Embed Size (px)
Citation preview

J Sign Process Syst (2012) 6765ndash78DOI 101007s11265-010-0563-9
Automated Mapping of the MapReduce Patternonto Parallel Computing Platforms
Qiang Liu middot Tim Todman middot Wayne Luk middotGeorge A Constantinides
Received 19 February 2010 Revised 15 July 2010 Accepted 9 November 2010 Published online 15 December 2010copy Springer Science+Business Media LLC 2010
Abstract The MapReduce pattern can be found inmany important applications and can be exploited tosignificantly improve system parallelism Unlike pre-vious work in which designers explicitly specify howto exploit the pattern we develop a compilation ap-proach for mapping applications with the MapReducepattern automatically onto Field-Programmable GateArray (FPGA) based parallel computing platforms Weformulate the problem of mapping the MapReduce pat-tern to hardware as a geometric programming modelthis model exploits loop-level parallelism and pipelin-ing to give an optimal implementation on given hard-ware resources The approach is capable of handlingsingle and multiple nested MapReduce patterns Fur-thermore we explore important variations of MapRe-duce such as using a linear structure rather than a treestructure for merging intermediate results generatedin parallel Results for six benchmarks show that ourapproach can find performance-optimal designs in thedesign space improving system performance by up to170 times compared to the initial designs on the targetplatform
Q Liu middot T Todman (B) middot W LukDepartment of Computing Imperial College LondonLondon SW7 2AZ UKe-mail tjt97docicacuk
Q Liue-mail qiangliu2imperialacuk
W Luke-mail wlukimperialacuk
G A ConstantinidesDepartment of Electrical Engineering Imperial CollegeLondon London SW7 2AZ UKe-mail gconstantinidesimperialacuk
Keywords Parallel computing middot MapReduce middotPipelining middot Geometric programming
1 Introduction
Recently there has been a great deal of interest in howto program parallel applications especially since paral-lel hardware is now common in desktop and portablecomputers However implementing complex applica-tions efficiently on parallel computing structures is stillhighly challenging Researchers [1] have explored waysto improve programmer productivity and maximizesystem efficiency In this paper we target advancedcompilation techniques which can compile sequentialdescriptions for parallel execution This allows pro-grammers in the traditional sequential programmingenvironment to focus on the algorithm level withoutworrying about the underlying hardware parallelismcan be automatically extracted afterwards by compilersWe propose an approach that automatically identifies acommon computation pattern the MapReduce patternin C-like descriptions and maps it onto an efficientparallel computing platform
MapReduce is a technique widely used to improveparallelism of large-scale computations [1ndash3] It parti-tions the computation into two phases first the Mapphase in which the same computation is performedindependently on multiple data elements second theReduce phase in which the final result is calculatedby reducing the results of the Map phase with anassociative operator A simple example of MapRe-duce is vector dot product where the Map phasemultiplies corresponding vector elements and the Re-duce phase sums the products MapReduce applies to
66 J Sign Process Syst (2012) 6765ndash78
computations where (1) there is no dependence be-tween computations working on different parts of theinput data set and (2) the reduction operation is as-sociative These characteristics can be obtained fromdata flow analysis tools such as SUIF [4] Examplesof the MapReduce pattern include matrix multiplica-tion Monte Carlo simulation and pattern match anddetection
In practice MapReduce can be limited by memorybandwidth and the number of processing units (hard-ware computation resources) Given a hardware plat-form it is often not obvious how to map a MapReducepattern onto the platform to maximise system perfor-mance Most previous methods require designers toidentify the MapReduce pattern and specify the Mapand Reduce functions explicitly To our best knowledgethe work [5] is the first one that targets automatingthe exploitation of the MapReduce pattern Howeverit is limited to a single-level MapReduce pattern anddoes not consider resource constraints on the reductionoperation in the Reduce phase that affects the finaldesigns of some applications
We have proposed a methodology [6] for auto-matically optimising hardware designs written in C-like descriptions by combining both model-based andpattern-based transforms Given system parametersmodel-based approaches map a design into underlyingmathematical models to enable rapid design space ex-ploration Pattern-based approaches perform optimisa-tions by matching and transforming syntax or data flowpatterns
In this paper we show how the methodology [6] canbe applied to automate mapping the MapReduce pat-tern We extend a previous model [5] to map applica-tions with multiple MapReduce patterns onto a parallelcomputing structure Customized loop-level paralleli-zation and pipelining are used to balance system per-formance and hardware resource utilization
The contributions of this paper are thus
bull an approach for automatically identifying the Map-Reduce computation pattern and mapping it to aparallel computing architecture
bull an extended geometric programming (GP) modelconsidering resource constraints in the Reduce phasewhen mapping MapReduce computations onto aparallel computing platform with constraints onmemory bandwidth and hardware resources
bull a geometric programming model for concurrentlymapping multiple nested MapReduce patterns onto a parallel platform and
bull an evaluation of the proposed automation ap-proach using six application kernels showing per-
formance improvement up to 170 times comparedto the initial designs on the target platform
The rest of the paper is organised as followsSection 2 details related work Section 3 illustrates theproblem under consideration using a simple exampleSection 4 describes the proposed approach to deal withthe problem The geometric programming model for-mulating the design space of mapping the MapReducepattern is presented in Section 5 Section 6 presentsexperimental results from applying the proposed ap-proach to six real applications and is followed by theconclusion and future work in Section 7
2 Related Work
In this paper we apply the methodology proposedin [6] which does not support the MapReduce pat-tern optimisation to automate the mapping of mul-tiple MapReduce patterns onto parallel computingplatforms by combining pattern-based and geometricprogramming (GP) based transformations Loop-levelparallelization and pipelining are exploited to extractparallelism in MapReduce patterns
The MapReduce programming model named af-ter the Map and Reduce functions in Lisp and otherfunctional languages has been developed and usedin Google [2] The Haskell functional language andGooglersquos Sawzall are used to describe the Map andReduce functions Yeung et al [3] apply the MapRe-duce programming model to design high performancesystems on FPGAs and GPUs All these methods re-quire designers to identify the MapReduce pattern andspecify the Map and Reduce functions explicitly Liuet al [5] proposes an approach for optimising designswith the MapReduce pattern at compile time How-ever it is limited to a single-level MapReduce patternand does not consider resource constraints on the re-duction operation in the Reduce phase that affects thefinal designs of some applications This paper extends[5] to map nested loops with multiple MapReducepatterns as well as considering the additional resourceconstraints
Loop-level parallelization has been widely used forimproving performance [7] Loop transformations suchas loop merging permutation and strip-mining areused to reveal parallelism A GP model [8] is usedto determine the tile size of multiple loops to im-prove data locality in a hierarchical memory systemEckhardt et al [9] recursively apply locally sequentialglobally parallel and locally parallel globally sequentialschemes to map an algorithm onto a processor array
J Sign Process Syst (2012) 6765ndash78 67
with a 2-level memory hierarchy Loop pipelining isapplied to pipeline the innermost loop [10] and outerloops [11] An integer linear programming model isproposed [12] for pipelining outer loops in FPGAhardware coprocessors Our proposed GP frameworkdetermines loop parallelization and pipelining for aMapReduce pattern at the same time
Pattern-based transforms for hardware compilationhave been explored by researchers like di Martinoet al [13] on data-parallel loops as part of a synthesismethod from C to hardware Unlike our method theydo not allow user-supplied transforms Compiler toolk-its such as SUIF [4] allow multiple patterns to be usedtogether but give no support for including model-basedtransforms Pattern matching and transforming can beachieved in tree rewriting systems such as TXL [14]but such systems do not incorporate hardware-specificknowledge into the transforms
3 Problem Statement
This paper considers how to map an obvious butinefficient description with a possibly implicit MapRe-duce pattern onto highly parallel hardware We useloop strip-mining and pipelining to extract parallelismfrom the sequential description When a loop is strip-mined for parallelism the loop that originally executessequentially is divided into two loops a new for looprunning sequentially and a for all loop that executesin parallel with the latter inside the former The mainconstraints on mapping MapReduce are the computa-tional resources of the target platform which affect thesize of each strip in strip-mining and the bandwidthbetween processing units and memories that affectshow operations are scheduled after loop partitioningWe use a locally parallel globally pipelined structureto balance use of memory bandwidth and hardwareresources
To illustrate this problem Fig 1a shows a simpleexample the dot product of two 8-bit vectors Assumethat arrays A and B are stored in off-chip SRAMwith single port and can be accessed every cycle af-ter pipelining Our proposed framework first appliespattern-based transforms to this code As shown inFig 1b the original complex expression is decomposedinto simple operations two memory accesses one mul-tiplication and the result accumulation (result merg-ing) This can reduce the number of logic levels of thegenerated circuits improving system latency [6] Werefer the statements merging results as merging state-ments in this paper Next we generate a data flow graph(DFG) for the code as shown in Fig 1c and use this to
Figure 1 Motivating example dot product
determine pipelining parameters From the DFG wecan see that this example has the characteristics of theMapReduce pattern multiplication executes indepen-dently on element pairs of array A and B and the resultmerging operation is addition which is associative
We thus map the dot product onto a parallel comput-ing structure Given a hardware platform with sufficientmultipliers and each assignment in the code takes oneclock cycle Table 1 shows some design options for
68 J Sign Process Syst (2012) 6765ndash78
dot product under different memory bandwidth con-straints Each design is represented by the number ofparallel partitions (k) of the strip-mined loop each withits own processing unit and the initiation interval (ii)of pipelining the outer for loop Ideally if the memorybandwidth is 2N bytes per execution cycle as shownin the second row of Table 1 then N multiplicationscan execute in parallel and the final result can bemerged using a tree structure as shown in Fig 1ewhere pipeline registers are not shown In this case theloop i is fully strip-mined and the dot product needslog2 N + 2 execution cycles log2 N execution cycles forresult merging one execution cycle for loading 2N dataand one for multiplication
In practice 2N bytes per execution cycle memorybandwidth is unrealistic for large N If memory band-width is one byte per execution cycle then the fullyparallel implementation in Fig 1e needs 2N + log2 N +1 execution cycles to finish the dot product where2N execution cycles are used to load 2N data In thisscenario pipelining the loop i with ii = 2 due to the twosequential memory accesses needs 2N + 2 executioncycles to compute the dot product as the design (1 2)in Table 1 If N gt 2 the pipelined implementation ismore promising than the fully parallel version not justin speed but also in resource usage Furthermore ifthe memory bandwidth is 2 bytes per execution cycleelements from each of A and B can be read at the sametime and the fully parallel version needs N + log2 N +1 execution cycles
Alternatively if the loop i is strip-mined by 2 thenevery two iterations of the loop i execute in parallelon two processing units and the results are mergedshown in Fig 1d This structure can be further pipelinedwith ii = 2 This design combining local parallelizationand global pipelining can perform the dot product in2N2 + 3 execution cycles The third design option isto pipeline loop i with ii = 1 without loop strip-miningand it is still promising as N + 2 execution cycles are
spent on the product Similarly if the memory band-width is 3 bytes per execution cycle Table 1 showsthree possible design options Here the second optioncombining loop strip-mining and pipelining achieves abalance between speed and resource utilization
We can see that there are multiple options for map-ping the dot product onto a given hardware platformunder different memory bandwidth constraints Evenmore design options result if multipliers are also con-strained Finding the best design in terms of variouscriteria is not easy and requires exploration of thedesign space to find the optimal design
This paper proposes an approach with model-basedand pattern-based transforms to deal with the problemof mapping the MapReduce pattern
4 The Proposed Approach
Figure 2 shows how our proposed approach combinesmodel-based and pattern-based transforms to map theMapReduce pattern onto a target hardware platformwhile achieving design goals
The approach takes as input the sequential descrip-tion of a design We initially apply pattern-based trans-formations such as function inlining and convertingpointers to arrays to the design to ease the dependenceanalysis We apply further pattern-based transforma-tions including loop merging and loop coalescing tothe design to ensure it is in a certain form This formenables us to simplify the mathematical model by re-moving variables enabling it to be solved faster
After dependence analysis we check that the designcontains the two characteristics of the MapReduce pat-tern given in Section 1 If they are found we applythe model-based transformation for the MapReducepattern shown in the shaded block in Fig 2
We formulate the problem of mapping the MapRe-duce pattern onto a target parallel computing platform
Table 1 Possible designoptions of the dot productexample
Mem_bandwidth Designs Exe_cycles Multipliers(Bytesexe_cycle) (k ii)
2N (N 1) log2 N + 2 N
(N 1) 2N + log2 N + 1 N(1 2) 2N + 2 1
2 (N 1) N + log2 N + 1 N(2 2) 2N2 + 3 2(1 1) N + 2 1
3 (N 1) 2N3 + log2 N + 1 N(3 2) 2N3 + 4 3(1 1) N + 2 1
J Sign Process Syst (2012) 6765ndash78 69
Input design(sequential)
InliningPtr2Array
Loop merge3-address
Loop coalesce
Dependenceanalysis
MapReduce+
Pipeline
Output design(parallel)
Hardware Platformparameters
Figure 2 Combining model-based (such as MapReduce) andpattern-based approaches (such as loop coalescing) into a singleapproach
as a geometric programming model Solving this prob-lem automatically generates an optimized design ex-ploiting loop-level parallelization and pipelining forgiven hardware platform parameters such as memorysize and computation resources This paper focusses onpresenting this geometric programming model
As output our approach produces a design with ex-plicit timing and parallelism The design can then beimplemented on the hardware platform using vendortools to synthesize place and route it Currently themodel is used to optimize design parameters we do notcurrently automate output hardware generation butthis is relatively straightforward
Our approach can adapt to several variations on theMapReduce pattern
bull applications with implicit MapReduce pattern suchas the motion estimation algorithm [15] used inX264
bull applications with MapReduce pattern at any looplevel such as the Monte Carlo simulation of AsianOptions [16]
bull applications with 2-D MapReduce patterns such asedge detection [17] and
bull application with multi-level MapReduce patternssuch as k-means clustering [18]
5 GP Model for Mapping MapReduce
As the MapReduce pattern is often present in sequen-tial loops we target a loop nest containing the MapRe-duce patterns with the number of iterations fixed atcompile time
We formulate the design exploration problem as apiecewise integer geometric program Geometric pro-gramming (GP) [19] is the following optimization problem
minimize f0(x)
subject to fi(x) le 1 i = 1 mhi(x) = 1 i = 1 p
where the objective function and inequality constraintfunctions are all in posynomial form while the equal-ity constraint functions are monomial Unlike generalnonlinear programming problems GP is convex andthus has efficient solution algorithms with guaranteedconvergence to a global solution [19]
In the next three subsections we present the pro-posed piecewise integer geometric programming modelfor mapping a single loop with the MapReduce patternan extension of the model to a variant of the MapRe-duce pattern and a further extension to map nestedloops with multiple MapReduce patterns Table 2 listsnotation used in the models capitals denote compiletime constants while lower case denotes integer vari-ables The models assume that assignments take oneclock cycle like Handel-C [20] This limits clock speedto the slowest expression used we ameliorate this bybreaking expressions into three-address code
51 Piecewise GP Model for MapReduce with TreeReduce
In this section a GP model for mapping a loop contain-ing the MapReduce pattern with a tree reduce structureis presented This model extends [5] to consider theconstraints of the resources for the merging operationsin the Reduce phase The design variables includethe number of parallel partitions of the loop and thepipeline initiation interval the loop is mapped to alocally parallel globally pipelined design
The objective is to minimize the number of executioncycles of a loop after loop strip-mining and pipelining asbelow
minimize v times ii +Isum
i=1
di +log2 ksum
j
c j + notFull (1)
This expression is derived from the standard moduloscheduling length of pipelining [10 11] assuming thatthe number of execution cycles for loading data frommemory dominates the initiation interval (ii) Section 6shows that this assumption is true for the tested bench-marks The number of loop iterations v executing ineach parallel partition is defined in Inequality 2
N times kminus1 le v (2)
70 J Sign Process Syst (2012) 6765ndash78
Table 2 Notation used in the models
Notations Description
k (kl) Parallel partitions of a loop (loop l)ii Initiation interval of pipelinev (vl) Iterations in one partition of a loop (loop l)x f No resources f being useddi Latency in execution cycles of computation
level i of DFGc j (csj) Execution cycles of level j of merging tree
(of statement s)m j (msj) Merging operations of level j of merging tree
(of statement s)rs Execution cycles of merging tree of statement s
L No nested loopsIs The loop level where statement s is located
1 le Is le LN (Nl) No iterations of a loop (loop l)A No array referencesRecII Data dependence constraint on ii in
the computationW f Computation resources f required in
a loop iterationRif Computation resources f required in
level i of DFGI No computation levels of DFGB (Ba) Required memory bandwidth (of array a)
in one loop iterationQa Set of loop variables in the indexing function
of array aMb Memory bandwidthC f Computational resources f availableMr Resources r available for merging operationsF F types of computation resources involvednotAlign 0 data are aligned 1 data are not aligned
(of array a)(notAligna)notFull 0 loop (l) is fully strip-mined 1 loop (l) is
partially strip-mined(notFulll)
The second term in the objective function 1 is theexecution cycles taken by computation There maybe I (I ge 1) computation levels in the DFG and thecomputation cycles of each loop iteration consist of theexecution cycles of every level The execution cycledi of computation level i is determined by Rif therequirement of each computation resource f in leveli and the number of allocated resources x f as definedin inequalities 3
Rif times xminus1f times dminus1
i le 1 1 le i le I f isin F (3)
The example in Fig 1 needs one multiplier in the singlecomputation level For this simplest case x f takingone results in d1 = 1 Assuming the computation level
requires two multipliers x f could take on the value 1or 2 depending on the resource constraint leading tod1 = 2 or d1 = 1 cycles respectively
The last two terms of the objective 1 are the execu-tion cycles taken by final result merging When a treestructure is used as in Fig 1d and e the number of levelsof the merging tree is log2 k and thus the numberof execution cycles taken by the merging tree is thesum of the execution cycles c j spent on every level jWe arrange the number of merging operations in eachlevel such that there are m1 merging operations in thetop level and subsequently the following level has m j
merging operations as defined in Eqs 4 and 5
m1 ge k2 (4)
m j ge m jminus12 2 le j le log2 k (5)
The number of execution cycles c j of level j is deter-mined by the number of merging operations in levelj and Mr the number of resources available for themerging operations in Eq 6 which is the resourceconstraint on the merging operations
c j ge m jMr 1 le j le log2 k (6)
The Boolean parameter notFull is added to Eq 1 forthe case where the loop is partially strip-mined andsequential accumulation of the results is needed Fig 1dshows an example
There are four constraints on the pipelining initiationinterval ii as shown in Eqs 7ndash10 Inequality 7 is thememory bandwidth constraint Given a fixed memorybandwidth Mb and the memory bandwidth required inone loop iteration B more parallel loop iterations krequire more input data and thus more data loadingtime leading to a larger initiation interval (ii) Herethe Boolean parameter notAlign is used to capture thesituation where data are not aligned between storageand computation this case may need one extra mem-ory access to obtain requested data Inequality 8 givesthe computation resource constraints where W f is thenumber of each computation resource f required inone loop iteration Inequality 9 is the data dependenceconstraint on ii as used in [10 11] The available re-source for merging operations also has impact on ii asshown in inequality 10 For k intermediate computationresults generated in parallel up to k merging operationsare needed to obtain the final result
B times k times Mminus1b times iiminus1 + notAlign times iiminus1 le 1 (7)
W f times xminus1f times iiminus1 le 1 f isin F (8)
J Sign Process Syst (2012) 6765ndash78 71
RecII times iiminus1 le 1 (9)
k times Mminus1r times iiminus1 le 1 (10)
Inequality 11 captures how computation resourcesconstrain parallelization We achieve an efficient so-lution by balancing the resources allocated to loopparallelization (k) and pipelining (ii) given that thenumber of resource f available is C f
k times x f le C f f isin F (11)
Inequalities 12 and 13 are the ranges of integer vari-ables k and x f respectively Inequality 13 may appearto be redundant but the GP solver requires explicitranges for all variables
1 le k le N (12)
1 le x f le C f f isin F (13)
Overall the only item making the relaxed problem1ndash13 (allowing all variables to be real numbers) not aGP problem is the logarithm log2 k The logarithmsmust be eliminated in order to use a GP solver How-ever we note that log2 k is constant in certain rangesof k Therefore the problem 1ndash13 can be seen as apiecewise integer geometric problem in different rangesof k the number of subproblems increases logarithmi-cally with k For large k = 1000 there are 11 integerGP problems and each problem can be quickly solvedusing a branch and bound algorithm used in [21] with aGP solver as the lower bounding procedure Section 6shows the performance of the piecewise GP model Thesolution (k ii) to the problem 1ndash13 tells us how toMapReduce and pipeline the loop under consideration
