Embed Size (px)
Citation preview

IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 12, DECEMBER 2006 3759
Automatic Object Extraction Over MultiscaleEdge Field for Multimedia Retrieval
Serkan Kiranyaz, Miguel Ferreira, and Moncef Gabbouj
Abstract—In this work, we focus on automatic extraction of ob-ject boundaries from Canny edge field for the purpose of content-based indexing and retrieval over image and video databases. Amultiscale approach is adopted where each successive scale pro-vides further simplification of the image by removing more details,such as texture and noise, while keeping major edges. At each stageof the simplification, edges are extracted from the image and gath-ered in a scale-map, over which a perceptual subsegment analysisis performed in order to extract true object boundaries. The anal-ysis is mainly motivated by Gestalt laws and our experimental re-sults suggest a promising performance for main objects extraction,even for images with crowded textural edges and objects with color,texture, and illumination variations. Finally, integrating the wholeprocess as feature extraction module into MUVIS framework al-lows us to test the mutual performance of the proposed object ex-traction method and subsequent shape description in the contextof multimedia indexing and retrieval. A promising retrieval perfor-mance is achieved, and especially in some particular examples, theexperimental results show that the proposed method presents sucha retrieval performance that cannot be achieved by using other fea-tures such as color or texture.
Index Terms—Canny edge detection, multimedia indexing andretrieval, multiscale, object extraction, subsegment analysis.
I. INTRODUCTION
THE shape of an object in a visual scene, if extractedproperly, is a powerful descriptor for the purpose of
content-based multimedia indexing and retrieval due to itssemantic value. Especially in generic multimedia databases,achieving efficient shape descriptors requires an automatic andhighly accurate segmentation operation. Various automaticsegmentation efforts have been reported in the literature. Re-gion-based methods [3], [10]–[12], [15] mainly depend onthe assumption of uniformity and homogeneity of color (orluminance) and texture features within the boundaries of objectsegments. However, this assumption may obviously fail since asingle object may exhibit several color and texture variations.Region merging/splitting techniques such as recursive shortestspanning tree (RSST) [18], [26], K-means connectivity con-straint (KMCC) [16], and JSEG [4] also belong to this category.
Manuscript received October 7, 2005; revised May 26, 2006. This work wassupported by the Academy of Finland, project No. 213462 (Finnish Centre ofExcellence Program 2006-2011). The associate editor coordinating the reviewof this manuscript and approving it for publication was Dr. Zhigang (Zeke) Fan.
S. Kiranyaz and M. Gabbouj are with the Institute of Signal Processing,Tampere University of Technology, FIN-33101 Tampere, Finland (e-mail:[email protected]; [email protected]).
M. Ferreira is with the Rua Cidade de Inhambane, 1800-085 Lisboa, Portugal(e-mail: [email protected]).
Color versions of Figs. 1, 3–11, and 17 are available online at http://ieeex-plore.ieee.org.
Digital Object Identifier 10.1109/TIP.2006.881966
Another alternative is seeded region growing (SRG) [1], whichpartitions the image into regions where each connected regioncorresponds to one of the seeds. It can be a quite promisingmethod provided that the initial seeds are sufficiently accurate;however, this represents its main limitation, that is, how toselect the most appropriate initial seeds? Thresholding-basedmethods [24] are based on the assumption that adjacent pixels,whose properties (color, texture, intensity, etc.) lie within a cer-tain threshold, belong to the same segment. These techniquesare usually adequate for binary images or images exhibiting“clean” edges, and their performance degrades drastically forimages with blurred object boundaries since they neglect thespatial information. Furthermore, noise and object occlusionfurther complicate the segmentation task. Alternative ap-proaches include boundary-based approaches [5], [7], [8], [13],[17], [20], [21] which are so far the most promising due to theperceptual evidence indicating that the human visual system(HVS) focuses on edges and tends to ignore uniform regions.This process, known as lateral inhibition, is similar to themathematical Laplacian operation. One of the most promisingboundary-based methods is a graph-based image segmentation(GBIS) proposed in [6].
In this paper, we propose a systematic approach which per-forms automatic object extraction by subsegment analysis over(object) boundaries in order to achieve visual content extraction.From basic visual features through low-level edge processing,we aim to achieve some form of mid-level meaningful descrip-tion based on the segmentation information extracted from theedge field for the purpose of multimedia retrieval. The maindrawback of the aforementioned segmentation algorithms is thatthey produce over- or under-segmented images, which are notuseful for shape-based retrieval. Apart from the biological mo-tivation based on HVS, the primary reason we propose an edge-based approach is that it brings generality, as edges are generallypresent across any type of visual content, colored or not, tex-tured or not. Moreover, edges mostly carry the boundary infor-mation of the object shapes. However, if extracted directly froma natural image, these edges tend to be incomplete, missing,noisy or saturated. Background and texture edges, which arenot related to object shape information, significantly degrade theextraction accuracy of the “true” object edges (boundaries). Inbrief, natural images are usually too “detailed” to achieve an ac-curate segmentation over the edge field. This is the main reasonbehind the proposed multiscale approach where the scale basi-cally represents the amount of simplification provided by iter-atively applying the bilateral filter [25] on the image. The ul-timate goal is the total removal of “details” so as to achieve a“cartoon-like” image on the higher scales where edge detection
1057-7149/$20.00 © 2006 IEEE

3760 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 12, DECEMBER 2006
Fig. 1. Overview of the proposed scheme.
would eventually yield true object boundaries. In practice, thereis, unfortunately, no guaranteed method where all details willvanish and only true object edges prevail. Furthermore, a pos-sible consequence of such a simplification step might as well bethe removal of some important parts of the object edges, whichmakes any further analysis infeasible. Moreover, without a priorknowledge, it is not possible to favor any particular scale either.Thus, the proposed approach uses the edge-information of allscaled (simplified in certain level) images in a scale-map of theedge field where all relevant information (i.e., the complete edgefield as well as their relevance information) exists for further(subsegment) analysis. Due to its robustness and better accuracy,Canny edge detection [2] is applied to extract the edges; how-ever, the proposed approach is independent from the choice ofthe edge detection scheme, and, hence, any other edge detectorcan be conveniently used, instead. In short, the main outcomeof such a multiscale approach is the classification of edge pixelswith respect to their relevance so that the following subsegmentanalysis can favor the more relevant edges in order to extract thetrue object boundaries.
Once the scale-map is obtained, certain analytical steps areperformed in order to achieve the extraction of object bound-aries. The edge pixels are first grouped into subsegments that arethen subject to further analysis to extract closed-loop (CL) andnonclosed-loop (NCL) segments, through subsegment linkage.The whole subsegment analysis is mainly motivated by certainperceptual rules, known as Gestalt laws, which were originatedby the German psychologist Max Wertheimer during the earlytwentieth century [27]. The guiding principle of this theory is
that the larger picture will be seen before its component parts.According to Gestalt laws, the way our mind groups these partsto form a whole was described in a set of rules, which can beexpressed by eight visual cues: proximity, similarity, good con-tinuation, closure, common fate, surroundedness, relative size,and symmetry. Henceforth, our subsegment analysis is based ona regularization function formed according to local rules suchas proximity and good continuation of edges and according tothe global concern of finding objects, i.e., closure. CL segmentsrepresent the objects (their boundaries) or the major parts of theobjects; whereas, NCL segments are for background scene andincomplete (overlapped or out-of-frame) objects.
