Embed Size (px)
Citation preview

Approximating Submodular FunctionsPart 2
Nick HarveyUniversity of British Columbia
Department of Computer Science
July 12th, 2015
Joint work with Nina Balcan (CMU)

f( ) ! R• n items, {1,2,…,n} = [n]• f : 2[n] ! R.
Focus on combinatorial settings:
Valuation FunctionsIndividuals have valuation functions givingutility for different outcomes or events.
This talk: Learning valuation functions froma distribution on the data.
• Motivating application: Bundle pricing

Submodular valuations
xS Tx
++
Large improvement
Small improvement
For TµS, xS, f(T [ {x}) – f(T) ¸ f(S [ {x}) – f(S)
TS S [ TSÅ T
++ ¸
• Equivalent to decreasing marginal return:
For all S,T µ [n]: f(S)+f(T) ¸ f(S [ T) + f(S Å T)
• [n]={1,…,n}; Function f : 2[n] ! R submodular if

Submodular valuations
• Concave Functions Let h : R ! R be concave. For each S µ [n], let f(S) = h(|S|)
• Vector Spaces Let V={v1,,vn}, each vi 2 Rd.
For each S µ [n], let f(S) = dim span { vi : i 2 S}
E.g.,
For TµS, xS, f(T [ {x}) – f(T) ¸ f(S [ {x}) – f(S)
• Decreasing marginal return:
xS Tx
++
Large improvement
Small improvement

S1,…, Sk
Labeled Examples
Passive Supervised Learning
Learning Algorithm
Expert / Oracle
Data Source
Alg. outputs
Distribution D on 2[n]
f : 2[n] ! R+
(S1,f(S1)),…, (Sk,f(Sk))
g : 2[n] ! R+

S1,…, Sk
PMAC model for learning real valued functions
Distribution D on 2[n]
Labeled Examples
Learning Algorithm
Expert / Oracle
Data Source
Alg.outputsf : 2[n] ! R+
g : 2[n] ! R+
(S1,f(S1)),…, (Sk,f(Sk))
• Alg. sees (S1,f(S1)),…, (Sk,f(Sk)), Si i.i.d. from D, produces g
Probably Mostly Approximately Correct
• With probability ¸ 1-±, we have PrS[ g(S) · f(S) · ® g(S) ] ¸ 1-²
PAC Boolean
{0,1}{0,1}

Learning submodular functions
Monotone, submodular functions can be PMAC-learned(w.r.t. an arbitrary distribution) with approximation factor ®=O(n1/2).
Monotone, submodular functions cannot be PMAC-learnedwith approximation factor õ(n1/3).
Theorem: (Our general lower bound)
Theorem: (Our general upper bound)
Lipschitz, monotone submodular funtions can be PMAC-learnedunder a product distribution with approximation factor O(1).
Theorem: (Product distributions)Corollary: Gross substitutes functions do not havea concise, approximate representation.

Learning submodular functions
Monotone, submodular functions can be PMAC-learned(w.r.t. an arbitrary distribution) with approximation factor ®=O(n1/2).
Monotone, submodular functions cannot be PMAC-learnedwith approximation factor õ(n1/3).
Theorem: (Our general lower bound)
Theorem: (Our general upper bound)
Lipschitz, monotone submodular funtions can be PMAC-learnedunder a product distribution with approximation factor O(1).
Theorem: (Product distributions)
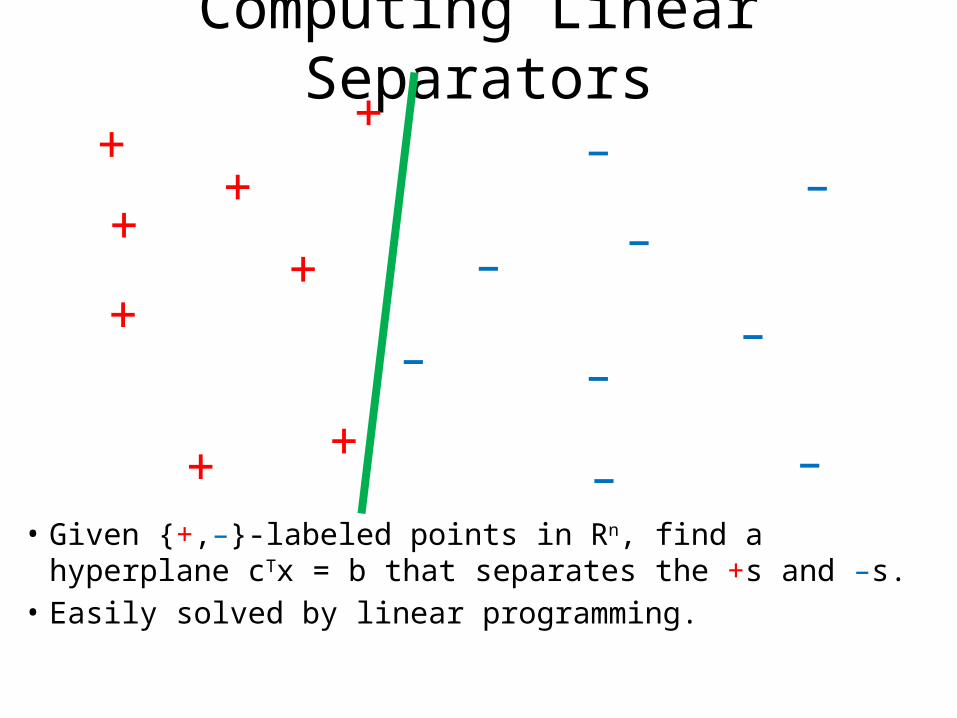
Computing Linear Separators+
– +
+
+
+–
–
–
– +
– +
+
–
– – • Given {+,–}-labeled points in Rn, find a hyperplane cTx
= b that separates the +s and –s.• Easily solved by linear programming.