The formulation 1ndash13 targets mapping a loop ontoa parallel computing structure The loop need not beinnermost For example in order to map a 2-levelloop nest unrolling the innermost loop allows the for-mulation to work Equivalently we can add severalconstraints as shown below to the formulation 1ndash13Then we can automatically determine pipelining theinnermost loop (iiprime) strip-mining (k) the outer loopand global pipelining (ii) the Monte Carlo simulationof Asian Option benchmark in Section 6 exhibits thiscase Inequality 14 shows the constraint the innermostloop (with Nprime iterations) scheduling length on the ini-tiation interval ii of the outer loop as the outer loopcannot start the next iteration before the innermostloop finishes Inequalities 15 and 16 are the compu-tation resource and data dependence constraints onthe initiation interval of pipelining the innermost loopThe required resources W prime
f in the innermost loop are
included in W f in order to share resources amongoperations
(Nprime minus 1) times iiprime times iiminus1 + iiminus1 timesIprimesum
i=1
dprimei le 1 (14)
W primef times xminus1
f times iiprimeminus1 le 1 f isin F (15)
RecIIprime times iiprimeminus1 le 1 (16)
Finally the MapReduce pattern is also present insome applications in 2-D form Our pattern-basedtransforms could coalesce 2-D loops into 1-D so the GPformulation described above can apply We extend in-equality 7 to cover 2-D data block (Row times Col) accessallowing for the 2-D data block access to not necessarilybe linearized
Row times (B times k times Mminus1
b times iiminus1 + notAlign times iiminus1) le 1
(17)
52 Extension of the Model for Linear Reduce
In the previous subsection the logarithm expression inthe objective function results from using a tree struc-ture for Reduce Alternatively a linear structure couldbe used Fig 1f shows an example for dot productFor k parallel computations the linear structure needsk execution cycles to merge all intermediate resultsAlthough longer than the tree structure some appli-cations with the MapReduce pattern using the linearstructure to merge results can both keep the samethroughput as the tree structure and reduce the mem-ory bandwidth requirement Other merging structuresare possible we have not yet found a compelling usecase for these
Figure 3a shows an example of 1-D correlation Theinnermost loop j of the code has a similar computa-tion pattern to the dot product and can map onto aparallel computing structure using MapReduce Thedifferences from the dot product are that one multipli-cation operand w j is constant and when the outer loopi iterates the data of A are shifted invariantly into thecomputation This is potentially suitable for pipelining
(a) The original code(b) Fully parallel structure for loop
j with linear merging
Figure 3 An example 1-D correlation
72 J Sign Process Syst (2012) 6765ndash78
If the innermost loop j can be fully strip-mined thenthe N multiplications execute at the same time and theintermediate computation results are linearly mergedas shown in Fig 3b An important characteristic of thisstructure is its regular shape which could benefit theplacement and routing of hardware resources Aftermapping loop j fully pipelining loop i produces a C[i]every cycle after N execution cycles If any multipliersand memory access bandwidth are still available loop icould be further partitioned
Many signal and image processing applications use1-D correlation or convolution or show similar be-havior so we extend the formulation in Section 51for linear reduction In the objective function 18 wereplace
sumlog2 kj c j with k Constraints 4ndash6 are no longer
applied When the loop is partially strip-mined notFullhere represents a delay of the accumulated result whichfeeds back to the linear structure in the next iterationBecause the number of cycles taken to multiply eachelement of A with the N coefficients decreases as thenumber of parallel partitions increases the data depen-dence distance of loop j similarly decreases Thereforewe add inequality 19
minimize v times ii +Isum
i=1
di + k + notFull (18)
N times kminus1 times iiminus1 le 1 (19)
Now the formulation with objective 18 and con-straints 7ndash19 is a GP model mapping MapReduce pat-terns to a parallel computing platform with a linearreduction
53 Extension of the Model for Multi-levelMapReduce
The GP models presented above are for mapping asingle loop level with the MapReduce pattern ontoa parallel computing platform This section extendsthe models to map nested loops with the MapReducepatterns We target a rectangular loop nest with L loops(I1 I2 IL) where I1 is the outermost loop IL is theinnermost loop and the loop length of loop l is Nl Forsimplicity we assume that all computational operationsreside in the innermost loop and only the innermostloop is pipelined The statements outside the innermostloop are divided into two disjoint sets S1 = mergingstatements outside the innermost loop and S2 = non-merging statements outside the innermost loop
Expressions 1 and 18 correspond to the executioncycles of the innermost loop alone using tree or linear
reduction structures We redefine them as e = vL timesii + sumI
i=1 di + rL + notFull where rL is the number ofexecution cycles of the merging statement sL in the in-nermost loop Then we can formulate the total execu-tion cycles of the target loop nest as the new objective
minimizeLminus1prod
l=1
vl timese+sum
sisinS2
Isprod
l=1
vl +sum
sisinS1
(vIs timesnotFullIs +rs
)
(20)
where Is is the loop level in which statement s is locatedand
rs =log2 kIs sum
j
csj or kIs (21)
is the number of execution cycles taken by mergingstatement s using tree reduction structure or linearreduction structure where csj have the same meaningas c j in Eq 1 but for merging statement s outside theinnermost loop rL also complies with Eq 21 for themerging statement in the innermost loop
The number of iterations vl of loop l after partition-ing into kl parallel segments is
Nl times kminus1l le vl 1 le l le L (22)
1 le kl le Nl 1 le l le L (23)
Moreover the constraints of the resources used formerging operations in the tree structure (4ndash6) and (10)need to be defined according to each merging statementin the loop nest
ms1 ge kIs2 s isin S1 cup sL (24)
msj ge msjminus12 s isin S1 cup sL 2 le j le log2 kIs (25)
csj ge msjMr s isin S1 cup sL 1 le j le log2 kIs (26)
kL times Mminus1r times iiminus1 le 1 (27)
Correspondingly the memory bandwidth constraint 7is redefined as
Ba timesprod
lisinQa
kl times Mminus1b times iiminus1 + notAligna times iiminus1 le 1 a isin A
(28)
where each of A array references under operations isstored in a memory bank with bandwidth Mb eachreference a requires Ba memory bandwidth in one loopiteration and Qa is the set of loop variables in theindexing function of reference a Unlike Eq 7 hereeach array reference is treated individually because dif-ferent array references may have different bandwidth
J Sign Process Syst (2012) 6765ndash78 73
Table 3 Benchmark details Benchmark loops Refs MapReduce pattern
MAT64 3 2 Two levels in the outer loopsand the innermost loop
ME Implicit 2 Two levels implicit and in SADSobel 4 2 Two levels in outer two loops
and inner two loopsMCS 2 0 In the outer loop1-D correlation 2 1 In the innermost loopk-means 4 1 In the inner three loops
requirements after mapping multiple MapReduce pat-terns Meanwhile the computational resource con-straint 11 is redefined as
Lprod
l=1
kl times x f le C f f isin F (29)
This model allows us to map the multi-level MapRe-duce pattern and thus extends the applicability of theproposed approach This model is still a piecewise GPproblem With multiple nested patterns however thisproblem has more variables and more subproblemscaused by the logarithm and thus could take longer tosolve
6 Experimental Results
We apply the proposed approach to six kernels multi-plication of two 64 times 64 matrices (MAT64) the motionestimation (ME) algorithm [15] used in X264 the Sobeledge detection algorithm (Sobel) [17] Monte Carlosimulation (MCS) of Asian Option Pricing [16] 1-Dcorrelation and k-means clustering [18] Table 3 showsbenchmark parameters Each benchmark contains theMapReduce patterns One level of the MapReducepattern exists in MCS and 1-D correlation to which themodels presented in Sections 51 and 52 are appliedrespectively Two levels of the MapReduce pattern areidentified in ME MAT64 and Sobel We apply thetransforms [6] to the outer level exploiting data reuseand loop-level parallelism For the MapReduce patternin the inner loops we apply the model in Section 51 toexploit inner loop parallelization and pipelining Lastlywe apply the extended model in Section 53 to k-meansclustering which has three levels of the MapReducepattern All GP models are solved by a MATLABtool box named YALMIP [21] Different designs arerepresented by the number of parallel loop partitionsand the pipelining initiation interval (kl ii)
In our experiments the target platform is an FPGA-based system with off-chip SRAM The Monte Carlosimulation of Asian Option involving floating point
arithmetic is implemented in Xilinx XC4VFX140 with192 DSP48 and the other five kernels are implementedin XC2v8000 which has 168 embedded hard multipli-ers and 168 dual-port RAM blocks On-chip RAMsconfigured as scratch-pad buffers and registers are usedto increase memory bandwidth All experimental re-sults are obtained on the target platform after synthesisplacement and routing For ME and Sobel the framesize is the QCIF luminance component (144 times 176pixels)
Matrixndashmatrix Multiplication is a typical arithmetickernel used in many applications Each element of theoutput matrix is the dot product of one row of one inputmatrix and one column of the other input matrix Thedot product is the inner MapReduce pattern level andcomputing multiple elements of the output matrix inparallel is the outer MapReduce level In our imple-mentation each matrix element is 8 bits Memory band-width and the number of hard multipliers embeddedin the FPGA are the constraints on mapping the innerlevel MapReduce pattern Figure 4 shows results fromapplying our proposed piecewise GP model (1ndash13) tothe innermost loop of MAT64 Given a memory band-width and the number of multipliers the figure reveals
12345678
0 2 4 6 8 10 12 14 16 17
0
20
40
60
80
100
120
140
MultipliersMemory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
(3 2)(2 1)
(1 1)
(4 1)(5 2)
Figure 4 Designs proposed by the framework for MAT64 Thebracket next to each design shows (k ii)
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL

66 J Sign Process Syst (2012) 6765ndash78
computations where (1) there is no dependence be-tween computations working on different parts of theinput data set and (2) the reduction operation is as-sociative These characteristics can be obtained fromdata flow analysis tools such as SUIF [4] Examplesof the MapReduce pattern include matrix multiplica-tion Monte Carlo simulation and pattern match anddetection
In practice MapReduce can be limited by memorybandwidth and the number of processing units (hard-ware computation resources) Given a hardware plat-form it is often not obvious how to map a MapReducepattern onto the platform to maximise system perfor-mance Most previous methods require designers toidentify the MapReduce pattern and specify the Mapand Reduce functions explicitly To our best knowledgethe work [5] is the first one that targets automatingthe exploitation of the MapReduce pattern Howeverit is limited to a single-level MapReduce pattern anddoes not consider resource constraints on the reductionoperation in the Reduce phase that affects the finaldesigns of some applications
We have proposed a methodology [6] for auto-matically optimising hardware designs written in C-like descriptions by combining both model-based andpattern-based transforms Given system parametersmodel-based approaches map a design into underlyingmathematical models to enable rapid design space ex-ploration Pattern-based approaches perform optimisa-tions by matching and transforming syntax or data flowpatterns
In this paper we show how the methodology [6] canbe applied to automate mapping the MapReduce pat-tern We extend a previous model [5] to map applica-tions with multiple MapReduce patterns onto a parallelcomputing structure Customized loop-level paralleli-zation and pipelining are used to balance system per-formance and hardware resource utilization
The contributions of this paper are thus
bull an approach for automatically identifying the Map-Reduce computation pattern and mapping it to aparallel computing architecture
bull an extended geometric programming (GP) modelconsidering resource constraints in the Reduce phasewhen mapping MapReduce computations onto aparallel computing platform with constraints onmemory bandwidth and hardware resources
bull a geometric programming model for concurrentlymapping multiple nested MapReduce patterns onto a parallel platform and
bull an evaluation of the proposed automation ap-proach using six application kernels showing per-
formance improvement up to 170 times comparedto the initial designs on the target platform
The rest of the paper is organised as followsSection 2 details related work Section 3 illustrates theproblem under consideration using a simple exampleSection 4 describes the proposed approach to deal withthe problem The geometric programming model for-mulating the design space of mapping the MapReducepattern is presented in Section 5 Section 6 presentsexperimental results from applying the proposed ap-proach to six real applications and is followed by theconclusion and future work in Section 7
2 Related Work
In this paper we apply the methodology proposedin [6] which does not support the MapReduce pat-tern optimisation to automate the mapping of mul-tiple MapReduce patterns onto parallel computingplatforms by combining pattern-based and geometricprogramming (GP) based transformations Loop-levelparallelization and pipelining are exploited to extractparallelism in MapReduce patterns
The MapReduce programming model named af-ter the Map and Reduce functions in Lisp and otherfunctional languages has been developed and usedin Google [2] The Haskell functional language andGooglersquos Sawzall are used to describe the Map andReduce functions Yeung et al [3] apply the MapRe-duce programming model to design high performancesystems on FPGAs and GPUs All these methods re-quire designers to identify the MapReduce pattern andspecify the Map and Reduce functions explicitly Liuet al [5] proposes an approach for optimising designswith the MapReduce pattern at compile time How-ever it is limited to a single-level MapReduce patternand does not consider resource constraints on the re-duction operation in the Reduce phase that affects thefinal designs of some applications This paper extends[5] to map nested loops with multiple MapReducepatterns as well as considering the additional resourceconstraints
Loop-level parallelization has been widely used forimproving performance [7] Loop transformations suchas loop merging permutation and strip-mining areused to reveal parallelism A GP model [8] is usedto determine the tile size of multiple loops to im-prove data locality in a hierarchical memory systemEckhardt et al [9] recursively apply locally sequentialglobally parallel and locally parallel globally sequentialschemes to map an algorithm onto a processor array
J Sign Process Syst (2012) 6765ndash78 67
with a 2-level memory hierarchy Loop pipelining isapplied to pipeline the innermost loop [10] and outerloops [11] An integer linear programming model isproposed [12] for pipelining outer loops in FPGAhardware coprocessors Our proposed GP frameworkdetermines loop parallelization and pipelining for aMapReduce pattern at the same time
Pattern-based transforms for hardware compilationhave been explored by researchers like di Martinoet al [13] on data-parallel loops as part of a synthesismethod from C to hardware Unlike our method theydo not allow user-supplied transforms Compiler toolk-its such as SUIF [4] allow multiple patterns to be usedtogether but give no support for including model-basedtransforms Pattern matching and transforming can beachieved in tree rewriting systems such as TXL [14]but such systems do not incorporate hardware-specificknowledge into the transforms
3 Problem Statement
This paper considers how to map an obvious butinefficient description with a possibly implicit MapRe-duce pattern onto highly parallel hardware We useloop strip-mining and pipelining to extract parallelismfrom the sequential description When a loop is strip-mined for parallelism the loop that originally executessequentially is divided into two loops a new for looprunning sequentially and a for all loop that executesin parallel with the latter inside the former The mainconstraints on mapping MapReduce are the computa-tional resources of the target platform which affect thesize of each strip in strip-mining and the bandwidthbetween processing units and memories that affectshow operations are scheduled after loop partitioningWe use a locally parallel globally pipelined structureto balance use of memory bandwidth and hardwareresources
To illustrate this problem Fig 1a shows a simpleexample the dot product of two 8-bit vectors Assumethat arrays A and B are stored in off-chip SRAMwith single port and can be accessed every cycle af-ter pipelining Our proposed framework first appliespattern-based transforms to this code As shown inFig 1b the original complex expression is decomposedinto simple operations two memory accesses one mul-tiplication and the result accumulation (result merg-ing) This can reduce the number of logic levels of thegenerated circuits improving system latency [6] Werefer the statements merging results as merging state-ments in this paper Next we generate a data flow graph(DFG) for the code as shown in Fig 1c and use this to
Figure 1 Motivating example dot product
determine pipelining parameters From the DFG wecan see that this example has the characteristics of theMapReduce pattern multiplication executes indepen-dently on element pairs of array A and B and the resultmerging operation is addition which is associative
We thus map the dot product onto a parallel comput-ing structure Given a hardware platform with sufficientmultipliers and each assignment in the code takes oneclock cycle Table 1 shows some design options for
68 J Sign Process Syst (2012) 6765ndash78
dot product under different memory bandwidth con-straints Each design is represented by the number ofparallel partitions (k) of the strip-mined loop each withits own processing unit and the initiation interval (ii)of pipelining the outer for loop Ideally if the memorybandwidth is 2N bytes per execution cycle as shownin the second row of Table 1 then N multiplicationscan execute in parallel and the final result can bemerged using a tree structure as shown in Fig 1ewhere pipeline registers are not shown In this case theloop i is fully strip-mined and the dot product needslog2 N + 2 execution cycles log2 N execution cycles forresult merging one execution cycle for loading 2N dataand one for multiplication
In practice 2N bytes per execution cycle memorybandwidth is unrealistic for large N If memory band-width is one byte per execution cycle then the fullyparallel implementation in Fig 1e needs 2N + log2 N +1 execution cycles to finish the dot product where2N execution cycles are used to load 2N data In thisscenario pipelining the loop i with ii = 2 due to the twosequential memory accesses needs 2N + 2 executioncycles to compute the dot product as the design (1 2)in Table 1 If N gt 2 the pipelined implementation ismore promising than the fully parallel version not justin speed but also in resource usage Furthermore ifthe memory bandwidth is 2 bytes per execution cycleelements from each of A and B can be read at the sametime and the fully parallel version needs N + log2 N +1 execution cycles
Alternatively if the loop i is strip-mined by 2 thenevery two iterations of the loop i execute in parallelon two processing units and the results are mergedshown in Fig 1d This structure can be further pipelinedwith ii = 2 This design combining local parallelizationand global pipelining can perform the dot product in2N2 + 3 execution cycles The third design option isto pipeline loop i with ii = 1 without loop strip-miningand it is still promising as N + 2 execution cycles are
spent on the product Similarly if the memory band-width is 3 bytes per execution cycle Table 1 showsthree possible design options Here the second optioncombining loop strip-mining and pipelining achieves abalance between speed and resource utilization
We can see that there are multiple options for map-ping the dot product onto a given hardware platformunder different memory bandwidth constraints Evenmore design options result if multipliers are also con-strained Finding the best design in terms of variouscriteria is not easy and requires exploration of thedesign space to find the optimal design
This paper proposes an approach with model-basedand pattern-based transforms to deal with the problemof mapping the MapReduce pattern
4 The Proposed Approach
Figure 2 shows how our proposed approach combinesmodel-based and pattern-based transforms to map theMapReduce pattern onto a target hardware platformwhile achieving design goals
The approach takes as input the sequential descrip-tion of a design We initially apply pattern-based trans-formations such as function inlining and convertingpointers to arrays to the design to ease the dependenceanalysis We apply further pattern-based transforma-tions including loop merging and loop coalescing tothe design to ensure it is in a certain form This formenables us to simplify the mathematical model by re-moving variables enabling it to be solved faster
After dependence analysis we check that the designcontains the two characteristics of the MapReduce pat-tern given in Section 1 If they are found we applythe model-based transformation for the MapReducepattern shown in the shaded block in Fig 2
We formulate the problem of mapping the MapRe-duce pattern onto a target parallel computing platform
Table 1 Possible designoptions of the dot productexample
Mem_bandwidth Designs Exe_cycles Multipliers(Bytesexe_cycle) (k ii)
2N (N 1) log2 N + 2 N
(N 1) 2N + log2 N + 1 N(1 2) 2N + 2 1
2 (N 1) N + log2 N + 1 N(2 2) 2N2 + 3 2(1 1) N + 2 1
3 (N 1) 2N3 + log2 N + 1 N(3 2) 2N3 + 4 3(1 1) N + 2 1
J Sign Process Syst (2012) 6765ndash78 69
Input design(sequential)
InliningPtr2Array
Loop merge3-address
Loop coalesce
Dependenceanalysis
MapReduce+
Pipeline
Output design(parallel)
Hardware Platformparameters
Figure 2 Combining model-based (such as MapReduce) andpattern-based approaches (such as loop coalescing) into a singleapproach
as a geometric programming model Solving this prob-lem automatically generates an optimized design ex-ploiting loop-level parallelization and pipelining forgiven hardware platform parameters such as memorysize and computation resources This paper focusses onpresenting this geometric programming model
As output our approach produces a design with ex-plicit timing and parallelism The design can then beimplemented on the hardware platform using vendortools to synthesize place and route it Currently themodel is used to optimize design parameters we do notcurrently automate output hardware generation butthis is relatively straightforward
Our approach can adapt to several variations on theMapReduce pattern
bull applications with implicit MapReduce pattern suchas the motion estimation algorithm [15] used inX264
bull applications with MapReduce pattern at any looplevel such as the Monte Carlo simulation of AsianOptions [16]
bull applications with 2-D MapReduce patterns such asedge detection [17] and
bull application with multi-level MapReduce patternssuch as k-means clustering [18]
5 GP Model for Mapping MapReduce
As the MapReduce pattern is often present in sequen-tial loops we target a loop nest containing the MapRe-duce patterns with the number of iterations fixed atcompile time
We formulate the design exploration problem as apiecewise integer geometric program Geometric pro-gramming (GP) [19] is the following optimization problem
minimize f0(x)
subject to fi(x) le 1 i = 1 mhi(x) = 1 i = 1 p
where the objective function and inequality constraintfunctions are all in posynomial form while the equal-ity constraint functions are monomial Unlike generalnonlinear programming problems GP is convex andthus has efficient solution algorithms with guaranteedconvergence to a global solution [19]