Finally, a shape-based feature extraction ( ) is performedover both types of segments in order to achieve an edge-basedshape description of the whole image. This description will dis-criminate between both types of segments, by providing con-tour-based shape description for CL segments, and backgroundinformation shape description for NCL segments. Forming thewhole process as a module into the Multimedia Video In-dexing System (MUVIS )[14], [19] allows us to test the overallperformance of the proposed method in the context of multi-media indexing and retrieval. An overview of the proposed ap-proach is illustrated in Fig. 1.
The whole process is automatic (i.e., without any supervision,feedback, or training involved) and designed with the minimalparameter dependency (i.e., the same set of parameters can beused indiscriminately for an indefinite number of images andwe used a default set for all the examples in this paper). The restof the paper is organized as follows. In Section II, an overview

KIRANYAZ et al.: AUTOMATIC OBJECT EXTRACTION OVER MULTISCALE EDGE FIELD 3761
about the entire CL/NCL through multiscale subsegment anal-ysis is introduced. We discuss the implementation of the pro-posed method as a module producing shape-based descrip-tors for a MUVIS multimedia database in Section III. Section IVpresents the experimental results, and Section V concludes thepaper and suggests topics for future research.
II. SUBSEGMENT ANALYSIS OVER EDGES
The proposed analysis is based upon the luminance compo-nent (intensity) of the frames extracted (decoded) either fromthe images or (key-) frames of the video clips in a host multi-media database. The method is designed to be robust againstpossible variations in frame size and image/video types. Fig. 1presents the fundamental steps in the CL/NCL segmentationphase, which can basically be divided into four major parts:Frame resampling, bilateral filtering, and scale-map formationover the Canny edge field, subsegment formation and analysis,and, finally, CL/NCL segment formation. The default param-eters for Canny edge detector, bilateral filter and the numberof CL/NCL (outcome) segments are user-defined. Once thesegmentation phase is completed, is performed over theCL/NCL segments as will be detailed in the next section.
The first and natural step is resampling (frame size transfor-mation if needed for too large or small frames) into a prac-tical dimension range, which is sufficiently large for perceivableshapes but small enough not to cause infeasible analysis time.A typical size can be between 200 and 400 pixels for both di-mensions. By this way, a standard approach can now be appliedfor the quantitative measures performed within certain analyt-ical steps. The resampled Y-frame can then be used for multi-scale analysis to form the scale-map of the image, as presentedin the following subsection. The subsegment formation from thescale-map and CL/NCL segmentation will then be explained inSection II-B.
A. Multiscale Analysis Over Scale-Map
Obviously, the most accurate edge field can be obtained frombinary (black and white) or cartoon images where no details(texture, noise, illumination effects, etc.) are present, the edgesare clean, and, therefore, true object boundaries can be extractedsimply using an ordinary edge detection algorithm. Complica-tions and degradations in the segmentation accuracy begin tooccur when the image gets more and more “detailed” and thisis usually the case for natural images. Therefore, in our mul-tiscale approach, the resampled image is iteratively simplified(or cartoonized) using a bilateral filter [25] where the “scales”are emerged from the iterations of bilateral filtering and repre-sent successively simplified versions of the original image. Asillustrated on a sample image in Fig. 1, at each scale, Cannyedge detection is applied over the (simplified) image (bilateral)filtered by the scale number based on a naïve expectation thatthe majority of the perceptually relevant edges will prevail onthe higher scales—yet some of the main object-boundary edgesmay also vanish along with the details. This is why we needthe information across all the scales, since the loss of a few oreven just one section of the object edge-boundary would makeany further segmentation operation difficult—if not impossible.
Fig. 2. Bilateral filtered image with different � and � .
Once the required number of scales ( in Fig. 1 is the it-eration number, which can be set to any value sufficiently bigenough, i.e., ) are achieved then by assigning themaximum scale number to each pixel where it still prevails, thescale-map can be formed in the lowest scale (i.e., the first iter-ation, ) edge field where all the edges (obtained fromobject boundaries, noise, textural details, etc.) are present.
1) Bilateral Filter: Bilateral filtering was first introducedin 1998 and it presents certain advantages over the traditionalGaussian (blur) filter such as it can smooth an image while pre-serving major edges. Let and be the input and outputimages, respectively. Then, the Gaussian filter can be formu-lated as follows:
(1)
where is the standard deviation. This is a linear filter, whichis widely used for noise reduction. On the contrary, a bilateralfilter is a nonlinear filter whose filtering coefficients depend onthe local image pixel differences and are expressed in the formof two combined Gaussian filters: One in (2-D) spatial domainand the other in the (intensity) range of the image. Let andbe the domain and range standard deviation values, respectively.A bilateral filter can then be expressed through the followingequation:
(2)
As , the bilateral filter approaches to a Gaussian. Fig. 2presents a bilateral filtered sample image with several andvalues.
It is clearly visible that textural details are significantly re-duced with increasing values of and , yet major edges arepreserved. However, a Gaussian filter while removing texturaldetails smears (blurs) major edges and, hence, causes degrada-tions in the edge detection accuracy and localization (the spatialposition of edges). A comparative illustration in 3-D is shown

3762 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 12, DECEMBER 2006
Fig. 3. Gaussian versus bilateral filtering in 3-D.
Fig. 4. Iterative (multiscale) bilateral filtering.
in Figs. 3 and 4. As seen in Fig. 4, the bilateral filter is espe-cially efficient for removing details when used iteratively. Eachiteration further removes details from the image until eventuallyreaching a cartoon-like image. Since strong edges remain withgood localization precision, this information is easily gatheredin an edge-pixel scale-map and the scale factor for each pixel(until what scale is the edge present for each particular loca-tion) can then be used in subsequent analysis.
2) Canny Edge Detection: Canny developed an algorithm foredge detection, which has been widely used since its publicationin 1986 [2]. Canny started from postulating three performancecriteria for the edge detector.
• The detector should have a low probability of failing tomark real edge points or falsely marking nonedge points(good detection).
• The points marked as edges by the detector should be asclose as possible to the center of the true edges (good lo-calization).
• There should be only one response to a single edge (singleresponse).
In his work, Canny proceeded to search for optimal opera-tors, which would exhibit the above mentioned properties. Con-sidering only the first two criteria, the optimal detector for stepedges in a 1-D signal was found to be the truncated step, or dif-ference of boxes operator. However, due to the large bandwidthof this operator, the output to a noisy step edge exhibits manymaxima which make it difficult to choose one as the wantedresponse. Considering also the third constraint, Canny tried tominimize the number of response “peaks” in the vicinity of thestep edge. By a numerical optimization method, the formula ofthe desired operator was derived. An approximation to this op-timal operator is the first derivative of a Gaussian, which is usedfor its computational efficiency. The optimized detector was firstderived in 1-D but is easily generalized to any dimension, no-tably for the 2-D space of image pixel positions. In the 2-D case,edges have not only intensity, but also orientation and the de-tector will be the first derivative of a 2-D Gaussian ( ).
