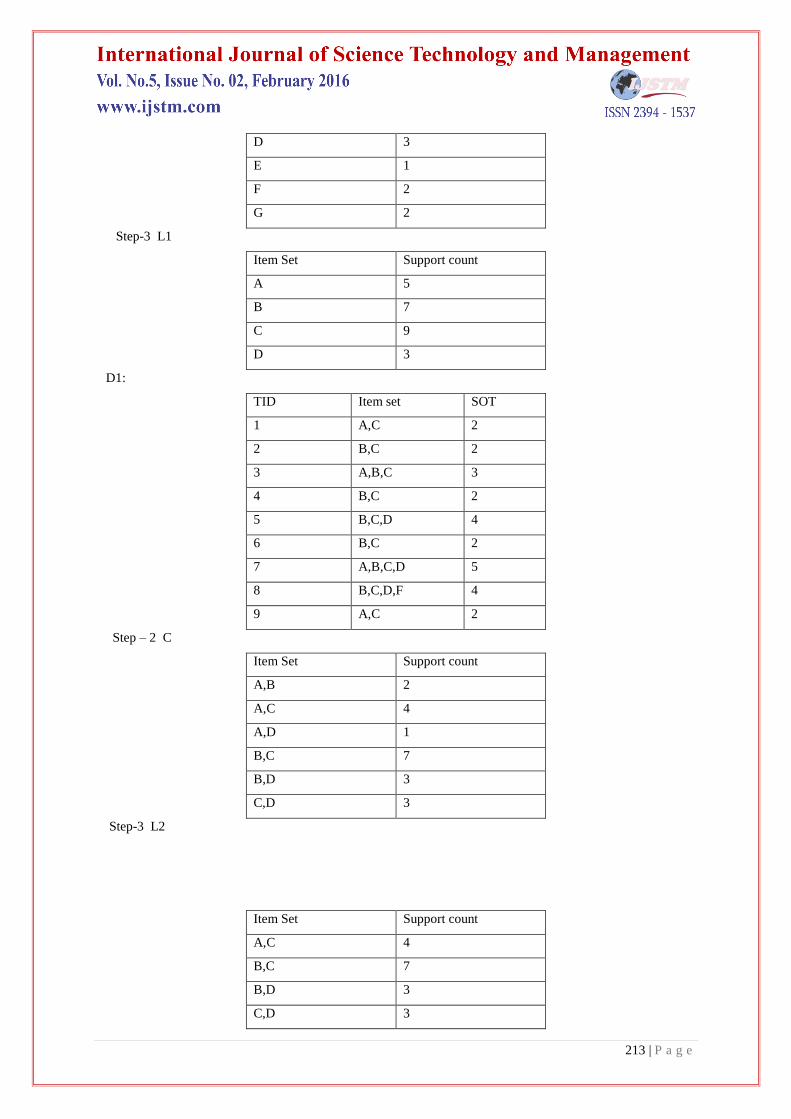
213 | P a g e
D 3
E 1
F 2
G 2
Step-3 L1
Item Set Support count
A 5
B 7
C 9
D 3
D1:
TID Item set SOT
1 A,C 2
2 B,C 2
3 A,B,C 3
4 B,C 2
5 B,C,D 4
6 B,C 2
7 A,B,C,D 5
8 B,C,D,F 4
9 A,C 2
Step – 2 C
Item Set Support count
A,B 2
A,C 4
A,D 1
B,C 7
B,D 3
C,D 3
Step-3 L2
Item Set Support count
A,C 4
B,C 7
B,D 3
C,D 3

214 | P a g e
D2:
TID Items SOT
3 A,B,C 3
5 B,C,D 3
7 A,B,C,D 4
8 B,C,D,F 4
Step-1 C3
Item Set Support Count
B,C,D 3
Step-2 L3
Item Set Support count
B,C,D 3
Advantage:
It helps in reducing query frequencies.
It helps in increasing the efficiency.
It reduces I/O load.
It helps in reducing storage space.
The application of database view is to find the frequent sub-structures and to discover the web site schema.
Its application is used to adverse drug reaction detection .Data mining towards tumultuous crimes concerning
women.
2.2.2 Web usage mining: In this identify the user behavior by identifying the browsing behavior. It helps in
automatic discovery using click streams patterns and other associated data collected or gathered. The main aim
is to capture, model, analysis of behavioral patterns and profile of user[8][9][10].
Fig : An illustration of web usage mining process
In the mining process stage can be divided into three parts:
Data collection and preprocessing, pattern discovery and pattern analysis.