In the next three subsections we present the pro-posed piecewise integer geometric programming modelfor mapping a single loop with the MapReduce patternan extension of the model to a variant of the MapRe-duce pattern and a further extension to map nestedloops with multiple MapReduce patterns Table 2 listsnotation used in the models capitals denote compiletime constants while lower case denotes integer vari-ables The models assume that assignments take oneclock cycle like Handel-C [20] This limits clock speedto the slowest expression used we ameliorate this bybreaking expressions into three-address code
51 Piecewise GP Model for MapReduce with TreeReduce
In this section a GP model for mapping a loop contain-ing the MapReduce pattern with a tree reduce structureis presented This model extends [5] to consider theconstraints of the resources for the merging operationsin the Reduce phase The design variables includethe number of parallel partitions of the loop and thepipeline initiation interval the loop is mapped to alocally parallel globally pipelined design
The objective is to minimize the number of executioncycles of a loop after loop strip-mining and pipelining asbelow
minimize v times ii +Isum
i=1
di +log2 ksum
j
c j + notFull (1)
This expression is derived from the standard moduloscheduling length of pipelining [10 11] assuming thatthe number of execution cycles for loading data frommemory dominates the initiation interval (ii) Section 6shows that this assumption is true for the tested bench-marks The number of loop iterations v executing ineach parallel partition is defined in Inequality 2
N times kminus1 le v (2)
70 J Sign Process Syst (2012) 6765ndash78
Table 2 Notation used in the models
Notations Description
k (kl) Parallel partitions of a loop (loop l)ii Initiation interval of pipelinev (vl) Iterations in one partition of a loop (loop l)x f No resources f being useddi Latency in execution cycles of computation
level i of DFGc j (csj) Execution cycles of level j of merging tree
(of statement s)m j (msj) Merging operations of level j of merging tree
(of statement s)rs Execution cycles of merging tree of statement s
L No nested loopsIs The loop level where statement s is located
1 le Is le LN (Nl) No iterations of a loop (loop l)A No array referencesRecII Data dependence constraint on ii in
the computationW f Computation resources f required in
a loop iterationRif Computation resources f required in
level i of DFGI No computation levels of DFGB (Ba) Required memory bandwidth (of array a)
in one loop iterationQa Set of loop variables in the indexing function
of array aMb Memory bandwidthC f Computational resources f availableMr Resources r available for merging operationsF F types of computation resources involvednotAlign 0 data are aligned 1 data are not aligned
(of array a)(notAligna)notFull 0 loop (l) is fully strip-mined 1 loop (l) is
partially strip-mined(notFulll)
The second term in the objective function 1 is theexecution cycles taken by computation There maybe I (I ge 1) computation levels in the DFG and thecomputation cycles of each loop iteration consist of theexecution cycles of every level The execution cycledi of computation level i is determined by Rif therequirement of each computation resource f in leveli and the number of allocated resources x f as definedin inequalities 3
Rif times xminus1f times dminus1
i le 1 1 le i le I f isin F (3)
The example in Fig 1 needs one multiplier in the singlecomputation level For this simplest case x f takingone results in d1 = 1 Assuming the computation level
requires two multipliers x f could take on the value 1or 2 depending on the resource constraint leading tod1 = 2 or d1 = 1 cycles respectively
The last two terms of the objective 1 are the execu-tion cycles taken by final result merging When a treestructure is used as in Fig 1d and e the number of levelsof the merging tree is log2 k and thus the numberof execution cycles taken by the merging tree is thesum of the execution cycles c j spent on every level jWe arrange the number of merging operations in eachlevel such that there are m1 merging operations in thetop level and subsequently the following level has m j
merging operations as defined in Eqs 4 and 5
m1 ge k2 (4)
m j ge m jminus12 2 le j le log2 k (5)
The number of execution cycles c j of level j is deter-mined by the number of merging operations in levelj and Mr the number of resources available for themerging operations in Eq 6 which is the resourceconstraint on the merging operations
c j ge m jMr 1 le j le log2 k (6)
The Boolean parameter notFull is added to Eq 1 forthe case where the loop is partially strip-mined andsequential accumulation of the results is needed Fig 1dshows an example
There are four constraints on the pipelining initiationinterval ii as shown in Eqs 7ndash10 Inequality 7 is thememory bandwidth constraint Given a fixed memorybandwidth Mb and the memory bandwidth required inone loop iteration B more parallel loop iterations krequire more input data and thus more data loadingtime leading to a larger initiation interval (ii) Herethe Boolean parameter notAlign is used to capture thesituation where data are not aligned between storageand computation this case may need one extra mem-ory access to obtain requested data Inequality 8 givesthe computation resource constraints where W f is thenumber of each computation resource f required inone loop iteration Inequality 9 is the data dependenceconstraint on ii as used in [10 11] The available re-source for merging operations also has impact on ii asshown in inequality 10 For k intermediate computationresults generated in parallel up to k merging operationsare needed to obtain the final result
B times k times Mminus1b times iiminus1 + notAlign times iiminus1 le 1 (7)
W f times xminus1f times iiminus1 le 1 f isin F (8)
J Sign Process Syst (2012) 6765ndash78 71
RecII times iiminus1 le 1 (9)
k times Mminus1r times iiminus1 le 1 (10)
Inequality 11 captures how computation resourcesconstrain parallelization We achieve an efficient so-lution by balancing the resources allocated to loopparallelization (k) and pipelining (ii) given that thenumber of resource f available is C f
k times x f le C f f isin F (11)
Inequalities 12 and 13 are the ranges of integer vari-ables k and x f respectively Inequality 13 may appearto be redundant but the GP solver requires explicitranges for all variables
1 le k le N (12)
1 le x f le C f f isin F (13)
Overall the only item making the relaxed problem1ndash13 (allowing all variables to be real numbers) not aGP problem is the logarithm log2 k The logarithmsmust be eliminated in order to use a GP solver How-ever we note that log2 k is constant in certain rangesof k Therefore the problem 1ndash13 can be seen as apiecewise integer geometric problem in different rangesof k the number of subproblems increases logarithmi-cally with k For large k = 1000 there are 11 integerGP problems and each problem can be quickly solvedusing a branch and bound algorithm used in [21] with aGP solver as the lower bounding procedure Section 6shows the performance of the piecewise GP model Thesolution (k ii) to the problem 1ndash13 tells us how toMapReduce and pipeline the loop under consideration
The formulation 1ndash13 targets mapping a loop ontoa parallel computing structure The loop need not beinnermost For example in order to map a 2-levelloop nest unrolling the innermost loop allows the for-mulation to work Equivalently we can add severalconstraints as shown below to the formulation 1ndash13Then we can automatically determine pipelining theinnermost loop (iiprime) strip-mining (k) the outer loopand global pipelining (ii) the Monte Carlo simulationof Asian Option benchmark in Section 6 exhibits thiscase Inequality 14 shows the constraint the innermostloop (with Nprime iterations) scheduling length on the ini-tiation interval ii of the outer loop as the outer loopcannot start the next iteration before the innermostloop finishes Inequalities 15 and 16 are the compu-tation resource and data dependence constraints onthe initiation interval of pipelining the innermost loopThe required resources W prime
f in the innermost loop are
included in W f in order to share resources amongoperations
(Nprime minus 1) times iiprime times iiminus1 + iiminus1 timesIprimesum
i=1
dprimei le 1 (14)
W primef times xminus1
f times iiprimeminus1 le 1 f isin F (15)
RecIIprime times iiprimeminus1 le 1 (16)
Finally the MapReduce pattern is also present insome applications in 2-D form Our pattern-basedtransforms could coalesce 2-D loops into 1-D so the GPformulation described above can apply We extend in-equality 7 to cover 2-D data block (Row times Col) accessallowing for the 2-D data block access to not necessarilybe linearized
Row times (B times k times Mminus1
b times iiminus1 + notAlign times iiminus1) le 1
(17)
52 Extension of the Model for Linear Reduce
In the previous subsection the logarithm expression inthe objective function results from using a tree struc-ture for Reduce Alternatively a linear structure couldbe used Fig 1f shows an example for dot productFor k parallel computations the linear structure needsk execution cycles to merge all intermediate resultsAlthough longer than the tree structure some appli-cations with the MapReduce pattern using the linearstructure to merge results can both keep the samethroughput as the tree structure and reduce the mem-ory bandwidth requirement Other merging structuresare possible we have not yet found a compelling usecase for these
Figure 3a shows an example of 1-D correlation Theinnermost loop j of the code has a similar computa-tion pattern to the dot product and can map onto aparallel computing structure using MapReduce Thedifferences from the dot product are that one multipli-cation operand w j is constant and when the outer loopi iterates the data of A are shifted invariantly into thecomputation This is potentially suitable for pipelining
(a) The original code(b) Fully parallel structure for loop
j with linear merging
Figure 3 An example 1-D correlation
72 J Sign Process Syst (2012) 6765ndash78
If the innermost loop j can be fully strip-mined thenthe N multiplications execute at the same time and theintermediate computation results are linearly mergedas shown in Fig 3b An important characteristic of thisstructure is its regular shape which could benefit theplacement and routing of hardware resources Aftermapping loop j fully pipelining loop i produces a C[i]every cycle after N execution cycles If any multipliersand memory access bandwidth are still available loop icould be further partitioned
Many signal and image processing applications use1-D correlation or convolution or show similar be-havior so we extend the formulation in Section 51for linear reduction In the objective function 18 wereplace
sumlog2 kj c j with k Constraints 4ndash6 are no longer
applied When the loop is partially strip-mined notFullhere represents a delay of the accumulated result whichfeeds back to the linear structure in the next iterationBecause the number of cycles taken to multiply eachelement of A with the N coefficients decreases as thenumber of parallel partitions increases the data depen-dence distance of loop j similarly decreases Thereforewe add inequality 19
minimize v times ii +Isum
i=1
di + k + notFull (18)
N times kminus1 times iiminus1 le 1 (19)
Now the formulation with objective 18 and con-straints 7ndash19 is a GP model mapping MapReduce pat-terns to a parallel computing platform with a linearreduction
53 Extension of the Model for Multi-levelMapReduce
The GP models presented above are for mapping asingle loop level with the MapReduce pattern ontoa parallel computing platform This section extendsthe models to map nested loops with the MapReducepatterns We target a rectangular loop nest with L loops(I1 I2 IL) where I1 is the outermost loop IL is theinnermost loop and the loop length of loop l is Nl Forsimplicity we assume that all computational operationsreside in the innermost loop and only the innermostloop is pipelined The statements outside the innermostloop are divided into two disjoint sets S1 = mergingstatements outside the innermost loop and S2 = non-merging statements outside the innermost loop
Expressions 1 and 18 correspond to the executioncycles of the innermost loop alone using tree or linear
reduction structures We redefine them as e = vL timesii + sumI
i=1 di + rL + notFull where rL is the number ofexecution cycles of the merging statement sL in the in-nermost loop Then we can formulate the total execu-tion cycles of the target loop nest as the new objective
minimizeLminus1prod
l=1
vl timese+sum
sisinS2
Isprod
l=1
vl +sum
sisinS1
(vIs timesnotFullIs +rs
)
(20)
where Is is the loop level in which statement s is locatedand
rs =log2 kIs sum
j
csj or kIs (21)
is the number of execution cycles taken by mergingstatement s using tree reduction structure or linearreduction structure where csj have the same meaningas c j in Eq 1 but for merging statement s outside theinnermost loop rL also complies with Eq 21 for themerging statement in the innermost loop
The number of iterations vl of loop l after partition-ing into kl parallel segments is
Nl times kminus1l le vl 1 le l le L (22)
1 le kl le Nl 1 le l le L (23)
Moreover the constraints of the resources used formerging operations in the tree structure (4ndash6) and (10)need to be defined according to each merging statementin the loop nest
ms1 ge kIs2 s isin S1 cup sL (24)
msj ge msjminus12 s isin S1 cup sL 2 le j le log2 kIs (25)
csj ge msjMr s isin S1 cup sL 1 le j le log2 kIs (26)
kL times Mminus1r times iiminus1 le 1 (27)
Correspondingly the memory bandwidth constraint 7is redefined as
Ba timesprod
lisinQa
kl times Mminus1b times iiminus1 + notAligna times iiminus1 le 1 a isin A
(28)
where each of A array references under operations isstored in a memory bank with bandwidth Mb eachreference a requires Ba memory bandwidth in one loopiteration and Qa is the set of loop variables in theindexing function of reference a Unlike Eq 7 hereeach array reference is treated individually because dif-ferent array references may have different bandwidth
J Sign Process Syst (2012) 6765ndash78 73
Table 3 Benchmark details Benchmark loops Refs MapReduce pattern
MAT64 3 2 Two levels in the outer loopsand the innermost loop
ME Implicit 2 Two levels implicit and in SADSobel 4 2 Two levels in outer two loops
and inner two loopsMCS 2 0 In the outer loop1-D correlation 2 1 In the innermost loopk-means 4 1 In the inner three loops
requirements after mapping multiple MapReduce pat-terns Meanwhile the computational resource con-straint 11 is redefined as
Lprod
l=1
kl times x f le C f f isin F (29)
This model allows us to map the multi-level MapRe-duce pattern and thus extends the applicability of theproposed approach This model is still a piecewise GPproblem With multiple nested patterns however thisproblem has more variables and more subproblemscaused by the logarithm and thus could take longer tosolve
6 Experimental Results
We apply the proposed approach to six kernels multi-plication of two 64 times 64 matrices (MAT64) the motionestimation (ME) algorithm [15] used in X264 the Sobeledge detection algorithm (Sobel) [17] Monte Carlosimulation (MCS) of Asian Option Pricing [16] 1-Dcorrelation and k-means clustering [18] Table 3 showsbenchmark parameters Each benchmark contains theMapReduce patterns One level of the MapReducepattern exists in MCS and 1-D correlation to which themodels presented in Sections 51 and 52 are appliedrespectively Two levels of the MapReduce pattern areidentified in ME MAT64 and Sobel We apply thetransforms [6] to the outer level exploiting data reuseand loop-level parallelism For the MapReduce patternin the inner loops we apply the model in Section 51 toexploit inner loop parallelization and pipelining Lastlywe apply the extended model in Section 53 to k-meansclustering which has three levels of the MapReducepattern All GP models are solved by a MATLABtool box named YALMIP [21] Different designs arerepresented by the number of parallel loop partitionsand the pipelining initiation interval (kl ii)
In our experiments the target platform is an FPGA-based system with off-chip SRAM The Monte Carlosimulation of Asian Option involving floating point
arithmetic is implemented in Xilinx XC4VFX140 with192 DSP48 and the other five kernels are implementedin XC2v8000 which has 168 embedded hard multipli-ers and 168 dual-port RAM blocks On-chip RAMsconfigured as scratch-pad buffers and registers are usedto increase memory bandwidth All experimental re-sults are obtained on the target platform after synthesisplacement and routing For ME and Sobel the framesize is the QCIF luminance component (144 times 176pixels)
Matrixndashmatrix Multiplication is a typical arithmetickernel used in many applications Each element of theoutput matrix is the dot product of one row of one inputmatrix and one column of the other input matrix Thedot product is the inner MapReduce pattern level andcomputing multiple elements of the output matrix inparallel is the outer MapReduce level In our imple-mentation each matrix element is 8 bits Memory band-width and the number of hard multipliers embeddedin the FPGA are the constraints on mapping the innerlevel MapReduce pattern Figure 4 shows results fromapplying our proposed piecewise GP model (1ndash13) tothe innermost loop of MAT64 Given a memory band-width and the number of multipliers the figure reveals
12345678
0 2 4 6 8 10 12 14 16 17
0
20
40
60
80
100
120
140
MultipliersMemory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
(3 2)(2 1)
(1 1)
(4 1)(5 2)
Figure 4 Designs proposed by the framework for MAT64 Thebracket next to each design shows (k ii)
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL

J Sign Process Syst (2012) 6765ndash78 67
with a 2-level memory hierarchy Loop pipelining isapplied to pipeline the innermost loop [10] and outerloops [11] An integer linear programming model isproposed [12] for pipelining outer loops in FPGAhardware coprocessors Our proposed GP frameworkdetermines loop parallelization and pipelining for aMapReduce pattern at the same time
Pattern-based transforms for hardware compilationhave been explored by researchers like di Martinoet al [13] on data-parallel loops as part of a synthesismethod from C to hardware Unlike our method theydo not allow user-supplied transforms Compiler toolk-its such as SUIF [4] allow multiple patterns to be usedtogether but give no support for including model-basedtransforms Pattern matching and transforming can beachieved in tree rewriting systems such as TXL [14]but such systems do not incorporate hardware-specificknowledge into the transforms
3 Problem Statement
This paper considers how to map an obvious butinefficient description with a possibly implicit MapRe-duce pattern onto highly parallel hardware We useloop strip-mining and pipelining to extract parallelismfrom the sequential description When a loop is strip-mined for parallelism the loop that originally executessequentially is divided into two loops a new for looprunning sequentially and a for all loop that executesin parallel with the latter inside the former The mainconstraints on mapping MapReduce are the computa-tional resources of the target platform which affect thesize of each strip in strip-mining and the bandwidthbetween processing units and memories that affectshow operations are scheduled after loop partitioningWe use a locally parallel globally pipelined structureto balance use of memory bandwidth and hardwareresources
To illustrate this problem Fig 1a shows a simpleexample the dot product of two 8-bit vectors Assumethat arrays A and B are stored in off-chip SRAMwith single port and can be accessed every cycle af-ter pipelining Our proposed framework first appliespattern-based transforms to this code As shown inFig 1b the original complex expression is decomposedinto simple operations two memory accesses one mul-tiplication and the result accumulation (result merg-ing) This can reduce the number of logic levels of thegenerated circuits improving system latency [6] Werefer the statements merging results as merging state-ments in this paper Next we generate a data flow graph(DFG) for the code as shown in Fig 1c and use this to
Figure 1 Motivating example dot product
determine pipelining parameters From the DFG wecan see that this example has the characteristics of theMapReduce pattern multiplication executes indepen-dently on element pairs of array A and B and the resultmerging operation is addition which is associative
We thus map the dot product onto a parallel comput-ing structure Given a hardware platform with sufficientmultipliers and each assignment in the code takes oneclock cycle Table 1 shows some design options for
68 J Sign Process Syst (2012) 6765ndash78
dot product under different memory bandwidth con-straints Each design is represented by the number ofparallel partitions (k) of the strip-mined loop each withits own processing unit and the initiation interval (ii)of pipelining the outer for loop Ideally if the memorybandwidth is 2N bytes per execution cycle as shownin the second row of Table 1 then N multiplicationscan execute in parallel and the final result can bemerged using a tree structure as shown in Fig 1ewhere pipeline registers are not shown In this case theloop i is fully strip-mined and the dot product needslog2 N + 2 execution cycles log2 N execution cycles forresult merging one execution cycle for loading 2N dataand one for multiplication
In practice 2N bytes per execution cycle memorybandwidth is unrealistic for large N If memory band-width is one byte per execution cycle then the fullyparallel implementation in Fig 1e needs 2N + log2 N +1 execution cycles to finish the dot product where2N execution cycles are used to load 2N data In thisscenario pipelining the loop i with ii = 2 due to the twosequential memory accesses needs 2N + 2 executioncycles to compute the dot product as the design (1 2)in Table 1 If N gt 2 the pipelined implementation ismore promising than the fully parallel version not justin speed but also in resource usage Furthermore ifthe memory bandwidth is 2 bytes per execution cycleelements from each of A and B can be read at the sametime and the fully parallel version needs N + log2 N +1 execution cycles
Alternatively if the loop i is strip-mined by 2 thenevery two iterations of the loop i execute in parallelon two processing units and the results are mergedshown in Fig 1d This structure can be further pipelinedwith ii = 2 This design combining local parallelizationand global pipelining can perform the dot product in2N2 + 3 execution cycles The third design option isto pipeline loop i with ii = 1 without loop strip-miningand it is still promising as N + 2 execution cycles are
spent on the product Similarly if the memory band-width is 3 bytes per execution cycle Table 1 showsthree possible design options Here the second optioncombining loop strip-mining and pipelining achieves abalance between speed and resource utilization
We can see that there are multiple options for map-ping the dot product onto a given hardware platformunder different memory bandwidth constraints Evenmore design options result if multipliers are also con-strained Finding the best design in terms of variouscriteria is not easy and requires exploration of thedesign space to find the optimal design
This paper proposes an approach with model-basedand pattern-based transforms to deal with the problemof mapping the MapReduce pattern
4 The Proposed Approach
Figure 2 shows how our proposed approach combinesmodel-based and pattern-based transforms to map theMapReduce pattern onto a target hardware platformwhile achieving design goals
The approach takes as input the sequential descrip-tion of a design We initially apply pattern-based trans-formations such as function inlining and convertingpointers to arrays to the design to ease the dependenceanalysis We apply further pattern-based transforma-tions including loop merging and loop coalescing tothe design to ensure it is in a certain form This formenables us to simplify the mathematical model by re-moving variables enabling it to be solved faster
After dependence analysis we check that the designcontains the two characteristics of the MapReduce pat-tern given in Section 1 If they are found we applythe model-based transformation for the MapReducepattern shown in the shaded block in Fig 2
We formulate the problem of mapping the MapRe-duce pattern onto a target parallel computing platform
Table 1 Possible designoptions of the dot productexample
Mem_bandwidth Designs Exe_cycles Multipliers(Bytesexe_cycle) (k ii)
2N (N 1) log2 N + 2 N
(N 1) 2N + log2 N + 1 N(1 2) 2N + 2 1
2 (N 1) N + log2 N + 1 N(2 2) 2N2 + 3 2(1 1) N + 2 1
3 (N 1) 2N3 + log2 N + 1 N(3 2) 2N3 + 4 3(1 1) N + 2 1
J Sign Process Syst (2012) 6765ndash78 69
Input design(sequential)
InliningPtr2Array
Loop merge3-address
Loop coalesce
Dependenceanalysis
MapReduce+
Pipeline
Output design(parallel)
Hardware Platformparameters
