Embed Size (px)
Citation preview

1
Automated Functional Testing of Web Search Engines in the Absence of an Oracle * Zhi Quan Zhou †
University of Wollongong, Australia
T. H. Tse The University of Hong Kong, Pokfulam, Hong Kong
F.-C. Kuo Swinburne University of Technology, Australia
T. Y. Chen Swinburne University of Technology, Australia
ABSTRACT
A software product is functionally correct if it behaves according to the functional specification. Compared with other quality aspects of Web search engines such as performance and capacity, functional correctness is more fundamental but its verification suffers from the oracle problem: It is often difficult or impossible to decide whether outcomes of test case executions are correct. For example, how can testers decide whether the results returned by a Web search engine are actually correct and complete? In this paper, we present an approach to help alleviate the oracle problem in testing search engines. The testing process is fully automatic, including test case generation, execution, output collection, and verification. A tool has been developed to implement the approach and detected failures in popular search engines including Google, Yahoo!, and Microsoft’s Live Search. The failures are illustrated using screenshots, and more experimental results are analyzed.
Categories and Subject Descriptors D.2.5 [Software Engineering]: Testing and Debugging — testing tools.
D.2.4 [Software Engineering]: Software/Program Verification — reliability.
General Terms Verification, Reliability, Experimentation.
Keywords Automated testing, search engines, oracle problem, metamorphic testing.
1. INTRODUCTION Suppose we search the Web for hotels in Boston that offer a rate less than $50 per night for July 1. Suppose the search engine returns 0
results. How can we be sure that there is no hotel with vacancy less than the requested rate, listed in the Web? Or is it an erroneous response owing to some software fault? Software testers of Web search engines are facing this kind of problem: The huge amount of data in the World Wide Web prohibits them from verifying the results of the search engines. Testing by means of mock databases at the developers’ sites may give false positive results.
The difficulty in verifying testing outputs is known as the oracle problem, which is a fundamental challenge in software testing. An oracle is a mechanism against which a tester can decide whether the outcomes of given test cases for a program are correct [11]. In some situations, the oracle is not available or too expensive to apply. For example, if we test a compiler using a randomly selected program, it is very difficult to decide whether the generated machine code will behave according to the source code. In cryptographic systems, very large integers are involved in computations and, hence, it is very expensive to verify the computation results unless an inverse function happens to be present and correctly implemented. When testing object-oriented programs, it is very difficult to decide whether two objects have equivalent behaviors [3]. Other examples include, to name a few, the testing of simulation programs; the testing of numerical programs such as those for solving partial differential equations; and the testing of graphics-rendering programs. Furthermore, even when an oracle does exist, if it cannot be automated, manual predictions and verifications of test results can be very time-consuming and error prone.
There is an oracle problem when conventional strategies for evaluating information retrieval systems are applied to Web search engines. Two basic evaluation measures are known as precision and recall [9, 12]. Given a search criterion, let A be the set of all items
* This project is supported in part by a Virtual Earth Award from Microsoft Research, a Discovery grant of the Australian Research Council
(Project No. DP0771733), and a Small Grant of the University of Wollongong. † All correspondence should be addressed to Dr. Zhi Quan Zhou, School of Computer Sciencd and Software Engineering, University of
Wollongong, Wollongong, NSW 2522, Australia. Email: [email protected]. Telephone: +61 2 4221 5399.

2
retrieved, R (⊆ A) be the set of relevant items retrieved, and R� be the set of relevant items in the database but not retrieved. Precision is defined as |R| ÷ |A|, that is, the proportion of relevant items retrieved to all the items retrieved. Recall is defined as |R| ÷ (|R| + |R�|), that is, the proportion of relevant items retrieved out of all relevant items available in the entire database. It is infeasible to measure recall for Web search engines because it requires the knowledge of not only retrieved records but also the records in the database not retrieved. For example, Chu and Rosenthal [6] reported that ‘Recall ... is deliberately omitted from this study because it is impossible to assume how many relevant items there are for a particular query in the huge and ever changing Web system.’ Similarly, Su [10] also pointed out that ‘Recall, one of the most important traditional measures of retrieval effectiveness, was not used at all due to the difficulty of its implementation in the vast Web information environment.’ To alleviate this problem, Clarke and Willett [7] proposed an approach using relative recall instead of absolute recall, which searches with different engines and then pools the relevant documents for computation. In short, one of the two major evaluation measures is often ignored or sidestepped when testing Web search engines.
To tackle the oracle problem in the functional testing of Web search engines, we propose in this paper an innovative approach that is quite different from conventional strategies. Rather than attempting to give an evaluation measure of recall, we focus on the identification of failures, which, after all, is the primary target of functional testing. Our method automatically tests and verifies necessary functional properties despite the absence of a tangible oracle of the search results.
