Embed Size (px)
Citation preview

Background
Knowledge Attack for Generalization based Privacy-Preserving Data Mining

Discussion Outline
(sigmod08-4)Privacy-MaxEnt: Integrating Background Knowledge in Privacy Quantification
(kdd08-4) Composition Attacks and Auxiliary Information in Data Privacy
(vldb07-4) Privacy Skyline: Privacy with Multidimensional Adversarial Knowledge

Anonymization techniques
Generalization & suppression Consistency property: multiple occurrences of the
same value are always generalized the same way. (all old methods and recent Incognito)
No consistency property (Mondrain) Anatomy (Tao vldb06) Permutation (Koudas ICDE07)

Anonymization through Anatomy
Anatomy: simple and effective privacy preservation

Anonymization through permutation

Background knowledge
K-anonymity Attacker has access to public databases, i.e., quasi-
identifier values of the individuals. The target individual is in the released database.
L-diversity Homogeneity attack background knowledge about some individuals’ sensitive
attribute values T-closeness
The distribution of sensitive attribute in the overall table

Type of background knowledge Known facts
A male patient cannot have ovarian cancer Demographical information
It is unlikely that a young patient of certain ethnic groups has heart disease
Some combination of the quasi-identifier values cannot entail some sensitive attribute values

Type of background knowledge Adversary-specific knowledge
target individual has no specific sensitive attribute value , e.g., Bob does not have flu
Sensitive attribute values of some other individuals, Joe, John, and Mike (as Bob’s neighbor) have flu
Knowledge about same-value family

Some extension
Multiple sensitive values per individual Flu \in Bob[S] Basic implication (adopted in Martin ICDE07)
cannot practically express the above --- |s|-1 basic implications are needed
Probabilistic knowledge vs. deterministic knowledge

Data SetsIdentifier Quasi-Identifier (QI) Sensitive Attribute (SA)
how much adversaries can know about an individual’s sensitive attributes if they know the individual’s quasi-identifiers

we need to measure P(SA|QI)
Quasi-Identifier (QI) Sensitive Attribute (SA)
Background Background KnowledgeKnowledge

Impact of Background Knowledge
Background Knowledge:
It’s rare for male to have breast cancer.

[Martin, et al. ICDE’07]
first formal study of the effect of background knowledge on privacy-
preserving
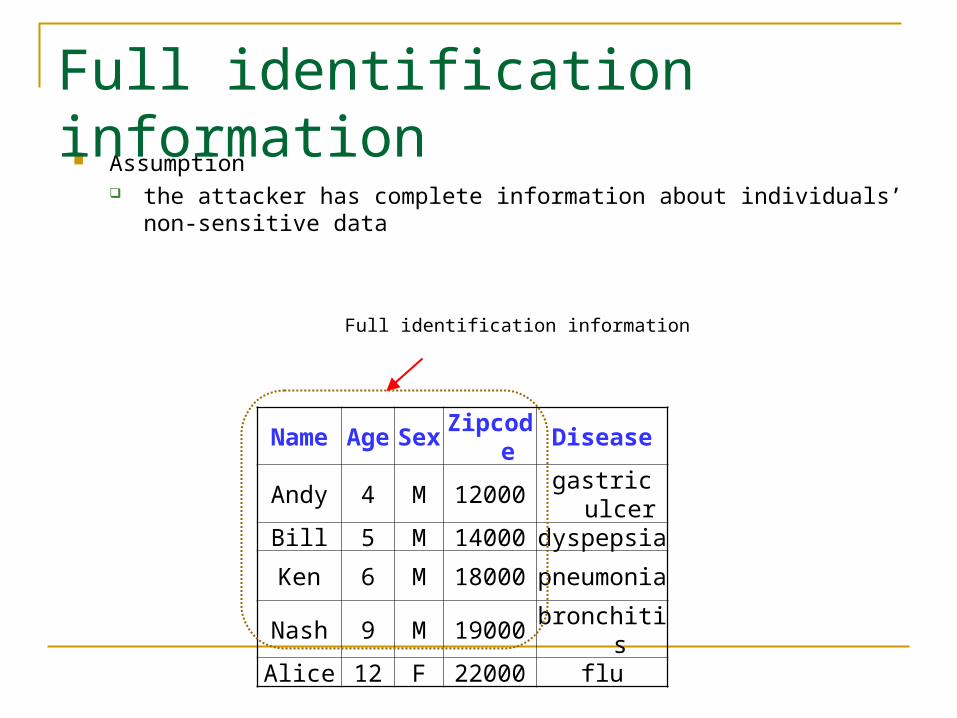
Assumption the attacker has complete information about individuals’ non-sensitive data
Full identification information
Name Age Sex Zipcode Disease
Andy 4 M 12000 gastric ulcer
Bill 5 M 14000 dyspepsia
Ken 6 M 18000 pneumonia
Nash 9 M 19000 bronchitisAlice 12 F 22000 flu
Full identification information