Learning Linear Separators+
– +
+
+
+–
–
–
– +
– +
+
–
– – • Given random sample of {+,–}-labeled points in Rn,
find a hyperplane cTx = b that separates most ofthe +s and –s.
• Classic machine learning problem.
Error!

Learning Linear Separators+
– +
+
+
+–
–
–
– +
– +
+
–
– – • Classic Theorem: [Vapnik-Chervonenkis 1971]
O( n/²2 ) samples suffice to get error ².
Error!
~

Approximating Submodular Functions
• Existential result from last time:
• In other words:Given a non-negative, monotone, submodular function f,there exists a linear function g (= 2)such that f2(S) · g(S) · n¢f2(S) for all S.

V
f2
n¢f2
g
Approximating Submodular Functions

V+ +
+
+
+ +
+ f2
n¢f2
• Randomly sample {S1,…,Sk} from distribution
• Create + for f2(Si) and – for n¢f2(Si)• Now just learn a linear separator!
–
––
–
– –
– g

V
f2
n¢f2
• Theorem: g approximates f to within a factor on a 1-² fraction of the distribution.
g

Learning submodular functions
Monotone, submodular functions can be PMAC-learned(w.r.t. an arbitrary distribution) with approximation factor ®=O(n1/2).
Monotone, submodular functions cannot be PMAC-learnedwith approximation factor õ(n1/3).
Theorem: (Our general lower bound)
Theorem: (Our general upper bound)
Lipschitz, monotone submodular funtions can be PMAC-learnedunder a product distribution with approximation factor O(1).
Theorem: (Product distributions)
Corollary: Gross substitutes functions do not havea concise, approximate representation.
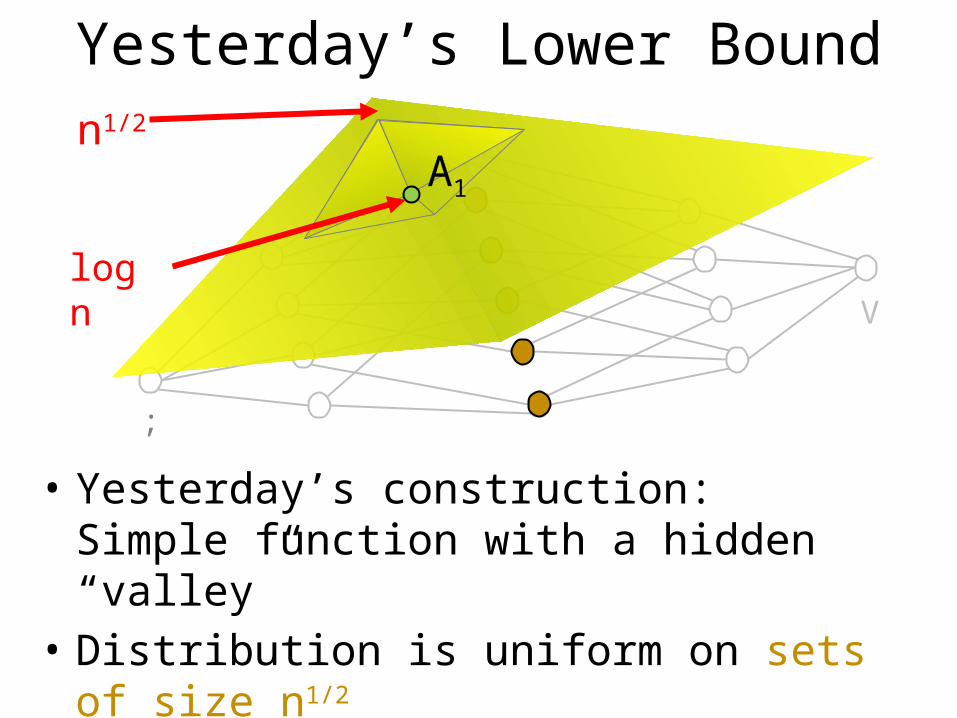
Yesterday’s Lower Bound
;
V
A1
• Yesterday’s construction:Simple function with a hidden “valley”
• Distribution is uniform on sets of size n1/2
• Is this example hard to learn?
n1/2
log n

