Embed Size (px)
Citation preview

Aspect-augmented Adversarial Networks for Domain Adaptation
Yuan Zhang, Regina Barzilay, and Tommi JaakkolaComputer Science and Artificial Intelligence Laboratory
Massachusetts Institute of Technologyyuanzh, regina, [email protected]
Abstract
We introduce a neural method for transferlearning between two (source and target) clas-sification tasks or aspects over the same do-main. Rather than training on target la-bels, we use a few keywords pertaining tosource and target aspects indicating sentencerelevance instead of document class labels.Documents are encoded by learning to em-bed and softly select relevant sentences in anaspect-dependent manner. A shared classi-fier is trained on the source encoded docu-ments and labels, and applied to target en-coded documents. We ensure transfer throughaspect-adversarial training so that encodeddocuments are, as sets, aspect-invariant. Ex-perimental results demonstrate that our ap-proach outperforms different baselines andmodel variants on two datasets, yielding animprovement of 27% on a pathology datasetand 5% on a review dataset.1
1 Introduction
Many NLP problems are naturally multitask classi-fication problems. For instance, values extracted fordifferent fields from the same document are oftendependent as they share the same context. Exist-ing systems rely on this dependence (transfer acrossfields) to improve accuracy. In this paper, we con-sider a version of this problem where there is a cleardependence between two tasks but annotations areavailable only for the source task. For example,
1The code is available at https://github.com/yuanzh/aspect_adversarial.
Pathology report:• Final diagnosis: BREAST (LEFT) … Invasive ductal
carcinoma: identified. Carcinoma tumor size: num cm. Grade: 3. … Lymphatic vessel invasion: identified. Blood vessel invasion: Suspicious. Margin of invasive carcinoma …
Diagnosis results:Source (IDC): Positive Target (LVI): Positive
Figure 1: A snippet of a breast pathology report withdiagnosis results for two types of disease (aspects):carcinoma (IDC) and lymph invasion (LVI). Notehow the same phrase indicating positive results (e.g.identified) is applicable to both aspects. A transfermodel learns to map other key phrases (e.g. Grade3) to such shared indicators.
the target goal may be to classify pathology reports(shown in Figure 1) for the presence of lymph in-vasion but training data are available only for car-cinoma in the same reports. We call this problemaspect transfer as the objective is to learn to classifyexamples differently, focusing on different aspects,without access to target aspect labels. Clearly, suchtransfer learning is possible only with auxiliary in-formation relating the tasks together.
The key challenge is to articulate and incorpo-rate commonalities across the tasks. For instance,in classifying reviews of different products, senti-ment words (referred to as pivots) can be sharedacross the products. This commonality enables oneto align feature spaces across multiple products, en-abling useful transfer (Blitzer et al., 2006). Similarproperties hold in other contexts and beyond senti-

ment analysis. Figure 1 shows that certain wordsand phrases like “identified”, which indicates thepresence of a histological property, are applicable toboth carcinoma and lymph invasion. Our methodlearns and relies on such shared indicators, and uti-lizes them for effective transfer.
The unique feature of our transfer problem is thatboth the source and the target classifiers operate overthe same domain, i.e., the same examples. In thissetting, traditional transfer methods will always pre-dict the same label for both aspects and thus lead-ing to failure. Instead of supplying the target classi-fier with direct training labels, our approach buildson a secondary relationship between the tasks usingaspect-relevance annotations of sentences. Theserelevance annotations indicate a possibility that theanswer could be found in a sentence, not what theanswer is. One can often write simple keyword rulesthat identify sentence relevance to a particular as-pect through representative terms, e.g., specific hor-monal markers in the context of pathology reports.Annotations of this kind can be readily provided bydomain experts, or extracted from medical literaturesuch as codex rules in pathology (Pantanowitz et al.,2008). We assume a small number of relevance an-notations (rules) pertaining to both source and targetaspects as a form of weak supervision. We use thissentence-level aspect relevance to learn how to en-code the examples (e.g., pathology reports) from thepoint of view of the desired aspect. In our approach,we construct different aspect-dependent encodingsof the same document by softly selecting sentencesrelevant to the aspect of interest. The key to effectivetransfer is how these encodings are aligned.
This encoding mechanism brings the problemcloser to the realm of standard domain adaptation,where the derived aspect-specific representations areconsidered as different domains. Given these rep-resentations, our method learns a label classifiershared between the two domains. To ensure that itcan be adjusted only based on the source class la-bels, and that it also reasonably applies to the tar-get encodings, we must align the two sets of en-coded examples.2 Learning this alignment is pos-
2This alignment or invariance is enforced on the level of sets,not individual reports; aspect-driven encoding of any specificreport should remain substantially different for the two taskssince the encoded examples are passed on to the same classifier.
sible because, as discussed above, some keywordsare directly transferable and can serve as anchorsfor constructing this invariant space. To learn thisinvariant representation, we introduce an adversar-ial domain classifier analogous to the recent suc-cessful use of adversarial training in computer vi-sion (Ganin and Lempitsky, 2014). The role of thedomain classifier (adversary) is to learn to distin-guish between the two types of encodings. Duringtraining we update the encoder with an adversarialobjective to cause the classifier to fail. The encodertherefore learns to eliminate aspect-specific infor-mation so that encodings look invariant (as sets) tothe classifier, thus establishing aspect-invariance en-codings and enabling transfer. All three componentsin our approach, 1) aspect-driven encoding, 2) clas-sification of source labels, and 3) domain adversary,are trained jointly (concurrently) to complement andbalance each other.
Adversarial training of domain and label classi-fiers can be challenging to stabilize. In our setting,sentences are encoded with a convolutional model.Feedback from adversarial training can be an un-stable guide for how the sentences should be en-coded. To address this issue, we incorporate an ad-ditional word-level auto-encoder reconstruction lossto ground the convolutional processing of sentences.We empirically demonstrate that this additional ob-jective yields richer and more diversified feature rep-resentations, improving transfer.
We evaluate our approach on pathology reports(aspect transfer) as well as on a more standard re-view dataset (domain adaptation). On the pathologydataset, we explore cross-aspect transfer across dif-ferent types of breast disease. Specifically, we teston six adaptation tasks, consistently outperformingall other baselines. Overall, our full model achieves27% and 20.2% absolute improvement arising fromaspect-driven encoding and adversarial training re-spectively. Moreover, our unsupervised adaptationmethod is only 5.7% behind the accuracy of a super-vised target model. On the review dataset, we testadaptations from hotel to restaurant reviews. Ourmodel outperforms the marginalized denoising au-toencoder (Chen et al., 2012) by 5%. Finally, weexamine and illustrate the impact of individual com-ponents on the resulting performance.