After applying operator to an image, thinning is per-formed over the result by the Canny edge algorithm, in the re-gions of high amplitude response, since the resulting output isusually broader than one pixel. A method known as nonmax-imum suppression is used for that purpose.
Thresholds are set by the algorithm to decide which pixelswill be marked as “edges.” These thresholds depend on a statis-tical analysis of the response magnitudes such as the estimatednoise energy present in the image. Canny considered that twothresholds should be used to prevent streaking, which occurswhen noise causes the output along an edge to fluctuate, aboveand below a single threshold. This results in the breaking of con-tinuous edges. A high threshold is set according to the noise en-ergy estimate, and a low threshold is set as a fraction of the highthreshold (this fraction is in the range of two or three to one ac-cording to Canny). Pixels are marked as edges automatically iftheir response amplitude is above the high threshold, but if theiramplitude is between the high and low thresholds, they are onlyconsidered as edge pixels if they are in the 8-neighborhood ofanother pixel already marked as an edge pixel. This so-calledhysteresis process is used to follow strong edges. Furthermore,the probability of isolated false edge points is reduced, since theresulting gradient strength at these points must be abovethe high threshold.
Canny edge detection is applied for each scale (after bilateralfiltering). The default Canny parameters, , , ,can be kept fixed and have minimal effect due to the presence ofmultiscale information collected in the scale-map, the formationof which is explained next.
3) Scale-Map Formation: Recall from the earlier discussionthat for a particular scale, bilateral filter is first applied over theimage from previous iteration (scale-1) and then a new edgefield is extracted. Since iterative application of bilateral filterhas a desired “cartoon” affect, which mainly preserves the ob-ject boundary edges while removing all the other details, theedge population tends to decrease drastically for higher scales(e.g., see Fig. 5). The remaining edges in higher scales, how-ever, have more relevance and priority for the object extrac-tion purpose—yet lower scales may still contain some importantedges that are lost in a higher scale and in this aspect the lowestscale has the utmost completeness. Therefore, the

KIRANYAZ et al.: AUTOMATIC OBJECT EXTRACTION OVER MULTISCALE EDGE FIELD 3763
Fig. 5. Sample scale-map formation.
scale-map is formed over the edge field of the lowest scale byassigning each edge pixel to the maximum scale at which it pre-vails. Two typical examples are shown in Figs. 1 and 5. In thisway, all the crucial information, particularly the localization andscale factor of each constituent edge pixel, can be embeddedinto the scale-map, which becomes the primary input for furtheranalysis. After the formation of subsegments, the proposed ob-ject extraction method can rely on the scale information duringsearching, tracing, and linking the relevant subsegments formedfrom the scale-map.
4) Subsegment Formation: An interesting issue raised ishow to choose the starting elements for edge analysis towardsgrouping. Pixel-level analysis does not lead to a clear identifi-cation of image structures, since human visual system (HVS)does not perceive individual pixels separately. When lookingat an edge image, how exactly does HVS perception combineedge pixels together, to form natural shape outlines (i.e., ob-ject boundaries)? The first low-level structures that HVS canclearly perceive are continuous and connected series of pixels.However, abrupt direction changes in a connected series, canlead to the impression of two different edge sections, which areconsidered separately in mental grouping. We use these per-ceptual facts to build such basic elements that will be the basisfor further analysis. These elements are so-called subsegments,through which both forms (CL and NCL) of segmentation areachieved. A subsegment can basically be defined as an orderedseries of connected edge pixels with two end-points and theyare formed using a tracing algorithm, which performs thefollowing steps over the scale-map.
Fig. 6. Subsegment formation from an initial Canny edge field.
• Thinning: Nonmaximum suppression in Canny’s algo-rithm, although providing usually thin edges, does notguarantee that the resulting edges are one pixel thick asdesired. Therefore, thinning is performed beforehand,using simple sliding window operations. Afterwards thetracing operation re-commences for the rest of the steps.
• “Noisy Edge” Removal: If the number of connected edgepixels is below a certain threshold (e.g., five bpixels), theyare assumed to be edge detection noise for the sake of ac-curacy and speed; therefore, such edges are removed fromthe scale-map.
• Junction Decomposition: In order to achieve a better seg-mentation from the subsegment analysis, junctions needto be decomposed into their branches (separated subseg-ments). For that, an algorithm breaks the tracing procedureat a certain edge pixel location where there is more thanone valid branch to follow. This pixel location is consid-ered as an end-point for the traced subsegment.
• CL Segment Detection: During subsegment tracing, when-ever it returns back to the initial end-point, thus creating aloop-back, the respective subsegment is assigned as a CLsegment or simply as a potential “ready” object where nofurther analysis is needed. Otherwise, the tracing eventu-ally breaks when no more connected pixels exist, and asecond end-point is assigned to complete the formation ofthe subsegment.
A sample subsegment formation is shown in Fig. 6.Once all the subsegments are formed from the edge pixels of
the scale-map, a scale weight, W(SS), of each subsegment, ,is then calculated as in (3)
(3)
where is the scale factor of an edge pixel in , andis the total length of . The weight and length of a particularsubsegment both signify its relevance, and, thus, the list of sub-segments formed can now be used conveniently in the followingsubsegment analysis to form CL segments.
B. CL and NCL Segmentation From Subsegments
Both types of segmentations (CL and NCL) are performedover the subsegment list extracted in the previous step. Due tospace limitations, NCL segmentation is not described in this

3764 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 12, DECEMBER 2006
paper and focus is drawn particularly on CL segmentation that isbasically the extraction of the primary object boundaries in theimage. The purpose of the aforementioned subsegment forma-tion is twofold. First, a generic analysis can now be performedover thinned, decomposed and well-formed subsegments in-stead of individual edge pixels. In this way, a better modelingof Gestalt laws can be adopted (i.e., proximity, relative size,and good continuation) for linking subsegments to form CLsegments (i.e., closure). Second, by means of the subsegmentformation with two end-points, CL segmentation problem canbe converted into a search process in a state-space where theend-points are assigned as “states” and the aim is to visit (link)certain number of states to loop back to the initial state withthe minimum Gestalt cost. Therefore, the search process linksone or more individual subsegment(s) using an abstract linkageelement, so-called virtual link, by minimizing a cost functionformed according to Gestalt laws. A virtual link is defined asthe virtual connection between two states (end-points) and itis performed “virtually” during the search and “artificially”for the subsegments belonging to a CL segment. Note that inany CL segment, there can be one or more virtual links, whichconnects the “gaps” where the edge detection algorithm failsto link in the first place. According to proximity law, a virtuallink threshold can be defined as the maximum pos-sible linkage that can be established between two end-points,i.e., and . Therefore, a virtual link, , is onlyconsidered if its length is below , i.e.,
. Its purpose is twofold: it serves as aquantitative level of tolerance for proximity and it is also used toreduce the number of state transitions, so as to make the searchprocess more tractable. It is, however, fairly difficult to proposea precise measure for since proximity law is based onhuman psychology and HVS (perception). So it can furtherdepend on several factors such as the content in the image (i.e.,the size of the objects in the scenery, their relative distances,etc.), image (frame) size, etc. should be big enough tolink the gaps due to the deficiency of the edge detector (e.g., seeFig. 7), but not too big to cause infeasible search time. Sincethere is usually a close relation with object sizes and their basicelements, i.e., subsegments, we set according to firstorder statistics obtained from the subsegment list, as in (4)
(4)
where is an empirical coefficient, is the total number ofsubsegments formed. According to an extended set of experi-mental results, is a reasonable range for andnote that is, thus, set to a fraction of the average subseg-ment length, . In this way, only small (virtual) links will bepossible in an image with comparatively smaller, texture-like ornoisy edges (and subsegments), as intended.