Rule based knowledge
Atom Ai a predicate about a person and his/her sensitive
values tJack[Disease] = flu
says that the Jack’s tuple has the value flu for the sensitive attribute Disease.
Basic implication
Background knowledge formulated as conjunctions of k basic implications

The idea
use k to bound the background knowledge, and compute the maximum disclosure of a bucket data set with respect to the background knowledge.

(vldb07-4)
[Bee-Chung, et al. VLDB’07]
use a triple (l, k,m) to specify the bound ofthe background rather than a single k

Introduction
[Martin, et al. ICDE’07] limitation of using a single number k to bound background knowledge
quantifying an adversary’s external knowledge by a novel multidimensional novel multidimensional approachapproach

Problem formulation
Pr(Pr(t t has has s s | | KK, , DD*)*)
data owner has a table of data (denoted by D)data owner publishes the resulting release candidate D*
S: a sensitive attributes: a target sensitive valuet: a target individual
new bound specifies that adversaries know l other people’s sensitive value; adversaries know k sensitive values that the
target does not have adversaries know a group of m−1 people who
share the same sensitive value with the target

Theoretical framework

(sigmod08-4)
[Wenliang, et al. SIGMOD’08]

Introduction
The impact of background knowledge: How does it affect privacy? How to measure its impact on privacy?
Integrate background knowledge in privacy quantification. Privacy-MaxEnt: A systematic approach. Based on well-established theories.
maximum entropy estimate

Challenges
Directly computing P( S | Q ) is hard.
What do we want to compute? P( S | Q ), given the background knowledge and
the published data set.
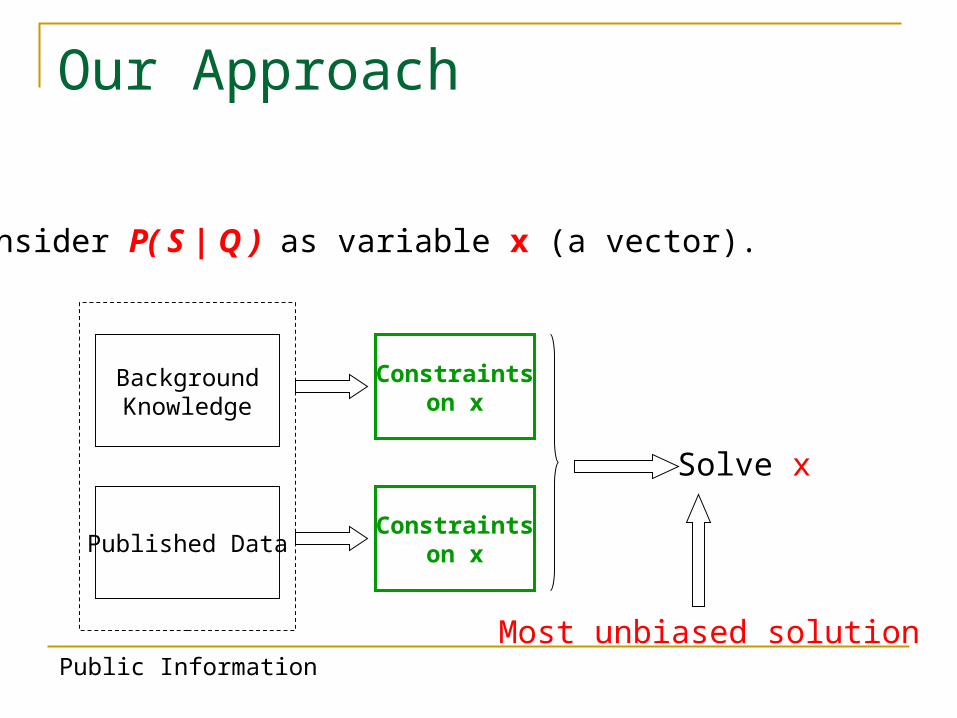
Our Approach
BackgroundKnowledge
Published Data
Public Information
Constraintson x
Constraintson x
Solve x
Consider P( S | Q ) as variable x (a vector).
Most unbiased solution

