Embed Size (px)
Citation preview

Artificial Intelligence and Lisp #5
Causal Nets (continued)
Learning in Decision Trees and Causal Nets
Lab Assignment 3

Causal Nets
A causal net consists of: A set of independent terms A partially ordered set of dependent terms An assignment of a dependency expression to
each dependent term. (These may be decision trees)
The dependency expression for a term may use independent terms, and also dependent terms that are lower than the term at hand. This means the dependency graph is not cyclic
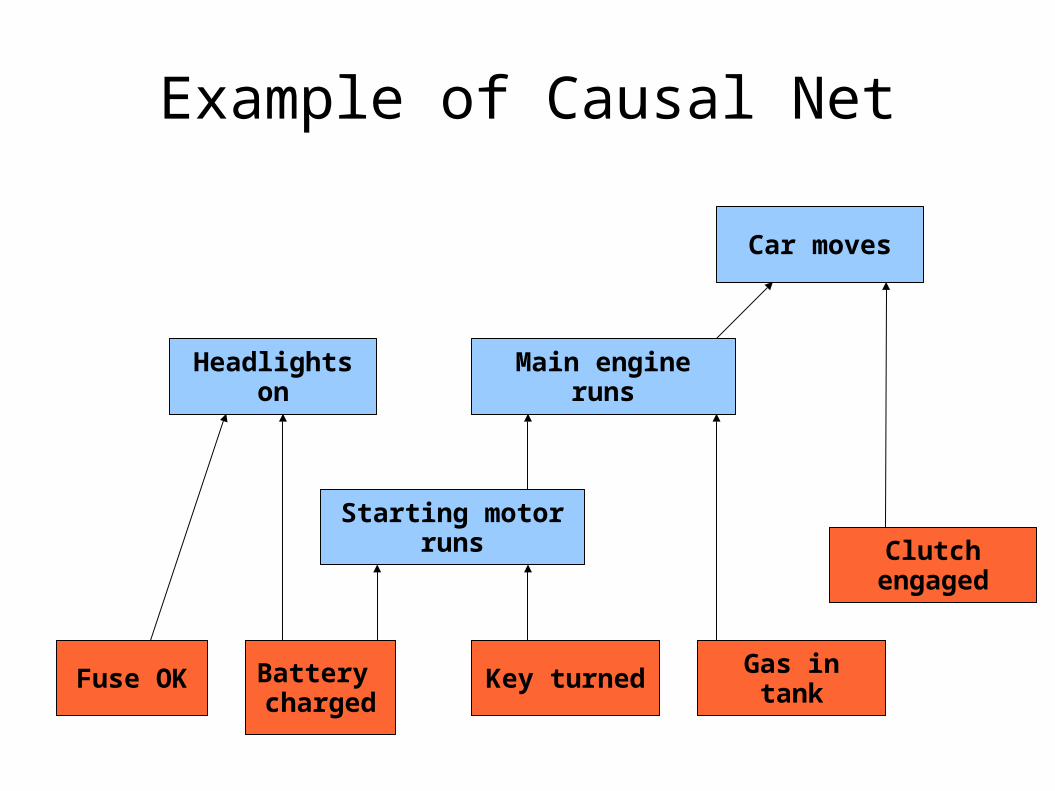
Example of Causal Net
Battery charged
Headlights on
Car moves
Starting motor runs
Gas in tank
Main engine runs
Key turnedFuse OK
Clutch engaged

Causal Nets II
A causal net is an acyclic graph where each node (called a term) represents some condition in the world (i.e., a feature) and each link indicates a dependency relationship between two terms
Terms in a causal net that do not have any predecessor are called independent terms
A dependence specification for a causal net is an assignment, to each dependent term, of an expression using its immediate predecessors
A causal net is exhaustive iff all actual dependencies are represented by links in it.

Dependence specification for one of the termsusing discrete term values
Headlights-on =
[fuse-ok? [battery-charged? true false] [battery-charged? false false]]
[fuse-ok? [battery-charged? true false] false ]
[<fuse-ok battery-charged>? true false false false :range <<true true><true false> <false true><false false>> ]

Observations on previous slide
A decision tree, where the same term is used throughout on each level, may become unnecessarily large
A decision tree can always be converted to an equivalent tree of depth 1 by introducing sequences of terms, and corresponding sequences of values for the terms

Main topic for first part of lecture Given: An exhaustive causal net equipped with
dependence specifications that may also use probabilities
A specification of a priori probabilities for each one of the independent terms (more exactly, a probability distribution over its admitted values)
A value for one of the dependent terms Desired: Inferred probabilities for the
independent terms, alone or in combination, based on this information.

