Embed Size (px)
Citation preview

IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 4, NO. 4, DECEMBER 2002 459
Automatic Detection and Indexing of Video-EventShots for Surveillance Applications
Gian Luca Foresti, Senior Member, IEEE, Lucio Marcenaro, and Carlo S. Regazzoni, Senior Member, IEEE
Abstract—Increased communication capabilities and automaticscene understanding allow human operators to simultaneouslymonitor multiple environments. Due to the amount of data tobe processed in new surveillance systems, the human operatormust be helped by automatic processing tools in the work of in-specting video sequences. In this paper, a novel approach allowinglayered content-based retrieval of video-event shots referring topotentially interesting situations is presented. Interpretation ofevents is used for defining new video-event shot detection andindexing criteria. Interesting events refer to potentially dangeroussituations: abandoned objects and predefined human events areconsidered in this paper. Video-event shot detection and indexingcapabilities are used for online and offline content-based retrievalof scenes to be detected.
Index Terms—Information retrieval, object detection, surveil-lance, video signal processing.
I. INTRODUCTION
I N THE LAST decade, automatic surveillance systems havebeen developed in order to improve the efficiency of the pre-
vention of dangerous situations [1], [2]. User requirements indi-cate that a surveillance system should be able to alert the atten-tion of a human operator when a dangerous situation occurs inthe guarded environment and to help him in retrieving the videosequence part related to the event that represents the reason whyhe has been alerted (called hereafter video-event shot).
The development of content-based retrieval techniques hassuggested the idea of integrating video-based surveillance tech-niques and video-event shot detection and indexing algorithms,allowing one to automate the task of recovering causes of alarmsas well [3], [4].
In the literature, many approaches to video shot detection andcontent-based retrieval are presented which use low-level fea-ture based approaches [5]–[17]. Such techniques usually detectvideo shots on the basis of color or texture features that are com-pared for consecutive frames in order to detect scene changes.The retrieval is performed on the basis of feature vectors that areextracted from the data (i.e., the key frame of the sequences) andthen used as index.
Manuscript received April 1, 2001; revised March 7, 2002. The associate ed-itor coordinating the review of this paper and approving it for publication wasDr. H.-J. Zhang.
G. L. Foresti is with the Department of Mathematics and Com-puter Science (DIMI), University of Udine, 33100 Udine, Italy (e-mail:[email protected]).
L. Marcenaro and C. S. Regazzoni are with the Department of Biophysicaland Electronic Engineering (DIBE), University of Genoa, 16145 Genoa, Italy(e-mail: [email protected]; [email protected]).
Digital Object Identifier 10.1109/TMM.2002.802024
For the application considered in this work, low-level (i.e.,mean gray level, shape of the histogram, etc.) feature-basedapproaches are not sufficient to detect the changes of interest.Often, the fraction of the image that changes during a video-event shot is too small to create detectable changes in the low-level features. Moreover, color and intensity of the newly in-troduced objects do not necessarily change significantly his-togram-derived features.
Layered methods [18]–[20] are more suitable for the integra-tion of video surveillance systems and content based retrievaltechniques. In the proposed system, human operator is alertedwhenever an alarm is detected. The layer is represented by theforeground image and related descriptive metadata associatedwith a dangerous object or by people generating the event of in-terest and the retrieval is performed on the basis of descriptivefeatures associated with the layer.
Irani and Anandan [21] present an example of such a layeredevent representation. Their method transforms video data froma sequential frame-based representation into a single, commonscene-based representation to which each frame (layer) can bedirectly related. This method is based on the mosaic representa-tion of the scene, obtained by composing the information fromdifferent views of the scene into a single image. Each frame canbe mapped to the mosaic representation by using a three-dimen-sional (3-D) scene structure.
In the application described here, however, only one view ofthe scene is available. Therefore, instead of the mosaic repre-sentation, we use as a reference image a background image rep-resenting the guarded environment with no extraneous objectsor persons. Therefore here the concept of layer is referred toa subimage containing the object which is superimposed to thebackground image: in this sense, the layer is similar to a MPEG4object [32]. In [21], the sequence is segmented in video-clips,the beginning and the end of which are determined by drasticchanges in the scene, expressed in terms of color and gray-leveldistribution. Sequences acquired by the proposed surveillancesystem usually contain clips, too, associated with changes rep-resented by the appearing or disappearing of objects or persons;these kinds of changes usually do not vary the color distribu-tion of the image but they introduce a relevant variation in thesemantic content of the sequence. The detection and indexingof the video-event shot is then performed at the layer level ofobjects. As the object layer can be further classified dependingon the type of video-event with which it is associated, a specificfeature vector can be used for detection and indexing that char-acterizes the layer representing the alarm (abandoned objects orpeople with suspect behavior).
1520-9210/02$17.00 © 2002 IEEE

460 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 4, NO. 4, DECEMBER 2002
A first attempt of joining surveillance systems and contentbased retrieval techniques is presented in [4]. In [4], the appli-cation was considered of detecting both the presence of aban-doned objects and the video-event shot containing the personwho left it. The results were promising, but the system detectedvideo-event shots consisting of a fixed number of frames foreach situation in which an abandoned object was found withoutconsidering if the alarm-generating object was present in allthe frames of the video-event shot. Moreover, in the approachthere described, limitations were present related to the analysisof human behavior.
Substantial improvement to the system presented in [4] is de-scribed in this work, in which the task of tracking moving ob-jects has been introduced as a parallel process with respect toabandoned object detection in order to determine more preciselythe video-event shots in which dangerous objects are present.Moreover, this new module allows also the system to performmultifunctional object retrieval, i.e., to be able to retrieve eventsof different types. In particular, people in the scene assuminga predefined kind of behavior can be detected. The proposedsystem reaches this goal by integrating two modules: abandonedobject detection, that has some improvements with respect tothe one described in [4] and a new moving object detection andtracking module, that is more deeply described here.
Recently, researchers have investigated techniques for de-scribing and recognizing human activities. The main objectiveof this type of research is to analyze the human behavior froman image sequence in order to automatically detect interestingevents, e.g., suspicious behaviors. Hogg [22] first addressedthe problem of detecting a walking person in image sequences.His approach integrates image processing and geometricreasoning techniques and it has been recently extended totake into account the nonrigidity of human shape in motion[23]. Image sequences of human behavior have been studiedto detect and identify activities that exhibit regular and cycliccharacteristics (e.g., walking) [24]–[27]. Galton [28] generatescomplex descriptions of human actions on a set of genericbasic spatio-temporal proposition to distinguish differenthuman behaviors. Brandet al. [29] propose to use probabilisticmodels, i.e., hidden Markov models, to capture the uncertaintyof mobile object properties, while Chleq and Thonnat [30]propose a generic framework for the real-time interpretationof real world scene with humans. As an example of behaviordetection, the problem of intruder detection near high securityzones has been explored by Rosin and Ellis [31]. In their work,simple processing of sequences of images was used to extractregions of interest (blobs) and the motion of these blobs wasanalyzed using a frame-based system. The system is able todifferentiate between flocks of birds, small animals and otherorganizms in poor quality images.