215 | P a g e
In data collection and preprocessing, the data in the click stream is removed and partitioned according to
the user behavior during every visits. In the pattern discovery different application areas are used to extract
the hidden pattern and reflecting the behavior of user. It can also be used to obtain statistical values related
to it. In the final stage, the obtained input is filtered and operations are performed to give input to generate
reports. In this the primary data sources are the server log files ,including application server logs and Web
server access logs. Another types of data such as meta-data , site files and operational databases are used to
prepare data and to discover the pattern. The data is divided into four groups:
Usage data: It is primary form of data as each hit against the server correspond to an HTTP request and
generate an entry in the server. FOR this cookies is used to identify a repeat visitor. Each entry correspond
to details such as: date, time, IP requested resource and certain parameters.
Content data: The data used in it is of the form static HTML/XML pages, page segments from scripts and
collection of records .It also include semantic or structural meta-data.
Structure data: It is used to represent the designer’s view of the content. In this it is used to convey the
linkage between pages. Example both the HTML and XML documents can be represented in form of graph
and trees.
User data: It is used to represent user profile information such as past purchase, products or visit history.
This data can be seen by other as long as the users are not differentiated.
In this the data is represented in the form of relational table, graph. The data can be extracted with the help of
Machine learning, Statistical and Association rules. Its application categories are site construction, adaptation
and management, marketing and user modeling.
2.2.3 Web Structure mining:
In this the web pages is viewed in the form of link structure. It is basically represented in the form of graph. In
this the proprietary algorithms is used[11][12][13].In this the structure is formed with the help of links and
hyperlinks through which we can get additional information. It uses the concept of clustering, document
categorization and information extraction from web pages. The web may be viewed as a directed labeled graph
whose nodes are the documents and the edges are the hyperlinks connecting them[2][14].
The web pages are dynamic in nature some contains little text (making it difficult for text mining), multimedia
(multimedia data mining).The web is a graph. In this we use the predecessor page- that have a hyperlink
pointing to the target page. It may contain particular useful information for classifying a page[15][16][17]:
Redundancy: There is a probability there may be more than one page pointing to a single point on the web,
so as to combine the data from multiple source of information.
Independent encoding: The information is less sensitive to vocabulary used by particular author.
Sparse or non-existing text: Web pages contain limited amount of text as it contain images and no machine
readable text at all.
Irrelevant or misleading text: Most of the pages contain unnecessary data and misleading information.
Graph structure can be used for retrieval, classification and Classification with hyperlinks.
There are a number of algorithms associated with it: Page Rank, Weighted Page Rank and Hypertext Induced
Topic Search (HITS).

216 | P a g e
Page Rank: This algorithm is given by Brin and Page (1998) at Stanford University during their Ph.D. Page
rank is used to simply count the number of pages that are linked to it. These links are called backlinks. The
backlinks are considered of high weightage as they come from important pages. The link which is used to
connect one page to another is called vote and is of great importance. In this the input parameters are the
backlinks and forward links. Page and Brin proposed a formula to calculate the page rank:
PR(A)=(1-d)+d(PR(T1)/C(T1))+…+PR(Tn/C(Tn)) ……(1)
Where, PR(Ti) is the page rank of pages Ti
C(Ti)is number of outlinks on page Ti
D is the dumping factor.
It is used to calculate the probability so that the other pages have no effect on it. It is done to show that the
sum of Page Rank of all web pages to be 1. The complexity is O(log N). The search engine used in it is
Google. The only limitation is that it is query independent.
Weighted page rank: This algorithm is proposed by Wenpu Xing and Ali Ghorbani .It is the extension of
page ranking algorithm as rank values are assigned to it according to their importance. The importance is
calculated on the basis of the links: incoming links, outgoing links.
The formula is:
WPR(n)=(1-d)+d ∑m€B(n) WPR (m)Win
(m,n) Wout
(m,n) …………(1)
Win
is the weight of link(m,n) on the number of
incoming links of page n.
WOut
is the weight of link(m,n) calculated on the
number of outgoing links of page n w.r.f page m.
According to experimental result , it has been found that the weighted page rank has larger relevancy than page
rank.
Its complexity is <O(log N). The search engine used in it is research model.
Hyper-Induced Topic Search: This algorithm is given by Klienberg in 1999 and propose two forms of web
pages called hubs and authorities. Hubs are pages that are used to give authorities to users. So, if a page is
good authoritative then it should be pointed out by good hubs at the same time. Klienberg also pointed out
that a page can be a good hub and a good authority at the same time. The formula used to calculate it:
Fig : Calculation of hubs and authorities