The rest of this paper is organized as follows: Section 2 introduces the concept of metamorphic testing, a conceptually simple but practically useful testing method to be adopted to tackle the problem. Section 3 proposes to apply the method to test search functions in Web applications and shows with examples how failures can be detected in search engines. Section 4 presents results of a case study, where our approach has been applied to test the functional correctness of Google, Yahoo!, and Microsoft’s Live Search (MSN). Section 5 concludes the paper and points to future research directions.
2. METAMORPHIC TESTING In this section, we shall introduce a testing method known as metamorphic testing (MT) [4, 5]. First of all, consider standard software testing. Let p be a program implementing function f on domain D. To test p, a set T = {t1, t2, …,
tn} of test cases is generated according to test case selection strategies, where n > 0 and ti ∈ D. The tester will then run program p on T and obtain the outputs p(t1), p(t2), …, p(tn). If an oracle is available, the tester will verify these outputs against the expected results f(t1), f(t2), …, f(tn). If p(ti) � f(ti) for some i, then a failure has been detected. Otherwise, T is called a set of successful test cases. Since successful test cases do not reveal any failure, they are often considered useless and are retained only for regression testing.
On the other hand, metamorphic testing argues that successful test cases are not useless but carry useful information! Based on these original test cases, and by making reference to properties of the target function f, we can generate follow-up test cases to further test the program. An important point here is that the generation of the follow-up test cases and the verification of their outputs may be fully automated regardless of whether a test oracle exists.
As an example, consider a program p(x, y) calculating xy. There is an oracle problem when testing this program using random real numbers x and y. Nevertheless, we can apply MT. The first step is to identify one or more metamorphic relations (MRs), which are necessary properties of the target function and involves multiple executions of p. A sample MR can be ‘if x2 = x1 and y2 = –y1, then x1
y1 ×
x2y
2 = 1.’ Suppose (x1 = 1.234, y1 = 5.678) is a test case. A follow-up test case is (x2 = 1.234, y2 = –5.678), on which the program p will be
run again. Finally, the value of p(1.234, 5.678) × p(1.234, –5.678) will be calculated. After taking into consideration the rounding errors in floating point arithmetic, if the result is not 1, then a failure is revealed. Note that, firstly, an oracle is not required in MT because the correctness of individual outputs is not checked; instead, MT only checks the relation among inputs and outputs. Secondly, if the MR is not satisfied, then a failure is immediately identified; however, if the MR is satisfied, we still cannot say the program is correct. In other words, MT checks necessary conditions (which may not be sufficient) for program correctness. This is in fact a limitation of all testing methods. Thirdly, for a given problem, usually more than one MR can be identified. How to select the best MR that has the highest chance to reveal a failure is beyond the scope of this paper. Fourthly, metamorphic testing may be fully automated because, by making reference to the MR, follow-up test cases can be generated automatically and the outputs may also be verified automatically.
It must be pointed out that the use of identity relations in software quality assurance, such as the example above, is not a fresh idea. For instance, identity relations have been used for the testing of numeric functions [8], for fault tolerance [1], and for program checkers [2]. There are, however, notable differences between these methods and MT. For example, while all identity relations can be used as MRs for MT, MRs are not limited to identity relations. Any necessary property involving multiple executions of the program can be regarded as an MR. In this paper, we shall show how to employ non-identity MRs for testing Web search engines.
Figure 1. Excerpts from Yahoo! help page explaining logic operators for the search engine.

3
3. METAMORPHIC TESTING OF WEB SEARCH ENGINES 3.1 Introductory Examples
As explained previously, there is an oracle problem in testing Web search engines. Let us, for example, go to Google at www.google.com and enter: ‘ACM Transactions.’ Note that, according to the specification in Google, spaces among words imply the AND-relation. The system returns ‘about 8,660,000’ results. How can testers decide whether this output is correct, that is, whether Google has correctly counted all the relevant Web pages indexed in its database? Suppose a user is also interested in the Web and, hence, types the following list of words: ‘ACM Transactions "World Wide Web".’ According to the specification in Google, the quotation marks (" ") mean that the returned page must contain the exact phrase. This time, the system returns ‘about 834,000’ results. How can the user know whether there were really only ‘about 834,000’ relevant pages indexed in the Google database?
While conventional testing methods would probably fail to answer these questions, metamorphic testing can be applied: Instead of checking the correctness of each individual output, let us check metamorphic relations among the inputs and outputs. Let X be a search criterion (such as a condition “Page contains string S.”) and #(X) be the number of pages returned for search criterion X. A useful general metamorphic relation is
MRSEARCH: if X2 implies X1, then #(X2) � #(X1).
A special case is
MROR: if A2 ≡ (A1 OR B), then #(A1) � #(A2),
which means that the number of pages satisfying condition A1 should be less than or equal to the number of pages satisfying condition A1 or condition B.
Similarly, we have MRAND: if A2 ≡ (A1 AND B), then #(A2) � #(A1).