LB for Learning Submodular Functions
;
VA2
A1
• Can we have multiple “valleys”?• If there are exponentially many valleys,
the algorithm can’t learn all themin polynomially many queries.

Matroids
• Ground Set V• Family of Independent Sets I• Axioms:• ; 2 I “nonempty”
• J ½ I 2 I ) J 2 I “downwards closed”
• J, I 2 I and |J|<|I| ) 9x2InJ s.t. J+x 2 I “maximum-size sets can be found
greedily”
• Rank function: r(S) = max { |I| : I2I and IµS }
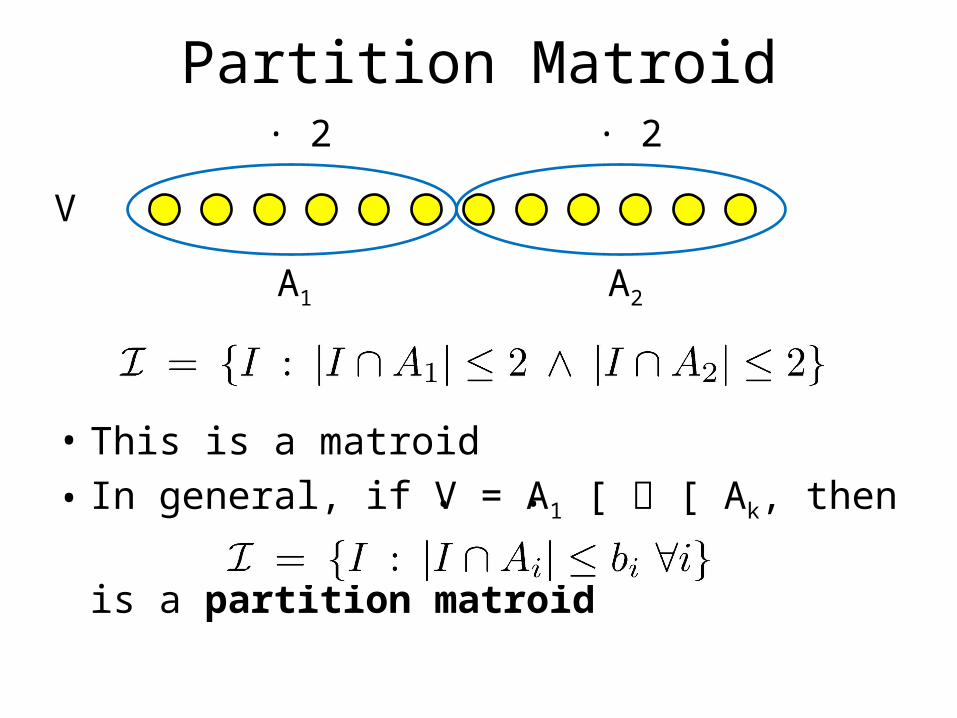
Partition Matroid· 2 · 2
A1 A2
• This is a matroid• In general, if V = A1 [ [ Ak, then
is a partition matroid
V
. .