Recently, Wrenet al. [33] propose a real-time system,called Pfinder, for tracking human body and interpreting theirbehavior in a controlled indoor environment. The system usesa multi-class statistical model of color and shape to obtaina two-dimensional (2-D) representation of head and handsin a wide range of viewing conditions. Pfinder has beensuccessfully used in a wide range of applications includingwireless interfaces, video databases, and low-bandwidth
coding. Haritaogluet al. [34] propose a real-time visual-basedsurveillance system, called , for detecting and trackingmultiple people and monitoring their activities in an outdoorenvironment. employs a combination of shape analysisand tracking to locate people and their parts (head, hands, feet,torso) and to create models of people’s appearance so thatthey can be tracked through interactions such as occlusions.It can recognize events between people and objects, such asdepositing an object, exchanging bags, or removing an object.McKennaet al. [35] present a system able to track multiplepeople in relatively unconstrained environments. Tracking isperformed at three levels of abstraction: regions, people, andgroups. A novel, adaptive background subtraction method thatcombines color and gradient information is used to cope withshadows and unreliable color cues. People are tracked throughmutual occlusions as they form groups and separate from oneanother. The system is tested using both indoor and outdoorsequences. An interesting survey on the visual analysis ofhuman motion can be found in [41].
Most of the above mentioned studies assume a complete or,at least sufficient isolation of objects or human bodies; for thisreason, they are not suitable for complex surveillance applica-tions, for which the proposed assumption of no occlusions is notrealistic. The proposed system is robust to temporary or partialocclusions between moving objects, thanks to the long memoryalgorithm that is able to correctly re-assign objects identitiesafter occlusion and improves the performances for the detectionof abandoned objects; moreover, the proposed system is able todetect, index and retrieve interesting video-event shots of humanactivities.
This paper is organized as follows. Section II describes thegeneral architecture of the proposed system, composed by sev-eral subsystems dedicated to particular tasks. The subsystemsfor detecting abandoned objects, for tracking moving objectsand recognizing anomalous human behaviors are also briefly ex-plained. The method used for detecting, indexing and retrievinginteresting video-event shots is described in Section III. In Sec-tion IV, results are shown in terms of success rate in detectingabandoned objects, in classifying behaviors, in detecting inter-esting video-event shot boundaries and in layer retrieval. Fi-nally, conclusions are reported in Section V.
II. GENERAL SYSTEM ARCHITECTURE
The proposed system aims at performing three tasks: the on-line detection of abandoned objects, the online classificationof events including humans as actors and the automatic-detec-tion and the indexing of video-event shots showing the causeof alarms (Fig. 1). For what concerns abandoned objects, it isassumed that the cause of an alarm consists in the person wholeft the object in the scene. While in [4] the number of framesof the retrieved video-event shot was fixed, a new step is hereintroduced in order to estimate the number of frames containingthe person that was carrying the abandoned object in the scene.The link between an abandoned object and the person who leftit is here performed with the help of a further subsystem whoseaim is the detection and tracking of objects moving in the scene.

FORESTIet al.: AUTOMATIC DETECTION AND INDEXING OF VIDEO-EVENT SHOTS 461
Fig. 1. General architecture of the proposed system.
Data about detected and tracked objects are also used by the sub-system aiming at detecting human events. As regards to the clas-sification of human events, the cause of an alarm is contained inthe video-event shot in which persons are found by the systemto act in a way close to a description of the event of interest.
Therefore a video-event shot can be defined as a temporalsubpart of the considered sequence associated with a set of in-formation that can be structured in layers. The layers correspondto
— the entire video sequence containing the person asso-ciated with the event i.e., the base layer;
— the sequence of the part of the video containing onlythe person that caused the event i.e., the video-objectlayer;
— the metadata describing the video object layer i.e., themetadata object layer.
In our system there exists a separate video-object layer foreach active process. An object tracking layer (OTL) is associ-ated to the tracking module and different higher level video-ob-ject layers are associated with different processes of the system.In particular, there exists an abandoned object layer (AOL) incorrespondence of the abandoned object detection module anda human event layer (HEL) connected to the human event de-tection module.
In this way, the scene that contains the event of interest (aban-doned object, anomalous human events, etc.), can be fully de-scribed by using extracted information structured in the abovedescribed different layers.
In this section, we briefly present the modules for detectingabandoned objects, for tracking moving objects and for recog-nizing anomalous human events. The module for video-eventdetection, indexing and retrieval, which represent the main nov-elty of the paper, will be described in detail in Section III
A. Detection of Abandoned Objects
The architecture of the subsystem for detecting abandonedobjects is shown in Fig. 2. This system is based on a long-termchange detection algorithm [4], [42] that is able to extract pixels
Fig. 2. Architecture of the subsystem for abandoned objects detection.
in the image related to static changes in the scene by differencingthe current acquired image with respect to a reference scene keptupdated through a background updating algorithm. Consideredtechnique is able to absorb slow environmental changes in thescene (i.e., moving cast shadows), while leaving untouched thebackground regions corresponding to detected objects (static ormoving) at least until a static object is classified as an aban-doned object and its identity is passed to the abandoned objectsdetection module. It must be noticed that the method is robust toocclusions, occurring for few frames and hiding the abandonedobjects from the sensor point of view. Clearly, when image com-plexity increases (in terms of moving objects present in a scene)the probability of missed detection gets higher. Pixels detectedas potential abandoned objects, are filtered and compacted in re-gions of interest (namedblobs) by means of morphological op-erations [4], [38]. Blobs are then classified by a neural networkin order to avoid false alarms when a static change is detectedwhich is not due to a lost object (e.g., persons remaining rela-tively still for some time, like a seated person). Shape featuresare used to discriminate among different causes of permanentchange [4]. A multilayer perceptron (MLP) has been selectedas neural classifier because of the time constraints on the classi-fication process. The architecture of the MLP has been obtainedby trials [4]: a three-layer network with one hidden layer com-posed by 20 hidden neurons has reached the best results. Theclassification step considers four possible causes of permanentchanges; these are
— abandoned objects;— persons—a person seated on a chair (e.g., waiting for a
train) generates a permanent change in a scene similarto the change generated by an abandoned object;

462 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 4, NO. 4, DECEMBER 2002
Fig. 3. Example of event detected by the system for detecting abandoned objects: in the last frame, the area is shown containing the video-object layerrelated tothe detected abandoned object.
— lighting effects—waiting rooms have at least one doorand often also windows. The opening of the door orwindows, and persons passing near the windows cangenerate some local changes in the lighting of guardedenvironments that may persist in time. In this case,not performing the classification step would generatea false alarm;
— structural changes—permanent changes in the scenemay happen when the positions of the objects in thescene (doors, chairs, etc.) vary.
By means of the above reported operations, the system is ableto detect isolated events as shown in the temporal diagrams ofFig. 3. Each event detected at generic instant islabeled by a feature vector containing the features used for theobject classification [4].