The latter should hold because any page satisfying condition A1 AND B must also satisfy condition A1, but not vice versa. Using this MR to check the above results, we can verify that 8,660,000 is greater than 834,000 and, hence, no failure is detected.
Another relation is
MREXCLUDE: if A2 ≡ (A1 AND B ), then #(A2) � #(A1),
where A1 AND B denotes that condition A1 is satisfied but not condition B. Most search engines support these kinds of search functions. Figure 1 shows Yahoo! specifications that introduce ‘–’ (for EXCLUDE) and ‘OR’ operators, and Google supports the same operators as shown in Figure 2.
Readers might doubt the effectiveness of failure detection of these simple metamorphic relations. In fact, even using these simple MRs, our automated testing tool has detected many significant failures. We shall show some examples of failures detected in three major search engines, namely Google, Yahoo! and Live Search. Note that in the result page of Google and Yahoo!, there is sometimes a statement “In order to show you the most relevant results, we have omitted some entries very similar to the XXX already displayed. If you like, you can repeat the search with the omitted results included.” We click the link “repeat the search with the omitted results included”, which effectively disables filters, to obtain the results of our experiment.
Let us look at the screenshot shown in Figure 3. The upper part of the figure is a browser window that shows the output of Google for the keyword ‘ "cousinry" ’ — about 589 results were found. The lower part of the figure is another browser window that shows the output of Google for the keywords ‘ "cousinry" ’ and ‘ "cochlear" ’ — about 2,660 pages were found. The second search was conducted
Figure 2. Excerpts from Google explaining logic operators for the search engine.

4
immediately after the first search. Although we do not know whether each individual output is correct, we identified an anomaly: The latter was 4.5 times as large as the former. This obviously violated the expected MRAND, which requires that the number of pages containing both "cousinry" and "cochlear" must be smaller than or equal to the number of pages containing "cousinry".
Now, the question is: Is this anomaly a failure? Before we draw a conclusion, we must consider the following possibilities. (1) Did we use correct syntax in the search? By referring to the help page of Google, it can be easily confirmed that the space means the AND-relation and the quotation marks mean exact-word search. Hence, the syntax was correct and the test was valid. (2) Was this anomaly caused by the dynamic nature of the Web and the search engine? Since the database of the search engine changes dynamically, it might happen that there were originally 589 pages indexed in the Google database, but updated to 2,660 a second later. We, therefore, repeated the test immediately after detecting the original anomaly. The same anomaly was identified in the second attempt. (3) Could the anomaly be due to approximate results given by search engines? Yes, this would be a valid explanation if the difference between the two outputs were small, but the argument would not hold for large differences. Hence, it is beyond reasonable doubt for us to conclude that a failure has been revealed, which indicates a fault in the search engine.
Having said that, we must point out that many of the failures shown in the screenshots have disappeared when this paper is being finalized. This would really be due to the dynamic nature of the Web and the search engines. However, while earlier failures disappeared, new failures are showing up. Every time we run our testing tool with valid random words and strings, new failures are always found.
3.2 More Examples Apart from MRAND, failures have been detected for both MROR and MREXCLUDE. Screenshots of some of these failures are shown in
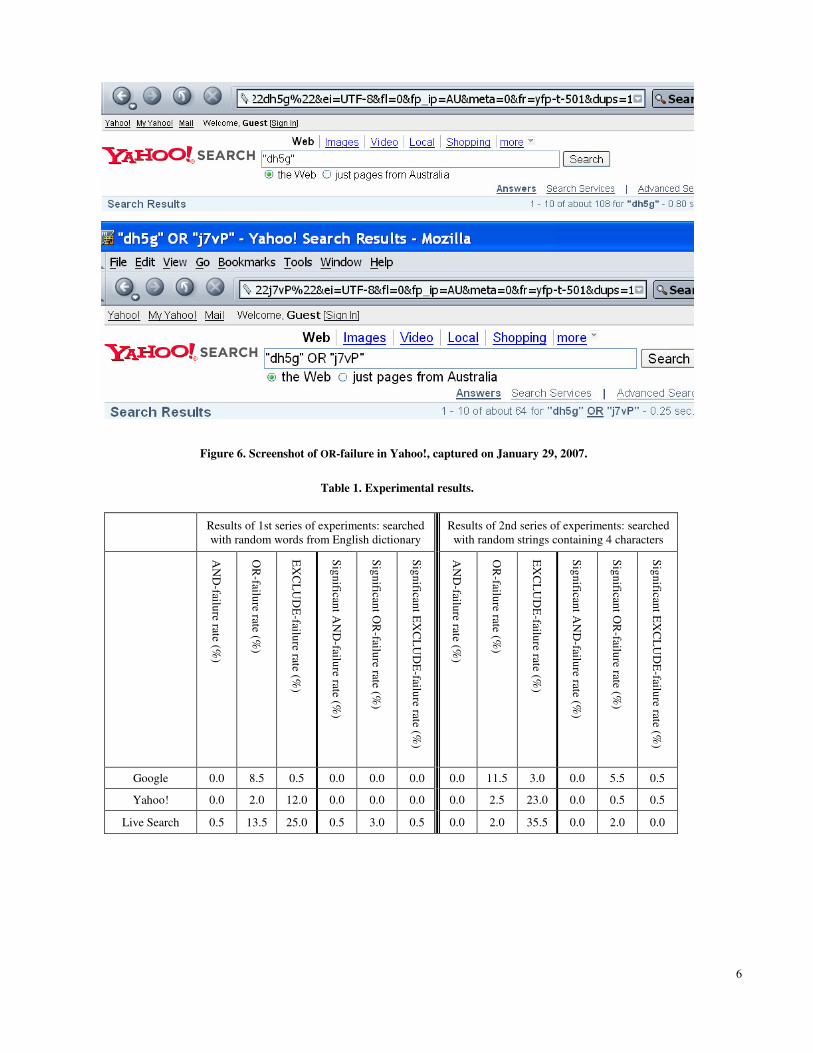
Figures 4 and 5. Similar failures have also been detected in other Web search engines tested. For example, Figure 6 shows the screenshot of a Yahoo!
