Embed Size (px)
Citation preview

BAZY DANYCH
wprowadzenie
Opracował:
dr inż. Piotr Suchomski

Prowadzący
Katedra Systemów Multimedialnych
dr inż. Piotr Suchomski (e-mail:
[email protected]) (pok. 730)
dr inż. Andrzej Leśnicki (e-mail:
[email protected] ) (pok. 636)
mgr inż. Dariusz Tkaczuk (e-mail:
[email protected]) (pok.
636)

Materiały
Materiały do wykładu i laboratorium
będą umieszczane w portalu:
http://www.sound.eti.pg.gda.pl
Login: student
Hasło: lab@kaesem

Zaliczenie
40% z wykładu + 60% laboratorium
Wykład - zaliczenie na podstawie
kolokwium.
Laboratorium – punkty za wykonywane
ćwiczenia + projekt i wykonanie bazy
danych (szczegółowe informacje
zostaną podane przez prowadzących
na zajęciach).

Lista prezentowanych zagadnień
Zagadnienia ogólne
Model związków encji
Relacyjny model danych
Inne modele danych
Multimedialne bazy danych
Język SQL
Projektowanie baz danych
Programowanie baz danych

Co to jest baza danych?
Jest to skomputeryzowany system
przechowywania rekordów z danymi.
Podstawowa funkcjonalność tego
systemu wymaga:
– Możliwość dodawania i usuwania zbiorów
danych,
– Możliwość dodawania, usuwania i
modyfikacji pojedynczych rekordów
danych,
– Możliwość wydobywania danych

Z czego składa się baza danych
Dane – przechowywane są w bazie w
sposób trwały, zintegrowany i mogą być
współdzielone.
Sprzęt – głównie to urządzenia pamięci
masowej (dyski magnetyczne,
optyczne) oraz procesory i
stowarzyszone z nimi pamięci
operacyjne, w których wykonywane są
programy.

Z czego składa się baza danych?
Programy – tworzą warstwę
pośredniczącą między użytkownikami a
fizyczną strukturą i magazynami
danych. Oprogramowanie to nazywane
jest systemem zarządzania bazą
danych (SZBD lub ang. DBMS –
database managment system). Uwalnia
użytkowników bazy od jej szczegółów
technicznych.

Z czego składa się baza danych?
Użytkownicy – zasadniczo można
wyróżnić 3 grupy:
– Programiści aplikacji – tworzą aplikacje
wykorzystujące bazy danych,
– „Użytkownicy końcowi” (end uesers) – za
pomocą specjalnie przygotowanych
interfejsów użytkownika (np. formularze)
korzystają z zasobów bazy danych,
bardziej zaawansowana grupa potrafi
korzystać z języka zapytań do bazy danych

Z czego składa się baza danych?
– Administrator danych (DA) i administrator
bazy danych (DBA) – wyznaczone osoby
pełniące funkcję kierowniczą. Administrator
danych jest osobą kompetentną w kwestii
definiowania danych (zna specyfikę danej
dziedziny danych), natomiast administrator
bazy danych jest specjalistą IT i nadzoruje
bazę danych od strony technicznej,
decyduje o sposobie implementacji struktur
danych

Cechy bazy danych
Trwałe i nezawodne przechowywanie
dużej ilości informacji,
Szybki dostęp do żądanych informacji,
Możliwość modyfikacji informacji,
Zapewnienie logicznej spójności
(integralności) danych,
Ochrona (bezpieczeństwo)
zgromadzonych danych.

Integracja danych
W bazie danych dane powinny tworzyć
logiczną całość. Projektując schemat
bazy danych należy tak zdefiniować
zbiory danych aby uniknąć redundancji
danych (należy unikać wielokrotnego
przechowywania tych samych danych).
Operacje wykonywane na bazie danych
nie mogą powodować przypadkowego
usuwania potrzebnych danych oraz
pozostawiania danych niepotrzebnych.

Składniki bazy danych
Język zapytań
System DBMS
Pamięć zewnętrzna

Pamięć zewnętrzna
Trwała – dane powinny być
przechowywane tak długo jak wymagają
tego użytkownicy bazy danych.
Niezawodna – częstotliwość
występowania awarii powinna być
pomijalna
– Zwielokrotnianie urządzeń pamięci (np.
macierze),
– Kontrola poprawności zapisu,
– Kody detekcji i korekcji błędów

Funkcje DBMS
Realizacja operacji dostępu do danych
na poziomie fizycznym (np. sterowniki,
algorytmy dostępu, struktury danych itp.)
Zapewnienie integralności danych
(przetwarzanie transakcyjne, kontrola
ograniczeń nałożonych na dane itp.),
Obsługa współbieżności przetwarzania
(rozstrzyganie konfliktów przy próbie
dostępu do tych samych danych)

Funkcje DBMS
Ochrona danych (kontrola praw dostępu
dla określonych grup użytkowników,
Restart po awariach (przywracanie z
kopii zapasowej),
Przetwarzanie danych rozproszonych,
Przetwarzanie równoległe (przetwarzanie
przy wykorzystaniu wielu procesorów).