B. Tracking Module
The main novelty in the indexing and retrieval step with re-spect to [4] is the capability of indexing also the video objectlayer and not only the base sequence layer. This is achievedthanks to the more efficient integration with the tracking algo-rithm. Such integration allows also one to adaptively estimatethe temporal boundaries of a video-event shot in a more preciseway, with respect to the fixed shot extension introduced in [4].The tracking subsystem shown in Fig. 4 aims at detecting andtracking static and moving objects that are present in the scene.Objects are detected in the scene by performing a difference be-tween the currently acquired image and a continuously updatedreference frame. A background updating algorithm [45] updatesthe reference frame with two different speed for image areascorresponding to detected objects (no update) and backgroundzones (fast update for dealing with illumination variations in thescene). As soon as a still object is recognized as abandoned, thecorresponding image portion is marked as background and up-dated: in this way, the abandoned object is absorbed in the ref-erence image.
Fig. 4. Architecture of the system for tracking objects and temporal graphdescribing the OTL.
This system is based on a long-memory matching algorithm[42], which uses information from blobs extracted by change de-tection and focus of attention methods [39]. The long-memorymatching algorithm is able to track objects related to changes inthe scene with respect to a reference situation. The term “long-memory” is referred to the fact that the algorithm is able to re-cover blob identity after merging of more objects into aggre-gated blobs and successive splitting (Fig. 5). Identity estimationis performed by means of a matching measure between the his-togram of involved objects based on the Bhattacharyya coeffi-cient [49]. Features used for correspondence matching are color-based features (mean and variance of the color of regions com-posing the blob) [40], geometric features (area and perimeter ofthe blob) and 3-D position of the blob [16].

FORESTIet al.: AUTOMATIC DETECTION AND INDEXING OF VIDEO-EVENT SHOTS 463
Fig. 5. (a) Objects detected before the merge event; (b) the “merge” phase; (c)after the split, the identity of the objects are preserved; (d) associated temporalgraph.
Fig. 6. Examples of different kinds of nodes labeled by the tracking module.
By means of the previously reported operations, the systemis able to detect events continuously in time as shown in thetemporal diagrams of Fig. 5 in parallel with detection of aban-doned objects. Each event , corresponding to a trackedblob detected at generic instant, is labeled by a feature vectorcontaining the features used for the object tracking (i.e., meta-data). Moreover, the events are linked in time and representedby means of a temporal graph in which each node represents atracked object and the features of the related blob. Four types ofnodes are considered (Fig. 6):
— new nodes —this label is given to objects detectedby the system as new object in the scene;
— overlapped nodes —this label is given to objectsthat are not new in the scene; usually, the minimumrectangles bounding these blobs are partially over-lapped in two consecutive frames;
— split nodes —this label is assigned when a nodeis split in two ore more nodes; this may occur, forexample, when two persons walking together start tomove in different directions;
— merge nodes —this label is assigned when two oremore objects merge into one.
The characteristics of the temporal graph (link between nodesand label of the node) are the basis for the video-event shotdetection and layered indexing, as shown in Section III.
C. Human Action Recognition
The human action recognition (HAR) subsystem takesas input features extracted from each image of a temporalsequence and performs real-time scene interpretation [41]. Theinterpretation process is performed with respect to a finite li-brary of scenario models representing both normal and unusualevents produced by human actions. A scenario model is definedas a set of event models and/or temporal constraints [42]. Theaim of the HAR subsystem is to automatically detect patternsof human actions that correspond to predefined model events,e.g., vandalism actions, entrance in prohibited areas, etc., inorder to generate alarms or require further data acquisition.
In order to detect patterns of human actions generated by aninteresting event in the scene, it is necessary to define the boundsof normal actions, which are obviously different from appli-cation to application. It is therefore necessary to calibrate thesurveillance system to monitor a particular scene and to learnthe characteristics of normal and unusual human actions. Forexample, people remaining stationary, or almost stationary, fora long period in front of a bank entrance may be consideredas suspicious events. People moving on the area of a railwaylevel-crossing or on a metroline station with an abnormal tra-jectory (e.g., crossing the tracks) can be considered as unusualhuman actions.
The HAR subsystem (Fig. 7) is composed by two main mod-ules, the human recognition and the event detector. It uses in-formation from blobs extracted by the detection and trackingsubsystems over a long image sequence. In particular, it ana-lyzes, in a hierarchical way, the temporal graph which containsthe events corresponding to tracked blobs and the related fea-tures.
The minimum rectangle bounding the blob is divided intofour parts, , called quartils [44], according to theposition of its center of mass . The four distances,
, between and the center of mass of the four quar-tils are computed. These distances give a measure of the blobshape. In order to increase the robustness of such a represen-tation, the angles , formed by the distance vec-tors, , with the horizontal axis of the 2-D referencesystem centered in have been considered. The pattern ,related to the detected blob, is composed by the followingeight values:
(1)
A neural tree (NT) [43], is applied to recognize blobs whichrepresent humans moving in the scene.
In order to eliminate the dependency of the obtained patternson scale variations and on rotation around theaxis, a large setof 2-D object shapes, obtained by observing 3-D object modelsfrom different viewpoints, have been taken into account [43]. Inparticular, for each object model, eight different representativeviews (taken at camera viewpoints separated by 45) have beenconsidered to learn the neural tree. Different 2-D human shapeshave been used to learn the neural tree. These blobs have beenobtained both from 3-D models and from real scenes. The pro-posed approach has been focalized on scenes containing a singlemoving human or multiple human whose motion produces alimitated number of occlusions over the whole sequence. Aninteresting work on tracking groups of people can be found in[35].
The output of the NT is represented by two classes: the classhuman and the class nonhuman. At the end of the classificationphase, the obtained classification is added to the correspondingnode of the temporal graph.
The event detector module considers a set ofconsecutivegraph nodes, i.e., a brief history of the object motion, 1) to givea more robust classification of the detected object and 2) toindividuate interesting events. In particular, a winner-takes-allscheme is applied to find the best object classification on theconsidered frames as the majority of the classification results

464 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 4, NO. 4, DECEMBER 2002
Fig. 7. General architecture of the HAR module.
over a temporal window. If the detected object has been classi-fied as a human, information about its location and about its tra-jectory on the ground plane is used to identify interesting events.
Let be the human speed and letbe the human directionat the -th frame, measured with respect to the center of mass ofthe blob, i.e.,
(2a)
(2b)
Let be the feature vector, associated with the recognizedhuman blob at the time instant. It contains the positions of thecenter of mass (in the coordinates of the image plane)of the blob, its speed and its direction , measured at each ofthe last frames, i.e.,
(3)
Changes in human speed and direction can be used as easilymodels of interesting events. Moreover, availablea-prioriknowledge about the environment (presence of static objects,forbidden areas, etc.) can be related to the localization ofhuman and used to define specific models of interesting events,e.g., entrance in prohibited zones, anomalous trajectories, etc.
To this aim, a set of scenario models, comprehensive of bothnormal and unusual events, is created. An event is characterizedby a set of human features observed over a sequence offrames, . For example, let us considerthe scenario of a metro station where the event “an human over-passes the yellow line which limits the track area” is consideredas dangerous event. This event can be represented by a given setof feature vectors , obtained by varying the human po-sition, speed and trajectory. The whole set of scenario models isstored into an Event database, and used to learn a binary neuraltree. Each node of the NT is characterized by input, i.e., the com-ponents of the feature vector , and output, i.e., normaland unusual human actions.

