Embed Size (px)
Citation preview

1
1
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Outline
Part 1: Basic Concepts of data clustering
Non-Supervised Learning and Clustering
: Problem formulation – cluster analysis
: Taxonomies of Clustering Techniques
: Data types and Proximity Measures
: Difficulties and open problems
Part 2: Clustering Algorithms
Hierarchical methods
: Single-link
: Complete-link
: Clustering Based on Dissimilarity Increments Criteria
From Single Clustering to Ensemble Methods - April 2009
2
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Pattern Recognition – Decision Making
Supervised Learning
: training samples, labeled by their category membership, are used
to design a classifier
. Labeled training patterns
. Labels represent true categories of patterns
Unsupervised Learning
: Based on a collection of samples without being told their
categories
. Learn the number of classes and the structure of each class using
similarity between unlabeled training patterns
. Datamining
From Single Clustering to Ensemble Methods - April 2009

2
3
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Unsupervised Learning / Clustering
Unsupervised Learning
: Learn the structure of multidimensional patterns
. Mixture Densities
– Gaussian Mixture Decomposition
» The probability structure is known with the exception of the values of
the parameters
Clustering Procedures
: Find subclasses
. Data description in terms of clusters or groups of data points that
possess strong internal similarities
Typical applications:
. As a stand-alone tool to get insight into data distribution
. As a preprocessing step for other algorithms
From Single Clustering to Ensemble Methods - April 2009
4
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Organize data into sensible groupings (either as a grouping of patterns or a
hierarchy of groups)
Clustering
: The process of grouping a set of objects into classes of similar objects
(extracting hidden structure from data)
Cluster
: A collection of objects that are similar to one another within the same
cluster and are dissimilar to the objects in other clusters
Cluster Analysis
From Single Clustering to Ensemble Methods - April 2009
3
5
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
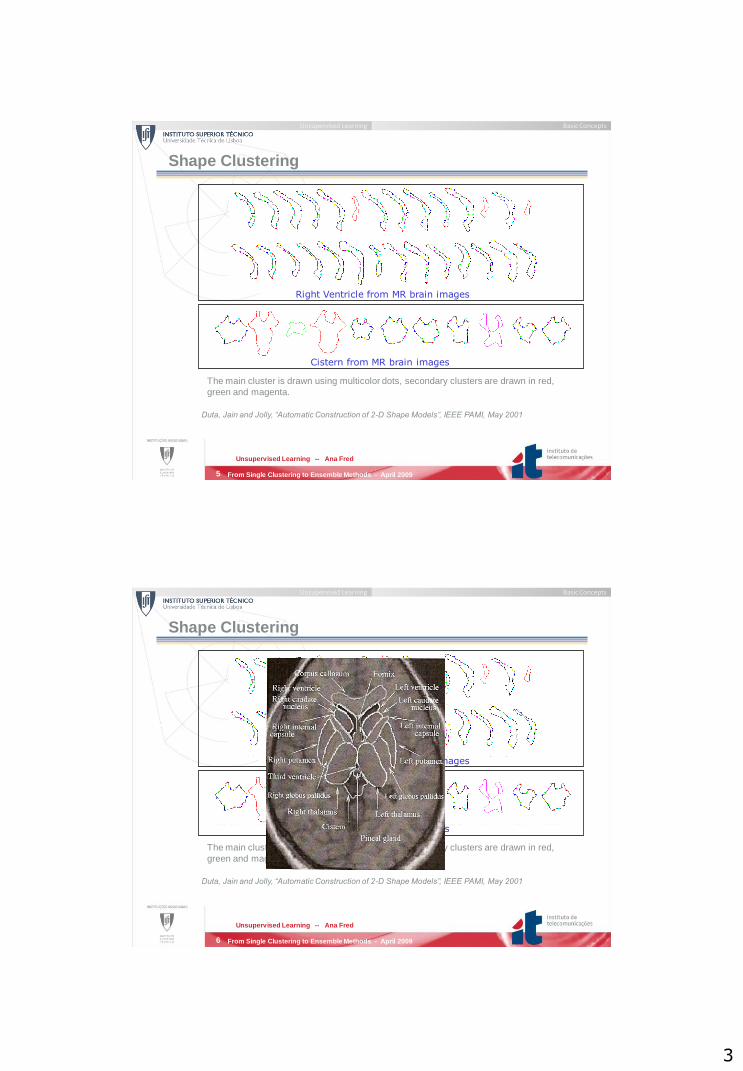
Shape Clustering
Right Ventricle from MR brain images
Duta, Jain and Jolly, “Automatic Construction of 2-D Shape Models”, IEEE PAMI, May 2001
Cistern from MR brain images
The main cluster is drawn using multicolor dots, secondary clusters are drawn in red,
green and magenta.
From Single Clustering to Ensemble Methods - April 2009
6
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Shape Clustering
Right Ventricle from MR brain images
Duta, Jain and Jolly, “Automatic Construction of 2-D Shape Models”, IEEE PAMI, May 2001
Cistern from MR brain images
The main cluster is drawn using multicolor dots, secondary clusters are drawn in red,
green and magenta.
From Single Clustering to Ensemble Methods - April 2009