In order to improve the accuracy and speed of the searchprocess for CL segmentation over subsegments, two consecutiveprocesses are first performed: preprocessing over subsegmentsand then filtering irrelevant subsegments.
1) Preprocessing Over Subsegments: The preprocessingprocess can be split in three separate phases.
Fig. 7. Preprocessing steps applied on a sample subsegment field.
• Direct Linkage: two subsegments with particularend-points , which can only be linked witheach other (satisfying ) can beimmediately linked. A virtual link, , betweenboth end-points is created as a straight line with one pixelwidth and both subsegments are merged into one.
• Junction Proximity Decomposition: Canny edge detectorhas a particular flaw in dealing with “T-junctions,” wherethree different homogeneous regions meet. What the de-tector frequently does is to output the “T-junction” as asingle branch for two of its branches, leaving the thirdbranch of the junction separated by a small gap. Once thesubsegments are formed from edge field (scale-map), thebranches become subsegments where one of them has anend-point in the close vicinity of the other two merged. Thesearch process needs to trace each branch separately; there-fore, we decompose the merged subsegment into two fromthe closest point to the end-point of the third one.
• Loose Subsegment Removal: In case a particular subseg-ment has an end-point that cannot be linked to any otherend-point within the virtual link threshold, that subseg-ment cannot be a part of a CL segment. In order to reducethe number of states that the search algorithm will haveto process, such “loose” subsegments are removed before-hand.
Fig. 7 illustrates typical examples of the each preprocessingstep over a sample subsegment field.
2) Filtering the Least Relevant Subsegments: Upon comple-tion of the preprocessing steps, the least relevant subsegmentsare filtered out in order to reduce their noisy disturbance andto further speed up the search operation leading to the final CLsegmentation. As mentioned earlier the most relevant subseg-ments, which bear the major object edges, are usually longerwith higher scale weight values and the opposite is true forthe least relevant ones (i.e., from textural details, noise, etc.).Therefore, the relevance, , of a subsegment , can then beexpressed as follows:
(5)
where is the scale weight and is the length (totalnumber of edge pixels) of . Sorting all the subsegmentsformed over the scale-map and removing the least relevantones—or equivalently choosing an overestimated number (i.e.,

KIRANYAZ et al.: AUTOMATIC OBJECT EXTRACTION OVER MULTISCALE EDGE FIELD 3765
Fig. 8. Preprocessing and irrelevant subsegment filtering applied (N = 100)on a sample image.
) of the most relevant subsegments completes thisfiltering stage. The effect of this step and due segmentationresult can be clearly seen in the example image shown in Fig. 8.
3) CL Segmentation via Subsegment Analysis: Havingformed, preprocessed and filtered the initial subsegments, thecore of our method lies in the perceptual linking of the finalsubsegments, trying to achieve a natural shape closure. Recallthat the final subsegment list may contain both types of subseg-ments: CL and NCL. Such CL subsegments, which are extracteddirectly from the edge scale-map and survive the subsegmentpreprocessing and filtering stages, or that are formed by (direct)linkage during the same stage, represent stable and “ready”objects. Thus, among NCL subsegments, the aim is to searchfor objects (CL segments) by successive linking operations (viavirtual links) whenever possible. As mentioned earlier, four ofGestalt laws, proximity, good continuation, relative size andclosure, are used in the model in order to achieve perceptuallymeaningful CL segments.
Consider subsegments, with two end-points each, the ob-jective is to form objects where is the desired numberof CL segments (objects). A CL segment, , consisting ofsubsegments can be defined as
(6)
We define a state space, which consists of end-points.Each state is represented by its respective end-point coordi-nates and the segment identification number. By choosing oneof the end-points, of a particular subsegment as being the startstate, we automatically set the end state as its other end-point. Asearch algorithm, from one state to another , algorith-mically traces all possible state transitions by performing virtuallinks (if to end up in the end-state). Inaddition to virtual link length, the length and scale weight ofthe traced subsegment are used to calculate the transition cost,which is modelled based on the aforementioned Gestalt laws.One such virtual connections between two end-points (states) isshown in Fig. 9.
Fig. 9. State space for a given subsegment layout.
It becomes clear that this particular problem fits well in agraph-based search approach. In the general case, there can bemultiple paths, which lead to the solution (end state). Note thatthe links are reversible, i.e., valid for both directions. In thesearch algorithm, all data regarding a particular state of theproblem is collected in a structure called a node. The virtuallinks are then considered as the operators for node expansion asthey supply the transition network of the state space. The searchis repeated for each subsegment in the list and the (selected) finalpath closing the initial subsegment, in case multiple paths exist,will be the one with the least cumulative cost. The transition costfunction , to jump from an end-point belonging tosubsegment to an end-point in subsegment can be ex-pressed by
(7)
where is the virtual link length, is the subsegmentlength and is the subsegment scale weight operators. Ob-viously, this cost function is formed to favor shorter transitions(proximity) to a neighboring end-point belonging to longer sub-segments (relative size) with higher scale weight (good contin-uation). Arriving to an end-point of a subsegment and leavingfrom the other end-point with a new transition, this cost cumu-lates from one transition to the next, and the trace (and search)terminates when the end-state is reached, providing eventuallya CL segment (closure).
As for the search method, uniform cost search [23] is usedfor its completeness and optimality but also for its low timecomplexity, since it generally converges faster to the optimalpath, by expanding least cost nodes first. Once the method hasfound a solution node, it uses the solution path cost to pruneany node with a cost exceeding it. Additional techniques wereimplemented to further reduce time and space complexities,taking into consideration that this problem belongs to the“route-finding” class of problems, which have reversible oper-ators and repetition of states. By using a hash table, storing allgenerated least-cost nodes for each state, node pruning can startbefore reaching a solution state, which results in a significantreduction in search time. Nodes in the hash table will be either“closed” or “open,” whether they have been, or have yet to beexpanded, with “open” nodes forming the fringe. By consulting

3766 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 12, DECEMBER 2006
Fig. 10. Uniform cost search applied on a sample state space, where state 0 as the initial state and state 6 as the target state.
the hash table, with all visited states stored in the form of theirleast-cost node, entire path subtrees can be avoided by notgoing through the same state again, which has been visitedwith lower cost along a different path. However, when a newnode is generated, which contains the same state informationand exhibits a lower cost than a previously stored node thenthe corresponding entry in the hash table is updated to the newnode. Since the new node has its status still set to “open,” itssubsequent descendant nodes subtree is regenerated with lowerfcost values which will eventually update more nodes in thehash-table.