FORESTIet al.: AUTOMATIC DETECTION AND INDEXING OF VIDEO-EVENT SHOTS 465
Note that scene complexity can affect feature vectors in sev-eral ways. First, the number of frames in which a pedestrianappears as isolated decreases when the number of moving ob-jects in the scene increases. Second, when the pedestrian reap-pears as isolated after merging with other objects, the prob-ability of correct recognition decreases with increasing com-plexity as well. Moreover, as trajectory during merging is in-terpolated between positions first and after merging, complexin the scene may cause trajectory features to deteriorate. How-ever, in many medium complexity scenes the proposed approachworks well. For either more complex scenes or more accuratetrajectory estimation some complex very recent multi-objecttrackers as the one proposed in PETS [46], [47] could be used.
III. V IDEO-EVENT SHOT DETECTION AND INDEXING
The proposed method for video-event shot detection and in-dexing is obtained by integrating at the metadata level the threesubsystems mentioned in the previous sections, as well as byaddressing video-object layers represented by blobs associatedwith data. Three different kind of video object layers are con-sidered:
— a base layer corresponding to the entire video se-quence;
— a video object layer corresponding to each detectedobject in the scene; this layer can be divided into threesublayers as described in the previous sections (i.e.,OTL, AOL, and HEL);
— a metadata object layer associated with features ex-tracted from detected objects in the scene.
A. Abandoned Object Detection
We first analyze the procedure for the boundary detection ofthe video-event shot related to abandoned objects, that is herebased on the integration between the output of the subsystemsfor detecting abandoned objects and for detecting and trackingmoving objects. These two subsystems provide one with twotypologies of metadata: static events (abandoned ob-jects) and blobs associated with the abandoned object layer de-tected at generic instant and dynamic events (fore-ground objects) and related blobs in the object tracking layer,that are integrated in order to perform content based video-eventshot detection and indexing.
More precisely, in order to detect video-event shot temporalboundaries and indexes, the system performs the followingsteps.
— abandoned object event detection and video-event shotfinal frame identification ;
— computation of video-event shot initial frame andlayered indexing of the detected video-event shot;
1) Video-Event Shot Final Frame Identification:The first op-eration is based on blob label matching and it aims at detectinga correspondence between an object detected by the abandonedobjects detection module and a static object detected in the ob-ject tracking layer.
The graph analysis starts by locating the blob correspondingto the event in the tracking graph. As a latency ofseconds occurs between abandoned object appearance and its
(a)
(b)
Fig. 8. Example of abandoned object detection: (a) temporal graph associatedwith OTL and AOL; (b) video-object layer associated with the detected event:OTL and AOL data are superimposed on the base layer.
detection, a back search is necessary in the tracking graph inorder to detect the corresponding blob and the frame that cor-responds to the abandonment . The search is driven by thetime instant of the detected event: a blob is searched backward inthe tracking graph approximately for a number of frames equalto where is the latency of the abandoned ob-ject detection subsystem and is the frame rate (fps) of thetracking module. It can be supposed that corresponds toa split between unattended object and the abandoning personapproximately happened seconds before the alarm genera-tion: the frame corresponding to this split is the last frame ofthe video-event shot (in Fig. 8, the frame). In order to besure not to miss the abandoning event, each blob detected ina spatial window centered in the position where theabandoned object has been detected are checked in the objecttracking graph.
Let be the intensity of the generic color componentof the pixel at the position of the image lattice. The
normalized histogram of a generic blobcorresponding to the event is a function defined as thenumber of pixels of color belonging to the blob
, normalized with respect to the number of pixels (area) ofthe blob itself. For computational reasons, the histogram of ablob has been derived by considering only 32 intensity levelsfor each color component. This simplification does not affectthe performances of the blob matching operation if the numberof considered colors is not too limited [40].
The event corresponds to the event withinthe considered spatio-temporal search window in the objecttracking layer, containing the histogram more similar to the

466 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 4, NO. 4, DECEMBER 2002
Fig. 9. Example of video-objects in the (a) object tracking layer and(b) abandoned object layer.
Fig. 10. Example of backwarsearch in the temporal graph associated to theOTL in order to find video-event shot boundaries.
one of the detected abandoned object in the AOL. The distancebetween two histograms is the mean square error betweenthem:
(4)
In this way, the final time instant of the video-eventshot can be retrieved. A representation of the event matching isshown in Figs. 8 Fig. 9 both for what concerns object trackingand abandoned object layers.
2) Video-event shot initial frame identification and layeredindexing:In order to estimate the instant when first the aban-doned object is present, a search is performed in the temporalgraph extracted by the object tracker. By using blob identity in-formation, a foreground object in the OTL can be associatedwith a considered abandoned object event through a back-ward inspection of the OTL graph: for simplicity the backwardsearch is performed in the OTL among blobs associated withthe node connected with the one where is detected untila single-connected path (i.e., a set of nodes of successive timeinstants linked to in the OTL graph) can be identified. Forexample, when a merge event previous to is met the pathis interrupted (Fig. 10). In this way, the number of frames ofthe retrieved video-event shot is given by the maximum lengthof the single-connected path backward searched in the trackinggraph. A video-event sequence is also produced,corresponding to a specific video-object layer in the OTL, aswell as to the metadata associated with.
A segmentation driven validation step is performed in orderto find the abandoned object inside each video-event object in
. To this end the normalized histogram of the in-teresting object is searched inside the detected video-object byusing the above described similarity measure based on color.
In particular, the following steps are performed:
— segmentation of the foreground moving blob related tothe dangerous object;
— matching between the abandoned object histogram andthe histogram of the regions in the segmented blob;
— selection of the region that best fits the abandoned ob-ject histogram.
A video object can be segmented in different regions [38] andone can suppose that, if the considered blob contains the aban-doned object, one of the regions resulting from the segmentationstep corresponds to the dangerous object. The matching opera-tion, based on the normalized histogram as in the video-eventshot boundary detection, allows one to isolate the interestingobject from the other regions. The probabilistic approach forselecting regions is made possible by the definition of the nor-malized color histogram introduced in the event matching. Eachvalue assumed by the histogram function ranges from 0 to 1 andit can be seen as the probability that a pixel associated with agiven color, belongs to the object represented by the histogram:if this probability is higher than a threshold, then the pixel isconsidered. More formally, by considering a region , a pixel
with intensity is extracted if:
(5)
where indicates the threshold, andrepresents the color of the
pixel. The pixels extracted with the thresholding operation arethen compacted by means of the focus of attention procedureused during the blob detection task and, finally, the interestingobject is retrieved by considering the minimum distance be-tween its normalized histogram and the normalized histogramof the remaining regions.
Human Event Sequence Detection:A similar procedure isused to detect boundaries of the video-event shots in whichpeople assume suspicious behaviors in the guarded environ-ment by relating the events in the HEL with those in theOTL. The system performs a data integration between thesubsystem for classifying human behavior and the subsystemfor tracking moving objects: a dangerous behavior is an event
linked to the correspondent dynamic eventby means of the blob label matching operation according to thesame strategy for linking an abandoned object to the temporalgraph. In this case, the last frame of the video shot is theone corresponding to the instant in which the suspiciousbehavior is detected (i.e., no latency is assured); the firstframe is determined by means of graph analysis, by searchingthe first frame in which the blob appeared in the scene, asperformed for video-event shots related to abandoned objects.Single-connection is used also in this case to fix the path.