2 Related Work
Domain Adaptation for Deep Learning Exist-ing approaches commonly induce abstract represen-tations without pulling apart different aspects in thesame example, and therefore are likely to fail on theaspect transfer problem. The majority of these priormethods first learn a task-independent representa-tion, and then train a label predictor (e.g. SVM)on this representation in a separate step. For ex-ample, earlier researches employ a shared autoen-coder (Glorot et al., 2011; Chopra et al., 2013) tolearn a cross-domain representation. Chen et al.(2012) further improve and stabilize the represen-tation learning by utilizing marginalized denoisingautoencoders. Later, Zhou et al. (2016) propose tominimize domain-shift of the autoencoder in a lineardata combination manner. Other researches have fo-cused on learning transferable representations in anend-to-end fashion. Examples include using trans-duction learning for object recognition (Sener et al.,2016) and using residual transfer networks for imageclassification (Long et al., 2016). In contrast, we useadversarial training to encourage learning domain-invariant features in a more explicit way. Our ap-proach offers another two advantages over priorwork. First, we jointly optimize features with thefinal classification task while many previous worksonly learn task-independent features using autoen-coders. Second, our model can handle traditionaldomain transfer as well as aspect transfer, while pre-vious methods can only handle the former.
Adversarial Learning in Vision and NLP Ourapproach closely relates to the idea of domain-adversarial training. Adversarial networks wereoriginally developed for image generation (Good-fellow et al., 2014; Makhzani et al., 2015; Sprin-genberg, 2015; Radford et al., 2015; Taigman et al.,2016), and were later applied to domain adaptationin computer vision (Ganin and Lempitsky, 2014;Ganin et al., 2015; Bousmalis et al., 2016; Tzeng etal., 2014) and speech recognition (Shinohara, 2016).The core idea of these approaches is to promote theemergence of invariant image features by optimizingthe feature extractor as an adversary against the do-main classifier. While Ganin et al. (2015) also applythis idea to sentiment analysis, their practical gainshave remained limited.
Our approach presents two main departures. Incomputer vision, adversarial learning has been usedfor transferring across domains, while our methodcan also handle aspect transfer. In addition, we in-troduce a reconstruction loss which results in morerobust adversarial training. We believe that this for-mulation will benefit other applications of adversar-ial training, beyond the ones described in this paper.
Semi-supervised Learning with Keywords Inour work, we use a small set of keywords as a sourceof weak supervision for aspect-relevance scoring.This relates to prior work on utilizing prototypes andseed words in semi-supervised learning (Haghighiand Klein, 2006; Grenager et al., 2005; Chang etal., 2007; Mann and McCallum, 2008; Jagarlamudiet al., 2012; Li et al., 2012; Eisenstein, 2017). Allthese prior approaches utilize prototype annotationsprimarily targeting model bootstrapping but not forlearning representations. In contrast, our model usesprovided keywords to learn aspect-driven encodingof input examples.
Attention Mechanism in NLP One may viewour aspect-relevance scorer as a sentence-level“semi-supervised attention”, in which relevant sen-tences receive more attention during feature extrac-tion. While traditional attention-based models typ-ically induce attention in an unsupervised manner,they have to rely on a large amount of labeled datafor the target task (Bahdanau et al., 2014; Rush etal., 2015; Chen et al., 2015; Cheng et al., 2016;Xu et al., 2015; Xu and Saenko, 2015; Yang etal., 2015; Martins and Astudillo, 2016; Lei et al.,2016). Unlike these methods, our approach assumesno label annotations in the target domain. Other re-searches have focused on utilizing human-providedrationales as “supervised attention” to improve pre-diction (Zaidan et al., 2007; Marshall et al., 2015;Zhang et al., 2016; Brun et al., 2016). In contrast,our model only assumes access to a small set of key-words as a source of weak supervision. Moreover,all these prior approaches focus on in-domain clas-sification. In this paper, however, we study the taskin the context of domain adaptation.
Multitask Learning Existing multitask learn-ing methods focus on the case where supervisionis available for all tasks. A typical architecture in-volves using a shared encoder with a separate clas-

sifier for each task. (Caruana, 1998; Pan and Yang,2010; Collobert and Weston, 2008; Liu et al., 2015;Bordes et al., 2012). In contrast, our work assumeslabeled data only for the source aspect. We train asingle classifier for both aspects by learning aspect-invariant representation that enables the transfer.
3 Problem Formulation
We begin by formalizing aspect transfer with theidea of differentiating it from standard domain adap-tation. In our setup, we have two classification taskscalled the source and the target tasks. In contrast tosource and target tasks in domain adaptation, bothof these tasks are defined over the same set of ex-amples (here documents, e.g., pathology reports).What differentiates the two classification tasks isthat they pertain to different aspects in the examples.If each training document were annotated with boththe source and the target aspect labels, the problemwould reduce to multi-label classification. However,in our setting training labels are available only forthe source aspect so the goal is to solve the targettask without any associated training label.
To fix notation, let d = si|d|i=1 be a documentthat consists of a sequence of |d| sentences si. Givena document d, and the aspect of interest, we wishto predict the corresponding aspect-dependent classlabel y (e.g., y ∈ −1, 1). We assume that the setof possible labels are the same across aspects. Weuse ysl;k to denote the k-th coordinate of a one-hotvector indicating the correct training source aspectlabel for document dl. Target aspect labels are notavailable during training.
Beyond labeled documents for the source aspectdl, y
sl l∈L, and shared unlabeled documents for
source and target aspects dll∈U , we assume fur-ther that we have relevance scores pertaining to eachaspect. The relevance is given per sentence, forsome subset of sentences across the documents, andindicates the possibility that the answer for that doc-ument would be found in the sentence but withoutindicating which way the answer goes. Relevance isalways aspect dependent yet often easy to provide inthe form of simple keyword rules.
We use rai ∈ 0, 1 to denote the given relevancelabel pertaining to aspect a for sentence si. Only asmall subset of sentences in the training set have as-
sociated relevance labels. Let R = (a, l, i) de-note the index set of relevance labels such that if(a, l, i) ∈ R then aspect a’s relevance label ral,i isavailable for the ith sentence in document dl. In ourcase relevance labels arise from aspect-dependentkeyword matches. rai = 1 when the sentence con-tains any keywords pertaining to aspect a and rai = 0if it has any keywords of other aspects.3 Separatesubsets of relevance labels are available for each as-pect as the keywords differ.
The transfer that is sought here is between twotasks over the same set of examples rather than be-tween two different types of examples for the sametask as in standard domain adaptation. However, thetwo formulations can be reconciled if full relevanceannotations are assumed to be available during train-ing and testing. In this scenario, we could simply liftthe sets of relevant sentences from each documentas new types of documents. The goal would be thento learn to classify documents of type T (consistingof sentences relevant to the target aspect) based onhaving labels only for type S (source) documents,a standard domain adaptation task. Our problemis more challenging as the aspect-relevance of sen-tences must be learned from limited annotations.