4
7
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Identification of Writing Styles
122,000 “online” characters written by 100 writers
Lexemes are identified by clustering data within each character class into subclasses:
a string matching measure used to calculate distance between 2 characters
Connell and Jain, “Writer Adaptation for Online Handwriting Recognition”, IEEE PAMI, Mar 2002
From Single Clustering to Ensemble Methods - April 2009
8
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Segmentation of Natural Scenes
Hermes, Zoller, Bumannn, “Parametric Distributional Clustering for Image Segmentation”, ECCV 2002
From Single Clustering to Ensemble Methods - April 2009

5
9
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
What is a Cluster?
A set of entities which are alike; entities from different clusters are
not alike
An aggregation of points such that the distance between any two
points in a cluster is less than the distance between any point in the
cluster and any point not in it.
A relatively high density of points, surrounded by a relatively low
density of points
Ideal cluster: Compact and Isolated
From Single Clustering to Ensemble Methods - April 2009
10
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Taxonomy of Clustering Approaches
Two main strategies:
Hierarchical Methods
:Propose a sequence of nested data
partitions in a hierarchical structure
. Single-Link
. Complete Link
Partitional Methods
:Organize patterns into a small
number of clusters
. K-means
. Spectral clustering
From Single Clustering to Ensemble Methods - April 2009

6
11
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Taxonomy of Clustering Approaches
Clustering Principles:
Compactness
: K-means
: Complete-link
: Histogram clustering
: Pairwise data clustering
Connectedness
: Single-linkage
: Dissimilarity Increments
: Mean Shift clustering
Separation
: Normalized Cut
: Spectral clustering
From Single Clustering to Ensemble Methods - April 2009
12
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Taxonomy of Clustering Approaches
Clustering Principles:
Compactness
: K-means
: Complete-link
: Histogram clustering
: Pairwise data clustering
Connectedness
: Single-linkage
: Dissimilarity Increments
: Mean Shift clustering
Separation
: Normalized Cut
: Spectral clustering
From Single Clustering to Ensemble Methods - April 2009

7
13
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
2 3 4 5 6 7 8 9 101
2
3
4
5
6
7
8
9
10
2 3 4 5 6 7 8 9 101
2
3
4
5
6
7
8
9
10
Taxonomy of Clustering Approaches
Clustering Principles:
Compactness
: K-means
: Complete-link
: Histogram clustering
: Pairwise data clustering
Connectedness
: Single-linkage
: Dissimilarity Increments
: Mean Shift clustering
Separation
: Normalized Cut
: Spectral clustering
From Single Clustering to Ensemble Methods - April 2009
14
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Taxonomy of Clustering Approaches
Approaches:
Model-based
: Patterns can be given a simple and compact description in terms of
. Parametrical distribution -- Parametric density approaches (Mixture
models)
. A representative element, such as a centroid, median (central
clustering, square-error clustering, k-means, k-medoids) – or
multiple prototypes per cluster (CURE) -- Prototype-based methods
. Some geometrical primitives (lines, planes, circles, curves,
surfaces) – Shape fitting approaches
: These approaches assume particular cluster shapes, partitions
being in general obtained as a result of an optimization process
using a global criterion
From Single Clustering to Ensemble Methods - April 2009