Inverse operation (from previous lecture)Consider this simple case first:lights-are-on [noone-home? <70 30> <20 80>]
If it is known that lights-are-on is true, what is the probability for noone-home ?
Possible combinations: lights-are-on noone-home true 0.70 0.30 false 0.20 0.80
Suppose noone-home is true in 20% of overall cases, obtain: lights-are-on noone-home true 0.14 0.06 false 0.16 0.64
Given lights-are-on, noone-home has 14/30 = 46.7%probability. .

Inverse operation (from previous lecture)Consider this simple case first:lights-are-on [noone-home? <70 30> <20 80>]
If it is known that lights-are-on is true, what is the probability for noone-home ?
Possible combinations:
lights-are-on noone-home 0.70 0.30 false 0.20 0.80
Suppose noone-home is true in 20% of overall cases, obtain: lights-are-on noone-home 0.14 0.06 false 0.16 0.64
Given lights-are-on, noone-home has 14/30 = 46.7%probability. The probability estimate has changed from 20% to 46.7% according to the additional information.

Redoing the example systematically
lights-are-on noone-home true 0.70 0.30 probabilities cond'l ------------ on noone-home false 0.20 0.80
Suppose noone-home is true in 20% of overall cases, i.e. thea priori probabillity for noone-home is 0.20
lights-are-on noone-home true 0.14 0.06 a priori probabilities false 0.16 0.64
lights-are-on noone-home true 14/30 | 6/70 probabilities cond'l false 16/30 | 64/70 on lights-are-on

Bayes' Rule
E = lights-are-on noone-home true 0.70 0.30 P(A|E) = ------------ P(E|A)*P(A)/P(E) false 0.20 0.80
noone-home is true in 20% of overall cases:a priori probabillity for noone-home is 0.20
lights-are-on noone-home true 0.14 0.06 14/30 = false 0.16 0.64 0.70*0.20/0.30
E = lights-are-on noone-home true 14/30 | 6/70 false 16/30 | 64/70

Bayes' Rule
E = lights-are-on noone-home true 0.70 0.30 P(A|E) = ------------ P(E|A)*P(A)/P(E) false 0.20 0.80
Known:noone-home is true in 20% of overall cases: P(A) = 0.20, P(~A) = 0.80 P(E|A) = 0.70 P(~E|A) = 0.30 P(E|~A) = 0.20 P(~E|~A) = 0.80
P(E) = P(E|A)*P(A) + P(E|~A)*P(~A) = 0.70 * 0.20 + 0.20 * 0.80 = 0.30
P(A|E) = 0.70 * 0.20 / 0.30 = 14/30

Derivation of Bayes' Rule
To prove: P(A|E) = P(E|A)*P(A)/P(E)
P(E&A) = P(E|A) * P(A)P(A&E) = P(A|E) * P(E)
P(A|E)*P(E) = P(E|A)*P(A)
By a similar proof (exercise!)
P(A|E&B) = P(E|A&B)*P(A|B)/P(E|B)

More than two term values
E = lights-are-on 0 home 0.70 0.30 P(A|E) = ------------ P(E|A)*P(A)/P(E) 1 home 0.20 0.80 ------------ >1 home 0.05 0.95
Only difference: we need P(A) for each one of the three possible outcomes for A, i.e., we need a probabilitydistribution over the possible values of A

Two-level Decision Tree
dog-outside [noone-home? [dog-sick? <80 20> <70 30>] [dog-sick? <70 30> <30 70>] ]E [A? [B? 0.80 0.70] [B? 0.70 0.30] ]
E [<A B>? 0.80 0.70 0.70 0.30 :range <<true true> <true false> <false true> <false false>> ]

Two-level Decision Tree
P(A) = 0.20
E [<A B>? 0.80 0.70 0.70 0.30 ]
P(A|E) = P(E|A)*P(A)/P(E) which means thatP(A&B|E) = P(E|A&B)*P(A&B)/P(E)
P(A|E) can be obtained as P(A&B|E) + P(A&~B|E)
P(E|A&B) = 0.80
1. What is P(A&B) ?2. What is P(E) ? Before it was obtained as P(E) = P(E|A)*P(A) + P(E|~A)*P(~A)