Intersecting Ai’s
a b c d e f g h i j k l
· 2 · 2
A1 A2
• Our lower bound considers the question:What if Ai’s intersect? Then I is not a matroid.
• For example, {a,b,k,l} and {f,g,h} are both maximal sets in I.
V

A fix
a b c d e f g h i j k l
· 2 · 2
A1 A2
• After truncating the rank to 3, then {a,b,k,l}I.• Checking a few cases shows that I is a matroid.
V

A general fix (for two Ai’s)
a b c d e f g h i j k l
· b1 · b2
A1 A2
• This works for any A1,A2 and bounds b1,b2
(unless b1+b2-|A1ÅA2|<0)
• Summary: There is a matroid that’s like a partition matroid, if bi’s large relative to |A1ÅA2|
V

The Main Question• Let V = A1[[Ak and b1,,bk2N
• Is there a matroid s.t.• r(Ai) · bi 8i
• r(S) is “as large as possible” for SAi (this is not formal)
• If Ai’s are disjoint, solution is partition matroid
• If Ai’s are “almost disjoint”, can we find a matroid that’s “almost” a partition matroid?
Next: formalize this

Lossless Expander Graphs
• Definition:G =(U[V, E) is a (D,K,²)-lossless expander if– Every u2U has degree D– |¡ (S)| ¸ (1-²)¢D¢|S| 8SµU with |S|·K,
where ¡ (S) = { v2V : 9u2S s.t. {u,v}2E }
“Every small left-set has nearly-maximalnumber of right-neighbors”
U V
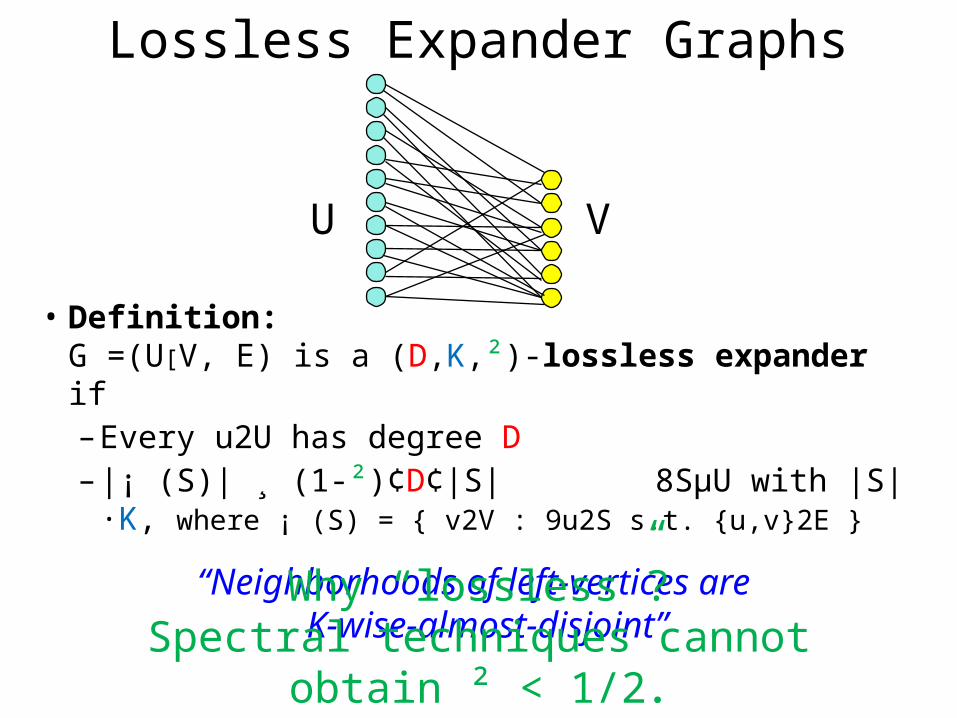
Lossless Expander Graphs
• Definition:G =(U[V, E) is a (D,K,²)-lossless expander if– Every u2U has degree D– |¡ (S)| ¸ (1-²)¢D¢|S| 8SµU with |S|·K,
where ¡ (S) = { v2V : 9u2S s.t. {u,v}2E }
“Neighborhoods of left-vertices areK-wise-almost-disjoint”
Why “lossless”?Spectral techniques cannot obtain ² < 1/2.
U V

Trivial Example: Disjoint Neighborhoods
• Definition:G =(U[V, E) is a (D,K,²)-lossless expander if– Every u2U has degree D– |¡ (S)| ¸ (1-²)¢D¢|S| 8SµU with |S|·K,
where ¡ (S) = { v2V : 9u2S s.t. {u,v}2E }
• If left-vertices have disjoint neighborhoods, this gives an expander with ²=0, K=1
U V