Such node expansions, applied to an example state space arehighlighted by black boxes in Fig. 10, which also shows theoverall pruning operations performed. In Fig. 10, states 0 and6 are the start and end states, respectively. Note that in the ex-panding step 2, the node containing state 3 with cost 6 is pruned,along with its subtree, since a node with the same state but lowercost had been found and kept in the hash table in step 1.Another immediate pruning applied is to avoid repeated statesalong a path, thus not generating any older relatives as childnodes, as can be seen in steps 2 and 3. Once the solution stateis found for a given node (in the case of the figure, after theexpanding step 4) its cost value can also be used forpruning any node with a higher cost, i.e., after step 4 and 5 whereboth generated child nodes are above the solution cost that isfound earlier. The optimal solution is found when all the nodesin the fringe have a higher cost value than the current solution
node, which happens in this case after only five steps. After thecompletion of the search algorithm, one can trace the solutionpath from the hash table by starting in the node containing theend-state and tracing back each successive parent node, whichlies in the path with minimum (cumulative) cost, until the initialnode with start-state is reached. For each subsegment, a searchtree in the form of a hash table, similar to the one in Fig. 10, isbuilt each time, and the optimal (the least cost) path is extractedafter the aforementioned pruning operations are applied.
4) Relevance Model: Choosing the Right Objects: Uponcompletion of the uniform cost search, the extracted CL seg-ments are inserted in a list, which might contain some “ready”CL segments extracted directly from the scale-map (i.e., the“ready” objects). A relevance model is now needed to choose
segments among all (ready and extracted via uniform costsearch) CL segments in the list. The proposed model dependson the maximization of the following (relevance) func-tion:
(8)
where is the total weight, is the total length, andis the total cost of a CL segment , respectively. This bal-
anced model obviously favors the CL segments exhibiting a lowcumulative (Gestalt) cost , with long and highly relevant(having higher scale weights) subsegments. As a result,

KIRANYAZ et al.: AUTOMATIC OBJECT EXTRACTION OVER MULTISCALE EDGE FIELD 3767
segments with the highest values are the CL objects ex-tracted and used for the feature extraction, as explained in thefollowing section.
III. INDEXING AND RETRIEVAL
For a MUVIS multimedia database [19], the indexing processinvolves operations applied onto visual items such as key-frames of the video clips or frame buffer of the images. A partic-ular module [9] formed from the proposed algorithm needsto provide both feature extraction of visual frames, and a sim-ilarity distance function for retrieval. The default moduleparameters such as Canny edge detection and bilateral filter pa-rameters, number of CL/NCL segments ( , ) to be ex-tracted, the feature vector dimension, etc., can be set by the userdepending on the database content and type. In the next sub-section we will present the feature extraction process from CLsegments and due to space limitations feature extraction fromNCL segments is not described in this paper.
A. Feature Extraction From CL Segments
The histogram of normalized angular first moment calculatedfrom the center of mass ( ) of a CL segment is used as themain feature vector. From the contour points are dividedaccording to angular partitions each of which has an angularresolution as follows:
(9)
-dimensional, unit length feature vector, , can then beformed from the discrete angular moments as follows:
(10)where represents the distance from the to theboundary at angle . The formation of for a sample CLsegment can be visualized as in Fig. 11.
Apart from unit normalization, this feature vector is furtherdesigned to be translation, rotation and size invariant. Transla-tion invariance comes naturally as a result of using the asthe reference point. Size (area) invariance and unit normaliza-tion are achieved by dividing each bin value in the histogramby the area of the CL segment. Rotation invariance is achievedduring the similarity distance calculation of the retrieval phaseand will be described in the next subsection.
Once all feature vectors for each CL segment are calculated,they are indexed into a descriptor file for that particular frame(image or key-frame) and appended into the MUVIS databasestructure.
B. Retrieval for CL Segments
The retrieval process in MUVIS is based on the traditionalquery-by-example (QBE) operation. The features of the queryitem are used for (dis-) similarity measurement among all the
Fig. 11. Feature vector formation from first moment inserted in kth bin of theN-bins angle histogram.
features of the visual items in the database. Ranking the databaseitems according to their similarity distances yields the retrievalresult.
Between the query frame and a particular frame in the data-base, the feature vectors of all segments are used forsimilarity distance calculation with the following matching cri-teria: for each CL segment in the query frame, a “matching” CLsegment in the compared frame is found. The Euclidean metricbased minimum similarity distance is used as the matching cri-terion. Afterwards the total similarity distance will be the sumof matching similarity distances of all segments present in thequery frame.
In order to achieve rotation invariance, the feature vector ofa CL segment (angular histogram bins) is shifted one bin at atime with the other vector kept fixed and the similarity distanceis calculated per step. The particular shift, which gives minimumsimilarity distance, is chosen for that particular CL segment ofthe query frame. Since this sliding operation on the histogrambins basically represents the feature vector of the rotated CLsegment, rotation invariance can, therefore, be achieved.
IV. EXPERIMENTAL RESULTS
The experiments are performed to test the object extractionefficiency with respect to HVS perceptive criteria (subjectivetest) and the retrieval performance via QBE within MUVIS mul-timedia databases indexed by the proposed module. Allexperiments are carried out on a Pentium 5 1.8-GHz computerwith 1024-MB memory. Images used in this section are gath-ered from several sources including Corel database and personalimage archives. The following Canny and bilateral filter param-eters are used for all the experiments in this section: ,
, for Canny edge detectors, and, for bilateral filters. The rest of the parameters
are as follows: for , for scale number(number of iterations) and we used , as the number ofrelevant subsegments.

3768 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 12, DECEMBER 2006
Fig. 12. Three-scale simplification process over a natural image and the finalCL segment extracted.
The section is organized as follows. Section IV-A presents acomparative performance evaluation of the proposed object ex-traction algorithm with respect to three segmentation methodsthat were proposed recently, while Section IV-B evaluates theshape-based retrieval performance via ground truth methodwhile providing both visual and numerical results.
A. Visual Evaluation of Object Extraction Results
In Fig. 1, the key role of bilateral filter within the proposedmultiscale approach is clearly visible on an image where strongtextural details are present in the background. Such a “cartoon”effect can also be seen in Fig. 12, where, in this case, the objecthas a significant textural overlay. In this figure, although bilat-eral filter is applied once in the first scale, the Canny edge fieldat this scale is still too detailed. The second and particularly thefinal scales exhibit a clear enough edge field; however, someparts of the object edges (e.g., the mouth of the fish) are alsolost. This particular example justifies the need of the multiscaleapproach, where the analysis should be performed in the lowestscale due to its completeness, but should also use higher scalesto favor particular subsegments showing higher relevance.