Figure 2 Combining model-based (such as MapReduce) andpattern-based approaches (such as loop coalescing) into a singleapproach
as a geometric programming model Solving this prob-lem automatically generates an optimized design ex-ploiting loop-level parallelization and pipelining forgiven hardware platform parameters such as memorysize and computation resources This paper focusses onpresenting this geometric programming model
As output our approach produces a design with ex-plicit timing and parallelism The design can then beimplemented on the hardware platform using vendortools to synthesize place and route it Currently themodel is used to optimize design parameters we do notcurrently automate output hardware generation butthis is relatively straightforward
Our approach can adapt to several variations on theMapReduce pattern
bull applications with implicit MapReduce pattern suchas the motion estimation algorithm [15] used inX264
bull applications with MapReduce pattern at any looplevel such as the Monte Carlo simulation of AsianOptions [16]
bull applications with 2-D MapReduce patterns such asedge detection [17] and
bull application with multi-level MapReduce patternssuch as k-means clustering [18]
5 GP Model for Mapping MapReduce
As the MapReduce pattern is often present in sequen-tial loops we target a loop nest containing the MapRe-duce patterns with the number of iterations fixed atcompile time
We formulate the design exploration problem as apiecewise integer geometric program Geometric pro-gramming (GP) [19] is the following optimization problem
minimize f0(x)
subject to fi(x) le 1 i = 1 mhi(x) = 1 i = 1 p
where the objective function and inequality constraintfunctions are all in posynomial form while the equal-ity constraint functions are monomial Unlike generalnonlinear programming problems GP is convex andthus has efficient solution algorithms with guaranteedconvergence to a global solution [19]
In the next three subsections we present the pro-posed piecewise integer geometric programming modelfor mapping a single loop with the MapReduce patternan extension of the model to a variant of the MapRe-duce pattern and a further extension to map nestedloops with multiple MapReduce patterns Table 2 listsnotation used in the models capitals denote compiletime constants while lower case denotes integer vari-ables The models assume that assignments take oneclock cycle like Handel-C [20] This limits clock speedto the slowest expression used we ameliorate this bybreaking expressions into three-address code
51 Piecewise GP Model for MapReduce with TreeReduce
In this section a GP model for mapping a loop contain-ing the MapReduce pattern with a tree reduce structureis presented This model extends [5] to consider theconstraints of the resources for the merging operationsin the Reduce phase The design variables includethe number of parallel partitions of the loop and thepipeline initiation interval the loop is mapped to alocally parallel globally pipelined design
The objective is to minimize the number of executioncycles of a loop after loop strip-mining and pipelining asbelow
minimize v times ii +Isum
i=1
di +log2 ksum
j
c j + notFull (1)
This expression is derived from the standard moduloscheduling length of pipelining [10 11] assuming thatthe number of execution cycles for loading data frommemory dominates the initiation interval (ii) Section 6shows that this assumption is true for the tested bench-marks The number of loop iterations v executing ineach parallel partition is defined in Inequality 2
N times kminus1 le v (2)
70 J Sign Process Syst (2012) 6765ndash78
Table 2 Notation used in the models
Notations Description
k (kl) Parallel partitions of a loop (loop l)ii Initiation interval of pipelinev (vl) Iterations in one partition of a loop (loop l)x f No resources f being useddi Latency in execution cycles of computation
level i of DFGc j (csj) Execution cycles of level j of merging tree
(of statement s)m j (msj) Merging operations of level j of merging tree
(of statement s)rs Execution cycles of merging tree of statement s
L No nested loopsIs The loop level where statement s is located
1 le Is le LN (Nl) No iterations of a loop (loop l)A No array referencesRecII Data dependence constraint on ii in
the computationW f Computation resources f required in
a loop iterationRif Computation resources f required in
level i of DFGI No computation levels of DFGB (Ba) Required memory bandwidth (of array a)
in one loop iterationQa Set of loop variables in the indexing function
of array aMb Memory bandwidthC f Computational resources f availableMr Resources r available for merging operationsF F types of computation resources involvednotAlign 0 data are aligned 1 data are not aligned
(of array a)(notAligna)notFull 0 loop (l) is fully strip-mined 1 loop (l) is
partially strip-mined(notFulll)
The second term in the objective function 1 is theexecution cycles taken by computation There maybe I (I ge 1) computation levels in the DFG and thecomputation cycles of each loop iteration consist of theexecution cycles of every level The execution cycledi of computation level i is determined by Rif therequirement of each computation resource f in leveli and the number of allocated resources x f as definedin inequalities 3
Rif times xminus1f times dminus1
i le 1 1 le i le I f isin F (3)
The example in Fig 1 needs one multiplier in the singlecomputation level For this simplest case x f takingone results in d1 = 1 Assuming the computation level
requires two multipliers x f could take on the value 1or 2 depending on the resource constraint leading tod1 = 2 or d1 = 1 cycles respectively
The last two terms of the objective 1 are the execu-tion cycles taken by final result merging When a treestructure is used as in Fig 1d and e the number of levelsof the merging tree is log2 k and thus the numberof execution cycles taken by the merging tree is thesum of the execution cycles c j spent on every level jWe arrange the number of merging operations in eachlevel such that there are m1 merging operations in thetop level and subsequently the following level has m j
merging operations as defined in Eqs 4 and 5
m1 ge k2 (4)
m j ge m jminus12 2 le j le log2 k (5)
The number of execution cycles c j of level j is deter-mined by the number of merging operations in levelj and Mr the number of resources available for themerging operations in Eq 6 which is the resourceconstraint on the merging operations
c j ge m jMr 1 le j le log2 k (6)
The Boolean parameter notFull is added to Eq 1 forthe case where the loop is partially strip-mined andsequential accumulation of the results is needed Fig 1dshows an example
There are four constraints on the pipelining initiationinterval ii as shown in Eqs 7ndash10 Inequality 7 is thememory bandwidth constraint Given a fixed memorybandwidth Mb and the memory bandwidth required inone loop iteration B more parallel loop iterations krequire more input data and thus more data loadingtime leading to a larger initiation interval (ii) Herethe Boolean parameter notAlign is used to capture thesituation where data are not aligned between storageand computation this case may need one extra mem-ory access to obtain requested data Inequality 8 givesthe computation resource constraints where W f is thenumber of each computation resource f required inone loop iteration Inequality 9 is the data dependenceconstraint on ii as used in [10 11] The available re-source for merging operations also has impact on ii asshown in inequality 10 For k intermediate computationresults generated in parallel up to k merging operationsare needed to obtain the final result
B times k times Mminus1b times iiminus1 + notAlign times iiminus1 le 1 (7)
W f times xminus1f times iiminus1 le 1 f isin F (8)
J Sign Process Syst (2012) 6765ndash78 71
RecII times iiminus1 le 1 (9)
k times Mminus1r times iiminus1 le 1 (10)
Inequality 11 captures how computation resourcesconstrain parallelization We achieve an efficient so-lution by balancing the resources allocated to loopparallelization (k) and pipelining (ii) given that thenumber of resource f available is C f
k times x f le C f f isin F (11)
Inequalities 12 and 13 are the ranges of integer vari-ables k and x f respectively Inequality 13 may appearto be redundant but the GP solver requires explicitranges for all variables
1 le k le N (12)
1 le x f le C f f isin F (13)
Overall the only item making the relaxed problem1ndash13 (allowing all variables to be real numbers) not aGP problem is the logarithm log2 k The logarithmsmust be eliminated in order to use a GP solver How-ever we note that log2 k is constant in certain rangesof k Therefore the problem 1ndash13 can be seen as apiecewise integer geometric problem in different rangesof k the number of subproblems increases logarithmi-cally with k For large k = 1000 there are 11 integerGP problems and each problem can be quickly solvedusing a branch and bound algorithm used in [21] with aGP solver as the lower bounding procedure Section 6shows the performance of the piecewise GP model Thesolution (k ii) to the problem 1ndash13 tells us how toMapReduce and pipeline the loop under consideration
The formulation 1ndash13 targets mapping a loop ontoa parallel computing structure The loop need not beinnermost For example in order to map a 2-levelloop nest unrolling the innermost loop allows the for-mulation to work Equivalently we can add severalconstraints as shown below to the formulation 1ndash13Then we can automatically determine pipelining theinnermost loop (iiprime) strip-mining (k) the outer loopand global pipelining (ii) the Monte Carlo simulationof Asian Option benchmark in Section 6 exhibits thiscase Inequality 14 shows the constraint the innermostloop (with Nprime iterations) scheduling length on the ini-tiation interval ii of the outer loop as the outer loopcannot start the next iteration before the innermostloop finishes Inequalities 15 and 16 are the compu-tation resource and data dependence constraints onthe initiation interval of pipelining the innermost loopThe required resources W prime
f in the innermost loop are
included in W f in order to share resources amongoperations
(Nprime minus 1) times iiprime times iiminus1 + iiminus1 timesIprimesum
i=1
dprimei le 1 (14)
W primef times xminus1
f times iiprimeminus1 le 1 f isin F (15)
RecIIprime times iiprimeminus1 le 1 (16)
Finally the MapReduce pattern is also present insome applications in 2-D form Our pattern-basedtransforms could coalesce 2-D loops into 1-D so the GPformulation described above can apply We extend in-equality 7 to cover 2-D data block (Row times Col) accessallowing for the 2-D data block access to not necessarilybe linearized
Row times (B times k times Mminus1
b times iiminus1 + notAlign times iiminus1) le 1
(17)
52 Extension of the Model for Linear Reduce
In the previous subsection the logarithm expression inthe objective function results from using a tree struc-ture for Reduce Alternatively a linear structure couldbe used Fig 1f shows an example for dot productFor k parallel computations the linear structure needsk execution cycles to merge all intermediate resultsAlthough longer than the tree structure some appli-cations with the MapReduce pattern using the linearstructure to merge results can both keep the samethroughput as the tree structure and reduce the mem-ory bandwidth requirement Other merging structuresare possible we have not yet found a compelling usecase for these
Figure 3a shows an example of 1-D correlation Theinnermost loop j of the code has a similar computa-tion pattern to the dot product and can map onto aparallel computing structure using MapReduce Thedifferences from the dot product are that one multipli-cation operand w j is constant and when the outer loopi iterates the data of A are shifted invariantly into thecomputation This is potentially suitable for pipelining
(a) The original code(b) Fully parallel structure for loop
j with linear merging
Figure 3 An example 1-D correlation
72 J Sign Process Syst (2012) 6765ndash78
If the innermost loop j can be fully strip-mined thenthe N multiplications execute at the same time and theintermediate computation results are linearly mergedas shown in Fig 3b An important characteristic of thisstructure is its regular shape which could benefit theplacement and routing of hardware resources Aftermapping loop j fully pipelining loop i produces a C[i]every cycle after N execution cycles If any multipliersand memory access bandwidth are still available loop icould be further partitioned
Many signal and image processing applications use1-D correlation or convolution or show similar be-havior so we extend the formulation in Section 51for linear reduction In the objective function 18 wereplace
sumlog2 kj c j with k Constraints 4ndash6 are no longer
applied When the loop is partially strip-mined notFullhere represents a delay of the accumulated result whichfeeds back to the linear structure in the next iterationBecause the number of cycles taken to multiply eachelement of A with the N coefficients decreases as thenumber of parallel partitions increases the data depen-dence distance of loop j similarly decreases Thereforewe add inequality 19
minimize v times ii +Isum
i=1
di + k + notFull (18)
N times kminus1 times iiminus1 le 1 (19)
Now the formulation with objective 18 and con-straints 7ndash19 is a GP model mapping MapReduce pat-terns to a parallel computing platform with a linearreduction
53 Extension of the Model for Multi-levelMapReduce
The GP models presented above are for mapping asingle loop level with the MapReduce pattern ontoa parallel computing platform This section extendsthe models to map nested loops with the MapReducepatterns We target a rectangular loop nest with L loops(I1 I2 IL) where I1 is the outermost loop IL is theinnermost loop and the loop length of loop l is Nl Forsimplicity we assume that all computational operationsreside in the innermost loop and only the innermostloop is pipelined The statements outside the innermostloop are divided into two disjoint sets S1 = mergingstatements outside the innermost loop and S2 = non-merging statements outside the innermost loop
Expressions 1 and 18 correspond to the executioncycles of the innermost loop alone using tree or linear
reduction structures We redefine them as e = vL timesii + sumI
i=1 di + rL + notFull where rL is the number ofexecution cycles of the merging statement sL in the in-nermost loop Then we can formulate the total execu-tion cycles of the target loop nest as the new objective
minimizeLminus1prod
l=1
vl timese+sum
sisinS2
Isprod
l=1
vl +sum
sisinS1
(vIs timesnotFullIs +rs
)
(20)
where Is is the loop level in which statement s is locatedand
rs =log2 kIs sum
j
csj or kIs (21)
is the number of execution cycles taken by mergingstatement s using tree reduction structure or linearreduction structure where csj have the same meaningas c j in Eq 1 but for merging statement s outside theinnermost loop rL also complies with Eq 21 for themerging statement in the innermost loop
The number of iterations vl of loop l after partition-ing into kl parallel segments is
Nl times kminus1l le vl 1 le l le L (22)
1 le kl le Nl 1 le l le L (23)
Moreover the constraints of the resources used formerging operations in the tree structure (4ndash6) and (10)need to be defined according to each merging statementin the loop nest
ms1 ge kIs2 s isin S1 cup sL (24)
msj ge msjminus12 s isin S1 cup sL 2 le j le log2 kIs (25)
csj ge msjMr s isin S1 cup sL 1 le j le log2 kIs (26)
kL times Mminus1r times iiminus1 le 1 (27)
Correspondingly the memory bandwidth constraint 7is redefined as
Ba timesprod
lisinQa
kl times Mminus1b times iiminus1 + notAligna times iiminus1 le 1 a isin A
(28)
where each of A array references under operations isstored in a memory bank with bandwidth Mb eachreference a requires Ba memory bandwidth in one loopiteration and Qa is the set of loop variables in theindexing function of reference a Unlike Eq 7 hereeach array reference is treated individually because dif-ferent array references may have different bandwidth
J Sign Process Syst (2012) 6765ndash78 73
Table 3 Benchmark details Benchmark loops Refs MapReduce pattern
MAT64 3 2 Two levels in the outer loopsand the innermost loop
ME Implicit 2 Two levels implicit and in SADSobel 4 2 Two levels in outer two loops
and inner two loopsMCS 2 0 In the outer loop1-D correlation 2 1 In the innermost loopk-means 4 1 In the inner three loops
requirements after mapping multiple MapReduce pat-terns Meanwhile the computational resource con-straint 11 is redefined as
Lprod
l=1
kl times x f le C f f isin F (29)
This model allows us to map the multi-level MapRe-duce pattern and thus extends the applicability of theproposed approach This model is still a piecewise GPproblem With multiple nested patterns however thisproblem has more variables and more subproblemscaused by the logarithm and thus could take longer tosolve
6 Experimental Results
We apply the proposed approach to six kernels multi-plication of two 64 times 64 matrices (MAT64) the motionestimation (ME) algorithm [15] used in X264 the Sobeledge detection algorithm (Sobel) [17] Monte Carlosimulation (MCS) of Asian Option Pricing [16] 1-Dcorrelation and k-means clustering [18] Table 3 showsbenchmark parameters Each benchmark contains theMapReduce patterns One level of the MapReducepattern exists in MCS and 1-D correlation to which themodels presented in Sections 51 and 52 are appliedrespectively Two levels of the MapReduce pattern areidentified in ME MAT64 and Sobel We apply thetransforms [6] to the outer level exploiting data reuseand loop-level parallelism For the MapReduce patternin the inner loops we apply the model in Section 51 toexploit inner loop parallelization and pipelining Lastlywe apply the extended model in Section 53 to k-meansclustering which has three levels of the MapReducepattern All GP models are solved by a MATLABtool box named YALMIP [21] Different designs arerepresented by the number of parallel loop partitionsand the pipelining initiation interval (kl ii)
In our experiments the target platform is an FPGA-based system with off-chip SRAM The Monte Carlosimulation of Asian Option involving floating point
arithmetic is implemented in Xilinx XC4VFX140 with192 DSP48 and the other five kernels are implementedin XC2v8000 which has 168 embedded hard multipli-ers and 168 dual-port RAM blocks On-chip RAMsconfigured as scratch-pad buffers and registers are usedto increase memory bandwidth All experimental re-sults are obtained on the target platform after synthesisplacement and routing For ME and Sobel the framesize is the QCIF luminance component (144 times 176pixels)
Matrixndashmatrix Multiplication is a typical arithmetickernel used in many applications Each element of theoutput matrix is the dot product of one row of one inputmatrix and one column of the other input matrix Thedot product is the inner MapReduce pattern level andcomputing multiple elements of the output matrix inparallel is the outer MapReduce level In our imple-mentation each matrix element is 8 bits Memory band-width and the number of hard multipliers embeddedin the FPGA are the constraints on mapping the innerlevel MapReduce pattern Figure 4 shows results fromapplying our proposed piecewise GP model (1ndash13) tothe innermost loop of MAT64 Given a memory band-width and the number of multipliers the figure reveals
12345678
0 2 4 6 8 10 12 14 16 17
0
20
40
60
80
100
120
140
MultipliersMemory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
(3 2)(2 1)
(1 1)
(4 1)(5 2)
Figure 4 Designs proposed by the framework for MAT64 Thebracket next to each design shows (k ii)
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL

68 J Sign Process Syst (2012) 6765ndash78
dot product under different memory bandwidth con-straints Each design is represented by the number ofparallel partitions (k) of the strip-mined loop each withits own processing unit and the initiation interval (ii)of pipelining the outer for loop Ideally if the memorybandwidth is 2N bytes per execution cycle as shownin the second row of Table 1 then N multiplicationscan execute in parallel and the final result can bemerged using a tree structure as shown in Fig 1ewhere pipeline registers are not shown In this case theloop i is fully strip-mined and the dot product needslog2 N + 2 execution cycles log2 N execution cycles forresult merging one execution cycle for loading 2N dataand one for multiplication
In practice 2N bytes per execution cycle memorybandwidth is unrealistic for large N If memory band-width is one byte per execution cycle then the fullyparallel implementation in Fig 1e needs 2N + log2 N +1 execution cycles to finish the dot product where2N execution cycles are used to load 2N data In thisscenario pipelining the loop i with ii = 2 due to the twosequential memory accesses needs 2N + 2 executioncycles to compute the dot product as the design (1 2)in Table 1 If N gt 2 the pipelined implementation ismore promising than the fully parallel version not justin speed but also in resource usage Furthermore ifthe memory bandwidth is 2 bytes per execution cycleelements from each of A and B can be read at the sametime and the fully parallel version needs N + log2 N +1 execution cycles
Alternatively if the loop i is strip-mined by 2 thenevery two iterations of the loop i execute in parallelon two processing units and the results are mergedshown in Fig 1d This structure can be further pipelinedwith ii = 2 This design combining local parallelizationand global pipelining can perform the dot product in2N2 + 3 execution cycles The third design option isto pipeline loop i with ii = 1 without loop strip-miningand it is still promising as N + 2 execution cycles are
spent on the product Similarly if the memory band-width is 3 bytes per execution cycle Table 1 showsthree possible design options Here the second optioncombining loop strip-mining and pipelining achieves abalance between speed and resource utilization
We can see that there are multiple options for map-ping the dot product onto a given hardware platformunder different memory bandwidth constraints Evenmore design options result if multipliers are also con-strained Finding the best design in terms of variouscriteria is not easy and requires exploration of thedesign space to find the optimal design
This paper proposes an approach with model-basedand pattern-based transforms to deal with the problemof mapping the MapReduce pattern
4 The Proposed Approach
Figure 2 shows how our proposed approach combinesmodel-based and pattern-based transforms to map theMapReduce pattern onto a target hardware platformwhile achieving design goals
The approach takes as input the sequential descrip-tion of a design We initially apply pattern-based trans-formations such as function inlining and convertingpointers to arrays to the design to ease the dependenceanalysis We apply further pattern-based transforma-tions including loop merging and loop coalescing tothe design to ensure it is in a certain form This formenables us to simplify the mathematical model by re-moving variables enabling it to be solved faster
After dependence analysis we check that the designcontains the two characteristics of the MapReduce pat-tern given in Section 1 If they are found we applythe model-based transformation for the MapReducepattern shown in the shaded block in Fig 2
We formulate the problem of mapping the MapRe-duce pattern onto a target parallel computing platform
Table 1 Possible designoptions of the dot productexample
Mem_bandwidth Designs Exe_cycles Multipliers(Bytesexe_cycle) (k ii)
2N (N 1) log2 N + 2 N
(N 1) 2N + log2 N + 1 N(1 2) 2N + 2 1
2 (N 1) N + log2 N + 1 N(2 2) 2N2 + 3 2(1 1) N + 2 1
3 (N 1) 2N3 + log2 N + 1 N(3 2) 2N3 + 4 3(1 1) N + 2 1
J Sign Process Syst (2012) 6765ndash78 69
Input design(sequential)
InliningPtr2Array
Loop merge3-address
Loop coalesce
Dependenceanalysis
MapReduce+
Pipeline
Output design(parallel)
Hardware Platformparameters
Figure 2 Combining model-based (such as MapReduce) andpattern-based approaches (such as loop coalescing) into a singleapproach
as a geometric programming model Solving this prob-lem automatically generates an optimized design ex-ploiting loop-level parallelization and pipelining forgiven hardware platform parameters such as memorysize and computation resources This paper focusses onpresenting this geometric programming model
As output our approach produces a design with ex-plicit timing and parallelism The design can then beimplemented on the hardware platform using vendortools to synthesize place and route it Currently themodel is used to optimize design parameters we do notcurrently automate output hardware generation butthis is relatively straightforward