Finally, we note that the aspect transfer problemand the method we develop to solve it work the sameeven when source and target documents are a prioridifferent, something we will demonstrate later.
4 Methods
4.1 Overview of our approach
Our model consists of three key components asshown in Figure 2. Each document is encodedin a relevance weighted, aspect-dependent manner(green, left part of Figure 2) and classified using thelabel predictor (blue, top-right). During training, theencoded documents are also passed on to the domainclassifier (orange, bottom-right). The role of the do-main classifier, as the adversary, is to ensure that theaspect-dependent encodings of documents are distri-butionally matched. This matching justifies the useof the same end-classifier to provide the predictedlabel regardless of the task (aspect).
3rai = 1 if the sentence contains keywords pertaining to bothaspect a and other aspects.

Pathology report
INVASIVE DUCTAL CAR-CINOMA Tumor size …Grade: 3.
……………….
Lymphatic vessel in-vasion: Not identified.
… (IDC) is identified …
……
…
r = 1.0
Predicted Relevance Score
……
r = 0.0r = 0.9
…
…
Docum
ent representation
Transformation Layer
…
…
Class label yl
Objective: predict labels
Sentence embeddings Weighted combination
Adversary objective: confuse the domain classifier
… Domain label ya
Objective: predict domains
backprop
backprop
(b) Label predictor
(c) Domain classifier
(a) Document encoderr = 1.0
r = 0.0
r = 0.9
Figure 2: Aspect-augmented adversarial network for transfer learning. The model is composed of (a) anaspect-driven document encoder, (b) a label predictor and (c) a domain classifier.
To encode a document, the model first maps eachsentence into a vector and then passes the vector to ascoring network to determine whether the sentenceis relevant for the chosen aspect. These predictedrelevance scores are used to obtain document vec-tors by taking relevance-weighted sum of the asso-ciated sentence vectors. Thus, the manner in whichthe document vector is constructed is always aspect-dependent due to the chosen relevance weights.
During training, the resulting adjusted documentvectors are consumed by the two classifiers. The pri-mary label classifier aims to predict the source labels(when available), while the domain classifier deter-mines whether the document vector pertains to thesource or target aspect, which is the label that weknow by construction. Furthermore, we jointly up-date the document encoder with a reverse of the gra-dient from the domain classifier, so that the encoderlearns to induce document representations that foolthe domain classifier. The resulting encoded repre-sentations will be aspect-invariant, facilitating trans-fer.
Our adversarial training scheme uses all the train-ing losses concurrently to adjust the model param-eters. During testing, we simply encode each testdocument in a target-aspect dependent manner, andapply the same label predictor. We expect that thesame label classifier does well on the target tasksince it solves the source task, and operates onrelevance-weighted representations that are matchedacross the tasks. While our method is designed towork in the extreme setting that the examples for thetwo aspects are the same, this is by no means a re-
reconstruction of
ductal carcinoma is identified
… … … …
… …… …
……
…sentence embeddings
max-pooling:
…
x0 x1 x2 x3
x2 = tanh(Wch2 + bc)
x2
h1 h2
xsen = maxh1,h2, . . .
Figure 3: Illustration of the convolutional model andthe reconstruction of word embeddings from the as-sociated convolutional layer.
quirement. Our method will also work fine in themore traditional domain adaptation setting, whichwe will demonstrate later.
4.2 Components in detail
Sentence embedding We apply a convolutionalmodel illustrated in Figure 3 to each sentence si toobtain sentence-level vector embeddings xsen
i . Theuse of RNNs or bi-LSTMs would result in more flex-ible sentence embeddings but based on our initial ex-periments, we did not observe any significant gainsover the simpler CNNs.
We further ground the resulting sentence embed-dings by including an additional word-level recon-struction step in the convolutional model. The pur-pose of this reconstruction step is to balance adver-sarial training signals propagating back from the do-main classifier. Specifically, it forces the sentenceencoder to keep rich word-level information in con-trast to adversarial training that seeks to eliminateaspect specific features. We provide an empiricalanalysis of the impact of this reconstruction in the

experiment section (Section 7).More concretely, we reconstruct word embed-
ding from the corresponding convolutional layer, asshown in Figure 3.4 We use xi,j to denote the em-bedding of the j-th word in sentence si. Let hi,j bethe convolutional output when xi,j is at the center ofthe window. We reconstruct xi,j by
xi,j = tanh(Wchi,j + bc) (1)
where Wc and bc are parameters of the reconstruc-tion layer. The loss associated with the reconstruc-tion for document d is
Lrec(d) =1
n
∑i,j
||xi,j − tanh(xi,j)||22 (2)
where n is the number of tokens in the document andindexes i, j identify the sentence and word, respec-tively. The overall reconstruction loss Lrec is ob-tained by summing over all labeled/unlabeled docu-ments.
Relevance prediction We use a small set ofkeyword rules to generate binary relevance labels,both positive (r = 1) and negative (r = 0). These la-bels represent the only supervision available to pre-dict relevance. The prediction is made on the basisof the sentence vector xsen
i passed through a feed-forward network with a ReLU output unit. The net-work has a single shared hidden layer and a separateoutput layer for each aspect. Note that our relevanceprediction network is trained as a non-negative re-gression model even though the available labels arebinary, as relevance varies more on a linear ratherthan binary scale.
Given relevance labels indexed by R =(a, l, i), we minimize
Lrel =∑
(a,l,i)∈R
(ral,i − ral,i
)2 (3)
where ral,i is the predicted (non-negative) relevancescore pertaining to aspect a for the ith sentence indocument dl, as shown in the left part of Figure 2.ral,i, defined earlier, is the given binary (0/1) rele-vance label. We use a score in [0, 1] scale because itcan be naturally used as a weight for vector combi-nations, as shown next.
4 This process is omitted in Figure 2 for brevity.
Document encoding The initial vector repre-sentation for each document such as dl is obtainedas a relevance weighted combination of the associ-ated sentence vectors, i.e.,
xdoc,al =
∑i r
al,i · xsen
l,i∑i r
al,i
(4)
The resulting vector selectively encodes informationfrom the sentences based on relevance to the focalaspect.
Transformation layer The manner in whichdocument vectors arise from sentence vectors meansthat they will retain aspect-specific information thatwill hinder transfer across aspects. To help re-move non-transferable information, we add a trans-formation layer to map the initial document vectorsxdoc,al to their domain invariant (as a set) versions, as
shown in Figure 2. Specifically, the transformed rep-resentation is given by xtr,a
l = Wtrxdoc,al . Mean-
while, the transformation has to be strongly regular-ized lest the gradient from the adversary would wipeout all the document signal. We add the followingregularization term
Ωtr = λtr||Wtr − I||2F (5)
to discourage significant deviation away from iden-tity I. λtr is a regularization parameter that has tobe set separately based on validation performance.We show an empirical analysis of the impact of thistransformation layer in Section 7.