8
15
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Taxonomy of Clustering Approaches
Graph-theoretical
: Mostly explored in hierarchical methods that can be represented
graphically as a tree or dendrogram
. Agglomerative methods (Single-link, complete-link)
. Divisive approaches (ex. Based on Minimum Spanning Tree)
: View clustering as a graph partitioning problem
Non parametric density-based
: Attempt to identify high density clusters separated by low density
regions (local cluster criterion, such as density-connected points)
(valley seeking clustering algorithms)
. DBSCAN, OPTICS, DENCLUE, CLIQUE
. Discover clusters of arbitrary shape
From Single Clustering to Ensemble Methods - April 2009
16
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Data Types in Clustering Problems
Data representations:
Vector data: n vectors in Rd
Proximity data: n x n pairwise
proximity matrix
:All types of data may be
addressed by choosing adequate
proximity measures
From Single Clustering to Ensemble Methods - April 2009

9
17
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Similarity and Dissimilarity Between Objects
Distances are normally used to measure the similarity or
dissimilarity between two data objects
Metrics:
: Positivity: d(a, b) >0 and d(a, b)=0 , a=b
: Symmetry property: d(a,b)=d(b,a).
: Triangle inequality: d(a,c)· d(a,b) + d(b,c).
From Single Clustering to Ensemble Methods - April 2009
18
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Metric Models in Feature Spaces
Minskowski distance:
(Euclidean distance corresponds to r = 2)
Maximum Value Metric:
. Considers only most distant features
From Single Clustering to Ensemble Methods - April 2009

10
19
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Metric Models in Feature Spaces
Absolute Value Metric, Manhattan Distance or City-block (r = 1)
. Reduced computational time; does not penalize much the features with higher dissimilarity
. In R2: dist1((x1,y1),(x2,y2))=|x2-x1|+|y2-y1| , city-block:It is not possible to make short-cuts through corners: it counts the number of
blocks that is necessary to pass in order to move from one corner to another
Constant Manhattan distance curves:
1
1
( , ) ( , )d
M i i
i
d a b d a b b a
From Single Clustering to Ensemble Methods - April 2009
20
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Metric Models in Feature Spaces
Euclidean Distance:
. R2: dist2((x1,y1),(x2,y2))=((x2-x1)2+(y2-y1)2)1/2.
. Emphasizes more features with higher dissimilarity.
Mahalanobis Distance
2
2
1
( , ) ( , )d
e i i
i
d a b d a b b a
1( , )T
Mahalanobisd x y x y x y
From Single Clustering to Ensemble Methods - April 2009