failure. We would like to emphasize again that all the tests reported in the paper involved correct syntax compatible with the online specifications or help pages provided by the search engines under test, and all the failures reported were confirmed by additional tests conducted after anomalies were first detected. In all the reported experiments, any pair of searches involved in a metamorphic test (such as the two searches shown in Figure 4) were conducted consecutively within a very short period of time (usually seconds).
The logic operations are but a few of the useful metamorphic relations that can be derived from MRSEARCH. It is not difficult to find many other useful MRs for the testing of search engines. Consider, for example, the advanced search option supported by most search engines. Searches can be performed for ‘all of these items’ or ‘any of these items;’ ‘any language’ or a specific language; for ‘any format’ or a specific file format; for ‘anytime’ or ‘past n months;’ and for ‘anywhere in the page’ or a specific place in the page. All these features can be derived from MRSEARCH and employed as specific metamorphic relations in testing, thus:
MRITEMS_1: #(items:all(A1 A2 ... An)) � #(items:any(A1 A2 ... An)),
Figure 3. Screenshot of AND-failure in Google, captured on January 29, 2007.

5
MRITEMS_2: #(A1) � #(items:any(A1 A2 ... An)),
MRITEMS_3: #(items:all(A1 A2 ... An)) � #(A1),
MRLANGUAGE: #(language:English(A1)) � #(language:any(A1)),
MRFILETYPE: #(filetype:specific(A1)) � #(filetype:any(A1)),
and so on. Here, ‘items:all(A1 A2 ... An)’ refers to a search of the co-existence of all the items A1, A2, ..., An, ‘items:any(A1 A2 ... An)’ refers to a search for any of the items A1, A2, ..., An, ‘language:English(A1)’ refers to a search of A1 in English Web pages, ‘language:any(A1)’ refers to a search of A1 in Web pages in any languages, ‘filetype:PDF(A1)’ refers to a search of A1 in Web pages in PDF format, and ‘filetype:any(A1)’ refers to a search of A1 in Web pages in any format.
Figure 4. Screenshot of OR-failure in Google, captured on January 29, 2007.
Figure 5. Screenshot of EXCLUDE-failure in Google, captured on January 29, 2007.
6
Figure 6. Screenshot of OR-failure in Yahoo!, captured on January 29, 2007.
Table 1. Experimental results.