Primary label classifier As shown in the top-right part of Figure 2, the classifier takes in theadjusted document representation as an input andpredicts a probability distribution over the possibleclass labels. The classifier is a feed-forward net-work with a single hidden layer using ReLU acti-vations and a softmax output layer over the possibleclass labels. Note that we train only one label clas-sifier that is shared by both aspects. The classifieroperates the same regardless of the aspect to whichthe document was encoded. It must therefore be co-operatively learned together with the encodings.
Let pl;k denote the predicted probability of classk for document dl when the document is encodedfrom the point of view of the source aspect. Recallthat [ysl;1, . . . , y
sl;m] is a one-hot vector for the correct

(given) source class label for document dl, hencealso a distribution. We use the cross-entropy loss forthe label classifier
Llab =∑l∈L
[−
m∑k=1
ysl;k log pl;k
](6)
Domain classifier As shown in the bottom-right part of Figure 2, the domain classifier func-tions as an adversary to ensure that the documentsencoded with respect to the source and target as-pects look the same as sets of examples. The in-variance is achieved when the domain classifier (asthe adversary) fails to distinguish between the two.Structurally, the domain classifier is a feed-forwardnetwork with a single ReLU hidden layer and a soft-max output layer over the two aspect labels.
Let ya = [ya1 , ya2 ] denote the one-hot domain la-
bel vector for aspect a ∈ s, t. In other words,ys = [1, 0] and yt = [0, 1]. We use qk(xtr,a
l ) as thepredicted probability that the domain label is k whenthe domain classifier receives xtr,a
l as the input. Thedomain classifier is trained to minimize
Ldom =∑
l∈L∪U
∑a∈s,t
[−
2∑k=1
yak log qk(xtr,al )
](7)
4.3 Joint learningWe combine the individual component losses per-taining to word reconstruction, relevance labels,transformation layer regularization, source class la-bels, and domain adversary into an overall objectivefunction
Lall = Lrec + Lrel + Ωtr + Llab − ρLdom (8)
which is minimized with respect to the model pa-rameters except for the adversary (domain classi-fier). The adversary is maximizing the same objec-tive with respect to its own parameters. The last term−ρLdom corresponds to the objective of causing thedomain classifier to fail. The proportionality con-stant ρ controls the impact of gradients from the ad-versary on the document representation; the adver-sary itself is always directly minimizing Ldom.
All the parameters are optimized jointly usingstandard backpropagation (concurrent for the adver-sary). Each mini-batch is balanced by aspect, half
DATASET #Labeled #Unlabeled
PATHOLOGY
DCIS 23.8k
96.6kLCIS 10.7kIDC 22.9kALH 9.2k
REVIEWHotel 100k 100kRestaurant - 200k
Table 1: Statistics of the pathology reports datasetand the reviews dataset that we use for training. Ourmodel utilizes both labeled and unlabeled data.
ASPECT KEYWORDS
IDC IDC, Invasive Ductal CarcinomaALH ALH, Atypical Lobular Hyperplasia
Table 2: Examples of aspects and their correspond-ing keywords (case insensitive) in the pathologydataset.
coming from the source, the other half from the tar-get. All the loss functions except Llab make use ofboth labeled and unlabeled documents. Addition-ally, it would be straightforward to add a loss termfor target labels if they are available.
5 Experimental Setup
Pathology dataset This dataset contains 96.6kbreast pathology reports collected from three hos-pitals (Yala et al., 2016). A portion of this datasetis manually annotated with 20 categorical values,representing various aspects of breast disease. Inour experiments, we focus on four aspects relatedto carcinomas and atypias: Ductal Carcinoma In-Situ (DCIS), Lobular Carcinoma In-Situ (LCIS), In-vasive Ductal Carcinoma (IDC) and Atypical Lob-ular Hyperplasia (ALH). Each aspect is annotatedusing binary labels. We use 500 held out reports asour test set and use the rest of the labeled data as ourtraining set: 23.8k reports for DCIS, 10.7k for LCIS,22.9k for IDC, and 9.2k for ALH. Table 1 summa-rizes statistics of the dataset.
We explore the adaptation problem from one as-pect to another. For example, we want to train amodel on annotations of DCIS and apply it on LCIS.For each aspect, we use up to three common names

as a source of supervision for learning the relevancescorer, as illustrated in Table 2. Note that the pro-vided list is by no means exhaustive. In fact Buckleyet al. (2012) provide example of 60 different verbal-izations of LCIS, not counting negations.
Review dataset Our second experiment isbased on a domain transfer of sentiment classifica-tion. For the source domain, we use the hotel re-view dataset introduced in previous work (Wang etal., 2010; Wang et al., 2011), and for the targetdomain, we use the restaurant review dataset fromYelp.5 Both datasets have ratings on a scale of 1to 5 stars. Following previous work (Blitzer et al.,2007), we label reviews with ratings > 3 as posi-tive and those with ratings < 3 as negative, discard-ing the rest. The hotel dataset includes a total ofaround 200k reviews collected from TripAdvisor,6
so we split 100k as labeled and the other 100k asunlabeled data. We randomly select 200k restaurantreviews as the unlabeled data in the target domain.Our test set consists of 2k reviews. Table 1 summa-rizes the statistics of the review dataset.
The hotel reviews naturally have ratings for sixaspects, including value, room quality, checkin ser-vice, room service, cleanliness and location. We usethe first five aspects because the sixth aspect loca-tion has positive labels for over 95% of the reviewsand thus the trained model will suffer from the lackof negative examples. The restaurant reviews, how-ever, only have single ratings for an overall impres-sion. Therefore, we explore the task of adaptationfrom each of the five hotel aspects to the restau-rant domain. The hotel reviews dataset also pro-vides a total of 280 keywords for different aspectsthat are generated by the bootstrapping method usedin Wang et al. (2010). We use those keywords assupervision for learning the relevance scorer.
Baselines and our method We first compareagainst a linear SVM trained on the raw bag-of-words representation of labeled data in source.Second, we compare against our SourceOnlymodel that assumes no target domain data or key-words. It thus has no adversarial training or tar-get aspect-relevance scoring. Next we compare
5The restaurant portion of https://www.yelp.com/dataset_challenge.
6https://www.tripadvisor.com/
METHODSOURCE TARGET Key-
wordLab. Unlab. Lab. Unlab.