Our approach can adapt to several variations on theMapReduce pattern
bull applications with implicit MapReduce pattern suchas the motion estimation algorithm [15] used inX264
bull applications with MapReduce pattern at any looplevel such as the Monte Carlo simulation of AsianOptions [16]
bull applications with 2-D MapReduce patterns such asedge detection [17] and
bull application with multi-level MapReduce patternssuch as k-means clustering [18]
5 GP Model for Mapping MapReduce
As the MapReduce pattern is often present in sequen-tial loops we target a loop nest containing the MapRe-duce patterns with the number of iterations fixed atcompile time
We formulate the design exploration problem as apiecewise integer geometric program Geometric pro-gramming (GP) [19] is the following optimization problem
minimize f0(x)
subject to fi(x) le 1 i = 1 mhi(x) = 1 i = 1 p
where the objective function and inequality constraintfunctions are all in posynomial form while the equal-ity constraint functions are monomial Unlike generalnonlinear programming problems GP is convex andthus has efficient solution algorithms with guaranteedconvergence to a global solution [19]
In the next three subsections we present the pro-posed piecewise integer geometric programming modelfor mapping a single loop with the MapReduce patternan extension of the model to a variant of the MapRe-duce pattern and a further extension to map nestedloops with multiple MapReduce patterns Table 2 listsnotation used in the models capitals denote compiletime constants while lower case denotes integer vari-ables The models assume that assignments take oneclock cycle like Handel-C [20] This limits clock speedto the slowest expression used we ameliorate this bybreaking expressions into three-address code
51 Piecewise GP Model for MapReduce with TreeReduce
In this section a GP model for mapping a loop contain-ing the MapReduce pattern with a tree reduce structureis presented This model extends [5] to consider theconstraints of the resources for the merging operationsin the Reduce phase The design variables includethe number of parallel partitions of the loop and thepipeline initiation interval the loop is mapped to alocally parallel globally pipelined design
The objective is to minimize the number of executioncycles of a loop after loop strip-mining and pipelining asbelow
minimize v times ii +Isum
i=1
di +log2 ksum
j
c j + notFull (1)
This expression is derived from the standard moduloscheduling length of pipelining [10 11] assuming thatthe number of execution cycles for loading data frommemory dominates the initiation interval (ii) Section 6shows that this assumption is true for the tested bench-marks The number of loop iterations v executing ineach parallel partition is defined in Inequality 2
N times kminus1 le v (2)
70 J Sign Process Syst (2012) 6765ndash78
Table 2 Notation used in the models
Notations Description
k (kl) Parallel partitions of a loop (loop l)ii Initiation interval of pipelinev (vl) Iterations in one partition of a loop (loop l)x f No resources f being useddi Latency in execution cycles of computation
level i of DFGc j (csj) Execution cycles of level j of merging tree
(of statement s)m j (msj) Merging operations of level j of merging tree
(of statement s)rs Execution cycles of merging tree of statement s
L No nested loopsIs The loop level where statement s is located
1 le Is le LN (Nl) No iterations of a loop (loop l)A No array referencesRecII Data dependence constraint on ii in
the computationW f Computation resources f required in
a loop iterationRif Computation resources f required in
level i of DFGI No computation levels of DFGB (Ba) Required memory bandwidth (of array a)
in one loop iterationQa Set of loop variables in the indexing function
of array aMb Memory bandwidthC f Computational resources f availableMr Resources r available for merging operationsF F types of computation resources involvednotAlign 0 data are aligned 1 data are not aligned
(of array a)(notAligna)notFull 0 loop (l) is fully strip-mined 1 loop (l) is
partially strip-mined(notFulll)
The second term in the objective function 1 is theexecution cycles taken by computation There maybe I (I ge 1) computation levels in the DFG and thecomputation cycles of each loop iteration consist of theexecution cycles of every level The execution cycledi of computation level i is determined by Rif therequirement of each computation resource f in leveli and the number of allocated resources x f as definedin inequalities 3
Rif times xminus1f times dminus1
i le 1 1 le i le I f isin F (3)
The example in Fig 1 needs one multiplier in the singlecomputation level For this simplest case x f takingone results in d1 = 1 Assuming the computation level
requires two multipliers x f could take on the value 1or 2 depending on the resource constraint leading tod1 = 2 or d1 = 1 cycles respectively
The last two terms of the objective 1 are the execu-tion cycles taken by final result merging When a treestructure is used as in Fig 1d and e the number of levelsof the merging tree is log2 k and thus the numberof execution cycles taken by the merging tree is thesum of the execution cycles c j spent on every level jWe arrange the number of merging operations in eachlevel such that there are m1 merging operations in thetop level and subsequently the following level has m j
merging operations as defined in Eqs 4 and 5
m1 ge k2 (4)
m j ge m jminus12 2 le j le log2 k (5)
The number of execution cycles c j of level j is deter-mined by the number of merging operations in levelj and Mr the number of resources available for themerging operations in Eq 6 which is the resourceconstraint on the merging operations
c j ge m jMr 1 le j le log2 k (6)
The Boolean parameter notFull is added to Eq 1 forthe case where the loop is partially strip-mined andsequential accumulation of the results is needed Fig 1dshows an example
There are four constraints on the pipelining initiationinterval ii as shown in Eqs 7ndash10 Inequality 7 is thememory bandwidth constraint Given a fixed memorybandwidth Mb and the memory bandwidth required inone loop iteration B more parallel loop iterations krequire more input data and thus more data loadingtime leading to a larger initiation interval (ii) Herethe Boolean parameter notAlign is used to capture thesituation where data are not aligned between storageand computation this case may need one extra mem-ory access to obtain requested data Inequality 8 givesthe computation resource constraints where W f is thenumber of each computation resource f required inone loop iteration Inequality 9 is the data dependenceconstraint on ii as used in [10 11] The available re-source for merging operations also has impact on ii asshown in inequality 10 For k intermediate computationresults generated in parallel up to k merging operationsare needed to obtain the final result
B times k times Mminus1b times iiminus1 + notAlign times iiminus1 le 1 (7)
W f times xminus1f times iiminus1 le 1 f isin F (8)
J Sign Process Syst (2012) 6765ndash78 71
RecII times iiminus1 le 1 (9)
k times Mminus1r times iiminus1 le 1 (10)
Inequality 11 captures how computation resourcesconstrain parallelization We achieve an efficient so-lution by balancing the resources allocated to loopparallelization (k) and pipelining (ii) given that thenumber of resource f available is C f
k times x f le C f f isin F (11)
Inequalities 12 and 13 are the ranges of integer vari-ables k and x f respectively Inequality 13 may appearto be redundant but the GP solver requires explicitranges for all variables
1 le k le N (12)
1 le x f le C f f isin F (13)
Overall the only item making the relaxed problem1ndash13 (allowing all variables to be real numbers) not aGP problem is the logarithm log2 k The logarithmsmust be eliminated in order to use a GP solver How-ever we note that log2 k is constant in certain rangesof k Therefore the problem 1ndash13 can be seen as apiecewise integer geometric problem in different rangesof k the number of subproblems increases logarithmi-cally with k For large k = 1000 there are 11 integerGP problems and each problem can be quickly solvedusing a branch and bound algorithm used in [21] with aGP solver as the lower bounding procedure Section 6shows the performance of the piecewise GP model Thesolution (k ii) to the problem 1ndash13 tells us how toMapReduce and pipeline the loop under consideration
The formulation 1ndash13 targets mapping a loop ontoa parallel computing structure The loop need not beinnermost For example in order to map a 2-levelloop nest unrolling the innermost loop allows the for-mulation to work Equivalently we can add severalconstraints as shown below to the formulation 1ndash13Then we can automatically determine pipelining theinnermost loop (iiprime) strip-mining (k) the outer loopand global pipelining (ii) the Monte Carlo simulationof Asian Option benchmark in Section 6 exhibits thiscase Inequality 14 shows the constraint the innermostloop (with Nprime iterations) scheduling length on the ini-tiation interval ii of the outer loop as the outer loopcannot start the next iteration before the innermostloop finishes Inequalities 15 and 16 are the compu-tation resource and data dependence constraints onthe initiation interval of pipelining the innermost loopThe required resources W prime
f in the innermost loop are
included in W f in order to share resources amongoperations
(Nprime minus 1) times iiprime times iiminus1 + iiminus1 timesIprimesum
i=1
dprimei le 1 (14)
W primef times xminus1
f times iiprimeminus1 le 1 f isin F (15)
RecIIprime times iiprimeminus1 le 1 (16)
Finally the MapReduce pattern is also present insome applications in 2-D form Our pattern-basedtransforms could coalesce 2-D loops into 1-D so the GPformulation described above can apply We extend in-equality 7 to cover 2-D data block (Row times Col) accessallowing for the 2-D data block access to not necessarilybe linearized
Row times (B times k times Mminus1
b times iiminus1 + notAlign times iiminus1) le 1
(17)
52 Extension of the Model for Linear Reduce
In the previous subsection the logarithm expression inthe objective function results from using a tree struc-ture for Reduce Alternatively a linear structure couldbe used Fig 1f shows an example for dot productFor k parallel computations the linear structure needsk execution cycles to merge all intermediate resultsAlthough longer than the tree structure some appli-cations with the MapReduce pattern using the linearstructure to merge results can both keep the samethroughput as the tree structure and reduce the mem-ory bandwidth requirement Other merging structuresare possible we have not yet found a compelling usecase for these
Figure 3a shows an example of 1-D correlation Theinnermost loop j of the code has a similar computa-tion pattern to the dot product and can map onto aparallel computing structure using MapReduce Thedifferences from the dot product are that one multipli-cation operand w j is constant and when the outer loopi iterates the data of A are shifted invariantly into thecomputation This is potentially suitable for pipelining
(a) The original code(b) Fully parallel structure for loop
j with linear merging
Figure 3 An example 1-D correlation
72 J Sign Process Syst (2012) 6765ndash78
If the innermost loop j can be fully strip-mined thenthe N multiplications execute at the same time and theintermediate computation results are linearly mergedas shown in Fig 3b An important characteristic of thisstructure is its regular shape which could benefit theplacement and routing of hardware resources Aftermapping loop j fully pipelining loop i produces a C[i]every cycle after N execution cycles If any multipliersand memory access bandwidth are still available loop icould be further partitioned
Many signal and image processing applications use1-D correlation or convolution or show similar be-havior so we extend the formulation in Section 51for linear reduction In the objective function 18 wereplace
sumlog2 kj c j with k Constraints 4ndash6 are no longer
applied When the loop is partially strip-mined notFullhere represents a delay of the accumulated result whichfeeds back to the linear structure in the next iterationBecause the number of cycles taken to multiply eachelement of A with the N coefficients decreases as thenumber of parallel partitions increases the data depen-dence distance of loop j similarly decreases Thereforewe add inequality 19
minimize v times ii +Isum
i=1
di + k + notFull (18)
N times kminus1 times iiminus1 le 1 (19)
Now the formulation with objective 18 and con-straints 7ndash19 is a GP model mapping MapReduce pat-terns to a parallel computing platform with a linearreduction
53 Extension of the Model for Multi-levelMapReduce
The GP models presented above are for mapping asingle loop level with the MapReduce pattern ontoa parallel computing platform This section extendsthe models to map nested loops with the MapReducepatterns We target a rectangular loop nest with L loops(I1 I2 IL) where I1 is the outermost loop IL is theinnermost loop and the loop length of loop l is Nl Forsimplicity we assume that all computational operationsreside in the innermost loop and only the innermostloop is pipelined The statements outside the innermostloop are divided into two disjoint sets S1 = mergingstatements outside the innermost loop and S2 = non-merging statements outside the innermost loop
Expressions 1 and 18 correspond to the executioncycles of the innermost loop alone using tree or linear
reduction structures We redefine them as e = vL timesii + sumI
i=1 di + rL + notFull where rL is the number ofexecution cycles of the merging statement sL in the in-nermost loop Then we can formulate the total execu-tion cycles of the target loop nest as the new objective
minimizeLminus1prod
l=1
vl timese+sum
sisinS2
Isprod
l=1
vl +sum
sisinS1
(vIs timesnotFullIs +rs
)
(20)
where Is is the loop level in which statement s is locatedand
rs =log2 kIs sum
j
csj or kIs (21)
is the number of execution cycles taken by mergingstatement s using tree reduction structure or linearreduction structure where csj have the same meaningas c j in Eq 1 but for merging statement s outside theinnermost loop rL also complies with Eq 21 for themerging statement in the innermost loop
The number of iterations vl of loop l after partition-ing into kl parallel segments is
Nl times kminus1l le vl 1 le l le L (22)
1 le kl le Nl 1 le l le L (23)
Moreover the constraints of the resources used formerging operations in the tree structure (4ndash6) and (10)need to be defined according to each merging statementin the loop nest
ms1 ge kIs2 s isin S1 cup sL (24)
msj ge msjminus12 s isin S1 cup sL 2 le j le log2 kIs (25)
csj ge msjMr s isin S1 cup sL 1 le j le log2 kIs (26)
kL times Mminus1r times iiminus1 le 1 (27)
Correspondingly the memory bandwidth constraint 7is redefined as
Ba timesprod
lisinQa
kl times Mminus1b times iiminus1 + notAligna times iiminus1 le 1 a isin A
(28)
where each of A array references under operations isstored in a memory bank with bandwidth Mb eachreference a requires Ba memory bandwidth in one loopiteration and Qa is the set of loop variables in theindexing function of reference a Unlike Eq 7 hereeach array reference is treated individually because dif-ferent array references may have different bandwidth
J Sign Process Syst (2012) 6765ndash78 73
Table 3 Benchmark details Benchmark loops Refs MapReduce pattern
MAT64 3 2 Two levels in the outer loopsand the innermost loop
ME Implicit 2 Two levels implicit and in SADSobel 4 2 Two levels in outer two loops
and inner two loopsMCS 2 0 In the outer loop1-D correlation 2 1 In the innermost loopk-means 4 1 In the inner three loops
requirements after mapping multiple MapReduce pat-terns Meanwhile the computational resource con-straint 11 is redefined as
Lprod
l=1
kl times x f le C f f isin F (29)
This model allows us to map the multi-level MapRe-duce pattern and thus extends the applicability of theproposed approach This model is still a piecewise GPproblem With multiple nested patterns however thisproblem has more variables and more subproblemscaused by the logarithm and thus could take longer tosolve
6 Experimental Results
We apply the proposed approach to six kernels multi-plication of two 64 times 64 matrices (MAT64) the motionestimation (ME) algorithm [15] used in X264 the Sobeledge detection algorithm (Sobel) [17] Monte Carlosimulation (MCS) of Asian Option Pricing [16] 1-Dcorrelation and k-means clustering [18] Table 3 showsbenchmark parameters Each benchmark contains theMapReduce patterns One level of the MapReducepattern exists in MCS and 1-D correlation to which themodels presented in Sections 51 and 52 are appliedrespectively Two levels of the MapReduce pattern areidentified in ME MAT64 and Sobel We apply thetransforms [6] to the outer level exploiting data reuseand loop-level parallelism For the MapReduce patternin the inner loops we apply the model in Section 51 toexploit inner loop parallelization and pipelining Lastlywe apply the extended model in Section 53 to k-meansclustering which has three levels of the MapReducepattern All GP models are solved by a MATLABtool box named YALMIP [21] Different designs arerepresented by the number of parallel loop partitionsand the pipelining initiation interval (kl ii)
In our experiments the target platform is an FPGA-based system with off-chip SRAM The Monte Carlosimulation of Asian Option involving floating point
arithmetic is implemented in Xilinx XC4VFX140 with192 DSP48 and the other five kernels are implementedin XC2v8000 which has 168 embedded hard multipli-ers and 168 dual-port RAM blocks On-chip RAMsconfigured as scratch-pad buffers and registers are usedto increase memory bandwidth All experimental re-sults are obtained on the target platform after synthesisplacement and routing For ME and Sobel the framesize is the QCIF luminance component (144 times 176pixels)
Matrixndashmatrix Multiplication is a typical arithmetickernel used in many applications Each element of theoutput matrix is the dot product of one row of one inputmatrix and one column of the other input matrix Thedot product is the inner MapReduce pattern level andcomputing multiple elements of the output matrix inparallel is the outer MapReduce level In our imple-mentation each matrix element is 8 bits Memory band-width and the number of hard multipliers embeddedin the FPGA are the constraints on mapping the innerlevel MapReduce pattern Figure 4 shows results fromapplying our proposed piecewise GP model (1ndash13) tothe innermost loop of MAT64 Given a memory band-width and the number of multipliers the figure reveals
12345678
0 2 4 6 8 10 12 14 16 17
0
20
40
60
80
100
120
140
MultipliersMemory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
(3 2)(2 1)
(1 1)
(4 1)(5 2)
Figure 4 Designs proposed by the framework for MAT64 Thebracket next to each design shows (k ii)
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL

J Sign Process Syst (2012) 6765ndash78 69
Input design(sequential)
InliningPtr2Array
Loop merge3-address
Loop coalesce
Dependenceanalysis
MapReduce+
Pipeline
Output design(parallel)
Hardware Platformparameters
Figure 2 Combining model-based (such as MapReduce) andpattern-based approaches (such as loop coalescing) into a singleapproach
as a geometric programming model Solving this prob-lem automatically generates an optimized design ex-ploiting loop-level parallelization and pipelining forgiven hardware platform parameters such as memorysize and computation resources This paper focusses onpresenting this geometric programming model
As output our approach produces a design with ex-plicit timing and parallelism The design can then beimplemented on the hardware platform using vendortools to synthesize place and route it Currently themodel is used to optimize design parameters we do notcurrently automate output hardware generation butthis is relatively straightforward
Our approach can adapt to several variations on theMapReduce pattern
bull applications with implicit MapReduce pattern suchas the motion estimation algorithm [15] used inX264
bull applications with MapReduce pattern at any looplevel such as the Monte Carlo simulation of AsianOptions [16]
bull applications with 2-D MapReduce patterns such asedge detection [17] and
bull application with multi-level MapReduce patternssuch as k-means clustering [18]
5 GP Model for Mapping MapReduce
As the MapReduce pattern is often present in sequen-tial loops we target a loop nest containing the MapRe-duce patterns with the number of iterations fixed atcompile time
We formulate the design exploration problem as apiecewise integer geometric program Geometric pro-gramming (GP) [19] is the following optimization problem
minimize f0(x)
subject to fi(x) le 1 i = 1 mhi(x) = 1 i = 1 p
where the objective function and inequality constraintfunctions are all in posynomial form while the equal-ity constraint functions are monomial Unlike generalnonlinear programming problems GP is convex andthus has efficient solution algorithms with guaranteedconvergence to a global solution [19]
In the next three subsections we present the pro-posed piecewise integer geometric programming modelfor mapping a single loop with the MapReduce patternan extension of the model to a variant of the MapRe-duce pattern and a further extension to map nestedloops with multiple MapReduce patterns Table 2 listsnotation used in the models capitals denote compiletime constants while lower case denotes integer vari-ables The models assume that assignments take oneclock cycle like Handel-C [20] This limits clock speedto the slowest expression used we ameliorate this bybreaking expressions into three-address code
51 Piecewise GP Model for MapReduce with TreeReduce
In this section a GP model for mapping a loop contain-ing the MapReduce pattern with a tree reduce structureis presented This model extends [5] to consider theconstraints of the resources for the merging operationsin the Reduce phase The design variables includethe number of parallel partitions of the loop and thepipeline initiation interval the loop is mapped to alocally parallel globally pipelined design
The objective is to minimize the number of executioncycles of a loop after loop strip-mining and pipelining asbelow
minimize v times ii +Isum
i=1
di +log2 ksum
j
c j + notFull (1)
This expression is derived from the standard moduloscheduling length of pipelining [10 11] assuming thatthe number of execution cycles for loading data frommemory dominates the initiation interval (ii) Section 6shows that this assumption is true for the tested bench-marks The number of loop iterations v executing ineach parallel partition is defined in Inequality 2
N times kminus1 le v (2)
70 J Sign Process Syst (2012) 6765ndash78
Table 2 Notation used in the models
Notations Description
k (kl) Parallel partitions of a loop (loop l)ii Initiation interval of pipelinev (vl) Iterations in one partition of a loop (loop l)x f No resources f being useddi Latency in execution cycles of computation
level i of DFGc j (csj) Execution cycles of level j of merging tree
(of statement s)m j (msj) Merging operations of level j of merging tree
(of statement s)rs Execution cycles of merging tree of statement s
L No nested loopsIs The loop level where statement s is located
1 le Is le LN (Nl) No iterations of a loop (loop l)A No array referencesRecII Data dependence constraint on ii in
the computationW f Computation resources f required in
a loop iterationRif Computation resources f required in
level i of DFGI No computation levels of DFGB (Ba) Required memory bandwidth (of array a)
in one loop iterationQa Set of loop variables in the indexing function
of array aMb Memory bandwidthC f Computational resources f availableMr Resources r available for merging operationsF F types of computation resources involvednotAlign 0 data are aligned 1 data are not aligned
(of array a)(notAligna)notFull 0 loop (l) is fully strip-mined 1 loop (l) is
partially strip-mined(notFulll)
The second term in the objective function 1 is theexecution cycles taken by computation There maybe I (I ge 1) computation levels in the DFG and thecomputation cycles of each loop iteration consist of theexecution cycles of every level The execution cycledi of computation level i is determined by Rif therequirement of each computation resource f in leveli and the number of allocated resources x f as definedin inequalities 3
Rif times xminus1f times dminus1
i le 1 1 le i le I f isin F (3)
The example in Fig 1 needs one multiplier in the singlecomputation level For this simplest case x f takingone results in d1 = 1 Assuming the computation level
requires two multipliers x f could take on the value 1or 2 depending on the resource constraint leading tod1 = 2 or d1 = 1 cycles respectively