FORESTIet al.: AUTOMATIC DETECTION AND INDEXING OF VIDEO-EVENT SHOTS 467
Fig. 11. Real image sequence containing a group of persons inside a metrostation. (a) Temporal graph associated with the tracker; (b) image sequence withthe video-object layers; (c) the OTL and (d) the HEL.
Also for human event related events, indexing is introducedby using the normalized histogram of the person causing thealarm. Layer retrieval is made as in the case of abandoned ob-jects, with the difference of considering all the entire extractedblobs, instead of regions composing the blob, in the matchingoperations: the retrieved person corresponds to the blob pre-senting the minimum distance histogram with respect to theblobs of the image.
Figs. 11 and 12 show respectively human event shots indexingprocesses for two different kind of human events, i.e., yellowline crossings and suspicious trajectory detection.
IV. EXPERIMENTAL RESULTS
The performances of the proposed system are presented inorder to evaluate the robustness in both event detection and layerretrieval tasks. This section is organized as follows: first, detec-tion results are presented by means of values that indicate thesuccess rate in classifying abandoned objects and human ac-tions; then, video-event shot detection and retrieval results arepresented.
A. Abandoned Object Detection
The system for detecting abandoned objects has been testedin three different environments: an “artificial” environment(the laboratory) and the waiting room in the railway stationsof Genova-Rivarolo and Genova-Borzoli, Italy. In the tests,each environment corresponds to an acquired video-sequence.The sequences were acquired at a frame rate of 1 frame/s andthe size of each frame is 256256 pixels. For each test, we
Fig. 12. (a) Temporal graph. Image sequence containing three peoplemoving in (b) an outdoor parking area, (c) associated OTL, and (d) HEL.
considered about 2800–3000 events equally distributed on thefour classes (abandoned objects, persons, lighting effects andstructural changes) considered by the system (about 700–750abandoned objects, 700–750 humans, etc).
Performances of the system are measured in terms of prob-ability of false alarm and probability of misdetection
for classifying detected objects. A false alarm is pre-sented whenever a change not related to an abandoned objectis classified as an abandoned object. A misdetection happenswhenever an abandoned object is classified as it was not. On thebasis of these definitions, the performance rates of the systemin the different environments were as follows:
— laboratory: % and %;— Genova-Rivarolo Railway station: % and
%;— Genova-Borzoli Railway station: % and
%It is possible to notice that the performances are satisfactory
also in the real case.
B. Human Action Recognition
A real metro station and an outdoor parking areas have beenchosen to test the performances of the HAR system. Fig. 11shows an image sequence containing a group of people inside ametroline station. The considered video-sequence, which wasacquired in a Belgium underground [39], is characterized bythe following parameters: frame rate of 1 frame/s, image sizeof 256 256 pixels, and sequence length of 500 frames. Twoevents have been considered as unusual human actions: (a) one
468 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 4, NO. 4, DECEMBER 2002
Fig. 13. Blob images extracted form sequence acquired in a metro station withstrong shadows (gray level pixel indicate shadow points).
TABLE IOBJECT CLASSIFICATION (P = ONE OR
MORE ISOLATED PERSONS ORGP = GROUP OFPERSONS) AND DANGEROUS
EVENT DETECTION (YL = PERSON ORGROUP OFPERSONSBEYOND THE
YELLOW LINE) IN THE IMAGE SEQUENCE INFig. 14
or more persons overpass the yellow line and (b) one or morepersons cross the tracks. If the scene is illuminated with artificiallights, each object projects long shadows on the ground floor.Fig. 13 shows a sequence acquired in a metro station and the ex-tracted blobs. The presence of shadows (symmetric with respectto the intersection of the blob with the ground plane) modifiesthe blob’s shape and increases the complexity of the classifi-cation process. A shadow detection procedure [48] has been ap-plied to eliminate the shadows from the detected blobs. In partic-ular, the gray pixels in Fig. 16 represent detected shadows. Theneural tree used for pedestrian recognition is composed by 74 in-ternal perceptron nodes and 54 leaf nodes (distributed onlevels), while the neural tree applied for suspicious event detec-tion recognition is composed by 36 internal perceptron nodesand 21 leaf nodes (distributed on levels). Table I showsthe object classification obtained for each frame of the sequence,and the event classification obtained over a set of se-quence frames. It worth noting that the HAR system is able tocorrectly classify the persons present in the scene as one or more
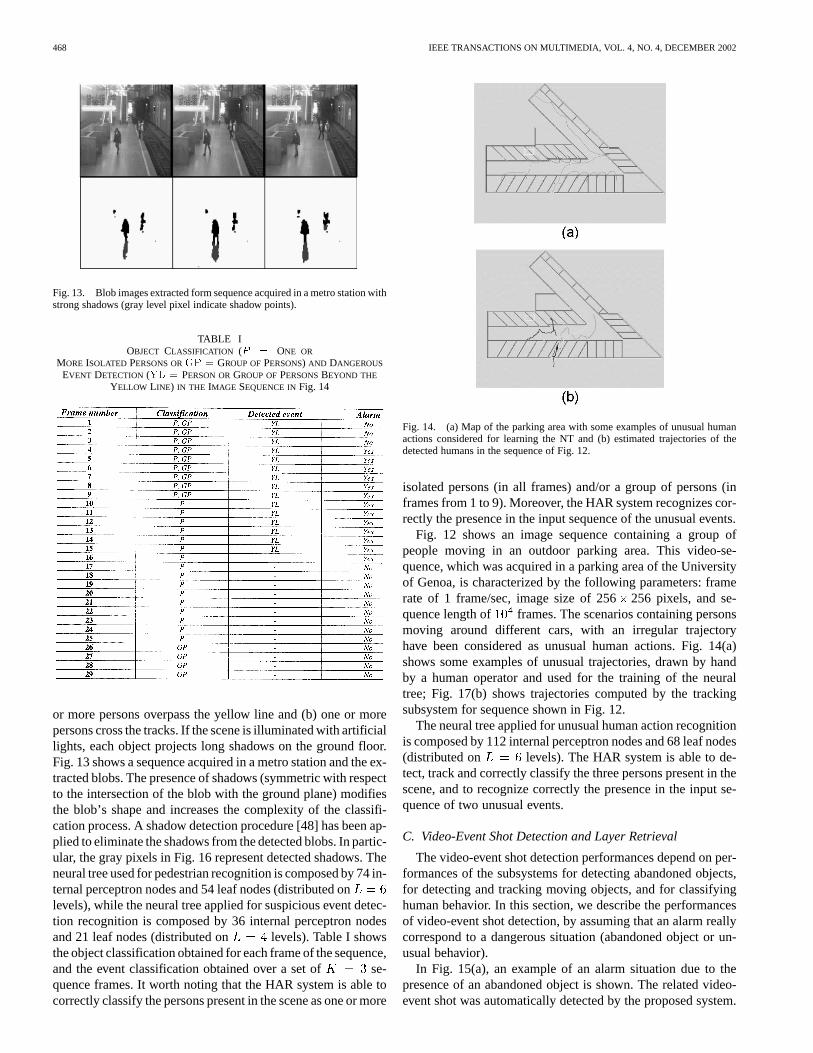
Fig. 14. (a) Map of the parking area with some examples of unusual humanactions considered for learning the NT and (b) estimated trajectories of thedetected humans in the sequence of Fig. 12.
isolated persons (in all frames) and/or a group of persons (inframes from 1 to 9). Moreover, the HAR system recognizes cor-rectly the presence in the input sequence of the unusual events.