SVM X × × × ×SourceOnly X X × × XmSDA X X × X ×AAN-NA X X × X XAAN-NR X X × X ×In-Domain × × X × XAAN-Full X X × X X
Table 3: Usage of labeled (Lab.), unlabeled (Un-lab.) data and keyword rules in each domain by ourmodel and other baseline methods. AAN-* denoteour model and its variants.
with marginalized Stacked Denoising Autoencoders(mSDA) (Chen et al., 2012), a domain adaptationalgorithm that outperforms both prior deep learningand shallow learning approaches.7
In the rest part of the paper, we name ourmethod and its variants as AAN (Aspect-augmentedAdversarial Networks). We compare against AAN-NA and AAN-NR that are our model variantswithout adversarial training and without aspect-relevance scoring respectively. Finally we in-clude supervised models trained on the full set ofIn-Domain annotations as the performance upperbound. Table 3 summarizes the usage of labeled andunlabeled data in each domain as well as keywordrules by our model (AAN-Full) and different base-lines. Note that our model assumes the same set ofdata as the AAN-NA, AAN-NR and mSDA meth-ods.
Implementation details Following prior work(Ganin and Lempitsky, 2014), we gradually increasethe adversarial strength ρ and decay the learning rateduring training. We also apply batch normalization(Ioffe and Szegedy, 2015) on the sentence encoderand apply dropout with ratio 0.2 on word embed-dings and each hidden layer activation. We set thehidden layer size to 150 and pick the transforma-tion regularization weight λt = 0.1 for the pathol-
7We use the publicly available implementation provided bythe authors at http://www.cse.wustl.edu/˜mchen/code/mSDA.tar. We use the hyper-parameters from the au-thors and their models have more parameters than ours.
DOMAINSVM
SourcemSDA AAN-NA AAN-NR AAN-Full In-Domain
SOURCE TARGET Only
LCISDCIS
45.8 25.2 45.0 81.2 50.0 93.096.2IDC 71.8 62.4 73.0 87.6 81.4 94.8
ALH 37.2 20.6 39.0 49.2 48.0 84.6
DCISLCIS
73.8 75.4 76.2 89.0 81.2 95.297.8IDC 71.4 66.4 71.6 84.8 52.0 85.0
ALH 54.4 46.4 54.2 84.8 52.4 93.2
DCISIDC
94.0 77.4 94.0 92.4 93.8 95.496.8LCIS 51.6 29.5 53.2 89.6 51.2 93.8
ALH 41.0 26.8 39.2 68.0 31.6 89.6
DCISALH
74.6 75.0 75.0 52.6 74.2 90.496.8LCIS 59.0 51.6 60.4 52.6 60.0 92.8
IDC 67.6 66.4 68.8 52.6 69.2 87.0
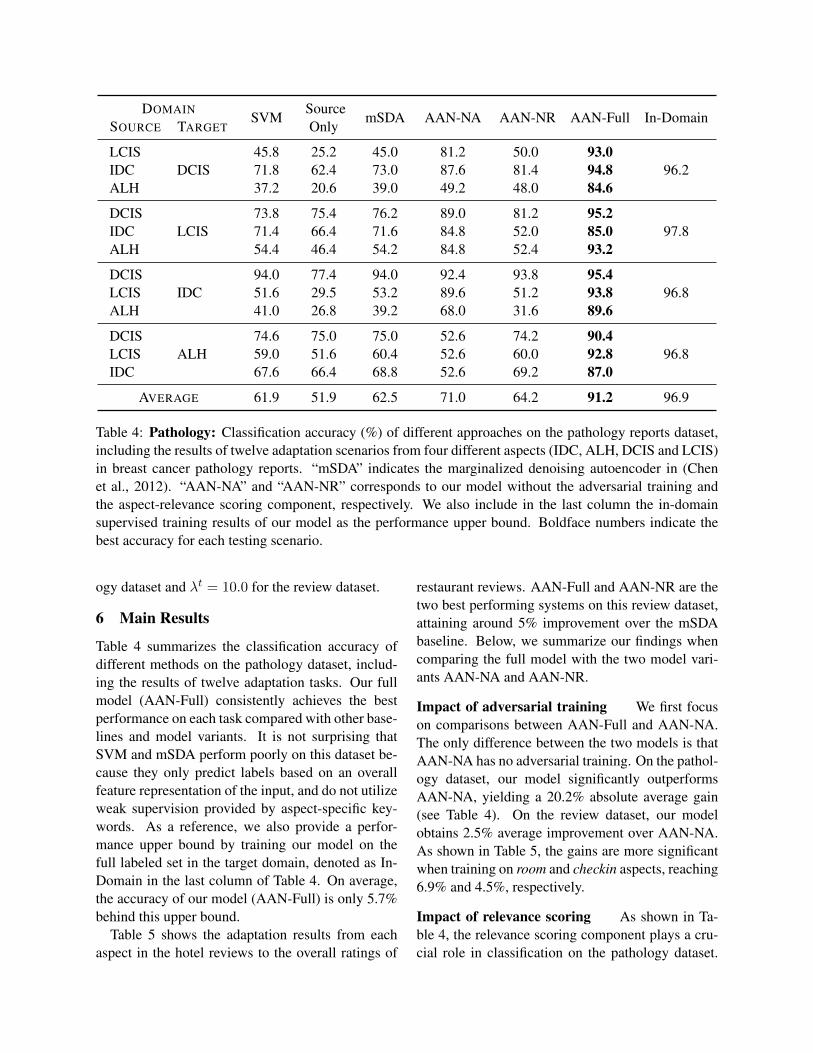
AVERAGE 61.9 51.9 62.5 71.0 64.2 91.2 96.9
Table 4: Pathology: Classification accuracy (%) of different approaches on the pathology reports dataset,including the results of twelve adaptation scenarios from four different aspects (IDC, ALH, DCIS and LCIS)in breast cancer pathology reports. “mSDA” indicates the marginalized denoising autoencoder in (Chenet al., 2012). “AAN-NA” and “AAN-NR” corresponds to our model without the adversarial training andthe aspect-relevance scoring component, respectively. We also include in the last column the in-domainsupervised training results of our model as the performance upper bound. Boldface numbers indicate thebest accuracy for each testing scenario.
ogy dataset and λt = 10.0 for the review dataset.
6 Main Results
Table 4 summarizes the classification accuracy ofdifferent methods on the pathology dataset, includ-ing the results of twelve adaptation tasks. Our fullmodel (AAN-Full) consistently achieves the bestperformance on each task compared with other base-lines and model variants. It is not surprising thatSVM and mSDA perform poorly on this dataset be-cause they only predict labels based on an overallfeature representation of the input, and do not utilizeweak supervision provided by aspect-specific key-words. As a reference, we also provide a perfor-mance upper bound by training our model on thefull labeled set in the target domain, denoted as In-Domain in the last column of Table 4. On average,the accuracy of our model (AAN-Full) is only 5.7%behind this upper bound.