Maximum Entropy Principle
“Information theory provides a constructive criterion for setting up probability distributions on the basis of partial knowledge, and leads to a type of statistical inference which is called the maximum entropy estimate. It is least biased estimate possible on the given information.” — by E. T. Jaynes, 1957.

The MaxEnt Approach
BackgroundKnowledge
Published Data
Public Information
Constraintson P( S | Q )
Constraintson P( S | Q )
Estimate P( S | Q )
Maximum Entropy Estimate

Entropy
Because H(S | Q, B) = H(Q, S, B) – H(Q, B)
Constraint should use P(Q, S, B) as variables
BSQ
BQSPBQSPBQPBQSH,,
).,|(log),|(),(),|( :Entropy
BSQ
BSQPBSQPBSQH,,
).,,(log),,(),,( :Entropy

Maximum Entropy Estimate
Let vector x = P(Q, S, B). Find the value for x that maximizes its
entropy H(Q, S, B), while satisfying h1(x) = c1, …, hu(x) = cu : equality constraints
g1(x) ≤ d1, …, gv(x) ≤ dv : inequality constraints
A special case of Non-Linear Programming.

Putting Them Together
BackgroundKnowledge
Published Data
Public Information
Constraintson P( S | Q )
Constraintson P( S | Q )
Estimate P( S | Q )
Maximum Entropy Estimate
Tools: LBFGS, TOMLAB, KNITRO, etc.

Conclusion
Privacy-MaxEnt is a systematic method Model various types of knowledge Model the information from the published data Based on well-established theory.

(kdd08-2)
[Srivatsava, et al. KDD’08]

Introduction
reason about privacy in the face of rich, realistic sources of auxiliary information.
investigate the effectiveness of current anonymization schemes in preserving privacy when multiple organizations independently release anonymized data
present a composition attacks an adversary uses independently anonymized
releases to breach privacy