Main Theorem: Trivial Case
• Suppose G =(U[V, E) has disjoint left-neighborhoods.• Let A={A1,…,Ak} be defined by A = { ¡(u) : u2U }.
• Let b1, …, bk be non-negative integers.
• Theorem:
is family of independent sets of a matroid.
I = f I : jI \ [ j 2 J A j j ·X
j 2 J
bj 8J gI = f I : jI \ A j j · bj 8j g
A1
A2
· b1
· b2U V

Main Theorem• Let G =(U[V, E) be a (D,K,²)-lossless expander• Let A={A1,…,Ak} be defined by A = { ¡(u) : u2U }
• Let b1, …, bk satisfy bi ¸ 4²D 8i
A1
· b1
A2
· b2

Main Theorem• Let G =(U[V, E) be a (D,K,²)-lossless expander• Let A={A1,…,Ak} be defined by A = { ¡(u) : u2U }
• Let b1, …, bk satisfy bi ¸ 4²D 8i
• “Wishful Thinking”: I is a matroid, whereI =f I : jI \ [ j 2 J A j j ·
X
j 2 J
bj 8J g

Main Theorem• Let G =(U[V, E) be a (D,K,²)-lossless expander• Let A={A1,…,Ak} be defined by A = { ¡(u) : u2U }
• Let b1, …, bk satisfy bi ¸ 4²D 8i
• Theorem: I is a matroid, whereI =f I : jI \ [ j 2 J A j j ·
X
j 2 J
bj ¡³ X
j 2 J
jA j j ¡ j [ j 2 J A j j´
8J s.t. jJ j · K
^ jI j · ²DK g

Main Theorem• Let G =(U[V, E) be a (D,K,²)-lossless expander• Let A={A1,…,Ak} be defined by A = { ¡(u) : u2U }
• Let b1, …, bk satisfy bi ¸ 4²D 8i
• Theorem: I is a matroid, where
• Trivial case: G has disjoint neighborhoods,i.e., K=1 and ²=0.
I =f I : jI \ [ j 2 J A j j ·X
j 2 J
bj ¡³ X
j 2 J
jA j j ¡ j [ j 2 J A j j´
8J s.t. jJ j · K
^ jI j · ²DK g
= 0
= 1
= 0
= 1

LB for Learning Submodular Functions
;
VA2
A1
n1/3
log2 n
• Let G =(U[V, E) be a (D,K,²)-lossless expander,where Ai = ¡(ui) and
– |V|=n − |U|=nlog n
– D = K = n1/3 − ² = log2(n)/n1/3
• So, nlog n valleys. Depth of valley is 1/² = n1/3 /log2(n)

LB for Learning Submodular Functions• Let G =(U[V, E) be a (D,K,²)-lossless expander, where Ai =
¡(ui) and– |V|=n − |U|=nlog n
– D = K = n1/3 − ² = log2(n)/n1/3
• Lower bound using (D,K,²)-lossless expanders:– Delete each node in U with prob. ½, then use main theorem
to get a matroid– If ui2U was not deleted then r(Ai) · bi = 4²D = O(log2 n)
– Claim: If ui deleted then Ai 2 I (Needs a proof) ) r(Ai) = |Ai| = D = n1/3
– Distribution is uniform on the points { Ai : i 2 U }
– Since # Ai’s = |U| = nlog n, no algorithm can learna significant fraction of r(Ai) values in polynomial time

I =f I : jI \ Cj · f (C) 8C 2 C gLemma: Slight extension of [Edmonds ’70, Thm 15]Letwhere f : C ! Z is some function. For any I 2 I, let
T(I ) = f C : jI \ Cj = f (C) gbe the “tight sets” for I. Suppose that
C1 2 T(I ) ^ C2 2 T(I ) =) C1 [ C2 2 T(I )Then I is independent sets of a matroid.
Proof: Let J,I 2 I and |J|<|I|. Must show 9x2InJ s.t. J+x 2 I.Let C be the maximal set in T(J). Then |IÅC| · f(C) = |JÅC|.Since |I|>|J|, 9x in In(C [ J).We must have J+x 2 I,because every C’3x has C’T(J).So |(J+x) Å C’|·f(C’). So J+x 2 I.
C JI
x

Learning submodular functions
Monotone, submodular functions can be PMAC-learned(w.r.t. an arbitrary distribution) with approximation factor ®=O(n1/2).
Monotone, submodular functions cannot be PMAC-learnedwith approximation factor õ(n1/3).
Theorem: (Our general lower bound)
Theorem: (Our general upper bound)
Lipschitz, monotone submodular funtions can be PMAC-learnedunder a product distribution with approximation factor O(1).
Theorem: (Product distributions)
Corollary: Gross substitutes functions do not havea concise, approximate representation.