Table 5 shows the adaptation results from eachaspect in the hotel reviews to the overall ratings of
restaurant reviews. AAN-Full and AAN-NR are thetwo best performing systems on this review dataset,attaining around 5% improvement over the mSDAbaseline. Below, we summarize our findings whencomparing the full model with the two model vari-ants AAN-NA and AAN-NR.
Impact of adversarial training We first focuson comparisons between AAN-Full and AAN-NA.The only difference between the two models is thatAAN-NA has no adversarial training. On the pathol-ogy dataset, our model significantly outperformsAAN-NA, yielding a 20.2% absolute average gain(see Table 4). On the review dataset, our modelobtains 2.5% average improvement over AAN-NA.As shown in Table 5, the gains are more significantwhen training on room and checkin aspects, reaching6.9% and 4.5%, respectively.
Impact of relevance scoring As shown in Ta-ble 4, the relevance scoring component plays a cru-cial role in classification on the pathology dataset.

DOMAINSVM
SourcemSDA AAN-NA AAN-NR AAN-Full In-Domain
SOURCE TARGET Only
Value
RestaurantOverall
82.2 87.4 84.7 87.1 91.1 89.6
93.4Room 75.6 79.3 80.3 79.7 86.1 86.6Checkin 77.8 83.0 81.0 80.9 87.2 85.4Service 82.2 88.0 83.8 88.8 87.9 89.1Cleanliness 77.9 83.2 78.4 83.1 84.5 81.4
AVERAGE 79.1 84.2 81.6 83.9 87.3 86.4 93.4
Table 5: Review: Classification accuracy (%) of different approaches on the reviews dataset. Columns havethe same meaning as in Table 4. Boldface numbers indicate the best accuracy for each testing scenario.
1.0
0.8
0.6
0.4
0.2
0.0
w/o reconstruction with reconstruction
1.0
0.8
0.6
0.4
0.2
0.0+adversarial, -reconstruction-adversarial, -reconstruction +adversarial, +reconstruction
Figure 4: Heat map of 150×150 matrices. Each row corresponds to the vector representation of a documentthat comes from either the source domain (top half) or the target domain (bottom half). Models are trainedon the review dataset when room quality is the source aspect.
Our model achieves more than 27% improvementover AAN-NR. This is because in general aspectshave zero correlations to each other in pathologyreports. Therefore, it is essential for the model tohave the capacity of distinguishing across differentaspects in order to succeed in this task.
On the review dataset, however, we observe thatrelevance scoring has no significant impact on per-formance. On average, AAN-NR actually outper-forms AAN-Full by 0.9%. This observation can beexplained by the fact that different aspects in ho-tel reviews are highly correlated to each other. Forexample, the correlation between room quality andcleanliness is 0.81, much higher than aspect corre-lations in the pathology dataset. In other words,the sentiment is typically consistent across all sen-tences in a review, so that selecting aspect-specificsentences becomes unnecessary. Moreover, our su-pervision for the relevance scorer is weak and noisybecause the aspect keywords are obtained in a semi-automatic way. Therefore, it is not surprising thatAAN-NR sometimes delivers a better classification
DATASETAAN-Full AAN-NA
-REC. +REC. -REC. +REC.
PATHOLOGY 86.2 91.2 68.6 72.0REVIEW 80.8 86.4 85.0 83.9
Table 6: Impact of adding the reconstruction com-ponent in the model, measured by the average ac-curacy on each dataset. +REC. and -REC. denotethe presence and absence of the reconstruction loss,respectively.
accuracy than AAN-Full.
7 Analysis
Impact of the reconstruction loss Table 6summarizes the impact of the reconstruction loss onthe model performance. For our full model (AAN-Full), adding the reconstruction loss yields an aver-age of 5.0% gain on the pathology dataset and 5.6%on the review dataset.

Restaurant Reviews
• the fries were undercooked and thrown haphazardly into the sauce holder . the shrimp was over cooked and just deepfried . … even the water tasted weird . …
• i had the shrimp boil and it was very under-seasoned . much closer to bland than anything . …
• the room was old . … we did n’t like the night shows at all . …
• however , the decor was just fair . … the doorknob to our bathroom door fell off , as well as the handle on the toilet . … in the second bedroom it literally rained water from above .
• the room decor was not entirely modern . … we just had the run of the mill hotel room without a view .
• stay away from fresh vegetable like lettuce , etc . …
• rest room in this restaurant is very dirty . …
• the only problem i had was that … i was very ill with what was suspected to be food poison
• probably the noisiest room he could have given us in the whole hotel .
Nearest Hotel Reviews by Ours-Full Nearest Hotel Reviews by Ours-NA
Restaurant Reviews
• the fries were undercooked and thrown haphazardly into the sauce holder . the shrimp was over cooked and just deepfried . … even the water tasted weird . …
• the room was old . … we did n’t like the night shows at all . …
• however , the decor was just fair . … in the second bedroom it literally rained water from above .
• rest room in this restaurant is very dirty . …
• the only problem i had was that … i was very ill with what was suspected to be food poison
Nearest Hotel Reviews by Ours-Full Nearest Hotel Reviews by Ours-NA
Figure 5: Examples of restaurant reviews and their nearest neighboring hotel reviews induced by differentmodels (column 2 and 3). We use room quality as the source aspect. The sentiment phrases of each revieware in blue, and some reviews are also shortened for space.
DATASET λt = 0 0 < λt <∞ λt =∞PATHOLOGY 77.4 91.2 81.4REVIEW 80.9 86.4 84.3
Table 7: The effect of regularization of the transfor-mation layer λt on the performance.
To analyze the reasons behind this difference,consider Figure 4 that shows the heat maps ofthe learned document representations on the reviewdataset. The top half of the matrices correspondsto input documents from the source domain and thebottom half corresponds to the target domain. Un-like the first matrix, the other two matrices have nosignificant difference between the two halves, in-dicating that adversarial training helps learning ofdomain-invariant representations. However, adver-sarial training also removes a lot of information fromrepresentations, as the second matrix is much moresparse than the first one. The third matrix shows thatadding reconstruction loss effectively addresses thissparsity issue. Almost 85% entries of the secondmatrix have small values (< 10−6) while the spar-sity is only about 30% for the third one. Moreover,the standard deviation of the third matrix is also tentimes higher than the second one. These compar-isons demonstrate that the reconstruction loss func-tion improves both the richness and diversity of thelearned representations. Note that in the case of noadversarial training (AAN-NA), adding the recon-struction component has no clear effect. This is ex-pected because the main motivation of adding thiscomponent is to achieve a more robust adversarialtraining.