For a comparative evaluation, we implemented three seg-mentation algorithms recently proposed, K-means connectivityconstraint (KMCC) [16], graph-based image segmentation (aswe refer to GBIS) [6], and JSEG [4], each of which showspromising results in terms of segmentation accuracy. Note thatthe proposed method is not a segmentation algorithm, ratheran object extraction method and there are major differencesbetween the two; segmentation is a process of pixel classifi-cation and clustering into subregions, i.e., segments, whereasobject extraction, as its name implies, is the act of findingboundaries of object(s) in an image. Therefore, it can be used asa segmentation algorithm by defining each object as a segmentand the background as another, but the reverse is obviouslynot true, i.e., any segmentation algorithm cannot distinguishbetween the objects or background—instead they form somesegments showing similarities in terms of color, texture, etc.For this reason we tuned the parameters of these segmentationalgorithms in order to obtain the highest segmentation accuracypossible for the set of images used in this section. For example,we set the crucial parameter, maximum segment number, as 4for all three algorithms, in order to reduce over-segmentation
Fig. 13. Typical segmentation results. The leftmost column shows the originalimage, the second and other three columns show the segmentation masks of theproposed method and other three algorithms.
since all images contain three or less objects. Figs. 13 and14 show typical natural images in the left column where theproposed method’s outcome, the boundaries of object(s)are used to create the object segments as given in the secondcolumn using a flooding method and the rest of the threecolumns belong to the segmentation masks obtained from threealgorithms, KMCC, GBIS, and JSEG, respectively. Since sig-nificant textural components are present as well as significantvariations or nonuniformity properties in color, intensity andtexture within the example images, it is not surprising to seethat the segmentation methods usually fail to extract true objectboundaries and over- and under-segmentation occur as a resultof this. Only in some examples where there is a certain degreeof uniformity and homogeneity in color/texture distribution[e.g., (c, f, i) in Fig. 13 and (b, i, j, k) in Fig. 14] reasonablesegmentation results can only be obtained from some of them.Among these particular examples, since the proposed methodperforms analysis over subsegments with one-pixel thick, notealso that a higher segmentation resolution and accuracy is,thus, achieved on the extraction of the “true” object boundariescompared to the existing segmentation algorithms.
As some typical examples shown in Fig. 15, slight segmen-tation errors can also be encountered, such as one or few tinyobject parts being missed or slight background disturbance over
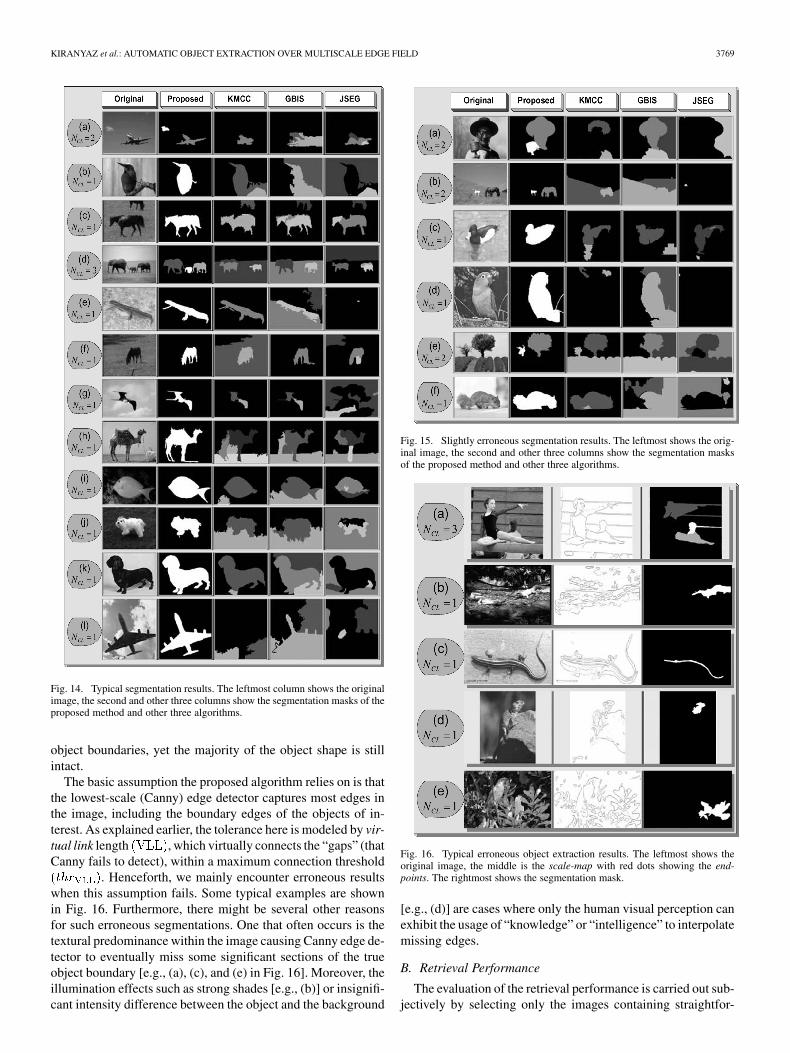
KIRANYAZ et al.: AUTOMATIC OBJECT EXTRACTION OVER MULTISCALE EDGE FIELD 3769
Fig. 14. Typical segmentation results. The leftmost column shows the originalimage, the second and other three columns show the segmentation masks of theproposed method and other three algorithms.
object boundaries, yet the majority of the object shape is stillintact.
The basic assumption the proposed algorithm relies on is thatthe lowest-scale (Canny) edge detector captures most edges inthe image, including the boundary edges of the objects of in-terest. As explained earlier, the tolerance here is modeled by vir-tual link length , which virtually connects the “gaps” (thatCanny fails to detect), within a maximum connection threshold
. Henceforth, we mainly encounter erroneous resultswhen this assumption fails. Some typical examples are shownin Fig. 16. Furthermore, there might be several other reasonsfor such erroneous segmentations. One that often occurs is thetextural predominance within the image causing Canny edge de-tector to eventually miss some significant sections of the trueobject boundary [e.g., (a), (c), and (e) in Fig. 16]. Moreover, theillumination effects such as strong shades [e.g., (b)] or insignifi-cant intensity difference between the object and the background
Fig. 15. Slightly erroneous segmentation results. The leftmost shows the orig-inal image, the second and other three columns show the segmentation masksof the proposed method and other three algorithms.
Fig. 16. Typical erroneous object extraction results. The leftmost shows theoriginal image, the middle is the scale-map with red dots showing the end-points. The rightmost shows the segmentation mask.
[e.g., (d)] are cases where only the human visual perception canexhibit the usage of “knowledge” or “intelligence” to interpolatemissing edges.
B. Retrieval Performance
The evaluation of the retrieval performance is carried out sub-jectively by selecting only the images containing straightfor-

3770 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 12, DECEMBER 2006
Fig. 17. Two examples showing 12-best retrievals from binary shape database.The top-left is the query image.
ward (obvious) content. In other words, if there is any subjectiveambiguity on what the retrieval results should be for a partic-ular image, that sample is simply discarded from the database.Therefore, the experimental results presented in this section de-pend only on the decisive subjective evaluation via ground truthmethod.