Fig. 12 shows an image sequence containing a group ofpeople moving in an outdoor parking area. This video-se-quence, which was acquired in a parking area of the Universityof Genoa, is characterized by the following parameters: framerate of 1 frame/sec, image size of 256256 pixels, and se-quence length of frames. The scenarios containing personsmoving around different cars, with an irregular trajectoryhave been considered as unusual human actions. Fig. 14(a)shows some examples of unusual trajectories, drawn by handby a human operator and used for the training of the neuraltree; Fig. 17(b) shows trajectories computed by the trackingsubsystem for sequence shown in Fig. 12.
The neural tree applied for unusual human action recognitionis composed by 112 internal perceptron nodes and 68 leaf nodes(distributed on levels). The HAR system is able to de-tect, track and correctly classify the three persons present in thescene, and to recognize correctly the presence in the input se-quence of two unusual events.
C. Video-Event Shot Detection and Layer Retrieval
The video-event shot detection performances depend on per-formances of the subsystems for detecting abandoned objects,for detecting and tracking moving objects, and for classifyinghuman behavior. In this section, we describe the performancesof video-event shot detection, by assuming that an alarm reallycorrespond to a dangerous situation (abandoned object or un-usual behavior).
In Fig. 15(a), an example of an alarm situation due to thepresence of an abandoned object is shown. The related video-event shot was automatically detected by the proposed system.

FORESTIet al.: AUTOMATIC DETECTION AND INDEXING OF VIDEO-EVENT SHOTS 469
Fig. 15. Example of alarms and related video-event shot detected in the case of (a) abandoned object and (b) predefined human event.
In Fig. 15(b), one can see the alarm generated by the suspi-cious behavior of persons who passed the yellow line, and therelated video-event shot automatically detected by the proposedsystem.
The performances of the video-event shot detector are mea-sured by counting how many times the system is able to storethe whole sequence containing a particular dangerous situation.Errors concern the precise detection of the boundaries of thevideo-event shot. In detecting the beginning of video-eventshots, possible errors are due to temporary occlusions of theobject or person that caused the alarm. The system for trackingmoving objects [39] has a mechanism to recover the object if itdisappears for few consecutive frames, so that the video-eventshot detection procedure is more robust to partial occlusion ofthe object (layer) representing the video content to be extracted.
The detection of the end of video-event shots may be criticalonly for what concerns an abandoned object because a split inthe temporal graph may occur with a little delay with respect tothe instant in which the object is left, as can be seen in Fig. 8.Nevertheless, this error is not dramatic for the operator that mustreconstruct an alarming situation.
It is interesting to measure how the performances of thesystem vary with the complexity of the scene, where thecomplexity is identified with the number of persons moving inthe guarded environment. In fact, the probability of temporaryocclusion of objects increases when the presence of movingpersons is higher in the scene. For laboratory tests, we definethree levels of complexity:
— low complexity: two persons, at maximum, in thescene, corresponding to a maximum density of 0.12person/m;
— medium complexity: four persons, at maximum, in thescene, corresponding to a maximum density of 0.24person/m;
— high complexity: more than four persons (i.e., more that0.24 person/m).
These definitions, introduced during experiments in laboratory,have been considered also in real transport environments.
Numerical results are shown in Fig. 16 that shows the meansuccess probability in detecting video-event shot boundariesconsidering different levels of scene complexity. It is possibleto notice that, although the performances decay with the
Fig. 16. Performances obtained by the proposed method for video-event shotboundary-detection versus the complexity of the guarded environment.
Fig. 17. Performances obtained by the proposed retrieval procedure.
complexity increasing, good results are obtained also with amedium level of complexity of the scene.
Moreover, performances are measured for the layer re-trieval step. In this case, after having detected the interestingvideo-event shot, the system retrieves the layer (dangerous ob-ject and person who left it or person with suspicious behavior)that caused the alarm. Evaluations are performed by consid-ering probabilities of success, false alarm and misdetectionprobabilities in retrieving layers. Two different kinds of successare considered. The system reaches the full success when it isable to retrieve the searched object for at least 80% of its areain the image plane. When the system retrieves only from 20%to 80% pixels of the searched object, then a partial success hasbeen reached. A misdetection occurs when the system does notretrieve the object or it retrieves less than 20% of the pixels

470 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 4, NO. 4, DECEMBER 2002
of the object. Finally, the system provides the operator with afalse alarm when regions different from the searched object areretrieved. Numerical results are shown in Fig. 17, in which itis possible to notice that the success rate is quite high (71%),and the probability of full success (65%) is considerably higherthan the number of partial success (6%). This considerationproves the efficiency of the proposed retrieval procedure.
V. CONCLUSION
In this paper, a novel approach for video shot detectionand layered indexing has been presented with applications tovideo-based surveillance systems. The considered video-basedsurveillance system aims at supporting a human operatorin guarding indoor environments, such as waiting rooms ofrailway stations or metro stations, by providing him with analarm signal whenever a dangerous situation is detected. Bymeans of the method introduced in this paper, the humanoperator has also the possibility of retrieving the video-eventshot in which the causes of alarms (person leaving abandonedobjects or people with a suspicious behavior) are shown.
The system considered in this paper presents a success eventdetection rate of about 97%. Within this set of events correctlydetected, the proposed method for semantic video shot bound-aries detection works correctly with a rate of 95%, 75%, and33% in case of low, medium and high complexity of the scene,respectively. The proposed procedure for content-based retrievalextracts the correct layers in 71% of cases in the performed ex-periments. From the numerical results, it is concluded that theproposed system provides the human operators with a powerfulinstrument for reconstructing dangerous situations that can behappen in transport environments.
ACKNOWLEDGMENT
The authors thank the anonymous reviewers for their usefulsuggestion and F. Oberti for valuable discussion and technicalsupport.
REFERENCES
[1] C. S. Regazzoni, G. Vernazza, and G. Fabri,Advanced Video-BasedSurveillance Systems. Dordrecht, The Netherlands: Kluwer, 1998.
[2] G. L. Foresti, P. Mahonen, and C. S. Regazzoni,MultimediaVideo-Based Surveillance Systems: Requirements, Issues and Solu-tions. Dordrecht, The Netherlands: Kluwer, 2000.
[3] E. Stringa and C. S. Regazzoni, “Content-based retrieval and real timedetection from video sequences acquired by surveillance systems,”Proc.IEEE Int. Conf. Image Processing, vol. 3, pp. 138–142, Oct. 4–7, 1998.