Results of 1st series of experiments: searched with random words from English dictionary
Results of 2nd series of experiments: searched with random strings containing 4 characters
AN
D-failure rate (%
)
OR
-failure rate (%)
EX
CL
UD
E-failure rate (%
)
Significant AN
D-failure rate (%
)
Significant OR
-failure rate (%)
Significant EX
CL
UD
E-failure rate (%
)
AN
D-failure rate (%
)
OR
-failure rate (%)
EX
CL
UD
E-failure rate (%
)
Significant AN
D-failure rate (%
)
Significant OR
-failure rate (%)
Significant EX
CL
UD
E-failure rate (%
)
Google 0.0 8.5 0.5 0.0 0.0 0.0 0.0 11.5 3.0 0.0 5.5 0.5
Yahoo! 0.0 2.0 12.0 0.0 0.0 0.0 0.0 2.5 23.0 0.0 0.5 0.5
Live Search 0.5 13.5 25.0 0.5 3.0 0.5 0.0 2.0 35.5 0.0 2.0 0.0
7
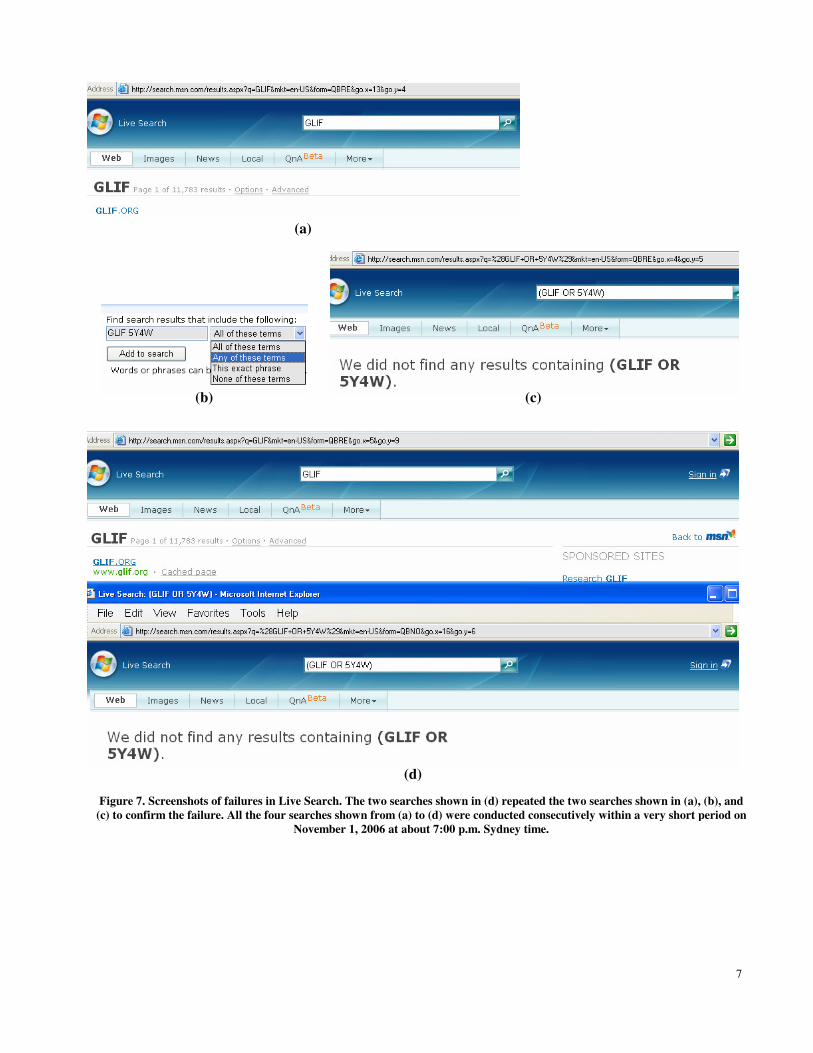
Figure 7. Screenshots of failures in Live Search. The two searches shown in (d) repeated the two searches shown in (a), (b), and (c) to confirm the failure. All the four searches shown from (a) to (d) were conducted consecutively within a very short period on
November 1, 2006 at about 7:00 p.m. Sydney time.
(a)
(b) (c)
(d)

8
Figure 7 shows an example of a failure of MRITEMS_2 captured in Live Search. We first entered a keyword GLIF, and Live Search returned 11,783 results, as shown in Figure 7(a). We then clicked the advanced search option and entered two keywords: ‘GLIF 5Y4W,’ as shown in Figure 7(b). Using the drop-down menu, we selected ‘any of these terms.’ To our great surprise, Live Search reported, ‘We did not find any results containing (GLIF OR 5Y4W),’ as shown in Figure 7(c). Immediately after this anomaly had been detected, we repeated the two searches and obtained the same results, as shown in Figure 7(d).
One may argue that a relation such as ‘#(A1) � #(items:any(A1 A2 ... An))’ is equivalent to ‘#(A1) � #(A1 OR A2 OR ... OR An),’ so that the testing of MRITEMS_2 is subsumed by the testing of MROR. Please note, however, whether the equivalence has been implemented correctly is exactly what software testers need to verify.
3.3 The Metamorphic Testing Tool We have developed a tool to conduct metamorphic testing for search functions of Web applications. It is implemented in JavaScript.
The entire testing process has been fully automated: It can generate random strings or select random words from user-provided dictionaries, and then either directly send HTTP requests to search engines or simulate keyboard and mouse inputs to fill in Windows-based forms and click the buttons. After a search engine returns a dynamically generated page, the tool can extract the number of results (or other text) from the page and compare it against prescribed metamorphic relations. This tool has been made robust to handle exceptions such as network connection failures as well as server-not-found and server-not-available failures. We have applied the tool to test search engines and search functions of various Web applications against selected MRs. Many failures have been detected. Some experimental results will be reported in the next section.
4. A CASE STUDY ON SEARCH ENGINES Many metamorphic relations for Web search engines can be derived from the basic relation
MRSEARCH: if X2 implies X1, then #(X2) � #(X1).
Do these MRs have similar effectiveness for failure detection? The answer to this question is very important not only for testing but also for debugging: If they have similar effectiveness, the failure may be due to the same fault. If they have dissimilar effectiveness, the failures may be caused by distinct faults.