For the analytical notion of performance along with the sub-jective evaluation, we used the traditional precision-recall (PR)performance metric measured under relevant (and unbiased)conditions, notably using the aforementioned ground truthmethodology. Note that recall, , and precision, , are definedas
and (11)
where is the number of relevant items retrieved (i.e., cor-rect matches) among total number of relevant items, . isthe total number of items retrieved. Forpractical considerations, we fixed as 12.
In order to test the retrieval performance, we have indexedtwo image databases using the proposed module. The firstdatabase is the binary shape database, which contains 1400 bi-nary images. This database is basically used to examine the ef-fectiveness of the proposed feature extraction method, since thecorrect segmentation for this particular kind of images is guar-anteed by setting . The correct retrieval results, as wellas the achieved scale and rotation invariance are illustrated inthe two typical examples shown in Fig. 17. For this database,we observed a significant retrieval performance, i.e., 85% orhigher Recall for 78% average Precision level. The second data-base is composed of 400 natural images carrying various con-tent (i.e., sports, cars, objects, wild-life scenery, animals, out-door city-scape, etc.). Among several retrieval experiments, weobserved a range of 21%–78% Recall versus 8%–100% of Pre-cision level. We have seen that some of the retrieval results canhardly be otherwise achieved using color or texture features,e.g., see Fig. 18. During the indexing of the natural image data-base bearing 400 images, five iterations (scales) are used andthe average indexing time per image is calculated as 9.82 s. Noiterations (0 scales) are used for the binary image database andthe average indexing time per image is 1.21 s.
Fig. 18. Four examples showing 12-best retrievals from natural image data-base. The top-left is the query image.
V. CONCLUSION
The proposed shape based indexing scheme based on auto-matic and multiscale object extraction method via subsegmentanalysis over Canny edge field achieves the following major in-novative properties.
• The overall algorithm is unsupervised (no training), withminimal parameter dependency. To our knowledge, it isone of the first attempts to index a natural image databaseaccording to object shape description in a fully automaticway.
• It is based on Gestalt laws to yield perceptually meaningfulsegmentation as the final product.
• A multiscale approach is employed to simplify the imageiteratively, removing “details” at each scale and, thus, cre-ating a priority measure for edges, improving the knowl-edge about the image constitution (major object bound-aries).
• The search space is reduced by such a multiscale approach.Moreover, a uniform cost search algorithm modified withintensive pruning schemes, related to the scale information,increases the search speed significantly.
• The cost function used in the relevance model increasesthe likelihood of finding true object boundaries by favoringthe longest and the most relevant CL segments with theminimal usage of virtual links.
• The experimental results approve that the proposed methodcan be a good alternative to the traditional segmentationalgorithms particularly for natural image databases wheretheir primary assumptions usually fail and furthermore a

KIRANYAZ et al.: AUTOMATIC OBJECT EXTRACTION OVER MULTISCALE EDGE FIELD 3771
high (one-pixel) resolution (accuracy) is achieved for theextracted object boundaries.
• Finally, the features extracted from the overall segmenta-tion scheme provide an effective indexing and retrieval per-formance, as assessed via subjective query results.
Current and planned research work include designing of abetter and more semantically meaningful feature vector fromCL/NCL segments, applying an adaptive merging operation toobtain global object(s) from the extracted CL parts and adaptmore Gestalt laws such as symmetry and surroundedness inthe cost function, to achieve a better object extraction scheme.By using the proposed module, integrating the “query bysketch” capability into MUVIS framework is also considered.
REFERENCES
[1] R. Adams and L. Bischof, “Seeded region growing,” IEEE Trans. Pat-tern Anal. Mach. Intell., vol. 16, no. 6, pp. 641–647, Jun. 1994.
[2] J. Canny, “A computational approach to edge detection,” IEEE Trans.Pattern Anal. Mach. Intell., vol. 8, no. 6, pp. 679–698, Nov. 1986.
[3] Y.-L. Chang and X. Li, “Adaptive image region growing,” IEEE Trans.Image Process., vol. 3, no. 6, pp. 868–872, Nov. 1994.
[4] Y. Deng and B. S. Manjunath, “Unsupervised segmentation of color-texture regions in images and video,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 23, no. 8, pp. 800–810, Aug. 2001.
[5] J. P. Fan, D. K. Y. Yau, A. K. Elmagarmid, and W. G. Aref, “Au-tomatic image segmentation by integrating color-edge extraction andseeded region growing,” IEEE Trans. Image Process., vol. 10, no. 10,pp. 1454–1466, Oct. 2001.
[6] P. F. Felzenszwalb and D. P. Huttenlocher, “Efficient graph-basedimage segmentation,” Int. J. Comput. Vis., vol. 59, no. 2, Sep. 2004.
[7] Q. Gao, “Extracting object silhouettes by perceptual edge tracking,”in Proc. IEEE Int. Conf. Systems, Man and Cybernetics, Orlando, FL,Oct. 11–15, 1997, vol. 3, pp. 2450–2454.
[8] Q. Gao, D. Qing, and S. Lu, “Fuzzy classification of generic edgefeatures,” in Proc. Int. Conf. Pattern Recognition, 2000, vol. 3, pp.668–671.
[9] O. Guldogan, E. Guldogan, S. Kiranyaz, K. Caglar, and M. Gabbouj,“Dynamic integration of explicit feature extraction algorithms intoMUVIS framework,” in Proc. Finnish Signal Processing Symp.,Tampere, Finland, May 19–20, 2003, pp. 120–123.
[10] D. Geiger and A. Yuille, “A common framework for image segmenta-tion,” Int. J. Comput. Vis., vol. 6, pp. 227–243, 1991.
[11] R. M. Haralick and L. G. Shapiro, “Survey: image segmentation tech-niques,” Comput. Vis. Graph. Image Process., vol. 29, pp. 100–132,1985.
[12] S. A. Hijjatoleslami and J. Kitter, “Region growing: a new approach,”IEEE Trans. Image Process., vol. 7, no. 7, pp. 1079–1084, Jul. 1998.
[13] M. Kass, A. Witkin, and D. Terzopulos, “Snakes: active contourmodels,” Int. J. Comput. Vis., vol. 1, pp. 312–331, 1988.
[14] S. Kiranyaz, K. Caglar, O. Guldogan, and E. Karaoglu, “MUVIS: amultimedia browsing, indexing and retrieval framework,” presented atthe 3rd Int. Workshop Content Based Multimedia Indexing, Rennes,France, Sep. 22–24, 2003.
[15] I. Kompatsiaris and M. G. Strintzis, “Content-based representation ofcolour image sequences,” presented at the IEEE Int. Conf. Acoustics,Speech and Signal Processing, Salt Lake City, UT, May 2001.
[16] V. Mezaris, I. Kompatsiaris, and M. G. Strintzis, “Still image segmen-tation tools for object-based multimedia applications,” Int. J. PatternRecognit. Artif. Intell., vol. 18, no. 4, pp. 701–725, Jun. 2004.
[17] S. Mahamud, L. R. Williams, K. K. Thornber, and K. Xu, “Segmenta-tion of multiple salient closed contours from real images,” IEEE Trans.Pattern Anal. Mach. Intell., vol. 25, no. 4, pp. 433–444, Apr. 2003.