[4] , “Real-time video-shot detection for scene surveillance applica-tions,” IEEE Trans. Image Processing, vol. 9, pp. 69–79, Jan. 2000.
[5] T. Rachidi, S. A. Maelainin, and A. Bensaid, “Scene change detectionusing adaptive skip factors,”Proc. IEEE Int. Conf. Image Processing(ICIP97), Oct. 26–29, 1997.
[6] H. H. Yu and W. Wolf, “A hierarchical multiresolution video shot tran-sition detection scheme,”Comput. Vis. Image Understand., vol. 75, no.1–2, pp. 196–213, 1999.
[7] N. V. Patel and I. K. Sethi, “Video shot detection and characterization forvideo databases,”Pattern Recognit., vol. 30, no. 4, pp. 583–592, 1997.
[8] A. D. Doulamis, N. D. Doulamis, and S. D. Kollias, “A fuzzy videocontent representation for video summarization and content-based re-trieval,” Signal Process., vol. 80, no. 6, pp. 1049–1067, 2000.
[9] H. J. Zhang, J. H. Wu, D. Zhong, and S. W. Smoliar, “An integratedsystem for content-based video retrieval and browsing,”PatternRecognit., vol. 30, no. 4, pp. 643–658, 1997.
[10] J. D. Courtney, “Automatic video indexing via object motion analysis,”Pattern Recognit., vol. 30, no. 4, pp. 607–625, 1997.
[11] M. S. Drew, J. Wei, and Z. N. Li, “Illumination-invariant image re-trieval and video segmentation,”Pattern Recognit., vol. 32, no. 8, pp.1369–1388, 1999.
[12] S. Dagtas, W. Al-Khatib, A. Ghafoor, and R. L. Kashyap, “Models formotion-based video indexing and retrieval,”IEEE Trans. Image Pro-cessing, vol. 9, pp. 88–101, Jan. 2000.
[13] V. Roth, “Content-based retrieval from digital video,”Image Vis.Comput., vol. 17, no. 7, pp. 531–540, 1999.
[14] W. G. Chen, G. B. Giannakis, and N. Nandhakumar, “A harmonic re-trieval framework for discontinuous motion estimation,”IEEE Trans.Image Processing, vol. 7, pp. 1242–1257, Sept. 1998.
[15] T. Rachidi, S. A. Maelainin, and A. Bensaid, “Scene change detectionusing adaptive skip factors,”Proc. IEEE Int. Conf. Image Processing(ICIP97), Oct. 26–29, 1997.
[16] B. Furht, S. W. Smoliar, and H. Zhang,Video and Image Processing inMultimedia Systems. Dordrecht, The Netherlands: Kluwer, 1995.
[17] H. Hampapur, R. Jain, and T. E. Weymouth, “Indexing in videodatabases,” inProc. SPIE, Storage and Retrieval for Image and VideoDatabases II, vol. 2420, Feb. 1995, pp. 292–306.
[18] J. Y. A. Wang and E. H. Adelson, “Layered representation for imagesequence coding,”Proc. IEEE Int. Conf. Acoustics, Speech, and SignalProcessing, pp. 221–224, Apr. 1993.
[19] , “Layered representation for motion analysis,”Proc. IEEE Conf.Computer Vision and Pattern Recognition, pp. 361–366, June 1993.
[20] H. S. Sawhney and S. Ayer, “Compact representations of videos throughdominant and multiple motion estimation,”IEEE Trans. Pattern Anal.Machine Intell., vol. 18, pp. 814–830, Aug. 1996.
[21] M. Irani and P. Anandan, “Video indexing based on mosaic representa-tions,” Proc. IEEE, vol. 86, pp. 905–921, May 1998.
[22] D. C. Hogg, “Model-based vision: A program to see a walking person,”Image Vis. Comput., vol. 1, no. 1, pp. 5–20, 1983.
[23] A. Baunberg and D. Hogg, “Learning flexible models from image se-quences,” inProc. 3rd Eur. Conf. Computer Vision, vol. I, 1994, pp.299–308.
[24] R. Polana and R. Nelson, “Detecting activities,”Proc. IEEE Conf. Com-puter Vision and Pattern Recognition, pp. 2–7, June 1993.
[25] K. Rohr, “Incremental recognition of pedestrian from image sequences,”Proc. IEEE Conf. Computer Vision and Pattern Recognition, pp. 8–13,June 1993.
[26] A. J. Lipton, H. Fujiyoshi, and C. Thorpe, “Moving target classificationand tracking from real-time video,”Proc. 4th IEEE Workshop of Appli-cations of Computer Vision, pp. 8–14, Oct. 1998.
[27] H. Fujiyoshi and A. J. Lipton, “Real-time human motion analysis byimage skeletonization,”Proc. 4th IEEE Workshop of Applications ofComputer Vision, pp. 15–21, Oct. 1998.
[28] A. Galton, “Toward an integrated logic of space, time and motion,” pre-sented at the Int. Joint Conf. Artificial Intelligence (IJCAI), Chambery,France, Aug. 1993.
[29] M. Brand, N. Oliver, and A. Pentland, “Coupled hidden Markov modelsfor compelx action recognition,”Proc. IEEE Conf. Computer Vision andPattern Recognition, June 1997.
[30] N. Chleq and M. Thonnat, “Real-time image sequence interpretationfor video-surveillance applications,”Proc. IEEE Int. Conf. Image Pro-cessing (ICIP96), vol. III, pp. 801–804, Sept. 1996.
[31] P. L. Rosin and T. J. Ellis, “Frame-based system for image interpreta-tion,” Image Vis. Comput., vol. 9, pp. 353–361, 1991.
[32] R. Koenen, “Profiles and levels in MPEG-4: Approach and overview,”Signal Process.: Image Commun., no. 4–5, pp. 463–478, Jan. 2000.
[33] C. Wren, A. Azerbayejani, T. Darrel, and A. Pentalnd, “Pfinder:Real-time tracking of the human body,”IEEE Trans. Pattern Anal.Machine Intell., vol. 19, pp. 780–785, July 1997.
[34] I. Haritaoglu, D. Harwood, and L. S. Davis, “W : Real-time surveil-lance of people and their activities,”IEEE Trans. Pattern Anal. MachineIntell., vol. 22, pp. 809–830, Aug. 2000.
[35] S. J. McKenna, S. Jabri, Z. Duric, H. Wechsler, and A. Rosenfeld,“Tracking groups of people,”Comput. Vis. Image Understand., vol. 80,pp. 42–56, 2000.
[36] D. Gavrila, “The visual analysis of human movement: A survey,”Comput. Vis. Image Understand., vol. 73, no. 1, pp. 82–98, 1999.
[37] A. Tesei, A. Teschioni, C. S. Regazzoni, and G. Vernazza,“Long-memory matching of interacting complex objects fromreal image sequences,” inTime-Varying Image Processing and MovingObject Recognition, V. Cappellini, Ed. Amsterdam, The Netherlands:Elsevier, 1997, pp. 283–288.