In this section, we present a case study on the effectiveness of failure detection of different MRs and different sets of inputs, using Google, Yahoo!, and Live Search as our subject applications under test. We have selected the following three basic metamorphic relations for study:
MROR: if A2 ≡ (A1 OR B), then #(A1) � #(A2);
Figure 8. Multi-AND-failures in Live Search. All searches were conducted consecutively at 1-second intervals on November 4, 2006 at 5:57 p.m. Sydney time. Upper left: 1st search. Upper right: 2nd search. Lower left: 3rd search. Lower right: 4th search.

9
MRAND: if A2 ≡ (A1 AND B), then #(A2) � #(A1);
MREXCLUDE: if A2 ≡ (A1 AND B ), then #(A2) � #(A1).
We would like to reiterate that many other MRs can be identified and many of them may not involve logic operators. The aim of this pilot study, however, is not to give a comprehensive list of effective MRs. Instead, we want to see how reliable the real-world search engines are in terms of functional correctness, and how different MRs may exhibit different effectiveness for failure detection.
Two series of experiments were conducted. In the first series, search keywords were randomly selected from a dictionary that contains 109,582 English words downloaded from http://www.umich.edu/~archive/linguistics/texts/lexica on September 4, 2006. In the second series, search keywords were randomly generated strings containing any four characters from the set {A B, …, Z, a, b, …, z, 0, 1, …, 9}. For example, A1 = ‘DtM3’ and A2 = ‘9yQu.’ The length of each random string was set to 4 by design. If they are too long, no results will be found. If they are too short, some of them (such as ‘it’) are too common and may be ignored by the search engines, thus affecting the experimental results. In each search, quotation marks were used to enclose each keyword. Examples of such searches are shown in Figures 3 to 6. Note that the quotation marks mean exact-word search in Google, Yahoo!, and Live Search. The general flow of experiments for each search engine is as follows:
Initialize all counters to 0; repeat 200 times {
1 generate two random words key1 and key2; 2 conduct the following searches using the appropriate syntax and store the number of returned pages in the corresponding variables as
follows: numResults_key1 = search(key1); numResults_Or = search(key1 OR key2); numResults_Excl = search(key1 EXCLUDE key2); numResults_And = search(key1 AND key2);
/* search(X) runs the search engine using string X and returns the number of results returned by the search engine. */ 3.1 if (numResults_key1 > numResults_Or) {
repeatedNumResults_key1 = search(key1); repeatedNumResults_Or = search(key1 OR key2);
3.2 if (repeatedNumResults_key1 > repeatedNumResults_Or) { increase FailureCounter_Or by 1;
3.3 if (numResults_key1 >= 2 × numResults_Or) and (repeatedNumResults_key1 >= 2 × repeatedNumResults_Or) Increase significantFailureCounter_Or by 1; }}
4 if (numResults_And > numResults_key1) { repeatedNumResults_key1 = search(key1); repeatedNumResults_And = search(key1 AND key2); if (repeatedNumResults_And > repeatedNumResults_key1) {
increase FailureCounter_And by 1; if (numResults_And >= 2 × numResults_key1) and (repeatedNumResults_And >= 2 × repeatedNumResults_key1)
increase significantFailureCounter_And by 1; }} 5 if (numResults_Excl > numResults_key1) {
repeatedNumResults_key1 = search(key1); repeatedNumResults_Excl = search(key1 EXCLUDE key2); if (repeatedNumResults_Excl > repeatedNumResults_key1) {
increase FailureCounter_Excl by 1; if (numResults_Excl >= 2 × numResults_key1) and (repeatedNumResults_Excl >= 2 × repeatedNumResults_key1)
increase significantFailureCounter_Excl by 1; }}}
Statement 1 randomly selects two words from the English dictionary in the first series of experiments, or generates two random strings in the second series of experiments. The selection/ generation of random inputs in all the experiments was with replacement. Although there are various black-box test case selection approaches, in this research we simply adopted the random testing method as it is easy to implement and can serve as an objective benchmark for comparison.Statement 2 conducts four searches using different combinations of inputs. Statement 3.1 checks whether there is an OR-anomaly. Statement 3.2 confirms whether the detected anomaly can be repeated. A repeatable anomaly is treated as a failure. Statement 3.3 checks whether it is a significant OR-failure, in which the number of results for key1 at least doubles that of the OR-expression in both the original and repeated tests. For example, suppose a search for A1 returns 1,000 results and a follow-up search for A1 OR B returns 900 results. In this case, the counter for OR-failures will increase by 1 but the counter for significant OR-failures will not change. The next question is: when is a difference ‘significant’? Different testers may have different criteria. In our experiments, we consider a failure to be significant if and only if search(A1) � 2 × search(A1 OR B). The treatments of AND- and EXCLUDE-failures are identical.