217 | P a g e
In HITS there are two steps, first step is Sampling and second step is Iterative .
In sampling step the relevant pages are collect .And in Iterative step, use the output of sampling step and find
hubs , authorities.
Hp=∑q€I (p) Aq
AP =∑q€B (p) Hq
Where:
Hp = The hub weight
Ap = The Authority weight
I(p) and B(p) = Denotes the set of reference and referrer pages of page p
HITS algoritham has following constraints:
a) The differentiation between hubs and authorities is not possible .
b) Sometimes did not search the relevant pages.
c) It did not generate relevant link for user query.
d) It is not efficient in real time.
The complexity is <O(log N). The input parameter are backlinks, forwardlinks and content.
III. CONCLUSION
Web data mining is an interdisciplinary field. This paper covers all the basic aspects of web mining. In the web
mining it has been divided in to three parts: web content mining , web usage mining and web structure mining.
Web content mining is presented in two views: information retrieval and database view. In database view ,we
are dealing with traditional apriori algorithm and then the improved apriori algorithm. In Web usage mining we
are dealing with the user behavior and different types of data . Web structure mining deals with the links and
hyperlinks. The algorithms associated with it : Page Rank, Weighted PageRank and HITS algorithm is
discussed.
As, the web is very diverse in nature and apriori algorithm is the basic algorithm so many improvements are
needed in this direction so more and more optimization is possible.
REFERENCES
[1] XindongWu,Vipin Kumar, J. Ross Quinlan, Top 10 algorithms in data mining, (2008), pp-1–37.
[2] Lihui Chen, Wai Lian Chue ,Using Web structure and summarization techniques for Web content
mining,2005,pp1225-1242.
[3] Pragya Agarwal, Madan Lal Yadav, Nupur Anand, Study on Apriori Algorithm and its Application in
Grocery Store, International Journal of Computer Applications , Volume 74,14 July 2013.
[4] Pratibha Mandave, Megha Mane , Data mining using Association rule based on Apriori Algorithm and
Improved Approach with illustration, International Journal of Latest Trends in Engineering and
Technology, Vol. 3 Issue2 November 2013.
[5] jaishree Singh, Hari Ram, Improved efficiency of Apriori Algorithm Using Trsnsaction Reduction,
International Journal of Scientific and Research Publications, January 2013.

218 | P a g e
[6] Osmar R. Zaıane ,Web Usage Mining for a BetterWeb-Based Learning Environment, Department of
Computing Science University of Alberta Canada ,.
[7] Rekha Jain ,Page Ranking Algorithms for Web Mining, International Journal of Computer
Applications,Volume 13– No.5, January 2011,pp-22-25.
[8] Bamshad Mobasher and Olfa Nasraoui, Web usage mining.
[9] Bamshad Mobasher, Web usage mining.
[10] P. Ravi Kumar and Ashutosh Kumar Singh,Web Structure Mining: Exploring Hyperlinks and Algorithms
for Information Retrieval, American Journal of Applied Sciences ,pp- 840-845, 2010.
[11] Prof. Vinitkumar Gupta, Survey on several improved Apriori algorithms , IOSR Journal of Computer
Engineering,2013, PP 57-61.
[12] Divya Bansal ,Execution of Apriori Algorithm of Data Mining Directed Towards Tumultuous Crimes
Concerning Women, International Journal of Advanced Research in Computer Science and Software
Engineering,2013,pp-54-62.
[13] Yoon Ho Choa , Application of Web usage mining and product taxonomy to collaborative
recommendations in e-commerce, Expert Systems with Applications,2014, pp- 233–246.
[14] Ming syan, Efficient Data Mining For Path Traversal Patterns.
[15] Robort Cooley, Data Preparation For Mining World Wide Web Brosing Pattern,October 1998.
[16] Robert Cooley, The Use of Web Structure and Content to Identify Subjectively Interesting Web Usage
Patterns,ACM Transaction on Intrernet Technology 2013.
[17] Johannes F¨urnkranz,Web Structure Mining Exploiting the Graph Structure of the World-Wide Web, pp-1-
10.





