Two-level Decision TreeP(A) = 0.20P(B) = 0.05 aprioriE <A B> <T T> 0.80 0.01 0.008 <T F> 0.70 0.19 0.133 <F T> 0.70 0.04 0.028 <F F> 0.30 0.76 0.228 P(E) = 0.397
P(A&B|E) = P(E|A&B)*P(A&B)/P(E)P(A|E) can be obtained as P(A&B|E) + P(A&~B|E)
P(E|A&B) = 0.80
1. P(A&B) = 0.012. P(E) = 0.397P(A&B|E) = 0.80 * 0.01 / 0.397 ~ 0.02

Two-level Decision TreeExplanation of the second line in the tableP(A) = 0.20P(B) = 0.05 apriori <A B> <T T> 0.80 0.01 0.008 <T F> 0.70 0.19 0.133 ... P(E|A&~B) = 0.70 conditional probability, given in the decision tree
P(A&~B) = 0.19 a priori probability (using independence)
P(E&A&~B) = P(E|A&~B)*P(A&~B) = 0.133 a priori probability
P(E) = P(E&A&B) + P(E&A&~B) + P(E&~A&B) + P(E&~A&~B) = 0.397 a priori probability

Re-view assumptions made above Given: An exhaustive decision tree using probabilities, so that P(A&B) = P(A) * P(B) for each combination of independent terms A specification of a priori probabilities for each one of the
independent terms (more exactly, a probability distribution over its admitted values)
A value for one of the dependent terms Desired: Inferred probabilities for the independent terms,
alone or in combination, based on this information.
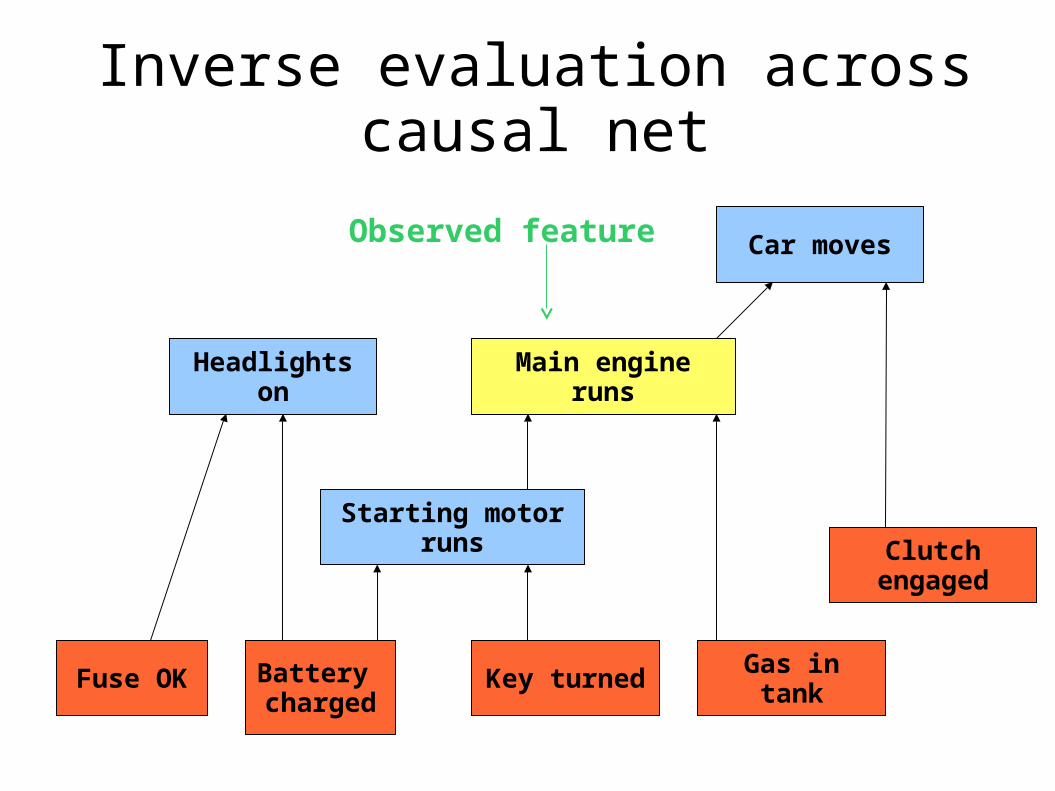
Inverse evaluation across causal net
Battery charged
Headlights on
Car moves
Starting motor runs
Gas in tank
Main engine runs
Key turnedFuse OK
Clutch engaged
Observed feature