Gross Substitutes Functions• Class of utility functions commonly used in
mechanism design [Kelso-Crawford ‘82, Gul-Stacchetti ‘99, Milgrom ‘00, …]
• Intuitively, increasing the prices for some items does not decrease demand for the other items.
• Question: [Blumrosen-Nisan, Bing-Lehman-Milgrom]
Do GS functions have a concise representation?

Gross Substitutes Functions• Class of utility functions commonly used in
mechanism design [Kelso, Crawford, Gul, Stacchetti, …]
• Question: [Blumrosen-Nisan, Bing-Lehman-Milgrom]
Do GS functions have a concise representation?• Fact: Every matroid rank function is GS.
• Corollary: The answer to the question is no.
There is a distribution D and a randomly chosen function f s.t.• f is a matroid rank function• poly(n) bits of information do not suffice to predict the value
of f on samples from D, even to within a factor o(n1/3).
Theorem: (Main lower bound construction)
~

Learning submodular functions
Monotone, submodular functions can be PMAC-learned(w.r.t. an arbitrary distribution) with approximation factor ®=O(n1/2).
Monotone, submodular functions cannot be PMAC-learnedwith approximation factor õ(n1/3).
Theorem: (Our general lower bound)
Theorem: (Our general upper bound)
Lipschitz, monotone submodular funtions can be PMAC-learnedunder a product distribution with approximation factor O(1).
Theorem: (Product distributions)
Corollary: Gross substitutes functions do not havea concise, approximate representation.

Learning submodular functions
• Hypotheses:– PrX»D[ X=x ] = i Pr[ Xi = xi ] (“Product distribution”)
– f({i}) 2 [0,1] for all i 2 [n] (“Lipschitz function”)
– f({i}) 2 {0,1} for all i 2 [n] Stronger condition!
Lipschitz, monotone submodular funtions can be PMAC-learnedunder a product distribution with approximation factor O(1).
Theorem: (Product distributions)

;
V
Technical Theorem:For any ²>0, there exists a concave function h : [0,n] ! R s.t.for every k2[n], and for a 1-² fraction of SµV with |S|=k,we have:
In fact, h(k) is just E[ f(S) ], where S is uniform on sets of size k.h(k) · f(S) · O(log2(1/²))¢h(k).

Concentration• Let f : 2[n] ! R be the function
f(S) = §i2S ai where each ai 2 [0,1].• Let X have a product distribution on [n]
(each i included in X independently)• Chernoff Bound: For any ® 2 [0,1],
• What if f is an arbitrary Lipschitz function?• Azuma’s Inequality: For any ® 2 [0,1],
• This is useless unless E[f(X)] ¸ n1/2.

Talagrand’s Inequality
• Def: The function f : 2[n] ! R is certifiableif, whenever f(S) ¸ x, there exists a set I µ S, |I| · x, such that f(T) ¸ x whenever I µ T.
• Theorem: [Talagrand] For any Lipschitz, certifiable function f, and any ® 2 [0,1],
• Suppose f is a matroid rank function.Is it certifiable?
• Yes! Just let I be a maximal independent set.

Concentration forMatroid Rank Functions
• Linear Functions: Let f : 2[n] ! R be f(S) = §i2S ai where each ai 2 [0,1].
• Chernoff: For any ® 2 [0,1],
• Matroid Rank Functions: Let f : 2[n] ! R be a matroid rank function.
• Theorem: For any ® 2 [0,1],
• Chekuri-Vondrak-Zenklusen ‘10 improve 422 to 3.

Conclusions• Learning-theoretic view of submodular fns• Structural properties:– Very “bumpy” under arbitrary distributions– Very “smooth” under product distributions
• Learnability in PMAC model:– O(n1/2) approximation algorithm– (n1/3) inapproximability– O(1) approx for Lipschitz fns & product distrs
• No concise representation for gross substitutes







![Submodular Optimization with Submodular Cover and ... · discrete optimization problems. For example the Submodular Set Cover problem (henceforth SSC) [47] occurs as a special case](https://img.pdfslide.net/doc/110x75/5cdba12d88c993a6778d0d6d/submodular-optimization-with-submodular-cover-and-discrete-optimization.jpg)





