The last two terms of the objective 1 are the execu-tion cycles taken by final result merging When a treestructure is used as in Fig 1d and e the number of levelsof the merging tree is log2 k and thus the numberof execution cycles taken by the merging tree is thesum of the execution cycles c j spent on every level jWe arrange the number of merging operations in eachlevel such that there are m1 merging operations in thetop level and subsequently the following level has m j
merging operations as defined in Eqs 4 and 5
m1 ge k2 (4)
m j ge m jminus12 2 le j le log2 k (5)
The number of execution cycles c j of level j is deter-mined by the number of merging operations in levelj and Mr the number of resources available for themerging operations in Eq 6 which is the resourceconstraint on the merging operations
c j ge m jMr 1 le j le log2 k (6)
The Boolean parameter notFull is added to Eq 1 forthe case where the loop is partially strip-mined andsequential accumulation of the results is needed Fig 1dshows an example
There are four constraints on the pipelining initiationinterval ii as shown in Eqs 7ndash10 Inequality 7 is thememory bandwidth constraint Given a fixed memorybandwidth Mb and the memory bandwidth required inone loop iteration B more parallel loop iterations krequire more input data and thus more data loadingtime leading to a larger initiation interval (ii) Herethe Boolean parameter notAlign is used to capture thesituation where data are not aligned between storageand computation this case may need one extra mem-ory access to obtain requested data Inequality 8 givesthe computation resource constraints where W f is thenumber of each computation resource f required inone loop iteration Inequality 9 is the data dependenceconstraint on ii as used in [10 11] The available re-source for merging operations also has impact on ii asshown in inequality 10 For k intermediate computationresults generated in parallel up to k merging operationsare needed to obtain the final result
B times k times Mminus1b times iiminus1 + notAlign times iiminus1 le 1 (7)
W f times xminus1f times iiminus1 le 1 f isin F (8)
J Sign Process Syst (2012) 6765ndash78 71
RecII times iiminus1 le 1 (9)
k times Mminus1r times iiminus1 le 1 (10)
Inequality 11 captures how computation resourcesconstrain parallelization We achieve an efficient so-lution by balancing the resources allocated to loopparallelization (k) and pipelining (ii) given that thenumber of resource f available is C f
k times x f le C f f isin F (11)
Inequalities 12 and 13 are the ranges of integer vari-ables k and x f respectively Inequality 13 may appearto be redundant but the GP solver requires explicitranges for all variables
1 le k le N (12)
1 le x f le C f f isin F (13)
Overall the only item making the relaxed problem1ndash13 (allowing all variables to be real numbers) not aGP problem is the logarithm log2 k The logarithmsmust be eliminated in order to use a GP solver How-ever we note that log2 k is constant in certain rangesof k Therefore the problem 1ndash13 can be seen as apiecewise integer geometric problem in different rangesof k the number of subproblems increases logarithmi-cally with k For large k = 1000 there are 11 integerGP problems and each problem can be quickly solvedusing a branch and bound algorithm used in [21] with aGP solver as the lower bounding procedure Section 6shows the performance of the piecewise GP model Thesolution (k ii) to the problem 1ndash13 tells us how toMapReduce and pipeline the loop under consideration
The formulation 1ndash13 targets mapping a loop ontoa parallel computing structure The loop need not beinnermost For example in order to map a 2-levelloop nest unrolling the innermost loop allows the for-mulation to work Equivalently we can add severalconstraints as shown below to the formulation 1ndash13Then we can automatically determine pipelining theinnermost loop (iiprime) strip-mining (k) the outer loopand global pipelining (ii) the Monte Carlo simulationof Asian Option benchmark in Section 6 exhibits thiscase Inequality 14 shows the constraint the innermostloop (with Nprime iterations) scheduling length on the ini-tiation interval ii of the outer loop as the outer loopcannot start the next iteration before the innermostloop finishes Inequalities 15 and 16 are the compu-tation resource and data dependence constraints onthe initiation interval of pipelining the innermost loopThe required resources W prime
f in the innermost loop are
included in W f in order to share resources amongoperations
(Nprime minus 1) times iiprime times iiminus1 + iiminus1 timesIprimesum
i=1
dprimei le 1 (14)
W primef times xminus1
f times iiprimeminus1 le 1 f isin F (15)
RecIIprime times iiprimeminus1 le 1 (16)
Finally the MapReduce pattern is also present insome applications in 2-D form Our pattern-basedtransforms could coalesce 2-D loops into 1-D so the GPformulation described above can apply We extend in-equality 7 to cover 2-D data block (Row times Col) accessallowing for the 2-D data block access to not necessarilybe linearized
Row times (B times k times Mminus1
b times iiminus1 + notAlign times iiminus1) le 1
(17)
52 Extension of the Model for Linear Reduce
In the previous subsection the logarithm expression inthe objective function results from using a tree struc-ture for Reduce Alternatively a linear structure couldbe used Fig 1f shows an example for dot productFor k parallel computations the linear structure needsk execution cycles to merge all intermediate resultsAlthough longer than the tree structure some appli-cations with the MapReduce pattern using the linearstructure to merge results can both keep the samethroughput as the tree structure and reduce the mem-ory bandwidth requirement Other merging structuresare possible we have not yet found a compelling usecase for these
Figure 3a shows an example of 1-D correlation Theinnermost loop j of the code has a similar computa-tion pattern to the dot product and can map onto aparallel computing structure using MapReduce Thedifferences from the dot product are that one multipli-cation operand w j is constant and when the outer loopi iterates the data of A are shifted invariantly into thecomputation This is potentially suitable for pipelining
(a) The original code(b) Fully parallel structure for loop
j with linear merging
Figure 3 An example 1-D correlation
72 J Sign Process Syst (2012) 6765ndash78
If the innermost loop j can be fully strip-mined thenthe N multiplications execute at the same time and theintermediate computation results are linearly mergedas shown in Fig 3b An important characteristic of thisstructure is its regular shape which could benefit theplacement and routing of hardware resources Aftermapping loop j fully pipelining loop i produces a C[i]every cycle after N execution cycles If any multipliersand memory access bandwidth are still available loop icould be further partitioned
Many signal and image processing applications use1-D correlation or convolution or show similar be-havior so we extend the formulation in Section 51for linear reduction In the objective function 18 wereplace
sumlog2 kj c j with k Constraints 4ndash6 are no longer
applied When the loop is partially strip-mined notFullhere represents a delay of the accumulated result whichfeeds back to the linear structure in the next iterationBecause the number of cycles taken to multiply eachelement of A with the N coefficients decreases as thenumber of parallel partitions increases the data depen-dence distance of loop j similarly decreases Thereforewe add inequality 19
minimize v times ii +Isum
i=1
di + k + notFull (18)
N times kminus1 times iiminus1 le 1 (19)
Now the formulation with objective 18 and con-straints 7ndash19 is a GP model mapping MapReduce pat-terns to a parallel computing platform with a linearreduction
53 Extension of the Model for Multi-levelMapReduce
The GP models presented above are for mapping asingle loop level with the MapReduce pattern ontoa parallel computing platform This section extendsthe models to map nested loops with the MapReducepatterns We target a rectangular loop nest with L loops(I1 I2 IL) where I1 is the outermost loop IL is theinnermost loop and the loop length of loop l is Nl Forsimplicity we assume that all computational operationsreside in the innermost loop and only the innermostloop is pipelined The statements outside the innermostloop are divided into two disjoint sets S1 = mergingstatements outside the innermost loop and S2 = non-merging statements outside the innermost loop
Expressions 1 and 18 correspond to the executioncycles of the innermost loop alone using tree or linear
reduction structures We redefine them as e = vL timesii + sumI
i=1 di + rL + notFull where rL is the number ofexecution cycles of the merging statement sL in the in-nermost loop Then we can formulate the total execu-tion cycles of the target loop nest as the new objective
minimizeLminus1prod
l=1
vl timese+sum
sisinS2
Isprod
l=1
vl +sum
sisinS1
(vIs timesnotFullIs +rs
)
(20)
where Is is the loop level in which statement s is locatedand
rs =log2 kIs sum
j
csj or kIs (21)
is the number of execution cycles taken by mergingstatement s using tree reduction structure or linearreduction structure where csj have the same meaningas c j in Eq 1 but for merging statement s outside theinnermost loop rL also complies with Eq 21 for themerging statement in the innermost loop
The number of iterations vl of loop l after partition-ing into kl parallel segments is
Nl times kminus1l le vl 1 le l le L (22)
1 le kl le Nl 1 le l le L (23)
Moreover the constraints of the resources used formerging operations in the tree structure (4ndash6) and (10)need to be defined according to each merging statementin the loop nest
ms1 ge kIs2 s isin S1 cup sL (24)
msj ge msjminus12 s isin S1 cup sL 2 le j le log2 kIs (25)
csj ge msjMr s isin S1 cup sL 1 le j le log2 kIs (26)
kL times Mminus1r times iiminus1 le 1 (27)
Correspondingly the memory bandwidth constraint 7is redefined as
Ba timesprod
lisinQa
kl times Mminus1b times iiminus1 + notAligna times iiminus1 le 1 a isin A
(28)
where each of A array references under operations isstored in a memory bank with bandwidth Mb eachreference a requires Ba memory bandwidth in one loopiteration and Qa is the set of loop variables in theindexing function of reference a Unlike Eq 7 hereeach array reference is treated individually because dif-ferent array references may have different bandwidth
J Sign Process Syst (2012) 6765ndash78 73
Table 3 Benchmark details Benchmark loops Refs MapReduce pattern
MAT64 3 2 Two levels in the outer loopsand the innermost loop
ME Implicit 2 Two levels implicit and in SADSobel 4 2 Two levels in outer two loops
and inner two loopsMCS 2 0 In the outer loop1-D correlation 2 1 In the innermost loopk-means 4 1 In the inner three loops
requirements after mapping multiple MapReduce pat-terns Meanwhile the computational resource con-straint 11 is redefined as
Lprod
l=1
kl times x f le C f f isin F (29)
This model allows us to map the multi-level MapRe-duce pattern and thus extends the applicability of theproposed approach This model is still a piecewise GPproblem With multiple nested patterns however thisproblem has more variables and more subproblemscaused by the logarithm and thus could take longer tosolve
6 Experimental Results
We apply the proposed approach to six kernels multi-plication of two 64 times 64 matrices (MAT64) the motionestimation (ME) algorithm [15] used in X264 the Sobeledge detection algorithm (Sobel) [17] Monte Carlosimulation (MCS) of Asian Option Pricing [16] 1-Dcorrelation and k-means clustering [18] Table 3 showsbenchmark parameters Each benchmark contains theMapReduce patterns One level of the MapReducepattern exists in MCS and 1-D correlation to which themodels presented in Sections 51 and 52 are appliedrespectively Two levels of the MapReduce pattern areidentified in ME MAT64 and Sobel We apply thetransforms [6] to the outer level exploiting data reuseand loop-level parallelism For the MapReduce patternin the inner loops we apply the model in Section 51 toexploit inner loop parallelization and pipelining Lastlywe apply the extended model in Section 53 to k-meansclustering which has three levels of the MapReducepattern All GP models are solved by a MATLABtool box named YALMIP [21] Different designs arerepresented by the number of parallel loop partitionsand the pipelining initiation interval (kl ii)
In our experiments the target platform is an FPGA-based system with off-chip SRAM The Monte Carlosimulation of Asian Option involving floating point
arithmetic is implemented in Xilinx XC4VFX140 with192 DSP48 and the other five kernels are implementedin XC2v8000 which has 168 embedded hard multipli-ers and 168 dual-port RAM blocks On-chip RAMsconfigured as scratch-pad buffers and registers are usedto increase memory bandwidth All experimental re-sults are obtained on the target platform after synthesisplacement and routing For ME and Sobel the framesize is the QCIF luminance component (144 times 176pixels)
Matrixndashmatrix Multiplication is a typical arithmetickernel used in many applications Each element of theoutput matrix is the dot product of one row of one inputmatrix and one column of the other input matrix Thedot product is the inner MapReduce pattern level andcomputing multiple elements of the output matrix inparallel is the outer MapReduce level In our imple-mentation each matrix element is 8 bits Memory band-width and the number of hard multipliers embeddedin the FPGA are the constraints on mapping the innerlevel MapReduce pattern Figure 4 shows results fromapplying our proposed piecewise GP model (1ndash13) tothe innermost loop of MAT64 Given a memory band-width and the number of multipliers the figure reveals
12345678
0 2 4 6 8 10 12 14 16 17
0
20
40
60
80
100
120
140
MultipliersMemory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
(3 2)(2 1)
(1 1)
(4 1)(5 2)
Figure 4 Designs proposed by the framework for MAT64 Thebracket next to each design shows (k ii)
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL

70 J Sign Process Syst (2012) 6765ndash78
Table 2 Notation used in the models
Notations Description
k (kl) Parallel partitions of a loop (loop l)ii Initiation interval of pipelinev (vl) Iterations in one partition of a loop (loop l)x f No resources f being useddi Latency in execution cycles of computation
level i of DFGc j (csj) Execution cycles of level j of merging tree
(of statement s)m j (msj) Merging operations of level j of merging tree
(of statement s)rs Execution cycles of merging tree of statement s
L No nested loopsIs The loop level where statement s is located
1 le Is le LN (Nl) No iterations of a loop (loop l)A No array referencesRecII Data dependence constraint on ii in
the computationW f Computation resources f required in
a loop iterationRif Computation resources f required in
level i of DFGI No computation levels of DFGB (Ba) Required memory bandwidth (of array a)
in one loop iterationQa Set of loop variables in the indexing function
of array aMb Memory bandwidthC f Computational resources f availableMr Resources r available for merging operationsF F types of computation resources involvednotAlign 0 data are aligned 1 data are not aligned
(of array a)(notAligna)notFull 0 loop (l) is fully strip-mined 1 loop (l) is
partially strip-mined(notFulll)
The second term in the objective function 1 is theexecution cycles taken by computation There maybe I (I ge 1) computation levels in the DFG and thecomputation cycles of each loop iteration consist of theexecution cycles of every level The execution cycledi of computation level i is determined by Rif therequirement of each computation resource f in leveli and the number of allocated resources x f as definedin inequalities 3
Rif times xminus1f times dminus1
i le 1 1 le i le I f isin F (3)
The example in Fig 1 needs one multiplier in the singlecomputation level For this simplest case x f takingone results in d1 = 1 Assuming the computation level
requires two multipliers x f could take on the value 1or 2 depending on the resource constraint leading tod1 = 2 or d1 = 1 cycles respectively
The last two terms of the objective 1 are the execu-tion cycles taken by final result merging When a treestructure is used as in Fig 1d and e the number of levelsof the merging tree is log2 k and thus the numberof execution cycles taken by the merging tree is thesum of the execution cycles c j spent on every level jWe arrange the number of merging operations in eachlevel such that there are m1 merging operations in thetop level and subsequently the following level has m j
merging operations as defined in Eqs 4 and 5
m1 ge k2 (4)
m j ge m jminus12 2 le j le log2 k (5)
The number of execution cycles c j of level j is deter-mined by the number of merging operations in levelj and Mr the number of resources available for themerging operations in Eq 6 which is the resourceconstraint on the merging operations
c j ge m jMr 1 le j le log2 k (6)
The Boolean parameter notFull is added to Eq 1 forthe case where the loop is partially strip-mined andsequential accumulation of the results is needed Fig 1dshows an example
There are four constraints on the pipelining initiationinterval ii as shown in Eqs 7ndash10 Inequality 7 is thememory bandwidth constraint Given a fixed memorybandwidth Mb and the memory bandwidth required inone loop iteration B more parallel loop iterations krequire more input data and thus more data loadingtime leading to a larger initiation interval (ii) Herethe Boolean parameter notAlign is used to capture thesituation where data are not aligned between storageand computation this case may need one extra mem-ory access to obtain requested data Inequality 8 givesthe computation resource constraints where W f is thenumber of each computation resource f required inone loop iteration Inequality 9 is the data dependenceconstraint on ii as used in [10 11] The available re-source for merging operations also has impact on ii asshown in inequality 10 For k intermediate computationresults generated in parallel up to k merging operationsare needed to obtain the final result
B times k times Mminus1b times iiminus1 + notAlign times iiminus1 le 1 (7)
W f times xminus1f times iiminus1 le 1 f isin F (8)
J Sign Process Syst (2012) 6765ndash78 71
RecII times iiminus1 le 1 (9)
k times Mminus1r times iiminus1 le 1 (10)
Inequality 11 captures how computation resourcesconstrain parallelization We achieve an efficient so-lution by balancing the resources allocated to loopparallelization (k) and pipelining (ii) given that thenumber of resource f available is C f
k times x f le C f f isin F (11)
Inequalities 12 and 13 are the ranges of integer vari-ables k and x f respectively Inequality 13 may appearto be redundant but the GP solver requires explicitranges for all variables
1 le k le N (12)
1 le x f le C f f isin F (13)
Overall the only item making the relaxed problem1ndash13 (allowing all variables to be real numbers) not aGP problem is the logarithm log2 k The logarithmsmust be eliminated in order to use a GP solver How-ever we note that log2 k is constant in certain rangesof k Therefore the problem 1ndash13 can be seen as apiecewise integer geometric problem in different rangesof k the number of subproblems increases logarithmi-cally with k For large k = 1000 there are 11 integerGP problems and each problem can be quickly solvedusing a branch and bound algorithm used in [21] with aGP solver as the lower bounding procedure Section 6shows the performance of the piecewise GP model Thesolution (k ii) to the problem 1ndash13 tells us how toMapReduce and pipeline the loop under consideration
The formulation 1ndash13 targets mapping a loop ontoa parallel computing structure The loop need not beinnermost For example in order to map a 2-levelloop nest unrolling the innermost loop allows the for-mulation to work Equivalently we can add severalconstraints as shown below to the formulation 1ndash13Then we can automatically determine pipelining theinnermost loop (iiprime) strip-mining (k) the outer loopand global pipelining (ii) the Monte Carlo simulationof Asian Option benchmark in Section 6 exhibits thiscase Inequality 14 shows the constraint the innermostloop (with Nprime iterations) scheduling length on the ini-tiation interval ii of the outer loop as the outer loopcannot start the next iteration before the innermostloop finishes Inequalities 15 and 16 are the compu-tation resource and data dependence constraints onthe initiation interval of pipelining the innermost loopThe required resources W prime
f in the innermost loop are
included in W f in order to share resources amongoperations
(Nprime minus 1) times iiprime times iiminus1 + iiminus1 timesIprimesum
i=1
dprimei le 1 (14)
W primef times xminus1
f times iiprimeminus1 le 1 f isin F (15)
RecIIprime times iiprimeminus1 le 1 (16)
Finally the MapReduce pattern is also present insome applications in 2-D form Our pattern-basedtransforms could coalesce 2-D loops into 1-D so the GPformulation described above can apply We extend in-equality 7 to cover 2-D data block (Row times Col) accessallowing for the 2-D data block access to not necessarilybe linearized
Row times (B times k times Mminus1
b times iiminus1 + notAlign times iiminus1) le 1
(17)
52 Extension of the Model for Linear Reduce
In the previous subsection the logarithm expression inthe objective function results from using a tree struc-ture for Reduce Alternatively a linear structure couldbe used Fig 1f shows an example for dot productFor k parallel computations the linear structure needsk execution cycles to merge all intermediate resultsAlthough longer than the tree structure some appli-cations with the MapReduce pattern using the linearstructure to merge results can both keep the samethroughput as the tree structure and reduce the mem-ory bandwidth requirement Other merging structuresare possible we have not yet found a compelling usecase for these
Figure 3a shows an example of 1-D correlation Theinnermost loop j of the code has a similar computa-tion pattern to the dot product and can map onto aparallel computing structure using MapReduce Thedifferences from the dot product are that one multipli-cation operand w j is constant and when the outer loopi iterates the data of A are shifted invariantly into thecomputation This is potentially suitable for pipelining
(a) The original code(b) Fully parallel structure for loop
j with linear merging
Figure 3 An example 1-D correlation
72 J Sign Process Syst (2012) 6765ndash78
If the innermost loop j can be fully strip-mined thenthe N multiplications execute at the same time and theintermediate computation results are linearly mergedas shown in Fig 3b An important characteristic of thisstructure is its regular shape which could benefit theplacement and routing of hardware resources Aftermapping loop j fully pipelining loop i produces a C[i]every cycle after N execution cycles If any multipliersand memory access bandwidth are still available loop icould be further partitioned
Many signal and image processing applications use1-D correlation or convolution or show similar be-havior so we extend the formulation in Section 51for linear reduction In the objective function 18 wereplace
sumlog2 kj c j with k Constraints 4ndash6 are no longer
applied When the loop is partially strip-mined notFullhere represents a delay of the accumulated result whichfeeds back to the linear structure in the next iterationBecause the number of cycles taken to multiply eachelement of A with the N coefficients decreases as thenumber of parallel partitions increases the data depen-dence distance of loop j similarly decreases Thereforewe add inequality 19
minimize v times ii +Isum
i=1
di + k + notFull (18)
N times kminus1 times iiminus1 le 1 (19)
Now the formulation with objective 18 and con-straints 7ndash19 is a GP model mapping MapReduce pat-terns to a parallel computing platform with a linearreduction
53 Extension of the Model for Multi-levelMapReduce
The GP models presented above are for mapping asingle loop level with the MapReduce pattern ontoa parallel computing platform This section extendsthe models to map nested loops with the MapReducepatterns We target a rectangular loop nest with L loops(I1 I2 IL) where I1 is the outermost loop IL is theinnermost loop and the loop length of loop l is Nl Forsimplicity we assume that all computational operationsreside in the innermost loop and only the innermostloop is pipelined The statements outside the innermostloop are divided into two disjoint sets S1 = mergingstatements outside the innermost loop and S2 = non-merging statements outside the innermost loop
Expressions 1 and 18 correspond to the executioncycles of the innermost loop alone using tree or linear