11
21
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
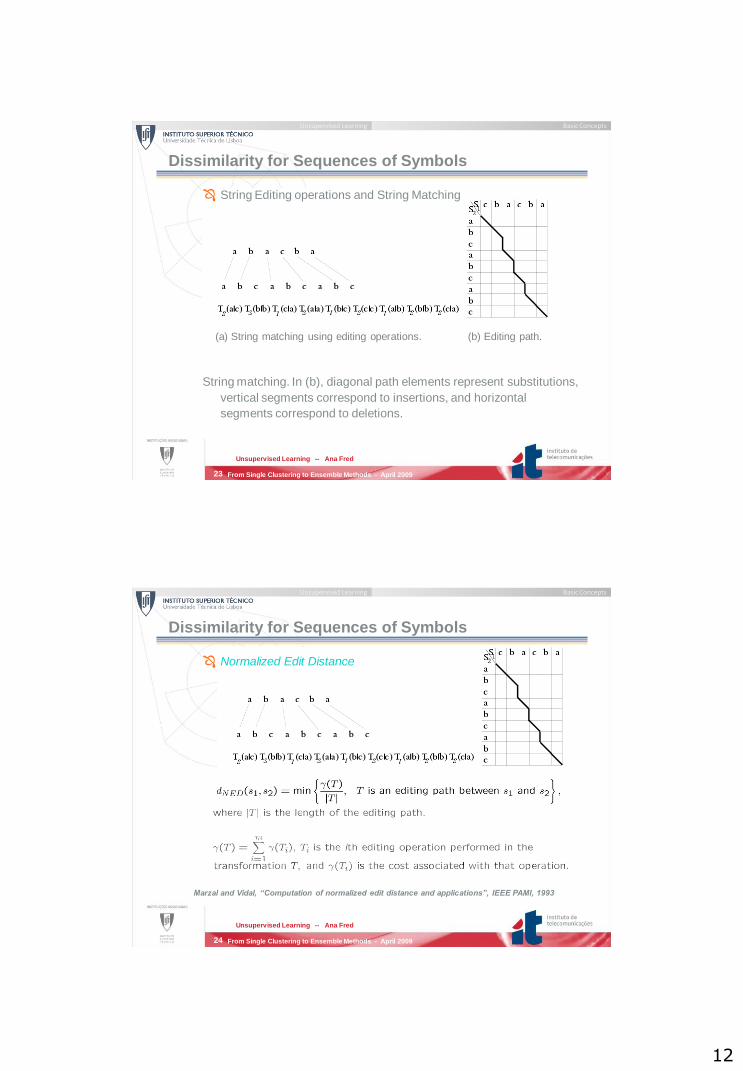
Dissimilarity for Sequences of Symbols
Dissimilarity based on String Editing operations
.
.
.
.
The Levensthein distance between two strings s1, s2 2 *, DL(s1, s2), is
defined as the minimum number of editing operations needed in order to
transform s1 into s2.
From Single Clustering to Ensemble Methods - April 2009
22
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Dissimilarity for Sequences of Symbols
The Weighted Levensthein distance between two strings s1, s2 2 *, is
defined by
where
Normalized Weighted Levensthein distance
From Single Clustering to Ensemble Methods - April 2009
12
23
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Dissimilarity for Sequences of Symbols
String Editing operations and String Matching
String matching. In (b), diagonal path elements represent substitutions,
vertical segments correspond to insertions, and horizontal
segments correspond to deletions.
(a) String matching using editing operations. (b) Editing path.
From Single Clustering to Ensemble Methods - April 2009
24
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
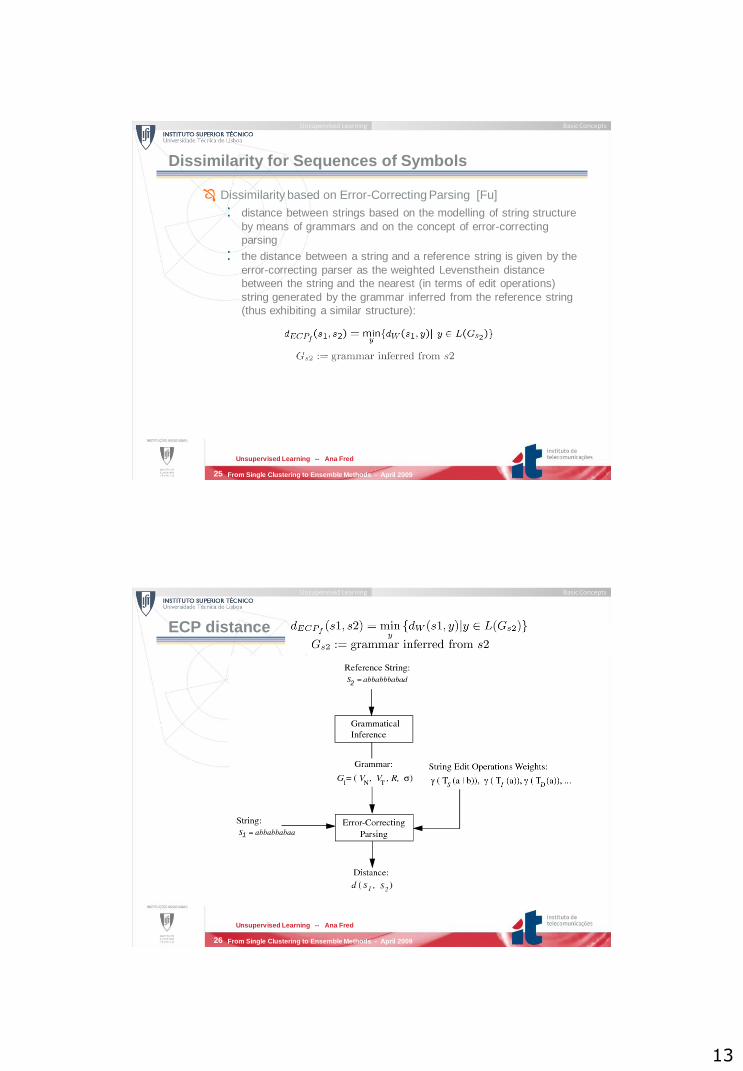
Dissimilarity for Sequences of Symbols
Normalized Edit Distance
Marzal and Vidal, “Computation of normalized edit distance and applications”, IEEE PAMI, 1993
From Single Clustering to Ensemble Methods - April 2009
13
25
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Dissimilarity for Sequences of Symbols
Dissimilarity based on Error-Correcting Parsing [Fu]
: distance between strings based on the modelling of string structure
by means of grammars and on the concept of error-correcting
parsing
: the distance between a string and a reference string is given by the
error-correcting parser as the weighted Levensthein distance
between the string and the nearest (in terms of edit operations)
string generated by the grammar inferred from the reference string
(thus exhibiting a similar structure):
From Single Clustering to Ensemble Methods - April 2009
26
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
ECP distance
1
2
From Single Clustering to Ensemble Methods - April 2009