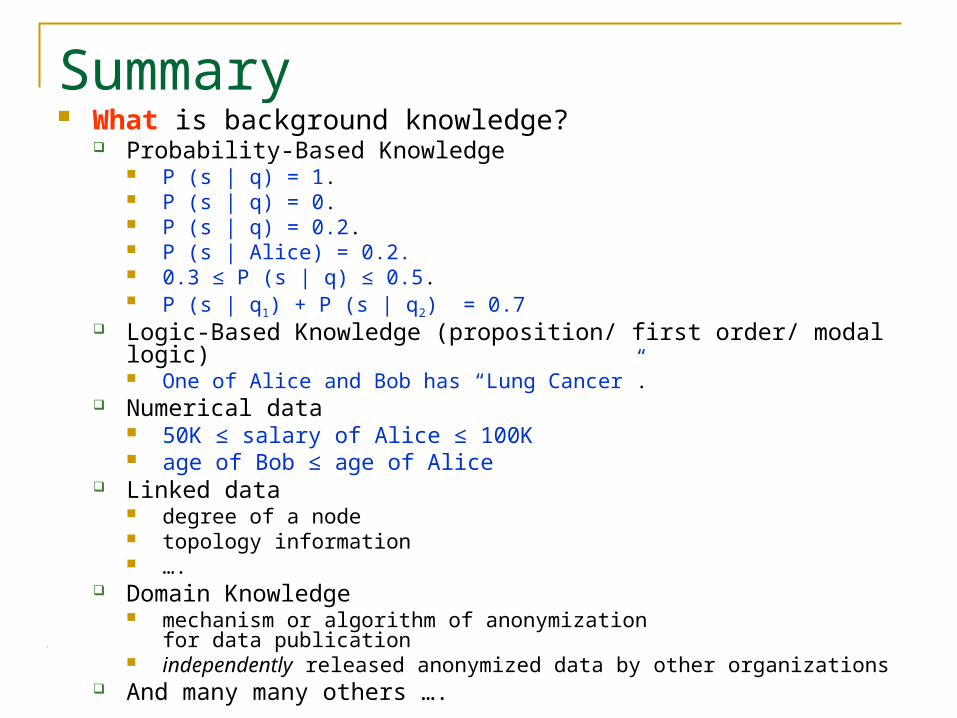
Summary What is background knowledge?
Probability-Based Knowledge P (s | q) = 1. P (s | q) = 0. P (s | q) = 0.2. P (s | Alice) = 0.2. 0.3 ≤ P (s | q) ≤ 0.5. P (s | q1) + P (s | q2) = 0.7
Logic-Based Knowledge (proposition/ first order/ modal logic) One of Alice and Bob has “Lung Cancer”.
Numerical data 50K ≤ salary of Alice ≤ 100K age of Bob ≤ age of Alice
Linked data degree of a node topology information ….
Domain Knowledge mechanism or algorithm of anonymization
for data publication independently released anonymized data by other organizations
And many many others ….

Summary How to represent background knowledge?
Probability-Based Knowledge P (s | q) = 1. P (s | q) = 0. P (s | q) = 0.2. P (s | Alice) = 0.2. 0.3 ≤ P (s | q) ≤ 0.5. P (s | q1) + P (s | q2) = 0.7
Logic-Based Knowledge (proposition/ first order/ modal logic) One of Alice and Bob has “Lung Cancer”.
Numerical data 50K ≤ salary of Alice ≤ 100K age of Bob ≤ age of Alice
Linked data degree of a node topology information ….
Domain Knowledge mechanism or algorithm of anonymization
for data publication independently released anonymized data by other organizations
And many many others ….
[Martin, et al. ICDE’07]Rule-based
[Wenliang, et al. SIGMOD’08]
[Srivatsava, et al. KDD’08]
[Raymond, et al. VLDB’07]
general knowledge framework
too hard to give a unified framework and give a general solution

Summary
How to quantify background knowledge? by the number of basic implications(association rules)
by a novel multidimensional approach formulated as linear constraints
How one can reason about privacy in the presence of external knowledge? quantify the privacy quantify the degree of randomization required quantify the precise effect of background knowledge
[Charu ICDE’07]
[Martin, et al. ICDE’07]
[Wenliang, et al. SIGMOD’08]
[Bee-Chung, et al. VLDB’07]
[Martin, et al. ICDE’07]
[Wenliang, et al. SIGMOD’08]

Questions? Thanks to Zhiwei Li




![arXiv:1905.13040v2 [cs.CV] 10 Apr 2020Domain Generalization via Universal Non-volume Preserving Approach Dat T. Truong 1;3 4, Chi Nhan Duong2, Khoa Luu , Minh-Triet Tran3;4, Ngan Le1](https://img.pdfslide.net/doc/110x75/5f4bbabdd75a0e5717670816/arxiv190513040v2-cscv-10-apr-2020-domain-generalization-via-universal-non-volume.jpg)
