FORESTIet al.: AUTOMATIC DETECTION AND INDEXING OF VIDEO-EVENT SHOTS 471
[38] A. Chanda, “Application of binary mathematical morphology to separateoverlapped objects,”Pattern Recognit. Lett., vol. 13, no. 9, pp. 639–645,Sept. 1992.
[39] M. Bogaert, N. Chleq, P. Cornez, C. S. Regazzoni, A. Teschioni, andM. Thonnat, “The PASSWORDS project,”Proc. IEEE Int. Conf. ImageProcessing, pp. 675–678, Sept. 1996.
[40] M. J. Swain and D. H. Ballard, “Color indexing,”Int. J. Comput. Vis.,vol. 7, no. 1, pp. 11–32, 1991.
[41] G. L. Foresti and F. Roli, “Real-time recognition of suspicious eventsfor advanced visual-based surveillance,” inMultimedia Video-BasedSurveillance Systems: From User Requirements to Research Solutions,G. L. Foresti, C. S. Regazzoni, and P. Mahonen, Eds. Dordrecht, TheNetherlands: Kluwer, 2000, pp. 84–93.
[42] F. Bremond and M. Thonnat, “Tracking multiple nonrigid objects invideo sequences,”IEEE Trans. Circuits Syst. Video Technol., vol. 8, pp.585–591, 1998.
[43] G. L. Foresti, “Outdoor scene classification by a neural tree based ap-proach,”Pattern Analysis and Applications, vol. 2, pp. 129–142, 1999.
[44] E. James, L. Hollins, D. J. Brown, I. C. Luckraft, and C. R. Gent, “Fea-ture vectors for road vehicle scene classification,”Neural Networks, vol.9, no. 2, pp. 337–344, 1996.
[45] L. Marcenaro, F. Oberti, and C. S. Regazzoni, “Multiple objects color-based tracking using multiple cameras in complex time-varying outdoorscenes,”Proceedings of the 2nd IEEE Int. Workshop on PETS, Dec. 9,2001.
[46] F. Oberti, “Reconfigurable, Distributed and Intelligent Video Surveil-lance Networks,” Ph.D. thesis, Univ. Genoa, Italy, Feb. 2002.
[47] J. H. Piater and J. L. Crowley, “Multi-modal tracking targets usingGaussian approximations,”Proc. 2nd IEEE Int. Workshop on PETS,Dec. 9, 2001.
[48] G. L. Foresti, “Object detection and tracking in time-varying andbadly illuminated outdoor environments,”Opt. Eng., vol. 37, no. 9, pp.2550–2564, 1998.
[49] T. Kailath, “The divergence and Bhattacharyya distance measures insignal selection,”IEEE Trans. Commun. Tech., vol. COM-15, pp. 52–60,1967.
Gian Luca Foresti (S’93–M’95–SM’01) was bornin Savona, Italy, in 1965. He received the Laurea de-gree (cum laude) in electronic engineering and thePh.D. degree in computer science from University ofGenoa, Italy, in 1990 and 1994, respectively.
Since 1998, he is Professor of computer science,Department of Mathematics and Computer Science(DIMI), University of Udine, Italy, and Directorof the Artificial Vision and Real-Time System(AVIRES) Lab. His main interests involve activevision, image processing, multisensor data fusion,
and artificial neural networks. Techniques proposed found applications inthe following fields: automatic video-based systems for surveillance andmonitoring of outdoor environments, vision systems for autonomous vehicledriving and/or road traffic control, 3-D scene interpretation, human behaviorunderstanding. He is author or coauthor of more than 100 papers publishedin international journals and refereed international conferences. He hascontributed to seven books in his area of interest and is coauthor of the bookMultimedia Video-based Surveillance Systems(Dordrecht, The Netherlands:Kluwer, 2000). He has served as a reviewer for several international journals,and for the European Union in different research programs (MAST III, LongTerm Research, Brite-CRAFT). He has been responsible for DIMI for severalEuropean and National research projects in the field of computer vision andimage processing.
Prof. Foresti was general co-chair, chairman, and member of technical com-mittees at several conferences. He has been organizer of several special ses-sions on video-based surveillance systems and data fusion at international con-ferences. He has been Guest Editor of a Special Issue on “Video Communi-cations, Processing and Understanding for Third Generation Surveillance Sys-tems” of the PROCEEDINGS OF THEIEEE. In February 2000, he has been ap-pointed as Italian member of the Information Systems Technology (IST) panelof the NATO-RTO. He is a member of IAPR.
Lucio Marcenaro was born in Genoa, Italy, in1974. He received the Laurea degree in electronicengineering with telecommunication and telematicspecialization from the University of Genoa in 1999,with a thesis about flexible models for human motionto analyze images from multiple video surveillancecameras. He is currently pursuing the Ph.D. degreein electronic engineering and computer science atthe University of Genoa, where he is a memberof the Signal Processing & TelecommunicationsGroup. His main research interests include image
and sequence processing for video-surveillance systems and statistical patternrecognition.
Carlo S. Regazzoni(S’90–M’92–SM’00) was bornin Savona, Italy, in 1963. He received the Laurea de-gree in electronic engineering and the Ph.D. degree intelecommunications and signal processing from theUniversity of Genoa, in 1987 and 1992, respectively.
Since 1998, he is Professor of telecommunicationsystems in the Engineering Faculty of the Universityof Genoa, and, also since 1998, is responsible forthe Signal Processing and Telecommunications(SP&T) Research Group, Department of Biophysicaland Electronic Engineering (DIBE), University
of Genoa, which he joined in 1987. His main current research interests aremultimedia and nonlinear signal and video processing, signal processing fortelecommunications, multimedia broadband wireless and wired telecommuni-cations systems. He is involved in research on multimedia surveillance systemssince 1988. He co-editor of the booksAdvanced Video-based Surveillance Sys-tems(Dordrecht, The Netherlands: Kluwer, 1999) andMultimedia Video-BasedSurveillance Systems(Kluwer, 2000). He is author or coauthor of 43 papersin international scientific journals and of more than 130 papers presented atrefereed international conferences.
Dr. Regazzoni has been co-organizer and chairman of the first two Inter-national Workshops on Advanced Video Based Surveillance, held in Genoa,Italy, 1998 and Kingston, U.K., 2001. He has also organized several SpecialSessions in the same field at International Conferences (Image Analysis andProcessing, Venice 1999 (ICIAP99), European Signal Processing Conf. (Eu-sipco2000), Tampere Finland, 2000). He is a consultant of the EU Commissionfor the definition of the 6th research framework program in the ambient intel-ligence domain. He has been responsible for several EU research and develop-ment projects dealing with video surveillance methodologies and applicationsin the transport field (ESPRIT Dimus, Athena, Passwords, AVS-PV, AVS-RIO);he has been also responsible of several research contracts with italian industries;he served as a referee for international journals, and as reviewer for EU in dif-ferent research programs. He is a member of AEI and IAPR.




























![1050113 a Wi-Fi ] w 覡) - HiNet](https://img.pdfslide.net/doc/110x75/61d0916d0bfee765423646b6/1050113-a-wi-fi-w-hinet.jpg)