In each series of experiments, for each search engine, and for each metamorphic relation, two hundred metamorphic tests were conducted, where each metamorphic test involved two runs of the search engine. At the end of the two hundred tests, the failure rate and significant failure rate were calculated for each metamorphic relation. For example, the OR-failure rate was given by (FailureCounter_Or ÷ 200), and the significant OR-failure rate was given by (significantFailureCounter_Or ÷ 200). The other failure rates were computed in the same way.

10
Figure 9. Excerpt from MSN (Live Search) help page explaining the symbol ‘+’.
Table 1 summarizes the results of the experiments. Let us first look at the left half of the table, representing the first series of experiments, where searches were conducted using dictionary words. In this series of experiments, no AND-failure was detected for Google or Yahoo!, but Live Search had an AND-failure rate of 0.5%, which means that only one (= 0.5% × 200) AND-failure was detected out of the 200 metamorphic tests. Among the three MRs used in testing, MREXCLUDE was the most effective in detecting failures in Live Search and Yahoo! (25.0% and 12.0%, respectively); whereas MROR was the most effective in detecting Google failures. Data in columns 5 to 7 show that all the failures detected in Google and Yahoo! were not significant; whereas all MRs detected significant failures in Live Search.
Let us look at the right half of Table 1, representing the second series of experiments, where searches were conducted using 4-character random strings. A notable phenomenon is that the failure rates of both Google and Yahoo! have increased, and some rates have increased significantly as compared with the first series of experiments. In the absence of more information on the design of the search engines, it is not possible for us to find the cause for this phenomenon. However, we notice two obvious differences between a dictionary word and a random string: Firstly, their frequencies of occurrence in Web pages are different; secondly, a random string does not have a meaning in natural languages, but a dictionary word does. Hence, some faults should exist in the modules related to word frequencies or semantics, such as prioritization modules. Debuggers should be able to verify the hypothesis if the source code is available.
For Live Search, it exhibited a failure pattern opposite to that of Google and Yahoo!: It produced more failures on dictionary words than random strings (especially OR-failures) except EXCLUDE-failures. Our preceding discussion related to word frequencies or semantics for Google and Yahoo!, therefore, should also apply here, albeit with an opposite effect.
In both series of experiments, Google produced the smallest number of failures, namely (0.0 + 8.5 + 0.5)% × 200 = 18 for dictionary words and (0.0 + 11.5 + 3.0)% × 200 = 29 for random strings.
Comparing the effectiveness of failure detection by the three metamorphic relations, MREXCLUDE was the most effective for Yahoo! and Live Search in both series of experiments; whereas MROR was the most effective for Google. MRAND appeared to be ineffective since only one failure was identified among all the search engines. Since different MRs exhibited significantly different effectiveness in detecting failures, such failures should be due to different faults in the systems. Debuggers should be able to verify the hypothesis if the source code is available.
Nevertheless, we would like to find out more about the AND-relation since it is probably the most useful operator for users, and keywords submitted to search engines are joined with ‘AND’ by default. In our previous experiments, an AND-expression only involved two keywords. We conducted a further series of experiments to include more keywords in AND-expressions. Another dictionary, consisting only of the top 5,000 most popular English words, was used to generate the keywords. Each word in the AND-expression was enclosed with quotation marks. An example of such a search is shown in Figure 3. The general flow of experiments for each search engine was as follows:
Initialize all counters to 0; repeat 200 times { 1 generate two random words key1 and key2; 2 previousExpression = ‘key1’; 3 currentExpression = ‘key1 AND key2’; 4 previousResult = search(previousExpression); 5 currentResult = search(currentExpression); 6 numTerms = 2; 7 while (currentResult <= previousResult)
and (numTerms < 10) { generate a random word key; previousExpression = currentExpression; currentExpression = ‘currentExpression AND key’; increase numTerms by 1; previousResult = currentResult; currentResult = search(currentExpression); } /* no more than 10 terms in currentExpression */
8 if (currentResult > previousResult) { /* an anomaly has been detected */ repeatedPreviousResult = search(previousExpression); repeatedCurrentResult = search(currentExpression); if (repeatedCurrentResult > repeatedPreviousResult) {

11
/* the anomaly has been verified as a failure */ increase failureCounter by 1;
if (currentResult >= previousResult × 2) and (repeatedCurrentResult >= repeatedPreviousResult × 2)
increase significantFailureCounter by 1; }}}
Two hundred iterations were carried out for each search engine under study, where each iteration involved 2 to 10 searches. The failure rates of each search engine were computed. For Google, the overall AND-failure rate (= failureCounter ÷ 200) was 6.5% and the overall significant AND-failure rate (= significantFailureCounter ÷ 200) was 0. The respective rates for Yahoo! were 7.5% and 0 while those for Live Search were 6.75% and 0.25%. The experiments were conducted from November 2006 to March 2007. An example of such failures in Live Search is shown in Figure 8: The searches shown in the upper windows confirmed a failure detected by the automated testing tool. The searches were repeated as shown in the lower windows using one more operator ‘+’ (which is specified in MSN help page shown in Figure 9) without quotation marks. The same failure was detected.