Język zapytań
Dla użytkowników typu „end user”
polecenia wybierane z menu lub
polecenia wydawane z wiersza poleceń.
Dla programistów:
– Kompletny język programowania baz
danych (4GL),
– Typowy język trzeciej generacji (np.
C/C++, Pascal) rozbudowany o funkcje
obsługi baz danych

Język zapytań
Składa się z:
– Język definiowania danych (DDL – data
definition language),
– Język manipulowania danymi (DML – data
manipulation language),
– Język kontrolowania danych (DCL – data
control language).

Architektura systemu baz danych
Poziom
użytkownika
Poziom
pojęciowy
Poziom
fizyczny
aplikacje
DBMS

Niezależność od danych
Oddzielenie poziomu użytkowników od
poziomu fizycznego bazy danych
pozwala uniezależnić logikę aplikacji od
struktury danych. Korzyści:
– można zmienić urządzenia pamięciowe,
– można modyfikować/tworzyć nowe
struktury danych,
– można zmienić fizyczną reprezentację
danych
bez zmian w kodzie aplikacji bazodanowej

Poziom zewnętrzny
Poziom indywidualnego użytkownika,
jego widok bazy jest nieco abstrakcyjny
w stosunku do fizycznego sposobu
przechowywania danych.
Indywidualny użytkownik może nie mieć
pojęcia o istnieniu w bazie innych
danych, niż te które go nie interesują.

Poziom pojęciowy
Pojęciowy model danych stanowi
reprezentację zawartości informacyjnej
bazy danych.
Dane prezentowane są takimi jakimi są
naprawdę a nie jakimi widzi je
użytkownik.
Pojęciowy model danych jest sposobem
widzenia całej zawartości bazy danych.

Poziom wewnętrzny
Wewnętrzny model danych opisywany
jest za pomocą schematu
wewnętrznego, który definiuje typy
zachowanych rekordów, precyzuje jakie
są indeksy, jak reprezentowane są pola
rekordu, w jakiej kolejności zapisane są
rekordy itp.
Poziom wewnętrzny nie uwzględnia
fizycznego poziomu bazy (pliki, dyski,
cylindry itp.)

Rodzaje baz danych
Płaskie, jednotabelowe zbiory danych,
Hierarchiczne,
Sieciowe,
Relacyjne,
Obiektowe,
Relacyjno-obiektowe.

Proste bazy danych
Obejmują uporządkowane dane w
formie prostej tabeli lub tabel nie
powiązanych ze sobą (np. forma
arkusza).
W tabelach o określonej strukturze
gromadzone są przyrostowo kolejne
rekordy danych. Gromadzenie danych
polega na wypełnianiu kolejnych
wierszy tabeli danymi.

Proste bazy danych
Zaletą jest proste, intuicyjne
gromadzenie danych.
Mała funkcjonalność w przypadku dużej
liczby danych, dodatkowo problem
komplikuje się w przypadku dużego
zróżnicowania tych danych.
Brak łatwej identyfikacji poszukiwanego
rekordu danych.
Brak powiązań, problem redundancji.

Hierarchiczny model danych Dane grupowane są w postaci kolejnych
poziomów drzewa. Model typu rodzic-
potomek. Początek struktury tworzy
jeden korzeń i przez poziomy kolejnych
potomków aż do potomków „liści”.
Zbiór danych w tym modelu jest
powiązany z innymi danymi w tym
samym drzewie.
Hierarchia często budowana jest w
sposób indukcyjny: od ogółu do
szczegółu

Hierarchiczny model danych
Układ hierarchiczny pozwala tworzyć
proste zapytania. Zapytania mogą być
iteracyjnie uszczegóławiane.
Hierarchiczna baza danych zakłada
podstawowe warunki integralności
danych:– każdy rekord ma dokładnie jednego rodzica (z wyjątkiem
korzenia),
– jeżeli dany rekord posiada więcej rodziców niż jeden musi
być skopiowany dla każdego rodzica oddzielnie,
– jeżeli usunięty zostaje dany rekord oznacza to, że usunięte
zostają również wszystkie wywodzące się z niego rekordy -
potomkowie

Hierarchiczny model danych
Wadą tego modelu jest brak możliwości
budowania relacji między rekordami
różnych drzew.
Dobrym przykładem wykorzystania tego
modelu jest system plików systemu
Windows.

XML – dane semistrukturalne
Obecnie popularnym formatem
zapisywania danych w modelu
hierarchicznym są dokumenty XML
(eXtensible Markup Language).
Model danych semistrukturalnych
wykorzystywany jest często do
integracji danych z różnych baz danych
zawierających podobne dane.

XML a bazy danych:
1. XML jest uniwersalnym formatem składowania
danych.
2. Dokument XML zawiera logicznie uporządkowane
dane.
3. Dokument XML może zawierać opisy
wielokrotnych instancji tej samej klasy.
4. Dokument XML jest bazą danych.
5. XML nie jest systemem zarządzania bazami
danych.
6. Dokumenty XML lub dane dokumentów XML
podlegają składowaniu w bazach danych.