Regularization on the transformation layerTable 7 shows the averaged accuracy with differ-
ent regularization weights λt in Equation 5. Wechange λt to reflect different model variants. First,λt = ∞ corresponds to the removal of the transfor-mation layer because the transformation is alwaysidentity in this case. Our model performs better thanthis variant on both datasets, yielding an averageimprovement of 9.8% on the pathology dataset and2.1% on the review dataset. This result indicates theimportance of adding the transformation layer. Sec-ond, using zero regularization (λt = 0) also consis-tently results in inferior performance, such as 13.8%loss on the pathology dataset. We hypothesize thatzero regularization will dilute the effect from re-construction because there is too much flexibility intransformation. As a result, the transformed repre-sentation will become sparse due to the adversarialtraining, leading to a performance loss.
Examples of neighboring reviews Finally, weillustrate in Figure 5 a case study on the charac-teristics of learned abstract representations by dif-ferent models. The first column shows an examplerestaurant review. Sentiment phrases in this exampleare mostly food-specific, such as “undercooked” and“tasted weird”. In the other two columns, we showexample hotel reviews that are nearest neighbors tothe restaurant reviews, measured by cosine simi-larity between their representations. In column 2,many sentiment phrases are specific for room qual-ity, such as “old” and “rained water from above”.In column 3, however, most sentiment phrases areeither common sentiment expressions (e.g. dirty)or food-related (e.g. food poison), even though thefocus of the reviews is based on the room qualityof hotels. This observation indicates that adversar-ial training (AAN-Full) successfully learns to elim-inate domain-specific information and to map thosedomain-specific words into similar domain-invariant

Figure 6: Classification accuracy (y-axis) on twotransfer scenarios (one on review and one on pathol-ogy dataset) with a varied number of keyword rulesfor learning sentence relevance (x-axis).
representations. In contrast, AAN-NA only capturesdomain-invariant features from phrases that com-monly present in both domains.
Impact of keyword rules Finally, Figure 6shows the accuracy of our full model (y-axis) whentrained with various amount of keyword rules forrelevance learning (x-axis). As expected, the trans-fer accuracy drops significantly when using fewerrules on the pathology dataset (LCIS as source andALH as target). In contrary, the accuracy on the re-view dataset (hotel service as source and restaurantas target) is not sensitive to the amount of used rel-evance rules. This can be explained by the observa-tion from Table 5 that the model without relevancescoring performs equally well as the full model dueto the tight dependence in aspect labels.
8 Conclusions
In this paper, we propose a novel aspect-augmentedadversarial network for cross-aspect and cross-domain adaptation tasks. Experimental resultsdemonstrate that our approach successfully learnsinvariant representation from aspect-relevant frag-ments, yielding significant improvement over themSDA baseline and our model variants. The effec-tiveness of our approach suggests the potential ap-plication of adversarial networks to a broader rangeof NLP tasks for improved representation learning,such as machine translation and language genera-tion.
Acknowledgments
The authors acknowledge the support of theU.S. Army Research Office under grant numberW911NF-10-1-0533. We thank the MIT NLP groupand the TACL reviewers for their comments. Anyopinions, findings, conclusions, or recommenda-tions expressed in this paper are those of the authors,and do not necessarily reflect the views of the fund-ing organizations.
ReferencesDzmitry Bahdanau, Kyunghyun Cho, and Yoshua Ben-
gio. 2014. Neural machine translation by jointlylearning to align and translate. arXiv preprintarXiv:1409.0473.
John Blitzer, Ryan McDonald, and Fernando Pereira.2006. Domain adaptation with structural correspon-dence learning. In Proceedings of the 2006 conferenceon empirical methods in natural language processing,pages 120–128. Association for Computational Lin-guistics.
John Blitzer, Mark Dredze, Fernando Pereira, et al. 2007.Biographies, bollywood, boom-boxes and blenders:Domain adaptation for sentiment classification. InACL, volume 7, pages 440–447.
Antoine Bordes, Xavier Glorot, Jason Weston, andYoshua Bengio. 2012. Joint learning of words andmeaning representations for open-text semantic pars-ing. In AISTATS, volume 22, pages 127–135.
Konstantinos Bousmalis, George Trigeorgis, Nathan Sil-berman, Dilip Krishnan, and Dumitru Erhan. 2016.Domain separation networks. In Neural InformationProcessing Systems (NIPS).
Caroline Brun, Julien Perez, and Claude Roux. 2016.XRCE at SemEval-2016 task 5: Feedbacked ensem-ble modeling on syntactico-semantic knowledge foraspect based sentiment analysis. In Proceedings of the10th International Workshop on Semantic Evaluation(SemEval-2016), pages 277–281.
Julliette M Buckley, Suzanne B Coopey, John Sharko,Fernanda Polubriaginof, Brian Drohan, Ahmet KBelli, Elizabeth MH Kim, Judy E Garber, Barbara LSmith, Michele A Gadd, et al. 2012. The feasibilityof using natural language processing to extract clinicalinformation from breast pathology reports. Journal ofpathology informatics, 3(1):23.
Rich Caruana. 1998. Multitask learning. In Learning tolearn, pages 95–133. Springer.
Ming-Wei Chang, Lev Ratinov, and Dan Roth.2007. Guiding semi-supervision with constraint-

driven learning. In Annual Meeting-Association forComputational Linguistics, volume 45, page 280.
Minmin Chen, Zhixiang Xu, Kilian Weinberger, and FeiSha. 2012. Marginalized denoising autoencoders fordomain adaptation. arXiv preprint arXiv:1206.4683.
Kan Chen, Jiang Wang, Liang-Chieh Chen, HaoyuanGao, Wei Xu, and Ram Nevatia. 2015. Abc-cnn: An attention based convolutional neural net-work for visual question answering. arXiv preprintarXiv:1511.05960.
Jianpeng Cheng, Li Dong, and Mirella Lapata. 2016.Long short-term memory-networks for machine read-ing. arXiv preprint arXiv:1601.06733.
Sumit Chopra, Suhrid Balakrishnan, and RaghuramanGopalan. 2013. Dlid: Deep learning for domain adap-tation by interpolating between domains. In ICMLWorkshop on Challenges in Representation Learning.
Ronan Collobert and Jason Weston. 2008. A unified ar-chitecture for natural language processing: Deep neu-ral networks with multitask learning. In Proceedingsof the 25th international conference on Machine learn-ing, pages 160–167. ACM.
Jacob Eisenstein. 2017. Unsupervised learning forlexicon-based classification. In Proceedings of the Na-tional Conference on Artificial Intelligence (AAAI).
Yaroslav Ganin and Victor Lempitsky. 2014. Unsuper-vised domain adaptation by backpropagation. arXivpreprint arXiv:1409.7495.
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, PascalGermain, Hugo Larochelle, Francois Laviolette, MarioMarchand, and Victor Lempitsky. 2015. Domain-adversarial training of neural networks. arXiv preprintarXiv:1505.07818.