Apart from Google, Yahoo!, and Live Search, we also tested other major search engines using a wider range of metamorphic relations, and none of them survived the tests. We further applied the same method to test Web sites that are not search engines but have search functions, such as the intranets of organizations, digital libraries, digital maps, and e-Business sites. A large number of failures have been detected. Owing to the page limit, however, we shall not report these failures in detail. All these results demonstrate that metamorphic testing is effective for the testing of search functions.
5. DISCUSSIONS AND CONCLUSION The oracle problem is a major challenge in automated testing of Web search engines. In this research, we apply the metamorphic testing
method to help alleviate the problem. Our method has been implemented into a tool and the whole testing process has been fully automated. We have applied the tool to test various Web search engines and detected a large number of failures. In this paper, we report some of these failures identified in three major search engines: Google, Yahoo!, and Live Search.
Experiment results have been further analyzed to compare the effectiveness of different metamorphic relations to provide some hints for the faults that cause the failures. Our results are useful for the quality assurance of search engines. We are seeking opportunities for collaborative projects with the industry to study the implications on a larger scale.
We would like to point out potential threats to validity of the experiments conducted in Section 4. For internal validity, although we have tested our testing tool thoroughly, there may be special cases that the tool did not handle properly, such as certain failures due to network communication errors or client-site problems rather than functional errors of the search engines. For external validity, the experiments reported in Section 4 were based on only a small number of test executions performed in Australia. As there are many factors affecting a search engine’s performance, it is not the aim of this study to give a comprehensive comparison of the functional correctness of search engines. However, this study shows that metamorphic testing though simple is an effective testing method for search engines, and different metamorphic relations have different failure-detection effectiveness.
In future research, we shall study how to systematically apply metamorphic testing to information retrieval systems in general, and how to debug when failures have been detected. This includes more understanding of the implications of the significant failure rates. We shall also study how to apply metamorphic testing to functions other than searches for interactive Web applications.
6. ACKNOWLEDGEMENTS We are grateful to Microsoft Research for selecting our project for one of ten specially funded Virtual Earth Awards from “close to 80
very highly qualified applications.” We would like also to thank the undergraduate students of the course CSCI311 in the University of Wollongong for their experiments involving numerous Web sites and Web services.
7. REFERENCES [1] Ammann, P. E. and Knight, J. C. Data diversity: an approach to software fault tolerance. IEEE Transactions on Computers, 37 (4):
418–425, 1988. [2] Blum, M. and Kannan, S. Designing programs that check their work. In Proceedings of the 31st Annual ACM Symposium on Theory of
Computing (STOC ’89), pages 86–97. ACM Press, New York, 1989. [3] Chen, H. Y., Tse, T. H., and Chen, T. Y. TACCLE: a methodology for object-oriented software testing at the class and cluster levels.
ACM Transactions on Software Engineering and Methodology, 10 (1): 56–109, 2001. [4] Chen, T. Y., Cheung, S. C., and Yiu, S. M. Metamorphic testing: new approach for generating next test cases. Technical Report
HKUST-CS98-01. Department of Computer Science, Hong Kong University of Science and Technology, Hong Kong, 1998. [5] Chen, T. Y., Tse, T. H., and Zhou, Z. Q. Semi-proving: an integrated method based on global symbolic evaluation and metamorphic
testing. In Proceedings of the 2002 ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2002), ACM SIGSOFT Software Engineering Notes, 27 (4): 191–195, 2002.
[6] Chu, H. and Rosenthal, M. Search engines for the World Wide Web: a comparative study and evaluation methodology. In ASIS 1996 Annual Conference Proceedings, 1996. Available at http://www.asis.org/annual-96/ElectronicProceedings/chu .html.
[7] Clarke, S. J. and Willett, P. Estimating the recall performance of Web search engines. Aslib Proceedings: New Information Perspectives, 49 (7): 184–189, 1997.
[8] Cody, W. J., Jr. and Waite, W. Software Manual for the Elementary Functions. Prentice Hall, Englewood Cliffs, New Jersey, 1980.

12
[9] Landoni, M. and Bell, S. Information retrieval techniques for evaluating search engines: a critical overview. Aslib Proceedings: New Information Perspectives, 52 (3): 124–129, 2000.
[10] Su, L. T. A comprehensive and systematic model of user evaluation of Web search engines: I. theory and background. Journal of the American Society for Information Science and Technology, 54 (13): 1175–1192, 2003.
[11] Weyuker, E. J. On testing non-testable programs. The Computer Journal, 25 (4): 465–470, 1982. [12] Zhao, H., Meng, W., and Yu, C. Automatic extraction of dynamic record sections from search engine result pages. In Proceedings of
the 32nd International Conference on Very Large Data Bases, pages 989–1000. VLDB Endowment, 2006.





