[18] O. J. Morris, M. J. Lee, and A. G. Constantinides, “Graph theory forimage analysis: an approach based on the shortest spanning tree,” Proc.Inst. Elect. Eng., vol. 133, no. 2, pp. 146–152, 1986.
[19] MUVIS [Online]. Available: http://muvis.cs.tut.fi[20] L. H. Staib and J. S. Duncan, “Boundary finding with parametric de-
formable models,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 14, no.1, pp. 161–175, Jan 1992.
[21] P. L. Palmer, H. Dabis, and J. Kittler, “A performance measure forboundary detection algorithms,” Comput. Vis. Image Understand., vol.63, pp. 476–494, 1996.
[22] P. Perona and J. Malik, “Scale-space and edge detection usinganisotropic diffusion,” IEEE Trans. Pattern Anal. Mach. Intell., vol.12, no. 7, pp. 629–639, Jul. 1990.
[23] S. Russell and P. Norvig, Artificial Intelligence: A Modern Ap-proach. Englewood Cliffs, NJ: Prentice-Hall, 1995.
[24] P. K. Sahoo, S. Soltani, and A. K. C. Wong, “A survey of thresh-olding techniques,” Computer Vis. Graph. Image Process., vol. 41, pp.233–260, 1988.
[25] C. Tomasi and R. Manduchi, “Bilateral filtering for gray and color im-ages,” presented at the 6th Int. Conf. Computer Vision, Bombay, India,Jan. 1998.
[26] E. Tuncel and L. Onural, “Utilization of the recursive shortest span-ning tree algorithm for video-object segmentation by 2-D affine mo-tion modeling,” IEEE Trans. Circuits Syst. Video Technol., vol. 10, no.5, pp. 776–781, Aug. 2000.
[27] M. Wertheimer, “Laws of organization in perceptual forms,” in ASourcebook of Gestalt Psychology, W. B. Ellis, Ed. New York:Harcourt Brace, 1938, pp. 71–88.
Serkan Kiranyaz was born in Turkey in 1972.He received the B.S. degree from the Electricaland Electronics Department, Bilkent University,Ankara, Turkey, in 1994, and the M.S. degree insignal and video processing from Bilkent Universityin 1996. He received the Ph.D. degree from theInstitute of Signal Processing, Tampere Universityof Technology, Tampere, Finland,
He was a Researcher with the Nokia ResearchCenter and later with Nokia Mobile Phones, Tam-pere, where he is currently a Senior Researcher.
He is the Architect and Principal Developer of the ongoing content-basedmultimedia indexing and retrieval framework, MUVIS. His research interestsinclude content-based multimedia indexing, browsing and retrieval algorithms,audio analysis and audio-based multimedia retrieval, video summarization,automatic subsegment analysis from the edge field and object extraction, mo-tion estimation and VLBR video coding, and MPEG4 over IP and multimediaprocessing.
Miguel Ferreira was born in Portugal in 1979. Hereceived the Licenciatura degree in electrical andcomputer engineering from the Instituto SuperiorTécnico, Lisbon, Portugal, in 2004, where his majorwas telecommunications and his minor was artificialintelligence and decision theory.
Since 2003, he has been a Research Assistantand, more recently, a Researcher with the Insti-tute of Signal Processing, Tampere University ofTechnology, Finland. He is working on the MUVISproject, developing new feature-extraction algo-
rithms for content-based image indexing and retrieval. His research interestsinclude content-based multimedia indexing and retrieval, image analysis,segmentation, and description.

3772 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 15, NO. 12, DECEMBER 2006
Moncef Gabbouj received the B.S. degree in elec-trical engineering in 1985 from Oklahoma State Uni-versity, Stillwater, and the M.S. and Ph.D. degrees inelectrical engineering from Purdue University, WestLafayette, IN, in 1986 and 1989, respectively.
He is currently a Professor and Head of theInstitute of Signal Processing, Tampere University ofTechnology, Tampere, Finland. He is the co-founderand past CEO of SuviSoft Oy, Ltd. From 1995 to1998, he was a Professor with the Department ofInformation Technology, Pori School of Technology
and Economics, and from 1997 to 1998, he was a Senior Research Scientist withthe Academy of Finland. From 1994 to 1995, he was an Associate Professorwith the Signal Processing Laboratory, Tampere University of Technology.From 1990 to 1993, he was a Senior Research scientist with the ResearchInstitute for Information Technology, Tampere. He is an Honorary GuestProfessor at Jilin University, China (2005 to 2010). He is is the Director of theInternational University Programs in Information Technology and vice memberof the Council of the Department of Information Technology at Tampere Uni-versity of Technology. He is also the Vice-Director of the Academy of FinlandCenter of Excellence SPAG, Secretary of the International Advisory Board ofTampere International Center of Signal Processing, TICSP, and member of theBoard of the Digital Media Institute. He serves as the Tutoring Professor forNokia Mobile Phones Leading Science Program (2005 to 2006 and 1998 to2001). He is co-author of over 300 publications. His research interests includemultimedia content-based analysis, indexing, and retrieval; nonlinear signaland image processing and analysis; and video processing and coding.
Dr. Gabbouj is a member of the Eta Kappa Nu, Phi Kappa Phi, and CASsocieties. He served as Distinguished Lecturer for the IEEE Circuits andSystems Society in 2004 and 2005, and Past Chairman of the IEEE-EURASIPNSIP Board. He was Chairman of the Algorithm Group of the EC COST211quat. He served as an Associate Editor of the IEEE TRANSACTIONS ON
IMAGE PROCESSING, and was a Guest Editor of the European Journal AppliedSignal Processing (Image Analysis for Interactive Multimedia Services, Part Iin April 2002 and Part II in June 2002) and the Signal Processing Special Issueon nonlinear digital signal processing (August 1994). He is the Past Chairmanof the IEEE Finland Section and Past Chair of the IEEE Circuits and SystemsSociety, Technical Committee on Digital Signal Processing, and the IEEESP/CAS Finland Chapter. He was also Chairman of CBMI 2005, WIAMIS2001, the TPC Chair of ISCCSP 2006 and 2004, CBMI 2003, EUSIPCO2000, NORSIG 1996, and the DSP track chair of the 1996 IEEE ISCAS. Heis also member of EURASIP Advisory Board and past member of AdCom.He also served as Publication Chair and Publicity Chair of IEEE ICIP 2005and IEEE ICASSP 2006, respectively. He was the recipient of the 2005 NokiaFoundation Recognition Award and co-recipient of the Myril B. Reed BestPaper Award of the 32nd Midwest Symposium on Circuits and Systems andco-recipient of the NORSIG 94 Best Paper Award of the 1994 Nordic SignalProcessing Symposium. He has been involved in several past and current EUResearch and education projects and programs, including ESPRIT, HCM, IST,COST, Tempus, and Erasmus. He also served as an Evaluator of IST proposalsand Auditor of a number of ACTS and IST projects on multimedia security,augmented and virtual reality, and image and video signal processing.





