reduction structures We redefine them as e = vL timesii + sumI
i=1 di + rL + notFull where rL is the number ofexecution cycles of the merging statement sL in the in-nermost loop Then we can formulate the total execu-tion cycles of the target loop nest as the new objective
minimizeLminus1prod
l=1
vl timese+sum
sisinS2
Isprod
l=1
vl +sum
sisinS1
(vIs timesnotFullIs +rs
)
(20)
where Is is the loop level in which statement s is locatedand
rs =log2 kIs sum
j
csj or kIs (21)
is the number of execution cycles taken by mergingstatement s using tree reduction structure or linearreduction structure where csj have the same meaningas c j in Eq 1 but for merging statement s outside theinnermost loop rL also complies with Eq 21 for themerging statement in the innermost loop
The number of iterations vl of loop l after partition-ing into kl parallel segments is
Nl times kminus1l le vl 1 le l le L (22)
1 le kl le Nl 1 le l le L (23)
Moreover the constraints of the resources used formerging operations in the tree structure (4ndash6) and (10)need to be defined according to each merging statementin the loop nest
ms1 ge kIs2 s isin S1 cup sL (24)
msj ge msjminus12 s isin S1 cup sL 2 le j le log2 kIs (25)
csj ge msjMr s isin S1 cup sL 1 le j le log2 kIs (26)
kL times Mminus1r times iiminus1 le 1 (27)
Correspondingly the memory bandwidth constraint 7is redefined as
Ba timesprod
lisinQa
kl times Mminus1b times iiminus1 + notAligna times iiminus1 le 1 a isin A
(28)
where each of A array references under operations isstored in a memory bank with bandwidth Mb eachreference a requires Ba memory bandwidth in one loopiteration and Qa is the set of loop variables in theindexing function of reference a Unlike Eq 7 hereeach array reference is treated individually because dif-ferent array references may have different bandwidth
J Sign Process Syst (2012) 6765ndash78 73
Table 3 Benchmark details Benchmark loops Refs MapReduce pattern
MAT64 3 2 Two levels in the outer loopsand the innermost loop
ME Implicit 2 Two levels implicit and in SADSobel 4 2 Two levels in outer two loops
and inner two loopsMCS 2 0 In the outer loop1-D correlation 2 1 In the innermost loopk-means 4 1 In the inner three loops
requirements after mapping multiple MapReduce pat-terns Meanwhile the computational resource con-straint 11 is redefined as
Lprod
l=1
kl times x f le C f f isin F (29)
This model allows us to map the multi-level MapRe-duce pattern and thus extends the applicability of theproposed approach This model is still a piecewise GPproblem With multiple nested patterns however thisproblem has more variables and more subproblemscaused by the logarithm and thus could take longer tosolve
6 Experimental Results
We apply the proposed approach to six kernels multi-plication of two 64 times 64 matrices (MAT64) the motionestimation (ME) algorithm [15] used in X264 the Sobeledge detection algorithm (Sobel) [17] Monte Carlosimulation (MCS) of Asian Option Pricing [16] 1-Dcorrelation and k-means clustering [18] Table 3 showsbenchmark parameters Each benchmark contains theMapReduce patterns One level of the MapReducepattern exists in MCS and 1-D correlation to which themodels presented in Sections 51 and 52 are appliedrespectively Two levels of the MapReduce pattern areidentified in ME MAT64 and Sobel We apply thetransforms [6] to the outer level exploiting data reuseand loop-level parallelism For the MapReduce patternin the inner loops we apply the model in Section 51 toexploit inner loop parallelization and pipelining Lastlywe apply the extended model in Section 53 to k-meansclustering which has three levels of the MapReducepattern All GP models are solved by a MATLABtool box named YALMIP [21] Different designs arerepresented by the number of parallel loop partitionsand the pipelining initiation interval (kl ii)
In our experiments the target platform is an FPGA-based system with off-chip SRAM The Monte Carlosimulation of Asian Option involving floating point
arithmetic is implemented in Xilinx XC4VFX140 with192 DSP48 and the other five kernels are implementedin XC2v8000 which has 168 embedded hard multipli-ers and 168 dual-port RAM blocks On-chip RAMsconfigured as scratch-pad buffers and registers are usedto increase memory bandwidth All experimental re-sults are obtained on the target platform after synthesisplacement and routing For ME and Sobel the framesize is the QCIF luminance component (144 times 176pixels)
Matrixndashmatrix Multiplication is a typical arithmetickernel used in many applications Each element of theoutput matrix is the dot product of one row of one inputmatrix and one column of the other input matrix Thedot product is the inner MapReduce pattern level andcomputing multiple elements of the output matrix inparallel is the outer MapReduce level In our imple-mentation each matrix element is 8 bits Memory band-width and the number of hard multipliers embeddedin the FPGA are the constraints on mapping the innerlevel MapReduce pattern Figure 4 shows results fromapplying our proposed piecewise GP model (1ndash13) tothe innermost loop of MAT64 Given a memory band-width and the number of multipliers the figure reveals
12345678
0 2 4 6 8 10 12 14 16 17
0
20
40
60
80
100
120
140
MultipliersMemory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
(3 2)(2 1)
(1 1)
(4 1)(5 2)
Figure 4 Designs proposed by the framework for MAT64 Thebracket next to each design shows (k ii)
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL

J Sign Process Syst (2012) 6765ndash78 71
RecII times iiminus1 le 1 (9)
k times Mminus1r times iiminus1 le 1 (10)
Inequality 11 captures how computation resourcesconstrain parallelization We achieve an efficient so-lution by balancing the resources allocated to loopparallelization (k) and pipelining (ii) given that thenumber of resource f available is C f
k times x f le C f f isin F (11)
Inequalities 12 and 13 are the ranges of integer vari-ables k and x f respectively Inequality 13 may appearto be redundant but the GP solver requires explicitranges for all variables
1 le k le N (12)
1 le x f le C f f isin F (13)
Overall the only item making the relaxed problem1ndash13 (allowing all variables to be real numbers) not aGP problem is the logarithm log2 k The logarithmsmust be eliminated in order to use a GP solver How-ever we note that log2 k is constant in certain rangesof k Therefore the problem 1ndash13 can be seen as apiecewise integer geometric problem in different rangesof k the number of subproblems increases logarithmi-cally with k For large k = 1000 there are 11 integerGP problems and each problem can be quickly solvedusing a branch and bound algorithm used in [21] with aGP solver as the lower bounding procedure Section 6shows the performance of the piecewise GP model Thesolution (k ii) to the problem 1ndash13 tells us how toMapReduce and pipeline the loop under consideration
The formulation 1ndash13 targets mapping a loop ontoa parallel computing structure The loop need not beinnermost For example in order to map a 2-levelloop nest unrolling the innermost loop allows the for-mulation to work Equivalently we can add severalconstraints as shown below to the formulation 1ndash13Then we can automatically determine pipelining theinnermost loop (iiprime) strip-mining (k) the outer loopand global pipelining (ii) the Monte Carlo simulationof Asian Option benchmark in Section 6 exhibits thiscase Inequality 14 shows the constraint the innermostloop (with Nprime iterations) scheduling length on the ini-tiation interval ii of the outer loop as the outer loopcannot start the next iteration before the innermostloop finishes Inequalities 15 and 16 are the compu-tation resource and data dependence constraints onthe initiation interval of pipelining the innermost loopThe required resources W prime
f in the innermost loop are
included in W f in order to share resources amongoperations
(Nprime minus 1) times iiprime times iiminus1 + iiminus1 timesIprimesum
i=1
dprimei le 1 (14)
W primef times xminus1
f times iiprimeminus1 le 1 f isin F (15)
RecIIprime times iiprimeminus1 le 1 (16)
Finally the MapReduce pattern is also present insome applications in 2-D form Our pattern-basedtransforms could coalesce 2-D loops into 1-D so the GPformulation described above can apply We extend in-equality 7 to cover 2-D data block (Row times Col) accessallowing for the 2-D data block access to not necessarilybe linearized
Row times (B times k times Mminus1
b times iiminus1 + notAlign times iiminus1) le 1
(17)
52 Extension of the Model for Linear Reduce
In the previous subsection the logarithm expression inthe objective function results from using a tree struc-ture for Reduce Alternatively a linear structure couldbe used Fig 1f shows an example for dot productFor k parallel computations the linear structure needsk execution cycles to merge all intermediate resultsAlthough longer than the tree structure some appli-cations with the MapReduce pattern using the linearstructure to merge results can both keep the samethroughput as the tree structure and reduce the mem-ory bandwidth requirement Other merging structuresare possible we have not yet found a compelling usecase for these
Figure 3a shows an example of 1-D correlation Theinnermost loop j of the code has a similar computa-tion pattern to the dot product and can map onto aparallel computing structure using MapReduce Thedifferences from the dot product are that one multipli-cation operand w j is constant and when the outer loopi iterates the data of A are shifted invariantly into thecomputation This is potentially suitable for pipelining
(a) The original code(b) Fully parallel structure for loop
j with linear merging
Figure 3 An example 1-D correlation
72 J Sign Process Syst (2012) 6765ndash78
If the innermost loop j can be fully strip-mined thenthe N multiplications execute at the same time and theintermediate computation results are linearly mergedas shown in Fig 3b An important characteristic of thisstructure is its regular shape which could benefit theplacement and routing of hardware resources Aftermapping loop j fully pipelining loop i produces a C[i]every cycle after N execution cycles If any multipliersand memory access bandwidth are still available loop icould be further partitioned
Many signal and image processing applications use1-D correlation or convolution or show similar be-havior so we extend the formulation in Section 51for linear reduction In the objective function 18 wereplace
sumlog2 kj c j with k Constraints 4ndash6 are no longer
applied When the loop is partially strip-mined notFullhere represents a delay of the accumulated result whichfeeds back to the linear structure in the next iterationBecause the number of cycles taken to multiply eachelement of A with the N coefficients decreases as thenumber of parallel partitions increases the data depen-dence distance of loop j similarly decreases Thereforewe add inequality 19
minimize v times ii +Isum
i=1
di + k + notFull (18)
N times kminus1 times iiminus1 le 1 (19)
Now the formulation with objective 18 and con-straints 7ndash19 is a GP model mapping MapReduce pat-terns to a parallel computing platform with a linearreduction
53 Extension of the Model for Multi-levelMapReduce
The GP models presented above are for mapping asingle loop level with the MapReduce pattern ontoa parallel computing platform This section extendsthe models to map nested loops with the MapReducepatterns We target a rectangular loop nest with L loops(I1 I2 IL) where I1 is the outermost loop IL is theinnermost loop and the loop length of loop l is Nl Forsimplicity we assume that all computational operationsreside in the innermost loop and only the innermostloop is pipelined The statements outside the innermostloop are divided into two disjoint sets S1 = mergingstatements outside the innermost loop and S2 = non-merging statements outside the innermost loop
Expressions 1 and 18 correspond to the executioncycles of the innermost loop alone using tree or linear
reduction structures We redefine them as e = vL timesii + sumI
i=1 di + rL + notFull where rL is the number ofexecution cycles of the merging statement sL in the in-nermost loop Then we can formulate the total execu-tion cycles of the target loop nest as the new objective
minimizeLminus1prod
l=1
vl timese+sum
sisinS2
Isprod
l=1
vl +sum
sisinS1
(vIs timesnotFullIs +rs
)
(20)
where Is is the loop level in which statement s is locatedand
rs =log2 kIs sum
j
csj or kIs (21)
is the number of execution cycles taken by mergingstatement s using tree reduction structure or linearreduction structure where csj have the same meaningas c j in Eq 1 but for merging statement s outside theinnermost loop rL also complies with Eq 21 for themerging statement in the innermost loop
The number of iterations vl of loop l after partition-ing into kl parallel segments is
Nl times kminus1l le vl 1 le l le L (22)
1 le kl le Nl 1 le l le L (23)
Moreover the constraints of the resources used formerging operations in the tree structure (4ndash6) and (10)need to be defined according to each merging statementin the loop nest
ms1 ge kIs2 s isin S1 cup sL (24)
msj ge msjminus12 s isin S1 cup sL 2 le j le log2 kIs (25)
csj ge msjMr s isin S1 cup sL 1 le j le log2 kIs (26)
kL times Mminus1r times iiminus1 le 1 (27)
Correspondingly the memory bandwidth constraint 7is redefined as
Ba timesprod
lisinQa
kl times Mminus1b times iiminus1 + notAligna times iiminus1 le 1 a isin A
(28)
where each of A array references under operations isstored in a memory bank with bandwidth Mb eachreference a requires Ba memory bandwidth in one loopiteration and Qa is the set of loop variables in theindexing function of reference a Unlike Eq 7 hereeach array reference is treated individually because dif-ferent array references may have different bandwidth
J Sign Process Syst (2012) 6765ndash78 73
Table 3 Benchmark details Benchmark loops Refs MapReduce pattern
MAT64 3 2 Two levels in the outer loopsand the innermost loop
ME Implicit 2 Two levels implicit and in SADSobel 4 2 Two levels in outer two loops
and inner two loopsMCS 2 0 In the outer loop1-D correlation 2 1 In the innermost loopk-means 4 1 In the inner three loops
requirements after mapping multiple MapReduce pat-terns Meanwhile the computational resource con-straint 11 is redefined as
Lprod
l=1
kl times x f le C f f isin F (29)
This model allows us to map the multi-level MapRe-duce pattern and thus extends the applicability of theproposed approach This model is still a piecewise GPproblem With multiple nested patterns however thisproblem has more variables and more subproblemscaused by the logarithm and thus could take longer tosolve
6 Experimental Results
We apply the proposed approach to six kernels multi-plication of two 64 times 64 matrices (MAT64) the motionestimation (ME) algorithm [15] used in X264 the Sobeledge detection algorithm (Sobel) [17] Monte Carlosimulation (MCS) of Asian Option Pricing [16] 1-Dcorrelation and k-means clustering [18] Table 3 showsbenchmark parameters Each benchmark contains theMapReduce patterns One level of the MapReducepattern exists in MCS and 1-D correlation to which themodels presented in Sections 51 and 52 are appliedrespectively Two levels of the MapReduce pattern areidentified in ME MAT64 and Sobel We apply thetransforms [6] to the outer level exploiting data reuseand loop-level parallelism For the MapReduce patternin the inner loops we apply the model in Section 51 toexploit inner loop parallelization and pipelining Lastlywe apply the extended model in Section 53 to k-meansclustering which has three levels of the MapReducepattern All GP models are solved by a MATLABtool box named YALMIP [21] Different designs arerepresented by the number of parallel loop partitionsand the pipelining initiation interval (kl ii)
In our experiments the target platform is an FPGA-based system with off-chip SRAM The Monte Carlosimulation of Asian Option involving floating point
arithmetic is implemented in Xilinx XC4VFX140 with192 DSP48 and the other five kernels are implementedin XC2v8000 which has 168 embedded hard multipli-ers and 168 dual-port RAM blocks On-chip RAMsconfigured as scratch-pad buffers and registers are usedto increase memory bandwidth All experimental re-sults are obtained on the target platform after synthesisplacement and routing For ME and Sobel the framesize is the QCIF luminance component (144 times 176pixels)
Matrixndashmatrix Multiplication is a typical arithmetickernel used in many applications Each element of theoutput matrix is the dot product of one row of one inputmatrix and one column of the other input matrix Thedot product is the inner MapReduce pattern level andcomputing multiple elements of the output matrix inparallel is the outer MapReduce level In our imple-mentation each matrix element is 8 bits Memory band-width and the number of hard multipliers embeddedin the FPGA are the constraints on mapping the innerlevel MapReduce pattern Figure 4 shows results fromapplying our proposed piecewise GP model (1ndash13) tothe innermost loop of MAT64 Given a memory band-width and the number of multipliers the figure reveals
12345678
0 2 4 6 8 10 12 14 16 17
0
20
40
60
80
100
120
140
MultipliersMemory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
(3 2)(2 1)
(1 1)
(4 1)(5 2)
Figure 4 Designs proposed by the framework for MAT64 Thebracket next to each design shows (k ii)
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL

72 J Sign Process Syst (2012) 6765ndash78
If the innermost loop j can be fully strip-mined thenthe N multiplications execute at the same time and theintermediate computation results are linearly mergedas shown in Fig 3b An important characteristic of thisstructure is its regular shape which could benefit theplacement and routing of hardware resources Aftermapping loop j fully pipelining loop i produces a C[i]every cycle after N execution cycles If any multipliersand memory access bandwidth are still available loop icould be further partitioned
Many signal and image processing applications use1-D correlation or convolution or show similar be-havior so we extend the formulation in Section 51for linear reduction In the objective function 18 wereplace
sumlog2 kj c j with k Constraints 4ndash6 are no longer
applied When the loop is partially strip-mined notFullhere represents a delay of the accumulated result whichfeeds back to the linear structure in the next iterationBecause the number of cycles taken to multiply eachelement of A with the N coefficients decreases as thenumber of parallel partitions increases the data depen-dence distance of loop j similarly decreases Thereforewe add inequality 19
minimize v times ii +Isum
i=1
di + k + notFull (18)
N times kminus1 times iiminus1 le 1 (19)
Now the formulation with objective 18 and con-straints 7ndash19 is a GP model mapping MapReduce pat-terns to a parallel computing platform with a linearreduction
53 Extension of the Model for Multi-levelMapReduce
The GP models presented above are for mapping asingle loop level with the MapReduce pattern ontoa parallel computing platform This section extendsthe models to map nested loops with the MapReducepatterns We target a rectangular loop nest with L loops(I1 I2 IL) where I1 is the outermost loop IL is theinnermost loop and the loop length of loop l is Nl Forsimplicity we assume that all computational operationsreside in the innermost loop and only the innermostloop is pipelined The statements outside the innermostloop are divided into two disjoint sets S1 = mergingstatements outside the innermost loop and S2 = non-merging statements outside the innermost loop
Expressions 1 and 18 correspond to the executioncycles of the innermost loop alone using tree or linear
reduction structures We redefine them as e = vL timesii + sumI
i=1 di + rL + notFull where rL is the number ofexecution cycles of the merging statement sL in the in-nermost loop Then we can formulate the total execu-tion cycles of the target loop nest as the new objective
minimizeLminus1prod
l=1
vl timese+sum
sisinS2
Isprod
l=1
vl +sum
sisinS1
(vIs timesnotFullIs +rs
)
(20)
where Is is the loop level in which statement s is locatedand
rs =log2 kIs sum
j
csj or kIs (21)
is the number of execution cycles taken by mergingstatement s using tree reduction structure or linearreduction structure where csj have the same meaningas c j in Eq 1 but for merging statement s outside theinnermost loop rL also complies with Eq 21 for themerging statement in the innermost loop
The number of iterations vl of loop l after partition-ing into kl parallel segments is
Nl times kminus1l le vl 1 le l le L (22)
1 le kl le Nl 1 le l le L (23)
Moreover the constraints of the resources used formerging operations in the tree structure (4ndash6) and (10)need to be defined according to each merging statementin the loop nest
ms1 ge kIs2 s isin S1 cup sL (24)
msj ge msjminus12 s isin S1 cup sL 2 le j le log2 kIs (25)
csj ge msjMr s isin S1 cup sL 1 le j le log2 kIs (26)
kL times Mminus1r times iiminus1 le 1 (27)
Correspondingly the memory bandwidth constraint 7is redefined as
Ba timesprod
lisinQa
kl times Mminus1b times iiminus1 + notAligna times iiminus1 le 1 a isin A
(28)
where each of A array references under operations isstored in a memory bank with bandwidth Mb eachreference a requires Ba memory bandwidth in one loopiteration and Qa is the set of loop variables in theindexing function of reference a Unlike Eq 7 hereeach array reference is treated individually because dif-ferent array references may have different bandwidth
J Sign Process Syst (2012) 6765ndash78 73
Table 3 Benchmark details Benchmark loops Refs MapReduce pattern
MAT64 3 2 Two levels in the outer loopsand the innermost loop
ME Implicit 2 Two levels implicit and in SADSobel 4 2 Two levels in outer two loops
and inner two loopsMCS 2 0 In the outer loop1-D correlation 2 1 In the innermost loopk-means 4 1 In the inner three loops
requirements after mapping multiple MapReduce pat-terns Meanwhile the computational resource con-straint 11 is redefined as
Lprod
l=1
kl times x f le C f f isin F (29)
This model allows us to map the multi-level MapRe-duce pattern and thus extends the applicability of theproposed approach This model is still a piecewise GPproblem With multiple nested patterns however thisproblem has more variables and more subproblemscaused by the logarithm and thus could take longer tosolve
6 Experimental Results
We apply the proposed approach to six kernels multi-plication of two 64 times 64 matrices (MAT64) the motionestimation (ME) algorithm [15] used in X264 the Sobeledge detection algorithm (Sobel) [17] Monte Carlosimulation (MCS) of Asian Option Pricing [16] 1-Dcorrelation and k-means clustering [18] Table 3 showsbenchmark parameters Each benchmark contains theMapReduce patterns One level of the MapReducepattern exists in MCS and 1-D correlation to which themodels presented in Sections 51 and 52 are appliedrespectively Two levels of the MapReduce pattern areidentified in ME MAT64 and Sobel We apply thetransforms [6] to the outer level exploiting data reuseand loop-level parallelism For the MapReduce patternin the inner loops we apply the model in Section 51 toexploit inner loop parallelization and pipelining Lastlywe apply the extended model in Section 53 to k-meansclustering which has three levels of the MapReducepattern All GP models are solved by a MATLABtool box named YALMIP [21] Different designs arerepresented by the number of parallel loop partitionsand the pipelining initiation interval (kl ii)
In our experiments the target platform is an FPGA-based system with off-chip SRAM The Monte Carlosimulation of Asian Option involving floating point
arithmetic is implemented in Xilinx XC4VFX140 with192 DSP48 and the other five kernels are implementedin XC2v8000 which has 168 embedded hard multipli-ers and 168 dual-port RAM blocks On-chip RAMsconfigured as scratch-pad buffers and registers are usedto increase memory bandwidth All experimental re-sults are obtained on the target platform after synthesisplacement and routing For ME and Sobel the framesize is the QCIF luminance component (144 times 176pixels)
Matrixndashmatrix Multiplication is a typical arithmetickernel used in many applications Each element of theoutput matrix is the dot product of one row of one inputmatrix and one column of the other input matrix Thedot product is the inner MapReduce pattern level andcomputing multiple elements of the output matrix inparallel is the outer MapReduce level In our imple-mentation each matrix element is 8 bits Memory band-width and the number of hard multipliers embeddedin the FPGA are the constraints on mapping the innerlevel MapReduce pattern Figure 4 shows results fromapplying our proposed piecewise GP model (1ndash13) tothe innermost loop of MAT64 Given a memory band-width and the number of multipliers the figure reveals