Xavier Glorot, Antoine Bordes, and Yoshua Bengio.2011. Domain adaptation for large-scale sentimentclassification: A deep learning approach. In Proceed-ings of the 28th International Conference on MachineLearning (ICML-11), pages 513–520.
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza,Bing Xu, David Warde-Farley, Sherjil Ozair, AaronCourville, and Yoshua Bengio. 2014. Generative ad-versarial nets. In Advances in Neural Information Pro-cessing Systems, pages 2672–2680.
Trond Grenager, Dan Klein, and Christopher D Manning.2005. Unsupervised learning of field segmentationmodels for information extraction. In Proceedingsof the 43rd annual meeting on association for com-putational linguistics, pages 371–378. Association forComputational Linguistics.
Aria Haghighi and Dan Klein. 2006. Prototype-drivenlearning for sequence models. In Proceedings ofthe main conference on Human Language Technol-ogy Conference of the North American Chapter of the
Association of Computational Linguistics, pages 320–327. Association for Computational Linguistics.
Sergey Ioffe and Christian Szegedy. 2015. Batchnormalization: Accelerating deep network trainingby reducing internal covariate shift. arXiv preprintarXiv:1502.03167.
Jagadeesh Jagarlamudi, Hal Daume III, and Raghaven-dra Udupa. 2012. Incorporating lexical priors intotopic models. In Proceedings of the 13th Conferenceof the European Chapter of the Association for Com-putational Linguistics, pages 204–213. Association forComputational Linguistics.
Tao Lei, Regina Barzilay, and Tommi Jaakkola. 2016.Rationalizing neural predictions. arXiv preprintarXiv:1606.04155.
Shen Li, Joao V Graca, and Ben Taskar. 2012. Wiki-ly supervised part-of-speech tagging. In Proceedingsof the 2012 Joint Conference on Empirical Methodsin Natural Language Processing and ComputationalNatural Language Learning, pages 1389–1398. Asso-ciation for Computational Linguistics.
Xiaodong Liu, Jianfeng Gao, Xiaodong He, Li Deng,Kevin Duh, and Ye-Yi Wang. 2015. Representa-tion learning using multi-task deep neural networks forsemantic classification and information retrieval. InHLT-NAACL, pages 912–921.
Mingsheng Long, Jianmin Wang, and Michael I Jordan.2016. Unsupervised domain adaptation with residualtransfer networks. arXiv preprint arXiv:1602.04433.
Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, andIan Goodfellow. 2015. Adversarial autoencoders.arXiv preprint arXiv:1511.05644.
Gideon S Mann and Andrew McCallum. 2008. General-ized expectation criteria for semi-supervised learningof conditional random fields.
Iain J Marshall, Joel Kuiper, and Byron C Wallace. 2015.Robotreviewer: evaluation of a system for automat-ically assessing bias in clinical trials. Journal ofthe American Medical Informatics Association, pageocv044.
Andre FT Martins and Ramon Fernandez Astudillo.2016. From softmax to sparsemax: A sparse model ofattention and multi-label classification. arXiv preprintarXiv:1602.02068.
Sinno Jialin Pan and Qiang Yang. 2010. A survey ontransfer learning. IEEE Transactions on knowledgeand data engineering, 22(10):1345–1359.
Liron Pantanowitz, Maryanne Hornish, and Robert AGoulart. 2008. Informatics applied to cytology. Cyto-journal, 5.
Alec Radford, Luke Metz, and Soumith Chintala. 2015.Unsupervised representation learning with deep con-volutional generative adversarial networks. arXivpreprint arXiv:1511.06434.

Alexander M Rush, Sumit Chopra, and Jason We-ston. 2015. A neural attention model for ab-stractive sentence summarization. arXiv preprintarXiv:1509.00685.
Ozan Sener, Hyun Oh Song, Ashutosh Saxena, and Sil-vio Savarese. 2016. Learning transferrable repre-sentations for unsupervised domain adaptation. InAdvances In Neural Information Processing Systems,pages 2110–2118.
Yusuke Shinohara. 2016. Adversarial multi-task learn-ing of deep neural networks for robust speech recogni-tion. Interspeech 2016, pages 2369–2372.
Jost Tobias Springenberg. 2015. Unsupervised and semi-supervised learning with categorical generative adver-sarial networks. arXiv preprint arXiv:1511.06390.
Yaniv Taigman, Adam Polyak, and Lior Wolf. 2016.Unsupervised cross-domain image generation. arXivpreprint arXiv:1611.02200.
Eric Tzeng, Judy Hoffman, Ning Zhang, Kate Saenko,and Trevor Darrell. 2014. Deep domain confusion:Maximizing for domain invariance. arXiv preprintarXiv:1412.3474.
Hongning Wang, Yue Lu, and Chengxiang Zhai. 2010.Latent aspect rating analysis on review text data: a rat-ing regression approach. In Proceedings of the 16thACM SIGKDD international conference on Knowl-edge discovery and data mining, pages 783–792.ACM.
Hongning Wang, Yue Lu, and ChengXiang Zhai. 2011.Latent aspect rating analysis without aspect key-word supervision. In Proceedings of the 17th ACMSIGKDD international conference on Knowledge dis-covery and data mining, pages 618–626. ACM.
Huijuan Xu and Kate Saenko. 2015. Ask, attendand answer: Exploring question-guided spatial atten-tion for visual question answering. arXiv preprintarXiv:1511.05234.
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho,Aaron Courville, Ruslan Salakhutdinov, Richard SZemel, and Yoshua Bengio. 2015. Show, attend andtell: Neural image caption generation with visual at-tention. arXiv preprint arXiv:1502.03044, page 5.
Adam Yala, Regina Barzilay, Laura Salama, MollyGriffin, Grace Sollender, Aditya Bardia, ConstanceLehman, Julliette M Buckley, Suzanne B Coopey, Fer-nanda Polubriaginof, J Garber, BL Smith, MA Gadd,MC Specht, and TM Gudewicz. 2016. Using machinelearning to parse breast pathology reports. Breast Can-cer Research and Treatment.
Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng,and Alex Smola. 2015. Stacked attention net-works for image question answering. arXiv preprintarXiv:1511.02274.
Omar Zaidan, Jason Eisner, and Christine D Piatko.2007. Using “annotator rationales” to improve ma-chine learning for text categorization. In HLT-NAACL,pages 260–267. Citeseer.
Ye Zhang, Iain Marshall, and Byron C Wallace.2016. Rationale-augmented convolutional neuralnetworks for text classification. arXiv preprintarXiv:1605.04469.
Guangyou Zhou, Zhiwen Xie, Jimmy Xiangji Huang, andTingting He. 2016. Bi-transferring deep neural net-works for domain adaptation. ACL.





