14
27
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Dissimilarity for Sequences of Symbols
Dissimilarity based on Error-Correcting Parsing [Fu]
: distance between strings based on the modelling of string structure
by means of grammars and on the concept of error-correcting
parsing
: the distance between a string and a reference string is given by the
error-correcting parser as the weighted Levensthein distance
between the string and the nearest (in terms of edit operations)
string generated by the grammar inferred from the reference string
(thus exhibiting a similar structure):
: In order to preserve symmetry
From Single Clustering to Ensemble Methods - April 2009
28
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Dissimilarity for Sequences of Symbols
Grammar Complexity-based Similarity
The basic idea is that, if two sentences are structurally similar, then
their joint description will be more compact than their isolated
description due to sharing of rules of symbol composition; the
compactness of the representation is quantified by the grammar
complexity, and the similarity is measured by the ratio of decrease
in grammar complexity
where C(Gsi) denotes grammar complexity.
Fred. “Similarity measures and clustering of string patterns”. In Dechang Chen and Xiuzhen Cheng, editors,
Pattern Recognition and String Matching, Kluwer Academic, 2002,
Fred, “Clustering of Sequences using a Minimum Grammar Complexity Criterion”, ICGI 1996
From Single Clustering to Ensemble Methods - April 2009

15
29
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
RDGC Similarity
From Single Clustering to Ensemble Methods - April 2009
30
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Dissimilarity for Sequences of Symbols
Grammar Complexity-based Similarity– RDGC
Let G=(VN , , R, ) be a context-free grammar, where VN, are the sets
of nonterminal and terminal symbols, respectively, is the grammar’s
start symbol and R is the set of productions written in the form:
Let 2 (VN )*, be a grammatical sentence of length n, in which the
symbols a1, a2, … , am appear k1, k2, … , km times, respectively. The
complexity of the sentence, C(), is given by [Fu]
The complexity of the grammar G is defined as
From Single Clustering to Ensemble Methods - April 2009

16
31
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Dissimilarity for Sequences of Symbols
Minimum Code Length-based Similarity
: Based on Solomonoff’s code: a string is represented by a triplet
where a coded string is obtained in an iterative procedure where, in
each step, intermediate codes are produced by defining sequences of
two symbols, which are represented by special symbols, and rewriting
the sequences using them. Compact codes are produced when
sequences exhibit local or distant inter-symbol interactions.
. Code length: sum of the lengths of the descriptions of the three part
code above
: Extension to sets of strings
Fred. “Similarity measures and clustering of string patterns”. In Dechang Chen and Xiuzhen Cheng, editors,
Pattern Recognition and String Matching, Kluwer Academic, 2002,
Fred and Leitão, “A Minimum Code Length Technique for Clustering of Syntactic Patterns”, ICPR 1996
From Single Clustering to Ensemble Methods - April 2009
32
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Dissimilarity for Sequences of Symbols
Minimum Code Length-based Similarity
: The basic idea is that global compact codes are produced by
considering the inter-symbol dependencies on the ensemble of the
strings. The quantification of this reduction in code length forms the
basis of the similarity measure designated by Normalized Ratio of
decrease in code length - NRDCL
with
From Single Clustering to Ensemble Methods - April 2009

17
33
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Requirements of Clustering in Data Mining
Discovery of clusters with arbitrary shape
Ability to deal with different types of attributes
Scalability
Minimal requirements for domain knowledge to determine input
parameters
Insensitivity to the order of input records
Ability to deal with noisy data
High dimensionality
From Single Clustering to Ensemble Methods - April 2009
34
Unsupervised Learning Basic Concepts
Unsupervised Learning -- Ana Fred
Issues in Clustering
Which similarity measure and features to use?
How many clusters?
Which is the “best” clustering method?
Are the individual clusters and the partition valid?
How to choose algorithmic parameters?
K-means clustering of uniform data
(k=4)
K-means using Euclidean (blue) and
Mahalanobis distance (k=2) (red)
From Single Clustering to Ensemble Methods - April 2009





