12345678
0 2 4 6 8 10 12 14 16 17
0
20
40
60
80
100
120
140
MultipliersMemory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
(3 2)(2 1)
(1 1)
(4 1)(5 2)
Figure 4 Designs proposed by the framework for MAT64 Thebracket next to each design shows (k ii)
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL
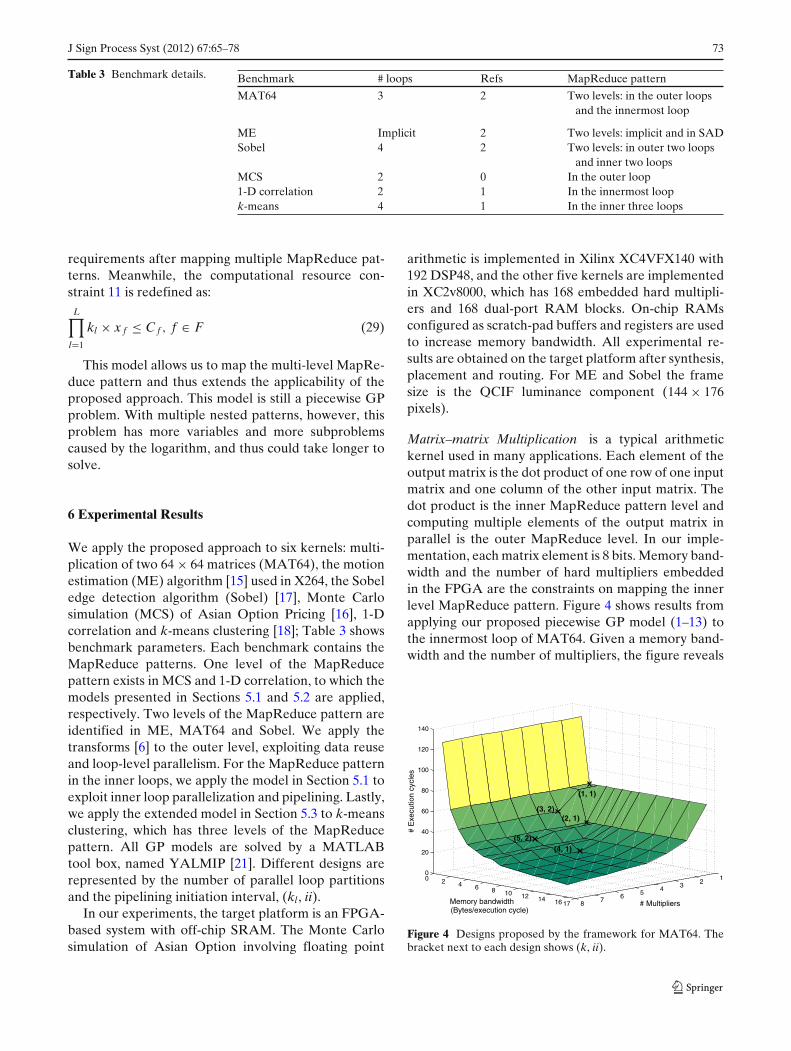
J Sign Process Syst (2012) 6765ndash78 73
Table 3 Benchmark details Benchmark loops Refs MapReduce pattern
MAT64 3 2 Two levels in the outer loopsand the innermost loop
ME Implicit 2 Two levels implicit and in SADSobel 4 2 Two levels in outer two loops
and inner two loopsMCS 2 0 In the outer loop1-D correlation 2 1 In the innermost loopk-means 4 1 In the inner three loops
requirements after mapping multiple MapReduce pat-terns Meanwhile the computational resource con-straint 11 is redefined as
Lprod
l=1
kl times x f le C f f isin F (29)
This model allows us to map the multi-level MapRe-duce pattern and thus extends the applicability of theproposed approach This model is still a piecewise GPproblem With multiple nested patterns however thisproblem has more variables and more subproblemscaused by the logarithm and thus could take longer tosolve
6 Experimental Results
We apply the proposed approach to six kernels multi-plication of two 64 times 64 matrices (MAT64) the motionestimation (ME) algorithm [15] used in X264 the Sobeledge detection algorithm (Sobel) [17] Monte Carlosimulation (MCS) of Asian Option Pricing [16] 1-Dcorrelation and k-means clustering [18] Table 3 showsbenchmark parameters Each benchmark contains theMapReduce patterns One level of the MapReducepattern exists in MCS and 1-D correlation to which themodels presented in Sections 51 and 52 are appliedrespectively Two levels of the MapReduce pattern areidentified in ME MAT64 and Sobel We apply thetransforms [6] to the outer level exploiting data reuseand loop-level parallelism For the MapReduce patternin the inner loops we apply the model in Section 51 toexploit inner loop parallelization and pipelining Lastlywe apply the extended model in Section 53 to k-meansclustering which has three levels of the MapReducepattern All GP models are solved by a MATLABtool box named YALMIP [21] Different designs arerepresented by the number of parallel loop partitionsand the pipelining initiation interval (kl ii)
In our experiments the target platform is an FPGA-based system with off-chip SRAM The Monte Carlosimulation of Asian Option involving floating point
arithmetic is implemented in Xilinx XC4VFX140 with192 DSP48 and the other five kernels are implementedin XC2v8000 which has 168 embedded hard multipli-ers and 168 dual-port RAM blocks On-chip RAMsconfigured as scratch-pad buffers and registers are usedto increase memory bandwidth All experimental re-sults are obtained on the target platform after synthesisplacement and routing For ME and Sobel the framesize is the QCIF luminance component (144 times 176pixels)
Matrixndashmatrix Multiplication is a typical arithmetickernel used in many applications Each element of theoutput matrix is the dot product of one row of one inputmatrix and one column of the other input matrix Thedot product is the inner MapReduce pattern level andcomputing multiple elements of the output matrix inparallel is the outer MapReduce level In our imple-mentation each matrix element is 8 bits Memory band-width and the number of hard multipliers embeddedin the FPGA are the constraints on mapping the innerlevel MapReduce pattern Figure 4 shows results fromapplying our proposed piecewise GP model (1ndash13) tothe innermost loop of MAT64 Given a memory band-width and the number of multipliers the figure reveals
12345678
0 2 4 6 8 10 12 14 16 17
0
20
40
60
80
100
120
140
MultipliersMemory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
(3 2)(2 1)
(1 1)
(4 1)(5 2)
Figure 4 Designs proposed by the framework for MAT64 Thebracket next to each design shows (k ii)
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL
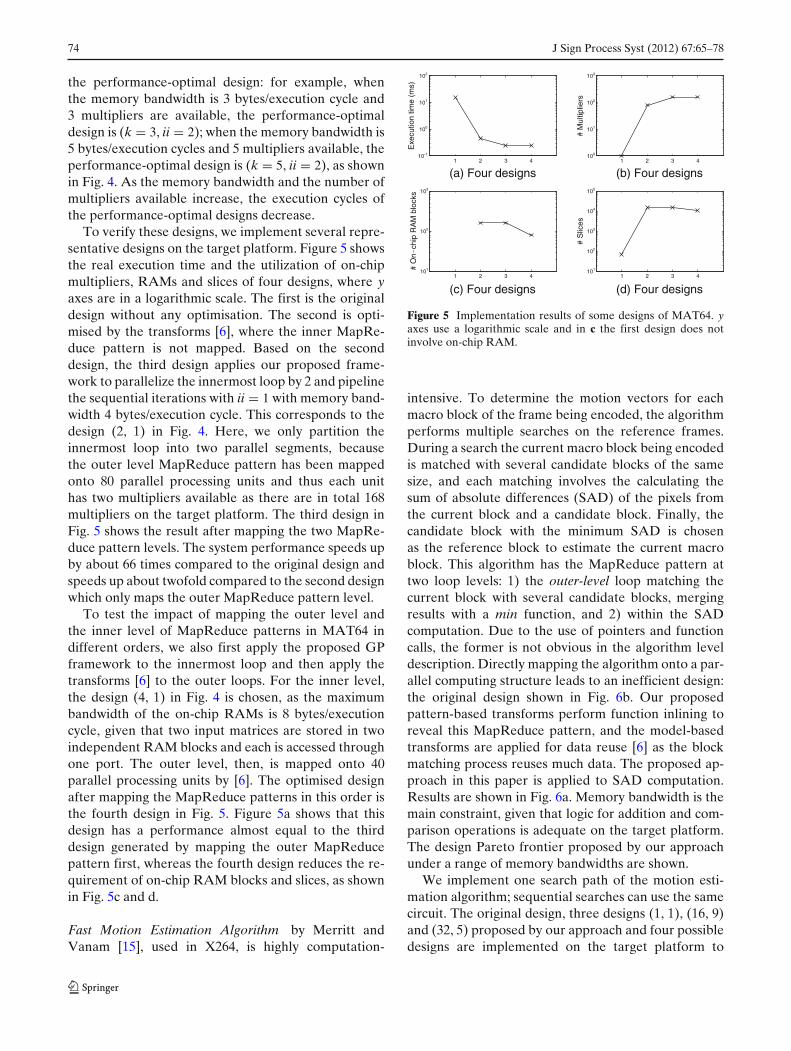
74 J Sign Process Syst (2012) 6765ndash78
the performance-optimal design for example whenthe memory bandwidth is 3 bytesexecution cycle and3 multipliers are available the performance-optimaldesign is (k = 3 ii = 2) when the memory bandwidth is5 bytesexecution cycles and 5 multipliers available theperformance-optimal design is (k = 5 ii = 2) as shownin Fig 4 As the memory bandwidth and the number ofmultipliers available increase the execution cycles ofthe performance-optimal designs decrease
To verify these designs we implement several repre-sentative designs on the target platform Figure 5 showsthe real execution time and the utilization of on-chipmultipliers RAMs and slices of four designs where yaxes are in a logarithmic scale The first is the originaldesign without any optimisation The second is opti-mised by the transforms [6] where the inner MapRe-duce pattern is not mapped Based on the seconddesign the third design applies our proposed frame-work to parallelize the innermost loop by 2 and pipelinethe sequential iterations with ii = 1 with memory band-width 4 bytesexecution cycle This corresponds to thedesign (2 1) in Fig 4 Here we only partition theinnermost loop into two parallel segments becausethe outer level MapReduce pattern has been mappedonto 80 parallel processing units and thus each unithas two multipliers available as there are in total 168multipliers on the target platform The third design inFig 5 shows the result after mapping the two MapRe-duce pattern levels The system performance speeds upby about 66 times compared to the original design andspeeds up about twofold compared to the second designwhich only maps the outer MapReduce pattern level
To test the impact of mapping the outer level andthe inner level of MapReduce patterns in MAT64 indifferent orders we also first apply the proposed GPframework to the innermost loop and then apply thetransforms [6] to the outer loops For the inner levelthe design (4 1) in Fig 4 is chosen as the maximumbandwidth of the on-chip RAMs is 8 bytesexecutioncycle given that two input matrices are stored in twoindependent RAM blocks and each is accessed throughone port The outer level then is mapped onto 40parallel processing units by [6] The optimised designafter mapping the MapReduce patterns in this order isthe fourth design in Fig 5 Figure 5a shows that thisdesign has a performance almost equal to the thirddesign generated by mapping the outer MapReducepattern first whereas the fourth design reduces the re-quirement of on-chip RAM blocks and slices as shownin Fig 5c and d
Fast Motion Estimation Algorithm by Merritt andVanam [15] used in X264 is highly computation-
1 2 3 410-1
100
101
102
Exe
cutio
n tim
e (m
s)
(a) Four designs1 2 3 4
100
101
102
103
(b) Four designs
M
ultip
liers
1 2 3 4101
102
103
(c) Four designs
O
nch
ip R
AM
blo
cks
1 2 3 4101
102
103
104
105
(d) Four designs
S
lices
Figure 5 Implementation results of some designs of MAT64 yaxes use a logarithmic scale and in c the first design does notinvolve on-chip RAM
intensive To determine the motion vectors for eachmacro block of the frame being encoded the algorithmperforms multiple searches on the reference framesDuring a search the current macro block being encodedis matched with several candidate blocks of the samesize and each matching involves the calculating thesum of absolute differences (SAD) of the pixels fromthe current block and a candidate block Finally thecandidate block with the minimum SAD is chosenas the reference block to estimate the current macroblock This algorithm has the MapReduce pattern attwo loop levels 1) the outer-level loop matching thecurrent block with several candidate blocks mergingresults with a min function and 2) within the SADcomputation Due to the use of pointers and functioncalls the former is not obvious in the algorithm leveldescription Directly mapping the algorithm onto a par-allel computing structure leads to an inefficient designthe original design shown in Fig 6b Our proposedpattern-based transforms perform function inlining toreveal this MapReduce pattern and the model-basedtransforms are applied for data reuse [6] as the blockmatching process reuses much data The proposed ap-proach in this paper is applied to SAD computationResults are shown in Fig 6a Memory bandwidth is themain constraint given that logic for addition and com-parison operations is adequate on the target platformThe design Pareto frontier proposed by our approachunder a range of memory bandwidths are shown
We implement one search path of the motion esti-mation algorithm sequential searches can use the samecircuit The original design three designs (1 1) (16 9)and (32 5) proposed by our approach and four possibledesigns are implemented on the target platform to
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL
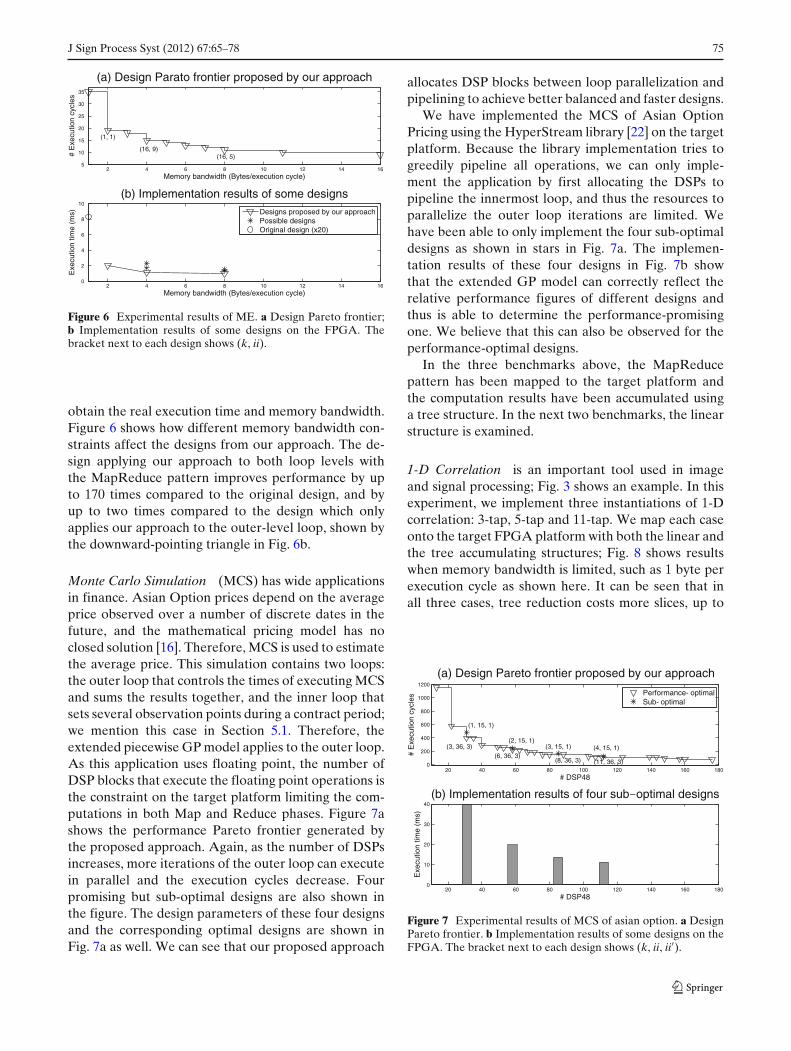
J Sign Process Syst (2012) 6765ndash78 75
2 4 6 8 10 12 14 165
10
15
20
25
30
35
(a) Design Parato frontier proposed by our approach
Memory bandwidth (Bytesexecution cycle)
E
xecu
tion
cycl
es
2 4 6 8 10 12 14 160
2
4
6
8
10
(b) Implementation results of some designs
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Designs proposed by our approachPossible designsOriginal design (x20)
(1 1)
(16 9)(16 5)
Figure 6 Experimental results of ME a Design Pareto frontierb Implementation results of some designs on the FPGA Thebracket next to each design shows (k ii)
obtain the real execution time and memory bandwidthFigure 6 shows how different memory bandwidth con-straints affect the designs from our approach The de-sign applying our approach to both loop levels withthe MapReduce pattern improves performance by upto 170 times compared to the original design and byup to two times compared to the design which onlyapplies our approach to the outer-level loop shown bythe downward-pointing triangle in Fig 6b
Monte Carlo Simulation (MCS) has wide applicationsin finance Asian Option prices depend on the averageprice observed over a number of discrete dates in thefuture and the mathematical pricing model has noclosed solution [16] Therefore MCS is used to estimatethe average price This simulation contains two loopsthe outer loop that controls the times of executing MCSand sums the results together and the inner loop thatsets several observation points during a contract periodwe mention this case in Section 51 Therefore theextended piecewise GP model applies to the outer loopAs this application uses floating point the number ofDSP blocks that execute the floating point operations isthe constraint on the target platform limiting the com-putations in both Map and Reduce phases Figure 7ashows the performance Pareto frontier generated bythe proposed approach Again as the number of DSPsincreases more iterations of the outer loop can executein parallel and the execution cycles decrease Fourpromising but sub-optimal designs are also shown inthe figure The design parameters of these four designsand the corresponding optimal designs are shown inFig 7a as well We can see that our proposed approach
allocates DSP blocks between loop parallelization andpipelining to achieve better balanced and faster designs
We have implemented the MCS of Asian OptionPricing using the HyperStream library [22] on the targetplatform Because the library implementation tries togreedily pipeline all operations we can only imple-ment the application by first allocating the DSPs topipeline the innermost loop and thus the resources toparallelize the outer loop iterations are limited Wehave been able to only implement the four sub-optimaldesigns as shown in stars in Fig 7a The implemen-tation results of these four designs in Fig 7b showthat the extended GP model can correctly reflect therelative performance figures of different designs andthus is able to determine the performance-promisingone We believe that this can also be observed for theperformance-optimal designs
In the three benchmarks above the MapReducepattern has been mapped to the target platform andthe computation results have been accumulated usinga tree structure In the next two benchmarks the linearstructure is examined
1-D Correlation is an important tool used in imageand signal processing Fig 3 shows an example In thisexperiment we implement three instantiations of 1-Dcorrelation 3-tap 5-tap and 11-tap We map each caseonto the target FPGA platform with both the linear andthe tree accumulating structures Fig 8 shows resultswhen memory bandwidth is limited such as 1 byte perexecution cycle as shown here It can be seen that inall three cases tree reduction costs more slices up to
20 40 60 80 100 120 140 160 1800
200
400
600
800
1000
1200
(a) Design Pareto frontier proposed by our approach
DSP48
E
xecu
tion
cycl
es
20 40 60 80 100 120 140 160 1800
10
20
30
40
(b) Implementation results of four sub optimal designs
DSP48
Exe
cutio
n tim
e (m
s)
Performance- optimalSub- optimal
(1 15 1)
(2 15 1)(3 36 3)
(6 36 3)(8 36 3)
(4 15 1)
(11 36 3)
(3 15 1)
Figure 7 Experimental results of MCS of asian option a DesignPareto frontier b Implementation results of some designs on theFPGA The bracket next to each design shows (k ii iiprime)
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL
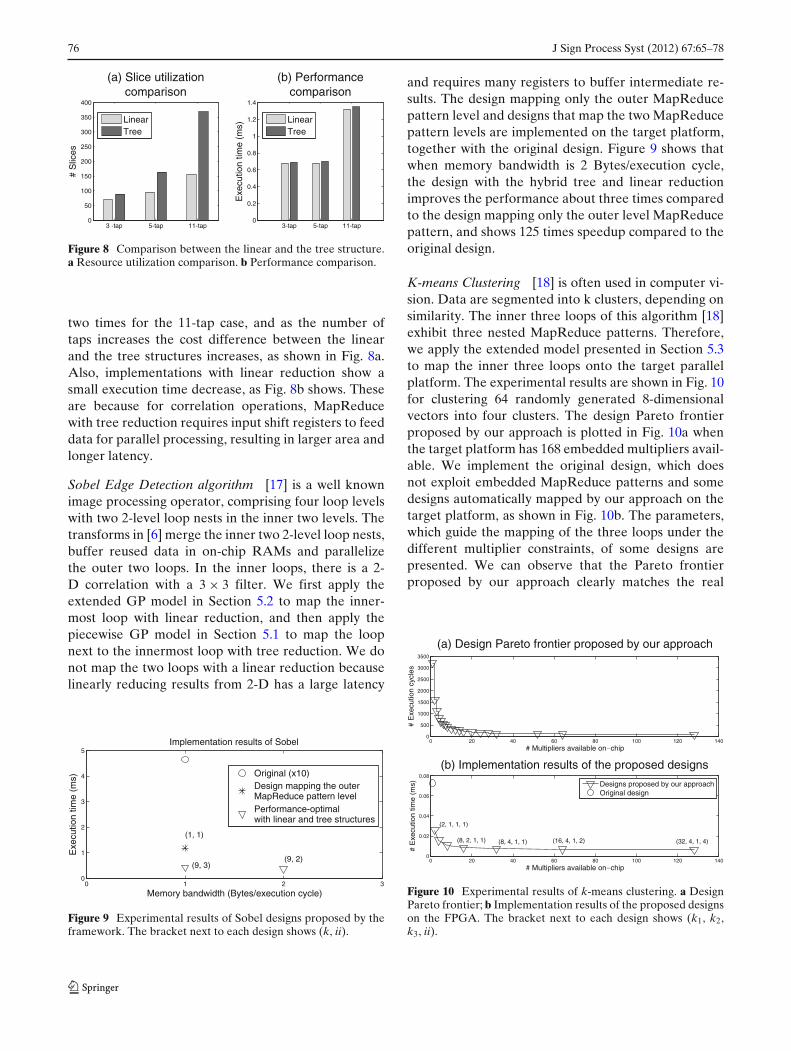
76 J Sign Process Syst (2012) 6765ndash78
3 -tap 5-tap 11-tap0
50
100
150
200
250
300
350
400
S
lices
(a) Slice utilization
3-tap 5-tap 11-tap0
02
04
06
08
1
12
14
Exe
cutio
n tim
e (m
s)
(b) Performance
LinearTree
LinearTree
comparison comparison
Figure 8 Comparison between the linear and the tree structurea Resource utilization comparison b Performance comparison
two times for the 11-tap case and as the number oftaps increases the cost difference between the linearand the tree structures increases as shown in Fig 8aAlso implementations with linear reduction show asmall execution time decrease as Fig 8b shows Theseare because for correlation operations MapReducewith tree reduction requires input shift registers to feeddata for parallel processing resulting in larger area andlonger latency
Sobel Edge Detection algorithm [17] is a well knownimage processing operator comprising four loop levelswith two 2-level loop nests in the inner two levels Thetransforms in [6] merge the inner two 2-level loop nestsbuffer reused data in on-chip RAMs and parallelizethe outer two loops In the inner loops there is a 2-D correlation with a 3 times 3 filter We first apply theextended GP model in Section 52 to map the inner-most loop with linear reduction and then apply thepiecewise GP model in Section 51 to map the loopnext to the innermost loop with tree reduction We donot map the two loops with a linear reduction becauselinearly reducing results from 2-D has a large latency
0 1 2 30
1
2
3
4
5
Memory bandwidth (Bytesexecution cycle)
Exe
cutio
n tim
e (m
s)
Implementation results of Sobel
Original (x10)Design mapping the outerMapReduce pattern levelPerformance-optimalwith linear and tree structures
(1 1)
(9 3)(9 2)
Figure 9 Experimental results of Sobel designs proposed by theframework The bracket next to each design shows (k ii)
and requires many registers to buffer intermediate re-sults The design mapping only the outer MapReducepattern level and designs that map the two MapReducepattern levels are implemented on the target platformtogether with the original design Figure 9 shows thatwhen memory bandwidth is 2 Bytesexecution cyclethe design with the hybrid tree and linear reductionimproves the performance about three times comparedto the design mapping only the outer level MapReducepattern and shows 125 times speedup compared to theoriginal design
K-means Clustering [18] is often used in computer vi-sion Data are segmented into k clusters depending onsimilarity The inner three loops of this algorithm [18]exhibit three nested MapReduce patterns Thereforewe apply the extended model presented in Section 53to map the inner three loops onto the target parallelplatform The experimental results are shown in Fig 10for clustering 64 randomly generated 8-dimensionalvectors into four clusters The design Pareto frontierproposed by our approach is plotted in Fig 10a whenthe target platform has 168 embedded multipliers avail-able We implement the original design which doesnot exploit embedded MapReduce patterns and somedesigns automatically mapped by our approach on thetarget platform as shown in Fig 10b The parameterswhich guide the mapping of the three loops under thedifferent multiplier constraints of some designs arepresented We can observe that the Pareto frontierproposed by our approach clearly matches the real
0 20 40 60 80 100 120 1400
500
1000
1500
2000
2500
3000
3500
(a) Design Pareto frontier proposed by our approach
Multipliers available on chip
E
xecu
tion
cycl
es
0 20 40 60 80 100 120 1400
002
004
006
008
(b) Implementation results of the proposed designs
Multipliers available on chip
E
xecu
tion
time
(ms)
Designs proposed by our approachOriginal design
(8 2 1 1) (32 4 1 4)(16 4 1 2)(8 4 1 1)
(2 1 1 1)
Figure 10 Experimental results of k-means clustering a DesignPareto frontier b Implementation results of the proposed designson the FPGA The bracket next to each design shows (k1 k2k3 ii)
J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL

J Sign Process Syst (2012) 6765ndash78 77
design trend over the multiplier constraints On thetarget platform the designs proposed by our approachimprove the speed of the tested clustering algorithm byup to 12 times compared to the initial design
The execution time for solving the piecewise GPmodels proposed in this paper increases linearly asthe number of pieces increases and exponentially withthe number of nested MapReduce pattern levels Onaverage for the first five benchmarks an optimal de-sign is generated by the piecewise GP framework within15 s while for the last one with three nested MapRe-duce patterns about 190 s are needed to obtain a designthe execution times are obtained on a machine with asingle 3 GHz CPU Since each piece of the piecewiseGP models is independent it is possible to speed up thesolving process on a multi-core machine
7 Conclusion
In this paper we present an automated approach formapping designs in a sequential description exhibit-ing the MapReduce pattern onto parallel comput-ing platforms Our approach combining model-basedand pattern-based transformations automates the iden-tification and mapping of MapReduce patterns usinggeometric programming Using our approach on sixapplications achieves up to 170 times speedup on thetarget platform compared to the unoptimised initialdesigns The experimental results also demonstratethat our approach can find performance-optimal de-signs within the design space of each application underdifferent platform constraints
Future work includes identifying other possible vari-ants of the MapReduce pattern and dealing with othercommon patterns for parallel applications These mayfurther improve system performance
Acknowledgements We thank FP6 hArtes project the EPSRCAlphaData and Xilinx for their support We also thank theanonymous reviewers for their comments
References
1 Asanovic K Bodik R Catanzaro B C Gebis J JHusbands P Keutzer K et al (2006) The landscape ofparallel computing research A view from Berkeley EECSDepartment University of California Berkeley Tech RepUCBEECS-2006-183
2 Dean J amp Ghemawat S (2004) MapReduce Simplifieddata processing on large clusters In 6th symp on OSDI(pp 137ndash150)
3 Yeung J H Tsang C Tsoi K Kwan B S CheungC C Chan A P et al (2008) Map-reduce as a program-ming model for custom computing machines In Proc FCCM(pp 149ndash159)
4 Hall M W Anderson J M Amarasinghe S P MurphyB R Liao S-W Bugnion E et al (1996) Maximizingmultiprocessor performance with the SUIF compiler IEEEComputer 29(12) 84ndash89
5 Liu Q Todman T Luk W amp Constantinides G A(2009) Automatic optimisation of mapreduce designs by geo-metric programming In Proc int conf on FPT SydneyAustralia (pp 215ndash222)
6 Liu Q Todman T Coutinho J G de F Luk W ampConstantinides G A (2009) Optimising designs by combin-ing model-based and pattern-based transformations In ProcFPL (pp 308ndash313)
7 Banerjee U K Loop parallelization Kluwer Academic(1994)
8 Renganarayana L amp Rajopadhye S (2004) A geomet-ric programming framework for optimal multi-level tilingIn Proc conf supercomputing (p 18) IEEE ComputerSociety
9 Eckhardt U amp Merker R (1999) Hierarchical algorithmpartitioning at system level for an improved utilization ofmemory structures IEEE Trans CAD (Vol 18 pp 14ndash24)
10 Allan V Jones R Lee R amp Allan S (1995) Softwarepipelining ACM Computing Surveys 27(3) 367ndash432
11 Rong H Tang Z Govindarajan R Douillet A amp GaoG R (2004) Single-dimension software pipelining for multi-dimensional loops In IEEE Proc on CGO (pp 163ndash174)
12 Turkington K Constantinides G A Masselos K ampCheung P Y K (2008) Outer loop pipelining for applicationspecific datapaths in FPGAs IEEE Transactions on VLSI16(10) 1268ndash1280
13 di Martino B Mazzoca N Saggese G P amp StrolloA G M (2002) A technique for FPGA synthesis drivenby automatic source code synthesis and transformations InProc FPL
14 The TXL programming language (2010) httpwwwtxlcaAccessed 2010
15 Merritt L amp Vanam R (2007) Improved rate control andmotion estimation for h264 encoder In Proc ICIP (pp 309ndash312)
16 Financial modelingndashMonte Carlo analysis httpwwwinteractivesupercomputingcomsuccesspdfcaseStudy_financialmodelingpdf Accessed 2009
17 Green B (2002) Edge detection tutorial httpwwwpagesdrexeledusimweg22edgehtml Accessed 2010
18 Russell M (2004) C programme to demonstrate k-meansclustering on 2D data University of Birmingham Accessed2010
19 Boyd S amp Vandenberghe L (2004) Convex optimizationCambridge University Press
20 Mentor Graphics DK design suite Handel-C to FPGAfor algorithm design httpwwwmentorcomproductsfpgahandel-cdk-design-suite Accessed 2010
21 Loumlfberg J (2004) YALMIP A toolbox for modeling andoptimization in MATLAB In Proc CACSD
22 Morris G W amp Aubury M (2007) Design space ex-ploration of the European option benchmark using hyper-streams In Proc FPL (pp 5ndash10)
78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL

78 J Sign Process Syst (2012) 6765ndash78
Qiang Liu received the BS and MSc degrees in electrical andelectronic engineering from Tianjin University Tianjin Chinaand the PhD degree from Imperial College London in 20012004 and 2009 respectively He is currently a research associatein the Department of Computing Imperial College LondonLondon UK From 2004 to 2005 he was with the STMicro-electronics Company Ltd Beijing China His research interestsinclude high level synthesis design methods and optimizationtechniques for heterogeneous computing systems
Tim Todman received the BSc degree from the University ofNorth London and the MSc and PhD degrees from ImperialCollege London in 1997 1998 and 2004 respectively He iscurrently a research associate in the Department of ComputingImperial College London London UK His research interestsinclude hardware compilation and implementation of graphicsalgorithms on reconfigurable architectures
Wayne Luk is Professor of Computer Engineering with ImperialCollege London He was a Visiting Professor with Stanford Uni-versity California and with Queenrsquos University Belfast UK Hisresearch includes theory and practice of customizing hardwareand software for specific application domains such as multi-media financial modeling and medical computing His currentwork involves high-level compilation techniques and tools forhigh-performance computers and embedded systems particu-larly those containing accelerators such as FPGAs and GPUs Hereceived a Research Excellence Award from Imperial Collegeand 11 awards for his publications from various internationalconferences He is a Fellow of the IEEE and the BCS
George A Constantinides (S96M01SM08) received theMEng degree (with honors) in information systems engineeringand the PhD degree from Imperial College London LondonUK in 1998 and 2001 respectively
Since 2002 he has been with the faculty at Imperial Col-lege London where he is currently Reader in Digital Sys-tems and Head of the Circuits and Systems research groupDr Constantinides is a Fellow of the BCS He is an Associate Ed-itor of the IEEE Transactions on Computers and the Journal ofVLSI Signal Processing He was a Program Cochair of the IEEEInternational Conference on Field-Programmable Technology in2006 and Field Programmable Logic and Applications in 2003and is a member of the steering committee of the InternationalSymposium on Applied Reconfigurable Computing He serveson the technical program committees of several conferencesincluding DAC FPT and FPL