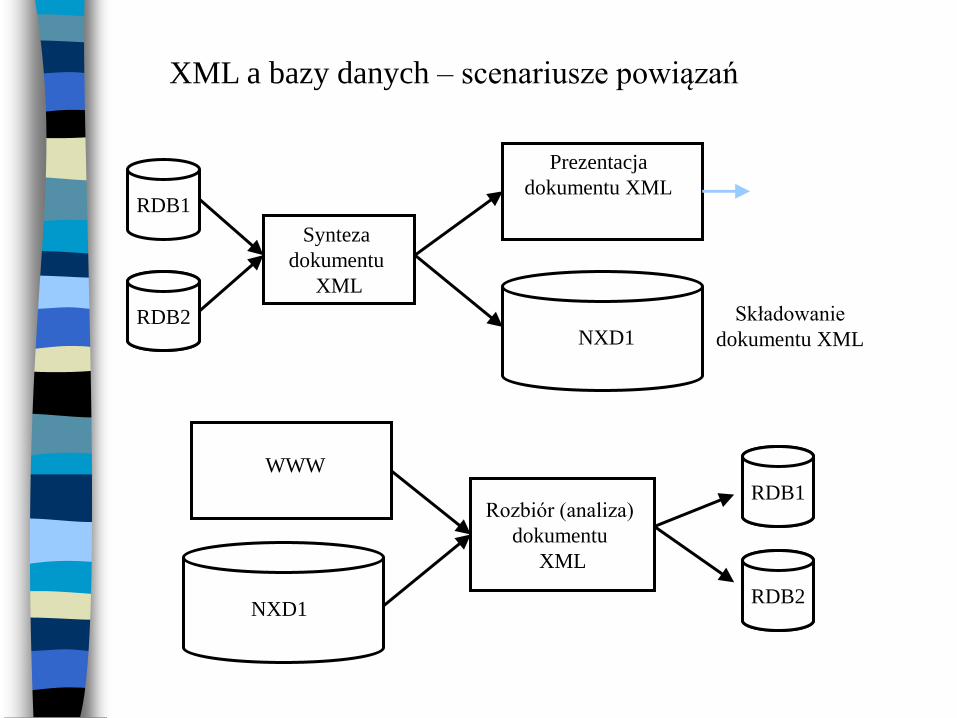
XML a bazy danych – podstawowe zadania:
1. Składowanie danych w dokumentach XML
2. Składowanie dokumentów XML
3. Wyszukiwanie dokumentów XML
4. Wyszukiwanie danych z dokumentów XML
RDB1
Synteza
dokumentu
XML
RDB2
RDB1
RDB2
Prezentacja
dokumentu XML
Składowanie
dokumentu XMLNXD1
WWW
NXD1
Rozbiór (analiza)
dokumentu
XML
XML a bazy danych – scenariusze powiązań

Sieciowy model danych
Nie ma nic wspołnego z sieciami
komputerowymi.
W modelu tym możliwe jest powiązanie
dowolnego zbioru danych z każdym
innym. Poprzez formę specyficznych
wskaźników zbiór A wskazuje na zbiory
B,C, zbiór C na zbiór D, zbiór D na zbiór
B, itp.

Sieciowy model danych

Sieciowy model danych
Różni się od modelu hierarchicznego tym,
że każdy rekord danych może mieć wielu
rodziców, jak również żadnego.
Sieciowa baza danych składa się z dwóch
typów zbiorów: zbioru formatów rekordów
i powiązań. Każdy typ powiązania określa
łączone ze sobą rekordy: typ rekordu
rodzica i typ rekordu dziecka.
Każde powiązanie wymaga zdefiniowania
wskaźnika.

Sieciowy model danych
W przypadku małych baz danych
wyszukiwanie danych jest szybkie.
W przypadku dużych baz danych z
dużą liczbą powiązań proces
wyszukiwania jest trudny i
czasochłonny.
W przypadku rozbudowanej sieci
powiązań wskaźniki mogą zajmować
więcej miejsca niż same dane!

Relacyjne bazy danych
Obecnie najczęściej implementowany
system baz danych.
Podstawową zasadą działania jest
gromadzenie danych w postaci tabel,
zwanych relacjami.
Identyfikacja pojedynczego rekordu
danych odbywa się na podstawie
wartości klucza (klucz definiowany jest
dla całej relacji).

Obiektowe bazy danych
Bazuje na modelu danych, który
wykorzystuje paradygmaty
programowania obiektowego.
W praktyce rzadko stosowane, sa
raczej przedmiotem badań
akademickich.
Model obiektowy może być
wykorzystywany w procesie
projektowania relacyjnych baz danych.

Bazy obiektowo-relacyjne
Połączenie zalet baz relacyjnych i
obiektowych.
Pozwalają manipulować danymi w
postaci obiektów. Mechanizm
manipulowania jest relacyny.





