1. Remove irrelevant terms
Battery charged
Starting motor runs
Gas in tank
Main engine runs
Key turned
Observed feature

Inverse evaluation across causal net
1. Remove irrelevant terms (both “sideways” and “upward”; also “downward” if apriori probabilities are available anyway)
2. Calculate apriori probabilities “upward” from independent terms to the observed one
3. Calculate inferred probabilities “downward” from observed term to combinations of independent ones
4. Add up probabilities for combinations of independent terms

Learning in Decision Trees and Causal Nets
Obtaining a priori probabilities for given terms Obtaining conditional probabilities in a decision
tree with a given set of independent terms, based on a set of observed cases
Choosing the structure of a decision tree using a given set of terms (assuming there is a cost for obtaining the value of a term)
Identifying the structure of a causal net using a given set of terms

Choosing (the structure of) a decision treeAlso applicable for trees without probabilities
Given a set of independent variables A, B,... and a large number of instances of the values of these + value of E
Consider the decision tree for E only having the node A, and similarly for B, C, etc.
Calculate P(E,A) and P(E,~A), and similarly for the other alternative trees
Favor the choice that costs the least and that gives the most information in the sense of information theory (the “difference” between P(E,A) and P(E,~A) is as big as possible)
Form subtrees recursively as long as it is worthwhile This produces both structure and probabilities for the
decision tree

Assessing the precision of the decision tree
Obtain a sufficiently large set of instances of the problem
Divide it into a training set and a test set Construct a decision tree using the training set Evaluate the elements of the test set in the
decision tree and check how well predicted values match actual values

Roll-dice scenario
Roll a number of 6-sided dice and register the following independent variables:
The color of the dice (ten different colors) The showing of the 'seconds' dial on the watch,
ranging from 0 to 59 The showing of another dice that is thrown at
the same time A total of 3600 different combinations Consider a training set where no combination
occurs more than once

Roll-dice scenario Conclusion from this scenario: It is important to have a way of determining
whether the size of the (remaining) training set at a particular node in the decision tree being designed, is at all significant
This may be done by testing it against a null hypothesis: could the training set at hand have been obtained purely by chance?
It may also be done using human knowledge of the domain at hand
Finally it can be done using a test set

Continuous-valued termsand terms with a large number of discrete values
In order to be used in a decision tree, one must aggregate the range of values into a limited number of cases, for example by introducing intervals (for value domains having a natural ordering)

Identifying the structure of a causal net
This is very often done manually and using the human knowledge about the problem domain.
Other possibility: select or generate a number of alternative causal nets, learn dependence specifications (e.g. decision trees) for each of them using training sets, and assess their precision using test sets

There is much more to learn about Learning in A.I.
Statistically oriented learning: major part of the field at present. Based on Bayesian methods and/or on neural networks
Logic-oriented learning: identifying compact representations of observed phenomena and behavior patterns in terms of logic formulas
Case-based learning: the agent maintains a case base of previously encountered situations, the actions it took then, and the outcome of those actions. New situations are addressed by finding a similar case that was successful and adapting the actions that were used then.

Lab 3: Using Decision Trees and Causal Nets – the Scenario
Three classes of terms (features): illnesses, symptoms, and cures
Cures include both use of medicines and other kinds of cures
Causal net can model the relation from illness to symptom
Another causal net can model the relation from current illness + cure to updated illness
Both of these make use of dependency expressions that are probabilistic decision trees

Milestone 3a
Downloaded lab materials will contain the causal net going from disease to symptom, but without the dependency expressions
It will also contain operations for direct evaluation and inverse evaluation of decision trees
The task will be to define plausible dependency expressions for this causal net, and to run test examples on it.
This includes both test examples given by us, and test examples that you write yourself.

Milestone 3b
Additional downloaded materials will contain a set of terms for medicines and cures, but without the causal net, and a generator for (animals with) illnesses
The first part of the task is to define a plausible causal net and associated dependency expressions for the step from cures to update of illnesses
The second part of the task is to run a combined system where animals with illnesses are diagnosed and treated, and the outcome is observed.

Updated Plan for the Course
Please check the course webpage where the plan for lectures and labs has been modified. Lab 2 has been given one more week in the tutorial sessions, and labs 4 and 5 have been commuted.






















![May the LISP be with You - Nerd2NerdWhy Lisp? More on Macros [ What Lisp?, How Lisp? ]Problems/Features [ When Lisp? ] May the LISP be with You Andrew (kqb) Easton nerd2nerd: nerdend](https://img.pdfslide.net/doc/110x75/5ed9946d1b54311e7967d3e5/may-the-lisp-be-with-you-nerd2nerd-why-lisp-more-on-macros-what-lisp-how.jpg)






